Špeciálne znaky Unicode. Problém rozlíšenia externe podobných čísel a písmen.
Každý používateľ internetu, ktorý sa pokúša nakonfigurovať jednu alebo druhú z jeho funkcií, aspoň raz videl na displeji napísané slovo „Unicode“. Čo to je, zistíte prečítaním tohto článku.
Definícia
Kódovanie Unicode je štandard kódovania znakov. Ponúkla ho nezisková organizácia Unicode Inc. v roku 1991. Norma je navrhnutá tak, aby kombinovala čo najviac rôznych typov znakov v jednom dokumente. Stránka, ktorá bola vytvorená na jej základe, môže obsahovať písmená a hieroglyfy z rôzne jazyky(z ruštiny do kórejčiny) a matematické znaky... V tomto prípade sa všetky znaky v tomto kódovaní zobrazia bez problémov.
Dôvody pre vznik
Kedysi dávno, dávno predtým jednotný systém„Unicode“, kódovanie bolo zvolené na základe preferencií autora dokumentu. Z tohto dôvodu je často potrebné na čítanie jedného dokumentu použiť rôzne tabuľky. Niekedy to bolo treba urobiť viackrát, čo bežnému používateľovi výrazne skomplikovalo život. Ako už bolo spomenuté, riešenie tohto problému v roku 1991 navrhla nezisková organizácia Unicode Inc., ktorá navrhla nový typ kódovania znakov. Jeho zámerom bolo spojiť zastarané a rôznorodé štandardy. "Unicode" je kódovanie, ktoré umožnilo dosiahnuť v tej dobe nemysliteľné: vytvoriť nástroj, ktorý podporuje obrovské množstvo znakov. Výsledok prekonal mnohé očakávania – súčasne sa objavili dokumenty obsahujúce anglický aj ruský text, latinské a matematické výrazy.
Vytvoreniu jednotného kódovania však predchádzala potreba vyriešiť množstvo problémov, ktoré vznikli v dôsledku obrovskej rozmanitosti štandardov, ktoré už v tom čase existovali. Najbežnejšie sú:
- elfské písmená alebo „krakozyabry“;
- obmedzená sada znakov;
- problém prevodu kódovania;
- duplikácia fontov.

Malý historický exkurz
Predstavte si, že sú 80. roky. Počítačová technika ešte nie je taká rozšírená a má inú podobu ako dnes. Vtedy je každý OS svojim spôsobom jedinečný a každý nadšenec si ho upravuje pre špecifické potreby. Potreba výmeny informácií sa mení na ďalšie zdokonaľovanie všetkého na svete. Pokus o prečítanie dokumentu vytvoreného pod iným OS často zobrazí na obrazovke nezrozumiteľnú sadu znakov a začnú sa hry s kódovaním. Nie je to vždy možné urobiť rýchlo a niekedy je možné potrebný dokument otvoriť po šiestich mesiacoch alebo dokonca neskôr. Ľudia, ktorí si vymieňajú informácie, si často vytvárajú konverzné tabuľky. A tak práca na nich odhaľuje zaujímavý detail: treba ich vytvárať v dvoch smeroch: „od môjho k vášmu“ a naopak. Stroj nemôže vykonať banálnu inverziu výpočtov, pretože v pravom stĺpci je zdroj a v ľavom - výsledok, ale nie naopak. Ak by bolo potrebné nejaké použiť Špeciálne symboly v dokumente ich bolo treba najskôr doplniť a potom partnerovi aj vysvetliť, čo musí urobiť, aby sa tieto symboly nezmenili na „krakozyabry“. A nezabúdajme, že pre každé kódovanie ste museli vyvinúť alebo implementovať vlastné fonty, čo viedlo k vytvoreniu obrovského množstva duplikátov v OS.
Predstavte si tiež, že na stránke fontov uvidíte 10 rovnakých Times New Roman s malými anotáciami: pre UTF-8, UTF-16, ANSI, UCS-2. Už chápete, že bolo nevyhnutné vytvoriť univerzálny štandard?

"Otcovia tvorcovia"
Počiatky Unicode možno vystopovať do roku 1987, keď Joe Becker zo spoločnosti Xerox spolu s Lee Collinsom a Markom Davisom z Apple začal výskum praktickej tvorby univerzálnej znakovej sady. V auguste 1988 zverejnil Joe Becker návrh 16-bitového medzinárodného viacjazyčného kódovacieho systému.
O niekoľko mesiacov neskôr bola Unicode WG rozšírená o Kena Whistlera a Mikea Kernegana z RLG, Glenna Wrighta zo Sun Microsystems a niekoľkých ďalších, čím sa dokončili prípravné práce na spoločnom štandarde kódovania.

všeobecný popis
Unicode je založený na koncepte znaku. Táto definícia sa chápe ako abstraktný jav, ktorý existuje v špecifickej forme písma a realizuje sa prostredníctvom grafém (ich „portrétov“). Každý znak je špecifikovaný v "Unicode" jedinečný kód patriace do konkrétneho bloku normy. Napríklad graféma B je v anglickej aj ruskej abecede, ale v Unicode zodpovedá 2 rôznym znakom. Aplikuje sa na ne transformácia, to znamená, že každý z nich je opísaný databázovým kľúčom, sadou vlastností a celým menom.
Výhody Unicode
Kódovanie Unicode sa líšilo od zvyšku svojich súčasníkov obrovským množstvom znakov na „šifrovanie“ znakov. Faktom je, že jeho predchodcovia mali 8 bitov, to znamená, že podporovali 28 znakov, ale nový vývoj už mal 216 postáv, čo bol obrovský krok vpred. To umožnilo zakódovať takmer všetky existujúce a bežné abecedy.
S príchodom „Unicode“ nebolo potrebné používať konverzné tabuľky: ako jediný štandard jednoducho eliminoval ich potrebu. Rovnako aj „krakozyabry“ upadli do zabudnutia – jediný štandard ich znemožnil a zároveň eliminoval potrebu vytvárať duplicitné fonty.
Vývoj Unicode
Pokrok samozrejme nestojí a od prvej prezentácie ubehlo 25 rokov. Kódovanie Unicode si však tvrdohlavo udržuje svoju pozíciu vo svete. V mnohých ohľadoch to bolo možné vďaka tomu, že sa to stalo ľahko implementovateľným a rozšíreným, pričom bol uznávaný ako vývojári proprietárneho (plateného) a open source softvéru.

