Kódování znaků - PIE.Wiki. Kódování textových informací
Unicode je systém kódování znaků, který používají počítače k ukládání a výměně textových dat. Unicode má jedinečné číslo (nebo kódový bod) pro každý znak v hlavních světových systémech psaní. Tento systém také zahrnuje technické symboly, interpunkční znaménka a mnoho dalších symbolů používaných při psaní.
Kromě toho, že je Unicode mapou znaků, obsahuje také algoritmy pro párování a kódování oboustranných skriptů, jako je arabština, a také specifikace pro normalizaci textových forem.
Tato část poskytuje obecný popis Unicode. Více kompletní informace a seznam podporovaných jazyků, jejichž znaky lze kódovat pomocí Unicode, naleznete na webu Unicode Consortium.
Kódové body
Symboly jsou jednotky informací, které zhruba odpovídají jednotce textu v přirozeném jazyce. Unicode definuje, jak jsou znaky interpretovány, nikoli zobrazovány.
Obraz znaku (glyf), který je zobrazen, nebo vizuální reprezentace znaku, je znak, který se objeví na obrazovce monitoru nebo na vytištěné stránce. V některých systémech psaní může jeden znak odpovídat více glyfům nebo více znaků může odpovídat jednomu glyfu. Například „ll“ ve španělštině je jeden glyf, ale dva znaky: „l“ a „l“.
V Unicode jsou znaky převedeny na kódové body. Body kódu jsou čísla, která jsou přiřazena Unicode Consortium každému znaku v každém systému zápisu. Body kódu jsou reprezentovány jako „U +“ a čtyři čísla a/nebo písmena. Následují příklady bodů kódu pro čtyři různé znaky: malé písmeno l, malé písmeno u s přehláskou, beta a malé písmeno e s akutním.
Unicode obsahuje 1 114 112 kódových bodů; k dnešnímu dni mají přiřazeno přes 96 000 znaků.
Úrovně (letadla)
Prostor kódu Unicode pro znaky je rozdělen do 17 rovin, z nichž každá obsahuje 65 536 bodů kódu.
První úroveň (rovina) -rovina 0- je základní vícejazyčná rovina (BMP). Většina nejpoužívanějších znaků je kódována pomocí BMP, a to je vrstva, na které se dnes kóduje nejvíce znaků. BMP obsahuje kódové body pro téměř všechny znaky v moderních jazycích a mnoho speciální znaky... V BMP je asi 6 300 nevyužitých kódových bodů, které budou v budoucnu použity pro přidání dalších znaků.
Další úroveň (rovina) - rovina 1- je doplňková vícejazyčná rovina (SMP). SMP se používá ke kódování starověkých znaků, stejně jako hudebních a matematické symboly.
Kódování znaků
Kódování znaků definuje každý znak, jeho kódový bod a způsob, jakým je kódový bod reprezentován v bitech. Bez znalosti použitého kódování nebudete schopni správně interpretovat řetězec znaků.
Existuje velmi velké množství kódovacích schémat, ale je velmi obtížné mezi nimi převádět jejich data a jen málo z nich dokáže zohlednit přítomnost znaků ve více než dvou nebo třech různých jazycích. Pokud je například váš počítač nastaven tak, aby ve výchozím nastavení používal OEM-Latin II a prohlížíte webovou stránku, která používá IBM EBCDIC-Cyrillic, pak žádné znaky, které budou zastoupeny v azbuce, které nebudou zakódovány ve schématu Latin II, nebudou Tyto znaky budou nahrazeny jinými znaky, jako jsou otazníky a čtverečky.
Protože Unicode obsahuje kódové body pro většinu znaků ve všech moderní jazyky, pak použití kódování znaků Unicode umožní vašemu počítači interpretovat téměř každý známý znak.
Existují tři hlavní schémata Unicode pro kódování znaků: UTF-8, UTF-16 a UTF-32. UTF je zkratka pro Unicode Transformation Format. Čísla, která následují po UTF, označují velikost jednotek (v bajtech) použitých pro kódování.
- UTF-8 používá 8bitovou kódovou jednotku s proměnnou šířkou. UTF-8 používá 1 až 6 bajtů ke kódování znaku; ke kódování stejného znaku může použít méně, stejný nebo více bajtů než UTF-16. V systému Windows-1251 je každý kód od 0 do 127 (U + 0000 až U + 0127) uložen v jednom bajtu. Pouze kódové body 128 (U + 0128) a vyšší jsou uloženy pomocí 2 až 6 bajtů.
- UTF-16 používá jednu 16bitovou kódovou jednotku s pevnou šířkou. Je poměrně kompaktní a všechny nejpoužívanější znaky lze zakódovat jednou 16bitovou kódovou jednotkou. K dalším znakům lze přistupovat pomocí dvojic 16bitových kódových jednotek.
- UTF-32 zakódování jakéhokoli znaku trvá 4 bajty. Ve většině případů bude mít dokument s kódováním UTF-32 přibližně dvojnásobnou velikost než dokument s kódováním UTF-16. Každý znak je zakódován v jedné 32bitové kódovací jednotce s pevnou šířkou. UTF-32 můžete použít, pokud nejste omezeni prostorem na disku a chcete pro každý znak použít jednu kódovou jednotku.
Všechny tři formy kódování mohou kódovat stejné znaky a lze je překládat z jednoho do druhého bez ztráty dat.
Existují i další kódování: například UTF-7 a UTF-EBCDIC. K dispozici je také GB18030, což je čínský ekvivalent UTF-8 a podporuje zjednodušené a tradiční čínské znaky. Pro ruský jazyk je vhodné použít windows-1251.
Copyright © 1995-2014 Esri. Všechna práva vyhrazena.
Unicode je velmi rozsáhlý a složitý svět, protože standard umožňuje reprezentovat a pracovat v počítači se všemi hlavními skripty světa. Některé systémy psaní existují již více než tisíc let a mnohé z nich se vyvíjely téměř nezávisle na sobě v různých částech světa. Lidé vymysleli tolik věcí a často se od sebe tak liší, že bylo nesmírně obtížným a ambiciózním úkolem toto vše spojit do jediného standardu.
Abyste Unicode skutečně pochopili, musíte si alespoň povrchně představit vlastnosti všech skriptů, se kterými vám standard umožňuje pracovat. Ale je to opravdu nutné pro každého vývojáře? Řekneme ne. Pro použití Unicode ve většině každodenních úkolů stačí znát rozumné minimum informací a pak se podle potřeby ponořit do standardu.
V tomto článku budeme hovořit o základních principech Unicode a upozorníme na ty důležité praktické problémy, se kterými se vývojáři budou určitě potýkat při své každodenní práci.
Proč jste potřebovali Unicode?
Před příchodem Unicode se téměř všeobecně používalo jednobajtové kódování, ve kterém byla hranice mezi samotnými znaky, jejich reprezentace v paměti počítače a zobrazení na obrazovce spíše libovolné. Pokud jste pracovali s jedním nebo druhým národním jazykem, pak byla do vašeho systému nainstalována odpovídající kódování písem, což umožnilo čerpat bajty z disku na obrazovku tak, aby dávaly uživateli smysl.Pokud jste na tiskárně vytiskli textový soubor a na papírové stránce viděli sadu nesrozumitelných krakozyabrů, znamenalo to, že odpovídající fonty nebyly načteny do tiskového zařízení a neinterpretovalo bajty tak, jak byste chtěli.
Tento přístup obecně a jednobajtové kódování zvláště mělo řadu významných nevýhod:
- Souběžně bylo možné pracovat pouze s 256 znaky a prvních 128 bylo vyhrazeno pro latinku a řídicí znaky a ve druhé polovině bylo nutné kromě znaků národní abecedy najít místo pro pseudografické znaky (╔ ╗).
- Písma byla vázána na konkrétní kódování.
- Každé kódování představovalo vlastní sadu znaků a převod z jednoho na druhý byl možný pouze s částečnými ztrátami, kdy byly chybějící znaky nahrazeny graficky podobnými.
- Přenos souborů mezi zařízeními s různými operačními systémy byl obtížný. Bylo nutné buď mít konvertorový program, nebo nést další fonty spolu se souborem. Existence internetu, jak ho známe, byla nemožná.
- Na světě existují neabecední systémy zápisu (hieroglyfické písmo), které v jednobajtovém kódování nejsou z principu reprezentovatelné.
