Kodiranje znakov. Unicode
Všeč mi je bilo, mogoče bo koga zanimalo in koristilo.
Unicode je videti zelo zmedeno, kar sproža veliko vprašanj in težav. Mnogi ljudje mislijo, da je to kodiranje ali nabor znakov, kar je nekoliko pravilno, v resnici pa je zabloda. Dejstvo, da je bil Unicode prvotno ustvarjen kot kodiranje in nabor znakov, samo še krepi napačne predstave. To je poskus, da bi vse razjasnili, ne samo s tem, da povemo, kaj je Unicode, ampak z zagotavljanjem mentalni model Unicode.
Popolnoma napačen, vendar uporaben model za razumevanje Unicode (v nadaljevanju PMPY):
- Unicode je način za obdelavo besedilnih podatkov... To ni nabor znakov ali kodiranje.
- Unicode je besedilo, vse ostalo so binarni podatki... In celo besedilo ASCII je binarni podatki.
- Unicode uporablja nabor znakov UCS... Toda UCS ni Unicode.
- Unicode je mogoče binarno kodirati z uporabo UTF... Toda UTF ni Unicode.
Zdaj, če veste kaj o Unicode, boste rekli: "No, ja, ampak res ni." Zato bomo poskušali ugotoviti, zakaj je ta model razumevanja, čeprav ni pravilen, še vedno koristen. Začnimo z naborom znakov ...
O naboru znakov
Za obdelavo besedila na računalniku morate grafeme, ki jih napišete na papir, povezati s številkami. To primerjavo določa nabor znakov ali tabela znakov, ki določa številko za znak. To se imenuje "nabor znakov"... Simbol ne ustreza nujno nobenemu grafemu. Na primer, obstaja kontrolni znak "BEL", zaradi katerega vaš računalnik "piska". Število znakov v naboru znakov je običajno 256, toliko paše v en bajt. Obstajajo nabori znakov, ki so dolgi le 6 bitov. Dolgo časa so 7-bitni nabori znakov ASCII prevladovali v računalništvu, vendar so 8-bitni najpogostejši.
Toda 256 očitno ni število, ki lahko sprejme vse simbole, ki jih potrebujemo v našem svetu. Zato je nastal Unicode. Ko sem rekel, da Unicode ni nabor znakov, sem lagal. Unicode je bil prvotno 16-bitni nabor znakov. Toda medtem ko so ustvarjalci Unicode verjeli, da je 16 bitov dovolj (in imeli so prav), so nekateri menili, da 16 bitov ni dovolj (in imeli so tudi prav). Na koncu so ustvarili konkurenčno kodiranje in ga poimenovali Universal Character Set (UCS). Čez nekaj časa sta se ekipi odločili, da združita moči in oba nabora likov sta postala enaka. Zato lahko domnevamo, da Unicode uporablja UCS kot nabor znakov. Ampak to je tudi laž - pravzaprav ima vsak standard svoj nabor znakov, le tako se zgodi, da so enaki (čeprav UCS nekoliko zaostaja).
Ampak za naš PMPYu - "Unicode ni nabor znakov".
O UCS
UCS je 31-bitni nabor znakov z več kot 100.000 znaki. 31 bitov - da ne bi rešili problema "podpisani proti nepodpisani". Ker je zdaj uporabljenih manj kot 0,005 % možnega števila znakov, ta dodatni bit sploh ni potreben.
Čeprav 16 bitov ni bilo dovolj za sprejem vseh likov, ki jih je kdaj ustvarilo človeštvo, je povsem dovolj, če ste se pripravljeni omejiti šele zdaj. obstoječih jezikih... Zato se večina znakov UCS prilega prvih 65536 številk. Poimenovali so jih "Basic Multilingual Plane" ali BMP. Pravzaprav gre za 16-bitni nabor znakov Unicode, čeprav ga vsaka različica UCS razširi z vedno več znaki. BMP postane pomemben, ko gre za kodiranja, vendar več o tem spodaj.
Vsak znak v UCS ima ime in številko. Znak "H" se imenuje "LATINSKA VELIKA ČRKA H" in je številka 72. Številka je običajno v šestnajstiškem in je pogosto predpona z "U +" in 4, 5 ali 6 števkami, ki označujejo, kaj pomeni znak Unicode. Zato je številka znaka "H" pogosteje predstavljena kot U + 0048 kot - 72, čeprav sta ista stvar. Drug primer je znak "-", imenovan "EM DASH" ali U + 2012. Znak "乨" se imenuje "CJK UNIFIED IDEOGRAPH-4E68", pogosteje predstavljen kot U + 4E68. simbol "
Ker so imena in številke znakov v Unicode in UCS enaki, bomo za naš PMPU domnevali, da UCS ni Unicode, ampak Unicode uporablja UCS... To je laž, vendar uporabna laž, ki vam omogoča razlikovanje med Unicode in naborom znakov.
Glede kodiranja
Tako je nabor znakov zbirka znakov, od katerih ima vsak svojo številko. Toda kako jih shraniti ali poslati na drug računalnik? Za 8-bitne znake je enostavno, uporabite en bajt na znak. Toda UCS uporablja 31 bitov in potrebujete 4 bajte na znak, kar povzroča težave z razvrščanjem bajtov in neučinkovitostjo pomnilnika. Prav tako ne vse aplikacije tretjih oseb lahko deluje z vsemi znaki Unicode, vendar moramo še vedno komunicirati s temi aplikacijami.
Izhod je uporaba kodiranja, ki označujejo, kako pretvoriti besedilo Unicode v 8-bitne binarne podatke. Omeniti velja, da je ASCII kodiranje, podatki ASCII z vidika PMPU pa so binarni!
V večini primerov je kodiranje isti nabor znakov in je poimenovano enako kot nabor znakov, ki ga kodira. To velja za Latin-1, ISO-8859-15, cp1252, ASCII in druge. Čeprav je večina naborov znakov tudi kodiranja, to ne velja za UCS. Zmedeno je tudi, da je UCS tisto, v kar dekodiraš in iz česar kodiraš, medtem ko so ostali nabori znakov tisto, iz česar dekodiraš in v kar kodiraš (ker je ime kodiranja in nabora znakov isto). Zato bi morali nabore znakov in kodiranja obravnavati kot različne stvari, čeprav se ti izrazi pogosto uporabljajo zamenljivo v pomenu.
O UTF
Večina kodiranj deluje na naboru znakov, ki je le majhen del UCS. To postane problem za večjezične podatke, zato je potrebno kodiranje, ki uporablja vse znake UCS. Kodiranje 8-bitnih znakov je zelo preprosto, saj iz enega bajta dobite en znak, vendar UCS uporablja 31 bitov in potrebujete 4 bajte na znak. Problem vrstnega reda bajtov se pojavi, ker nekateri sistemi uporabljajo visoko zaporedje do nizkega, drugi obratno. Tudi nekateri bajti bodo vedno prazni, to je izguba pomnilnika. Pravilno kodiranje mora uporabljati drugačno število bajtov za različni liki, vendar bo takšno kodiranje v nekaterih primerih učinkovito in v drugih ne.
Rešitev te uganke je uporaba več kodiranja, med katerimi lahko izberete ustrezno. Imenujejo se Unicode Transformation Formats ali UTF.
UTF-8 je najbolj razširjeno kodiranje na internetu. Uporablja en bajt za znake ASCII in 2 ali 4 bajte za vse druge znake UCS. To je zelo učinkovito za jezike, ki uporabljajo latinične črke, saj so vsi v ASCII, precej učinkovito za grščino, cirilico, japonščino, armenščino, sirsko, arabščino itd., saj uporabljajo 2 bajta na znak. Vendar to ni učinkovito za vse druge jezike BMP, saj bodo uporabljeni 3 bajti na znak, za vse druge znake UCS, kot je gotski, pa bodo uporabljeni 4 bajti.
UTF-16 uporablja eno 16-bitno besedo za vse znake BMP in dve 16-bitni besedi za vse druge znake. Če torej ne delate z enim od zgoraj omenjenih jezikov, je bolje, da uporabite UTF-16. Ker UTF-16 uporablja 16-bitne besede, imamo na koncu težavo z vrstnim redom bajtov. Rešuje se s prisotnostjo treh možnosti: UTF-16BE za vrstni red bajtov od visoke do nizke, UTF-16LE - od nizkega do visokega in preprosto UTF-16, ki je lahko UTF-16BE ali UTF-16LE, ko se kodira na začetku se uporablja marker, ki označuje vrstni red bajtov. Ta oznaka se imenuje "oznaka vrstnega reda bajtov" ali "BOM".
Obstaja tudi UTF-32, ki je lahko v dveh različicah BE in LE ter UTF-16 in shranjuje znak Unicode kot 32-bitno celo število. To ni učinkovito za skoraj vse znake, razen za tiste, ki zahtevajo 4 bajte za shranjevanje. Toda takšne podatke je zelo enostavno obdelati, saj imate vedno 4 bajte na znak.
Pomembno je ločiti kodirane podatke od podatkov Unicode. Zato ne predstavljajte podatkov UTF-8/16/32 kot Unicode. Čeprav so kodiranja UTF opredeljena v standardu Unicode, menimo, da UTF ni Unicode pod PMPU.
O Unicode
UCS vsebuje poenotene znake, kot je trema, ki doda dve piki nad znakom. To vodi do nejasnosti pri izražanju enega grafema (črke ali znaka) z več simboli. Vzemimo na primer 'ö', ki ga lahko predstavimo kot znak LATINSKA MALA ČRKA O Z DIAERESIS, hkrati pa kot kombinacija znakov LATINSKA MALA ČRKA O, ki ji sledi KOMBINIRANJE DIAERESIS.
Toda v resničnem življenju nobenega simbola ne morete dopolniti s tremi. Na primer, ni smiselno dodati dve piki nad simbol evra. Unicode vsebuje pravila za take stvari. Označuje, da lahko "ö" izrazite na dva načina in je isti znak, če pa za znak evra uporabite tri, delate napako. Zato so pravila za kombiniranje znakov del standarda Unicode.
Standard Unicode vsebuje tudi pravila za primerjavo in razvrščanje znakov, pravila za delitev besedila na stavke in besede (če mislite, da je tako preprosto, ne pozabite, da večina azijskih jezikov ne vsebuje presledkov med besedami) in številna druga pravila, ki določiti, kako je prikazano in obdelano.besedilo. Vsega tega vam verjetno ne bo treba vedeti, razen če uporabljate azijske jezike.
Z uporabo PMPU smo ugotovili, da je Unicode UCS plus pravila za obdelavo besedil. Ali z drugimi besedami: Unicode je način dela z besedilnimi podatki in ni pomembno, kateri jezik ali črko uporabljajo. V Unicode 'H' ni le znak, ima določen pomen. Nabor znakov označuje, da je »H« znak s številko 72, medtem ko vam Unicode pove, da je pri razvrščanju »H« pred »I« in lahko uporabite dve piki nad njim, da dobite »Ḧ«.
Unicode torej ni kodiranje ali niz znakov, je način dela z besedilnimi podatki.
Sam ne maram naslovov, kot je "Pokemon v lastnem soku za lutke / lonce / ponve", vendar se zdi, da je to ravno tako - govorili bomo o osnovnih stvareh, delo s katerimi pogosto vodi v predal, poln udarci in veliko izgubljenega časa okoli vprašanja – Zakaj ne deluje? Če vas je še vedno strah in/ali ne razumete Unicode, prosim, pod kat.
Kaj za?
Glavno vprašanje za začetnika, ki se sooča z impresivnim številom kodiranj in navidez zmedenih mehanizmov za delo z njimi (na primer v Pythonu 2.x). Kratek odgovor je, ker se je zgodilo :)Kodiranje, kdor ne ve, je način predstavitve v računalniškem pomnilniku (beri - v ničlah-enicah/številkah) števk, bukev in vseh drugih znakov. Na primer, presledek je predstavljen kot 0b100000 (binarno), 32 (decimalno) ali 0x20 (šestnajstiško).
Torej, nekoč je bilo pomnilnika zelo malo in so imeli vsi računalniki dovolj 7 bitov, da so predstavljali vse potrebne znake (številke, mala / velika latinična abeceda, kup znakov in tako imenovanih nadzorovanih znakov - vseh možnih 127 številk je bilo danih nekomu) . Takrat je bilo samo eno kodiranje - ASCII. Sčasoma so bili vsi zadovoljni, kdor pa ni bil srečen (beri - komu je manjkal znak "" ali izvorna črka "u") - je preostalih 128 znakov uporabil po lastni presoji, torej je ustvaril nova kodiranja. Tako sta se pojavila ISO-8859-1 in naša (torej cirilica) cp1251 in KOI8. Skupaj z njimi se je pojavil problem interpretacije bajtov, kot je 0b1 ******* (to je znakov / številk od 128 do 255) - na primer, 0b11011111 v kodiranju cp1251 je hkrati naš lastni "jaz". v kodiranju ISO 8859-1 je grško nemško Eszett (poziva) "ß". Kot je bilo pričakovano, omrežna komunikacija in samo izmenjava datotek med različnih računalnikov spremenilo v hudiča-kaj-kaj, kljub dejstvu, da so glave, kot je "Content-Encoding" v protokolu HTTP, e-pošta in strani HTML, malo rešile dan.
