Koliko bitov se uporablja za kodiranje 1 znaka v unicode. Kodiranje besedila
V poznih šestdesetih letih so se računalniki vse pogosteje uporabljali za obdelavo besedilne informacije in trenutno največ osebni računalniki v svetu (in večino časa) je zaposlen pri obdelavi besedilnih informacij.
ASCII - osnovno kodiranje besedila za latinico
Tradicionalno se za kodiranje enega znaka uporabi enaka količina informacij 1 bajt, to je I = 1 bajt = 8 bitov.
Za kodiranje enega znaka je potreben 1 bajt informacij. Če simbole obravnavamo kot možne dogodke, lahko izračunamo, koliko različni liki se lahko kodira: N = 2I = 28 = 256.
To število znakov je povsem dovolj za predstavitev besedilnih informacij, vključno z velikimi in malimi črkami ruske in latinske abecede, številkami, znaki, grafičnimi simboli itd. Kodiranje pomeni, da je vsakemu znaku dodeljena edinstvena decimalna koda od 0 do 255 ali ustrezna binarna koda od 00000000 do 11111111.
Tako oseba razlikuje simbole po slogu, računalnik pa po kodah. Ko se v računalnik vnesejo besedilne informacije, pride do njihovega binarnega kodiranja, slika simbola se pretvori v njegovo binarno kodo.
Uporabnik pritisne tipko s simbolom na tipkovnici, v računalnik pa se pošlje določeno zaporedje osmih električnih impulzov (binarna koda simbola). Koda znaka je shranjena v pomnilnik z naključnim dostopom računalnik, kjer traja en bajt. V procesu prikaza znaka na zaslonu računalnika se izvede obratni postopek - dekodiranje, to je pretvorba kode znakov v njeno podobo. Kodna tabela ASCII (ameriški standardni kodeks za izmenjavo informacij) je bila sprejeta kot mednarodni standard Tabela standardnih delov ASCII Pomembno je, da je dodelitev posebne kode znaku stvar dogovora, ki je določen v kodni tabeli. . Prvih 33 kod (od 0 do 32) ne ustrezajo znakom, ampak operacijam (vnos vrstic, vnos presledka itd.). Kode od 33 do 127 so mednarodne in ustrezajo simbolom latinske abecede, številkam, aritmetičnim znakom in ločilom. Kode od 128 do 255 so nacionalne, to pomeni, da različni znaki ustrezajo isti kodi v nacionalnih kodiranjih.
Na žalost trenutno obstaja pet različnih kodnih tabel za ruske črke (KOI8, CP1251, CP866, Mac, ISO), zato besedila, ustvarjena v enem kodiranju, v drugem ne bodo pravilno prikazana.
Trenutno nova mednarodna Standard Unicode, ki za vsak znak ne dodeli enega bajta, ampak dva, zato ga je mogoče uporabiti za kodiranje ne 256 znakov, ampak N = 216 = 65536 različnih
Unicode - pojav univerzalnega kodiranja besedila (UTF 32, UTF 16 in UTF 8)
Teh tisoč znakov iz jezikovne skupine jugovzhodne Azije ni bilo mogoče opisati v enem samem bajtu informacij, ki je bil dodeljen za kodiranje znakov v razširjenih kodiranjih ASCII. Posledično je konzorcij poklical Unicode(Unicode - konzorcij Unicode) v sodelovanju s številnimi vodilnimi v IT industriji (tistimi, ki proizvajajo programsko opremo, kodirajo strojno opremo, ustvarjajo pisave), ki so bili zainteresirani za nastanek univerzalnega kodiranja besedila.
Prvo kodiranje besedila, objavljeno pod okriljem konzorcija Unicode, je bilo kodiranje UTF 32... Številka v imenu kodiranja UTF 32 pomeni število bitov, ki se uporabljajo za kodiranje enega znaka. 32 bitov so 4 bajti informacij, ki bodo potrebni za kodiranje enega samega znaka v novem univerzalnem kodiranju UTF 32.
