Kaj je kodiranje unicode. Zakaj ste potrebovali Unicode? Predpogoji za ustvarjanje in razvoj Unicode
Kaj je kodiranje
V ruščini se "nabor znakov" imenuje tudi "nabor znakov", postopek uporabe te tabele za prevajanje informacij iz računalniške reprezentacije v človeško in značilnost besedilna datoteka, ki odraža uporabo določenega sistema kod v njem pri prikazovanju besedila.
Predstavitveni sistem je opredeljen s številnimi pravili, uporaba teh pravil za izvirne informacije pa poteka s postopkom kodiranja. Povratni postopek se imenuje dekodiranje. Nato pogledamo bolj specifične vidike, kot so kodiranje signala, kodiranje znakov, kodiranje človeškega genoma in kvantno kodiranje. Na koncu bodo razloženi osnovni koncepti stiskanja podatkov in najpogosteje uporabljene metode šifriranja.
V tem razdelku bomo videli, kako so si ljudje skozi zgodovino zelo prizadevali, da bi se s preostalimi sorodniki izrazili na preprost in intuitiven način, pri čemer so informacije kodirali z različnimi metodami. Te metode so se skozi zgodovino razvijale, ne da bi predstavljale sofisticirane metode, ki jih danes uporabljamo za prve, ki so bile uporabljene, saj je bilo potrebno veliko evolucije, kot bo razvidno v tem razdelku.
Kako je besedilo kodirano
Nabor simbolov, ki se uporabljajo pri pisanju besedila, se v računalniški terminologiji imenuje abeceda; število znakov v abecedi se običajno imenuje njegova moč. Za predstavitev besedilne informacije računalnik najpogosteje uporablja abecedo z zmogljivostjo 256 znakov. Eden od njegovih znakov nosi 8 bitov informacij, zato binarna koda vsakega znaka zavzame 1 bajt računalniškega pomnilnika. Vsi znaki takšne abecede so oštevilčeni od 0 do 255, vsaka številka pa ustreza 8-bitni binarni kodi, ki je redna številka znaka v dvojiškem zapisnem sistemu – od 00000000 do 11111111. Samo prvih 128 znakov z števila od nič (binarna koda 00000000) do 127 (01111111). Sem spadajo male črke in velike črke Latinska abeceda, številke, ločila, oklepaji itd. Preostalih 128 kod, ki se začnejo s 128 (binarna koda 10000000) in končajo s 255 (11111111), se uporablja za kodiranje črk nacionalnih abeced, uradnih in znanstvenih simbolov.
Razvoj kodiranja signalov
Biti zastarel je vse, o čemer vemo ta trenutek, kot je bilo pravočasno s prejšnjimi metodami. Mornarji so skozi zgodovino uporabljali signale za posredovanje nujnih sporočil drugim mornarjem. To so svetlobni signali, ki se proizvajajo z velikimi projektorji s sistemi, ki omogočajo svetlobne izbruhe, običajno z uporabo rešetk, ki se nahajajo pred fokusom. Za vzpostavitev povezave se s svetlobnimi signali uporablja Morsejeva abeceda.
To so signali, ki se prenašajo z vibracijami v zraku. Zaradi počasnosti naprav, potrebnih za prenos, je to zelo počasen medij. Preneseni signali uporabljajo Morsejevo kodo za prenos informacij. Poleg tradicionalne Morsejeve kode v vključeni mednarodni kodi obstajajo še druge vrste standardiziranih signalov, ki bi jih moral vsak mornar odlično razumeti.
