Kodiranje besedilnih informacij. Kodiranje znakov - PIE wiki
Standard je leta 1991 predlagal konzorcij Unicode, Unicode Inc., neprofitna organizacija. Uporaba tega standarda omogoča kodiranje zelo velikega števila znakov iz različnih pisem: v dokumentih Unicode lahko soobstajajo kitajski znaki, matematični znaki, črke grške abecede, latinice in cirilice, zato preklapljanje med kodnimi stranmi postane nepotrebno.
Standard je sestavljen iz dveh glavnih delov: univerzalnega nabora znakov (UCS) in formata transformacije Unicode (UTF). Univerzalni nabor znakov definira medsebojno korespondenco znakov s kodami - elementi kodnega prostora, ki predstavljajo nenegativna cela števila. Družina kodiranja definira strojno predstavitev zaporedja kod UCS.
Standard Unicode je bil razvit z namenom ustvariti enotno kodiranje znakov za vse sodobne in številne starodavne pisne jezike. Vsak znak v tem standardu je kodiran v 16 bitov, kar mu omogoča, da pokrije neprimerljivo večje število znakov kot prej sprejeta 8-bitna kodiranja. Druga pomembna razlika med Unicode in drugimi sistemi kodiranja je, da ne dodeli samo vsakemu znaku edinstvena koda, ampak tudi opredeljuje različne značilnosti tega simbola, na primer:
Vrsta znaka (velike črke, male črke, številka, ločila itd.);
Atributi znakov (zaslon od leve proti desni ali od desne proti levi, presledek, prelom vrstice itd.);
Ustrezna velika ali mala črka (za male in velike črke);
Ustrezna številska vrednost (za številske znake).
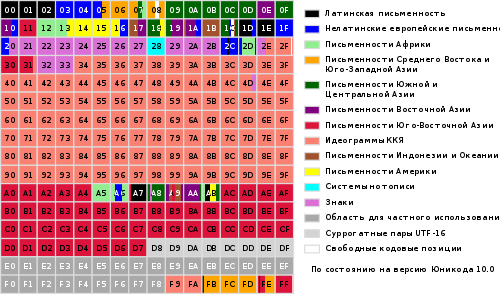
Celoten obseg kod od 0 do FFFF je razdeljen na več standardnih podmnožic, od katerih vsaka ustreza bodisi abecedi jezika bodisi skupini posebni znaki, podobni po svojih funkcijah. Spodnji diagram ponuja splošen seznam podmnožic Unicode 3.0 (slika 2).
slika 2
Standard Unicode je osnova za shranjevanje in besedilo v mnogih sodobnih računalniških sistemih. Vendar pa ni združljiv z večino internetnih protokolov, saj lahko njegove kode vsebujejo poljubne bajtne vrednosti, protokoli pa običajno uporabljajo bajte 00 - 1F in FE - FF kot obremenitve. Za dosego interoperabilnosti je bilo razvitih več formatov Unicode transformacije (UTF, Unicode Transformation Formats), od katerih je danes najpogostejši UTF-8. Ta oblika določa naslednja pravila pretvorbe za vsako Unicode koda v nabor bajtov (od enega do treh), primernih za prenos po internetnih protokolih.
Tukaj x, y, z označujejo bite izvorne kode, ki jih je treba ekstrahirati, začenši z najmanj pomembnim, in vnesti v rezultatske bajte od desne proti levi, dokler niso zapolnjena vsa navedena mesta.
Nadaljnji razvoj standard Unicode je povezan z dodajanjem novih jezikovnih ravnin, t.j. znaki v obsegih 10000 - 1FFFF, 20000 - 2FFFF itd., kjer naj bi vključevalo kodiranje za skripte mrtvih jezikov, ki niso vključeni v zgornjo tabelo. Za kodiranje teh dodatnih znakov je bil razvit nov format UTF-16.
Tako obstajajo 4 glavni načini kodiranja Unicode bajtov:
UTF-8: 128 znakov je kodiranih v enem bajtu (format ASCII), 1920 znakov je kodiranih v 2 bajtih ((rimski, grški, cirilični, koptski, armenski, hebrejski, arabski znaki), 63488 znakov je kodiranih v 3 bajtih (kitajski , japonščina in drugi) Preostalih 2.147.418.112 znakov (še niso uporabljeni) je mogoče kodirati s 4, 5 ali 6 bajti.
UCS-2: Vsak znak je predstavljen z 2 bajtoma. To kodiranje vključuje samo prvih 65.535 znakov iz formata Unicode.
UTF-16: To je razširitev UCS-2 in vključuje 1 114 112 znakov Unicode. Prvih 65.535 znakov je predstavljenih z 2 bajtoma, preostale pa s 4 bajti.
USC-4: Vsak znak je kodiran v 4 bajtih.
Unicode
Logotip konzorcija Unicode
Unicode(najpogosteje) oz Unicode(angl. Unicode) je standard za kodiranje znakov, ki omogoča, da so znaki predstavljeni v skoraj vseh pisnih jezikih.
Standard je leta 1991 predlagala neprofitna organizacija "Unicode Consortium" (eng. Unicode Consortium, Unicode Inc.).
Uporaba tega standarda omogoča kodiranje zelo velikega števila znakov iz različnih pisem: v dokumentih Unicode lahko soobstajajo kitajski znaki, matematični znaki, črke grške abecede, latinice in cirilice, zato preklapljanje med kodnimi stranmi postane nepotrebno.
Standard je sestavljen iz dveh glavnih delov: univerzalnega nabora znakov (eng. UCS, univerzalni nabor znakov) in družino kodiranja (eng. UTF, Unicode format transformacije).
Univerzalni nabor znakov definira medsebojno korespondenco znakov s kodami - elementi kodnega prostora, ki predstavljajo nenegativna cela števila. Družina kodiranja definira strojno predstavitev zaporedja kod UCS.
Kode Unicode so razdeljene na več področij. Območje s kodami U + 0000 do U + 007F vsebuje znake ASCII z ustreznimi kodami. Sledijo področja znakov različnih pisav, ločil in tehničnih simbolov.
Nekatere kode so rezervirane za prihodnjo uporabo. Pod ciriličnimi znaki so dodeljena področja znakov s kodami od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (glej Cirilica v Unicode).
- 1 Predpogoji za ustvarjanje in razvoj Unicode
- 2 različici Unicode
- 3 Kodni prostor
- 4 Sistem kodiranja
- 4.1 Politika konzorcija
- 4.2 Združevanje in podvajanje simbolov
- 5 Spreminjanje znakov
- 6 Normalizacijski algoritmi
- 6.1 NFD
- 6.2 NFC
- 6.3 NFKD
- 6.4 NFKC
- 6.5 Primeri
- 7 Dvosmerno pisanje
- 8 predstavljenih simbolov
- 9 ISO / IEC 10646
- 10 načinov predstavitve
- 10.1 UTF-8
- 10.2 Vrstni red bajtov
- 10.3 Unicode in tradicionalna kodiranja
- 10.4 Izvedbe
- 11 Načini vnosa
- 11.1 Microsoft Windows
- 11.2 Macintosh
- 11.3 GNU / Linux
- 12 Težave z Unicode
- 13 "Unicode" ali "Unicode"?
Predpogoji za nastanek in razvoj Unicode
Do poznih osemdesetih let prejšnjega stoletja so 8-bitni znaki postali standard. Hkrati je bilo veliko različnih 8-bitnih kodiranj in nenehno so se pojavljala nova.
To je bilo razloženo tako z nenehnim širjenjem obsega podprtih jezikov kot z željo po ustvarjanju kodiranja, ki je delno združljiva z nekaterimi drugimi (tipičen primer je pojav alternativnega kodiranja za ruski jezik zaradi izkoriščanja zahodnih jezikov). programi, ustvarjeni za kodiranje CP437).
Posledično se je pojavilo več težav:
- problem "krakozyabra";
- problem omejenega nabora znakov;
- problem pretvorbe enega kodiranja v drugo;
- problem podvojenih pisav.
Problem "krakozyabr"- problem prikaza dokumentov v napačnem kodiranju. Problem bi lahko rešili bodisi z doslednim uvajanjem metod za določanje uporabljenega kodiranja bodisi z uvedbo enotnega (skupnega) kodiranja za vse.
Težava z omejenim naborom znakov... Težavo bi lahko rešili bodisi s preklopom pisav v dokumentu bodisi z uvedbo "širokega" kodiranja. Preklapljanje pisav se v urejevalnikih besedil že dolgo izvaja, pogosto pa so bile uporabljene pisave z nestandardnim kodiranjem, t.i. "Dingbat pisave". Kot rezultat, so se pri poskusu prenosa dokumenta v drug sistem vsi nestandardni znaki spremenili v "krakozyabry".
Problem pretvorbe enega kodiranja v drugega... Težavo bi lahko rešili bodisi s prevajanjem pretvorbenih tabel za vsak par kodiranj ali z uporabo vmesne pretvorbe v tretje kodiranje, ki vključuje vse znake vseh kodiranj.
Težava s podvojenimi pisavami... Za vsako kodiranje je bila ustvarjena lastna pisava, tudi če so nabori znakov v kodiranju delno ali v celoti sovpadali. Težavo bi lahko rešili z ustvarjanjem "velikih" pisav, iz katerih bi nato izbrali znake, potrebne za dano kodiranje. Vendar je to zahtevalo ustvarjanje enotnega registra simbolov, da bi ugotovili, kaj čemu ustreza.
Prepoznana je bila potreba po enem samem "širokem" kodiranju. Ugotovljeno je bilo, da so kodiranja s spremenljivo dolžino, ki se pogosto uporabljajo v vzhodni Aziji, pretežka za uporabo, zato je bilo odločeno za uporabo znakov s fiksno širino.
Uporaba 32-bitnih znakov se je zdela preveč potratna, zato je bilo odločeno, da uporabimo 16-bitne.
