Encoding of text information. Character encoding - PIE wiki
The standard was proposed in 1991 by the Unicode Consortium, Unicode Inc., a non-profit organization. The use of this standard makes it possible to encode a very large number of characters from different scripts: in Unicode documents, Chinese characters, mathematical characters, letters of the Greek alphabet, Latin and Cyrillic alphabet can coexist, thus switching code pages becomes unnecessary.
The standard consists of two main sections: the universal character set (UCS) and the Unicode transformation format (UTF). The universal character set defines a one-to-one correspondence of characters to codes - elements of the code space that represent non-negative integers. The family of encodings defines the machine representation of a sequence of UCS codes.
The Unicode standard was developed with the goal of creating a uniform character encoding for all modern and many ancient written languages. Each character in this standard is encoded in 16 bits, which allows it to cover an incomparably larger number of characters than previously accepted 8-bit encodings. Another important difference between Unicode and other encoding systems is that it not only assigns a unique code to each character, but also defines various characteristics of this character, for example:
Character type (uppercase letter, lowercase letter, number, punctuation mark, etc.);
Character attributes (left-to-right or right-to-left display, space, line break, etc.);
The corresponding uppercase or lowercase letter (for lowercase and uppercase letters, respectively);
The corresponding numeric value (for numeric characters).
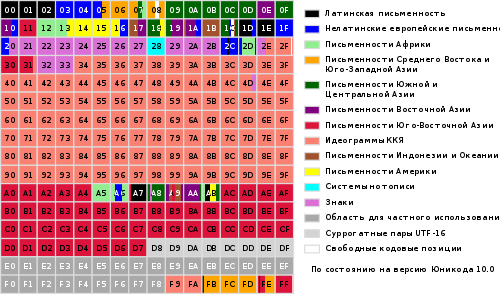
The entire range of codes from 0 to FFFF is divided into several standard subsets, each of which corresponds to either the alphabet of a language or a group special characters, similar in their functions. The diagram below provides a general listing of the Unicode 3.0 subsets (Figure 2).
Figure 2
The Unicode standard is the basis for storage and text in many modern computer systems. However, it is not compatible with most Internet protocols, since its codes can contain any byte values, and the protocols usually use bytes 00 - 1F and FE - FF as overhead. To achieve compatibility, several Unicode transformation formats (UTFs, Unicode Transformation Formats) have been developed, of which UTF-8 is the most common today. This format defines the following conversion rules for each Unicode code into a set of bytes (one to three) suitable for transport by Internet protocols.
Here x, y, z denote the bits of the source code that should be extracted, starting with the least significant one, and entered into the result bytes from right to left until all specified positions are filled.
Further development the Unicode standard is associated with the addition of new language planes, i.e. characters in the ranges 10000 - 1FFFF, 20000 - 2FFFF, etc., where it is supposed to include the encoding for the scripts of dead languages not included in the table above. A new UTF-16 format was developed to encode these additional characters.
Thus, there are 4 main ways to encode Unicode bytes:
UTF-8: 128 characters are encoded in one byte (ASCII format), 1920 characters are encoded in 2 bytes ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic characters), 63488 characters are encoded in 3 bytes (Chinese, Japanese and others) The remaining 2,147,418,112 characters (not yet used) can be encoded with 4, 5 or 6 bytes.
UCS-2: Each character is represented by 2 bytes. This encoding includes only the first 65,535 characters from the Unicode format.
UTF-16: This is an extension to UCS-2 and includes 1 114 112 Unicode characters. The first 65,535 characters are represented by 2 bytes, the rest by 4 bytes.
USC-4: Each character is encoded in 4 bytes.
Unicode
Unicode Consortium logo
Unicode(most often) or Unicode(eng. Unicode) is a character encoding standard that allows characters to be represented in almost all written languages.
The standard was proposed in 1991 by the non-profit organization "Unicode Consortium" (eng. Unicode Consortium, Unicode Inc.).
The use of this standard makes it possible to encode a very large number of characters from different scripts: in Unicode documents, Chinese characters, mathematical characters, letters of the Greek alphabet, Latin and Cyrillic alphabet can coexist, thus switching code pages becomes unnecessary.
The standard consists of two main sections: universal character set (eng. UCS, universal character set) and the family of encodings (eng. UTF, Unicode transformation format).
The universal character set defines a one-to-one correspondence of characters to codes - elements of the code space that represent non-negative integers. The family of encodings defines the machine representation of a sequence of UCS codes.
Unicode codes are divided into several areas. The area with codes from U + 0000 to U + 007F contains the ASCII characters with the corresponding codes. Next are the areas of signs of various scripts, punctuation and technical symbols.
Some of the codes are reserved for future use. Under the Cyrillic characters areas of characters with codes from U + 0400 to U + 052F, from U + 2DE0 to U + 2DFF, from U + A640 to U + A69F are allocated (see Cyrillic in Unicode).
- 1 Prerequisites for the creation and development of Unicode
- 2 Unicode versions
- 3 Code space
- 4 Coding system
- 4.1 Consortium Policy
- 4.2 Combining and Duplicating Symbols
- 5 Modifying characters
- 6 Normalization algorithms
- 6.1 NFD
- 6.2 NFC
- 6.3 NFKD
- 6.4 NFKC
- 6.5 Examples
- 7 Bidirectional writing
- 8 Featured Symbols
- 9 ISO / IEC 10646
- 10 Ways of presentation
- 10.1 UTF-8
- 10.2 Byte order
- 10.3 Unicode and traditional encodings
- 10.4 Implementations
- 11 Input Methods
- 11.1 Microsoft Windows
- 11.2 Macintosh
- 11.3 GNU / Linux
- 12 Unicode Problems
- 13 "Unicode" or "Unicode"?
Prerequisites for the creation and development of Unicode
By the late 1980s, 8-bit characters had become the standard. At the same time, there were many different 8-bit encodings, and new ones constantly appeared.
This was explained both by the constant expansion of the range of supported languages, and by the desire to create an encoding partially compatible with some other (a typical example is the emergence of an alternative encoding for the Russian language, due to the exploitation of Western programs created for the CP437 encoding).
As a result, several problems appeared:
- the problem of "krakozyabr";
- the problem of limited character set;
- the problem of converting one encoding to another;
- the problem of duplicate fonts.
The problem "krakozyabr"- the problem of displaying documents in the wrong encoding. The problem could be solved either by consistently introducing methods for specifying the encoding used, or by introducing a single (common) encoding for all.
The limited character set problem... The problem could be solved either by switching fonts within the document, or by introducing a "wide" encoding. Font switching has long been practiced in word processors, and fonts with a non-standard encoding were often used, the so-called. "Dingbat fonts". As a result, when trying to transfer a document to another system, all non-standard characters turned into "krakozyabry".
The problem of converting one encoding to another... The problem could be solved either by compiling conversion tables for each pair of encodings, or by using an intermediate conversion to a third encoding that includes all characters of all encodings.
Duplicate fonts problem... For each encoding, its own font was created, even if the character sets in the encodings coincided partially or completely. The problem could be solved by creating "large" fonts, from which the characters needed for a given encoding would subsequently be selected. However, this required the creation of a single registry of symbols in order to determine what corresponds to what.
