Tabulka kódů Ansi. Kódování: užitečné informace a krátká retrospektiva
Pokud potřebujete zadat pouze několik speciální znaky nebo znaky, můžete použít tabulku znaků nebo klávesové zkratky. Seznam znaků ASCII najdete v níže uvedených tabulkách nebo Vkládání národních písmen pomocí klávesových zkratek.
Poznámky:
Vkládání znaků ASCII
Chcete -li vložit znak ASCII, stiskněte a podržte klávesu ALT a poté zadejte kód znaku. Chcete -li například vložit znak stupně (º), podržte klávesu ALT a zadejte numerická klávesnice kód 0176.
Poznámka:
Vkládání znaků Unicode
Důležité: Nějaký Programy Microsoft Office, například PowerPoint a InfoPath, nemůže převádět kódy znaků Unicode. Pokud požadujete znak Unicode a používáte některý z programů, které nepodporují znaky Unicode, zadejte znaky, které budete potřebovat.
Poznámky:
Ukončete všechny programy.
Poklepejte na ikonu Instalace a odebrání programů na ovládací panely.
Proveďte jednu z následujících akcí:
pokud aplikace Microsoft Office nainstalován jako součást Microsoft Office, vyberte Microsoft Office v poli Nainstalované programy a poté stiskněte tlačítko Nahradit;
Li Kancelářská aplikace byl nainstalován samostatně, klikněte na jeho název v seznamu Nainstalované programy a poté stiskněte tlačítko Změna.
Čísla by měla být zadávána na numerické klávesnici, nikoli alfanumerická. Pokud potřebujete stisknutím zadat čísla na numerické klávesnici Klávesa NUM LOCK, ujistěte se, že je to hotovo.
Pokud máte potíže s převodem kódu Unicode na znak, zadejte kód na numerické klávesnici, vyberte jej a stiskněte Alt + X.
PROTI Microsoft Windows XP a novější verze univerzálního písma Unicode se instalují automaticky. V systému Microsoft Windows 2000 musí být písmo Unicode nainstalováno ručně.
V systému Microsoft Windows 2000
V dialogovém okně Instalace Microsoft Office 2003 Vyberte možnost Přidejte nebo odeberte součásti a poté stiskněte tlačítko Dále.
Prosím vyberte Dodatečné přizpůsobení aplikace a stiskněte tlačítko Dále.
Rozbalte seznam Běžné kancelářské nástroje.
Rozbalte seznam Vícejazyčná podpora.
Klikněte na ikonu Univerzální písmo a vyberte požadovanou možnost instalace.
Pomocí tabulky symbolů
Tabulku symbolů sestavila společnost Microsoft Program Windows což vám umožňuje zobrazit znaky dostupné ve vybraném písmu. Pomocí tabulky symbolů můžete zkopírovat jednotlivé symboly nebo skupiny symbolů do schránky a poté je vložit do programu, který je podporuje.
Klikněte na tlačítko Start a poté vyberte Programy, Standard, Servis a tabulka symbolů.
Chcete -li vybrat symbol v tabulce symbolů, klikněte na něj, klikněte na Vybrat, klikněte klikněte pravým tlačítkem myši myší v místě dokumentu, kam chcete symbol přidat, a vyberte příkaz Vložit.
Kódy běžných znaků
Další znaky najdete v článku nainstalovaném ve vašem počítači, kódech znaků ASCII nebo diagramu skriptu znakového kódu Unicode.
|
Podepsat |
Podepsat |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Symboly měny |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Právní symboly |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Zlomky |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Interpunkční a nářeční symboly |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Tvořte symboly |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Běžné diacritické kódyÚplný seznam glyfů a souvisejících znakových kódů viz.
|
Někdy vám i docela zkušený specialista hned neřekne, jaká konkrétní hodnota tlaku nebo délky v jednom systému odpovídá hodnotám v jiném systému hodnot.
Na usnadnit vám tento úkol, nabízíme tabulky poměru hodnot tlaku a délky v evropských a amerických systémech s malými vysvětlení... Nejprve ale pár slov o samotných normách.
RÁMUS je německý standard (znamená Deutsches Institut für Normung, tj. vyvinutý Německým institutem pro normalizaci), který je vyvíjen striktně v rámci ustanovení Mezinárodní organizace pro normalizaci - ISO (Mezinárodní organizace pro normalizaci).
