Kódování znaků. Unicode
Líbilo se mi to, třeba to někoho zaujme a bude užitečné.
Unicode vypadá velmi zmateně, což vyvolává spoustu otázek a problémů. Mnoho lidí si myslí, že se jedná o kódování nebo znakovou sadu, což je do jisté míry správné, ale ve skutečnosti je to klam. Skutečnost, že Unicode byl původně vytvořen jako kódovací a znaková sada, jen posiluje mylné představy. Toto je pokus vše objasnit, nejen tím, že řekneme, co je Unicode, ale také tím, že poskytneme mentální model Unicode.
Zcela nesprávný, ale užitečný model pro pochopení Unicode (dále PMPY):
- Unicode je způsob zpracování textových dat... Nejedná se o znakovou sadu nebo kódování.
- Unicode je text, vše ostatní jsou binární data... A dokonce i ASCII text jsou binární data.
- Unicode používá znakovou sadu UCS... Ale UCS není Unicode.
- Unicode může být binárně kódováno pomocí UTF... Ale UTF není Unicode.
Nyní, pokud víte něco o Unicode, řeknete: "No, jo, ale to opravdu není." Proto se pokusíme zjistit, proč je tento model porozumění, i když není správný, stále užitečný. Začněme znakovou sadou...
O znakové sadě
Pro zpracování textu na počítači je potřeba spojit grafémy, které píšete na papír, s čísly. Toto řazení je určeno znakovou sadou nebo tabulkou znaků, která určuje číslo znaku. Tomu se říká "sada znaků"... Symbol nemusí nutně odpovídat žádnému grafému. Existuje například kontrolní znak „BEL“, který způsobí, že váš počítač „pípne“. Počet znaků ve znakové sadě je obvykle 256, tedy tolik, kolik se vejde do jednoho bajtu. Existují znakové sady, které jsou dlouhé pouze 6 bitů. Po dlouhou dobu dominovaly ve výpočetní technice 7bitové znakové sady ASCII, ale 8bitové jsou nejběžnější.
Ale 256 zjevně není číslo, které pojme všechny symboly, které v našem světě potřebujeme. Proto vznikl Unicode. Když jsem řekl, že Unicode není znaková sada, lhal jsem. Unicode byla původně 16bitová znaková sada. Ale zatímco tvůrci Unicode věřili, že 16 bitů je dost (a měli pravdu), někteří věřili, že 16 bitů je málo (a také měli pravdu). Nakonec vytvořili konkurenční kódování a nazvali ho Universal Character Set (UCS). Po chvíli se týmy rozhodly spojit síly a dvě sady postav se staly stejnými. To je důvod, proč můžeme předpokládat, že Unicode používá jako svou znakovou sadu UCS. Ale to je také lež - ve skutečnosti má každý standard svou vlastní sadu znaků, náhodou jsou stejné (ačkoli UCS je mírně pozadu).
Ale pro naše PMPYu - "Unicode není znaková sada".
O UCS
UCS je 31bitová znaková sada s více než 100 000 znaky. 31 bitů – aby se neřešil problém „podepsané versus nepodepsané“. Protože se nyní používá méně než 0,005 % z možného počtu znaků, není tento extra bit vůbec potřeba.
I když 16 bitů nestačilo na to, aby se vešly všechny postavy, které kdy lidstvo vytvořilo, je to docela dost, pokud jste připraveni se omezit až nyní. existující jazyky... Proto se většina znaků UCS vejde do prvních 65536 čísel. Dostaly název „Basic Multilingual Plane“ neboli BMP. Ve skutečnosti se jedná o 16bitovou znakovou sadu Unicode, i když každá verze UCS ji rozšiřuje o další a další znaky. BMP se stává relevantním, pokud jde o kódování, ale o tom níže.
Každý znak v UCS má jméno a číslo. Znak „H“ se nazývá „LATINSKÉ VELKÉ PÍSMENO H“ a je to číslo 72. Číslo je obvykle v šestnáctkové soustavě a často má předponu „U +“ a 4, 5 nebo 6 číslic, které označují, co znamená znak Unicode. Proto je číslo znaku "H" častěji reprezentováno jako U + 0048 než - 72, ačkoli jsou to stejné. Dalším příkladem je znak „-“ s názvem „EM DASH“ nebo U + 2012. Znak "乨" se nazývá "CJK UNIFIED IDEOGRAPH-4E68", běžněji reprezentovaný jako U + 4E68. symbol "
Protože názvy a počty znaků v Unicode a UCS jsou stejné, pro náš PMPU to budeme předpokládat UCS není Unicode, ale Unicode používá UCS... Toto je lež, ale užitečná lež, která vám umožňuje rozlišovat mezi Unicode a znakovou sadou.
O kódování
Znaková sada je tedy soubor znaků, z nichž každá má své vlastní číslo. Jak je ale uložit nebo poslat do jiného počítače? Pro 8bitové znaky je to snadné, použijete jeden bajt na znak. Ale UCS používá 31 bitů a vy potřebujete 4 bajty na znak, což vytváří problém s řazením bajtů a neefektivností paměti. Také ne všechny aplikace třetích stran může pracovat se všemi znaky Unicode, ale stále potřebujeme s těmito aplikacemi komunikovat.
Cesta ven je použití kódování, která indikují, jak převést text Unicode na 8bitová binární data. Je pozoruhodné, že ASCII je kódování a data ASCII z pohledu PMPU jsou binární!
Ve většině případů je kódování stejná znaková sada a jmenuje se stejně jako znaková sada, kterou kóduje. To platí pro Latin-1, ISO-8859-15, cp1252, ASCII atd. Zatímco většina znakových sad jsou také kódování, u UCS tomu tak není. Je také matoucí, že UCS je to, do čeho dekódujete a z čeho kódujete, zatímco zbytek znakových sad je to, z čeho dekódujete a do čeho kódujete (protože název kódování a znakové sady je stejný). Znakové sady a kódování byste tedy měli považovat za různé věci, i když se tyto termíny často používají zaměnitelně.
O UTF
Většina kódování funguje na znakové sadě, která je pouze malou částí UCS. To se stává problémem pro vícejazyčná data, takže je potřeba kódování, které používá všechny znaky UCS. Kódování 8bitových znaků je velmi jednoduché, protože z jednoho bajtu získáte jeden znak, ale UCS používá 31 bitů a potřebujete 4 bajty na znak. Problém pořadí bajtů nastává, protože některé systémy používají vyšší řád k nižšímu, jiné naopak. Také některé bajty budou vždy prázdné, což je plýtvání pamětí. Správné kódování by mělo používat jiný počet bajtů různé postavy, ale takové kódování bude v některých případech účinné a v jiných ne.
Řešením této hádanky je použití několika kódování, ze kterého si můžete vybrat to správné. Říká se jim Unicode Transformation Formats neboli UTF.
UTF-8 je nejrozšířenější kódování na internetu. Používá jeden bajt pro znaky ASCII a 2 nebo 4 bajty pro všechny ostatní znaky UCS. To je velmi efektivní pro jazyky používající latinská písmena, protože všechny jsou v ASCII, docela efektivní pro řečtinu, azbuku, japonštinu, arménštinu, syrštinu, arabštinu atd., protože používají 2 bajty na znak. To však není účinné pro všechny ostatní jazyky BMP, protože budou použity 3 bajty na znak a pro všechny ostatní znaky UCS, jako je Gothic, budou použity 4 bajty.
UTF-16 používá jedno 16bitové slovo pro všechny znaky BMP a dvě 16bitová slova pro všechny ostatní znaky. Pokud tedy nepracujete s jedním z výše uvedených jazyků, je lepší používat UTF-16. Protože UTF-16 používá 16bitová slova, skončíme s problémem pořadí bajtů. Je to vyřešeno přítomností tří možností: UTF-16BE pro pořadí bajtů od vysoké po nízkou, UTF-16LE - od nízké po vysokou a jednoduše UTF-16, což může být UTF-16BE nebo UTF-16LE, při kódování na začátku se používá značka, která udává pořadí bajtů. Tato značka se nazývá "značka pořadí bajtů" nebo "BOM".
Existuje také UTF-32, které může být ve dvou variantách BE a LE a také UTF-16, a ukládá znak Unicode jako 32bitové celé číslo. To není efektivní pro téměř všechny znaky kromě těch, které vyžadují uložení 4 bajtů. Zpracovat taková data je ale velmi snadné, protože máte vždy 4 bajty na znak.
Je důležité oddělit kódovaná data od dat Unicode. Nepovažujte proto data UTF-8/16/32 za Unicode. Ačkoli jsou tedy kódování UTF definována ve standardu Unicode, věříme, že UTF není Unicode podle PMPU.
O Unicode
UCS obsahuje sjednocující znaky, jako je trema, která přidává dvě tečky nad znak. To vede k nejednoznačnosti při vyjádření jednoho grafému (písmeno nebo znak) prostřednictvím více symbolů. Vezměme si jako příklad ‚ö‘, které lze znázornit jako znak LATNICKÉ MALÉ PÍSMENO O S DIAERESIS, ale zároveň jako kombinaci znaků LAtinské MALÉ PÍSMENO O následované KOMBINOVÁNÍM DIAERESIS.
Ale ve skutečném životě nemůžete žádný symbol doplnit třemi. Například nemá smysl přidávat dvě tečky nad symbol eura. Unicode obsahuje pravidla pro takové věci. Označuje, že „ö“ můžete vyjádřit dvěma způsoby a je to stejný znak, ale pokud použijete trojku pro znak eura, děláte chybu. Proto jsou pravidla pro kombinování znaků součástí standardu Unicode.
Standard Unicode také obsahuje pravidla pro porovnávání a řazení znaků, pravidla pro rozdělování textu na věty a slova (pokud si myslíte, že je to tak jednoduché, mějte na paměti, že většina asijských jazyků neobsahuje mezery mezi slovy) a mnoho dalších pravidel, která určit, jak se zobrazí a zpracuje.text. To vše pravděpodobně nebudete potřebovat vědět, kromě používání asijských jazyků.
Pomocí PMPU jsme určili, že Unicode je UCS plus pravidla pro zpracování textu. Nebo jinými slovy: Unicode je způsob práce s textovými daty a nezáleží na tom, jaký jazyk nebo písmeno používají. V Unicode, 'H' není jen znak, má nějaký význam. Znaková sada označuje, že ‚H‘ je znak s číslem 72, zatímco Unicode vám říká, že při řazení ‚H‘ předchází ‚I‘ a můžete použít dvě tečky nad ním, abyste získali ‚Ḧ‘.
Unicode tedy není kódování nebo sada znaků, je to způsob práce s textovými daty.
Sám nemám moc rád titulky jako "Pokémoni ve vlastní šťávě pro panáky / hrnce / pánve", ale zdá se, že je to přesně ten případ - budeme se bavit o základních věcech, s nimiž práce dost často vede k přihrádce plné hrboly a spousta ztraceného času kolem otázky - Proč to nefunguje? Pokud se stále bojíte a/nebo nerozumíte Unicode, prosím, pod kat.
za co?
Hlavní otázka pro začátečníka, který se potýká s působivým množstvím kódování a zdánlivě matoucích mechanismů pro práci s nimi (například v Pythonu 2.x). Krátká odpověď je, protože se to stalo :)Kódování, kdo neví, je způsob reprezentace číslic, buků a všech ostatních znaků v paměti počítače (čteno - nula-jedna / čísla). Například mezera je reprezentována jako 0b100000 (binární), 32 (desítková) nebo 0x20 (hexadecimální).
Takže, jakmile bylo velmi málo paměti a všechny počítače měly dostatek 7 bitů, aby reprezentovaly všechny potřebné znaky (čísla, malá / velká latinská abeceda, hromada znaků a tzv. řízené znaky – všech možných 127 čísel bylo někomu dáno) . V té době existovalo pouze jedno kódování - ASCII. Jak šel čas, všichni byli spokojeni a kdo spokojený nebyl (čti - komu chybělo znaménko "" nebo rodné písmeno "u") - zbylých 128 znaků použil podle svého uvážení, čili vytvářel nová kódování. Tak se objevila ISO-8859-1 a naše (tedy azbuka) cp1251 a KOI8. Spolu s nimi se objevil problém interpretace bajtů jako 0b1 ******* (tedy znaků / čísel od 128 do 255) - například 0b11011111 v kódování cp1251 je naše vlastní "já", zároveň v kódování ISO 8859-1 je řeckoněmecká Eszett (výzvy) „ß“. Jak se očekávalo, síťová komunikace a jen výměna souborů mezi sebou různé počítače se změnilo v sakra-co-co, navzdory skutečnosti, že hlavičky jako "Content-Encoding" v protokolu HTTP, e-maily a stránky HTML trochu zachránily den.
