What is unicode encoding. Why did you need Unicode? Prerequisites for the creation and development of Unicode
What is encoding
In Russian, "character set" is also called a "character set", and the process of using this table to translate information from a computer representation into a human one, and a characteristic text file, reflecting the use of a certain system of codes in it when displaying text.
The presentation system is defined by a number of rules, and the application of these rules to the original information is done by the encoding process. The reverse process is called decoding. We then look at more specific aspects such as signal coding, character coding, human genome coding, and quantum coding. Finally, the basic concepts of data compression and the most commonly used encryption methods will be explained.
In this section, we will see how humans throughout history have made great efforts to express themselves with the rest of their relatives in a simple and intuitive way, coding information using different methods... These methods have evolved throughout history without representing the sophisticated methods we use today for the first ones that were used as it took a lot of evolution, as will be seen in this section.
How text is encoded
The set of symbols used in writing text is referred to in computer terminology as an alphabet; the number of symbols in the alphabet is usually called its power. For presentation text information the computer most often uses an alphabet with a capacity of 256 characters. One of its characters carries 8 bits of information, therefore, the binary code of each character takes 1 byte of computer memory. All characters of such an alphabet are numbered from 0 to 255, and each number corresponds to an 8-bit binary code, which is the ordinal number of a character in the binary number system - from 00000000 to 11111111. Only the first 128 characters with numbers from zero ( binary code 00000000) to 127 (01111111). These include lowercase and uppercase letters Latin alphabet, numbers, punctuation marks, brackets, etc. The remaining 128 codes, starting with 128 (binary code 10000000) and ending with 255 (11111111), are used to encode letters of national alphabets, official and scientific symbols.
Evolution of signal coding
Being outdated is everything we know on this moment, as it was in due time with the previous methods. Throughout history, sailors have used signals to convey urgent messages to other sailors. These are light signals that are produced using large projectors with systems that allow light bursts, usually used by gratings located in front of the focus. To make a connection, Morse code is used through light signals.
These are signals transmitted through vibration in the air. Due to the sluggishness of the devices required for transmission, this is a very slow medium. The transmitted signals use Morse code to transmit information. In addition to the traditional Morse code in international code which was included, there are other types of standardized signals and that every sailor should understand perfectly well.
Types of encodings
The most famous encoding table is ASCII (American Standard Code for Information Interchange). It was originally developed for the transmission of texts by telegraph, and at that time it was 7-bit, that is, only 128 7-bit combinations were used to encode English characters, service and control characters. In this case, the first 32 combinations (codes) served to encode control signals (start of text, end of line, carriage return, call, end of text, etc.). In the development of the first IBM computers, this code was used to represent symbols in a computer. Since in source code ASCII was only 128 characters, for their encoding were enough byte values with the 8th bit equal to 0. Byte values with the 8th bit equal to 1 began to be used to represent pseudo-graphic characters, mathematical signs and some characters from languages other than English (Greek, German umlauts, French diacritics, etc.). When they began to adapt computers for other countries and languages, there was no longer enough room for new symbols. To fully support languages other than English, IBM has introduced several country-specific code tables. So for the Scandinavian countries, table 865 (Nordic) was proposed, for the Arab countries - table 864 (Arabic), for Israel - table 862 (Israel), and so on. In these tables, some of the codes from the second half of the code table were used to represent the characters of the national alphabets (by excluding some pseudo-graphic characters). The situation with the Russian language developed in a special way. Obviously, the replacement of characters in the second half of the code table can be done different ways... So, several different tables of Cyrillic character encoding appeared for the Russian language: KOI8-R, IBM-866, CP-1251, ISO-8551-5. All of them represent the symbols of the first half of the table in the same way (from 0 to 127) and differ in the representation of the symbols of the Russian alphabet and pseudo-graphics. For languages like Chinese or Japanese, 256 characters are generally not enough. In addition, there is always the problem of outputting or saving in one file at the same time texts on different languages(for example, when quoting). Therefore, a universal code table UNICODE, containing