Ascii character codes 1251
Data carriers
Data is a dialectical component of information. They represent recorded signals. In this case, the physical method of registration can be any: mechanical movement of physical bodies, change in their shape or surface quality parameters, change in electrical, magnetic, optical characteristics, chemical composition and (or) the nature of chemical bonds, change in the state of the electronic system, and much more.
According to the registration method, data can be stored and transported on different types of media. The most common storage medium, although not the most economical, appears to be paper. On paper, data is recorded by changing the optical characteristics of its surface. Changing the optical properties (changing the surface reflection coefficient in a certain wavelength range) is also used in devices that record with a laser beam on plastic media with a reflective coating ( CD-ROM). Magnetic tapes and disks can be cited as media that use the change in magnetic properties. Data registration by changing the chemical composition of the surface substances of the carrier is widely used in photography. At the biochemical level, data is accumulated and transmitted in living nature.
Data carriers are of interest to us not by themselves, but insofar as the properties of information are very closely related to the properties of its carriers. Any carrier can be characterized by the parameter resolution(the amount of data recorded in the unit of measurement accepted for the media) and dynamic range(the logarithmic ratio of the intensity of the amplitudes of the maximum and minimum recorded signals). Such properties of information as completeness, availability and reliability often depend on these properties of the medium. So, for example, we can count on the fact that in a database located on a CD, it is easier to ensure the completeness of information than in a database of a similar purpose, located on a floppy disk, since in the first case, the density of data recording per unit length the tracks are much higher. For an ordinary consumer, the availability of information in a book is noticeably higher than that of the same information on a CD, since not all consumers have the necessary equipment. And finally, it is known that the visual effect from viewing a slide in a projector is much greater than from viewing a similar illustration printed on paper, since the range of luminance signals in transmitted light is two to three orders of magnitude greater than in reflected light.
The task of transforming data in order to change the medium is one of the most important tasks of computer science. In the structure of the cost of computing systems, devices for input and output of data, working with storage media, account for up to half of the cost of hardware.
^ Data operations
During the information process, data is converted from one type to another using methods. Data processing includes many different operations. With the development of scientific and technological progress and the general complication of connections in human society, labor costs for data processing are steadily increasing. First of all, this is due to the constant complication of the conditions for managing production and society. The second factor, which also causes a general increase in the volume of processed data, is also associated with scientific and technological progress, namely, with the rapid pace of emergence and implementation of new data carriers, data storage and delivery facilities.
In the structure of possible operations with data, the following main ones can be distinguished:
data collection - accumulation of data in order to ensure sufficient completeness of information for decision-making;
data formalization - bringing data coming from different sources to the same form in order to make them comparable with each other, that is, to increase their level of accessibility;
filtering data - filtering out "unnecessary" data, which is not necessary for making decisions; at the same time, the level of "noise" should decrease, and the reliability and adequacy of the data should increase;
sorting data - ordering of data according to a given criterion for the purpose of ease of use; increases the availability of information;
grouping data - combining data on a given basis in order to improve usability; increases the availability of information;
archiving data - organization of data storage in a convenient and easily accessible form; serves to reduce the economic costs of storing data and increases the overall reliability of the information process as a whole;
data protection - a set of measures aimed at preventing the loss, reproduction and modification of data;
data transport - reception and transmission (delivery and delivery) of data between remote participants in the information process; in this case, the data source in informatics is usually called server, and the consumer - the client;
data transformation - transfer of data from one form to another or from one structure to another. Converting data often involves changing the type of media, for example, books can be stored in conventional paper form, but both electronic form and microfilm can be used for this. The need for multiple transformations of data also arises during their transportation, especially if it is carried out by means that are not intended for transporting this type of data. As an example, we can mention that for the transportation of digital data streams over telephone networks (which were initially focused only on the transmission analog signals in a narrow frequency range), it is necessary to convert digital data into a kind of sound signals, which is what special devices do - telephone modems.
