Ansi code table. Encodings: useful information and a brief retrospective
If you only need to enter a few special characters or characters, you can use the character table or keyboard shortcuts. For a list of ASCII characters, see the tables below or Inserting National Letters Using Keyboard Shortcuts.
Notes:
Inserting ASCII Characters
To insert an ASCII character, press and hold the ALT key, and then type the character code. For example, to insert a degree sign (º), hold down the ALT key and type in numeric keypad code 0176.
Note:
Inserting Unicode Characters
Important: Some Microsoft programs Office, such as PowerPoint and InfoPath, cannot convert Unicode character codes. If you require a Unicode character and are using one of the programs that do not support Unicode characters, use to enter characters, which you may need.
Notes:
Quit all programs.
Double click the icon Installation and removal of programms on control panels.
Do one of the following:
if application Microsoft Office installed as part of Microsoft Office, select Microsoft Office in field Installed programs and then press the button Replace;
If Office application was installed separately, click its name in the list Installed programs and then press the button Change.
Numbers should be typed on the numeric keypad, not alphanumeric. If you need to press to enter numbers on the numeric keypad NUM key LOCK, make sure this is done.
If you're having trouble converting a Unicode code to a character, type the code on the numeric keypad, select it, and then press Alt + X.
V Microsoft Windows XP and later versions of the Universal Unicode Font are installed automatically. In Microsoft Windows 2000, the Unicode font must be installed manually.
On Microsoft Windows 2000
In the dialog box Installing Microsoft Office 2003 select an option Add or remove components and then press the button Further.
Please select Additional customization applications and press the button Further.
Expand the list Common Office Tools.
Expand the list Multilingual support.
Click the icon Universal font and select the desired installation option.
Using the symbol table
Symbol table is Microsoft's built-in Windows program, which allows you to view the characters available in the selected font. Using a symbol table, you can copy individual symbols or groups of symbols to the clipboard and then paste them into a program that supports them.
Click the button Start, and then select Programs, Standard, Service and table of symbols.
To select a symbol in the symbol table, click it, press the button Select, click right click mouse in the place of the document where you want to add the symbol, and select the command Insert.
Common character codes
For more character characters, see the article installed on your computer, ASCII character codes, or a Unicode character code script diagram.
|
Sign |
Sign |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Currency symbols |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Legal Symbols |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Fractions |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Punctuation and dialect symbols |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Form symbols |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Common diacritical codesFor a complete list of glyphs and associated character codes, see.
|
Sometimes even a fairly experienced specialist will not immediately tell you what a particular value of pressure or length in one system corresponds to values in another system of values.
To facilitate you this task, we offer tables of the ratio of pressure and length values in the European and American systems with small explanations... But first, a few words about the standards themselves.
DIN is the German standard (stands for Deutsches Institut für Normung, that is, developed by the German Institute for Standardization), which is developed strictly within the framework of the provisions of the International Organization for Standardization - ISO (International Organization for Standardization).
ANSI- the standard adopted in the United States of America. Stands for American National Standards Institute, that is, the standard of the American National Standards Institute.
Accordingly, ANSI standards are determined by this institution, and far not always between standards DIN and ANSI the exact conformity in various fields.
Converting pressure units from ANSI to DIN
Everything is simple here: if the standard ANSI the number 150 stands opposite the pressure - this means that the nominal (for which the valve is designed) pressure is 20 bar, 300 - 50 bar, etc. Maximum value by ANSI Class- 2500 will be equal to 420 bar according to the European standard DIN.
Using this table, not difficult translate pressure values and back: from DIN v ANSI, although our engineers need to carry out such a translation much less often.
Conversion of units of length from the American system to the European (Russian)
As is known, the americans everything is measured in inches and feet, and we and Europeans- millimeters, centimeters and meters, that is, like the vast majority of states in the world, we live in metric system of units.
How to convert inches to millimeters? In fact, this is also not difficult, just remember that 1 inch equals 25.4 mm. However, often a digit after the decimal point neglected and for even counting indicate that 1 inch = 25mm.