The need to create a single "wide" encoding was recognized. Variable-length encodings, widely used in East Asia, were found to be too difficult to use, so it was decided to use fixed-width characters.
Using 32-bit characters seemed too wasteful, so it was decided to use 16-bit ones.
The first version of Unicode was an encoding with a fixed character size of 16 bits, that is, the total number of codes was 2 16 (65 536). Since then, characters have been denoted by four hexadecimal digits (for example, U + 04F0). At the same time, it was planned to encode in Unicode not all existing characters, but only those that are necessary in everyday life. Rarely used symbols had to be placed in the "private use area" that originally occupied the codes U + D800 ... U + F8FF.
In order to use Unicode also as an intermediate in converting different encodings to each other, all characters represented in all the most famous encodings were included in it.
In the future, however, it was decided to encode all symbols and, in this connection, significantly expand the code domain.
At the same time, character codes began to be considered not as 16-bit values, but as abstract numbers that can be represented in a computer in many different ways (see representation methods).
Since in a number of computer systems (for example, Windows NT) fixed 16-bit characters were already used as the default encoding, it was decided to encode all the most important characters only within the first 65,536 positions (the so-called English. basic multilingual plane, BMP).
The rest of the space is used for "additional characters" (eng. supplementary characters): writing systems of extinct languages or very rarely used Chinese characters, mathematical and musical symbols.
For compatibility with old 16-bit systems, the UTF-16 system was invented, where the first 65,536 positions, with the exception of positions from the interval U + D800 ... U + DFFF, are displayed directly as 16-bit numbers, and the rest are represented as "surrogate pairs »(The first element of the pair from the U + D800… U + DBFF region, the second element of the pair from the U + DC00… U + DFFF region). For surrogate couples, a part of the code space (2048 positions) was used, set aside "for private use".
Since UTF-16 can display only 2 20 +2 16 −2048 (1 112 064) characters, this number was chosen as the final value of the Unicode code space (code range: 0x000000-0x10FFFF).
Although the Unicode code area was extended beyond 2-16 as early as version 2.0, the first characters in the "top" area were only placed in version 3.1.
The role of this encoding in the web sector is constantly growing. At the beginning of 2010, the share of websites using Unicode was about 50%.
Unicode versions
Work on finalizing the standard continues. New versions are released as the symbol tables change and are updated. In parallel, new ISO / IEC 10646 documents are being issued.
The first standard was released in 1991, the last in 2016, the next is expected in the summer of 2017. The standards versions 1.0-5.0 were published as books, and have an ISBN.
The version number of the standard is made up of three digits (for example, "4.0.1"). The third digit is changed when minor changes are made to the standard that do not add new characters.
Code space
Although the notation forms UTF-8 and UTF-32 allow up to 2,331 (2,147,483,648) code points to be encoded, it was decided to use only 1,112,064 for compatibility with UTF-16. However, even this is more than enough for the moment - in version 6.0 a little less than 110,000 code points are used (109,242 graphic and 273 other symbols).
The code space is split into 17 planes(eng. planes) 2 16 (65 536) characters each. Ground plane ( plane 0) is called basic (basic) and contains the symbols of the most common scripts. The rest of the planes are additional ( supplementary). The first plane ( plane 1) is used mainly for historical scripts, the second ( plane 2) - for rarely used Chinese characters (CJK), the third ( plane 3) is reserved for archaic Chinese characters. Planes 15 and 16 are reserved for private use.
To denote Unicode characters a notation of the form “U + xxxx"(For codes 0 ... FFFF), or" U + xxxxx"(For codes 10000 ... FFFFF), or" U + xxxxxx"(For codes 100000 ... 10FFFF), where xxx- hexadecimal digits. For example, the symbol "i" (U + 044F) has the code 044F 16 = 1103 10.
Coding system
The universal coding system (Unicode) is a set of graphic symbols and a way of encoding them for computer processing of text data.
Graphic symbols are symbols that have a visible image. Graphical characters are opposed to control and formatting characters.
Graphic symbols include the following groups:
- letters contained in at least one of the supported alphabets;
- numbers;
- punctuation marks;
- special signs (mathematical, technical, ideograms, etc.);
- separators.
Unicode is a system for the linear representation of text. Characters that have additional superscripts or subscripts can be represented as a sequence of codes built according to certain rules (composite character) or as a single character (monolithic version, precomposed character). On this moment(2014), it is believed that all letters of large scripts are included in Unicode, and if a symbol is available in a composite version, it is not necessary to duplicate it in a monolithic form.
Consortium policy
The consortium does not create a new one, but states the established order of things. For example, emoji pictures were added because Japanese operators mobile communications they were widely used.
To do this, adding a symbol goes through a complex process. And, for example, the symbol of the Russian ruble passed it in three months simply because it received official status.
Trademarks are only coded by way of exception. So, in Unicode there is no Windows flag or Apple apple.
Once a character has appeared in the encoding, it will never move or disappear. If you need to change the order of characters, this is done not by changing positions, but by the national sorting order. There are other, more subtle guarantees of stability - for example, normalization tables will not change.
Combining and Duplicating Symbols
The same symbol can take several forms; in Unicode, these forms are contained in one code point:
- if it happened historically. For example, Arabic letters have four forms: detached, at the beginning, in the middle and at the end;
- or if one language is adopted in one form, and in another - another. Bulgarian Cyrillic differs from Russian, and Chinese characters from Japanese.
On the other hand, if historically fonts had two different code points, they remain different in Unicode. The lowercase Greek sigma has two forms, and they have different positions. Extended Latin letter Å (A with a circle) and angstrom sign Å, Greek letterμ and the prefix “micro” µ are different symbols.
Of course, similar characters in unrelated scripts are put in different code positions. For example, the letter A in Latin, Cyrillic, Greek and Cherokee are different symbols.
It is extremely rare that the same character is placed in two different code positions to simplify text processing. The mathematical stroke and the same stroke for indicating the softness of sounds are different symbols, the second is considered a letter.
Modifying characters
Representation of the character "Y" (U + 0419) in the form of the base character "I" (U + 0418) and the modifying character "" (U + 0306)
Graphic characters in Unicode are divided into extended and non-extended (widthless). Non-extended characters do not take up space in the line when displayed. These include, in particular, accent marks and other diacritical marks. Both extended and non-extended characters have their own codes. Extended symbols are otherwise called basic (eng. base characters), and non-extended ones - modifying (eng. combining characters); and the latter cannot meet independently. For example, the character "á" can be represented as a sequence of the base character "a" (U + 0061) and the modifier character "́" (U + 0301), or as a monolithic character "á" (U + 00E1).
A special type of modifying characters is the style selectors (eng. variation selectors). They only apply to those symbols for which such variants are defined. In version 5.0, style options are defined for a series mathematical symbols, for the symbols of the traditional Mongolian alphabet and for the symbols of the Mongolian square writing.
Normalization algorithms
Since the same symbols can be represented different codes, comparison of strings byte by byte becomes impossible. Normalization Algorithms normalization forms) solve this problem by converting the text to a certain standard form.
Casting is carried out by replacing symbols with equivalent ones using tables and rules. "Decomposition" is the replacement (decomposition) of one character into several constituent characters, and "composition", on the contrary, is the replacement (connection) of several constituent characters with one character.
The Unicode standard defines 4 text normalization algorithms: NFD, NFC, NFKD, and NFKC.
