Co je kódování unicode. Proč jste potřebovali Unicode? Předpoklady pro vytvoření a vývoj Unicode
Co je kódování
V ruštině se „znaková sada“ také nazývá „znaková sada“ a proces použití této tabulky k převodu informací z počítačové reprezentace do lidské reprezentace a textový soubor, odrážející použití určitého systému kódů v něm při zobrazování textu.
Prezentační systém je definován řadou pravidel a aplikace těchto pravidel na původní informace se provádí procesem kódování. Opačný proces se nazývá dekódování. Poté se podíváme na specifičtější aspekty, jako je kódování signálu, kódování znaků, kódování lidského genomu a kvantové kódování. Na závěr budou vysvětleny základní pojmy komprese dat a nejčastěji používané metody šifrování.
V této části uvidíme, jak lidé v průběhu historie vynaložili velké úsilí, aby se vyjadřovali se zbytkem svých příbuzných jednoduchým a intuitivním způsobem, kódováním informací pomocí různé metody... Tyto metody se vyvíjely v průběhu historie, aniž by představovaly sofistikované metody, které dnes používáme pro ty první, které byly použity, protože to vyžadovalo hodně evoluce, jak uvidíme v této části.
Jak je text kódován
Soubor symbolů používaných při psaní textu je v počítačové terminologii označován jako abeceda; počet symbolů v abecedě se obvykle nazývá jeho síla. Pro prezentaci textové informace počítač používá nejčastěji abecedu s kapacitou 256 znaků. Jeden z jeho znaků nese 8 bitů informace, proto binární kód každého znaku zabírá 1 bajt paměti počítače. Všechny znaky takové abecedy jsou číslovány od 0 do 255 a každé číslo odpovídá 8bitovému binárnímu kódu, což je pořadové číslo znaku v binární číselné soustavě – od 00000000 do 11111111. Pouze prvních 128 znaků s čísla od nuly ( binární kód 00000000) do 127 (01111111). Patří mezi ně malá písmena a velká písmena Latinská abeceda, čísla, interpunkční znaménka, závorky atd. Zbývajících 128 kódů, počínaje 128 (binární kód 10000000) a konče 255 (11111111), se používá ke kódování písmen národních abeced, služebních a vědeckých symbolů.
Vývoj kódování signálů
Být zastaralý je vše, co víme tento moment, jak tomu bylo v pravý čas u předchozích metod. V průběhu historie námořníci používali signály k předávání naléhavých zpráv ostatním námořníkům. Jedná se o světelné signály, které jsou produkovány pomocí velkých projektorů se systémy, které umožňují světelné záblesky, obvykle využívané mřížkami umístěnými před ohniskem. K navázání spojení se pomocí světelných signálů používá morseovka.
Jsou to signály přenášené vibracemi ve vzduchu. Vzhledem k pomalosti zařízení potřebných pro přenos se jedná o velmi pomalé médium. Vysílané signály využívají k přenosu informací Morseovu abecedu. Kromě tradiční Morseovy abecedy v mezinárodní kód který byl zahrnut, existují další typy standardizovaných signálů, kterým by každý námořník měl dokonale rozumět.
