How many bits are used to encode 1 character in unicode. Text encoding
Beginning in the late 60s, computers were increasingly used to process text information and currently most personal computers in the world (and most of the time) it is busy processing textual information.
ASCII - basic text encoding for Latin
Traditionally, to encode one character, an amount of information is used equal to 1 byte, that is, I = 1 byte = 8 bits.
To encode one character, 1 byte of information is required. If we consider symbols as possible events, then we can calculate how many different characters can be coded: N = 2I = 28 = 256.
This number of characters is quite enough to represent textual information, including uppercase and lowercase letters of the Russian and Latin alphabets, numbers, signs, graphic symbols, etc. binary code from 00000000 to 11111111.
Thus, a person distinguishes symbols by their style, and a computer - by their codes. When text information is entered into a computer, its binary encoding occurs, the image of the symbol is converted into its binary code.
The user presses a key with a symbol on the keyboard, and a specific sequence of eight electrical impulses (binary code of the symbol) is sent to the computer. The character code is stored in random access memory computer where it takes one byte. In the process of displaying a character on the computer screen, the reverse process is performed - decoding, that is, the conversion of the character code into its image. The ASCII code table (American Standard Code for Information Interchange) has been adopted as an international standard. ASCII standard part table It is important that the assignment of a specific code to a character is a matter of agreement, which is fixed in the code table. The first 33 codes (from 0 to 32) correspond not to characters, but to operations (line feed, space entry, and so on). Codes from 33 to 127 are international and correspond to symbols of the Latin alphabet, numbers, arithmetic signs and punctuation marks. Codes from 128 to 255 are national, that is, different characters correspond to the same code in national encodings.
Unfortunately, there are currently five different code tables for Russian letters (KOI8, CP1251, CP866, Mac, ISO), so texts created in one encoding will not display correctly in another.
Currently, a new international Unicode standard, which allocates not one byte for each character, but two, so it can be used to encode not 256 characters, but N = 216 = 65536 different
Unicode - the emergence of universal text encoding (UTF 32, UTF 16 and UTF 8)
These thousands of characters from the Southeast Asian language group could not be described in a single byte of information, which was allocated for encoding characters in extended ASCII encodings. As a result, a consortium called Unicode(Unicode - Unicode Consortium) with the collaboration of many IT industry leaders (those who produce software, who code hardware, who create fonts) who were interested in the emergence of a universal text encoding.
The first text encoding published under the auspices of the Unicode consortium was the encoding UTF 32... The number in the name of the UTF 32 encoding means the number of bits that are used to encode one character. 32 bits are 4 bytes of information that will be needed to encode one single character in the new universal UTF 32 encoding.
As a result, the same file with text encoded in the extended ASCII encoding and in the UTF 32 encoding, in the latter case, will have the size (weight) four times more. This is bad, but now we have the opportunity to encode with UTF 32 a number of characters equal to two to the thirty-second power (billions of characters that will cover any really necessary value with a colossal margin).
But many countries with languages of the European group did not need to use such a huge number of characters in the encoding at all, however, when using UTF 32, they received a fourfold increase in weight for nothing. text documents, and as a result, an increase in the volume of Internet traffic and the amount of stored data. This is a lot and no one could afford such a waste.
As a result of the development of a universal Unicode encoding appeared UTF 16, which turned out to be so successful that it was accepted by default as the base space for all the symbols that we use. UTF 16 uses two bytes to encode one character. For example, in the operating room Windows system you can follow the path Start - Programs - Accessories - System Tools - Symbol Table.