Vrste kodiranja
Najbolj znana kodirna tabela je ASCII (ameriška standardna koda za izmenjavo informacij). Prvotno je bil razvit za prenos besedil po telegrafu, takrat pa je bil 7-bitni, torej je bilo za kodiranje angleških znakov, službenih in kontrolnih znakov uporabljenih le 128 7-bitnih kombinacij. V tem primeru je prvih 32 kombinacij (kod) služilo za kodiranje kontrolnih signalov (začetek besedila, konec vrstice, vrnitev nosilca, klic, konec besedila itd.). Pri razvoju prvih IBM-ovih računalnikov je bila ta koda uporabljena za predstavitev simbolov v računalniku. Odkar v izvorno kodo ASCII je bil samo 128 znakov, za njihovo kodiranje so bile dovolj bajtne vrednosti, v katerih je 8. bit 0. Angleščina (grški, nemški pregovori, francoski diakritiki itd.). Ko so začeli računalnike prilagajati drugim državam in jezikom, ni bilo več dovolj prostora za nove simbole. Za popolno podporo jezikom, ki niso angleščina, je IBM predstavil več kodnih tabel za posamezne države. Tako je bila za skandinavske države predlagana tabela 865 (nordijska), za arabske države - tabela 864 (arabščina), za Izrael - tabela 862 (Izrael) itd. V teh tabelah so bile nekatere kode iz druge polovice kodne tabele uporabljene za predstavitev znakov nacionalnih abeced (z izključitvijo nekaterih psevdografičnih znakov). Razmere z ruskim jezikom so se razvile na poseben način. Očitno je mogoče zamenjati znake v drugi polovici kodne tabele različne poti... Tako se je za ruski jezik pojavilo več različnih tabel za kodiranje cirilicnih znakov: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Vsi predstavljajo simbole prve polovice tabele na enak način (od 0 do 127) in se razlikujejo po predstavitvi simbolov ruske abecede in psevdografike. Za jezike, kot sta kitajščina ali japonščina, 256 znakov na splošno ni dovolj. Poleg tega vedno obstaja težava pri tiskanju ali shranjevanju besedil v eni datoteki hkrati različnih jezikih(na primer pri citiranju). Zato univerzalno kodna tabela UNICODE, ki vsebuje simbole, ki se uporabljajo v jezikih vseh ljudstev sveta, pa tudi različne službene in pomožne simbole (ločila, matematični in tehnični simboli, puščice, diakritični znaki itd.). Očitno en bajt ni dovolj za kodiranje tako velikega nabora znakov. Zato UNICODE uporablja 16-bitne (2-bajtne) kode za predstavitev 65.536 znakov. Do danes je bilo uporabljenih okoli 49.000 kod (zadnja pomembna sprememba je bila uvedba simbola valute EURO septembra 1998). Zaradi združljivosti s prejšnjimi kodami je prvih 256 kod enakih standardu ASCII. V standardu UNICODE, razen nekaterih binarna koda(te kode so običajno označene s črko U, ki ji sledi znak + in dejanska koda v šestnajstiški predstavitvi) vsakemu znaku je dodeljeno posebno ime. Druga komponenta standard UNICODE so algoritmi za pretvorbo kod UNICODE ena proti ena v zaporedju bajtov spremenljive dolžine. Potreba po takšnih algoritmih je posledica dejstva, da vse aplikacije ne morejo delovati z UNICODE. Nekatere aplikacije razumejo le 7-bitne kode ASCII, druge aplikacije razumejo 8-bitne kode ASCII. Takšne aplikacije uporabljajo tako imenovane razširjene kode ASCII za predstavitev znakov, ki ne ustrezajo naboru s 128 ali 256 znaki, kadar so znaki kodirani z nizi bajtov spremenljive dolžine. UTF-7 se uporablja za reverzibilno pretvorbo kod UNICODE v razširjene 7-bitne kode ASCII, UTF-8 pa za reverzibilno pretvorbo kod UNICODE v razširjene 8-bitne kode ASCII. Upoštevajte, da tako ASCII kot UNICODE ter drugi standardi za kodiranje znakov ne opredeljujejo podob znakov, temveč le sestavo nabora znakov in način, kako je predstavljen v računalniku. Poleg tega je (kar morda ni takoj očitno) zelo pomemben vrstni red naštevanja znakov v nizu, saj najbolj vpliva na algoritme razvrščanja. To je tabela ujemanja simbolov iz določenega niza (recimo simbolov, ki se uporabljajo za predstavljanje informacij o angleški jezik, ali v različnih jezikih, kot v primeru UNICODE) in označuje izraz tabela kodiranja znakov ali nabor znakov. Vsako standardno kodiranje ima ime, na primer KOI8-R, ISO_8859-1, ASCII. Na žalost ni standarda za kodiranje imen.
Uporablja se za komunikacijo med bližnjimi ladjami, da bi lahko spoštovali frekvenco uporabljenega radia, da ga ne bi po nepotrebnem uporabljali z zasedbo tega kanala po nepotrebnem ali ker je treba vzpostaviti komunikacijo in radio ne deluje pravilno.