NFD
NFD, eng. n ormalization f orm D ("D" from the English. d ecomposition), the normalization form D is canonical decomposition - an algorithm according to which recursive replacement of monolithic symbols is performed (eng. precomposed characters) into several components (eng. composite characters) according to the decomposition tables.
Å U + 00C5 →
A U + 0041
̊ U + 030A
ṩ U + 1E69 →
s U + 0073
̣ U + 0323
̇ U + 0307
ḍ̇ U + 1E0B U + 0323 →
d U + 0064
̣ U + 0323
̇ U + 0307
q̣̇ U + 0071 U + 0307 U + 0323 →
q U + 0071
̣ U + 0323
̇ U + 0307 NFC
NFC, eng. n ormalization f orm C ("C" from the English. c omposition), the normalization form C is an algorithm according to which canonical decomposition and canonical composition are performed sequentially. First, canonical decomposition (NFD algorithm) reduces the text to the form D. Then canonical composition, the inverse of NFD, processes the text from beginning to end, taking into account the following rules:
- symbol S counts initial if it has a modification class equal to zero according to the Unicode character table;
- in any sequence of characters starting with the character S, symbol C blocked from S, only if between S and C is there any symbol B which is either initial or has the same or greater modification class than C... This rule applies only to strings that have gone through canonical decomposition;
- the symbol is considered primary a composite if it has a canonical decomposition in the Unicode character table (or canonical decomposition for Hangul and it is not included in the exclusion list);
- symbol X can be combined with the symbol first Y if and only if there is a primary composite Z, canonically equivalent to the sequence<X, Y>;
- if the next character C not blocked by the last start base character encountered L and it can be successfully combined with it first, then L replaced by composite L-C, a C removed.
o U + 006F
̂ U + 0302 → →
H U + 0048
① U + 2460 →
1 U + 0031
カ U + FF76 →
カ U + 30AB →
fi U + FB01
fi U + FB01
f i U + 0066 U + 0069
f i U + 0066 U + 0069
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 5 U + 0032 U + 0035
2 5 U + 0032 U + 0035
ẛ̣ U + 1E9B U + 0323
ſ ̣ ̇ U + 017F U + 0323 U + 0307
ẛ ̣ U + 1E9B U + 0323
s ̣ ̇ U + 0073 U + 0323 U + 0307
ṩ U + 1E69
th U + 0439
and ̆ U + 0438 U + 0306
th U + 0439
and ̆ U + 0438 U + 0306
th U + 0439
e U + 0451
e ̈ U + 0435 U + 0308
e U + 0451
e ̈ U + 0435 U + 0308
e U + 0451
A U + 0410
A U + 0410
A U + 0410
A U + 0410
A U + 0410
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
Ⅷ U + 2167
Ⅷ U + 2167
Ⅷ U + 2167
V I I I U + 0056 U + 0049 U + 0049 U + 0049
V I I I U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
c ̧ U + 0063 U + 0327
ç U + 00E7
c ̧ U + 0063 U + 0327
ç U + 00E7 Bi-directional letter
The Unicode standard supports writing languages with a left-to-right direction (eng. left-to-right, LTR), and with writing from right to left (eng. right-to-left, RTL) - for example, Arabic and Hebrew letters. In both cases, the characters are stored in a "natural" order; their display, taking into account the desired direction of the letter, is provided by the application.
In addition, Unicode supports combined texts that combine fragments with different directions of the letter. This feature is called bidirectionality(eng. bidirectional text, BiDi). Some simplified text processors (for example, in cell phones) can support Unicode, but not bidirectional support. All Unicode characters are divided into several categories: written from left to right, written from right to left, and written in any direction. Symbols of the latter category (mainly punctuation marks), when displayed, take the direction of the surrounding text.
Featured Symbols
Diagram of the basic multilingual plane of Unicode
Unicode includes virtually all modern scripts, including:
- Arabic
- Armenian,
- Bengali,
- Burmese,
- verb,
- Greek
- Georgian,
- devanagari,
- Jewish,
- Cyrillic,
- Chinese (Chinese characters are actively used in Japanese, as well as occasionally in Korean),
- Coptic,
- Khmer,
- Latin,
- Tamil,
- Korean (Hangul),
- Cherokee,
- Ethiopian,
- Japanese (which includes, in addition to the syllabic alphabet, also Chinese characters)
other.
For academic purposes, many historical scripts have been added, including: Germanic runes, ancient Türkic runes, ancient Greek writing, Egyptian hieroglyphs, cuneiform, Mayan writing, Etruscan alphabet.
Unicode provides a wide range of mathematical and musical symbols and pictograms.
In principle, Unicode does not include state flags, company and product logos, although they are found in fonts (for example, the Apple logo in the MacRoman encoding (0xF0) or the Windows logo in the Wingdings font (0xFF)). In Unicode fonts, logos should only be placed in the custom character area.
ISO / IEC 10646
The Unicode Consortium works closely with working group ISO / IEC / JTC1 / SC2 / WG2, which is developing international standard 10646 (ISO / IEC 10646). Synchronization is established between the Unicode standard and ISO / IEC 10646, although each standard uses its own terminology and documentation system.
Cooperation of the Unicode Consortium with the International Organization for Standardization (eng. International Organization for Standardization, ISO ) began in 1991. In 1993, ISO issued the DIS 10646.1 standard. To synchronize with it, the Consortium approved the version 1.1 of the Unicode standard, which added additional characters from DIS 10646.1. As a result, the values of the encoded characters in Unicode 1.1 and DIS 10646.1 are exactly the same.
In the future, cooperation between the two organizations continued. In 2000, the Unicode 3.0 standard was synchronized with ISO / IEC 10646-1: 2000. The upcoming third version of ISO / IEC 10646 will be synchronized with Unicode 4.0. Perhaps these specifications will even be published as a single standard.
Similar to the UTF-16 and UTF-32 formats in the Unicode standard, the ISO / IEC 10646 standard also has two main forms of character encoding: UCS-2 (2 bytes per character, similar to UTF-16) and UCS-4 (4 bytes per character, similar to UTF-32). UCS means universal multi-octet(multibyte) coded character set(eng. universal multiple-octet coded character set ). UCS-2 can be considered a subset of UTF-16 (UTF-16 without surrogate pairs) and UCS-4 is a synonym for UTF-32.
Differences between Unicode and ISO / IEC 10646 standards:
- slight differences in terminology;
- ISO / IEC 10646 does not include the sections required to fully implement Unicode support:
- no data on binary encoding of characters;
- there is no description of comparison algorithms (eng. collation) and rendering (eng. rendering) characters;
- there is no list of properties of symbols (for example, there is no list of properties necessary to implement support for bidirectional (eng. bi-directional) letters).
Presentation methods
Unicode has several forms of representation (eng. Unicode transformation format, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) and UTF-32 (UTF-32BE, UTF-32LE). The UTF-7 representation form was also developed for transmission over seven-bit channels, but due to incompatibility with ASCII, it was not spread and was not included in the standard. On April 1, 2005, two humorous submissions were proposed: UTF-9 and UTF-18 (RFC 4042).
Microsoft Windows NT and Windows 2000 and Windows XP-based systems primarily use the UTF-16LE form. UNIX-like operating systems GNU / Linux, BSD, and Mac OS X adopt UTF-8 for files and UTF-32 or UTF-8 for character processing in random access memory.
