Kódování textových informací. Kódování znaků - PIE wiki
Norma byla navržena v roce 1991 Unicode Consortium, Unicode Inc., neziskovou organizací. Použití této normy umožňuje kódovat velmi velký počet znaků z různých skriptů: v dokumentech Unicode mohou současně existovat čínské znaky, matematické znaky, písmena řecké abecedy, latinské a azbuky, takže přepínání kódových stránek se stává zbytečným.
Standard se skládá ze dvou hlavních částí: univerzální znakové sady (UCS) a formátu transformace Unicode (UTF). Univerzální znaková sada definuje individuální korespondenci znaků s kódy-prvky kódového prostoru, které představují nezáporná celá čísla. Rodina kódování definuje strojovou reprezentaci posloupnosti kódů UCS.
Standard Unicode byl vyvinut s cílem vytvořit jednotné kódování znaků pro všechny moderní a mnoho starověkých psaných jazyků. Každý znak v tomto standardu je zakódován v 16 bitech, což mu umožňuje pokrýt nesrovnatelně větší počet znaků než dříve přijímané 8bitové kódování. Další důležitý rozdíl mezi Unicode a jinými systémy kódování spočívá v tom, že každému znaku nejen přiřazuje jedinečný kód, ale také definuje různé charakteristiky tohoto znaku, například:
Typ znaků (velká písmena, malá písmena, číslice, interpunkční znaménka atd.);
Atributy znaků (zobrazení zleva doprava nebo zprava doleva, mezera, konec řádku atd.);
Odpovídající velká nebo malá písmena (pro malá a velká písmena);
Odpovídající číselná hodnota (pro číselné znaky).
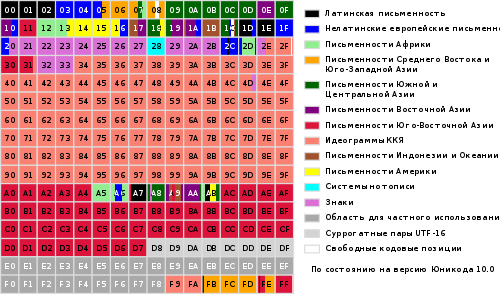
Celá řada kódů od 0 do FFFF je rozdělena do několika standardních podmnožin, z nichž každá odpovídá buď abecedě jazyka nebo skupiny speciální znaky, podobné svými funkcemi. Níže uvedený diagram poskytuje obecný seznam podmnožin Unicode 3.0 (obrázek 2).
Obrázek 2
Standard Unicode je základem pro ukládání a text v mnoha moderních počítačových systémech. Není však kompatibilní s většinou internetových protokolů, protože jeho kódy mohou obsahovat libovolné bajtové hodnoty a protokoly obvykle používají jako režii bajty 00 - 1F a FE - FF. Aby bylo dosaženo kompatibility, bylo vyvinuto několik formátů transformace Unicode (UTF, Unicode Transformation Formats), z nichž je dnes UTF-8 nejběžnější. Tento formát definuje pro všechna následující pravidla převodu Unicode kód do sady bajtů (jeden až tři) vhodných pro přenos internetovými protokoly.
Zde x, y, z označují bity zdrojového kódu, které by měly být extrahovány, počínaje nejméně významným a zadávány do bajtů výsledků zprava doleva, dokud nejsou vyplněny všechny určené pozice.
Další vývoj standard Unicode je spojen s přidáním nových jazykových rovin, tj. znaky v rozsahu 10 000 - 1 FFFF, 20 000 - 2FFFF atd., kde má zahrnovat kódování skriptů mrtvých jazyků, které nejsou uvedeny v tabulce výše. Pro kódování těchto dalších znaků byl vyvinut nový formát UTF-16.
Existují tedy 4 hlavní způsoby kódování bytů Unicode:
UTF-8: 128 znaků je zakódováno v jednom bajtu (formát ASCII), 1920 znaků je zakódováno ve 2 bajtech ((římské, řecké, cyrilice, koptské, arménské, hebrejské, arabské znaky), 63488 znaků je zakódováno ve 3 bajtech (Japonština a další) Zbývajících 2 147 418 110 znaků (dosud nepoužitých) lze kódovat 4, 5 nebo 6 bajty.
UCS-2: Každý znak je reprezentován 2 bajty. Toto kódování obsahuje pouze prvních 65 535 znaků z formátu Unicode.
UTF-16: Toto je rozšíření UCS-2 a obsahuje 1 114 112 znaků Unicode. Prvních 65 535 znaků je reprezentováno 2 bajty, zbytek 4 bajty.
USC-4: Každý znak je zakódován ve 4 bajtech.
Unicode
Logo konsorcia Unicode
Unicode(nejčastěji) popř Unicode(angl. Unicode) je standard kódování znaků, který umožňuje zastoupení znaků téměř ve všech psaných jazycích.
Normu navrhla v roce 1991 nezisková organizace „Unicode Consortium“ (angl. Unicode Consortium, Unicode Inc.).
Použití této normy umožňuje kódovat velmi velký počet znaků z různých skriptů: v dokumentech Unicode mohou současně existovat čínské znaky, matematické znaky, písmena řecké abecedy, latinské a azbuky, takže přepínání kódových stránek se stává zbytečným.
Standard se skládá ze dvou hlavních částí: univerzální znaková sada (angl. UCS, univerzální znaková sada) a rodina kódování (angl. UTF, formát transformace Unicode).
Univerzální znaková sada definuje individuální korespondenci znaků s kódy-prvky kódového prostoru, které představují nezáporná celá čísla. Rodina kódování definuje strojovou reprezentaci posloupnosti kódů UCS.
Kódy Unicode jsou rozděleny do několika oblastí. Oblast s kódy od U + 0000 do U + 007F obsahuje znaky ASCII s odpovídajícími kódy. Další jsou oblasti znaků různých skriptů, interpunkčních znamének a technických symbolů.
Některé kódy jsou vyhrazeny pro budoucí použití. Pod znaky cyrilice jsou přiřazeny oblasti znaků s kódy od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (viz azbuka v Unicode).
- 1 Předpoklady pro tvorbu a vývoj Unicode
- 2 verze Unicode
- 3 Prostor pro kód
- 4 Systém kódování
- 4.1 Zásady konsorcia
- 4.2 Kombinace a kopírování symbolů
- 5 Úpravy znaků
- 6 Normalizační algoritmy
- 6.1 NFD
- 6.2 NFC
- 6,3 NFKD
- 6,4 NFKC
- 6.5 Příklady
- 7 Obousměrné psaní
- 8 doporučených symbolů
- 9 ISO / IEC 10646
- 10 způsobů prezentace
- 10.1 UTF-8
- 10.2 Byte order
- 10.3 Unicode a tradiční kódování
- 10.4 Implementace
- 11 Metody zadávání
- 11.1 Microsoft Windows
- 11.2 Macintosh
- 11.3 GNU / Linux
- 12 Problémy s Unicode
- 13 „Unicode“ nebo „Unicode“?
Předpoklady pro tvorbu a vývoj Unicode
Koncem 80. let se standardem staly 8bitové postavy. Současně existovalo mnoho různých 8bitových kódování a stále se objevovala nová.
To bylo vysvětleno jednak neustálým rozšiřováním rozsahu podporovaných jazyků, jednak touhou vytvořit kódování částečně kompatibilní s některými jinými (typickým příkladem je vznik alternativního kódování pro ruský jazyk, kvůli využívání západního jazyka programy vytvořené pro kódování CP437).
V důsledku toho se objevilo několik problémů:
- problém „krakozyabr“;
- problém omezené sady znaků;
- problém převodu jednoho kódování na druhé;
- problém duplicitních písem.
Problém „krakozyabr“- problém zobrazování dokumentů ve špatném kódování. Problém by mohl být vyřešen buď důsledným zavedením metod pro specifikaci použitého kódování, nebo zavedením jediného (společného) kódování pro všechny.
Problém omezené sady znaků... Problém lze vyřešit buď přepnutím písem v dokumentu, nebo zavedením „širokého“ kódování. Přepínání písem se v textových procesorech dlouhodobě praktikuje a často se používala písma s nestandardním kódováním, tzv. „Dingbat fonty“. Výsledkem bylo, že při pokusu o přenos dokumentu do jiného systému se všechny nestandardní znaky změnily na „krakozyabry“.
Problém převodu jednoho kódování na druhé... Problém by mohl být vyřešen buď kompilací převodních tabulek pro každý pár kódování, nebo použitím přechodného převodu na třetí kódování, které obsahuje všechny znaky všech kódování.
Problém s duplicitními fonty... Pro každé kódování bylo vytvořeno vlastní písmo, i když se znakové sady v kódování shodovaly částečně nebo úplně. Problém bylo možné vyřešit vytvořením „velkých“ písem, ze kterých by se následně vybíraly znaky potřebné pro dané kódování. To však vyžadovalo vytvoření jediného registru symbolů, aby bylo možné určit, co odpovídá čemu.
Byla uznána potřeba jediného „širokého“ kódování. Ukázalo se, že kódování s proměnnou délkou, široce používané ve východní Asii, je příliš obtížné používat, a proto bylo rozhodnuto použít znaky s pevnou šířkou.
Používání 32bitových znaků se zdálo příliš nehospodárné, proto bylo rozhodnuto použít 16bitové.