As a result, a table with vector forms of all fonts installed in your system will open. If you select the Unicode character set in the Advanced options, you will be able to see for each font separately the entire assortment of characters included in it. By the way, by clicking on any of these characters, you can see its two-byte code in UTF 16 encoding, consisting of four hexadecimal digits:
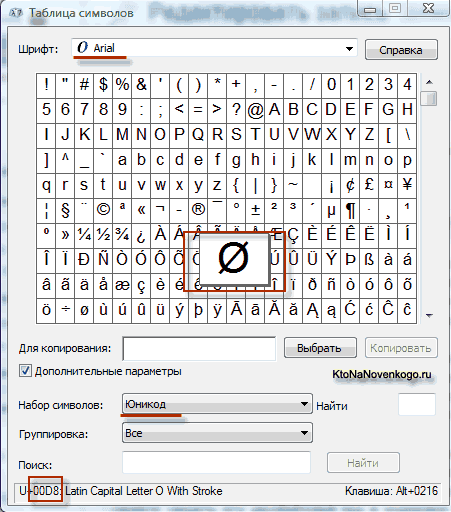
How many characters can be encoded in UTF 16 with 16 bits? 65,536 characters (two to the power of sixteen) have been taken as base space in Unicode. In addition, there are ways to encode with UTF 16 about two million characters, but were limited to the extended space of a million characters of text.
But even a successful version of the Unicode encoding called UTF 16 did not bring much satisfaction to those who wrote, for example, programs only in English language, because after the transition from the extended version of the ASCII encoding to UTF 16, the weight of the documents doubled (one byte for one character in ASCII and two bytes for the same character in UTF 16 encoding). It was precisely for the satisfaction of everyone and everything in the Unicode consortium that it was decided to come up with variable length text encoding.
This encoding in Unicode was called UTF 8... Despite the eight in the name, UTF 8 is a full-fledged variable-length encoding, i.e. each character of the text can be encoded into a sequence of one to six bytes long. In practice, in UTF 8, only the range from one to four bytes is used, because beyond four bytes of code, nothing is even theoretically possible to imagine.
In UTF 8, all Latin characters are encoded in one byte, just like in the old ASCII encoding. What is noteworthy, in the case of encoding only the Latin alphabet, even those programs that do not understand Unicode will still read what is encoded in UTF 8. That is, the basic part of ASCII encoding moved to UTF 8.
Cyrillic characters in UTF 8 are encoded in two bytes, and, for example, Georgian ones - in three bytes. The Unicode Consortium, after creating the UTF 16 and UTF 8 encodings, solved the main problem - now we have a single code space in our fonts. The only thing left to font manufacturers is to fill this code space with vector forms of text symbols based on their strengths and capabilities.
In theory, there has long been a solution to these problems. It's called Unicode Unicode Is an encoding table in which 2 bytes are used to encode each character, i.e. 16 bit. Based on such a table, N = 2 16 = 65 536 characters can be encoded.
Unicode includes almost all modern scripts, including: Arabic, Armenian, Bengali, Burmese, Greek, Georgian, Devanagari, Hebrew, Cyrillic, Coptic, Khmer, Latin, Tamil, Hangul, Han (China, Japan, Korea), Cherokee, Ethiopian, Japanese (Katakana, Hiragana, Kanji) and others.
For academic purposes, many historical scripts have been added, including: Ancient Greek, Egyptian hieroglyphs, cuneiform, Mayan writing, Etruscan alphabet.
Unicode provides a wide range of mathematical and musical symbols and pictograms.
There are two code ranges for Cyrillic characters in Unicode:
Cyrillic (# 0400 - # 04FF)
Cyrillic Supplement (# 0500 - # 052F).
But table injection Unicode in its pure form it is restrained for the reason that if the code of one character will occupy not one byte, but two bytes, it will take twice as much disk space to store the text, and twice as much time to transfer it over communication channels.
Therefore, in practice, the Unicode representation of UTF-8 (Unicode Transformation Format) is now more common. UTF-8 provides the best compatibility with systems using 8-bit characters. Text containing only characters numbered less than 128 is converted to plain ASCII text when written in UTF-8. The rest of the Unicode characters are represented by sequences of 2 to 4 bytes in length. In general, since the most common characters in the world - the characters of the Latin alphabet - in UTF-8 still occupy 1 byte, this encoding is more economical than pure Unicode.