Základní principy Unicode
Všichni dobře rozumíme, že počítač nezná žádné ideální entity, ale pracuje s bity a bajty. Ale počítačové systémy jsou stále vytvářeny lidmi, ne stroji, a pro vás a mě je někdy pohodlnější pracovat se spekulativními pojmy a pak přejít od abstraktního ke konkrétnímu.Důležité! Jedním z ústředních principů filozofie Unicode je jasné rozlišení mezi znaky, jejich reprezentací v počítači a jejich zobrazením na výstupním zařízení.
Zavádí se pojem abstraktního unicode znaku, který existuje výhradně ve formě spekulativního konceptu a dohody mezi lidmi, zakotvené ve standardu. Každý znak Unicode je spojen s nezáporným celým číslem, které se nazývá jeho kódový bod.
Takže například znak unicode U + 041F je velké písmeno P v azbuce. Existuje několik způsobů, jak tento znak znázornit v paměti počítače, stejně jako existuje několik tisíc způsobů, jak jej zobrazit na obrazovce monitoru. Ale zároveň P to bude v Africe i P nebo U + 041F.
Toto je známé zapouzdření nebo oddělení rozhraní od implementace, koncept, který se dobře osvědčil v programování.
Ukazuje se, že podle standardu lze jakýkoli text zakódovat jako sekvenci znaků Unicode
Dobrý den U + 041F U + 0440 U + 0438 U + 0432 U + 0435 U + 0442
napište to na kus papíru, zabalte do obálky a pošlete do kterékoli části světa. Pokud vědí o existenci Unicode, pak text budou vnímat úplně stejně jako vy a já. Nebudou mít nejmenší pochyby o tom, že předposledním znakem je právě azbuka E(U + 0435) neříkej latinsky malé E(U + 0065). Všimněte si, že jsme neřekli ani slovo o reprezentaci bajtů.
Přestože se znaky unicode nazývají symboly, ne vždy odpovídají znaku v tradičním naivním smyslu, jako je písmeno, číslo, interpunkční znaménko nebo hieroglyf. (Podrobnosti najdete pod spoilerem.)
Příklady různých unicode znaků
Existují čistě technické znaky unicode, například:
- U + 0000: nulový znak;
- U + D800 – U + DFFF: vedlejší a hlavní náhrady pro technickou reprezentaci bodů kódu v rozsahu od 10 000 do 10 FFFF (čti: mimo BMP / BMP) v rodině kódování UTF-16;
- atd.
Existuje celá kohorta prostorů různých šířek a účelů (viz výborný článek habr :):
- U + 0020 (mezera);
- U + 00A0 (nezalomitelná mezera, v HTML);
- U + 2002 (půlkruhový prostor nebo En Space);
- U + 2003 (kulatý prostor nebo Em Space);
- atd.
- U + 0300 a U + 0301: známky primárního (akutního) a sekundárního (slabého) stresu;
- U + 0306: krátký (horní index), jako v th;
- U + 0303: vlnovka horního indexu
- atd.
Co je symbol, jaký je rozdíl mezi shlukem grafémů (čti: vnímáno jako jeden celý obraz symbolu) od unicode symbolu a od kvanta kódu, si povíme příště.
Unicode kódový prostor
Kódový prostor Unicode se skládá z 1 114 112 kódových bodů v rozsahu od 0 do 10FFFF. Z toho pouze 128 237 byly přiřazeny hodnoty pro devátou verzi standardu. Část prostoru je vyhrazena pro soukromé použití a konsorcium Unicode slibuje, že nikdy nepřiřadí hodnoty pozicím z těchto speciálních oblastí.Pro pohodlí je celý prostor rozdělen do 17 rovin (nyní je jich zapojeno šest). Donedávna bylo zvykem říkat, že s největší pravděpodobností musíte čelit pouze základní vícejazyčné rovině (BMP), která obsahuje znaky Unicode od U + 0000 do U + FFFF. (Trochu dopředu: znaky BMP jsou v UTF-16 zastoupeny ve dvou bytech, nikoli ve čtyřech). V roce 2016 je tato teze již zpochybňována. Takže například oblíbené znaky Emoji mohou být dobře nalezeny v uživatelské zprávě a musíte je umět správně zpracovat.
Kódování
Pokud chceme posílat text přes internet, pak musíme zakódovat sekvenci znaků unicode jako sekvenci bajtů.Standard Unicode zahrnuje řadu kódování Unicode, jako je UTF-8 a UTF-16BE / UTF-16LE, která umožňují zakódovat celý prostor kódu. Převod mezi těmito kódováními lze volně provádět bez ztráty informací.
Nikdo také nezrušil jednobajtová kódování, ale umožňují vám zakódovat vlastní individuální a velmi úzký kousek spektra Unicode – 256 nebo méně kódových bodů. Pro taková kódování existují a jsou dostupné všem tabulky, kde každá hodnota jednoho bajtu je spojena se znakem unicode (viz například CP1251.TXT). Navzdory omezením se jednobajtová kódování ukázala jako velmi praktická, pokud jde o práci s velkým množstvím jednojazyčných textové informace.
UTF-8 je nejrozšířenější kódování Unicode na internetu (zvítězilo v roce 2008), a to především díky své hospodárnosti a transparentní kompatibilitě se sedmibitovým ASCII. Latinské a služební znaky, základní interpunkční znaménka a číslice - tzn. všechny sedmibitové znaky ASCII jsou kódovány v UTF-8 v jednom bajtu, stejně jako v ASCII. Znaky mnoha hlavních písem, kromě některých vzácnějších hieroglyfických znaků, jsou v něm zastoupeny dvěma nebo třemi byty. Největší kódový bod definovaný standardem, 10FFFF, je zakódován do čtyř bajtů.
Všimněte si, že UTF-8 je kódování s proměnnou délkou. Každý znak Unicode v něm je reprezentován sekvencí kódových kvant o minimální délce jednoho kvanta. Číslo 8 znamená bitovou délku kódové jednotky - 8 bitů. Pro rodinu kódování UTF-16 je velikost kvanta kódu 16 bitů. Pro UTF-32 - 32 bitů.
Pokud posíláte HTML stránku s textem v azbuce přes síť, pak UTF-8 může poskytnout velmi hmatatelnou výhodu, protože všechny značky i bloky JavaScriptu a CSS budou efektivně zakódovány do jednoho bajtu. Například domovská stránka Habra v UTF-8 je 139 Kb a v UTF-16 již 256 Kb. Pro srovnání, pokud použijete win-1251 se ztrátou možnosti ukládat některé znaky, tak se velikost oproti UTF-8 zmenší jen o 11Kb na 128Kb.
Pro ukládání informací o řetězcích v aplikacích se často používají 16bitové kódování unicode díky své jednoduchosti a také skutečnosti, že znaky hlavních světových psacích systémů jsou zakódovány v jednom šestnáctibitovém kvantu. Takže například Java úspěšně používá UTF-16 pro interní reprezentaci řetězců. Operační systém Windows také interně používá UTF-16.
V každém případě, pokud zůstaneme v prostoru Unicode, nezáleží na tom, jak jsou informace o řetězcích uloženy v rámci jedné aplikace. Pokud formát interního úložiště umožňuje správně zakódovat všech více než milion kódových bodů a nedochází ke ztrátě informací na hranici aplikace, například při čtení ze souboru nebo kopírování do schránky, pak je vše v pořádku.
Pro správnou interpretaci textu čteného z disku nebo ze síťového soketu musíte nejprve určit jeho kódování. To se provádí buď pomocí uživatelem dodaných metainformací zapsaných v textu nebo v jeho blízkosti, nebo se určuje heuristicky.
V suchém zbytku
Informací je mnoho a má smysl uvést stručné shrnutí všeho, co bylo napsáno výše:- Unicode předpokládá jasné rozlišení mezi znaky, jejich reprezentací v počítači a jejich zobrazením na výstupním zařízení.
- Znaky Unicode ne vždy odpovídají znaku v tradičním naivním smyslu, jako je písmeno, číslo, interpunkční znaménko nebo hieroglyf.
- Kódový prostor Unicode se skládá z 1 114 112 kódových bodů v rozsahu od 0 do 10FFFF.
- Základní vícejazyčná rovina obsahuje znaky Unicode U + 0000 až U + FFFF, které jsou zakódovány v UTF-16 ve dvou bytech.
- Jakékoli kódování Unicode vám umožňuje zakódovat celý prostor bodů kódu Unicode a převod mezi různými takovými kódováními se provádí bez ztráty informací.
- Jednobajtová kódování mohou zakódovat pouze malou část spektra unicode, ale mohou být užitečná při práci s velkým množstvím jednojazyčných informací.
- Kódování UTF-8 a UTF-16 mají proměnnou délku kódu. V UTF-8 může být každý znak Unicode zakódován jedním, dvěma, třemi nebo čtyřmi bajty. V UTF-16 dva nebo čtyři bajty.