Posledično bo ista datoteka z besedilom, kodiranim v razširjenem kodiranju ASCII in v kodiranju UTF 32, v zadnjem primeru štirikrat večja (teža). To je slabo, zdaj pa imamo priložnost, da z UTF 32 kodiramo število znakov, ki je enako dvema do triintrideseti stopnji (milijarde znakov, ki bodo pokrili vsako resnično potrebno vrednost z ogromno mejo).
Toda mnogim državam z jeziki evropske skupine sploh ni bilo treba uporabiti tako velikega števila znakov v kodiranju, vendar so pri uporabi UTF 32 za nič prejeli štirikratno povečanje teže. besedilne dokumente in posledično povečanje obsega internetnega prometa in količine shranjenih podatkov. To je veliko in nihče si ne more privoščiti takšnih odpadkov.
Kot rezultat razvoja univerzalnega Pojavilo se je kodiranje Unicode UTF 16, ki se je izkazal za tako uspešnega, da je bil privzeto sprejet kot osnovni prostor za vse simbole, ki jih uporabljamo. UTF 16 uporablja dva bajta za kodiranje enega znaka. Na primer v operacijski dvorani Sistem Windows lahko sledite poti Start - Programi - Pripomočki - Sistemska orodja - Tabela simbolov.
Posledično se bo odprla tabela z vektorskimi oblikami vseh pisav, nameščenih v vašem sistemu. Če v naprednih možnostih izberete niz znakov Unicode, si lahko za vsako pisavo posebej ogledate celoten obseg znakov, ki so v njej vključeni. Mimogrede, s klikom na katerega koli od teh znakov si lahko ogledate njegovo dvobajtno kodo v kodiranju UTF 16, sestavljeno iz štirih šestnajstiških številk:
Koliko znakov je mogoče kodirati v UTF 16 s 16 bitov? 65.536 znakov (dva z močjo šestnajst) je bilo vzetih kot osnovni prostor v Unicodeju. Poleg tega obstajajo načini za kodiranje z UTF 16 približno dva milijona znakov, vendar so bili omejeni na razširjen prostor milijona znakov besedila.
Toda tudi uspešna različica kodiranja Unicode, imenovana UTF 16, ni prinesla velikega zadovoljstva tistim, ki so na primer programe pisali le v angleški jezik, ker se je po prehodu s razširjene različice kodiranja ASCII na UTF 16 teža dokumentov podvojila (en bajt za en znak v ASCII in dva bajta za isti znak v kodiranju UTF 16). Odločili so se, da bodo prišli prav v zadovoljstvo vseh in vsega v konzorciju Unicode kodiranje besedila s spremenljivo dolžino.
To kodiranje v Unicode se je imenovalo UTF 8... Kljub osmici v imenu je UTF 8 polnopravno kodiranje s spremenljivo dolžino, tj. vsak znak besedila je lahko kodiran v zaporedje, dolgo od enega do šestih bajtov. V praksi se v UTF 8 uporablja le obseg od enega do štirih bajtov, ker si poleg štirih bajtov kode ni niti teoretično mogoče predstavljati.
V UTF 8 so vsi latinski znaki kodirani v enem bajtu, tako kot v starem kodiranju ASCII. Omeniti velja, da bodo v primeru kodiranja samo latinične abecede tudi tisti programi, ki ne razumejo Unicode, še vedno brali, kar je kodirano v UTF 8. To je, osnovni del kodiranja ASCII se je premaknil v UTF 8.
Cirillični znaki v UTF 8 so kodirani v dveh bajtih, na primer gruzijski - v treh bajtih. Po ustvarjanju kodir UTF 16 in UTF 8 je konzorcij Unicode rešil glavni problem - zdaj imamo v pisavah en sam kodni prostor. Proizvajalcem pisav preostane le, da ta kodni prostor zapolnijo z vektorskimi oblikami besedilnih znakov glede na njihove prednosti in zmožnosti.
Teoretično že dolgo obstaja rešitev za te težave. To se imenuje Unicode Unicode Je tabela za kodiranje, v kateri se za kodiranje vsakega znaka uporabljata 2 bajta, tj. 16 bit. Na podlagi take tabele je mogoče kodirati N = 2 16 = 65 536 znakov.