^ Binary data encoding
To automate work with data related to different types, it is very important to unify their presentation form - for this, the technique is usually used coding, that is, the expression of data of one type through data of another type. Natural human languages - they are nothing more than concept coding systems for expressing thoughts through speech. Languages are closely adjacent ABCs(systems for coding language components using graphic symbols). History knows interesting, albeit unsuccessful, attempts to create "universal" languages and alphabets. Apparently, the failure of attempts to introduce them is due to the fact that national and social education naturally understand that a change in the coding system of public data will inevitably lead to a change in social methods (that is, the norms of law and morality), and this may be associated with social upheavals.
The same problem of a universal coding tool is quite successfully implemented in certain branches of technology, science and culture. Examples include the writing system for mathematical expressions, the telegraph alphabet, the nautical flag alphabet, the Braille system for the blind, and much more.
Rice. 1.8. Examples of different coding systems
The system also exists in computing - it is called binary coding and is based on the representation of data by a sequence of only two characters: 0 and 1. These characters are called binary digits, in English - binary digit, or, in short, bit (bit).
Two concepts can be expressed with one bit: 0 or 1 (Yes or no black or white, true or Lying etc.). If the number of bits is increased to two, then four different concepts can already be expressed:
Three bits can encode eight different values:
000 001 010 01l 100 101 110 111
Increasing the number of digits in the system by one binary encoding, we double the number of values that can be expressed in this system.
^ Integer and real numbers encoding
To encode integers from 0 to 255, it is sufficient to have 8 bits of binary code (8 bits).
0000 0000 = 0
…………………
1111 1110 = 254
1111 1111 = 255
Sixteen bits allow you to encode integers from 0 to 65535, and 24 bits already more than 16.5 million different values.
To encode real numbers, 80-bit encoding is used. In this case, the number is preliminarily converted to normalized form:
3,1415926 = 0,31415926 10 1
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 9
The first part of the number is called mantissa, and the second one is characteristic. Most of the 80 bits are allocated for storing the mantissa (together with the sign) and a certain fixed number of bits are allocated for storing the characteristic (also signed).
^ Encoding text data
If each character of the alphabet is associated with a certain integer (for example, a serial number), then using a binary code, you can encode text information. Eight binary bits are enough for 256 encoding different characters... This is enough to express with various combinations of eight bits all the characters of the English and Russian alphabets, both lowercase and uppercase, as well as punctuation marks, symbols of basic arithmetic operations and some generally accepted Special symbols, for example the character "§".
Technically, it looks very simple, but there have always been quite weighty organizational difficulties. In the early years of the development of computer technology, they were associated with the lack of necessary standards, and now they are caused, on the contrary, by the abundance of simultaneously operating and conflicting standards. In order for the whole world to equally encode text data, unified coding tables are needed, and this is still impossible due to contradictions between the symbols of national alphabets, as well as corporate contradictions.
For in English, which has captured the de facto niche of the international means of communication, the contradictions have already been removed. US Institute for Standardization (ANSI - American National Standard Institute) put in place a coding system ASCII (American Standard Code for Information Interchange). In system ASCII fixed two coding tables: basic and extended. The base table fixes the values of codes from 0 to 127, and the extended table refers to characters with numbers from 128 to 255.
The first 32 codes of the base table, starting with zero, are given to hardware manufacturers (primarily to manufacturers of computers and printing devices). In this area are located the so-called control codes, which do not correspond to any characters of languages, and, accordingly, these codes are not displayed either on the screen or on printing devices, but they can be controlled by how other data is output.
Starting from code 32 to code 127, codes of characters of the English alphabet, punctuation marks, numbers, arithmetic operations and some auxiliary symbols are placed. Basic encoding table ASCII is given in table 1.1.
