How many bits are in unicode encoding. Units of data volume and memory capacity measurement: kilobytes, megabytes, gigabytes…. Unicode character encoding standard
Information coding
Any numbers (within certain limits) in the computer memory are encoded by numbers in the binary number system. There are simple and clear translation rules for this. However, today the computer is used much more widely than in the role of a performer of labor-intensive calculations. For example, computer memory stores text and multimedia information. Therefore, the first question arises:
Each character is encoded from 1 to 4 bytes. Replacement characters use 4 bytes and therefore require additional storage. Each character is encoded with at least 4 bytes. Alternatively, you can use the conversion tool to convert automatically. As said, this is a standard that suits Americans well. It ranges from 0 to 127, and the first 32 and the last are considered control, the rest are "printed characters", that is, recognized by people. It can only be represented by 7 bits, although usually one byte is used.
How are characters (letters) stored in the computer's memory?
Each letter belongs to a certain alphabet in which the characters follow each other and, therefore, can be numbered with consecutive integers. Each letter can be associated with a positive integer and call it a character code... It is this code that will be stored in the computer's memory, and when displayed on the screen or on paper, it will be "converted" into its corresponding character. To distinguish the representation of numbers from the representation of characters in computer memory, you also have to store information about which data is encoded in a particular area of memory.
Depending on the context and even the time, this means something else. So it depends on what you are talking about. It means little alone. There are some encodings that use this acronym. They are very complex and almost no one knows how to properly use their fullness, myself included.
But not with any other character encoding system. This is the most complete and complex encoding that exists. Some are in love with her and others hate her, although they recognize her usefulness. It is difficult for a person to understand, but for a computer it is difficult to deal.
The correspondence of letters of a certain alphabet with numbers-codes forms the so-called coding table... In other words, each character of a specific alphabet has its own numerical code in accordance with a specific encoding table.
However, there are a lot of alphabets in the world (English, Russian, Chinese, etc.). So the next question is:
There is a comparison between the two. It is a standard for the presentation of texts created by a consortium. Among the norms established by him are some encodings. But in reality, it refers to much more than that. An article that everyone should read, even if they disagree with everything they have.
Supported character sets are subdivided into planes. The two computers use different operating systems; the same happens with character set, structure and file format which are usually different. Communication over control connection.
How to encode all alphabets used on a computer?
To answer this question, we will follow the historical path.
In the 60s of the XX century in American National Standards Institute (ANSI) a character encoding table was developed, which was subsequently used in all operating systems. This table is called ASCII (American Standard Code for Information Interchange)... A little later appeared extended ASCII version.
Communication takes place through a sequence of commands and responses. This simple method is suitable for a control connection because we can send one command at a time. Each command or response spans one line, so we don't need to worry about the file format or structure. Each line ends with two characters.
Data link. The purpose and implementation of the data connection are different from those specified in the control connection. Basic fact: we want to transfer files over a data connection. The client must determine the type of file to transfer, the data structure, and the transfer mode.
According to the ASCII coding table, 1 byte (8 bits) is allocated to represent one character. A set of 8 cells can take 2 8 = 256 different values. The first 128 values (from 0 to 127) are constant and form the so-called main part of the table, which includes decimal digits, letters of the Latin alphabet (uppercase and lowercase), punctuation marks (period, comma, brackets, etc.), as well as a space and various service characters (tabulation, line feed, etc.). Values from 128 to 255 form additional part tables where it is customary to encode symbols of national alphabets.
In addition, the transfer must be prepared by the control connection before the file can be transferred over the data link. The problem of heterogeneity is solved by defining three attributes of the link: file type, data structure, and transfer mode.
The file is sent as a continuous stream of bits without any interpretation or encoding. This format is mainly used to transfer binary files such as compiled programs or images encoded in 0 and 1 sec. The file does not contain vertical specifications for printing. This means that the file cannot be printed without additional processing because there are no understandable characters to be interpreted by the vertical movement of the print engine. This format is used by files that will be stored and processed in the future.
Since there are a huge variety of national alphabets, extended ASCII tables exist in many variants. Even for the Russian language, there are several coding tables (Windows-1251 and Koi8-r are common). All this creates additional difficulties. For example, we send a letter written in one encoding, and the recipient tries to read it in another. As a result, he sees krakozyabry. Therefore, the reader needs to apply a different coding table for the text.