ANSI- standard přijatý ve Spojených státech amerických. Stojí za Americký národní normalizační institut, tj. standard Amerického národního normalizačního institutu.
V souladu s tím jsou standardy ANSI určeny touto institucí a daleko ne vždy mezi standardy RÁMUS a ANSI přesný shoda v různých oborech.
Převod jednotek tlaku z ANSI na DIN
Všechno je zde jednoduché: pokud standardní ANSIčíslo 150 stojí naproti tlaku - to znamená, že nominální tlak (pro který je ventil určen) je 20 barů, 300 - 50 barů atd. Maximální hodnota do Třída ANSI- 2500 se bude rovnat 420 bar podle evropské normy RÁMUS.
Pomocí této tabulky není těžký přeložit hodnoty tlaku a zpět: od RÁMUS proti ANSI, i když naši inženýři musí takový překlad hodně provádět méně často.
Převod jednotek délky z amerického systému na evropský (ruský)
Jak je známo, Američané všechno se měří v palcích a stopách a my a Evropané- milimetry, centimetry a metry, to znamená, že stejně jako drtivá většina států světa žijeme metrický soustava jednotek.
Jak převést palce na milimetry? Ve skutečnosti to také není obtížné, nezapomeňte, že 1 palec se rovná 25,4 mm. Často však číslice za desetinnou čárkou zanedbané a pro rovnoměrné počítání to naznačte 1 palec = 25 mm.
Pokud je tedy například průřez vstupu 2 palce podle amerického systému měr, pak při převodu této hodnoty do našeho systému měr podle výše uvedeného pravidla dostaneme 50 mm nebo přesněji 51 mm (zaokrouhlení 50,8 podle pravidel) ...
Zbývá dodat, že průměr v technický charakteristiky jsou označeny latinskými písmeny DN a je často uveden přesně v palce, a tlak je indikován písmeny PN a je indikován nejčastěji v tyče- v každém případě používáme právě takové označení jako nejvíce komfortní.
A následující tabulka pomůže můžete nejen vypočítat přesný počet milimetrů na jeden palec (s přesností na tisícinu milimetru), ale také vám pomůže zjistit, kolik milimetrů je obsaženo například v 2,5 palcích.
Chcete -li to provést, najděte sloupec 2 "" (2 palce) a vlevo vyhledejte 1/2. Celkem 2,5 palce = 63,501 mm, což je docela možné zaokrouhlit až na 64 mm, a například 6,25 palce (tj. 6 a 1/4) = 158,753 mm nebo 159 mm.
|
| Palce "" v milimetrech |
|||||||
|
| ||||||||
|
| ||||||||
Bootstrap framework: rychle reagující rozložení
Podrobný video tutoriál o základech responzivního rozvržení v rámci Bootstrap.
Naučte se sazet snadno, rychle a efektivně pomocí výkonného a praktického nástroje.
Rozvržení na objednávku a získání výplaty.
Bezplatný kurz „Web WordPress“
Chcete zvládnout WordPress CMS?
Získejte návody na design a rozložení webových stránek WordPress.
Naučte se pracovat s motivy a rozřízněte rozvržení.
Bezplatný video kurz o návrhu, rozložení a instalaci stránek na CMS WordPress!
* Posunutím myši pozastavíte posouvání.
Zpět dopředu
Kódování: užitečné informace a krátká retrospektiva
Rozhodl jsem se napsat tento článek jako malý přehled v problematice kódování.
Zjistíme, co je kódování obecně, a dotkneme se historie, jak se v zásadě objevily.
Promluvíme si o některých jejich funkcích a také vezmeme v úvahu momenty, které nám umožňují vědoměji pracovat s kódováním a vyhnout se vzhledu na místě tzv. krakozyabrov, tj. nečitelné znaky.
Tak pojďme ...
Co je to kódování?
Jednoduše řečeno, kódování je tabulka mapování znaků, které můžeme na obrazovce vidět na určité číselné kódy.
Tito. každý znak, který zadáme z klávesnice nebo vidíme na obrazovce monitoru, je kódován určitou posloupností bitů (nuly a jedničky). 8 bitů, jak pravděpodobně víte, se rovná 1 bajtu informací, ale o tom později.