Unicode vključuje skoraj vse sodobne pisave, vključno z: arabsko, armensko, bengalsko, burmansko, grško, gruzijsko, devanagari, hebrejsko, cirilico, koptsko, kmersko, latinsko, tamilsko, hangulsko, hansko (kitajsko, japonsko, korejsko), čeroško, etiopsko, Japonski (Katakana, Hiragana, Kanji) in drugi.
Za akademske namene so bili dodani številni zgodovinski pisavi, med drugim: starogrški, egipčanski hieroglifi, klinopis, pisava Majev, etruščanska abeceda.
Unicode ponuja široko paleto matematičnih in glasbenih simbolov in piktogramov.
Za cirilične znake v Unicode sta dodeljena dva obsega kod:
Cirilica ( # 0400 - # 04FF)
Cirillični dodatek ( # 0500 - # 052F).
Toda namizna injekcija Unicode v svoji čisti obliki je zadržan iz razloga, da če koda enega znaka zavzame ne en bajt, ampak dva bajta, da bo za shranjevanje besedila porabila dvakrat več prostora na disku, za prenos po komunikacijskih kanalih pa dvakrat tako dolgo.
Zato je v praksi predstavitev Unicode UTF-8 (Format za pretvorbo Unicode) zdaj pogostejša. UTF-8 zagotavlja najboljšo združljivost s sistemi, ki uporabljajo 8-bitne znake. Besedilo, ki vsebuje samo znake, ki so manjši od 128, se pri zapisu v UTF-8 pretvori v navadno besedilo ASCII. Preostali znaki Unicode so predstavljeni z zaporedji od 2 do 4 bajtov. Na splošno, ker najpogostejši znaki na svetu - znaki latinske abecede - v UTF -8 še vedno zasedajo 1 bajt, je to kodiranje bolj ekonomično kot čisto Unicode.
Kodirano angleško besedilo uporablja le 26 črk latinske abecede in še 6 ločil. V tem primeru je mogoče zagotoviti, da bo besedilo, ki vsebuje 1000 znakov, stisnjeno brez izgube podatkov na velikost:
Ellochkin slovar - "kanibali" (lik v romanu "Dvanajst stolov") je 30 besed. Koliko bitov je dovolj za kodiranje celotnega besedišča Ellochke? Možnosti: 8, 5, 3, 1.
Enote za merjenje obsega podatkov in zmogljivosti pomnilnika: kilobajti, megabajti, gigabajti ...
Tako smo ugotovili, da je v večini sodobnih kodir 1 bajt namenjen shranjevanju enega znaka besedila na elektronski medij. Tisti. v bajtih se volumen (V), ki ga zasedejo podatki, izmeri med njihovim shranjevanjem in prenosom (datoteke, sporočila).
Volumen podatkov (V) - število bajtov, potrebnih za shranjevanje v pomnilniku elektronskega nosilca podatkov.
Medijski pomnilnik pa je omejen zmogljivosti, tj. sposobnost, da vsebuje določeno količino. Zmogljivost shranjevanja elektronskih pomnilniških medijev se seveda meri tudi v bajtih.
Vendar je bajt majhna enota za merjenje količine podatkov, večji so kilobajti, megabajti, gigabajti, terabajti ...
Ne pozabite, da predpone "kilo", "mega", "giga" ... v tem primeru niso decimalne. Torej "kilo" v besedi "kilobajt" ne pomeni "tisoč", tj. ne pomeni "103". Bit je binarna enota, zato je v računalništvu priročno uporabiti merske enote, ki so večkratniki števila "2" in ne številke "10".
1 bajt = 2 3 = 8 bitov, 1 kilobajt = 2 10 = 1024 bajtov. V binarnem sistemu je 1 kilobajt = & 1.000.000.000 bajtov.
Tisti. "Kilo" tukaj označuje število, ki je najbližje tisoč, kar je moč števila 2, tj. ki je "okroglo" število v binarnem zapisu.
