kode znakov ascii 1251
Nosilci podatkov
Podatki so dialektična komponenta informacije. So registrirani signali. V tem primeru je fizična metoda registracije lahko katera koli: mehansko gibanje fizičnih teles, spreminjanje njihove oblike ali parametrov kakovosti površine, spreminjanje električnih, magnetnih, optičnih lastnosti, kemične sestave in (ali) narave kemičnih vezi, spreminjanje stanja. elektronskega sistema in še veliko več.
Glede na način registracije se lahko podatki shranjujejo in prenašajo na različnih vrstah medijev. Zdi se, da je najpogostejši medij za shranjevanje, čeprav ne najbolj ekonomičen, papir. Na papirju se podatki beležijo s spreminjanjem optičnih lastnosti njegove površine. Spreminjanje optičnih lastnosti (spreminjanje odbojnosti površine v določenem območju valovnih dolžin) se uporablja tudi v napravah, ki snemajo z laserskim žarkom na plastični medij z odsevno prevleko ( CD ROM). Kot medije, ki uporabljajo spremembo magnetnih lastnosti, lahko imenujemo magnetne trakove in diske. Snemanje podatkov s spreminjanjem kemične sestave površinskih snovi nosilca se pogosto uporablja v fotografiji. Na biokemični ravni prihaja do kopičenja in prenosa podatkov v prostoživečih živalih.
Nosilci podatkov nas ne zanimajo sami po sebi, ampak v kolikor so lastnosti informacije zelo tesno povezane z lastnostmi njenih nosilcev. S parametrom je lahko označen kateri koli nosilec resolucija(količina zapisanih podatkov v merski enoti, sprejeti za medij) in dinamični razpon(logaritemsko razmerje intenzivnosti amplitud največjega in najmanjšega zabeleženega signala). Takšne lastnosti informacij, kot so popolnost, dostopnost in zanesljivost, so pogosto odvisne od teh lastnosti nosilca. Tako lahko na primer računamo na dejstvo, da je lažje zagotoviti popolnost informacij v bazi podatkov, ki se nahaja na CD-ju kot v bazi podatkov podobnega namena, ki se nahaja na disketi, saj je v prvem primeru gostota podatkov zapisovanje podatkov na enoto dolžine poti so veliko višje. Za navadnega potrošnika je dostopnost informacij v knjigi veliko višja od istih informacij na CD-ju, saj vsi potrošniki nimajo potrebne opreme. In končno, znano je, da je vizualni učinek pri gledanju diapozitiva v projektorju veliko večji kot pri gledanju podobne ilustracije, natisnjene na papir, saj je razpon svetlobnih signalov v oddani svetlobi za dva do tri reda velikosti večji kot v odbita svetloba.
Naloga preoblikovanja podatkov za spremembo nosilca je ena najpomembnejših nalog informatike. V strukturi stroškov računalniških sistemov predstavljajo naprave za vnos in izhod podatkov, ki delujejo s pomnilniškimi mediji, do polovice stroškov strojne opreme.
^ Podatkovne operacije
Med informacijskim procesom se podatki preoblikujejo iz ene vrste v drugo z uporabo metod. Obdelava podatkov vključuje veliko različnih operacij. Z razvojem znanstvenega in tehnološkega napredka ter splošnim zapletom komunikacij v človeški družbi se stroški dela za obdelavo podatkov vztrajno povečujejo. Najprej je to posledica nenehnega zapletanja pogojev za upravljanje proizvodnje in družbe. Drugi dejavnik, ki povzroča tudi splošno povečanje obsega obdelanih podatkov, je povezan tudi z znanstvenim in tehnološkim napredkom, in sicer s hitrim nastajanjem in uvajanjem novih nosilcev podatkov, sredstev za shranjevanje in dostavo podatkov.