Prva različica Unicode je bila kodiranje s fiksno velikostjo znakov 16 bitov, kar pomeni, da je bilo skupno število kod 2 16 (65 536). Od takrat so bili simboli označeni s štirimi šestnajstiškimi številkami (npr. U + 04F0). Hkrati je bilo načrtovano, da se v Unicode kodirajo ne vsi obstoječi znaki, ampak le tisti, ki so potrebni v vsakdanjem življenju. Redko uporabljene simbole je bilo treba postaviti v "območje zasebne uporabe", ki je prvotno zasedlo kode U + D800 ... U + F8FF.
Da bi Unicode uporabljali tudi kot posrednik pri medsebojnem pretvarjanju različnih kodiranj, so bili vanj vključeni vsi znaki, predstavljeni v vseh najbolj znanih kodiranju.
V prihodnosti pa je bilo odločeno, da se vsi simboli kodirajo in v zvezi s tem znatno razširijo kodno domeno.
Hkrati so se znakovne kode začele obravnavati ne kot 16-bitne vrednosti, temveč kot abstraktne številke, ki jih je mogoče v računalniku predstaviti na različne načine (glej metode predstavitve).
Ker so bili v številnih računalniških sistemih (na primer Windows NT) fiksni 16-bitni znaki že uporabljeni kot privzeto kodiranje, je bilo odločeno, da se vsi najpomembnejši znaki kodirajo le znotraj prvih 65.536 mest (t. i. angleščina. osnovno večjezično letalo, BMP).
Preostali prostor se uporablja za "dodatne znake" (eng. dopolnilni znaki): sistemi pisanja izumrlih jezikov ali zelo redko uporabljenih kitajskih črk, matematičnih in glasbenih simbolov.
Za združljivost s starimi 16-bitnimi sistemi je bil izumljen sistem UTF-16, kjer je prvih 65.536 pozicij, z izjemo pozicij iz intervala U + D800 ... U + DFFF, prikazanih neposredno kot 16-bitna števila, ostali pa so predstavljeni kot "nadomestni pari" (prvi element para iz regije U + D800... U + DBFF, drugi element para iz regije U + DC00... U + DFFF). Za nadomestne pare je bil uporabljen del kodnega prostora (2048 mest), ki je bil namenjen »zasebni rabi«.
Ker je v UTF-16 mogoče prikazati samo 2 20 +2 16 −2048 (1 112 064) znakov, je bila ta številka izbrana kot končna vrednost kodnega prostora Unicode (območje kod: 0x000000-0x10FFFF).
Čeprav je bilo območje kode Unicode razširjeno preko 2-16 že v različici 2.0, so bili prvi znaki v "top" območju postavljeni šele v različici 3.1.
Vloga tega kodiranja v spletnem sektorju nenehno narašča. V začetku leta 2010 je bil delež spletnih mest, ki uporabljajo Unicode, približno 50-odstoten.
Različice Unicode
Delo na dokončnem oblikovanju standarda se nadaljuje. Nove različice so izdane, ko se tabele simbolov spreminjajo in posodabljajo. Vzporedno se izdajajo novi dokumenti ISO/IEC 10646.
Prvi standard je bil izdan leta 1991, zadnji leta 2016, naslednjega pričakujemo poleti 2017. Različice standardov 1.0-5.0 so bile objavljene kot knjige in imajo ISBN.
Številka različice standarda je sestavljena iz treh števk (na primer "4.0.1"). Tretja številka se spremeni, ko se v standard izvedejo manjše spremembe, ki ne dodajajo novih znakov.
Kodni prostor
Čeprav zapisni obliki UTF-8 in UTF-32 omogočata kodiranje do 2.331 (2.147.483.648) kodnih točk, je bilo odločeno, da se za združljivost z UTF-16 uporabi samo 1.112.064. Vendar je tudi to za zdaj več kot dovolj - v različici 6.0 je uporabljenih nekaj manj kot 110.000 kodnih točk (109.242 grafičnih in 273 drugih simbolov).
Kodni prostor je razdeljen na 17 letala(angl. letala) 2 16 (65 536) znakov vsak. talna ravnina ( ravnina 0) se imenuje osnovni (osnovni) in vsebuje simbole najpogostejših skript. Ostala letala so dodatna ( dopolnilno). Prvo letalo ( letalo 1) se uporablja predvsem za zgodovinske pisave, drugi ( letalo 2) - za redko uporabljene kitajske črke (CJK), tretji ( letalo 3) je rezerviran za arhaične kitajske znake. Letala 15 in 16 sta rezervirana za zasebno uporabo.
Za označevanje Znaki Unicode zapis v obliki "U + xxxx"(Za kode 0 ... FFFF) ali" U + xxxxx"(Za kode 10000 ... FFFFF) ali" U + xxxxxx"(Za kode 100000 ... 10FFFF), kjer xxx- šestnajstiške številke. Na primer, znak "i" (U + 044F) ima kodo 044F 16 = 1103 10.
Sistem kodiranja
Univerzalni kodirni sistem (Unicode) je nabor grafičnih simbolov in način njihovega kodiranja za računalniško obdelavo besedilnih podatkov.
Grafični simboli so simboli, ki imajo vidno sliko. Grafični znaki so v nasprotju s kontrolnimi znaki in znaki za oblikovanje.
Grafični simboli vključujejo naslednje skupine:
- črke, ki jih vsebuje vsaj ena od podprtih abeced;
- številke;
- ločila;
- posebni znaki (matematični, tehnični, ideogrami itd.);
- ločevalniki.
Unicode je sistem za linearno predstavitev besedila. Znake z dodatnimi nadpisi ali podpisi lahko predstavimo kot zaporedje kod, zgrajenih po določenih pravilih (sestavljeni znak) ali kot en sam znak (monolitna različica, vnaprej sestavljen znak). Na ta trenutek(2014) velja, da so vse črke velikih skript vključene v Unicode, in če je simbol na voljo v sestavljeni različici, ga ni treba podvajati v monolitni obliki.
Politika konzorcija
Konzorcij ne ustvarja novega, ampak navaja ustaljeni red stvari. Na primer, slike emoji so bile dodane zaradi japonskih operaterjev mobilne komunikacije so bili široko uporabljeni.
Če želite to narediti, dodajanje simbola poteka skozi zapleten postopek. In na primer, simbol ruskega rublja ga je v treh mesecih prenesel preprosto zato, ker je dobil uradni status.
Blagovne znamke so kodirane le izjemoma. Torej, v Unicode ni zastave Windows ali jabolka Apple.
Ko se znak enkrat pojavi v kodiranju, se ne bo nikoli premaknil ali izginil. Če morate spremeniti vrstni red znakov, to ne storite s spreminjanjem položajev, temveč z nacionalnim vrstnim redom razvrščanja. Obstajajo tudi druga, bolj subtilna zagotovila stabilnosti - na primer normalizacijske tabele se ne bodo spremenile.
Združevanje in podvajanje simbolov
Isti simbol ima lahko več oblik; v Unicode so ti obrazci v eni kodni točki:
- če se je zgodilo zgodovinsko. Na primer, arabske črke imajo štiri oblike: ločeno, na začetku, na sredini in na koncu;
- ali če je en jezik sprejet v eni obliki, v drugi pa - drugi. Bolgarska cirilica se razlikuje od ruske, kitajske črke pa od japonščine.
Po drugi strani pa, če sta v preteklosti obstajali dve različni kodni točki v pisavah, ostajata različni v Unicode. Mala grška sigma ima dve obliki in imata različne položaje. Razširjena latinska črka Å (A s krogom) in znak angstroma Å, grško pismoμ in predpona »mikro« µ sta različna simbola.
Seveda so podobni znaki v nepovezanih skriptah postavljeni v različne kodne točke. Na primer, črka A v latinici, cirilici, grščini in Cherokeeju so različni simboli.
Izjemno redko je, da je isti znak postavljen na dva različna kodna mesta, da se poenostavi obdelava besedila. Matematična poteza in ista poteza za označevanje mehkobe zvokov sta različna simbola, druga se šteje za črko.
Spreminjanje znakov
Predstavitev znaka "Y" (U + 0419) v obliki osnovnega znaka "I" (U + 0418) in modificirajočega znaka "" (U + 0306)
Grafični znaki v Unicode se delijo na razširjene in nerazširjene (brez širine). Nerazširjeni znaki ne zavzamejo prostora v vrstici, ko so prikazani. Sem spadajo zlasti naglasna znamenja in druga diakritična znamenja. Tako razširjeni kot nerazširjeni znaki imajo svoje kode. Razširjeni simboli se sicer imenujejo osnovni (eng. osnovni znaki), in nepodaljšani - modificirajoči (eng. kombiniranje znakov); slednji pa se ne morejo samostojno srečati. Znak "á" je na primer lahko predstavljen kot zaporedje osnovnega znaka "a" (U + 0061) in modifikatorskega znaka "́" (U + 0301) ali kot monoliten znak "á" (U + 00E1).
Posebna vrsta spreminjajočih se znakov so izbirniki sloga obraza (eng. izbirniki variacij). Veljajo samo za tiste simbole, za katere so opredeljene takšne različice. V različici 5.0 so za serijo definirane slogovne možnosti matematični simboli, za simbole tradicionalne mongolske abecede in za simbole mongolske kvadratne pisave.
Algoritmi za normalizacijo
Ker so lahko predstavljeni enaki simboli različne kode, primerjava nizov bajt za bajtom postane nemogoča. Algoritmi za normalizacijo normalizacijske oblike) rešite ta problem s pretvorbo besedila v določeno standardno obliko.
Ulivanje se izvaja z zamenjavo simbolov z enakovrednimi s pomočjo tabel in pravil. "Dekompozicija" je zamenjava (razgradnja) enega znaka na več sestavnih znakov, "sestava" pa je, nasprotno, zamenjava (povezava) več sestavnih znakov z enim znakom.