Punycode is another form of encoding sequences of Unicode characters into so-called ACE sequences, which consist only of alphanumeric characters, as permitted in domain names.
UTF-8
UTF-8 is the Unicode representation that provides the best compatibility with older systems that used 8-bit characters.
Text containing only characters numbered less than 128 is converted to plain ASCII text when written in UTF-8. Conversely, in UTF-8 text, any byte with a value less than 128 displays ASCII character with the same code.
The rest of the Unicode characters are represented by sequences from 2 to 6 bytes long (in fact, only up to 4 bytes, since there are no characters with a code greater than 10FFFF in Unicode, and there are no plans to introduce them in the future), in which the first byte always has the form 11xxxxxx, and the rest - 10xxxxxx... No surrogate pairs are used in UTF-8, 4 bytes is enough to write any unicode character.
The UTF-8 format was invented on September 2, 1992 by Ken Thompson and Rob Pike and implemented in Plan 9... The UTF-8 standard is now officially enshrined in RFC 3629 and ISO / IEC 10646 Annex D.
UTF-8 characters are derived from Unicode as follows:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Theoretically possible, but also not included in the standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Although UTF-8 allows you to specify the same character in several ways, only the shortest one is correct. The rest of the forms should be rejected for security reasons.
Byte order
In a UTF-16 data stream, the low byte can be written either before the high one (eng. UTF-16 little-endian), or after the older one (eng. UTF-16 big-endian). Similarly, there are two variants of the four-byte encoding - UTF-32LE and UTF-32BE.
To define the format of the Unicode representation at the beginning text file the signature is written - the character U + FEFF (non-breaking space with zero width), also called byte sequence marker(eng. byte order mark (BOM)). This makes it possible to distinguish between UTF-16LE and UTF-16BE since there is no U + FFFE character. It is also sometimes used to denote the UTF-8 format, although the notion of byte order does not apply to this format. Files that follow this convention begin with these byte sequences:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Unfortunately, this method does not reliably distinguish between UTF-16LE and UTF-32LE, since the character U + 0000 is allowed by Unicode (although real texts rarely start with it).
Files in UTF-16 and UTF-32 encodings that do not contain a BOM must be in big-endian (unicode.org) byte order.
Unicode and traditional encodings
The introduction of Unicode changed the approach to traditional 8-bit encodings. If earlier the encoding was specified by the font, now it is specified by the correspondence table between this encoding and Unicode.
In fact, 8-bit encodings have become a form of representing a subset of Unicode. This made it much easier to create programs that need to work with many different encodings: now, to add support for one more encoding, you just need to add another Unicode lookup table.
In addition, many data formats allow you to insert any Unicode characters, even if the document is written in the old 8-bit encoding. For example, you can use ampersand codes in HTML.
Implementation
Most modern operating systems provide some degree of Unicode support.
In operating systems of the Windows NT family, the double-byte UTF-16LE encoding is used for the internal representation of file names and other system strings. System calls that take string parameters are available in single-byte and double-byte variants. For more information, see the article Unicode on the Microsoft Windows family of operating systems.
UNIX-like OS, including GNU / Linux, BSD, OS X, use UTF-8 encoding to represent Unicode. Most programs can handle UTF-8 as traditional single-byte encodings, regardless of the fact that a character is represented as several consecutive bytes. To work with individual characters, strings are usually recoded to UCS-4, so that each character has a machine word.
One of the first successful commercial implementations of Unicode was Wednesday Java programming... It basically abandoned the 8-bit representation of characters in favor of the 16-bit one. This solution increased memory consumption, but allowed us to return an important abstraction to programming: an arbitrary single character (type char). In particular, a programmer could work with a string as with a simple array. Unfortunately, the success was not final, Unicode outgrew the 16-bit limit and by J2SE 5.0, an arbitrary character again began to occupy a variable number of memory units - one char or two (see surrogate pair).
Most programming languages now support Unicode strings, although their representation may differ depending on the implementation.
Input Methods
Because no keyboard layout can allow all Unicode characters to be entered at the same time, operating systems and applications are required to support alternative methods for entering arbitrary Unicode characters.
Microsoft Windows
Although starting in Windows 2000, the Character Map utility (charmap.exe) supports Unicode characters and allows you to copy them to the clipboard, this support is limited to the base plane only (character codes U + 0000… U + FFFF). Symbols with codes from U + 10000 "Symbol table" does not display.
There is a similar table, for example, in Microsoft Word.
Sometimes you can type a hexadecimal code, press Alt + X, and the code will be replaced with the appropriate character, for example, in WordPad, Microsoft Word. In editors, Alt + X performs the reverse transformation as well.
In many MS Windows programs, to get a Unicode character, you need to press the Alt key and type the decimal value of the character code on numeric keypad... For example, the combinations Alt + 0171 ("), Alt + 0187 (") and Alt + 0769 (accent mark) will be useful when typing Cyrillic texts. The combinations Alt + 0133 (…) and Alt + 0151 (-) are also interesting.
Macintosh
Mac OS 8.5 and later supports an input method called "Unicode Hex Input". While holding down the Option key, you need to type the four-digit hexadecimal code of the required character. This method allows you to enter characters with codes greater than U + FFFF using surrogate pairs; such pairs will be automatically replaced by the operating system with single characters. Before use, this input method must be activated in the appropriate section of system settings and then select as the current input method in the keyboard menu.
Starting with Mac OS X 10.2, there is also a Character Palette application that allows you to select characters from a table in which you can select characters from a specific block or characters supported by a specific font.
GNU / Linux
GNOME also has a Symbol Map utility (formerly gucharmap) that allows you to display symbols for a specific block or writing system and provides the ability to search by name or description of a symbol. When the code of the desired character is known, it can be entered in accordance with the ISO 14755 standard: while holding down the Ctrl + ⇧ Shift keys, enter the hexadecimal code (starting with some version of GTK +, the code must be entered by pressing "U"). The entered hexadecimal code can be up to 32 bits in length, allowing you to enter any Unicode characters without using surrogate pairs.
All X Window applications, including GNOME and KDE, support Compose key input. For keyboards that do not have a dedicated Compose key, you can assign any key for this purpose - for example, ⇪ Caps lock.
The GNU / Linux console also allows entering a Unicode character by its code - for this, the decimal code of the character must be entered as digits of the extended keyboard block while holding down the Alt key. You can enter characters by their hexadecimal code: for this you need to hold down the AltGr key, and to enter digits A-F use the keys on the extended keyboard block from NumLock to ↵ Enter (clockwise). Input in accordance with ISO 14755 is also supported. In order for the above methods to work, you need to enable Unicode mode in the console by calling unicode_start(1) and select a suitable font by calling setfont(8).
Mozilla Firefox for Linux supports ISO 14755 character input.
Unicode problems
In Unicode, English "a" and Polish "a" are the same character. In the same way, the Russian "a" and the Serbian "a" are considered the same symbol (but different from the Latin "a"). This coding principle is not universal; apparently, a solution "for all occasions" cannot exist at all.
- Chinese, Korean, and Japanese are traditionally written from top to bottom, starting at the top right corner. Switching between horizontal and vertical spellings for these languages is not provided for in Unicode - this must be done by means of markup languages or internal mechanisms of word processors.