Za komunikacijo se uporabljajo zastavice, zato bo glede na položaj osebe, ki izvaja signale, imela vrednost ali kaj drugega. Povezani pomeni so enaki kot pri uporabi zastav s črkami A do Z, številkami od 0 do 9 ter signali za premor in napake.
Radiotelegrafija in radiotelefonija
Z zgoraj obravnavanimi metodami je hkratna komunikacija v obe smeri nemogoča, zato so bili od točke do točke. Zahvaljujoč pojavu radiotelegrafije je ta vrsta komunikacije mogoča. Radiotelegrafija temelji na Maxwellovi teoriji širjenja valov v vesolju. Tako se rodi brezžična telegrafija, ki je eden najpomembnejših napredkov v telekomunikacijah vseh časov.
Pogosta kodiranja
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1-ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Microsoftova kodiranja Windows: o Windows-1250 za srednjeevropske jezike, ki uporabljajo latinične črke o Windows-1251 za cirilično abecedo o Windows-1252 za zahodne jezike o Windows-1253 za grščino o Windows-1254 za turščino o Windows-1255 za hebrejščino o Windows-1256 za arabski jezik o Windows-1257 za baltske jezike o Windows-1258 za vietnamski jezik MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 bolgarsko kodiranje ISCII VISCII Big5 (najbolj znana različica Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS za japonsko (Microsoft CP932) EUC-KR za korejsko (Microsoft CP949) ISO-2022 in UTF za kitajsko pisanje 8 in UTF-16 kodiranja Znaki UnicodeTa dokumentacija je bila premaknjena v arhiv in ni več podprta.
Kodiranje danes
Pred nami bo še radiotelefonija, ki ni nič drugega kot zmožnost moduliranja glasu prek radijskih valov z uporabo teoretično podlago razstavljen v radiotelegrafiji.
Kodiranje signala
To je zelo pogosto uporabljen postopek, pri katerem pred serijo signalov analogni tip prepisano v digitalne signale. Tako olajša kasnejšo obdelavo in izboljša fizikalne lastnosti.To pomeni, da je analogni signal zelo občutljiv na spremembe možnih motenj, to je posledica dejstva, da je prvotni signal zelo težko obnoviti, saj so vrednosti, ki jih ima lahko ta signal, lahko neskončne. Če ga primerjamo z digitalnim signalom, ki ima določeno število možnih vrednosti. To dejstvo olajša pridobivanje vrednosti v digitalnem signalu in se zato lahko uporablja za komunikacijo na dolge razdalje.
Uporaba kodiranja Unicode
.NET Framework 3.5
Posodobljeno: november 2007
Običajne aplikacije za izvajanje uporabljajo kodiranje za pretvorbo znakov iz notranje predstavitve (Unicode) v drugo predstavitev. Dekodiranje se uporablja za pretvorbo znakov nazaj iz zunanjega kodiranja (ne-Unicode) v notranjo predstavitev. Imenski prostor vsebuje številne razrede, ki aplikacijam omogočajo kodiranje in dekodiranje znakov. Za pregled teh razredov glej.
Pri tem postopku lahko ločimo tri dobro diferencirane faze: vzorčenje, kvantifikacija in kodifikacija. Kvantifikacija: sestoji iz vrednotenja vrednosti vsakega od vzorcev, tako da je vsakemu od vzorcev dodeljena ena od možnih vrednosti nastalega digitalni signal... Postopek kvantizacije povzroča kvantizacijski šum, ki ga povzroča število možnih vrednosti analogni signal za digitalni signal. Sestoji iz pretvorbe vrednosti, pridobljenih med postopkom kvantizacije, v binarni sistem z uporabo številnih prednastavljenih kod.
- Vzorčenje: Sestoji iz vzorčenja amplitude vhodnega signala.
- Zelo pomemben parameter v tem procesu s številom vzorcev na sekundo.
- Kodiranje.
Uporablja se za kodiranje, ki ni Unicode. Razred podpira širok nabor kodiranja ANSI/ISO.
Spodnji primer kode uporablja metodo GetEncoding zahtevani objekt kodiranja za določeno kodno stran. Metoda GetBytes pokliče na želeni objekt kodiranja, da pretvori niz Unicode v bajtno predstavitev v želenem kodiranju. Zaslon bo prikazal bajtno predstavitev niza na določeni kodni strani.
