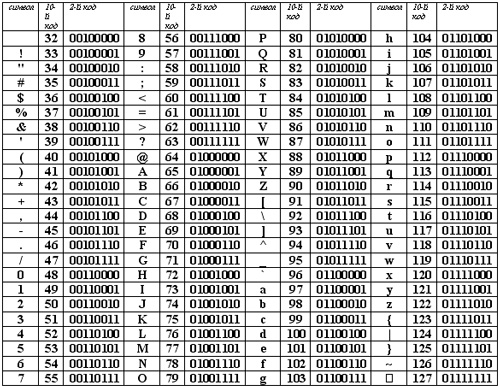
Kódy znaků Ascii 1251
Datové nosiče
Data jsou dialektická složka informace. Představují zaznamenané signály. Fyzikální způsob registrace může být v tomto případě jakýkoli: mechanický pohyb fyzických těles, změna jejich tvaru nebo parametrů kvality povrchu, změna elektrických, magnetických, optických charakteristik, chemického složení a (nebo) povahy chemických vazeb, změna ve stavu elektronického systému a mnoho dalšího.
Podle způsobu registrace mohou být data ukládána a přenášena na různých typech médií. Nejběžnějším paměťovým médiem, i když ne nejekonomičtějším, se zdá být papír. Na papíře se data zaznamenávají změnou optických charakteristik jeho povrchu. Změna optických vlastností (změna koeficientu odrazu povrchu v určitém rozsahu vlnových délek) se využívá i u zařízení, která zaznamenávají laserovým paprskem na plastová média s reflexním povlakem ( CD ROM). Jako média využívající změny magnetických vlastností lze uvést magnetické pásky a disky. Registrace dat změnou chemického složení povrchových látek nosiče je široce používána ve fotografii. Na biochemické úrovni se data shromažďují a přenášejí v živé přírodě.
Datové nosiče nás nezajímají samy o sobě, ale pokud vlastnosti informace velmi úzce souvisejí s vlastnostmi jejích nosičů. Parametrem lze charakterizovat jakýkoli nosič řešení(množství dat zaznamenaných v měrné jednotce akceptované pro média) a dynamický rozsah(logaritmický poměr intenzity amplitud maximálního a minimálního zaznamenaného signálu). Takové vlastnosti informací, jako je úplnost, dostupnost a spolehlivost, často závisí na těchto vlastnostech média. Můžeme tedy například počítat s tím, že v databázi umístěné na CD je snazší zajistit úplnost informací než v databázi podobného účelu umístěné na disketě, jelikož v prvním případě hustota záznamu dat na jednotku délky stopy je mnohem vyšší. Pro běžného spotřebitele je dostupnost informací v knize znatelně vyšší než u stejných informací na CD, protože ne všichni spotřebitelé mají potřebné vybavení. A konečně je známo, že vizuální efekt při prohlížení diapozitivu v projektoru je mnohem větší než při prohlížení podobné ilustrace vytištěné na papíře, protože rozsah jasových signálů v procházejícím světle je o dva až tři řády větší než v odraženém světlo.
Úkol transformace dat za účelem změny média je jedním z nejdůležitějších úkolů informatiky. Ve struktuře nákladů na výpočetní systémy tvoří zařízení pro vstup a výstup dat, pracující s paměťovými médii, až polovinu nákladů na hardware.
^ Datové operace
Během informačního procesu se data převádějí z jednoho typu na jiný pomocí metod. Zpracování dat zahrnuje mnoho různých operací. S rozvojem vědeckého a technologického pokroku a obecnými komplikacemi vazeb v lidské společnosti neustále rostou mzdové náklady na zpracování dat. Především je to dáno neustálým komplikováním podmínek pro řízení výroby a společnosti. Druhý faktor, který rovněž způsobuje obecný nárůst objemu zpracovávaných dat, souvisí rovněž s vědeckotechnickým pokrokem, a to s rychlým tempem vzniku a zavádění nových datových nosičů, datových úložišť a doručovacích zařízení.
