Character encoding. Unicode
I liked it, maybe someone will be interested and useful.
Unicode looks very confusing, which raises a lot of questions and problems. Many people think that this is an encoding or character set, which is somewhat correct, but in fact it is a delusion. The fact that Unicode was originally created as an encoding and character set only reinforces the misconceptions. This is an attempt to clarify everything, not just by telling what Unicode is, but by providing mental model Unicode.
Completely incorrect, but a Useful Model for Understanding Unicode (hereinafter PMPY):
- Unicode is a way to process text data... It is not a character set or encoding.
- Unicode is text, everything else is binary data... And even ASCII text is binary data.
- Unicode uses the UCS character set... But UCS is not Unicode.
- Unicode can be binary encoded using UTF... But UTF is not Unicode.
Now, if you know something about Unicode, you say, "Well, yeah, but it really isn't." Therefore, we will try to find out why this model of understanding, while not correct, is still useful. Let's start with the character set ...
About character set
To process text on a computer, you need to match the graphemes that you write on paper with numbers. This collation is determined by the character set, or character table, which specifies the number for the character. This is what is called "character set"... The symbol does not necessarily correspond to any grapheme. For example, there is a "BEL" check character that makes your computer "beep". The number of characters in a character set is usually 256, that is how much it fits into one byte. There are character sets that are only 6 bits long. For a long time, 7-bit ASCII character sets have dominated computing, but 8-bit ones are the most common.
But 256 is clearly not the number that can accommodate all the symbols we need in our world. This is why Unicode came into being. When I said that Unicode is not a character set, I was lying. Unicode was originally a 16-bit character set. But while the creators of Unicode believed that 16 bits was enough (and they were right), some believed that 16 bits were not enough (and they were right too). They eventually created a competing encoding and called it the Universal Character Set (UCS). After a while, the teams decided to join forces and the two sets of characters became the same. This is why we can assume that Unicode uses UCS as its character set. But this is also a lie - in fact, each standard has its own set of characters, it just so happens that they are the same (although UCS is slightly behind).
But for our PMPYu - "Unicode is not a character set".
About UCS
UCS is a 31-bit character set with over 100,000 characters. 31 bits - so as not to solve the "signed versus unsigned" problem. Since now less than 0.005% of the possible number of characters is used, this extra bit is not needed at all.
Although 16 bits was not enough to accommodate all the characters ever created by humanity, it is quite enough if you are ready to limit yourself only now. existing languages... Therefore, the bulk of the UCS characters fit into the first 65536 numbers. They were named "Basic Multilingual Plane" or BMP. In fact, they are the 16-bit Unicode character set, although each version of UCS expands it with more and more characters. BMP becomes relevant when it comes to encodings, but more about that below.
Each character in UCS has a name and number. The character "H" is named "LATIN CAPITAL LETTER H" and is number 72. The number is usually in hexadecimal, and is often prefixed with "U +" and 4, 5 or 6 digits to indicate what is meant Unicode character. Therefore, the character number "H" is more often represented as U + 0048 than - 72, although they are the same thing. Another example is the "-" character called "EM DASH", or U + 2012. The "乨" character is called "CJK UNIFIED IDEOGRAPH-4E68", more commonly represented as U + 4E68. Symbol "
Since the names and numbers of characters in Unicode and UCS are the same, for our PMPU we will assume that UCS is not Unicode, but Unicode uses UCS... This is a lie, but a useful lie that allows you to distinguish between Unicode and character set.
About encodings
Thus, a character set is a collection of characters, each of which has its own number. But how should you store them, or send them to another computer? For 8-bit characters it's easy, you use one byte per character. But UCS uses 31 bits and you need 4 bytes per character, which creates a problem with byte ordering and memory inefficiency. Also, not all third party applications can work with all Unicode characters, but we still need to interact with these applications.
The way out is to use encodings that indicate how to convert Unicode text to 8-bit binary data. It is noteworthy that ASCII is an encoding, and ASCII data from the point of view of the PMPU is binary!
In most cases, the encoding is the same character set and is named the same as the character set it encodes. This is true for Latin-1, ISO-8859-15, cp1252, ASCII, and others. While most character sets are also encodings, this is not the case for UCS. It is also confusing that UCS is what you decode into and what you encode from, while the rest of the character sets are what you decode from and what you encode into (since the name of the encoding and character set is the same). Thus, you should treat character sets and encodings as different things, even though these terms are often used interchangeably in meaning.
About UTF
Most encodings operate on a character set that is only a small part of the UCS. This becomes a problem for multilingual data, so an encoding is needed that uses all UCS characters. The encoding of 8-bit characters is very simple as you get one character from one byte, but UCS uses 31 bits and you need 4 bytes per character. The problem of byte order arises as some systems use high-order to low-order, others the other way around. Also, some of the bytes will always be empty, this is a waste of memory. Correct encoding should use a different number of bytes for different characters, but such encoding will be effective in some cases and not effective in others.
The solution to this puzzle is to use several encodings from which you can choose the appropriate one. They are called Unicode Transformation Formats, or UTF.
UTF-8 is the most widely used encoding on the Internet. It uses one byte for ASCII characters and 2 or 4 bytes for all other UCS characters. This is very effective for languages using Latin letters, since they are all in ASCII, quite effective for Greek, Cyrillic, Japanese, Armenian, Syriac, Arabic, etc., since they use 2 bytes per character. But this is not effective for all other BMP languages, since 3 bytes per character will be used, and for all other UCS characters, such as Gothic, 4 bytes will be used.
UTF-16 uses one 16-bit word for all BMP characters and two 16-bit words for all other characters. Therefore, if you are not working with one of the languages mentioned above, you are better off using UTF-16. Since UTF-16 uses 16-bit words, we end up with a byte order problem. It is solved by the presence of three options: UTF-16BE for byte order from high to low, UTF-16LE - from low to high, and simply UTF-16, which can be UTF-16BE or UTF-16LE, when encoding a marker is used at the beginning, which indicates the order of the bytes. This marker is called the "byte order mark" or "BOM".
There is also UTF-32, which can be in two flavors BE and LE as well as UTF-16, and stores the Unicode character as a 32-bit integer. This is not efficient for almost all characters except those that require 4 bytes to store. But it is very easy to process such data, since you always have 4 bytes per character.
It is important to separate encoded data from Unicode data. Therefore, don't think of UTF-8/16/32 data as Unicode. Thus, although UTF encodings are defined in the Unicode standard, we believe that UTF is not Unicode under the PMPU.
About Unicode
UCS contains unifying characters, such as the trema, which adds two dots above the character. This leads to ambiguity when expressing one grapheme (letter or sign) through several symbols. Take ‘ö’ as an example, which can be represented as the character LATIN SMALL LETTER O WITH DIAERESIS, but at the same time as a combination of characters LATIN SMALL LETTER O followed by COMBINING DIAERESIS.
But in real life, you cannot complement any symbol with three. For example, it makes no sense to add two dots above the Euro symbol. Unicode contains rules for such things. It indicates that you can express ‘ö’ in two ways and it’s the same character, but if you use three for the Euro sign, you’re making a mistake. Therefore, the rules for combining characters are part of the Unicode standard.
The Unicode standard also contains rules for character comparison and sorting, rules for splitting text into sentences and words (if you think it's that simple, keep in mind that most Asian languages do not contain spaces between words), and many other rules that determine how it is displayed and processed. text. You probably won't need to know all this, except when using Asian languages.
Using the PMPU, we have determined that Unicode is UCS plus word processing rules. Or in other words: Unicode is a way of working with text data and it doesn't matter what language or letter they use. In Unicode, 'H' is not just a character, it has some meaning. The character set indicates that ‘H’ is character numbered 72, while Unicode tells you that when sorting ‘H’ comes before ‘I’ and you can use two dots above it to get ‘Ḧ’.
Thus, Unicode is not an encoding or a set of characters, it is a way of working with text data.
I myself do not really like headlines like "Pokemon in their own juice for dummies / pots / pans", but this seems to be exactly the case - we will talk about basic things, work with which quite often leads to a compartment of full of bumps and a lot of wasted time around the question - Why doesn't it work? If you are still afraid and / or do not understand Unicode, please, under cat.
What for?
The main question for a beginner who is faced with an impressive number of encodings and seemingly confusing mechanisms for working with them (for example, in Python 2.x). The short answer is because it happened :)An encoding, who does not know, is the way of representing in the computer memory (read - in zeros-ones / numbers) digits, beeches and all other characters. For example, a space is represented as 0b100000 (binary), 32 (decimal), or 0x20 (hexadecimal).
So, once there was very little memory and all computers had enough 7 bits to represent all the necessary characters (numbers, lowercase / uppercase Latin alphabet, a bunch of characters and so-called controlled characters - all possible 127 numbers were given to someone). At that time there was only one encoding - ASCII. As time went on, everyone was happy, and whoever was not happy (read - who lacked the sign "" or the native letter "u") - used the remaining 128 characters at their discretion, that is, they created new encodings. This is how ISO-8859-1 and our (that is, Cyrillic) cp1251 and KOI8 appeared. Together with them, the problem of interpreting bytes like 0b1 ******* (that is, characters / numbers from 128 to 255) appeared - for example, 0b11011111 in cp1251 encoding is our own "I", at the same time in ISO encoding 8859-1 is the Greek German Eszett (prompts) "ß". As expected, network communication and just file exchange between different computers turned into heck-what-what, despite the fact that headers like "Content-Encoding" in HTTP protocol, emails and HTML pages saved the day a little.
At that moment, bright minds gathered and proposed a new standard - Unicode. This is a standard, not an encoding - Unicode itself does not determine how characters will be stored on the hard disk or transmitted over the network. It only defines the relationship between a character and a certain number, and the format according to which these numbers will be converted into bytes is determined by Unicode encodings (for example, UTF-8 or UTF-16). On this moment there are a little over 100 thousand characters in the Unicode standard, while UTF-16 can support over one million (UTF-8 is even more).