- Vnitřní formát ukládání textových informací v rámci samostatné aplikace může být libovolný za předpokladu, že správně funguje s celým prostorem bodů Unicode kódu a nedochází ke ztrátě při přeshraničním přenosu dat.
Rychlá poznámka ke kódování
S pojmem kódování může dojít k určité záměně. V rámci Unicode se kódování vyskytuje dvakrát. Při prvním zakódování znakové sady v tom smyslu, že každému znaku Unicode je přiřazen odpovídající kódový bod. Tento proces převede znakovou sadu Unicode na kódovanou znakovou sadu. Při druhém převodu sekvence znaků unicode na bajtový řetězec se tento proces také nazývá kódování.V anglické terminologii existují dvě různá slovesa kódovat a kódovat, ale i rodilí mluvčí jsou v nich často zmateni. Kromě toho se termín znaková sada nebo znaková sada používá jako synonymum s termínem kódovaná znaková sada.
To vše říkáme k tomu, že má smysl věnovat pozornost kontextu a rozlišovat situace, kdy jde o kódovou pozici abstraktního unicode znaku a pokud jde o jeho bytovou reprezentaci.
Konečně
Existuje tolik různých aspektů Unicode, že je nemožné pokrýt vše v jednom článku. A zbytečné. Výše uvedené informace stačí k tomu, aby nedošlo k záměně v základních principech a práci s textem ve většině každodenních úkolů (čtěte: aniž byste překračovali rámec BMP). V dalších článcích budeme hovořit o normalizaci, poskytneme úplnější historický přehled o vývoji kódování, budeme hovořit o problémech terminologie Unicode v ruském jazyce a také o praktických aspektech používání UTF-8 a UTF- 16.Unicode
Logo Unicode Consortium
Unicode(nejčastěji) popř Unicode(angl. Unicode) je standard kódování znaků, který umožňuje zastoupení znaků téměř ve všech psaných jazycích.
Standard byl navržen v roce 1991 neziskovou organizací „Unicode Consortium“ (angl. Unicode Consortium, Unicode Inc.).
Použití tohoto standardu umožňuje zakódovat velmi velké množství znaků z různých písem: čínské znaky, matematické znaky, písmena řecké abecedy, latinky a azbuky mohou koexistovat v dokumentech Unicode, takže přepínání kódových stránek se stává zbytečným.
Standard se skládá ze dvou hlavních částí: univerzální znaková sada (angl. UCS, univerzální znaková sada) a rodina kódování (angl. UTF, transformační formát Unicode).
Univerzální znaková sada definuje vzájemnou shodu znaků s kódy - prvky kódového prostoru, které představují nezáporná celá čísla. Rodina kódování definuje strojovou reprezentaci sekvence kódů UCS.
Kódy Unicode jsou rozděleny do několika oblastí. Oblast s kódy U + 0000 až U + 007F obsahuje znaky ASCII s odpovídajícími kódy. Dále jsou to oblasti znaků různých písem, interpunkčních znamének a technických symbolů.
Některé z kódů jsou vyhrazeny pro budoucí použití. Pod znaky azbuky jsou přiděleny oblasti znaků s kódy od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (viz azbuka v Unicode).
- 1 Předpoklady pro vytvoření a rozvoj Unicode
- 2 verze Unicode
- 3 Kódový prostor
- 4 Kódovací systém
- 4.1 Zásady konsorcia
- 4.2 Kombinování a kopírování symbolů
- 5 Úprava znaků
- 6 Normalizační algoritmy
- 6.1 NFD
- 6.2 NFC
- 6.3 NFKD
- 6.4 NFKC
- 6.5 Příklady
- 7 Obousměrné psaní
- 8 Doporučené symboly
- 9 ISO / IEC 10646
- 10 způsobů prezentace
- 10.1 UTF-8
- 10.2 Pořadí bajtů
- 10.3 Unicode a tradiční kódování
- 10.4 Implementace
- 11 Metody zadávání
- 11.1 Microsoft Windows
- 11.2 Macintosh
- 11.3 GNU / Linux
- 12 Problémy s Unicode
- 13 "Unicode" nebo "Unicode"?
Předpoklady pro vytvoření a rozvoj Unicode
Koncem osmdesátých let se 8bitové znaky staly standardem. Zároveň existovalo mnoho různých 8bitových kódování a neustále se objevovala nová.
To bylo vysvětleno jak neustálým rozšiřováním škály podporovaných jazyků, tak touhou vytvořit kódování částečně kompatibilní s některým jiným (typickým příkladem je vznik alternativního kódování pro ruský jazyk, kvůli vykořisťování západní programy vytvořené pro kódování CP437).
V důsledku toho se objevilo několik problémů:
- problém "krakozyabr";
- problém omezené znakové sady;
- problém převodu jednoho kódování na druhé;
- problém duplicitních písem.
Problém "krakozyabr"- problém se zobrazováním dokumentů ve špatném kódování. Problém by bylo možné vyřešit buď důsledným zavedením metod pro specifikaci použitého kódování, nebo zavedením jediného (společného) kódování pro všechny.
Problém omezené znakové sady... Problém by bylo možné vyřešit buď přepínáním písem v rámci dokumentu, nebo zavedením „širokého“ kódování. Přepínání fontů se v textových procesorech dlouho praktikovalo a často se používaly fonty s nestandardním kódováním, tzv. "Dingbat fonty". V důsledku toho se při pokusu o přenos dokumentu do jiného systému všechny nestandardní znaky změnily na „krakozyabry“.
Problém převodu jednoho kódování na druhé... Problém by mohl být vyřešen buď kompilací převodních tabulek pro každý pár kódování, nebo použitím přechodného převodu na třetí kódování, které zahrnuje všechny znaky všech kódování.
Problém s duplicitními fonty... Pro každé kódování bylo vytvořeno vlastní písmo, i když se znakové sady v kódování částečně nebo úplně shodovaly. Problém by se dal vyřešit vytvořením „velkých“ fontů, ze kterých by se následně vybíraly znaky potřebné pro dané kódování. To však vyžadovalo vytvoření jednotného registru symbolů, aby bylo možné určit, co čemu odpovídá.
Byla uznána potřeba jediného „širokého“ kódování. Kódování s proměnnou délkou, široce používané ve východní Asii, bylo shledáno jako příliš obtížné na použití, takže bylo rozhodnuto použít znaky s pevnou šířkou.
Používání 32bitových znaků se zdálo příliš nehospodárné, a tak bylo rozhodnuto použít 16bitové.
První verze Unicode byla kódování s pevnou velikostí znaků 16 bitů, to znamená, že celkový počet kódů byl 2 16 (65 536). Od té doby se symboly označují čtyřmi hexadecimálními číslicemi (např. U + 04F0). Zároveň bylo plánováno zakódovat v Unicode ne všechny existující znaky, ale pouze ty, které jsou nezbytné v každodenním životě. Zřídka používané symboly musely být umístěny v „oblasti soukromého použití“, která původně zabírala kódy U + D800 ... U + F8FF.
Aby bylo možné použít Unicode také jako meziprodukt při vzájemném převodu různých kódování, byly do něj zahrnuty všechny znaky zastoupené ve všech nejznámějších kódováních.
Do budoucna však bylo rozhodnuto všechny symboly zakódovat a v souvislosti s tím výrazně rozšířit doménu kódu.
Ve stejné době se znakové kódy začaly považovat nikoli za 16bitové hodnoty, ale za abstraktní čísla, která lze v počítači znázornit mnoha různými způsoby (viz způsoby reprezentace).
Protože v řadě počítačových systémů (například Windows NT) se již jako výchozí kódování používaly pevné 16bitové znaky, bylo rozhodnuto zakódovat všechny nejdůležitější znaky pouze v rámci prvních 65 536 pozic (tzv. anglických. základní vícejazyčná rovina, BMP).
Zbytek místa je použit pro "doplňkové znaky" (angl. doplňkové znaky): systémy psaní zaniklých jazyků nebo velmi zřídka používané čínské znaky, matematické a hudební symboly.
Pro kompatibilitu se starými 16bitovými systémy byl vynalezen systém UTF-16, kde prvních 65 536 pozic, s výjimkou pozic z intervalu U + D800 ... U + DFFF, je zobrazeno přímo jako 16bitová čísla, a zbytek je reprezentován jako "náhradní páry" (první prvek z páru z oblasti U + D800… U + DBFF, druhý prvek z páru z oblasti U + DC00… U + DFFF). Pro náhradní páry byla použita část kódového prostoru (2048 pozic) přidělená pro „soukromé použití“.
