Kolik bitů je použito ke kódování 1 znaku v unicode. Kódování textu
Počínaje koncem 60. let byly počítače stále více využívány ke zpracování textové informace a aktuálně nejvíce osobní počítače ve světě (a většinu času) je zaneprázdněn zpracováním textových informací.
ASCII - základní kódování textu pro latinskou abecedu
Ke kódování jednoho znaku se tradičně používá stejné množství informací 1 bajt, to znamená, že I = 1 bajt = 8 bitů.
Ke kódování jednoho znaku je zapotřebí 1 bajt informací. Pokud považujeme symboly za možné události, můžeme vypočítat, kolik jich je různé postavy lze kódovat: N = 2I = 28 = 256.
Tento počet znaků je dostačující k reprezentaci textových informací, včetně velkých a malých písmen ruské a latinské abecedy, čísel, znaků, grafických symbolů atd. Binárního kódu od 00000000 do 11111111.
Osoba tedy rozlišuje symboly podle stylu a počítač podle kódů. Když jsou do počítače vloženy textové informace, dojde k jejich binárnímu kódování, obraz symbolu se převede na jeho binární kód.
Uživatel stiskne klávesu se symbolem na klávesnici a do počítače se odešle konkrétní sekvence osmi elektrických impulsů (binární kód symbolu). Kód znaku je uložen v paměť s náhodným přístupem počítač, kde to trvá jeden bajt. V procesu zobrazování znaku na obrazovce počítače se provádí opačný proces - dekódování, to znamená převod kódu znaku na jeho obrázek. Tabulka kódů ASCII (American Standard Code for Information Interchange) byla přijata jako mezinárodní standard Tabulka standardních částí ASCII Je důležité, aby přiřazení konkrétního kódu znaku bylo věcí dohody, která je pevně stanovena v tabulce kódů . Prvních 33 kódů (od 0 do 32) neodpovídá znakům, ale operacím (podávání řádků, zadávání mezer atd.). Kódy od 33 do 127 jsou mezinárodní a odpovídají symbolům latinské abecedy, číslům, aritmetickým znakům a interpunkčním znaménkům. Kódy od 128 do 255 jsou národní, to znamená, že různé znaky odpovídají stejnému kódu v národních kódováních.
V současné době bohužel existuje pět různých tabulek kódů pro ruská písmena (KOI8, CP1251, CP866, Mac, ISO), takže texty vytvořené v jednom kódování se v jiném nezobrazí správně.
V současné době nový mezinárodní Standard Unicode, který přiděluje ne jeden bajt pro každý znak, ale dva, takže jej lze použít ke kódování ne 256 znaků, ale N = 216 = 65536 různých
Unicode - vznik univerzálního kódování textu (UTF 32, UTF 16 a UTF 8)
Tyto tisíce znaků ze skupiny jazyků jihovýchodní Asie nebylo možné popsat v jediném bajtu informací, který byl přidělen pro kódování znaků v rozšířeném kódování ASCII. V důsledku toho se ozvalo konsorcium Unicode(Unicode - Unicode Consortium) se spoluprací mnoha lídrů IT průmyslu (ti, kteří vyrábějí software, kteří kódují hardware, vytvářejí písma), kteří měli zájem na vzniku univerzálního kódování textu.
První kódování textu publikované pod záštitou konsorcia Unicode bylo kódování UTF 32... Číslo v názvu kódování UTF 32 znamená počet bitů, které jsou použity ke kódování jednoho znaku. 32 bitů jsou 4 bajty informací, které budou potřebné ke kódování jednoho jediného znaku v novém univerzálním kódování UTF 32.
Výsledkem je, že stejný soubor s textem kódovaným v rozšířeném kódování ASCII a kódování UTF 32, v druhém případě, bude mít velikost (hmotnost) čtyřikrát větší. To je špatné, ale nyní máme možnost zakódovat pomocí UTF 32 počet znaků rovnající se dvěma až třicetisekundové mocnině (miliardy znaků, které pokryjí jakoukoli skutečně nezbytnou hodnotu s kolosálním okrajem).