^ Table 1.1. Basic ASCII encoding table
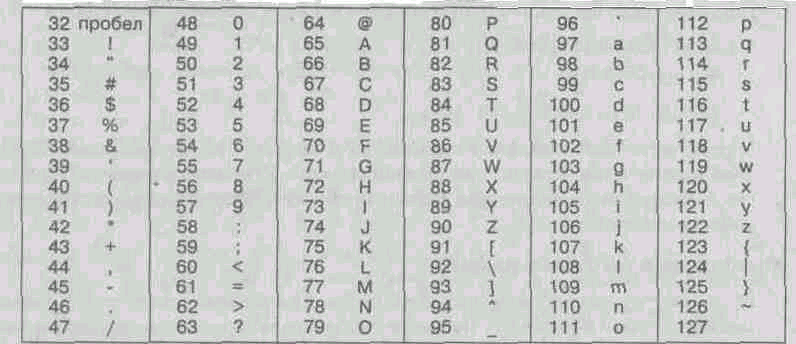
Similar systems for coding text data have been developed in other countries. So, for example, in the USSR in this area, the KOI-7 coding system operated (communication code, seven-digit). However, the support of hardware and software manufacturers brought out the American code ASCII to the level of an international standard, and national coding systems had to "retreat" to the second, extended part of the coding system, which determines the values of codes from 128 to 255. The lack of a single standard in this area led to a plurality of simultaneously operating encodings. Only in Russia, you can specify three current encoding standards and two more outdated ones.
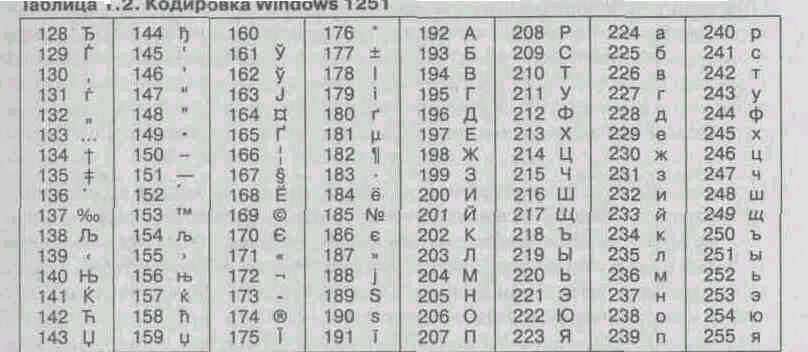
So, for example, the character encoding of the Russian language, known as the encoding Windows-1251, was introduced "from the outside" - by Microsoft, but given the widespread distribution of operating systems and other products of this company in Russia, it is deeply entrenched and widespread (Table 1.2). This encoding is used by most local computers running on the Windows platform. De facto, it has become standard in the Russian sector of the World Wide Web.
^ Table 1.2. Windows encoding 1251
Another common encoding is called KOI-8 (communication code, eight digits) - its origin dates back to the times of the Council for Mutual Economic Assistance of the states of Eastern Europe (table 1.3). On the basis of this coding, the KOI8-R (Russian) and KOI8-U (Ukrainian) encodings are currently in effect. Today the KOI8-R encoding is widely used in computer networks on the territory of Russia and in some services of the Russian sector of the Internet. In particular, in Russia, it is de facto standard in messages Email and teleconferencing.
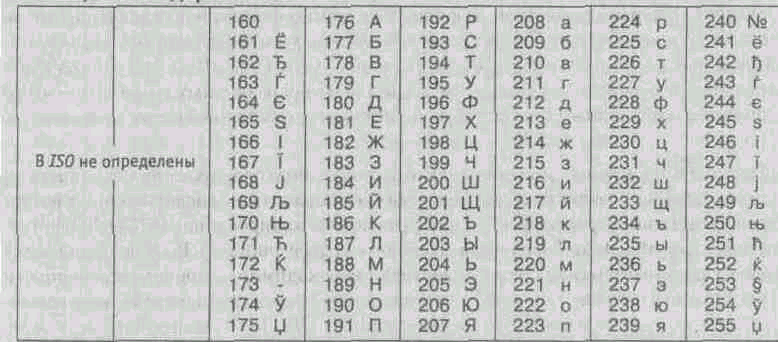
The international standard, which provides for the encoding of the characters of the Russian alphabet, is called the ISO encoding (International Standard Organization - International Institute for Standardization). In practice, this encoding is rarely used (Table 1.4).
