Od kod Unicode do črk. Problem razlikovanja navzven podobnih številk in črk.
Včasih morate svoji zasnovi dodati ikono, vendar vam ni všeč vstavljanje dodatnih slik ali celotne pisave ikone, kot je Font Awesome? Potem imamo za vas dobro novico - v vašem brskalniku je na voljo obsežna knjižnica ikon in simbolov. Imenuje se Unicode in je standardni standard edinstvene identifikatorje za vedno večje število (trenutno več kot 110.000) simbolov in ikon.
To pa ne pomeni, da imate na izbiro več sto tisoč ikon. Odvisno od brskalnika, ki jih upodobi, in za to uporablja pisave, ki so nameščene v sistemu. V tem članku smo zbrali številne nabore znakov, ki so na voljo v sistemih Windows, Linux, OS X, Android in IOS. Danes jih lahko uporabite pri oblikovanju!
Namig: ki pojasnjuje vse, kar morate vedeti o kodiranju in Unicodeju, ki ga priporočamo vsakemu razvijalcu programske opreme.
Kako uporabljati te ikone
Ikone, prikazane v spodnjih tabelah, so običajni simboli, ki jih lahko kopirate in prilepite, kot da so črke abecede. Če pa se kodiranje uporablja za shranjevanje datotek HTML / CSS ne UTF-8 ne bodo prikazani. Zato smo uvedli kodo za izhod HTML, ki bo vedno delovala. Če želite uporabiti te ikone, morate storiti naslednje:
- Poiščite ikono, ki vam je všeč. Zagotovili smo majhne in velike predoglede.
- Kopirajte kodo.
- Prilepite ga v HTML kot navadno besedilo. V CSS jih lahko uporabite kot vrednost lastnosti vsebino... V JS, PHP in drugih programskih jezikih jih lahko uporabite kot navadno besedilo v nizih.
- Ikone lahko prilagodite tako, da nastavite velikost pisave, barvo, besedilo in sence tako kot običajno besedilo.
Ikone
| Ime | Predogled | Koda | |
|---|---|---|---|
| Nasmeh | ☺ | ☺ | ☺ |
| Opozorilni znak | ⚠ | ⚠ | ⚠ |
| Vrelci | ♨ | ♨ | ♨ |
| Invalidski voziček | ♿ | ♿ | ♿ |
| Reciklirajte | ♻ | ♻ | ♻ |
| 8-žoga | ➑ | ➑ | ➑ |
| Visokonapetostni | ⚡ | ⚡ | ⚡ |
| Bela zvezda | ☆ | ☆ | ☆ |
| Črna zvezda | ★ | ★ | ★ |
| Belo srce | ♡ | ♡ | ♡ |
| Črno srce | ❤ | ❤ | ❤ |
| Kava | ☕ | ☕ | ☕ |
| Letalo | ✈ | ✈ | ✈ |
| Peščena ura | ⌛ | ⌛ | ⌛ |
| Ura | ⌚ | ⌚ | ⌚ |
| Črne škarje | ✂ | ✂ | ✂ |
| Bele škarje | ✄ | ✄ | ✄ |
| Krona | ♕ | ♕ | ♕ |
| Sidro | ⚓ | ⚓ | ⚓ |
| Križ | ✝ | ✝ | ✝ |
| Črno-beli krog | ◑ | ◑ | ◑ |
| Osem opomb | ♪ | ♪ | ♪ |
| Žarile so osme note | ♫ | ♫ | ♫ |
| Štiri zvezdice z balonom | ✣ | ✣ | ✣ |
| Bela zvezda obkrožena | ✪ | ✪ | ✪ |
| Bela zvezda | ✰ | ✰ | ✰ |
| Bela štirikraka zvezda | ✧ | ✧ | ✧ |
| Črna štirikraka zvezda | ✦ | ✦ | ✦ |
| Preverjanje volilne skrinje | ☑ | ☑ | ☑ |
| Kljukica | ✔ | ✔ | ✔ |
| Križna oznaka | ✘ | ✘ | ✘ |
| Svinčnik | ✎ | ✎ | ✎ |
| Roka za pisanje | ✍ | ✍ | ✍ |
| Ženska | ♀ | ♀ | ♀ |
| Moški | ♂ | ♂ | ♂ |
| Črni telefon | ☎ | ☎ | ☎ |
| Beli telefon | ☏ | ☏ | ☏ |
| Ovojnica | ✉ | ✉ | ✉ |
| Lokacija telefona | ✆ | ✆ | ✆ |
Puščice Unicode
| Ime | Predogled | Koda | |
|---|---|---|---|
| Puščica levo | ← | ← | ← |
| Puščica desno | → | → | → |
| Puščica navzgor | |||
| Puščica navzdol | ↓ | ↓ | ↓ |
| Puščica levo desno | ↔ | ↔ | ↔ |
| Puščica gor navzdol | ↕ | ↕ | ↕ |
| Puščice desno in levo | ⇄ | ⇄ | ⇄ |
| Puščice gor in dol | ⇅ | ⇅ | ⇅ |
| Puščica 90 stopinj navzdol levo | ↲ | ↲ | ↲ |
| Puščica 90 stopinj navzdol-desno | ↳ | ↳ | ↳ |
| Puščica 90 stopinj navzgor levo | ↰ | ↰ | ↰ |
| Puščica gor-desno 90 stopinj | ↱ | ↱ | ↱ |
| Severozahodna puščica do kota | ⇱ | ⇱ | ⇱ |
| Jugovzhodna puščica do kota | ⇲ | ⇲ | ⇲ |
| Puščica levo do vrstice | ⇤ | ⇤ | ⇤ |
| Puščica desno proti vrstici | ⇥ | ⇥ | ⇥ |
| Polkrožna puščica v nasprotni smeri urinega kazalca | ↶ | ↶ | ↶ |
| Polkrožna puščica v smeri urinega kazalca | ↷ | ↷ | ↷ |