Ve struktuře možných operací s daty lze rozlišit tyto hlavní:
sběr dat - shromažďování údajů za účelem zajištění dostatečné úplnosti informací pro rozhodování;
formalizace dat - převádění dat pocházejících z různých zdrojů do stejné podoby, aby byla vzájemně srovnatelná, tj. aby se zvýšila jejich dostupnost;
filtrování dat - odfiltrování „zbytečných“ dat, která nejsou nezbytná pro rozhodování; zároveň by se měla snížit míra „šumu“ a zvýšit spolehlivost a přiměřenost dat;
řazení dat - uspořádání údajů podle daného kritéria za účelem snadnosti použití; zvyšuje dostupnost informací;
seskupení dat - kombinování dat na daném základě za účelem zlepšení použitelnosti; zvyšuje dostupnost informací;
archivace dat - organizace ukládání dat v pohodlné a snadno dostupné formě; slouží ke snížení ekonomických nákladů na ukládání dat a zvyšuje celkovou spolehlivost informačního procesu jako celku;
ochrana dat - soubor opatření, jejichž cílem je zabránit ztrátě, reprodukci a úpravě dat;
přenos dat - příjem a přenos (doručení a doručení) dat mezi vzdálenými účastníky informačního procesu; v tomto případě se obvykle nazývá zdroj dat v informatice server, a spotřebitel - klient;
transformace dat - přenos dat z jednoho formuláře do druhého nebo z jedné struktury do druhé. Převod dat často zahrnuje změnu typu média, například knihy lze uchovávat v klasické papírové podobě, ale lze k tomu využít jak elektronickou formu, tak mikrofilm. Potřeba vícenásobné transformace dat vzniká i při jejich přepravě, zejména pokud je prováděna prostředky, které nejsou určeny pro přepravu tohoto typu dat. Jako příklad lze uvést, že pro přenos digitálních datových toků po telefonních sítích (které byly zpočátku zaměřeny pouze na přenos analogové signály v úzkém frekvenčním rozsahu), je nutné převést digitální data na druh zvukové signály, což dělají speciální zařízení - telefonní modemy.
^ Binární kódování dat
Pro automatizaci práce s daty souvisejícími odlišné typy, je velmi důležité sjednotit jejich prezentační formu - k tomu se obvykle používá technika kódování, tedy vyjádření dat jednoho typu prostřednictvím dat jiného typu. Přirozený člověk jazyky - nejsou ničím jiným než pojmovými kódovacími systémy pro vyjádření myšlenek řečí. Jazyky spolu těsně sousedí ABC(systémy pro kódování jazykových komponent pomocí grafických symbolů). Historie zná zajímavé, i když neúspěšné pokusy o vytvoření „univerzálních“ jazyků a abeced. Neúspěch pokusů o jejich zavedení je zřejmě dán tím, že národní a sociální výchova přirozeně pochopit, že změna v systému kódování veřejných dat nevyhnutelně povede ke změně společenských metod (tedy norem práva a morálky), a to může být spojeno se společenskými otřesy.
Stejný problém univerzálního kódovacího nástroje je poměrně úspěšně implementován v určitých odvětvích techniky, vědy a kultury. Příklady zahrnují systém psaní pro matematické výrazy, telegrafní abecedu, abecedu námořních vlajek, systém Braillova písma pro nevidomé a mnoho dalšího.
Rýže. 1.8. Příklady různých kódovacích systémů
Systém existuje i ve výpočetní technice – je tzv binární kódování a je založen na reprezentaci dat posloupností pouze dvou znaků: 0 a 1. Tyto znaky se nazývají binární číslice, v angličtině - binární číslice, nebo ve zkratce bit (bit).
Jedním bitem lze vyjádřit dva pojmy: 0 nebo 1 (Ano nebo žádná černá nebo bílá, pravda nebo Ležící atd.). Pokud se počet bitů zvýší na dva, lze již vyjádřit čtyři různé koncepty:
Tři bity mohou kódovat osm různých hodnot:
000 001 010 01 l 100 101 110 111
Zvýšení počtu číslic v systému o jednu binární kódování, zdvojnásobíme počet hodnot, které lze v tomto systému vyjádřit.
^ Kódování celých a reálných čísel
Pro kódování celých čísel od 0 do 255 stačí mít 8 bitů binárního kódu (8 bitů).
0000 0000 = 0
…………………
1111 1110 = 254
1111 1111 = 255
Šestnáct bitů umožňuje kódovat celá čísla od 0 do 65535 a 24 bitů již více než 16,5 milionů různých hodnot.
Pro kódování reálných čísel se používá 80bitové kódování. V tomto případě je číslo předběžně převedeno na normalizovaná forma:
3,1415926 = 0,31415926 10 1
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 9
První část čísla je volána mantisa, a ten druhý je charakteristický. Většina z 80 bitů je přidělena pro uložení mantisy (spolu se znaménkem) a určitý pevný počet bitů je přidělen pro uložení charakteristiky (také se znaménkem).