Standard Unicode opredeljuje 4 algoritme za normalizacijo besedila: NFD, NFC, NFKD in NFKC.
NFD
NFD, inž. n ormalizacija f orm D ("D" iz angleščine. d ekompozicija), normalizacijska oblika D je kanonična dekompozicija - algoritem, po katerem se izvaja rekurzivna zamenjava monolitnih simbolov (eng. vnaprej sestavljeni znaki) na več komponent (eng. sestavljeni znaki) v skladu s tabelami razgradnje.
Å U + 00C5 →
A U + 0041
̊ U + 030A
ṩ U + 1E69 →
s U + 0073
̣ U + 0323
̇ U + 0307
ḍ̇ U + 1E0B U + 0323 →
d U + 0064
̣ U + 0323
̇ U + 0307
q̣̇ U + 0071 U + 0307 U + 0323 →
q U + 0071
̣ U + 0323
̇ U + 0307 NFC
NFC, inž. n ormalizacija f orm C ("C" iz angleščine. c nasprotovanje), normalizacijska oblika C je algoritem, po katerem se kanonična razgradnja in kanonična kompozicija izvajata zaporedno. Prvič, kanonična razgradnja (algoritem NFD) reducira besedilo na obliko D. Nato kanonična sestava, inverzna NFD, obdela besedilo od začetka do konca, pri čemer upošteva naslednja pravila:
- simbol Sšteje začetniče ima modifikacijski razred enak nič glede na tabelo znakov Unicode;
- v katerem koli zaporedju znakov, ki se začne z znakom S, simbol C blokiran od S, le če med S in C ali obstaja kakšen simbol B ki je bodisi začetni ali ima enak ali večji modifikacijski razred kot C... To pravilo velja samo za nize, ki so šli skozi kanonično razgradnjo;
- simbol šteje primarni sestavljeno, če ima kanonično razgradnjo v tabeli znakov Unicode (ali kanonično razgradnjo za hangul in ni vključena na seznam izključitev);
- simbol X lahko najprej kombinirate s simbolom Yče in samo če obstaja primarni kompozit Z, kanonično enakovredno zaporedju<X, Y>;
- če je naslednji znak C ne blokira zadnji začetni osnovni znak L in ga je mogoče z njim najprej uspešno kombinirati, potem L nadomesti s kompozitnim L-C, a C odstranili.
o U + 006F
̂ U + 0302 → →
H U + 0048
① U + 2460 →
1 U + 0031
カ U + FF76 →
カ U + 30AB →
fi U + FB01
fi U + FB01
f jaz U + 0066 U + 0069
f jaz U + 0066 U + 0069
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 5 U + 0032 U + 0035
2 5 U + 0032 U + 0035
ẛ̣ U + 1E9B U + 0323
ſ ̣ ̇ U + 017F U + 0323 U + 0307
ẛ ̣ U + 1E9B U + 0323
s ̣ ̇ U + 0073 U + 0323 U + 0307
ṩ U + 1E69
th U + 0439
in ̆ U + 0438 U + 0306
th U + 0439
in ̆ U + 0438 U + 0306
th U + 0439
e U + 0451
e ̈ U + 0435 U + 0308
e U + 0451
e ̈ U + 0435 U + 0308
e U + 0451
A U + 0410
A U + 0410
A U + 0410
A U + 0410
A U + 0410
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
Ⅷ U + 2167
Ⅷ U + 2167
Ⅷ U + 2167
V jaz jaz jaz U + 0056 U + 0049 U + 0049 U + 0049
V jaz jaz jaz U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
c ̧ U + 0063 U + 0327
ç U + 00E7
c ̧ U + 0063 U + 0327
ç U + 00E7 Dvosmerno pismo
Standard Unicode podpira jezike pisanja s smerjo od leve proti desni (eng. od leve proti desni, LTR), in s pisanjem od desne proti levi (eng. od desne proti levi, RTL) - na primer arabske in hebrejske črke. V obeh primerih so znaki shranjeni v "naravnem" vrstnem redu; njihov prikaz ob upoštevanju želene smeri črke zagotavlja aplikacija.
Poleg tega Unicode podpira kombinirana besedila, ki združujejo fragmente z različnimi smermi črke. Ta funkcija se imenuje dvosmernost(angl. dvosmerno besedilo, BiDi). Nekateri poenostavljeni besedilni procesorji (na primer v mobilni telefon) lahko podpira Unicode, ne pa dvosmerne podpore. Vsi znaki Unicode so razdeljeni v več kategorij: napisani od leve proti desni, napisani od desne proti levi in napisani v kateri koli smeri. Simboli slednje kategorije (predvsem ločila), ko so prikazani, zavzamejo smer okoliškega besedila.
Predstavljeni simboli
Diagram osnovne večjezične ravnine Unicode
Unicode vključuje skoraj vse sodobne skripte, vključno z:
- arabsko
- armenski,
- bengalščina,
- birmanščina,
- glagol
- grški
- gruzijski,
- devanagari,
- judovski,
- cirilica,
- kitajski (kitajski znaki se aktivno uporabljajo v japonščini, pa tudi občasno v korejščini),
- koptski,
- kmerski,
- latinščina,
- tamilščina,
- korejščina (hangul),
- Cherokee,
- etiopski,
- japonščina (ki poleg zlogovne abecede vključuje tudi kitajske znake)
drugo.
Za akademske namene so dodane številne zgodovinske pisave, med drugim: germanske rune, staroturške rune, starogrška pisava, egipčanski hieroglifi, klinopis, majevska pisava, etruščanska abeceda.
Unicode ponuja široko paleto matematičnih in glasbenih simbolov ter piktogramov.
Unicode načeloma ne vključuje državnih zastav, logotipov podjetij in izdelkov, čeprav jih najdemo v pisavah (na primer logotip Apple v kodiranju MacRoman (0xF0) ali logotip Windows v pisavi Wingdings (0xFF)). V pisavah Unicode je treba logotipe postaviti samo v območje znakov po meri.
ISO/IEC 10646
Konzorcij Unicode tesno sodeluje z delovna skupina ISO / IEC / JTC1 / SC2 / WG2, ki razvija mednarodni standard 10646 (ISO / IEC 10646). Sinhronizacija je vzpostavljena med standardom Unicode in ISO/IEC 10646, čeprav vsak standard uporablja svojo terminologijo in dokumentacijski sistem.
Sodelovanje konzorcija Unicode z Mednarodno organizacijo za standardizacijo (eng. Mednarodna organizacija za standardizacijo, ISO ) se je začelo leta 1991. Leta 1993 je ISO izdal standard DIS 10646.1. Za sinhronizacijo z njim je konzorcij odobril različico 1.1 standarda Unicode, ki je bila dopolnjena z dodatnimi znaki iz DIS 10646.1. Posledično so vrednosti kodiranih znakov v Unicode 1.1 in DIS 10646.1 popolnoma enake.
Sodelovanje med obema organizacijama se je nadaljevalo tudi v prihodnje. Leta 2000 je bil standard Unicode 3.0 sinhroniziran z ISO / IEC 10646-1: 2000. Prihajajoča tretja različica ISO/IEC 10646 bo sinhronizirana z Unicode 4.0. Morda bodo te specifikacije celo objavljene kot enoten standard.
Podobno kot formata UTF-16 in UTF-32 v standardu Unicode ima standard ISO / IEC 10646 tudi dve glavni obliki kodiranja znakov: UCS-2 (2 bajta na znak, podobno kot UTF-16) in UCS-4 (4 bajti na znak, podobno kot UTF-32). UCS pomeni univerzalni multi-oktet(večbajtni) nabor kodiranih znakov(angl. univerzalni nabor kodiranih znakov z več okteti ). UCS-2 se lahko šteje za podmnožico UTF-16 (UTF-16 brez nadomestnih parov), UCS-4 pa je sinonim za UTF-32.
Razlike med standardi Unicode in ISO/IEC 10646:
- rahle razlike v terminologiji;
- ISO / IEC 10646 ne vključuje razdelkov, potrebnih za popolno implementacijo podpore Unicode:
- ni podatkov o binarno kodiranje liki;
- ni opisa primerjalnih algoritmov (eng. primerjanje) in upodabljanje (eng. upodabljanje) znaki;
- ni seznama lastnosti simbolov (na primer ni seznama lastnosti, potrebnih za implementacijo podpore za dvosmerno (eng. dvosmerni) črke).
Predstavitvene metode
Unicode ima več oblik predstavitve (eng. Format transformacije Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) in UTF-32 (UTF-32BE, UTF-32LE). Predstavitveni obrazec UTF-7 je bil razvit tudi za prenos po sedembitnih kanalih, vendar zaradi nezdružljivosti z ASCII ni bil razširjen in ni bil vključen v standard. 1. aprila 2005 sta bili predlagani dve humoristični vlogi: UTF-9 in UTF-18 (RFC 4042).
Sistemi, ki temeljijo na Microsoft Windows NT in Windows 2000 ter Windows XP, uporabljajo predvsem obrazec UTF-16LE. Unixu podobni operacijski sistemi GNU / Linux, BSD in Mac OS X sprejemajo UTF-8 za datoteke in UTF-32 ali UTF-8 za obdelavo znakov v pomnilnik z naključnim dostopom.
Punycode je druga oblika kodiranja zaporedij znakov Unicode v tako imenovana zaporedja ACE, ki so sestavljena samo iz alfanumeričnih znakov, kot je dovoljeno v imenih domen.
UTF-8
UTF-8 je predstavitev Unicode, ki zagotavlja najboljšo združljivost s starejšimi sistemi, ki so uporabljali 8-bitne znake.
Besedilo, ki vsebuje samo znake, oštevilčene manj kot 128, se pretvori v navadno besedilo ASCII, če je napisano v UTF-8. Nasprotno pa se v besedilu UTF-8 prikaže kateri koli bajt z vrednostjo manjšo od 128 Znak ASCII z isto kodo.