Zároveň by sme nemali predpokladať, že dnes máme k dispozícii rovnaké kódovanie Unicode ako pred štvrťstoročím. zapnuté tento moment jeho verzia sa zmenila na 5.х.х a počet kódovaných znakov sa zvýšil na 231. Možnosť použiť väčšiu zásobu znakov bola opustená, aby sa zachovala podpora pre Unicode-16 (kódovania, kde bol ich maximálny počet obmedzený na 216). Od svojho vzniku až po verziu 2.0.0 „Štandard Unicode“ takmer zdvojnásobil počet znakov, ktoré obsahuje. Rast príležitostí pokračoval aj v nasledujúcich rokoch. Do verzie 4.0.0 bolo potrebné zvýšiť samotný štandard, čo sa aj podarilo. Vďaka tomu získal „Unicode“ podobu, v akej ho poznáme dnes.

Čo je ešte v Unicode?
Okrem obrovského, neustále rastúceho počtu symbolov má ešte jednu užitočnú funkciu. Ide o takzvanú normalizáciu. Namiesto posúvania celého dokumentu znak po znaku a nahrádzania príslušných ikon z vyhľadávacej tabuľky sa používa jeden z existujúcich normalizačných algoritmov. o čom to hovoríme?
Namiesto plytvania výpočtovými prostriedkami na pravidelnú kontrolu rovnakého symbolu, ktorý môže byť podobný v rôznych abecedách, sa používa špeciálny algoritmus. Umožňuje vám vyňať podobné znaky v samostatnom stĺpci substitučnej tabuľky a odkazovať na ne, namiesto toho, aby ste znova a znova kontrolovali všetky údaje.
Boli vyvinuté a implementované štyri takéto algoritmy. V každom z nich prebieha transformácia podľa striktne definovaného princípu, ktorý sa líši od ostatných, preto nie je možné označiť žiadnu z nich za najúčinnejšiu. Každý z nich bol vyvinutý pre špecifické potreby, bol implementovaný a úspešne používaný.

Distribúcia normy
Za 25 rokov svojej histórie je kódovanie Unicode pravdepodobne najrozšírenejšie na svete. Tomuto štandardu sú prispôsobené aj programy a webové stránky. Skutočnosť, že Unicode dnes používa viac ako 60% internetových zdrojov, môže naznačovať šírku aplikácie.
Teraz už viete, kedy vznikol štandard Unicode. Čo to je, tiež viete a budete môcť oceniť plný význam vynálezu, ktorý vytvorila skupina špecialistov z Unicode Inc. pred viac ako 25 rokmi.
Potrebujete hosting alebo doménu? Kliknite tu! Chcete vytvoriť internetový obchod? Kliknite tu! (Shopify)Niekedy je pri písaní príspevku potrebný znak (znak), ktorý nie je na klávesnici, v takýchto situáciách vám pomôže tabuľka znakov unicode. Dnes budeme uvažovať online službu, v ktorom sú zoskupené všetky znaky Unicode ...
Tabuľka znakov Unicode
Pre tých, ktorí sa zaujímajú o pozadie vzhľadu Unicode- tu je odkaz na wikipediu
Označme teda svoje záujmy znaky unicode- toto je ich použitie v ich článkoch, na ich stránkach.
Najprv poďme na stránku servisné znaky Unicode:


Poďme sa trochu pozrieť na rozhranie tejto služby. Úplne hore je vyhľadávacie pole, do ktorého stačí zadať názov hľadaného prvku, napr.: „Šípka“ alebo „Elipsa“, po zadaní kliknite na vyhľadávanie, aby ste získali výsledok .
Vedľa vyhľadávania je prepínač jazyka stránky.
Nižšie je uvedený zoznam často požadovaných symbolov, možno medzi nimi bude ten, ktorý potrebujete, ak áno, stačí kliknúť na symbol a prejsť na stránku s podrobnými informáciami o ňom.
Hlavnú časť stránky zaberá tabuľka znakov Unicode, pre pohodlnejšie vyhľadávanie môžete kliknúť aj na "Ovládacie znaky" a vybrať skupinu znakov, napríklad: "Grécke znaky", ak potrebujete vložiť grécky znak.
Nájdite požadovanú položku v tabuľke znakov Unicode
Využime napríklad vyhľadávanie a zadáme doň slovo „Šípka“ a stlačíme hľadať.

Na stránke s výsledkami vyhľadávania hľadáme symbol, ktorý potrebujeme, a kliknutím naň prejdeme na stránku detailné informácie o ňom.
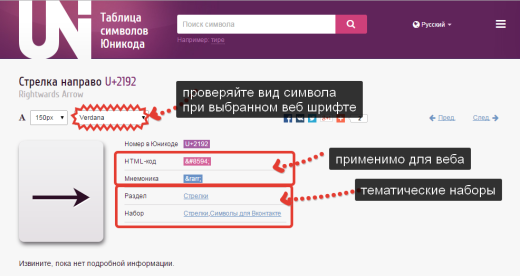
Na stránke Unicode znak zaujíma nás jeho HTML kód alebo Mnemotechnický kód, oboje je možné použiť na webovej stránke, ak to chcete urobiť, skopírujte kód a vložte ho na správne miesto v značke HTML, prehliadač ho interpretuje a zobrazí ako symbol na strana.
Upozorňujeme, že na stránke znakov Unicode je možnosť výberu písma. Vždy otestujte, ako sa bude vaše písmo zobrazovať s písmami Verdana, Arial (a inými webovými písmami). nie všetky znaky sú nimi podporované.
(kódy od 0 do 127), t.j. jeden bajt kóduje latinské písmená, čísla a špeciálne znaky. Ruské písmená (cyrilika) sú reprezentované 16-bitovými (dvojbajtovými) kódmi:
110XXXX 10XXXXXX,
kde X označuje binárne číslice na umiestnenie kódu znaku v súlade s tabuľkou UNICODE.
Unicode (anglicky Unicode) je štandard kódovania znakov, ktorý umožňuje, aby boli znaky reprezentované takmer vo všetkých písaných jazykoch. Znaky Unicode sú zakódované ako celé čísla bez znamienka. Tieto čísla sa budú nazývať kódy znakov Unicode alebo jednoducho UNICODE... Unicode má niekoľko foriem reprezentácie znakov v počítači: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) a UTF-32 (UTF-32BE, UTF-32LE)... (Anglický formát transformácie Unicode - UTF).