Mnoho zemí s jazyky evropské skupiny ale vůbec nemuselo v kódování používat tak obrovské množství znaků, nicméně při použití UTF 32 obdržely čtyřnásobné zvýšení hmotnosti za nic. textové dokumenty, a v důsledku toho zvýšení objemu internetového provozu a množství uložených dat. To je hodně a takový odpad, který si nikdo nemohl dovolit.
V důsledku vývoje univerzálního Kódování Unicode se objevilo UTF 16, který se ukázal být tak úspěšný, že byl ve výchozím nastavení přijat jako základní prostor pro všechny symboly, které používáme. UTF 16 používá ke kódování jednoho znaku dva bajty. Například na operačním sále Systém Windows můžete sledovat cestu Start - Programy - Příslušenství - Systémové nástroje - Tabulka symbolů.
V důsledku toho se otevře tabulka s vektorovými formami všech písem nainstalovaných ve vašem systému. Pokud v rozšířených možnostech vyberete znakovou sadu Unicode, uvidíte pro každé písmo samostatně celý rozsah znaků, které jsou v něm obsaženy. Mimochodem, kliknutím na některý z těchto znaků můžete vidět jeho dvoubajtový kód v kódování UTF 16, který se skládá ze čtyř hexadecimálních číslic:
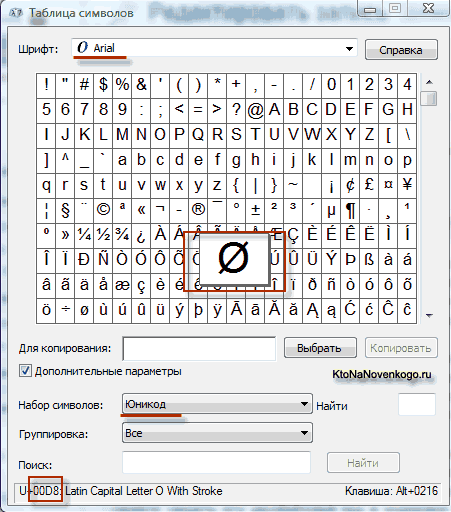
Kolik znaků lze kódovat v UTF 16 se 16 bity? 65 536 znaků (dva až šestnáct) bylo vzato jako základní prostor v Unicode. Kromě toho existují způsoby, jak pomocí UTF 16 zakódovat zhruba dva miliony znaků, ale byly omezeny na rozšířený prostor milionu znaků textu.
Ale ani úspěšná verze kódování Unicode s názvem UTF 16 nepřinesla velké uspokojení těm, kteří psali například programy pouze v anglický jazyk, protože po přechodu z rozšířené verze kódování ASCII na UTF 16 se hmotnost dokumentů zdvojnásobila (jeden bajt pro jeden znak v ASCII a dva bajty pro stejný znak v kódování UTF 16). Bylo to právě pro spokojenost všech a všeho v konsorciu Unicode, o kterém bylo rozhodnuto přijít kódování textu s proměnnou délkou.
Toto kódování v Unicode bylo voláno UTF 8... Navzdory osmi v názvu je UTF 8 plnohodnotným kódováním s proměnnou délkou, tj. každý znak textu může být zakódován do sekvence dlouhé jeden až šest bajtů. V praxi se v UTF 8 používá pouze rozsah od jednoho do čtyř bajtů, protože za hranicí čtyř bajtů kódu si ani teoreticky nelze představit nic.
V UTF 8 jsou všechny znaky latinky kódovány do jednoho bajtu, stejně jako ve starém kódování ASCII. Co je pozoruhodné, v případě kódování pouze latinské abecedy, i ty programy, které nerozumí Unicode, budou stále číst to, co je kódováno v UTF 8. To znamená, základní část kódování ASCII přesunuta do UTF 8.