I advise you to read The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets for more and more fun on the topic.
Get to the point!
Naturally, there is support for Unicode in Python. But, unfortunately, only in Python 3 all strings became unicode, and beginners have to kill themselves about an error like:>>> with open ("1.txt") as fh: s = fh.read () >>> print s koshchey >>> parser_result = u "baba-yaga" # assignment for clarity, let's imagine that this is the result some parser works >>>
or like this:
>>> str (parser_result) Traceback (most recent call last): File "
Let's figure it out, but in order.
Why would anyone use Unicode?
Why is my favorite html parser returning Unicode? Let it return an ordinary string, and I'll deal with it there! Right? Not really. Although each of the characters existing in Unicode can (probably) be represented in some single-byte encoding (ISO-8859-1, cp1251 and others are called single-byte, since they encode any character in exactly one byte), but what to do if there should be characters in the string from different encodings? Assign a separate encoding to each character? No, of course you have to use Unicode.Why do we need a new type "unicode"?
So we got to the most interesting thing. What is a string in Python 2.x? It's simple bytes... Just binary data that can be anything. In fact, when we write something like: >>> x = "abcd" >>> x "abcd" the interpreter does not create a variable that contains the first four letters of the Latin alphabet, but only the sequence ("a", "b "," c "," d ") with four bytes, and Latin letters are used here exclusively to denote this particular byte value. So "a" here is just a synonym for "\ x61", and not a bit more. For example:>>> "\ x61" "a" >>> struct.unpack ("> 4b", x) # "x" is just four signed / unsigned chars (97, 98, 99, 100) >>> struct.unpack ("> 2h", x) # or two short (24930, 25444) >>> struct.unpack ("> l", x) # or one long (1633837924,) >>> struct.unpack ("> f", x) # or float (2.6100787562286154e + 20,) >>> struct.unpack ("> d", x * 2) # or half a double (1.2926117739473244e + 161,)
And that's it!
And the answer to the question - why do we need "unicode" is already more obvious - we need a type that will be represented by characters, not bytes.
Okay, I figured out what the string is. Then what is Unicode in Python?
"Type unicode" is primarily an abstraction that implements the idea of Unicode (a set of characters and associated numbers). An object of the "unicode" type is no longer a sequence of bytes, but a sequence of actual characters without any idea of how these characters can be effectively stored in computer memory. If you want, this is more high level abstraction than byte strings (this is what Python 3 calls regular strings that are used in Python 2.6).How do I use Unicode?
A Unicode string in Python 2.6 can be created in three (at least naturally) ways:- u "" literal: >>> u "abc" u "abc"
- Method "decode" for byte string: >>> "abc" .decode ("ascii") u "abc"
- "Unicode" function: >>> unicode ("abc", "ascii") u "abc"
"\ x61" -> ascii encoding -> lowercase latin "a" -> u "\ u0061" (unicode-point for this letter) or "\ xe0" -> encoding c1251 -> lowercase cyrillic "a" -> u " \ u0430 "
How to get a regular string from a unicode string? Encode it:
>>> u "abc" .encode ("ascii") "abc"
The coding algorithm is naturally the opposite of the one given above.
Remember and not confused - unicode == characters, string == bytes, and bytes -> something meaningful (characters) is decode, and characters -> bytes are encode.
Not encoded :(
Let's look at examples from the beginning of the article. How does string and unicode string concatenation work? A simple string must be turned into a unicode string, and since the interpreter does not know the encoding, it uses the default encoding - ascii. If this encoding fails to decode the string, we get an ugly error. In this case, we need to convert the string to a unicode string ourselves, using the correct encoding:>>> print type (parser_result), parser_result
A "UnicodeDecodeError" is usually an indication to decode the string to Unicode using the correct encoding.
Now using "str" and unicode strings. Do not use "str" and unicode strings :) In "str" there is no way to specify the encoding, so the default encoding will always be used and any characters> 128 will lead to an error. Use the "encode" method:
>>> print type (s), s
"UnicodeEncodeError" is a sign that we need to specify the correct encoding when converting a unicode string to a regular one (or use the second parameter "ignore" \ "replace" \ "xmlcharrefreplace" in the "encode" method).
I want more!
Okay, let's use Baba Yaga from the example above again:>>> parser_result = u "baba-yaga" # 1 >>> parser_result u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" # 2 >>> print parser_result áàáà-ÿãà # 3 >>> print parser_result.encode ("latin1") # 4 baba yaga >>> print parser_result.encode ("latin1"). decode ("cp1251") # 5 baba yaga >>> print unicode ("baba yaga", "cp1251") # 6 baba-yaga
The example is not entirely simple, but there is everything (well, or almost everything). What's going on here:
- What do we have at the entrance? The bytes that IDLE passes to the interpreter. What do you need at the exit? Unicode, that is, characters. It remains to turn the bytes into characters - but you need an encoding, right? What encoding will be used? We look further.
- Here is an important point: >>> "baba-yaga" "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" >>> u "\ u00e1 \ u00e0 \ u00e1 \ u00e0- \ u00ff \ u00e3 \ u00e0" == u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" True, as you can see, Python does not bother with the choice of encoding - bytes are simply converted into unicode points:
>>> ord ("a") 224 >>> ord (u "a") 224 - Only here is the problem - the 224th character in cp1251 (the encoding used by the interpreter) is not at all the same as 224 in Unicode. It is because of this that we get cracked when trying to print our unicode string.
- How to help a woman? It turns out that the first 256 Unicode characters are the same as in the ISO-8859-1 \ latin1 encoding, respectively, if we use it to encode a unicode string, we get the bytes that we entered ourselves (who cares - Objects / unicodeobject.c, looking for the definition of the function "unicode_encode_ucs1"):
>>> parser_result.encode ("latin1") "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" - How do you get a baba in unicode? It is necessary to indicate which encoding to use:
>>> parser_result.encode ("latin1"). decode ("cp1251") u "\ u0431 \ u0430 \ u0431 \ u0430- \ u044f \ u0433 \ u0430" - The method from point # 5 is certainly not so hot, it is much more convenient to use built-in unicode.
There is also a way to use "u" "" to represent, for example, Cyrillic, without specifying the encoding or unreadable unicode points (that is, "u" \ u1234 ""). The way is not entirely convenient, but interesting is to use unicode entity codes:
>>> s = u "\ N (CYRILLIC SMALL LETTER KA) \ N (CYRILLIC SMALL LETTER O) \ N (CYRILLIC SMALL LETTER SHCHA) \ N (CYRILLIC SMALL LETTER IE) \ N (CYRILLIC SMALL LETTER SHORT I)"> >> print s koshchey
Well, that's all. The main advice is not to confuse "encode" \ "decode" and understand the differences between bytes and characters.
Python 3
Here without a code, because there is no experience. Witnesses say that everything is much simpler and more fun there. Who will undertake on cats to demonstrate the differences between here (Python 2.x) and there (Python 3.x) - respect and respect.Healthy
Since we are talking about encodings, I will recommend a resource that from time to time helps to overcome krakozyabry - http://2cyr.com/decode/?lang=ru.The Unicode HOWTO is an official document on where, how, and why Unicode in Python 2.x.
Thank you for the attention. I would be grateful for your comments in private. Add tags
Unicode code points and Russian characters in Java source codes and programs. JDK 1.6.
Enough developers software in fact, do not have a clear understanding of character sets, encodings, Unicode and related materials. Even nowadays, many programs often ignore the character conversions encountered, even programs that seem to be designed with Unicode-friendly Java technologies. Often used carelessly for 8-bit characters, making it impossible to develop good multilingual web applications. This article is a compilation of a series of articles on Unicode encoding, but the foundational article is Joel Spolsky's revised article The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (10/08/2003).The history of the creation of various types of encodings
All the stuff that says "plain text = ASCII = 8-bit characters" is not correct. The only characters that could display correctly under any circumstance were English letters without diacritics with codes 32 to 127. For these characters there is a code called ASCII that was able to represent all characters. The letter "A" would have a code of 65, a space would be a code of 32, and so on. These characters could be conveniently stored in 7 bits. Most computers in those days used 8-bit registers, so not only could you store every possible ASCII character, but you also had a whole bit of savings that, if you had such a whim, you could use for your own purposes. Codes less than 32 were called non-printable and were used for control characters, for example, character 7 caused your computer to emit a speaker beep, and character 12 was the end-of-page character, causing the printer to scroll the current sheet of paper and load a new one.
Since bytes are eight bits, many thought "we can use codes 128-255 for our own purposes." The trouble was that for so many people this idea came almost simultaneously, but everyone had their own ideas about what should be placed in place with codes 128 through 255. The IBM-PC had something that became known as the character set OEM, which had some diacritics for European languages and a set of characters for drawing lines: horizontal stripes, vertical stripes, corners, crosses, etc. And you could use these symbols to make elegant buttons and draw lines on the screen that you can still see on some older computers. For example, on some PCs the character code 130 was shown as e, but on computers sold in Israel it was the Hebrew letter Gimel (?). If Americans sent their resume to Israel, it would arrive as r? Sum ?. In many cases, such as in the case of the Russian language, there were many different ideas as to what to do with the upper 128 characters, and therefore you could not even reliably exchange Russian-language documents.
Ultimately, the variety of OEM encodings was reduced to the ANSI standard. The ANSI standard specified which characters were below 128, this area was basically the same as in ASCII, but there were many different ways handle characters 128 and up depending on where you lived. These various systems have been called code pages. For example, in Israel, DOS used code page 862, while Greek users used page 737. They were the same below 128, but different from 128, where all these characters were located. National versions of MS-DOS supported many of these code pages, handling all languages from English to Icelandic, and there were even a few "multilingual" code pages that Esperanto and Galician could make. group of languages, widespread in Spain, native speakers of 4 million people) on the same computer! But getting, say, Hebrew and Greek on the same computer was absolutely impossible, unless you wrote your own program that displayed everything using bitmap graphics, because Hebrew and Greek required different code pages with different interpretations. major numbers.