V tu chvíli se sešly bystré hlavy a navrhly nový standard – Unicode. Jedná se o standard, nikoli o kódování – samotný Unicode neurčuje, jak budou znaky uloženy na pevném disku nebo přenášeny po síti. Definuje pouze vztah mezi znakem a určitým číslem a formát, podle kterého budou tato čísla převedena na bajty, je určen kódováním Unicode (například UTF-8 nebo UTF-16). Na tento moment ve standardu Unicode je něco málo přes 100 tisíc znaků, zatímco UTF-16 může podporovat přes jeden milion (UTF-8 je ještě více).
Doporučuji vám, abyste si přečetli Absolutní minimum, které musí každý vývojář softwaru absolutně, pozitivně znát o Unicode a znakových sadách, abyste na toto téma měli stále více zábavy.
Dostat se k věci!
Samozřejmostí je podpora Unicode v Pythonu. Ale bohužel pouze v Pythonu 3 se všechny řetězce staly unicode a začátečníci se musí zabít kvůli chybě, jako je:>>> s open ("1.txt") jako fh: s = fh.read () >>> print s koshchey >>> parser_result = u "baba-yaga" # zadání pro názornost, představme si, že jde o výsledek nějaký parser funguje >>>
nebo takhle:
>>> str (parser_result) Traceback (poslední poslední volání): Soubor "
Pojďme na to přijít, ale popořadě.
Proč by někdo používal Unicode?
Proč můj oblíbený html parser vrací Unicode? Ať to vrátí obyčejný provázek a tam si s tím poradím! Že jo? Spíš ne. Každý ze znaků existujících v Unicode sice může být (pravděpodobně) reprezentován v nějakém jednobajtovém kódování (ISO-8859-1, cp1251 a další se nazývají jednobajtové, protože kódují jakýkoli znak přesně na jeden bajt), ale co na to dělat, pokud by v řetězci měly být znaky z různých kódování? Přiřadit každému znaku samostatné kódování? Ne, samozřejmě musíte použít Unicode.Proč potřebujeme nový typ „unicode“?
Tak jsme se dostali k tomu nejzajímavějšímu. Co je to řetězec v Pythonu 2.x? Je to jednoduché bajtů... Jen binární data, která mohou být cokoli. Ve skutečnosti, když napíšeme něco jako: >>> x = "abcd" >>> x "abcd", interpret nevytvoří proměnnou obsahující první čtyři písmena latinské abecedy, ale pouze sekvenci ("a" , "b "," c "," d ") se čtyřmi bajty a písmeny latinky se zde používají výhradně k označení této konkrétní hodnoty bajtů. Takže „a“ je zde jen synonymem pro „\ x61“ a ani trochu víc. Například:>>> "\ x61" "a" >>> struct.unpack ("> 4b", x) # "x" jsou pouze čtyři podepsané / nepodepsané znaky (97, 98, 99, 100) >>> struct.unpack ("> 2h", x) # nebo dvě krátké (24930, 25444) >>> struct.unpack ("> l", x) # nebo jedna dlouhá (1633837924,) >>> struct.unpack ("> f" , x) # nebo float (2,6100787562286154e + 20,) >>> struct.unpack ("> d", x * 2) # nebo polovina double (1,2926117739473244e + 161,)
A to je vše!
A odpověď na otázku - proč potřebujeme "unicode" je již zřejmější - potřebujeme typ, který bude reprezentován znaky, nikoli byty.
Dobře, přišel jsem na to, co je to řetězec. Co je tedy Unicode v Pythonu?
"Type unicode" je primárně abstrakce, která implementuje myšlenku Unicode (soubor znaků a souvisejících čísel). Objekt typu „unicode“ již není sekvencí bajtů, ale sekvencí skutečných znaků bez jakékoli představy o tom, jak lze tyto znaky efektivně uložit do paměti počítače. Pokud chcete, tohle je víc vysoká úroveň abstrakce než bajtové řetězce (to je to, co Python 3 nazývá běžné řetězce, které se používají v Pythonu 2.6).Jak mohu používat Unicode?
Řetězec Unicode v Pythonu 2.6 lze vytvořit třemi (alespoň přirozeně) způsoby:- u "" doslovné: >>> u "abc" u "abc"
- Metoda "decode" pro bajtový řetězec: >>> "abc" .decode ("ascii") u "abc"
- Funkce "Unicode": >>> unicode ("abc", "ascii") u "abc"
"\ x61" -> kódování ascii -> malá latinka "a" -> u "\ u0061" (bod Unicode pro toto písmeno) nebo "\ xe0" -> kódování c1251 -> malá azbuka "a" -> u " \ u0430 "
Jak získat běžný řetězec z řetězce unicode? Zakódujte to:
>>> u "abc" .encode ("ascii") "abc"
Kódovací algoritmus je přirozeně opakem výše uvedeného.
Pamatujte a nepleťte - unicode == znaky, řetězec == bajty a bajty -> něco smysluplného (znaky) se dekóduje a znaky -> bajty se zakódují.
Není zakódováno :(
Podívejme se na příklady ze začátku článku. Jak funguje řetězení řetězců a unicode řetězců? Jednoduchý řetězec se musí změnit na řetězec unicode, a protože interpret nezná kódování, použije výchozí kódování - ascii. Pokud toto kódování nedokáže dekódovat řetězec, dostaneme ošklivou chybu. V tomto případě musíme řetězec převést na řetězec unicode sami pomocí správného kódování:>>> typ tisku (parser_result), parser_result
"UnicodeDecodeError" je obvykle označení pro dekódování řetězce do Unicode pomocí správného kódování.
Nyní pomocí řetězců "str" a unicode. Nepoužívejte řetězce „str“ a unicode :) V „str“ neexistuje způsob, jak specifikovat kódování, takže bude vždy použito výchozí kódování a jakékoli znaky > 128 povedou k chybě. Použijte metodu "kódování":
>>> typ tisku (y), s
"UnicodeEncodeError" je známkou toho, že musíme zadat správné kódování při převodu řetězce unicode na běžný (nebo použít druhý parametr "ignore" \ "replace" \ "xmlcharrefreplace" v metodě "encode").
Chci víc!
Dobře, pojďme znovu použít Baba Yaga z příkladu výše:>>> parser_result = u "baba-yaga" # 1 >>> parser_result u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" # 2 >>> print parser_result áàáà-ÿãà # 3 >>> print parser_result.encode ("latin1") # 4 baba yaga >>> print parser_result.encode ("latin1"). decode ("cp1251") # 5 baba yaga >>> tisk unicode ("baba yaga", "cp1251" ) # 6 baba-yaga
Příklad není úplně jednoduchý, ale je tam všechno (no, nebo skoro všechno). Co se tam děje:
- Co máme u vchodu? Byty, které IDLE předá interpretu. Co potřebujete na výstupu? Unicode, tedy znaky. Zbývá převést bajty na znaky - ale potřebujete kódování, že? Jaké kódování bude použito? Díváme se dále.
- Zde je důležitý bod: >>> "baba-yaga" "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" >>> u "\ u00e1 \ u00e0 \ u00e1 \ u00e0- \ u00ff \ u00e3 \ u00e0" == u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" Pravda, jak vidíte, Python se neobtěžuje s výběrem kódování - bajty jsou jednoduše převedeny na body unicode:
>>> ord ("a") 224 >>> ord (u "a") 224 - Pouze zde je problém - 224. znak v cp1251 (kódování používané interpretem) není vůbec stejné jako 224 v Unicode. Je to kvůli tomu, že se při pokusu o tisk našeho řetězce unicode dostaneme k prasknutí.
- Jak pomoci ženě? Ukazuje se, že prvních 256 znaků Unicode je stejných jako v kódování ISO-8859-1 \ latin1, respektive, pokud jej použijeme ke kódování řetězce unicode, získáme bajty, které jsme sami zadali (koho to zajímá - Objekty / unicodeobject.c, hledám definici funkce "unicode_encode_ucs1"):
>>> parser_result.encode ("latin1") "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" - Jak získáte baba v unicode? Je nutné uvést, jaké kódování použít:
>>> parser_result.encode ("latin1"). dekódovat ("cp1251") u "\ u0431 \ u0430 \ u0431 \ u0430- \ u044f \ u0433 \ u0430" - Metoda z bodu #5 určitě není tak žhavá, mnohem pohodlnější je použít vestavěný unicode.
Existuje také způsob, jak použít "u" "" k reprezentaci například azbuky, aniž by bylo nutné specifikovat kódování nebo nečitelné body unicode (tj. "u" \ u1234 ""). Způsob není úplně pohodlný, ale zajímavé je použití kódů entit unicode:
>>> s = u "\ N (MALÉ PÍSMENO KA) \ N (MALÉ PÍSMENO O) \ N (MALÉ PÍSMENO SHCHA) \ N (MALÉ PÍSMENO IE) \ N (MALÉ PÍSMENO KRÁTKÉ I)"> >> tisknout s koshchey
No, to je vše. Hlavní radou je nezaměňovat „kódování“ \ „dekódovat“ a rozumět rozdílům mezi bajty a znaky.
Python 3
Zde bez kódu, protože nejsou žádné zkušenosti. Pamětníci říkají, že je tam všechno mnohem jednodušší a zábavnější. Kdo se zaváže na kočkách demonstrovat rozdíly mezi tady (Python 2.x) a tam (Python 3.x) - respekt a respekt.Zdravý
Protože mluvíme o kódování, doporučím zdroj, který čas od času pomůže překonat krakozyabry - http://2cyr.com/decode/?lang=ru.Unicode HOWTO je oficiální dokument o tom, kde, jak a proč Unicode v Pythonu 2.x.
děkuji za pozornost. Budu rád za vaše soukromé komentáře. Přidat štítky
Body kódu Unicode a ruské znaky ve zdrojových kódech a programech Java. JDK 1.6.
Dost vývojářů software ve skutečnosti nemají jasnou představu o znakových sadách, kódování, Unicode a souvisejících materiálech. Dokonce i v dnešní době mnoho programů často ignoruje konverze znaků, se kterými se setkáváme, dokonce i programy, které se zdají být navrženy s technologiemi Java vstřícnými vůči Unicode. Často se neopatrně používá pro 8bitové znaky, což znemožňuje vývoj dobrých vícejazyčných webových aplikací. Tento článek je kompilací série článků o kódování Unicode, ale přelomový článek od Joela Spolského je Absolutní minimum, které musí každý vývojář softwaru absolutně, pozitivně znát o Unicode a znakových sadách (10. 8. 2003).Historie tvorby různých typů kódování
Všechno, co říká „prostý text = ASCII = 8bitové znaky“, není správné. Jediné znaky, které se mohly za jakýchkoliv okolností zobrazit správně, byly anglická písmena bez diakritiky s kódy 32 až 127. Pro tyto znaky existuje kód zvaný ASCII, který dokázal reprezentovat všechny znaky. Písmeno „A“ by mělo kód 65, mezera by kód 32 a tak dále. Tyto znaky mohly být pohodlně uloženy v 7 bitech. Většina počítačů v té době používala 8bitové registry, takže jste nejen mohli ukládat každý možný znak ASCII, ale měli jste také spoustu úspor, které byste, pokud byste měli takový rozmar, mohli použít pro své vlastní účely. Kódy menší než 32 se nazývaly netisknutelné a používaly se pro řídicí znaky, například znak 7 způsobil, že počítač vydal pípnutí reproduktoru, a znak 12 byl znak na konci stránky, což způsobilo, že tiskárna posouvala aktuální list. papíru a vložte nový.
Protože bajty jsou osmibitové, mnozí si mysleli, že „můžeme použít kódy 128-255 pro naše vlastní účely“. Problém byl v tom, že pro tolik lidí tento nápad přišel téměř současně, ale každý měl své vlastní představy o tom, co by mělo být umístěno s kódy 128 až 255. IBM-PC mělo něco, co se stalo známým jako znaková sada OEM, která měla nějaká diakritika pro evropské jazyky a sada znaků pro kreslení čar: vodorovné pruhy, svislé pruhy, rohy, křížky atd. A pomocí těchto symbolů můžete vytvářet elegantní tlačítka a kreslit čáry na obrazovce, které můžete stále vidět na některých starších počítačích. Například na některých počítačích byl kód znaku 130 zobrazen jako e, ale na počítačích prodávaných v Izraeli to bylo hebrejské písmeno Gimel (?). Pokud by Američané poslali svůj životopis do Izraele, dorazil by jako r? Sum?. V mnoha případech, jako například v případě ruského jazyka, existovalo mnoho různých nápadů, co dělat s horními 128 znaky, a proto nebylo možné spolehlivě vyměnit ani ruskojazyčné dokumenty.