V tistem trenutku so se zbrali bistri umi in predlagali nov standard - Unicode. To je standard, ne kodiranje - Unicode sam ne določa, kako bodo znaki shranjeni na trdem disku ali posredovani po omrežju. Opredeljuje le razmerje med znakom in določeno številko, format, po katerem bodo te številke pretvorjene v bajte, pa določajo kodiranja Unicode (na primer UTF-8 ali UTF-16). Na ta trenutek v standardu Unicode je nekaj več kot 100 tisoč znakov, medtem ko UTF-16 podpira več kot milijon (UTF-8 je še več).
Svetujem vam, da preberete Absolutni minimum, ki ga mora vsak razvijalec programske opreme popolnoma, pozitivno vedeti o Unicode in naborih znakov za več in več zabave na to temo.
Pojdi k bistvu!
Seveda je v Pythonu podpora za Unicode. Toda na žalost so samo v Pythonu 3 vsi nizi postali unicode in začetniki se morajo ubiti zaradi napake, kot je:>>> z odprtim ("1.txt") kot fh: s = fh.read () >>> print s koshchey >>> parser_result = u "baba-yaga" # naloga zaradi jasnosti, predstavljajmo si, da je to rezultat nekaj razčlenjevalnika deluje >>>
ali takole:
>>> str (parser_result) Traceback (zadnji zadnji klic): datoteka "
Ugotovimo, vendar po vrsti.
Zakaj bi kdo uporabljal Unicode?
Zakaj moj najljubši razčlenjevalnik html vrača Unicode? Naj vrne navaden niz, jaz pa se bom tam ukvarjal z njim! Prav? res ne. Čeprav je vsak od znakov, ki obstajajo v Unicode, lahko (verjetno) predstavljen v nekem enobajtnem kodiranju (ISO-8859-1, cp1251 in drugi se imenujejo enobajtni, saj kodirajo kateri koli znak v točno en bajt), toda kaj naj storiti, če bi morali biti v nizu znaki iz različnih kodiranja? Želite vsakemu znaku dodeliti ločeno kodiranje? Ne, seveda morate uporabiti Unicode.Zakaj potrebujemo novo vrsto "unicode"?
Tako smo prišli do najbolj zanimivega. Kaj je niz v Pythonu 2.x? To je preprosto bajtov... Samo binarni podatki, ki so lahko karkoli. Pravzaprav, ko napišemo nekaj takega: >>> x = "abcd" >>> x "abcd", tolmač ne ustvari spremenljivke, ki vsebuje prve štiri črke latinske abecede, ampak samo zaporedje ("a" , "b "," c "," d ") s štirimi bajti in latinske črke se tukaj uporabljajo izključno za označevanje te posebne bajtne vrednosti. Torej je "a" tukaj samo sinonim za "\ x61" in ne malo več. Na primer:>>> "\ x61" "a" >>> struct.unpack ("> 4b", x) # "x" so samo štirje podpisani/nepodpisani znaki (97, 98, 99, 100) >>> struct.unpack ("> 2h", x) # ali dva kratka (24930, 25444) >>> struct.unpack ("> l", x) # ali ena dolga (1633837924,) >>> struct.unpack ("> f") , x) # ali float (2.6100787562286154e + 20,) >>> struct.unpack ("> d", x * 2) # vdolbino ali pol dvojnega (1.2926117739473244e + 161,)
In to je to!
In odgovor na vprašanje - zakaj potrebujemo "unicode" je že bolj očiten - potrebujemo tip, ki bo predstavljen z znaki, ne z bajti.
V redu, ugotovil sem, kaj je vrvica. Kaj je potem Unicode v Pythonu?
"Type unicode" je predvsem abstrakcija, ki izvaja idejo Unicode (nabor znakov in povezanih številk). Objekt tipa "unicode" ni več zaporedje bajtov, temveč zaporedje dejanskih znakov brez kakršne koli ideje o tem, kako je mogoče te znake učinkovito shraniti v računalniški pomnilnik. Če želite, je to več visoka stopnja abstrakcija kot bajtni nizi (to Python 3 imenuje običajni nizi, ki se uporabljajo v Pythonu 2.6).Kako uporabljam Unicode?
Niz Unicode v Pythonu 2.6 je mogoče ustvariti na tri (vsaj naravno) načine:- u "" dobesedno: >>> u "abc" u "abc"
- Metoda "decode" za bajtni niz: >>> "abc" .decode ("ascii") u "abc"
- Funkcija "Unicode": >>> unicode ("abc", "ascii") u "abc"
"\ x61" -> kodiranje ascii -> mala latinična "a" -> u "\ u0061" (unicode-točka za to črko) ali "\ xe0" -> kodiranje c1251 -> mala cirilica "a" -> u " \ u0430 "
Kako dobiti navaden niz iz niza unicode? Kodiraj ga:
>>> u "abc" .encode ("ascii") "abc"
Algoritem kodiranja je seveda nasproten od zgoraj navedenega.
Zapomnite si in ne zamenjujte - unicode == znaki, niz == bajti in bajti -> nekaj smiselnega (znakov) je dekodirano, znaki -> bajti pa so kodirani.
Ni kodirano :(
Poglejmo si primere z začetka članka. Kako deluje povezovanje nizov in nizov Unicode? Preprost niz je treba spremeniti v niz unicode, in ker tolmač ne pozna kodiranja, uporablja privzeto kodiranje - ascii. Če to kodiranje ne uspe dekodirati niza, dobimo grdo napako. V tem primeru moramo sami pretvoriti niz v niz unicode s pravilnim kodiranjem:>>> vrsta tiskanja (parser_result), parser_result
"UnicodeDecodeError" je običajno znak za dekodiranje niza v Unicode z uporabo pravilnega kodiranja.
Zdaj uporabljate nize "str" in unicode. Ne uporabljajte nizov "str" in unicode :) V "str" ni mogoče določiti kodiranja, zato bo vedno uporabljeno privzeto kodiranje in vsi znaki> 128 bodo povzročili napako. Uporabite metodo "kodiranja":
>>> tip (e), s
"UnicodeEncodeError" je znak, da moramo določiti pravilno kodiranje pri pretvorbi niza unicode v navaden (ali uporabiti drugi parameter "ignore" \ "replace" \ "xmlcharrefreplace" v metodi "encode").
Hočem več!
V redu, spet uporabimo Babo Yago iz zgornjega primera:>>> parser_result = u "baba-yaga" # 1 >>> parser_result u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" # 2 >>> natisni parser_result baaba-jaga # 3 >>> print parser_result.encode ("latin1") # 4 baba yaga >>> print parser_result.encode ("latin1"). decode ("cp1251") # 5 baba yaga >>> print unicode ("baba yaga", "cp1251") ) # 6 baba-yaga
Primer ni povsem preprost, vendar obstaja vse (no ali skoraj vse). Kaj se tukaj dogaja:
- Kaj imamo na vhodu? Bajti, ki jih IDLE posreduje tolmaču. Kaj potrebuješ na izhodu? Unicode, torej znaki. Ostaja še, da spremenite bajte v znake - vendar potrebujete kodiranje, kajne? Kakšno kodiranje bo uporabljeno? Iščemo dalje.
- Tukaj je pomembna točka: >>> "baba-yaga" "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" >>> u "\ u00e1 \ u00e0 \ u00e1 \ u00e0- \ u00ff \ u00e3 \ u00e0" == u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" Res je, kot lahko vidite, se Python ne obremenjuje z izbiro kodiranja - bajti se preprosto pretvorijo v točke unicode:
>>> ord ("a") 224 >>> ord (u "a") 224 - Samo tukaj je težava - 224. znak v cp1251 (kodiranje, ki ga uporablja tolmač) sploh ni enak 224 v Unicode. Prav zaradi tega pride do razpoke, ko poskušamo natisniti naš niz unicode.
- Kako pomagati ženski? Izkazalo se je, da je prvih 256 znakov Unicode enakih kot v kodiranju ISO-8859-1 \ latin1, oziroma če ga uporabimo za kodiranje niza unicode, dobimo bajte, ki smo jih vnesli sami (koga zanima - Objekti / unicodeobject.c, iščem definicijo funkcije "unicode_encode_ucs1"):
>>> parser_result.encode ("latin1") "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" - Kako dobiti babo v unicode? Treba je navesti, katero kodiranje uporabiti:
>>> parser_result.encode ("latin1"). decode ("cp1251") u "\ u0431 \ u0430 \ u0431 \ u0430- \ u044f \ u0433 \ u0430" - Metoda iz točke # 5 zagotovo ni tako vroča, veliko bolj priročno je uporabljati vgrajeno Unicode.
Obstaja tudi način za uporabo "u" "" za predstavljanje, na primer cirilice, brez določanja kodiranja ali neberljivih točk unicode (to je "u" \ u1234 ""). Način ni povsem priročen, zanimiva pa je uporaba kod entitet entitet Unicode:
>>> s = u "\ N (CIRILIČNA MALA ČRKA KA) \ N (CIRILIČNA MALA ČRKA O) \ N (CIRILIČNA MALA ČRKA SHCHA) \ N (CIRILIČNA MALA ČRKA IE) \ N (CIRILIČNA MALA ČRKA KRATKA I)"> >> tiskanje s koshchey
No, to je vse. Glavni nasvet je, da ne zamenjate "kodiranja" \ "dekodiranja" in razumete razlike med bajti in znaki.
Python 3
Tukaj brez kode, ker ni izkušenj. Priče pravijo, da je tam vse veliko bolj preprosto in zabavno. Kdo se bo na mačkah lotil dokazovanja razlik med tukaj (Python 2.x) in tam (Python 3.x) - spoštovanje in spoštovanje.zdravo
Ker govorimo o kodiranju, bom priporočil vir, ki občasno pomaga premagati krakozyabry - http://2cyr.com/decode/?lang=ru.Unicode HOWTO je uradni dokument o tem, kje, kako in zakaj Unicode v Pythonu 2.x.
Hvala za vašo pozornost. Hvaležen bi bil za vaše zasebne komentarje. Dodajte oznake
Kodne točke Unicode in ruski znaki v izvornih kodah in programih Java. JDK 1.6.
Dovolj razvijalcev programsko opremo pravzaprav nimajo jasnega razumevanja naborov znakov, kodiranja, Unicode in sorodnih materialov. Tudi dandanes mnogi programi pogosto prezrejo pretvorbe znakov, na katere naletijo, tudi programi, za katere se zdi, da so bili zasnovani z Unicode prijaznimi tehnologijami Java. Pogosto se uporablja neprevidno za 8-bitne znake, zaradi česar je nemogoče razviti dobre večjezične spletne aplikacije. Ta članek je kompilacija serije člankov o kodiranju Unicode, vendar je temeljni članek revidirani članek Joela Spolskyja Absolutni minimum, ki ga mora vsak razvijalec programske opreme popolnoma, pozitivno vedeti o Unicode in naborih znakov (10/08/2003).Zgodovina ustvarjanja različnih vrst kodiranja
Vse stvari, ki pravijo "navadno besedilo = ASCII = 8-bitni znaki", niso pravilne. Edini znaki, ki so se lahko v kakršnih koli okoliščinah pravilno prikazali, so bile angleške črke brez diakritičnih znakov s kodami od 32 do 127. Za te znake obstaja koda, imenovana ASCII, ki je lahko predstavljala vse znake. Črka "A" bi imela kodo 65, presledek bi bila koda 32 itd. Te znake je mogoče priročno shraniti v 7 bitov. Večina računalnikov v tistih časih je uporabljala 8-bitne registre, tako da si lahko shranil vse možne znake ASCII, imel pa si tudi cel del prihrankov, ki bi jih, če bi imel takšno muhavost, lahko uporabil za svoje namene. Kode, manjše od 32, so se imenovale nenatisljive in so bile uporabljene za kontrolne znake, na primer znak 7 je povzročil, da je vaš računalnik oddajal pisk zvočnika, znak 12 pa je bil znak na koncu strani, zaradi česar se je tiskalnik pomikal po trenutnem listu. papirja in naložite novega.
Ker so bajti osem bitov, so mnogi mislili, da "lahko uporabimo kode 128-255 za lastne namene." Težava je bila v tem, da je za toliko ljudi ta ideja prišla skoraj istočasno, vendar je vsak imel svoje ideje o tem, kaj bi bilo treba postaviti na svoje mesto s kodami od 128 do 255. IBM-PC je imel nekaj, kar je postalo znano kot nabor znakov OEM, ki je imel nekaj diakritičnih znakov za evropske jezike in niz znakov za risanje črt: vodoravne črte, navpične črte, vogali, križi itd. S temi simboli lahko naredite elegantne gumbe in narišete črte na zaslonu, ki jih lahko še vedno vidite na nekaterih starejših računalnikih. Na primer, na nekaterih osebnih računalnikih je bila znakska koda 130 prikazana kot e, na računalnikih, ki se prodajajo v Izraelu, pa je bila hebrejska črka Gimel (?). Če bi Američani poslali svoj življenjepis v Izrael, bi prispel kot r? Sum?. V mnogih primerih, na primer v primeru ruskega jezika, je bilo veliko različnih idej, kaj storiti z zgornjimi 128 znaki, in zato niste mogli zanesljivo zamenjati niti dokumentov v ruskem jeziku.