První verze Unicode byla kódování s pevnou velikostí znaků 16 bitů, to znamená, že celkový počet kódů byl 2 16 (65 536). Od té doby jsou znaky označovány čtyřmi hexadecimálními číslicemi (např. U + 04F0). Současně bylo plánováno zakódovat v Unicode všechny existující znaky, ale pouze ty, které jsou nezbytné v každodenním životě. Zřídka používané symboly musely být umístěny v „oblasti soukromého použití“, která původně zabírala kódy U + D800 ... U + F8FF.
Aby bylo možné používat Unicode také jako meziprodukt při převodu různých kódování na sebe, byly do něj zahrnuty všechny znaky zastoupené ve všech nejslavnějších kódováních.
Do budoucna však bylo rozhodnuto zakódovat všechny symboly a v této souvislosti výrazně rozšířit doménu kódu.
Ve stejné době začaly být znakové kódy považovány nikoli za 16bitové hodnoty, ale za abstraktní čísla, která lze v počítači reprezentovat mnoha různými způsoby (viz způsoby reprezentace).
Protože v řadě počítačových systémů (například Windows NT) byly již jako výchozí kódování použity pevné 16bitové znaky, bylo rozhodnuto zakódovat všechny nejdůležitější znaky pouze v rámci prvních 65 536 pozic (takzvaná angličtina. základní vícejazyčná rovina, BMP).
Zbytek prostoru je použit pro „další znaky“ (angl. doplňkové znaky): systémy psaní zaniklých jazyků nebo velmi zřídka používané čínské znaky, matematické a hudební symboly.
Pro kompatibilitu se starými 16bitovými systémy byl vynalezen systém UTF-16, kde je prvních 65 536 pozic, s výjimkou pozic z intervalu U + D800 ... U + DFFF, zobrazeno přímo jako 16bitová čísla, a zbytek jsou reprezentovány jako „náhradní páry“ (první prvek páru z oblasti U + D800… U + DBFF, druhý prvek z páru z oblasti U + DC00… U + DFFF). U náhradních párů byla použita část kódového prostoru (2048 pozic), vyčleněná „pro soukromé použití“.
Protože UTF-16 dokáže zobrazit pouze 2 20 +2 16-2048 (1 112 064) znaků, bylo toto číslo vybráno jako konečná hodnota kódového prostoru Unicode (rozsah kódů: 0x000000-0x10FFFF).
Přestože byla oblast kódu Unicode rozšířena nad 2-16 již ve verzi 2.0, první znaky v oblasti „nahoře“ byly umístěny pouze ve verzi 3.1.
Role tohoto kódování ve webovém sektoru neustále roste. Na začátku roku 2010 byl podíl webových stránek využívajících Unicode zhruba 50%.
Verze Unicode
Práce na dokončení standardu pokračují. Nové verze jsou vydávány se změnami tabulek symbolů a jsou aktualizovány. Souběžně s tím jsou vydávány nové dokumenty ISO / IEC 10646.
První standard byl vydán v roce 1991, poslední v roce 2016, další se očekává v létě 2017. Verze standardů 1.0-5.0 byly publikovány jako knihy a mají ISBN.
Číslo verze standardu se skládá ze tří číslic (například „4.0.1“). Třetí číslice se změní, když jsou provedeny drobné změny standardu, které nepřidávají nové znaky.
Prostor pro kód
Ačkoli zápisové formuláře UTF-8 a UTF-32 umožňují kódování až 2 31 (2 147 483 648) kódových bodů, bylo rozhodnuto použít pouze 1 112 064 pro kompatibilitu s UTF-16. I to je však prozatím více než dost - ve verzi 6.0 je použito o něco méně než 110 000 kódových bodů (109 242 grafických a 273 dalších symbolů).
Prostor pro kód je rozdělen na 17 letadla(angl. letadla) 2 16 (65 536) znaků každý. Pozemní letadlo ( letadlo 0) je nazýván základní (základní) a obsahuje symboly nejběžnějších skriptů. Zbytek letadel je dodatečný ( doplňkový). První letadlo ( letadlo 1) se používá hlavně pro historické skripty, druhý ( letadlo 2) - pro zřídka používané čínské znaky (CJK), třetí ( letadlo 3) je vyhrazeno pro archaické čínské znaky. Letadla 15 a 16 jsou vyhrazena pro soukromé použití.
Označovat Znaky Unicode zápis formuláře „U + xxxx"(Pro kódy 0 ... FFFF) nebo" U + xxxxx"(Pro kódy 10 000 ... FFFFF) nebo" U + xxxxxx"(Pro kódy 100000 ... 10FFFF), kde xxx- hexadecimální číslice. Například symbol „i“ (U + 044F) má kód 044F 16 = 1103 10.
Systém kódování
Univerzální kódovací systém (Unicode) je sada grafických symbolů a způsob jejich kódování pro počítačové zpracování textových dat.
Grafické symboly jsou symboly, které mají viditelný obrázek. Grafické znaky jsou proti ovládání a formátování znaků.
Grafické symboly zahrnují následující skupiny:
- písmena obsažená alespoň v jedné z podporovaných abeced;
- čísla;
- interpunkční znaménka;
- speciální znaky (matematické, technické, ideogramy atd.);
- separátory.
Unicode je systém pro lineární reprezentaci textu. Znaky s dalšími horními nebo dolními indexy mohou být reprezentovány jako posloupnost kódů vytvořených podle určitých pravidel (složený znak) nebo jako jeden znak (monolitická verze, předkomponovaný znak). Na tento moment(2014) věří se, že všechna písmena velkých skriptů jsou zahrnuta v Unicode, a pokud je symbol k dispozici ve složené verzi, není nutné jej duplikovat v monolitické formě.
Zásady konsorcia
Konsorcium nevytváří nové, ale uvádí zavedený řád věcí. Například byly přidány obrázky emodži, protože japonští operátoři mobilní komunikace byly široce používány.
Za tímto účelem přidání symbolu prochází složitým procesem. A například symbol ruského rublu jej za tři měsíce prošel jednoduše proto, že získal oficiální status.
Ochranné známky jsou kódovány pouze výjimečně. V Unicode tedy není žádný příznak Windows ani Apple apple.
Jakmile se postava objeví v kódování, nikdy se nepohybuje ani nezmizí. Pokud potřebujete změnit pořadí znaků, neprovádí se to změnou pozic, ale národním pořadím řazení. Existují i další, jemnější záruky stability - například normalizační tabulky se nezmění.
Kombinování a kopírování symbolů
Stejný symbol může mít několik podob; v Unicode jsou tyto formuláře obsaženy v jednom bodu kódu:
- pokud se to stalo historicky. Například arabská písmena mají čtyři formy: oddělené, na začátku, uprostřed a na konci;
- nebo pokud je jeden jazyk přijat v jedné formě a v jiném - jiném. Bulharská azbuka se liší od ruštiny a čínské znaky od japonštiny.
Na druhou stranu, pokud historicky písma měla dva různé body kódu, zůstávají v Unicode odlišné. Řecká sigma s malými písmeny má dvě formy a mají různé polohy. Rozšířené latinské písmeno Å (A s kruhem) a znak angstromu Å, Řecké písmenoμ a předpona „mikro“ µ jsou různé symboly.
Podobné znaky v nesouvisejících skriptech jsou samozřejmě umístěny na různé pozice kódu. Například písmeno A v latině, azbuce, řečtině a čerokeje jsou různé symboly.
Je extrémně vzácné, že stejný znak je umístěn na dvou různých pozicích kódu, aby se zjednodušilo zpracování textu. Matematický tah a stejný zdvih pro indikaci měkkosti zvuků jsou různé symboly, druhý je považován za písmeno.
Úpravy znaků
Znázornění znaku „Y“ (U + 0419) ve formě základního znaku „I“ (U + 0418) a modifikujícího znaku „“ (U + 0306)
Grafické znaky v Unicode jsou rozděleny na rozšířené a nerozšířené (bez šířky). Znaky, které nejsou rozšířeny, nezabírají při zobrazení místo v řádku. Patří sem zejména znaménka přízvuku a další diakritická znaménka. Rozšířené i nerozšířené znaky mají své vlastní kódy. Rozšířené symboly se jinak nazývají základní (angl. základní postavy), a ty nerozšířené - upravující (angl. kombinování postav); a ten se nemůže sejít samostatně. Například znak „á“ může být reprezentován jako posloupnost základního znaku „a“ (U + 0061) a modifikačního znaku „́“ (U + 0301), nebo jako monolitický znak „á“ (U + 00E1).
Zvláštním typem upravujících znaků jsou selektory stylu (angl. voliče variací). Vztahují se pouze na ty symboly, pro které jsou takové varianty definovány. Ve verzi 5.0 jsou pro řadu definovány možnosti stylu matematické symboly, pro symboly tradiční mongolské abecedy a pro symboly mongolského čtvercového písma.
Normalizační algoritmy
Protože mohou být zastoupeny stejné symboly různé kódy„Porovnání řetězců bajt po bajtu je nemožné. Normalizační algoritmy normalizační formy) vyřešit tento problém převedením textu do určité standardní podoby.
Casting se provádí nahrazením symbolů ekvivalentními symboly pomocí tabulek a pravidel. „Rozklad“ je nahrazení (rozložení) jednoho znaku na několik základních znaků a „složení“ je naopak nahrazení (spojení) několika základních znaků jedním znakem.