Thus, if, for example, the cross-section of the inlet is 2 inches according to the American system of measures, then, by translating this value into our system of measures according to the above rule, we get 50 mm or, more precisely, 51 mm (rounding 50.8 according to the rules) ...
It remains to add that the diameter in technical characteristics are marked with Latin letters DN and is often indicated precisely in inches, and pressure is indicated by the letters PN and is indicated most often in bars- in any case, we use just such a marking as the most comfortable.
And the following table will help you can calculate not only precise the number of millimeters in one inch (with an accuracy of a thousandth of a millimeter), but it will also help you find out how many millimeters are contained, for example, in 2.5 inches.
To do this, find column 2 "" (2 inches), and on the left look for 1/2. Total 2.5 inches = 63.501 mm, which is quite possible to round up to 64 mm, and, for example, 6.25 inches (i.e. 6 and 1/4) = 158.753 mm or 159 mm.
|
| Inches "" in millimeters |
|||||||
|
| ||||||||
|
| ||||||||
Bootstrap framework: fast responsive layout
A step-by-step video tutorial on the basics of responsive layout in the Bootstrap framework.
Learn to typeset easily, quickly and efficiently using a powerful and practical tool.
Layout to order and get paid.
Free Course "WordPress Site"
Want to master a WordPress CMS?
Get tutorials on WordPress website design and layout.
Learn to work with themes and slice the layout.
Free video course on drawing site design, layout and installation on CMS WordPress!
* Hover your mouse to pause scrolling.
Back forward
Encodings: useful information and a brief retrospective
I decided to write this article as a small overview on the issue of encodings.
We will figure out what encoding is in general and touch on the history of how they appeared in principle.
We will talk about some of their features and also consider the moments that allow us to work with encodings more consciously and avoid the appearance on the site of the so-called krakozyabrov, i.e. unreadable characters.
So let's go ...
What is encoding?
To put it simply, encoding is a table of character mappings that we can see on the screen, to certain numeric codes.
Those. each character that we enter from the keyboard, or see on the monitor screen, is encoded with a certain sequence of bits (zeros and ones). 8 bits, as you probably know, are equal to 1 byte of information, but more on that later.
The appearance of the symbols themselves is determined by the font files that are installed on your computer. Therefore, the process of displaying text on the screen can be described as a constant mapping of sequences of zeros and ones to some specific characters that make up the font.
The progenitor of all modern encodings can be considered ASCII.
This abbreviation stands for American Standard Code for Information Interchange(American Standard Coding Table for printable characters and some special codes).
it single-byte encoding, which initially contained only 128 characters: letters of the Latin alphabet, Arabic numerals, etc.

Later it was expanded (initially it did not use all 8 bits), so it became possible to use not 128, but 256 (2 to the 8th power) different characters that can be encoded in one byte of information.
This improvement made it possible to add to ASCII symbols of national languages, in addition to the already existing Latin alphabet.
There are a lot of options for extended ASCII encoding due to the fact that there are also many languages in the world. I think that many of you have heard of such an encoding as KOI8-R is also an extended ASCII encoding designed to work with the characters of the Russian language.
The next step in the development of encodings can be considered the emergence of the so-called ANSI encodings.
In fact, they were the same extended ASCII versions however, various pseudo-graphic elements have been removed from them and typographic symbols have been added, for which there was not enough "free space" before.
An example of such an ANSI encoding is the well-known Windows-1251... In addition to typographic characters, this encoding also included letters of the alphabets of languages close to Russian (Ukrainian, Belarusian, Serbian, Macedonian and Bulgarian).
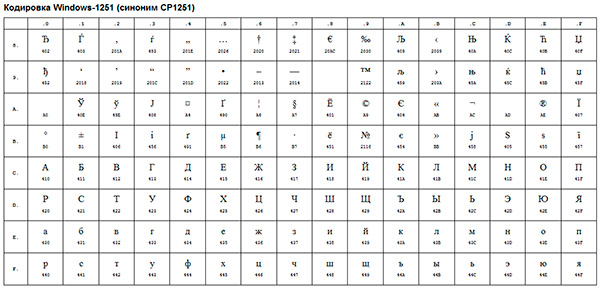
ANSI encoding is a collective name... In fact, the actual encoding when using ANSI will be determined by what is specified in the registry of your operating system Windows. In the case of the Russian language, it will be Windows-1251, however, for other languages it will be a different kind of ANSI.