Navsezadnje je bila raznolikost kodiranja OEM zmanjšana na standard ANSI. Standard ANSI je določal, kateri znaki so pod 128, to področje je bilo v bistvu enako kot v ASCII, vendar jih je bilo veliko različne poti upravljajte znake 128 in več, odvisno od tega, kje ste živeli. Te različne sisteme imenujemo kodne strani. Na primer, v Izraelu je DOS uporabil kodno stran 862, grški uporabniki pa stran 737. Pod 128 so bili enaki, vendar različni od 128, kjer so bili vsi ti znaki. Nacionalne različice MS-DOS so podpirale številne od teh kodnih strani, obdelovale so vse jezike od angleščine do islandščine in obstajalo je celo nekaj "večjezičnih" kodnih strani, ki bi jih lahko naredila esperanto in galicijski. Skupina jezikov, razširjena v Španiji, domača zvočnikov 4 milijonov ljudi) na istem računalniku! Toda pridobivanje, recimo, hebrejščine in grščine na istem računalniku je bilo absolutno nemogoče, razen če nisi napisal lastnega programa, ki je vse prikazal z uporabo bitne grafike, ker sta hebrejščina in grščina zahtevala različne kodne strani z različnimi interpretacijami.glavne številke.
Medtem je v Aziji, glede na dejstvo, da imajo azijske abecede na tisoče črk, ki se nikoli ne morejo prilegati 8 bitov, to težavo rešil zapleten sistem DBCS, "dvobajtni nabor znakov", kjer so bili nekateri znaki shranjeni v enem bajtu, drugi pa vzel dve. Bilo je zelo enostavno premikati naprej vzdolž črte, absolutno nemogoče pa se je premikati nazaj. Programerji niso mogli uporabljati s++ in s-- za premikanje naprej in nazaj, zato so morali poklicati posebne funkcije ki je vedel, kako se spopasti s to zmešnjavo.
Vendar pa je večina ljudi zatiskala oči pred dejstvom, da je bajt znak, znak pa 8 bitov, in dokler vam ni bilo treba premakniti vrstice iz enega računalnika v drugega ali če niste govorili več kot en jezik, je delovalo. Seveda pa je takoj, ko se je internet začel množično uporabljati, postalo precej običajno prenašati linije z enega računalnika na drugega. Kaos v tej zadevi je bil premagan z Unicode.
Unicode
Unicode je bil drzen poskus ustvariti en sam nabor znakov, ki bi vključeval vse resnične sisteme pisanja na planetu, pa tudi nekatere izmišljene. Nekateri ljudje imajo napačno prepričanje, da je Unicode običajna 16-bitna koda, kjer je vsak znak dolg 16 bitov in je zato možnih 65.536 znakov. Pravzaprav to ni res. To je najpogostejša napačna predstava o Unicode.
Pravzaprav Unicode uporablja nenavaden pristop k razumevanju koncepta znaka. Doslej smo domnevali, da so znaki preslikani v niz bitov, ki jih lahko shranite na disk ali v pomnilnik:
A - & gt 0100 0001
V Unicode se znak preslika v nekaj, kar se imenuje kodna točka, kar je le teoretični koncept. Kako je ta kodna točka predstavljena v pomnilniku ali na disku, je druga zgodba. V Črka Unicode In to je samo platonska ideja (eidos) (pribl. prevod: koncept Platonove filozofije, eidos so idealne entitete, brez telesnosti in so resnično objektivna realnost, zunaj specifičnih stvari in pojavov).
A E to Platonov A je drugačen od B in drugačen od a, ampak je isto A kot A in A. Ideja, da In v Times New Roman je enako kot A v Helvetici, vendar se razlikuje od male črke "a" v razumevanju ljudi ne zdi preveč kontroverzna. Toda z vidika računalništva in z vidika jezika je sama definicija črke protislovna. Ali je nemška črka ß prava črka ali le domišljen način pisanja ss? Če se črkovanje črke na koncu besede spremeni, ali postane druga črka? Hebrejščina pravi da, arabščina pravi ne. Kakorkoli že, pametni ljudje v konzorciju Unicode so to ugotovili po dolgi politični razpravi in ni vam treba skrbeti za to. Pred nami je že vse razumljeno.Vsaki platonski črki v vsaki abecedi je konzorcij Unicode dodelil čarobno številko, ki je zapisana takole: U + 0645. Ta čarobna številka se imenuje kodna točka. U + pomeni "Unicode", številke pa so šestnajstiške. Številka U + FEC9 je arabska črka Ain. Angleška črka A ustreza U + 0041.
Število črk, ki jih je mogoče identificirati z Unicode, res ni, in dejansko so že presegle mejo 65.536, tako da se vsake črke iz Unicode dejansko ne da stisniti v dva bajta.
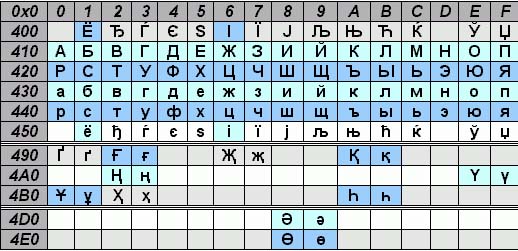
Za cirilico v UNICODE je razpon kod od 0x0400 do 0x04FF. Ta tabela prikazuje le del znakov v tem obsegu, vendar standard definira večino kod v tem obsegu.
Predstavljajmo si, da imamo vrstico:
Zdravo! ki se v Unicode ujema s temi sedmimi kodnimi točkami: U + 041F U + 0440 U + 0438 U + 0432 U + 0435 U + 0442 U + 0021
Samo kup kodnih točk. Številke so resnične.
Če želite videti, kako bo izgledala besedilna datoteka Unicode, lahko zaženete program beležnice v sistemu Windows, vstavite dano vrstico in pri shranjevanju besedilna datoteka izberite kodiranje Unicode.
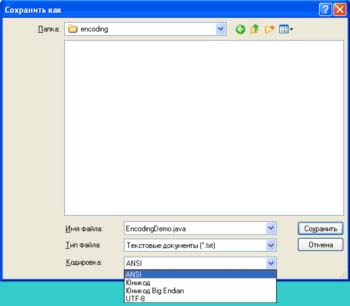
Program ponuja varčevanje v treh različicah Kodiranja Unicode... Prva možnost je način pisanja z najmanjšim bajtom spredaj (mali endian), druga z najpomembnejšim bajtom spredaj (big endian). Katera možnost je pravilna?
Tako izgleda datoteka velikega endian dump z nizom "Hello!":
In takole izgleda izpis datoteke z nizom "Hello!", shranjen v formatu Unicode (mali endian):
In takole izgleda izpis datoteke z nizom "Hello!", shranjen v formatu Unicode (UTF-8):
Zgodnje izvedbe so želele imeti možnost shranjevanja kodnih točk Unicode v formatu visokega ali nizkega konca, odvisno od tega, v kateri obliki je bil njihov procesor hitrejši. Potem sta obstajala dva načina za shranjevanje Unicode. To je privedlo do izmišljene konvencije shranjevanja kode \ uFFFE na začetku vsake vrstice Unicode. Ta podpis se imenuje oznaka zaporedja bajtov. Če zamenjate visoke in nizke bajte, mora biti \ uFFFE na začetku in oseba, ki bere vašo vrstico, bo vedela, da zamenja bajte v vsakem paru. Ta podpis je rezerviran v standardu Unicode.
Standard Unicode pravi, da je privzeti vrstni red bajtov bodisi big endian ali small endian. Dejansko sta oba naročila pravilna in oblikovalci sistemov si izberejo enega izmed njih. Ne skrbite, če vaš sistem komunicira z drugim sistemom in oba uporabljata mali endian.
Če pa vaš Windows komunicira s strežnikom UNIX, ki uporablja big endian, mora en od sistemov izvesti prekodiranje. V tem primeru Standard Unicode navaja, da lahko izberete katero koli od naslednjih rešitev problema:
- Ko dva sistema, ki uporabljata različen vrstni red bajtov Unicode, izmenjujeta podatke (brez uporabe posebnih protokolov), mora biti vrstni red bajtov big endian. Standard to imenuje kanonično vrstni red bajtov.
- Vsak niz Unicode se mora začeti s kodo \ uFEFF. Koda \ uFFFE, ki je inverzija znaka naročila. Če torej prejemnik vidi kodo \ uFEFF kot prvi znak, to pomeni, da so bajti v malem endianem vrstnem redu. Vendar v resnici vsak niz Unicode nima oznake za vrstni red bajtov na začetku.
Druga metoda je bolj vsestranska in boljša.
Nekaj časa so se vsi zdeli zadovoljni, a angleško govoreči programerji so gledali večinoma angleško besedilo in redko uporabljali kodne točke nad U + 00FF. Že samo zaradi tega so Unicode mnogi ignorirali že nekaj let.
Briljanten koncept UTF-8 je bil izumljen posebej za to.
UTF-8
UTF-8 je bil še en sistem za shranjevanje vašega zaporedja kodnih točk Unicode, samih U + številk, z uporabo istih 8 bitov v pomnilniku. V UTF-8 je bila vsaka kodna točka od 0 do 127 shranjena v enem bajtu.
Pravzaprav je to kodiranje s spremenljivim številom kodirnih bajtov za shranjevanje, uporabljenih je 2, 3 in dejansko do 6 bajtov. Če znak pripada naboru ASCII (koda v območju 0x00-0x7F), je v enem bajtu kodiran na enak način kot v ASCII. Če je unicode znaka večji ali enak 0x80, so njegovi biti zapakirani v zaporedje bajtov v skladu z naslednjim pravilom:
Morda boste opazili, da če se bajt začne z ničelnim bitom, je to enobajtni znak ASCII. Če se bajt začne z 11 ..., potem je to začetni bajt večbajtnega zaporedja, ki kodira znak, katerega število glavnih enot je enako številu bajtov v zaporedju. Če se bajt začne z 10 ..., potem gre za serijski "transportni" bajt iz zaporedja bajtov, katerih število je bilo določeno z začetnim bajtom. no in Unicode bit znaki so pakirani v "transportne" bite začetnih in serijskih bajtov, ki so v tabeli označeni kot zaporedje "xx..x".
Spremenljivo število bajtov kodiranja je razvidno iz spodnjega izpisa datoteke.
Izpis datoteke z nizom »Hello!« Shranjen v formatu Unicode (UTF-8):
Dump datoteko z nizom "Hello!", shranjeno v formatu Unicode (UTF-8):
Lep stranski učinek tega je, da je angleško besedilo v UTF-8 videti popolnoma enako kot v ASCII, tako da Američani niti ne opazijo, da je nekaj narobe. Le preostali svet mora premagati ovire. Natančneje, Pozdravljeni, kar je bilo U + 0048 U + 0065 U + 006C U + 006C U + 006F bo zdaj shranjeno v istem 48 65 6C 6C 6F, tako kot ASCII in ANSI ter kateri koli drugi nastavljeni OEM simboli na planetu. Če ste dovolj pogumni, da uporabite diakritične znake oz grške črke ali črke klingonske, boste morali uporabiti več bajtov za shranjevanje ene kodne točke, a Američani tega ne bodo nikoli opazili. UTF-8 ima tudi lepo lastnost: stara koda, ki ne pozna novega formata niza in ravna z nizi z ničelnim bajtom na koncu vrstice, ne bo skrajšala nizov.
Druga kodiranja Unicode
Vrnimo se na tri načine kodiranja Unicode. Tradicionalne metode"shrani v dveh bajtih" se imenuje UCS-2 (ker ima dva bajta) ali UTF-16 (ker ima 16 bitov), in še vedno morate ugotoviti, ali je to koda UCS-2 z visokim bajtom na začetek ali z najpomembnejšim bajtom na koncu. In tu je priljubljen standard UTF-8, katerega nizi imajo lepo funkcijo, da delujejo tudi v starih programih, ki delujejo z angleškim besedilom, in v novih pametnih programih, ki odlično delujejo na drugih naborih znakov poleg ASCII.
Pravzaprav obstaja cel kup drugih načinov za kodiranje Unicode. Obstaja nekaj, kar se imenuje UTF-7, ki je zelo podoben UTF-8, vendar zagotavlja, da je najpomembnejši bit vedno nič. Potem je tu še UCS-4, ki vsako kodno točko shrani v 4 bajte in zagotavlja, da so absolutno vsi znaki shranjeni v enakem številu bajtov, vendar takšna zapravljanje pomnilnika ni vedno upravičena s takšno garancijo.
Lahko na primer Unicode niz Hello (U + 0048 U + 0065 U + 006C U + 006C U + 006F) v ASCII ali stari OEM grščini ali hebrejščini ANSI kodiranje, ali v katerem koli od več sto kodiranj, ki so bili izumljeni do danes, z eno težavo: nekateri znaki morda ne bodo prikazani! Če ni enakovrednega za kodno točko Unicode, za katero poskušate najti enakovredno v nekaterih kodna tabela za katerega poskušate izvesti pretvorbo, običajno dobite majhen vprašaj:? ali, če si res dober programer, potem kvadrat.
Obstaja na stotine tradicionalnih kodiranj, ki lahko pravilno shranijo le nekatere kodne točke in vse druge kodne točke nadomestijo z vprašaji. Na primer, nekatera priljubljena kodiranja angleškega besedila so Windows 1252 ( Windows standard 9x za zahodnoevropske jezike) in ISO-8859-1, tudi latinski-1 (primeren tudi za kateri koli zahodnoevropski jezik). Toda poskusite pretvoriti ruske ali hebrejske črke v ta kodiranja in na koncu boste imeli precej vprašanj. Odlična stvar pri UTF 7, 8, 16 in 32 je njihova sposobnost, da pravilno shranijo katero koli kodno točko.