Meanwhile in Asia, given the fact that Asian alphabets have thousands of letters that could never fit into 8 bits, this problem was addressed by the convoluted DBCS system, the "double byte character set", in which some characters were stored in one byte, while others took two. It was very easy to move forward along the line, but absolutely impossible to move backward. Programmers could not use s ++ and s-- to move forward and backward, and had to call special functions who knew how to deal with this mess.
However, most people turned a blind eye to the fact that a byte was a character and a character was 8 bits, and as long as you didn't have to move a line from one computer to another, or if you didn't speak more than one language, it worked. But, of course, as soon as the Internet began to be used en masse, it became quite common to transfer lines from one computer to another. The chaos in this matter has been overcome with Unicode.
Unicode
Unicode was a bold attempt to create a single character set that would include all the real writing systems on the planet, as well as some fictional ones. Some people have the misconception that Unicode is a regular 16-bit code where each character is 16 bits long and therefore there are 65,536 possible characters. In fact, this is not true. This is the most common misconception about Unicode.
In fact, Unicode takes an unusual approach to understanding the concept of a character. So far, we've assumed that characters are mapped to a set of bits that you can store on disk or in memory:
A - & gt 0100 0001
In Unicode, a character maps to something called a code point, which is just a theoretical concept. How this code point is represented in memory or on disk is another story. V Unicode letter And this is just a Platonic idea (eidos) (approx.translate: the concept of Plato's philosophy, eidos are ideal entities, devoid of corporeality and are truly objective reality, outside of specific things and phenomena).
A NS that Platonov A is different from B, and different from a, but it's the same A as A and A. Idea that And in Times New Roman it is the same as A in Helvetica, but different from the lowercase "a" does not seem too controversial in people's understanding. But from the point of view of computer science and from the point of view of language, the very definition of a letter is contradictory. Is the German letter ß a real letter or just a fancy way to write ss? If the spelling of a letter at the end of a word changes, does it become a different letter? Hebrew says yes, Arabic says no. Either way, the smart people at the Unicode consortium figured it out after a lot of political debate, and you don't have to worry about it. Everything has already been understood before us.Each Platonic letter in each alphabet has been assigned a magic number by the Unicode consortium, which is written like this: U + 0645. This magic number is called a code point. U + stands for "Unicode" and numbers are hexadecimal. The number U + FEC9 is the Arabic letter Ain. The English letter A corresponds to U + 0041.
There is really no limit to the number of letters that can be identified by Unicode, and in fact they have already crossed the 65,536 limit, so not every letter from Unicode can actually be compressed into two bytes.
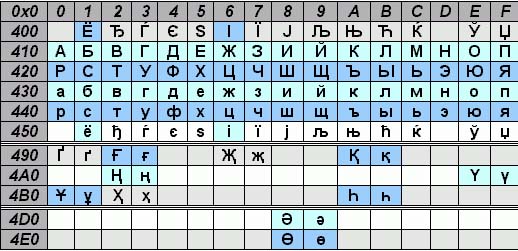
For Cyrillic in UNICODE, the range of codes is from 0x0400 to 0x04FF. This table shows only a part of the characters in this range, but the standard defines most of the codes in this range.
Let's imagine we have a line:
Hey! which, in Unicode, matches these seven code points: U + 041F U + 0440 U + 0438 U + 0432 U + 0435 U + 0442 U + 0021
Just a bunch of code points. The numbers are real.
To see what a Unicode text file will look like, you can run the notepad program in Windows, insert the given line, and on save text file choose Unicode encoding.
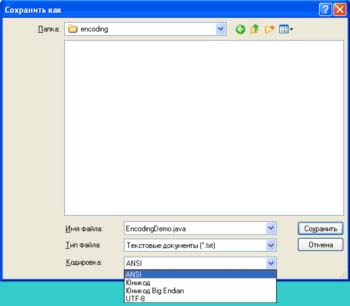
The program offers saving in three varieties Unicode encodings... The first option is a way of writing with the least significant byte in front (little endian), the second with the most significant byte in front (big endian). Which option is correct?
This is what a big endian dump file with the string “Hello!” Looks like:
And this is how a file dump with the string “Hello!” Looks like, saved in Unicode (little endian) format:
And this is how a file dump with the string “Hello!” Looks like, saved in Unicode (UTF-8) format:
Early implementations wanted to be able to store Unicode code points in a high-endian or low-endian format, depending on which format their processor was faster in. Then there were two ways to store Unicode. This led to the fancy convention of storing the \ uFFFE code at the beginning of every Unicode line. This signature is called a byte order mark. If you swap your high and low bytes, then there must be \ uFFFE at the beginning, and the person reading your line will know to swap the bytes in each pair. This signature is reserved in the Unicode standard.
The Unicode standard says that the default byte order is either big endian or little endian. Indeed, both orders are correct, and system designers choose one of them for themselves. Don't worry if your system communicates with another system and both use little endian.
However, if your Windows communicates with a UNIX server that uses big endian, one of the systems must do the transcoding. In this case Unicode standard states that you can choose any of the following solutions to the problem:
- When two systems, using a different Unicode byte order, exchange data (without using any special protocols), the byte order must be big endian. The standard calls it canonical byte order.
- Each Unicode string must begin with a \ uFEFF code. The \ uFFFE code, which is an inversion of the order sign. Therefore, if the recipient sees the code \ uFEFF as the first character, it means that the bytes are in little endian order. However, in reality, not every Unicode string has a byte order mark at the beginning.
The second method is more versatile and preferable.
For a while, everyone seemed happy, but English-speaking programmers looked at mostly English text and rarely used code points above U + 00FF. For this reason alone, Unicode has been ignored by many for several years.
The brilliant concept of UTF-8 was invented specifically for this.
UTF-8
UTF-8 was another system for storing your sequence of Unicode code points, the very U + numbers, using the same 8 bits in memory. In UTF-8, each code point numbered 0 through 127 was stored in a single byte.
In fact, this is an encoding with a variable number of encoding bytes for storage, 2, 3, and, in fact, up to 6 bytes are used. If the character belongs to the ASCII set (code in the range 0x00-0x7F), then it is encoded in the same way as in ASCII in one byte. If the unicode of a character is greater than or equal to 0x80, then its bits are packed into a sequence of bytes according to the following rule:
You may notice that if a byte starts with a zero bit, then it is a single-byte ASCII character. If the byte starts with 11 ..., then this is the start byte of a several-byte sequence that encodes a character, the number of head units of which is equal to the number of bytes in the sequence. If the byte starts with 10 ..., then it is a serial "transport" byte from a sequence of bytes, the number of which was determined by the start byte. well and Unicode bits characters are packed into "transport" bits of the start and serial bytes, indicated in the table as the sequence "xx..x".
The variable number of encoding bytes can be seen from the file dump below.
Dump file with string “Hello!” Saved in Unicode (UTF-8) format:
Dump file with the string “Hello!” Saved in Unicode (UTF-8) format:
A nice side effect of this is that English text looks exactly the same in UTF-8 as it does in ASCII, so Americans don't even notice that something is wrong. Only the rest of the world has to overcome obstacles. Specifically, Hello, what was U + 0048 U + 0065 U + 006C U + 006C U + 006F will now be stored in the same 48 65 6C 6C 6F, just like ASCII and ANSI and any other set OEM symbols on the planet. If you are brave enough to use diacritics or Greek letters or the letters Klingon, you'll have to use multiple bytes to store a single code point, but Americans will never notice. UTF-8 also has a nice feature: old code, ignorant of the new string format, and handling strings with a null byte at the end of the line, will not truncate the strings.
Other Unicode encodings
Let's go back to the three ways to encode Unicode. Traditional methods"store it in two bytes" is called UCS-2 (because it has two bytes) or UTF-16 (because it has 16 bits), and you still have to figure out if it is UCS-2 code with the high byte at the beginning or with the most significant byte at the end. And there is the popular UTF-8 standard, the strings on which have a nice feature to also work in old programs that work with English text, and in new smart programs that perfectly operate on other character sets besides ASCII.
There are actually a whole bunch of other ways to encode Unicode. There is something called UTF-7, which is a lot like UTF-8, but ensures that the most significant bit is always zero. Then there is UCS-4, which stores each code point in 4 bytes and guarantees that absolutely all characters are stored in the same number of bytes, but such a waste of memory is not always justified by such a guarantee.
For example, you can Unicode the string Hello (U + 0048 U + 0065 U + 006C U + 006C U + 006F) in ASCII or old OEM Greek or Hebrew ANSI encoding, or in any of the several hundred encodings that have been invented to this day, with one problem: some of the characters may not be displayed! If there is no equivalent for the Unicode code point for which you are trying to find an equivalent in some code table for which you are trying to do the conversion, you usually get a little question mark:? or, if you are a really good programmer, then a square.
There are hundreds of traditional encodings that can only store some code points correctly and replace all other code points with question marks. For example, some popular English text encodings are Windows 1252 ( Windows standard 9x for Western European languages) and ISO-8859-1, aka Latin-1 (also suitable for any Western European language). But try to convert Russian or Hebrew letters in these encodings, and you will end up with a fair amount of question marks. The great thing about UTF 7, 8, 16, and 32 is their ability to store any code point correctly.
32 bit code points for Unicode characters in Java
Java 2 5.0 introduces significant enhancements to the Character and String types to support 32-bit Unicode characters... In the past, all Unicode characters could be stored in sixteen bits, which are equal to the size of a char value (and the size of the value contained in a Character object), since these values were in the range 0 to FFFF. But for some time, the Unicode character set has been expanded and now requires more than 16 bits to store a character. The new version of the Unicode character sets includes characters ranging from 0 to 10FFFF.
Code point or code point, code unit or code unit, and supplemental character. For Java, a code point is a character code in the range 0 to 10FFFF. In the Java language, the term “code unit” is used to refer to 16-bit characters. Characters with values greater than FFFF are called complementary.