Preostali znaki Unicode so predstavljeni z zaporedji dolžine od 2 do 6 bajtov (pravzaprav le do 4 bajtov, saj v Unicode ni znakov s kodo, večjo od 10FFFF, in ni načrtov, da bi jih uvedli v prihodnost), v kateri ima prvi bajt vedno obliko 11xxxxxx in ostalo - 10xxxxxx... V UTF-8 se ne uporabljajo nadomestni pari, 4 bajti so dovolj za pisanje katerega koli znaka Unicode.
UTF-8 sta izumila Ken Thompson in Rob Pike 2. septembra 1992 in implementirana v načrtu 9... Standard UTF-8 je zdaj uradno vključen v RFC 3629 in ISO/IEC 10646 Priloga D.
Znaki UTF-8 so izpeljani iz Unicode, kot sledi:
UNICODE UTF-8: 0x00000000 - 0x000000007F: 0xxxxxxx 0x0000000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000fff: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001fffff: 11110xxx 10xxxxx 10xxxxx 10xxxx
Teoretično možno, vendar tudi ni vključeno v standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 11111100xxx 1xxxxx 1xxx 1xxxx 1xxxxxxxxxxxxxxxxxxxxxx
Čeprav UTF-8 omogoča, da isti znak določite na več načinov, je pravilen le najkrajši. Preostale obrazce je treba iz varnostnih razlogov zavrniti.
Vrstni red bajtov
V podatkovnem toku UTF-16 se lahko nizki bajt zapiše bodisi pred visokim (eng. UTF-16 mali-endian), ali po starejšem (eng. UTF-16 big-endian). Podobno obstajata dve različici štiribajtnega kodiranja - UTF-32LE in UTF-32BE.
Za določitev formata predstavitve Unicode na začetku besedilna datoteka podpis je napisan - znak U + FEFF (neprekinjeni presledek z ničelno širino), imenovan tudi oznaka zaporedja bajtov(angl. oznaka vrstnega reda bajtov (BOM)). To omogoča razlikovanje med UTF-16LE in UTF-16BE, saj znak U + FFFE ne obstaja. Včasih se uporablja tudi za označevanje formata UTF-8, čeprav pojem vrstnega reda bajtov za to obliko ne velja. Datoteke, ki sledijo tej konvenciji, se začnejo s temi zaporedji bajtov:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Na žalost ta metoda ne razlikuje zanesljivo med UTF-16LE in UTF-32LE, saj Unicode dovoljuje znak U + 0000 (čeprav se prava besedila redko začnejo z njim).
Datoteke v kodiranju UTF-16 in UTF-32, ki ne vsebujejo BOM, morajo biti v bajtnem vrstnem redu big-endian (unicode.org).
Unicode in tradicionalna kodiranja
Uvedba Unicode je spremenila pristop k tradicionalnim 8-bitnim kodiranjem. Če je bilo prej kodiranje določeno s pisavo, je zdaj določeno s korespondenčno tabelo med tem kodiranjem in Unicode.
Pravzaprav so 8-bitna kodiranja postala predstavitev podmnožice Unicode. To je precej olajšalo ustvarjanje programov, ki morajo delati z veliko različnimi kodiranjemi: zdaj, če želite dodati podporo za še eno kodiranje, morate dodati še eno iskalno tabelo Unicode.
Poleg tega številni formati podatkov omogočajo vstavljanje poljubnih znakov Unicode, tudi če je dokument napisan v starem 8-bitnem kodiranju. Na primer, lahko uporabite kode ampersand v HTML.
Izvajanje
Večina sodobnih operacijskih sistemov zagotavlja določeno stopnjo podpore Unicode.
V operacijskih sistemih družine Windows NT se za interno predstavitev imen datotek in drugih sistemskih nizov uporablja dvobajtno kodiranje UTF-16LE. Sistemski klici, ki sprejemajo parametre niza, so na voljo v enobajtnih in dvobajtnih različicah. Za več informacij glejte članek Unicode o družini operacijskih sistemov Microsoft Windows.
podoben UNIX-u OS, vključno z GNU / Linux, BSD, OS X, uporabite kodiranje UTF-8 za predstavitev Unicode. Večina programov lahko obravnava UTF-8 kot tradicionalna enobajtna kodiranja, ne glede na to, da je znak predstavljen kot več zaporednih bajtov. Za delo s posameznimi znaki se nizi običajno prekodirajo v UCS-4, tako da ima vsak znak strojno besedo.
Ena prvih uspešnih komercialnih implementacij Unicode je bila sreda Java programiranje... V bistvu je opustil 8-bitno predstavitev znakov v korist 16-bitne. Ta rešitev je povečala porabo pomnilnika, vendar nam je omogočila vrnitev pomembne abstrakcije v programiranje: poljuben posamezen znak (vrsta char). Zlasti programer bi lahko delal z nizom kot s preprostim nizom. Žal uspeh ni bil dokončen, Unicode je prerasel 16-bitno omejitev in do J2SE 5.0 je poljuben znak spet začel zasedati spremenljivo število pomnilniških enot - ena char ali dva (glej nadomestni par).
Večina programskih jezikov zdaj podpira nize Unicode, čeprav se njihova predstavitev lahko razlikuje glede na izvedbo.
Metode vnosa
Ker nobena postavitev tipkovnice ne more dovoliti vnosa vseh znakov Unicode hkrati, je potrebna podpora operacijskih sistemov in aplikacij. alternativne metode vnesite poljubne znake Unicode.
Microsoft Windows
Čeprav pripomoček Character Map (charmap.exe) od začetka v sistemu Windows 2000 podpira znake Unicode in vam omogoča, da jih kopirate v odložišče, je ta podpora omejena samo na osnovno ravnino (znakovne kode U + 0000… U + FFFF). Simboli s kodami iz U + 10000 "Tabela simbolov" se ne prikaže.
Podobna tabela je na primer v Microsoft Word.
Včasih lahko vnesete šestnajstiško kodo, pritisnete Alt + X in koda bo zamenjana z ustreznim znakom, na primer v WordPadu, Microsoft Wordu. V urejevalnikih Alt + X izvede tudi obratno transformacijo.
V mnogih programih MS Windows, da dobite znak Unicode, morate pritisniti tipko Alt in vnesti decimalno vrednost kode znaka številsko tipkovnico... Kombinacije Alt + 0171 ("), Alt + 0187 (") in Alt + 0769 (naglasni znak) bodo na primer uporabne pri tipkanju cirilic. Zanimivi sta tudi kombinaciji Alt + 0133 (…) in Alt + 0151 (-).
Macintosh
Mac OS 8.5 in novejši podpira metodo vnosa, imenovano "Unicode Hex Input". Medtem ko držite tipko Option, morate vnesti štirimestno šestnajstiško kodo zahtevanega znaka. Ta metoda omogoča vnašanje znakov s kodami, večjimi od U + FFFF, z uporabo nadomestnih parov; take pare bo operacijski sistem samodejno zamenjal z enojnimi znaki. Ta način vnosa mora biti pred uporabo aktiviran v ustreznem razdelku. sistemske nastavitve in nato v meniju tipkovnice izberite kot trenutni način vnosa.
Od Mac OS X 10.2 obstaja tudi aplikacija Paleta znakov, ki vam omogoča, da izberete znake iz tabele, v kateri lahko izberete znake iz določenega bloka ali znake, ki jih podpira določena pisava.
GNU / Linux
GNOME ima tudi pripomoček Symbol Map (prej gucharmap), ki vam omogoča prikaz simbolov za določen blok ali sistem pisanja in ponuja možnost iskanja po imenu ali opisu simbola. Ko je koda želenega znaka znana, jo lahko vnesete v skladu s standardom ISO 14755: medtem ko držite tipke Ctrl + ⇧ Shift, vnesite šestnajstiško kodo (začenši z neko različico GTK +, morate vnesti kodo s pritiskom "U"). Vnesena šestnajstiška koda je lahko dolga do 32 bitov, kar vam omogoča, da vnesete poljubne znake Unicode brez uporabe nadomestnih parov.
Vse aplikacije X Window, vključno z GNOME in KDE, podpirajo vnos s tipko Compose. Za tipkovnice, ki nimajo namenske tipke Compose, lahko v ta namen dodelite katero koli tipko - na primer ⇪ Caps lock.
Konzola GNU / Linux omogoča tudi vnos znaka Unicode s svojo kodo - za to je treba decimalno kodo znaka vnesti kot števke razširjenega bloka tipkovnice, medtem ko držite tipko Alt. Znake lahko vnesete z njihovo šestnajstiško kodo: za to morate držati tipko AltGr in vnesti števke A-F uporabite tipke na razširjenem bloku tipkovnice od NumLock do ↵ Enter (v smeri urinega kazalca). Podprt je tudi vnos v skladu z ISO 14755. Za delovanje zgornjih metod morate v konzoli omogočiti način Unicode s klicem unicode_start(1) in s klicem izberite ustrezno pisavo setfont(8).
Mozilla Firefox za Linux podpira vnos znakov ISO 14755.
Težave z Unicode
V Unicode sta angleška "a" in poljska "a" enak znak. Na enak način se ruski "a" in srbski "a" štejeta za isti simbol (vendar se razlikuje od latinskega "a"). To načelo kodiranja ni univerzalno; očitno rešitev "za vse priložnosti" sploh ne more obstajati.
- Kitajska, korejska in japonska besedila so tradicionalno napisana od zgoraj navzdol, začenši v zgornjem desnem kotu. Preklapljanje med vodoravnim in navpičnim črkovanjem za te jezike v Unicode ni predvideno - to je treba storiti z označevalnimi jeziki ali notranjimi mehanizmi urejevalnikov besedil.
