อักขระยูนิโค้ดพิเศษ ปัญหาการแยกแยะตัวเลขและตัวอักษรที่คล้ายคลึงกันภายนอก
ผู้ใช้อินเทอร์เน็ตทุกคนที่พยายามกำหนดค่าฟังก์ชันอย่างใดอย่างหนึ่ง อย่างน้อยหนึ่งครั้งก็เห็นคำว่า "Unicode" ที่เขียนอยู่บนจอแสดงผล คุณจะพบว่ามันคืออะไรโดยการอ่านบทความนี้
คำนิยาม
การเข้ารหัส Unicode เป็นมาตรฐานการเข้ารหัสอักขระ นำเสนอโดยองค์กรไม่แสวงหาผลกำไร Unicode Inc. ในปี 1991 มาตรฐานนี้ได้รับการออกแบบเพื่อรวมอักขระประเภทต่างๆ ให้มากที่สุดเท่าที่จะมากได้ในเอกสารฉบับเดียว หน้าที่สร้างขึ้นบนพื้นฐานของมันอาจมีตัวอักษรและอักษรอียิปต์โบราณจาก ภาษาที่แตกต่างกัน(จากภาษารัสเซียเป็นภาษาเกาหลี) และ สัญญาณทางคณิตศาสตร์... ในกรณีนี้ อักขระทั้งหมดในการเข้ารหัสนี้จะแสดงโดยไม่มีปัญหา
เหตุผลในการสร้างสรรค์
กาลครั้งหนึ่งนานมาแล้ว ระบบครบวงจร"Unicode" การเข้ารหัสถูกเลือกตามความชอบของผู้เขียนเอกสาร ด้วยเหตุนี้ จึงมักจำเป็นต้องใช้ตารางต่างๆ เพื่ออ่านเอกสารฉบับเดียว บางครั้งต้องทำหลายครั้งซึ่งทำให้ชีวิตของผู้ใช้ทั่วไปซับซ้อนอย่างมาก ดังที่ได้กล่าวไปแล้ว องค์กรไม่แสวงหากำไร Unicode Inc. เสนอวิธีแก้ปัญหานี้ในปี 2534 ซึ่งเสนอการเข้ารหัสอักขระประเภทใหม่ มีวัตถุประสงค์เพื่อรวมมาตรฐานที่ล้าสมัยและหลากหลายเข้าด้วยกัน "Unicode" เป็นการเข้ารหัสที่ช่วยให้บรรลุสิ่งที่คิดไม่ถึงในขณะนั้น: เพื่อสร้างเครื่องมือที่รองรับอักขระจำนวนมาก ผลลัพธ์เกินความคาดหมายมากมาย - เอกสารปรากฏขึ้นพร้อม ๆ กันซึ่งประกอบด้วยข้อความภาษาอังกฤษและรัสเซีย ละติน และนิพจน์ทางคณิตศาสตร์
แต่การสร้างรหัสเดียวนำหน้าด้วยความจำเป็นในการแก้ไขปัญหาจำนวนหนึ่งซึ่งเกิดจากมาตรฐานที่หลากหลายที่มีอยู่แล้วในขณะนั้น ที่พบบ่อยที่สุดคือ:
- ตัวอักษรพรายหรือ "krakozyabry";
- ชุดอักขระจำกัด;
- ปัญหาการแปลงการเข้ารหัส
- การทำสำเนาแบบอักษร

ทัวร์ประวัติศาสตร์เล็ก ๆ
ลองนึกภาพว่าเป็นยุค 80 เทคโนโลยีคอมพิวเตอร์ยังไม่แพร่หลายและมีรูปแบบที่แตกต่างจากปัจจุบัน ในเวลานั้น OS แต่ละ OS มีลักษณะเฉพาะในแบบของตัวเอง และถูกแก้ไขโดยผู้สนใจแต่ละรายเพื่อตอบสนองความต้องการเฉพาะ ความจำเป็นในการแลกเปลี่ยนข้อมูลกลายเป็นการปรับแต่งเพิ่มเติมของทุกสิ่งในโลก ความพยายามที่จะอ่านเอกสารที่สร้างขึ้นภายใต้ระบบปฏิบัติการอื่นมักจะแสดงชุดอักขระที่เข้าใจยากบนหน้าจอ และเกมที่มีการเข้ารหัสเริ่มต้นขึ้น ไม่สามารถทำได้อย่างรวดเร็วเสมอไป และบางครั้งสามารถเปิดเอกสารที่จำเป็นได้หลังจากหกเดือนหรือหลังจากนั้น ผู้ที่แลกเปลี่ยนข้อมูลมักสร้างตารางการแปลงสำหรับตนเอง ดังนั้นงานของพวกเขาจึงเผยให้เห็นรายละเอียดที่น่าสนใจ: พวกเขาจะต้องสร้างขึ้นในสองทิศทาง: "จากของฉันถึงของคุณ" และในทางกลับกัน เครื่องไม่สามารถทำการคำนวณแบบผกผันซ้ำ ๆ ได้เพราะในคอลัมน์ด้านขวาคือแหล่งที่มาและในด้านซ้าย - ผลลัพธ์ แต่ไม่ใช่ในทางกลับกัน หากมีความจำเป็นต้องใช้ใด ๆ สัญลักษณ์พิเศษในเอกสารต้องเพิ่มพวกเขาก่อนแล้วจึงอธิบายให้คู่ค้าทราบถึงสิ่งที่เขาต้องทำเพื่อไม่ให้สัญลักษณ์เหล่านี้กลายเป็น "krakozyabry" และอย่าลืมว่าในการเข้ารหัสแต่ละครั้ง คุณต้องพัฒนาหรือใช้แบบอักษรของคุณเอง ซึ่งนำไปสู่การสร้างสำเนาจำนวนมากในระบบปฏิบัติการ
ลองนึกภาพด้วยว่าในหน้าแบบอักษรคุณจะเห็น 10 Times New Roman ที่เหมือนกันพร้อมคำอธิบายประกอบขนาดเล็ก: สำหรับ UTF-8, UTF-16, ANSI, UCS-2 ตอนนี้คุณเข้าใจหรือไม่ว่าจำเป็นต้องพัฒนามาตรฐานสากล?