^ Kódování textových dat
Pokud je každému znaku abecedy přiřazeno určité celé číslo (například sériové číslo), pak pomocí binárního kódu můžete kódovat textové informace. Osm binárních číslic stačí pro 256 kódování různé postavy... To stačí k tomu, abychom různými kombinacemi osmi bitů vyjádřili všechny znaky anglické a ruské abecedy, malá i velká, stejně jako interpunkční znaménka, symboly základních aritmetických operací a některé obecně uznávané Speciální symboly, například znak "§".
Technicky to vypadá velmi jednoduše, ale vždy se vyskytly poměrně závažné organizační potíže. V prvních letech rozvoje výpočetní techniky byly spojeny s nedostatkem potřebných norem a nyní jsou naopak způsobeny nadbytkem současně fungujících a protichůdných norem. Aby celý svět rovnoměrně kódoval textová data, jsou potřeba jednotné kódovací tabulky, a to je stále nemožné kvůli rozporům mezi symboly národních abeced a také firemním rozporům.
Pro anglického jazyka, který zachytil de facto niku mezinárodních komunikačních prostředků, byly rozpory již odstraněny. Americký institut pro standardizaci (ANSI – American National Standard Institute) zavést kódovací systém ASCII (Americký standardní kód pro výměnu informací). V systému ASCII opraveny dvě kódovací tabulky: základní a prodloužený. Základní tabulka fixuje hodnoty kódů od 0 do 127 a rozšířená tabulka odkazuje na znaky s čísly od 128 do 255.
Prvních 32 kódů základní tabulky, počínaje nulou, je přiděleno výrobcům hardwaru (především výrobcům počítačů a tiskových zařízení). V této oblasti se nacházejí tzv kontrolní kódy, které neodpovídají žádným znakům jazyků, a proto se tyto kódy nezobrazují ani na obrazovce, ani na tiskových zařízeních, ale lze je řídit tím, jak se vydávají jiná data.
Počínaje kódem 32 až po kód 127 jsou umístěny kódy znaků anglické abecedy, interpunkční znaménka, čísla, aritmetické operace a některé pomocné symboly. Základní kódovací tabulka ASCII je uveden v tabulce 1.1.
^ Tabulka 1.1. Základní kódovací tabulka ASCII
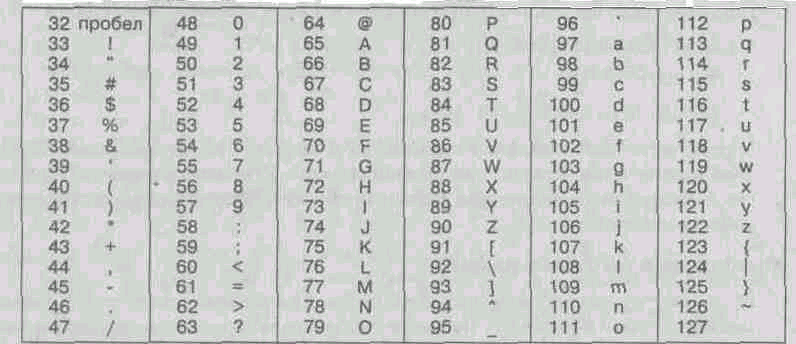
Podobné systémy pro kódování textových dat byly vyvinuty v jiných zemích. Takže například v SSSR v této oblasti fungoval kódovací systém KOI-7 (kód komunikace, sedmimístný). Podpora výrobců hardwaru a softwaru však přinesla americký kód ASCII na úroveň mezinárodního standardu a národní kódovací systémy musely „ustoupit“ do druhé, rozšířené části kódovacího systému, která určuje hodnoty kódů od 128 do 255. Neexistence jednotného standardu v této oblasti vedl k množství současně pracujících kódování. Pouze v Rusku můžete zadat tři aktuální standardy kódování a dva další zastaralé.
Takže například kódování znaků ruského jazyka, známé jako kódování Windows-1251, byl představen „zvenčí“ – společností Microsoft, ale vzhledem k široké distribuci operačních systémů a dalších produktů této společnosti v Rusku je hluboce zakořeněný a rozšířený (tabulka 1.2). Toto kódování používá většina místní počítače běžící na platformě Windows. De facto se stal standardem v ruském sektoru World Wide Web.