V strukturi možnih operacij s podatki je mogoče razlikovati naslednje glavne:
Zbiranje podatkov - zbiranje podatkov, da se zagotovi zadostna popolnost informacij za odločanje;
formalizacija podatkov - združevanje podatkov iz različnih virov v isto obliko, da bi bili med seboj primerljivi, torej da bi povečali njihovo raven dostopnosti;
filtriranje podatkov - pregledovanje "odvečnih" podatkov, ki niso potrebni za odločanje; hkrati bi se morala zmanjšati raven "šuma", povečati pa se mora zanesljivost in ustreznost podatkov;
razvrščanje podatkov - naročanje podatkov glede na dani atribut za enostavno uporabo; poveča dostopnost informacij;
združevanje podatkov - združevanje podatkov glede na določen atribut, da se izboljša enostavnost uporabe; poveča dostopnost informacij;
arhiviranje podatkov - organizacija shranjevanja podatkov v priročni in lahko dostopni obliki; služi zmanjšanju ekonomskih stroškov shranjevanja podatkov in povečuje splošno zanesljivost informacijskega procesa kot celote;
varstvo podatkov - sklop ukrepov za preprečevanje izgube, razmnoževanja in spreminjanja podatkov;
prenos podatkov - sprejem in prenos (dostava in dostava) podatkov med oddaljenimi udeleženci informacijskega procesa; medtem ko se vir podatkov v računalništvu običajno imenuje strežnik, in potrošnika stranka;
pretvorba podatkov - prenos podatkov iz ene oblike v drugo ali iz ene strukture v drugo. Pretvorba podatkov je pogosto povezana s spremembo vrste medija, na primer knjige je mogoče shraniti v navadni papirni obliki, za to pa lahko uporabite tako elektronsko obliko kot mikrofilm. Potreba po večkratni pretvorbi podatkov se pojavi tudi pri njihovem prenosu, še posebej, če se izvaja s sredstvi, ki niso namenjena prenosu tovrstnih podatkov. Kot primer lahko omenimo, da za prenos digitalnih podatkovnih tokov po kanalih telefonskih omrežij (ki so bila prvotno osredotočena le na prenos analogni signali v ozkem frekvenčnem območju) je treba digitalne podatke pretvoriti v neke vrste zvočni signali, kar delajo posebne naprave - telefonski modemi.
^ Binarno kodiranje podatkov
Za avtomatizacijo dela s podatki v zvezi z različni tipi, zelo pomembno je poenotiti njihovo obliko predstavitve - za to se običajno uporablja tehnika kodiranje, to je izražanje podatkov ene vrste v smislu podatkov druge vrste. naravni človek jeziki - niso nič drugega kot sistemi za kodiranje konceptov za izražanje misli z govorom. jeziki so tesno povezani abeceda(sistemi za kodiranje jezikovnih komponent z uporabo grafičnih simbolov). Zgodovina pozna zanimive, čeprav neuspešne poskuse ustvarjanja "univerzalnih" jezikov in abeced. Očitno je neuspeh poskusov njihovega izvajanja posledica dejstva, da nacionalni in socialna vzgoja seveda razumeti, da bo sprememba sistema kodiranja javnih podatkov neizogibno privedla do spremembe družbenih metod (to je pravnih in moralnih norm), kar je lahko povezano z družbenimi pretresi.
Isti problem univerzalnega kodirnega orodja se dokaj uspešno izvaja v nekaterih vejah tehnologije, znanosti in kulture. Primeri vključujejo sistem pisanja matematičnih izrazov, telegrafsko abecedo, abecedo morske zastave, Braillov sistem za slepe in še veliko več.
riž. 1.8. Primeri različnih sistemov kodiranja
Računalniška tehnologija ima tudi svoj sistem - to se imenuje binarno kodiranje in temelji na predstavitvi podatkov z zaporedjem samo dveh znakov: 0 in 1. Ti znaki se imenujejo binarne števke, v angleščini - binarna številka, ali na kratko, bit (bit).
V enem bitu se lahko izrazita dva pojma: 0 ali 1 (da oz ne, črna oz belo, res oz Laganje itd.). Če se število bitov poveča na dva, se lahko izrazijo že štirje različni koncepti:
Trije biti lahko kodirajo osem različnih vrednosti:
000 001 010 01l 100 101 110 111
Povečanje števila bitov v sistemu za eno binarno kodiranje, podvojimo število vrednosti, ki jih je mogoče izraziti v tem sistemu.
^ Kodiranje celih in realnih števil
Za kodiranje celih števil od 0 do 255 je dovolj, da imate 8 bitov binarne kode (8 bitov).
0000 0000 = 0
…………………
1111 1110 = 254
1111 1111 = 255
Šestnajst bitov vam omogoča kodiranje celih števil od 0 do 65535 in 24 bitov - več kot 16,5 milijona različnih vrednosti.
Realna števila so kodirana z 80-bitnim kodiranjem. V tem primeru se številka najprej pretvori v normalizirana oblika:
3,1415926 = 0,31415926 10 1
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 9
Prvi del števila se imenuje mantisa in drugi - značilnost. Večina od 80 bitov je dodeljenih za shranjevanje mantise (skupaj z znakom) in določeno število bitov je dodeljenih za shranjevanje značilnosti (tudi podpisano).