Cyrilice v UTF 8 jsou kódovány ve dvou bajtech, a například gruzínské - ve třech bajtech. Po vytvoření kódování UTF 16 a UTF 8 vyřešilo Unicode Consortium hlavní problém - nyní máme v písmech jeden kódový prostor. Jediná věc, která zbývá výrobcům písem, je vyplnit tento kódový prostor vektorovými formami textových symbolů na základě jejich silných stránek a schopností.
Řešení těchto problémů teoreticky existuje již dlouhou dobu. Jmenuje se to Unicode Unicode Je kódovací tabulka, ve které jsou použity 2 bajty ke kódování každého znaku, tj. 16 bitů. Na základě takové tabulky lze kódovat N = 2 16 = 65 536 znaků.
Unicode obsahuje téměř všechny moderní skripty, včetně: arabštiny, arménštiny, bengálštiny, barmštiny, řečtiny, gruzínštiny, devanagari, hebrejštiny, azbuky, koptštiny, khmérštiny, latiny, tamilštiny, hangulu, han (Čína, Japonsko, Korea), čerokeje, etiopštiny, Japonci (Katakana, Hiragana, Kanji) a další.
Pro akademické účely bylo přidáno mnoho historických skriptů, mezi které patří: starověká řečtina, egyptské hieroglyfy, klínové písmo, mayské písmo, etruská abeceda.
Unicode poskytuje širokou škálu matematických a hudebních symbolů a piktogramů.
Pro znaky cyrilice v Unicode jsou přiděleny dva rozsahy kódů:
Azbuka ( # 0400 - # 04FF)
Cyrilský dodatek ( # 0500 - # 052F).
Ale stolní injekce Unicode v čisté podobě je zadržován z toho důvodu, že pokud kód jednoho znaku nezabere jeden bajt, ale dva bajty, že pro ukládání textu zabere dvakrát tolik místa na disku a pro jeho přenos komunikačními kanály - dvakrát tak dlouho.
V praxi je proto nyní běžnější reprezentace Unicode UTF-8 (Unicode Transformation Format). UTF-8 poskytuje nejlepší kompatibilitu se systémy využívajícími 8bitové znaky. Text obsahující pouze znaky číslované méně než 128 je při zápisu v UTF-8 převeden na prostý text ASCII. Zbývající znaky Unicode jsou reprezentovány sekvencemi o délce 2 až 4 bajty. Obecně platí, že protože nejběžnější znaky na světě - znaky latinské abecedy - v UTF -8 stále zabírají 1 bajt, je toto kódování ekonomičtější než čistý Unicode.
Kódovaný anglický text používá pouze 26 písmen latinské abecedy a 6 dalších interpunkčních znaků. V tomto případě lze zaručit komprimaci textu obsahujícího 1000 znaků bez ztráty informací na velikost:
Ellochkův slovník - „lidožrouti“ (postava v románu „Dvanáct židlí“) má 30 slov. Kolik bitů stačí k zakódování celé slovní zásoby Ellochky? Možnosti: 8, 5, 3, 1.
Jednotky měření objemu dat a kapacity paměti: kilobajty, megabajty, gigabajty ...
Takže jsme zjistili, že ve většině moderních kódování je 1 bajt přidělen pro uložení jednoho znaku textu na elektronická média. Tito. v bajtech se objem (V) obsazený daty měří během jejich ukládání a přenosu (soubory, zprávy).
Datový objem (V) - počet bytů potřebných k jejich uložení do paměti elektronického datového nosiče.
Paměť médií je zase omezená kapacita, tj. schopnost obsahovat určitý objem. Úložná kapacita elektronických paměťových médií se samozřejmě měří také v bajtech.
Bajt je však malá jednotka měření množství dat, větší jsou kilobajty, megabajty, gigabajty, terabajty ...