- Unicode allows for different weights of the same character depending on the language. So, Chinese characters can have different weights in Chinese, Japanese (kanji) and Korean (hancha), but at the same time in Unicode they are denoted by the same symbol (the so-called CJK unification), although simplified and full characters still have different codes ... Likewise, Russian and Serbian languages use different cursive italics. NS and T(in Serbian they look like u and w, see Serbian italics). Therefore, you need to ensure that the text is always correctly marked as related to one or another language.
- The translation from lowercase to uppercase also depends on the language. For example: in Turkish there are letters İi and Iı - thus, the Turkish case-changing rules conflict with the English ones, which require “i” to be translated into “I”. Similar problems exist in other languages - for example, in the Canadian dialect of French, the register is translated a little differently than in France.
- Even with Arabic numerals, there are certain typographic subtleties: the numbers are "uppercase" and "lowercase", proportional and monospaced - for Unicode there is no difference between them. Such nuances remain with the software.
Some of the disadvantages are not related to Unicode itself, but rather to the capabilities of the text processors.
- Files of non-Latin text in Unicode always take up more space, since one character is encoded not by one byte, as in various national encodings, but by a sequence of bytes (the exception is UTF-8 for languages whose alphabet fits into ASCII, as well as the presence of two characters in the text and more languages, the alphabet of which not fits into ASCII). The font file required to display all the characters in the Unicode table takes up relatively large memory space and is more computationally intensive than the user's national language font alone. With the increase in the power of computer systems and the reduction in the cost of memory and disk space, this problem becomes less and less significant; however, it remains relevant for portable devices such as mobile phones.
- Although Unicode support is implemented in the most common operating systems, still not all applied software supports correct work with him. In particular, Byte Order Marks (BOM) are not always processed and accented characters are poorly supported. The problem is temporary and is a consequence of the comparative novelty of Unicode standards (in comparison with single-byte national encodings).
- The performance of all string processing programs (including sorts in the database) decreases when Unicode is used instead of single-byte encodings.
Some rare writing systems are still not represented properly in Unicode. The depiction of "long" superscript characters extending over several letters, as, for example, in Church Slavonic, has not yet been implemented.
Unicode or Unicode?
"Unicode" is both a proper name (or part of a name, for example, the Unicode Consortium) and a common name derived from the English language.
At first glance, it is preferable to use the spelling "Unicode". In the Russian language there are already morphemes “uni-” (words with the Latin element “uni-” were traditionally translated and written through “uni-”: universal, unipolar, unification, uniform) and “code”. Against, trade marks, borrowed from the English language, are usually transmitted through practical transcription, in which the de-etymologized combination of letters "uni-" is written as "uni-" ("Unilever", "Unix", etc.), that is, in the same way as in the case of letter-by-letter acronyms like UNICEF “United Nations International Children's Emergency Fund” - UNICEF.
The spelling of "Unicode" has already firmly entered the Russian-language texts. Wikipedia uses a more common version. On MS Windows, the Unicode option is used.
There is a special page on the Consortium's website, where the problems of transferring the word "Unicode" to different languages and writing systems. For the Russian Cyrillic alphabet, the option "Unicode" is specified.
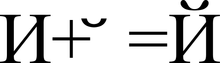
The problems associated with encodings are usually taken care of by the software, so there is usually no difficulty in using encodings. If difficulties arise, then they are usually generated by bad programs - feel free to send them to the trash.
I invite everyone to speak out in
ASCII (English American Standard Code for Information Interchange) is the American standard encoding table for printable characters and some special codes. In American English, [eśski] is pronounced, while in the UK, [aski] is more pronounced; in Russian it is also pronounced [aski] or [aski].
ASCII is an encoding for decimal digits, Latin and national alphabets, punctuation and control characters. Originally designed as 7-bit, with the widespread use of the 8-bit ASCII byte, it has come to be thought of as half of the 8-bit. Computers usually use ASCII extensions with the 8th bit involved and the second half of the code table (for example, KOI-8).
Unicode
In 1991, a non-profit organization Unicode Consortium was created in California, which includes representatives of many computer firms (Borland, IBM, Lotus, Microsoft, Novell, Sun, WordPerfect, etc.), and which is developing and implementing the standard "The Unicode Standard" ... The Unicode character encoding standard is becoming dominant in international multilingual software environments. Microsoft Windows NT and its descendants Windows 2000, 2003, XP use Unicode, more precisely UTF-16, as the internal text representation. UNIX-like operating systems such as Linux, BSD, and Mac OS X have adopted Unicode (UTF-8) as the primary representation of multilingual text. Unicode reserves 1,114,112 (220 + 216) code characters, currently over 96,000 characters are used. The first 256 character codes correspond exactly to those of ISO 8859-1, the most popular 8-bit character table in the Western world; as a result, the first 128 characters are also identical to the ASCII table. The Unicode code space is divided into 17 "planes", and each plan has 65536 (= 216) code points. The first plane (plane 0), the Basic Multilingual Plane (BMP) is the one in which most of the characters are described. BMP contains symbols for almost everyone modern languages, and a large number of special characters. Two more planes are used for "graphic" symbols. Plane 1, Supplementary Multilingual Plane (SMP) is primarily used for historical symbols, and is also used for musical and mathematical symbols. Plan 2, Supplementary Ideographic Plane (SIP), is used for approximately 40,000 rare Chinese characters. Plan 15 and Plan 16 are open to any private use. Figure 1.10 shows the Russian Unicode block (U + 0400 to U + 04FF).
Common encodings
ISO 646 ASCII BCDIC EBCDIC ISO 8859: ISO 8859-1, ISO 8859-2, ISO 8859-3, ISO 8859-4, ISO 8859-5, ISO 8859-6, ISO 8859-7, ISO 8859-8, ISO 8859 -9, ISO 8859-10, ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866 , CP869 Microsoft encodings Windows: Windows-1250 for Central European languages that use Latin spelling (Polish, Czech, Slovak, Hungarian, Slovenian, Croatian, Romanian and Albanian) Windows-1251 for Cyrillic alphabets Windows-1252 for Western languages Windows-1253 for Greek Windows-1254 for Turkish Windows-1255 for Hebrew Windows-1256 for Arabic Windows-1257 for Baltic languages Windows-1258 for Vietnamese MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 Bulgarian ISCII encoding VISCII Big5 (most famous variant of Microsoft CP950) HKSCS Guobiao GB2312 GBK (Microsoft CP936) GB18030 Shift JIS for Japanese (Microsoft CP932) EUC-KR for Korean (Microsoft CP949) ISO-2022 and EUC for Chinese UTF-8 encodings, UTF-16 and UTF-32 Unicode character sets \
Graphic information encoding
Since the 80s. the technology of processing graphic information on a PC is developing. The form of representation on the display screen of a graphic image consisting of individual dots (pixels) is called raster. The minimum object in a raster graphics editor is a point. The raster graphics editor is designed to create pictures, diagrams. The resolution of the monitor (the number of horizontal and vertical dots), as well as the number of possible colors of each dot are determined by the monitor type. 1 pixel of a black-and-white screen is encoded with 1 bit of information (black dot or white dot). The number of different colors K and the number of bits for their encoding are related by the formula: K = 2b. Modern monitors have the following color palettes: 16 colors, 256 colors; 65,536 colors (high color), 16,777,216 colors (true color).