Zvážte, ako je to zakódované UTF-8 list F... jej UNICODE- 1046 10 alebo 0416 16 alebo 10 000 010110 2. UNICODE v binárnom systéme je rozdelený na dve časti: päť ľavých bitov a šesť pravých bitov. Ľavá strana je doplnená na bajt so znakom 110 dvojbajtový kód UTF-8: 110 10 000. Dva bity sú priradené pravej strane 10 znak pokračovania viacbajtového kódu: 10 010110. Kód záverečného písmena F v UTF-8 vyzerá takto:
110
10000 10
010110 2
alebo D0 96 16
Ruské písmeno je teda zakódované dvakrát: najprv do 11-bitov UNICODE a potom do 16-bitového UTF-8.
V tabuľke nižšie okrem kódov UNICODE a UTF-8 v hexadecimálnom zápise sú uvedené kódy UTF-8 v desiatkovom zápise a pre porovnanie cyrilské kódy v kódovaní CP-1251, inak nazývaný windovs-1251.
| Symbol | UNICODE | UTF-8 | CP-1251 | ||
|---|---|---|---|---|---|
| Hex | Desať | Hex | Desať | ||
| A | 0410 | 1040 | D090 | 208 144 | 192 |
| B | 0411 | 1041 | D091 | 208 145 | 193 |
| V | 0412 | 1042 | D092 | 208 146 | 194 |
| G | 0413 | 1043 | D093 | 208 147 | 195 |
| D | 0414 | 1044 | D094 | 208 148 | 196 |
| E | 0415 | 1045 | D095 | 208 149 | 197 |
| F | 0416 | 1046 | D096 | 208 150 | 198 |
| Z | 0417 | 1047 | D097 | 208 151 | 199 |
| A | 0418 | 1048 | D098 | 208 152 | 200 |
| Th | 0419 | 1049 | D099 | 208 153 | 201 |
| TO | 041A | 1050 | D09A | 208 154 | 202 |
| L | 041B | 1051 | D09B | 208 155 | 203 |
| M | 041C | 1052 | D09C | 208 156 | 204 |
| N | 041D | 1053 | D09D | 208 157 | 205 |
| O | 041E | 1054 | D09E | 208 158 | 206 |
| NS | 041F | 1055 | D09F | 208 159 | 207 |
| R | 0420 | 1056 | D0A0 | 208 160 | 208 |
| S | 0421 | 1057 | D0A1 | 208 161 | 209 |
| T | 0422 | 1058 | D0A2 | 208 162 | 210 |
| Mať | 0423 | 1059 | D0A3 | 208 163 | 211 |
| F | 0424 | 1060 | D0A4 | 208 164 | 212 |
| NS | 0425 | 1061 | D0A5 | 208 165 | 213 |
| C | 0426 | 1062 | D0A6 | 208 166 | 214 |
| H | 0427 | 1063 | D0A7 | 208 167 | 215 |
| NS | 0428 | 1064 | D0A8 | 208 168 | 216 |
| SCH | 0429 | 1065 | D0A9 | 208 169 | 217 |
| B | 042A | 1066 | D0AA | 208 170 | 218 |
| NS | 042B | 1067 | D0AB | 208 171 | 219 |
| B | 042C | 1068 | D0AC | 208 172 | 220 |
| NS | 042D | 1069 | D0AD | 208 173 | 221 |
| NS | 042E | 1070 | D0AE | 208 174 | 222 |
| SOM | 042F | 1071 | D0AF | 208 175 | 223 |
| a | 0430 | 1072 | D0B0 | 208 176 | 224 |
| b | 0431 | 1073 | D0B1 | 208 177 | 225 |
| v | 0432 | 1074 | D0B2 | 208 178 | 226 |
| G | 0433 | 1075 | D0B3 | 208 179 | 227 |
| d | 0434 | 1076 | D0B4 | 208 180 | 228 |
| e | 0435 | 1077 | D0B5 | 208 181 | 229 |
| f | 0436 | 1078 | D0B6 | 208 182 | 230 |
| s | 0437 | 1079 | D0B7 | 208 183 | 231 |
| a | 0438 | 1080 | D0B8 | 208 184 | 232 |
| th | 0439 | 1081 | D0B9 | 208 185 | 233 |
| Komu | 043A | 1082 | D0BA | 208 186 | 234 |
| l | 043B | 1083 | D0BB | 208 187 | 235 |
| m | 043C | 1084 | D0BC | 208 188 | 236 |
| n | 043D | 1085 | D0BD | 208 189 | 237 |
| O | 043E | 1086 | D0BE | 208 190 | 238 |
| NS | 043F | 1087 | D0BF | 208 191 | 239 |
| R | 0440 | 1088 | D180 | 209 128 | 240 |
| s | 0441 | 1089 | D181 | 209 129 | 241 |
| T | 0442 | 1090 | D182 | 209 130 | 242 |
| pri | 0443 | 1091 | D183 | 209 131 | 243 |
| f | 0444 | 1092 | D184 | 209 132 | 244 |
| NS | 0445 | 1093 | D185 | 209 133 | 245 |
| c | 0446 | 1094 | D186 | 209 134 | 246 |
| h | 0447 | 1095 | D187 | 209 135 | 247 |
| NS | 0448 | 1096 | D188 | 209 136 | 248 |
| SCH | 0449 | 1097 | D189 | 209 137 | 249 |
| b | 044A | 1098 | D18A | 209 138 | 250 |
| NS | 044B | 1099 | D18B | 209 139 | 251 |
| b | 044C | 1100 | D18C | 209 140 | 252 |
| NS | 044D | 1101 | D18D | 209 141 | 253 |
| NS | 044E | 1102 | D18E | 209 142 | 254 |
| som | 044F | 1103 | D18F | 209 143 | 255 |
| Symboly mimo všeobecného pravidla | |||||
| Jo | 0401 | 1025 | D001 | 208 101 | 168 |
| e | 0451 | 1025 | D191 | 209 145 | 184 |
Niekedy potrebujete do svojho dizajnu pridať ikonu, ale nechcete vkladať ďalšie obrázky alebo celé písmo ikony, ako napríklad Font Awesome? Potom máme pre vás dobrú správu – vo vašom prehliadači je už rozsiahla knižnica dostupných ikon a symbolov. Volá sa Unicode a je to štandard, ktorý priraďuje jedinečné identifikátory pre stále rastúci počet (v súčasnosti viac ako 110 000) symbolov a ikon.
To však neznamená, že máte na výber zo stoviek tisíc ikon. Závisí to od prehliadača, ktorý ich vykresľuje, a používa na to fonty, ktoré sú nainštalované v systéme. V tomto článku sme zostavili množstvo znakových sád, ktoré sú dostupné v systémoch Windows, Linux, OS X, Android a IOS. Dnes ich môžete použiť vo svojich návrhoch!