Je třeba si uvědomit, že předpony „kilo“, „mega“, „giga“ ... nejsou v tomto případě desetinné. „Kilo“ ve slově „kilobyte“ tedy neznamená „tisíc“, tzn neznamená „10 3“. Bit je binární jednotka, a proto je v informatice vhodné používat měrné jednotky, které jsou násobky čísla „2“ místo čísla „10“.
1 bajt = 2 3 = 8 bitů, 1 kilobyte = 2 10 = 1024 bajtů. V binárním formátu 1 kilobajt = & 1 000 000 000 bajtů.
Tito. „Kilo“ zde označuje číslo nejblíže tisíci, což je mocnina čísla 2, tj. což je „kulaté“ číslo v binárním zápisu.
Tabulka 10.
|
Pojmenování |
Označení |
Hodnota v bajtech |
|
|
kilobyte | |||
|
megabajt |
2 10 Kb = 2 20 b | ||
|
gigabajt |
2 10 Mb = 2 30 b | ||
|
terabajt |
2 10 Gb = 2 40 b |
1 099 511 627 776 b |
|
Vzhledem k tomu, že měrné jednotky objemu a kapacity informačních nosičů jsou násobky 2 a nikoli násobky 10, lze většinu problémů na toto téma snáze vyřešit, když hodnoty v nich uvedené jsou reprezentovány mocninami 2 . Zvažte příklad takového problému a jeho řešení:
Textový soubor obsahuje 400 stran textu. Každá stránka obsahuje 3200 znaků. Pokud je použito kódování KOI-8 (8 bitů na znak), pak velikost souboru bude:
Řešení
Určete celkový počet znaků v textovém souboru. V tomto případě reprezentujeme čísla, která jsou násobky mocniny 2 jako mocniny 2, tj. místo 4 píšeme 2 2 atd. K určení stupně lze použít tabulku 7.
znaky.
2) Podle podmínky problému zabírá 1 znak 8 bitů, tj. 1 bajt => soubor zabírá 2 7 * 10 000 bajtů.
3) 1 kilobyte = 2 10 bytů => velikost souboru v kilobajtech je:
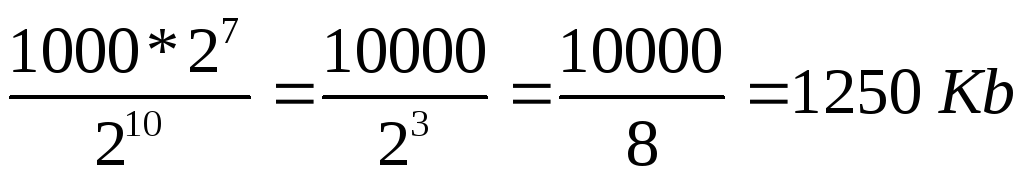 .
.
Kolik bitů je v jednom kilobajtu?
&10000000000000.
Co je 1 MB?
1 000 000 bajtů.
1024 bajtů;
1024 kilobajtů;
Kolik bitů obsahuje čtvrtkilobajtová zpráva? Možnosti: 250, 512, 2000, 2048.
Objem textový soubor 640 Kb... Soubor obsahuje knihu, která je napsána v průměru 32 řádky na stránku a podle 64 znak v řetězci. Kolik stran je v knize: 160, 320, 540, 640, 1280?
Dokumentace pro zaměstnance 8 Mb... Každý z nich obsahuje 16 stránky ( 32 řádky podle 64 znak na řádek). Kolik zaměstnanců v organizaci: 256; 512; 1024; 2048?
Tento příspěvek je pro ty, kteří nerozumí tomu, co je UTF-8, ale chtějí mu porozumět a dostupná dokumentace často tento problém velmi obsáhle pokrývá. Pokusím se to zde popsat tak, že bych sám chtěl, aby mi to někdo řekl dříve. Protože jsem často měl v hlavě nepořádek ohledně UTF-8.