^ Kodiranje besedilnih podatkov
Če je vsak znak abecede povezan z določenim celim številom (na primer z zaporedno številko), potem lahko s pomočjo binarne kode kodiramo tudi besedilne informacije. Osem bitov je dovolj za kodiranje 256 različni simboli. To je dovolj, da v različnih kombinacijah osmih bitov izrazimo vse znake angleške in ruske abecede, tako male kot velike, pa tudi ločila, simbole osnovnih računskih operacij in nekatere splošno sprejete Posebni simboli, kot je simbol "§".
Tehnično je videti zelo preprosto, vendar so se vedno pojavljale precejšnje organizacijske težave. V prvih letih razvoja računalniške tehnologije so bili povezani s pomanjkanjem potrebnih standardov, zdaj pa jih povzroča, nasprotno, obilo istočasno delujočih in nasprotujočih si standardov. Da bi ves svet lahko kodiral besedilne podatke na enak način, so potrebne enotne kodne tabele, kar pa je še vedno nemogoče zaradi nasprotij med znaki nacionalnih abeced, pa tudi protislovij podjetij.
Za v angleščini, ki je zavzelo dejansko nišo mednarodnih komunikacijskih sredstev, so protislovja že odstranjena. Inštitut za standarde Združenih držav Amerike (ANSI - American National Standard Institute) implementirali kodirni sistem ASCII (ameriška standardna koda za izmenjavo informacij - standardna koda ZDA za izmenjavo informacij). V sistemu ASCII dve kodirni tabeli sta fiksni: osnovni in podaljšan. Osnovna tabela določa vrednosti kod od 0 do 127, razširjena tabela pa se nanaša na znake s številkami od 128 do 255.
Prvih 32 kod osnovne tabele, začenši z ničlo, so dobili proizvajalci strojne opreme (predvsem proizvajalci računalnikov in tiskalnih naprav). To področje vsebuje t.i kontrolne kode, ki ne ustrezajo nobenemu znaku jezikov, zato te kode niso prikazane niti na zaslonu niti na tiskalnih napravah, lahko pa jih nadzorujemo s tem, kako se izpisujejo drugi podatki.
Od kode 32 do kode 127 obstajajo kode za znake angleške abecede, ločila, številke, aritmetične operacije in nekatere pomožne znake. Osnovna kodirna tabela ASCII je podana v tabeli 1.1.
^ Tabela 1.1. Osnovna tabela kodiranja ASCII
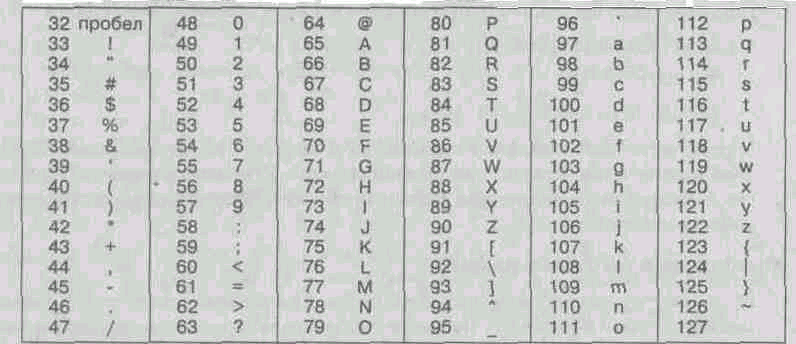
Podobni sistemi kodiranja besedilnih podatkov so bili razviti v drugih državah. Tako je na primer v ZSSR na tem področju deloval sistem kodiranja KOI-7. (komunikacijska koda, sedem mest). Vendar pa je podpora proizvajalcev strojne in programske opreme prinesla ameriško kodo ASCII na raven mednarodnega standarda, nacionalni kodirni sistemi pa so se morali "umakniti" v drugi, razširjeni del kodirnega sistema, ki določa vrednosti kod od 128 do 255. Pomanjkanje enotnega standarda v to področje je privedlo do množice istočasno delujočih kodiranj. Samo v Rusiji lahko določite tri trenutne standarde kodiranja in še dva zastarela.