32-bitne kodne točke za znake Unicode v Javi
Java 2 5.0 uvaja pomembne izboljšave tipov znakov in nizov za podporo 32-bitnim Znaki Unicode... V preteklosti je bilo mogoče vse znake Unicode shraniti v šestnajst bitov, ki so enaki velikosti znaka (in velikosti vrednosti, ki jo vsebuje objekt Character), saj so bile te vrednosti v območju od 0 do FFFF. Toda že nekaj časa je bil nabor znakov Unicode razširjen in zdaj zahteva več kot 16 bitov za shranjevanje znaka. Nova različica naborov znakov Unicode vključuje znake v razponu od 0 do 10FFFF.
Kodna točka ali kodna točka, kodna enota ali kodna enota in dodatni znak. Za Javo je kodna točka znakovna koda v območju od 0 do 10FFFF. V jeziku Java se izraz "enota kode" uporablja za označevanje 16-bitnih znakov. Znaki z vrednostmi, večjimi od FFFF, se imenujejo komplementarni.
Razširitev nabora znakov Unicode je povzročila temeljne težave za jezik Java... Ker ima dodatni znak večjo vrednost, kot jo lahko sprejme tip char, so bila potrebna nekatera sredstva za shranjevanje in obdelavo dodatnih znakov. V različice Java 2 5.0 odpravlja to težavo na dva načina. Prvič, jezik Java uporablja dve vrednosti char za predstavitev dodatnega znaka. Prvi se imenuje visoki nadomestek, drugi pa nizki nadomestek. Razvite so bile nove metode, kot je codePointAt (), za pretvorbo kodnih točk v dodatne znake in obratno.
Drugič, Java preobremeni nekatere že obstoječe metode v razredih Character in String. Preobremenjene različice metod uporabljajo podatke tipa int namesto char. Ker je velikost spremenljivke ali konstante tipa int dovolj velika, da sprejme kateri koli znak kot eno samo vrednost, je ta tip mogoče uporabiti za shranjevanje katerega koli znaka. Na primer, metoda isDigit () ima zdaj dve možnosti, kot je prikazano spodaj:
Prva od teh možnosti je izvirna, druga pa različica, ki podpira 32-bitne kodne točke. Metode All is…, kot sta isLetter () in isSpaceChar (), imajo različice kodne točke, tako kot metode to…, kot sta toUpperCase () in toLowerCase ().
Poleg metod, ki so preobremenjene za obdelavo kodnih točk, jezik Java vključuje nove metode v razred Character, ki zagotavljajo dodatno podporo za kodne točke. Nekateri od njih so navedeni v tabeli:
| Metoda | Opis |
| statični int charCount (int cp) | Vrne 1, če je cp mogoče predstaviti z enim samim znakom. Vrne 2, če sta potrebni dve vrednosti znakov. |
| static int codePointAt (znaki zaporedja znakov, int loc) | |
| static int codePointAt (char chars, int loc) | Vrne kodno točko za položaj znaka, podan v parametru loc |
| static int codePointBefore (znaki zaporedja znakov, int loc) | |
| static int codePointBefore (char chars, int loc) | Vrne kodno točko za položaj znaka pred tistim, ki je podan v parametru loc |
| statični logični isSupplementaryCodePoint (int cp) | Vrne true, če cp vsebuje dodaten znak |
| statični logični jeHighSurrogate (char ch) | Vrne true, če ch vsebuje veljaven nadomestek zgornjega znaka. |
| statični boolean isLowSurrogate (char ch) | Vrne true, če ch vsebuje veljaven nadomestek nižjega znaka. |
| statični logični isSurrogatePair (char highCh, char lowCh) | Vrne true, če highCh in lowCh tvorita veljaven nadomestni par. |
| statična logična vrednost isValidCodePoint (int cp) | Vrne true, če cp vsebuje veljavno kodno točko. |
| statični znak toChars (int cp) | Pretvori kodno točko, ki jo vsebuje cp, v njen ekvivalent char, kar lahko zahteva dve vrednosti char. Vrne matriko, ki vsebuje rezultat ... Dodaj !!! |
| statični int toChars (int cp, char target, int loc) | Pretvori kodno točko, ki jo vsebuje cp, v njen ekvivalent char, shrani rezultat v cilj, začenši na položaju, določenem v loc. Vrne 1, če je cp mogoče predstaviti z enim znakom, in 2 v nasprotnem primeru. |
| statični int toCodePoint (char ighCh, char lowCh) | Pretvori highCh in lowCh v njuni enakovredni kodni točki. |
Razred String ima številne metode za ravnanje s kodnimi točkami. Razredu String je bil dodan tudi naslednji konstruktor, ki podpira razširjen nabor znakov Unicode:
String (int codePoints, int startIndex, int numChars)
V zgornji sintaksi je codePoints matrika, ki vsebuje kodne točke. Nastali niz dolžine numChars se oblikuje, začenši s položaja startIndex.
Več metod razreda String, ki zagotavljajo podporo za 32-bitne kodne točke za znake Unicode.
Izhod konzole v sistemu Windows. Ukaz Chcp
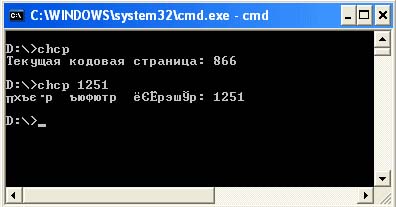
večina preprosti programi napisano v Javi, izpis vseh podatkov v konzolo. Izhod konzole omogoča izbiro kodiranja, v katerem bodo izpisani podatki vašega programa. Okno konzole lahko zaženete tako, da kliknete Start -> Zaženi, nato pa vstopite in zaženite ukaz cmd... Privzeto je izhod na konzolo v sistemu Windows v kodiranju Cp866. Če želite izvedeti, v kakšnem kodiranju so znaki prikazani v konzoli, vnesite ukaz chcp. Z istim ukazom lahko nastavite kodiranje, v katerem bodo prikazani znaki. Na primer chcp 1251. Pravzaprav je ta ukaz ustvarjen samo zato, da odraža ali spremeni trenutno številko kodne strani ukazne mize.
Kodne strani, ki niso Cp866, se bodo pravilno prikazale samo v celozaslonskem načinu ali v oknu ukazna vrstica z uporabo pisav TrueType. Na primer:
Če želite videti nadaljnji izpis, morate trenutno pisavo spremeniti v pisavo True Type. Premaknite kazalec nad naslov okna konzole, kliknite desni klik miško in izberite možnost "Lastnosti". V oknu, ki se prikaže, pojdite na zavihek Pisava in v njem izberite pisavo, nasproti katere bo dvojna črka T. Pozvani boste, da shranite to nastavitev za trenutno okno ali za vsa okna.
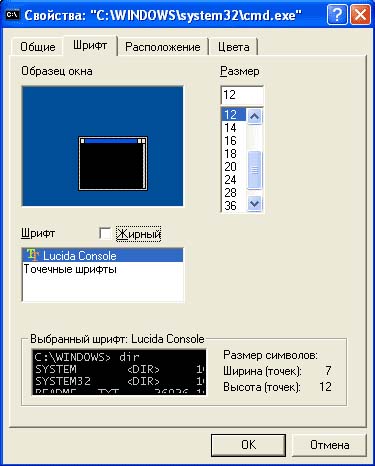
Posledično bo okno vaše konzole videti tako:
Tako lahko z manipuliranjem tega ukaza vidite rezultate izhoda vašega programa, odvisno od kodiranja.
Lastnosti sistema file.encoding, console.encoding in izhod konzole
Preden se dotaknete teme kodiranja v izvornih kodah programov, morate jasno razumeti, čemu služijo in kako delujejo sistemske lastnosti file.encoding in console.encoding. Poleg teh sistemskih lastnosti obstajajo še številne druge. Vse trenutne lastnosti sistema lahko prikažete z naslednjim programom:
Uvozi java.io. *; uvozi java.util. *; javni razred getPropertiesDemo (javni statični void main (String args) (String s; for (Enumeration e = System.getProperties (). propertyNames (); e.hasMoreElements ();) (s = e.nextElement (). toString () ; System.out.println (s + "=" + System.getProperty (s));)))
Vzorčni izhod programa:
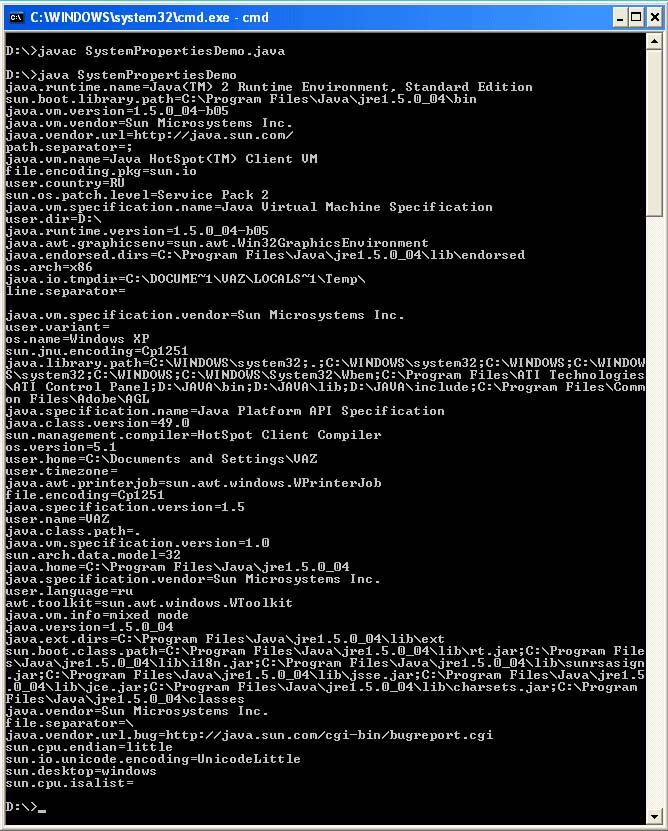
V operacijskem sistemu Windows je privzeto file.encoding = Сp1251. Vendar pa obstaja še ena lastnost, console.encoding, ki določa, v katerem kodiranju se izpiše v ukazno mizo. file.encoding pove stroju Java, v katerem kodiranju naj prebere izvorne kode programov, če kodiranja med prevajanjem uporabnik ne določi. Pravzaprav ta lastnost sistema velja tudi za izhod z uporabo System.out.println ().
Ta lastnost privzeto ni nastavljena. Te sistemske lastnosti lahko nastavite tudi v vašem programu, vendar zanj ne bodo več pomembne, saj virtualni stroj uporablja vrednosti, ki so bile prebrane pred prevajanjem in izvajanjem vašega programa. Prav tako se takoj, ko se vaš program zažene, obnovijo lastnosti sistema. To lahko preverite tako, da dvakrat zaženete naslednji program.
/ ** * @author & lta href = "mailto: [email protected]"& gt Victor Zagrebin & lt / a & gt * / javni razred SetPropertyDemo (javni statični void main (String args) (System.out.println (" file.encoding before = "+ System.getProperty (" file.encoding ") ); System. out.println ("console.encoding pred =" + System.getProperty ("console.encoding")); System.setProperty ("file.encoding", "Cp866"); System.setProperty ("console. kodiranje", " Cp866 "); System.out.println (" file.encoding after = "+ System.getProperty (" file.encoding ")); System.out.println (" console.encoding after = "+ System. getProperty (" console .encoding "));)) 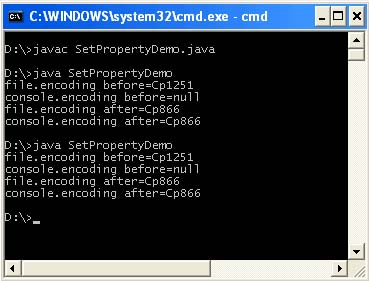
Nastavitev teh lastnosti v programu je potrebna, če se uporablja v naslednji kodi, preden se program zaključi.
Reproducirajmo nekaj tipičnih primerov s težavami, s katerimi se srečujejo programerji med izpisom. Recimo, da imamo naslednji program:
Javni razred CyryllicDemo (javni statični void main (String args) (String s1 = ""; String s2 = ""; System.out.println (s1); System.out.println (s1);)) Poleg tega programa , bomo uporabili dodatne dejavnike:
- ukaz za prevajanje;
- ukaz za zagon;
- kodiranje izvorne kode programa (nameščeno v večini urejevalnikov besedil);
- kodiranje izhoda konzole (Cp866 se uporablja privzeto ali nastavljen z ukazom chcp);
- viden izhod v oknu konzole.
javac CyrillicDemo.java
java CyrillicDemo
Kodiranje datoteke: Cp1251
Kodiranje konzole: Cp866
Zaključek:
└┴┬├─┼╞╟╚╔╩╦╠═╬╧╨╤╥╙╘╒╓╫╪┘▄█┌▌▐ ▀
rstufhtschshshch'yueyuyoЄєЇїЎў °∙№√ ·¤■
javac CyrillicDemo.java
Kodiranje datoteke: Cp866
Kodiranje konzole: Cp866
Zaključek:
CyryllicDemo.java:5: opozorilo: znak, ki ga ni mogoče preslikati za kodiranje Cp1251
Niz s1 = "ABVGDEZHZYKLMNOPRSTUFHTSCH? SHY'EUYA";
javac CyryllicDemo.java -kodiranje Cp866
java -
Kodiranje datoteke: Cp 866
Kodiranje konzole: Cp866
Zaključek:
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshshchyyueyuya
javac CyryllicDemo.java -kodiranje Cp1251
java -Dfile.encoding = Cp866 CyrillicDemo
Kodiranje datoteke: Cp1251
Kodiranje konzole: Cp866
Zaključek:
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshshchyyueyuya
Posebno pozornost je treba nameniti problemu "Kam je šla črka Ш?" iz druge serije izstrelitev. Na to težavo bi morali biti še bolj pozorni, če ne veste vnaprej, katero besedilo bo shranjeno v izhodnem nizu in bo naivno prevedeno brez navedbe kodiranja. Če v vrstici res nimate črke Ш, bo kompilacija uspešna in tudi zagon bo uspešen. In pri tem boste celo pozabili, da vam manjka malenkost (črka W), ki se lahko pojavi v izhodni vrstici in bo neizogibno vodila v nadaljnje napake.