Tip: ktorý vysvetľuje všetko, čo je potrebné vedieť o kódovaní a kódovaní Unicode, ktoré odporúčame prečítať každému vývojárovi softvéru.
Ako používať tieto ikony
Ikony zobrazené v tabuľkách nižšie sú bežné symboly, ktoré môžete skopírovať a prilepiť, ako keby to boli písmená abecedy. Ak sa však kódovanie používa na uloženie súborov HTML / CSS nie UTF-8 nebudú zobrazené. Preto sme zaviedli kód HTML escape, ktorý bude vždy fungovať. Tu je to, čo musíte urobiť, aby ste tieto ikony mohli používať.:
- Nájdite ikonu, ktorá sa vám páči. Poskytli sme malé a veľké ukážky.
- Skopírujte kód.
- Vložte ho do HTML ako obyčajný text. V CSS ich môžete použiť ako hodnotu vlastnosti obsahu... V JS, PHP a iných programovacích jazykoch ich môžete použiť ako obyčajný text v reťazcoch.
- Ikony si môžete prispôsobiť nastavením veľkosti písma, farby, textu a tieňov rovnako ako normálny text.
ikony
| názov | Náhľad | kód | |
|---|---|---|---|
| usmievavý | ☺ | ☺ | ☺ |
| Varovné znamenie | ⚠ | ⚠ | ⚠ |
| Horúce pramene | ♨ | ♨ | ♨ |
| Invalidný vozík | ♿ | ♿ | ♿ |
| Recyklovať | ♻ | ♻ | ♻ |
| 8-loptička | ➑ | ➑ | ➑ |
| Vysoké napätie | ⚡ | ⚡ | ⚡ |
| Biela hviezda | ☆ | ☆ | ☆ |
| Čierna hviezda | ★ | ★ | ★ |
| Biele srdce | ♡ | ♡ | ♡ |
| Čierne srdce | ❤ | ❤ | ❤ |
| Káva | ☕ | ☕ | ☕ |
| Lietadlo | ✈ | ✈ | ✈ |
| Presýpacie hodiny | ⌛ | ⌛ | ⌛ |
| Hodiny | ⌚ | ⌚ | ⌚ |
| Čierne nožnice | ✂ | ✂ | ✂ |
| Biele nožnice | ✄ | ✄ | ✄ |
| koruna | ♕ | ♕ | ♕ |
| Kotva | ⚓ | ⚓ | ⚓ |
| Kríž | ✝ | ✝ | ✝ |
| Čierno-biely kruh | ◑ | ◑ | ◑ |
| Osem poznámok | ♪ | ♪ | ♪ |
| Vyžarované osminové tóny | ♫ | ♫ | ♫ |
| Hviezdička so štyrmi balónikmi | ✣ | ✣ | ✣ |
| Zakrúžkovaná biela hviezda | ✪ | ✪ | ✪ |
| Biela hviezda | ✰ | ✰ | ✰ |
| Biela štvorcípa hviezda | ✧ | ✧ | ✧ |
| Čierna štvorcípa hviezda | ✦ | ✦ | ✦ |
| Kontrola volebnej urny | ☑ | ☑ | ☑ |
| Fajka | ✔ | ✔ | ✔ |
| Krížová značka | ✘ | ✘ | ✘ |
| Ceruzka | ✎ | ✎ | ✎ |
| Ruka na písanie | ✍ | ✍ | ✍ |
| Žena | ♀ | ♀ | ♀ |
| Muž | ♂ | ♂ | ♂ |
| Čierny telefón | ☎ | ☎ | ☎ |
| Biely telefón | ☏ | ☏ | ☏ |
| Obálka | ✉ | ✉ | ✉ |
| Poloha telefónu | ✆ | ✆ | ✆ |
Unicode šípky
| názov | Náhľad | kód | |
|---|---|---|---|
| Šípka doľava | ← | ← | ← |
| Šípka doprava | → | → | → |
| Šípka nahor | |||
| Šípka nadol | ↓ | ↓ | ↓ |
| Šípka doľava doprava | ↔ | ↔ | ↔ |
| Šípka hore dole | ↕ | ↕ | ↕ |
| Šípky doprava a doľava | ⇄ | ⇄ | ⇄ |
| Šípky hore a dole | ⇅ | ⇅ | ⇅ |
| Šípka dole-vľavo 90° | ↲ | ↲ | ↲ |
| Šípka dole-vpravo 90° | ↳ | ↳ | ↳ |
| Šípka hore-vľavo 90° | ↰ | ↰ | ↰ |
| Šípka hore-doprava 90° | ↱ | ↱ | ↱ |
| Severozápadná šípka do rohu | ⇱ | ⇱ | ⇱ |
| Juhovýchodná šípka do rohu | ⇲ | ⇲ | ⇲ |
| Šípka doľava na lištu | ⇤ | ⇤ | ⇤ |
| Šípka doprava na lištu | ⇥ | ⇥ | ⇥ |
| Polkruhová šípka proti smeru hodinových ručičiek | ↶ | ↶ | ↶ |
| Polkruhová šípka v smere hodinových ručičiek | ↷ | ↷ | ↷ |
| Kruhová šípka proti smeru hodinových ručičiek | ↺ | ↺ | ↺ |
| Kruhová šípka v smere hodinových ručičiek | ↻ | ↻ | ↻ |
| Široká šípka doprava | ➔ | ➔ | ➔ |
| Kľukatá šípka nadol | ↯ | ↯ | ↯ |
| Severozápadná šípka | ↖ | ↖ | ↖ |
| Ťažká juhovýchodná šípka | ➘ | ➘ | ➘ |
| Ťažká šípka doprava | ➙ | ➙ | ➙ |
| Ťažká severovýchodná šípka | ➚ | ➚ | ➚ |
| Prerušovaná šípka doprava | ➟ | ➟ | ➟ |
| Bodkovaná šípka doľava | ⇠ | ⇠ | ⇠ |
| Čierna šípka doprava | ➤ | ➤ | ➤ |
| Biela šípka doľava | ⇦ | ⇦ | ⇦ |
| Biela šípka doprava | ⇨ | ⇨ | ⇨ |
| Ľavý uhol úvodzovky | « | « | « |
| Pravý uhol úvodzovky | » | » | » |
| Pravý čierny ukazovateľ | |||
| Ľavý čierny ukazovateľ | ◀ | ◀ | ◀ |
| Hore čierny ukazovateľ | ▲ | ▲ | ▲ |
| Dole čierny ukazovateľ | ▼ | ▼ | ▼ |
| Pravý biely ukazovateľ | ▷ | ▷ | ▷ |
| Ľavý biely ukazovateľ | ◁ | ◁ | ◁ |
| Hore biely ukazovateľ | △ | △ | △ |
| Biely ukazovateľ nadol | ▽ | ▽ | ▽ |
| Luk šíp | ➴ | ➴ | ➴ |
Špeciálne znaky v unicode
Mena Unicode
Ikony počasia
| názov | Náhľad | kód | |