The encoded English text uses only 26 letters of the Latin alphabet and 6 more punctuation characters. In this case, text containing 1000 characters can be guaranteed to be compressed without loss of information to the size:
Ellochka's dictionary - "cannibals" (a character in the novel "The Twelve Chairs") is 30 words. How many bits are enough to encode Ellochka's entire vocabulary? Options: 8, 5, 3, 1.
Units of data volume and memory capacity measurement: kilobytes, megabytes, gigabytes ...
So, in we found out that in most modern encodings, 1 byte is allocated for storing one character of the text on electronic media. Those. in bytes, the volume (V) occupied by data is measured during their storage and transmission (files, messages).
Data volume (V) - the number of bytes required to store them in the memory of an electronic data carrier.
Media memory, in turn, has limited capacity, i.e. the ability to contain a certain volume. The storage capacity of electronic storage media, of course, is also measured in bytes.
However, a byte is a small unit for measuring the amount of data, the larger ones are kilobytes, megabytes, gigabytes, terabytes ...
It should be remembered that the prefixes "kilo", "mega", "giga" ... are not decimal in this case. So “kilo” in the word “kilobyte” does not mean “thousand”, i.e. does not mean “10 3”. A bit is a binary unit, and for this reason in computer science it is convenient to use units of measurement that are multiples of the number “2” rather than the number “10”.
1 byte = 2 3 = 8 bits, 1 kilobyte = 2 10 = 1024 bytes. In binary, 1 kilobyte = & 1,000,000,000 bytes.
Those. “Kilo” here denotes the number closest to a thousand, which is a power of the number 2, i.e. which is a “round” number in binary notation.
Table 10.
|
Naming |
Designation |
Value in bytes |
|
|
kilobyte | |||
|
megabyte |
2 10 Kb = 2 20 b | ||
|
gigabyte |
2 10 Mb = 2 30 b | ||
|
terabyte |
2 10 Gb = 2 40 b |
1,099 511 627 776 b |
|
Due to the fact that the units of measurement of volume and capacity of information carriers are multiples of 2 and not multiples of 10, most problems on this topic are easier to solve when the values appearing in them are represented by powers of 2. Consider an example of such a problem and its solution:
The text file contains 400 pages of text. Each page contains 3200 characters. If KOI-8 encoding is used (8 bits per character), then the file size will be:
Solution
Determine the total number of characters in the text file. In this case, we represent numbers that are multiples of a power of 2 as a power of 2, i.e. instead of 4, we write 2 2, etc. Table 7 can be used to determine the degree.
characters.
2) By the condition of the problem, 1 character occupies 8 bits, i.e. 1 byte => file occupies 2 7 * 10000 bytes.
3) 1 kilobyte = 2 10 bytes => file size in kilobytes is:
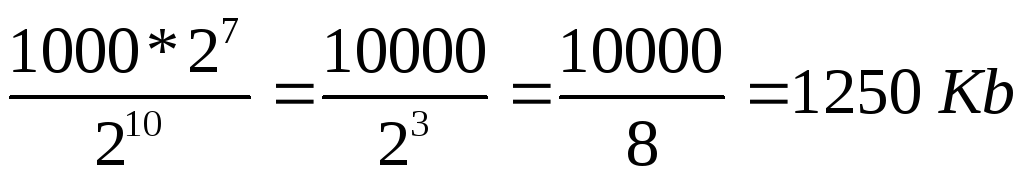 .
.
How many bits are there in one kilobyte?
&10000000000000.
What is 1 MB?
1,000,000 bytes.
1024 bytes;
1024 kilobytes;
How many bits are in a quarter-kilobyte message? Options: 250, 512, 2000, 2048.
Volume text file 640 Kb... The file contains a book that is typed on average 32 lines per page and by 64 character in the string. How many pages are in the book: 160, 320, 540, 640, 1280?
Dossier on employees 8 Mb... Each of them contains 16 pages ( 32 lines by 64 character per line). How many employees in the organization: 256; 512; 1024; 2048?
This post is for those who do not understand what UTF-8 is, but want to understand it, and the available documentation often covers this issue very extensively. I will try to describe it here in the way that I myself would like someone to tell me that before. Since often I had a mess in my head about UTF-8.