Tabela 10.
|
Poimenovanje |
Označba |
Vrednost v bajtih |
|
|
kilobajt | |||
|
megabajt |
2 10 Kb = 2 20 b | ||
|
gigabajt |
2 10 Mb = 2 30 b | ||
|
terabajt |
2 10 Gb = 2 40 b |
1.099 511 627 776 b |
|
Zaradi dejstva, da so merske enote prostornine in zmogljivosti nosilcev informacij večkratniki 2 in ne večkratniki 10, je večino težav na to temo lažje rešiti, če so vrednosti, ki se pojavljajo v njih, predstavljene z močmi 2. Razmislite o primeru take težave in njeni rešitvi:
Besedilna datoteka vsebuje 400 strani besedila. Vsaka stran vsebuje 3200 znakov. Če je kodiranje KOI-8 (8 bitov na znak), bo velikost datoteke:
Rešitev
Določite skupno število znakov v besedilni datoteki. V tem primeru predstavljamo števila, ki so večkratnika moči 2 kot moč 2, tj. namesto 4 napišemo 2 2 itd. Za določitev stopnje lahko uporabite tabelo 7.
znakov.
2) Glede na problem problema 1 znak zaseda 8 bitov, tj. 1 bajt => datoteka zaseda 2 7 * 10000 bajtov.
3) 1 kilobajt = 2 10 bajtov => velikost datoteke v kilobajtih je:
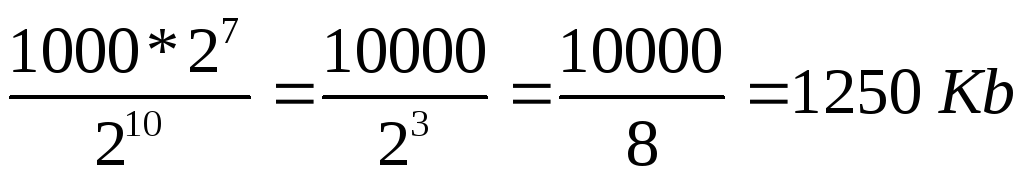 .
.
Koliko bitov je v enem kilobajtu?
&10000000000000.
Kaj je 1 MB?
1.000.000 bajtov.
1024 bajtov;
1024 kilobajtov;
Koliko bitov je v četrt kilobajtnem sporočilu? Možnosti: 250, 512, 2000, 2048.
Glasnost besedilno datoteko 640 Kb... Datoteka vsebuje knjigo, ki je povprečno tipkana 32 vrstic na stran in po 64 znak v nizu. Koliko strani je v knjigi: 160, 320, 540, 640, 1280?
Dokumentacija o zaposlenih 8 Mb... Vsak od njih vsebuje 16 strani ( 32 vrstice avtorja 64 znak v vrstici). Koliko zaposlenih v organizaciji: 256; 512; 1024; 2048?
Ta objava je namenjena tistim, ki ne razumejo, kaj je UTF-8, vendar jo želijo razumeti, in razpoložljiva dokumentacija pogosto zelo obsežno pokriva to vprašanje. Tukaj bom poskušal opisati tako, kot bi sam želel, da mi to kdo prej pove. Ker sem pogosto imel nered v glavi glede UTF-8.
Nekaj preprostih pravil
- UTF-8 je torej ovoj okoli Unicode. To ni ločeno kodiranje znakov, je zavito v Unicode. Verjetno poznate kodiranje Base64 ali ste že slišali za to - lahko zavije binarne podatke v znake za tiskanje. Raca, UTF-8 je enaka Base64 za Unicode kot Base64 za binarne podatke. Tokrat. Če to razumete, bo marsikaj že postalo jasno. Prav tako je, tako kot Base64, priznan za reševanje problema združljivosti znakov (Base64 je bil izumljen za e -pošto, za prenos datotek po pošti, v katerih so natisnjeni vsi znaki)
- Nadalje, če koda deluje z UTF-8, potem znotraj še vedno deluje s kodiranji Unicode, torej nekje globoko v notranjosti so tabele s simboli natančno znakov Unicode. Res je, da morda nimate tabel znakov Unicode, če morate na primer samo šteti, koliko znakov je v vrstici (glejte spodaj)
- UTF-8 je narejen tako, da lahko stari programi in današnji računalniki normalno delujejo z znaki Unicode, na primer s starimi kodiranji, kot so KOI8, Windows-1251 itd. V UTF-8 ni bajtov z ničlami, vsi bajti so bodisi iz 0x01 - 0x7F, kot je običajni ASCII, ali 0x80 - 0xFF, ki deluje tudi za programe, napisane v C, saj bi deloval z znaki, ki niso ASCII. Res je, za pravilno delo s simboli mora program poznati tabele Unicode.