^ Table 1.3. KOI-8 encoding
![]()
Table 1.4. ISO encoding
On computers running operating systems MS-DOS, two more encodings can operate (encoding GOST and encoding GOST-alternative). The first of them was considered obsolete even in the early years of the appearance of personal computing, but the second is still used today (see Table 1.5).
^ Table 1.5. GOST alternative encoding
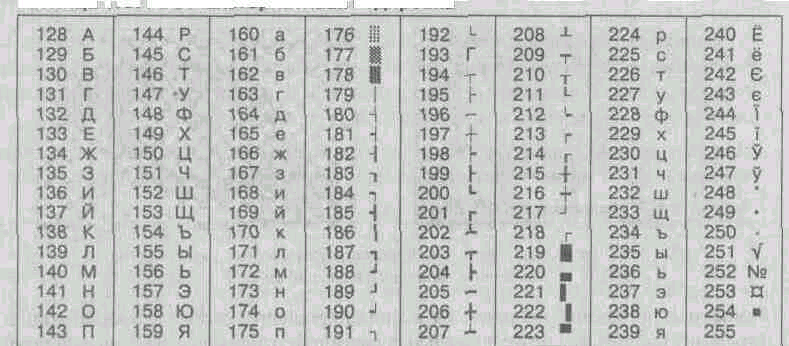
In connection with the abundance of text data coding systems operating in Russia, the problem of intersystem data transformation arises - this is one of the common tasks of computer science.
^ Universal text data coding system
If we analyze the organizational difficulties associated with the creation of a unified system for coding text data, then we can come to the conclusion that they are caused by a limited set of codes (256). At the same time, it is obvious that if, for example, the characters are encoded not with eight-bit binary numbers, but with numbers with a large number of digits, then the range of possible values of the codes will become much larger. Such a system based on 16-bit character coding is called universal - UNICODE. Sixteen digits allow you to provide unique codes for 65536 different characters - this field is enough to accommodate most of the planet's languages in one character table.
Despite the trivial obviousness of this approach, a simple mechanical transition to this system was held back for a long time due to insufficient resources of computer technology (in the coding system UNICODE all text documents are automatically doubled in length). In the second half of the 90s technical means have reached the required level of resource availability, and today we are seeing a gradual transfer of documents and software to a universal coding system. For individual users, this has added even more worries about the coordination of documents executed in different systems coding, with by software, but this must be understood as the difficulties of the transition period.
^ Graphic data encoding
If you examine with a magnifying glass a black and white graphic image printed in a newspaper or book, you can see that it consists of the smallest dots that form a characteristic pattern called raster(fig. 1.9).

Rice. 1.9. Raster is a method of encoding graphic information that has long been adopted in the printing industry.
Since the linear coordinates and the individual properties of each point (brightness) can be expressed using integers, it can be said that bitmap coding allows the use of binary code to represent graphical data. It is generally accepted today to represent black and white illustrations as a combination of dots with 256 shades of gray, and thus an eight-bit binary number is usually sufficient to encode the brightness of any dot.
For coding color graphic images applied decomposition principle arbitrary color into the main components. Three primary colors are used as such components: red (Red, R), green (Green, G) and blue (Blue, B). In practice, it is believed (although theoretically this is not entirely true) that any color visible to the human eye can be obtained by mechanically mixing these three primary colors. Such a coding system is called a system RGB by the first letters of the names of the primary colors.