Nakonec byla rozmanitost OEM kódování zredukována na standard ANSI. Standard ANSI specifikoval, které znaky byly pod 128, tato oblast byla v podstatě stejná jako v ASCII, ale bylo jich mnoho různé způsoby zpracovávat znaky 128 a vyšší v závislosti na tom, kde jste bydleli. Tyto různé systémy se nazývají kódové stránky. Například v Izraeli DOS používal kódovou stránku 862, zatímco řečtí uživatelé používali stránku 737. Byly stejné pod 128, ale lišily se od 128, kde byly všechny tyto znaky umístěny. Národní verze systému MS-DOS podporovaly mnoho z těchto kódových stránek, zvládaly všechny jazyky od angličtiny po islandštinu, a dokonce existovalo několik „vícejazyčných“ kódových stránek, které dokázalo vytvořit esperanto a galicijština. skupina jazyků rozšířená ve Španělsku, nativní reproduktory 4 milionů lidí) na stejném počítači! Ale dostat, řekněme, hebrejštinu a řečtinu na stejném počítači bylo absolutně nemožné, pokud jste nenapsali svůj vlastní program, který vše zobrazoval pomocí bitmapové grafiky, protože hebrejština a řečtina vyžadovaly různé kódové stránky s různými interpretacemi.
Mezitím v Asii, vzhledem k tomu, že asijské abecedy mají tisíce písmen, která se nikdy nevejdou do 8 bitů, tento problém vyřešil spletitý systém DBCS, „dvoubajtová znaková sada“, ve které byly některé znaky uloženy v jednom bajtu, zatímco jiní brali dva. Bylo velmi snadné se posunout vpřed po čáře, ale absolutně nemožné se posunout zpět. Programátoři nemohli používat s ++ a s-- k pohybu vpřed a vzad a museli volat speciální funkce kteří věděli, jak si s tímto nepořádkem poradit.
Většina lidí však přimhouřila oči nad skutečností, že bajt je znak a znak má 8 bitů, a pokud jste nemuseli přesouvat řádek z jednoho počítače na druhý, nebo pokud jste nemluvili více než jeden jazyk, fungovalo to. Ale samozřejmě, jakmile se začal masově používat internet, začalo se zcela běžně přenášet linky z jednoho počítače na druhý. Chaos v této věci byl překonán pomocí Unicode.
Unicode
Unicode byl odvážným pokusem o vytvoření jediné znakové sady, která by zahrnovala všechny skutečné systémy psaní na planetě, stejně jako některé fiktivní. Někteří lidé mají mylnou představu, že Unicode je běžný 16bitový kód, kde je každý znak dlouhý 16 bitů, a proto existuje 65 536 možných znaků. Ve skutečnosti to není pravda. Toto je nejčastější mylná představa o Unicode.
Ve skutečnosti Unicode zaujímá neobvyklý přístup k pochopení konceptu postavy. Dosud jsme předpokládali, že znaky jsou mapovány na sadu bitů, které můžete uložit na disk nebo do paměti:
A - & gt 0100 0001
V Unicode se znak mapuje na něco, co se nazývá bod kódu, což je pouze teoretický koncept. Jak je tento kódový bod reprezentován v paměti nebo na disku, je jiný příběh. PROTI Unicode písmeno A to je jen platónská představa (eidos) (cca.překlad: pojem Platónovy filozofie, eidos jsou ideální entity, postrádající tělesnost a jsou skutečně objektivní realitou, mimo konkrétní věci a jevy).
A NSže Platonov A se liší od B a liší se od A, ale je to stejné A jako A a A. Představte si to A v Times New Roman je to stejné jako A v Helvetice, ale odlišné od malého „a“ se v chápání lidí nezdá příliš kontroverzní. Ale z hlediska informatiky a z hlediska jazyka je samotná definice písmene rozporuplná. Je německé písmeno ß skutečné písmeno, nebo jen nóbl způsob, jak psát ss? Pokud se změní pravopis písmene na konci slova, stane se z něj jiné písmeno? Hebrejština říká ano, arabština říká ne. Ať tak či onak, chytří lidé z konsorcia Unicode na to po dlouhých politických debatách přišli a nemusíte se o to starat. Vše už bylo pochopeno před námi.Každému platónskému písmenu v každé abecedě bylo konsorciem Unicode přiděleno magické číslo, které se zapisuje takto: U + 0645. Toto magické číslo se nazývá kódový bod. U + znamená „Unicode“ a čísla jsou hexadecimální. Číslo U + FEC9 je arabské písmeno Ain. Anglické písmeno A odpovídá U + 0041.
Skutečně neexistuje žádný limit na počet písmen, která lze pomocí Unicode identifikovat, a ve skutečnosti již překročili hranici 65 536, takže ne každé písmeno z Unicode lze skutečně zkomprimovat do dvou bajtů.
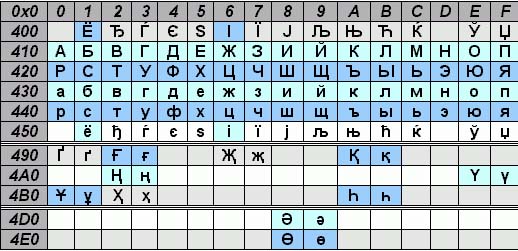
Pro azbuku v UNICODE je rozsah kódů od 0x0400 do 0x04FF. Tato tabulka zobrazuje pouze část znaků v tomto rozsahu, ale standard definuje většinu kódů v tomto rozsahu.
Představme si, že máme řádek:
Ahoj! který v Unicode odpovídá těmto sedmi kódovým bodům: U + 041F U + 0440 U + 0438 U + 0432 U + 0435 U + 0442 U + 0021
Jen hromada bodů kódu. Čísla jsou skutečná.
Chcete-li vidět, jak bude textový soubor Unicode vypadat, můžete spustit program Poznámkový blok ve Windows, vložit daný řádek a uložit textový soubor zvolte kódování Unicode.
Program nabízí spoření ve třech variantách Kódování Unicode... První možností je způsob zápisu s nejméně významným bytem na začátku (little endian), druhou s nejvýznamnějším bytem na začátku (big endian). Která možnost je správná?
Takto vypadá soubor výpisu big endian s řetězcem „Ahoj!“:
A takto vypadá výpis souboru s řetězcem „Ahoj!“, uložený ve formátu Unicode (little endian):
A takto vypadá výpis souboru s řetězcem „Ahoj!“, uložený ve formátu Unicode (UTF-8):
První implementace chtěly být schopny ukládat body kódu Unicode ve formátu high-endian nebo low-endian, v závislosti na tom, ve kterém formátu byl jejich procesor rychlejší. Pak byly dva způsoby, jak uložit Unicode. To vedlo k nápadité konvenci ukládání kódu \uFFFE na začátek každého řádku Unicode. Tento podpis se nazývá značka pořadí bajtů. Pokud zaměníte své vysoké a nízké bajty, pak \uFFFE musí být na začátku a osoba, která čte váš řádek, bude vědět, že má prohodit bajty v každém páru. Tento podpis je vyhrazen ve standardu Unicode.
Standard Unicode říká, že výchozí pořadí bajtů je buď big endian nebo little endian. Ve skutečnosti jsou obě objednávky správné a projektanti systému si jednu z nich vyberou. Nedělejte si starosti, pokud váš systém komunikuje s jiným systémem a oba používají little endian.
Pokud však váš Windows komunikuje se serverem UNIX, který používá big endian, musí překódování provést jeden ze systémů. V tomto případě Standard Unicode uvádí, že si můžete vybrat kterékoli z následujících řešení problému:
- Když si dva systémy používající různé pořadí bajtů Unicode vyměňují data (bez použití jakýchkoli speciálních protokolů), pořadí bajtů musí být big endian. Standard tomu říká kanonický pořadí bajtů.
- Každý řetězec Unicode musí začínat kódem \uFEFF. Kód \ uFFFE, který je inverzí znaku objednávky. Pokud tedy příjemce vidí kód \uFEFF jako první znak, znamená to, že bajty jsou v pořadí typu little endian. Ve skutečnosti však ne každý řetězec Unicode má na začátku značku pořadí bajtů.
Druhá metoda je univerzálnější a výhodnější.
Chvíli se zdálo, že všichni jsou šťastní, ale anglicky mluvící programátoři se dívali převážně na anglický text a zřídka používali kódové body nad U + 00FF. Už jen z tohoto důvodu bylo Unicode mnoho let ignorováno.
Geniální koncept UTF-8 byl vynalezen speciálně pro tento účel.
UTF-8
UTF-8 byl další systém pro ukládání vaší sekvence bodů kódu Unicode, samotných čísel U +, pomocí stejných 8 bitů v paměti. V UTF-8 byl každý kódový bod s číslem 0 až 127 uložen v jednom bajtu.
Ve skutečnosti se jedná o kódování s proměnným počtem kódovacích bytů pro úložiště, používá se 2, 3 a ve skutečnosti až 6 bytů. Pokud znak patří do sady ASCII (kód v rozsahu 0x00-0x7F), pak je zakódován stejně jako v ASCII do jednoho bajtu. Pokud je unicode znaku větší nebo roven 0x80, pak jsou jeho bity zabaleny do sekvence bajtů podle následujícího pravidla:
Můžete si všimnout, že pokud bajt začíná nulovým bitem, jedná se o jednobajtový znak ASCII. Pokud bajt začíná 11..., jedná se o počáteční bajt několikabajtové sekvence, která kóduje znak, jehož počet hlaviček se rovná počtu bajtů v sekvenci. Pokud bajt začíná 10 ..., pak se jedná o sériový "transportní" bajt ze sekvence bajtů, jejichž počet byl určen počátečním bajtem. dobře a Unicode bity znaky jsou zabaleny do "transportních" bitů počátečních a sériových bajtů, označených v tabulce jako sekvence "xx..x".
Proměnný počet bajtů kódování lze vidět z výpisu souboru níže.
Soubor výpisu s řetězcem „Ahoj!“ Uložený ve formátu Unicode (UTF-8):
Dump soubor s řetězcem „Ahoj!“ Uložený ve formátu Unicode (UTF-8):
Příjemným vedlejším efektem je, že anglický text vypadá v UTF-8 úplně stejně jako v ASCII, takže Američané si ani nevšimnou, že je něco špatně. Jen zbytek světa musí překonávat překážky. Konkrétně Dobrý den, to, co bylo U + 0048 U + 0065 U + 006C U + 006C U + 006F, bude nyní uloženo ve stejném 48 65 6C 6C 6F, stejně jako ASCII a ANSI a jakékoli jiné sady OEM symbolů na planetě. Pokud máte odvahu používat diakritiku popř Řecká písmena nebo klingonská písmena, budete muset použít více bajtů k uložení jednoho bodu kódu, ale Američané si toho nikdy nevšimnou. UTF-8 má také příjemnou vlastnost: starý kód, neznalý nového formátu řetězců a manipulace s řetězci s prázdným bajtem na konci řádku, řetězce nezkrátí.
Další kódování Unicode
Vraťme se ke třem způsobům kódování Unicode. Tradiční metody"uložte to do dvou bajtů" se nazývá UCS-2 (protože má dva bajty) nebo UTF-16 (protože má 16 bitů) a stále musíte zjistit, zda se jedná o kód UCS-2 s vysokým byte na začátek nebo s nejvýznamnějším bytem na konci. A je tu oblíbený standard UTF-8, jehož řetězce mají příjemnou vlastnost, že fungují i ve starých programech, které pracují s anglickým textem, a v nových chytrých programech, které perfektně fungují i na jiných znakových sadách kromě ASCII.
Ve skutečnosti existuje celá řada dalších způsobů, jak kódovat Unicode. Existuje něco, co se nazývá UTF-7, což je hodně podobné UTF-8, ale zajišťuje, že nejvýznamnější bit je vždy nula. Pak je tu UCS-4, který ukládá každý kódový bod do 4 bajtů a zaručuje, že absolutně všechny znaky jsou uloženy ve stejném počtu bajtů, ale ne vždy je takové plýtvání pamětí ospravedlnitelné takovou zárukou.
Můžete například kódovat Unicode řetězec Hello (U + 0048 U + 0065 U + 006C U + 006C U + 006F) v ASCII nebo ve starém řeckém kódování OEM nebo v hebrejštině ANSI kódování, nebo v některém z několika stovek kódování, která byla dodnes vynalezena, s jedním problémem: některé znaky se nemusí zobrazit! Pokud neexistuje ekvivalent pro bod kódu Unicode, pro který se v některých pokoušíte najít ekvivalent tabulka kódů pro které se pokoušíte provést konverzi, obvykle dostanete malý otazník:? nebo, pokud jste opravdu dobrý programátor, pak čtverec.
Existují stovky tradičních kódování, která dokážou správně uložit pouze některé body kódu a nahradit všechny ostatní body otazníky. Například některá populární kódování anglického textu jsou Windows 1252 ( Windows standardní 9x pro západoevropské jazyky) a ISO-8859-1, neboli Latin-1 (vhodné také pro jakýkoli západoevropský jazyk). Ale zkuste převést ruská nebo hebrejská písmena v těchto kódováních a skončíte s pořádným množstvím otazníků. Skvělá věc na UTF 7, 8, 16 a 32 je jejich schopnost správně uložit jakýkoli bod kódu.