Vzhled samotných symbolů je určen soubory písem které jsou nainstalovány ve vašem počítači. Proces zobrazování textu na obrazovce lze tedy popsat jako neustálé mapování sekvencí nul a jedniček na některé konkrétní znaky, které tvoří písmo.
Lze uvažovat o předchůdci všech moderních kódování ASCII.
Tato zkratka znamená Americký standardní kód pro výměnu informací(Americká standardní kódovací tabulka pro tisknutelné znaky a některé speciální kódy).
to jednobajtové kódování, který původně obsahoval pouze 128 znaků: písmena latinské abecedy, arabské číslice atd.

Později byl rozšířen (zpočátku nepoužíval všech 8 bitů), takže bylo možné použít ne 128, ale 256 (2 až 8. výkon) různé postavy které lze zakódovat do jednoho bajtu informace.
Toto vylepšení umožnilo přidat do ASCII symboly národních jazyků, navíc k již existující latinské abecedě.
Vzhledem k tomu, že na světě existuje také mnoho jazyků, existuje mnoho možností pro rozšířené kódování ASCII. Myslím, že mnoho z vás slyšelo o takovém kódování jako KOI8-R je také rozšířené kódování ASCII navržen tak, aby pracoval s postavami ruského jazyka.
Za další krok ve vývoji kódování lze považovat vznik tzv Kódování ANSI.
Ve skutečnosti byli stejní rozšířené verze ASCII byly z nich ale odstraněny různé pseudografické prvky a přidány typografické symboly, pro které dříve nebylo dost „volného místa“.
Příkladem takového kódování ANSI je dobře známý Windows-1251... Toto kódování zahrnovalo kromě typografických znaků také písmena abeced jazyků blízkých ruštině (ukrajinštině, bělorusštině, srbštině, makedonštině a bulharštině).
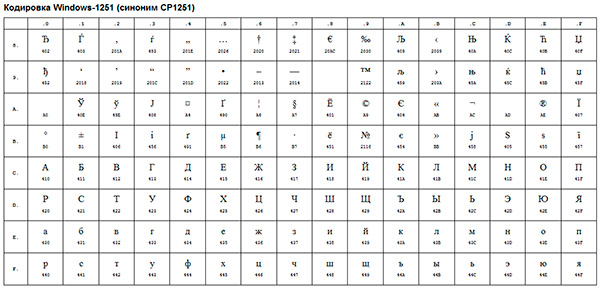
Kódování ANSI je souhrnný název... Skutečné kódování při použití ANSI bude ve skutečnosti určeno tím, co je uvedeno v registru vašeho operační systém Okna. V případě ruského jazyka to bude Windows-1251, u ostatních jazyků to však bude jiný druh ANSI.
Jak jste pochopili, hromada kódování a nedostatek jediného standardu nepřinesly k dobrému, což byl důvod častých setkání s tzv. krakozyabrami- nečitelná nesmyslná sada znaků.
Důvod jejich vzhledu je jednoduchý - je pokouší se zobrazit znaky kódované jednou kódovací tabulkou pomocí jiné kódovací tabulky.
V kontextu vývoje webu se s krakozyabras můžeme setkat, když např. Ruský text je omylem uložen ve špatném kódování, které je použito na serveru.
Samozřejmě to není jediný případ, kdy můžeme získat nečitelný text - zde je spousta možností, zvláště když vezmete v úvahu, že existuje také databáze, ve které jsou informace uloženy také v určitém kódování, existuje mapování připojení k databázi atd.
Vznik všech těchto problémů sloužil jako podnět k vytvoření něčeho nového. Muselo to být kódování, které dokázalo zakódovat jakýkoli jazyk na světě (koneckonců pomocí jednobajtových kódování nelze při jakékoli touze popsat všechny znaky, řekněme, čínského jazyka, kde je zjevně více než 256 z nich), další speciální znaky a typografie.
Zkrátka bylo nutné tvořit univerzální kódování, které by jednou provždy vyřešilo problém krakozyabrov.
Unicode-univerzální kódování textu (UTF-32, UTF-16 a UTF-8)
Samotný standard navrhla v roce 1991 nezisková organizace Konsorcium Unicode(Unicode Consortium, Unicode Inc.), a prvním výsledkem jeho práce bylo vytvoření kódování UTF-32.