The expansion of the Unicode character set created fundamental problems for Java language... Since the supplementary character has a larger value than the char type can accommodate, some means were required to store and process the extra characters. V Java versions 2 5.0 fixes this problem in two ways. First, the Java language uses two char values to represent an additional character. The first is called the high surrogate and the second is called the low surrogate. New methods have been developed, such as codePointAt (), to convert code points to supplementary characters and vice versa.
Second, Java overloads some of the pre-existing methods in the Character and String classes. The overloaded variants of the methods use data of type int instead of char. Since the size of a variable or constant of type int is large enough to accommodate any character as a single value, this type can be used to store any character. For example, the isDigit () method now has two options, as shown below:
The first of these options is the original, the second is the version that supports 32-bit code points. All is… methods, such as isLetter () and isSpaceChar (), have code point versions, as do to… methods such as toUpperCase () and toLowerCase ().
In addition to the methods overloaded for handling code points, the Java language includes new methods in the Character class that provide additional support for code points. Some of them are listed in the table:
| Method | Description |
| static int charCount (int cp) | Returns 1 if cp can be represented by a single char. Returns 2 if two char values are required. |
| static int codePointAt (CharSequence chars, int loc) | |
| static int codePointAt (char chars, int loc) | Returns the code point for the character position specified in the loc parameter |
| static int codePointBefore (CharSequence chars, int loc) | |
| static int codePointBefore (char chars, int loc) | Returns the code point for the character position preceding the one given in the loc parameter |
| static boolean isSupplementaryCodePoint (int cp) | Returns true if cp contains an extra character |
| static boolean isHighSurrogate (char ch) | Returns true if ch contains a valid upper character surrogate. |
| static boolean isLowSurrogate (char ch) | Returns true if ch contains a valid lower character surrogate. |
| static boolean isSurrogatePair (char highCh, char lowCh) | Returns true if highCh and lowCh form a valid surrogate pair. |
| static boolean isValidCodePoint (int cp) | Returns true if cp contains a valid code point. |
| static char toChars (int cp) | Converts the code point contained in cp to its char equivalent, which may require two char values. Returns an array containing the result ... Append !!! |
| static int toChars (int cp, char target, int loc) | Converts the code point contained in cp to its char equivalent, stores the result in target, starting at the position specified in loc. Returns 1 if cp can be represented by a single char, and 2 otherwise. |
| static int toCodePoint (char ighCh, char lowCh) | Converts highCh and lowCh to their equivalent code points. |
The String class has a number of methods for handling code points. The following constructor has also been added to the String class to support the extended Unicode character set:
String (int codePoints, int startIndex, int numChars)
In the above syntax, codePoints is an array containing code points. The resulting string of length numChars is formed, starting from the startIndex position.
Several methods of the String class that provide 32-bit code point support for Unicode characters.
Console output in Windows. Chcp command
Majority simple programs written in Java output any data to the console. Console output provides the ability to choose the encoding in which your program's data will be output. You can launch the console window by clicking Start -> Run, and then enter and run cmd command... By default, output to the console in Windows is in Cp866 encoding. To find out in what encoding the characters are displayed in the console, you should type the chcp command. Using the same command, you can set the encoding in which the characters will be displayed. For example chcp 1251. In fact, this command is only created to reflect or change the current code page number of the console.
Codepages other than Cp866 will only display correctly in full screen mode or in a window command line using TrueType fonts. For example:
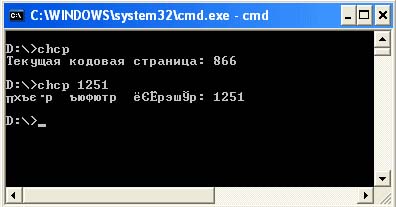
In order to see the subsequent output, you need to change the current font to a True Type font. Move the cursor over the title of the console window, click right click mouse and select the "Properties" option. In the window that appears, go to the Font tab and in it select the font opposite which there will be a double letter T. You will be prompted to save this setting for the current window or for all windows.
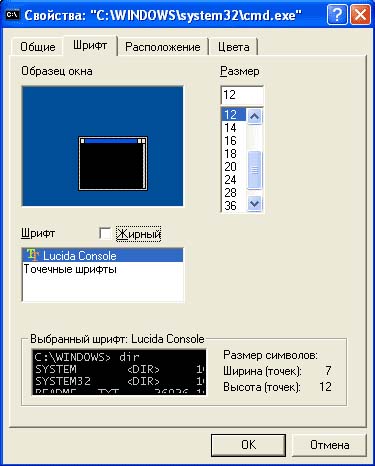
As a result, your console window will look like this:
Thus, by manipulating this command, you can see the results of the output of your program, depending on the encoding.
System properties file.encoding, console.encoding and console output
Before touching on the topic of encodings in source codes of programs, you should clearly understand what they are for and how the file.encoding and console.encoding system properties work. In addition to these system properties, there are a number of others. You can display all current system properties using the following program:
Import java.io. *; import java.util. *; public class getPropertiesDemo (public static void main (String args) (String s; for (Enumeration e = System.getProperties (). propertyNames (); e.hasMoreElements ();) (s = e.nextElement (). toString () ; System.out.println (s + "=" + System.getProperty (s));)))
Sample program output:
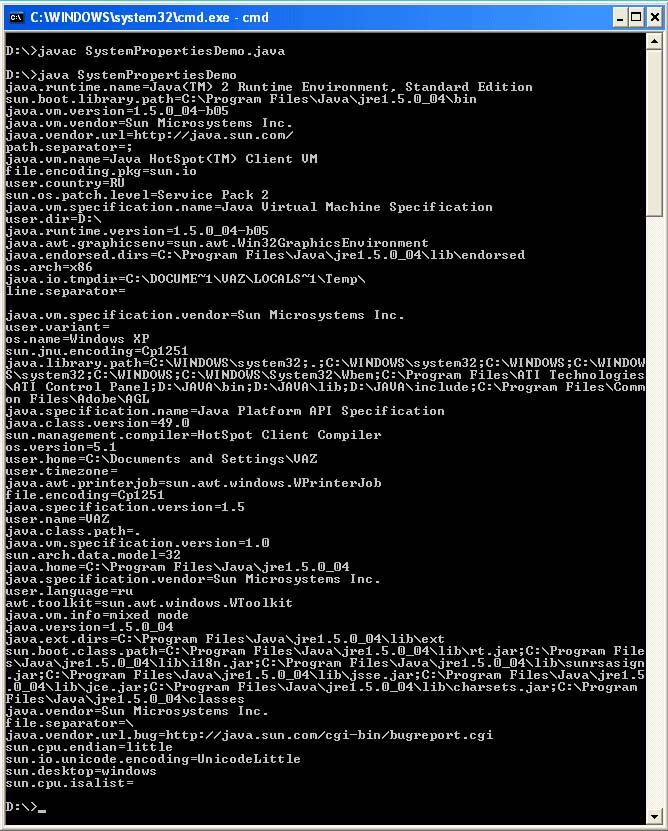
In Windows operating system, by default file.encoding = Сp1251. However, there is another property, console.encoding, which specifies in which encoding to output to the console. file.encoding tells the Java machine in which encoding to read the source codes of programs, if the encoding is not specified by the user during compilation. In fact, this system property also applies to output using System.out.println ().
By default, this property is not set. These system properties can also be set in your program, however, this will no longer be relevant for it, since the virtual machine uses the values that were read before compiling and running your program. Also, as soon as your program runs, the system properties are restored. You can verify this by running the following program twice.
/ ** * @author & lta href = "mailto: zag [email protected]"& gt Victor Zagrebin & lt / a & gt * / public class SetPropertyDemo (public static void main (String args) (System.out.println (" file.encoding before = "+ System.getProperty (" file.encoding ")); System. out.println ("console.encoding before =" + System.getProperty ("console.encoding")); System.setProperty ("file.encoding", "Cp866"); System.setProperty ("console.encoding", " Cp866 "); System.out.println (" file.encoding after = "+ System.getProperty (" file.encoding ")); System.out.println (" console.encoding after = "+ System.getProperty (" console .encoding "));)) 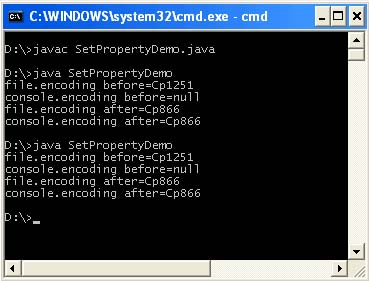
Setting these properties in the program is necessary when it is used in the subsequent code before the program terminates.
Let us reproduce a number of typical examples with problems that programmers encounter during output. Let's say we have the following program:
Public class CyryllicDemo (public static void main (String args) (String s1 = ""; String s2 = ""; System.out.println (s1); System.out.println (s1);)) In addition to this program, we will operate additional factors:
- compilation command;
- launch command;
- program source code encoding (installed in most text editors);
- console output encoding (Cp866 is used by default or set using the chcp command);
- visible output in the console window.
javac CyryllicDemo.java
java CyryllicDemo
File encoding: Cp1251
Console encoding: Cp866
Output :
└┴┬├─┼╞╟╚╔╩╦╠═╬╧╨╤╥╙╘╒╓╫╪┘▄█┌▌▐ ▀
rstufhtschshshch'yueyuyoЄєЇїЎў °∙№√ ·¤■
javac CyryllicDemo.java
File encoding: Cp866
Console encoding: Cp866
Output :
CyryllicDemo.java:5: warning: unmappable character for encoding Cp1251
String s1 = "ABVGDEZHZYKLMNOPRSTUFHTSCH? SHY'EUYA";
javac CyryllicDemo.java -encoding Cp866
java -
File encoding: Cp 866
Console encoding: Cp866
Output :
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshshchyyueyuya
javac CyryllicDemo.java -encoding Cp1251
java -Dfile.encoding = Cp866 CyryllicDemo
File encoding: Cp1251
Console encoding: Cp866
Output :
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshshchyyueyuya
Particular attention should be paid to the problem "Where did the letter Ш go?" from the second series of launches. You should be even more attentive to this problem if you do not know in advance what text will be stored in the output string, and, naively, will compile without specifying the encoding. If you really do not have the letter Ш in the line, then the compilation will be successful and the launch will also be successful. And on this you will even forget that you are missing a trifle (the letter W), which can potentially occur in the output line and will inevitably lead to further errors.