| Krožna puščica v nasprotni smeri urinega kazalca | ↺ | ↺ | ↺ |
| Krožna puščica v smeri urinega kazalca | ↻ | ↻ | ↻ |
| Puščica s široko glavo | ➔ | ➔ | ➔ |
| Zigzag puščica navzdol | ↯ | ↯ | ↯ |
| Puščica severozahodno | ↖ | ↖ | ↖ |
| Težka jugovzhodna puščica | ➘ | ➘ | ➘ |
| Težka puščica v desno | ➙ | ➙ | ➙ |
| Težka puščica proti severovzhodu | ➚ | ➚ | ➚ |
| Črtkana puščica v desno | ➟ | ➟ | ➟ |
| Puščica v levo puščica | ⇠ | ⇠ | ⇠ |
| Črna puščica v desno | ➤ | ➤ | ➤ |
| Bela puščica v levo | ⇦ | ⇦ | ⇦ |
| Bela puščica v desno | ⇨ | ⇨ | ⇨ |
| Navednik levega kota | « | « | « |
| Pravokotni narekovaj | » | » | » |
| Desni črni kazalec | |||
| Levi črni kazalec | ◀ | ◀ | ◀ |
| Črni kazalec navzgor | ▲ | ▲ | ▲ |
| Črni kazalec navzdol | ▼ | ▼ | ▼ |
| Desni beli kazalec | ▷ | ▷ | ▷ |
| Levi beli kazalec | ◁ | ◁ | ◁ |
| Beli kazalec navzgor | △ | △ | △ |
| Beli kazalec navzdol | ▽ | ▽ | ▽ |
| Lok puščica | ➴ | ➴ | ➴ |
Posebni znaki v unicode
Valuta Unicode
Ikone vremena
| Ime | Predogled | Koda | |
|---|---|---|---|
| Stopnja | ° | ° | ° |
| Majhno sonce | ☀ | ☀ | ☀ |
| Veliko sonce | ☼ | ☼ | ☼ |
| Oblak | ☁ | ☁ | ☁ |
| Dežnik | ☔ | ☔ | ☔ |
| Snežinka 1 | ❆ | ❆ | ❆ |
| Snežinka 2 | ❅ | ❅ | ❅ |
| Snežinka 3 | ❄ | ❄ | ❄ |
Kazalci Unicode
| Ime | Predogled | Koda | |
|---|---|---|---|
| Kazalec levo črn | ☚ | ☚ | ☚ |
| Kazalec desno črno | ☛ | ☛ | ☛ |
| Kazalec levo bela | ☜ | ☜ | ☜ |
| Beli kazalec navzgor | ☝ | ☝ | ☝ |
| Kazalec desno bela | ☞ | ☞ | ☞ |
| Beli kazalec navzdol | ☟ | ☟ | ☟ |
Zodiakalni znaki v unicode
| Ime | Predogled | Koda | |
|---|---|---|---|
| Oven | ♈ | ♈ | ♈ |
| Bik | ♉ | ♉ | ♉ |
| Dvojčka | ♊ | ♊ | ♊ |
| Rak | ♋ | ♋ | ♋ |
| lev | ♌ | ♌ | ♌ |
| Devica | ♍ | ♍ | ♍ |
| luske | ♎ | ♎ | ♎ |
| Škorpijon | ♏ | ♏ | ♏ |
| Strelec | ♐ | ♐ | ♐ |
| Kozorog | ♑ | ♑ | ♑ |
| Vodnar | ♒ | ♒ | ♒ |
| Ribe | ♓ | ♓ | ♓ |
Znaki kartice Unicode
| Ime | Predogled | Koda | |
|---|---|---|---|
| Klubi črni | ♠ | ♠ | ♠ |
| Črna srca | ♥ | ♥ | ♥ |
| Črni diamanti | ♦ | ♦ | ♦ |
| Pike črne barve | ♣ | ♣ | ♣ |
| Klubi bele barve | ♤ | ♤ | ♤ |
| Srca bela | ♡ | ♡ | ♡ |
| Beli diamanti | ♢ | ♢ | ♢ |
| Pike bele barve | ♧ | ♧ | ♧ |
Šahovske figure v unicode
| Ime | Predogled | Koda | |
|---|---|---|---|
| Kralj bel | ♔ | ♔ | ♔ |
| Kraljica bela | ♕ | ♕ | ♕ |
| Topa bela | ♖ | ♖ | ♖ |
| Škof White | ♗ | ♗ | ♗ |
| Vitez bel | ♘ | ♘ | ♘ |
| Zastava bela | ♙ | ♙ | ♙ |
| Kralj črn | ♚ | ♚ | ♚ |
| Kraljica črna | ♛ | ♛ | ♛ |
| Topa črna | ♜ | ♜ | ♜ |
| Škof Black | ♝ | ♝ | ♝ |
| Vitez črn | ♞ | ♞ | ♞ |
| Črna zastavka | ♟ | ♟ | ♟ |
Igra s kockami
| Ime | Predogled | Koda | |
|---|---|---|---|
| Kocke zvijte eno | ⚀ | ⚀ | ⚀ |
| Kocka dva | ⚁ | ⚁ | ⚁ |
| Kocke tri | ⚂ | ⚂ | ⚂ |
| Kockica štiri | ⚃ | ⚃ | ⚃ |
| Kocka kocka pet | ⚄ | ⚄ | ⚄ |
| Kocka igra šest | ⚅ | ⚅ | ⚅ |
Matematični simboli Unicode
| Ime | Predogled | Koda | |
|---|---|---|---|
| neskončnost | ∞ | ∞ | ∞ |
| Plus minus | ± | ± | ± |
| Manj kot ali enako | ≤ | ≤ | ≤ |
| Več kot ali enako | ≥ | ≥ | ≥ |
| Ni enako | ≠ | ≠ | ≠ |
| Divizija | ÷ | ÷ | ÷ |
| Množenje x | × | × | × |
| Veliko množenje x | ✖ | ✖ | ✖ |
| Nadznak ena | ¹ | ¹ | ¹ |
| Nadnapis dva | ² | ² | ² |
| Nadnapis tri | ³ | ³ | ³ |
| Obkrožen plus | ⊕ | ⊕ | ⊕ |
| Množenje v krogu | ⊗ | ⊗ | ⊗ |
| Logično IN | ∧ | ∧ | ∧ |
| Logično ALI | ∨ | ∨ | ∨ |
| Delta | ∆ | ∆ | ∆ |
| Pita | ∏ | ∏ | ∏ |
| Sigma (SUM) | ∑ | ∑ | ∑ |
| Omega | Ω | Ω | Ω |
| Prazen komplet | ∅ | ∅ | ∅ |
| Kot | ∠ | ∠ | ∠ |
| Vzporedno | ∥ | ∥ | ∥ |
| Pravokotno | ⊥ | ⊥ | ⊥ |
| Skoraj enako | ≈ | ≈ | ≈ |
| Trikotnik | △ | △ | △ |