If to encode the brightness of each of the main components to use 256 values (eight binary bits), as is customary for grayscale black-and-white images, then 24 bits are needed to encode the color of one point. At the same time, the coding system provides an unambiguous definition of 16.5 million different colors, which is actually close to the sensitivity of the human eye. The mode of displaying color graphics using 24 bits is called full color (True Color).
Each of the primary colors can be assigned a complementary color, that is, a color that complements the primary color to white. It is easy to see that for any of the primary colors, the additional color will be the sum of a pair of other primary colors. Accordingly, the complementary colors are: blue (Cyan, C), purple (Magenta, M) and yellow ( Yellow, Y). The principle of decomposition of an arbitrary color into component components can be applied not only for primary colors, but also for additional ones, that is, any color can be represented as a sum of cyan, magenta and yellow components. This method of color coding is adopted in the printing industry, but the fourth ink is also used in the printing industry - black. (Black, K). So this system coding is indicated by four letters CMYK(black color is denoted by the letter TO, because the letter V already occupied in blue), and to represent color graphics in this system, you need to have 32 bits. This mode is also called full color (True Color).
If you reduce the number of bits used to encode the color of each point, you can reduce the amount of data, but the range of encoded colors is significantly reduced. The encoding of color graphics with 16-bit binary numbers is called the mode High Color.
When color information is encoded using eight data bits, only 256 color shades can be transmitted. This color coding method is called index. The meaning of the name is that, since 256 values are completely insufficient to convey the entire range of colors available to the human eye, the code of each raster point does not express the color itself, but only its number (index) in some look-up table called palette. Of course, this palette must be applied to graphic data - without it, you cannot use the methods of displaying information on a screen or paper (that is, you can, of course, use it, but due to incompleteness of the data, the information received will not be adequate: the foliage on the trees may turn out to be red, and the sky is green).
^ Audio coding
Techniques and methods for working with sound information came to computer technology most recently. In addition, unlike numeric, textual and graphic data, sound recordings did not have an equally long and proven coding history. As a result, the methods of encoding audio information with binary code are far from standardization. Many individual companies have developed their own corporate standards.
The site creator always faces a problem: in what encoding to create a project. The Russian-speaking Internet uses two encodings:
UTF-8(from the English. Unicode Transformation Format) is a currently widespread encoding that implements a Unicode representation that is compatible with 8-bit text encoding.
Windows-1251(or cp1251) - character set and encoding, which is the standard 8-bit encoding for all Russian versions of Microsoft Windows.
UTF-8 is more promising. But every thing has its drawbacks. And the decision to use some kind of encoding just because it is promising, without taking into account many other factors, does not seem correct. The choice will be optimal only when it fully takes into account all the nuances of a particular project. Another thing is that it is not easy to foresee all the nuances.
We believe that using UTF-8 is preferable, but it is up to the project developer to decide which to choose. And to facilitate this choice, use the comparative table of the features of both encodings.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
How to translate a site from win1251 encoding to UTF-8
General procedure:
1. Recode the entire database to UTF-8 (most likely you will have to contact the server administrator for help).
2. Recode all site files in UTF-8 (you can do it yourself).
3. Add the lines to the file /bitrix/php_interface/dbconn.php:
4. Add the following lines to the /.htaccess file:
Php_value mbstring.func_overload 2 php_value mbstring.internal_encoding UTF-8
You can recode all site files to UTF-8 (second item) by running the command via SSH in the root folder of the site:
Find. -name "* .php" -type f -exec iconv -fcp1251 -tutf8 -o / tmp / tmp_file () \; -exec mv / tmp / tmp_file () \;
Windows 1251 encoding was created in the early 90s for Russification software products produced by Microsoft Corporation:
The encoding is 8-bit and includes characters from the Slavic group of languages, which includes Russian, Belarusian, Ukrainian, Bulgarian, Macedonian, Serbian - this gives an advantage over other Cyrillic encodings ( ISO 8859-5, KOI8-R, CP866). However, the 1251 encoding also has significant drawbacks:
- 0xFF (25510) is a code that is reserved for the "i" character. Programs that do not support pure 8th bit often have unpredictable problems;
- There is no pseudo-graphics present in KOI8, CP866.
