Ile bitów jest w kodowaniu Unicode. Jednostki miary objętości danych i pojemności pamięci: kilobajty, megabajty, gigabajty…. Standard kodowania znaków Unicode
Kodowanie informacji
Wszelkie liczby (w określonych granicach) w pamięci komputera są kodowane liczbami w systemie liczb binarnych. Istnieją proste i jasne zasady tłumaczenia. Jednak dziś komputer jest wykorzystywany znacznie szerzej niż w roli wykonawcy pracochłonnych obliczeń. Na przykład pamięć komputera przechowuje informacje tekstowe i multimedialne. Dlatego pojawia się pierwsze pytanie:
Każdy znak jest zakodowany od 1 do 4 bajtów. Znaki zastępcze zajmują 4 bajty i dlatego wymagają dodatkowej pamięci. Każdy znak jest zakodowany co najmniej 4 bajtami. Alternatywnie możesz użyć narzędzia do konwersji, aby przekonwertować automatycznie. Jak już powiedziano, jest to standard, który dobrze pasuje do Amerykanów. Waha się od 0 do 127, a pierwsze 32 i ostatnie są uważane za kontrolne, reszta to "znaki drukowane", czyli rozpoznawane przez ludzi. Może być reprezentowany tylko przez 7 bitów, chociaż zwykle używany jest jeden bajt.
Jak znaki (litery) są przechowywane w pamięci komputera?
Każda litera należy do pewnego alfabetu, w którym znaki następują po sobie i dlatego mogą być numerowane kolejnymi liczbami całkowitymi. Każda litera może być powiązana z dodatnią liczbą całkowitą i nazwać ją kodem znakowym... To właśnie ten kod zostanie zapisany w pamięci komputera, a po wyświetleniu na ekranie lub na papierze zostanie „przekonwertowany” na odpowiedni znak. Aby odróżnić reprezentację liczb od reprezentacji znaków w pamięci komputera, trzeba również przechowywać informacje o tym, jakie dane są zakodowane w konkretnym obszarze pamięci.
W zależności od kontekstu, a nawet czasu, oznacza to coś innego. Więc to zależy od tego, o czym mówisz. To niewiele znaczy samotnie. Istnieje kilka kodowań, które używają tego akronimu. Są bardzo złożone i prawie nikt nie wie, jak właściwie wykorzystać ich pełnię, łącznie ze mną.
Ale nie z żadnym innym systemem kodowania znaków. Jest to najbardziej kompletne i złożone kodowanie, jakie istnieje. Niektórzy są w niej zakochani, a inni nienawidzą, chociaż dostrzegają jej użyteczność. Człowiekowi trudno jest zrozumieć, ale komputerowi trudno sobie z tym poradzić.
Korespondencja liter określonego alfabetu z cyframi-kodami tworzy tzw tabela kodowania... Innymi słowy, każdy znak określonego alfabetu ma swój własny kod numeryczny zgodnie z określoną tabelą kodowania.
Jednak na świecie istnieje wiele alfabetów (angielski, rosyjski, chiński itp.). Więc następne pytanie brzmi:
Istnieje porównanie między tymi dwoma. Jest to standard prezentacji tekstów tworzonych przez konsorcjum. Wśród ustanowionych przez niego norm znajdują się niektóre kodowania. Ale w rzeczywistości odnosi się do znacznie więcej. Artykuł, który każdy powinien przeczytać, nawet jeśli nie zgadza się ze wszystkim, co ma.
Obsługiwane zestawy znaków są podzielone na płaszczyzny. Oba komputery korzystają z różnych systemów operacyjnych; to samo dzieje się z zestawem znaków, strukturą i format pliku które zwykle są różne. Komunikacja przez połączenie sterujące.
Jak zakodować wszystkie alfabety używane na komputerze?
Aby odpowiedzieć na to pytanie, podążymy ścieżką historyczną.
W latach 60. XX wieku w Amerykański Narodowy Instytut Norm (ANSI) opracowano tabelę kodowania znaków, która była następnie używana we wszystkich systemach operacyjnych. Ta tabela nazywa się ASCII (amerykański standardowy kod wymiany informacji)... Nieco później pojawił się rozszerzona wersja ASCII.