| Krog | ○ | ○ | ○ |
| Kvadrat | □ | □ | □ |
Ulomki
| Ime | Predogled | Koda | |
|---|---|---|---|
| Ena četrtina (1/4) | ¼ | ¼ | ¼ |
| Pol (1/2) | ½ | ½ | ½ |
| Tri četrtine (3/4) | ¾ | ¾ | ¾ |
| Ena tretjina (1/3) | ⅓ | ⅓ | ⅓ |
| Dve tretjini (2/3) | ⅔ | ⅔ | ⅔ |
| Ena osem (1/8) | ⅛ | ⅛ | ⅛ |
| Tri osmice (3/8) | ⅜ | ⅜ | ⅜ |
| Pet osmic (5/8) | ⅝ | ⅝ | ⅝ |
| Sedem osmic (7/8) | ⅞ | ⅞ | ⅞ |
Rimske številke v unicode
| Ime | Predogled | Koda | |
|---|---|---|---|
| Rimska številka ena | Ⅰ | Ⅰ | Ⅰ |
| Rimska številka dva | Ⅱ | Ⅱ | Ⅱ |
| Rimska številka tri | Ⅲ | Ⅲ | Ⅲ |
| Rimska številka štiri | Ⅳ | Ⅳ | Ⅳ |
| Rimska številka pet | Ⅴ | Ⅴ | Ⅴ |
| Rimska številka šest | Ⅵ | Ⅵ | Ⅵ |
| Rimska številka sedem | Ⅶ | Ⅶ | Ⅶ |
| Rimska številka osem | Ⅷ | Ⅷ | Ⅷ |
| Rimska številka devet | Ⅸ | Ⅸ | Ⅸ |
| Rimska številka deset | Ⅹ | Ⅹ | Ⅹ |
| Rimska številka enajst | Ⅺ | Ⅺ | Ⅺ |
| Rimska številka dvanajst | Ⅻ | Ⅻ | Ⅻ |
Pri upodabljanju teh simbolov je nekaj različnih operacijski sistemi Oh. To je posledica različnih družin pisav, ki se uporabljajo. Poleg tega iOS in Android nekatere znake Unicode zamenjata s čustvenimi simboli, zato preverite dodane znake, da se prepričate, da se to ne zgodi in da so ikone prikazane, kot je predvideno.
Unicode (angleško Unicode) je standard za kodiranje znakov. Preprosto povedano, to je tabela korespondence besedilnih znakov (, črk, ločila) binarne kode... Računalnik razume le zaporedje ničel in enot. Da bi vedel, kaj točno naj prikaže na zaslonu, je treba vsakemu znaku dodeliti edinstveno številko. V osemdesetih letih so bili znaki kodirani v enem bajtu, torej v osmih bitih (vsak bit je 0 ali 1). Tako se je izkazalo, da lahko ena tabela (znana tudi kot kodiranje ali niz) vsebuje samo 256 znakov. To morda ne bo dovolj niti za en jezik. Zato se je pojavilo veliko različnih kodir, katerih zmeda je pogosto vodila v dejstvo, da se je namesto berljivega besedila na zaslonu pojavila neka čudna krakozyabry. Potreben je bil en sam standard, ki je postal Unicode. Najbolj uporabljeno kodiranje je UTF-8 (format pretvorbe Unicode), ki uporablja 1 do 4 bajte za prikaz znaka.
Simboli
Znaki v tabelah Unicode so oštevilčeni s šestnajstiškimi števili. Na primer, velika ćirilska črka M je označena z U + 041C. To pomeni, da stoji na presečišču vrstice 041 in stolpca C. Lahko ga preprosto kopirate in nato nekam prilepite. Da ne bi brskali po večkilometrskem seznamu, uporabite iskanje. Ko ste vstopili na stran s simboli, boste v Unicode videli njeno številko in način narisa v različnih pisavah. Znak lahko vnesete tudi v iskalno vrstico, tudi če je namesto tega narisan kvadrat, vsaj zato, da ugotovite, kaj je bil. Tudi na tem spletnem mestu so za lažjo uporabo posebni (in - naključni) nabori iste vrste ikon, zbrani iz različnih razdelkov.
Standard Unicode je mednarodni. Vključuje znake iz skoraj vseh pisav na svetu. Vključno s tistimi, ki se ne uporabljajo več. Egipčanski hieroglifi, germanske rune, pisanje Majev, klinopisi in abecede starih držav. Predstavljeni in označevanje mer in uteži, notni zapis, matematični koncepti.
Konzorcij Unicode sam ne izumlja novih likov. Tiste ikone, ki najdejo svojo uporabo v družbi, se dodajo k tabelam. Na primer, znak rubelj se je aktivno uporabljal šest let, preden je bil dodan v Unicode. Piktogrami emojijev (emotikoni) so se prvič široko uporabljali tudi na Japonskem, preden so bili vključeni v kodiranje. Toda blagovne znamke in logotipi podjetij načeloma niso dodani. Tudi tako pogosta kot jabolko Apple ali zastava Windows. Danes je v različici 8.0 kodiranih približno 120 tisoč znakov.