In the third and fourth series, when compiling and running, the following keys are used: -encoding Cp866 and -Dfile.encoding = Cp866. The -encoding switch specifies in which encoding to read the file from source code programs. The -Dfile.encoding = Cp866 switch indicates in what encoding should be output.
Unicode prefix \ u and Russian characters in source codes
Java has a special prefix \ u for writing Unicode characters, followed by four hexadecimal digits that define the character itself. For example, \ u2122 is the character brand(™). This form of notation expresses a character of any alphabet using numbers and a prefix - characters that are contained in the stable range of codes from 0 to 127, which is not affected when the source code is converted. And, theoretically, any Unicode character can be used in a Java application or applet, but whether it will display correctly on the display screen and whether it will display at all depends on many factors. For applets, the type of browser matters, and for programs and applets, the type of operating system and the encoding in which the source code of the program is written matters.
For example, on computers running the American version Windows systems, it is not possible to display Japanese characters using Java language due to internationalization issue.
As a second example, we can cite quite a common mistake of programmers. Many people think that specifying Russian characters in Unicode format using the \ u prefix in the source code of the program can solve the problem of displaying Russian characters under any circumstances. After all, the Java virtual machine translates the source code of the program into Unicode. However, before translating to Unicode, the virtual machine must know what encoding your program's source code is written in. After all, you can write a program both in Cp866 (DOS) and Cp1251 (Windows) encoding, which is typical for this situation. If you have not specified any encoding, the Java virtual machine reads your file with the source code of the program in the encoding specified in the system property file.encoding.
However, back to the default parameters, we will assume that file.encoding = Сp1251, and the output to the console is done in Cp866. It is in this case that the following situation comes out: let's say you have a file encoded in Сp1251:
MsgDemo1.java file
Public class MsgDemo1 (public static void main (String args) (String s = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A \ u0430"; System.out.println (s );))
And you expect the word “encoding” to be printed to the console, but you get:
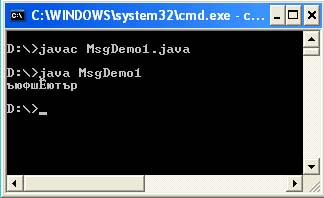
The fact is that the codes with the \ u prefix listed in the program really encode the required Cyrillic characters in the Unicode code table, however, they are designed for the fact that the source code of your program will be read in Cp866 (DOS) encoding. By default, the Cp1251 encoding is specified in the system properties (file.encoding = Cp1251). Naturally, the first and wrong thing that comes to mind is to change the encoding of the file with the source code of the program in a text editor. But that won't get you anywhere. The Java VM will still read your file in Cp1251 encoding, and the \ u codes are for Cp866.
There are three ways out of this situation. The first option is to use the -encoding switch at compile time and –Dfile.encoding at the program launch stage. In this case, you force the Java virtual machine to read the source file in the specified encoding and output in the specified encoding.
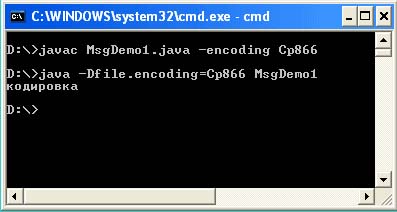
As you can see from the console output, the additional parameter –encoding Cp866 must be set during compilation, and the –Dfile.encoding = Cp866 parameter must be set at startup.
The second option is to recode the characters in the program itself. It is designed to restore correct letter codes if they have been misinterpreted. The essence of the method is simple: from the received incorrect characters, using the appropriate code page, the original byte array is restored. Then, from this array of bytes, using the already correct page, the normal character codes are obtained.
To convert a stream of bytes to a String and vice versa, the String class has the following capabilities: the String constructor (byte bytes, String enc), which receives a stream of bytes as input with an indication of their encoding; if you omit the encoding, it will accept the default encoding from the system property file.encoding. The getBytes (String enc) method returns a stream of bytes written in the specified encoding; the encoding can also be omitted and the default encoding from the file.encoding system property will be accepted.
Example:
MsgDemo2.java file
Import java.io.UnsupportedEncodingException; public class MsgDemo2 (public static void main (String args) throws UnsupportedEncodingException (String str = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A \ u0430"; byte b = str getBytes ("Cp866"); String str2 = new String (b, "Cp1251"); System.out.println (str2);))
Output of the program:
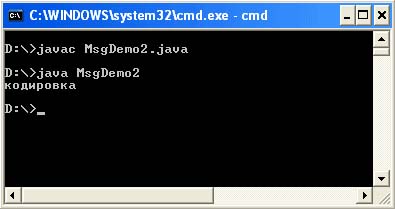
This method is less flexible if you are guided by the fact that the encoding in the file.encoding system property will not change. However, this method can become the most flexible if you poll the file.encoding system property and substitute the resulting encoding value when forming strings in your program. Using this method you should be careful that not all pages perform an unambiguous conversion of byte char.
The third way is to select the correct Unicode codes for displaying the word “encoding” on the assumption that the file will be read in the default encoding - Cp1251. For these purposes, there is special utility native2ascii.
This utility is part of the Sun JDK and is designed to convert source code to ASCII format. When launched without parameters, it works with standard input (stdin), and does not display a key hint like other utilities. This leads to the fact that many do not even realize that it is necessary to specify parameters (except for those who have looked at the documentation). Meanwhile, this utility for correct work you must, at a minimum, specify the encoding used using the -encoding switch. If this is not done, then the default encoding (file.encoding) will be used, which may differ somewhat from the expected one. As a result, having received incorrect letter codes (due to incorrect encoding), you can spend a lot of time looking for errors in an absolutely correct code.
The following screenshot shows the difference in Unicode code sequences for the same word when the source file will be read in Cp866 encoding and Cp1251 encoding.
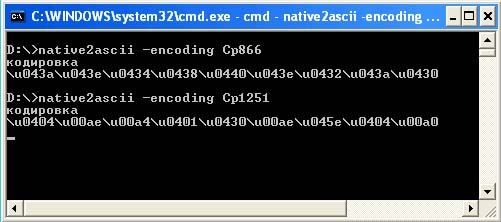
Thus, if you do not force encoding for virtual machine Java at compile time and at startup, and the default encoding (file.encoding) is Cp1251, then the source code of the program should look like this:
MsgDemo3.java file
Public class MsgDemo3 (public static void main (String args) (String s = "\ u0404 \ u00AE" + "\ u00A4 \ u0401 \ u0430 \ u00AE \ u045E" + "\ u0404 \ u00A0"; System.out.println (s );)) 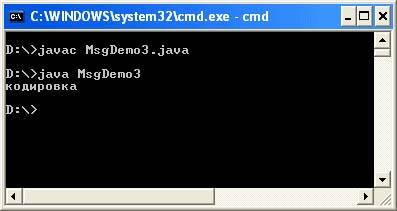
Using the third method, we can conclude: if the encoding of the file with the source code in the editor coincides with the encoding in the system, then the “encoding” message will appear in its normal form.
Reading and writing to a file Russian characters expressed by Unicode prefix \ u
To read data written in both MBCS format (using UTF-8 encoding) and Unicode, you can use the InputStreamReader class from the java.io package, substituting various encodings in its constructor. An OutputStreamWriter is used for writing. The description of the java.lang package says that each JVM implementation will support the following encodings:
WriteDemo.java file
Import java.io.Writer; import java.io.OutputStreamWriter; import java.io.FileOutputStream; import java.io.IOException; / ** * Output a Unicode string to a file in the specified encoding. * @author & lta href = "mailto: [email protected]"& gt Victor Zagrebin & lt / a & gt * / public class WriteDemo (public static void main (String args) throws IOException (String str =" \ u043A \ u043E "+" \ u0434 \ u0438 \ u0440 \ u043E \ u0432 "+" \ u043A \ u0430 "; Writer out1 = new OutputStreamWriter (new FileOutputStream (" out1.txt ")," Cp1251 "); Writer out2 = new OutputStreamWriter (new FileOutputStream (" out2.txt ")," Cp866 "); Writer out3 = new OutputStreamWriter (new FileOutputStream ("out3.txt"), "UTF-8"); Writer out4 = new OutputStreamWriter (new FileOutputStream ("out4.txt"), "Unicode"); out1.write (str); out1.close (); out2.write (str); out2.close (); out3.write (str); out3.close (); out4.write (str); out4.close ();)) Compilation: javac WriteDemo.java Run: java WriteDemo
As a result of program execution, four files should be created (out1.txt out2.txt out3.txt out4.txt) in the program launch directory, each of which will contain the word “encoding” in a different encoding, which can be checked in text editors or by viewing a file dump.
The following program will read and display the contents of each of the generated files.