32bitové kódové body pro znaky Unicode v Javě
Java 2 5.0 zavádí významná vylepšení typů znaků a řetězců pro podporu 32bitových verzí Unicode znaky... V minulosti mohly být všechny znaky Unicode uloženy v šestnácti bitech, které se rovnají velikosti znaku (a velikosti hodnoty obsažené v objektu Character), protože tyto hodnoty byly v rozsahu 0 až FFFF. Ale nějakou dobu byla znaková sada Unicode rozšířena a nyní vyžaduje více než 16 bitů pro uložení znaku. Nová verze znakových sad Unicode obsahuje znaky v rozsahu od 0 do 10FFFF.
Kódový bod nebo kódový bod, kódová jednotka nebo kódová jednotka a doplňkový znak. Pro Java je bod kódu znakový kód v rozsahu 0 až 10FFFF. V jazyce Java se termín „kódová jednotka“ používá k označení 16bitových znaků. Znaky s hodnotami vyššími než FFFF se nazývají doplňkové.
Rozšíření znakové sady Unicode způsobilo zásadní problémy pro jazyk Java... Vzhledem k tomu, že doplňkový znak má větší hodnotu, než může pojmout typ znaku, bylo zapotřebí některých prostředků k uložení a zpracování dalších znaků. PROTI verze Java 2 5.0 řeší tento problém dvěma způsoby. Za prvé, jazyk Java používá dvě hodnoty znaků k reprezentaci dalšího znaku. První se nazývá vysoká náhrada a druhá se nazývá nízká náhrada. Byly vyvinuty nové metody, jako je codePointAt (), pro převod bodů kódu na doplňkové znaky a naopak.
Za druhé, Java přetěžuje některé z již existujících metod ve třídách Character a String. Přetížené varianty metod používají data typu int místo char. Protože velikost proměnné nebo konstanty typu int je dostatečně velká, aby se do ní vešel jakýkoli znak jako jediná hodnota, lze tento typ použít k uložení libovolného znaku. Například metoda isDigit () má nyní dvě možnosti, jak je uvedeno níže:
První z těchto možností je originál, druhá je verze, která podporuje 32bitové kódové body. Metody All is…, jako je isLetter () a isSpaceChar (), mají verze kódu, stejně jako metody to… jako toUpperCase () a toLowerCase ().
Kromě metod přetížených zpracováním kódových bodů obsahuje jazyk Java nové metody ve třídě Character, které poskytují další podporu pro kódové body. Některé z nich jsou uvedeny v tabulce:
| Metoda | Popis |
| static int charCount (int cp) | Vrátí 1, pokud cp může být reprezentováno jedním znakem. Vrátí 2, pokud jsou vyžadovány dvě hodnoty znaků. |
| statický int codePointAt (znaky znakové sekvence, int loc) | |
| static int codePointAt (char chars, int loc) | Vrátí kódový bod pro pozici znaku zadanou v parametru loc |
| static int codePointBefore (znaky CharSequence, int loc) | |
| static int codePointBefore (char chars, int loc) | Vrátí kódový bod pro pozici znaku předcházející pozici zadanou v parametru loc |
| statický booleovský isSupplementaryCodePoint (int cp) | Vrátí hodnotu true, pokud cp obsahuje znak navíc |
| statický booleovský isHighSurrogate (char ch) | Vrátí hodnotu true, pokud ch obsahuje platný zástupný znak horního znaku. |
| statický booleovský isLowSurrogate (char ch) | Vrátí hodnotu true, pokud ch obsahuje platný náhradní znak nižšího znaku. |
| statický booleovský isSurrogatePair (char highCh, char lowCh) | Vrátí hodnotu true, pokud highCh a lowCh tvoří platný náhradní pár. |
| statický booleovský isValidCodePoint (int cp) | Vrátí hodnotu true, pokud cp obsahuje platný kódový bod. |
| statický znak toChars (int cp) | Převede bod kódu obsažený v cp na jeho ekvivalent char, který může vyžadovat dvě hodnoty char. Vrátí pole obsahující výsledek ... Append !!! |
| static int toChars (int cp, char target, int loc) | Převede bod kódu obsažený v cp na jeho ekvivalent char, uloží výsledek do cíle, počínaje pozicí zadanou v loc. Vrátí 1, pokud cp může být reprezentováno jedním znakem, a 2 jinak. |
| static int toCodePoint (char ighCh, char lowCh) | Převede highCh a lowCh na jejich ekvivalentní kódové body. |
Třída String má řadu metod pro práci s kódovými body. Do třídy String byl také přidán následující konstruktor, který podporuje rozšířenou znakovou sadu Unicode:
Řetězec (int codePoints, int startIndex, int numChars)
Ve výše uvedené syntaxi je codePoints pole obsahující body kódu. Vytvoří se výsledný řetězec délky numChars počínaje pozicí startIndex.
Několik metod třídy String, které poskytují podporu 32bitového kódu pro znaky Unicode.
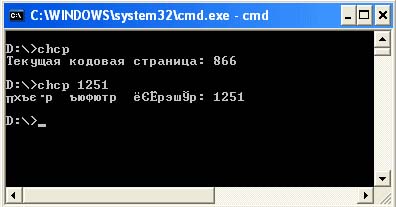
Výstup konzoly ve Windows. Příkaz chcp
Většina jednoduché programy napsaný v Javě vypíše všechna data do konzole. Výstup konzoly poskytuje možnost zvolit kódování, ve kterém budou data vašeho programu vystupovat. Okno konzoly můžete spustit kliknutím na Start -> Spustit a poté zadejte a spusťte příkaz cmd... Ve výchozím nastavení je výstup do konzoly ve Windows v kódování Cp866. Chcete-li zjistit, v jakém kódování jsou znaky zobrazeny v konzole, měli byste zadat příkaz chcp. Pomocí stejného příkazu můžete nastavit kódování, ve kterém se budou znaky zobrazovat. Například chcp 1251. Ve skutečnosti je tento příkaz vytvořen pouze proto, aby odrážel nebo změnil aktuální číslo kódové stránky konzoly.
Jiné kódové stránky než Cp866 se správně zobrazí pouze v režimu celé obrazovky nebo v okně příkazový řádek pomocí TrueType písem. Například:
Abyste viděli následný výstup, musíte změnit aktuální písmo na písmo True Type. Přesuňte kurzor nad titulek okna konzoly a klikněte klikněte pravým tlačítkem myši myši a vyberte možnost "Vlastnosti". V okně, které se objeví, přejděte na kartu Písmo a v ní vyberte písmo, naproti kterému bude dvojité písmeno T. Budete vyzváni k uložení toto nastavení pro aktuální okno nebo pro všechna okna.
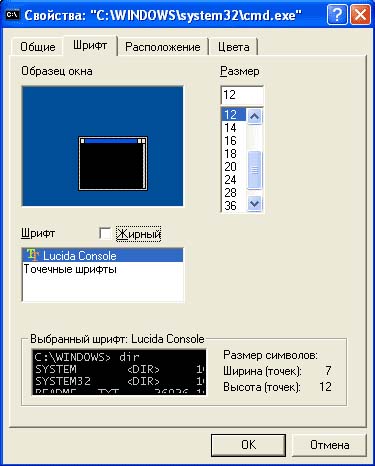
V důsledku toho bude vaše okno konzoly vypadat takto:
Manipulací s tímto příkazem tedy můžete vidět výsledky výstupu vašeho programu v závislosti na kódování.
Vlastnosti systému file.encoding, console.encoding a konzolový výstup
Než se dotknete tématu kódování ve zdrojových kódech programů, měli byste jasně pochopit, k čemu slouží a jak fungují vlastnosti systému file.encoding a console.encoding. Kromě těchto vlastností systému existuje řada dalších. Všechny aktuální vlastnosti systému můžete zobrazit pomocí následujícího programu:
Importovat java.io. *; import java.util. *; public class getPropertiesDemo (public static void main (String args) (String s; for (Výčet e = System.getProperties (). propertyNames (); e.hasMoreElements ();) (s = e.nextElement (). toString () ; System.out.println (s + "=" + System.getProperty (s));)))
Ukázkový výstup programu:
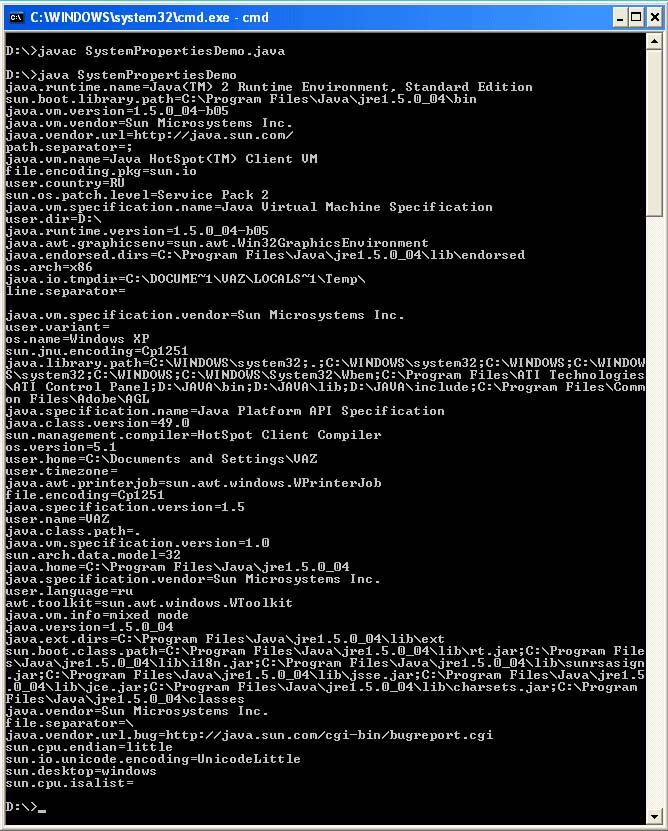
V operačním systému Windows je ve výchozím nastavení file.encoding = Сp1251. Existuje však další vlastnost console.encoding, která určuje, v jakém kódování má být výstup na konzoli. file.encoding říká stroji Java, ve kterém kódování má číst zdrojové kódy programů, pokud kódování není specifikováno uživatelem během kompilace. Ve skutečnosti se tato systémová vlastnost vztahuje také na výstup pomocí System.out.println ().
Ve výchozím nastavení není tato vlastnost nastavena. Tyto systémové vlastnosti lze také nastavit ve vašem programu, pro něj však již nebude relevantní, protože virtuální stroj používá hodnoty, které byly načteny před kompilací a spuštěním vašeho programu. Jakmile se váš program spustí, také se obnoví vlastnosti systému. Můžete to ověřit dvojitým spuštěním následujícího programu.
/ ** * @author & lta href = "mailto: [e-mail chráněný]"& gt Victor Zagrebin & lt / a & gt * / veřejná třída SetPropertyDemo (veřejné statické void main (string args) (System.out.println (" file.encoding before = "+ System.getProperty (" file.encoding ")) ); System. out.println ("console.encoding před =" + System.getProperty ("console.encoding")); System.setProperty ("file.encoding", "Cp866"); System.setProperty ("console. encoding", " Cp866 "); System.out.println (" file.encoding after = "+ System.getProperty (" file.encoding ")); System.out.println (" console.encoding after = "+ System. getProperty ("console .encoding "));)) 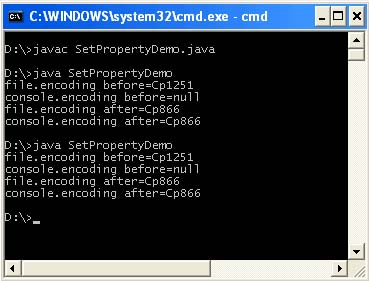
Nastavení těchto vlastností v programu je nutné, když je použito v následujícím kódu před ukončením programu.
Zopakujme si několik typických příkladů s problémy, se kterými se programátoři setkávají při výstupu. Řekněme, že máme následující program:
Veřejná třída CyryllicDemo (veřejné statické void main (String args) (String s1 = ""; Řetězec s2 = ""; System.out.println (s1); System.out.println (s1);)) Kromě tohoto programu , budeme provozovat další faktory:
- kompilační příkaz;
- příkaz ke spuštění;
- kódování zdrojového kódu programu (instalované ve většině textových editorů);
- kódování výstupu konzoly (standardně se používá Cp866 nebo se nastavuje pomocí příkazu chcp);
- viditelný výstup v okně konzoly.
javac CyryllicDemo.java
Jáva Cyryllic Demo
Kódování souboru: Cp1251
Kódování konzoly: Cp866
Výstup :
└┴┬├─┼╞╟╚╔╩╦╠═╬╧╨╤╥╙╘╒╓╫╪┘▄█┌▌▐ ▀
rstufhtschshshch'yueyuyoЄєЇїЎў °∙№√ ·¤■
javac CyryllicDemo.java
Kódování souboru: Cp866
Kódování konzole: Cp866
Výstup :
CyryllicDemo.java:5: varování: nemapovatelný znak pro kódování Cp1251
Řetězec s1 = "ABVGDEZHZYKLMNOPRSTUFHTSCH? SHY'EUYA";
javac CyryllicDemo.java -kódování Cp866
Jáva -
Kódování souboru: Cp 866
Kódování konzole: Cp866
Výstup :
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshshchyyueyuya
javac CyryllicDemo.java -kódování Cp1251
Jáva -Dfile.encoding = Cp866 CyryllicDemo
Kódování souboru: Cp1251
Kódování konzoly: Cp866
Výstup :
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshshchyyueyuya
Zvláštní pozornost by měla být věnována problému "Kam zmizelo písmeno Ш?" z druhé série startů. Tomuto problému byste měli věnovat ještě větší pozornost, pokud předem nevíte, jaký text bude uložen ve výstupním řetězci, a naivně se zkompiluje bez zadání kódování. Pokud opravdu nemáte v řádku písmeno Ш, pak bude kompilace úspěšná a spuštění bude také úspěšné. A u toho ještě zapomenete, že vám chybí maličkost (písmeno W), která se ve výstupním řádku může vyskytnout a nevyhnutelně povede k dalším chybám.