Kot že ime pove, temelji na enopolarnem kodiranju. Tako običajno binarna vrednost, enaka ena, prevzame vrednost v izhodnem signalu, ki je enaka eni, vrednost, enaka nič, pa omogoča ničelno vrednost v izhodnem signalu.
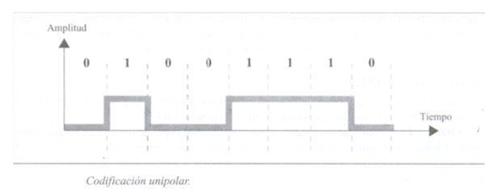
To je tip kodiranja, ki se danes najpogosteje uporablja. Temelji na kodiranju dveh polarnosti za predstavljanje binarnih informacij. Najdemo lahko naslednjo klasifikacijo polarnega kodiranja. 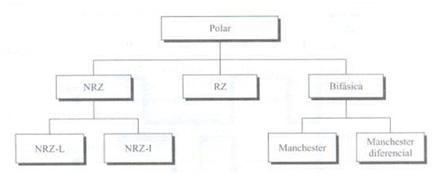
Zanj je značilno, da ima signal vedno pozitivno ali negativno vrednost. Jasno lahko ločimo vrste.
Uvozi sistem Uvozi System.IO Uvozi System.Globalization Uvozi System.Text Javni razred Encoding_UnicodeToCP Javno v skupni rabi Sub Main () "Pretvori znake ASCII v bajte. "Prikaže predstavitev bajtov niza v"določena kodna stran. "Kodna stran 1252 predstavlja latinične znake. PrintCPBytes ("Pozdravljeni, svet!", 1252) "Kodna stran 932 predstavlja japonske znake. PrintCPBytes ("Pozdravljeni, svet!", 932) "Pretvori japonske črke. PrintCPBytes (, 1252) PrintCPBytes ( "\ u307b, \ u308b, \ u305a, \ u3042, \ u306d", 932) End Sub Public Shared Sub PrintCPBytes (str Kot niz, kodna stran kot celo število) Dim targetEncoding Kot Encoding Dim encodedChars () Kot bajt "Pridobi kodiranje za določeno kodno stran. targetEncoding = Encoding.GetEncoding (codePage) "Pridobi bajtno predstavitev podanega niza. encodedChars = targetEncoding.GetBytes (str) "Natisne bajte. Console.WriteLine ( "Predstavitev bajtov" (0) "v CP" (1) ":", _ str, codePage) Dim i As Integer For i = 0 Za kodirani znaki.Length - 1 Console.WriteLine ("Byte (0): (1)", i, encodedChars (i)) Next i End Sub End Class
Običajno, če je bit ena, bo signal pozitiven, če je nič, bo signal negativen. Tako ta vrednost ni odvisna samo od trenutnega bita, ampak tudi od prejšnjega bita. Tako je bolj zanesljiv.
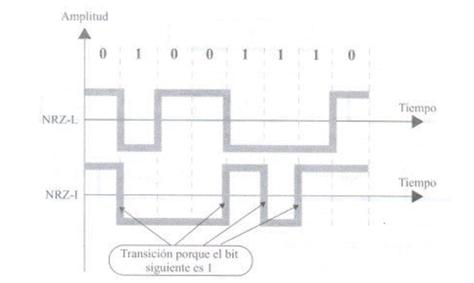
Zanj je značilna uporaba treh možnih izhodnih stopenj. Malčka je predstavljena s spremembo iz pozitivnega v nič in iz nič v negativno v pozitivno. Vsaka transakcija se zgodi na sredini intervala, kot je prikazano na naslednji sliki. Ta vrsta kodiranja omogoča tudi sprožitev postopka sinhronizacije z uporabo prehodov, ustvarjenih na polovičnih režah.
 Kateri je boljši iPhone 6s ali 6 plus
Kateri je boljši iPhone 6s ali 6 plus Kje so posnetki zaslona in igre v mapi Steam?
Kje so posnetki zaslona in igre v mapi Steam? Kako izbrisati ali obnoviti vsa izbrisana pogovorna okna VKontakte naenkrat?
Kako izbrisati ali obnoviti vsa izbrisana pogovorna okna VKontakte naenkrat?