Mimochodem, samotná zkratka UTF znamená Transformační formát Unicode(Formát převodu Unicode).
V tomto kódování mělo použít ke kódování jeden znak tolik 32 bitů, tj. 4 bajty informací. Pokud toto číslo porovnáme s jednobajtovým kódováním, dojdeme k jednoduchému závěru: pro kódování 1 znaku v tomto univerzálním kódování potřebujete 4krát více bitů, což činí soubor 4krát těžším.
Je také zřejmé, že počet znaků, které by bylo možné potenciálně popsat pomocí tohoto kódování, překračuje všechny rozumné limity a je technicky omezen na číslo rovnající se 2 až 32. výkonu. Je zřejmé, že se jednalo o jasné přehnané a zbytečné z hlediska hmotnosti souborů, takže se toto kódování nerozšířilo.
Byla nahrazena nový vývoj- UTF-16.
Jak naznačuje název, v tomto kódování je kódován jeden znak již ne 32 bitů, ale pouze 16(tj. 2 bajty). Je zřejmé, že díky tomu je jakýkoli znak dvakrát „lehčí“ než UTF-32, ale dvakrát „těžší“ než jakýkoli jednobajtový kódovaný znak.
Počet znaků dostupných pro kódování v UTF-16 je nejméně 2 až 16. mocniny, tj. 65 536 znaků. Všechno se zdá být dobré, kromě toho byla konečná velikost kódového prostoru v UTF-16 rozšířena na více než 1 milion znaků.
Toto kódování však plně neuspokojilo potřeby vývojářů. Pokud například píšete výhradně pomocí latinských znaků, pak po přepnutí z rozšířené verze kódování ASCII na UTF-16 se hmotnost každého souboru zdvojnásobí.
Jako výsledek, byl učiněn další pokus vytvořit něco univerzálního, a to je známé kódování UTF-8.
UTF-8- tohle je vícebajtové kódování s proměnnou délkou znaků... Při pohledu na název si můžete myslet, analogicky s UTF-32 a UTF-16, že pro kódování jednoho znaku je použito 8 bitů, ale není tomu tak. Přesněji, ne tak docela.
Důvodem je, že UTF-8 poskytuje nejlepší kompatibilitu se staršími systémy, které používaly 8bitové znaky. Ke kódování jednoho znaku v UTF-8 se skutečně používá 1 až 4 bajty(hypoteticky je možné až 6 bajtů).
V UTF-8 jsou všechny znaky latinky kódovány v 8 bitech, stejně jako v kódování ASCII... Jinými slovy, základní část kódování ASCII (128 znaků) se přesunula do UTF-8, což umožňuje „utratit“ za jejich reprezentaci pouze 1 byte, při zachování univerzálnosti kódování, pro které bylo vše spuštěno.
Pokud je tedy prvních 128 znaků kódováno 1 bajtem, pak všechny ostatní znaky jsou kódovány 2 nebo více bajty. Zejména je každý znak cyrilice kódován přesně 2 bajty.
Dostali jsme tedy univerzální kódování, které nám umožňuje pokrýt všechny možné znaky, které je třeba zobrazit, aniž by soubory zbytečně „vážily“.
S nebo bez kusovníku?
Pokud jste pracovali s textové editory(editory kódu) jako Poznámkový blok ++, phpDesigner, rychlé php atd., pravděpodobně jste upozornili na skutečnost, že při zadávání kódování, ve kterém bude stránka vytvořena, můžete zvolit zpravidla 3 možnosti:
ANSI
- UTF-8
- UTF-8 bez kusovníku
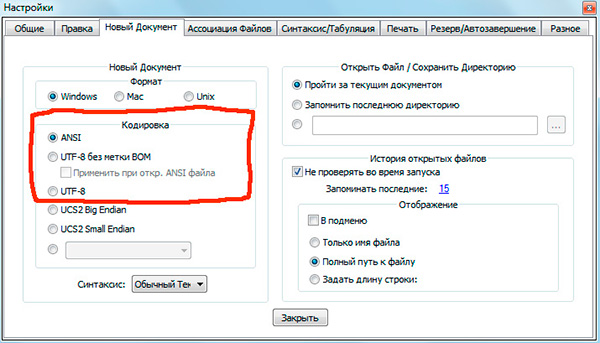

Hned musím říci, že je to vždy poslední možnost, kterou stojí za výběr - UTF-8 bez kusovníku.