Ve třetí a čtvrté sérii se při kompilaci a spuštění používají následující klíče: -encoding Cp866 a -Dfile.encoding = Cp866. Přepínač -encoding určuje, ve kterém kódování se má soubor číst zdrojový kód programy. Přepínač -Dfile.encoding = Cp866 označuje, v jakém kódování má být výstup.
Předpona Unicode \ u a ruské znaky ve zdrojových kódech
Java má speciální předponu \u pro psaní znaků Unicode, za kterou následují čtyři hexadecimální číslice, které definují samotný znak. Například \u2122 je znak značka(™). Tato forma zápisu vyjadřuje znak libovolné abecedy pomocí čísel a prefixu - znaků, které jsou obsaženy ve stabilním rozsahu kódů od 0 do 127, který není ovlivněn převodem zdrojového kódu. A teoreticky lze v Java aplikaci nebo appletu použít jakýkoli znak Unicode, ale zda se na obrazovce zobrazí správně a zda se vůbec zobrazí, závisí na mnoha faktorech. U appletů záleží na typu prohlížeče a u programů a appletů na typu operačního systému a kódování, ve kterém je zdrojový kód programu napsán.
Například na počítačích s americkou verzí Systémy Windows, není možné zobrazit japonské znaky pomocí jazyka Java kvůli problému s internacionalizací.
Jako druhý příklad můžeme uvést celkem častou chybu programátorů. Mnoho lidí si myslí, že zadáním ruských znaků ve formátu Unicode pomocí předpony \ u ve zdrojovém kódu programu lze vyřešit problém se zobrazováním ruských znaků za všech okolností. Koneckonců, virtuální stroj Java překládá zdrojový kód programu do Unicode. Před překladem do Unicode však musí virtuální stroj vědět, v jakém kódování je zdrojový kód vašeho programu napsán. Ostatně program můžete napsat jak v kódování Cp866 (DOS), tak i Cp1251 (Windows), což je pro tuto situaci typické. Pokud jste nezadali žádné kódování, virtuální stroj Java načte váš soubor se zdrojovým kódem programu v kódování zadaném v systémové vlastnosti file.encoding.
Nicméně, zpět k výchozím parametrům, budeme předpokládat, že file.encoding = Сp1251 a výstup do konzole se provádí v Cp866. V tomto případě nastává následující situace: řekněme, že máte soubor zakódovaný v Сp1251:
Soubor MsgDemo1.java
Veřejná třída MsgDemo1 (veřejná statická void main (String args) (String s = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A \ u0430"; System.out. ;)))
A očekáváte, že slovo „kódování“ bude vytištěno na konzole, ale dostanete:
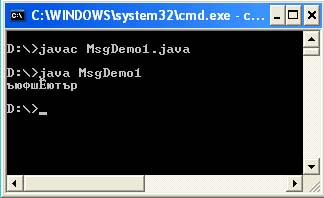
Faktem je, že kódy s předponou \ u uvedené v programu skutečně kódují požadované znaky azbuky v tabulce kódů Unicode, jsou však navrženy tak, aby byl zdrojový kód vašeho programu načten v Cp866 (DOS) kódování. Standardně je kódování Cp1251 specifikováno ve vlastnostech systému (file.encoding = Cp1251). Přirozeně první a nesprávná věc, která vás napadne, je změnit kódování souboru se zdrojovým kódem programu v textovém editoru. Ale tím se nikam nedostanete. Java VM bude stále číst váš soubor v kódování Cp1251 a kódy \ u jsou pro Cp866.
Z této situace existují tři cesty. První možností je použít přepínač -encoding při kompilaci a –Dfile.encoding ve fázi spouštění programu. V tomto případě přinutíte virtuální stroj Java číst zdrojový soubor v zadaném kódování a vystupovat v zadaném kódování.
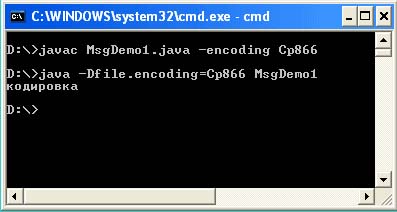
Jak můžete vidět z výstupu konzole, další parametr –encoding Cp866 musí být nastaven během kompilace a parametr –Dfile.encoding = Cp866 musí být nastaven při spuštění.
Druhou možností je překódování znaků v samotném programu. Je navržen tak, aby obnovil správné kódy písmen, pokud byly nesprávně interpretovány. Podstata metody je jednoduchá: z přijatých nesprávných znaků se pomocí příslušné kódové stránky obnoví původní bajtové pole. Potom se z tohoto pole bajtů s použitím již správné stránky získají normální kódy znaků.
Pro převod proudu bajtů na řetězec a naopak má třída String následující možnosti: konstruktor String (byte bytes, String enc), který přijímá proud bajtů jako vstup s indikací jejich kódování; pokud kódování vynecháte, bude akceptovat výchozí kódování ze systémové vlastnosti file.encoding. Metoda getBytes (String enc) vrací proud bajtů zapsaných v zadaném kódování; kódování lze také vynechat a bude přijato výchozí kódování ze systémové vlastnosti file.encoding.
Příklad:
Soubor MsgDemo2.java
Importovat java.io.UnsupportedEncodingException; veřejná třída MsgDemo2 (veřejná statická void main (argumenty řetězce) vyvolá výjimku UnsupportedEncodingException (String str = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A" \ u043 byte b" \ u043 byte ("Cp866"); String str2 = nový řetězec (b, "Cp1251"); System.out.println (str2);))
Výstup z programu:
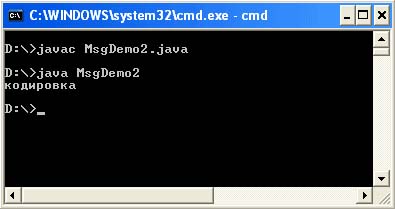
Tato metoda je méně flexibilní, pokud se řídíte tím, že kódování v systémové vlastnosti file.encoding se nezmění. Tato metoda se však může stát nejflexibilnější, pokud se dotazujete na systémovou vlastnost file.encoding a nahradíte výslednou hodnotu kódování při vytváření řetězců ve vašem programu. Použitím tato metoda měli byste si dát pozor, aby ne všechny stránky prováděly jednoznačnou konverzi bajtových znaků.
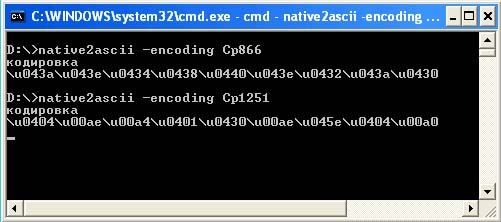
Třetím způsobem je vybrat správné kódy Unicode pro zobrazení slova „kódování“ za předpokladu, že soubor bude načten ve výchozím kódování - Cp1251. Pro tyto účely existuje speciální utilita native2ascii.
Tento nástroj je součástí Sun JDK a je určen pro převod zdrojového kódu do formátu ASCII. Při spuštění bez parametrů pracuje se standardním vstupem (stdin) a nezobrazuje klíčovou nápovědu jako jiné nástroje. To vede k tomu, že si mnozí ani neuvědomují, že je nutné parametry specifikovat (kromě těch, kteří nahlédli do dokumentace). Mezitím tento nástroj pro správná práce musíte minimálně určit použité kódování pomocí přepínače -encoding. Pokud tak neučiníte, použije se výchozí kódování (file.encoding), které se může poněkud lišit od očekávaného. V důsledku toho můžete po obdržení nesprávných písmenových kódů (kvůli nesprávnému kódování) strávit spoustu času hledáním chyb v absolutně správném kódu.
Následující snímek obrazovky ukazuje rozdíl v sekvencích kódu Unicode pro stejné slovo, když bude zdrojový soubor načten v kódování Cp866 a kódování Cp1251.
Pokud tedy nevynutíte kódování pro virtuální stroj Java v době kompilace a při spuštění a výchozí kódování (file.encoding) je Cp1251, pak by zdrojový kód programu měl vypadat takto:
Soubor MsgDemo3.java
Veřejná třída MsgDemo3 (veřejná statická void main (String args) (String s = "\ u0404 \ u00AE" + "\ u00A4 \ u0401 \ u0430 \ u00AE \ u045E" + "\ u0404 \ u00A0"; (System.out.println ;))) 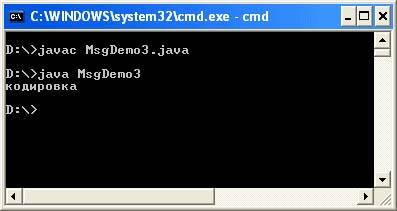
Pomocí třetí metody můžeme dojít k závěru: pokud se kódování souboru se zdrojovým kódem v editoru shoduje s kódováním v systému, objeví se zpráva „kódování“ ve své normální podobě.
Čtení a zápis do souboru ruské znaky vyjádřené předponou Unicode \ u
Pro čtení dat zapsaných ve formátu MBCS (s použitím kódování UTF-8) i Unicode můžete použít třídu InputStreamReader z balíku java.io, která v jeho konstruktoru nahradí různá kódování. Pro zápis se používá OutputStreamWriter. Popis balíčku java.lang říká, že každá implementace JVM bude podporovat následující kódování:
Soubor WriteDemo.java
Importovat java.io.Writer; import java.io.OutputStreamWriter; import java.io.FileOutputStream; import java.io.IOException; / ** * Výstup řetězce Unicode do souboru v určeném kódování. * @author & lta href = "mailto: [e-mail chráněný]"& gt Victor Zagrebin & lt / a & gt * / veřejná třída WriteDemo (veřejné statické void main (String args) vyvolá výjimku IOException (String str =" \ u043A \ u043E "+" \ u0434 \ u0438 \ u0440 \ u043E \ u0432 " +" \ u043A \ u0430 "; Writer out1 = nový OutputStreamWriter (nový FileOutputStream (" out1.txt "), Cp1251 "); Writer out2 = nový OutputStreamWriter (nový FileOutputStream (" out2.txt ")," Cp866 "); Writer out3 = nový OutputStreamWriter (nový FileOutputStream ("out3.txt"), "UTF-8"); Writer out4 = nový OutputStreamWriter (nový FileOutputStream ("out4.txt"), "Unicode"); out1.write (str) ; out1.close (); out2.write (str); out2.close (); out3.write (str); out3.close (); out4.write (str); out4.close ();)) Kompilace: javac WriteDemo.java Spustit: java WriteDemo
V důsledku spuštění programu by se ve spouštěcím adresáři programu měly vytvořit čtyři soubory (out1.txt out2.txt out3.txt out4.txt), z nichž každý bude obsahovat slovo „kódování“ v jiném kódování, které může být kontrolováno textové editory nebo zobrazením výpisu souborů.
Následující program přečte a zobrazí obsah každého z vygenerovaných souborů.