Typy kódování
Nejznámější kódovací tabulkou je ASCII (American Standard Code for Information Interchange). Původně byl vyvinut pro přenos textů telegrafem a v té době byl 7bitový, to znamená, že ke kódování anglických znaků, obslužných a řídicích znaků bylo použito pouze 128 sedmibitových kombinací. V tomto případě prvních 32 kombinací (kódů) sloužilo ke kódování řídicích signálů (začátek textu, konec řádku, návrat vozíku, volání, konec textu atd.). Při vývoji prvních počítačů IBM byl tento kód použit k reprezentaci symbolů v počítači. Protože v zdrojový kód ASCII měl pouze 128 znaků, pro jejich kódování stačily bytové hodnoty s 8. bitem rovným 0. Bytové hodnoty s 8. bitem rovným 1 se začaly používat k reprezentaci pseudografických znaků, matematických znaků a některých znaků z jiných jazyků než angličtiny (řečtina, německé přehlásky, francouzská diakritika atd.). Když začali přizpůsobovat počítače pro jiné země a jazyky, nebylo již dost místa pro nové symboly. Aby společnost IBM plně podporovala jiné jazyky než angličtinu, zavedla několik tabulek kódů pro jednotlivé země. Takže pro skandinávské země byla navržena tabulka 865 (severská), pro arabské země - tabulka 864 (arabština), pro Izrael - tabulka 862 (Izrael) a tak dále. V těchto tabulkách byly některé kódy z druhé poloviny kódové tabulky použity k reprezentaci znaků národních abeced (vyloučením některých pseudografických znaků). Zvláštním způsobem se vyvíjela situace s ruským jazykem. Je zřejmé, že nahrazení znaků ve druhé polovině kódové tabulky lze provést různé způsoby... Pro ruský jazyk se tedy objevilo několik různých tabulek kódování znaků azbuky: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Všechny znázorňují stejně (od 0 do 127) symboly první poloviny tabulky a liší se zastoupením symbolů ruské abecedy a pseudografiky. U jazyků, jako je čínština nebo japonština, 256 znaků obecně nestačí. Kromě toho je vždy problém s výstupem nebo uložením textů do jednoho souboru ve stejnou dobu různé jazyky(například při citaci). Proto univerzální tabulka kódů UNICODE, obsahující symboly používané v jazycích všech národů světa, jakož i různé servisní a pomocné symboly (interpunkční znaménka, matematické a technické symboly, šipky, diakritika atd.). Je zřejmé, že jeden bajt k zakódování tak velkého počtu znaků nestačí. Proto UNICODE používá 16bitové (2bajtové) kódy k reprezentaci 65 536 znaků. Dodnes bylo použito asi 49 000 kódů (poslední významnou změnou bylo zavedení symbolu měny EURO v září 1998). Kvůli kompatibilitě s předchozími kódováními je prvních 256 kódů stejných jako ve standardu ASCII. Ve standardu UNICODE, kromě specifického binární kód(tyto kódy jsou obvykle označeny písmenem U, následovaným znaménkem + a skutečným kódem v hexadecimálním zobrazení) každému znaku je přiřazeno specifické jméno. Další součást standard UNICODE jsou algoritmy pro konverzi kódů UNICODE jedna ku jedné v posloupnosti bajtů proměnné délky. Potřeba takových algoritmů je způsobena skutečností, že ne všechny aplikace jsou schopny pracovat s UNICODE. Některé aplikace rozumí pouze 7bitovým ASCII kódům, jiné aplikace 8bitovým ASCII kódům. Takové aplikace používají takzvané rozšířené kódy ASCII k reprezentaci znaků, které se nevejdou do sady 128 znaků nebo sady 256 znaků, když jsou znaky kódovány bajtovými řetězci s proměnnou délkou. UTF-7 se používá k reverzibilnímu převodu kódů UNICODE na rozšířené 7bitové kódy ASCII a UTF-8 se používá k reverzibilnímu převodu kódů UNICODE na rozšířené 8bitové kódy ASCII. Všimněte si, že jak ASCII, tak UNICODE a další standardy kódování znaků nedefinují obrázky znaků, ale pouze složení znakové sady a způsob, jakým je reprezentována v počítači. Kromě toho (což nemusí být hned zřejmé) je velmi důležité pořadí výčtu znaků v sadě, protože nejvíce ovlivňuje třídicí algoritmy. Je to tabulka korespondence symbolů z určité množiny (řekněme symboly používané k reprezentaci informací na anglický jazyk, nebo v různých jazycích, jako v případě UNICODE) a označují se termínem tabulka kódování znaků nebo znaková sada. Každé standardní kódování má název, například KOI8-R, ISO_8859-1, ASCII. Bohužel neexistuje žádný standard pro kódování jmen.
Používá se pro komunikaci mezi blízkými loděmi, aby bylo možné respektovat frekvenci používaného rádia, nevyužívat jej zbytečně zbytečným obsazením tohoto kanálu nebo proto, že je třeba navázat komunikaci a rádio nefunguje správně.