ReadDemo.java file import java.io.Reader; import java.io.InputStreamReader; import java.io.InputStream; import java.io.FileInputStream; import java.io.IOException; / ** * Read Unicode characters from a file in the specified encoding. * @author & lta href = "mailto: [email protected]"& gt Victor Zagrebin & lt / a & gt * / public class ReadDemo (public static void main (String args) throws IOException (String out_enc = System.getProperty (" console.encoding "," Cp866 "); System.out.write (readStringFromFile ( "out1.txt", "Cp1251", out_enc)); System.out.write ("\ n"); System.out.write (readStringFromFile ("out2.txt", "Cp866", out_enc)); System. out.write ("\ n"); System.out.write (readStringFromFile ("out3.txt", "UTF-8", out_enc)); System.out.write ("\ n"); System.out. write (readStringFromFile ("out4.txt", "Unicode", out_enc));) public static byte readStringFromFile (String filename, String file_enc, String out_enc) throws IOException (int size; InputStream f = new FileInputStream (filename); size = f.available (); Reader in = new InputStreamReader (f, file_enc); char ch = new char; in.read (ch, 0, size); in.close (); return (new String (ch)). getBytes (out_enc);)) Compilation: javac ReadDemo.java Run: java ReadDemo Output of the program: 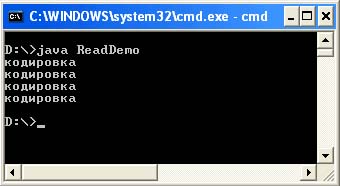
Of particular note is the use of the following line of code in this program:
String out_enc = System.getProperty ("console.encoding", "Cp866");
Using the getProperty method, an attempt is made to read the value of the console.encoding system property, which sets the encoding in which data will be output to the console. If this property is not set (often it is not set), then the variable out_enc will be assigned "Cp866". And further, the variable out_enc is used where it is necessary to convert a string read from a file to an encoding suitable for output to the console.
Also, a logical question arises: “why is System.out.write used and not System.out.println”? As described above, the system property file.encoding is used not only to read the source file, but also to output using System.out.println, which in this case will lead to incorrect output.
Incorrect display of encoding in web-oriented programs
The programmer should first of all know: it doesn't make sense to have a string without knowing what encoding it is using... There is no such thing as plain text in ASCII. If you have a string, in memory, in a file, or in a message Email, you must know what encoding it is in, otherwise you will not be able to interpret it correctly or show it to the user.
Almost all the traditional problems like "my website looks like gibberish" or "my emails are unreadable if I use accented characters" are the responsibility of the programmer who does not understand the simple fact that if you do not know what encoding the UTF-8 string is in or ASCII or ISO 8859-1 (Latin-1) or Windows 1252 (Western European), you just won't be able to output it correctly. There are over a hundred character encodings above code point 127, and there is no information to figure out which encoding is needed. How do we store information about what encoding strings use? Exists standard methods to indicate this information. For email messages, you must put the line in the HTTP header
Content-Type: text / plain; charset = "UTF-8"
For the web page, the original idea was that the web server would send the HTTP header itself, just before HTML page... But this causes certain problems. Suppose you have a large web server with a large number of sites and hundreds of pages created by a large number of people on a huge number different languages and they all don't use a specific encoding. The web server itself really cannot know what encoding each file is, and therefore cannot send a header specifying the Content-Type. Therefore, to indicate the correct encoding in the http header, it remained to keep the encoding information inside the html file by inserting a special tag. The server would then read the name of the encoding from the meta tag and put it in the HTTP header.
The pertinent question arises: “how to start reading an HTML file until you know what encoding it uses ?! Fortunately, almost all encodings use the same character table with codes from 32 to 127, and the HTML code itself consists of these characters, and you may not even see encoding information in the html file if it consists entirely of such characters. Therefore, ideally, the & ltmeta & gt tag indicating the encoding should really be in the very first line in the & lthead & gt section, because as soon as the web browser sees this sign, it will stop parsing the page and start all over again using the encoding you specified.
& lthtml & gt & lthead & gt & ltmeta http-equiv = "Content-Type" content = "text / html; charset = utf-8" & gt
What do web browsers do if they don't find any Content-Type, neither in the http header nor in the Meta tag? Internet Explorer in fact it does something quite interesting: it tries to recognize the encoding and language based on the frequency with which different bytes appear in typical text in typical encodings of different languages. Since different old 8-byte code pages have placed differently National symbols between 128 and 255, and since all human languages have different frequency probabilities of using letters, this approach often works well.
It's quite bizarre, but it does seem to work quite often, and naive web page authors who never knew they needed a Content-Type tag in their page titles in order for the pages to display correctly until that beautiful day. when they write something that doesn't exactly match the typical frequency distribution of their native language letters, and Internet Explorer decides it's Korean and displays it accordingly.
Anyway, what is left for the reader of this website, which was written in Bulgarian but displayed in Korean (and not even meaningful Korean)? It uses the View | Encoding and tries several different encodings (there are at least a dozen for Eastern European languages) until the picture is clearer. If, of course, he knows how to do it, because most people do not know this.
It is worth noting that for UTF-8, which has been perfectly supported by web browsers for years, no one has yet encountered a problem with the correct display of web pages.
Links:
- Joel Spolsky. The absolute minimum every software developer absolutely, positively must know about Unicode and character sets (No Excuses!) 10/08/2003 http://www.joelonsoftware.com/articles/Unicode.html
- Sergey Astakhov.
- Sergey Semikhatov. ... 08.2000 - 27.07.2005
- Horstman K.S., Cornell G. Library of the professional. Java 2. Volume 1. Basics. - M .: Williams Publishing House, 2003 .-- 848 p.
- Dan Chisholms. Java Programmer Mock Exams. Objective 2, InputStream and OutputStream Reader / Writer. Java Character Encoding: UTF and Unicode. http://www.jchq.net/certkey/1102_12certkey.htm
- Package java.io. JavaTM 2 Platform Standard Edition 6.0 API Specification.
Unicode: UTF-8, UTF-16, UTF-32.
Unicode is a set of graphical characters and a way of encoding them for computer processing of text data.
Unicode not only assigns to each character unique code, but also defines various characteristics of this symbol, for example:
character type (uppercase letter, lowercase letter, number, punctuation mark, etc.);
character attributes (left-to-right or right-to-left display, space, line break, etc.);
the corresponding uppercase or lowercase letter (for lowercase and uppercase letters respectively);
the corresponding numeric value (for numeric characters).
Standards UTF(abbreviation for Unicode Transformation Format) to represent characters:
UTF-16: Windows Vista uses UTF-16 to represent all Unicode characters. In UTF-16, characters are represented by two bytes (16 bits). This encoding is used in Windows because 16-bit values can represent the characters that make up the alphabets of most languages in the world, this allows programs to process strings and calculate their length faster. However, 16-bit is not enough to represent alphabetical characters in some languages. For such cases, UTE-16 supports "surrogate" encodings, allowing characters to be encoded in 32 bits (4 bytes). However, there are few applications that have to deal with the characters of such languages, so UTF-16 is a good compromise between saving memory and ease of programming. Note that in the .NET Framework all characters are encoded using UTF-16, so using UTF-16 in Windows applications improves performance and reduces memory consumption when passing strings between native and managed code.
UTF-8: In UTF-8 encoding, different characters can be represented by 1,2,3 or 4 bytes. Characters with values less than 0x0080 are compressed to 1 byte, which is very convenient for US characters. Characters that match values in the range 0x0080-0x07FF are converted to 2-byte values, which works well with European and Middle Eastern alphabets. Characters with larger values are converted to 3-byte values, useful for working with Central Asian languages. Finally, surrogate pairs are written in 4-byte format. UTF-8 is an extremely popular encoding. However, it is less effective than UTF-16 if characters with values 0x0800 and higher are frequently used.
UTF-32: In UTF-32, all characters are represented by 4 bytes. This encoding is convenient for writing simple algorithms for enumerating characters in any language that do not require processing characters represented by a different number of bytes. For example, when using UTF-32, you can forget about "surrogates", since any character in this encoding is represented by 4 bytes. Clearly, from a memory usage standpoint, UTF-32's efficiency is far from ideal. Therefore, this encoding is rarely used to transfer strings over the network and save them to files. Typically, UTF-32 is used as an internal format for presenting data in a program.
UTF-8
In the near future, a special Unicode (and ISO 10646) format called UTF-8... This "derived" encoding uses strings of bytes of various lengths (from one to six) to write characters, which are converted to Unicode codes using a simple algorithm, with shorter strings corresponding to more common characters. The main advantage of this format is compatibility with ASCII not only in the values of the codes, but also in the number of bits per character, since one byte is enough to encode any of the first 128 characters in UTF-8 (although, for example, for Cyrillic letters, two bytes).
The UTF-8 format was invented on September 2, 1992 by Ken Thompson and Rob Pike and implemented in Plan 9. The UTF-8 standard is now formalized in RFC 3629 and ISO / IEC 10646 Annex D.
For a web designer, this encoding is of particular importance, since it is it that has been declared the "standard document encoding" in HTML since version 4.
Text containing only characters numbered less than 128 is converted to plain ASCII text when written in UTF-8. Conversely, in UTF-8 text, any byte with a value less than 128 represents an ASCII character with the same code. The rest of the Unicode characters are represented by sequences from 2 to 6 bytes long (actually only up to 4 bytes, since the use of codes greater than 221 is not planned), in which the first byte always looks like 11xxxxxx, and the rest - 10xxxxxx.
Simply put, in UTF-8 format, Latin characters, punctuation marks and control ASCII characters are written in US-ASCII codes, and all other characters are encoded using several octets with the most significant bit of 1. This has two effects.
Even if the program does not recognize Unicode, Latin letters, Arabic numerals and punctuation marks will be displayed correctly.
If Latin letters and simple punctuation marks (including space) occupy a significant amount of text, UTF-8 gives a gain in volume compared to UTF-16.
At first glance, it might seem that UTF-16 is more convenient, since most characters are encoded in exactly two bytes. However, this is negated by the need to support surrogate pairs, which are often overlooked when using UTF-16, implementing only support for UCS-2 characters.
Unicode
From Wikipedia, the free encyclopedia
Go to: navigation, Search
Unicod (most often) or Unicode (English Unicode) - standard character encoding, allowing you to represent the signs of almost all written languages.
Standard proposed in 1991 year non-profit organization "Unicode Consortium" ( English Unicode Consortium, Unicode Inc. ). The use of this standard allows a very large number of characters from different scripts to be encoded: Chinese hieroglyphs, math symbols, letters Greek alphabet, latin and cyrillic, in this case it becomes unnecessary to switch code pages.