symbols used in languages of all peoples of the world, as well as various service and auxiliary symbols (punctuation marks, mathematical and technical symbols, arrows, diacritics, etc.). Obviously, one byte is not enough to encode such a large number of characters. Therefore UNICODE uses 16-bit (2-byte) codes to represent 65,536 characters. To date, about 49,000 codes have been used (the last significant change was the introduction of the EURO currency symbol in September 1998). For compatibility with previous encodings, the first 256 codes are the same as in the ASCII standard. In the UNICODE standard, except for the specific binary code(these codes are usually denoted by the letter U, followed by a + sign and the actual code in hexadecimal representation) each character is assigned a specific name. Another component UNICODE standard are algorithms for one-to-one conversion of UNICODE codes in a sequence of bytes of variable length. The need for such algorithms is due to the fact that not all applications are able to work with UNICODE. Some applications only understand 7-bit ASCII codes, other applications understand 8-bit ASCII codes. Such applications use the so-called extended ASCII codes to represent characters that do not fit into a 128-character or 256-character set, respectively, when characters are encoded with variable-length byte strings. UTF-7 is used to reversibly convert UNICODE codes to extended 7-bit ASCII codes, and UTF-8 is used to reversibly convert UNICODE codes to extended 8-bit ASCII codes. Note that both ASCII and UNICODE and other character encoding standards do not define the images of characters, but only the composition of the character set and the way it is represented in a computer. In addition (which may not be immediately obvious), the order of the enumeration of characters in the set is very important, since it affects the sorting algorithms in the most significant way. It is the table of correspondence of symbols from a certain set (say, symbols used to represent information on English language, or in different languages, as in the case of UNICODE) and denote by the term character encoding table or charset. Each standard encoding has a name, for example, KOI8-R, ISO_8859-1, ASCII. Unfortunately, there is no standard for encoding names.
It is used for communication between nearby ships in order to be able to respect the frequency of the radio in use, not give it unnecessary use by occupying that channel unnecessarily, or because communication needs to be established and the radio is not working properly.
Flags are used to perform the communication, so depending on the position taken by the person performing the signals, it will have a value or something else. The associated meanings are the same as using flags with letters A to Z, numbers 0 to 9, and pause and error signals.
Radiotelegraphy and radiotelephony
With the methods discussed above, simultaneous communication in both directions is impossible, so they were point-to-point. Thanks to the advent of radiotelegraphy, this type of communication is possible. Radiotelegraphy is based on Maxwell's theory of wave propagation in space. Thus, wireless telegraphy was born, which is one of the most important advances in telecommunications of all time.
Common encodings
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Microsoft encodings Windows: o Windows-1250 for Central European languages that use Latin letters o Windows-1251 for Cyrillic alphabets o Windows-1252 for Western languages o Windows-1253 for Greek o Windows-1254 for Turkish o Windows-1255 for Hebrew o Windows-1256 for Arabic o Windows-1257 for Baltic languages o Windows-1258 for Vietnamese MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 Bulgarian coding ISCII VISCII Big5 (the most famous version of Microsoft CP950 ) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS for Japanese (Microsoft CP932) EUC-KR for Korean (Microsoft CP949) ISO-2022 and EUC for Chinese Writing UTF-8 and UTF-16 encodings Unicode charactersThis documentation has been moved to the archive and is no longer supported.
Coding today
Still ahead will be radiotelephony, which is nothing more than the ability to modulate voice over radio waves using theoretical basis exhibited in radiotelegraphy.
Signal coding
It is a very commonly used procedure in which, before a series of analog-type signals is transcribed into signals digital type... Thus, it facilitates the subsequent processing as well as improves the physical characteristics.That is, an analog signal is very sensitive to changes in possible interference, this is due to the fact that the original signal is very difficult to recover, since the values that this signal can have can be infinite. If we compare it to a digital signal that has a certain number of possible values. This fact makes it easier to retrieve values in a digital signal and therefore can be used for long distance communication.
Using Unicode encoding
.NET Framework 3.5
Updated: Nov 2007
Common runtime applications use encoding to convert characters from internal representation (Unicode) to another representation. Decoding is used to convert characters back from external (non-Unicode) encodings to internal representation. The namespace contains a number of classes that enable applications to encode and decode characters. For an overview of these classes, see.