|---|---|---|---|
| stupňa | ° | ° | ° |
| Malé slnko | ☀ | ☀ | ☀ |
| Veľké slnko | ☼ | ☼ | ☼ |
| Cloud | ☁ | ☁ | ☁ |
| Dáždnik | ☔ | ☔ | ☔ |
| Snehová vločka 1 | ❆ | ❆ | ❆ |
| Snehová vločka 2 | ❅ | ❅ | ❅ |
| Snehová vločka 3 | ❄ | ❄ | ❄ |
Unicode ukazovatele
| názov | Náhľad | kód | |
|---|---|---|---|
| Ukazovateľ vľavo čierny | ☚ | ☚ | ☚ |
| Ukazovateľ Pravý Čierny | ☛ | ☛ | ☛ |
| Ukazovateľ vľavo biely | ☜ | ☜ | ☜ |
| Ukazovateľ hore biely | ☝ | ☝ | ☝ |
| Ukazovateľ Pravý Biely | ☞ | ☞ | ☞ |
| Ukazovateľ nadol biely | ☟ | ☟ | ☟ |
Znamenia zverokruhu v unicode
| názov | Náhľad | kód | |
|---|---|---|---|
| Baran | ♈ | ♈ | ♈ |
| Býk | ♉ | ♉ | ♉ |
| Dvojičky | ♊ | ♊ | ♊ |
| Rakovina | ♋ | ♋ | ♋ |
| Lev | ♌ | ♌ | ♌ |
| Panna | ♍ | ♍ | ♍ |
| váhy | ♎ | ♎ | ♎ |
| Scorpion | ♏ | ♏ | ♏ |
| Strelec | ♐ | ♐ | ♐ |
| Kozorožec | ♑ | ♑ | ♑ |
| Vodnár | ♒ | ♒ | ♒ |
| Ryby | ♓ | ♓ | ♓ |
Unicode symboly kariet
| názov | Náhľad | kód | |
|---|---|---|---|
| Kluby Black | ♠ | ♠ | ♠ |
| Srdce čierne | ♥ | ♥ | ♥ |
| Diamanty čierne | ♦ | ♦ | ♦ |
| Piky čierne | ♣ | ♣ | ♣ |
| Biele kluby | ♤ | ♤ | ♤ |
| Srdiečka biele | ♡ | ♡ | ♡ |
| Diamanty biele | ♢ | ♢ | ♢ |
| Piky biele | ♧ | ♧ | ♧ |
Šachové figúrky v unicode
| názov | Náhľad | kód | |
|---|---|---|---|
| Kráľ biely | ♔ | ♔ | ♔ |
| Kráľovná biela | ♕ | ♕ | ♕ |
| Veža biela | ♖ | ♖ | ♖ |
| biskup White | ♗ | ♗ | ♗ |
| Rytier biely | ♘ | ♘ | ♘ |
| Pešiak biely | ♙ | ♙ | ♙ |
| Kráľ čierny | ♚ | ♚ | ♚ |
| Kráľovná čierna | ♛ | ♛ | ♛ |
| Veža čierna | ♜ | ♜ | ♜ |
| biskup Black | ♝ | ♝ | ♝ |
| Rytier čierny | ♞ | ♞ | ♞ |
| Pešiak čierny | ♟ | ♟ | ♟ |
Hra s kockami
| názov | Náhľad | kód | |
|---|---|---|---|
| Hod kockou jeden | ⚀ | ⚀ | ⚀ |
| Hod kockou dva | ⚁ | ⚁ | ⚁ |
| Hod kockou tri | ⚂ | ⚂ | ⚂ |
| Hod kockami štyri | ⚃ | ⚃ | ⚃ |
| Kocka päť | ⚄ | ⚄ | ⚄ |
| Hoď kockami šesť | ⚅ | ⚅ | ⚅ |
Unicode matematické symboly
| názov | Náhľad | kód | |
|---|---|---|---|
| Nekonečno | ∞ | ∞ | ∞ |
| Plus mínus | ± | ± | ± |
| Menej ako alebo rovné | ≤ | ≤ | ≤ |
| Viac-Than Or Equal To | ≥ | ≥ | ≥ |
| Nerovná sa | ≠ | ≠ | ≠ |
| divízie | ÷ | ÷ | ÷ |
| Násobenie x | × | × | × |
| Ťažké násobenie x | ✖ | ✖ | ✖ |
| Horný index jeden | ¹ | ¹ | ¹ |
| Horný index dva | ² | ² | ² |
| Horný index tri | ³ | ³ | ³ |
| Zakrúžkované plus | ⊕ | ⊕ | ⊕ |
| Násobenie v krúžku | ⊗ | ⊗ | ⊗ |
| Logické AND | ∧ | ∧ | ∧ |
| Logické ALEBO | ∨ | ∨ | ∨ |
| Delta | ∆ | ∆ | ∆ |
| Koláč | ∏ | ∏ | ∏ |
| Sigma (SUM) | ∑ | ∑ | ∑ |
| Omega | Ω | Ω | Ω |
| Prázdna sada | ∅ | ∅ | ∅ |
| Uhol | ∠ | ∠ | ∠ |
| Paralelné | ∥ | ∥ | ∥ |
| Kolmý | ⊥ | ⊥ | ⊥ |
| Takmer sa rovná | ≈ | ≈ | ≈ |
| Trojuholník | △ | △ | △ |
| Kruh | ○ | ○ | ○ |
| Námestie | □ | □ | □ |
Zlomky
| názov | Náhľad | kód | |
|---|---|---|---|
| Jedna štvrtina (1/4) | ¼ | ¼ | ¼ |
| Jedna polovica (1/2) | ½ | ½ | ½ |
| Tri štvrtiny (3/4) | ¾ | ¾ | ¾ |
| Jedna tretina (1/3) | ⅓ | ⅓ | ⅓ |
| Dve tretiny (2/3) | ⅔ | ⅔ | ⅔ |
| Jedna osem (1/8) | ⅛ | ⅛ | ⅛ |
| Tri osmičky (3/8) | ⅜ | ⅜ | ⅜ |
| Five Eights (5/8) | ⅝ | ⅝ | ⅝ |
| Seven Eights (7/8) | ⅞ | ⅞ | ⅞ |
Rímske číslice v unicode
| názov | Náhľad | kód | |
|---|---|---|---|
| Rímske číslo jedna | Ⅰ | Ⅰ | Ⅰ |
| Rímska číslica dva | Ⅱ | Ⅱ | Ⅱ |
| Rímska číslica tri | Ⅲ | Ⅲ | Ⅲ |
| Rímska číslica štyri | Ⅳ | Ⅳ | Ⅳ |
| Rímska číslica päť | Ⅴ | Ⅴ | Ⅴ |
| Rímske číslo šesť | Ⅵ | Ⅵ | Ⅵ |
| Rímska číslica sedem | Ⅶ | Ⅶ | Ⅶ |
| Rímska číslica osem | Ⅷ | Ⅷ | Ⅷ |
| Rímska číslica deväť | Ⅸ | Ⅸ | Ⅸ |
| Rímske číslo desať | Ⅹ | Ⅹ | Ⅹ |
| Rímske číslo jedenásť | Ⅺ | Ⅺ | Ⅺ |
| Rímska číslica dvanásť | Ⅻ | Ⅻ | Ⅻ |
Vo vykresľovaní týchto symbolov sú určité rozdiely operačné systémy... Je to spôsobené rôznymi rodinami písiem, ktoré sa používajú. Okrem toho systémy iOS a Android nahrádzajú niektoré znaky Unicode emoji, takže nezabudnite skontrolovať pridané znaky, aby ste sa uistili, že nie a že ikony sa zobrazujú podľa plánu.