As you understand, a bunch of encodings and the lack of a single standard did not bring to good luck, which became the reason for frequent meetings with the so-called krakozyabrami- an unreadable meaningless set of characters.
The reason for their appearance is simple - it is trying to display characters encoded with one encoding table using a different encoding table.
In the context of web development, we may encounter krakozyabras when, for example, Russian text is mistakenly saved in the wrong encoding that is used on the server.
Of course, this is not the only case when we can get unreadable text - there are a lot of options here, especially when you consider that there is also a database in which information is also stored in a certain encoding, there is a mapping of a connection to a database, etc.
The emergence of all these problems served as an incentive to create something new. It had to be an encoding that could encode any language in the world (after all, with the help of single-byte encodings, at all desire, one cannot describe all characters, say, of the Chinese language, where there are clearly more than 256 of them), any additional special characters and typography.
In short, it was necessary to create a universal encoding that would solve the problem of krakozyabrov once and for all.
Unicode - Universal Text Encoding (UTF-32, UTF-16, and UTF-8)
The standard itself was proposed in 1991 by a non-profit organization Unicode Consortium(Unicode Consortium, Unicode Inc.), and the first result of his work was the creation of the encoding UTF-32.
By the way, the abbreviation itself UTF stands for Unicode Transformation Format(Unicode Conversion Format).
In this encoding, to encode one character, it was supposed to use as much 32 bit, i.e. 4 bytes of information. If we compare this number with single-byte encodings, then we come to a simple conclusion: to encode 1 character in this universal encoding, you need 4 times more bits, which makes the file 4 times heavier.
It is also obvious that the number of characters that could potentially be described using this encoding exceeds all reasonable limits and is technically limited to a number equal to 2 to the 32nd power. It is clear that this was a clear overkill and waste in terms of the weight of the files, so this encoding has not become widespread.
She was replaced by new development- UTF-16.
As the name implies, in this encoding one character is encoded no longer 32 bits, but only 16(i.e. 2 bytes). Obviously, this makes any character twice "lighter" than UTF-32, but twice as "heavy" as any single-byte encoded character.
The number of characters available for encoding in UTF-16 is at least 2 to the 16th power, i.e. 65536 characters. Everything seems to be good, besides the final size of the code space in UTF-16 has been expanded to more than 1 million characters.
However, this encoding did not fully satisfy the needs of the developers. For example, if you write using exclusively Latin characters, then after switching from the extended version of the ASCII encoding to UTF-16, the weight of each file doubled.
As a result, another attempt was made to create something universal, and that something is the well-known UTF-8 encoding.
UTF-8- this is multibyte encoding with variable character length... Looking at the name, you might think, by analogy with UTF-32 and UTF-16, that 8 bits are used to encode one character, but this is not the case. More precisely, not quite so.
This is because UTF-8 provides the best compatibility with older systems that used 8-bit characters. To encode one character in UTF-8 is actually used 1 to 4 bytes(hypothetically, up to 6 bytes are possible).
In UTF-8, all Latin characters are encoded in 8 bits, just like in ASCII encoding... In other words, the basic part of the ASCII encoding (128 characters) has moved to UTF-8, which allows you to "spend" only 1 byte on their representation, while maintaining the universality of the encoding, for which everything was started.
So, if the first 128 characters are encoded with 1 byte, then all other characters are encoded with 2 or more bytes. In particular, each Cyrillic character is encoded with exactly 2 bytes.
Thus, we got a universal encoding that allows us to cover all possible characters that need to be displayed, without unnecessarily "weighting" the files.
With or without BOM?