Standard Unicode definuje 4 algoritmy normalizace textu: NFD, NFC, NFKD a NFKC.
NFD
NFD, angl. n ormalizace F orm D („D“ z angličtiny. d ekompozice), normalizační forma D je kanonický rozklad - algoritmus, podle kterého se provádí rekurzivní náhrada monolitických symbolů (angl. předkomponované postavy) do několika komponent (angl. složené znaky) podle rozkladových tabulek.
Å U + 00C5 →
A U + 0041
̊ U + 030A
ṩ U + 1E69 →
s U + 0073
̣ U + 0323
̇ U + 0307
ḍ̇ U + 1E0B U + 0323 →
d U + 0064
̣ U + 0323
̇ U + 0307
q̣̇ U + 0071 U + 0307 U + 0323 →
q U + 0071
̣ U + 0323
̇ U + 0307 NFC
NFC, angl. n ormalizace F orm C („C“ z angličtiny. C omposition), normalizační forma C je algoritmus, podle kterého se kanonický rozklad a kanonické složení provádí postupně. Za prvé, kanonický rozklad (algoritmus NFD) redukuje text na formu D. Poté kanonická kompozice, inverzní NFD, zpracovává text od začátku do konce s přihlédnutím k následujícím pravidlům:
- symbol S počítá počáteční pokud má modifikační třídu rovnou nule podle tabulky znaků Unicode;
- v libovolném sledu znaků začínajících znakem S, symbol C zablokováno z S, pouze pokud mezi S a C je tam nějaký symbol B který je buď počáteční, nebo má stejnou nebo větší třídu modifikací než C... Toto pravidlo platí pouze pro řetězce, které prošly kanonickým rozkladem;
- symbol je brán v úvahu hlavní kompozit, pokud má kanonický rozklad v tabulce znaků Unicode (nebo kanonický rozklad pro Hangul a není zahrnut do seznamu vyloučení);
- symbol X lze nejprve kombinovat se symbolem Y právě tehdy, pokud existuje primární kompozit Z, kanonicky ekvivalentní sekvenci<X, Y>;
- pokud další znak C není blokován poslední spuštěnou základní postavou L a lze ji s ní nejprve úspěšně zkombinovat L nahrazen kompozitem L-C, a C odstraněny.
Ó U + 006F
̂ U + 0302 → →
H U + 0048
① U + 2460 →
1 U + 0031
カ U + FF76 →
カ U + 30AB →
fi U + FB01
fi U + FB01
F já U + 0066 U + 0069
F já U + 0066 U + 0069
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 5 U + 0032 U + 0035
2 5 U + 0032 U + 0035
ẛ̣ U + 1E9B U + 0323
ſ ̣ ̇ U + 017F U + 0323 U + 0307
ẛ ̣ U + 1E9B U + 0323
s ̣ ̇ U + 0073 U + 0323 U + 0307
ṩ U + 1E69
th U + 0439
a ̆ U + 0438 U + 0306
th U + 0439
a ̆ U + 0438 U + 0306
th U + 0439
E U + 0451
E ̈ U + 0435 U + 0308
E U + 0451
E ̈ U + 0435 U + 0308
E U + 0451
A U + 0410
A U + 0410
A U + 0410
A U + 0410
A U + 0410
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
Ⅷ U + 2167
Ⅷ U + 2167
Ⅷ U + 2167
PROTI Já Já Já U + 0056 U + 0049 U + 0049 U + 0049
PROTI Já Já Já U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
C ̧ U + 0063 U + 0327
ç U + 00E7
C ̧ U + 0063 U + 0327
ç U + 00E7 Obousměrný dopis
Standard Unicode podporuje jazyky psaní ve směru zleva doprava (angl. zleva doprava, LTR) a psaním zprava doleva (angl. zprava doleva, RTL) - například arabská a hebrejská písmena. V obou případech jsou postavy uloženy v „přirozeném“ pořadí; jejich zobrazení s přihlédnutím k požadovanému směru písmene zajišťuje aplikace.
Unicode navíc podporuje kombinované texty, které kombinují fragmenty s různými směry písmene. Tato funkce se nazývá obousměrnost(angl. obousměrný text, BiDi). Některé zjednodušené textové procesory (například v mobily) může podporovat Unicode, ale ne obousměrnou podporu. Všechny znaky Unicode jsou rozděleny do několika kategorií: psané zleva doprava, psané zprava doleva a psané libovolným směrem. Symboly druhé kategorie (hlavně interpunkční znaménka) při zobrazení udávají směr okolního textu.
Doporučené symboly
Schéma základní vícejazyčné roviny Unicode
Unicode obsahuje prakticky všechny moderní skripty, včetně:
- arabština
- Arménský,
- Bengálský,
- Barmská,
- sloveso,
- řecký
- Gruzínština,
- devanagari,
- Židovský,
- Cyrilice,
- Čínština (čínské znaky se aktivně používají v japonštině a příležitostně v korejštině),
- Koptský,
- Khmer,
- Latinský,
- Tamilština,
- Korejština (Hangul),
- Cherokee,
- Etiopský,
- Japonština (která zahrnuje kromě slabičné abecedy také čínské znaky)
jiný.
Pro akademické účely bylo přidáno mnoho historických skriptů, včetně: germánských run, starověkých turkických run, starořeckého písma, egyptských hieroglyfů, klínového písma, mayského písma, etruské abecedy.
Unicode poskytuje širokou škálu matematických a hudebních symbolů a piktogramů.
Unicode v zásadě neobsahuje státní vlajky, loga společnosti a produktů, přestože se nacházejí ve fontech (například logo Apple v kódování MacRoman (0xF0) nebo logo Windows v písmu Wingdings (0xFF)). V písmech Unicode by loga měla být umístěna pouze do oblasti vlastních znaků.
ISO / IEC 10646
Konsorcium Unicode úzce spolupracuje s pracovní skupina ISO / IEC / JTC1 / SC2 / WG2, která vyvíjí mezinárodní standard 10646 (ISO / IEC 10646). Synchronizace je zavedena mezi standardem Unicode a ISO / IEC 10646, ačkoli každá norma používá vlastní terminologický a dokumentační systém.
Spolupráce konsorcia Unicode s Mezinárodní organizací pro normalizaci (angl. Mezinárodní organizace pro normalizaci, ISO ) začala v roce 1991. V roce 1993 vydala ISO normu DIS 10646.1. K synchronizaci s ním Konsorcium schválilo verzi 1.1 standardu Unicode, která přidala další znaky z DIS 10646.1. V důsledku toho jsou hodnoty kódovaných znaků v Unicode 1.1 a DIS 10646.1 přesně stejné.
Do budoucna spolupráce mezi oběma organizacemi pokračovala. V roce 2000 byl standard Unicode 3.0 synchronizován s ISO / IEC 10646-1: 2000. Nadcházející třetí verze ISO / IEC 10646 bude synchronizována s Unicode 4.0. Možná budou tyto specifikace dokonce publikovány jako jeden standard.
Podobně jako formáty UTF-16 a UTF-32 ve standardu Unicode má norma ISO / IEC 10646 také dvě hlavní formy kódování znaků: UCS-2 (2 bajty na znak, podobné UTF-16) a UCS-4 (4 bajty na znak, podobné UTF-32). UCS znamená univerzální multi-oktet(vícebajtový) kódovaná znaková sada(angl. univerzální znaková sada kódovaná více oktety ). UCS-2 lze považovat za podmnožinu UTF-16 (UTF-16 bez náhradních párů) a UCS-4 je synonymem pro UTF-32.
Rozdíly mezi standardy Unicode a ISO / IEC 10646:
- nepatrné rozdíly v terminologii;
- ISO / IEC 10646 nezahrnuje oddíly potřebné k plné implementaci podpory Unicode:
- žádná data o binárním kódování znaků;
- neexistuje popis srovnávacích algoritmů (angl. řazení) a vykreslování (angl. vykreslování) znaky;
- neexistuje žádný seznam vlastností symbolů (například neexistuje žádný seznam vlastností nutných k implementaci podpory pro obousměrné (angl. obousměrné) písmena).
Metody prezentace
Unicode má několik forem zobrazení (angl. Transformační formát Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) a UTF-32 (UTF-32BE, UTF-32LE). Forma UTF-7 byla také vyvinuta pro přenos přes sedmbitové kanály, ale kvůli nekompatibilitě s ASCII nebyla rozšířena a nebyla zahrnuta do standardu. 1. dubna 2005 byla navržena dvě vtipná podání: UTF-9 a UTF-18 (RFC 4042).
Systémy Microsoft Windows NT a Windows 2000 a Windows XP primárně používají formulář UTF-16LE. Operační systémy podobné UNIX GNU / Linux, BSD a Mac OS X přijímají UTF-8 pro soubory a UTF-32 nebo UTF-8 pro zpracování znaků v paměť s náhodným přístupem.
Punycode je další forma kódování sekvencí znaků Unicode do takzvaných sekvencí ACE, které se skládají pouze z alfanumerických znaků, jak je povoleno v názvech domén.
UTF-8
UTF-8 je reprezentace Unicode, která poskytuje nejlepší kompatibilitu se staršími systémy, které používaly 8bitové znaky.