Below are the symbols from Code Page 1251 or CP1251 for short ( the numbers below the characters are the hexadecimal code of the same Unicode character):
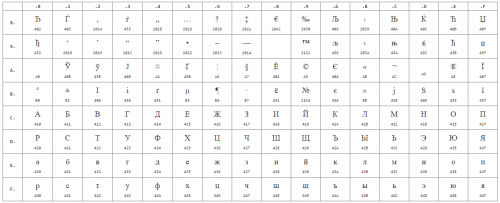
Often, web developers and bloggers with different qualifications have a problem with page encoding: instead of prepared text, unknown, unreadable characters appear. To deal with this problem, it is necessary to understand the essence of the term “ page encoding».
The text in the computer memory is stored in the form of a certain number of bytes, and not in the form in which it is displayed in text editor... Each byte is a code that corresponds to one character. In order for the text on the page to be displayed as it should, you need to tell the browser which code table it should use for decryption and display.
The encoding table is not universal, that is, to decrypt the text, you must use the one that corresponds to the character encoding:

In order for the html document to be displayed correctly in the browser, you must specify the encoding used. This is done as follows:
Between tag
and covering it need to register - based on this string, the browser will use the characters of the Russian alphabet to display the text on the page.Windows 1251 encoding in PHP
It is not a secret for anyone that the generation of pages takes place by sampling and using some part of the information that is stored in the database. When writing a website in PHP, most often it is mysql.
3 votesHello dear readers of my blog. Today we will talk with you about encoding. If you have read my article about how you know that any document on the Internet is not stored in the form in which we are used to seeing it. It is written using symbols and signs incomprehensible to humans. Everything is exactly the same with the text.
There are several encodings, and therefore, sometimes seeing incomprehensible characters when opening a book in mobile application or by uploading an article to the site, by changing some values in the settings, you will see the alphabet familiar to the eye.

Windows-1251 encoding - what it is, what value does it have when creating a site, what characters will be available and whether it is the best solution to date? All this is in today's article. As always, simple language, as clear as possible and with a minimum of terms.
A bit of theory
Any document on a computer or on the Internet, as I said, is stored as binary code. For example, if you use ASCII encoding, the letter "K" will be written as 10001010, and windows 1251 hides the symbol - Љ under this number. As a result, if a browser or a program accesses another table and reads instead of ASCII windows codes 1251, then the reader will see symbols completely incomprehensible to him.
The question is logical, what for it was to come up with a lot of tables with codes? The fact is that in addition to the Russian alphabet, there is also English, German, and Chinese. By some estimates, there are about 200,000 characters. Although, I do not really trust these statistics, remembering about Japanese.
Do not forget that for uppercase and lowercase letters you need to come up with your own code, there are commas, dashes, and so on.
The more symbols in the table, the longer the code of each of them, and hence the weight of the document becomes more.
Imagine if one book weighed 4 GB! It would take a very long time to load, take everything free place on the computer. The decision to download would be difficult.
If you think about websites, it’s generally scary to think about what would have happened. Each page opened even on high-speed fiber for more than an hour! Think, mobile phones could be safely thrown out. Using them on the street even with 4G? I doubt.
For these reasons, each programmer at one time tried to come up with his own symbol table. So that it is convenient to use and the weight is kept optimal.
Microsoft, for example, created windows-1251 for the Russian-speaking segment. It certainly has its merits and demerits. Like any other product.
Now, only 2% of all pages on the Internet are written in 1251. Most webmasters use UTF-8. Why is that?