- Kar koli z najpomembnejšim 7. bitom v bajtu (štetje bitov od nič) UTF-8 je del kodnega toka Unicode.
UTF-8 od znotraj navzven
Če poznate bitni sistem, potem je tukaj za vas hitra beležka kako je kodiran UTF-8:
Prvi bajt Unicode znaka UTF-8 se začne z bajtom, kjer je 7. bit vedno ena, 6. bit pa vedno ena. V tem primeru je v prvem bajtu, če pogledate bite od leve proti desni (7., 6. in tako naprej do nič), toliko enot, kolikor bajtov, vključno s prvim, gre za kodiranje enega znaka Unicode. Zaporedje enot se konča z ničlo. Za tem so koščki samega znaka Unicode. Preostali deli znakov Unicode spadajo v drugi ali celo tretji bajt (največ trije, zakaj - glej malo spodaj). Preostali bajti, razen prvega, so vedno na začetku '10' in nato 6 bitov naslednjega dela znaka Unicode.
Primer
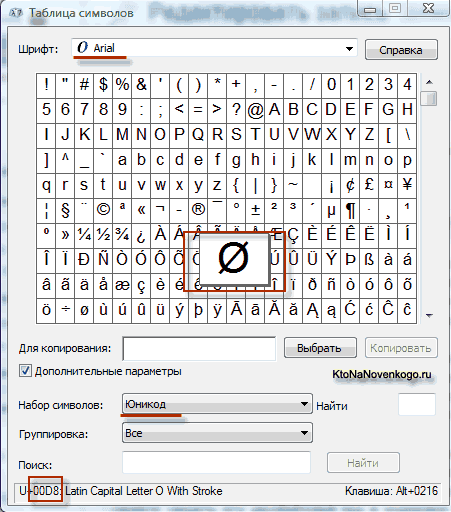
Na primer: obstajajo bajti 110 10000 in drugi 10 011110 ... Prvi se začne z '110', kar pomeni, da če sta dva, bosta dva bajta toka UTF-8, drugi bajt, tako kot vsi drugi, pa se začne z '10'. In ta dva bajta kodirata znak Unicode, ki je sestavljen iz 10100 bitov iz prvega dela + 101101 iz drugega, se izkaže -> 10000011110 -> 41E v šestnajstiškem sistemu, oz U + 041E v pisni obliki zapis Unicode. To je simbol velikega ruskega O.
Koliko znaša največ bajtov na znak?
Poglejmo tudi, koliko bajtov gre največ v UTF-8 za kodiranje 16 bitov kodiranja Unicode. Drugi in nadaljnji bajti lahko vsebujejo največ 6 bitov. Če torej začnete z zadnjimi bajti, bosta dva bata izginila točno (2. in tretji), prvi pa se mora začeti z '1110', da kodirate tri. To pomeni, da lahko prvi bajt v tem primeru kodira prve 4 bite znaka Unicode. Izkazalo se je 4 + 6 + 6 = 16 bajt. Izkazalo se je, da ima UTF -8 lahko 2 ali 3 bajte na znak Unicode (enega ne moremo, saj ni potrebe po kodiranju 6 bitov (8 - 2 bitov '10') - to bo znak ASCII. Zato prvi bajt je UTF 8, ki se nikoli ne more začeti z '10').