Text obsahující pouze znaky číslované méně než 128 je při zápisu v UTF-8 převeden na prostý text ASCII. Naopak v textu UTF-8 se zobrazí jakýkoli bajt s hodnotou menší než 128 ASCII znak se stejným kódem.
Zbytek znaků Unicode jsou reprezentovány sekvencemi dlouhými 2 až 6 bajtů (ve skutečnosti pouze až 4 bajty, protože v Unicode nejsou žádné znaky s kódem větším než 10 FFFF a neexistují žádné plány na jejich zavedení do budoucnost), ve kterém má první bajt vždy formu 11xxxxxx a zbytek jsou 10xxxxxx... V UTF-8 nejsou použity žádné náhradní páry, 4 bajty stačí k napsání libovolného znaku unicode.
Formát UTF-8 byl vynalezen 2. září 1992 Kenem Thompsonem a Robem Pikem a implementován do plánu 9... Standard UTF-8 je nyní oficiálně zakotven v RFC 3629 a ISO / IEC 10646, příloze D.
Znaky UTF-8 jsou odvozeny z Unicode následovně:
Unicode UTF -8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx
Teoreticky možné, ale také nezahrnuté ve standardu:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Přestože vám UTF-8 umožňuje určit stejný znak několika způsoby, správný je pouze ten nejkratší. Zbylé formuláře by měly být z bezpečnostních důvodů odmítnuty.
Bajtová objednávka
V datovém proudu UTF-16 lze nízký bajt zapsat buď před vysoký (angl. Little-endian UTF-16), nebo po té starší (angl. Big-endian UTF-16). Podobně existují dvě varianty čtyřbajtového kódování-UTF-32LE a UTF-32BE.
Chcete -li definovat formát reprezentace Unicode na začátku textový soubor podpis je napsán - znak U + FEFF (nepřerušovaný prostor s nulovou šířkou), také nazývaný značka bajtové sekvence(angl. značka pořadí bajtů (kusovník)). Díky tomu je možné rozlišovat mezi UTF-16LE a UTF-16BE, protože znak U + FFFE neexistuje. Někdy se také používá k označení formátu UTF-8, ačkoli pojem pořadí bajtů se na tento formát nevztahuje. Soubory, které dodržují tuto konvenci, začínají těmito bajtovými sekvencemi:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Tato metoda bohužel nerozlišuje spolehlivě mezi UTF-16LE a UTF-32LE, protože znak U + 0000 je povolen Unicode (ačkoli skutečné texty s ním začínají jen zřídka).
Soubory v kódování UTF-16 a UTF-32, které neobsahují kusovník, musí být v bajtovém pořadí big-endian (unicode.org).
Unicode a tradiční kódování
Zavedení Unicode změnilo přístup k tradičním 8bitovým kódováním. Pokud bylo dříve kódování určeno písmem, nyní je určeno korespondenční tabulkou mezi tímto kódováním a Unicode.
Ve skutečnosti se 8bitové kódování stalo formou reprezentující podmnožinu Unicode. Díky tomu bylo mnohem jednodušší vytvářet programy, které potřebují pracovat s mnoha různými kódováními: nyní, abyste přidali podporu pro další kódování, stačí přidat další vyhledávací tabulku Unicode.
Mnoho datových formátů vám navíc umožňuje vložit libovolné znaky Unicode, i když je dokument zapsán ve starém 8bitovém kódování. Můžete například použít kódy ampersandů v HTML.
Implementace
Většina moderních operačních systémů poskytuje určitý stupeň podpory Unicode.
V operačních systémech rodiny Windows NT se pro interní reprezentaci názvů souborů a dalších systémových řetězců používá dvoubajtové kódování UTF-16LE. Systémová volání, která přebírají parametry řetězce, jsou k dispozici v jednobajtových a dvoubajtových variantách. Další informace najdete v článku Unicode o rodině operačních systémů Microsoft Windows.
Jako UNIX OS, včetně GNU / Linux, BSD, OS X, používají k reprezentaci Unicode kódování UTF-8. Většina programů zvládá UTF-8 jako tradiční jednobajtová kódování, bez ohledu na to, že znak je reprezentován jako několik po sobě jdoucích bytů. Pro práci s jednotlivými znaky jsou řetězce obvykle překódovány do UCS-4, takže každý znak má strojové slovo.
Jednou z prvních úspěšných komerčních implementací Unicode byla středa Programování v Javě... V zásadě upustilo od 8bitové reprezentace postav ve prospěch 16bitové. Toto řešení zvýšilo spotřebu paměti, ale umožnilo nám vrátit se k programování důležitou abstrakcí: libovolný jeden znak (typ char). Zejména programátor mohl pracovat s řetězcem jako s jednoduchým polem. Úspěch bohužel nebyl konečný, Unicode přerostl 16bitový limit a v J2SE 5.0 začal libovolný znak opět zabírat variabilní počet paměťových jednotek - jeden char nebo dva (viz náhradní pár).
Většina programovacích jazyků nyní podporuje řetězce Unicode, i když se jejich reprezentace může lišit v závislosti na implementaci.
Vstupní metody
Protože žádné rozložení klávesnice neumožňuje zadat všechny znaky Unicode současně, jsou operační systémy a aplikace povinny podporovat alternativní metody zadávání libovolných znaků Unicode.
Microsoft Windows
Přestože v systému Windows 2000 nástroj Character Map (charmap.exe) podporuje znaky Unicode a umožňuje je zkopírovat do schránky, je tato podpora omezena pouze na základní rovinu (kódy znaků U + 0000… U + FFFF). Symboly s kódy z U + 10 000 „Tabulka symbolů“ se nezobrazuje.
Podobná tabulka je například v Microsoft Word.
Někdy můžete zadat hexadecimální kód, stisknout Alt + X a kód bude nahrazen příslušným znakem, například v WordPad, Microsoft Word. V editorech Alt + X provádí také reverzní transformaci.
V mnoha programech MS Windows potřebujete pro získání znaku Unicode stisknutí klávesy Alt a zadání desetinné hodnoty kódu znaku na numerická klávesnice... Například kombinace Alt + 0171 ("), Alt + 0187 (") a Alt + 0769 (značka přízvuku) budou užitečné při psaní cyrilice. Zajímavé jsou také kombinace Alt + 0133 (…) a Alt + 0151 (-).
Macintosh
Mac OS 8.5 a novější podporuje metodu zadávání s názvem „Unicode Hex Input“. Podržte klávesu Option a zadejte čtyřmístný hexadecimální kód požadovaného znaku. Tato metoda vám umožňuje zadávat znaky s kódy většími než U + FFFF pomocí náhradních párů; takové páry budou operačním systémem automaticky nahrazeny jednotlivými znaky. Před použitím musí být tato metoda zadávání aktivována v příslušné sekci nastavení systému a poté vybrána jako aktuální metoda zadávání v nabídce klávesnice.
Počínaje Mac OS X 10.2 existuje také aplikace Character Palette, která vám umožňuje vybrat znaky z tabulky, ve které můžete vybrat znaky z konkrétního bloku nebo znaky podporované konkrétním písmem.
GNU / Linux
GNOME má také nástroj Mapa symbolů (dříve gucharmap), který vám umožňuje zobrazovat symboly pro konkrétní blokový nebo zapisovací systém a poskytuje možnost vyhledávání podle názvu nebo popisu symbolu. Když je znám kód požadovaného znaku, lze jej zadat v souladu s normou ISO 14755: podržte klávesy Ctrl + ⇧ Shift a zadejte hexadecimální kód (počínaje některou verzí GTK +, kód musí být zadán stisknutím "U"). Zadaný hexadecimální kód může mít až 32 bitů, což vám umožní zadat libovolné znaky Unicode bez použití náhradních párů.
Všechny aplikace X Window, včetně GNOME a KDE, podporují zadání klíčového slova Compose. U klávesnic, které nemají vyhrazenou klávesu pro psaní, můžete k tomuto účelu přiřadit libovolnou klávesu - například ⇪ Caps lock.
Konzole GNU / Linux také umožňuje zadávat znak Unicode jeho kódem - za tímto účelem musí být desítkový kód znaku zadán jako číslice rozšířeného bloku klávesnice při současném podržení klávesy Alt. Znaky můžete zadávat podle hexadecimálního kódu: K tomu musíte podržet klávesu AltGr a zadat číslice A-F použijte klávesy na rozšířeném bloku klávesnice z NumLock na ↵ Enter (ve směru hodinových ručiček). Podporován je také vstup v souladu s ISO 14755. Aby výše uvedené metody fungovaly, je třeba v konzole povolit režim Unicode zavoláním unicode_start(1) a voláním vyberte vhodné písmo setfont(8).
Mozilla Firefox pro Linux podporuje zadávání znaků ISO 14755.
Problémy s Unicode
V Unicode jsou anglické „a“ a polské „a“ stejné znaky. Stejně tak ruské „a“ a srbské „a“ jsou považovány za stejný symbol (ale odlišný od latinského „a“). Tento princip kódování není univerzální; řešení „pro všechny příležitosti“ zjevně nemůže vůbec existovat.
- Čínské, korejské a japonské texty se tradičně píší odshora dolů, začínají v pravém horním rohu. Přepínání mezi horizontálním a vertikálním pravopisem pro tyto jazyky není v Unicode stanoveno - to je třeba provést pomocí značkovacích jazyků nebo interních mechanismů textových procesorů.