Protože UTF-16 může zobrazit pouze 2 20 +2 16 −2048 (1 112 064) znaků, bylo toto číslo zvoleno jako konečná hodnota kódového prostoru Unicode (rozsah kódu: 0x000000-0x10FFFF).
Přestože byla oblast kódu Unicode rozšířena za 2-16 již ve verzi 2.0, první znaky v oblasti „top“ byly umístěny až ve verzi 3.1.
Role tohoto kódování ve webovém sektoru neustále roste. Na začátku roku 2010 byl podíl webů využívajících Unicode asi 50 %.
Unicode verze
Práce na finalizaci standardu pokračují. Nové verze jsou vydávány se změnou a aktualizací tabulek symbolů. Souběžně s tím jsou vydávány nové dokumenty ISO / IEC 10646.
První standard byl vydán v roce 1991, poslední v roce 2016, další se očekává v létě 2017. Verze standardů 1.0-5.0 byly vydány jako knihy a mají ISBN.
Číslo verze normy se skládá ze tří číslic (například „4.0.1“). Třetí číslice se změní, když jsou provedeny drobné změny standardu, které nepřidávají nové znaky.
Kódový prostor
Ačkoli formy zápisu UTF-8 a UTF-32 umožňují zakódovat až 2 331 (2 147 483 648) kódových bodů, bylo rozhodnuto použít pouze 1 112 064 pro kompatibilitu s UTF-16. I to je však pro tuto chvíli více než dost – ve verzi 6.0 je použito o něco méně než 110 000 kódových bodů (109 242 grafických a 273 dalších symbolů).
Kódový prostor je rozdělen na 17 letadla(angl. letadla) 2 16 (65 536) znaků každý. Pozemní rovina ( letadlo 0) je nazýván základní (základní) a obsahuje symboly nejběžnějších skriptů. Zbývající letadla jsou další ( doplňkový). První letadlo ( letadlo 1) se používá především pro historická písma, druhý ( letadlo 2) - pro zřídka používané čínské znaky (CJK), třetí ( letadlo 3) je vyhrazen pro archaické čínské znaky. Letadla 15 a 16 jsou vyhrazena pro soukromé použití.
Pro označení znaků Unicode použijte zápis jako „U + xxxx"(Pro kódy 0 ... FFFF), nebo" U + xxxxx"(Pro kódy 10000 ... FFFFF), nebo" U + xxxxxx"(Pro kódy 100000 ... 10FFFF), kde xxx- hexadecimální číslice. Například znak „i“ (U + 044F) má kód 044F 16 = 1103 10.
Systém kódování
Univerzální kódovací systém (Unicode) je soubor grafických symbolů a způsob jejich kódování pro počítačové zpracování textových dat.
Grafické symboly jsou symboly, které mají viditelný obrázek. Grafické znaky jsou protikladem k ovládacím a formátovacím znakům.
Grafické symboly zahrnují následující skupiny:
- písmena obsažená alespoň v jedné z podporovaných abeced;
- čísla;
- interpunkční znaménka;
- speciální znaky (matematické, technické, ideogramy atd.);
- oddělovače.
Unicode je systém pro lineární reprezentaci textu. Znaky s dalšími horními nebo dolními indexy mohou být reprezentovány jako sekvence kódů sestavené podle určitých pravidel (složený znak) nebo jako jeden znak (monolitická verze, předem složený znak). Na tento moment(2014), má se za to, že všechna písmena velkých písem jsou zahrnuta v Unicode, a pokud je symbol k dispozici ve složené verzi, není nutné jej duplikovat v monolitické podobě.
Politika konsorcia
Konsorcium nevytváří nový, ale uvádí zavedený řád věcí. Přibyly například obrázky emotikonů, protože je japonští mobilní operátoři hojně používali.
Chcete-li to provést, přidání symbolu prochází složitým procesem. A například symbol ruského rublu ji prošel za tři měsíce jen proto, že získal oficiální status.
Ochranné známky jsou kódovány pouze výjimečně. V Unicode tedy není žádná vlajka Windows ani jablko Apple.
Jakmile se postava objeví v kódování, nikdy se nepohne ani nezmizí. Pokud potřebujete změnit pořadí znaků, neprovedete to změnou pozic, ale národním pořadím řazení. Existují další, jemnější záruky stability – například normalizační tabulky se nezmění.
Kombinování a kopírování symbolů
Stejný symbol může mít několik podob; v Unicode jsou tyto formuláře obsaženy v jednom bodě kódu:
- kdyby se to stalo historicky. Například arabská písmena mají čtyři formy: oddělená, na začátku, uprostřed a na konci;
- nebo pokud je jeden jazyk přijat v jedné formě a v jiné - jiné. Bulharská azbuka se liší od ruštiny a čínské znaky od japonštiny.
Na druhou stranu, pokud historicky existovaly dva různé kódové body ve fontech, zůstávají v Unicode odlišné. Malé řecké sigma má dvě formy a mají různé polohy. Rozšířené latinské písmeno Å (A s kroužkem) a znak angstrom Å, Řecké písmenoμ a předpona „mikro“ µ jsou různé symboly.
Podobné znaky v nesouvisejících skriptech jsou samozřejmě umístěny do různých bodů kódu. Například písmeno A v latince, azbuce, řečtině a čerokíštině jsou různé symboly.
Je extrémně vzácné, že je stejný znak umístěn na dvou různých pozicích kódu, aby se zjednodušilo zpracování textu. Matematický tah a stejný tah pro označení měkkosti zvuků jsou různé symboly, druhý je považován za písmeno.
Úprava postav
Znázornění znaku "Y" (U + 0419) ve formě základního znaku "I" (U + 0418) a modifikačního znaku "" (U + 0306)
Grafické znaky se v Unicode dělí na rozšířené a nerozšířené (bez šířky). Nerozšířené znaky při zobrazení nezabírají místo v řádku. Patří sem zejména diakritická znaménka a další diakritická znaménka. Rozšířené i neprodloužené znaky mají své vlastní kódy. Rozšířené symboly se jinak nazývají základní (angl. základní znaky), a nerozšířené - upravující (angl. kombinování znaků); a tito se nemohou setkat nezávisle. Například znak "á" může být reprezentován jako posloupnost základního znaku "a" (U + 0061) a modifikačního znaku " ́" (U + 0301), nebo jako monolitický znak "á" (U + 00E1).
Speciálním typem modifikujících postav jsou selektory stylu obličeje (angl. selektory variací). Vztahují se pouze na ty symboly, pro které jsou takové varianty definovány. Ve verzi 5.0 jsou definovány váhy pro řadu matematických symbolů, pro symboly tradiční mongolské abecedy a pro symboly mongolského čtvercového písma.
Normalizační algoritmy
Protože mohou být zastoupeny stejné symboly různé kódy, srovnání řetězců byte po byte se stává nemožné. Normalizační algoritmy normalizační formy) vyřešit tento problém převodem textu do určité standardní formy.
Odlévání se provádí nahrazením symbolů ekvivalentními pomocí tabulek a pravidel. "Rozklad" je nahrazení (rozklad) jednoho znaku na několik základních znaků a "složení" je naopak nahrazení (spojení) několika základních znaků jedním znakem.
Standard Unicode definuje 4 algoritmy normalizace textu: NFD, NFC, NFKD a NFKC.
NFD
NFD, eng. n ormalizace F orm D ("D" z angličtiny. d ekompozice), normalizační forma D je kanonický rozklad - algoritmus, podle kterého se provádí rekurzivní náhrada monolitických symbolů (angl. předem složené znaky) na několik komponent (angl. složené znaky) podle rozkladových tabulek.