^ Tabulka 1.2. Kódování Windows 1251
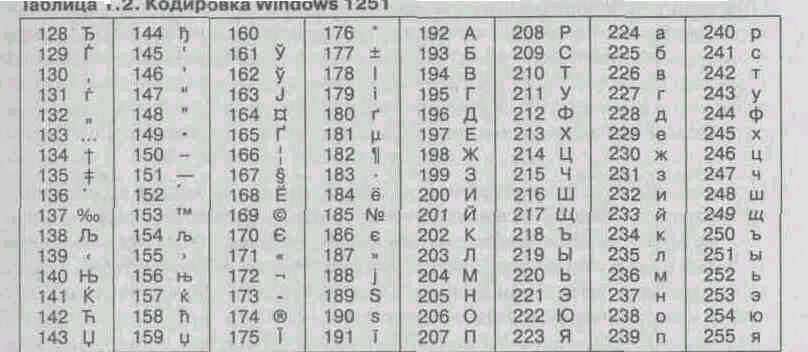
Další běžné kódování se nazývá KOI-8 (komunikační kód, osm číslic) - její vznik sahá do dob Rady vzájemné hospodářské pomoci států východní Evropy (tabulka 1.3). Na základě tohoto kódování jsou aktuálně platná kódování KOI8-R (ruština) a KOI8-U (ukrajinská). Dnes je kódování KOI8-R široce používáno v počítačových sítích na území Ruska a v některých službách ruského sektoru internetu. Zejména v Rusku je to ve zprávách de facto standard E-mailem a telekonference.
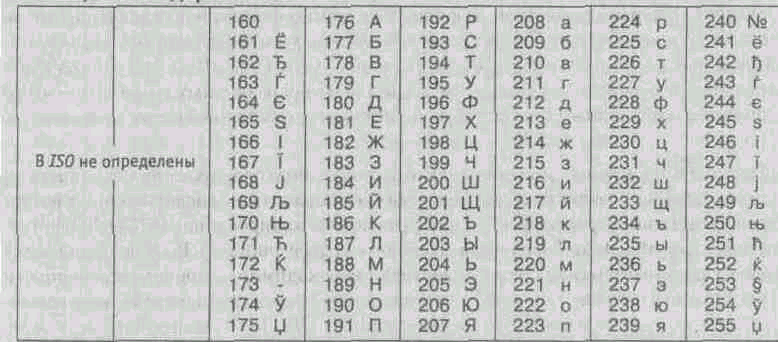
Mezinárodní standard, který zajišťuje kódování znaků ruské abecedy, se nazývá kódování ISO. (International Standard Organization - International Institute for Standardization). V praxi se toto kódování používá zřídka (tabulka 1.4).
^ Tabulka 1.3. Kódování KOI-8
![]()
Tabulka 1.4. ISO kódování
Na běžících počítačích operační systémy MS-DOS, mohou fungovat další dvě kódování (kódování GOST a kódování GOST-alternativní). První z nich byl považován za zastaralý již v prvních letech vzniku osobních počítačů, ale druhý se používá dodnes (viz tabulka 1.5).
^ Tabulka 1.5. Alternativní kódování GOST
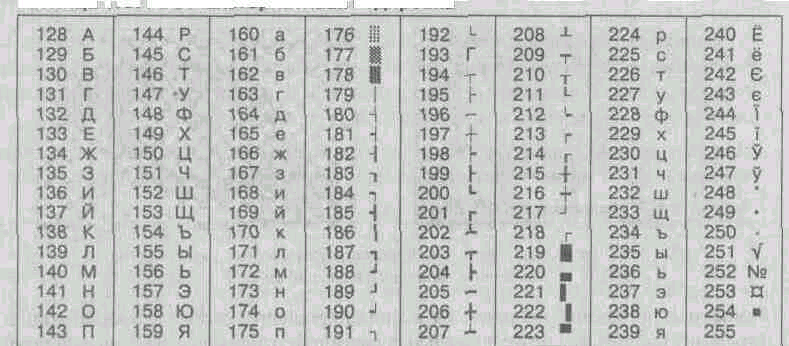
V souvislosti s množstvím systémů kódování textových dat fungujících v Rusku vyvstává problém mezisystémové transformace dat - to je jeden z běžných úkolů informatiky.
^ Univerzální systém kódování textových dat
Pokud analyzujeme organizační potíže spojené s vytvořením jednotného systému kódování textových dat, pak můžeme dojít k závěru, že jsou způsobeny omezeným souborem kódů (256). Zároveň je zřejmé, že pokud například znaky nebudou kódovány osmibitovými binárními čísly, ale čísly s velkým počtem číslic, rozsah možných hodnot kódů bude mnohem větší. Takový systém založený na 16bitovém kódování znaků se nazývá univerzální - UNICODE.Šestnáct číslic vám umožní poskytnout unikátní kódy pro 65536 různých znaků - toto pole je dostatečné pro umístění většiny jazyků planety v jedné tabulce znaků.