- Unicode umožňuje různé váhy stejného znaku v závislosti na jazyce. Čínské znaky tedy mohou mít různou váhu v čínštině, japonštině (kanji) a korejštině (hancha), ale zároveň jsou v Unicode označeny stejným symbolem (takzvané sjednocení CJK), přestože jsou zjednodušené a plné znaky stále mají různé kódy ... Stejně tak ruské a srbské jazyky používají různé kurzívy. NS a T(v srbštině vypadají jako u a w, viz srbská kurzíva). Proto musíte zajistit, aby byl text vždy správně označen jako související s jedním nebo jiným jazykem.
- Překlad z malých na velká písmena také závisí na jazyce. Například: v turečtině jsou písmena İi a Iı - turecká pravidla pro změnu případu jsou tedy v rozporu s těmi anglickými, která vyžadují překlad „i“ do „I“. Podobné problémy existují i v jiných jazycích- například v kanadském dialektu francouzštiny je registr přeložen trochu jinak než ve Francii.
- I u arabských číslic existují určité typografické jemnosti: čísla mohou být „velká písmena“ a „malá písmena“, proporcionální a monospacovaná - pro Unicode mezi nimi není žádný rozdíl. Takové nuance zůstávají u softwaru.
Některé z nevýhod nesouvisejí se samotným Unicode, ale spíše s možnostmi textových procesorů.
- Soubory nelatinského textu v Unicode vždy zabírají více místa, protože jeden znak není kódován jedním bajtem, jako v různých národních kódováních, ale posloupností bajtů (výjimkou je UTF-8 pro jazyky, jejichž abeceda odpovídá do ASCII, stejně jako přítomnost dvou znaků v textu a dalších jazycích, jejichž abeceda ne zapadá do ASCII). Soubor písem požadovaný k zobrazení všech znaků v tabulce Unicode zabírá relativně velkou paměť a výpočetní prostředky než písmo v národním jazyce pouze jednoho uživatele. S nárůstem výkonu počítačových systémů a snížením nákladů na paměť a místo na disku se tento problém stává stále méně významným; zůstává však relevantní pro přenosná zařízení, jako jsou mobilní telefony.
- Přestože je podpora Unicode implementována v nejběžnějších operačních systémech, stále nejsou všechny použity software podporuje správnou práci s ním. Zejména značky pořadí bajtů (BOM) nejsou vždy zpracovány a znaky s diakritikou jsou špatně podporovány. Problém je dočasný a je důsledkem srovnávací novosti standardů Unicode (ve srovnání s jednobajtovými národními kódováními).
- Výkon všech programů pro zpracování řetězců (včetně řazení v databázi) klesá, když se místo jednobajtového kódování používá Unicode.
Některé vzácné systémy psaní stále nejsou v Unicode správně zastoupeny. Vyobrazení „dlouhých“ horních indexů přesahujících několik písmen, jako například v církevní slovanštině, dosud nebylo implementováno.
Unicode nebo Unicode?
„Unicode“ je jak vlastní název (nebo část názvu, například Unicode Consortium), tak běžný název odvozený z angličtiny.
Na první pohled je vhodnější použít pravopis „Unicode“. V ruském jazyce již existují morfémy „uni-“ (slova s latinským prvkem „uni-“ byla tradičně překládána a psána prostřednictvím „uni-“: univerzální, unipolární, unifikační, jednotná) a „kód“. Proti, ochranné známky, vypůjčené z angličtiny, jsou obvykle přenášeny prostřednictvím praktického přepisu, ve kterém je deetymologizovaná kombinace písmen „uni-“ zapsána jako „uni-“ („Unilever“, „Unix“ atd.), tj. stejným způsobem jako v případě zkratek písmen po písmenu, jako je UNICEF „Mezinárodní fond OSN pro mimořádné situace dětí“-UNICEF.
Pravopis „Unicode“ již pevně vstoupil do textů v ruském jazyce. Wikipedia používá běžnější verzi. Na MS Windows se používá možnost Unicode.
Na webových stránkách Konsorcia je speciální stránka, kde jsou problémy s přenesením slova „Unicode“ do různé jazyky a systémy psaní. Pro ruskou azbuku je uvedena možnost „Unicode“.
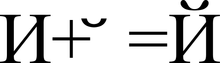
Problémy spojené s kódováním obvykle řeší software, takže s používáním kódování obvykle není žádný problém. Pokud nastanou potíže, jsou obvykle generovány špatnými programy - klidně je pošlete do koše.
Zvu všechny, aby se ozvali
ASCII (English American Standard Code for Information Interchange) je americká standardní kódovací tabulka pro tisknutelné znaky a některé speciální kódy. V americké angličtině se [eśski] vyslovuje, zatímco ve Velké Británii je [aski] výraznější; v ruštině se také vyslovuje [aski] nebo [aski].
ASCII je kódování desetinných číslic, latinské a národní abecedy, interpunkce a kontrolních znaků. Původně navržený jako 7bitový, s rozšířeným používáním 8bitového bajtu ASCII, je považován za polovinu 8bitového. Počítače obvykle používají rozšíření ASCII s 8. zapojeným bitem a druhou polovinou tabulky kódu (například KOI-8).
Unicode
V roce 1991 byla v Kalifornii vytvořena nezisková organizace Unicode Consortium, která zahrnuje zástupce mnoha počítačových firem (Borland, IBM, Lotus, Microsoft, Novell, Sun, WordPerfect atd.) A která vyvíjí a implementuje standard " Standard Unicode "... Standard kódování znaků Unicode se stává dominantní v mezinárodních vícejazyčných softwarových prostředích. Microsoft Windows NT a jeho potomci Windows 2000, 2003, XP používají jako interní reprezentaci textu Unicode, přesněji UTF-16. UNIXové operační systémy jako Linux, BSD a Mac OS X přijaly Unicode (UTF-8) jako primární reprezentaci vícejazyčného textu. Unicode rezervuje 1 114 112 (220 + 216) kódových znaků, v současné době se používá více než 96 000 znaků. Prvních 256 znakových kódů přesně odpovídá kódům ISO 8859-1, nejpopulárnější 8bitové tabulce znaků v západním světě; v důsledku toho je prvních 128 znaků shodných s tabulkou ASCII. Prostor pro kód Unicode je rozdělen na 17 "rovin" a každý plán má 65536 (= 216) kódových bodů. První rovina (rovina 0), základní vícejazyčná rovina (BMP), je ta, ve které je popsána většina postav. BMP obsahuje symboly téměř pro každého moderní jazyky, a velké množství speciálních znaků. Pro „grafické“ symboly jsou použity další dvě roviny. Rovina 1, doplňková vícejazyčná rovina (SMP) se používá hlavně pro historické symboly a používá se také pro hudební a matematické symboly. Plán 2, doplňková ideografická rovina (SIP), se používá pro přibližně 40 000 vzácných čínských znaků. Plán 15 a plán 16 jsou přístupné jakémukoli soukromému použití. Obrázek 1.10 ukazuje ruský blok Unicode (U + 0400 až U + 04FF).
Běžné kódování
ISO 646 ASCII BCDIC EBCDIC ISO 8859: ISO 8859-1, ISO 8859-2, ISO 8859-3, ISO 8859-4, ISO 8859-5, ISO 8859-6, ISO 8859-7, ISO 8859-8, ISO 8859 -9, ISO 8859-10, ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866 , CP869 Kódování Microsoft Windows: Windows-1250 pro středoevropské jazyky používající latinský pravopis (polština, čeština, slovenština, maďarština, slovinština, chorvatština, rumunština a albánština) Windows-1251 pro azbuky Windows-1252 pro západní jazyky Windows-1253 pro Řecké Windows-1254 pro turecké Windows-1255 pro hebrejské Windows-1256 pro arabské Windows-1257 pro baltské jazyky Windows-1258 pro vietnamské MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 bulharské Kódování ISCII VISCII Big5 (nejznámější varianta Microsoft CP950) HKSCS Guobiao GB2312 GBK (Microsoft CP936) GB18030 Shift JIS pro japonštinu (Microsoft CP932) EUC-KR pro korejštinu (Microsoft CP949) ISO-2022 a EUC pro čínské kódování UTF-8, Znakové sady Unicode UTF-16 a UTF-32 \
Kódování grafických informací
Od 80. vyvíjí se technologie zpracování grafických informací na PC. Forma zobrazení grafického obrázku sestávajícího z jednotlivých bodů (pixelů) na displeji se nazývá rastr. Minimální objekt v editoru rastrové grafiky je bod. Rastrový grafický editor je určen k vytváření obrázků, diagramů. Rozlišení monitoru (počet vodorovných a svislých bodů) a počet možných barev každého bodu jsou určeny typem monitoru. 1 pixel černobílé obrazovky je kódován 1 bitem informací (černá tečka nebo bílá tečka). Počet různých barev K a počet bitů pro jejich kódování souvisí podle vzorce: K = 2b. Moderní monitory mají následující barevné palety: 16 barev, 256 barev; 65 536 barev (vysoké barvy), 16 777 216 barev (skutečná barva).