Komunikacja odbywa się poprzez sekwencję poleceń i odpowiedzi. Ta prosta metoda jest odpowiednia dla połączenia sterującego, ponieważ możemy wysłać jedno polecenie na raz. Każde polecenie lub odpowiedź zajmuje jeden wiersz, więc nie musimy się martwić o format ani strukturę pliku. Każda linia kończy się dwoma znakami.
Łącza danych. Cel i realizacja połączenia danych różnią się od tych określonych w połączeniu sterującym. Podstawowy fakt: chcemy przesyłać pliki przez połączenie danych. Klient musi określić typ przesyłanego pliku, strukturę danych i tryb przesyłania.
Zgodnie z tabelą kodowania ASCII, 1 bajt (8 bitów) jest przydzielany do reprezentowania jednego znaku. Zestaw 8 komórek może przyjąć 2 8 = 256 różnych wartości. Pierwsze 128 wartości (od 0 do 127) są stałe i tworzą tzw. główną część tabeli, która zawiera cyfry dziesiętne, litery alfabetu łacińskiego (duże i małe), znaki interpunkcyjne (kropka, przecinek, nawiasy). , itp.), a także spację i różne znaki usługowe (tabulatory, nowe wiersze itp.). Wartości od 128 do 255 formularz część dodatkowa tabele, w których zwyczajowo koduje się symbole alfabetów narodowych.
Ponadto transfer musi być przygotowany przez połączenie sterujące, zanim plik będzie mógł zostać przesłany przez łącze danych. Problem niejednorodności został rozwiązany poprzez zdefiniowanie trzech atrybutów łącza: typu pliku, struktury danych i trybu przesyłania.
Plik jest przesyłany jako ciągły strumień bitów bez jakiejkolwiek interpretacji lub kodowania. Ten format jest używany głównie do przesyłania plików binarnych, takich jak skompilowane programy lub obrazy zakodowane w 0 i 1 sek. Plik nie zawiera specyfikacji pionowych do druku. Oznacza to, że plik nie może zostać wydrukowany bez dodatkowej obróbki, ponieważ nie ma zrozumiałych znaków, które można by zinterpretować przy pionowym ruchu silnika drukującego. Ten format jest używany przez pliki, które będą przechowywane i przetwarzane w przyszłości.
Ponieważ istnieje ogromna różnorodność alfabetów narodowych, rozszerzone tablice ASCII istnieją w wielu wariantach. Nawet dla języka rosyjskiego istnieje kilka tabel kodowania (powszechne są Windows-1251 i Koi8-r). Wszystko to stwarza dodatkowe trudności. Na przykład wysyłamy list zapisany jednym kodowaniem, a odbiorca próbuje go odczytać w innym. W rezultacie widzi krakozyabry. Dlatego czytelnik musi zastosować inną tabelę kodowania tekstu.
Plik można wydrukować po przesłaniu. Strony: Plik jest podzielony na strony, z których każda jest poprawnie ponumerowana i oznaczona nagłówkiem. Strony można zapisywać lub otwierać, losowo lub sekwencyjnie. Jeśli dane są tylko ciągiem bajtów, nie jest wymagana identyfikacja końca wiersza. W takim przypadku wskazaniem końca linii jest zamknięcie połączenia danych przez nadajnik. Pierwszy bajt nazywa się blokiem deskryptora; pozostałe dwa bajty definiują rozmiar bloku w bajtach. Kompresja: Jeśli plik jest zbyt duży, dane mogą zostać skompresowane przed wysłaniem. Powszechnie stosowana metoda kompresji polega na tym, że jednostka danych, która pojawia się sekwencyjnie, zastępuje je jednym wystąpieniem, po którym następuje kilka powtórzeń. V plik tekstowy dużo pustych przestrzeni. W pliku binarnym znaki null są zwykle kompresowane.
- Pliki: plik nie ma struktury.
- Jest przesyłany w ciągłym strumieniu bajtów.
- Tego typu można używać tylko z plikami tekstowymi.
- Łańcuchy: To jest tryb domyślny.
- W takim przypadku każdy blok jest poprzedzony 3-bajtowym nagłówkiem.
Jest też inny problem. Alfabety niektórych języków mają zbyt wiele znaków i nie mieszczą się w przydzielonych im pozycjach od 128 do 255 jednobajtowego kodowania.