Zaključek
Mimogrede, zahvaljujoč temu kodiranju lahko vzamete kateri koli bajt v toku in ugotovite, ali je bajt Znak Unicode(če 7. bit ne pomeni ASCII), če da, potem je prvi v toku UTF-8 ali ne prvi (če je '10', potem ne prvi), če ne prvi, se lahko premaknemo nazaj bajt, da poiščete prvo kodo UTF-8 (pri čemer je 6. bit 1), ali pa se pomaknite v desno in preskočite vse '10' bajtov, da poiščete naslednji znak. Zahvaljujoč temu kodiranju lahko programi tudi brez poznavanja Unicode-a preberejo, koliko znakov je v nizu (na podlagi prvega bajta UTF-8 izračuna dolžino znakov v bajtih). Na splošno, če pomislite, je bilo kodiranje UTF-8 izumljeno zelo kompetentno in hkrati zelo učinkovito.
Kodiranje informacij
Vse številke (v določenih mejah) v pomnilniku računalnika so kodirane s številkami v binarnem številčnem sistemu. Za to obstajajo preprosta in jasna pravila prevajanja. Vendar se danes računalnik uporablja veliko širše kot v vlogi izvajalca delovno intenzivnih izračunov. V računalniškem pomnilniku so na primer shranjeni besedilni in večpredstavnostni podatki. Zato se poraja prvo vprašanje:
Kako so znaki (črke) shranjeni v pomnilniku računalnika?
Vsaka črka pripada določeni abecedi, v kateri si znaki sledijo in so zato lahko oštevilčeni z zaporednimi celimi števili. Vsako črko lahko povežemo s pozitivnim celim številom in jo imenujemo koda znaka... Prav ta koda bo shranjena v pomnilniku računalnika, in ko bo prikazana na zaslonu ali na papirju, bo "pretvorjena" v ustrezen znak. Če želite razlikovati predstavitev števil od predstavitve znakov v računalniškem pomnilniku, morate shraniti tudi podatke o tem, kakšni podatki so kodirani na določenem področju pomnilnika.
Ujemanje črk določene abecede s številkami-kodami tvori tako imenovano kodirna tabela... Z drugimi besedami, vsak znak določene abecede ima svojo številčno kodo v skladu s posebno tabelo za kodiranje.
Vendar pa je na svetu veliko abeced (angleščina, ruščina, kitajščina itd.). Torej naslednje vprašanje je:
Kako kodirati vse abecede, ki se uporabljajo v računalniku?
Za odgovor na to vprašanje bomo sledili zgodovinski poti.
V 60. letih 20. stoletja v Ameriški nacionalni inštitut za standarde (ANSI) je bila razvita tabela za kodiranje znakov, ki je bila pozneje uporabljena pri vseh operacijski sistemi... Ta miza se imenuje ASCII (ameriška standardna koda za izmenjavo informacij)... Malo kasneje se je pojavil razširjena različica ASCII.
V skladu s kodno tabelo ASCII je 1 bajt (8 bitov) dodeljen za prikaz enega znaka. Niz 8 celic lahko sprejme 2 8 = 256 različnih vrednosti. Prvih 128 vrednosti (od 0 do 127) je konstantnih in tvorijo tako imenovani glavni del tabele, ki vključuje decimalne številke, črke latinične abecede (velike in male črke), ločila (pika, vejica, oklepaji itd.), kot tudi presledek in različne storitvene znake (tabeliranje, vir vrstic itd.). Vrednosti od 128 do 255 dodatni del tabele, kjer je običajno kodiranje simbolov nacionalnih abeced.
Ker obstaja velika raznolikost nacionalnih abeced, obstajajo razširjene tabele ASCII v številnih različicah. Tudi za ruski jezik obstaja več kodirnih tabel (Windows-1251 in Koi8-r sta pogosta). Vse to ustvarja dodatne težave. Na primer, pošljemo pismo, napisano v enem kodiranju, prejemnik pa ga poskuša prebrati v drugem. Posledično vidi krakozyabry. Zato mora bralec za besedilo uporabiti drugačno kodirno tabelo.