The file can be printed after transmission. Pages: The file is divided into pages, each of which is correctly numbered and identified by a heading. Pages can be saved or accessed, randomly or sequentially. If the data is just a string of bytes, no end-of-line identification is required. In this case, the end-of-line indication is the closing of the data connection by the transmitter. The first byte is called the descriptor block; the other two bytes define the block size in bytes. Compression: If the file is too large, the data may be compressed before being sent. A commonly used compression method takes a unit of data that appears sequentially and replaces it with a single occurrence, followed by a number of repetitions. V text file lots of empty spaces. In a binary file, null characters are usually compressed.
- Files: The file has no structure.
- It is transmitted in a continuous stream of bytes.
- This type can only be used with text files.
- Chains: This is the default mode.
- In this case, each block is preceded by a 3-byte header.
There is another problem as well. The alphabets of some languages have too many characters and they do not fit into their allotted positions from 128 to 255 single-byte encoding.
The third problem is what to do if the text uses several languages (for example, Russian, English and French)? You can't use two tables at once ...
To solve these problems, the Unicode encoding was developed in one go.
Many have no idea about the differences between these sets and stick to what is close. The detail about the encoding is that they are maps for two different things. The first is a numeric value map that represents a specific character.
Other planes are add-ons with characters that complement the functions of the main plane and other "specials" such as "emoticons". In these patterns, each plane character is encoded into only 1 byte, and therefore we only have 256 "possible" characters. We must, of course, remove the non-printable ones by decreasing the range.
Unicode character encoding standard
To solve the above problems in the early 90s, a character coding standard was developed, called Unicode. This standard allows you to use almost any languages and symbols in the text.
Unicode provides 31 bits for character encoding (4 bytes minus one bit). The number of possible combinations gives an exorbitant number: 2 31 = 2 147 483 684 (ie more than two billion). Therefore, Unicode describes the alphabets of all known languages, even the "dead" and invented, includes many mathematical and other Special symbols... However, the information capacity of 31-bit Unicode is still too large. Therefore, the abbreviated 16-bit version (2 16 = 65 536 values) is more often used, where all modern alphabets are encoded.
And if you need to do comparisons between characters, there is no performance loss, since comparing two 8-bit, 16-bit, or 32-bit values spends the same time on modern processors... The meaning associated with the acronym is of course the size of each sequence unit that makes up the character encoding. When the code has more bits, the following encoding is used.
Thus, any character can be expressed in sizes from 1 to 4 bytes. Is this a unique "special" character? This means that some of the character images are very similar and sometimes redundant. To give another example, a few years ago there was a joke about changing the '; ' on '; ' v source codes... While compiling the code, the programmer went crazy to try and figure out the problem.
In Unicode, the first 128 codes are the same as the ASCII table.
Beginning in the late 60s, computers were increasingly used to process text information and currently most personal computers in the world (and most of the time) it is busy processing textual information.
ASCII - basic text encoding for the Latin alphabet
Traditionally, to encode one character, an amount of information is used equal to 1 byte, that is, I = 1 byte = 8 bits.
To encode one character, 1 byte of information is required. If we consider symbols as possible events, then we can calculate how many different characters can be coded: N = 2I = 28 = 256.
This number of characters is quite enough to represent textual information, including uppercase and lowercase letters of the Russian and Latin alphabets, numbers, signs, graphic symbols, etc. Coding means that each character is assigned a unique decimal code from 0 to 255 or corresponding binary code from 00000000 to 11111111.
Thus, a person distinguishes symbols by their style, and a computer - by their codes. When text information is entered into a computer, it binary encoding, the symbol image is converted to its binary code.
The user presses a key with a symbol on the keyboard, and a certain sequence of eight electrical impulses (binary code of the symbol) is sent to the computer. The character code is stored in random access memory computer where it takes one byte. In the process of displaying a character on the computer screen, the reverse process is performed - decoding, that is, the conversion of the character code into its image. The ASCII code table (American Standard Code for Information Interchange) has been adopted as an international standard. ASCII standard part table It is important that the assignment of a specific code to a character is a matter of agreement, which is fixed in the code table. The first 33 codes (from 0 to 32) correspond not to characters, but to operations (line feed, space input, and so on). Codes from 33 to 127 are international and correspond to symbols of the Latin alphabet, numbers, arithmetic signs and punctuation marks. Codes from 128 to 255 are national, that is, different characters correspond to the same code in national encodings.
Unfortunately, there are currently five different code tables for Russian letters (KOI8, CP1251, CP866, Mac, ISO), so texts created in one encoding will not be displayed correctly in another.