A few simple rules
- So UTF-8 is a wrapper around Unicode. It is not a separate character encoding, it is wrapped in Unicode. You probably know Base64 encoding, or have heard of it - it can wrap binary data in printable characters. Duck, UTF-8 is the same Base64 for Unicode as Base64 for binary data. This time. If you understand this, then a lot will already become clear. And it also, like Base64, is recognized to solve the problem of compatibility in characters (Base64 was invented for email, in order to transfer files by mail, in which all characters are printable)
- Further, if the code works with UTF-8, then internally it still works with Unicode encodings, that is, somewhere deep inside there are tables of symbols of exactly Unicode characters. True, you may not have Unicode character tables if you just need to count how many characters are in a line, for example (see below)
- UTF-8 is made so that old programs and today's computers can work normally with Unicode characters, like with old encodings, such as KOI8, Windows-1251, etc. In UTF-8 there are no bytes with zeros, all bytes are they are either from 0x01 - 0x7F, like normal ASCII, or 0x80 - 0xFF, which also works for programs written in C, as it would work with non-ASCII characters. True, for correct work with symbols the program must know Unicode tables.
- Anything with the most significant 7th bit in a byte (counting bits from zero) UTF-8 is part of the Unicode codestream.
UTF-8 from the inside out
If you know the bit system, then here's to you quick memo how is UTF-8 encoded:
The first Unicode byte of a UTF-8 character starts with a byte, where the 7th bit is always one, and the 6th bit is always one. In this case, in the first byte, if you look at the bits from left to right (7th, 6th, and so on to zero), there are as many units as bytes, including the first, go to encoding one Unicode character. The sequence of ones ends with a zero. And after that are the bits of the Unicode character itself. The rest of the Unicode bits of the character fall into the second, or even the third bytes (maximum three, why - see below). The rest of the bytes, except for the first one, always come with the beginning '10' and then 6 bits of the next part of the Unicode character.
Example
For example: there are bytes 110 10000 and the second 10 011110 ... The first one starts with ‘110’, which means that if there are two ones, there will be two bytes of the UTF-8 stream, and the second byte, like all the others, starts with ’10’. And these two bytes encode the Unicode character, which consists of 10100 bits from the first chunk + 101101 from the second, it turns out -> 10000011110 -> 41E in hexadecimal system, or U + 041E in writing Unicode notation. This is the symbol of the big Russian O.
How many bytes are maximum per character?
Also, let's see how many bytes maximum goes into UTF-8 to encode 16 bits of Unicode encoding. The second and further bytes can always accommodate a maximum of 6 bits. So if you start with the trailing bytes, then two bytes will go away exactly (2nd and third), and the first must start with '1110' to encode three. This means that the first byte in this case can encode the first 4 bits of a Unicode character. It turns out 4 + 6 + 6 = 16 byte. It turns out that UTF-8 can have either 2 or 3 bytes per Unicode character (one cannot, since there is no need to encode 6 bits (8 - 2 bits '10') - they will be an ASCII character. That is why the first byte is UTF 8 can never start with '10').
Conclusion
By the way, thanks to this encoding, you can take any byte in the stream and determine whether the byte is Unicode character(if the 7th bit means not ASCII), if yes, then is it the first in the UTF-8 stream or not the first (if '10', then not the first), if not the first, then we can move back byte to find the first UTF-8 code (with the 6th bit being 1), or move to the right and skip all '10' bytes to find the next character. Thanks to this encoding, programs can also, without knowing Unicode, read how many characters are in a string (based on the first UTF-8 byte, calculate the character length in bytes). In general, if you think about it, the UTF-8 encoding was invented very competently, and at the same time, very efficient.
Information coding
Any numbers (within certain limits) in the computer memory are encoded by numbers in the binary number system. There are simple and clear translation rules for this. However, today the computer is used much more widely than in the role of a performer of labor-intensive calculations. For example, computer memory stores text and multimedia information. Therefore, the first question arises:
How are characters (letters) stored in the computer's memory?