Přes triviální samozřejmost tohoto přístupu byl jednoduchý mechanický přechod na tento systém dlouhou dobu zdržen kvůli nedostatečným zdrojům výpočetní techniky (v kódovacím systému UNICODE všechny textové dokumenty se automaticky zdvojnásobí). V druhé polovině 90. let technické prostředky dosáhly požadované úrovně dostupnosti zdrojů a dnes jsme svědky postupného přesunu dokumentů a softwaru do univerzálního kódovacího systému. Pro jednotlivé uživatele to přineslo ještě více starostí s koordinací dokumentů zpracovávaných v různé systémy kódování, s pomocí softwaru, ale to je třeba chápat jako potíže přechodného období.
^ Kódování grafických dat
Pokud si lupou prohlédnete černobílý grafický obrázek vytištěný v novinách nebo knize, uvidíte, že se skládá z nejmenších bodů, které tvoří charakteristický vzor tzv. rastr(obr. 1.9).

Rýže. 1.9. Rastr je metoda kódování grafických informací, která je již dlouho přijata v polygrafickém průmyslu.
Vzhledem k tomu, že lineární souřadnice a jednotlivé vlastnosti každého bodu (jas) lze vyjádřit pomocí celých čísel, lze říci, že bitmapové kódování umožňuje použití binárního kódu pro reprezentaci grafických dat. Dnes je obecně přijímáno představovat černobílé ilustrace jako kombinaci bodů s 256 odstíny šedi, a proto osmibitové binární číslo obvykle postačuje pro zakódování jasu libovolného bodu.
Pro kódování barvy grafické obrázky aplikovaný princip rozkladu libovolnou barvu do hlavních komponent. Jako takové komponenty se používají tři základní barvy: červená (červená, R), zelená (zelená, G) a modrá (Modrá, B). V praxi se má za to (ačkoli to teoreticky není úplně pravda), že jakoukoli barvu viditelnou lidským okem lze získat mechanickým smícháním těchto tří základních barev. Takový kódovací systém se nazývá systém RGB podle prvních písmen názvů základních barev.
Pokud pro zakódování jasu každé z hlavních komponent použijete 256 hodnot (osm binárních bitů), jak je zvykem u černobílých obrázků ve stupních šedi, pak je pro zakódování barvy jednoho bodu potřeba 24 bitů. Kódovací systém přitom poskytuje jednoznačnou definici 16,5 milionů různých barev, což se vlastně blíží citlivosti lidského oka. Nazývá se režim zobrazování barevné grafiky pomocí 24 bitů plná barva (True Color).
Každé z primárních barev lze přiřadit doplňkovou barvu, tedy barvu, která doplňuje primární barvu k bílé. Je snadné vidět, že pro kteroukoli ze základních barev bude doplňková barva součtem dvojice dalších primárních barev. V souladu s tím jsou doplňkové barvy: modrá (azurová, C), nachový (purpurová, M) a žlutá ( Žlutá, Y). Princip rozkladu libovolné barvy na komponentní složky lze uplatnit nejen pro základní barvy, ale i pro doplňkové, to znamená, že jakákoliv barva může být reprezentována jako součet azurové, purpurové a žluté složky. Tento způsob barevného kódování se ujal v polygrafickém průmyslu, ale v polygrafickém průmyslu se používá i čtvrtý inkoust – černý. (Černý, K). Proto tento systém kódování je označeno čtyřmi písmeny CMYK(černá barva je označena písmenem NA, protože dopis PROTI již obsazeno v modré barvě) a k reprezentaci barevné grafiky v tomto systému musíte mít 32 bitů. Tento režim se také nazývá plná barva (True Color).
Pokud snížíte počet bitů použitých ke kódování barvy každého bodu, můžete snížit množství dat, ale rozsah kódovaných barev se výrazně zmenší. Kódování barevné grafiky pomocí 16bitových binárních čísel se nazývá režim Vysoká barva.
Když je barevná informace zakódována pomocí osmi datových bitů, lze přenést pouze 256 barevných odstínů. Tato metoda barevného kódování se nazývá index. Význam názvu je v tom, že vzhledem k tomu, že 256 hodnot je zcela nedostačujících k přenosu celé škály barev dostupných lidskému oku, nevyjadřuje kód každého rastrového bodu barvu samotnou, ale pouze její počet. (index) v nějaké vyhledávací tabulce tzv paleta. Tuto paletu je samozřejmě nutné aplikovat na grafická data - bez ní nelze použít způsoby zobrazování informací na obrazovce nebo papíru (tedy ji samozřejmě použít můžete, ale kvůli neúplnosti dat se obdržené informace nebudou dostatečné: listy na stromech mohou být červené a obloha zelená).