Trzeci problem to co zrobić, jeśli tekst używa kilku języków (na przykład rosyjskiego, angielskiego i francuskiego)? Nie możesz korzystać z dwóch stołów jednocześnie...
Aby rozwiązać te problemy, za jednym razem opracowano kodowanie Unicode.
Wielu nie ma pojęcia o różnicach między tymi zestawami i trzyma się tego, co jest bliskie. Szczegóły dotyczące kodowania polegają na tym, że są to mapy dwóch różnych rzeczy. Pierwsza to mapa wartości liczbowych, która reprezentuje określony znak.
Inne samoloty to dodatki z postaciami, które uzupełniają funkcje głównego samolotu i inne „specjalne”, takie jak „emotikony”. W tych wzorcach każdy znak płaszczyzny jest zakodowany w zaledwie 1 bajcie, a zatem mamy tylko 256 „możliwych” znaków. Musimy oczywiście usunąć te niedrukowalne, zmniejszając zakres.
Standard kodowania znaków Unicode
Aby rozwiązać powyższe problemy na początku lat 90. opracowano standard kodowania znaków, zwany Unicode. Ten standard pozwala na użycie w tekście niemal dowolnych języków i symboli.
Unicode zapewnia 31 bitów do kodowania znaków (4 bajty minus jeden bit). Liczba możliwych kombinacji daje wygórowaną liczbę: 2 31 = 2 147 483 684 (czyli ponad dwa miliardy). Dlatego Unicode opisuje alfabety wszystkich znanych języków, nawet „martwych” i wymyślonych, zawiera wiele matematycznych i innych Symbole specjalne... Jednak pojemność informacyjna 31-bitowego Unicode jest nadal zbyt duża. Dlatego częściej używana jest skrócona wersja 16-bitowa (2 16 = 65 536 wartości), w której zakodowane są wszystkie współczesne alfabety.
A jeśli musisz dokonywać porównań między znakami, nie ma utraty wydajności, ponieważ porównywanie dwóch wartości 8-bitowych, 16-bitowych lub 32-bitowych zajmuje tyle samo czasu nowoczesne procesory... Znaczenie związane z akronimem to oczywiście rozmiar każdej jednostki sekwencji, która tworzy kodowanie znaków. Gdy kod ma więcej bitów, używane jest następujące kodowanie.
W ten sposób każdy znak może być wyrażony w rozmiarach od 1 do 4 bajtów. Czy to wyjątkowa „specjalna” postać? Oznacza to, że niektóre obrazy postaci są bardzo podobne, a czasem zbędne. Podam inny przykład, kilka lat temu żartowano o zmianie '; ' na '; ' v kody źródłowe... Podczas kompilowania kodu programista oszalał, próbując rozwiązać problem.
W Unicode pierwsze 128 kodów jest takich samych jak tabela ASCII.
Od końca lat 60. komputery były coraz częściej wykorzystywane do przetwarzania informacje tekstowe a obecnie najbardziej komputery osobiste na świecie (i przez większość czasu) jest zajęty przetwarzaniem informacji tekstowych.
ASCII - podstawowe kodowanie tekstu dla łaciny
Tradycyjnie do zakodowania jednego znaku używa się ilości informacji równej 1 bajt, czyli I = 1 bajt = 8 bitów.
Do zakodowania jednego znaku wymagany jest 1 bajt informacji. Jeśli weźmiemy pod uwagę symbole jako możliwe zdarzenia, możemy obliczyć, ile różne postacie można zakodować: N = 2I = 28 = 256.
Ta liczba znaków wystarcza do przedstawienia informacji tekstowych, w tym wielkich i małych liter alfabetu rosyjskiego i łacińskiego, cyfr, znaków, symboli graficznych itp. Kodowanie oznacza, że każdemu znakowi przypisany jest unikalny kod dziesiętny od 0 do 255 lub odpowiedni kod binarny od 00000000 do 11111111.
W ten sposób człowiek rozróżnia symbole po stylu, a komputer po kodach. Gdy informacje tekstowe są wprowadzane do komputera, to kodowanie binarne, obraz symbolu jest konwertowany na jego kod binarny.