Elementi kodnega prostora, ki predstavljajo negativna cela števila. Družina kodiranja definira strojno predstavitev zaporedja kod UCS.
Kode Unicode so razdeljene na več področij. Področje s kodami od U + 0000 do U + 007F vsebuje znake ASCII z ustreznimi kodami. Sledijo področja znakov različnih pisav, ločil in tehničnih simbolov. Nekatere kode so rezervirane za prihodnjo uporabo. Pod cirilicnimi znaki so dodeljena podrocja znakov s kodami od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (glej cirilico v Unicode).
Predpogoji za ustvarjanje in razvoj Unicode
Ker so bili v številnih računalniških sistemih (na primer Windows NT) kot privzeto kodiranje že uporabljeni fiksni 16-bitni znaki, je bilo odločeno, da se vsi najpomembnejši znaki kodirajo le znotraj prvih 65.536 mest (tako imenovana angleščina. osnovna večjezična ravnina, BMP). Preostali prostor se uporablja za "dodatne znake" (sl. dodatni znaki): pisni sistemi izumrlih jezikov ali zelo redko uporabljenih kitajskih znakov, matematičnih in glasbenih simbolov.
Za združljivost s starimi 16-bitnimi sistemi je bil izumljen sistem UTF-16, kjer se prvih 65.536 položajev, razen položajev iz intervala U + D800 ... U + DFFF, prikaže neposredno kot 16-bitno število, ostali pa so predstavljeni kot "nadomestni pari" (prvi element para iz območja U + D800 ... U + DBFF, drugi element para iz območja U + DC00 ... U + DFFF). Za nadomestne pare je bil uporabljen del kodnega prostora (2048 mest), ki je bil prej rezerviran za "znake za zasebno uporabo".
Ker lahko UTF-16 prikaže le 2 20 + 2 16 −2048 (1 112 064) znakov, je bila ta številka izbrana kot končna vrednost kodnega prostora Unicode.
Čeprav je bilo območje kode Unicode že v različici 2.0 razširjeno na 2-16, so bili prvi znaki v "zgornjem" območju postavljeni le v različici 3.1.
Vloga tega kodiranja v spletnem sektorju nenehno narašča, v začetku leta 2010 je bil delež spletnih mest, ki uporabljajo Unicode, okoli 50%.
Različice Unicode
Ko se tabela znakov Unicode spreminja in dopolnjuje ter izidejo nove različice tega sistema - in to delo poteka, saj je prvotni sistem Unicode vseboval le ravnino 0 - dvobajtne kode - izidejo tudi novi dokumenti ISO. Sistem Unicode skupaj obstaja v naslednjih različicah:
- 1.1 (v skladu z ISO / IEC 10646-1: 1993), standardom 1991-1995.
- 2.0, 2.1 (isti standard ISO / IEC 10646-1: 1993 in dodatki: "Spremembe" 1 do 7 in "Tehnični popravki" 1 in 2), standard 1996.
- 3.0 (standard ISO / IEC 10646-1: 2000) standard 2000.
- 3.1 (standardi ISO / IEC 10646-1: 2000 in ISO / IEC 10646-2: 2001) standard 2001.
- 3.2, standard 2002.
- 4.0, standard 2003.
- 4.01, standard 2004.
- 4.1, standard 2005.
- 5.0, standard 2006.
- 5.1, standard 2008.
- 5.2, standard 2009.
- 6.0, standard 2010.
- 6.1, standard 2012.
- 6.2, standard 2012.
Kodni prostor
Čeprav zapisa zapisa UTF-8 in UTF-32 omogočata kodiranje do 2 31 (2 147 483 648) kodnih točk, je bilo za združljivost z UTF-16 odločeno, da se uporabi le 1 112 064. Vendar je tudi to več kot dovolj - danes (v različici 6.0) je uporabljenih nekaj manj kot 110.000 kodnih točk (109.242 grafičnih in 273 drugih simbolov).
Kodni prostor je razdeljen na 17 letala 2 16 (65536) znakov. Ničelna ravnina se imenuje osnovno, vsebuje simbole najpogostejših pisav. Prva ravnina se uporablja predvsem za zgodovinske spise, druga se uporablja za redko uporabljene znake CJK, tretja pa je rezervirana za arhaične kitajske znake. Letala 15 in 16 sta rezervirana za zasebno uporabo.
Za označevanje Znaki Unicode zapis oblike „U + xxxx"(Za kode 0 ... FFFF) ali" U + xxxxx"(Za kode 10000 ... FFFFF) ali" U + xxxxxx"(Za kode 100000 ... 10FFFF), kje xxx- šestnajstiške števke. Na primer, znak "i" (U + 044F) ima kodo 044F = 1103.
Kodni sistem
Univerzalni kodirni sistem (Unicode) je niz grafičnih simbolov in način njihovega kodiranja za računalniško obdelavo besedilnih podatkov.
Grafični simboli so simboli, ki imajo vidno sliko. Grafični znaki so v nasprotju s kontrolnimi in oblikovnimi znaki.
Grafični simboli vključujejo naslednje skupine:
- črke, ki jih vsebuje vsaj ena od podprtih abeced;
- številke;
- ločila;
- posebni znaki (matematični, tehnični, ideogrami itd.);
- ločevalniki.
Unicode je sistem za linearno predstavitev besedila. Znake z dodatnimi nadnapisi ali podnapisi lahko predstavimo kot zaporedje kod, zgrajenih po določenih pravilih (sestavljeni znak) ali kot en sam znak (monolitna različica, vnaprej sestavljen znak).
Spreminjanje znakov
Predstavitev znaka "Y" (U + 0419) v obliki osnovnega znaka "I" (U + 0418) in spreminjajočega se znaka "" (U + 0306)
Grafični znaki v Unicode so razdeljeni na razširjene in nerazširjene (brez širine). Nerazširjeni znaki ne zavzamejo prostora v vrstici, ko so prikazani. Sem spadajo zlasti naglasni znaki in druge diakritične oznake. Tako razširjeni kot nerazširjeni znaki imajo svoje kode. Razširjeni simboli se sicer imenujejo osnovni (eng. osnovni znaki) in tiste, ki niso razširjene - spreminjajo (eng. združevanje likov); slednji pa se ne moreta sestati samostojno. Na primer, lahko znak "á" predstavimo kot zaporedje osnovnega znaka "a" (U + 0061) in modifikatorskega znaka "́" (U + 0301) ali kot monolitni znak "á" (U + 00C1).