V tretji in četrti seriji se pri prevajanju in izvajanju uporabljajo naslednji ključi: -encoding Cp866 in -Dfile.encoding = Cp866. Stikalo -encoding določa, v katerem kodiranju naj se prebere datoteka izvorno kodo programi. Stikalo -Dfile.encoding = Cp866 označuje, v kakšnem kodiranju naj se izpiše.
Predpona Unicode \ u in ruski znaki v izvornih kodah
Java ima posebno predpono \ u za pisanje znakov Unicode, ki ji sledijo štiri šestnajstiške številke, ki definirajo sam znak. Na primer, \ u2122 je znak blagovna znamka(™). Ta oblika zapisa izraža znak katere koli abecede z uporabo številk in predpone - znakov, ki so vsebovani v stabilnem območju kod od 0 do 127, na kar ne vpliva pretvorba izvorne kode. Teoretično je mogoče kateri koli znak Unicode uporabiti v aplikaciji ali programčku Java, toda ali se bo pravilno prikazal na zaslonu in ali se bo sploh prikazal, je odvisno od številnih dejavnikov. Pri programčkih je pomembna vrsta brskalnika, za programe in programčke pa vrsta operacijskega sistema in kodiranje, v katerem je zapisana izvorna koda programa.
Na primer v računalnikih z ameriško različico sistemi Windows, zaradi internacionalizacije ni mogoče prikazati japonskih znakov v jeziku Java.
Kot drugi primer lahko navedemo precej pogosto napako programerjev. Mnogi ljudje mislijo, da lahko določitev ruskih znakov v formatu Unicode s predpono \ u v izvorni kodi programa reši težavo s prikazovanjem ruskih znakov v vseh okoliščinah. Navsezadnje navidezni stroj Java prevede izvorno kodo programa v Unicode. Vendar pa mora navidezni stroj pred prevajanjem v Unicode vedeti, v kakšnem kodiranju je zapisana izvorna koda vašega programa. Navsezadnje lahko napišete program tako v kodiranju Cp866 (DOS) kot Cp1251 (Windows), kar je značilno za to situacijo. Če niste navedli nobenega kodiranja, navidezni stroj Java prebere vašo datoteko z izvorno kodo programa v kodiranju, podanem v sistemski lastnosti file.encoding.
Vendar pa se vrnemo k privzetim parametrom, predpostavimo, da je file.encoding = Сp1251, izhod v konzolo pa se izvede v Cp866. V tem primeru se pojavi naslednja situacija: recimo, da imate datoteko, kodirano v Сp1251:
Datoteka MsgDemo1.java
Javni razred MsgDemo1 (javni statični void main (String args) (String s = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A \ u0430"; System.out.printl ;))
In pričakujete, da bo beseda "kodiranje" natisnjena na konzolo, vendar dobite:
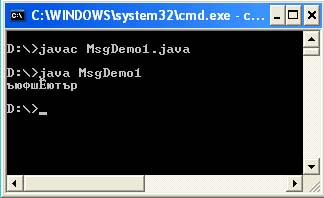
Dejstvo je, da kode s predpono \u, ki je navedena v programu, resnično kodirajo zahtevane cirilice v kodni tabeli Unicode, vendar so zasnovane za dejstvo, da bo izvorna koda vašega programa prebrana v Cp866 (DOS) kodiranje. Kodiranje Cp1251 je privzeto določeno v sistemskih lastnostih (file.encoding = Cp1251). Seveda je prva in napačna stvar, ki pride na misel, spremeniti kodiranje datoteke z izvorno kodo programa v urejevalniku besedil. Ampak to te ne bo pripeljalo nikamor. Java VM bo vašo datoteko še vedno prebral v kodiranju Cp1251, kode \u pa so za Cp866.
Obstajajo trije izhodi iz te situacije. Prva možnost je uporaba stikala -encoding v času prevajanja in –Dfile.encoding v fazi zagona programa. V tem primeru prisilite navidezni stroj Java, da prebere izvorno datoteko v podanem kodiranju in izpiše v podanem kodiranju.
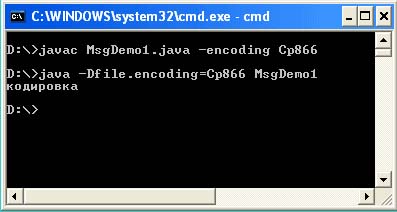
Kot lahko vidite iz izhoda konzole, je treba med prevajanjem nastaviti dodatni parameter –encoding Cp866, ob zagonu pa je treba nastaviti parameter –Dfile.encoding = Cp866.
Druga možnost je prekodiranje znakov v samem programu. Zasnovan je za obnovitev pravilnih črkovnih kod, če so bile napačno razložene. Bistvo metode je preprosto: iz prejetih napačnih znakov se z uporabo ustrezne kodne strani obnovi izvirni bajtni niz. Nato se iz tega niza bajtov z uporabo že pravilne strani pridobijo običajne kode znakov.
Za pretvorbo toka bajtov v niz in obratno ima razred String naslednje zmožnosti: konstruktor niza (byte bytes, String enc), ki prejme tok bajtov kot vhod z navedbo njihovega kodiranja; če izpustite kodiranje, bo sprejelo privzeto kodiranje iz sistemske lastnosti file.encoding. Metoda getBytes (String enc) vrne tok bajtov, napisanih v podanem kodiranju; kodiranje lahko tudi izpustite in sprejeto bo privzeto kodiranje iz sistemske lastnosti file.encoding.
Primer:
Datoteka MsgDemo2.java
Uvozi java.io.UnsupportedEncodingException; javni razred MsgDemo2 (javni statični void main (String args) vrže UnsupportedEncodingException (String str = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A \ u0432" + "\ u043A" \ u043A" \ ute b ("Cp866"); String str2 = nov niz (b, "Cp1251"); System.out.println (str2);))
Izhod programa:
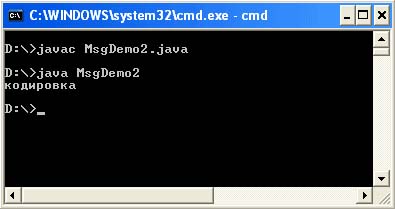
Ta metoda je manj prilagodljiva, če vas vodi dejstvo, da se kodiranje v sistemski lastnosti file.encoding ne bo spremenilo. Vendar pa lahko ta metoda postane najbolj prilagodljiva, če vprašate sistemsko lastnost file.encoding in nadomestite nastalo vrednost kodiranja pri oblikovanju nizov v vašem programu. Uporaba ta metoda pazite, da vse strani ne izvedejo nedvoumne pretvorbe bajtnih znakov.
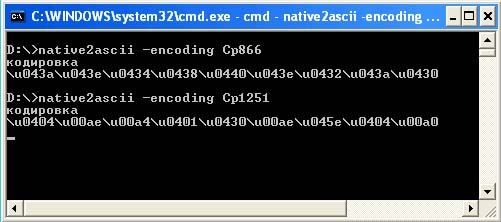
Tretji način je, da izberete pravilne kode Unicode za prikaz besede "kodiranje" ob predpostavki, da bo datoteka prebrana v privzetem kodiranju - Cp1251. Za te namene obstaja poseben pripomoček native2ascii.
Ta pripomoček je del Sun JDK in je zasnovan za pretvorbo izvorne kode v format ASCII. Ko se zažene brez parametrov, deluje s standardnim vnosom (stdin) in ne prikaže namiga za ključe kot drugi pripomočki. To vodi v dejstvo, da se mnogi sploh ne zavedajo, da je treba določiti parametre (razen tistih, ki so si ogledali dokumentacijo). Medtem pa ta pripomoček za pravilno delo morate vsaj določiti uporabljeno kodiranje s stikalom -encoding. Če tega ne storite, bo uporabljeno privzeto kodiranje (file.encoding), ki se lahko nekoliko razlikuje od pričakovanega. Posledično, ko ste prejeli napačne črkovne kode (zaradi napačnega kodiranja), lahko porabite veliko časa za iskanje napak v popolnoma pravilni kodi.
Naslednji posnetek zaslona prikazuje razliko v kodnih zaporedjih Unicode za isto besedo, ko bo izvorna datoteka prebrana v kodiranju Cp866 in Cp1251.
Torej, če ne vsilite kodiranja za navidezni stroj Java v času prevajanja in ob zagonu, privzeto kodiranje (file.encoding) pa je Cp1251, potem naj bi izvorna koda programa izgledala takole:
Datoteka MsgDemo3.java
Javni razred MsgDemo3 (javni statični void main (String args) (String s = "\ u0404 \ u00AE" + "\ u00A4 \ u0401 \ u0430 \ u00AE \ u045E" + "\ u0404 \ u00A0"; System.out.println) ;)) 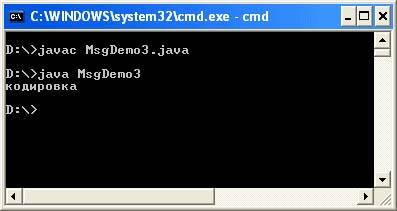
S tretjo metodo lahko sklepamo: če kodiranje datoteke z izvorno kodo v urejevalniku sovpada s kodiranjem v sistemu, se bo sporočilo o "kodiranju" prikazalo v običajni obliki.
Branje in zapisovanje v datoteko ruskih znakov, izraženih s predpono Unicode \ u
Za branje podatkov, zapisanih tako v obliki zapisa MBCS (z uporabo kodiranja UTF-8) kot v formatu Unicode, lahko uporabite razred InputStreamReader iz paketa java.io in v njegovem konstruktorju nadomestite različna kodiranja. Za pisanje se uporablja OutputStreamWriter. Opis paketa java.lang pravi, da bo vsaka implementacija JVM podpirala naslednja kodiranja:
WriteDemo.java datoteko
Uvozi java.io.Writer; uvoz java.io.OutputStreamWriter; uvoz java.io.FileOutputStream; uvoz java.io.IOException; / ** * Iznesite niz Unicode v datoteko v podanem kodiranju. * @author & lta href = "mailto: [email protected]"& gt Victor Zagrebin & lt / a & gt * / javni razred WriteDemo (javni statični void main (String args) vrže IOException (String str =" \ u043A \ u043E "+" \ u0434 \ u0438 \ u0440 \ u043E \ u0432 " +" \ u043A \ u0430 "; Writer out1 = nov OutputStreamWriter (nov FileOutputStream (" out1.txt ")," Cp1251 "); Writer out2 = nov OutputStreamWriter (nov FileOutputStream (" out2.txt ")," C); Writer out3 = nov OutputStreamWriter (nov FileOutputStream ("out3.txt"), "UTF-8"); Writer out4 = nov OutputStreamWriter (nov FileOutputStream ("out4.txt"), "Unicode"); out1.write (str) ; out1.close (); out2.write (str); out2.close (); out3.write (str); out3.close (); out4.write (str); out4.close ();)) Kompilacija: javac WriteDemo.java Zaženi: java WriteDemo
Kot rezultat izvajanja programa je treba v imeniku za zagon programa ustvariti štiri datoteke (out1.txt out2.txt out3.txt out4.txt), od katerih bo vsaka vsebovala besedo "kodiranje" v drugem kodiranju, ki ga je mogoče prijavljen urejevalniki besedil ali z ogledom izpisa datoteke.
Naslednji program bo prebral in prikazal vsebino vsake od ustvarjenih datotek.
ReadDemo.java uvoz datoteke java.io.Reader; uvoz java.io.InputStreamReader; uvoz java.io.InputStream; uvoz java.io.FileInputStream; uvoz java.io.IOException; / ** * Branje znakov Unicode iz datoteke v določenem kodiranju. * @author & lta href = "mailto: [email protected]"& gt Victor Zagrebin & lt / a & gt * / javni razred ReadDemo (javni statični void main (String args) vrže IOException (String out_enc = System.getProperty (" console.encoding "," Cp866 "); System.out. pisanje (readStringFromFile ( "out1.txt", "Cp1251", out_enc)); System.out.write ("\ n"); System.out.write (readStringFromFile ("out2.txt", "Cp866", out_enc) ); System.out.write ("\ n"); System.out.write (readStringFromFile ("out3.txt", "UTF-8", out_enc)); System.out.write ("\ n"); System.out.write (readStringFromFile ("out4.txt", "Unicode", out_enc));) javni statični bajt readStringFromFile (String filename, String file_enc, String out_enc) vrže IOException (int size; InputStream f = new FileInputStream (ime datoteke) ); velikost = f.na voljo (); Reader in = nov InputStreamReader (f, file_enc); char ch = nov znak; in.read (ch, 0, velikost); in.close (); return (nov niz (ch )). getBytes (out_enc);)) Kompilacija: javac ReadDemo.java Zaženi: java ReadDemo Izhod programa: 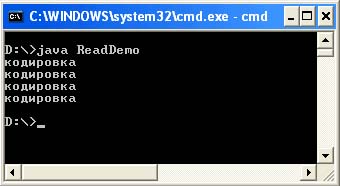
Posebej velja omeniti uporabo naslednje vrstice kode v tem programu:
String out_enc = System.getProperty ("console.encoding", "Cp866");
Z metodo getProperty se poskuša prebrati vrednost sistemske lastnosti console.encoding, ki nastavi kodiranje, v katerem bodo podatki izpisani v ukazno mizo. Če ta lastnost ni nastavljena (pogosto ni nastavljena), bo spremenljivki out_enc dodeljena "Cp866". Poleg tega se spremenljivka out_enc uporablja tam, kjer je treba pretvoriti niz, prebran iz datoteke, v kodiranje, primerno za izpis v konzolo.