- Unicode omogoča različne teže istega znaka, odvisno od jezika. Torej imajo lahko kitajski znaki različne sloge v kitajščini, japonščini (kanji) in korejščini (hancha), hkrati pa so v Unicode označeni z istim simbolom (tako imenovana poenotenje CJK), čeprav so še vedno poenostavljeni in polni znaki. imajo različne kode... Prav tako ruski in srbski jezik uporabljata različen poševni slog. P in T(v srbščini sta videti kot u in w, glej srbski poševni tisk). Zato morate zagotoviti, da je besedilo vedno pravilno označeno kot povezano z enim ali drugim jezikom.
- Prevod iz malih črk v velike je odvisen tudi od jezika. Na primer: v turščini sta črki İi in Iı - tako so turška pravila o spreminjanju velikih in malih črk v nasprotju z angleškimi, ki zahtevajo, da se "i" prevede v "I". Podobne težave obstajajo v drugih jezikih - na primer v kanadskem francoskem narečju je register preveden nekoliko drugače kot v Franciji.
- Tudi pri arabskih številkah obstajajo določene tipografske tankosti: številke so lahko "velike" in "male črke", sorazmerne in enoprostorne - za Unicode med njimi ni razlike. Takšni odtenki ostajajo pri programski opremi.
Nekatere pomanjkljivosti niso povezane s samim Unicode, temveč z zmogljivostmi besedilnih procesorjev.
- Datoteke nelatinskega besedila v Unicode vedno zavzamejo več prostora, saj en znak ni kodiran z enim bajtom, kot v različnih nacionalnih kodirjih, temveč z zaporedjem bajtov (izjema je UTF-8 za jezike, katerih abeceda ustreza v ASCII, pa tudi prisotnost dveh znakov v besedilu in več jezikov, katerih abeceda ne ustreza ASCII). Datoteka pisave, potrebna za prikaz vseh znakov v tabeli Unicode, zavzema razmeroma velik pomnilniški prostor in je računsko bolj intenzivna kot samo pisava v uporabniškem nacionalnem jeziku. S povečanjem moči računalniških sistemov in znižanjem stroškov pomnilnika in diskovnega prostora postaja ta problem vse manj pomemben; vendar ostaja pomemben za prenosne naprave, kot so mobilni telefoni.
- Čeprav je podpora Unicode implementirana v najpogostejših operacijskih sistemih, se še vedno ne uporabljajo vsi programsko opremo podpira pravilno delo z njim. Zlasti oznake za zaporedje bajtov (BOM) niso vedno obdelane in naglašeni znaki so slabo podprti. Težava je začasna in je posledica primerjalne novosti standardov Unicode (v primerjavi z enobajtnimi nacionalnimi kodami).
- Zmogljivost vseh programov za obdelavo nizov (vključno z razvrščanjem v bazi podatkov) se zmanjša, če se namesto enobajtnih kodiranj uporabi Unicode.
Nekateri redki sistemi pisanja še vedno niso pravilno predstavljeni v Unicode. Upodobitev "dolgih" nadpisnih znakov, ki segajo na več črk, kot na primer v cerkvenoslovanščini, še ni izvedena.
Unicode ali Unicode?
"Unicode" je lastno ime (ali del imena, na primer Unicode Consortium) in splošno ime, ki izhaja iz angleškega jezika.
Na prvi pogled je bolje uporabiti črkovanje "Unicode". V ruskem jeziku že obstajajo morfemi "uni-" (besede z latinskim elementom "uni-" so bile tradicionalno prevedene in zapisane z "uni-": univerzalno, enopolarno, poenotenje, enotno) in "koda". proti, blagovne znamke, izposojeni iz angleškega jezika, se običajno prenašajo s pomočjo praktične transkripcije, v kateri je deetimologizirana kombinacija črk "uni-" zapisana v obliki "uni-" ("Unilever", "Unix" itd.) , torej na enak način kot v primeru črk za črko okrajšav, kot je UNICEF »Mednarodni sklad Združenih narodov za izredne razmere« - UNICEF.
Črkovanje "Unicode" je že trdno vstopilo v besedila v ruskem jeziku. Wikipedia uporablja pogostejšo različico. V MS Windows se uporablja možnost Unicode.
Na spletni strani konzorcija je posebna stran, kjer so težave s prenosom besede "Unicode" na različnih jezikih in sistemi pisanja. Za rusko cirilično abecedo je določena možnost "Unicode".
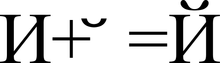
Za težave, povezane s kodiranjem, običajno poskrbi programska oprema, zato pri uporabi kodiranja običajno ni težav. Če se pojavijo težave, jih običajno ustvarijo slabi programi - pošljite jih v smeti.
Vabim vse, da spregovorijo
ASCII (angleško American Standard Code for Information Interchange) - ameriška standardna kodna tabela za natisljive znake in nekatere posebne kode. Ameriška angleščina se izgovarja [aski], medtem ko je v Združenem kraljestvu [aski] bolj izrazita; v ruščini se izgovarja tudi [aski] ali [aski].
ASCII je kodiranje za decimalne števke, latinsko in nacionalno abecedo, ločila in kontrolne znake. Prvotno zasnovan kot 7-bitni, s široko uporabo 8-bitnega bajta ASCII so ga začeli obravnavati kot polovico 8-bitnega. Računalniki običajno uporabljajo razširitve ASCII z vključenim 8. bitom in drugo polovico kodne tabele (na primer KOI-8).
Unicode
Leta 1991 je bila v Kaliforniji ustanovljena neprofitna organizacija Unicode Consortium, ki vključuje predstavnike številnih računalniških podjetij (Borland, IBM, Lotus, Microsoft, Novell, Sun, WordPerfect itd.) in ki razvija in izvaja standard " Standard Unicode"... Standard za kodiranje znakov Unicode postaja prevladujoč v mednarodnih večjezičnih programskih okoljih. Microsoft Windows NT in njegovi potomci Windows 2000, 2003, XP uporabljajo Unicode, natančneje UTF-16, kot notranjo predstavitev besedila. UNIX-u podobni operacijski sistemi, kot so Linux, BSD in Mac OS X, so sprejeli Unicode (UTF-8) kot primarno predstavitev večjezičnega besedila. Unicode rezervira 1.114.112 (220 + 216) kodnih znakov, trenutno se uporablja več kot 96.000 znakov. Prvih 256 znakovnih kod se zelo ujema s tistimi iz ISO 8859-1, najbolj priljubljene 8-bitne tabele znakov v zahodnem svetu; posledično je prvih 128 znakov tudi enakih tabeli ASCII. Kodni prostor Unicode je razdeljen na 17 "ravnin", vsak načrt pa ima 65536 (= 216) kodnih točk. Prva ravnina (ravnina 0), osnovna večjezična ravnina (BMP), je tista, v kateri je opisana večina znakov. BMP vsebuje simbole za skoraj vsakogar sodobnih jezikih, in veliko število posebnih znakov. Za "grafične" simbole se uporabljata še dve ravnini. Ravnina 1, dopolnilna večjezična ravnina (SMP) se uporablja predvsem za zgodovinske simbole, uporablja pa se tudi za glasbene in matematične simbole. Načrt 2, dopolnilna ideografska ravnina (SIP), se uporablja za približno 40.000 redkih kitajskih znakov. Načrt 15 in načrt 16 sta odprta za vsako zasebno uporabo. Slika 1.10 prikazuje ruski blok Unicode (U + 0400 do U + 04FF).
Pogosta kodiranja
ISO 646 ASCII BCDIC EBCDIC ISO 8859: ISO 8859-1, ISO 8859-2, ISO 8859-3, ISO 8859-4, ISO 8859-5, ISO 8859-6, ISO 8859-7, ISO 8859-8, ISO 8859-8 -9, ISO 8859-10, ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP865, CP865, CP866 , CP869 Microsoftova kodiranja Windows: Windows-1250 za srednjeevropske jezike, ki uporabljajo latinično črkovanje (poljski, češki, slovaški, madžarski, slovenski, hrvaški, romunski in albanski) Windows-1251 za cirilično abecedo Windows-1252 za zahodne jezike Windows-1253 za Grški Windows-1254 za turški Windows-1255 za hebrejski Windows-1256 za arabski Windows-1257 za baltske jezike Windows-1258 za vietnamščine MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 bolgarščina ISCII kodiranje VISCII Big5 (najbolj znana različica Microsoft CP950) HKSCS Guobiao GB2312 GBK (Microsoft CP936) GB18030 Shift JIS za japonsko (Microsoft CP932) EUC-KR za korejsko (Microsoft CP949) ISO-2022 in EUC en za kitajske UTF UTF-16 in UTF-32 nabor znakov Unicode \
Kodiranje grafičnih informacij
Od 80. let dalje. razvija se tehnologija obdelave grafičnih informacij na osebnem računalniku. Oblika prikaza na zaslonu grafične slike, sestavljene iz posameznih pik (pikslov), se imenuje rastrska. Najmanjši predmet v urejevalniku rastrske grafike je točka. Rasterski grafični urejevalnik je zasnovan za ustvarjanje slik, diagramov. Ločljivost monitorja (število vodoravnih in navpičnih pik) ter število možnih barv vsake pike je določeno z vrsto monitorja. 1 piksel črno-belega zaslona je kodiran z 1 bitom informacij (črna pika ali bela pika). Število različnih barv K in število bitov za njihovo kodiranje sta povezana s formulo: K = 2b. Sodobni monitorji imajo naslednje barvne palete: 16 barv, 256 barv; 65.536 barv (visoka barva), 16.777.216 barv (prava barva).