“บิดาผู้สร้าง”
ต้นกำเนิดของ Unicode สามารถสืบย้อนไปถึงปี 1987 เมื่อ Joe Becker แห่ง Xerox พร้อมด้วย Lee Collins และ Mark Davis แห่ง แอปเปิ้ลเริ่มการวิจัยเกี่ยวกับการสร้างชุดอักขระสากลในทางปฏิบัติ ในเดือนสิงหาคม พ.ศ. 2531 Joe Becker ได้เผยแพร่ร่างข้อเสนอสำหรับระบบการเข้ารหัสหลายภาษาแบบ 16 บิตแบบหลายภาษา
ไม่กี่เดือนต่อมา คณะทำงาน Unicode ได้รับการขยายเพื่อรวม Ken Whistler และ Mike Kernegan จาก RLG, Glenn Wright จาก Sun Microsystems และอีกหลายคน ทำงานเบื้องต้นเกี่ยวกับมาตรฐานการเข้ารหัสทั่วไปให้เสร็จสิ้น

คำอธิบายทั่วไป
Unicode ขึ้นอยู่กับแนวคิดของตัวละคร คำจำกัดความนี้เข้าใจว่าเป็นปรากฏการณ์นามธรรมที่มีอยู่ในรูปแบบการเขียนเฉพาะและรับรู้ผ่านกราฟ ("ภาพเหมือน") อักขระแต่ละตัวระบุไว้ใน "Unicode" รหัสเฉพาะเป็นของบล็อกเฉพาะของมาตรฐาน ตัวอย่างเช่น มีกราฟ B ทั้งในตัวอักษรภาษาอังกฤษและรัสเซีย แต่ใน Unicode จะตรงกับอักขระ 2 ตัวที่แตกต่างกัน การแปลงถูกนำไปใช้กับการเปลี่ยนแปลง กล่าวคือ แต่ละรายการมีคำอธิบายโดยคีย์ฐานข้อมูล ชุดคุณสมบัติ และชื่อเต็ม
ประโยชน์ของ Unicode
การเข้ารหัส Unicode แตกต่างจากรุ่นอื่นๆ เนื่องจากมีอักขระจำนวนมากสำหรับ "การเข้ารหัส" ความจริงก็คือว่ารุ่นก่อนมี 8 บิตนั่นคือรองรับ 28 ตัวอักษรแต่ การพัฒนาใหม่มีตัวละครอยู่แล้ว 216 ตัวซึ่งเป็นก้าวที่ยิ่งใหญ่ ทำให้สามารถเข้ารหัสตัวอักษรที่มีอยู่และตัวอักษรทั่วไปเกือบทั้งหมดได้
ด้วยการถือกำเนิดของ "Unicode" ไม่จำเป็นต้องใช้ตารางการแปลง เนื่องจากเป็นมาตรฐานเดียว จึงขจัดความต้องการของพวกเขาออกไป ในทำนองเดียวกัน "krakozyabry" ได้จมลงสู่การลืมเลือน - มาตรฐานเดียวที่ทำให้พวกเขาเป็นไปไม่ได้ รวมทั้งขจัดความจำเป็นในการสร้างแบบอักษรที่ซ้ำกัน
การพัฒนา Unicode
แน่นอน ความคืบหน้าไม่หยุดนิ่ง และผ่านไป 25 ปีนับตั้งแต่การนำเสนอครั้งแรก อย่างไรก็ตาม การเข้ารหัส Unicode ยังคงรักษาตำแหน่งของตนไว้อย่างดื้อรั้น ในหลาย ๆ ด้าน สิ่งนี้เกิดขึ้นได้เนื่องจากการที่มันถูกนำไปใช้อย่างง่ายดายและแพร่หลาย โดยได้รับการยอมรับว่าเป็นนักพัฒนาซอฟต์แวร์ที่เป็นกรรมสิทธิ์ (แบบชำระเงิน) และโอเพ่นซอร์ส

ในเวลาเดียวกัน เราไม่ควรทึกทักเอาเองว่าวันนี้การเข้ารหัส Unicode แบบเดียวกันพร้อมให้เราใช้งานได้เมื่อหนึ่งในสี่ของศตวรรษที่ผ่านมา บน ช่วงเวลานี้เวอร์ชันของมันถูกเปลี่ยนเป็น 5.х.х และจำนวนอักขระที่เข้ารหัสเพิ่มขึ้นเป็น 231 ตัว ความสามารถในการใช้อักขระที่มากขึ้นถูกละทิ้งเพื่อให้ยังคงรองรับ Unicode-16 (การเข้ารหัสซึ่งจำกัดจำนวนสูงสุดไว้ที่ 216). ตั้งแต่เริ่มก่อตั้งจนถึงเวอร์ชัน 2.0.0 "Unicode Standard" ได้เพิ่มจำนวนอักขระที่มีอยู่เกือบสองเท่า การเติบโตของโอกาสยังคงดำเนินต่อไปในปีต่อๆ ไป โดยเวอร์ชัน 4.0.0 นั้นจำเป็นต้องเพิ่มมาตรฐานของตัวเองซึ่งทำเสร็จแล้ว เป็นผลให้ "Unicode" ได้รับรูปแบบที่เรารู้จักในปัจจุบัน

Unicode มีอะไรอีกบ้าง?
นอกเหนือจากสัญลักษณ์จำนวนมากที่เติบโตอย่างต่อเนื่องแล้ว ยังมีคุณสมบัติที่มีประโยชน์อีกอย่างหนึ่งอีกด้วย นี่คือสิ่งที่เรียกว่าการทำให้เป็นมาตรฐาน แทนที่จะเลื่อนดูทั้งอักขระในเอกสารทีละอักขระและแทนที่ไอคอนที่เหมาะสมจากตารางค้นหา หนึ่งในอัลกอริธึมการทำให้เป็นมาตรฐานที่มีอยู่จะถูกใช้ เรากำลังพูดเรื่องอะไรอยู่?
