Koliko bitov je v kodiranju Unicode. Enote za merjenje prostornine podatkov in kapacitete pomnilnika: kilobajti, megabajti, gigabajti…. Standard kodiranja znakov Unicode
Kodiranje informacij
Vse številke (v določenih mejah) v pomnilniku računalnika so kodirane s številkami v binarnem številskem sistemu. Za to obstajajo preprosta in jasna pravila prevajanja. Vendar se danes računalnik uporablja veliko širše kot v vlogi izvajalca delovno intenzivnih izračunov. Računalniški pomnilnik na primer shranjuje besedilne in večpredstavnostne informacije. Zato se poraja prvo vprašanje:
Vsak znak je kodiran od 1 do 4 bajtov. Nadomestni znaki uporabljajo 4 bajte in zato zahtevajo dodatno shranjevanje. Vsak znak je kodiran z najmanj 4 bajti. Za samodejno pretvorbo lahko uporabite tudi orodje za pretvorbo. Kot rečeno, je to standard, ki Američanom dobro ustreza. Ta se giblje od 0 do 127, prvih 32 in zadnjih pa se štejejo za kontrolne, ostale pa so "natisnjeni znaki", torej ljudje prepoznajo. Predstavlja ga lahko samo 7 bitov, čeprav se običajno uporablja en bajt.
Kako so znaki (črke) shranjeni v pomnilniku računalnika?
Vsaka črka pripada določeni abecedi, v kateri si znaki sledijo in jih je zato mogoče oštevilčiti z zaporednimi celimi števili. Vsako črko je mogoče povezati s pozitivnim celim številom in jo poimenovati z znakom... Prav ta koda bo shranjena v pomnilniku računalnika, ob prikazu na zaslonu ali na papirju pa se bo »pretvorila« v svoj ustrezen znak. Če želite razlikovati predstavitev številk od predstavitve znakov v računalniškem pomnilniku, morate shraniti tudi informacije o tem, kakšni podatki so kodirani v določenem območju pomnilnika.
Glede na kontekst in celo čas to pomeni nekaj drugega. Torej odvisno o čem govoriš. Samo malo pomeni. Obstaja nekaj kodiranj, ki uporabljajo to kratico. So zelo zapletene in skoraj nihče ne zna pravilno uporabiti njihove polnosti, vključno z mano.
Vendar ne z nobenim drugim sistemom kodiranja znakov. To je najbolj popolno in zapleteno kodiranje, ki obstaja. Nekateri so vanjo zaljubljeni, drugi jo sovražijo, čeprav prepoznajo njeno uporabnost. Človek je težko razumeti, za računalnik pa se je težko spopasti.
Korespondenca črk določene abecede s številkami-kodami tvori t.i kodirna tabela... Z drugimi besedami, vsak znak določene abecede ima svojo številčno kodo v skladu s specifično kodirno tabelo.
Vendar pa je na svetu veliko abeced (angleški, ruski, kitajski itd.). Torej je naslednje vprašanje:
Obstaja primerjava med obema. Je standard za predstavitev besedil, ki jih ustvari konzorcij. Med normami, ki jih je določil, je nekaj kodiranja. Toda v resnici se nanaša na veliko več kot to. Članek, ki bi ga moral prebrati vsak, tudi če se ne strinja z vsem, kar ima.
Podprti nabori znakov so razdeljeni na ravnine. Oba računalnika uporabljata različne operacijske sisteme; enako se zgodi z naborom znakov, strukturo in format datoteke ki so običajno različni. Komunikacija preko nadzorne povezave.
Kako kodirati vse abecede, ki se uporabljajo v računalniku?
Za odgovor na to vprašanje bomo sledili zgodovinski poti.
V 60-ih letih XX stoletja v Ameriški nacionalni inštitut za standarde (ANSI) razvita je bila tabela za kodiranje znakov, ki je bila kasneje uporabljena v vseh operacijskih sistemih. Ta tabela se imenuje ASCII (ameriška standardna koda za izmenjavo informacij)... Malo kasneje se je pojavilo razširjena različica ASCII.
