Kolik bitů je v kódování unicode. Jednotky měření objemu dat a kapacity paměti: kilobajty, megabajty, gigabajty…. Standard kódování znaků Unicode
Informační kódování
Jakákoli čísla (v rámci určitých limitů) v paměti počítače jsou kódována čísly v binární číselné soustavě. Na to jsou jednoduchá a jasná pravidla překladu. V dnešní době je však počítač využíván mnohem šířeji než v roli vykonavatele pracně náročných výpočtů. Například v paměti počítače jsou uloženy textové a multimediální informace. Proto vyvstává první otázka:
Každý znak je kódován od 1 do 4 bajtů. Náhradní znaky mají 4 bajty, a proto vyžadují další úložiště. Každý znak je zakódován minimálně 4 bajty. Případně můžete použít převodní nástroj pro automatický převod. Jak již bylo řečeno, jde o standard, který Američanům dobře vyhovuje. Pohybuje se od 0 do 127, přičemž prvních 32 a poslední jsou považovány za ovládací prvky, zbytek jsou „tištěné znaky“, tedy uznávané lidmi. Může být reprezentován pouze 7 bity, i když se obvykle používá jeden bajt.
Jak se ukládají znaky (písmena) do paměti počítače?
Každé písmeno patří do určité abecedy, ve které znaky následují za sebou, a proto mohou být číslovány po sobě jdoucími celými čísly. Každé písmeno může být spojeno s kladným celým číslem a nazývá se kód znaku... Právě tento kód se uloží do paměti počítače a po zobrazení na obrazovce nebo na papíře se „převede“ na svůj odpovídající znak. Chcete-li odlišit reprezentaci čísel od reprezentace znaků v paměti počítače, musíte také uložit informace o tom, která data jsou zakódována v konkrétní oblasti paměti.
V závislosti na kontextu a dokonce i době to znamená něco jiného. Záleží tedy na tom, o čem mluvíte. Znamená to málo o samotě. Existují některá kódování, která používají tuto zkratku. Jsou velmi složité a téměř nikdo neví, jak správně využít jejich plnost, včetně mě.
Ale ne s jiným systémem kódování znaků. Toto je nejúplnější a nejkomplexnější kódování, které existuje. Někteří jsou do ní zamilovaní a jiní ji nenávidí, ačkoli uznávají její užitečnost. Pro člověka je to těžké pochopit, ale pro počítač je to těžké řešit.
Korespondence písmen určité abecedy s čísly-kódy tvoří t. zv kódovací tabulka... Jinými slovy, každý znak konkrétní abecedy má svůj vlastní číselný kód v souladu se specifickou kódovací tabulkou.
Na světě je však spousta abeced (anglická, ruská, čínská atd.). Takže další otázka zní:
Existuje srovnání mezi těmito dvěma. Je standardem pro prezentaci textů vytvořených konsorciem. Mezi jím stanovené normy patří některá kódování. Ale ve skutečnosti to znamená mnohem víc. Článek, který by si měl přečíst každý, i když nesouhlasí se vším, co má.
Podporované znakové sady jsou rozděleny do rovin. Tyto dva počítače používají různé operační systémy; totéž se děje se znakovou sadou, strukturou a formát souboru které se obvykle liší. Komunikace přes řídicí spojení.
Jak zakódovat všechny abecedy používané v počítači?
Abychom na tuto otázku odpověděli, vydáme se historickou cestou.
V 60. letech XX století v Americký národní institut pro normalizaci (ANSI) byla vyvinuta tabulka kódování znaků, která byla následně použita ve všech operačních systémech. Tato tabulka se nazývá ASCII (Americký standardní kód pro výměnu informací)... O něco později se objevil rozšířená verze ASCII.
Komunikace probíhá prostřednictvím sekvence příkazů a reakcí. Tato jednoduchá metoda je vhodná pro řídicí spojení, protože můžeme posílat jeden příkaz najednou. Každý příkaz nebo odpověď zahrnuje jeden řádek, takže se nemusíme starat o formát nebo strukturu souboru. Každý řádek končí dvěma znaky.
Datové spojení. Účel a implementace datového připojení se liší od těch, které jsou uvedeny v řídicím připojení. Základní fakt: chceme přenášet soubory přes datové připojení. Klient musí určit typ souboru k přenosu, datovou strukturu a režim přenosu.
Podle ASCII kódovací tabulky je 1 bajt (8 bitů) přidělen k reprezentaci jednoho znaku. Sada 8 buněk může nabývat 2 8 = 256 různých hodnot. Prvních 128 hodnot (od 0 do 127) je konstantních a tvoří tzv. hlavní část tabulky, která obsahuje desetinné číslice, písmena latinské abecedy (velká a malá písmena), interpunkční znaménka (tečka, čárka, závorky , atd.), stejně jako mezera a různé obslužné znaky (tabulka, posun řádku atd.). Hodnoty od 128 do 255 formuláře doplňková část tabulky, kde je zvykem kódovat symboly národních abeced.