แทนที่จะเปลืองทรัพยากรในการคำนวณไปกับการตรวจสอบสัญลักษณ์เดียวกันเป็นประจำ ซึ่งอาจคล้ายกันในตัวอักษรต่างกัน มีการใช้อัลกอริธึมพิเศษ ช่วยให้คุณสามารถนำอักขระที่คล้ายกันในคอลัมน์ที่แยกต่างหากของตารางการแทนที่และอ้างอิงถึงอักขระเหล่านี้ แทนที่จะตรวจสอบข้อมูลทั้งหมดซ้ำแล้วซ้ำอีก
สี่อัลกอริธึมดังกล่าวได้รับการพัฒนาและดำเนินการ ในแต่ละคน การเปลี่ยนแปลงเกิดขึ้นตามหลักการที่กำหนดไว้อย่างเคร่งครัดซึ่งแตกต่างจากที่อื่น ดังนั้นจึงเป็นไปไม่ได้ที่จะตั้งชื่อว่าข้อใดข้อหนึ่งที่มีประสิทธิภาพมากที่สุด แต่ละรายการได้รับการพัฒนาเพื่อตอบสนองความต้องการเฉพาะ มีการนำไปใช้งานและใช้งานได้สำเร็จ

การกระจายมาตรฐาน
กว่า 25 ปีของประวัติศาสตร์ การเข้ารหัส Unicode น่าจะใช้กันอย่างแพร่หลายมากที่สุดในโลก โปรแกรมและเว็บเพจได้รับการปรับแต่งให้เข้ากับมาตรฐานนี้เช่นกัน ความจริงที่ว่า Unicode ถูกใช้โดยทรัพยากรอินเทอร์เน็ตมากกว่า 60% ในปัจจุบันสามารถบ่งบอกถึงความกว้างของแอปพลิเคชัน
ตอนนี้คุณรู้แล้วว่ามาตรฐาน Unicode เกิดขึ้นเมื่อใด มันคืออะไร คุณรู้และจะสามารถชื่นชมความสำคัญอย่างเต็มที่ของการประดิษฐ์ที่ทำโดยกลุ่มผู้เชี่ยวชาญจาก Unicode Inc. เมื่อกว่า 25 ปีที่แล้ว
คุณต้องการโฮสต์หรือโดเมนหรือไม่? คลิกที่นี่! คุณต้องการสร้างร้านค้าออนไลน์หรือไม่? คลิกที่นี่! (Shopify)บางครั้งเมื่อเขียนโพสต์ จำเป็นต้องมีอักขระ (เครื่องหมาย) ที่ไม่ได้อยู่บนแป้นพิมพ์ ในสถานการณ์เช่นนี้ ตารางอักขระ Unicode จะช่วยคุณได้ วันนี้เราจะมาพิจารณา บริการออนไลน์ซึ่งอักขระ Unicode ทั้งหมดจะถูกจัดกลุ่ม ...
ตารางอักขระ Unicode
สำหรับผู้ที่สนใจเบื้องหลังของรูปลักษณ์ Unicode- นี่คือลิงค์ไปยังวิกิพีเดีย
ดังนั้นมากำหนดความสนใจของเราใน อักขระยูนิโค้ด- นี่คือการใช้งานของพวกเขาในบทความของพวกเขาบนเว็บไซต์ของตน
ไปที่เพจกันก่อนเลย อักขระยูนิโค้ดบริการ:


มาดูอินเทอร์เฟซของบริการนี้กันสักหน่อย ที่ด้านบนสุดมีช่องค้นหาในนั้นก็เพียงพอที่จะขับในชื่อขององค์ประกอบที่คุณกำลังมองหาเช่น: "ลูกศร" หรือ "จุดไข่ปลา" หลังจากป้อนให้คลิกที่การค้นหาเพื่อรับผลลัพธ์ .
ถัดจากการค้นหาจะมีตัวสลับภาษาของหน้า
ด้านล่างนี้คือรายการของสัญลักษณ์ที่ร้องขอบ่อยครั้ง บางทีในหมู่พวกมันอาจมีสัญลักษณ์ที่คุณต้องการ ในกรณีนี้ เพียงคลิกที่สัญลักษณ์เพื่อไปที่หน้าพร้อมข้อมูลโดยละเอียดเกี่ยวกับสัญลักษณ์นั้น
ส่วนหลักของหน้าถูกครอบครองโดย ตารางอักขระ Unicodeเพื่อการค้นหาที่สะดวกยิ่งขึ้น คุณยังสามารถคลิกที่ "Control Characters" เพื่อเลือกกลุ่มอักขระ เช่น "Greek Characters" หากคุณต้องการแทรกอักขระ Greek
ค้นหารายการที่คุณต้องการในตารางอักขระ Unicode
ตัวอย่างเช่น ลองใช้การค้นหาและป้อนคำว่า "ลูกศร" ลงไปแล้วกดค้นหา

ในหน้าผลการค้นหา เรากำลังมองหาสัญลักษณ์ที่เราต้องการและคลิกเพื่อไปที่หน้า รายละเอียดข้อมูลเกี่ยวกับเขา.
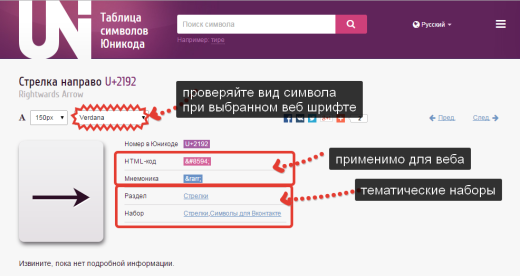
ในเพจ อักขระ Unicodeเรามีความสนใจในโค้ด HTML หรือโค้ด Mnemonic ของมัน ทั้งคู่สามารถใช้บนหน้าเว็บ การทำเช่นนี้ ให้คัดลอกโค้ดและวางในตำแหน่งที่ถูกต้องในมาร์กอัป HTML เบราว์เซอร์จะตีความและแสดงเป็นสัญลักษณ์บน หน้า.
โปรดทราบว่าในหน้าอักขระ Unicode มีแบบอักษรให้เลือก ทดสอบว่าแบบอักษรของคุณจะแสดงด้วย Verdana, Arial (และแบบอักษรเว็บอื่นๆ อย่างไร) เสมอ อักขระบางตัวไม่ได้รับการสนับสนุน
(รหัสตั้งแต่ 0 ถึง 127) เช่น หนึ่งไบต์เข้ารหัสตัวอักษรละติน ตัวเลข และอักขระพิเศษ ตัวอักษรรัสเซีย (ซิริลลิก) แสดงด้วยรหัส 16 บิต (สองไบต์):
110XXXXX 10XXXXXX,
โดยที่ X หมายถึงเลขฐานสองสำหรับวางรหัสอักขระตามตาราง UNICODE.