Import souboru ReadDemo.java java.io.Reader; import java.io.InputStreamReader; import java.io.InputStream; import java.io.FileInputStream; import java.io.IOException; / ** * Čtení znaků Unicode ze souboru v určeném kódování. * @author & lta href = "mailto: [e-mail chráněný]"& gt Victor Zagrebin & lt / a & gt * / veřejná třída ReadDemo (veřejné statické void main (argumenty řetězce) vyvolá výjimku IOException (String out_enc = System.getProperty (" console.encoding "," Cp866 "); System.out. write (readStringFromFile ( "out1.txt", "Cp1251", out_enc)); System.out.write ("\ n"); System.out.write (readStringFromFile ("out2.txt", "Cp866", out_enc) ); System. out.write ("\ n"); System.out.write (readStringFromFile ("out3.txt", "UTF-8", out_enc)); System.out.write ("\ n"); System.out. zápis (readStringFromFile ("out4.txt", "Unicode", out_enc));) veřejný statický bajt readStringFromFile (String název_souboru, Řetězec file_enc, String out_enc) vyvolá IOException (velikost int; InputStream f = nový FileInputStream (název souboru) ); size = f.available (); Reader in = new InputStreamReader (f, file_enc); char ch = nový znak; in.read (ch, 0, size); in.close (); return (new String (ch getBytes (out_enc);)) Kompilace: javac ReadDemo.java Spustit: java ReadDemo Výstup programu: 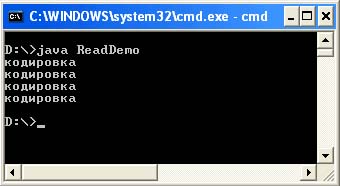
Za zmínku stojí zejména použití následujícího řádku kódu v tomto programu:
String out_enc = System.getProperty ("console.encoding", "Cp866");
Pomocí metody getProperty je proveden pokus o načtení hodnoty systémové vlastnosti console.encoding, která nastavuje kódování, ve kterém budou data vystupovat na konzoli. Pokud tato vlastnost není nastavena (často není nastavena), pak bude proměnné out_enc přiřazeno "Cp866". A dále se proměnná out_enc používá tam, kde je potřeba převést řetězec načtený ze souboru do kódování vhodného pro výstup do konzole.
Nabízí se také logická otázka: „proč se používá System.out.write a ne System.out.println“? Jak je popsáno výše, systémová vlastnost file.encoding se používá nejen ke čtení zdrojového souboru, ale také k výstupu pomocí System.out.println, což v tomto případě povede k nesprávnému výstupu.
Nesprávné zobrazení kódování ve webově orientovaných programech
Programátor by měl především vědět: nemá smysl mít řetězec, aniž bychom věděli, jaké kódování používá... V ASCII nic takového jako prostý text neexistuje. Pokud máte řetězec, v paměti, v souboru nebo ve zprávě E-mailem, musíte vědět, v jakém kódování to je, jinak to nebudete moci správně interpretovat ani ukázat uživateli.
Téměř za všechny tradiční problémy jako „můj web vypadá jako blábol“ nebo „moje e-maily jsou nečitelné, pokud používám znaky s diakritikou“ je zodpovědný programátor, který nechápe prostý fakt, že pokud nevíte, jaké kódování UTF-8 řetězec je v nebo ASCII nebo ISO 8859-1 (Latin-1) nebo Windows 1252 (západní Evropa), jen jej nebudete moci správně vytisknout. Nad bodem 127 kódu je více než sto kódování znaků a neexistují žádné informace, které by umožnily zjistit, které kódování je potřeba. Jak ukládáme informace o tom, jaké kódovací řetězce používají? existuje standardních metod k uvedení této informace. U e-mailových zpráv musíte vložit řádek do hlavičky HTTP
Content-Typ: text / prostý; znaková sada = "UTF-8"
U webové stránky byla původní myšlenka, že webový server pošle HTTP hlavičku sám, těsně předtím HTML stránku... To ale způsobuje určité problémy. Předpokládejme, že máte velký webový server s velkým počtem stránek a stovkami stránek vytvořených velkým počtem lidí na obrovském počtu různé jazyky a všechny nepoužívají specifické kódování. Samotný webový server skutečně nemůže vědět, jaké je kódování každého souboru, a proto nemůže odeslat hlavičku specifikující Content-Type. Pro označení správného kódování v hlavičce http tedy zbývalo ponechat informace o kódování uvnitř html souboru vložením speciální značky. Server by pak přečetl název kódování z metaznačky a vložil jej do hlavičky HTTP.
Vyvstává relevantní otázka: „jak začít číst soubor HTML, dokud nevíte, jaké kódování používá?! Naštěstí téměř všechna kódování používají stejnou tabulku znaků s kódy od 32 do 127 a samotný HTML kód se skládá z těchto znaků a v html souboru možná ani neuvidíte informace o kódování, pokud se skládá výhradně z takových znaků. V ideálním případě by tedy značka & ltmeta & gt označující kódování měla být opravdu na prvním řádku v sekci & lthead & gt, protože jakmile webový prohlížeč uvidí tento znak, přestane stránku analyzovat a začne znovu znovu pomocí vámi zadaného kódování.
& lthtml & gt & lthead & gt & ltmeta http-equiv = "Content-Type" content = "text / html; znaková sada = utf-8" & gt
Co udělají webové prohlížeče, když nenajdou žádný typ obsahu, ani v hlavičce http ani v značce Meta? internet Explorer ve skutečnosti dělá něco docela zajímavého: snaží se rozpoznat kódování a jazyk na základě frekvence, s jakou se různé bajty objevují v typickém textu v typických kódováních různých jazyků. Od té doby se různé staré 8bajtové kódové stránky umístily odlišně státní symboly mezi 128 a 255, a protože všechny lidské jazyky mají různé frekvenční pravděpodobnosti použití písmen, tento přístup často funguje dobře.
Je to docela bizarní, ale zdá se, že to docela často funguje a naivní autoři webových stránek, kteří nikdy nevěděli, že potřebují značku Content-Type v názvech svých stránek, aby se stránky zobrazovaly správně až do toho krásného dne. neodpovídá přesně typické distribuci frekvence jejich písmen v rodném jazyce a Internet Explorer rozhodne, že jde o korejštinu, a podle toho ji zobrazí.
Každopádně, co zbylo čtenáři tohoto webu, který byl napsán v bulharštině, ale zobrazen v korejštině (a dokonce ani ne smysluplné korejštině)? Používá View | Kódování a zkouší několik různých kódování (pro východoevropské jazyky existuje alespoň tucet), dokud nebude obraz jasnější. Pokud ovšem ví, jak na to, protože tohle většina lidí neví.
Sluší se podotknout, že u UTF-8, které je již léta dokonale podporováno webovými prohlížeči, se zatím nikdo nesetkal s problémem se správným zobrazením webových stránek.
Odkazy:
- Joel Spolsky. Absolutní minimum každý softwarový vývojář musí absolutně, pozitivně vědět o Unicode a znakových sadách (bez výmluv!) 10/08/2003 http://www.joelonsoftware.com/articles/Unicode.html
- Sergej Astakhov.
- Sergej Semichatov. ... 08.2000 - 27.07.2005
- Horstman K.S., Cornell G. Library of the professional. Java 2. Svazek 1. Základy. - M .: Williams Publishing House, 2003 .-- 848 s.
- Dan Chisholms. Předstírané zkoušky programátora Java. Cíl 2, InputStream a OutputStream Reader / Writer. Kódování znaků Java: UTF a Unicode. http://www.jchq.net/certkey/1102_12certkey.htm
- Balíček java.io. Specifikace API JavaTM 2 Platform Standard Edition 6.0.
Unicode: UTF-8, UTF-16, UTF-32.
Unicode je sada grafických znaků a způsob jejich kódování pro počítačové zpracování textových dat.
Unicode nejenže přiřazuje každému znaku unikátní kód, ale také definuje různé charakteristiky tohoto symbolu, například:
typ znaku (velké písmeno, malé písmeno, číslo, interpunkční znaménko atd.);
atributy znaků (zobrazení zleva doprava nebo zprava doleva, mezera, zalomení řádku atd.);
odpovídající velké nebo malé písmeno (pro malá a velká písmena v uvedeném pořadí);
odpovídající číselnou hodnotu (pro číselné znaky).
Normy UTF(zkratka pro Unicode Transformation Format), která představuje znaky:
UTF-16: Windows Vista používá UTF-16 k reprezentaci všech znaků Unicode. V UTF-16 jsou znaky reprezentovány dvěma byty (16 bitů). Toto kódování se používá ve Windows, protože 16bitové hodnoty mohou představovat znaky, které tvoří abecedy většiny jazyků na světě, což umožňuje programům zpracovávat řetězce a počítat jejich délku rychleji. V některých jazycích však 16 bitů nestačí k vyjádření abecedních znaků. Pro takové případy UTE-16 podporuje „náhradní“ kódování, které umožňuje kódování znaků do 32 bitů (4 bajtů). Existuje však málo aplikací, které se musí vypořádat se znaky takových jazyků, takže UTF-16 je dobrým kompromisem mezi úsporou paměti a snadností programování. Všimněte si, že v .NET Framework jsou všechny znaky kódovány pomocí UTF-16, takže použití UTF-16 v aplikace pro Windows zlepšuje výkon a snižuje spotřebu paměti při předávání řetězců mezi nativním a spravovaným kódem.
UTF-8: V kódování UTF-8 mohou být různé znaky reprezentovány 1, 2, 3 nebo 4 bajty. Znaky s hodnotami menšími než 0x0080 jsou komprimovány na 1 bajt, což je velmi výhodné pro americké znaky. Znaky, které odpovídají hodnotám v rozsahu 0x0080-0x07FF, jsou převedeny na 2bajtové hodnoty, což dobře funguje s evropskými a blízkovýchodními abecedami. Znaky s většími hodnotami jsou převedeny na 3bajtové hodnoty, což je užitečné pro práci se středoasijskými jazyky. Nakonec jsou náhradní páry zapsány ve 4bajtovém formátu. UTF-8 je extrémně populární kódování. Je však méně efektivní než UTF-16, pokud se často používají znaky s hodnotami 0x0800 a vyšší.
UTF-32: V UTF-32 jsou všechny znaky reprezentovány 4 bajty. Toto kódování je vhodné pro psaní jednoduchých algoritmů pro výčet znaků v jakémkoli jazyce, které nevyžadují zpracování znaků reprezentovaných různým počtem bajtů. Například při použití UTF-32 můžete zapomenout na „náhrady“, protože jakýkoli znak v tomto kódování je reprezentován 4 bajty. Je zřejmé, že z hlediska využití paměti není účinnost UTF-32 zdaleka ideální. Proto se toto kódování zřídka používá k přenosu řetězců po síti a jejich ukládání do souborů. Typicky se UTF-32 používá jako interní formát pro prezentaci dat v programu.
UTF-8
V blízké budoucnosti se nazývá speciální formát Unicode (a ISO 10646). UTF-8... Toto „odvozené“ kódování používá k zápisu znaků řetězce bajtů různých délek (od jedné do šesti), které jsou převedeny na kódy Unicode pomocí jednoduchého algoritmu, přičemž kratší řetězce odpovídají běžnějším znakům. Hlavní výhodou tohoto formátu je kompatibilita s ASCII nejen v hodnotách kódů, ale také v počtu bitů na znak, protože jeden bajt stačí k zakódování kteréhokoli z prvních 128 znaků v UTF-8 (i když , například pro písmena azbuky dva bajty).
Formát UTF-8 byl vynalezen 2. září 1992 Kenem Thompsonem a Robem Pikem a implementován v plánu 9. Standard UTF-8 je nyní formalizován v RFC 3629 a ISO / IEC 10646 Annex D.
Pro webového designéra je toto kódování obzvláště důležité, protože je od verze 4 deklarováno jako „standardní kódování dokumentu“ v HTML.
Text obsahující pouze znaky očíslované méně než 128 se při psaní v UTF-8 převede na prostý text ASCII. Naopak v textu UTF-8 každý bajt s hodnotou menší než 128 představuje znak ASCII se stejným kódem. Zbývající znaky Unicode jsou reprezentovány sekvencemi dlouhými od 2 do 6 bajtů (ve skutečnosti pouze do 4 bajtů, protože se neplánuje použití kódů větších než 221), ve kterých první bajt vždy vypadá jako 11xxxxxx a zbytek - 10xxxxxx.
Jednoduše řečeno, ve formátu UTF-8, znaky latinky, interpunkční znaménka a ovládání ASCII znaky jsou zapsány v kódech US-ASCII a všechny ostatní znaky jsou zakódovány pomocí několika oktetů s nejvýznamnějším bitem 1. To má dva efekty.
I když program nerozpozná Unicode, latinská písmena, arabské číslice a interpunkční znaménka se zobrazí správně.
Pokud latinská písmena a jednoduchá interpunkční znaménka (včetně mezer) zabírají značné množství textu, UTF-8 zvyšuje objem ve srovnání s UTF-16.
Na první pohled by se mohlo zdát, že UTF-16 je pohodlnější, protože většina znaků je kódována přesně do dvou bajtů. To je však negováno potřebou podporovat náhradní páry, které jsou často přehlíženy při použití UTF-16, implementujíc pouze podporu pro UCS-2 znaky.
Unicode
z Wikipedie, otevřené encyklopedie
Jít do: navigace, Vyhledávání
Unicod (nejčastěji) popř Unicode (Angličtina Unicode) - Standard Kódování znaků, což vám umožní reprezentovat znaky téměř všech písem jazyky.
Standard navržený v 1991 rok nezisková organizace "Unicode Consortium" ( Angličtina Unicode Konsorcium, Unicode Inc. ). Použití tohoto standardu umožňuje zakódovat velmi velký počet znaků z různých skriptů: v dokumentech Unicode, čínských hieroglyfy, matematické symboly, písmena Řecká abeceda, latinský a cyrilice, v tomto případě není nutné přepínat kódové stránky.