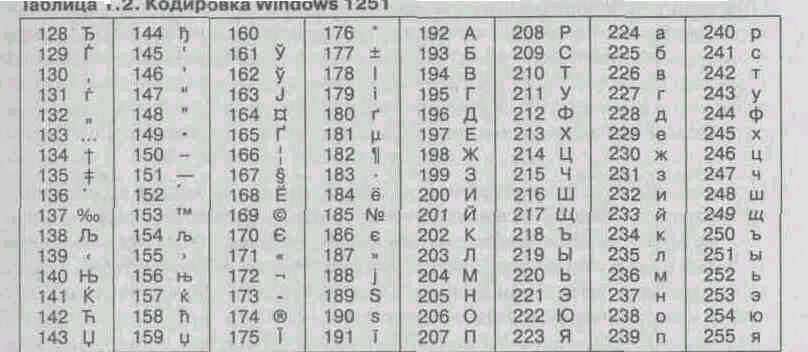
Tako je na primer kodiranje znakov ruskega jezika, znano kot kodiranje Windows-1251, je bil uveden "od zunaj" - s strani Microsofta, vendar je glede na široko uporabo operacijskih sistemov in drugih izdelkov tega podjetja v Rusiji globoko zakoreninjen in široko uporabljen (tabela 1.2). To kodiranje uporablja večina lokalne računalnike deluje na platformi Windows. De facto je postal standard v ruskem sektorju svetovnega spleta.
^ Tabela 1.2. Windows kodiranje 1251
Drugo običajno kodiranje se imenuje KOI-8 (komunikacijska koda, osem mest) - njen nastanek sega v čas Sveta za medsebojno gospodarsko pomoč držav Vzhodne Evrope (tabela 1.3). Na podlagi tega kodiranja sta zdaj v veljavi kodi KOI8-R (rusko) in KOI8-U (ukrajinsko). Danes se kodiranje KOI8-R pogosto uporablja v računalniških omrežjih v Rusiji in v nekaterih storitvah ruskega sektorja interneta. Zlasti v Rusiji je de facto standard v sporočilih E-naslov in telekonference.
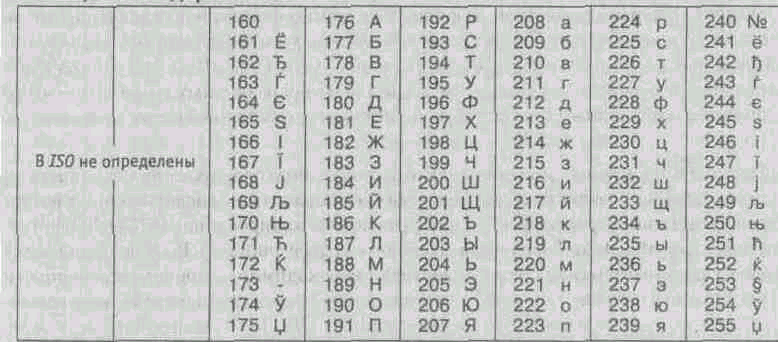
Mednarodni standard, ki predvideva kodiranje znakov ruske abecede, se imenuje ISO kodiranje. (Mednarodna organizacija za standardizacijo - Mednarodni inštitut za standardizacijo). V praksi se to kodiranje redko uporablja (tabela 1.4).
^ Tabela 1.3. Kodiranje KOI-8
![]()
Tabela 1.4. ISO kodiranje
Na računalnikih, ki se izvajajo operacijski sistemi MS DOS, lahko delujeta še dve kodi (kodiranje GOST in kodiranje GOST - alternativa). Prvi od njih je veljal za zastarelo že v prvih dneh osebnega računalništva, drugi pa je v uporabi še danes (glej tabelo 1.5).
^ Tabela 1.5. GOST-alternativno kodiranje
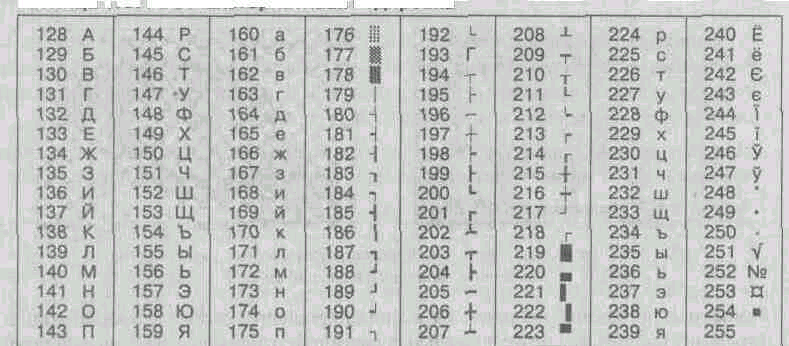
Zaradi številčnosti sistemov za kodiranje besedilnih podatkov, ki delujejo v Rusiji, se pojavlja problem medsistemske pretvorbe podatkov - to je ena od pogostih nalog računalništva.