Unicode (อังกฤษ Unicode) เป็นมาตรฐานการเข้ารหัสอักขระที่ช่วยให้สามารถแสดงอักขระในภาษาเขียนเกือบทั้งหมด อักขระ Unicode ถูกเข้ารหัสเป็นจำนวนเต็มที่ไม่ได้ลงนาม ตัวเลขเหล่านี้จะเรียกว่ารหัสอักขระ Unicode หรือเรียกง่ายๆ ว่า UNICODE... Unicode มีการแสดงอักขระหลายรูปแบบในคอมพิวเตอร์: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) และ UTF-32 (UTF-32BE, UTF-32LE)... (รูปแบบการแปลง Unicode ภาษาอังกฤษ - UTF)
พิจารณาวิธีการเข้ารหัสใน UTF-8จดหมาย NS... ของเธอ UNICODE- 1046 10 หรือ 0416 16 หรือ 10000 010110 2. UNICODEในระบบไบนารี จะแบ่งออกเป็นสองส่วน: บิตซ้ายห้าบิตและบิตขวาหกบิต ด้านซ้ายบุ๋มเป็นไบต์พร้อมสัญลักษณ์ 110 รหัสสองไบต์ UTF-8: 110 10000 สองบิตถูกกำหนดไว้ทางด้านขวา 10 สัญญาณของความต่อเนื่องของรหัสหลายไบต์: 10 010110. รหัสอักษรตัวสุดท้าย NSวี UTF-8ดูเหมือนว่า:
110
10000 10
010110 2
หรือ D0 96 16
ดังนั้น ตัวอักษรรัสเซียจึงถูกเข้ารหัสสองครั้ง: ตัวแรกเป็น 11 บิต UNICODEแล้วเปลี่ยนเป็น UTF-8 แบบ 16 บิต
ในตารางด้านล่างนอกเหนือจากรหัส UNICODEและ UTF-8ในรูปแบบเลขฐานสิบหก จะได้รับรหัส UTF-8ในรูปแบบทศนิยมและสำหรับการเปรียบเทียบรหัสซิริลลิกในการเข้ารหัส CP-1251หรือเรียกอีกอย่างว่า วินดอฟ-1251.
| เครื่องหมาย | UNICODE | UTF-8 | CP-1251 | ||
|---|---|---|---|---|---|
| Hex | สิบ | Hex | สิบ | ||
| NS | 0410 | 1040 | D090 | 208 144 | 192 |
| NS | 0411 | 1041 | D091 | 208 145 | 193 |
| วี | 0412 | 1042 | D092 | 208 146 | 194 |
| NS | 0413 | 1043 | D093 | 208 147 | 195 |
| NS | 0414 | 1044 | D094 | 208 148 | 196 |
| อี | 0415 | 1045 | D095 | 208 149 | 197 |
| NS | 0416 | 1046 | D096 | 208 150 | 198 |
| Z | 0417 | 1047 | D097 | 208 151 | 199 |
| และ | 0418 | 1048 | D098 | 208 152 | 200 |
| ไทย | 0419 | 1049 | D099 | 208 153 | 201 |
| ถึง | 041A | 1050 | D09A | 208 154 | 202 |
| หลี่ | 041B | 1051 | D09B | 208 155 | 203 |
| NS | 041C | 1052 | D09C | 208 156 | 204 |
| NS | 041D | 1053 | D09D | 208 157 | 205 |
| อู๋ | 041E | 1054 | D09E | 208 158 | 206 |
| NS | 041F | 1055 | D09F | 208 159 | 207 |
| NS | 0420 | 1056 | D0A0 | 208 160 | 208 |
| กับ | 0421 | 1057 | D0A1 | 208 161 | 209 |
| NS | 0422 | 1058 | D0A2 | 208 162 | 210 |
| มี | 0423 | 1059 | D0A3 | 208 163 | 211 |
| NS | 0424 | 1060 | D0A4 | 208 164 | 212 |
| NS | 0425 | 1061 | D0A5 | 208 165 | 213 |
| ค | 0426 | 1062 | D0A6 | 208 166 | 214 |
| ชม | 0427 | 1063 | D0A7 | 208 167 | 215 |
| NS | 0428 | 1064 | D0A8 | 208 168 | 216 |
| SCH | 0429 | 1065 | D0A9 | 208 169 | 217 |
| NS | 042A | 1066 | D0AA | 208 170 | 218 |
| NS | 042B | 1067 | D0AB | 208 171 | 219 |
| NS | 042C | 1068 | D0AC | 208 172 | 220 |
| NS | 042D | 1069 | D0AD | 208 173 | 221 |
| NS | 042E | 1070 | D0AE | 208 174 | 222 |
| ฉัน | 042F | 1071 | D0AF | 208 175 | 223 |
| NS | 0430 | 1072 | D0B0 | 208 176 | 224 |
| NS | 0431 | 1073 | D0B1 | 208 177 | 225 |
| วี | 0432 | 1074 | D0B2 | 208 178 | 226 |
| NS | 0433 | 1075 | D0B3 | 208 179 | 227 |
| NS | 0434 | 1076 | D0B4 | 208 180 | 228 |
| อี | 0435 | 1077 | D0B5 | 208 181 | 229 |
| NS | 0436 | 1078 | D0B6 | 208 182 | 230 |