Několik jednoduchých pravidel
- UTF-8 je tedy obálka kolem Unicode. Nejde o samostatné kódování znaků, je zabaleno v Unicode. Kódování Base64 pravděpodobně znáte, nebo jste o něm slyšeli - dokáže zabalit binární data do tisknutelných znaků. Duck, UTF-8 je stejný Base64 pro Unicode jako Base64 pro binární data. Tentokrát. Pokud to pochopíte, pak už bude mnoho jasného. A také je, stejně jako Base64, uznáván za účelem vyřešení problému s kompatibilitou znaků (Base64 byl vynalezen pro e -mail, za účelem přenosu souborů poštou, ve kterém lze tisknout všechny znaky)
- Dále, pokud kód pracuje s UTF-8, pak interně stále funguje s kódováním Unicode, to znamená, že někde hluboko uvnitř jsou tabulky znaků přesně znaků Unicode. Je pravda, že nemusíte mít tabulky znaků Unicode, pokud potřebujete například spočítat, kolik znaků je v řádku (viz níže)
- UTF-8 je vytvořen tak, aby staré programy a dnešní počítače mohly normálně pracovat se znaky Unicode, jako u starých kódování, jako jsou KOI8, Windows-1251 atd. V UTF-8 neexistují žádné bajty s nulami, všechny bajty jsou buď od 0x01 - 0x7F, jako normální ASCII, nebo 0x80 - 0xFF, který funguje také pro programy napsané v jazyce C, protože by fungoval i s jinými znaky než ASCII. Pravda, pro správnou práci se symboly musí program znát tabulky Unicode.
- Cokoli s nejvýznamnějším 7. bitem v bajtu (počítání bitů od nuly) UTF-8 je součástí Unicode codestream.
UTF-8 zevnitř ven
Pokud znáte bitový systém, pak je tu pro vás rychlá poznámka jak je kódován UTF-8:
První bajt Unicode znaku UTF-8 začíná bajtem, kde 7. bit je vždy jeden a 6. bit je vždy jeden. V tomto případě v prvním bajtu, pokud se podíváte na bity zleva doprava (7., 6. a tak dále na nulu), existuje tolik jednotek, kolik bajtů, včetně prvního, přejděte na kódování jednoho znaku Unicode. Pořadí jedniček končí nulou. A poté jsou to bity samotného znaku Unicode. Zbytek bitů Unicode znaku spadá do druhého, nebo dokonce třetího bajtu (maximálně tři, proč - viz trochu níže). Zbytek bajtů, kromě prvního, vždy přichází se začátkem „10“ a poté 6 bitů další části znaku Unicode.
Příklad
Například: existují bajty 110 10000 a druhý 10 011110 ... První začíná na „110“, což znamená, že pokud existují dvě jedničky, budou existovat dva bajty proudu UTF-8 a druhý bajt, stejně jako všechny ostatní, začíná na „10“. A tyto dva bajty kódují znak Unicode, který se skládá z 10100 bitů z prvního bloku + 101101 z druhého, ukazuje se -> 10000011110 -> 41E v šestnáctkové soustavě, popř U + 041E písemně zápis Unicode. Toto je symbol velkého ruského O.
Kolik bytů je maximálně na znak?
Podívejme se také, kolik maximálních bytů jde do UTF-8 pro kódování 16 bitů kódování Unicode. Druhý a další bajty mohou vždy pojmout maximálně 6 bitů. Pokud tedy začnete s koncovými bajty, dva bajty zmizí přesně (2. a 3.) a první musí začínat '1110' pro kódování tří. To znamená, že první bajt v tomto případě může kódovat první 4 bity znaku Unicode. Ukázalo se 4 + 6 + 6 = 16 byte. Ukazuje se, že UTF -8 může mít buď 2 nebo 3 bajty na znak Unicode (jeden nemůže, protože není třeba kódovat 6 bitů (8 - 2 bitů '10') - budou to znaky ASCII. Proto první bajt je UTF 8, nikdy nemůže začínat '10').