Postavlja se tudi logično vprašanje: "zakaj se uporablja System.out.write in ne System.out.println"? Kot je opisano zgoraj, se sistemska lastnost file.encoding ne uporablja samo za branje izvorne datoteke, ampak tudi za izpis z uporabo System.out.println, kar bo v tem primeru vodilo do napačnega izpisa.
Nepravilen prikaz kodiranja v spletnih programih
Programer mora najprej vedeti: ni smiselno imeti niza, ne da bi vedeli, katero kodiranje uporablja... V ASCII ni navadnega besedila. Če imate niz, v pomnilniku, v datoteki ali v sporočilu E-naslov, morate vedeti, v kakšnem kodiranju je, sicer ga ne boste mogli pravilno interpretirati ali pokazati uporabniku.
Za skoraj vse tradicionalne težave, kot je "moje spletno mesto izgleda kot neumnost" ali "moja e-poštna sporočila niso berljiva, če uporabljam naglašene znake", so odgovorni programerji, ki ne razumejo preprostega dejstva, da če ne veste, kakšno kodiranje UTF-8 niz je v ali ASCII ali ISO 8859-1 (Latin-1) ali Windows 1252 (Zahodnoevropski), ga preprosto ne boste mogli pravilno izpisati. Nad kodno točko 127 je več kot sto kodiranj znakov in ni informacij, da bi ugotovili, katero kodiranje je potrebno. Kako shranimo informacije o tem, katere kodirne nize uporabljajo? Obstaja standardne metode navesti te informacije. Za e-poštna sporočila morate vrstico postaviti v glavo HTTP
Vrsta vsebine: besedilo / navaden; nabor znakov = "UTF-8"
Za spletno stran je bila prvotna ideja, da bi spletni strežnik tik pred tem sam poslal glavo HTTP HTML stran... Toda to povzroča določene težave. Recimo, da imate velik spletni strežnik z velikim številom spletnih mest in na stotine strani, ki jih je ustvarilo veliko število ljudi na ogromnem številu različnih jezikih in vsi ne uporabljajo posebnega kodiranja. Spletni strežnik sam res ne more vedeti, kakšno kodiranje je posamezna datoteka, in zato ne more poslati glave, ki določa Content-Type. Zato je za navedbo pravilnega kodiranja v glavi http ostalo ohraniti informacije o kodiranju znotraj datoteke html z vstavljanjem posebne oznake. Strežnik bi nato prebral ime kodiranja iz meta oznake in ga dal v glavo HTTP.
Pojavi se ustrezno vprašanje: "kako začeti brati datoteko HTML, dokler ne veste, katero kodiranje uporablja?! Na srečo skoraj vsa kodiranja uporabljajo isto tabelo znakov s kodami od 32 do 127, sama koda HTML pa je sestavljena iz teh znakov in morda ne boste naleteli niti na informacije o kodiranju v datoteki html, če je v celoti sestavljena iz takšnih znakov. Zato bi morala biti v idealnem primeru oznaka & ltmeta & gt, ki označuje kodiranje, res v prvi vrstici v razdelku & lthead & gt, saj bo takoj, ko spletni brskalnik zagleda ta znak, prenehal razčlenjevati stran in začel znova znova z uporabo kodiranja, ki ste ga določili.
& lthtml & gt & lthead & gt & ltmeta http-equiv = "Content-Type" content = "text / html; charset = utf-8" & gt
Kaj storijo spletni brskalniki, če ne najdejo nobene vrste vsebine, niti v glavi http niti v oznaki Meta? internet Explorer pravzaprav počne nekaj zelo zanimivega: poskuša prepoznati kodiranje in jezik na podlagi pogostosti, s katero se različni bajti pojavljajo v tipičnem besedilu v tipičnih kodiranih jezikih. Ker so bile različne stare 8-bajtne kodne strani postavljene drugače Državni simboli med 128 in 255 in ker imajo vsi človeški jeziki različne frekvenčne verjetnosti uporabe črk, ta pristop pogosto dobro deluje.
To je precej bizarno, vendar se zdi, da deluje precej pogosto, in naivni avtorji spletnih strani, ki nikoli niso vedeli, da potrebujejo oznako Content-Type v naslovih svojih strani, da bi se strani pravilno prikazale do tistega čudovitega dne, ko napišejo nekaj, kar se ne ujema povsem s tipično pogostnostjo črk njihovega maternega jezika in Internet Explorer se odloči, da je korejski, in ga ustrezno prikaže.
Kakorkoli že, kaj preostane bralcu te spletne strani, ki je bila napisana v bolgarščini, a prikazana v korejščini (in sploh ne smiselni korejščini)? Uporablja pogled | Kodiranje in poskusi več različnih kodiranj (za vzhodnoevropske jezike jih je vsaj ducat), dokler slika ni jasnejša. Če seveda to zna narediti, saj večina ljudi tega ne ve.
Omeniti velja, da pri UTF-8, ki ga spletni brskalniki že leta odlično podpirajo, še nihče ni naletel na težave s pravilnim prikazom spletnih strani.
Povezave:
- Joel Spolsky. Absolutni minimum, ki ga mora vsak razvijalec programske opreme popolnoma, pozitivno vedeti o Unicode in naborih znakov (brez izgovorov!) 10/08/2003 http://www.joelonsoftware.com/articles/Unicode.html
- Sergej Astahov.
- Sergej Semihatov. ... 08.2000 - 27.07.2005
- Horstman K.S., Cornell G. Profesionalna knjižnica. Java 2. Zvezek 1. Osnove. - M .: Založba Williams, 2003 .-- 848 str.
- Dan Chisholms. Lažni izpiti programerja Java. Cilj 2, InputStream in OutputStream Reader / Writer. Kodiranje znakov Java: UTF in Unicode. http://www.jchq.net/certkey/1102_12certkey.htm
- Paket java.io. JavaTM 2 Platform Standard Edition 6.0 API Specifikacija.
Unicode: UTF-8, UTF-16, UTF-32.
Unicode je nabor grafičnih znakov in način njihovega kodiranja za računalniško obdelavo besedilnih podatkov.
Unicode ne dodeli le vsakemu znaku edinstvena koda, ampak tudi opredeljuje različne značilnosti tega simbola, na primer:
vrsta znaka (velike črke, male črke, številka, ločila itd.);
atributi znakov (prikaz od leve proti desni ali od desne proti levi, presledek, prelom vrstice itd.);
ustrezne velike ali male črke (za male in velike črke oziroma);
ustrezno številsko vrednost (za številske znake).
Standardi UTF(okrajšava za Unicode Transformation Format) za predstavljanje znakov:
UTF-16: Windows Vista uporablja UTF-16 za predstavitev vseh znakov Unicode. V UTF-16 so znaki predstavljeni z dvema bajtoma (16 bitov). To kodiranje se uporablja v sistemu Windows, ker lahko 16-bitne vrednosti predstavljajo znake, ki sestavljajo abecede večine jezikov na svetu, kar omogoča programom, da obdelujejo nize in hitreje izračunajo njihovo dolžino. Vendar pa 16-bit ni dovolj za predstavitev abecednih znakov v nekaterih jezikih. V takih primerih UTE-16 podpira "nadomestno" kodiranje, ki omogoča kodiranje znakov v 32-bitnih (4 bajtih). Vendar pa je malo aplikacij, ki se morajo ukvarjati z znaki takšnih jezikov, zato je UTF-16 dober kompromis med varčevanjem pomnilnika in enostavnostjo programiranja. Upoštevajte, da so v .NET Framework vsi znaki kodirani z UTF-16, zato uporaba UTF-16 v Windows aplikacije izboljša zmogljivost in zmanjša porabo pomnilnika pri posredovanju nizov med izvorno in upravljano kodo.
UTF-8: V kodiranju UTF-8 so lahko različni znaki predstavljeni z 1, 2, 3 ali 4 bajti. Znaki z vrednostmi manj kot 0x0080 so stisnjeni na 1 bajt, kar je zelo priročno za ameriške znake. Znaki, ki se ujemajo z vrednostmi v območju 0x0080-0x07FF, se pretvorijo v 2-bajtne vrednosti, kar dobro deluje z evropskimi in bližnjevzhodnimi abecedami. Znaki z večjimi vrednostmi se pretvorijo v 3-bajtne vrednosti, kar je uporabno za delo s srednjeazijskimi jeziki. Nazadnje so nadomestni pari zapisani v 4-bajtni obliki. UTF-8 je izjemno priljubljeno kodiranje. Vendar pa je manj učinkovit kot UTF-16, če se pogosto uporabljajo znaki z vrednostmi 0x0800 in višjimi.
UTF-32: V UTF-32 so vsi znaki predstavljeni s 4 bajti. To kodiranje je priročno za pisanje preprostih algoritmov za naštevanje znakov v katerem koli jeziku, ki ne zahteva obdelave znakov, predstavljenih z različnim številom bajtov. Na primer, ko uporabljate UTF-32, lahko pozabite na "nadomestke", saj je kateri koli znak v tem kodiranju predstavljen s 4 bajti. Jasno je, da z vidika uporabe pomnilnika učinkovitost UTF-32 še zdaleč ni idealna. Zato se to kodiranje redko uporablja za prenos nizov po omrežju in njihovo shranjevanje v datoteke. Običajno se UTF-32 uporablja kot notranji format za predstavitev podatkov v programu.
UTF-8
V bližnji prihodnosti se bo poklical poseben format Unicode (in ISO 10646). UTF-8... To "izpeljano" kodiranje uporablja nize bajtov različnih dolžin (od enega do šestih) za pisanje znakov, ki se s preprostim algoritmom pretvorijo v kode Unicode, s krajšimi nizi, ki ustrezajo pogostejšim znakom. Glavna prednost tega formata je združljivost z ASCII ne le v vrednostih kod, ampak tudi v številu bitov na znak, saj je en bajt dovolj za kodiranje katerega koli od prvih 128 znakov v UTF-8 (čeprav , na primer za cirilice dva bajta).
Format UTF-8 sta izumila 2. septembra 1992 Ken Thompson in Rob Pike in ga implementirala v načrtu 9. Standard UTF-8 je zdaj formaliziran v RFC 3629 in ISO/IEC 10646, Priloga D.
Za spletnega oblikovalca je to kodiranje še posebej pomembno, saj je bilo v HTML od različice 4 razglašeno za "standardno kodiranje dokumenta".
Besedilo, ki vsebuje samo znake, oštevilčene manj kot 128, se pretvori v navadno besedilo ASCII, če je napisano v UTF-8. Nasprotno pa v besedilu UTF-8 vsak bajt z vrednostjo, manjšo od 128, predstavlja znak ASCII z isto kodo. Preostali znaki Unicode so predstavljeni z zaporedji dolžine od 2 do 6 bajtov (pravzaprav le do 4 bajtov, saj uporaba kod večjih od 221 ni načrtovana), v katerih je prvi bajt vedno videti kot 11xxxxxx, preostali pa - 10xxxxxx.
Preprosto povedano, v formatu UTF-8, latinični znaki, ločila in kontrolnik ASCII znaki so napisani v kodah US-ASCII, vsi drugi znaki pa so kodirani z več okteti z najpomembnejšim bitom 1. To ima dva učinka.
Tudi če program ne prepozna Unicode, bodo latinične črke, arabske številke in ločila prikazani pravilno.
Če latinske črke in preprosta ločila (vključno s presledkom) zasedajo veliko količino besedila, UTF-8 poveča obseg v primerjavi z UTF-16.
Na prvi pogled se morda zdi, da je UTF-16 bolj priročen, saj je večina znakov kodiranih v točno dveh bajtih. Vendar to izniči potreba po podpori nadomestnih parov, ki so pri uporabi UTF-16 pogosto spregledani, pri čemer se izvaja samo podpora za znake UCS-2.
Unicode
Iz Wikipedije, proste enciklopedije
Pojdi do: navigacijo, Iskanje
Unicode (najpogosteje) oz Unicode (angleščina Unicode) - standardno kodiranje znakov, ki vam omogoča, da predstavljate znake skoraj vsega zapisanega jezikov.
Standard, predlagan v 1991 leto neprofitna organizacija "Unicode Consortium" ( angleščina Unicode konzorcij, Unicode Inc. ). Uporaba tega standarda omogoča kodiranje zelo velikega števila znakov iz različnih skript: v dokumentih Unicode, kitajski hieroglifi, matematični simboli, črke grška abeceda, latinščina in cirilica, v tem primeru preklop ni potreben kodne strani.
Standard je sestavljen iz dveh glavnih delov: univerzalnega nabora znakov ( angleščina UCS, univerzalni nabor znakov) in družino kodiranja ( angleščina. UTF, Unicode format transformacije). Univerzalni nabor znakov določa ujemanje ena proti ena med znaki kode- elementi kodnega prostora, ki predstavljajo nenegativna cela števila. Družina kodiranja definira strojno predstavitev zaporedja kod UCS.