Disadvantages and advantages
UTF-8, unlike windows-1251 universal encoding, contains letters of different alphabets. There is even UTF-128, where there are generally all languages - Teulu, Swahili, Lao, Maltese, and so on.

UTF-8 is poorer, letters take up much less space and take up only one byte of memory, as in 1251. UTP contains rare characters from other languages or special characters. They weigh 5-6 bytes, but they are rarely used in the document.
This encoding is more thoughtful, and therefore is used by most applications by default. That is, if you do not tell the program which encoding you are using, then the first thing it will check is UTF-8.
When you create an html document for a site, you tell browsers which table to look at when decrypting records.
To do this, you need to insert the following data into the head tag. After the characters "charset =" comes either UTF or Windows, as in the example below.
| <meta http-equiv = "Content-Type" content = "text / html; charset = windows-1251"> |
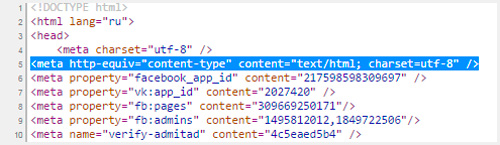
If in the future you want to change something and insert a phrase in Albanian using this decryption table, then nothing will work, because the encoding does not support this language. UTF ‑ 8 will let you do this without any problems.
If you are interested in the correct creation of the site, then I can recommend you the course of Mikhail Rusakov " Website development and promotion from A to Z ».

It contains a lot - 256 lessons, touching, JavaScript, and XML. In addition to programming languages, you will be able to understand how to monetize the site, that is, get more profit faster and more. One of the few courses that would explain everything you need in such detail.
I myself have been studying for a year now at the school of bloggers Alexander Borisov ... It takes many times more time, the end and the edge is not visible yet, but it is no less exhaustive and disciplining. Motivates to keep developing.
Well, if you have questions, you do not need to search on the Internet. There is always a competent mentor.

Something I have deviated from the topic. Let's get back to encodings.
Bath databases
When it comes to php, everything is scary. I have already talked about databases, they are used to speed up the work of the site. Usually, you do not contact them, but when the need arises to transfer the site, it becomes uncomfortable.
Difficulties happen to everyone, no matter what kind of work experience you have, length of service and length of service. Some pages in the database may contain all available symbols for Windows-1251, others, for example, in page templates, in a different encoding.
Until the transfer is needed, everything works and functions, although not quite correctly. But after the move, troubles begin. Ideally, you should use either only UTF or Windows-1251, but in fact, everyone always has such shortcomings.
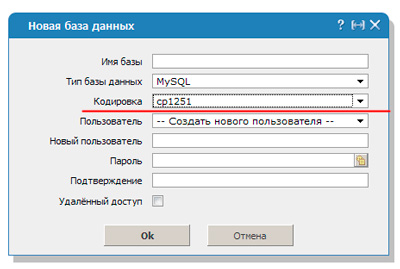
For the decryption to be consistent, you must enter the mysql_query code ("SET NAMES cp1251"). In this case, the conversion will be carried out using a different protocol - cp1251.
Htaccess
If you persistently decide to use 1251 on the site, then you should find or create an htaccess file. He is responsible for the configuration settings. You will have to add three more lines to it so that everything fits together.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset "cp1251"
I still highly recommend that you consider using UTF-8. He is more popular, simpler and more rich. Whatever decisions you make now, it is important that you can fix everything later. It will be much easier to add an English-language version of the site using this encoding. Nothing needs to be fixed.
Decision is on you. Subscribe to the newsletter to find out as quickly as possible where to study, so as not to repeat other people's mistakes, as well as which bloggers get the most visitors.
Until next time and good luck in your endeavors.
 Solving the problem with the missing brush outline in Photoshop
Solving the problem with the missing brush outline in Photoshop Technical details of PSD files
Technical details of PSD files Free download various watercolor textures with stains
Free download various watercolor textures with stains