Each letter belongs to a certain alphabet in which the characters follow each other and, therefore, can be numbered with consecutive integers. Each letter can be associated with a positive integer and call it a character code... It is this code that will be stored in the computer's memory, and when displayed on the screen or on paper, it will be "converted" into its corresponding character. To distinguish the representation of numbers from the representation of characters in computer memory, you also have to store information about what kind of data is encoded in a particular area of memory.
The correspondence of letters of a certain alphabet with numbers-codes forms the so-called coding table... In other words, each character of a specific alphabet has its own numerical code in accordance with a specific encoding table.
However, there are a lot of alphabets in the world (English, Russian, Chinese, etc.). So the next question is:
How to encode all alphabets used on a computer?
To answer this question, we will follow the historical path.
In the 60s of the XX century in American National Standards Institute (ANSI) a character encoding table was developed, which was subsequently used in all operating systems... This table is called ASCII (American Standard Code for Information Interchange)... A little later appeared extended ASCII version.
According to the ASCII coding table, 1 byte (8 bits) is allocated to represent one character. A set of 8 cells can take 2 8 = 256 different values. The first 128 values (from 0 to 127) are constant and form the so-called main part of the table, which includes decimal digits, letters of the Latin alphabet (uppercase and lowercase), punctuation marks (period, comma, brackets, etc.), as well as a space and various service characters (tabulation, line feed, etc.). Values from 128 to 255 form additional part tables where it is customary to encode symbols of national alphabets.
Since there are a huge variety of national alphabets, extended ASCII tables exist in many variants. Even for the Russian language, there are several coding tables (Windows-1251 and Koi8-r are common). All this creates additional difficulties. For example, we send a letter written in one encoding, and the recipient tries to read it in another. As a result, he sees krakozyabry. Therefore, the reader needs to apply a different coding table for the text.
There is another problem as well. The alphabets of some languages have too many characters and they do not fit into their allotted positions from 128 to 255 single-byte encoding.
The third problem is what to do if the text uses several languages (for example, Russian, English and French)? You can't use two tables at once ...
To solve these problems, the Unicode encoding was developed in one go.
Unicode character encoding standard
To solve the above problems in the early 90s, a character encoding standard was developed, called Unicode. This standard allows you to use almost any languages and symbols in the text.
Unicode provides 31 bits for character encoding (4 bytes minus one bit). The number of possible combinations gives an exorbitant number: 2 31 = 2 147 483 684 (ie more than two billion). Therefore, Unicode describes the alphabets of all known languages, even "dead" and invented, includes many mathematical and other Special symbols... However, the information capacity of 31-bit Unicode is still too large. Therefore, the abbreviated 16-bit version (2 16 = 65 536 values) is more often used, where all modern alphabets are encoded.
In Unicode, the first 128 codes are the same as the ASCII table.
Currently, most of the users using a computer processes text information, which consists of symbols: letters, numbers, punctuation marks, etc.
Based on one cell with information capacity of 1 bit, only 2 different states can be encoded. In order for each character that can be entered from the keyboard in the Latin register to receive its own unique binary code, 7 bits are required. Based on a sequence of 7 bits, in accordance with the Hartley formula, N = 2 7 = 128 different combinations of zeros and ones can be obtained, i.e. binary codes. By associating each character with its binary code, we get a coding table. A person operates with symbols, a computer - with their binary codes.