^ Zvukové kódování
Techniky a metody pro práci se zvukovou informací se do výpočetní techniky dostaly nejnověji. Na rozdíl od číselných, textových a grafických dat navíc zvukové nahrávky neměly stejně dlouhou a osvědčenou historii kódování. V důsledku toho jsou metody kódování zvukových informací binárním kódem daleko od standardizace. Mnoho jednotlivých společností vyvinulo své vlastní podnikové standardy.
Tvůrce webu vždy čelí problému: v jakém kódování vytvořit projekt. Rusky mluvící internet používá dvě kódování:
UTF-8(z angličtiny. Transformační formát Unicode) je v současnosti rozšířené kódování, které implementuje reprezentaci Unicode, která je kompatibilní s 8bitovým kódováním textu.
Windows-1251(nebo cp1251) - znaková sada a kódování, což je standardní 8bitové kódování pro všechny ruské verze systému Microsoft Windows.
UTF-8 je slibnější. Ale každá věc má své nevýhody. A rozhodnutí použít nějaký druh kódování jen proto, že je slibné, bez zohlednění mnoha dalších faktorů, se nezdá správné. Volba bude optimální pouze tehdy, když plně zohlední všechny nuance konkrétního projektu. Další věc je, že není snadné předvídat všechny nuance.
Domníváme se, že použití UTF-8 je vhodnější, ale je na vývojáři projektu, aby se rozhodl, který zvolit. A pro usnadnění této volby použijte srovnávací tabulku vlastností obou kódování.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Jak přeložit web z kódování win1251 do UTF-8
Obecný postup:
1. Překódujte celou databázi na UTF-8 (pravděpodobně budete muset požádat o pomoc administrátora serveru).
2. Překódujte všechny soubory webu v UTF-8 (můžete to udělat sami).
3. Přidejte řádky do souboru /bitrix/php_interface/dbconn.php:
4. Přidejte následující řádky do souboru /.htaccess:
Php_value mbstring.func_overload 2 php_value mbstring.internal_encoding UTF-8
Všechny soubory webu můžete překódovat na UTF-8 (druhá položka) spuštěním příkazu přes SSH v kořenové složce webu:
Nalézt. -name "* .php" -type f -exec iconv -fcp1251 -tutf8 -o / tmp / tmp_file () \; -exec mv / tmp / tmp_file () \;
Kódování Windows 1251 bylo vytvořeno na počátku 90. let pro rusifikaci softwarových produktů vyrobeno společností Microsoft Corporation:
Kódování je 8bitové a zahrnuje znaky ze slovanské skupiny jazyků, která zahrnuje ruštinu, běloruštinu, ukrajinštinu, bulharštinu, makedonštinu, srbštinu – to poskytuje výhodu oproti jiným kódováním azbuky ( ISO 8859-5, KOI8-R, CP866). Kódování 1251 má však také významné nevýhody:
- 0xFF (25510) je kód, který je vyhrazen pro znak "i". Programy, které nepodporují čistý 8. bit, mají často nepředvídatelné problémy;
- V KOI8, CP866 není přítomna žádná pseudo-grafika.
Níže jsou uvedeny symboly z kódové stránky 1251 nebo zkráceně CP1251 ( čísla pod znaky jsou hexadecimální kód stejného znaku Unicode):
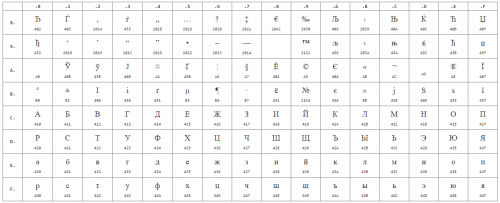
Často mají weboví vývojáři a blogeři s různou kvalifikací problém s kódováním stránek: místo připraveného textu se objevují neznámé, nečitelné znaky. Abychom se s tímto problémem vypořádali, je nutné pochopit podstatu pojmu „ kódování stránky».
Text v paměti počítače je uložen ve formě určitého počtu bajtů, nikoli ve formě, ve které je zobrazen v textový editor... Každý bajt je kód, který odpovídá jednomu znaku. Aby se text na stránce zobrazoval tak, jak má, musíte prohlížeči sdělit, jakou tabulku kódů má použít k dešifrování a zobrazení.