Å U + 00C5 →
A U + 0041
̊ U + 030A
ṩ U + 1E69 →
s U + 0073
̣ U + 0323
̇ U + 0307
ḍ̇ U + 1E0B U + 0323 →
d U + 0064
̣ U + 0323
̇ U + 0307
q̣̇ U + 0071 U + 0307 U + 0323 →
q U + 0071
̣ U + 0323
̇ U + 0307 NFC
NFC, eng. n ormalizace F orm C ("C" z angličtiny. C ompozice), normalizační forma C je algoritmus, podle kterého se kanonická dekompozice a kanonická kompozice provádějí postupně. Nejprve kanonická dekompozice (algoritmus NFD) redukuje text do tvaru D. Poté kanonická kompozice, inverzní k NFD, zpracuje text od začátku do konce, přičemž bere v úvahu následující pravidla:
- symbol S se počítá počáteční pokud má třídu modifikace rovnou nule podle tabulky znaků Unicode;
- v libovolné posloupnosti znaků počínaje znakem S, symbol C blokován od S, pouze pokud mezi S a C je tam nějaký symbol B který je buď počáteční, nebo má stejnou nebo větší třídu modifikace než C... Toto pravidlo platí pouze pro řetězce, které prošly kanonickým rozkladem;
- symbol se počítá hlavní kompozit, pokud má kanonický rozklad v tabulce znaků Unicode (nebo kanonický rozklad pro Hangul a není zahrnut v seznamu vyloučení);
- symbol X lze nejprve kombinovat se symbolem Y tehdy a jen tehdy, když existuje primární kompozit Z, kanonicky ekvivalentní posloupnosti<X, Y>;
- pokud další znak C není blokován posledním nalezeným počátečním základním znakem L a dá se s ním nejprve úspěšně kombinovat L nahrazeny kompozitem L-C, a C odstraněny.
Ó U + 006F
̂ U + 0302 → →
H U + 0048
① U + 2460 →
1 U + 0031
カ U + FF76 →
カ U + 30AB →
fi U + FB01
fi U + FB01
F i U + 0066 U + 0069
F i U + 0066 U + 0069
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 5 U + 0032 U + 0035
2 5 U + 0032 U + 0035
ẛ̣ U + 1E9B U + 0323
ſ ̣ ̇ U + 017F U + 0323 U + 0307
ẛ ̣ U + 1E9B U + 0323
s ̣ ̇ U + 0073 U + 0323 U + 0307
ṩ U + 1E69
čt U + 0439
a ̆ U + 0438 U + 0306
čt U + 0439
a ̆ U + 0438 U + 0306
čt U + 0439
E U + 0451
E ̈ U + 0435 U + 0308
E U + 0451
E ̈ U + 0435 U + 0308
E U + 0451
A U + 0410
A U + 0410
A U + 0410
A U + 0410
A U + 0410
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
Ⅷ U + 2167
Ⅷ U + 2167
Ⅷ U + 2167
PROTI já já já U + 0056 U + 0049 U + 0049 U + 0049
PROTI já já já U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
C ̧ U + 0063 U + 0327
ç U + 00E7
C ̧ U + 0063 U + 0327
ç U + 00E7 Obousměrné písmeno
Standard Unicode podporuje jazyky psaní se směrem zleva doprava (angl. zleva doprava, LTR), a s psaním zprava doleva (angl. zprava doleva, RTL) - například arabská a hebrejská písmena. V obou případech jsou postavy uloženy v „přirozeném“ pořadí; jejich zobrazení s přihlédnutím k požadovanému směru písmene zajišťuje aplikace.
Unicode navíc podporuje kombinované texty, které kombinují fragmenty s různými směry písmene. Tato funkce se nazývá obousměrnost(angl. obousměrný text, BiDi). Některé zjednodušené textové procesory (například v mobily) může podporovat Unicode, ale ne obousměrnou podporu. Všechny znaky Unicode jsou rozděleny do několika kategorií: psané zleva doprava, psané zprava doleva a psané v libovolném směru. Symboly posledně jmenované kategorie (hlavně interpunkční znaménka) se při zobrazení orientují ve směru okolního textu.
Doporučené symboly
Schéma základní vícejazyčné roviny Unicode
Unicode zahrnuje prakticky všechny moderní skripty, včetně:
- arabština
- arménština,
- Bengálský,
- barmský,
- sloveso
- řecký
- gruzínština,
- dévanágarí,
- Židovský,
- Cyrilice,
- Čínština (čínské znaky se aktivně používají v japonštině a příležitostně v korejštině),
- koptština,
- khmerské,
- Latinský,
- tamilština,
- korejština (hangul),
- čerokíz,
- etiopský,
- japonština (která zahrnuje kromě slabičné abecedy také čínské znaky)
jiný.
Pro akademické účely bylo přidáno mnoho historických písem, včetně: germánských run, starověkých tureckých run, starověkého řeckého písma, egyptských hieroglyfů, klínového písma, mayského písma, etruské abecedy.
Unicode poskytuje širokou škálu matematických a hudebních symbolů a piktogramů.
Unicode v zásadě nezahrnuje státní vlajky, loga firem a produktů, přestože se v fontech nacházejí (například logo Apple v kódování MacRoman (0xF0) popř. Logo Windows ve fontu Wingdings (0xFF)). V písmech Unicode musí být loga umístěna pouze v oblasti vlastních znaků.
ISO / IEC 10646
Unicode Consortium úzce spolupracuje s pracovní skupina ISO / IEC / JTC1 / SC2 / WG2, která vyvíjí mezinárodní standard 10646 (ISO / IEC 10646). Synchronizace je zavedena mezi normou Unicode a ISO / IEC 10646, ačkoli každá norma používá svou vlastní terminologii a systém dokumentace.
Spolupráce Unicode Consortium s Mezinárodní organizací pro standardizaci (angl. Mezinárodní organizace pro normalizaci, ISO ) začala v roce 1991. V roce 1993 vydala ISO normu DIS 10646.1. Pro synchronizaci s ním Konsorcium schválilo verzi 1.1 standardu Unicode, která byla doplněna o další znaky z DIS 10646.1. V důsledku toho jsou hodnoty kódovaných znaků v Unicode 1.1 a DIS 10646.1 naprosto stejné.
Do budoucna spolupráce obou organizací pokračovala. V roce 2000 byl standard Unicode 3.0 synchronizován s ISO / IEC 10646-1: 2000. Nadcházející třetí verze ISO / IEC 10646 bude synchronizována s Unicode 4.0. Možná budou tyto specifikace dokonce zveřejněny jako jednotný standard.
Podobně jako formáty UTF-16 a UTF-32 ve standardu Unicode má standard ISO / IEC 10646 také dvě hlavní formy kódování znaků: UCS-2 (2 bajty na znak, podobně jako UTF-16) a UCS-4 (4 bajty na znak, podobně jako UTF-32). UCS znamená univerzální víceoktet(multibajt) kódovaná znaková sada(angl. univerzální víceoktetová kódovaná znaková sada ). UCS-2 lze považovat za podmnožinu UTF-16 (UTF-16 bez náhradních párů) a UCS-4 je synonymem pro UTF-32.
Rozdíly mezi normami Unicode a ISO / IEC 10646:
- drobné rozdíly v terminologii;
- ISO / IEC 10646 nezahrnuje části požadované k plné implementaci podpory Unicode:
- žádná data o binárním kódování znaků;
- chybí popis srovnávacích algoritmů (angl. řazení) a vykreslování (ang. vykreslování) znaky;
- neexistuje žádný seznam vlastností symbolů (například neexistuje žádný seznam vlastností požadovaných pro implementaci podpory pro obousměrné (angl. obousměrný) písmena).
Prezentační metody
Unicode má několik forem reprezentace (eng. Transformační formát Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) a UTF-32 (UTF-32BE, UTF-32LE). Forma reprezentace UTF-7 byla vyvinuta také pro přenos přes sedmibitové kanály, ale kvůli nekompatibilitě s ASCII nebyla rozšířena a nebyla zahrnuta do standardu. 1. dubna 2005 byla navržena dvě vtipná podání: UTF-9 a UTF-18 (RFC 4042).
Systémy Microsoft Windows NT a Windows 2000 a založené na Windows XP primárně používají formulář UTF-16LE. Na typu UNIX operační systémy GNU / Linux, BSD a Mac OS X přijaly formát UTF-8 pro soubory a UTF-32 nebo UTF-8 pro zpracování znaků v paměť s náhodným přístupem.
Punycode je další forma kódování sekvencí Unicode znaků do tzv. ACE sekvencí, které jsou složeny pouze z alfanumerických znaků, jak je povoleno u doménových jmen.
UTF-8
UTF-8 je reprezentace Unicode, která poskytuje nejlepší kompatibilitu se staršími systémy, které používaly 8bitové znaky.
Text obsahující pouze znaky očíslované méně než 128 se při psaní v UTF-8 převede na prostý text ASCII. Naopak v textu UTF-8 se zobrazí jakýkoli bajt s hodnotou menší než 128 ASCII znak se stejným kódem.
Zbývající znaky Unicode jsou reprezentovány sekvencemi dlouhými od 2 do 6 bajtů (ve skutečnosti pouze do 4 bajtů, protože v Unicode nejsou žádné znaky s kódem větším než 10FFFF a ani se neplánuje jejich zavedení do future), ve kterém má první bajt vždy tvar 11xxxxxx a zbytek - 10xxxxxx... V UTF-8 se nepoužívají žádné zástupné páry, k zápisu jakéhokoli unicode znaku stačí 4 bajty.