Kromě toho musí být přenos připraven řídicím spojením před přenosem souboru přes datové spojení. Problém heterogenity je vyřešen definováním tří atributů odkazu: typ souboru, datová struktura a režim přenosu.
Soubor je odeslán jako nepřetržitý proud bitů bez jakékoli interpretace nebo kódování. Tento formát se používá hlavně pro přenos binárních souborů, jako jsou kompilované programy nebo obrázky zakódované v 0 a 1 sekundě. Soubor neobsahuje vertikální specifikace pro tisk. To znamená, že soubor nelze vytisknout bez dalšího zpracování, protože neexistují žádné srozumitelné znaky, které by bylo možné interpretovat vertikálním pohybem tiskového stroje. Tento formát používají soubory, které budou v budoucnu ukládány a zpracovávány.
Protože existuje obrovská škála národních abeced, existují rozšířené ASCII tabulky v mnoha variantách. Dokonce i pro ruský jazyk existuje několik kódovacích tabulek (běžné jsou Windows-1251 a Koi8-r). To vše vytváří další potíže. Například odešleme dopis napsaný v jednom kódování a příjemce se ho snaží přečíst v jiném. V důsledku toho vidí krakozyabry. Čtenář proto musí pro text použít jinou kódovací tabulku.
Soubor lze po přenosu vytisknout. Stránky: Soubor je rozdělen na stránky, z nichž každá je správně očíslována a označena nadpisem. Stránky lze ukládat nebo k nim přistupovat, náhodně nebo postupně. Pokud jsou data pouze řetězcem bajtů, není vyžadována žádná identifikace na konci řádku. V tomto případě je indikací konce linky uzavření datového spojení vysílačem. První byte se nazývá blok deskriptoru; další dva bajty definují velikost bloku v bajtech. Komprese: Pokud je soubor příliš velký, data mohou být před odesláním zkomprimována. Běžně používaná metoda komprese bere jednotku dat, která se objevuje postupně, a nahrazuje ji jedním výskytem, po kterém následuje řada opakování. PROTI textový soubor spousta prázdných míst. V binárním souboru jsou prázdné znaky obvykle komprimovány.
- Soubory: Soubor nemá žádnou strukturu.
- Přenáší se v nepřetržitém proudu bajtů.
- Tento typ lze použít pouze s textovými soubory.
- Řetězce: Toto je výchozí režim.
- V tomto případě každému bloku předchází 3bajtová hlavička.
Je tu i další problém. Abecedy některých jazyků mají příliš mnoho znaků a nevejdou se na jejich přidělené pozice od 128 do 255 jednobajtového kódování.
Třetím problémem je, co dělat, pokud text používá několik jazyků (například ruština, angličtina a francouzština)? Nemůžete používat dva stoly najednou...
K vyřešení těchto problémů bylo najednou vyvinuto kódování Unicode.
Mnozí nemají ponětí o rozdílech mezi těmito sadami a drží se toho, co je blízko. Detail kódování spočívá v tom, že jde o mapy pro dvě různé věci. První je číselná mapa hodnot, která představuje konkrétní znak.
Další roviny jsou doplňky s postavami, které doplňují funkce hlavní roviny a další „speciály“, jako jsou „emotikony“. V těchto vzorech je každý rovinný znak zakódován pouze do 1 bajtu, a proto máme pouze 256 "možných" znaků. Ty netisknutelné musíme samozřejmě odstranit zmenšením rozsahu.
Standard kódování znaků Unicode
K vyřešení výše uvedených problémů na počátku 90. let byl vyvinut standard kódování znaků, tzv Unicode. Tento standard umožňuje používat v textu téměř všechny jazyky a symboly.
Unicode poskytuje 31 bitů pro kódování znaků (4 bajty mínus jeden bit). Počet možných kombinací dává přemrštěné číslo: 2 31 = 2 147 483 684 (tj. více než dvě miliardy). Proto Unicode popisuje abecedy všech známých jazyků, dokonce i těch „mrtvých“ a vynalezených, zahrnuje mnoho matematických a dalších Speciální symboly... Informační kapacita 31bitového Unicode je však stále příliš velká. Častěji se proto používá zkrácená 16bitová verze (2 16 = 65 536 hodnot), kde jsou zakódovány všechny moderní abecedy.
A pokud potřebujete provádět srovnání mezi znaky, nedochází ke ztrátě výkonu, protože porovnávání dvou 8bitových, 16bitových nebo 32bitových hodnot zabere stejný čas moderní procesory... Význam spojený se zkratkou je samozřejmě velikost každé sekvenční jednotky, která tvoří kódování znaků. Když má kód více bitů, použije se následující kódování.