| NS | 0437 | 1079 | D0B7 | 208 183 | 231 |
| และ | 0438 | 1080 | D0B8 | 208 184 | 232 |
| NS | 0439 | 1081 | D0B9 | 208 185 | 233 |
| ถึง | 043A | 1082 | D0BA | 208 186 | 234 |
| l | 043B | 1083 | D0BB | 208 187 | 235 |
| NS | 043C | 1084 | D0BC | 208 188 | 236 |
| NS | 043D | 1085 | D0BD | 208 189 | 237 |
| อู๋ | 043E | 1086 | D0BE | 208 190 | 238 |
| NS | 043F | 1087 | D0BF | 208 191 | 239 |
| NS | 0440 | 1088 | D180 | 209 128 | 240 |
| กับ | 0441 | 1089 | D181 | 209 129 | 241 |
| NS | 0442 | 1090 | D182 | 209 130 | 242 |
| ที่ | 0443 | 1091 | D183 | 209 131 | 243 |
| NS | 0444 | 1092 | D184 | 209 132 | 244 |
| NS | 0445 | 1093 | D185 | 209 133 | 245 |
| ค | 0446 | 1094 | D186 | 209 134 | 246 |
| ชม | 0447 | 1095 | D187 | 209 135 | 247 |
| NS | 0448 | 1096 | D188 | 209 136 | 248 |
| SCH | 0449 | 1097 | D189 | 209 137 | 249 |
| NS | 044A | 1098 | D18A | 209 138 | 250 |
| NS | 044B | 1099 | D18B | 209 139 | 251 |
| NS | 044C | 1100 | D18C | 209 140 | 252 |
| NS | 044D | 1101 | D18D | 209 141 | 253 |
| NS | 044E | 1102 | D18E | 209 142 | 254 |
| ฉัน | 044F | 1103 | D18F | 209 143 | 255 |
| สัญลักษณ์ที่อยู่นอกกฎทั่วไป | |||||
| โย | 0401 | 1025 | D001 | 208 101 | 168 |
| อี | 0451 | 1025 | D191 | 209 145 | 184 |
บางครั้ง คุณจำเป็นต้องเพิ่มไอคอนในงานออกแบบของคุณ แต่ไม่อยากใส่รูปภาพเพิ่มเติมหรือแบบอักษรของไอคอนทั้งหมด เช่น Font Awesome ใช่ไหม เราก็มีข่าวดีสำหรับคุณ - มีคลังไอคอนและสัญลักษณ์มากมายที่พร้อมใช้งานในเบราว์เซอร์ของคุณแล้ว เรียกว่า Unicode และเป็นมาตรฐานที่กำหนด ตัวระบุที่ไม่ซ้ำสำหรับสัญลักษณ์และไอคอนที่เพิ่มมากขึ้นเรื่อยๆ (ปัจจุบันมีมากกว่า 110,000 รายการ)
นี่ไม่ได้หมายความว่าคุณมีไอคอนให้เลือกหลายแสนไอคอน ขึ้นอยู่กับเบราว์เซอร์ที่แสดง และใช้แบบอักษรที่ติดตั้งบนระบบเพื่อทำสิ่งนี้ ในบทความนี้ เราได้รวบรวมชุดอักขระจำนวนหนึ่งที่พร้อมใช้งานบน Windows, Linux, OS X, Android และ IOS คุณสามารถใช้มันในการออกแบบของคุณวันนี้!
เคล็ดลับ: ซึ่งจะอธิบายทุกอย่างที่ควรรู้เกี่ยวกับการเข้ารหัสและ Unicode ซึ่งเราแนะนำให้นักพัฒนาซอฟต์แวร์ทุกคนอ่าน
วิธีใช้ไอคอนเหล่านี้
ไอคอนที่แสดงในตารางด้านล่างเป็นสัญลักษณ์ทั่วไปที่คุณสามารถคัดลอกและวางได้เหมือนกับว่าเป็นตัวอักษรของตัวอักษร แต่ถ้าการเข้ารหัสที่ใช้ในการบันทึกไฟล์ HTML / CSS ไม่ใช่ UTF-8พวกเขาจะไม่ปรากฏ นี่คือเหตุผลที่เราแนะนำโค้ดหลีก HTML ที่จะใช้งานได้ตลอดเวลา นี่คือสิ่งที่คุณต้องทำเพื่อใช้ไอคอนเหล่านี้:
- ค้นหาไอคอนที่คุณชอบ เราได้จัดเตรียมตัวอย่างขนาดเล็กและขนาดใหญ่
- คัดลอกรหัส
- วางลงใน HTML เป็นข้อความธรรมดา ใน CSS คุณสามารถใช้มันเป็นค่าคุณสมบัติ เนื้อหา... ใน JS, PHP และภาษาการเขียนโปรแกรมอื่นๆ คุณสามารถใช้เป็นข้อความธรรมดาในสตริงได้
- คุณสามารถปรับแต่งไอคอนได้โดยการตั้งค่าขนาดแบบอักษร สี ข้อความและเงาเหมือนกับข้อความปกติ
ไอคอน
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ยิ้ม | ☺ | ☺ | ☺ |
| ป้ายเตือน | ⚠ | ⚠ | ⚠ |
| น้ำพุร้อน | ♨ | ♨ | ♨ |
| วีลแชร์ | ♿ | ♿ | ♿ |
| รีไซเคิล | ♻ | ♻ | ♻ |
| 8-Ball | ➑ | ➑ | ➑ |
| ไฟฟ้าแรงสูง | ⚡ | ⚡ | ⚡ |
| ไวท์สตาร์ | ☆ | ☆ | ☆ |
| ดาวสีดำ | ★ | ★ | ★ |
| หัวใจสีขาว | ♡ | ♡ | ♡ |
| ใจดำ | ❤ | ❤ | ❤ |
| กาแฟ | ☕ | ☕ | ☕ |