Co je tedy kusovník a proč ho nepotřebujeme?
BOM znamená Bajtová značka objednávky... Toto je speciální znak Unicode používaný k označení pořadí bajtů. textový soubor... Podle specifikace je jeho použití volitelné, ale pokud BOM se používá, pak musí být nastaven na začátku textového souboru.
Nebudeme se zabývat podrobnostmi práce. BOM... Pro nás je hlavní závěr následující: použití tohoto znaku služby společně s UTF-8 brání programům v normálním čtení kódování, v důsledku čehož dochází k chybám v práci skriptů.
Při práci s UTF-8 proto použijte přesně tuto možnost „UTF-8 bez kusovníku“... Je také lepší nepoužívat editory, ve kterých v zásadě nemůžete určit kódování (řekněme, Notebook od standardních programů po Okna).
Kódování aktuálního souboru otevřeného v editoru kódu je obvykle uvedeno ve spodní části okna.
Upozorňujeme, že vstup "ANSI jako UTF-8" v editoru Poznámkový blok ++ znamená totéž jako „UTF-8 bez kusovníku“... To je stejné.
![]()
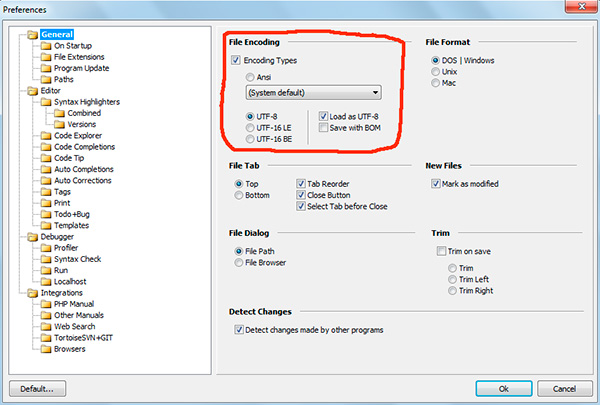
V programu phpDesigner nemůžete okamžitě s jistotou říci, zda je použit BOM, nebo ne. Chcete-li to provést, klikněte pravým tlačítkem na nápis "UTF-8", po kterém ve vyskakovacím okně uvidíte, zda BOM(volba Ušetřete s kusovníkem).
V editoru rychlé php kódování UTF-8 bez kusovníku označen jako "UTF-8 *".
Dokážete si asi představit, že v různých editorech vypadá vše trochu jinak, ale vy dostanete hlavní myšlenku.
Poté, co je dokument uložen v UTF-8 bez kusovníku, musíte se také ujistit, že správné kódování je uvedeno ve speciální meta značce v sekci hlava váš html dokument:
Dodržování těchto jednoduchých pravidel vám již umožní vyhnout se mnoha mezerám s kódováním.
To je vše, doufám, že vám tato malá exkurze a vysvětlení pomohla lépe porozumět tomu, co jsou kódování, co jsou a jak fungují.
Pokud vás toto téma zajímá z aplikovanějšího úhlu pohledu, pak vám doporučuji prostudovat můj video návod.
Dmitrij Naumenko.
P.S. Podívejte se blíže na prémiové návody k různým aspektům stavby stránek a také kurz zdarma při vytváření vlastního CMS systému v PHP od nuly. To vše vám pomůže rychleji a snadněji zvládnout různé technologie webového vývoje.
Líbil se vám materiál a chtěli byste poděkovat?
Stačí sdílet se svými přáteli a kolegy!
 Bezdrátové nabíjení Smartphony A5 podporuje bezdrátové nabíjení
Bezdrátové nabíjení Smartphony A5 podporuje bezdrátové nabíjení Proč na telefon nepřijdou sms zprávy MTS?
Proč na telefon nepřijdou sms zprávy MTS? Proč potřebujete úplný reset v systému Android nebo jak vrátit Android do továrního nastavení
Proč potřebujete úplný reset v systému Android nebo jak vrátit Android do továrního nastavení