UTF-8 bylo vynalezeno 2. září 1992 Kenem Thompsonem a Robem Pikem a implementováno v plánu 9.... Norma UTF-8 je nyní oficiálně zakotvena v RFC 3629 a ISO / IEC 10646 příloha D.
Znaky UTF-8 jsou odvozeny z Unicode takto:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Teoreticky možné, ale také nezahrnuté ve standardu:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFxx1x1x0x0x1011x10x0x1x1x1x0x
Ačkoli UTF-8 umožňuje zadat stejný znak několika způsoby, správný je pouze ten nejkratší. Zbytek formulářů by měl být z bezpečnostních důvodů odmítnut.
Pořadí bajtů
V datovém toku UTF-16 lze nízký bajt zapsat buď před horní bajt (ang. UTF-16 little-endian), nebo po starším (ang. UTF-16 big-endian). Podobně existují dvě varianty čtyřbajtového kódování - UTF-32LE a UTF-32BE.
Chcete-li definovat formát reprezentace Unicode na začátku textový soubor píše se podpis - znak U + FEFF (nezalomitelná mezera s nulovou šířkou), také tzv značka sekvence bajtů(angl. značka pořadí bajtů (BOM)). To umožňuje rozlišovat mezi UTF-16LE a UTF-16BE, protože znak U + FFFE neexistuje. Někdy se také používá k označení formátu UTF-8, i když pojem pořadí bajtů se na tento formát nevztahuje. Soubory, které se řídí touto konvencí, začínají těmito bajtovými sekvencemi:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Bohužel tato metoda spolehlivě nerozlišuje mezi UTF-16LE a UTF-32LE, protože znak U + 0000 je povolen Unicode (ačkoli skutečné texty jím začínají jen zřídka).
Soubory v kódování UTF-16 a UTF-32, které neobsahují kusovník, musí být v pořadí bajtů big-endian (unicode.org).
Unicode a tradiční kódování
Zavedení Unicode změnilo přístup k tradičnímu 8bitovému kódování. Pokud dříve bylo kódování určeno písmem, nyní je určeno korespondenční tabulkou mezi tímto kódováním a Unicode.
Ve skutečnosti se 8bitová kódování stala reprezentací podmnožiny Unicode. Díky tomu bylo mnohem snazší vytvářet programy, které musí pracovat s mnoha různými kódováními: nyní, abyste přidali podporu pro jedno další kódování, stačí přidat další vyhledávací tabulku Unicode.
Mnoho datových formátů navíc umožňuje vložení libovolných znaků Unicode, i když je dokument napsán ve starém 8bitovém kódování. Můžete například použít kódy ampersand v HTML.
Implementace
Většina moderních operačních systémů poskytuje určitý stupeň podpory Unicode.
V operačních systémech řady Windows NT se dvoubajtové kódování UTF-16LE používá pro interní reprezentaci názvů souborů a dalších systémových řetězců. Systémová volání, která přebírají parametry řetězce, jsou k dispozici v jednobajtových a dvoubajtových variantách. Další informace naleznete v článku Unicode o řadě operačních systémů Microsoft Windows.
Operační systémy podobné UNIXu, včetně GNU / Linux, BSD, OS X, používají k reprezentaci Unicode kódování UTF-8. Většina programů umí pracovat s UTF-8 jako s tradičním jednobajtovým kódováním, bez ohledu na skutečnost, že znak je reprezentován jako několik po sobě jdoucích bajtů. Pro práci s jednotlivými znaky jsou řetězce obvykle překódovány na UCS-4, takže každý znak má strojové slovo.
Jednou z prvních úspěšných komerčních implementací Unicode byla Wednesday Java programování... V podstatě opustilo 8bitovou reprezentaci znaků ve prospěch 16bitové. Toto řešení zvýšilo spotřebu paměti, ale umožnilo nám vrátit do programování důležitou abstrakci: libovolný jediný znak (typ char). Zejména programátor mohl pracovat s řetězcem jako s jednoduchým polem. Bohužel úspěch nebyl konečný, Unicode přerostlo 16bitový limit a do J2SE 5.0 začal libovolný znak opět zabírat proměnný počet paměťových jednotek - jednu char nebo dva (viz náhradní pár).
Většina programovacích jazyků nyní podporuje řetězce Unicode, i když jejich reprezentace se může lišit v závislosti na implementaci.
Metody zadávání
Protože žádné rozložení klávesnice neumožňuje zadání všech znaků Unicode současně, je vyžadována podpora ze strany operačních systémů a aplikací. alternativní metody zadejte libovolné znaky Unicode.
Microsoft Windows
Ačkoli počínaje Windows 2000 nástroj Mapa znaků (charmap.exe) podporuje znaky Unicode a umožňuje vám je zkopírovat do schránky, tato podpora je omezena pouze na základní rovinu (kódy znaků U + 0000… U + FFFF). Symboly s kódy od U + 10000 "Tabulka symbolů" se nezobrazuje.
Podobná tabulka je například v Microsoft Word.
Někdy můžete zadat hexadecimální kód, stisknout Alt + X a kód bude nahrazen příslušným znakem, například v aplikaci WordPad, Microsoft Word. V editorech Alt + X provádí také obrácenou transformaci.
V mnoha programech MS Windows získat Unicode znak, podržte klávesu Alt a zadejte desetinnou hodnotu kódu znaku on numerická klávesnice... Například kombinace Alt + 0171 ("), Alt + 0187 (") a Alt + 0769 (znak znaménka) budou užitečné při psaní textů v azbuce. Zajímavé jsou také kombinace Alt + 0133 (…) a Alt + 0151 (-).
Macintosh
Mac OS 8.5 a novější podporuje metodu zadávání nazvanou „Unicode Hex Input“. Zatímco držíte klávesu Option, musíte zadat čtyřmístný hexadecimální kód požadovaného znaku. Tato metoda umožňuje zadávat znaky s kódy většími než U + FFFF pomocí náhradních párů; takové páry budou operačním systémem automaticky nahrazeny jednotlivými znaky. Před použitím této metody zadávání musíte aktivovat v odpovídající části systémových nastavení a poté vybrat jako aktuální metodu zadávání v nabídce klávesnice.
Počínaje Mac OS X 10.2 je k dispozici také aplikace Paleta znaků, která umožňuje vybírat znaky z tabulky, ve které lze vybírat znaky z konkrétního bloku nebo znaky podporované konkrétním písmem.
GNU / Linux
GNOME má také nástroj Mapa symbolů (dříve gucharmap), který vám umožňuje zobrazit symboly pro konkrétní blok nebo systém psaní a poskytuje možnost vyhledávat podle názvu nebo popisu symbolu. Když je znám kód požadovaného znaku, lze jej zadat v souladu s normou ISO 14755: podržte klávesy Ctrl + ⇧ Shift a zadejte hexadecimální kód (od některé verze GTK + je nutné zadat kód stisknutím "U"). Zadaný hexadecimální kód může mít délku až 32 bitů, což vám umožní zadat libovolné znaky Unicode bez použití náhradních párů.
Všechny aplikace X Window, včetně GNOME a KDE, podporují zadávání pomocí klávesy Compose. U klávesnic, které nemají vyhrazenou klávesu Compose, můžete pro tento účel přiřadit jakoukoli klávesu – například ⇪ Caps lock.
Konzole GNU / Linux také umožňuje zadání znaku Unicode jeho kódem - k tomu je nutné zadat desetinný kód znaku jako číslice bloku rozšířené klávesnice při stisknuté klávese Alt. Znaky můžete zadávat pomocí jejich hexadecimálního kódu: k tomu musíte podržet klávesu AltGr a zadat číslice A-F použijte klávesy na rozšířeném bloku klávesnice od NumLock až po ↵ Enter (ve směru hodinových ručiček). Podporován je i vstup v souladu s ISO 14755. Aby výše uvedené metody fungovaly, musíte v konzole povolit režim Unicode voláním unicode_start(1) a zavoláním vyberte vhodné písmo setfont(8).
Mozilla Firefox pro Linux podporuje zadávání znaků ISO 14755.
Problémy s Unicode
V Unicode jsou anglické „a“ a polské „a“ stejný znak. Stejně tak ruské „a“ a srbské „a“ jsou považovány za stejný symbol (ale odlišný od latinského „a“). Tento princip kódování není univerzální; řešení „pro všechny příležitosti“ zjevně nemůže vůbec existovat.