Komunikacija poteka skozi zaporedje ukazov in odzivov. Ta preprosta metoda je primerna za nadzorno povezavo, ker lahko pošljemo en ukaz naenkrat. Vsak ukaz ali odgovor ima eno vrstico, zato nam ni treba skrbeti za obliko datoteke ali strukturo. Vsaka vrstica se konča z dvema znakoma.
Podatkovna povezava. Namen in izvedba podatkovne povezave se razlikujeta od tistih, ki so določeni v kontrolni povezavi. Osnovno dejstvo: želimo prenesti datoteke preko podatkovne povezave. Odjemalec mora določiti vrsto datoteke za prenos, strukturo podatkov in način prenosa.
V skladu s kodno tabelo ASCII je 1 bajt (8 bitov) dodeljen za predstavljanje enega znaka. Nabor 8 celic lahko sprejme 2 8 = 256 različnih vrednosti. Prvih 128 vrednosti (od 0 do 127) je konstantnih in tvorijo tako imenovani glavni del tabele, ki vključuje decimalne števke, črke latinske abecede (velike in male črke), ločila (pika, vejica, oklepaji). , itd.), pa tudi presledek in različni servisni znaki (tabela, pomik vrstice itd.). Oblikujejo se vrednosti od 128 do 255 dodatni del tabele, kjer je običajno kodiranje simbolov nacionalnih abeced.
Poleg tega mora prenos pripraviti kontrolna povezava, preden se datoteka lahko prenese prek podatkovne povezave. Problem heterogenosti je rešen z definiranjem treh atributov povezave: vrste datoteke, strukture podatkov in načina prenosa.
Datoteka se pošlje kot neprekinjen tok bitov brez kakršne koli interpretacije ali kodiranja. Ta oblika se uporablja predvsem za prenos binarnih datotek, kot so prevedeni programi ali slike, kodirane v 0 in 1 sekundi. Datoteka ne vsebuje vertikalnih specifikacij za tiskanje. To pomeni, da datoteke ni mogoče natisniti brez dodatne obdelave, ker ni razumljivih znakov, ki bi jih razlagali navpično premikanje tiskalnega stroja. To obliko uporabljajo datoteke, ki bodo shranjene in obdelane v prihodnosti.
Ker obstaja veliko različnih nacionalnih abeced, obstajajo razširjene tabele ASCII v številnih različicah. Tudi za ruski jezik obstaja več kodirnih tabel (običajna sta Windows-1251 in Koi8-r). Vse to povzroča dodatne težave. Na primer, pošljemo pismo, napisano v enem kodiranju, prejemnik pa ga poskuša prebrati v drugem. Kot rezultat, vidi krakozyabry. Zato mora bralec za besedilo uporabiti drugačno kodno tabelo.
Datoteko je mogoče natisniti po prenosu. Strani: datoteka je razdeljena na strani, od katerih je vsaka pravilno oštevilčena in označena z naslovom. Strani je mogoče shraniti ali do njih dostopati, naključno ali zaporedno. Če so podatki le niz bajtov, identifikacija konca vrstice ni potrebna. V tem primeru je indikator konca linije zaprtje podatkovne povezave s strani oddajnika. Prvi bajt se imenuje deskriptorski blok; druga dva bajta določata velikost bloka v bajtih. Stiskanje: če je datoteka prevelika, se lahko podatki pred pošiljanjem stisnejo. Običajno uporabljena metoda stiskanja vzame enoto podatkov, ki se pojavlja zaporedno, in jo nadomesti z enim samim pojavom, ki mu sledi več ponovitev. V besedilno datoteko veliko praznih prostorov. V binarni datoteki so ničelni znaki običajno stisnjeni.
- Datoteke: datoteka nima strukture.
- Prenaša se v neprekinjenem toku bajtov.
- Ta vrsta se lahko uporablja samo z besedilnimi datotekami.
- Verige: To je privzeti način.