The standard consists of two main sections: the universal character set ( English UCS, universal character set) and the family of encodings ( English. UTF, Unicode transformation format). Universal character set specifies one-to-one correspondence between characters codes- elements of the code space representing non-negative integers. The family of encodings defines the machine representation of a sequence of UCS codes.
Unicode codes are divided into several areas. Area with codes from U + 0000 to U + 007F contains dialing characters ASCII with the corresponding codes. Next are the areas of signs of various scripts, punctuation marks and technical symbols. Some of the codes are reserved for future use. Under the Cyrillic characters, areas of characters with codes from U + 0400 to U + 052F, from U + 2DE0 to U + 2DFF, from U + A640 to U + A69F (see. Cyrillic in Unicode).
1 Prerequisites for the creation and development of Unicode 2 Unicode versions 3 Code space 4 Coding system 5 Modifying characters 6 Forms of normalization 7 Bidirectional writing 8 Featured Symbols 9 ISO / IEC 10646 10 Ways of presentation 11 Input Methods 12 Unicode Problems 13 "Unicode" or "Unicode"? 14 See also |
Prerequisites for the creation and development of Unicode
By the end 1980s 8-bit characters became the standard, while there were many different 8-bit encodings, and new ones constantly appeared. This was explained both by the constant expansion of the range of supported languages, and by the desire to create an encoding partially compatible with some other (a typical example is the emergence alternative encoding for the Russian language, due to the exploitation of Western programs created for encoding CP437). As a result, several problems appeared:
Problem " krakozyabr»(Displaying documents in the wrong encoding): it could be solved either by consistently introducing methods for specifying the encoding used, or by introducing a single encoding for all.
Limited character set problem: it could be solved either by switching fonts within the document, or by introducing a "wide" encoding. Font switching has long been practiced in word processors, and were often used fonts with non-standard encoding, t. n. "Dingbat fonts" - as a result, when trying to transfer a document to another system, all non-standard characters turned into krakozyabry.
The problem of converting one encoding to another: it could be solved either by compiling conversion tables for each pair of encodings, or by using an intermediate conversion to a third encoding that includes all characters of all encodings.
The problem of font duplication: traditionally, for each encoding, a different font was made, even if these encodings partially (or completely) coincided in the set of characters: this problem could be solved by making "large" fonts, from which the characters needed for this encoding are then selected - however requires the creation of a single registry of symbols to determine which matches.
It was considered necessary to create a single "wide" encoding. Variable-length encodings, widely used in East Asia, were found to be too difficult to use, so it was decided to use fixed-width characters. Using 32-bit characters seemed too wasteful, so it was decided to use 16-bit ones.
Thus, the first version of Unicode was an encoding with a fixed character size of 16 bits, that is, the total number of codes was 2 16 (65 536). From here comes the practice of naming characters with four hexadecimal digits (for example, U + 04F0). At the same time, it was planned to encode in Unicode not all existing characters, but only those that are necessary in everyday life. Rarely used symbols had to be placed in the "private use area", which originally occupied the U + D800… U + F8FF codes. In order to use Unicode also as an intermediate in converting different encodings to each other, all characters represented in all the most famous encodings were included in it.
In the future, however, it was decided to encode all the symbols and, in connection with this, significantly expand the code domain. At the same time, character codes began to be viewed not as 16-bit values, but as abstract numbers that can be represented in a computer by a set different ways(cm. Presentation methods).
Since in a number of computer systems (for example, Windows NT ) fixed 16-bit characters were already used as the default encoding, it was decided to encode all the most important characters only within the first 65 536 positions (the so-called English basic multilingual plane, BMP). The rest of the space is used for "extra characters" ( English supplementary characters): writing systems of extinct languages or very rarely used Chinese hieroglyphs, mathematical and musical symbols.
For compatibility with older 16-bit systems, the system was invented UTF-16, where the first 65,536 positions, with the exception of positions from the U + D800 ... U + DFFF interval, are displayed directly as 16-bit numbers, and the rest are represented as "surrogate pairs" (the first element of a pair from the U + D800 ... U + DBFF , the second element of the pair from the region U + DC00 ... U + DFFF). For surrogate pairs, a portion of the code space (2048 positions) previously reserved for "characters for private use" was used.
Since UTF-16 can display only 2 20 + 2 16 −2048 (1 112 064) characters, this number was chosen as the final value for the Unicode code space.
Although the Unicode code area was extended beyond 2-16 as early as version 2.0, the first characters in the "top" area were only placed in version 3.1.
The role of this encoding in the web sector is constantly growing, at the beginning of 2010 the share of websites using Unicode was about 50%.
Unicode versions
As the Unicode character table changes and replenishes and new versions of this system are released - and this work is being done constantly, since initially the Unicode system included only Plane 0 - two-byte codes - new documents are also coming out. ISO... The Unicode system exists in total in the following versions:
1.1 (complies with ISO / IEC 10646-1: 1993 ), standard 1991-1995.
2.0, 2.1 (same standard ISO / IEC 10646-1: 1993 plus additions: "Amendments" 1 to 7 and "Technical Corrigenda" 1 and 2), 1996 standard.
3.0 (ISO / IEC 10646-1: 2000 standard) 2000 standard.
3.1 (ISO / IEC 10646-1: 2000 and ISO / IEC 10646-2: 2001 standards) 2001 standard.
3.2, standard 2002 year.
4.0 standard 2003 .
4.01, standard 2004 .
4.1, standard 2005 .
5.0, standard 2006 .
5.1, standard 2008 .
5.2, standard 2009 .
6.0, standard 2010 .
6.1, standard 2012 .
6.2, standard 2012 .
Code space
Although the notation forms UTF-8 and UTF-32 allow up to 2,331 (2,147,483,648) code points to be encoded, it was decided to use only 1,112,064 for compatibility with UTF-16. However, even this is more than enough for the moment - in version 6.0 slightly less than 110,000 code points (109,242 graphic and 273 other symbols) are used.
The code space is split into 17 planes 2 16 (65536) characters each. The zero plane is called basic, it contains the symbols of the most common scripts. The first plane is used mainly for historical scripts, the second for rarely used hieroglyphs. CJK, the third is reserved for archaic Chinese characters ... Planes 15 and 16 are reserved for private use.
To denote Unicode characters, use the notation like "U + xxxx"(For codes 0 ... FFFF), or" U + xxxxx"(For codes 10000 ... FFFFF), or" U + xxxxxx"(For codes 100000 ... 10FFFF), where xxx - hexadecimal numbers. For example, the character "i" (U + 044F) has the code 044F 16 = 1103 10 .
Coding system
The Universal Coding System (Unicode) is a set of graphic symbols and a way of encoding them for computer processing of text data.
Graphic symbols are symbols that have a visible image. Graphical characters are opposed to control and formatting characters.
Graphic symbols include the following groups:
punctuation marks;
special characters ( mathematical, technical, ideograms etc.);
separators.
Unicode is a system for the linear representation of text. Characters with additional superscripts or subscripts can be represented as a sequence of codes built according to certain rules (composite character) or as a single character (monolithic version, precomposed character).
Modifying characters
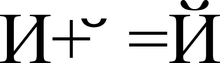
Representation of the character "Y" (U + 0419) in the form of the base character "I" (U + 0418) and the modifying character "" (U + 0306)
Graphic characters in Unicode are divided into extended and non-extended (widthless). Non-extended characters when displayed do not take up space in line... These include, in particular, accent marks and other diacritics... Both extended and non-extended characters have their own codes. Extended characters are otherwise called basic ( English base characters), and non-extended ones - modifying ( English combining characters); and the latter cannot meet independently. For example, the character "á" can be represented as a sequence of the base character "a" (U + 0061) and the modifier character "́" (U + 0301), or as a monolithic character "á" (U + 00C1).
A special type of modifying characters are face style selectors ( English variation selectors). They only apply to those symbols for which such variants are defined. In version 5.0, style options are defined for a series mathematical symbols, for symbols of traditional Mongolian alphabet and for symbols Mongolian square writing.
Normalization forms
Since the same characters can be represented by different codes, which sometimes complicates processing, there are normalization processes designed to bring text to a certain standard form.
The Unicode standard defines 4 forms of text normalization:
The S symbol is initial if it has a modification class of zero in the Unicode character base.
In any sequence of characters starting with an initial character S, a character C is blocked from S if and only if there is any character B between S and C that is either an initial character or has the same or greater modification class than C. This rule applies only to strings that have gone through canonical decomposition.
Primary a composite is a symbol that has a canonical decomposition in the Unicode character base (or canonical decomposition for Hangul and it is not included in exclusion list).
The X character can be primary aligned with the Y character if and only if there is a primary composite Z canonically equivalent to the sequence
If the next character C is not blocked by the last encountered initial base character L and it can be successfully aligned with it, then L is replaced by the composite L-C, and C is removed.
Normalization Form D (NFD) - Canonical Decomposition. In the process of converting the text into this form, all compound characters are recursively replaced by several compound ones, in accordance with the decomposition tables.
Normalization Form C (NFC) is canonical decomposition followed by canonical composition. First, the text is reduced to the D form, after which the canonical composition is performed - the text is processed from beginning to end and the following rules are followed:
Normalization Form KD (NFKD) - Compatible Decomposition. When cast into this form, all composite characters are replaced using both the canonical Unicode decomposition maps and compatible decomposition maps, after which the result is placed in canonical order.
Normalization Form KC (NFKC) - Compatible Decomposition followed by canonical composition.
The terms "composition" and "decomposition" mean, respectively, the connection or decomposition of symbols into their constituent parts.