- Čínské, korejské a japonské texty se tradičně píší shora dolů, počínaje pravým horním rohem. Přepínání mezi vodorovným a svislým pravopisem pro tyto jazyky není v Unicode zajištěno - musí to být provedeno pomocí značkovacích jazyků nebo vnitřních mechanismů textových procesorů.
- Unicode umožňuje různé váhy stejného znaku v závislosti na jazyku. Čínské znaky tedy mohou mít různé styly v čínštině, japonštině (kanji) a korejštině (hancha), ale zároveň jsou v Unicode označeny stejným symbolem (tzv. sjednocení CJK), i když stále zjednodušené a plné znaky mají různé kódy... Stejně tak ruština a srbština používají odlišný styl kurzívy. NS a T(v srbštině vypadají jako u a w, viz srbská kurzíva). Proto musíte zajistit, aby byl text vždy správně označen jako související s jedním nebo druhým jazykem.
- Překlad z malých písmen na velká také závisí na jazyku. Například: v turečtině jsou písmena İi a Iı – turecká pravidla pro změnu velikosti písmen jsou tedy v rozporu s anglickými, které vyžadují, aby bylo „i“ přeloženo na „I“. Podobné problémy existují i v jiných jazycích - například v kanadském dialektu francouzštiny je rejstřík přeložen trochu jinak než ve Francii.
- Dokonce i s arabskými číslicemi existují určité typografické jemnosti: čísla mohou být "velká" a "malá", proporcionální a bez mezer - pro Unicode mezi nimi není žádný rozdíl. Takové nuance zůstávají v softwaru.
Některé nevýhody se netýkají samotného Unicode, ale spíše schopností textových procesorů.
- Soubory jiného než latinského textu v Unicode vždy zabírají více místa, protože jeden znak není kódován jedním bajtem, jako v různých národních kódováních, ale sekvencí bajtů (výjimkou je UTF-8 pro jazyky, kterým abeceda vyhovuje do ASCII, dále přítomnost dvou znaků v textu a více jazyků, jejichž abeceda ne zapadá do ASCII). Soubor písem potřebný k zobrazení všech znaků v tabulce Unicode zabírá relativně velký paměťový prostor a je výpočetně náročnější než samotné písmo v národním jazyce uživatele. S nárůstem výkonu počítačových systémů a snížením nákladů na paměť a místo na disku se tento problém stává stále méně významným; zůstává však relevantní pro přenosná zařízení, jako jsou mobilní telefony.
- Ačkoli je podpora Unicode implementována v nejběžnějších operačních systémech, stále ne všechny jsou aplikovány software podporuje správná práce s ním. Zejména značky pořadí bajtů (BOM) nejsou vždy zpracovány a znaky s diakritikou jsou špatně podporovány. Problém je dočasný a je důsledkem srovnatelné novosti standardů Unicode (ve srovnání s jednobajtovými národními kódováními).
- Výkon všech programů pro zpracování řetězců (včetně řazení v databázi) se snižuje, když je místo jednobajtových kódování použito Unicode.
Některé vzácné systémy psaní stále nejsou v Unicode správně reprezentovány. Zobrazování "dlouhých" znaků horního indexu přesahujících několik písmen, jako např. v církevní slovanštině, dosud nebylo realizováno.
Unicode nebo Unicode?
„Unicode“ je jak vlastní jméno (nebo část názvu, např. Unicode Consortium), tak běžný název odvozený z angličtiny.
Na první pohled je vhodnější používat pravopis „Unicode“. V ruském jazyce již existují morfémy „uni-“ (slova s latinským prvkem „uni-“ se tradičně překládala a psala prostřednictvím „uni-“: univerzální, unipolární, sjednocení, uniforma) a „kód“. Proti, ochranné známky, převzaté z anglického jazyka, jsou obvykle přenášeny pomocí praktické transkripce, ve které je deetymologizovaná kombinace písmen "uni-" napsána ve tvaru "uni-" ("Unilever", "Unix" atd.) , tedy stejným způsobem jako v případě akronymů typu písmeno po písmenu jako UNICEF „United Nations International Children's Emergency Fund“ - UNICEF.
Pravopis „Unicode“ již pevně vstoupil do ruskojazyčných textů. Wikipedia používá běžnější verzi. Na MS Windows se používá možnost Unicode.
Na webu Konsorcia existuje speciální stránka, kde se řeší problémy s převodem slova „Unicode“ do různé jazyky a systémy psaní. Pro ruskou azbuku je určena volba "Unicode".
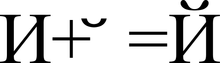
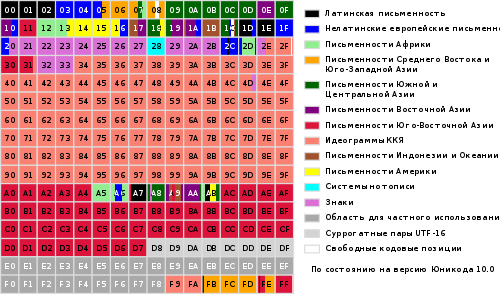
Problémy spojené s kódováním obvykle řeší software, takže při používání kódování obvykle nejsou žádné potíže. Pokud nastanou potíže, jsou obvykle generovány špatnými programy - klidně je pošlete do koše.
Vyzývám všechny, aby se vyjádřili
Co je kódování
V ruštině se „znaková sada“ také nazývá tabulka „znaková sada“ a proces použití této tabulky k převodu informací z počítačové reprezentace do lidské a charakteristika textového souboru, která odráží použití určitého systému kódů v něm při zobrazování textu.
Jak je text kódován
Soubor symbolů používaných při psaní textu je v počítačové terminologii označován jako abeceda; počet symbolů v abecedě se obvykle nazývá jeho síla. Pro znázornění textové informace v počítači se nejčastěji používá abeceda s kapacitou 256 znaků. Jeden z jeho znaků nese 8 bitů informace, proto binární kód každého znaku zabírá 1 bajt paměti počítače. Všechny znaky takové abecedy jsou číslovány od 0 do 255 a každé číslo odpovídá 8bitovému binárnímu kódu, což je pořadové číslo znaku v binární číselné soustavě – od 00000000 do 11111111. Pouze prvních 128 znaků s čísla od nuly ( binární kód 00000000) do 127 (01111111). Patří mezi ně malá písmena a velká písmena Latinská abeceda, čísla, interpunkční znaménka, závorky atd. Zbývajících 128 kódů, počínaje 128 (binární kód 10000000) a konče 255 (11111111), se používá ke kódování písmen národních abeced, oficiálních a vědeckých symbolů.