- V tem primeru je pred vsakim blokom 3-bajtna glava.
Obstaja tudi druga težava. Abecede nekaterih jezikov imajo preveč znakov in se ne prilegajo svojim dodeljenim položajem od 128 do 255 enobajtnega kodiranja.
Tretja težava je, kaj storiti, če besedilo uporablja več jezikov (na primer ruščino, angleščino in francoščino)? Ne morete uporabljati dveh miz hkrati ...
Za reševanje teh težav je bilo naenkrat razvito kodiranje Unicode.
Mnogi nimajo pojma o razlikah med temi sklopi in se držijo tistega, kar je blizu. Podrobnost o kodiranju je, da so zemljevidi za dve različni stvari. Prvi je zemljevid številske vrednosti, ki predstavlja določen znak.
Druga letala so dodatki, ki imajo znake, ki dopolnjujejo funkcije glavnega letala in druge »posebnosti«, kot so »emotikoni«. V teh vzorcih je vsak ravninski znak kodiran v samo 1 bajt, zato imamo le 256 "možnih" znakov. Seveda moramo odstraniti tiste, ki niso "natisljivi" z zmanjšanjem obsega.
Standard kodiranja znakov Unicode
Za rešitev zgornjih težav v zgodnjih 90. letih je bil razvit standard za kodiranje znakov, imenovan Unicode. Ta standard vam omogoča uporabo skoraj vseh jezikov in simbolov v besedilu.
Unicode zagotavlja 31 bitov za kodiranje znakov (4 bajti minus en bit). Število možnih kombinacij daje pretirano število: 2 31 = 2 147 483 684 (tj. več kot dve milijardi). Zato Unicode opisuje abecede vseh znanih jezikov, tudi "mrtvih" in izumljenih, vključuje številne matematične in druge Posebni simboli... Vendar je informacijska zmogljivost 31-bitnega Unicode še vedno prevelika. Zato se pogosteje uporablja skrajšana 16-bitna različica (2 16 = 65 536 vrednosti), kjer so kodirane vse sodobne abecede.
In če morate opraviti primerjave med znaki, ni izgube zmogljivosti, saj primerjava dveh 8-bitnih, 16-bitnih ali 32-bitnih vrednosti porabi enak čas za sodobnih procesorjev... Pomen, povezan z akronimom, je seveda velikost vsake enote zaporedja, ki sestavlja kodiranje znakov. Če ima koda več bitov, se uporabi naslednje kodiranje.
Tako je lahko kateri koli znak izražen v velikostih od 1 do 4 bajtov. Je to edinstven "poseben" lik? To pomeni, da so nekatere slike likov zelo podobne in včasih odveč. Če navedem še en primer, pred nekaj leti je bila šala o spremembi '; 'vklop'; ' v izvorne kode... Med prevajanjem kode je programer znorel, da bi poskušal ugotoviti težavo.
V Unicode je prvih 128 kod enakih kot v tabeli ASCII.
Od poznih 60. let prejšnjega stoletja so se za obdelavo vedno bolj uporabljali računalniki besedilne informacije in trenutno večina osebni računalniki v svetu (in večino časa) je zaposlen z obdelavo besedilnih informacij.
ASCII - osnovno kodiranje besedila za latinsko abecedo
Tradicionalno se za kodiranje enega znaka uporablja količina informacij, ki je enaka 1 bajt, to je I = 1 bajt = 8 bitov.
Za kodiranje enega znaka je potreben 1 bajt informacij. Če simbole obravnavamo kot možne dogodke, potem lahko izračunamo, koliko različni liki se lahko kodira: N = 2I = 28 = 256.
To število znakov je povsem dovolj za predstavljanje besedilnih informacij, vključno z velikimi in malimi črkami ruske in latinske abecede, številkami, znaki, grafičnimi simboli itd. binarno kodo od 00000000 do 11111111.
Tako oseba razlikuje like po slogu, računalnik pa po kodah. Ko se besedilne informacije vnesejo v računalnik, se binarno kodiranje, se slika simbola pretvori v svojo binarno kodo.