Posebna vrsta spreminjanja znakov so izbirniki slogov (sl. izbirniki variacij). Veljajo le za tiste simbole, za katere so opredeljene takšne različice. V različici 5.0 so možnosti pisave določene za številne matematične simbole, za simbole tradicionalne mongolske abecede in za simbole mongolske kvadratne pisave.
Normalizacijske oblike
Ker so lahko predstavljeni isti simboli različne kode, ki včasih otežuje obdelavo, obstajajo postopki normalizacije, namenjeni pripeljenju besedila v določeno standardno obliko.
Standard Unicode opredeljuje 4 oblike normalizacije besedila:
- Normalizacijski obrazec D (NFD) - kanonična razgradnja. V procesu pretvorbe besedila v to obliko se v skladu s tabelami razgradnje rekurzivno zamenjajo vsi sestavljeni znaki z več sestavljenimi.
- Normalizacijska oblika C (NFC) je kanonična razgradnja, ki ji sledi kanonična sestava. Najprej se besedilo reducira v obliko D, nato se izvede kanonska sestava - besedilo se obdeluje od začetka do konca in upoštevajo se naslednja pravila:
- Simbol S je začetniče ima razred spremembe nič v bazi znakov Unicode.
- V katerem koli zaporedju znakov, ki se začnejo z začetnim znakom S, je znak C blokiran iz S, če in samo, če je med S in C kateri koli znak B, ki je bodisi začetni znak ali ima enak ali večji razred spreminjanja kot C. To pravilo velja samo za nize, ki so šli skozi kanonično razgradnjo.
- Primarno Sestavljeni je znak, ki ima v bazi znakov Unicode kanonično razgradnjo (ali kanonično razgradnjo za Hangul in ni vključen na seznam izjem).
- Simbol X je lahko primarno poravnan s simbolom Y takrat in samo, če obstaja primarni kompozit Z, kanonično enakovreden zaporedju
- Če naslednji znak C ni blokiran z zadnjim začetnim osnovnim znakom L in ga je mogoče uspešno poravnati, se L nadomesti s kompozitom L-C in C se odstrani.
- Normalizacijski obrazec KD (NFKD) - združljiva razgradnja. Ko se oddajo v to obliko, se vsi sestavljeni znaki zamenjajo z uporabo kanoničnih zemljevidov razgradnje Unicode in združljivih zemljevidov razgradnje, nato pa se rezultat postavi v kanonični vrstni red.
- Normalizacijska oblika KC (NFKC) - združljiva razgradnja, čemur sledi kanonski sestava.
Izraza "sestava" in "razgradnja" pomenita povezavo oziroma razgradnjo simbolov na njihove sestavne dele.
Primeri
| Izvorno besedilo | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | Franc \ u0327ais | Fran \ xe7ais | Franc \ u0327ais | Fran \ xe7ais |
| A, E, Y | \ u0410, \ u0401, \ u0419 | \ u0410, \ u0415 \ u0308, \ u0418 \ u0306 | \ u0410, \ u0401, \ u0419 | |
| が | \ u304b \ u3099 | \ u304c | \ u304b \ u3099 | \ u304c |
| Henrik IV | Henrik IV | Henrik IV | Henrik IV | Henrik IV |
| Henry Ⅳ | Henry \ u2163 | Henry \ u2163 | Henrik IV | Henrik IV |
Dvosmerno pismo
Standard Unicode podpira pisne jezike v smeri od leve proti desni (sl. od leve proti desni, LTR) in s pisanjem od desne proti levi (sl. od desne proti levi, RTL) - na primer arabske in hebrejske črke. V obeh primerih so znaki shranjeni v "naravnem" vrstnem redu; njihov prikaz ob upoštevanju želene smeri črke zagotavlja aplikacija.
Poleg tega Unicode podpira kombinirana besedila, ki združujejo fragmente z različnimi smermi črke. Ta funkcija se imenuje dvosmernost(eng. dvosmerno besedilo, BiDi). Nekateri poenostavljeni besedilni procesorji (na primer v mobilni telefon) lahko podpira Unicode, ne pa tudi dvosmerne podpore. Vsi znaki Unicode so razdeljeni v več kategorij: napisani od leve proti desni, napisani od desne proti levi in v katero koli smer. Simboli zadnje kategorije (predvsem ločila), ko so prikazani, vodijo smer besedila v okolici.
Predstavljeni simboli
Unicode vključuje skoraj vse sodobne skripte, vključno z:
drugo.
Za akademske namene so bile dodane številne zgodovinske pisave, med drugim: rune, starogrški, egipčanski hieroglifi, klinasto pismo, pisava Majev, etruščanska abeceda.
Unicode ponuja široko paleto matematičnih in glasbenih simbolov in piktogramov.
Vendar Unicode v osnovi ne vključuje logotipov podjetij in izdelkov, čeprav jih najdemo v pisavah (na primer logotip Apple v kodiranju MacRoman (0xF0) ali logotip Windows v pisavi Wingdings (0xFF)). V pisavah Unicode je treba logotipe postaviti samo v območje znakov po meri.
ISO / IEC 10646
Konzorcij Unicode tesno sodeluje delovna skupina ISO / IEC / JTC1 / SC2 / WG2, ki razvija mednarodni standard 10646 (ISO / IEC 10646). Sinhronizacija je vzpostavljena med standardom Unicode in ISO / IEC 10646, čeprav vsak standard uporablja svojo terminologijo in sistem dokumentacije.