Prvky kódového priestoru, ktoré predstavujú nezáporné celé čísla. Rodina kódovaní definuje strojovú reprezentáciu sekvencie UCS kódov.
Kódy Unicode sú rozdelené do niekoľkých oblastí. Oblasť s kódmi U + 0000 až U + 007F obsahuje znaky ASCII s príslušnými kódmi. Ďalej sú to oblasti znakov rôznych písiem, interpunkčných znamienok a technických symbolov. Niektoré z kódov sú vyhradené pre budúce použitie. Pod znakmi cyriliky sú priradené oblasti znakov s kódmi od U + 0400 do U + 052F, od U + 2DE0 po U + 2DFF, od U + A640 po U + A69F (pozri azbuku v Unicode).
Predpoklady pre vytvorenie a rozvoj Unicode
Keďže v mnohých počítačových systémoch (napríklad Windows NT) sa už ako predvolené kódovanie používali pevné 16-bitové znaky, rozhodlo sa zakódovať všetky najdôležitejšie znaky len v rámci prvých 65 536 pozícií (tzv. základná viacjazyčná rovina, BMP). Zvyšok priestoru sa používa pre „ďalšie znaky“ (angl. doplnkové znaky): systémy písania zaniknutých jazykov alebo veľmi zriedkavo používaných čínskych znakov, matematických a hudobných symbolov.
Pre kompatibilitu so starými 16-bitovými systémami bol vynájdený systém UTF-16, kde prvých 65 536 pozícií, s výnimkou pozícií z intervalu U + D800 ... U + DFFF, je zobrazených priamo ako 16-bitové čísla, a zvyšok sú reprezentované ako "náhradné páry" (prvý prvok z páru z oblasti U + D800... U + DBFF, druhý prvok z páru z oblasti U + DC00... U + DFFF). Pre náhradné páry sa použila časť kódového priestoru (2048 pozícií), ktorá bola predtým vyhradená pre „znaky na súkromné použitie“.
Keďže UTF-16 dokáže zobraziť iba 2 20 + 2 16 −2048 (1 112 064) znakov, toto číslo bolo zvolené ako konečná hodnota pre kódový priestor Unicode.
Aj keď bola oblasť kódu Unicode rozšírená nad 2-16 už vo verzii 2.0, prvé znaky v oblasti „top“ boli umiestnené až vo verzii 3.1.
Úloha tohto kódovania vo webovom sektore neustále rastie, začiatkom roku 2010 bol podiel webov využívajúcich Unicode približne 50 %.
Unicode verzie
Keďže sa tabuľka znakov Unicode mení a dopĺňa a vydávajú sa nové verzie tohto systému – a táto práca pokračuje, keďže pôvodný systém Unicode obsahoval iba rovinu 0 – dvojbajtové kódy – sú vydávané aj nové dokumenty ISO. Systém Unicode existuje celkovo v týchto verziách:
- 1.1 (vyhovuje norme ISO / IEC 10646-1: 1993), 1991-1995.
- 2.0, 2.1 (rovnaká norma ISO / IEC 10646-1: 1993 plus dodatky: "Doplnky" 1 až 7 a "Technické opravy" 1 a 2), norma z roku 1996.
- 3.0 (ISO / IEC 10646-1: 2000 štandard) 2000 štandard.
- 3.1 (normy ISO / IEC 10646-1: 2000 a ISO / IEC 10646-2: 2001) z roku 2001.
- 3.2 štandard z roku 2002.
- 4.0, štandard 2003.
- 4.01, štandard 2004.
- 4.1, štandard 2005.
- 5.0, štandard 2006.
- 5.1, štandard 2008.
- 5.2, štandard 2009.
- 6.0, štandard 2010.
- 6.1, štandard 2012.
- 6.2, štandard 2012.
Kódový priestor
Hoci formy zápisu UTF-8 a UTF-32 umožňujú zakódovať až 2 331 (2 147 483 648) kódových bodov, pre kompatibilitu s UTF-16 sa rozhodlo použiť iba 1 112 064. Aj to je však viac než dosť – dnes sa (vo verzii 6.0) používa o niečo menej ako 110 000 kódových bodov (109 242 grafických a 273 iných symbolov).
Kódový priestor je rozdelený na 17 lietadlá 2 16 (65536) znakov každý. Nultá rovina sa nazýva základné, obsahuje symboly najbežnejších skriptov. Prvá rovina sa používa hlavne pre historické písma, druhá - pre zriedka používané znaky CJK, tretia je vyhradená pre archaické čínske znaky. Lietadlá 15 a 16 sú vyhradené pre súkromné použitie.