Kode Unicode so razdeljene na več področij. Območje s kodami od U + 0000 do U + 007F vsebuje znake za klicanje ASCII z ustreznimi kodami. Sledijo področja znakov različnih pisav, ločil in tehničnih simbolov. Nekatere kode so rezervirane za prihodnjo uporabo. Pod ciriličnimi znaki so področja znakov s kodami od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (glej. Cirilica v Unicode).
1 Predpogoji za ustvarjanje in razvoj Unicode 2 različici Unicode 3 Kodni prostor 4 Sistem kodiranja 5 Spreminjanje znakov 6 Oblike normalizacije 7 Dvosmerno pisanje 8 predstavljenih simbolov 9 ISO / IEC 10646 10 načinov predstavitve 11 Načini vnosa 12 Težave z Unicode 13 "Unicode" ali "Unicode"? 14 Glej tudi |
Predpogoji za nastanek in razvoj Unicode
Pri koncu 1980 8-bitni znaki so postali standard, medtem ko je bilo veliko različnih 8-bitnih kodiranj in nenehno so se pojavljali novi. To je bilo razloženo tako z nenehnim širjenjem nabora podprtih jezikov kot z željo po ustvarjanju kodiranja, ki je delno združljiva z nekaterimi drugimi (tipičen primer je pojav alternativno kodiranje za ruski jezik, zaradi izkoriščanja zahodnih programov, ustvarjenih za kodiranje CP437). Posledično se je pojavilo več težav:
Težava " krakozyabr»(Prikaz dokumentov v napačnem kodiranju): rešiti ga je mogoče z doslednim uvajanjem metod za določanje uporabljenega kodiranja ali z uvedbo enotnega kodiranja za vse.
Težava z omejenim naborom znakov: to bi bilo mogoče rešiti bodisi s preklopom pisav znotraj dokumenta bodisi z uvedbo "širokega" kodiranja. Preklapljanje pisave se že dolgo izvaja v urejevalniki besedil, in so bili pogosto uporabljeni pisave z nestandardnim kodiranjem, t. n. "Dingbat pisave" - kot rezultat, ko poskušate prenesti dokument v drug sistem, so se vsi nestandardni znaki spremenili v krakozyabry.
Problem pretvorbe enega kodiranja v drugo: rešiti ga je mogoče s prevajanjem pretvorbenih tabel za vsak par kodiranja ali z uporabo vmesne pretvorbe v tretje kodiranje, ki vključuje vse znake vseh kodiranja.
Problem podvajanja pisave: tradicionalno je bila za vsako kodiranje narejena drugačna pisava, tudi če se ta kodiranja delno (ali v celoti) ujemajo v naboru znakov: ta problem bi lahko rešili z izdelavo "velikih" pisav, iz katerih so znaki potrebni za to kodiranje, so nato izbrani - vendar zahteva ustvarjanje enotnega registra simbolov, da se določi, kateri se ujemajo.
Zdelo se je potrebno ustvariti eno samo "široko" kodiranje. Ugotovljeno je bilo, da so kodiranja s spremenljivo dolžino, ki se pogosto uporabljajo v vzhodni Aziji, pretežka za uporabo, zato je bilo odločeno za uporabo znakov s fiksno širino. Uporaba 32-bitnih znakov se je zdela preveč potratna, zato je bilo odločeno, da uporabimo 16-bitne.
Tako je bila prva različica Unicode kodiranje s fiksno velikostjo znakov 16 bitov, kar pomeni, da je bilo skupno število kod 2 16 (65 536). Od tu izhaja praksa poimenovanja znakov s štirimi šestnajstiškimi številkami (na primer U + 04F0). Hkrati je bilo načrtovano, da se v Unicode kodirajo ne vsi obstoječi znaki, ampak le tisti, ki so potrebni v vsakdanjem življenju. Redko uporabljene simbole je bilo treba postaviti v "območje zasebne uporabe", ki je prvotno zasedlo kode U + D800... U + F8FF. Da bi Unicode uporabljali tudi kot posrednik pri medsebojnem pretvarjanju različnih kodiranj, so bili vanj vključeni vsi znaki, predstavljeni v vseh najbolj znanih kodiranju.
V prihodnosti pa je bilo odločeno, da se vsi simboli kodirajo in v zvezi s tem znatno razširijo kodno domeno. Hkrati so se na kode znakov začele gledati ne kot na 16-bitne vrednosti, temveč kot na abstraktne številke, ki jih je mogoče v računalniku predstaviti z nizom različne poti(cm. Predstavitvene metode).
Ker v številnih računalniških sistemih (npr. Windows NT ) kot privzeto kodiranje so bili že uporabljeni fiksni 16-bitni znaki, odločeno je bilo, da se vsi najpomembnejši znaki kodirajo le znotraj prvih 65 536 pozicij (t.i. angleščina osnovni večjezično letalo, BMP). Preostali prostor se uporablja za "dodatne znake" ( angleščina dopolnilno znakov): pisni sistemi izumrlih jezikov ali zelo redko uporabljeni kitajski hieroglifi, matematični in glasbeni simboli.
Za združljivost s starejšimi 16-bitnimi sistemi je bil sistem izumljen UTF-16, kjer je prvih 65.536 pozicij, z izjemo pozicij iz intervala U + D800 ... U + DFFF, prikazanih neposredno kot 16-bitna števila, ostali pa so predstavljeni kot "nadomestni pari" (prvi element a par iz U + D800 ... U + DBFF , drugi element para iz regije U + DC00 ... U + DFFF). Za nadomestne pare je bil uporabljen del kodnega prostora (2048 mest), ki je bil prej rezerviran za "znake za zasebno uporabo".
Ker lahko UTF-16 prikaže samo 2 20 + 2 16 −2048 (1 112 064) znakov, je bila ta številka izbrana kot končna vrednost za kodni prostor Unicode.
Čeprav je bilo območje kode Unicode razširjeno preko 2-16 že v različici 2.0, so bili prvi znaki v "top" območju postavljeni šele v različici 3.1.
Vloga tega kodiranja v spletnem sektorju nenehno narašča, v začetku leta 2010 je bil delež spletnih strani, ki uporabljajo Unicode, približno 50 %.
Različice Unicode
Ker se tabela znakov Unicode spreminja in dopolnjuje ter izhajajo nove različice tega sistema - in to delo poteka nenehno, saj je sistem Unicode sprva vključeval samo ravnino 0 - dvobajtne kode - prihajajo tudi novi dokumenti. ISO... Sistem Unicode obstaja v celoti v naslednjih različicah:
1.1 (v skladu z ISO / IEC 10646-1: 1993 ), standard 1991-1995.
2.0, 2.1 (isti standard ISO / IEC 10646-1: 1993 plus dodatki: "Spremembe" 1 do 7 in "Tehnični popravki" 1 in 2), standard iz leta 1996.
3.0 (ISO / IEC 10646-1: standard 2000) 2000 standard.
3.1 (standarda ISO / IEC 10646-1: 2000 in ISO / IEC 10646-2: 2001) standard 2001.
3.2, standardno 2002 leto.
4.0 standard 2003 .
4.01, standardno 2004 .
4.1, standardno 2005 .
5.0, standardno 2006 .
5.1, standardno 2008 .
5.2, standardno 2009 .
6.0, standardno 2010 .
6.1, standardno 2012 .
6.2, standardno 2012 .
Kodni prostor
Čeprav zapisni obliki UTF-8 in UTF-32 omogočata kodiranje do 2.331 (2.147.483.648) kodnih točk, je bilo odločeno, da se za združljivost z UTF-16 uporabi samo 1.112.064. Vendar je tudi to za trenutek več kot dovolj – v različici 6.0 je uporabljenih nekaj manj kot 110.000 kodnih točk (109.242 grafičnih in 273 drugih simbolov).
Kodni prostor je razdeljen na 17 letala 2 po 16 (65536) znakov. Ničelna ravnina se imenuje osnovni, vsebuje simbole najpogostejših skript. Prva ravnina se uporablja predvsem za zgodovinske pisave, druga za redko uporabljene hieroglife. CJK, tretji je rezerviran za arhaične kitajske znake ... Letala 15 in 16 sta rezervirana za zasebno uporabo.
Za označevanje znakov Unicode uporabite zapis, kot je "U + xxxx"(Za kode 0 ... FFFF) ali" U + xxxxx"(Za kode 10000 ... FFFFF) ali" U + xxxxxx"(Za kode 100000 ... 10FFFF), kjer xxx - šestnajstiškištevilke. Na primer, znak "i" (U + 044F) ima kodo 044F 16 = 1103 10 .
Sistem kodiranja
Univerzalni sistem kodiranja (Unicode) je nabor grafičnih simbolov in način njihovega kodiranja za računalnik obdelava besedilnih podatkov.
Grafični simboli so simboli, ki imajo vidno sliko. Grafični znaki so v nasprotju s kontrolnimi znaki in znaki za oblikovanje.
Grafični simboli vključujejo naslednje skupine:
ločila;
posebni znaki ( matematični, tehnični, ideogrami itd.);
ločevalniki.
Unicode je sistem za linearno predstavitev besedila. Znake z dodatnimi nadpisi ali podpisi lahko predstavimo kot zaporedje kod, zgrajenih po določenih pravilih (sestavljeni znak) ali kot en sam znak (monolitna različica, vnaprej sestavljen znak).
Spreminjanje znakov
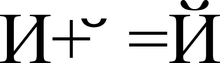
Predstavitev znaka "Y" (U + 0419) v obliki osnovnega znaka "I" (U + 0418) in modificirajočega znaka "" (U + 0306)
Grafični znaki v Unicode se delijo na razširjene in nerazširjene (brez širine). Nerazširjeni znaki, ko so prikazani, ne zavzamejo prostora vrstico... Sem spadajo zlasti naglasna znamenja in drugo diakritiki... Tako razširjeni kot nerazširjeni znaki imajo svoje kode. Razširjeni znaki se sicer imenujejo osnovni ( angleščina bazo znakov), in nepodaljšane - spreminjajoče ( angleščina združevanje znakov); slednji pa se ne morejo samostojno srečati. Znak "á" je na primer lahko predstavljen kot zaporedje osnovnega znaka "a" (U + 0061) in modifikatorskega znaka "́" (U + 0301) ali kot monoliten znak "á" (U + 00C1).
Posebna vrsta spreminjajočih se znakov so izbirniki slogov obraza ( angleščina variacija selektorji). Veljajo samo za tiste simbole, za katere so opredeljene takšne različice. V različici 5.0 so za serijo definirane slogovne možnosti matematični simboli, za simbole tradicionalnega mongolska abeceda in za simbole Mongolska kvadratna pisava.
Normalizacijske oblike
Ker so lahko isti znaki predstavljeni z različnimi kodami, kar včasih otežuje obdelavo, obstajajo postopki normalizacije, ki so zasnovani tako, da besedilo pripeljejo do določene standardne oblike.
Standard Unicode opredeljuje 4 oblike normalizacije besedila:
Simbol S je začetniče ima modifikacijski razred nič v bazi znakov Unicode.
V katerem koli zaporedju znakov, ki se začne z začetnim znakom S, je znak C blokiran pred S, če in samo če je med S in C kateri koli znak B, ki je bodisi začetni znak ali ima enak ali večji razred modifikacije kot C. To pravilo velja samo za nize, ki so šli skozi kanonično razgradnjo.
Primarni sestavljen je simbol, ki ima kanonično razgradnjo v bazi znakov Unicode (ali kanonično razgradnjo za hangul in ni vključen v seznam izključitev).
Znak X je lahko primarno poravnan z znakom Y, če in samo če obstaja primarni sestavljeni Z, ki je kanonično enakovreden zaporedju
Če naslednji znak C ni blokiran z zadnjim naletelim začetnim osnovnim znakom L in ga je mogoče uspešno poravnati z njim, se L nadomesti s sestavljenim L-C in C se odstrani.
Normalizacijski obrazec D (NFD) – kanonična razgradnja. V procesu pretvorbe besedila v to obliko se vsi sestavljeni znaki rekurzivno nadomestijo z več sestavljenimi, v skladu s tabelami razčlenitve.
Normalizacijski obrazec C (NFC) je kanonična razgradnja, ki ji sledi kanonična sestava. Najprej se besedilo reducira na obliko D, po kateri se izvede kanonična kompozicija - besedilo se obdela od začetka do konca in upošteva se naslednja pravila:
Normalizacijska oblika KD (NFKD) - združljiva razgradnja. Ko so vstavljeni v to obliko, se vsi sestavljeni znaki zamenjajo tako s kanoničnimi razkrojnimi preslikavami Unicode kot z združljivimi preslikavami razgradnje, rezultat pa se nato postavi v kanoničen vrstni red.
Normalizacijski obrazec KC (NFKC) – združljiva razgradnja, ki ji sledi kanonično sestavo.
Izraza "sestava" in "razgradnja" pomenita povezavo oziroma razgradnjo simbolov na njihove sestavne dele.
Primeri
|
Izvirno besedilo | ||||
|
\ u0410, \ u0401, \ u0419 |
\ u0410, \ u0415 \ u0308, \ u0418 \ u0306 |
\ u0410, \ u0401, \ u0419 |
||
Dvosmerno pismo
Standard Unicode podpira jezike pisanja od leve proti desni ( angleščina levo- do- prav, Ltr), in s pisanjem od desne proti levi ( angleščina prav- do- levo, RTL) - Npr. arabsko in judovski pismo. V obeh primerih so znaki shranjeni v "naravnem" vrstnem redu; njihov prikaz ob upoštevanju želene smeri črke zagotavlja aplikacija.