Sodelovanje konzorcija Unicode z Mednarodno organizacijo za standardizacijo (eng. Mednarodna organizacija za standardizacijo, ISO ) se je začelo leta 1991. Leta 1993 je ISO izdal standard DIS 10646.1. Za sinhronizacijo je konzorcij odobril različico 1.1 standarda Unicode, ki je dodala dodatne znake iz DIS 10646.1. Posledično so vrednosti kodiranih znakov v Unicode 1.1 in DIS 10646.1 popolnoma enake.
V prihodnje se je sodelovanje med obema organizacijama nadaljevalo. Leta 2000 Standard Unicode 3.0 je bil sinhroniziran z ISO / IEC 10646-1: 2000. Prihajajoča tretja različica standarda ISO / IEC 10646 bo sinhronizirana z Unicode 4.0. Morda bodo te specifikacije celo objavljene kot en sam standard.
Podobno kot formata UTF-16 in UTF-32 v standardu Unicode ima tudi standard ISO / IEC 10646 dve glavni obliki kodiranja znakov: UCS-2 (2 bajta na znak, podobno kot UTF-16) in UCS-4 (4 bajti na znak, podobno kot UTF-32). UCS pomeni univerzalni večoktet(več bajtov) kodiran nabor znakov(eng. univerzalni nabor znakov z več okteti ). UCS-2 lahko štejemo za podskupino UTF-16 (UTF-16 brez nadomestnih parov), UCS-4 pa je sinonim za UTF-32.
Metode predstavitve
Unicode ima več oblik predstavitve (eng. Format pretvorbe Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) in UTF-32 (UTF-32BE, UTF-32LE). Predstavitveni obrazec UTF-7 je bil razvit tudi za prenos po sedem-bitnih kanalih, vendar zaradi nezdružljivosti z ASCII ni bil razširjen in ni bil vključen v standard. 1. aprila 2005 sta bili predlagani dve humoristični vlogi: UTF-9 in UTF-18 (RFC 4042).
Unicode UTF -8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFFx: 11xxxxx 10xxxxx 10xxxxxxxxxxxxxxxxxxxxxxxx
Teoretično možno, vendar tudi ni vključeno v standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxxxxx
Čeprav vam UTF-8 omogoča, da na več načinov določite isti znak, je pravilen le najkrajši. Preostale obrazce je treba zavrniti iz varnostnih razlogov.
Vrstni red bajtov
V podatkovnem toku UTF-16 se lahko visoki bajt zapiše pred spodnjim (eng. UTF-16 big-endian) ali po mlajših (eng. UTF-16 mali endiian). Podobno obstajata dve različici štiri-bajtnega kodiranja-UTF-32BE in UTF-32LE.
Za določitev oblike predstavitve Unicode na začetku besedilno datoteko podpis je napisan - znak U + FEFF (neprekinjen presledek z ničelno širino), imenovan tudi oznaka vrstnega reda bajtov(eng. oznaka vrstnega reda bajtov, BOM ). To omogoča razlikovanje med UTF-16LE in UTF-16BE, saj znak U + FFFE ne obstaja. Včasih se uporablja tudi za označevanje formata UTF-8, čeprav pojem vrstnega reda bajtov ne velja za to obliko. Datoteke, ki sledijo tej konvenciji, se začnejo s temi bajtnimi zaporedji:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Na žalost ta metoda ne razlikuje zanesljivo med UTF-16LE in UTF-32LE, saj Unicode dovoljuje znak U + 0000 (čeprav se prava besedila le redko začnejo z njim).
Datoteke v kodiranjih UTF-16 in UTF-32, ki ne vsebujejo BOM, morajo biti v velikem endian (unicode.org) vrstnem redu bajtov.
Unicode in tradicionalno kodiranje
Uvedba Unicode je spremenila pristop k tradicionalnim 8-bitnim kodiranjem. Če je bilo prej kodiranje določeno s pisavo, ga zdaj določa korespondenčna tabela med tem kodiranjem in Unicode. Dejansko so 8-bitna kodiranja postala predstavitev podskupine Unicode. Tako je bilo veliko lažje ustvariti programe, ki morajo delovati z veliko različnimi kodiranji: zdaj, če želite dodati podporo za še eno kodiranje, morate dodati še eno iskalno tabelo Unicode.
Poleg tega številne oblike zapisa podatkov omogočajo vstavljanje vseh znakov Unicode, tudi če je dokument zapisan v starem 8-bitnem kodiranju. Na primer, lahko uporabite kode ampersand v HTML.
Izvajanje
Večina sodobnih operacijskih sistemov ponuja določeno stopnjo podpore Unicode.
V operacijskih sistemih družine Windows NT se dvobajtno kodiranje UTF-16LE uporablja za notranjo predstavitev imen datotek in drugih sistemskih nizov. Sistemski klici, ki sprejemajo parametre niza, so na voljo v enobajtni in dvobajtni različici. Za več podrobnosti glej članek
Če morate vnesti le nekaj posebni znaki ali znakov, lahko uporabite tabelo znakov ali bližnjice na tipkovnici. Seznam Znaki ASCII glejte spodnje tabele ali razdelek Za vstavljanje nacionalnih abeced z bližnjicami na tipkovnici.
Opombe:
Vstavljanje znakov ASCII
Če želite vstaviti znak ASCII, pritisnite in držite tipko ALT ter vnesite kodo znaka. Če želite na primer vstaviti znak stopinje (º), pridržite tipko ALT in vnesite številska tipkovnica koda 0176.
Opomba:
Vstavljanje znakov Unicode
Pomembno: Nekateri Microsoftovi programi Office, na primer PowerPoint in InfoPath, ne more pretvoriti kod znakov Unicode. Če potrebujete znak Unicode in uporabljate enega od programov, ki ne podpirajo znakov Unicode, uporabite za vnos znakov, ki jih boste morda potrebovali.
Opombe:
Zaprite vse programe.
Dvokliknite ikono Namestitev in odstranitev programov naprej nadzorne plošče.
Naredite nekaj od naslednjega:
če je vloga Microsoft Office nameščen kot del programa Microsoft Office, izberite Microsoft Office na terenu Nameščeni programi in nato kliknite Zamenjati;
Če Pisarniška aplikacija je bil nameščen ločeno, kliknite njegovo ime na seznamu Nameščeni programi in nato kliknite Spremenite.