Vlajky se používají k provádění komunikace, takže v závislosti na pozici, kterou zaujímá osoba provádějící signály, bude mít hodnotu nebo něco jiného. Přidružené významy jsou stejné jako při použití příznaků s písmeny A až Z, čísly 0 až 9 a pauzami a chybovými signály.
Radiotelegrafie a radiotelefonie
S metodami diskutovanými výše je současná komunikace v obou směrech nemožná, takže byly point-to-point. Díky nástupu radiotelegrafie je tento způsob komunikace možný. Radiotelegrafie je založena na Maxwellově teorii šíření vln v prostoru. Tak se zrodila bezdrátová telegrafie, která je jedním z nejdůležitějších pokroků v telekomunikacích všech dob.
Běžná kódování
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP852, CP85, CP852, CP85 CP861, CP863, CP865, CP866, CP869 Microsoft kódování Windows: o Windows-1250 pro středoevropské jazyky, které používají latinská písmena o Windows-1251 pro azbuku o Windows-1252 pro západní jazyky o Windows-1253 pro řečtinu o Windows-1254 pro turečtinu o Windows-1255 pro hebrejštinu o Windows-1256 pro arabštinu o Windows-1257 pro baltské jazyky o Windows-1258 pro vietnamštinu MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 bulharské kódování ISCII VISCII Big5 (nejznámější verze Microsoft CP950 ) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS pro japonštinu (Microsoft CP932) EUC-KR pro korejštinu (Microsoft CP949) ISO-2022 a EUC pro čínské psaní UTF-168 a UTF-168 kódování znaků UnicodeTato dokumentace byla přesunuta do archivu a již není podporována.
Dnešní kódování
Stále vepředu bude radiotelefonie, což není nic jiného než schopnost modulovat hlas pomocí rádiových vln teoretický základ vystavoval v radiotelegrafii.
Kódování signálu
Je to velmi běžně používaný postup, při kterém je před přepsáním série signálů analogového typu na signály digitální typ... Usnadňuje tak následné zpracování a také zlepšuje fyzikální vlastnosti.To znamená, že analogový signál je velmi citlivý na změny možného rušení, což je způsobeno skutečností, že původní signál je velmi obtížné obnovit, protože hodnoty, které tento signál může mít, mohou být nekonečné. Pokud to porovnáme s digitálním signálem, který má určitý počet možných hodnot. Tato skutečnost usnadňuje načítání hodnot v digitálním signálu, a proto může být použit pro komunikaci na dálku.
Použití kódování Unicode
.NET Framework 3.5
Aktualizováno: listopad 2007
Běžné runtime aplikace používají kódování k převodu znaků z interní reprezentace (Unicode) do jiné reprezentace. Dekódování se používá k převodu znaků zpět z externího (ne Unicode) kódování do interní reprezentace. Jmenný prostor obsahuje řadu tříd, které umožňují aplikacím kódovat a dekódovat znaky. Přehled těchto tříd viz.
V tomto postupu můžeme rozlišit tři dobře diferencované fáze: vzorkování, kvantifikace a kodifikace. Kvantifikace: spočívá ve vyhodnocení hodnoty každého ze vzorků tak, že každému ze vzorků je přiřazena jedna z možných hodnot výsledného digitální signál... Proces kvantování způsobuje kvantizační šum způsobený počtem možných hodnot analogový signál pro digitální signál. Spočívá v převodu hodnot získaných během kvantizačního procesu do binárního systému pomocí řady přednastavených kódů.
- Vzorkování: Skládá se ze vzorkování amplitudy vstupního signálu.
- Vysoce důležitý parametr v tomto procesu počtem vzorků za sekundu.
- Kódování.
Používá se pro kódování bez Unicode. Třída podporuje širokou škálu kódování ANSI / ISO.
Níže uvedený příklad kódu používá metodu GetEncoding požadovaný objekt kódování pro konkrétní kódovou stránku. Metoda GetBytes vyvolané na požadovaném kódovacím objektu pro převod řetězce Unicode na bajtovou reprezentaci v požadovaném kódování. Na obrazovce se zobrazí byte reprezentace řetězce na konkrétní kódové stránce.