Poleg tega Unicode podpira kombinirana besedila, ki združujejo fragmente z različnimi smermi črke. Ta funkcija se imenuje dvosmernost (angleščina dvosmerni besedilo, BiDi). Nekateri poenostavljeni besedilni procesorji (na primer v mobilni telefon) lahko podpira Unicode, ne pa dvosmerne podpore. Vsi znaki Unicode so razdeljeni v več kategorij: napisani od leve proti desni, napisani od desne proti levi in napisani v kateri koli smeri. Simboli zadnje kategorije (predvsem ločila), ko se prikaže, upoštevajte smer okoliškega besedila.
Predstavljeni simboli
Glavni članek: Znaki, predstavljeni v Unicode

Shema osnovne ravnine Unicode, glej opis
Unicode vključuje skoraj vse sodobne pisanje, vključno z:
Arabec,
armenski,
bengalščina,
birmanščina,
glagol,
grški,
gruzijski,
devanagari,
judovski,
cirilica,
kitajski(Kitajski znaki se aktivno uporabljajo v japonski, in tudi precej redko v korejščina),
koptski,
kmerski,
latinščina,
tamilščina,
korejščina (hangul),
cherokee,
etiopski,
japonski(kar vključuje poleg tega kitajski znaki tudi zlogovnik),
drugo.
Za akademske namene je bilo dodanih veliko zgodovinskih skript, vključno z: Germanske rune, starodavne turške rune, staro grško, Egiptovski hieroglifi, klinopis, Maja piše, Etruščanska abeceda.
Unicode ponuja široko paleto matematični in glasbeni tudi liki piktogrami.
Vendar Unicode v bistvu ne vključuje logotipov podjetij in izdelkov, čeprav jih najdemo v pisavah (na primer logotip Apple kodiran MacRoman(0xF0) ali logotip Windows v pisavi Wingdings (0xFF)). V pisavah Unicode je treba logotipe postaviti samo v območje znakov po meri.
ISO/IEC 10646
Konzorcij Unicode tesno sodeluje z delovno skupino ISO / IEC / JTC1 / SC2 / WG2, ki razvija mednarodni standard 10646 ( ISO/IEC 10646). Sinhronizacija je vzpostavljena med standardom Unicode in ISO/IEC 10646, čeprav vsak standard uporablja svojo terminologijo in dokumentacijski sistem.
Sodelovanje konzorcija Unicode z Mednarodno organizacijo za standardizacijo ( angleščina Mednarodna organizacija za standardizacijo, ISO) se je začelo v 1991 leto... V 1993 leto ISO je izdal standard DIS 10646.1. Za sinhronizacijo z njim je konzorcij odobril različico 1.1 standarda Unicode, ki je bila dopolnjena z dodatnimi znaki iz DIS 10646.1. Posledično so vrednosti kodiranih znakov v Unicode 1.1 in DIS 10646.1 popolnoma enake.
Sodelovanje med obema organizacijama se je nadaljevalo tudi v prihodnje. V 2000 leto standard Unicode 3.0 je bil sinhroniziran z ISO / IEC 10646-1: 2000. Prihajajoča tretja različica ISO/IEC 10646 bo sinhronizirana z Unicode 4.0. Morda bodo te specifikacije celo objavljene kot enoten standard.
Podobno kot formata UTF-16 in UTF-32 v standardu Unicode ima standard ISO / IEC 10646 tudi dve glavni obliki kodiranja znakov: UCS-2 (2 bajta na znak, podobno kot UTF-16) in UCS-4 (4 bajti na znak, podobno kot UTF-32). UCS pomeni univerzalni multi-oktet(večbajtni) nabor kodiranih znakov (angleščina univerzalna večkraten- oktet kodiran značaj set). UCS-2 se lahko šteje za podmnožico UTF-16 (UTF-16 brez nadomestnih parov), UCS-4 pa je sinonim za UTF-32.
Predstavitvene metode
Unicode ima več oblik predstavitve ( angleščina Format transformacije Unicode, UTF): UTF-8, UTF-16(UTF-16BE, UTF-16LE) in UTF-32 (UTF-32BE, UTF-32LE). Predstavitveni obrazec UTF-7 je bil razvit tudi za prenos po sedembitnih kanalih, vendar zaradi nezdružljivosti z ASCII ni prejel distribucije in ni vključen v standard. 1. aprila 2005 leto predlagani sta bili dve predstavitveni obliki stripa: UTF-9 in UTF-18 ( RFC 4042).
V Microsoft Windows NT in sistemi, ki temeljijo na tem Windows 2000 in Windows XP predvsem uporablja obrazec UTF-16LE. V UNIX-kot operacijski sistemi GNU / Linux, BSD in Mac OS X sprejeta oblika je UTF-8 za datoteke in UTF-32 ali UTF-8 za obdelavo znakov v pomnilnik z naključnim dostopom.
Punycode- druga oblika kodiranja zaporedij Unicode znakov v tako imenovana zaporedja ACE, ki so sestavljena samo iz alfanumeričnih znakov, kot je dovoljeno v domenskih imenih.
Glavni članek: UTF-8
UTF-8 je predstavitev Unicode, ki zagotavlja najboljšo združljivost s starejšimi sistemi, ki so uporabljali 8-bitne znake. Besedilo, ki vsebuje samo znake, oštevilčene manj kot 128, se pretvori v golo besedilo, če je napisano v UTF-8 ASCII... Nasprotno pa v besedilu UTF-8 poljubno bajt z vrednostjo, manjšo od 128, prikaže znak ASCII z isto kodo. Preostali znaki Unicode so predstavljeni z zaporedji dolžine od 2 do 6 bajtov (pravzaprav le do 4 bajtov, saj v Unicode ni znakov s kodo večjo od 10FFFF in jih v prihodnosti ne načrtujemo). ), v katerem je prvi bajt vedno videti kot 11xxxxxx, preostali pa 10xxxxxx.
UTF-8 je bil izumljen 2. september 1992 leto Ken Thompson in Rob Pike in se izvaja v Načrt 9 ... Zdaj je standard UTF-8 uradno zapisan v dokumentih RFC 3629 in ISO/IEC 10646 Priloga D.
Znaki UTF-8 so izpeljani iz Unicode na naslednji način:
0x00000000 - 0x0000007F: 0xxxxxxx
0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Teoretično možno, vendar tudi ni vključeno v standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Čeprav UTF-8 omogoča, da isti znak določite na več načinov, je pravilen le najkrajši. Preostale obrazce je treba iz varnostnih razlogov zavrniti.
Vrstni red bajtov
V podatkovnem toku UTF-16 se lahko visoki bajt zapiše bodisi pred nizkim ( angleščina UTF-16 mali-endian), ali po mlajšem ( angleščina. UTF-16 big-endian). Podobno obstajata dve različici štiribajtnega kodiranja - UTF-32LE in UTF-32BE.
Za določitev oblike predstavitve Unicode se na začetku besedilne datoteke zapiše podpis- znak U + FEFF (neprekinjeni presledek ničelne širine), imenovan tudi kot oznaka vrstnega reda bajtov (angleščina bajt naročilo oznaka, BOM ). To omogoča razlikovanje med UTF-16LE in UTF-16BE, saj znak U + FFFE ne obstaja. Včasih se uporablja tudi za označevanje formata UTF-8, čeprav pojem vrstnega reda bajtov za to obliko ne velja. Datoteke, ki sledijo tej konvenciji, se začnejo s temi zaporedji bajtov:
Žal ta metoda ne razlikuje zanesljivo med UTF-16LE in UTF-32LE, saj Unicode dovoljuje znak U + 0000 (čeprav se prava besedila redko začnejo z njim).
Datoteke v kodiranju UTF-16 in UTF-32, ki ne vsebujejo BOM, morajo biti v vrstnem redu big-endian ( unicode.org).
Unicode in tradicionalna kodiranja
Uvedba Unicode je spremenila pristop k tradicionalnim 8-bitnim kodiranjem. Če je bilo prej kodiranje določeno s pisavo, je zdaj določeno s korespondenčno tabelo med tem kodiranjem in Unicode. Pravzaprav so 8-bitna kodiranja postala predstavitev podmnožice Unicode. To je precej olajšalo ustvarjanje programov, ki morajo delati z veliko različnimi kodiranjemi: zdaj, če želite dodati podporo za še eno kodiranje, morate dodati še eno iskalno tabelo Unicode.
Poleg tega številni formati podatkov omogočajo vstavljanje poljubnih znakov Unicode, tudi če je dokument napisan v starem 8-bitnem kodiranju. Na primer, v HTML lahko uporabite ampersand kode.
Izvajanje
Večina sodobnih operacijskih sistemov zagotavlja določeno stopnjo podpore Unicode.
V operacijskih sistemih družine Windows NT imena datotek in drugi sistemski nizi so interno predstavljeni z dvobajtnim kodiranjem UTF-16LE. Sistemski klici, ki sprejemajo parametre niza, so na voljo v enobajtnih in dvobajtnih različicah. Za več podrobnosti si oglejte članek .
UNIX- podobni operacijski sistemi, vključno z GNU / Linux, BSD, Mac OS X uporabite kodiranje UTF-8 za predstavitev Unicode. Večina programov lahko obravnava UTF-8 kot tradicionalna enobajtna kodiranja, ne glede na to, da je znak predstavljen kot več zaporednih bajtov. Za delo s posameznimi znaki se nizi običajno prekodirajo v UCS-4, tako da ima vsak znak ustrezen strojna beseda.
Ena prvih uspešnih komercialnih izvedb Unicode je bilo programsko okolje Java... V bistvu je opustil 8-bitno predstavitev znakov v korist 16-bitne. Ta rešitev je povečala porabo pomnilnika, vendar nam je omogočila vrnitev pomembne abstrakcije v programiranje: poljuben posamezen znak (tip char). Zlasti programer bi lahko delal z nizom kot s preprostim nizom. Žal uspeh ni bil dokončen, Unicode je prerasel 16-bitno omejitev in do J2SE 5.0 je poljuben znak spet začel zasedati spremenljivo število pomnilniških enot - en znak ali dva (glej. nadomestni par).
Večina programskih jezikov zdaj podpira nize Unicode, čeprav se njihova predstavitev lahko razlikuje glede na izvedbo.
Metode vnosa
Ker nobena postavitev tipkovnice ne more dovoliti, da se vsi znaki Unicode vnesejo hkrati, from operacijski sistemi in aplikacijskih programov Zahteva podporo za alternativne metode vnosa za poljubne znake Unicode.
Microsoft Windows
Glavni članek: Unicode v operacijskih sistemih Microsoft
Začenši z Windows 2000, pripomoček Charmap (charmap.exe) prikaže vse znake v operacijskem sistemu in vam omogoča, da jih kopirate v odložišče... Podobna tabela je na primer v Microsoft Word.
Včasih lahko tipkate šestnajstiški kodo, pritisnite Alt+ X, koda pa bo zamenjana z ustreznim znakom, na primer v WordPad, Microsoft Word. V urejevalnikih Alt + X izvede tudi obratno transformacijo.
V mnogih programih MS Windows, da dobite znak Unicode, morate pritisniti tipko Alt in vnesti decimalno vrednost kode znaka številsko tipkovnico... Kombinacije Alt + 0171 (") in Alt + 0187 (") bodo na primer uporabne pri tipkanju cirilice. Zanimivi sta tudi kombinaciji Alt + 0133 (…) in Alt + 0151 (-).
Macintosh
V Mac OS 8.5 in novejše, je podprta metoda vnosa, imenovana "Unicode Hex Input". Medtem ko držite tipko Option, morate vnesti štirimestno šestnajstiško kodo zahtevanega znaka. Ta metoda omogoča vnašanje znakov s kodami, večjimi od U + FFFF, z uporabo nadomestnih parov; takšni pari operacijski sistem bo samodejno zamenjan z enojnimi znaki. Pred uporabo tega načina vnosa ga morate aktivirati v ustreznem razdelku sistemskih nastavitev in nato v meniju tipkovnice izbrati kot trenutni način vnosa.
Začenši z Mac OS X 10.2 obstaja tudi aplikacija "Paleta znakov", ki vam omogoča, da izberete znake iz tabele, v kateri lahko izberete znake določenega bloka ali znake, ki jih podpira določena pisava.
GNU / Linux
V GNOME obstaja tudi pripomoček "Tabela simbolov", ki omogoča prikaz simbolov določenega bloka ali sistema pisanja in omogoča iskanje po imenu ali opisu simbola. Ko je koda želenega znaka znana, jo lahko vnesemo v skladu s standardom ISO 14755: medtem ko držite pritisnjeno Ctrl + ⇧ Shift vnesite šestnajstiško kodo (začenši z neko različico GTK +, morate kodo vnesti s pritiskom na tipko "U"). Vnesena šestnajstiška koda je lahko dolga do 32 bitov, kar vam omogoča, da vnesete poljubne znake Unicode brez uporabe nadomestnih parov.
 Linkedin – kaj je in kako vam LinkedIn lahko pomaga najti vašo sanjsko službo Profesionalno omrežje Linkedin
Linkedin – kaj je in kako vam LinkedIn lahko pomaga najti vašo sanjsko službo Profesionalno omrežje Linkedin DDoS zaščita: DDoS GUARD - vaše varno gostovanje
DDoS zaščita: DDoS GUARD - vaše varno gostovanje Pametne telefone Windows je zdaj mogoče posodobiti z osebnim računalnikom
Pametne telefone Windows je zdaj mogoče posodobiti z osebnim računalnikom