^ Univerzalni sistem kodiranja besedilnih podatkov
Če analiziramo organizacijske težave, povezane z oblikovanjem enotnega sistema kodiranja besedilnih podatkov, lahko sklepamo, da jih povzroča omejen nabor kod (256). Hkrati je očitno, da če na primer znaki niso kodirani z osembitnimi binarnimi števili, temveč s številkami z velikim številom števk, bo obseg možnih vrednosti kode postal veliko večji. Tak sistem, ki temelji na 16-bitnem kodiranju znakov, se imenuje univerzalno - UNICODE. Navaja šestnajst števk edinstvene kode za 65536 različnih simbolov - to polje je dovolj, da postavite v eno tabelo simbolov večine jezikov planeta.
Kljub trivialni očitnosti takšnega pristopa je bil preprost mehanski prehod na ta sistem dolgo časa zadržan zaradi nezadostnih virov računalniške opreme (v kodirnem sistemu UNICODE vsi besedilni dokumenti samodejno postanejo dvakrat daljši). V drugi polovici 90. let tehnična sredstva dosegli zahtevano raven oskrbe z viri, danes pa smo priča postopnemu prehodu dokumentov in programske opreme na univerzalni kodirni sistem. Za posamezne uporabnike je to dodalo še več skrbi glede usklajevanja dokumentov, izdelanih v različni sistemi kodiranje, s programska orodja, vendar je to treba razumeti kot težave prehodnega obdobja.
^ Kodiranje slikovnih podatkov
Če s povečevalnim steklom pregledate črno-belo grafično podobo, natisnjeno v časopisu ali knjigi, lahko vidite, da je sestavljena iz drobnih pik, ki tvorijo značilen vzorec, imenovan raster(slika 1.9).

riž. 1.9. Raster je metoda kodiranja grafičnih informacij, ki je že dolgo sprejeta v tiskarski industriji.
Ker lahko linearne koordinate in posamezne lastnosti vsake točke (svetlost) izrazimo s celimi števili, lahko rečemo, da rastrsko kodiranje omogoča uporabo binarne kode za predstavitev grafičnih podatkov. Danes je splošno sprejeto, da se črno-bele ilustracije predstavljajo kot kombinacija pik s 256 odtenki sive, zato je za kodiranje svetlosti katere koli pike običajno dovolj osem-bitno binarno število.
Za kodiranje barve grafične slike uporabljeno načelo razgradnje poljubne barve v glavne komponente. Kot take komponente se uporabljajo tri osnovne barve: rdeča (Rdeča, R), zelena (Zelena, G) in modra (Modra, V). V praksi velja (čeprav teoretično to ni povsem res), da lahko z mehanskim mešanjem teh treh osnovnih barv dobimo katero koli barvo, ki je vidna človeškemu očesu. Tak sistem kodiranja se imenuje sistem RGB po prvih črkah imen primarnih barv.
Če se za kodiranje svetlosti vsake od glavnih komponent uporabi 256 vrednosti (osem bitov), kot je običajno za poltonske črno-bele slike, je treba za kodiranje barve ene točke porabiti 24 bitov. Hkrati sistem kodiranja zagotavlja nedvoumno definicijo 16,5 milijona različnih barv, kar je pravzaprav blizu občutljivosti človeškega očesa. Imenuje se način za predstavitev barvne grafike z uporabo 24 bitov polne barve (True Color).
Vsaki od primarnih barv je mogoče dodeliti komplementarno barvo, to je barvo, ki dopolnjuje primarno barvo beli. Preprosto je videti, da je za katero koli od primarnih barv komplementarna barva sestavljena iz vsote para drugih primarnih barv. V skladu s tem so komplementarne barve: modra (Cyan, C), vijolična (Magenta, M) in rumena ( Rumena, Y). Načelo razgradnje poljubne barve na sestavne komponente se lahko uporablja ne samo za primarne barve, temveč tudi za dodatne, to pomeni, da je lahko katera koli barva predstavljena kot vsota cian, magenta in rumene komponente. Ta način barvnega kodiranja je v tiskarski industriji sprejet, vendar se v tiskarski industriji uporablja tudi četrto črnilo - črno (Črna, K). Torej ta sistem kodiranje je označeno s štirimi črkami CMYK(črna barva je označena s črko DO, ker pismo Vže zasedeno z modro), in za prikaz barvne grafike v tem sistemu morate imeti 32 bitov. Ta način se imenuje tudi polne barve (True Color).
Če zmanjšate število bitov, ki se uporabljajo za kodiranje barve vsake pike, lahko zmanjšate količino podatkov, vendar se obseg kodiranih barv opazno zmanjša. Kodiranje barvne grafike s 16-bitnimi binarnimi številkami se imenuje način visoka barva.