Številke je treba vnesti na številsko tipkovnico, ne alfanumerično. Če morate pritisniti za vnos številk na številski tipkovnici Tipka NUM LOCK, preverite, ali je to storjeno.
Če imate težave s pretvorbo kode Unicode v znak, vnesite kodo na številski tipkovnici, jo izberite in pritisnite Alt + X.
V Microsoft Windows XP in novejše različice univerzalne pisave Unicode se samodejno namestijo. V sistemu Microsoft Windows 2000 je treba pisavo Unicode namestiti ročno.
V sistemu Microsoft Windows 2000
V pogovornem oknu Namestitev programa Microsoft Office 2003 izberite možnost Dodajte ali odstranite komponente in nato kliknite Nadalje.
Prosim izberite Dodatna prilagoditev aplikacije in pritisnite gumb Nadalje.
Razširite seznam Splošna pisarniška orodja.
Razširite seznam Večjezična podpora.
Kliknite ikono Univerzalna pisava in izberite želeno možnost namestitve.
Uporaba tabele simbolov
Tabela simbolov je Microsoftova vgrajena Program Windows ki vam omogoča ogled znakov, ki so na voljo v izbrani pisavi. S tabelo simbolov lahko posamezne simbole ali skupine simbolov kopirate v odložišče in jih nato prilepite v program, ki jih podpira.
Kliknite gumb Začni in nato izberite Programi, Standardno, Storitev in tabela simbolov.
Če želite izbrati simbol v tabeli simbolov, ga kliknite, kliknite Izberite, kliknite desni klik miško na mestu dokumenta, kamor želite dodati simbol, in izberite ukaz Vstavi.
Pogoste kode znakov
Če želite več znakov, glejte članek, nameščen v vašem računalniku, kode znakov ASCII ali diagram skripta kode znakov Unicode.
|
Podpiši |
Podpiši |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli valut |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Pravni simboli |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Ulomki |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Ločila in narečni simboli |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli obrazcev |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Splošne diakritične kodeZa celoten seznam glif in povezanih kod znakov glejte.
|
Unicode je mednarodni standard za kodiranje znakov, ki omogoča dosledno prikazovanje besedila na katerem koli računalniku na svetu, ne glede na sistemski jezik, ki ga uporablja.
Osnove
Če želimo razumeti, čemu služi tabela znakov Unicode, najprej razumemo mehanizem za prikaz besedila na zaslonu monitorja. Računalnik, kot vemo, obdeluje vse informacije v digitalni obliki in jih mora prikazati grafično za pravilno zaznavanje človeka. Zato, da lahko preberemo to besedilo, moramo rešiti vsaj dve nalogi:
- Digitalizirajte natisljive znake.
- Omogočite operacijskemu sistemu možnost ujemanja digitalnih oblik z vektorskimi znaki, z drugimi besedami, poiščite pravilne črke.
Prva kodiranja
Ameriški ASCII velja za prednika vseh kodir. Opisano je bilo uporabljeno v angleški jezik Latinska abeceda z ločili in arabskimi številkami. 128 znakov, ki so bili uporabljeni v njem, je postalo osnova za nadaljnji razvoj - uporablja jih celo sodobna tabela znakov Unicode. Od takrat so črke latinske abecede zasedle prva mesta v katerem koli kodiranju.
ASCII je skupaj omogočil shranjevanje 256 znakov, a ker je prvih 128 zasedala latinica, se je preostalih 128 po vsem svetu začelo uporabljati za oblikovanje nacionalnih standardov. Na primer, v Rusiji so na njegovi osnovi nastali CP866 in KOI8-R. Takšne različice so imenovali razširjene različice ASCII.
Kodne strani in "krakozyabry"
Nadaljnji razvoj tehnologije in pojav grafičnega vmesnika sta privedla do tega, da je bil ustanovljen Ameriški inštitut za standardizacijo ANSI kodiranje... Ruskim uporabnikom, zlasti z izkušnjami, je njegova različica znana pod Ime sistema Windows 1251. Prvič je uvedel koncept »kodne strani«. S pomočjo kodnih strani, ki vsebujejo simbole drugih abeced, razen latinice, je med računalniki, ki se uporabljajo v različnih državah, vzpostavljeno "medsebojno razumevanje".
Vendar pa je prisotnost velikega števila različnih kodir, uporabljenih za en jezik, začela povzročati težave. Pojavili so se tako imenovani krakozyabry. Nastale so zaradi neskladja med prvotno kodno stranjo, na kateri so bile ustvarjene vse informacije, in kodno stranjo, ki je privzeto uporabljena v računalniku končnega uporabnika.

Kot primer lahko navedemo zgornji cirilski kodir CP866 in KOI8-R. Črke v njih so se razlikovale po kodnih položajih in načelih umestitve. V prvem so bili razporejeni po abecednem vrstnem redu, v drugem pa v poljubnem vrstnem redu. Lahko si predstavljate, kaj se je dogajalo pred očmi uporabnika, ki je poskušal odpreti takšno besedilo, ne da bi imel zahtevano kodno stran, ali pa si ga je računalnik napačno razlagal.
Ustvarjanje Unicode
Širjenje interneta in sorodnih tehnologij, kot so npr E-naslov, je privedlo do tega, da na koncu situacija s popačenjem besedil ni več ustrezala vsem. Vodilna IT podjetja so ustanovila konzorcij Unicode. Tabela znakov, ki jo je leta 1991 predstavil pod imenom UTF-32, je lahko shranila več kot milijardo edinstvenih znakov. Bilo je ključni korak na poti dešifriranja besedil.

Vendar pa prva univerzalna tabela znakovnih kod Unicode, UTF-32, ni bila široko sprejeta. Glavni razlog je bila odvečnost shranjenih podatkov. Hitro je bilo izračunano, da bo v državah, ki uporabljajo latinsko abecedo, kodirano z novo univerzalno tabelo, besedilo zavzelo štirikrat več prostora kot pri uporabi razširjene tabele ASCII.