Závěr
Mimochodem, díky tomuto kódování můžete vzít jakýkoli bajt ve streamu a určit, zda bajt je Znak Unicode(pokud 7. bit není ASCII), pokud ano, pak je to první v proudu UTF-8 nebo ne první (pokud '10', pak ne první), pokud ne první, pak se můžeme přesunout zpět byte najít první kód UTF-8 (přičemž 6. bit je 1), nebo se přesuňte doprava a přeskočte všech '10' bytů, abyste našli další znak. Díky tomuto kódování mohou programy také bez znalosti Unicode číst, kolik znaků je v řetězci (na základě prvního bajtu UTF-8, vypočítat délku znaků v bajtech). Obecně, pokud se nad tím zamyslíte, kódování UTF-8 bylo vynalezeno velmi kompetentně a zároveň velmi efektivně.
Informační kódování
Jakákoli čísla (v určitých mezích) v paměti počítače jsou kódována čísly v systému binárních čísel. Na to existují jednoduchá a jasná pravidla překladu. Dnes je však počítač používán mnohem šířeji než v roli výkonných výpočtů náročných na práci. Například paměť počítače ukládá textové a multimediální informace. Proto vyvstává první otázka:
Jak jsou znaky (písmena) uloženy v paměti počítače?
Každé písmeno patří do určité abecedy, ve které na sebe znaky navazují, a proto je lze číslovat po sobě jdoucími celými čísly. Každé písmeno lze spojit s kladným číslem a nazývat jej znakovým kódem... Právě tento kód bude uložen v paměti počítače a při zobrazení na obrazovce nebo na papíře bude „převeden“ do odpovídajícího znaku. Chcete -li odlišit reprezentaci čísel od reprezentace znaků v paměti počítače, musíte také uložit informace o tom, která data jsou kódována v konkrétní oblasti paměti.
Korespondence písmen určité abecedy s číselnými kódy tvoří tzv kódovací tabulka... Jinými slovy, každý znak konkrétní abecedy má svůj vlastní číselný kód v souladu s konkrétní kódovací tabulkou.
Na světě je však spousta abeced (angličtina, ruština, čínština atd.). Další otázka tedy zní:
Jak zakódovat všechny abecedy používané v počítači?
Abychom na tuto otázku odpověděli, půjdeme historickou cestou.
V 60. letech 20. století v Americký národní normalizační institut (ANSI) byla vyvinuta tabulka kódování znaků, která byla následně použita ve všech operační systémy... Tato tabulka se nazývá ASCII (americký standardní kód pro výměnu informací)... O něco později se objevil rozšířená verze ASCII.
Podle kódovací tabulky ASCII je 1 znak (8 bitů) přidělen k reprezentaci jednoho znaku. Sada 8 buněk může nabývat 2 8 = 256 různých hodnot. Prvních 128 hodnot (od 0 do 127) je konstantních a tvoří takzvanou hlavní část tabulky, která obsahuje desetinná místa, písmena latinské abecedy (velká a malá písmena), interpunkční znaménka (tečka, čárka, závorky) atd.), stejně jako mezera a různé obslužné znaky (tabelace, řádkový posuv atd.). Hodnoty od 128 do 255 tvoří další část tabulky, kde je obvyklé kódovat symboly národních abeced.
Protože existuje velké množství národních abeced, existují rozšířené tabulky ASCII v mnoha variantách. I pro ruský jazyk existuje několik kódovacích tabulek (běžné jsou Windows-1251 a Koi8-r). To vše vytváří další potíže. Například pošleme dopis napsaný v jednom kódování a příjemce se jej pokusí přečíst v jiném. V důsledku toho vidí krakozyabry. Čtenář proto musí pro text použít jinou kódovací tabulku.