Uporabnik pritisne tipko s simbolom na tipkovnici in v računalnik se pošlje določeno zaporedje osmih električnih impulzov (binarna koda simbola). Koda znakov je shranjena v pomnilnik z naključnim dostopom računalnik, kjer zavzame en bajt. V procesu prikaza znaka na računalniškem zaslonu se izvaja obratni postopek - dekodiranje, to je pretvorba kode znaka v njeno sliko. Kodna tabela ASCII (American Standard Code for Information Interchange) je sprejeta kot mednarodni standard Tabela standardnih delov ASCII Pomembno je, da je dodelitev določene kode znaku stvar dogovora, kar je določeno v kodni tabeli. . Prvih 33 kod (od 0 do 32) ne ustreza znakom, ampak operacijam (premik vrstice, vnos presledka itd.). Šifre od 33 do 127 so mednarodne in ustrezajo simbolom latinske abecede, številkam, računskim znakom in ločilom. Kode od 128 do 255 so nacionalne, to pomeni, da različni znaki ustrezajo isti kodi v nacionalnih kodiranju.
Na žalost je trenutno pet različnih kodne tabele za ruske črke (KOI8, CP1251, CP866, Mac, ISO), zato besedila, ustvarjena v enem kodiranju, ne bodo pravilno prikazana v drugem.
Trenutno nova mednarodna Standard Unicode, ki vsakemu znaku ne dodeli en bajt, ampak dva, tako da se lahko uporablja za kodiranje ne 256 znakov, ampak N = 216 = 65536 različnih
Unicode - pojav univerzalnega kodiranja besedila (UTF 32, UTF 16 in UTF 8)
Teh tisoč znakov iz jezikovne skupine jugovzhodne Azije ni bilo mogoče opisati v enem samem bajtu informacij, ki je bil dodeljen za kodiranje znakov v razširjenih kodiranju ASCII. Posledično je poklical konzorcij Unicode(Unicode - Unicode Consortium) s sodelovanjem številnih vodilnih IT industrije (tisti, ki proizvajajo programsko opremo, ki kodirajo strojno opremo, ustvarjajo pisave), ki jih je zanimal nastanek univerzalnega kodiranja besedila.
Prvo kodiranje besedila, objavljeno pod okriljem konzorcija Unicode, je bilo kodiranje UTF 32... Številka v imenu kodiranja UTF 32 pomeni število bitov, ki se uporabljajo za kodiranje enega znaka. 32 bitov so 4 bajti informacij, ki bodo potrebni za kodiranje enega samega znaka v novem univerzalnem kodiranju UTF 32.
Posledično bo imela ista datoteka z besedilom, kodiranim v razširjenem kodiranju ASCII in v kodiranju UTF 32, v slednjem primeru štirikrat večjo velikost (težo). To je slabo, toda zdaj imamo možnost, da z UTF 32 kodiramo število znakov, ki je enako dve na dvaintrideset sekundo (milijarde znakov, ki bodo pokrile vsako resnično potrebno vrednost z ogromno mejo).
Toda številnim državam z jeziki evropske skupine sploh ni bilo treba uporabiti tako velikega števila znakov v kodiranju, vendar pri uporabi UTF 32 nikoli niso dosegle štirikratnega povečanja teže besedilni dokumenti, posledično pa se poveča obseg internetnega prometa in količina shranjenih podatkov. To je veliko in takšnega zapravljanja si nihče ne bi mogel privoščiti.
Kot rezultat razvoja univerzal Kodiranje Unicode se je pojavilo UTF 16, ki se je izkazal za tako uspešnega, da je bil privzeto sprejet kot osnovni prostor za vse simbole, ki jih uporabljamo. UTF 16 uporablja dva bajta za kodiranje enega znaka. Na primer, v operacijski sistem Windows, lahko sledite poti Start - Programi - Dodatki - Sistemska orodja - Zemljevid simbolov.