Kódovací tabulka není univerzální, to znamená, že k dešifrování textu musíte použít tu, která odpovídá kódování znaků:

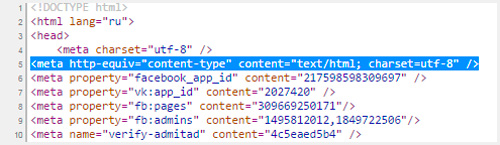
Aby se html dokument v prohlížeči zobrazil správně, musíte specifikovat použité kódování. To se provádí následovně:
Mezi štítkem
a zakrývá to potřeba se zaregistrovat - na základě tohoto řetězce prohlížeč použije znaky ruské abecedy pro zobrazení textu na stránce.Windows 1251 kódování v PHP
Pro nikoho není tajemstvím, že generování stránek probíhá vzorkováním a využitím nějaké části informací, které jsou uloženy v databázi. Při psaní webu v PHP je to nejčastěji mysql.
3 hlasyAhoj milí čtenáři mého blogu. Dnes s vámi budeme mluvit o kódování. Pokud jste četli můj článek o tom, jak víte, že žádný dokument na internetu není uložen ve formě, v jaké jsme zvyklí jej vídat. Je psána pomocí symbolů a znaků pro člověka nesrozumitelných. S textem je vše úplně stejné.
Existuje několik kódování, a proto někdy při otevírání knihy vidíte nepochopitelné znaky mobilní aplikace nebo nahráním článku na web, změnou některých hodnot v nastavení, uvidíte abecedu známou oku.

Kódování Windows-1251 – co to je, jakou hodnotu má při vytváření webu, jaké znaky budou dostupné a zda je nejlepší řešení dnes? To vše je v dnešním článku. Jako vždy, jednoduchý jazyk, co nejjasnější a s minimem podmínek.
Trochu teorie
Jakýkoli dokument v počítači nebo na internetu, jak jsem řekl, je uložen jako binární kód. Pokud například použijete kódování ASCII, písmeno „K“ se zapíše jako 10001010 a Windows 1251 pod tímto číslem skryje symbol - Љ. V důsledku toho, pokud prohlížeč nebo program přistupuje k jiné tabulce a čte místo ASCII Windows kódy 1251, pak čtenář uvidí pro něj zcela nepochopitelné symboly.
Otázka je logická, k čemu to bylo přijít se spoustou tabulek s kódy? Faktem je, že kromě ruské abecedy existuje také angličtina, němčina a čínština. Podle některých odhadů existuje asi 200 000 znaků. I když, vzhledem k japonštině, těmto statistikám moc nevěřím.
Nezapomeňte, že pro velká a malá písmena si musíte vymyslet vlastní kód, jsou tam čárky, pomlčky a tak dále.
Čím více symbolů je v tabulce, tím delší je kód každého z nich, a tím i hmotnost dokumentu.
Představte si, že by jedna kniha vážila 4 GB! Načíst, vzít vše by trvalo velmi dlouho volné místo na počítači. Rozhodnutí o stažení by bylo těžké.
Pokud přemýšlíte o webových stránkách, je obecně děsivé přemýšlet o tom, co by se stalo. Každá stránka se otevřela i na vysokorychlostním vláknu déle než hodinu! Myslet si, mobilní telefony mohl být bezpečně vyhozen. Používáte je na ulici i se 4G? Pochybuji.
Z těchto důvodů se každý programátor najednou snažil přijít s vlastní tabulkou symbolů. Aby bylo pohodlné použití a hmotnost byla udržována optimální.
Microsoft například vytvořil windows-1251 pro rusky mluvící segment. Určitě to má své výhody i nevýhody. Jako každý jiný produkt.
Nyní jsou pouze 2 % všech stránek na internetu napsána v 1251. Většina webmasterů používá UTF-8. proč tomu tak je?
Nevýhody a výhody
UTF-8 na rozdíl od univerzálního kódování windows-1251 obsahuje písmena různých abeced. Existuje dokonce UTF-128, kde jsou obecně všechny jazyky - teuluština, svahilština, laoština, maltština a tak dále.

UTF-8 je chudší, písmena zabírají mnohem méně místa a zabírají pouze jeden bajt paměti, jako v 1251. UTP obsahuje vzácné znaky z jiných jazyků nebo speciální znaky. Váží 5-6 bajtů, ale v dokumentu se používají jen zřídka.