Je založeno na kódování jedné polarity, jak název napovídá. Obvykle tedy binární hodnota rovna jedné předpokládá hodnotu ve výstupním signálu rovnou jedné a hodnota rovna nule umožňuje nulovou hodnotu ve výstupním signálu.
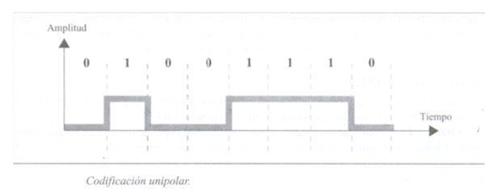
Toto je typ kódování, který se dnes nejčastěji používá. Je založen na kódování dvou polarit pro reprezentaci binární informace. Můžeme najít následující klasifikaci polárního kódování. 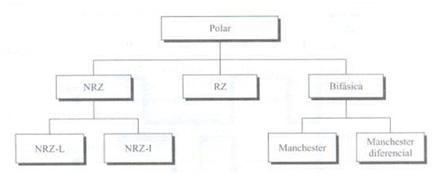
Vyznačuje se tím, že signál má vždy kladnou nebo zápornou hodnotu. Můžeme jasně rozlišovat mezi typy.
Importy Systém Importy System.IO Importy System.Globalization Importy System.Text Public Class Encoding_UnicodeToCP Public Shared Sub Main () "Převádí znaky ASCII na bajty. "Zobrazí bajtovou reprezentaci řetězce" v"zadaná kódová stránka. "Kódová stránka 1252 představuje znaky latinky. PrintCPBytes ("Ahoj, světe!", 1252) "Kódová stránka 932 představuje japonské znaky. PrintCPBytes ("Ahoj, světe!", 932) "Převádí japonské znaky. PrintCPBytes (, 1252) PrintCPBytes ( "\ u307b, \ u308b, \ u305a, \ u3042, \ u306d", 932) End Sub Public Shared Sub PrintCPBytes (str As String, codePage As Integer) Dim targetEncoding As Encoding Dim encodedChars () As Byte "Získá kódování pro zadanou kódovou stránku. targetEncoding = Encoding.GetEncoding (codePage) "Získá bajtovou reprezentaci zadaného řetězce. encodedChars = targetEncoding.GetBytes (str) "Vytiskne bajty. Console.WriteLine ( "Bytová reprezentace" (0) "v CP" (1) ":", _ str, codePage) Dim i As Integer For i = 0 To encodedChars.Length - 1 Console.WriteLine ("Byte (0): (1)", i, encodedChars (i)) Next i End Sub End Class
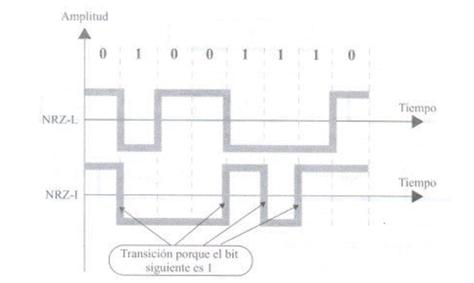
Obvykle, pokud je bit nastaven na jedničku, bude signál kladný, pokud je nula, signál bude záporný. Tato hodnota tedy nezávisí pouze na aktuálním bitu, ale také na bitu předchozím. Je tedy spolehlivější.
Vyznačuje se použitím tří možných výstupních úrovní. Malý je reprezentován změnou z kladného na nulu az nuly na záporné do kladného. Každá transakce probíhá uprostřed intervalu, jak je znázorněno na následujícím obrázku. Tento typ kódování také umožňuje spouštění synchronizační procedury pomocí přechodů generovaných v polovičních slotech.
 Přizpůsobitelný software
Přizpůsobitelný software Windows 8 vrátí tlačítko Start
Windows 8 vrátí tlačítko Start Instalace Skype do počítače (pokyny krok za krokem)
Instalace Skype do počítače (pokyny krok za krokem)