Bitmap
With the help of a magnifying glass, you can see that a black-and-white graphic image, for example from a newspaper, consists of the smallest dots that make up a certain pattern - a raster. In France in the 19th century, a new direction in painting arose - pointillism. His technique consisted in the fact that the drawing was applied to the canvas with a brush in the form of multi-colored dots. Also, this method has long been used in the printing industry to encode graphic information. The accuracy of the drawing depends on the number of dots and their size. After dividing the picture into points, starting from the left corner, moving along the lines from left to right, you can encode the color of each point. Further, one such point will be called a pixel (the origin of this word is associated with the English abbreviation "picture element" - a picture element). The volume of a raster image is determined by multiplying the number of pixels (by the information volume of one point, which depends on the number of possible colors. The image quality is determined by the resolution of the monitor. The higher it is, that is, the greater the number of raster lines and dots in a line, the higher the image quality. PCs mainly use the following screen resolutions: 640 by 480, 800 by 600, 1024 by 768 and 1280 by 1024 pixels.Since the brightness of each point and its linear coordinates can be expressed using integers, we can say that this coding method allows the use of binary code in order to process graphic data.
If we talk about black and white illustrations, then if you do not use halftones, then the pixel will assume one of two states: lit (white) and not lit (black). And since information about the color of a pixel is called a pixel code, one bit of memory is enough to encode it: 0 - black, 1 - white. If illustrations are considered in the form of a combination of dots with 256 shades of gray (namely, these are currently generally accepted), then an eight-bit binary number in order to encode the brightness of any point. V computer graphics color is extremely important. It acts as a means of enhancing the visual impression and increasing the information saturation of the image. How is the sense of color formed in the human brain? This occurs as a result of the analysis of the light flux entering the retina from reflective or emitting objects. It is generally accepted that human color receptors, which are also called cones, are divided into three groups, and each can perceive only one color - red, or green, or blue.
Color models
When it comes to coding color graphic images, then you need to consider the principle of decomposition of an arbitrary color into its main components. Several coding systems are used: HSB, RGB and CMYK. The first color model is simple and intuitive, that is, it is convenient for a person, the second is the most convenient for a computer, and the last CMYK model is for printing houses. The use of these color models is due to the fact that the luminous flux can be formed by radiation, which is a combination of "pure" spectral colors: red, green, blue or their derivatives. Distinguish between additive color reproduction (typical for emitting objects) and subtractive color reproduction (typical for reflective objects). An example of an object of the first type is a cathode-ray tube of a monitor, of the second type - a printed print.

The HSB model is characterized by three components: Hue, Saturation, and Brightness. You can get a lot of arbitrary colors by adjusting these components. This color model is best used in those graphic editors, in which the images are created by themselves, and not processed already ready. Then the created artwork can be converted to RGB color model if it is planned to be used as an on-screen illustration, or CMYK, if it is printed. The color value is selected as a vector outgoing from the center of the circle. The direction of the vector is specified in angular degrees and determines the hue. The color saturation is determined by the vector length, and the color brightness is set on a separate axis, the zero point of which is black. The center point is white (neutral), and the points around the perimeter are solid colors.
The principle of the RGB method is as follows: it is known that any color can be represented as a combination of three colors: red (Red, R), green (Green, G), blue (Blue, B). Other colors and their shades are obtained due to the presence or absence of these components. From the first letters of the primary colors, the system got its name - RGB. This color model is additive, that is, any color can be obtained by a combination of primary colors in various proportions. When one component of the primary color is superimposed on another, the brightness of the total radiation increases. If we combine all three components, then we get an achromatic gray color, with an increase in the brightness of which, an approach to white occurs.
With 256 tones (each point is encoded with 3 bytes), the minimum RGB values (0,0,0) correspond to black, and white - to the maximum with coordinates (255, 255, 255). The larger the byte value of the color component, the brighter this color is. For example, dark blue is encoded with three bytes (0, 0, 128) and bright blue (0, 0, 255).
The principle of the CMYK method. This color model is used when preparing publications for printing. Each of the primary colors is assigned a complementary color (complementary to the primary color to white). An additional color is obtained by summing up a pair of the remaining primary colors. This means that complementary colors for red are cyan (Cyan, C) = green + blue = white - red, for green - magenta (Magenta, M) = red + blue = white - green, for blue - yellow (Yellow, Y) = red + green = white - blue. Moreover, the principle of decomposition of an arbitrary color into components can be applied both for the main and for additional ones, that is, any color can be represented either as the sum of the red, green, blue component, or as the sum of the cyan, purple, yellow component. Basically, this method is adopted in the printing industry. But there they still use black (BlacK, since the letter B is already occupied by blue, it is denoted by the letter K). This is because superimposing complementary colors does not produce pure black.
Vector and fractal images
A vector image is a graphic object consisting of elementary lines and arcs. The basic element of the image is a line. Like any object, it has properties: shape (straight, curve), thickness., Color, style (dotted, solid). Closed lines have the property of filling (either with other objects, or with a selected color). All other objects vector graphics made up of lines. Since a line is described mathematically as a single object, the amount of data for displaying an object by means of vector graphics is much less than in raster graphics. Information about a vector image is encoded as normal alphanumeric and processed by special programs.
TO software creation and processing of vector graphics include the following GR: CorelDraw, Adobe Illustrator, as well as vectorizers (tracer) - specialized packages for converting raster images into vector.

Fractal graphics are based on mathematical calculations, just like vector graphics. But unlike the vector, its basic element is the mathematical formula itself. This leads to the fact that no objects are stored in the computer's memory and the image is built only by equations. Using this method, you can build the simplest regular structures, as well as complex illustrations that imitate landscapes.

Audio coding
The world is filled with a wide variety of sounds: the ticking of clocks and the hum of motors, the howling of the wind and rustling of leaves, the singing of birds and the voices of people. About how sounds are born and what they are, people began to guess a long time ago. Even the ancient Greek philosopher and scientist - the encyclopedist Aristotle, based on observations, explained the nature of sound, believing that the sounding body creates alternating compression and rarefaction of air. So, an oscillating string sometimes discharges, then compresses the air, and due to the elasticity of the air, these alternating influences are transmitted further into space - from layer to layer, elastic waves arise. When they reach our ear, they act on the eardrums and produce the sensation of sound.
By ear, a person perceives elastic waves with a frequency somewhere in the range from 16 Hz to 20 kHz (1 Hz - 1 vibration per second). In accordance with this, elastic waves in any medium, the frequencies of which lie within the specified limits, are called sound waves or simply sound. In the study of sound, concepts such as tone and timbre of sound are important. Any real sound, be it the play of musical instruments or the voice of a person, is a kind of mixture of many harmonic vibrations with a certain set of frequencies.
The oscillation that has the lowest frequency is called the fundamental, others are called overtones.
Timbre is a different number of overtones inherent in a particular sound, which gives it a special color. The difference between one timbre from another is due not only to the number, but also to the intensity of the overtones that accompany the sound of the main tone. It is by the timbre that we can easily distinguish between the sounds of a grand piano and a violin, a guitar and a flute, and recognize the voice of a familiar person.