Bitna slika
S pomočjo povečevalnega stekla lahko vidite, da je črno-bela grafična slika, na primer iz časopisa, sestavljena iz najmanjših pik, ki sestavljajo določen vzorec – raster. V Franciji v 19. stoletju se je pojavila nova smer v slikarstvu - pointilizem. Njegova tehnika je bila v tem, da je bila risba nanešena na platno s čopičem v obliki večbarvnih pik. Tudi ta metoda se že dolgo uporablja v tiskarski industriji za kodiranje grafičnih informacij. Natančnost risbe je odvisna od števila pik in njihove velikosti. Ko sliko razdelite na točke, začenši z levega vogala in se premikate po črtah od leve proti desni, lahko kodirate barvo vsake točke. Nadalje se bo ena taka točka imenovala piksel (izvor te besede je povezan z angleško okrajšavo "element slike" - element slike). Volumen rastrske slike določimo tako, da pomnožimo število slikovnih pik (z količino informacij ene točke, ki je odvisna od števila možnih barv. Kakovost slike določa ločljivost monitorja. Višja kot je, je, več rastrskih črt in pik v vrstici, višja je kakovost slike. Osebniki uporabljajo večinoma naslednje ločljivosti zaslona: 640 x 480, 800 x 600, 1024 x 768 in 1280 x 1024 slikovnih pik.Ker je svetlost vsake točke in njegove linearne koordinate lahko izrazimo s celimi števili, lahko rečemo, da ta metoda kodiranja omogoča uporabo binarne kode za obdelavo grafičnih podatkov.
Če govorimo o črno-belih ilustracijah, potem, če ne uporabljate poltonov, bo piksel prevzel eno od dveh stanj: sveti (belo) in ne sveti (črno). In ker se informacija o barvi slikovne pike imenuje koda slikovne pike, je za kodiranje dovolj en bit pomnilnika: 0 - črna, 1 - bela. Če ilustracije obravnavamo v obliki kombinacije pik s 256 odtenki sive (te so namreč trenutno splošno sprejete), potem je za kodiranje svetlosti katere koli pike dovolj že osembitna binarna številka. V računalniška grafika barva je izjemno pomembna. Deluje kot sredstvo za izboljšanje vizualnega vtisa in povečanje informacijske nasičenosti slike. Kako se v človeških možganih oblikuje čut za barvo? To se zgodi kot posledica analize svetlobnega toka, ki vstopa v mrežnico iz odsevnih ali oddajnih predmetov. Na splošno velja, da so človeški barvni receptorji, ki jih imenujemo tudi stožci, razdeljeni v tri skupine in vsaka lahko zazna samo eno barvo - rdečo, zeleno ali modro.
Barvni modeli
Ko gre za kodiranje barve grafične slike, potem morate upoštevati načelo razgradnje poljubne barve na njene glavne komponente. Uporablja se več sistemov kodiranja: HSB, RGB in CMYK. Prvi barvni model je preprost in intuitiven, torej je primeren za osebo, drugi je najprimernejši za računalnik, zadnji model CMYK pa za tiskarne. Uporaba teh barvnih modelov je posledica dejstva, da lahko svetlobni tok tvori sevanje, ki je kombinacija "čistih" spektralnih barv: rdeče, zelene, modre ali njihovih derivatov. Razlikujte med aditivno barvno reprodukcijo (tipično za oddajne predmete) in subtraktivno barvno reprodukcijo (tipično za odsevne predmete). Primer predmeta prve vrste je katodna cev monitorja, druge vrste - tisk.

Za model HSB so značilne tri komponente: odtenek, nasičenost in svetlost. S prilagajanjem teh komponent lahko dobite veliko poljubnih barv. Ta barvni model je najbolje uporabiti v teh grafični urejevalniki, v katerem so slike ustvarjene same in niso obdelane že pripravljene. Nato lahko ustvarjeno umetniško delo pretvorite v barvni model RGB, če ga nameravate uporabiti kot ilustracijo na zaslonu, ali CMYK, če je natisnjeno. Barvna vrednost je izbrana kot vektor, ki izhaja iz središča kroga. Smer vektorja je določena v kotnih stopinjah in določa odtenek. Nasičenost barve je določena z dolžino vektorja, svetlost barve pa je nastavljena na ločeni osi, katere ničelna točka je črna. Osrednja točka je bela (nevtralna), točke okoli oboda pa so enobarvne.
Načelo metode RGB je naslednje: znano je, da je vsako barvo mogoče predstaviti kot kombinacijo treh barv: rdeče (Red, R), zelene (Green, G), modre (Modra, B). Druge barve in njihovi odtenki so pridobljeni zaradi prisotnosti ali odsotnosti teh komponent.Iz prvih črk primarnih barv je sistem dobil ime - RGB. Ta barvni model je aditivni, to pomeni, da lahko s kombiniranjem primarnih barv v različnih razmerjih dobimo katero koli barvo. Ko se ena komponenta primarne barve prekrije z drugo, se svetlost celotnega sevanja poveča. Če združimo vse tri komponente, dobimo akromatsko sivo barvo, s povečanjem svetlosti katere pride do približevanja beli.
Z 256 toni (vsaka točka je kodirana s 3 bajti) minimalne vrednosti RGB (0,0,0) ustrezajo črni, bele pa največjemu s koordinatami (255, 255, 255). Večja kot je vrednost bajtov barvne komponente, svetlejša je ta barva. Na primer, temno modra je kodirana s tremi bajti (0, 0, 128) in svetlo modra (0, 0, 255).
Načelo metode CMYK. Ta barvni model se uporablja pri pripravi publikacij za tisk. Vsaki od primarnih barv je dodeljena komplementarna barva (komplementarna primarni barvi beli). Dodatno barvo dobimo tako, da seštejemo par preostalih primarnih barv. To pomeni, da so komplementarne barve za rdečo cian (Cyan, C) = zelena + modra = bela - rdeča, za zeleno - magenta (Magenta, M) = rdeča + modra = bela - zelena, za modro - rumena (Rumena, Y) = rdeča + zelena = bela - modra. Poleg tega se lahko načelo razgradnje poljubne barve na komponente uporablja tako za glavne kot za dodatne, to pomeni, da je lahko katera koli barva predstavljena bodisi kot vsota rdeče, zelene, modre komponente ali kot vsota cian, vijolična, rumena komponenta. V bistvu je ta metoda sprejeta v tiskarski industriji. Toda tam še vedno uporabljajo črno (BlacK, ker črko B že zaseda modra, je označena s črko K). To je zato, ker prekrivanje komplementarnih barv ne ustvari čiste črne barve.
Vektorske in fraktalne slike
Vektorska slika je grafični objekt, sestavljen iz osnovnih črt in lokov. Osnovni element slike je črta. Kot vsak predmet ima lastnosti: oblika (ravna, ukrivljena), debelina., Barva, slog (pikčasta, trdna). Zaprte črte imajo lastnost polnjenja (bodisi z drugimi predmeti ali z izbrano barvo). Vsi drugi predmeti vektorska grafika sestavljen iz črt. Ker je črta matematično opisana kot en sam objekt, je količina podatkov za prikaz objekta s pomočjo vektorske grafike veliko manjša kot pri rastrski grafiki. Informacije o vektorski sliki so kodirane kot običajne alfanumerične in obdelane s posebnimi programi.
TO programsko opremo ustvarjanje in obdelava vektorske grafike vključuje naslednje GR: CorelDraw, Adobe Illustrator, pa tudi vektorizatorje (tracer) - specializirane pakete za pretvorbo rastrskih slik v vektorske.

Fraktalna grafika temelji na matematičnih izračunih, tako kot vektorska grafika. Toda za razliko od vektorja je njegov osnovni element sama matematična formula. To vodi v dejstvo, da v pomnilniku računalnika niso shranjeni nobeni predmeti in se slika gradi samo z enačbami. S to metodo lahko zgradite najpreprostejše redne strukture, pa tudi zapletene ilustracije, ki posnemajo pokrajine.

Avdio kodiranje
Svet je poln najrazličnejših zvokov: tiktakanje ur in brnenje motorjev, tuljenje vetra in šelestenje listja, petje ptic in glasovi ljudi. Ljudje so že zelo dolgo začeli ugibati, kako se zvoki rodijo in kaj so. Tudi starogrški filozof in znanstvenik - enciklopedist Aristotel je na podlagi opazovanj razložil naravo zvoka, saj je verjel, da zvočno telo ustvarja izmenično stiskanje in redčenje zraka. Tako se nihajna struna včasih razelektri, nato zgosti zrak in zaradi elastičnosti zraka se ti izmenični vplivi prenašajo naprej v prostor – iz plasti v plast nastajajo elastični valovi. Ko pridejo do našega ušesa, delujejo na bobniče in ustvarijo občutek zvoka.
Na uho človek zazna elastične valove s frekvenco nekje v območju od 16 Hz do 20 kHz (1 Hz - 1 vibracija na sekundo). V skladu s tem se elastični valovi v katerem koli mediju, katerih frekvence so v določenih mejah, imenujemo zvočni valovi ali preprosto zvok. Pri preučevanju zvoka so pomembni pojmi, kot sta ton in tember zvoka. Vsak resničen zvok, pa naj bo to igra glasbil ali glas osebe, je nekakšna mešanica številnih harmoničnih vibracij z določenim naborom frekvenc.
Zamah, ki ga ima največ nizka frekvenca, se imenujejo glavni ton, drugi se imenujejo prizvoki.
Zvok je različno število prizvokov, ki so lastni določenemu zvoku, kar mu daje posebno barvo. Razlika med tembrom od drugega ni le posledica števila, temveč tudi intenzivnosti prizvokov, ki spremljajo zvok glavnega tona. Po tembru zlahka ločimo zvoke klavirja in violine, kitare in flavte ter prepoznamo glas znane osebe.
Glasbeni zvok lahko označujemo s tremi lastnostmi: tembra, to je barva zvoka, ki je odvisna od oblike tresljajev, višina, ki jo določa število tresljajev na sekundo (frekvenca), in glasnost, ki je odvisna od glede na intenzivnost vibracij.