Na označenie Unicode znaky zápis v tvare „U + xxxx"(Pre kódy 0 ... FFFF), alebo" U + xxxxx"(Pre kódy 10000 ... FFFFF), alebo" U + xxxxxx"(Pre kódy 100000 ... 10FFFF), kde xxx- hexadecimálne číslice. Napríklad znak „i“ (U + 044F) má kód 044F = 1103.
Systém kódovania
Univerzálny kódovací systém (Unicode) je súbor grafických symbolov a spôsob ich kódovania pre počítačové spracovanie textových údajov.
Grafické symboly sú symboly, ktoré majú viditeľný obrázok. Grafické znaky sú protikladom k ovládacím a formátovacím znakom.
Grafické symboly zahŕňajú nasledujúce skupiny:
- písmená obsiahnuté aspoň v jednej z podporovaných abecied;
- čísla;
- interpunkčné znamienka;
- špeciálne znaky (matematické, technické, ideogramy atď.);
- separátory.
Unicode je systém pre lineárnu reprezentáciu textu. Znaky s ďalšími hornými alebo dolnými indexmi môžu byť reprezentované ako sekvencia kódov zostavených podľa určitých pravidiel (zložený znak) alebo ako jeden znak (monolitická verzia, vopred zložený znak).
Úprava znakov
Vyobrazenie znaku "Y" (U + 0419) vo forme základného znaku "I" (U + 0418) a modifikujúceho znaku "" (U + 0306)
Grafické znaky v Unicode sa delia na rozšírené a nerozšírené (bez šírky). Nepredĺžené znaky pri zobrazení nezaberajú miesto v riadku. Patria sem najmä diakritické znamienka a iné diakritické znamienka. Rozšírené aj nepredĺžené znaky majú svoje vlastné kódy. Rozšírené symboly sa inak nazývajú základné (angl. základné znaky), a nerozšírené - upravujúce (angl. kombinovanie znakov); a títo sa nemôžu stretnúť nezávisle. Napríklad znak „á“ môže byť reprezentovaný ako postupnosť základného znaku „a“ (U + 0061) a znaku modifikátora „ ́“ (U + 0301), alebo ako monolitický znak „á“ (U + 00C1).
Špeciálnym typom modifikujúcich postáv sú selektory štýlu tváre (angl. selektory variácií). Vzťahujú sa len na tie symboly, pre ktoré sú takéto varianty definované. Vo verzii 5.0 sú pre sériu definované možnosti štýlu matematické symboly, za symboly tradičnej mongolskej abecedy a za symboly mongolského štvorcového písma.
Formy normalizácie
Pretože môžu byť reprezentované rovnaké symboly rôzne kódy, čo niekedy komplikuje spracovanie, existujú normalizačné procesy určené na to, aby sa text dostal do určitej štandardnej podoby.
Štandard Unicode definuje 4 formy normalizácie textu:
- Normalizačná forma D (NFD) - Kanonický rozklad. V procese prevodu textu do tejto formy sú všetky zložené znaky rekurzívne nahradené niekoľkými zloženými, v súlade s rozkladovými tabuľkami.
- Normalizačná forma C (NFC) je kanonický rozklad, po ktorom nasleduje kanonické zloženie. Najprv sa text zredukuje na formu D, potom sa vykoná kanonické zloženie - text sa spracuje od začiatku do konca a dodržia sa nasledujúce pravidlá:
- Symbol S je počiatočné ak má triedu modifikácie nulu v znakovej báze Unicode.
- V akejkoľvek sekvencii znakov, ktorá sa začína počiatočným znakom S, je znak C blokovaný od znaku S vtedy a len vtedy, ak je medzi S a C akýkoľvek znak B, ktorý je buď počiatočným znakom alebo má rovnakú alebo vyššiu triedu modifikácie ako C. Toto pravidlo platí len pre reťazce, ktoré prešli kanonickým rozkladom.
- Primárny Zložený je znak, ktorý má kanonický rozklad v znakovej báze Unicode (alebo kanonický rozklad pre Hangul a nie je zahrnutý v zozname výnimiek).
- Znak X možno primárne zarovnať so znakom Y vtedy a len vtedy, ak existuje primárne zložené Z kanonicky ekvivalentné sekvencii
- Ak nasledujúci znak C nie je blokovaný posledným nájdeným počiatočným základným znakom L a možno ho s ním úspešne zarovnať, potom sa L nahradí zloženým znakom L-C a C sa odstráni.
- Normalizačná forma KD (NFKD) - kompatibilný rozklad. Po prenesení do tejto formy sa všetky zložené znaky nahradia pomocou kanonických rozkladových máp Unicode a kompatibilných rozkladových máp, po ktorých sa výsledok umiestni do kanonického poradia.
- Normalizačná forma KC (NFKC) - Kompatibilný rozklad nasledovaný kanonický zloženie.
Výrazy „zloženie" a „rozklad" znamenajú spojenie alebo rozklad symbolov na ich jednotlivé časti.
Príklady
| Zdrojový text | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | frank \ u0327ais | Fran \ xe7ais | frank \ u0327ais | Fran \ xe7ais |
| A, E, Y | \ u0410, \ u0401, \ u0419 | \ u0410, \ u0415 \ u0308, \ u0418 \ u0306 | \ u0410, \ u0401, \ u0419 | |
| が | \ u304b \ u3099 | \ u304c | \ u304b \ u3099 | \ u304c |
| Henry iv | Henry iv | Henry iv | Henry iv | Henry iv |
| Henry Ⅳ | Henry \u2163 | Henry \u2163 | Henry iv | Henry iv |
Obojsmerné písmeno
Štandard Unicode podporuje jazyky písania v smere zľava doprava (angl. zľava doprava, LTR), a s písaním sprava doľava (angl. sprava doľava, RTL) - napríklad arabské a hebrejské písmená. V oboch prípadoch sú postavy uložené v „prirodzenom“ poradí; ich zobrazenie s prihliadnutím na požadovaný smer písmena zabezpečuje aplikácia.
Okrem toho Unicode podporuje kombinované texty, ktoré kombinujú fragmenty s rôznymi smermi písmena. Táto funkcia je tzv obojsmernosť(angl. obojsmerný text, BiDi). Niektoré zjednodušené textové procesory (napríklad v mobilné telefóny) môže podporovať Unicode, ale nie obojsmernú podporu. Všetky znaky Unicode sú rozdelené do niekoľkých kategórií: písané zľava doprava, písané sprava doľava a písané ľubovoľným smerom. Symboly druhej kategórie (hlavne interpunkčné znamienka), keď sú zobrazené, naberajú smer okolitého textu.