Posledično se odpre tabela z vektorskimi oblikami vseh pisav, nameščenih v vašem sistemu. Če v naprednih možnostih izberete nabor znakov Unicode, lahko za vsako pisavo posebej vidite celoten obseg znakov, ki so vključeni v njo. Mimogrede, s klikom na katerega koli od teh znakov lahko vidite njegovo dvobajtno kodo v kodiranju UTF 16, sestavljeno iz štirih šestnajstiških števk:
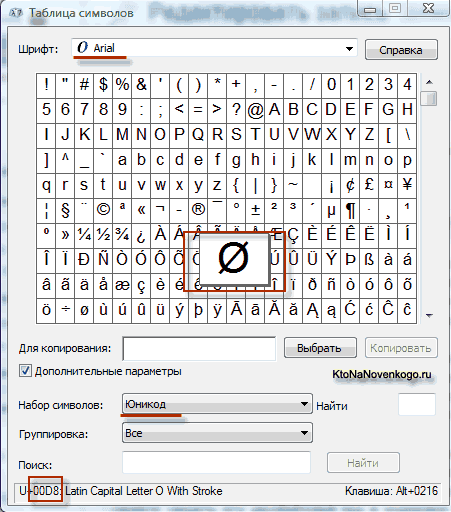
Koliko znakov je mogoče kodirati v UTF 16 s 16 biti? 65.536 znakov (dva na potenco šestnajstih) je bilo vzetih kot osnovni prostor v Unicode. Poleg tega obstajajo načini za kodiranje približno dveh milijonov znakov z uporabo UTF 16, vendar so bili omejeni na razširjen prostor milijona znakov besedila.
Toda tudi uspešna različica kodiranja Unicode, imenovana UTF 16, ni prinesla veliko zadovoljstva tistim, ki so na primer pisali programe samo v angleški jezik, ker se je po prehodu iz razširjene različice kodiranja ASCII na UTF 16 teža dokumentov podvojila (en bajt za en znak v ASCII in dva bajta za isti znak v kodiranju UTF 16). Prav v zadovoljstvo vseh in vsega v konzorciju Unicode je bilo odločeno, da pripravimo kodiranje besedila spremenljive dolžine.
To kodiranje v Unicode je bilo imenovano UTF 8... Kljub osmici v imenu je UTF 8 popolno kodiranje spremenljive dolžine, t.j. vsak znak besedila je mogoče kodirati v zaporedje od enega do šest bajtov. V praksi se v UTF 8 uporablja le razpon od enega do štirih bajtov, saj si poleg štirih bajtov kode niti teoretično ni mogoče ničesar zamisliti.
V UTF 8 so vsi latinični znaki kodirani v enem bajtu, tako kot v starem kodiranju ASCII. Kar je omembe vredno, bodo v primeru kodiranja samo latinske abecede tudi tisti programi, ki ne razumejo Unicode, še vedno prebrali, kar je kodirano v UTF 8. To je osnovni del kodiranja ASCII je premaknjen v UTF 8.
Cirilični znaki v UTF 8 so kodirani v dveh bajtih, na primer gruzijski - v treh bajtih. Konzorcij Unicode je po izdelavi kodiranja UTF 16 in UTF 8 rešil glavni problem - zdaj imamo v naših pisavah en sam kodni prostor. Edina stvar, ki je preostala proizvajalcem pisav, je, da ta prostor kode zapolnijo z vektorskimi oblikami besedilnih simbolov glede na njihove prednosti in zmožnosti.
 Odmik gumbov za glasnost in vklop na iPhoneu - poroka ali ne?
Odmik gumbov za glasnost in vklop na iPhoneu - poroka ali ne? Omrežna kartica ne vidi kabla: navodila za rešitev težave Kaj storiti, če internetni kabel ne deluje
Omrežna kartica ne vidi kabla: navodila za rešitev težave Kaj storiti, če internetni kabel ne deluje StoCard in Wallet: popustne kartice iz aplikacije
StoCard in Wallet: popustne kartice iz aplikacije