For the Latin keyboard layout, such a coding table is one for the whole world, therefore, the text typed using the Latin keyboard layout will be adequately displayed on any computer. This table is called ASCII(American Standard Code of Information Interchange) in English is pronounced [eski], in Russian it is pronounced [aski]. Below is the entire ASCII table, the codes in which are indicated in decimal form. It can be used to determine that when you enter, say, the character “*” from the keyboard, the computer perceives it as code 42 (10), in turn 42 (10) = 101010 (2) - this is the binary code of the character “* ”. Codes 0 through 31 are not used in this table.
table ASCII characters
| code | symbol | code | symbol | code | symbol | code | symbol | code | symbol | code | symbol |
| Space | . | @ | P | " | p | ||||||
| ! | A | Q | a | q | |||||||
| " | B | R | b | r | |||||||
| # | C | S | c | s | |||||||
| $ | D | T | d | t | |||||||
| % | E | U | e | u | |||||||
| & | F | V | f | v | |||||||
| " | G | W | g | w | |||||||
| ( | H | X | h | x | |||||||
| ) | I | Y | i | y | |||||||
| * | J | Z | j | z | |||||||
| + | : | K | [ | k | { | ||||||
| , | ; | L | \ | l | | | ||||||
| - | < | M | ] | m | } | ||||||
| . | > | N | ^ | n | ~ | ||||||
| / | ? | O | _ | o | DEL |
In order to encode one character, an amount of information equal to 1 byte is used, that is, I = 1 byte = 8 bits. Using a formula that connects the number of possible events K and the amount of information I, you can calculate how many different symbols can be encoded (assuming that symbols are possible events):
K = 2 I = 2 8 = 256,
that is, an alphabet with a capacity of 256 characters can be used to represent textual information.
The essence of coding is that each character is assigned a binary code from 00000000 to 11111111 or the corresponding decimal code from 0 to 255.
It must be remembered that currently for encoding Russian letters use five different code tables (KOI - 8, CP1251, CP866, Mac, ISO), moreover, texts encoded using one table will not display correctly in another encoding. This can be clearly represented as a fragment of the combined character encoding table.
Different symbols are assigned to the same binary code.
| Binary code | Decimal code | KOI8 | CP1251 | CP866 | Mac | ISO |
| b | V | - | - | T |
However, in most cases, the user takes care of the transcoding of text documents, and special programs- converters that are built into applications.
Since 1997 latest versions Microsoft Office support the new encoding. It is called Unicode (Unicode). Unicode Is an encoding table in which 2 bytes are used to encode each character, i.e. 16 bit. Based on such a table, N = 2 16 = 65 536 characters can be encoded.
Unicode includes almost all modern scripts, including: Arabic, Armenian, Bengali, Burmese, Greek, Georgian, Devanagari, Hebrew, Cyrillic, Coptic, Khmer, Latin, Tamil, Hangul, Han (China, Japan, Korea), Cherokee, Ethiopian, Japanese (Katakana, Hiragana, Kanji) and others.
For academic purposes, many historical scripts have been added, including: Ancient Greek, Egyptian hieroglyphs, cuneiform, Mayan writing, Etruscan alphabet.
Unicode provides a wide range of mathematical and musical symbols and pictograms.
For Cyrillic characters in Unicode, two ranges of codes are allocated:
Cyrillic (# 0400 - # 04FF)
Cyrillic Supplement (# 0500 - # 052F).
But the implementation of the Unicode table in its pure form is held back for the reason that if the code of one character will occupy not one byte, but two bytes, that for storing text it will take twice as much disk space, and for its transfer over communication channels - twice as long.
Therefore, in practice, the Unicode representation of UTF-8 (Unicode Transformation Format) is now more common. UTF-8 provides the best compatibility with systems using 8-bit characters. Text containing only characters numbered less than 128 is converted to plain ASCII text when written in UTF-8. The rest of the Unicode characters are represented by sequences of 2 to 4 bytes in length. In general, since the most common characters in the world - the characters of the Latin alphabet - in UTF-8 still occupy 1 byte, this encoding is more economical than pure Unicode.
To determine the numeric character code, you can either use code table... To do this, select the "Insert" - "Symbol" item in the menu, after which the Symbol dialog box appears on the screen. The symbol table for the selected font appears in the dialog box. The characters in this table are arranged line by line, sequentially from left to right, starting with the Space character.
 Bugs in Singularity?
Bugs in Singularity? Just Cause 2 crashes
Just Cause 2 crashes Terraria won't start, what should I do?
Terraria won't start, what should I do?