Typy kódování
Nejznámější kódovací tabulkou je ASCII (American Standard Code for Information Interchange). Původně byl vyvinut pro přenos textů telegrafem a v té době byl 7bitový, to znamená, že ke kódování anglických znaků, obslužných a řídicích znaků bylo použito pouze 128 sedmibitových kombinací. V tomto případě prvních 32 kombinací (kódů) sloužilo ke kódování řídicích signálů (začátek textu, konec řádku, návrat vozíku, volání, konec textu atd.). Při vývoji prvních počítačů IBM byl tento kód použit k reprezentaci symbolů v počítači. Protože v zdrojový kód ASCII měl pouze 128 znaků, pro jejich kódování stačily bytové hodnoty s 8. bitem rovným 0. Bytové hodnoty s 8. bitem rovným 1 se začaly používat k reprezentaci pseudografických znaků, matematických znaků a některých znaků z jiných jazyků než angličtiny (řečtina, německé přehlásky, francouzská diakritika atd.). Když začali přizpůsobovat počítače pro jiné země a jazyky, nebylo již dost místa pro nové symboly. Aby společnost IBM plně podporovala jiné jazyky než angličtinu, zavedla několik tabulek kódů pro jednotlivé země. Takže pro skandinávské země byla navržena tabulka 865 (severská), pro arabské země - tabulka 864 (arabština), pro Izrael - tabulka 862 (Izrael) a tak dále. V těchto tabulkách byly některé kódy z druhé poloviny kódové tabulky použity k reprezentaci znaků národních abeced (vyloučením některých pseudografických znaků). Zvláštním způsobem se vyvíjela situace s ruským jazykem. Je zřejmé, že nahrazení znaků ve druhé polovině kódové tabulky lze provést různé způsoby... Pro ruský jazyk se tedy objevilo několik různých tabulek kódování znaků azbuky: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Všechny znázorňují symboly první poloviny tabulky stejným způsobem (od 0 do 127) a liší se zastoupením symbolů ruské abecedy a pseudografiky. U jazyků, jako je čínština nebo japonština, 256 znaků obecně nestačí. Kromě toho je vždy problém s výstupem nebo uložením textů do jednoho souboru ve stejnou dobu různé jazyky(například při citaci). Proto univerzální tabulka kódů UNICODE, obsahující symboly používané v jazycích všech národů světa, dále různé servisní a pomocné symboly (interpunkční znaménka, matematické a technické symboly, šipky, diakritika atd.). Je zřejmé, že jeden bajt k zakódování tak velkého počtu znaků nestačí. Proto UNICODE používá 16bitové (2bajtové) kódy k reprezentaci 65 536 znaků. Dodnes bylo použito asi 49 000 kódů (poslední významnou změnou bylo zavedení symbolu měny EURO v září 1998). Kvůli kompatibilitě s předchozími kódováními je prvních 256 kódů stejných jako ve standardu ASCII. Ve standardu UNICODE, kromě specifického binární kód(tyto kódy jsou obvykle označeny písmenem U, následovaným znaménkem + a skutečným kódem v hexadecimálním zobrazení) každému znaku je přiřazeno specifické jméno. Další součástí standardu UNICODE jsou algoritmy pro převod kódů UNICODE jedna ku jedné v posloupnosti bajtů proměnné délky. Potřeba takových algoritmů je způsobena skutečností, že ne všechny aplikace jsou schopny pracovat s UNICODE. Některé aplikace rozumí pouze 7bitovým ASCII kódům, jiné aplikace 8bitovým ASCII kódům. Takové aplikace používají takzvané rozšířené kódy ASCII k reprezentaci znaků, které se nevejdou do sady 128 nebo 256 znaků, pokud jsou znaky kódovány bajtovými řetězci s proměnnou délkou. UTF-7 se používá k reverzibilnímu převodu kódů UNICODE na rozšířené 7bitové kódy ASCII a UTF-8 se používá k reverzibilnímu převodu kódů UNICODE na rozšířené 8bitové kódy ASCII. Všimněte si, že jak ASCII, tak UNICODE a další standardy kódování znaků nedefinují obrázky znaků, ale pouze složení znakové sady a způsob, jakým je reprezentována v počítači. Kromě toho (což nemusí být hned zřejmé) je velmi důležité pořadí výčtu znaků v sadě, protože nejvíce ovlivňuje třídicí algoritmy. Je to tabulka korespondence symbolů z určité množiny (řekněme symboly používané k reprezentaci informací na anglický jazyk, nebo v různých jazycích, jako v případě UNICODE) a označují se termínem tabulka kódování znaků nebo znaková sada. Každé standardní kódování má název, například KOI8-R, ISO_8859-1, ASCII. Bohužel neexistuje žádný standard pro kódování jmen.
Běžná kódování
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP852, CP85, CP852, CP85 CP861, CP863, CP865, CP866, CP869 Microsoft kódování Windows: o Windows-1250 pro středoevropské jazyky, které používají latinská písmena o Windows-1251 pro azbuku o Windows-1252 pro západní jazyky o Windows-1253 pro řečtinu o Windows-1254 pro turečtinu o Windows-1255 pro hebrejštinu o Windows-1256 pro arabštinu o Windows-1257 pro baltské jazyky o Windows-1258 pro vietnamštinu MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 bulharské kódování ISCII VISCII Big5 (nejznámější verze Microsoft CP950 ) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS pro japonštinu (Microsoft CP932) EUC-KR pro korejštinu (Microsoft CP949) ISO-2022 a EUC pro čínské psaní UTF-168 a UTF-168 kódování znaků UnicodeV kódovacím systému ASCII(American Standard Code for Information Interchange) každý znak je reprezentován jedním bajtem, který může kódovat 256 znaků.
ASCII má dvě kódovací tabulky – základní a rozšířenou. Základní tabulka fixuje hodnoty kódů od 0 do 127 a rozšířená se týká znaků s čísly od 128 do 255. To stačí k vyjádření různých kombinací osmi bitů všech znaků anglického a ruského jazyka. , a to jak malá, tak velká písmena, stejně jako interpunkční znaménka, symboly pro základní aritmetické operace a běžné speciální symboly, které lze na klávesnici pozorovat.
Prvních 32 kódů základní tabulky, počínaje nulou, je přiděleno výrobcům hardwaru (především výrobcům počítačů a tiskových zařízení). Tato oblast obsahuje tzv. řídicí kódy, které neodpovídají žádným jazykovým znakům, a proto se tyto kódy nezobrazují ani na obrazovce, ani na tiskových zařízeních, ale lze je řídit, jak se vydávají další data. Počínaje kódem 32 až po kód 127 jsou umístěny symboly anglické abecedy, interpunkční znaménka, čísla, aritmetické operace a pomocné symboly, všechny lze vidět na latinské části klávesnice počítače.
Druhá, rozšířená část je věnována národním kódovacím systémům. Na světě existuje mnoho nelatinských abeced (arabské, hebrejské, řecké atd.), včetně azbuky. Také rozložení klávesnice v němčině, francouzštině a španělštině se liší od anglického.
Anglická část klávesnice měla dříve mnoho standardů, ale nyní byly všechny nahrazeny jediným kódem ASCII. Pro ruskou klávesnici také existovalo mnoho norem: GOST, GOST-alternativa, ISO (International Standard Organization - International Institute for Standardization), ale tyto tři normy ve skutečnosti vymřely, i když se mohou někde setkat, v některých předpotopních počítačích nebo v počítačové sítě.
Hlavní znak kódování ruského jazyka, který se používá v počítačích s operačním systém Windows volala Windows-1251, byl vyvinut pro azbuku společností Microsoft. Přirozeně je naprostá většina počítačových textových dat zakódována ve Windows-1251. Mimochodem, kódování s jiným čtyřmístným číslem vyvinul Microsoft pro další běžné abecedy: arabskou, japonskou a další.
Další běžné kódování je tzv KOI-8(kód výměny informací, osmimístný) - jeho vznik sahá do dob Rady vzájemné hospodářské pomoci východoevropských států. Dnes je kódování KOI-8 rozšířeno v počítačových sítích na území Ruska a v ruském sektoru internetu. Stává se, že některý text dopisu nebo něco jiného není čitelné, což znamená, že musíte přejít z KOI-8 na Windows-1251. deset
V 90. letech se největší výrobci softwaru: Microsoft, Borland, stejný Adobe rozhodli pro potřebu vyvinout jiný systém kódování textu, ve kterém bude každému znaku přidělen ne 1, ale 2 bajty. Dostala jméno Unicode a je možné zakódovat 65 536 znaků tohoto pole, což stačí na to, aby se vešlo do jedné tabulky národních abeced pro všechny jazyky planety. Většinu Unicode (asi 70 %) zabírají čínské znaky, v Indii existuje 11 různých národních abeced, existuje mnoho exotických jmen, např.: písmo kanadských domorodců.
Protože kódování každého znaku v Unicode není přiděleno 8, ale 16 bitů, je velikost textového souboru dvojnásobná. To bylo kdysi překážkou pro zavedení 16bitového systému. a nyní s gigabajtovými pevnými disky, stovkami megabajtů RAM, gigahertzovými procesory, zdvojnásobením objemu textových souborů, které ve srovnání např. s grafikou zabírají velmi málo místa, je vlastně jedno.
Abeceda cyrilice v Unicode má hodnoty od 768 do 923 (základní znaky) a od 924 do 1023 (rozšířená azbuka, různá méně běžná národní písmena). Pokud program není přizpůsoben pro azbuku Unicode, pak je možné, že textové znaky nebudou rozpoznány jako azbuka, ale jako rozšířená latinka (kódy 256 až 511). A v tomto případě se na obrazovce místo textu objeví nesmyslná sada různých exotických symbolů.
To je možné, pokud je program zastaralý, vytvořený před rokem 1995. Nebo vzácný, o kterém se nikdo neobtěžoval rusifikovat. Je také možné, že operační systém Windows nainstalovaný v počítači není plně nakonfigurován pro azbuku. V takovém případě musíte provést příslušné záznamy v registru.
 Architektura distribuovaného řídicího systému založeného na rekonfigurovatelném multi-pipeline výpočetním prostředí L-Net „transparentní“ distribuované systémy souborů
Architektura distribuovaného řídicího systému založeného na rekonfigurovatelném multi-pipeline výpočetním prostředí L-Net „transparentní“ distribuované systémy souborů Stránka pro odesílání e-mailů Vyplňte soubor relay_recipients adresami z Active Directory
Stránka pro odesílání e-mailů Vyplňte soubor relay_recipients adresami z Active Directory Chybějící jazyková lišta ve Windows - co dělat?
Chybějící jazyková lišta ve Windows - co dělat?