Użytkownik naciska klawisz z symbolem na klawiaturze, a do komputera wysyłana jest pewna sekwencja ośmiu impulsów elektrycznych (kod binarny symbolu). Kod znaku jest przechowywany w pamięć o dostępie swobodnym komputer, na którym zajmuje jeden bajt. W procesie wyświetlania znaku na ekranie komputera wykonywany jest proces odwrotny - dekodowanie, czyli konwersja kodu znaku na jego obraz. Jako standard międzynarodowy przyjęto tabelę kodów ASCII (American Standard Code for Information Interchange) Tabela części standardu ASCII Ważne jest, aby przypisanie określonego kodu do znaku było kwestią uzgodnień, które są ustalone w tabeli kodów . Pierwsze 33 kody (od 0 do 32) odpowiadają nie znakom, ale operacjom (wysuw wiersza, wprowadzanie spacji itd.). Kody od 33 do 127 są międzynarodowe i odpowiadają symbolom alfabetu łacińskiego, cyfrom, znakom arytmetycznym i znakom interpunkcyjnym. Kody od 128 do 255 są narodowe, to znaczy, że różne znaki odpowiadają temu samemu kodowi w kodowaniach narodowych.
Niestety obecnie jest pięć różnych tabele kodów dla liter rosyjskich (KOI8, CP1251, CP866, Mac, ISO), dzięki czemu teksty utworzone w jednym kodowaniu nie będą wyświetlane poprawnie w innym.
Obecnie nowy międzynarodowy Standard Unicode, który przydziela każdemu znakowi nie jeden bajt, ale dwa, dzięki czemu można go użyć do zakodowania nie 256 znaków, ale N = 216 = 65536 różnych
Unicode - pojawienie się uniwersalnego kodowania tekstu (UTF 32, UTF 16 i UTF 8)
Tych tysięcy znaków z grupy języków Azji Południowo-Wschodniej nie można było opisać w jednym bajcie informacji, który został przydzielony do kodowania znaków w rozszerzonym kodowaniu ASCII. W efekcie powstało konsorcjum o nazwie Unicode(Unicode - Unicode Consortium) przy współpracy wielu liderów branży IT (produkujących oprogramowanie, kodujących sprzęt, tworzących czcionki), którzy byli zainteresowani pojawieniem się uniwersalnego kodowania tekstu.
Pierwszym kodowaniem tekstu opublikowanym pod auspicjami konsorcjum Unicode było kodowanie UTF 32... Liczba w nazwie kodowania UTF 32 oznacza liczbę bitów, które są używane do zakodowania jednego znaku. 32 bity to 4 bajty informacji, które będą potrzebne do zakodowania jednego pojedynczego znaku w nowym uniwersalnym kodowaniu UTF 32.
W rezultacie ten sam plik z tekstem zakodowanym w rozszerzonym kodowaniu ASCII oraz w kodowaniu UTF 32, w tym drugim przypadku, będzie miał czterokrotnie większy rozmiar (wagę). To źle, ale teraz mamy możliwość zakodowania za pomocą UTF 32 liczby znaków równej dwa do potęgi trzydziestej drugiej (miliardy znaków, które pokryją każdą naprawdę niezbędną wartość z kolosalnym marginesem).
Ale wiele krajów z językami grupy europejskiej w ogóle nie musiało używać tak ogromnej liczby znaków w kodowaniu, ale przy użyciu UTF 32 nigdy nie uzyskali czterokrotnego wzrostu wagi dokumenty tekstowe, a w efekcie wzrost natężenia ruchu internetowego i ilości przechowywanych danych. To dużo i nikogo nie stać na takie marnotrawstwo.
W wyniku rozwoju uniwersalnej Pojawiło się kodowanie Unicode UTF 16, która okazała się na tyle udana, że została domyślnie zaakceptowana jako przestrzeń bazowa dla wszystkich używanych przez nas symboli. UTF 16 używa dwóch bajtów do zakodowania jednego znaku. Na przykład w system operacyjny Windows, możesz podążać ścieżką Start - Programy - Akcesoria - Narzędzia systemowe - Mapa symboli.