| เครื่องบิน | ✈ | ✈ | ✈ |
| นาฬิกาทราย | ⌛ | ⌛ | ⌛ |
| นาฬิกา | ⌚ | ⌚ | ⌚ |
| กรรไกรดำ | ✂ | ✂ | ✂ |
| กรรไกรขาว | ✄ | ✄ | ✄ |
| มงกุฎ | ♕ | ♕ | ♕ |
| สมอ | ⚓ | ⚓ | ⚓ |
| ข้าม | ✝ | ✝ | ✝ |
| วงกลมขาวดำ | ◑ | ◑ | ◑ |
| โน้ตแปด | ♪ | ♪ | ♪ |
| บีมแปดโน้ต | ♫ | ♫ | ♫ |
| เครื่องหมายดอกจันสี่แฉก | ✣ | ✣ | ✣ |
| วงกลมสีขาวดาว | ✪ | ✪ | ✪ |
| ไวท์สตาร์ | ✰ | ✰ | ✰ |
| ดาวสี่แฉกสีขาว | ✧ | ✧ | ✧ |
| ดาวสี่แฉกสีดำ | ✦ | ✦ | ✦ |
| กาเครื่องหมายกล่องลงคะแนน | ☑ | ☑ | ☑ |
| เครื่องหมายถูก | ✔ | ✔ | ✔ |
| เครื่องหมายกากบาท | ✘ | ✘ | ✘ |
| ดินสอ | ✎ | ✎ | ✎ |
| เขียนมือ | ✍ | ✍ | ✍ |
| หญิง | ♀ | ♀ | ♀ |
| ชาย | ♂ | ♂ | ♂ |
| โทรศัพท์สีดำ | ☎ | ☎ | ☎ |
| โทรศัพท์สีขาว | ☏ | ☏ | ☏ |
| ซองจดหมาย | ✉ | ✉ | ✉ |
| ที่ตั้งโทรศัพท์ | ✆ | ✆ | ✆ |
ลูกศร Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ลูกศรซ้าย | ← | ← | ← |
| ลูกศรขวา | → | → | → |
| ลูกศรขึ้น | |||
| ลูกศรชี้ลง | ↓ | ↓ | ↓ |
| ลูกศรขวาซ้าย | ↔ | ↔ | ↔ |
| ลูกศรขึ้นลง | ↕ | ↕ | ↕ |
| ลูกศรขวาและซ้าย | ⇄ | ⇄ | ⇄ |
| ลูกศรขึ้นและลง | ⇅ | ⇅ | ⇅ |
| ลูกศรลง-ซ้าย 90 องศา | ↲ | ↲ | ↲ |
| ลูกศรลง-ขวา 90 องศา | ↳ | ↳ | ↳ |
| ลูกศรขึ้น-ซ้าย 90 องศา | ↰ | ↰ | ↰ |
| ลูกศรขวา 90 องศา | ↱ | ↱ | ↱ |
| North West Arrow To Corner | ⇱ | ⇱ | ⇱ |
| ลูกศรตะวันออกเฉียงใต้สู่มุม | ⇲ | ⇲ | ⇲ |
| ลูกศรซ้ายไปที่แถบ | ⇤ | ⇤ | ⇤ |
| ลูกศรชี้ขวาไปที่แถบ | ⇥ | ⇥ | ⇥ |
| ลูกศรครึ่งวงกลมทวนเข็มนาฬิกา | ↶ | ↶ | ↶ |
| ลูกศรครึ่งวงกลมตามเข็มนาฬิกา | ↷ | ↷ | ↷ |
| ลูกศรวงกลมทวนเข็มนาฬิกา | ↺ | ↺ | ↺ |
| ลูกศรวงกลมตามเข็มนาฬิกา | ↻ | ↻ | ↻ |
| ลูกศรชี้ขวาหัวกว้าง | ➔ | ➔ | ➔ |
| ลูกศรซิกแซกลง | ↯ | ↯ | ↯ |
| ลูกศรทิศตะวันตกเฉียงเหนือ | ↖ | ↖ | ↖ |
| ลูกศรตะวันออกเฉียงใต้หนัก | ➘ | ➘ | ➘ |
| ลูกศรขวาหนัก | ➙ | ➙ | ➙ |
| ลูกศรตะวันออกเฉียงเหนือหนัก | ➚ | ➚ | ➚ |
| ลูกศรชี้ไปทางขวา | ➟ | ➟ | ➟ |
| ลูกศรชี้ไปทางซ้าย | ⇠ | ⇠ | ⇠ |
| หัวลูกศรขวาสีดำ | ➤ | ➤ | ➤ |
| ลูกศรซ้ายสีขาว | ⇦ | ⇦ | ⇦ |
| ลูกศรขวาสีขาว | ⇨ | ⇨ | ⇨ |
| เครื่องหมายคำพูดมุมซ้าย | « | « | « |
| เครื่องหมายคำพูดมุมขวา | » | » | » |
| ตัวชี้สีดำขวา | |||
| ตัวชี้สีดำด้านซ้าย | ◀ | ◀ | ◀ |
| ตัวชี้สีดำ | ▲ | ▲ | ▲ |
| ตัวชี้สีดำลง | ▼ | ▼ | ▼ |
| ตัวชี้สีขาวขวา | ▷ | ▷ | ▷ |
| ตัวชี้สีขาวซ้าย | ◁ | ◁ | ◁ |
| ตัวชี้สีขาวขึ้น | △ | △ | △ |
| ตัวชี้สีขาวลง | ▽ | ▽ | ▽ |
| ธนูศร | ➴ | ➴ | ➴ |
อักขระพิเศษในยูนิโค้ด
สกุลเงินยูนิโค้ด
ไอคอนสภาพอากาศ
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ระดับ | ° | ° | ° |
| แดดน้อย | ☀ | ☀ | ☀ |
| บิ๊กซัน | ☼ | ☼ | ☼ |
| คลาวด์ | ☁ | ☁ | ☁ |
| ร่ม | ☔ | ☔ | ☔ |
| เกล็ดหิมะ 1 | ❆ | ❆ | ❆ |
| เกล็ดหิมะ 2 | ❅ | ❅ | ❅ |
| เกล็ดหิมะ 3 | ❄ | ❄ | ❄ |
ตัวชี้ Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ตัวชี้ซ้ายสีดำ | ☚ | ☚ | ☚ |
| ตัวชี้ ขวา สีดำ | ☛ | ☛ | ☛ |
| ตัวชี้ซ้ายสีขาว | ☜ | ☜ | ☜ |
| ตัวชี้ขึ้นสีขาว | ☝ | ☝ | ☝ |
| ตัวชี้ ขวา สีขาว | ☞ | ☞ | ☞ |
| ตัวชี้ลงสีขาว | ☟ | ☟ | ☟ |
ราศีในยูนิโคด
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ราศีเมษ | ♈ | ♈ | ♈ |
| ราศีพฤษภ | ♉ | ♉ | ♉ |
| ฝาแฝด | ♊ | ♊ | ♊ |
| มะเร็ง | ♋ | ♋ | ♋ |
| สิงโต | ♌ | ♌ | ♌ |
| ราศีกันย์ | ♍ | ♍ | ♍ |