Pri kodiranju barvnih informacij z osmimi biti podatkov je mogoče prenesti le 256 barvnih odtenkov. Ta metoda barvnega kodiranja se imenuje indeks. Pomen imena je, da ker 256 vrednosti popolnoma ne zadošča za prenos celotne palete barv, ki so na voljo človeškemu očesu, koda vsakega piksla rastra ne izraža same barve, temveč le njeno število. (indeks) v iskalni tabeli, ki se imenuje paleto. Seveda je treba to paleto uporabiti za grafične podatke - brez nje je nemogoče uporabiti metode reproduciranja informacij na zaslonu ali papirju (to je seveda lahko uporabite, vendar zaradi nepopolnosti podatkov , prejete informacije ne bodo zadostne: listje na drevesih se lahko izkaže za rdeče, nebo pa zeleno).
^ Kodiranje zvoka
Tehnike in metode dela z zvočnimi informacijami so prišle v računalniško tehnologijo najnovejše. Poleg tega zvočni posnetki za razliko od številčnih, besedilnih in grafičnih podatkov niso imeli enako dolge in preverjene zgodovine kodiranja. Posledično so metode za kodiranje zvočnih informacij v binarni kodi daleč od standardizacije. Številna posamezna podjetja so razvila lastne korporativne standarde.
Ustvarjalec spletne strani se vedno sooča s težavo: v kakšnem kodiranju ustvariti projekt. Na rusko govorečem internetu se uporabljata dve kodi:
UTF-8(iz angleščine. Format transformacije Unicode) je trenutno običajno kodiranje, ki izvaja predstavitev Unicode, ki je združljiva z 8-bitnim kodiranjem besedila.
Windows-1251(oz cp1251) je nabor znakov in kodiranje, ki je standardno 8-bitno kodiranje za vse ruske različice Microsoft Windows.
UTF-8 je bolj obetaven. Ampak vse ima pomanjkljivosti. In odločitev o uporabi neke vrste kodiranja samo zato, ker je obetavna, brez upoštevanja številnih drugih dejavnikov, se ne zdi pravilna. Izbira bo optimalna le, če bo v celoti upoštevala vse nianse določenega projekta. Druga stvar je, da predvideti vse nianse samo po sebi ni lahko.
Menimo, da je uporaba UTF-8 boljša, vendar se mora razvijalec projekta odločiti, kaj izbrati. Da bi olajšali to izbiro, uporabite primerjalno tabelo značilnosti obeh kodiranj.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Kako prevesti spletno mesto iz kodiranja win1251 v UTF-8
Splošni postopek:
1. Prekodirajte celotno bazo podatkov v UTF-8 (najverjetneje se boste morali za pomoč obrniti na skrbnika strežnika).
2. Prekodirajte vse datoteke spletnega mesta v UTF-8 (to lahko storite sami).
3. V datoteko /bitrix/php_interface/dbconn.php dodajte naslednje vrstice:
4. V datoteko /.htaccess dodajte naslednje vrstice:
php_value mbstring.func_overload 2 php_value mbstring.internal_encoding UTF-8
Vse datoteke spletnega mesta lahko prekodirate v UTF-8 (druga točka), tako da zaženete ukaz prek SSH v korenski mapi mesta:
najti. -name "*.php" -type f -exec iconv -fcp1251 -tutf8 -o /tmp/tmp_file () \; -exec mv /tmp/tmp_file() \;
Kodiranje Windows 1251 je bilo ustvarjeno v zgodnjih 90. letih za rusifikacija programskih izdelkov proizvaja Microsoft Corporation:
Kodiranje je 8-bitno in vključuje simbole slovanske jezikovne skupine, ki vključuje ruski, beloruski, ukrajinski, bolgarski, makedonski, srbski - to daje prednost pred drugimi ciriličnimi kodiranjem ( ISO 8859-5, KOI8-R, CP866). Vendar ima kodiranje 1251 tudi pomembne pomanjkljivosti:
- 0xFF (25510) je koda, ki je rezervirana za znak "i". Programi, ki ne podpirajo čistega 8. bita, imajo pogosto nepredvidljive težave;
- V KOI8, CP866 ni psevdo grafike.
Spodaj so simboli s kodne strani 1251 ali skrajšano kot CP1251 ( številke pod znaki so šestnajstiška koda istega znaka Unicode):
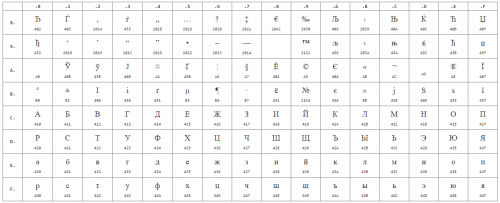
Pogosto imajo spletni razvijalci in blogerji z različnimi kvalifikacijami težave s kodiranjem strani: namesto pripravljenega besedila se pojavijo neznani, neberljivi znaki. Za reševanje tega problema je treba razumeti bistvo izraza " kodiranje strani».