Musical sound can be characterized by three qualities: timbre, that is, the color of the sound, which depends on the shape of the vibrations, the height, which is determined by the number of vibrations per second (frequency), and the loudness, which depends on the intensity of the vibrations.
The computer is now widely used in various fields. Processing of sound information and music were no exception. Until 1983, all recordings of music were released on vinyl records and compact cassettes. Currently, CDs are widely used. If you have a computer on which a studio sound card is installed, with a MIDI keyboard and microphone connected to it, then you can work with specialized music software.
Digital-to-analog and analog-to-digital conversion of audio information
Let's take a quick look at the processes of converting sound from analog to digital and vice versa. A rough idea of what is happening in the sound card can help to avoid some mistakes when working with sound.
Sound waves are converted into an analog alternating electrical signal using a microphone. It passes through the audio path and into an analog-to-digital converter (ADC), a device that converts the signal into digital form.
In a simplified form, the principle of operation of the ADC is as follows: it measures the signal amplitude at regular intervals and transmits further, already through the digital path, a sequence of numbers that carry information about the amplitude changes. During analog-to-digital conversion, no physical conversion occurs. An imprint or sample is taken from the electrical signal, as it were, which is a digital model of voltage fluctuations in the audio path. If this is depicted in the form of a diagram, then this model is presented in the form of a sequence of columns, each of which corresponds to a certain numerical value. The digital signal is discrete in nature - that is, discontinuous, so the digital model does not exactly match the analog waveform.
A sample is the time interval between two measurements of the amplitude of an analog signal.
Sample literally translates from English as "sample". In multimedia and professional audio terminology, this word has several meanings. In addition to a period of time, a sample is also called any sequence of digital data that is obtained by analog-to-digital conversion. The conversion process itself is called sampling. In the Russian technical language, it is called discretization.
Digital sound is output using a digital-to-analog converter (DAC), which, on the basis of the incoming digital data at the appropriate times, generates an electrical signal of the required amplitude
Sampling options
Frequency and bit depth are important sampling parameters. Frequency - the number of measurements of the analog signal amplitude per second.
If the sampling frequency is not more than twice the frequency of the upper boundary of the sound range, then on high frequencies losses will occur. This explains why the standard audio CD frequency is 44.1 kHz. Since the range of oscillations of sound waves is in the range from 20 Hz to 20 kHz, the number of signal measurements per second should be greater than the number of oscillations over the same period of time. If the sampling rate is significantly lower than the frequency of the sound wave, then the signal amplitude has time to change several times during the time between measurements, and this leads to the fact that the digital fingerprint carries a chaotic data set. During digital-to-analog conversion, such a sample does not transmit the main signal, but only produces noise.
In the new CD format Audio DVD, the signal is measured 96,000 times in one second, i.e. use a sampling rate of 96 kHz. To save space on the hard disk in multimedia applications, lower frequencies are often used: 11, 22, 32 kHz. This leads to a decrease in the audible frequency range, which means that there is a strong distortion of what is heard.
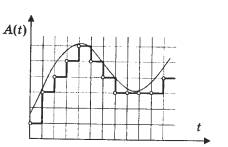
If in the form of a graph we represent the same sound with a height of 1 kHz (a note up to the seventh octave of the piano roughly corresponds to this frequency), but sampled with a different frequency (the lower part of the sinusoid is not shown in all graphs), then the differences will be visible. One division on the horizontal axis, which shows the time, corresponds to 10 samples. The scale is the same. You can see that at a frequency of 11 kHz, there are about five oscillations of the sound wave for every 50 samples, that is, one period of the sine wave is displayed using only 10 values. This is a rather imprecise transmission. At the same time, if we consider the sampling frequency of 44 kHz, then for each period of the sinusoid there are already almost 50 samples. This allows you to get a good quality signal.
The bit depth indicates the accuracy with which the amplitude of the analog signal changes. The accuracy with which the value of the signal amplitude is transmitted during digitization at each of the points in time determines the quality of the signal after the digital-to-analog conversion. The accuracy of the waveform reconstruction depends on the bit depth.
The amplitude value is encoded using the binary encoding principle. The audio signal should be presented as a sequence of electrical impulses (binary zeros and ones). Typically 8, 16-bit or 20-bit representations of the amplitude values are used. When binary coding continuous sound signal it is replaced by a sequence of discrete signal levels. The coding quality depends on the sampling rate (the number of measurements of the signal level per unit of time). With an increase in the sampling rate, the accuracy of the binary representation of information increases. At a frequency of 8 kHz (the number of measurements per second is 8000), the quality of the sampled sound signal corresponds to the quality of the radio broadcast, and at a frequency of 48 kHz (the number of measurements per second is 48000) - to the sound quality of an audio CD.
Currently, there is a new consumer digital format Audio DVD, which uses 24-bit and 96 kHz sampling rate. With its help, the abovementioned disadvantage of 16-bit encoding can be avoided.
To modern digital sound devices 20-bit converters are installed. The sound remains 16-bit, converters of increased bit depth are installed to improve the quality of recording at low levels. Their principle of operation is as follows: the original analog signal is digitized with a width of 20 bits. Then the digital signal processor DSPP reduces its width to 16 bits. In this case, a special calculation algorithm is used, with the help of which it is possible to reduce the distortion of low-level signals. The opposite process is observed during digital-to-analog conversion: the bit depth increases from 16 to 20 bits using a special algorithm that allows you to more accurately determine the amplitude values. That is, the sound remains 16-bit, but there is an overall improvement in sound quality.
What is encoding
In Russian, "character set" is also called a "character set" table, and the process of using this table to translate information from a computer representation into a human one, and a characteristic of a text file, reflecting the use of a certain system of codes in it when displaying text.
How text is encoded
The set of symbols used in writing text is referred to in computer terminology as an alphabet; the number of characters in the alphabet is usually called its power. For presentation text information the computer most often uses an alphabet with a capacity of 256 characters. One of its characters carries 8 bits of information, therefore, the binary code of each character takes 1 byte of computer memory. All characters of such an alphabet are numbered from 0 to 255, and each number corresponds to an 8-bit binary code, which is the ordinal number of a character in the binary number system - from 00000000 to 11111111. Only the first 128 characters with numbers from zero ( binary code 00000000) to 127 (01111111). These include lowercase and uppercase letters Latin alphabet, numbers, punctuation marks, brackets, etc. The remaining 128 codes, starting with 128 (binary code 10000000) and ending with 255 (11111111), are used to encode letters of national alphabets, official and scientific symbols.