| ตาชั่ง | ♎ | ♎ | ♎ |
| แมงป่อง | ♏ | ♏ | ♏ |
| ราศีธนู | ♐ | ♐ | ♐ |
| ราศีมังกร | ♑ | ♑ | ♑ |
| ราศีกุมภ์ | ♒ | ♒ | ♒ |
| ปลา | ♓ | ♓ | ♓ |
สัญลักษณ์การ์ด Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| Clubs Black | ♠ | ♠ | ♠ |
| Hearts Black | ♥ | ♥ | ♥ |
| เพชรสีดำ | ♦ | ♦ | ♦ |
| โพดำ | ♣ | ♣ | ♣ |
| คลับไวท์ | ♤ | ♤ | ♤ |
| หัวใจสีขาว | ♡ | ♡ | ♡ |
| เพชรขาว | ♢ | ♢ | ♢ |
| โพดำขาว | ♧ | ♧ | ♧ |
ตัวหมากรุกในยูนิโค้ด
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| คิงไวท์ | ♔ | ♔ | ♔ |
| ราชินีขาว | ♕ | ♕ | ♕ |
| Rook สีขาว | ♖ | ♖ | ♖ |
| บิชอปไวท์ | ♗ | ♗ | ♗ |
| อัศวิน ไวท์ | ♘ | ♘ | ♘ |
| เบี้ยขาว | ♙ | ♙ | ♙ |
| คิงแบล็ค | ♚ | ♚ | ♚ |
| ราชินีดำ | ♛ | ♛ | ♛ |
| โกงดำ | ♜ | ♜ | ♜ |
| บิชอปแบล็ก | ♝ | ♝ | ♝ |
| อัศวินดำ | ♞ | ♞ | ♞ |
| จำนำสีดำ | ♟ | ♟ | ♟ |
เกมลูกเต๋า
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ทอยลูกเต๋า | ⚀ | ⚀ | ⚀ |
| ลูกเต๋าม้วนสอง | ⚁ | ⚁ | ⚁ |
| ลูกเต๋าม้วนสาม | ⚂ | ⚂ | ⚂ |
| ลูกเต๋าม้วนสี่ | ⚃ | ⚃ | ⚃ |
| ลูกเต๋าทอยห้า | ⚄ | ⚄ | ⚄ |
| ลูกเต๋าม้วนหก | ⚅ | ⚅ | ⚅ |
สัญลักษณ์ทางคณิตศาสตร์ Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| อินฟินิตี้ | ∞ | ∞ | ∞ |
| บวก ลบ | ± | ± | ± |
| น้อยกว่าหรือเท่ากับ | ≤ | ≤ | ≤ |
| มากกว่าหรือเท่ากับ | ≥ | ≥ | ≥ |
| ไม่เท่ากับ | ≠ | ≠ | ≠ |
| แผนก | ÷ | ÷ | ÷ |
| คูณ x | × | × | × |
| คูณหนัก x | ✖ | ✖ | ✖ |
| ตัวยกหนึ่ง | ¹ | ¹ | ¹ |
| ตัวยกสอง | ² | ² | ² |
| ตัวยกสาม | ³ | ³ | ³ |
| Circled Plus | ⊕ | ⊕ | ⊕ |
| วงกลมคูณ | ⊗ | ⊗ | ⊗ |
| ตรรกะและ | ∧ | ∧ | ∧ |
| ตรรกะOR | ∨ | ∨ | ∨ |
| เดลต้า | ∆ | ∆ | ∆ |
| พาย | ∏ | ∏ | ∏ |
| ซิกม่า (SUM) | ∑ | ∑ | ∑ |
| โอเมก้า | Ω | Ω | Ω |
| ชุดเปล่า | ∅ | ∅ | ∅ |
| มุม | ∠ | ∠ | ∠ |
| ขนาน | ∥ | ∥ | ∥ |
| ตั้งฉาก | ⊥ | ⊥ | ⊥ |
| เกือบเท่ากับ | ≈ | ≈ | ≈ |
| สามเหลี่ยม | △ | △ | △ |
| วงกลม | ○ | ○ | ○ |
| สี่เหลี่ยม | □ | □ | □ |
เศษส่วน
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| หนึ่งไตรมาส (1/4) | ¼ | ¼ | ¼ |
| ครึ่งเดียว (1/2) | ½ | ½ | ½ |
| สามในสี่ (3/4) | ¾ | ¾ | ¾ |
| หนึ่งในสาม (1/3) | ⅓ | ⅓ | ⅓ |
| สองในสาม (2/3) | ⅔ | ⅔ | ⅔ |
| หนึ่งแปด (1/8) | ⅛ | ⅛ | ⅛ |
| สามแปด (3/8) | ⅜ | ⅜ | ⅜ |
| ห้าแปด (5/8) | ⅝ | ⅝ | ⅝ |
| เซเว่นเอทส์ (7/8) | ⅞ | ⅞ | ⅞ |
ตัวเลขโรมันใน Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| เลขโรมันหนึ่ง | Ⅰ | Ⅰ | Ⅰ |
| เลขโรมันสอง | Ⅱ | Ⅱ | Ⅱ |
| เลขโรมันสาม | Ⅲ | Ⅲ | Ⅲ |
| เลขโรมันสี่ | Ⅳ | Ⅳ | Ⅳ |
| เลขโรมันห้า | Ⅴ | Ⅴ | Ⅴ |
| เลขโรมันหก | Ⅵ | Ⅵ | Ⅵ |
| เลขโรมันเจ็ด | Ⅶ | Ⅶ | Ⅶ |
| เลขโรมันแปด | Ⅷ | Ⅷ | Ⅷ |
| เลขโรมันเก้า | Ⅸ | Ⅸ | Ⅸ |
| เลขโรมันสิบ | Ⅹ | Ⅹ | Ⅹ |
| เลขโรมันสิบเอ็ด | Ⅺ | Ⅺ | Ⅺ |
| เลขโรมันสิบสอง | Ⅻ | Ⅻ | Ⅻ |
มีความแตกต่างบางประการในการแสดงสัญลักษณ์เหล่านี้ในต่างกัน ระบบปฏิบัติการ... ซึ่งเกิดจากตระกูลฟอนต์ต่างๆ ที่ใช้ นอกจากนี้ iOS และ Android จะแทนที่อักขระ Unicode บางตัวด้วยอิโมจิ ดังนั้น โปรดตรวจสอบอักขระที่เพิ่มเข้าไปเพื่อให้แน่ใจว่าไม่มีอักขระดังกล่าว และไอคอนต่างๆ จะแสดงตามที่ตั้งใจไว้
องค์ประกอบของพื้นที่โค้ดที่แสดงจำนวนเต็มไม่เป็นลบ ตระกูลของการเข้ารหัสกำหนดการแสดงเครื่องของลำดับรหัส UCS