Razvoj Unicode
Naslednja tabela znakov Unicode UTF-16 je odpravila to težavo. Kodiranje v njem je bilo izvedeno v polovici števila bitov, hkrati pa se je zmanjšalo tudi število možnih kombinacij. Namesto milijard znakov shranjuje le 65 536. Vendar je bil tako uspešen, da se je konzorcij odločil, da je ta številka osnovni prostor za shranjevanje znakov Unicode.
Kljub temu uspehu UTF-16 ni ustrezal vsem, saj je količina shranjenega in posredovane informacije se je še vedno podvojilo. Univerzalna rešitev je bila UTF-8, tabela znakov Unicode s spremenljivo dolžino. Temu lahko rečemo preboj na tem področju.

Tako je z uvedbo zadnjih dveh standardov tabela znakov Unicode rešila problem enotnega kodnega prostora za vse pisave, ki se danes uporabljajo.
Unicode za ruščino
Zaradi spremenljive dolžine kode, ki se uporablja za prikaz znakov, je latinica kodirana v Unicode na enak način kot v njenem predniku ASCII, torej v enem bitu. Pri drugih abecedah je lahko slika videti drugače. Na primer znaki gruzijske abecede za kodiranje uporabljajo tri bajte, znaki cirilice pa dva. Vse to je mogoče v okviru uporabe standarda UTF-8 Unicode (tabela znakov). Ruski jezik ali cirilica zavzema 448 mest v skupnem kodnem prostoru, razdeljenih v pet blokov.
![]()
Teh pet blokov vključuje osnovno cirilico in cerkvenoslovansko abecedo ter dodatne črke iz drugih jezikov, ki uporabljajo cirilico. Za prikaz starih oblik predstavitve cirilice so označena številna mesta, 22 mest od skupnega števila pa je še prostih.
Trenutna različica Unicode
Z rešitvijo svoje primarne naloge, ki je bila standardizacija pisav in ustvarjanje enotnega kodnega prostora, Konzorcij ni ustavil svojega dela. Unicode se nenehno razvija in širi. Zadnja trenutna različica tega standarda, 9.0, je izšla leta 2016. Vključeval je šest dodatnih abeced in razširil seznam standardiziranih emojijev.
Moram reči, da so za poenostavitev raziskav v Unicode dodani tudi tako imenovani mrtvi jeziki. To ime so dobili, ker ljudje, za katere bi bil domač, ne obstajajo. V to skupino spadajo tudi jeziki, ki so se vse do našega časa približali le v obliki pisnih spomenikov.
Načeloma se lahko vsakdo prijavi za dodajanje znakov v nove specifikacije Unicode. Res je, da morate za to napolniti dostojno količino izvorni dokumenti in preživijo veliko časa. Živi primer tega je zgodba programerja Terencea Edena. Leta 2013 se je prijavil za vključitev v specifikacijo simbolov, povezanih z označevanjem gumbov za nadzor napajanja računalnika. V tehnični dokumentaciji so bili uporabljeni od sredine 70. let prejšnjega stoletja, vendar do uvedbe specifikacije 9.0 niso bili del Unicode.
tabela simbolov
Vsak računalnik, ne glede na uporabljeni operacijski sistem, uporablja tabelo znakov Unicode. Kako uporabljati te tabele, kje jih najti in zakaj so lahko koristne za navadnega uporabnika?
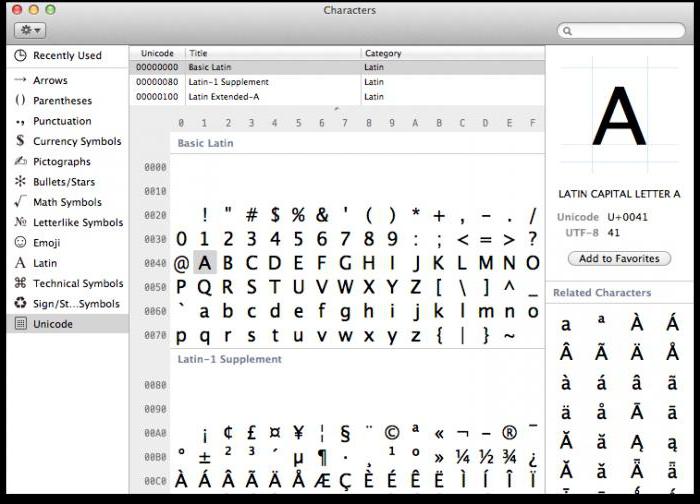
V OS Tabela Windows simboli se nahaja v razdelku "Storitev" v meniju. V družini operacijskih sistemov Linux ga običajno najdemo v pododdelku "Standard" in v MacOS -u v nastavitvah tipkovnice. Glavni namen te tabele je vstopiti besedilne dokumente znakov, ki niso na tipkovnici.
Uporaba takih tabel je najširša: od vnosa tehničnih simbolov in ikon nacionalnih denarnih sistemov do pisanja navodil za praktično uporabo kart Tarot.
Končno
Unicode se uporablja povsod in je vstopil v naše življenje skupaj z razvojem interneta in mobilne tehnologije... Zaradi svoje uporabe je bil sistem medetničnih komunikacij bistveno poenostavljen. Lahko rečemo, da je uvedba Unicode okvirni, a od zunaj popolnoma neviden primer uporabe tehnologije za skupno dobro vsega človeštva.
 Pametni telefoni za brezžično polnjenje A5 podpirajo brezžično polnjenje
Pametni telefoni za brezžično polnjenje A5 podpirajo brezžično polnjenje Zakaj sporočila MTS ne pridejo na telefon?
Zakaj sporočila MTS ne pridejo na telefon? Zakaj potrebujete popolno tovarniško ponastavitev v sistemu Android ali kako vrniti Android na tovarniške nastavitve
Zakaj potrebujete popolno tovarniško ponastavitev v sistemu Android ali kako vrniti Android na tovarniške nastavitve