Existuje také další problém. Abecedy některých jazyků mají příliš mnoho znaků a neodpovídají jejich přiděleným pozicím od 128 do 255 jednobajtového kódování.
Třetím problémem je, co dělat, když text používá několik jazyků (například ruštinu, angličtinu a francouzštinu)? Nelze použít dvě tabulky najednou ...
K vyřešení těchto problémů bylo kódování Unicode vyvinuto najednou.
Standard kódování znaků Unicode
K vyřešení výše uvedených problémů na počátku 90. let byl vyvinut standard kódování znaků, tzv Unicode. Tento standard umožňuje používat v textu téměř jakékoli jazyky a symboly.
Unicode poskytuje 31 bitů pro kódování znaků (4 bajty minus jeden bit). Počet možných kombinací dává přemrštěné číslo: 2 31 = 2 147 483 684 (tj. Více než dvě miliardy). Unicode proto popisuje abecedy všech známých jazyků, dokonce i „mrtvých“ a vynalezených, obsahuje mnoho matematických a dalších Speciální symboly... Informační kapacita 31bitového Unicode je však stále příliš velká. Proto se častěji používá zkrácená 16bitová verze (2 16 = 65 536 hodnot), kde jsou kódovány všechny moderní abecedy.
V Unicode je prvních 128 kódů shodných s tabulkou ASCII.
V současné době většina uživatelů používajících počítač zpracovává textové informace, které se skládají ze symbolů: písmena, číslice, interpunkční znaménka atd.
Na základě jedné buňky s informační kapacitou 1 bit lze kódovat pouze 2 různé stavy. Aby každý znak, který lze zadat z klávesnice v latinském registru, obdržel vlastní jedinečný binární kód, je zapotřebí 7 bitů. Na základě sekvence 7 bitů, podle Hartleyho vzorce, lze získat N = 27 = 128 různých kombinací nul a jedniček, tj. binárních kódů. Přidružením každého znaku k jeho binárnímu kódu získáme kódovací tabulku. Osoba pracuje se symboly, počítač - s jejich binárními kódy.
Pro rozložení latinské klávesnice je taková kódovací tabulka tabulkou pro celý svět, proto text zadaný pomocí rozložení latinské klávesnice bude adekvátně zobrazen na jakémkoli počítači. Tato tabulka se nazývá ASCII(American Standard Code of Information Interchange) v angličtině se vyslovuje [eski], v ruštině se vyslovuje [aski]. Níže je celá tabulka ASCII, kódy, ve kterých jsou uvedeny v desítkové formě. Lze jej použít k určení, že když zadáte řekněme znak „*“ z klávesnice, počítač jej vnímá jako kód 42 (10), podle pořadí 42 (10) = 101010 (2) - toto je binární kód znaku „*“. Kódy 0 až 31 se v této tabulce nepoužívají.
stůl ASCII znaky
| kód | symbol | kód | symbol | kód | symbol | kód | symbol | kód | symbol | kód | symbol |
| Prostor | . | @ | P | " | p | ||||||
| ! | A | Otázka | A | q | |||||||
| " | B | R. | b | r | |||||||
| # | C | S | C | s | |||||||
| $ | D | T | d | t | |||||||
| % | E | U | E | u | |||||||
| & | F | PROTI | F | proti | |||||||
| " | G | W | G | w | |||||||
| ( | H | X | h | X | |||||||
| ) | Já | Y | já | y | |||||||
| * | J. | Z | j | z | |||||||
| + | : | K | [ | k | { | ||||||
| , | ; | L | \ | l | | | ||||||
| - | < | M | ] | m | } | ||||||
| . | > | N. | ^ | n | ~ | ||||||
| / | ? | Ó | _ | Ó | DEL |
K zakódování jednoho znaku se použije množství informací rovné 1 bajtu, tj. I = 1 bajt = 8 bitů. Pomocí vzorce, který spojuje počet možných událostí K a množství informací I, můžete vypočítat, kolik různých symbolů lze zakódovat (za předpokladu, že symboly jsou možné události):
K = 2 I = 2 8 = 256,
to znamená, že k reprezentaci textových informací lze použít abecedu s kapacitou 256 znaků.