Toto kódování je promyšlenější, a proto jej většina aplikací standardně používá. To znamená, že pokud programu neřeknete, jaké kódování používáte, pak první věc, kterou zkontroluje, je UTF-8.
Když vytvoříte html dokument pro web, sdělíte prohlížečům, na kterou tabulku se mají při dešifrování záznamů dívat.
Chcete-li to provést, musíte do tagu head vložit následující údaje. Za znaky "charset =" následuje buď UTF nebo Windows, jako v příkladu níže.
| <meta http-equiv = obsah typu "Content-Type" = "text / html; znaková sada = windows-1251"> |
Pokud v budoucnu budete chtít něco změnit a vložit frázi v albánštině pomocí této dešifrovací tabulky, pak nebude fungovat nic, protože kódování tento jazyk nepodporuje. UTF - 8 vám to umožní bez problémů.
Pokud máte zájem o správnou tvorbu stránek, pak vám mohu doporučit kurz Michaila Rusakova “ Tvorba a propagace webu od A do Z ».

Obsahuje hodně - 256 lekcí, dotykové, JavaScript a XML. Kromě programovacích jazyků budete schopni porozumět tomu, jak zpeněžit web, to znamená získat větší zisk rychleji a více. Jeden z mála kurzů, který by tak podrobně vysvětlil vše potřebné.
Já sám studuji již rok ve škole bloggerů Alexandra Borisova ... Trvá to mnohonásobně více času, konec a hrana zatím není vidět, ale není o nic méně vyčerpávající a ukázněná. Motivuje k dalšímu rozvoji.
Pokud máte dotazy, nemusíte hledat na internetu. Vždy existuje kompetentní mentor.

Něco jsem odbočil od tématu. Vraťme se ke kódování.
Bath databáze
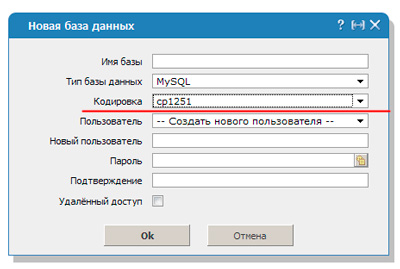
Pokud jde o php, všechno je děsivé. O databázích jsem již mluvil, slouží ke zrychlení práce webu. Obvykle je nekontaktujete, ale když je potřeba web převést, je to nepříjemné.
Potíže se stávají každému, bez ohledu na to, jaké máte pracovní zkušenosti, délku služby a délku služby. Některé stránky v databázi mohou obsahovat všechny dostupné symboly pro Windows-1251, jiné například v šablonách stránek v jiném kódování.
Dokud není potřeba přenos, vše funguje a funguje, i když ne zcela správně. Po přestěhování ale začnou potíže. V ideálním případě byste měli používat buď pouze UTF nebo Windows-1251, ale ve skutečnosti má každý vždy takové nedostatky.
Aby bylo dešifrování konzistentní, musíte zadat kód mysql_query ("SET NAMES cp1251"). V tomto případě bude konverze provedena pomocí jiného protokolu - cp1251.
Htaccess
Pokud se trvale rozhodnete používat 1251 na webu, měli byste najít nebo vytvořit soubor htaccess. Je zodpovědný za nastavení konfigurace. K tomu budete muset přidat další tři řádky, aby vše do sebe zapadalo.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset "cp1251"
Přesto velmi doporučuji zvážit použití UTF-8. Je oblíbenější, jednodušší a bohatší. Ať už nyní uděláte jakákoliv rozhodnutí, je důležité, abyste mohli vše napravit později. Bude mnohem snazší přidat anglickou verzi webu pomocí tohoto kódování. Nic není třeba opravovat.
Rozhodnutí je na vás. Přihlaste se k odběru newsletteru, abyste co nejrychleji zjistili, kde studovat, abyste neopakovali cizí chyby, a také to, kteří blogeři mají největší návštěvnost.
Do příště a hodně štěstí ve vašem snažení.
 Příklady funkce jQuery setTimeout () Javascript zabraňuje spuštění více časovačů setinterval současně
Příklady funkce jQuery setTimeout () Javascript zabraňuje spuštění více časovačů setinterval současně DIY amatérské rádiové obvody a domácí výrobky
DIY amatérské rádiové obvody a domácí výrobky Oříznutí jednořádkového nebo víceřádkového textu na výšku s přidáním elips Přidání přechodu k textu
Oříznutí jednořádkového nebo víceřádkového textu na výšku s přidáním elips Přidání přechodu k textu