Currently, a new international Unicode standard, which allocates for each character not one byte, but two, so it can be used to encode not 256 characters, but N = 216 = 65536 different
Unicode - the emergence of universal text encoding (UTF 32, UTF 16 and UTF 8)
These thousands of characters from the Southeast Asian language group could not be described in one byte of information, which was allocated for encoding characters in extended ASCII encodings. As a result, a consortium was created called Unicode(Unicode - Unicode Consortium) with the collaboration of many IT industry leaders (those who produce software, who code hardware, who create fonts) who were interested in the emergence of a universal text encoding.
The first text encoding published under the auspices of the Unicode consortium was the encoding UTF 32... The number in the name of the UTF 32 encoding means the number of bits that are used to encode one character. 32 bits are 4 bytes of information that will be needed to encode one single character in the new universal UTF 32 encoding.
As a result, the same file with text encoded in extended ASCII encoding and UTF 32 encoding, in the latter case, will have the size (weight) four times more. This is bad, but now we have the opportunity to encode with UTF 32 the number of characters equal to two to the thirty-second power (billions of characters that will cover any really necessary value with a colossal margin).
But many countries with languages of the European group did not need to use such a huge number of characters in the encoding at all, but when using UTF 32 they never got a fourfold increase in weight text documents, and as a result, an increase in the volume of Internet traffic and the amount of stored data. This is a lot and no one could afford such a waste.
As a result of the development of a universal Unicode encoding appeared UTF 16, which turned out to be so successful that it was accepted by default as the base space for all the symbols that we use. UTF 16 uses two bytes to encode one character. For example, in operating system Windows, you can follow the path Start - Programs - Accessories - System Tools - Symbol Map.
As a result, a table with vector forms of all fonts installed in your system will open. If you select the Unicode character set in the Advanced options, you will be able to see for each font separately the entire assortment of characters included in it. By the way, by clicking on any of these characters, you can see its two-byte code in UTF 16 encoding, consisting of four hexadecimal digits:
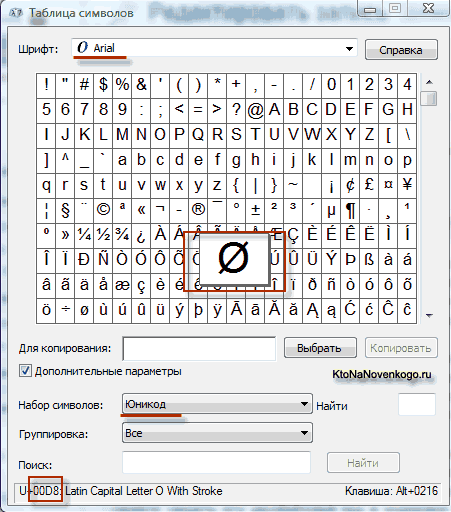
How many characters can be encoded in UTF 16 with 16 bits? 65,536 characters (two to the power of sixteen) have been taken as base space in Unicode. In addition, there are ways to encode with UTF 16 about two million characters, but they were limited to the extended space of a million characters of text.
But even a successful version of the Unicode encoding called UTF 16 did not bring much satisfaction to those who wrote, for example, programs only in English language, because after the transition from the extended version of ASCII encoding to UTF 16, the weight of the documents doubled (one byte for one character in ASCII and two bytes for the same character in UTF 16 encoding). It was precisely for the satisfaction of everyone and everything in the Unicode consortium that it was decided to come up with variable length text encoding.
This encoding in Unicode was called UTF 8... Despite the eight in the name, UTF 8 is a full-fledged variable-length encoding, i.e. each character of the text can be encoded into a sequence of one to six bytes long. In practice, in UTF 8, only the range from one to four bytes is used, because beyond four bytes of code, nothing is even theoretically possible to imagine.
In UTF 8, all Latin characters are encoded in one byte, just like in the old ASCII encoding. What is noteworthy, in the case of encoding only the Latin alphabet, even those programs that do not understand Unicode will still read what is encoded in UTF 8. That is, the basic part of ASCII encoding moved to UTF 8.
Cyrillic characters in UTF 8 are encoded in two bytes, and, for example, Georgian ones - in three bytes. The Unicode Consortium, after creating the UTF 16 and UTF 8 encodings, solved the main problem - now we have a single code space in our fonts. The only thing left to font manufacturers is to fill this code space with vector forms of text symbols based on their strengths and capabilities.
 Customizable software
Customizable software Windows 8 will return the start button
Windows 8 will return the start button Installing Skype on a computer (step by step instructions)
Installing Skype on a computer (step by step instructions)