Besedilo v pomnilniku računalnika je shranjeno kot določeno število bajtov in ne v obliki, v kateri je prikazano v urejevalnik besedil. Vsak bajt je koda, ki ustreza enemu znaku. Da se besedilo na strani pravilno prikaže, morate brskalniku povedati, katero tabelo kod za dešifriranje in prikaz naj uporablja.
Tabela kodiranja ni univerzalna, to pomeni, da morate za dešifriranje besedila uporabiti tisto, ki se ujema s kodiranjem znakov:

Da bi bil dokument html pravilno prikazan v brskalniku, morate določiti uporabljeno kodiranje. To se naredi na naslednji način:
Med oznako
in ga zapre se morate registrirati - na podlagi tega niza bo brskalnik uporabil znake ruske abecede za prikaz besedila na strani.Windows kodiranje 1251 v PHP
Nikomur ni skrivnost, da se generiranje strani izvede s pridobivanjem in uporabo nekaterih informacij, ki so shranjene v bazi podatkov. Pri pisanju strani v PHP je to največkrat mysql.
3 glasoviPozdravljeni dragi bralci mojega bloga. Danes se bomo z vami pogovarjali o kodiranju. Če berete moj članek o tem, potem veste, da noben dokument na internetu ni shranjen v obliki, v kateri smo ga vajeni videti. Napisano je s pomočjo simbolov in znakov, ki so človeku nerazumljivi. Enako velja za besedilo.
Obstaja več kodiranj, zato včasih pri odpiranju knjige opazite nerazumljive znake mobilno aplikacijo ali naložite članek na spletno mesto, boste s spremembo nekaterih vrednosti v nastavitvah videli abecedo, ki je znana očesu.

Kodiranje Windows-1251 - kaj je to, kaj pomeni pri ustvarjanju spletnega mesta, kateri znaki bodo na voljo in ali najboljša rešitev do danes? Vse to v današnjem članku. Kot vedno, preprost jezik, čim bolj jasno in z minimalnim številom izrazov.
Malo teorije
Vsak dokument na računalniku ali na internetu, kot sem rekel, je shranjen kot binarna koda. Na primer, če uporabljate kodiranje ASCII, bo črka "K" zapisana kot 10001010, Windows 1251 pa skrije simbol - Љ pod to številko. Posledično, če brskalnik ali program dostopa do druge tabele in upošteva namesto ASCII kode windows 1251 bo bralec videl simbol, ki mu je popolnoma nerazumljiv.
Vprašanje je logično, zakaj je bilo potrebno pripraviti veliko tabel s kodami? Dejstvo je, da poleg ruske abecede obstajajo tudi angleška, nemška, kitajska. Po nekaterih ocenah naj bi bilo okoli 200.000 znakov. Čeprav ne verjamem v te statistike, če se spomnim japonščine.
Ne pozabite, da morate pripraviti svojo kodo za velike in male črke, obstajajo vejice, pomišljaji in tako naprej.
Več kot je simbolov v tabeli, daljša je koda vsakega od njih, s tem pa je teža dokumenta večja.
Predstavljajte si, če bi ena knjiga tehtala 4 GB! Nalaganje bi trajalo zelo dolgo, vse prevzelo prosto mesto na računalniku. Odločitev za prenos bi bila težka.
Če pomislite na spletna mesta, je na splošno strašljivo pomisliti, kaj bi se zgodilo. Vsaka stran se je odprla tudi po hitrem optičnem vlaknu več kot eno uro! pomisli, Mobilni telefoni lahko varno zavržete. Ali jih uporabljate na prostem, tudi s 4G? Dvomim.
Iz teh razlogov je vsak programer naenkrat poskušal pripraviti svojo tabelo simbolov. Tako da je priročna za uporabo, teža pa optimalna.
Microsoft je na primer ustvaril windows-1251 za rusko govoreči segment. Vsekakor ima svoje prednosti in slabosti. Tako kot kateri koli drug izdelek.
Že zdaj je le 2 % vseh strani na internetu napisanih v 1251. Večina spletnih skrbnikov uporablja UTF-8. zakaj je tako?
Slabosti in prednosti
UTF-8 je za razliko od windows-1251 univerzalno kodiranje, vsebuje črke različnih abeced. Obstaja celo UTF-128, kjer so na splošno vsi jeziki - teulu, svahili, lao, malteščina in tako naprej.