Obstaja tudi druga težava. Abecede nekaterih jezikov imajo preveč znakov in ne ustrezajo svojim dodeljenim položajem od 128 do 255 enobajtnih kodir.
Tretji problem je, kaj storiti, če besedilo uporablja več jezikov (na primer ruski, angleški in francoski)? Ne morete uporabljati dveh miz hkrati ...
Za rešitev teh težav je bilo kodiranje Unicode razvito naenkrat.
Standard za kodiranje znakov Unicode
Za rešitev zgornjih težav v zgodnjih 90. letih je bil razvit standard za kodiranje znakov, imenovan Unicode. Ta standard omogoča uporabo skoraj vseh jezikov in simbolov v besedilu.
Unicode ponuja 31 bitov za kodiranje znakov (4 bajti minus en bit). Število možnih kombinacij daje pretirano število: 2 31 = 2 147 483 684 (tj. Več kot dve milijardi). Zato Unicode opisuje abecede vseh znanih jezikov, tudi "mrtvih" in izumljenih, vključuje številne matematične in druge Posebni simboli... Vendar je informacijska zmogljivost 31-bitnega Unicodeja še vedno prevelika. Zato se pogosteje uporablja skrajšana 16-bitna različica (2 16 = 65 536 vrednosti), kjer so kodirane vse sodobne abecede.
V Unicode je prvih 128 kod enakih tabeli ASCII.
Trenutno večina uporabnikov, ki uporabljajo računalnik, obdeluje besedilne informacije, ki so sestavljene iz simbolov: črk, številk, ločil itd.
Na podlagi ene celice z informacijsko zmogljivostjo 1 bita je mogoče kodirati samo 2 različni stanji. Da bi vsak znak, ki ga lahko vnesete s tipkovnice v latinični register, prejel svojo edinstveno binarno kodo, je potrebnih 7 bitov. Na podlagi zaporedja 7 bitov je v skladu s Hartleyjevo formulo mogoče dobiti N = 2 7 = 128 različnih kombinacij ničel in enot, t.j. binarne kode. Če vsak znak povežemo z njegovo binarno kodo, dobimo kodirno tabelo. Oseba deluje s simboli, računalnik - z binarnimi kodami.
Za latinsko postavitev tipkovnice je taka kodirna tabela ena za ves svet, zato bo besedilo, vneseno z latinsko postavitvijo tipkovnice, ustrezno prikazano na katerem koli računalniku. Ta miza se imenuje ASCII(American Standard Code of Information Interchange) v angleščini se izgovarja [eski], v ruščini se izgovarja [aski]. Spodaj je celotna tabela ASCII, kode v kateri so navedene v decimalni obliki. Z njim lahko ugotovimo, da računalnik, ko vnesete, recimo, znak "*", zazna kot kodo 42 (10), nato pa 42 (10) = 101010 (2) - to je binarna koda znaka "*". Kode od 0 do 31 se v tej tabeli ne uporabljajo.
miza Znaki ASCII
| Koda | simbol | Koda | simbol | Koda | simbol | Koda | simbol | Koda | simbol | Koda | simbol |
| Vesolje | . | @ | P | " | str | ||||||
| ! | A | Vprašanje | a | q | |||||||
| " | B | R | b | r | |||||||
| # | C | S | c | s | |||||||
| $ | D | T | d | t | |||||||
| % | E | U | e | u | |||||||
| & | F. | V | f | v | |||||||
| " | G | W | g | w | |||||||
| ( | H | X | h | x | |||||||
| ) | jaz | Y | jaz | y | |||||||
| * | J | Z | j | z | |||||||
| + | : | K | [ | k | { | ||||||
| , | ; | L | \ | l | | | ||||||
| - | < | M | ] | m | } | ||||||
| . | > | N | ^ | n | ~ | ||||||
| / | ? | O | _ | o | DEL |
Za kodiranje enega znaka se uporabi količina informacij, ki je enaka 1 bajtu, to je I = 1 bajt = 8 bitov. S formulo, ki povezuje število možnih dogodkov K in količino informacij I, lahko izračunate, koliko različnih simbolov je mogoče kodirati (ob predpostavki, da so simboli možni dogodki):
K = 2 I = 2 8 = 256,
to pomeni, da se lahko za predstavitev besedilnih informacij uporabi abeceda s kapaciteto 256 znakov.