Standard se skládá ze dvou hlavních částí: univerzální znakové sady ( Angličtina UCS, univerzální znaková sada) a rodina kódování ( Angličtina. UTF, transformační formát Unicode). Univerzální znaková sada určuje vzájemnou shodu mezi znaky kódy- prvky kódového prostoru představující nezáporná celá čísla. Rodina kódování definuje strojovou reprezentaci sekvence kódů UCS.
Kódy Unicode jsou rozděleny do několika oblastí. Oblast s kódy od U + 0000 do U + 007F obsahuje vytáčecí znaky ASCII s odpovídajícími kódy. Dále jsou to oblasti znaků různých písem, interpunkčních znamének a technických symbolů. Některé z kódů jsou vyhrazeny pro budoucí použití. Pod znaky azbuky jsou přiřazeny oblasti znaků s kódy od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (viz. Cyrilice v Unicode).
1 Předpoklady pro vytvoření a rozvoj Unicode 2 verze Unicode 3 Kódový prostor 4 Kódovací systém 5 Úprava znaků 6 Formy normalizace 7 Obousměrné psaní 8 Doporučené symboly 9 ISO / IEC 10646 10 způsobů prezentace 11 Metody zadávání 12 Problémy s Unicode 13 "Unicode" nebo "Unicode"? 14 Viz také |
Předpoklady pro vytvoření a rozvoj Unicode
Do konce 80. léta 20. století 8bitové znaky se staly standardem, zatímco existovalo mnoho různých 8bitových kódování a neustále se objevovaly nové. To bylo vysvětleno jak neustálým rozšiřováním škály podporovaných jazyků, tak snahou vytvořit kódování částečně kompatibilní s některými jinými (typickým příkladem je vznik alternativní kódování pro ruský jazyk, kvůli využívání západních programů vytvořených pro kódování CP437). V důsledku toho se objevilo několik problémů:
problém" Krakozyabr»(Zobrazení dokumentů ve špatném kódování): dalo by se to vyřešit buď důsledným zavedením metod pro specifikaci použitého kódování, nebo zavedením jediného kódování pro všechny.
Problém s omezenou znakovou sadou: dalo by se to vyřešit buď přepínáním písem v rámci dokumentu, nebo zavedením "širokého" kódování. Přepínání písem je již dlouho praktikováno v textové procesory a byly často používány fonty s nestandardním kódováním, t. n. "Dingbat fonty" - v důsledku toho se při pokusu o přenos dokumentu do jiného systému všechny nestandardní znaky změnily na krakozyabry.
Problém převodu jednoho kódování na druhé: mohl by být vyřešen buď kompilací převodních tabulek pro každý pár kódování, nebo použitím přechodného převodu na třetí kódování, které zahrnuje všechny znaky všech kódování.
Problém duplikace písem: tradičně se pro každé kódování dělalo jiné písmo, i když se tato kódování částečně (nebo úplně) shodovala v sadě znaků: tento problém by se dal vyřešit vytvořením "velkých" písem, ze kterých se znaky Poté se vyberou potřebné pro toto kódování - to však vyžaduje vytvoření jediného registru symbolů pro určení, které se shodují.
Bylo považováno za nutné vytvořit jediné „široké“ kódování. Kódování s proměnnou délkou, široce používané ve východní Asii, bylo shledáno jako příliš obtížné na použití, takže bylo rozhodnuto použít znaky s pevnou šířkou. Používání 32bitových znaků se zdálo příliš nehospodárné, a tak bylo rozhodnuto použít 16bitové.
První verze Unicode byla tedy kódování s pevnou velikostí znaků 16 bitů, to znamená, že celkový počet kódů byl 2 16 (65 536). Odtud pochází praxe pojmenování znaků se čtyřmi hexadecimálními číslicemi (například U + 04F0). Zároveň bylo plánováno zakódovat v Unicode ne všechny existující znaky, ale pouze ty, které jsou nezbytné v každodenním životě. Zřídka používané symboly musely být umístěny v „oblasti soukromého použití“, která původně zabírala kódy U + D800… U + F8FF. Aby bylo možné použít Unicode také jako meziprodukt při vzájemném převodu různých kódování, byly do něj zahrnuty všechny znaky zastoupené ve všech nejznámějších kódováních.
Do budoucna však bylo rozhodnuto všechny symboly zakódovat a v souvislosti s tím výrazně rozšířit doménu kódu. Ve stejné době se na znakové kódy začalo nahlížet nikoli jako na 16bitové hodnoty, ale jako na abstraktní čísla, která lze v počítači reprezentovat množinou různé způsoby(cm. Prezentační metody).
Protože v řadě počítačových systémů (např. Windows NT ) již byly jako výchozí kódování použity pevné 16bitové znaky, bylo rozhodnuto zakódovat všechny nejdůležitější znaky pouze v rámci prvních 65 536 pozic (tzv. Angličtina základní vícejazyčný letadlo, BMP). Zbytek prostoru se používá pro "znaky navíc" ( Angličtina doplňkový znaky): systémy psaní zaniklých jazyků nebo velmi zřídka používané čínština hieroglyfy, matematické a hudební symboly.
Kvůli kompatibilitě se staršími 16bitovými systémy byl systém vynalezen UTF-16, kde prvních 65 536 pozic, s výjimkou pozic z intervalu U + D800 ... U + DFFF, je zobrazeno přímo jako 16bitová čísla a zbytek je reprezentován jako "náhradní páry" (první prvek dvojice z oblasti U + D800 ... U + DBFF , druhý prvek dvojice z oblasti U + DC00 ... U + DFFF). Pro náhradní páry byla použita část kódového prostoru (2048 pozic) dříve vyhrazená pro „znaky pro soukromé použití“.
Protože UTF-16 může zobrazit pouze 2 20 + 2 16 −2048 (1 112 064) znaků, bylo toto číslo zvoleno jako konečná hodnota pro kódový prostor Unicode.
Přestože byla oblast kódu Unicode rozšířena za 2-16 již ve verzi 2.0, první znaky v oblasti „top“ byly umístěny až ve verzi 3.1.
Role tohoto kódování ve webovém sektoru neustále roste, na začátku roku 2010 byl podíl webů využívajících Unicode cca 50 %.
Unicode verze
Jak se tabulka znaků Unicode mění a doplňuje a jsou vydávány nové verze tohoto systému – a tato práce se provádí neustále, protože zpočátku systém Unicode zahrnoval pouze rovinu 0 – dvoubajtové kódy – také vycházejí nové dokumenty. ISO... Systém Unicode existuje celkem v následujících verzích:
1.1 (vyhovuje ISO / IEC 10646-1: 1993 ), standard 1991-1995.
2.0, 2.1 (stejná norma ISO / IEC 10646-1: 1993 plus dodatky: "Dodatky" 1 až 7 a "Technické opravy" 1 a 2), norma z roku 1996.
3.0 (ISO / IEC 10646-1: norma 2000) norma 2000.
3.1 (normy ISO / IEC 10646-1: 2000 a ISO / IEC 10646-2: 2001) z roku 2001.
3.2, standardní rok 2002.
standard 4.0 2003 .
4.01, standardní 2004 .
4.1, standardní 2005 .
5.0, standardní 2006 .
5.1, standardní 2008 .
5.2, standardní 2009 .
6.0, standardní 2010 .
6.1, standardní 2012 .
6.2, standardní 2012 .
Kódový prostor
Ačkoli formy zápisu UTF-8 a UTF-32 umožňují zakódovat až 2 331 (2 147 483 648) kódových bodů, bylo rozhodnuto použít pouze 1 112 064 pro kompatibilitu s UTF-16. I to je však pro tuto chvíli více než dostatečné - ve verzi 6.0 je použito o něco méně než 110 000 kódových bodů (109 242 grafických a 273 dalších symbolů).
Kódový prostor je rozdělen na 17 letadla 2 16 (65536) znaků každý. Říká se nulová rovina základní, obsahuje symboly nejběžnějších skriptů. První rovina se používá hlavně pro historická písma, druhá pro málo používané hieroglyfy. CJK, třetí je vyhrazena pro archaické čínské znaky ... Letadla 15 a 16 jsou vyhrazena pro soukromé použití.
Pro označení znaků Unicode použijte zápis jako „U + xxxx"(Pro kódy 0 ... FFFF), nebo" U + xxxxx"(Pro kódy 10000 ... FFFFF), nebo" U + xxxxxx"(Pro kódy 100000 ... 10FFFF), kde xxx - hexadecimálníčísla. Například znak „i“ (U + 044F) má kód 044F 16 = 1103 10 .
Systém kódování
Univerzální kódovací systém (Unicode) je sada grafických symbolů a způsob jejich kódování počítač zpracování textových dat.
Grafické symboly jsou symboly, které mají viditelný obrázek. Grafické znaky jsou protikladem k ovládacím a formátovacím znakům.
Grafické symboly zahrnují následující skupiny:
interpunkční znaménka;
speciální znaky ( matematický, technický, ideogramy atd.);
oddělovače.
Unicode je systém pro lineární reprezentaci textu. Znaky s dalšími horními nebo dolními indexy mohou být reprezentovány jako sekvence kódů sestavené podle určitých pravidel (složený znak) nebo jako jeden znak (monolitická verze, předem složený znak).
Úprava postav
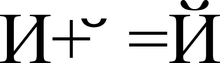
Znázornění znaku "Y" (U + 0419) ve formě základního znaku "I" (U + 0418) a modifikačního znaku "" (U + 0306)
Grafické znaky se v Unicode dělí na rozšířené a nerozšířené (bez šířky). Nerozšířené znaky při zobrazení nezabírají místo čára... Patří mezi ně zejména akcenty a další diakritika... Rozšířené i neprodloužené znaky mají své vlastní kódy. Rozšířené znaky se jinak nazývají základní ( Angličtina základna znaky), a nerozšířené - upravující ( Angličtina kombinování znaky); a tito se nemohou setkat nezávisle. Například znak "á" může být reprezentován jako posloupnost základního znaku "a" (U + 0061) a modifikačního znaku " ́" (U + 0301), nebo jako monolitický znak "á" (U + 00C1).
Speciálním typem modifikujících postav jsou selektory stylu obličeje ( Angličtina variace selektory). Vztahují se pouze na ty symboly, pro které jsou takové varianty definovány. Ve verzi 5.0 jsou pro sérii definovány možnosti stylu matematické symboly, pro symboly tradiční Mongolská abeceda a pro symboly Mongolské čtvercové písmo.
Normalizační formy
Vzhledem k tomu, že stejné znaky mohou být reprezentovány různými kódy, což někdy komplikuje zpracování, existují normalizační procesy určené k převedení textu do určité standardní formy.
Standard Unicode definuje 4 formy normalizace textu:
Symbol S je počáteční pokud má třídu modifikace nulu ve znakové základně Unicode.
V jakékoli posloupnosti znaků začínajících počátečním znakem S je znak C blokován od S právě tehdy, když je mezi S a C jakýkoli znak B, který je buď počátečním znakem nebo má stejnou nebo vyšší třídu modifikace než C. Toto pravidlo platí pouze pro řetězce, které prošly kanonickým rozkladem.
Hlavní kompozit je symbol, který má kanonickou dekompozici ve znakové základně Unicode (nebo kanonickou dekompozici pro Hangul a není součástí seznam vyloučení).
Znak X lze primárně zarovnat se znakem Y tehdy a pouze tehdy, pokud existuje primární složený Z kanonicky ekvivalentní sekvenci.
Pokud další znak C není blokován posledním nalezeným počátečním základním znakem L a lze jej s ním úspěšně zarovnat, pak je L nahrazeno složeným L-C a C je odstraněno.
Normalizační forma D (NFD) - Kanonický rozklad. V procesu převodu textu do této formy jsou všechny složené znaky rekurzivně nahrazeny několika složenými v souladu s rozkladovými tabulkami.
Normalizační forma C (NFC) je kanonický rozklad následovaný kanonickým složením. Nejprve je text redukován do tvaru D, poté je provedena kanonická kompozice - text je zpracován od začátku do konce a jsou dodržována následující pravidla:
Normalizační forma KD (NFKD) - Compatible Decomposition. Při obsazení do této formy jsou všechny složené znaky nahrazeny pomocí jak kanonických dekompozičních map Unicode, tak kompatibilních dekompozičních map, načež je výsledek umístěn v kanonickém pořadí.
Normalizační forma KC (NFKC) - Kompatibilní rozklad následovaný kanonický složení.
Termíny "složení" a "rozklad" znamenají v tomto pořadí spojení nebo rozklad symbolů na jejich součásti.
Příklady
|
Zdrojový text | ||||
|
\ u0410, \ u0401, \ u0419 |
\ u0410, \ u0415 \ u0308, \ u0418 \ u0306 |
\ u0410, \ u0401, \ u0419 |
||
Obousměrné písmeno
Standard Unicode podporuje jazyky psaní zleva doprava ( Angličtina vlevo, odjet- na- že jo, Ltr) a psaním zprava doleva ( Angličtina že jo- na- vlevo, odjet, RTL) - například, arabština a židovský dopis. V obou případech jsou postavy uloženy v „přirozeném“ pořadí; jejich zobrazení s přihlédnutím k požadovanému směru písmene zajišťuje aplikace.