Types of encodings
The most famous encoding table is ASCII (American Standard Code for Information Interchange). It was originally developed for the transmission of texts by telegraph, and at that time it was 7-bit, that is, only 128 7-bit combinations were used to encode English characters, service and control characters. In this case, the first 32 combinations (codes) served to encode control signals (start of text, end of line, carriage return, call, end of text, etc.). In the development of the first IBM computers, this code was used to represent symbols in a computer. Since in source code ASCII was only 128 characters, for their encoding were enough byte values with the 8th bit equal to 0. Byte values with the 8th bit equal to 1 were used to represent pseudo-graphic characters, mathematical signs and some characters from languages English (Greek, German umlauts, French diacritics, etc.). When they began to adapt computers for other countries and languages, there was no longer enough room for new symbols. To fully support languages other than English, IBM has introduced several country-specific code tables. So for the Scandinavian countries, table 865 (Nordic) was proposed, for the Arab countries - table 864 (Arabic), for Israel - table 862 (Israel), and so on. In these tables, some of the codes from the second half of the code table were used to represent the characters of the national alphabets (by excluding some of the pseudo-graphic characters). The situation with the Russian language developed in a special way. Obviously, the replacement of characters in the second half of the code table can be done different ways... So several different Cyrillic character encoding tables appeared for the Russian language: KOI8-R, IBM-866, CP-1251, ISO-8551-5. All of them represent the symbols of the first half of the table in the same way (from 0 to 127) and differ in the representation of the symbols of the Russian alphabet and pseudo-graphics. For languages like Chinese or Japanese, 256 characters are generally not enough. In addition, there is always the problem of outputting or saving in one file at the same time texts on different languages(for example, when quoting). Therefore, a universal code table UNICODE, containing symbols used in the languages of all peoples of the world, as well as various service and auxiliary symbols (punctuation marks, mathematical and technical symbols, arrows, diacritics, etc.). Obviously, one byte is not enough to encode such a large set of characters. Therefore UNICODE uses 16-bit (2-byte) codes to represent 65,536 characters. To date, about 49,000 codes have been used (the last significant change was the introduction of the EURO currency symbol in September 1998). For compatibility with previous encodings, the first 256 codes are the same as the ASCII standard. In the UNICODE standard, in addition to a certain binary code (these codes are usually denoted by the letter U, followed by a + sign and the actual code in hexadecimal representation), each character is assigned a specific name. Another component UNICODE standard are algorithms for one-to-one conversion of UNICODE codes in a sequence of bytes of variable length. The need for such algorithms is due to the fact that not all applications can work with UNICODE. Some applications only understand 7-bit ASCII codes, other applications understand 8-bit ASCII codes. Such applications use the so-called extended ASCII codes to represent characters that do not fit, respectively, in a 128-character or 256-character set, when characters are encoded with variable-length byte strings. UTF-7 is used to reversibly convert UNICODE codes to extended 7-bit ASCII codes, and UTF-8 is used to reversibly convert UNICODE codes to extended 8-bit ASCII codes. Note that both ASCII and UNICODE and other character encoding standards do not define the images of characters, but only the composition of the character set and the way it is represented in a computer. In addition (which may not be immediately obvious), the order of the enumeration of characters in the set is very important, since it affects the sorting algorithms in the most significant way. It is the table of correspondence of symbols from a certain set (say, symbols used to represent information on English language, or in different languages, as in the case of UNICODE) and denote by the term character encoding table or charset. Each standard encoding has a name such as KOI8-R, ISO_8859-1, ASCII. Unfortunately, there is no standard for encoding names.
Common encodings
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Microsoft Windows encodings: o Windows-1250 for Central European languages that use Latin letters o Windows-1251 for Cyrillic alphabets o Windows-1252 for Western languages o Windows-1253 for Greek o Windows -1254 for Turkish o Windows-1255 for Hebrew o Windows-1256 for Arabic o Windows-1257 for Baltic languages o Windows-1258 for Vietnamese MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 Bulgarian encoding ISCII VISCII Big5 (most famous variant of Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS for Japanese (Microsoft CP932) EUC-KR for Korean (Microsoft CP949) ISO-2022 and EUC for Chinese Writing System UTF-8 and UTF-16 encodings of the Yong character set icodeIn the coding system ASCII(American Standard Code for Information Interchange) each character is represented by one byte, which can encode 256 characters.
ASCII has two encoding tables - basic and extended. The base table fixes the values of the codes from 0 to 127, and the extended one refers to characters with numbers from 128 to 255. This is enough to express with various combinations of eight bits all the characters of the English and Russian languages, both lowercase and uppercase, as well as punctuation marks, symbols for basic arithmetic operations and common special symbols that can be observed on the keyboard.
The first 32 codes of the base table, starting from zero, are given to hardware manufacturers (primarily to manufacturers of computers and printing devices). This area contains the so-called control codes, which do not correspond to any language characters, and, accordingly, these codes are not displayed either on the screen or on printing devices, but they can be controlled by how other data is output. Starting from code 32 to code 127, the symbols of the English alphabet, punctuation marks, numbers, arithmetic operations and auxiliary symbols are placed, all of them can be seen on the Latin part of the computer keyboard.
The second, extended part is given to national coding systems. There are many non-Latin alphabets in the world (Arabic, Hebrew, Greek, etc.), including the Cyrillic alphabet. Also, the German, French, Spanish keyboard layouts are different from the English ones.
The English part of the keyboard used to have many standards, but now they have all been replaced by a single ASCII code. For the Russian keyboard, there were also many standards: GOST, GOST-alternative, ISO (International Standard Organization - International Institute for Standardization), but these three standards have actually died out, although they can meet somewhere, in some antediluvian computers or in computer networks.
The main character encoding of the Russian language, which is used in computers with an operating Windows system called Windows-1251, it was developed for the Cyrillic alphabets by Microsoft. Naturally, the absolute majority of computer text data is encoded in Windows-1251. By the way, encodings with a different four-digit number were developed by Microsoft for other common alphabets: Arabic, Japanese and others.
Another common encoding is called KOI-8(information exchange code, eight-digit) - its origin dates back to the times of the Council for Mutual Economic Assistance of Eastern European States. Today the KOI-8 encoding is widespread in computer networks on the territory of Russia and in the Russian sector of the Internet. It so happens that some text of the letter or something else is not readable, which means that you need to switch from KOI-8 to Windows-1251. ten
In the 90s, the largest software manufacturers: Microsoft, Borland, the same Adobe decided on the need to develop a different text encoding system, in which each character will be allocated not 1, but 2 bytes. She got the name Unicode, and it is possible to encode 65,536 characters of this field is enough to fit in one table of national alphabets for all languages of the planet. Most of Unicode (about 70%) is occupied by Chinese characters, in India there are 11 different national alphabets, there are many exotic names, for example: the writing of the Canadian aborigines.
Since the encoding of each character in Unicode is allocated not 8, but 16 bits, the size of the text file is doubled. This was once an obstacle to the introduction of a 16-bit system. and now with gigabyte hard drives, hundreds of megabytes of RAM, gigahertz processors, doubling the volume of text files, which, in comparison, for example, with graphics, take up very little space, does not really matter.
The Cyrillic alphabet in Unicode ranks from 768 to 923 (basic characters) and from 924 to 1023 (extended Cyrillic, various less common national letters). If the program is not adapted for the Cyrillic Unicode, then it is possible that the text characters are recognized not as Cyrillic, but as extended Latin (codes from 256 to 511). And in this case, instead of text, a meaningless set of various exotic symbols appears on the screen.
This is possible if the program is outdated, created before 1995. Or a rare one, about which no one bothered to Russify. It is also possible that the Windows OS installed on the computer is not fully configured for the Cyrillic alphabet. In this case, you need to make the appropriate entries in the registry.
 Differences Between GPT and MBR Partition Structures
Differences Between GPT and MBR Partition Structures Wipe Internet explorer clean
Wipe Internet explorer clean Windows updates are downloaded but not installed
Windows updates are downloaded but not installed