Podstatou kódování je, že každému znaku je přiřazen binární kód od 00000000 do 11111111 nebo odpovídající desetinný kód od 0 do 255.
Je třeba mít na paměti, že v současné době pro kódování ruštiny písmena používají pět různých tabulek kódů (KOI - 8, CP1251, CP866, Mac, ISO), navíc texty kódované pomocí jedné tabulky nebudou správně zobrazeny v jiném kódování. To lze jasně znázornit jako fragment kombinované tabulky kódování znaků.
Ke stejnému binárnímu kódu jsou přiřazeny různé symboly.
| Binární kód | Desetinný kód | KOI8 | CP1251 | CP866 | Mac | ISO |
| b | PROTI | - | - | T |
Ve většině případů se však uživatel stará o překódování textových dokumentů a speciální programy- převaděče zabudované do aplikací.
Od roku 1997 nejnovější verze Microsoft Office podporovat nové kódování. To se nazývá Unicode. Unicode Je kódovací tabulka, ve které jsou použity 2 bajty ke kódování každého znaku, tj. 16 bitů. Na základě takové tabulky lze kódovat N = 2 16 = 65 536 znaků.
Unicode obsahuje téměř všechny moderní skripty, včetně: arabštiny, arménštiny, bengálštiny, barmštiny, řečtiny, gruzínštiny, devanagari, hebrejštiny, azbuky, koptštiny, khmérštiny, latiny, tamilštiny, hangulu, han (Čína, Japonsko, Korea), čerokeje, etiopštiny, Japonci (Katakana, Hiragana, Kanji) a další.
Pro akademické účely bylo přidáno mnoho historických skriptů, mezi které patří: starověká řečtina, egyptské hieroglyfy, klínové písmo, mayské písmo, etruská abeceda.
Unicode poskytuje širokou škálu matematických a hudebních symbolů a piktogramů.
Pro znaky cyrilice v Unicode jsou přiděleny dva rozsahy kódů:
Azbuka ( # 0400 - # 04FF)
Cyrilský dodatek ( # 0500 - # 052F).
Implementace tabulky Unicode ve své čisté formě je však zdržována z toho důvodu, že pokud kód jednoho znaku nezabere jeden bajt, ale dva bajty, že pro ukládání textu bude trvat dvakrát tolik místa na disku a jeho přenos přes komunikační kanály - dvakrát delší.
Proto je nyní v praxi běžnější reprezentace Unicode UTF-8 (Unicode Transformation Format). UTF-8 poskytuje nejlepší kompatibilitu se systémy využívajícími 8bitové znaky. Text obsahující pouze znaky číslované méně než 128 je při zápisu v UTF-8 převeden na prostý text ASCII. Zbývající znaky Unicode jsou reprezentovány sekvencemi o délce 2 až 4 bajty. Obecně platí, že protože nejběžnější znaky na světě - znaky latinské abecedy - v UTF -8 stále zabírají 1 bajt, je toto kódování ekonomičtější než čistý Unicode.
K určení číselného znakového kódu můžete použít buď kódová tabulka... Chcete -li to provést, vyberte v nabídce položku „Vložit“ - „Symbol“ a poté se na obrazovce zobrazí dialogové okno Symbol. V dialogovém okně se zobrazí tabulka symbolů pro vybrané písmo. Znaky v této tabulce jsou uspořádány řádek po řádku, postupně zleva doprava, počínaje znakem mezery.
 Chyby v singularitě?
Chyby v singularitě? Just Cause 2 havaruje
Just Cause 2 havaruje Terraria nezačne, co mám dělat?
Terraria nezačne, co mám dělat?