Unicode navíc podporuje kombinované texty, které kombinují fragmenty s různými směry písmene. Tato funkce se nazývá obousměrnost (Angličtina obousměrný text, BiDi). Některé zjednodušené textové procesory (například v mobily) může podporovat Unicode, ale ne obousměrnou podporu. Všechny znaky Unicode jsou rozděleny do několika kategorií: psané zleva doprava, psané zprava doleva a psané v libovolném směru. Symboly poslední kategorie (hlavně interpunkční znaménka), když se zobrazí, vezměte směr okolního textu.
Doporučené symboly
Hlavní článek: Znaky reprezentované v Unicode

Schéma základní roviny Unicode, viz popis
Unicode zahrnuje téměř všechny moderní psaní, počítaje v to:
Arab,
arménský,
bengálský,
barmský,
sloveso,
řecký,
gruzínský,
dévanágarí,
židovský,
cyrilice,
čínština(Čínské znaky se aktivně používají v japonský, a také docela zřídka v korejština),
koptský,
khmerské,
latinský,
tamilština,
korejština (hangul),
čerokí,
etiopský,
japonský(což zahrnuje kromě toho čínské postavy taky slabikář),
jiný.
Pro akademické účely bylo přidáno mnoho historických skriptů, včetně: germánské runy, starověké turkické runy, starověké řečtiny, Egyptské hieroglyfy, klínové písmo, Maya píše, Etruská abeceda.
Unicode poskytuje širokou škálu matematický a hudební postavy také piktogramy.
Unicode však zásadně nezahrnuje loga společností a produktů, i když je lze nalézt ve fontech (např. Jablko zakódované MacRoman(0xF0) nebo logo Okna ve fontu Wingdings (0xFF)). V písmech Unicode musí být loga umístěna pouze v oblasti vlastních znaků.
ISO / IEC 10646
Unicode Consortium úzce spolupracuje s pracovní skupinou ISO / IEC / JTC1 / SC2 / WG2, která vyvíjí mezinárodní standard 10646 ( ISO/IEC 10646). Synchronizace je zavedena mezi normou Unicode a ISO / IEC 10646, ačkoli každá norma používá svou vlastní terminologii a systém dokumentace.
Spolupráce konsorcia Unicode s Mezinárodní organizací pro standardizaci ( Angličtina Mezinárodní organizace pro normalizaci, ISO) začalo v 1991 rok... PROTI 1993 rok ISO vydala standard DIS 10646.1. Pro synchronizaci s ním Konsorcium schválilo verzi 1.1 standardu Unicode, která byla doplněna o další znaky z DIS 10646.1. V důsledku toho jsou hodnoty kódovaných znaků v Unicode 1.1 a DIS 10646.1 naprosto stejné.
Do budoucna spolupráce obou organizací pokračovala. PROTI 2000 rok standard Unicode 3.0 byl synchronizován s ISO / IEC 10646-1: 2000. Nadcházející třetí verze ISO / IEC 10646 bude synchronizována s Unicode 4.0. Možná budou tyto specifikace dokonce zveřejněny jako jednotný standard.
Podobně jako formáty UTF-16 a UTF-32 ve standardu Unicode má standard ISO / IEC 10646 také dvě hlavní formy kódování znaků: UCS-2 (2 bajty na znak, podobně jako UTF-16) a UCS-4 (4 bajty na znak, podobně jako UTF-32). UCS znamená univerzální víceoktet(multibajt) kódovaná znaková sada (Angličtina univerzální násobek- oktet kódované charakter soubor). UCS-2 lze považovat za podmnožinu UTF-16 (UTF-16 bez náhradních párů) a UCS-4 je synonymem pro UTF-32.
Prezentační metody
Unicode má několik forem reprezentace ( Angličtina Transformační formát Unicode, UTF): UTF-8, UTF-16(UTF-16BE, UTF-16LE) a UTF-32 (UTF-32BE, UTF-32LE). Forma reprezentace UTF-7 byla také vyvinuta pro přenos přes sedmibitové kanály, ale kvůli nekompatibilitě s ASCII neobdržela distribuci a není součástí standardu. 1. dubna rok 2005 byly navrženy dvě formy komiksové prezentace: UTF-9 a UTF-18 ( RFC 4042).
PROTI Microsoft Windows NT a systémy na něm založené Windows 2000 a Windows XP většinou používá ve formátu UTF-16LE. PROTI UNIX-jako operační systémy GNU / Linux, BSD a Mac OS X přijatelná forma je UTF-8 pro soubory a UTF-32 nebo UTF-8 pro zpracování znaků paměť s náhodným přístupem.
Punycode- jiná forma kódování sekvencí znaků Unicode do tzv. ACE sekvencí, které se skládají pouze z alfanumerických znaků, jak je povoleno v názvech domén.
Hlavní článek: UTF-8
UTF-8 je reprezentace Unicode, která poskytuje nejlepší kompatibilitu se staršími systémy, které používaly 8bitové znaky. Text obsahující pouze znaky očíslované méně než 128 se při psaní v UTF-8 převede na prostý text ASCII... Naopak v textu UTF-8 libovolný byte s hodnotou menší než 128 zobrazí znak ASCII se stejným kódem. Zbývající znaky Unicode jsou reprezentovány sekvencemi dlouhými od 2 do 6 bajtů (ve skutečnosti pouze do 4 bajtů, protože v Unicode nejsou žádné znaky s kódem větším než 10FFFF a neplánuje se zavádět je do future), ve kterém první bajt vždy vypadá jako 11xxxxxx a zbytek - 10xxxxxx.
UTF-8 bylo vynalezeno 2. září rok 1992 Ken Thompson a Rob Pike a implementován v Plán 9 ... Nyní je standard UTF-8 oficiálně zakotven v dokumentech RFC 3629 a ISO / IEC 10646 příloha D.
Znaky UTF-8 jsou odvozeny z Unicode následujícím způsobem:
0x00000000 – 0x0000007F: 0xxxxxxx
0x00000080 – 0x000007FF: 110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Teoreticky možné, ale také nezahrnuté ve standardu:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Ačkoli UTF-8 umožňuje zadat stejný znak několika způsoby, správný je pouze ten nejkratší. Zbytek formulářů by měl být z bezpečnostních důvodů odmítnut.
Pořadí bajtů
V datovém toku UTF-16 lze horní bajt zapsat buď před dolní ( Angličtina UTF-16 little-endian), nebo po mladším ( Angličtina. UTF-16 big-endian). Podobně existují dvě varianty čtyřbajtového kódování - UTF-32LE a UTF-32BE.
Pro určení formátu reprezentace Unicode se na začátek textového souboru zapíše podpis- znak U + FEFF (mezera nulové šířky), také označovaný jako značka pořadí bajtů (Angličtina byte objednat označit, kusovník ). To umožňuje rozlišovat mezi UTF-16LE a UTF-16BE, protože znak U + FFFE neexistuje. Někdy se také používá k označení formátu UTF-8, i když pojem pořadí bajtů se na tento formát nevztahuje. Soubory, které se řídí touto konvencí, začínají těmito bajtovými sekvencemi:
Bohužel tato metoda spolehlivě nerozlišuje mezi UTF-16LE a UTF-32LE, protože znak U + 0000 je povolen Unicode (ačkoli skutečné texty jím začínají jen zřídka).
Soubory v kódování UTF-16 a UTF-32, které neobsahují kusovník, musí být v pořadí bajtů big-endian ( unicode.org).
Unicode a tradiční kódování
Zavedení Unicode změnilo přístup k tradičnímu 8bitovému kódování. Pokud dříve bylo kódování určeno písmem, nyní je určeno korespondenční tabulkou mezi tímto kódováním a Unicode. Ve skutečnosti se 8bitová kódování stala reprezentací podmnožiny Unicode. Díky tomu bylo mnohem snazší vytvářet programy, které musí pracovat s mnoha různými kódováními: nyní, abyste přidali podporu pro jedno další kódování, stačí přidat další vyhledávací tabulku Unicode.
Mnoho datových formátů navíc umožňuje vložení libovolných znaků Unicode, i když je dokument napsán ve starém 8bitovém kódování. Například v HTML lze použít ampersand kódy.
Implementace
Většina moderních operačních systémů poskytuje určitý stupeň podpory Unicode.
V operačních systémech rodiny Windows NT názvy souborů a další systémové řetězce jsou interně reprezentovány pomocí dvoubajtového kódování UTF-16LE. Systémová volání, která přebírají parametry řetězce, jsou k dispozici v jednobajtových a dvoubajtových variantách. Další podrobnosti naleznete v článku .
UNIX-jako operační systémy, včetně GNU / Linux, BSD, Mac OS X k reprezentaci Unicode použijte kódování UTF-8. Většina programů umí pracovat s UTF-8 jako s tradičním jednobajtovým kódováním, bez ohledu na skutečnost, že znak je reprezentován jako několik po sobě jdoucích bajtů. Pro práci s jednotlivými znaky jsou řetězce obvykle překódovány na UCS-4, takže každý znak má odpovídající strojové slovo.
Jednou z prvních úspěšných komerčních implementací Unicode bylo programovací prostředí Jáva... V podstatě opustilo 8bitovou reprezentaci znaků ve prospěch 16bitové. Toto řešení zvýšilo spotřebu paměti, ale umožnilo nám vrátit důležitou abstrakci do programování: libovolný jediný znak (typ char). Zejména programátor mohl pracovat s řetězcem jako s jednoduchým polem. Bohužel úspěch nebyl konečný, Unicode přerostlo 16bitový limit a do J2SE 5.0 začal libovolný znak opět zabírat proměnný počet paměťových jednotek - jeden nebo dva znaky (viz. náhradní pár).
Většina programovacích jazyků nyní podporuje řetězce Unicode, i když jejich reprezentace se může lišit v závislosti na implementaci.
Metody zadávání
Protože žádný rozložení klávesnice nemůže umožnit zadání všech znaků Unicode současně, od operační systémy a aplikační programy Vyžaduje podporu pro alternativní metody zadávání libovolných znaků Unicode.
Microsoft Windows
Hlavní článek: Unicode v operačních systémech Microsoft
Počínaje Windows 2000, nástroj Charmap (charmap.exe) zobrazuje všechny znaky v OS a umožňuje vám je zkopírovat Schránka... Podobná tabulka je například v Microsoft Word.
Někdy můžete psát hexadecimální kód, stiskněte Alt+ X a kód bude nahrazen odpovídajícím znakem, například in WordPad, Microsoft Word. V editorech Alt + X provádí také obrácenou transformaci.
V mnoha programech MS Windows, abyste získali znak Unicode, musíte stisknout klávesu Alt a zadat desetinnou hodnotu kódu znaku na numerická klávesnice... Například kombinace Alt + 0171 (") a Alt + 0187 (") budou užitečné při psaní textů v azbuce. Zajímavé jsou také kombinace Alt + 0133 (…) a Alt + 0151 (-).
Macintosh
PROTI Operační Systém Mac 8.5 a novější je podporována metoda zadávání nazvaná „Unicode Hex Input“. Zatímco držíte klávesu Option, musíte zadat čtyřmístný hexadecimální kód požadovaného znaku. Tato metoda umožňuje zadávat znaky s kódy většími než U + FFFF pomocí náhradních párů; takové páry operační systém budou automaticky nahrazeny jednotlivými znaky. Před použitím této metody zadávání musíte aktivovat v odpovídající části systémových nastavení a poté vybrat jako aktuální metodu zadávání v nabídce klávesnice.
Počínaje Mac OS X 10.2 je k dispozici také aplikace „Paleta znaků“, která umožňuje vybírat znaky z tabulky, ve které lze vybírat znaky konkrétního bloku nebo znaky podporované konkrétním písmem.
GNU / Linux
PROTI GNOME existuje také utilita „Symbol Table“, která umožňuje zobrazit symboly určitého bloku nebo systému psaní a poskytuje možnost vyhledávání podle názvu nebo popisu symbolu. Když je znám kód požadovaného znaku, lze jej zadat v souladu se standardem ISO 14755: podržte Ctrl + ⇧ Posun zadejte hexadecimální kód (od některé verze GTK + je nutné kód zadat stisknutím klávesy "U"). Zadaný hexadecimální kód může mít délku až 32 bitů, což vám umožní zadat libovolné znaky Unicode bez použití náhradních párů.
 Odnoklassniki: Registrace a vytvoření profilu
Odnoklassniki: Registrace a vytvoření profilu E je. E (funkce E). Výrazy z hlediska goniometrických funkcí
E je. E (funkce E). Výrazy z hlediska goniometrických funkcí Sociální sítě Ruska Nyní v sociálních sítích
Sociální sítě Ruska Nyní v sociálních sítích