Bitmapa
Pomocí lupy můžete vidět, že černobílý grafický obrázek, například z novin, se skládá z nejmenších teček, které tvoří určitý vzor - rastr. Ve Francii v 19. století vznikl nový směr v malbě - pointilismus. Jeho technika spočívala v tom, že kresba byla na plátno nanesena štětcem ve formě vícebarevných teček. Také tato metoda je již dlouho používána v polygrafickém průmyslu ke kódování grafických informací. Přesnost kresby závisí na počtu bodů a jejich velikosti. Po rozdělení obrázku na body, počínaje levým rohem a pohybujícím se podél čar zleva doprava, můžete kódovat barvu každého bodu. Dále bude jeden takový bod nazýván pixel (původ tohoto slova je spojen s anglickou zkratkou „picture element“ - obrazový prvek). Objem rastrového obrázku je určen vynásobením počtu pixelů (objemem informací jednoho bodu, který závisí na počtu možných barev. Kvalita obrazu je určena rozlišením monitoru. Čím vyšší je, tím je, čím více rastrových řádků a bodů na řádek, tím vyšší je kvalita obrazu. Počítače používají hlavně následující rozlišení obrazovky: 640 x 480, 800 x 600, 1024 x 768 a 1280 x 1024 pixelů. Protože jas každého bodu a jeho lineární souřadnice lze vyjádřit pomocí celých čísel, můžeme říci, že tato metoda kódování vám umožňuje používat binární kód ke zpracování grafických dat.
Pokud mluvíme o černobílých ilustracích, pak pokud nepoužíváte polotóny, pak pixel převezme jeden ze dvou stavů: svítí (bílá) a nesvítí (černá). A protože informace o barvě pixelu se nazývá kód pixelu, stačí k jeho zakódování jeden bit paměti: 0 - černý, 1 - bílý. Pokud jsou ilustrace uvažovány ve formě kombinace bodů s 256 odstíny šedé (konkrétně jsou v současné době obecně přijímány), pak osmibitové binární číslo za účelem zakódování jasu jakéhokoli bodu. PROTI počítačová grafika barva je nesmírně důležitá. Působí jako prostředek ke zlepšení vizuálního dojmu a zvýšení sytosti informací obrazu. Jak se v lidském mozku tvoří pocit barvy? K tomu dochází v důsledku analýzy světelného toku vstupujícího do sítnice z reflexních nebo vyzařujících předmětů. Obecně se uznává, že receptory lidských barev, kterým se také říká kužely, jsou rozděleny do tří skupin a každá může vnímat pouze jednu barvu - červenou nebo zelenou nebo modrou.
Barevné modely
Pokud jde o kódovací barvu grafické obrázky, pak musíte vzít v úvahu princip rozkladu libovolné barvy na její hlavní složky. Používá se několik kódovacích systémů: HSB, RGB a CMYK. První barevný model je jednoduchý a intuitivní, to znamená, že je vhodný pro osobu, druhý je nejvhodnější pro počítač a poslední model CMYK je pro tiskárny. Použití těchto barevných modelů je dáno skutečností, že světelný tok může být tvořen zářením, které je kombinací „čistých“ spektrálních barev: červené, zelené, modré nebo jejich derivátů. Rozlišujte mezi aditivní reprodukcí barev (typickou pro emitující objekty) a subtraktivní reprodukcí barev (typickou pro reflexní objekty). Příkladem objektu prvního typu je katodová trubice monitoru, druhého typu - tiskový tisk.

Model HSB se vyznačuje třemi složkami: odstín, sytost a jas. Úpravou těchto komponent můžete získat mnoho libovolných barev. Tento barevný model se v nich nejlépe používá grafické editory, ve kterém jsou obrázky vytvořeny samy a nejsou zpracovány již připravené. Potom lze vytvořené kresby převést na barevný model RGB, pokud je plánováno použití jako ilustrace na obrazovce, nebo CMYK, pokud je vytištěn. Hodnota barvy je vybrána jako vektor vycházející ze středu kruhu. Směr vektoru je určen v úhlových stupních a určuje odstín. Saturace barev je určena délkou vektoru a jas barev je nastaven na samostatné ose, jejíž nulový bod je černý. Středový bod je bílý (neutrální) a body po obvodu jsou plné barvy.
Princip metody RGB je následující: je známo, že jakoukoli barvu lze znázornit jako kombinaci tří barev: červená (červená, R), zelená (zelená, G), modrá (modrá, B). Další barvy a jejich odstíny jsou získány díky přítomnosti nebo nepřítomnosti těchto komponent.Od prvních písmen primárních barev dostal systém svůj název - RGB. Tento barevný model je aditivní, to znamená, že jakoukoli barvu lze získat kombinací primárních barev v různých poměrech. Když je jedna složka primární barvy překryta jinou, jas celkového záření se zvýší. Pokud zkombinujeme všechny tři složky, dostaneme achromatickou šedou barvu, jejíž zvýšení jasu nastane přístup k bílé.
Při 256 tónech (každý bod je kódován 3 bajty) odpovídají minimální hodnoty RGB (0,0,0) černé a bílé - maximálně souřadnicím (255, 255, 255). Čím větší je bajtová hodnota barevné složky, tím je tato barva jasnější. Například tmavě modrá je kódována třemi bajty (0, 0, 128) a jasně modrou (0, 0, 255).
Princip metody CMYK. Tento barevný model se používá při přípravě publikací pro tisk. Každé z primárních barev je přiřazena doplňková barva (komplementární k primární barvě k bílé). Další barvu získáme sečtením dvojice zbývajících primárních barev. To znamená, že doplňkové barvy pro červenou jsou azurová (azurová, C) = zelená + modrá = bílá - červená, pro zelenou - purpurová (purpurová, M) = červená + modrá = bílá - zelená, pro modrou - žlutá (žlutá, Y) = červená + zelená = bílá - modrá. Kromě toho lze princip rozkladu libovolné barvy na složky použít jak pro hlavní, tak pro další, to znamená, že jakoukoli barvu lze znázornit buď jako součet červené, zelené, modré složky, nebo jako součet azurová, purpurová, žlutá složka. V zásadě je tato metoda přijata v polygrafickém průmyslu. Ale tam stále používají černou (BlacK, protože písmeno B je již obsazeno modrou barvou, je označeno písmenem K). Důvodem je, že překrývání doplňkových barev nevytváří čistou černou.
Vektorové a fraktální obrázky
Vektorový obrázek je grafický objekt skládající se z elementárních čar a oblouků. Základním prvkem obrázku je čára. Jako každý objekt má vlastnosti: tvar (přímý, křivkový), tloušťku., Barvu, styl (tečkovaný, plný). Uzavřené řádky mají vlastnost vyplnění (buď jinými objekty, nebo vybranou barvou). Všechny ostatní objekty vektorová grafika tvořené řádky. Protože je čára matematicky popsána jako jeden objekt, je množství dat pro zobrazení objektu pomocí vektorové grafiky mnohem menší než v rastrové grafice. Informace o vektorovém obrázku jsou kódovány jako normální alfanumerické a zpracovávány speciálními programy.
NA software tvorba a zpracování vektorové grafiky zahrnuje následující GR: CorelDraw, Adobe Illustrator, stejně jako vectorizery (tracer) - specializované balíčky pro převod rastrových obrázků do vektoru.

Fraktální grafika je založena na matematických výpočtech, stejně jako vektorová grafika. Ale na rozdíl od vektoru je jeho základním prvkem samotný matematický vzorec. To vede k tomu, že v paměti počítače nejsou uloženy žádné objekty a obraz je sestaven pouze podle rovnic. Pomocí této metody můžete stavět nejjednodušší pravidelné struktury i složité ilustrace, které napodobují krajinu.

Kódování zvuku
Svět je plný nejrůznějších zvuků: tikot hodin a hukot motorů, kvílení větru a šustění listí, zpěv ptáků a hlasy lidí. O tom, jak se rodí zvuky a jaké jsou, začali lidé hádat už dávno. Dokonce i starověký řecký filozof a vědec - encyklopedista Aristoteles na základě pozorování vysvětlil podstatu zvuku a věřil, že znějící tělo vytváří střídavou kompresi a zředění vzduchu. Oscilační struna tedy někdy vybije, poté kondenzuje vzduch a díky pružnosti vzduchu se tyto střídavé vlivy přenášejí dále do prostoru - od vrstvy k vrstvě vznikají elastické vlny. Když se dostanou k našemu uchu, působí na ušní bubínky a vytvářejí pocit zvuku.
Uchem člověk vnímá elastické vlny s frekvencí někde v rozmezí od 16 Hz do 20 kHz (1 Hz - 1 vibrace za sekundu). V souladu s tím se elastické vlny v jakémkoli médiu, jejichž frekvence leží v určených mezích, nazývají zvukové vlny nebo jednoduše zvuk. Při studiu zvuku jsou důležité pojmy jako tón a zabarvení zvuku. Jakýkoli skutečný zvuk, ať už hra na hudební nástroje nebo hlas člověka, je jakousi směsicí mnoha harmonických vibrací s určitou sadou frekvencí.
Oscilace, která má nejnižší frekvenci, se nazývá základní, jiné se nazývají podtóny.
Timbre je jiný počet podtónů obsažených v konkrétním zvuku, což mu dodává zvláštní barvu. Rozdíl mezi jedním zabarvením od druhého je dán nejen počtem, ale také intenzitou podtónů, které doprovázejí zvuk hlavního tónu. Podle zabarvení snadno rozeznáme zvuky klavíru a houslí, kytary a flétny a rozeznáme hlas známého člověka.