Odporúčané symboly
Unicode zahŕňa prakticky všetky moderné skripty, vrátane:
iné.
Na akademické účely bolo pridaných mnoho historických písiem vrátane: run, starovekej gréčtiny, egyptských hieroglyfov, klinového písma, mayského písma, etruskej abecedy.
Unicode poskytuje širokú škálu matematických a hudobných symbolov a piktogramov.
Unicode však zásadne nezahŕňa logá spoločností a produktov, aj keď sa nachádzajú v fontoch (napríklad logo Apple v kódovaní MacRoman (0xF0) alebo logo Windows v fonte Wingdings (0xFF)). V písmach Unicode musia byť logá umiestnené iba v oblasti vlastných znakov.
ISO / IEC 10646
Konzorcium Unicode úzko spolupracuje s pracovná skupina ISO / IEC / JTC1 / SC2 / WG2, ktorá vyvíja medzinárodnú normu 10646 (ISO / IEC 10646). Synchronizácia je zavedená medzi štandardom Unicode a ISO / IEC 10646, hoci každý štandard používa vlastnú terminológiu a systém dokumentácie.
Spolupráca Unicode Consortium s Medzinárodnou organizáciou pre normalizáciu (angl. Medzinárodná organizácia pre normalizáciu, ISO ) začala v roku 1991. V roku 1993 vydala ISO normu DIS 10646.1. Na synchronizáciu s ním Konzorcium schválilo verziu 1.1 štandardu Unicode, ktorá bola doplnená o ďalšie znaky z DIS 10646.1. V dôsledku toho sú hodnoty kódovaných znakov v Unicode 1.1 a DIS 10646.1 úplne rovnaké.
V budúcnosti spolupráca medzi oboma organizáciami pokračovala. V roku 2000 Štandard Unicode 3.0 bol synchronizovaný s ISO / IEC 10646-1: 2000. Pripravovaná tretia verzia ISO / IEC 10646 bude synchronizovaná s Unicode 4.0. Možno budú tieto špecifikácie dokonca zverejnené ako jednotný štandard.
Podobne ako formáty UTF-16 a UTF-32 v štandarde Unicode, štandard ISO / IEC 10646 má tiež dve hlavné formy kódovania znakov: UCS-2 (2 bajty na znak, podobne ako UTF-16) a UCS-4 (4 bajty na znak, podobne ako UTF-32). UCS znamená univerzálny multioktet(viacbajt) sada kódovaných znakov(angl. univerzálna viacoktetová kódovaná znaková sada ). UCS-2 možno považovať za podmnožinu UTF-16 (UTF-16 bez náhradných párov) a UCS-4 je synonymom pre UTF-32.
Prezentačné metódy
Unicode má niekoľko foriem reprezentácie (eng. Transformačný formát Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) a UTF-32 (UTF-32BE, UTF-32LE). Forma reprezentácie UTF-7 bola vyvinutá aj na prenos cez sedembitové kanály, ale kvôli nekompatibilite s ASCII sa nerozšírila a nebola zahrnutá do štandardu. 1. apríla 2005 boli navrhnuté dva vtipné príspevky: UTF-9 a UTF-18 (RFC 4042).
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Teoreticky možné, ale tiež nie sú zahrnuté v norme:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFxFFx1x0x1x1x1x1x0x0x101x110x1x0x
Hoci UTF-8 umožňuje zadať rovnaký znak niekoľkými spôsobmi, správny je len ten najkratší. Zvyšok formulárov by sa mal z bezpečnostných dôvodov odmietnuť.
Poradie bajtov
V dátovom toku UTF-16 môže byť vysoký bajt zapísaný buď pred nízkym (eng. UTF-16 big-endian), alebo po mladšom (angl. UTF-16 little-endian). Podobne existujú dve možnosti pre štvorbajtové kódovanie - UTF-32BE a UTF-32LE.
Definovať formát reprezentácie Unicode na začiatku textový súbor podpis sa píše - znak U + FEFF (nezalomiteľná medzera s nulovou šírkou), tiež tzv značka poradia bajtov(angl. značka poradia bajtov, kusovník ). To umožňuje rozlíšiť medzi UTF-16LE a UTF-16BE, pretože znak U + FFFE neexistuje. Niekedy sa používa aj na označenie formátu UTF-8, aj keď pojem poradie bajtov sa na tento formát nevzťahuje. Súbory, ktoré dodržiavajú túto konvenciu, začínajú týmito bajtovými sekvenciami:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Bohužiaľ, táto metóda spoľahlivo nerozlišuje medzi UTF-16LE a UTF-32LE, pretože znak U + 0000 je povolený Unicode (hoci skutočné texty ním začínajú len zriedka).
Súbory v kódovaní UTF-16 a UTF-32, ktoré neobsahujú kusovník, musia byť v poradí bajtov big-endian (unicode.org).
Unicode a tradičné kódovanie
Zavedenie Unicode zmenilo prístup k tradičnému 8-bitovému kódovaniu. Ak bolo predtým kódovanie špecifikované písmom, teraz je špecifikované tabuľkou zhody medzi týmto kódovaním a Unicode. V skutočnosti sa 8-bitové kódovania stali reprezentáciou podmnožiny Unicode. Vďaka tomu bolo oveľa jednoduchšie vytvárať programy, ktoré musia pracovať s mnohými rôznymi kódovaniami: teraz, ak chcete pridať podporu pre jedno ďalšie kódovanie, stačí pridať ďalšiu vyhľadávaciu tabuľku Unicode.
Mnohé dátové formáty navyše umožňujú vloženie ľubovoľných znakov Unicode, aj keď je dokument napísaný v starom 8-bitovom kódovaní. Môžete napríklad použiť ampersand kódy v HTML.
Implementácia
Väčšina moderných operačných systémov poskytuje určitý stupeň podpory Unicode.
V operačných systémoch rodiny Windows NT sa na internú reprezentáciu názvov súborov a iných systémových reťazcov používa dvojbajtové kódovanie UTF-16LE. Systémové volania, ktoré preberajú parametre reťazca, sú dostupné v jednobajtových a dvojbajtových variantoch. Bližšie informácie nájdete v článku
 Odnoklassniki: Registrácia a vytvorenie profilu
Odnoklassniki: Registrácia a vytvorenie profilu E je. E (funkcie E). Výrazy z hľadiska goniometrických funkcií
E je. E (funkcie E). Výrazy z hľadiska goniometrických funkcií Sociálne siete Ruska Teraz v sociálnych sieťach
Sociálne siete Ruska Teraz v sociálnych sieťach