Jakýkoli znak tedy může být vyjádřen ve velikostech od 1 do 4 bajtů. Je to jedinečná „zvláštní“ postava? To znamená, že některé obrázky postav jsou velmi podobné a někdy nadbytečné. Abych uvedl další příklad, před několika lety tu byl vtip o změně '; ' na '; 'v zdrojové kódy... Při kompilaci kódu se programátor zbláznil, aby se pokusil problém vyřešit.
V Unicode je prvních 128 kódů stejných jako tabulka ASCII.
Počínaje koncem 60. let se ke zpracování stále více používaly počítače textové informace a v současnosti nejvíce osobní počítače ve světě (a většinou) je zaneprázdněn zpracováním textových informací.
ASCII - základní kódování textu pro latinku
Tradičně se pro zakódování jednoho znaku používá množství informací rovné 1 bajt, tedy I = 1 bajt = 8 bitů.
Pro zakódování jednoho znaku je vyžadován 1 bajt informací. Pokud vezmeme v úvahu symboly jako možné události, můžeme spočítat kolik různé postavy lze kódovat: N = 2I = 28 = 256.
Tento počet znaků je zcela dostačující pro reprezentaci textových informací, včetně velkých a malých písmen ruské a latinské abecedy, čísel, znaků, grafických symbolů atd. Kódování znamená, že každému znaku je přiřazen jedinečný desetinný kód od 0 do 255 nebo odpovídající binární kód od 00000000 do 11111111.
Člověk tedy rozlišuje symboly podle jejich stylu a počítač - podle jejich kódů. Když jsou textové informace zadány do počítače, je to binární kódování, je obraz symbolu převeden na svůj binární kód.
Uživatel stiskne klávesu se symbolem na klávesnici a do počítače je odeslána určitá sekvence osmi elektrických impulsů (binární kód symbolu). Kód znaku je uložen v paměť s náhodným přístupem počítač, kde to trvá jeden bajt. V procesu zobrazení znaku na obrazovce počítače se provádí opačný proces - dekódování, tedy převod znakového kódu na jeho obraz. Jako mezinárodní standard byla přijata tabulka kódů ASCII (American Standard Code for Information Interchange) Tabulka standardních součástí ASCII Je důležité, aby přiřazení konkrétního kódu ke znaku bylo věcí dohody, která je pevně stanovena v tabulce kódů. . Prvních 33 kódů (od 0 do 32) neodpovídá znakům, ale operacím (odřádkování, zadávání mezer atd.). Kódy od 33 do 127 jsou mezinárodní a odpovídají symbolům latinské abecedy, číslům, aritmetickým znaménkům a interpunkčním znaménkům. Kódy od 128 do 255 jsou národní, to znamená, že stejnému kódu v národních kódech odpovídají různé znaky.
Bohužel je jich v současnosti pět různých kódové tabulky pro ruská písmena (KOI8, CP1251, CP866, Mac, ISO), takže texty vytvořené v jednom kódování nebudou správně zobrazeny v jiném.
V současné době nová internacionála Standard Unicode, který každému znaku přiděluje ne jeden bajt, ale dva, takže jej lze použít ke kódování ne 256 znaků, ale N = 216 = 65536 různých
Unicode - vznik univerzálního kódování textu (UTF 32, UTF 16 a UTF 8)
Tyto tisíce znaků z jazykové skupiny jihovýchodní Asie nebylo možné popsat v jednom bajtu informací, který byl přidělen pro kódování znaků v rozšířených kódováních ASCII. V důsledku toho bylo vytvořeno konsorcium tzv Unicode(Unicode - Unicode Consortium) ve spolupráci s mnoha předními IT průmyslovými lídry (těch, kteří vyrábějí software, kteří kódují hardware, kteří vytvářejí fonty), kteří měli zájem na vzniku univerzálního kódování textu.
První kódování textu publikované pod záštitou konsorcia Unicode bylo kódování UTF 32... Číslo v názvu kódování UTF 32 znamená počet bitů, které jsou použity ke kódování jednoho znaku. 32 bitů jsou 4 bajty informací, které budou potřeba k zakódování jednoho jediného znaku v novém univerzálním kódování UTF 32.
Výsledkem je, že stejný soubor s textem zakódovaným v rozšířeném kódování ASCII a kódování UTF 32 v druhém případě bude mít velikost (váhu) čtyřikrát větší. To je špatné, ale nyní máme možnost zakódovat pomocí UTF 32 počet znaků rovný dvěma až třicetisekundové mocnině (miliardy znaků, které s kolosální rezervou pokryjí jakoukoli skutečně potřebnou hodnotu).