Bistvo kodiranja je, da je vsakemu znaku dodeljena binarna koda od 00000000 do 11111111 ali ustrezna decimalna koda od 0 do 255.
To si je treba zapomniti trenutno za kodiranje v ruščini črke uporabljajo pet različnih kodnih tabel (KOI - 8, CP1251, CP866, Mac, ISO), poleg tega se besedila, kodirana z eno tabelo, ne bodo pravilno prikazala v drugi kodi. To je mogoče jasno predstaviti kot fragment kombinirane tabele za kodiranje znakov.
Isti binarni kodi so dodeljeni različni simboli.
| Binarna koda | Decimalna koda | KOI8 | CP1251 | CP866 | Mac | ISO |
| b | V | - | - | T |
Vendar pa v večini primerov uporabnik skrbi za prekodiranje besedilnih dokumentov in posebni programi- pretvorniki, ki so vgrajeni v aplikacije.
Od leta 1997 najnovejše različice Microsoft Office podpirajo novo kodiranje. Se imenuje Unicode. Unicode Je tabela za kodiranje, v kateri se za kodiranje vsakega znaka uporabljata 2 bajta, tj. 16 bit. Na podlagi take tabele je mogoče kodirati N = 2 16 = 65 536 znakov.
Unicode vključuje skoraj vse sodobne pisave, vključno z: arabsko, armensko, bengalsko, burmansko, grško, gruzijsko, devanagari, hebrejsko, cirilico, koptsko, kmersko, latinsko, tamilsko, hangulsko, hansko (kitajsko, japonsko, korejsko), čeroško, etiopsko, Japonski (Katakana, Hiragana, Kanji) in drugi.
Za akademske namene so bili dodani številni zgodovinski pisavi, med drugim: starogrški, egipčanski hieroglifi, klinopis, pisava Majev, etruščanska abeceda.
Unicode ponuja široko paleto matematičnih in glasbenih simbolov in piktogramov.
Za cirilične znake v Unicode sta dodeljena dva obsega kod:
Cirilica ( # 0400 - # 04FF)
Cirillični dodatek ( # 0500 - # 052F).
Toda izvajanje tabele Unicode v njeni čisti obliki je zadržano iz razloga, da če koda enega znaka zavzame ne en bajt, ampak dva bajta, bo za shranjevanje besedila potrebovala dvakrat več prostora na disku in prenos po komunikacijskih kanalih - dvakrat daljši.
Zato je zdaj v praksi predstavitev Unicode UTF-8 (format pretvorbe Unicode) pogostejša. UTF-8 zagotavlja najboljšo združljivost s sistemi, ki uporabljajo 8-bitne znake. Besedilo, ki vsebuje samo znake, ki so manjši od 128, se pri zapisu v UTF-8 pretvori v navadno besedilo ASCII. Preostali znaki Unicode so predstavljeni z zaporedji od 2 do 4 bajtov. Na splošno, ker najpogostejši znaki na svetu - znaki latinske abecede - v UTF -8 še vedno zasedajo 1 bajt, je to kodiranje bolj ekonomično kot čisto Unicode.
Za določitev številske kode znakov lahko uporabite kodna miza... Če želite to narediti, v meniju izberite element "Vstavi" - "Simbol", nato pa se na zaslonu prikaže pogovorno okno Simbol. V pogovornem oknu se prikaže tabela simbolov za izbrano pisavo. Znaki v tej tabeli so razporejeni po vrsti, zaporedno od leve proti desni, začenši s presledkom.
 Razlike med particijskimi strukturami GPT in MBR
Razlike med particijskimi strukturami GPT in MBR Čisto obrišite Internet Explorer
Čisto obrišite Internet Explorer Posodobitve sistema Windows se prenesejo, vendar niso nameščene
Posodobitve sistema Windows se prenesejo, vendar niso nameščene