UTF-8 je slabši, črke zavzamejo veliko manj prostora in zavzamejo le en bajt pomnilnika, kot v 1251. UTF ima redke znake iz drugih jezikov ali posebne znake. Vsak tehta 5-6 bajtov, vendar se v dokumentu redko uporablja.
To kodiranje je bolj premišljeno, zato ga večina aplikacij uporablja privzeto. To pomeni, da če programu ne poveste, katero kodiranje uporabljate, bo prva stvar, ki jo bo preveril, UTF-8.
Ko ustvarite html dokument za spletno mesto, brskalnikom poveste, katero tabelo naj poiščejo pri dešifriranju zapisov.
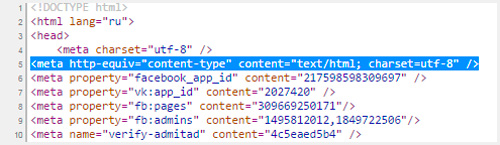
Če želite to narediti, morate v oznako glave vstaviti naslednje podatke. Za znakom "charset =" pride bodisi utf bodisi windows, kot v spodnjem primeru.
| <meta http-equiv="Content-Type" content= "text/html; charset=windows-1251"> |
Če želite v prihodnosti kaj spremeniti in vstaviti besedno zvezo v albanščini s to tabelo za dešifriranje, potem nič ne bo delovalo, ker kodiranje ne podpira tega jezika. UTF-8 vam bo to omogočil brez težav.
Če vas zanima pravilno ustvarjanje spletnega mesta, vam lahko priporočam tečaj Mihaila Rusakova " Izdelava in promocija strani od A do Ž ».

Vsebuje veliko - 256 lekcij, ki vplivajo na , JavaScript in XML. Poleg programskih jezikov boste lahko razumeli, kako spletno stran monetizirati, torej prej in več zaslužiti. Eden redkih tečajev, ki tako podrobno razloži vse, kar potrebujete.
študiram že eno leto na šoli blogerjev Aleksandra Borisova . Traja večkrat več časa, konca se še ne vidi, ni pa nič manj izčrpno in disciplinira. Motivira k nadaljnjemu razvoju.
No, če imate vprašanja, vam ni treba iskati po internetu. Vedno se najde dober mentor.

Nekaj sem se oddaljil od teme. Vrnimo se k kodiranju.
Podstavki za kopel
Ko gre za php, je na splošno vse strašljivo. O bazah podatkov sem že govoril, uporabljajo se za pospeševanje spletnega mesta. Običajno se z njimi ne obrnete, ko pa je treba prenesti spletno mesto, postane neprijetno.
Težave se dogajajo vsem, ne glede na vaše delovne izkušnje, delovno dobo in delovno dobo. Nekatere strani v bazi lahko vsebujejo vse razpoložljive znake za windows-1251, druge, na primer v predlogah strani, v drugem kodiranju.
Dokler ni potreben prenos, vse deluje in deluje, čeprav ne povsem pravilno. Toda po selitvi se začnejo težave. V idealnem primeru bi morali uporabljati samo UTF ali Windows-1251, v resnici pa se takšne pomanjkljivosti vedno zgodijo vsem.
Da bo dešifriranje dosledno, morate vnesti kodo mysql_query (»SET NAMES cp1251«). V tem primeru bo pretvorba izvedena z drugačnim protokolom - cp1251.
htaccess
Če ste se vztrajno odločili za uporabo 1251 na spletnem mestu, potem morate poiskati ali ustvariti datoteko htaccess. Odgovoren je za konfiguracijske nastavitve. Dodati mu bo treba še tri vrstice, da se bo vse ujemalo.
DefaultLanguage en; AddDefaultCharset windows-1251; php_value default_charset "cp1251"
Še vedno močno priporočam, da razmislite o uporabi UTF-8. Je bolj priljubljen, preprost in bogat. Ne glede na odločitve, ki jih sprejmete zdaj, je pomembno, da jih lahko pozneje popravite. S tem kodiranjem bo veliko lažje dodati angleško različico spletnega mesta. Nič ni treba popraviti.
Odločitev je na tebi. Naročite se na novice, da čim prej ugotovite, kje študirati, da ne bi ponavljali napak drugih, in tudi kateri blogerji dobijo več obiskovalcev.
Do ponovnega srečanja in sreče pri vaših prizadevanjih.
 Izbira programa za obdelavo GIS
Izbira programa za obdelavo GIS Izračun in analiza električnega tokokroga izmeničnega toka
Izračun in analiza električnega tokokroga izmeničnega toka Skenirni sondni mikroskop Trenutno stanje in razvoj skenirne sondne mikroskopije
Skenirni sondni mikroskop Trenutno stanje in razvoj skenirne sondne mikroskopije