Hudební zvuk lze charakterizovat třemi vlastnostmi: zabarvení, tj. Barva zvuku, která závisí na tvaru vibrací, výška, která je určena počtem vibrací za sekundu (frekvence), a hlasitost, což závisí na intenzitě vibrací.
Počítač je nyní široce používán v různých oblastech. Zpracování zvukových informací a hudby nebylo výjimkou. Do roku 1983 byly všechny nahrávky hudby vydávány na vinylových deskách a kompaktních kazetách. V současné době jsou CD disky široce používány. Pokud máte počítač, na kterém je nainstalována studiová zvuková karta, k níž je připojena MIDI klávesnice a mikrofon, můžete pracovat se specializovaným hudebním softwarem.
Převod zvukové informace na digitální a analogový a analogový na digitální
Pojďme se rychle podívat na procesy převodu zvuku z analogového na digitální a naopak. Hrubá představa o tom, co se děje ve zvukové kartě, může pomoci vyhnout se některým chybám při práci se zvukem.
Zvukové vlny jsou pomocí mikrofonu převedeny na analogový střídavý elektrický signál. Prochází audio cestou a do analogově-digitálního převodníku (ADC), zařízení, které převádí signál do digitální podoby.
Ve zjednodušené podobě je princip činnosti ADC následující: měří amplitudu signálu v pravidelných intervalech a vysílá dále, již digitální cestou, posloupnost čísel, která nesou informace o změnách amplitudy. Během převodu z analogového na digitální nedochází k žádné fyzické konverzi. Otisk nebo vzorek se odebírá jakoby z elektrického signálu, což je digitální model kolísání napětí ve zvukové cestě. Pokud je to znázorněno ve formě diagramu, pak je tento model prezentován ve formě posloupnosti sloupců, z nichž každý odpovídá konkrétní číselné hodnotě. Digitální signál je diskrétní povahy - to znamená nespojitý, takže digitální model přesně neodpovídá analogovému průběhu.
Vzorek je časový interval mezi dvěma měřeními amplitudy analogového signálu.
Ukázka se z angličtiny doslova překládá jako „ukázka“. V multimediální a profesionální zvukové terminologii má toto slovo několik významů. Kromě určitého časového období se vzorku také říká jakákoli sekvence digitálních dat, která byla získána převodem z analogového signálu na digitální. Samotný proces převodu se nazývá vzorkování. V ruském technickém jazyce se tomu říká diskretizace.
Digitální zvuk je přenášen pomocí převodníku digitálního signálu na analogový (DAC), který na základě příchozích digitálních dat ve vhodných časech generuje elektrický signál požadované amplitudy
Možnosti vzorkování
Frekvence a bitová hloubka jsou důležité parametry vzorkování. Frekvence - počet měření amplitudy analogového signálu za sekundu.
Pokud vzorkovací frekvence není větší než dvojnásobek frekvence horní hranice zvukového rozsahu, pak zapnuto vysoké frekvence dojde ke ztrátám. To vysvětluje, proč je standardní frekvence zvukového disku CD 44,1 kHz. Protože rozsah kmitů zvukových vln je v rozsahu od 20 Hz do 20 kHz, musí být počet měření signálu za sekundu větší než počet kmitů za stejnou dobu. Pokud je vzorkovací frekvence výrazně nižší než frekvence zvukové vlny, pak se amplituda signálu může během doby mezi měřeními několikrát změnit, což vede k tomu, že digitální otisk prstu nese chaotický soubor dat. Při převodu digitálního signálu na analogový takový vzorek nepřenáší hlavní signál, ale vytváří pouze šum.
V novém zvukovém DVD formátu CD je signál měřen 96 000krát za jednu sekundu, tj. použijte vzorkovací frekvenci 96 kHz. Aby se ušetřilo místo na pevném disku v multimediálních aplikacích, často se používají nižší frekvence: 11, 22, 32 kHz. To vede ke snížení slyšitelného frekvenčního rozsahu, což znamená, že dochází k silnému zkreslení slyšeného.
Pokud ve formě grafu představujeme stejný zvuk o výšce 1 kHz (nota až do sedmé oktávy klavíru přibližně odpovídá této frekvenci), ale vzorkováno s jinou frekvencí (spodní část sinusoidy je nezobrazí ve všech grafech), pak budou rozdíly viditelné. Jedna divize na vodorovné ose, která ukazuje čas, odpovídá 10 vzorkům. Měřítko je stejné. Můžete vidět, že na frekvenci 11 kHz existuje asi pět oscilací zvukové vlny na každých 50 vzorků, to znamená, že se zobrazí jedna perioda sinusové vlny s použitím pouze 10 hodnot. Jedná se o poměrně nepřesný přenos. Současně, pokud vezmeme v úvahu vzorkovací frekvenci 44 kHz, pak pro každou periodu sinusoidy existuje již téměř 50 vzorků. To vám umožní získat kvalitní signál.
Bitová hloubka udává přesnost, s jakou se mění amplituda analogového signálu. Přesnost, s jakou se při digitalizaci přenáší hodnota amplitudy signálu v každém časovém bodě, určuje kvalitu signálu po převodu digitálního signálu na analogový. Přesnost rekonstrukce křivky závisí na bitové hloubce.
Hodnota amplitudy je kódována na principu binárního kódování. Zvukový signál by měl být prezentován jako sled elektrických impulzů (binární nuly a jedničky). Obvykle se používá 8, 16bitová nebo 20bitová reprezentace hodnot amplitudy. Při kontinuálním binárním kódování zvukový signál je nahrazena sekvencí diskrétních úrovní signálu. Kvalita kódování závisí na vzorkovací frekvenci (počet měření úrovně signálu za jednotku času). S nárůstem vzorkovací frekvence se zvyšuje přesnost binární reprezentace informací. Při frekvenci 8 kHz (počet měření za sekundu je 8000) odpovídá kvalita vzorkovaného zvukového signálu kvalitě rozhlasového vysílání a při frekvenci 48 kHz (počet měření za sekundu je 48 000) - kvalita zvuku zvukového disku CD.
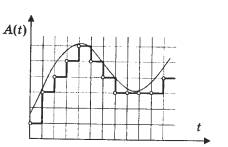
V současné době existuje nový spotřební digitální formát Audio DVD, který využívá vzorkovací frekvenci 24 bitů a 96 kHz. S jeho pomocí se lze vyhnout výše uvedené nevýhodě 16bitového kódování.
Do moderní digitální zvuková zařízení Jsou nainstalovány 20bitové převaděče. Zvuk zůstává 16bitový, jsou nainstalovány převaděče se zvýšenou bitovou hloubkou, aby se zlepšila kvalita záznamu na nízkých úrovních. Jejich princip činnosti je následující: původní analogový signál je digitalizován o šířce 20 bitů. Potom procesor digitálního signálu DSPP zmenší jeho šířku na 16 bitů. V tomto případě se používá speciální výpočetní algoritmus, pomocí kterého je možné snížit zkreslení nízkoúrovňových signálů. Při převodu digitálního signálu na analogový je pozorován opačný proces: bitová hloubka se zvyšuje ze 16 na 20 bitů pomocí speciálního algoritmu, který vám umožňuje přesněji určit hodnoty amplitudy. To znamená, že zvuk zůstává 16bitový, ale celkově došlo ke zlepšení kvality zvuku.
Co je to kódování
V ruštině se „znakové sadě“ také říká tabulka „znakové sady“ a procesu používání této tabulky k překladu informací z počítačové reprezentace do lidské podoby a charakterizaci textového souboru, která odráží použití určité systém kódů v něm při zobrazování textu.
Jak je kódován text
Mnoho symbolů používaných při psaní textu je v počítačové terminologii označováno jako abeceda; počet znaků v abecedě se obvykle nazývá jeho síla. Pro prezentaci textové informace počítač nejčastěji používá abecedu s kapacitou 256 znaků. Jeden z jeho znaků nese 8 bitů informací, proto binární kód každého znaku zabere 1 bajt počítačové paměti. Všechny znaky takové abecedy jsou očíslovány od 0 do 255 a každé číslo odpovídá 8bitovému binárnímu kódu, což je pořadové číslo znaku v systému binárních čísel - od 00000000 do 11111111. Pouze prvních 128 znaků s čísla od nuly (binární kód 00000000) do 127 (01111111). Patří sem malá písmena a velká písmena Latinská abeceda, čísla, interpunkční znaménka, závorky atd. Zbývajících 128 kódů, počínaje 128 (binární kód 10000000) a končící 255 (11111111), se používá ke kódování písmen národních abeced, servisních a vědeckých symbolů.