Računalnik se danes pogosto uporablja na različnih področjih. Obdelava zvočnih informacij in glasbe nista bila izjema. Do leta 1983 so bili vsi posnetki glasbe izdani na vinilnih ploščah in kompaktnih kasetah. Trenutno so CD-ji zelo razširjeni. Če imate računalnik, na katerem je nameščena studijska zvočna kartica, na katero sta priključena MIDI tipkovnica in mikrofon, potem lahko delate s specializirano glasbeno programsko opremo.
Digitalno-analogno in analogno-digitalno pretvorbo zvočnih informacij
Oglejmo si na hitro postopke pretvarjanja zvoka iz analognega v digitalni in obratno. Približna predstava o tem, kaj se dogaja na zvočni kartici, lahko pomaga preprečiti nekatere napake pri delu z zvokom.
Zvočni valovi se z mikrofonom pretvorijo v analogni izmenični električni signal. Gre skozi zvočno pot in v analogno-digitalni pretvornik (ADC) - napravo, ki pretvarja signal v digitalno obliko.
V poenostavljeni obliki je načelo delovanja ADC naslednje: meri amplitudo signala v rednih intervalih in oddaja naprej, že po digitalni poti, zaporedje številk, ki nosijo informacije o spremembah amplitude. Med analogno-digitalno pretvorbo ne pride do fizične pretvorbe. Odtis ali vzorec je tako rekoč odstranjen iz električnega signala, ki je digitalni model napetostnih nihanj na zvočni poti. Če je to prikazano v obliki diagrama, je ta model predstavljen v obliki zaporedja stolpcev, od katerih vsak ustreza določeni številčni vrednosti. Digitalni signal je diskretne narave – torej diskontinuiran, zato se digitalni model ne ujema povsem z valovno obliko analognega signala.
Vzorec je časovni interval med dvema meritvama amplitude analognega signala.
Sample se iz angleščine dobesedno prevaja kot "vzorec". V multimedijski in strokovni avdio terminologiji ima ta beseda več pomenov. Poleg časovnega obdobja se vzorec imenuje tudi vsako zaporedje digitalnih podatkov, ki je bilo pridobljeno z analogno-digitalno pretvorbo. Sam proces pretvorbe se imenuje vzorčenje. V ruskem tehničnem jeziku se to imenuje diskretizacija.
Digitalni zvok se oddaja s pomočjo digitalno-analognega pretvornika (DAC), ki na podlagi vhodnih digitalnih podatkov ob ustreznem času generira električni signal zahtevane amplitude
Možnosti vzorčenja
Frekvenca in bitna globina sta pomembna parametra vzorčenja. Frekvenca - število meritev amplitude analognega signala na sekundo.
Če frekvenca vzorčenja ni večja kot dvakratna frekvenca zgornje meje zvočnega območja, potem vklopi visoke frekvence bodo nastale izgube. To pojasnjuje, zakaj je standardna frekvenca avdio CD-ja 44,1 kHz. Ker je obseg nihanja zvočnih valov v območju od 20 Hz do 20 kHz, mora biti število meritev signala na sekundo večje od števila nihanj v istem časovnem obdobju. Če je hitrost vzorčenja bistveno nižja od frekvence zvočnega vala, se amplituda signala v času med meritvami večkrat spremeni, kar vodi v dejstvo, da digitalni prstni odtis nosi kaotičen nabor podatkov. Pri digitalno-analogni pretvorbi tak vzorec ne oddaja glavnega signala, ampak proizvaja le šum.
V novem formatu CD Audio DVD se signal izmeri 96.000-krat v eni sekundi, t.j. uporabite hitrost vzorčenja 96 kHz. Za prihranek prostora na trdem disku v večpredstavnostnih aplikacijah se pogosto uporabljajo nižje frekvence: 11, 22, 32 kHz. To vodi do zmanjšanja slišnega frekvenčnega območja, kar pomeni, da je slišano močno popačenje.
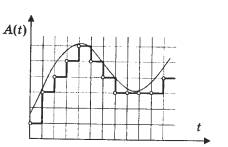
Če v obliki grafa predstavljamo enak zvok z višino 1 kHz (tej frekvenci približno ustreza nota do sedme oktave klavirja), vendar vzorčen z drugo frekvenco (spodnji del sinusoide je ni prikazano na vseh grafih), potem bodo razlike vidne. Ena delitev na vodoravni osi, ki prikazuje čas, ustreza 10 vzorcem. Lestvica je enaka. Vidite lahko, da je pri frekvenci 11 kHz približno pet nihanj zvočnega vala na vsakih 50 vzorcev, to pomeni, da je ena perioda sinusnega vala prikazana z uporabo samo 10 vrednosti. To je precej nenatančen prenos. Hkrati, če upoštevamo frekvenco vzorčenja 44 kHz, je za vsako obdobje sinusoide že skoraj 50 vzorcev. To vam omogoča, da dobite signal dobre kakovosti.
Bitna globina označuje natančnost, s katero se spreminja amplituda analognega signala. Natančnost, s katero se med digitalizacijo prenaša vrednost amplitude signala v vsaki točki časa, določa kakovost signala po digitalno-analogni pretvorbi. Zanesljivost rekonstrukcije valovne oblike je odvisna od bitne globine.
Amplitudna vrednost je kodirana po principu binarnega kodiranja. Zvočni signal naj bo predstavljen kot zaporedje električnih impulzov (binarne ničle in enote). Običajno se uporabljajo 8, 16-bitni ali 20-bitni prikazi amplitudnih vrednosti. Ko je binarno kodiranje neprekinjeno zvočni signal nadomesti se z zaporedjem diskretnih nivojev signala. Kakovost kodiranja je odvisna od hitrosti vzorčenja (števila meritev nivoja signala na enoto časa). S povečanjem stopnje vzorčenja se poveča natančnost binarne predstavitve informacij. Pri frekvenci 8 kHz (število meritev na sekundo je 8000) kakovost vzorčenega zvočnega signala ustreza kakovosti radijske oddaje, pri frekvenci 48 kHz (število meritev na sekundo je 48000) - kakovost zvoka avdio CD-ja.
Trenutno obstaja nov potrošniški digitalni format Audio DVD, ki uporablja bitno globino 24 bitov in hitrost vzorčenja 96 kHz. Z njegovo pomočjo se je mogoče izogniti zgoraj omenjeni pomanjkljivosti 16-bitnega kodiranja.
Na sodobno digitalno zvočne naprave Vgrajeni so 20-bitni pretvorniki. Zvok ostaja 16-bitni, nameščeni so visoko-bitni pretvorniki za izboljšanje kakovosti snemanja pri nizkih nivojih. Njihovo načelo delovanja je naslednje: originalni analogni signal je digitaliziran s širino 20 bitov. Nato digitalni signalni procesor DSPP zmanjša svojo širino na 16 bitov. V tem primeru se uporablja poseben algoritem za izračun, s pomočjo katerega je mogoče zmanjšati popačenje nizkonivojskih signalov. Med digitalno-analogno pretvorbo opazimo nasprotni proces: bitna globina se poveča s 16 na 20 bitov s posebnim algoritmom, ki vam omogoča natančnejše določanje vrednosti amplitude. To pomeni, da zvok ostane 16-bitni, vendar se kakovost zvoka na splošno izboljša.
Kaj je kodiranje
V ruščini se "nabor znakov" imenuje tudi tabela "nabor znakov", postopek uporabe te tabele za prevajanje informacij iz računalniške predstavitve v človeško in značilnost besedilne datoteke, ki odraža uporabo določenega sistema. kod v njej pri prikazovanju besedila.
Kako je besedilo kodirano
Nabor simbolov, ki se uporabljajo pri pisanju besedila, se v računalniški terminologiji imenuje abeceda; število simbolov v abecedi običajno imenujemo njegova moč. Za predstavitev besedilne informacije računalnik najpogosteje uporablja abecedo s kapaciteto 256 znakov. Eden od njegovih znakov nosi 8 bitov informacij, zato binarna koda vsakega znaka zavzame 1 bajt računalniškega pomnilnika. Vsi znaki takšne abecede so oštevilčeni od 0 do 255, vsaka številka pa ustreza 8-bitni binarni kodi, ki je redna številka znaka v dvojiškem številskem sistemu – od 00000000 do 11111111. Samo prvih 128 znakov z številke od nič (binarna koda 00000000) do 127 (01111111). Sem spadajo male črke in velike črke Latinska abeceda, številke, ločila, oklepaji itd. Preostalih 128 kod, ki se začnejo s 128 (binarna koda 10000000) in končajo z 255 (11111111), se uporablja za kodiranje črk nacionalnih abeced, uradnih in znanstvenih simbolov.