In this procedure, we can distinguish three well-differentiated phases: sampling, quantification and codification. Quantification: it consists in evaluating the value of each of the samples, so that each of the samples is assigned one of the possible values of the resulting digital signal... The quantization process causes quantization noise caused by the number of possible values analog signal for digital signal. Consists of converting the values obtained during the quantization process into a binary system using a number of preset codes.
- Sampling: Consists of a sampling of the amplitude of the input signal.
- Very important parameter in this process by the number of samples per second.
- Coding.
Used for non-Unicode encoding. The class supports a wide range of ANSI / ISO encodings.
The example code below uses the method GetEncoding the required encoding object for a specific code page. Method GetBytes invoked on the desired encoding object to convert a Unicode string to byte representation in the desired encoding. The screen will display the byte representation of the string at a specific code page.
It is based on single polarity coding, as the name suggests. Thus, typically a binary value equal to one assumes a value in the output signal equal to one, and a value equal to zero allows a zero value in the output signal.
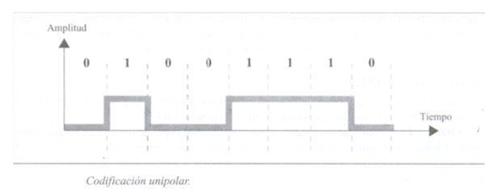
This is the type of encoding that is most commonly used today. It is based on the encoding of two polarities to represent binary information. We can find the following classification of polar coding. 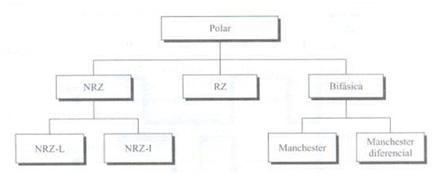
It is characterized by the fact that the signal always has a positive or negative value. We can clearly distinguish between types.
Imports System Imports System.IO Imports System.Globalization Imports System.Text Public Class Encoding_UnicodeToCP Public Shared Sub Main () "Converts ASCII characters to bytes. "Displays the string" s byte representation in the"specified code page. "Code page 1252 represents Latin characters. PrintCPBytes ("Hello, World!", 1252) "Code page 932 represents Japanese characters. PrintCPBytes ("Hello, World!", 932) "Converts Japanese characters. PrintCPBytes (, 1252) PrintCPBytes ( "\ u307b, \ u308b, \ u305a, \ u3042, \ u306d", 932) End Sub Public Shared Sub PrintCPBytes (str As String, codePage As Integer) Dim targetEncoding As Encoding Dim encodedChars () As Byte "Gets the encoding for the specified code page. targetEncoding = Encoding.GetEncoding (codePage) "Gets the byte representation of the specified string. encodedChars = targetEncoding.GetBytes (str) "Prints the bytes. Console.WriteLine ( "Byte representation of" (0) "in CP" (1) ":", _ str, codePage) Dim i As Integer For i = 0 To encodedChars.Length - 1 Console.WriteLine ("Byte (0): (1)", i, encodedChars (i)) Next i End Sub End Class
Usually, if a bit is set to one, the signal will be positive; if it is zero, the signal will be negative. Thus, this value depends not only on the current bit, but also on the previous bit. Thus, it is more reliable.
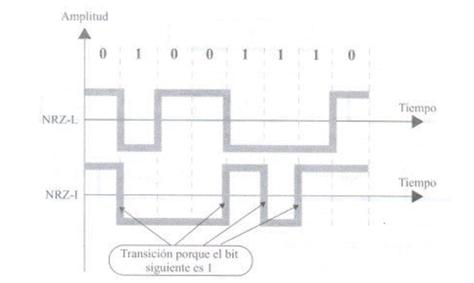
It is characterized by the use of three possible output levels. Little one is represented by a change from positive to zero and from zero to negative to positive. Each transaction occurs in the middle of the interval, as shown in the following figure. This type of encoding also allows the triggering of a synchronization procedure using transitions generated at half slots.
 How to download videos from Yandex Disk to iPhone: an easy way
How to download videos from Yandex Disk to iPhone: an easy way License Agreement for the terms of use of the Dr software
License Agreement for the terms of use of the Dr software Airyware Tuner - the best tuner in your smartphone Application for tuning guitar on Windows background
Airyware Tuner - the best tuner in your smartphone Application for tuning guitar on Windows background