Typy kódování
Nejznámější kódovací tabulkou je ASCII (American Standard Code for Information Interchange). Původně byl vyvinut pro přenos textů telegrafem a v té době to bylo 7bitové, to znamená, že ke kódování anglických znaků, obslužných a řídicích znaků bylo použito pouze 128 7bitových kombinací. V tomto případě sloužilo prvních 32 kombinací (kódů) ke kódování řídicích signálů (začátek textu, konec řádku, návrat na začátek řádku, volání, konec textu atd.). Při vývoji prvních počítačů IBM byl tento kód použit k reprezentaci symbolů v počítači. Od r zdrojový kód ASCII bylo pouze 128 znaků, pro jejich kódování stačilo bajtových hodnot, ve kterých je 8. bit 0. Angličtina (řečtina, němčina přehláska, francouzská diakritika atd.). Když začali přizpůsobovat počítače jiným zemím a jazykům, už na nové symboly nebyl dost místa. Aby IBM plně podporovala jiné jazyky než angličtinu, zavedla několik tabulek kódů pro jednotlivé země. Takže pro skandinávské země byla navržena tabulka 865 (severská), pro arabské země - tabulka 864 (arabská), pro Izrael - tabulka 862 (Izrael) atd. V těchto tabulkách byly některé kódy z druhé poloviny tabulky kódů použity k reprezentaci znaků národních abeced (vyloučením některých pseudo-grafických znaků). Situace s ruským jazykem se vyvíjela zvláštním způsobem. Očividně lze nahradit znaky ve druhé polovině tabulky kódu různé způsoby... Pro ruský jazyk se tedy objevilo několik různých tabulek kódování cyrilských znaků: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Všechny představují symboly první poloviny tabulky stejným způsobem (od 0 do 127) a liší se zastoupením symbolů ruské abecedy a pseudo-grafiky. Pro jazyky, jako je čínština nebo japonština, 256 znaků obecně nestačí. Kromě toho je vždy problém s výstupem nebo uložením textů do jednoho souboru současně různé jazyky(například při citování). Proto univerzální kódová tabulka UNICODE, obsahující symboly používané v jazycích všech národů světa, jakož i různé servisní a pomocné symboly (interpunkční znaménka, matematické a technické symboly, šipky, diakritika atd.). Je zřejmé, že jeden bajt nestačí na kódování tak velké sady znaků. Proto UNICODE používá 16bitové (2bajtové) kódy k reprezentaci 65 536 znaků. K dnešnímu dni bylo použito asi 49 000 kódů (poslední významnou změnou bylo zavedení symbolu měny EURO v září 1998). Z důvodu kompatibility s předchozím kódováním je prvních 256 kódů shodných se standardem ASCII. Ve standardu UNICODE je každému znaku kromě určitého binárního kódu (tyto kódy obvykle označeny písmenem U, následovaným znakem + a skutečným kódem v hexadecimálním vyjádření) přiřazen konkrétní název. Další součást Standard UNICODE jsou algoritmy pro individuální konverzi kódů UNICODE v sekvenci bytů proměnné délky. Potřeba takových algoritmů je dána skutečností, že ne všechny aplikace mohou pracovat s UNICODE. Některé aplikace rozumí pouze 7bitovým kódům ASCII, jiné aplikace rozumí 8bitovým kódům ASCII. Takové aplikace používají takzvané rozšířené kódy ASCII k reprezentaci znaků, které se nehodí do 128 nebo 256 znakové sady, pokud jsou znaky kódovány bajtovými řetězci s proměnnou délkou. UTF-7 slouží k reverzibilnímu převodu kódů UNICODE na rozšířené 7bitové kódy ASCII a UTF-8 slouží k reverzibilnímu převodu kódů UNICODE na rozšířené 8bitové kódy ASCII. Všimněte si, že jak ASCII, tak UNICODE a další standardy kódování znaků nedefinují obrázky znaků, ale pouze složení znakové sady a způsob, jakým je v počítači reprezentována. Kromě toho (což nemusí být hned zřejmé) je pořadí výčtu znaků v sadě velmi důležité, protože nejvýznamnějším způsobem ovlivňuje algoritmy řazení. Je to tabulka korespondence symbolů z určité sady (řekněme symbolů používaných k reprezentaci informací o anglický jazyk nebo v různých jazycích, jako v případě UNICODE) a označte tabulku nebo znakovou sadu kódování znaků. Každé standardní kódování má název, například KOI8-R, ISO_8859-1, ASCII. Bohužel neexistuje žádný standard pro kódování jmen.
Běžné kódování
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1-ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Kódování Microsoft Windows: o Windows-1250 pro středoevropské jazyky používající latinské písmena o Windows-1251 pro azbuku o Windows-1252 pro západní jazyky o Windows-1253 pro řecké o Windows -1254 pro turečtinu o Windows-1255 pro hebrejštinu o Windows-1256 pro arabštinu o Windows-1257 pro baltské jazyky o Windows-1258 pro vietnamské MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI -7 Bulharské kódování ISCII VISCII Big5 (nejslavnější varianta Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS pro japonštinu (Microsoft CP932) EUC-KR pro korejštinu (Microsoft CP949) ISO-2022 a EUC pro kódování čínského systému psaní UTF-8 a UTF-16 znakové sady Yong icodeV kódovacím systému ASCII(American Standard Code for Information Interchange) každý znak je reprezentován jedním bajtem, který může kódovat 256 znaků.
ASCII má dvě kódovací tabulky - základní a rozšířenou. Základní tabulka opravuje hodnoty kódů od 0 do 127 a rozšířená odkazuje na znaky s čísly od 128 do 255. To stačí k vyjádření různými kombinacemi osmi bitů všech znaků anglického a ruského jazyka „malá i velká písmena, interpunkční znaménka, symboly pro základní aritmetické operace a běžné speciální symboly, které lze pozorovat na klávesnici.
Prvních 32 kódů základní tabulky, počínaje nulou, je dáno výrobcům hardwaru (především výrobcům počítačů a tiskových zařízení). Tato oblast obsahuje takzvané řídicí kódy, které neodpovídají žádným jazykovým znakům, a proto se tyto kódy nezobrazují ani na obrazovce, ani na tiskových zařízeních, ale lze je ovládat, jak se výstup jiných dat provádí. Počínaje kódem 32 až kódem 127 jsou umístěny symboly anglické abecedy, interpunkčních znamének, číslic, aritmetických operací a pomocných symbolů, všechny jsou k vidění na latinské části počítačové klávesnice.
Druhá, rozšířená část je věnována národním kódovacím systémům. Na světě existuje mnoho nelatinských abeced (arabská, hebrejská, řecká atd.), Včetně azbuky. Také rozložení klávesnice v němčině, francouzštině a španělštině se liší od anglického.
Anglická část klávesnice mívala mnoho standardů, ale nyní byly všechny nahrazeny jediným kódem ASCII. Pro ruskou klávesnici existovalo také mnoho standardů: GOST, GOST -alternative, ISO (International Standard Organization - International Institute for Standardization), ale tyto tři standardy ve skutečnosti zanikly, i když se mohou někde setkat, v některých předpotopních počítačích nebo v počítačové sítě.
Hlavní kódování ruského jazyka, které se používá v operačních počítačích Systém Windows volala Windows-1251, byl vyvinut pro cyrilici podle Microsoftu. Naprostá většina počítačových textových dat je přirozeně kódována v systému Windows-1251. Mimochodem, kódování s jiným čtyřmístným číslem vyvinula společnost Microsoft pro další běžné abecedy: arabštinu, japonštinu a další.
Další běžné kódování se nazývá KOI-8(kód pro výměnu informací, osmimístný) - jeho původ sahá do dob Rady pro vzájemnou hospodářskou pomoc východoevropských států. Dnes je kódování KOI-8 rozšířené v počítačových sítích na území Ruska a v ruském sektoru internetu. Stává se, že některý text dopisu nebo něco jiného není čitelný, což znamená, že musíte přepnout z KOI-8 na Windows-1251. deset
V 90. letech největší výrobci softwaru: Microsoft, Borland, stejný Adobe rozhodl o potřebě vyvinout jiný systém kódování textu, ve kterém bude každému znaku přidělen ne 1, ale 2 bajty. Dostala jméno Unicode, a je možné kódovat 65 536 znaků tohoto pole, což je dost, aby se vešlo do jedné tabulky národních abeced pro všechny jazyky planety. Většinu Unicode (asi 70%) zaujímají čínské znaky, v Indii existuje 11 různých národních abeced, existuje mnoho exotických jmen, například: psaní kanadských domorodců.
Protože kódování každého znaku v Unicode je přiděleno ne 8, ale 16 bitů, velikost textového souboru se zdvojnásobí. To bylo kdysi překážkou zavedení 16bitového systému. Ale teď u gigabajtových pevných disků, stovek megabajtů RAM, gigahertzových procesorů, zdvojnásobení objemu textových souborů, které ve srovnání například s grafikou zabírají velmi málo místa, příliš nevadí.
Cyrilice v Unicode se řadí od 768 do 923 (základní znaky) a od 924 do 1023 (rozšířená azbuka, různá méně obvyklá národní písmena). Pokud program není přizpůsoben pro cyrilici Unicode, pak je možné, že textové znaky nejsou rozpoznávány jako azbuka, ale jako rozšířená latinka (kódy od 256 do 511). A v tomto případě se místo textu na obrazovce objeví nesmyslná sada různých exotických symbolů.
To je možné, pokud je program zastaralý, vytvořený před rokem 1995. Nebo vzácný, o kterém se nikdo neobtěžoval Russify. Je také možné, že operační systém Windows nainstalovaný v počítači není plně nakonfigurován pro azbuku. V takovém případě musíte provést příslušné položky v registru.
 Chyby v singularitě?
Chyby v singularitě? Just Cause 2 havaruje
Just Cause 2 havaruje Terraria nezačne, co mám dělat?
Terraria nezačne, co mám dělat?