Vrste kodiranja
Najbolj znana kodirna tabela je ASCII (ameriška standardna koda za izmenjavo informacij). Prvotno je bil razvit za prenos besedil po telegrafu, takrat pa je bil 7-bitni, torej je bilo za kodiranje angleških znakov, službenih in kontrolnih znakov uporabljenih le 128 7-bitnih kombinacij. V tem primeru je prvih 32 kombinacij (kod) služilo za kodiranje kontrolnih signalov (začetek besedila, konec vrstice, povratek na nosilec, klic, konec besedila itd.). Pri razvoju prvih IBM-ovih računalnikov je bila ta koda uporabljena za predstavitev simbolov v računalniku. Ker v izvorno kodo ASCII je imel samo 128 znakov, za njihovo kodiranje je bilo dovolj bajtnih vrednosti z 8. bitom enakim 0. Bajtne vrednosti z 8. bitom enakim 1 so se začele uporabljati za predstavljanje psevdografičnih znakov, matematičnih znakov in nekaterih znakov iz jezikov, ki niso angleščina (grščina, nemška preglasa, francoska diakritička itd.). Ko so začeli računalnike prilagajati drugim državam in jezikom, ni bilo več dovolj prostora za nove simbole. Za popolno podporo jezikom, ki niso angleščina, je IBM predstavil več kodnih tabel za posamezne države. Tako je bila za skandinavske države predlagana tabela 865 (nordijska), za arabske države - tabela 864 (arabščina), za Izrael - tabela 862 (Izrael) itd. V teh tabelah so bile nekatere kode iz druge polovice kodne tabele uporabljene za predstavitev znakov nacionalnih abeced (z izključitvijo nekaterih psevdografičnih znakov). Situacija z ruskim jezikom se je razvila na poseben način. Očitno je mogoče zamenjati znake v drugi polovici kodne tabele različne poti... Tako se je za ruski jezik pojavilo več različnih tabel kodiranja cirilice: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Vsi predstavljajo simbole prve polovice tabele na enak način (od 0 do 127) in se razlikujejo po predstavitvi simbolov ruske abecede in psevdografike. Za jezike, kot sta kitajščina ali japonščina, 256 znakov na splošno ni dovolj. Poleg tega vedno obstaja problem izpisovanja ali shranjevanja v eni datoteki hkrati različnih jezikih(na primer pri citiranju). Zato univerzalno kodna tabela UNICODE, ki vsebuje simbole, ki se uporabljajo v jezikih vseh ljudstev sveta, pa tudi različne službene in pomožne simbole (ločila, matematični in tehnični simboli, puščice, diakritični znaki itd.). Očitno en bajt ni dovolj za kodiranje tako velikega števila znakov. Zato UNICODE uporablja 16-bitne (2-bajtne) kode za predstavitev 65.536 znakov. Do danes je bilo uporabljenih okoli 49.000 kod (zadnja pomembna sprememba je bila uvedba simbola valute EURO septembra 1998). Zaradi združljivosti s prejšnjimi kodami je prvih 256 kod enakih kot v standardu ASCII. V standardu UNICODE je vsakemu znaku poleg določene binarne kode (te kode običajno označene s črko U, ki ji sledi znak + in dejanska koda v šestnajstiški predstavitvi) dodeljeno posebno ime. Druga komponenta Standard UNICODE so algoritmi za pretvorbo kod UNICODE ena proti ena v zaporedju bajtov spremenljive dolžine. Potreba po takšnih algoritmih je posledica dejstva, da vse aplikacije ne morejo delati z UNICODE. Nekatere aplikacije razumejo samo 7-bitne kode ASCII, druge aplikacije razumejo 8-bitne kode ASCII. Takšne aplikacije uporabljajo tako imenovane razširjene kode ASCII za predstavitev znakov, ki ne sodijo v nabor 128 ali 256 znakov, kadar so znaki kodirani z nizi bajtov spremenljive dolžine. UTF-7 se uporablja za reverzibilno pretvorbo kod UNICODE v razširjene 7-bitne kode ASCII, UTF-8 pa za reverzibilno pretvorbo kod UNICODE v razširjene 8-bitne kode ASCII. Upoštevajte, da tako ASCII kot UNICODE in drugi standardi za kodiranje znakov ne opredeljujejo podob znakov, temveč le sestavo nabora znakov in način, kako je predstavljen v računalniku. Poleg tega je (kar morda ni takoj očitno) zelo pomemben vrstni red naštevanja znakov v nizu, saj najbolj vpliva na algoritme razvrščanja. To je tabela ujemanja simbolov iz določenega niza (recimo simbolov, ki se uporabljajo za predstavljanje informacij o angleški jezik, ali v različnih jezikih, kot v primeru UNICODE) in označite z izrazom tabela kodiranja znakov ali nabor znakov. Vsako standardno kodiranje ima ime, na primer KOI8-R, ISO_8859-1, ASCII. Na žalost ni standarda za kodiranje imen.
Pogosta kodiranja
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP85 7, CP850, CP850 CP861, CP863, CP865, CP866, CP869 Kodiranja Microsoft Windows: o Windows-1250 za srednjeevropske jezike, ki uporabljajo latinske črke o Windows-1251 za cirilično abecedo o Windows-1252 za zahodne jezike o Windows-1253 za grščino o Windows -1254 za turščino o Windows-1255 za hebrejščino o Windows-1256 za arabščino o Windows-1257 za baltske jezike o Windows-1258 za vietnamščino MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI -7 bolgarsko kodiranje ISCII VISCII Big5 (najbolj znana različica Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS za japonsko (Microsoft CP932) EUC-KR za korejsko (Microsoft CP2042) in ISO za sistem kitajskega pisanja UTF-8 in UTF-16 kodiranja nabora znakov Yong IcodeV kodirnem sistemu ASCII(Ameriška standardna koda za izmenjavo informacij) vsak znak je predstavljen z enim bajtom, ki lahko kodira 256 znakov.
ASCII ima dve kodirni tabeli - osnovno in razširjeno. Osnovna tabela določa vrednosti kod od 0 do 127, razširjena pa se nanaša na znake s številkami od 128 do 255. To je dovolj, da z različnimi kombinacijami osmih bitov izrazimo vse znake angleškega in ruskega jezika. , tako male kot velike črke, kot tudi ločila, simbole za osnovne aritmetične operacije in pogoste posebne simbole, ki jih lahko opazimo na tipkovnici.
Prvih 32 kod osnovne tabele, ki se začnejo z ničlo, dobijo proizvajalci strojne opreme (predvsem proizvajalci računalnikov in tiskalnih naprav). To področje vsebuje tako imenovane kontrolne kode, ki ne ustrezajo nobenim jezikovnim znakom, zato te kode niso prikazane niti na zaslonu niti na tiskalnih napravah, lahko pa jih nadzorujemo, kako se izpisujejo drugi podatki. Od kode 32 do kode 127 so postavljeni simboli angleške abecede, ločila, številke, računske operacije in pomožni simboli, vse je vidno na latinskem delu računalniške tipkovnice.
Drugi, razširjeni del je namenjen nacionalnim kodnim sistemom. Na svetu obstaja veliko nelatiničnih abeced (arabska, hebrejska, grška itd.), vključno s cirilico. Tudi nemške, francoske, španske razporeditve tipkovnic se razlikujejo od angleških.
Angleški del tipkovnice je imel včasih veliko standardov, zdaj pa jih je vse nadomestila ena sama koda ASCII. Za rusko tipkovnico je bilo tudi veliko standardov: GOST, GOST-alternative, ISO (International Standard Organization - Mednarodni inštitut za standardizacijo), vendar so ti trije standardi dejansko zamrli, čeprav se lahko srečajo nekje, v nekaterih predpotopnih računalnikih ali v računalniških omrežij.
Glavno kodiranje znakov ruskega jezika, ki se uporablja v računalnikih z operacijskim sistemom sistem Windows poklical Windows-1251, je za cirilico razvil Microsoft. Seveda je absolutna večina računalniških besedilnih podatkov kodiranih v sistemu Windows-1251. Mimogrede, kodiranja z drugačno štirimestno številko je razvil Microsoft za druge običajne abecede: arabsko, japonsko in druge.
Drugo običajno kodiranje se imenuje KOI-8(koda za izmenjavo informacij, osemmestna) - njen nastanek sega v čase Sveta za medsebojno gospodarsko pomoč vzhodnoevropskih držav. Danes je kodiranje KOI-8 razširjeno v računalniških omrežjih na ozemlju Rusije in v ruskem sektorju interneta. Zgodi se, da neko besedilo pisma ali kaj drugega ni berljivo, kar pomeni, da morate preklopiti s KOI-8 na Windows-1251. 10
V 90. letih so največji proizvajalci programske opreme: Microsoft, Borland, isti Adobe odločili, da je treba razviti drugačen sistem kodiranja besedila, v katerem bo vsakemu znaku dodeljen ne 1, ampak 2 bajta. Ime je dobila Unicode, in je možno kodirati 65.536 znakov tega polja, kar je dovolj, da se prilega v eno tabelo nacionalnih abeced za vse jezike planeta. Večino Unicode (približno 70%) zasedajo kitajski znaki, v Indiji je 11 različnih nacionalnih abeced, obstaja veliko eksotičnih imen, na primer: pisanje kanadskih staroselcev.
Ker je kodiranju vsakega znaka v Unicode dodeljenih ne 8, ampak 16 bitov, se velikost besedilne datoteke podvoji. To je bila nekoč ovira za uvedbo 16-bitnega sistema. in zdaj, pri gigabajtnih trdih diskih, na stotine megabajtov RAM-a, gigahertz procesorji, podvojitev obsega besedilnih datotek, ki v primerjavi na primer z grafiko zavzamejo zelo malo prostora, pravzaprav ni pomembna.
Cirilica v Unicode se uvršča od 768 do 923 (osnovni znaki) in od 924 do 1023 (razširjena cirilica, različne manj pogoste nacionalne črke). Če program ni prilagojen za cirilično Unicode, je možno, da besedilni znaki niso prepoznani kot cirilica, ampak kot razširjena latinica (kode 256 do 511). In v tem primeru se namesto besedila na zaslonu prikaže nesmiseln niz različnih eksotičnih simbolov.
To je mogoče, če je program zastarel, ustvarjen pred letom 1995. Ali pa redka, o kateri se nihče ni trudil rusificirati. Možno je tudi, da operacijski sistem Windows, ki je nameščen v računalniku, ni v celoti konfiguriran za cirilično abecedo. V tem primeru morate narediti ustrezne vnose v register.
 Nastavitev ruske razporeditve tipkovnice na iphone 5s
Nastavitev ruske razporeditve tipkovnice na iphone 5s Kakšna je ločljivost zaslona na iPhoneu Kakšen je zaslon na iphoneu 6
Kakšna je ločljivost zaslona na iPhoneu Kakšen je zaslon na iphoneu 6 Kako pisati tehnično podporo tukaj
Kako pisati tehnično podporo tukaj