W rezultacie otworzy się tabela z formami wektorowymi wszystkich czcionek zainstalowanych w twoim systemie. Jeśli wybierzesz zestaw znaków Unicode w opcjach zaawansowanych, będziesz mógł zobaczyć dla każdej czcionki osobno cały zestaw znaków w niej zawartych. Nawiasem mówiąc, klikając dowolny z tych znaków, możesz zobaczyć jego dwubajtowy kod w kodowaniu UTF 16, składający się z czterech cyfr szesnastkowych:
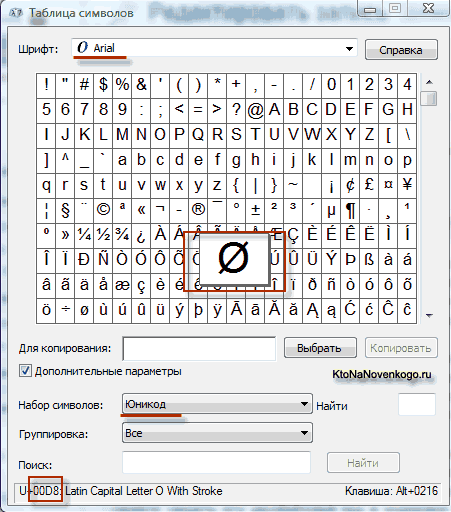
Ile znaków można zakodować w UTF 16 z 16 bitami? 65 536 znaków (dwa do potęgi szesnastej) zostało wziętych jako przestrzeń bazowa w Unicode. Ponadto istnieją sposoby na zakodowanie w UTF 16 około dwóch milionów znaków, ale były one ograniczone do rozszerzonej przestrzeni miliona znaków tekstu.
Ale nawet udana wersja kodowania Unicode o nazwie UTF 16 nie przyniosła wiele satysfakcji tym, którzy pisali np. programy tylko w język angielski, ponieważ po przejściu z rozszerzonej wersji kodowania ASCII na UTF 16 waga dokumentów podwoiła się (jeden bajt na jeden znak w ASCII i dwa bajty na ten sam znak w kodowaniu UTF 16). Właśnie dla zadowolenia wszystkich i wszystkiego w konsorcjum Unicode postanowiono wymyślić kodowanie tekstu o zmiennej długości.
To kodowanie w Unicode zostało nazwane UTF 8... Pomimo ośmiu w nazwie, UTF 8 to pełnoprawne kodowanie o zmiennej długości, tj. każdy znak tekstu może być zakodowany w sekwencji o długości od jednego do sześciu bajtów. W praktyce w UTF 8 używany jest tylko zakres od jednego do czterech bajtów, ponieważ poza czterema bajtami kodu nic nie jest nawet teoretycznie możliwe do wyobrażenia.
W UTF 8 wszystkie znaki łacińskie są zakodowane w jednym bajcie, tak jak w starym kodowaniu ASCII. Co godne uwagi, w przypadku kodowania tylko alfabetu łacińskiego, nawet te programy, które nie rozumieją Unicode, nadal będą czytać to, co jest zakodowane w UTF 8. To znaczy, podstawowa część kodowania ASCII przeniesiona do UTF 8.
Znaki cyrylicy w UTF 8 są zakodowane w dwóch bajtach, a np. gruzińskie - w trzech bajtach. Konsorcjum Unicode, po stworzeniu kodowań UTF 16 i UTF 8, rozwiązało główny problem - teraz w naszych czcionkach mamy jedną przestrzeń kodową. Jedyne, co pozostało producentom czcionek, to wypełnienie tej przestrzeni kodu wektorowymi formami symboli tekstowych w oparciu o ich mocne strony i możliwości.
 Architektura rozproszonego systemu sterowania opartego na rekonfigurowalnym wielopotokowym środowisku obliczeniowym „Przejrzyste” rozproszone systemy plików L-Net
Architektura rozproszonego systemu sterowania opartego na rekonfigurowalnym wielopotokowym środowisku obliczeniowym „Przejrzyste” rozproszone systemy plików L-Net Strona wysyłania e-maili Wypełnij plik relay_recipients adresami z Active Directory
Strona wysyłania e-maili Wypełnij plik relay_recipients adresami z Active Directory Brakujący pasek języka w systemie Windows - co robić?
Brakujący pasek języka w systemie Windows - co robić?