Examples of
|
Source text | ||||
|
\ u0410, \ u0401, \ u0419 |
\ u0410, \ u0415 \ u0308, \ u0418 \ u0306 |
\ u0410, \ u0401, \ u0419 |
||
Bi-directional letter
The Unicode standard supports writing languages in both left-to-right ( English left- to- right, Ltr), and with writing from right to left ( English right- to- left, RTL) - for example, arabic and Jewish letter. In both cases, the characters are stored in a "natural" order; their display, taking into account the desired direction of the letter, is provided by the application.
In addition, Unicode supports combined texts that combine fragments with different directions of the letter. This feature is called bidirectionality (English bidirectional text, BiDi). Some simplified text processors (for example, in cell phones) can support Unicode, but not bidirectional support. All Unicode characters are divided into several categories: written from left to right, written from right to left, and written in any direction. The symbols of the last category (mainly punctuation marks) when displayed, take the direction of the surrounding text.
Featured symbols
Main article: Characters represented in Unicode

Unicode base plane schema, see description
Unicode includes almost all modern writing, including:
Arab,
Armenian,
Bengali,
Burmese,
verb,
Greek,
Georgian,
devanagari,
Jewish,
Cyrillic,
Chinese(Chinese characters are actively used in Japanese, and also quite rarely in Korean),
Coptic,
Khmer,
Latin,
Tamil,
Korean (Hangul),
cherokee,
Ethiopian,
Japanese(which includes besides Chinese characters also syllabary),
other.
Many historical scripts have been added for academic purposes, including: Germanic runes, ancient Turkic runes, ancient greek, Egyptian hieroglyphs, cuneiform, Maya writing, Etruscan alphabet.
Unicode provides a wide range of mathematical and musical characters as well pictograms.
However, Unicode fundamentally does not include company and product logos, although they are found in fonts (for example, the logo Apple encoded MacRoman(0xF0) or logo Windows in font Wingdings (0xFF)). In Unicode fonts, logos must be placed in the custom character area only.
ISO / IEC 10646
The Unicode Consortium works closely with the ISO / IEC / JTC1 / SC2 / WG2 working group, which is developing the international standard 10646 ( ISO/IEC 10646). Synchronization is established between the Unicode standard and ISO / IEC 10646, although each standard uses its own terminology and documentation system.
Cooperation of the Unicode Consortium with the International Organization for Standardization ( English International Organization for Standardization, ISO) started in 1991 year... V 1993 year ISO has released the DIS 10646.1 standard. To synchronize with it, the Consortium approved the version 1.1 of the Unicode standard, which was supplemented with additional characters from DIS 10646.1. As a result, the values of the encoded characters in Unicode 1.1 and DIS 10646.1 are exactly the same.
In the future, cooperation between the two organizations continued. V 2000 year the Unicode 3.0 standard has been synchronized with ISO / IEC 10646-1: 2000. The upcoming third version of ISO / IEC 10646 will be synchronized with Unicode 4.0. Perhaps these specifications will even be published as a single standard.
Similar to the UTF-16 and UTF-32 formats in the Unicode standard, the ISO / IEC 10646 standard also has two main forms of character encoding: UCS-2 (2 bytes per character, similar to UTF-16) and UCS-4 (4 bytes per character, similar to UTF-32). UCS means universal multi-octet(multibyte) coded character set (English universal multiple- octet coded character set). UCS-2 can be considered a subset of UTF-16 (UTF-16 without surrogate pairs) and UCS-4 is a synonym for UTF-32.
Presentation methods
Unicode has several forms of representation ( English Unicode transformation format, UTF): UTF-8, UTF-16(UTF-16BE, UTF-16LE) and UTF-32 (UTF-32BE, UTF-32LE). A UTF-7 representation form was also developed for transmission over seven-bit channels, but due to incompatibility with ASCII it has not received distribution and is not included in the standard. April 1 2005 year two comic presentation forms have been proposed: UTF-9 and UTF-18 ( RFC 4042).
V Microsoft Windows NT and systems based on it Windows 2000 and Windows XP mostly used by form UTF-16LE. V UNIX-like operating systems GNU / Linux, BSD and Mac OS X the accepted form is UTF-8 for files and UTF-32 or UTF-8 for handling characters in random access memory.
Punycode- another form of encoding sequences of Unicode characters into so-called ACE sequences, which consist only of alphanumeric characters, as allowed in domain names.
Main article: UTF-8
UTF-8 is the Unicode representation that provides the best compatibility with older systems that used 8-bit characters. Text containing only characters numbered less than 128 is converted to plain text when written in UTF-8 ASCII... Conversely, in UTF-8 text, any byte with a value less than 128 displays an ASCII character with the same code. The rest of Unicode characters are represented by sequences from 2 to 6 bytes long (in fact, only up to 4 bytes, since there are no characters with a code greater than 10FFFF in Unicode, and there are no plans to introduce them in the future), in which the first byte always looks like 11xxxxxx, and the rest - 10xxxxxx.
UTF-8 was invented September 2 1992 year Ken Thompson and Rob Pike and implemented in Plan 9 ... Now the UTF-8 standard is officially enshrined in the documents RFC 3629 and ISO / IEC 10646 Annex D.
UTF-8 characters are derived from Unicode in the following way:
0x00000000 - 0x0000007F: 0xxxxxxx
0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Theoretically possible, but also not included in the standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Although UTF-8 allows you to specify the same character in several ways, only the shortest one is correct. The rest of the forms should be rejected for security reasons.
Byte order
In a UTF-16 data stream, the high byte can be written either before the low ( English UTF-16 little-endian), or after the younger one ( English. UTF-16 big-endian). Similarly, there are two variants of the four-byte encoding - UTF-32LE and UTF-32BE.
To determine the format of the Unicode representation, at the beginning of the text file is written signature- the character U + FEFF (zero-width non-breaking space), also referred to as byte order mark (English byte order mark, BOM ). This makes it possible to distinguish between UTF-16LE and UTF-16BE since the U + FFFE character does not exist. It is also sometimes used to denote the UTF-8 format, although the notion of byte order does not apply to this format. Files that follow this convention begin with these byte sequences:
Unfortunately, this method does not reliably distinguish between UTF-16LE and UTF-32LE, since the character U + 0000 is allowed by Unicode (although real texts rarely start with it).
Files in UTF-16 and UTF-32 encodings that do not contain a BOM must be in big-endian byte order ( unicode.org).
Unicode and traditional encodings
The introduction of Unicode changed the approach to traditional 8-bit encodings. If earlier the encoding was specified by the font, now it is specified by the correspondence table between this encoding and Unicode. In fact, 8-bit encodings have become a representation of a subset of Unicode. This made it much easier to create programs that have to work with many different encodings: now, to add support for one more encoding, you just need to add another Unicode lookup table.
In addition, many data formats allow any Unicode characters to be inserted, even if the document is written in the old 8-bit encoding. For example, in HTML one can use ampersand codes.
Implementation
Most modern operating systems provide some degree of Unicode support.
In operating systems of the family Windows NT file names and other system strings are internally represented using UTF-16LE double-byte encoding. System calls that take string parameters are available in single-byte and double-byte variants. For more details see the article .
UNIX-like operating systems, including GNU / Linux, BSD, Mac OS X use UTF-8 encoding to represent Unicode. Most programs can handle UTF-8 as traditional single-byte encodings, regardless of the fact that a character is represented as several consecutive bytes. To work with individual characters, strings are usually recoded to UCS-4, so that each character has a corresponding machine word.
One of the first successful commercial implementations of Unicode was the programming environment Java... It basically abandoned the 8-bit representation of characters in favor of the 16-bit one. This solution increased memory consumption, but allowed us to return an important abstraction to programming: an arbitrary single character (char type). In particular, a programmer could work with a string as with a simple array. Unfortunately, the success was not final, Unicode outgrew the 16-bit limit and by J2SE 5.0, an arbitrary character again began to occupy a variable number of memory units - one char or two (see. surrogate couple).
Most programming languages now support Unicode strings, although their representation may differ depending on the implementation.
Input Methods
Since none keyboard layout cannot allow all Unicode characters to be entered at the same time, from operating systems and application programs Requires support for alternative input methods for arbitrary Unicode characters.
Microsoft Windows
Main article: Unicode on Microsoft operating systems
Beginning with Windows 2000, the Charmap utility (charmap.exe) shows all characters in the OS and allows you to copy them to clipboard... There is a similar table, for example, in Microsoft Word.
Sometimes you can type hexadecimal code, press Alt+ X, and the code will be replaced with the corresponding character, for example, in WordPad, Microsoft Word. In editors, Alt + X performs the reverse transformation as well.
In many MS Windows programs, to get a Unicode character, you need to press the Alt key and type the decimal value of the character code on numeric keypad... For example, the combinations Alt + 0171 (") and Alt + 0187 (") will be useful when typing Cyrillic texts. The combinations Alt + 0133 (…) and Alt + 0151 (-) are also interesting.
Macintosh
V Mac OS 8.5 and later, an input method called "Unicode Hex Input" is supported. While holding down the Option key, you need to type the four-digit hexadecimal code of the required character. This method allows you to enter characters with codes greater than U + FFFF using surrogate pairs; such couples operating system will be automatically replaced with single characters. Before using this input method, you need to activate in the corresponding section of system settings and then select as the current input method in the keyboard menu.
Beginning with Mac OS X 10.2, there is also an application "Character Palette" that allows you to select characters from a table in which you can select characters of a particular block or characters supported by a particular font.
GNU / Linux
V GNOME there is also a utility "Symbol Table", which allows you to display the symbols of a certain block or writing system and provides the ability to search by the name or description of the symbol. When the code of the desired character is known, it can be entered in accordance with the standard ISO 14755: while holding down Ctrl + ⇧ Shift enter a hexadecimal code (starting with some version of GTK +, the code must be entered by pressing the key "U"). The entered hexadecimal code can be up to 32 bits in length, allowing you to enter any Unicode characters without using surrogate pairs.
 Customizable software
Customizable software Windows 8 will return the start button
Windows 8 will return the start button Installing Skype on a computer (step by step instructions)
Installing Skype on a computer (step by step instructions)