Ale mnoho zemí s jazyky evropské skupiny vůbec nepotřebovalo používat tak velké množství znaků v kódování, ale při použití UTF 32 nikdy nezískalo čtyřnásobný nárůst hmotnosti textové dokumenty a v důsledku toho zvýšení objemu internetového provozu a množství uložených dat. To je hodně a nikdo by si nemohl dovolit takové plýtvání.
V důsledku vývoje univers Objevilo se kódování Unicode UTF 16, který se ukázal být natolik úspěšný, že byl standardně akceptován jako základní prostor pro všechny námi používané symboly. UTF 16 používá dva bajty ke kódování jednoho znaku. Například v operační systém Windows, můžete postupovat podle cesty Start - Programy - Příslušenství - Systémové nástroje - Mapa symbolů.
V důsledku toho se otevře tabulka s vektorovými tvary všech písem nainstalovaných ve vašem systému. Zvolíte-li v Pokročilých možnostech znakovou sadu Unicode, uvidíte pro každé písmo zvlášť celý sortiment znaků v něm obsažených. Mimochodem, kliknutím na kterýkoli z těchto znaků můžete vidět jeho dvoubajtový kód v kódování UTF 16, který se skládá ze čtyř hexadecimálních číslic:
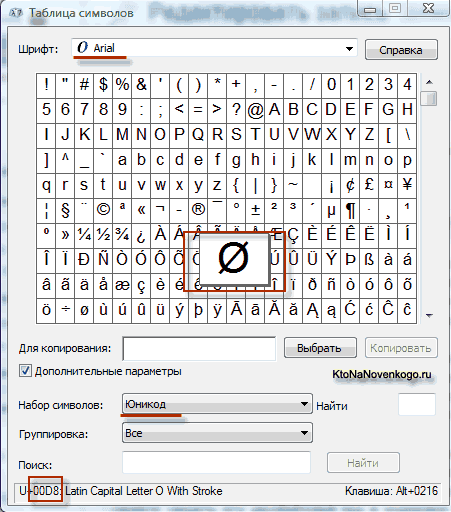
Kolik znaků lze zakódovat v UTF 16 s 16 bity? 65 536 znaků (dva mocniny šestnácti) bylo v Unicode použito jako základní prostor. Kromě toho existují způsoby, jak kódovat pomocí UTF 16 asi dva miliony znaků, ale ty byly omezeny na rozšířený prostor milionu znaků textu.
Ale ani povedená verze kódování Unicode nazvaná UTF 16 nepřinesla příliš uspokojení těm, kteří psali např. programy pouze v anglický jazyk, protože po přechodu z rozšířené verze kódování ASCII na UTF 16 se váha dokumentů zdvojnásobila (jeden bajt pro jeden znak v ASCII a dva bajty pro stejný znak v kódování UTF 16). Právě pro spokojenost všech a všeho v konsorciu Unicode bylo rozhodnuto přijít kódování textu s proměnnou délkou.
Toto kódování v Unicode bylo voláno UTF 8... Navzdory osmičce v názvu je UTF 8 plnohodnotné kódování s proměnnou délkou, tzn. každý znak textu lze zakódovat do sekvence dlouhé od jednoho do šesti bajtů. V praxi se v UTF 8 používá pouze rozsah od jednoho do čtyř bajtů, protože za čtyřmi bajty kódu si není možné nic ani teoreticky představit.
V UTF 8 jsou všechny znaky latinky zakódovány do jednoho bajtu, stejně jako ve starém kódování ASCII. Co je pozoruhodné, v případě kódování pouze latinské abecedy i ty programy, které nerozumí Unicode, budou stále číst to, co je zakódováno v UTF 8. základní část kódování ASCII přesunuta do UTF 8.
Znaky azbuky v UTF 8 jsou kódovány ve dvou bytech a například gruzínské - ve třech bytech. Unicode Consortium po vytvoření kódování UTF 16 a UTF 8 vyřešilo hlavní problém – nyní máme v našich fontech jediný kódový prostor. Jediné, co výrobcům písem zbývá, je vyplnit tento kódový prostor vektorovými formami textových symbolů na základě jejich silných stránek a schopností.
 Linkedin – co to je a jak vám LinkedIn může pomoci najít vaši vysněnou práci Profesní síť Linkedin
Linkedin – co to je a jak vám LinkedIn může pomoci najít vaši vysněnou práci Profesní síť Linkedin DDoS ochrana: DDoS GUARD - váš bezpečný hosting
DDoS ochrana: DDoS GUARD - váš bezpečný hosting Smartphony se systémem Windows lze nyní aktualizovat pomocí počítače
Smartphony se systémem Windows lze nyní aktualizovat pomocí počítače