If you worked with text editors(code editors) like Notepad ++, phpDesigner, rapid php etc., you probably drew attention to the fact that when specifying the encoding in which the page will be created, you can choose, as a rule, 3 options:
ANSI
- UTF-8
- UTF-8 without BOM
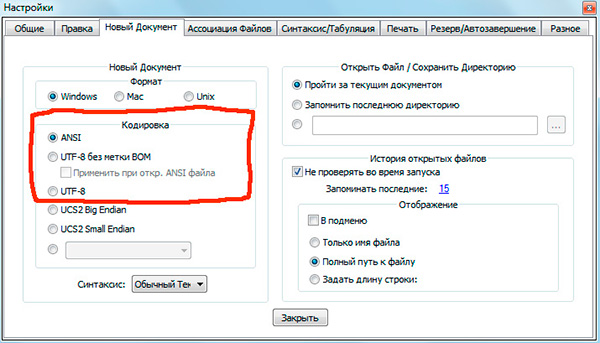

I must say right away that it is always the last option that is worth choosing - UTF-8 without BOM.
So what is BOM and why don't we need it?
BOM stands for Byte order mark... This is a special Unicode character used to indicate byte order. text file... According to the specification, its use is optional, but if BOM is used, then it must be set at the beginning of the text file.
We will not go into details of the work. BOM... For us, the main conclusion is as follows: using this service character together with UTF-8 prevents programs from reading the encoding normally, as a result of which errors occur in the work of scripts.
Therefore, when working with UTF-8, use exactly the option "UTF-8 without BOM"... It is also better not to use editors in which, in principle, you cannot specify the encoding (say, Notebook from standard programs to Windows).
The encoding of the current file opened in the code editor is usually indicated at the bottom of the window.
Please note that the entry "ANSI as UTF-8" in the editor Notepad ++ means the same as "UTF-8 without BOM"... This is the same.
![]()
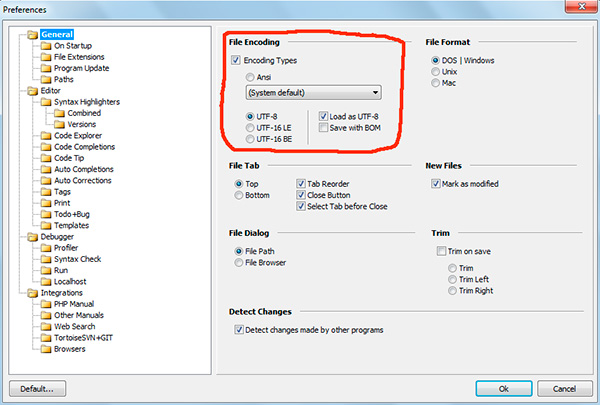
In a programme phpDesigner you cannot immediately say for sure whether it is used BOM, or not. To do this, right-click on the inscription "UTF-8", after which in the pop-up window you can see if BOM(option Save with BOM).
In the editor rapid php encoding UTF-8 without BOM denoted as "UTF-8 *".
As you can imagine, in different editors everything looks a little different, but you get the main idea.
After the document is saved in UTF-8 without BOM, you also need to make sure that the correct encoding is specified in the special meta tag in the section head your html document:
Following these simple rules will already allow you to avoid many spaces with encodings.
That's all, I hope that this little excursion and explanations helped you better understand what encodings are, what they are and how they work.
If you are interested in this topic from a more applied point of view, then I recommend that you study my video tutorial.
Dmitry Naumenko.
P.S. Take a closer look at premium tutorials on various aspects of site building, as well as free course on creating your own CMS-system in PHP from scratch. All this will help you to master various web development technologies faster and easier.
Did you like the material and want to thank you?
Just share with your friends and colleagues!
 Wireless Charging Smartphones A5 Supports Wireless Charging
Wireless Charging Smartphones A5 Supports Wireless Charging Why do not MTS sms come to the phone?
Why do not MTS sms come to the phone? Why do you need a full factory reset on Android or how to return Android to factory settings
Why do you need a full factory reset on Android or how to return Android to factory settings