รหัส Unicode แบ่งออกเป็นหลายส่วน พื้นที่ที่มีรหัส U + 0000 ถึง U + 007F มีอักขระ ASCII พร้อมรหัสที่เกี่ยวข้อง ถัดไปเป็นพื้นที่ของสัญลักษณ์ของสคริปต์ เครื่องหมายวรรคตอน และสัญลักษณ์ทางเทคนิคต่างๆ รหัสบางส่วนสงวนไว้สำหรับใช้ในอนาคต ภายใต้อักขระ Cyrillic พื้นที่ของอักขระที่มีรหัสจาก U + 0400 ถึง U + 052F จาก U + 2DE0 ถึง U + 2DFF จาก U + A640 ถึง U + A69F จะได้รับการจัดสรร (ดู Cyrillic ใน Unicode)
ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode
เนื่องจากในระบบคอมพิวเตอร์จำนวนหนึ่ง (เช่น Windows NT) อักขระ 16 บิตแบบคงที่ถูกใช้เป็นการเข้ารหัสเริ่มต้นอยู่แล้ว จึงตัดสินใจเข้ารหัสอักขระที่สำคัญที่สุดทั้งหมดภายใน 65,536 ตำแหน่งแรกเท่านั้น (หรือที่เรียกว่าภาษาอังกฤษ ระนาบหลายภาษาพื้นฐาน BMP). พื้นที่ที่เหลือใช้สำหรับ "อักขระเพิ่มเติม" (อังกฤษ. ตัวละครเสริม): ระบบการเขียนภาษาที่สูญพันธุ์หรือตัวอักษรจีน สัญลักษณ์ทางคณิตศาสตร์และดนตรีที่ไม่ค่อยได้ใช้
เพื่อความเข้ากันได้กับระบบ 16 บิตแบบเก่า ระบบ UTF-16 ถูกประดิษฐ์ขึ้นโดยที่ตำแหน่ง 65,536 แรก ยกเว้นตำแหน่งจากช่วง U + D800 ... U + DFFF จะแสดงเป็นตัวเลข 16 บิตโดยตรง และส่วนที่เหลือจะแสดงเป็น "คู่ตัวแทน" (องค์ประกอบแรกของคู่จากภูมิภาค U + D800… U + DBFF องค์ประกอบที่สองของคู่จากภูมิภาค U + DC00… U + DFFF) สำหรับคู่ตัวแทนเสมือน ส่วนหนึ่งของพื้นที่รหัส (2048 ตำแหน่ง) ที่สงวนไว้ก่อนหน้านี้สำหรับ "อักขระสำหรับใช้ส่วนตัว" ก่อนหน้านี้ถูกใช้
เนื่องจาก UTF-16 สามารถแสดงอักขระได้เพียง 2 20 + 2 16 −2048 (1 112 064) ตัวเลขนี้จึงถูกเลือกให้เป็นค่าสุดท้ายสำหรับพื้นที่โค้ด Unicode
แม้ว่าพื้นที่โค้ด Unicode จะขยายเกิน 2-16 เร็วเท่าเวอร์ชัน 2.0 แต่อักขระตัวแรกในพื้นที่ "บนสุด" จะถูกวางไว้ในเวอร์ชัน 3.1 เท่านั้น
บทบาทของการเข้ารหัสในภาคเว็บนั้นเพิ่มขึ้นอย่างต่อเนื่อง เมื่อต้นปี 2010 ส่วนแบ่งของเว็บไซต์ที่ใช้ Unicode อยู่ที่ประมาณ 50%
เวอร์ชัน Unicode
เนื่องจากตารางอักขระ Unicode มีการเปลี่ยนแปลงและเติมเต็ม และเวอร์ชันใหม่ของระบบนี้ได้รับการเผยแพร่ และงานนี้ยังคงดำเนินต่อไป เนื่องจากระบบ Unicode ดั้งเดิมมีเฉพาะ Plane 0 - รหัสสองไบต์เท่านั้น - เอกสาร ISO ใหม่ก็จะถูกเผยแพร่เช่นกัน ระบบ Unicode มีอยู่ในเวอร์ชันต่อไปนี้:
- 1.1 (เป็นไปตามมาตรฐาน ISO / IEC 10646-1: 1993), 1991-1995
- 2.0, 2.1 (มาตรฐานเดียวกัน ISO / IEC 10646-1: 1993 บวกเพิ่มเติม: "การแก้ไข" 1 ถึง 7 และ "Technical Corrigenda" 1 และ 2), 1996 มาตรฐาน
- 3.0 (มาตรฐาน ISO / IEC 10646-1: 2000) มาตรฐาน 2000
- 3.1 (มาตรฐาน ISO / IEC 10646-1: 2000 และ ISO / IEC 10646-2: 2001) มาตรฐาน 2001
- มาตรฐาน 3.2 2002
- 4.0 มาตรฐาน 2003
- 4.01 มาตรฐานปี 2547
- 4.1 มาตรฐานปี 2548
- 5.0 มาตรฐานปี 2549
- 5.1 มาตรฐาน 2008
- 5.2 มาตรฐานปี 2552
- 6.0 มาตรฐาน 2010
- 6.1 มาตรฐานปี 2555
- 6.2 มาตรฐานปี 2555
รหัสพื้นที่
แม้ว่าสัญกรณ์รูปแบบ UTF-8 และ UTF-32 จะอนุญาตให้เข้ารหัสจุดโค้ดได้มากถึง 2,331 (2,147,483,648) โค้ด แต่ก็ตัดสินใจใช้เพียง 1,112,064 เท่านั้นสำหรับความเข้ากันได้กับ UTF-16 อย่างไรก็ตาม เท่านี้ก็เกินพอแล้ว วันนี้ (ในเวอร์ชัน 6.0) มีการใช้จุดโค้ดน้อยกว่า 110,000 จุด (กราฟิก 109,242 และสัญลักษณ์อื่นๆ 273 ตัว) เล็กน้อย
พื้นที่รหัสแบ่งออกเป็น17 เครื่องบิน 2 16 (65536) อักขระแต่ละตัว ระนาบศูนย์เรียกว่า ขั้นพื้นฐานมีสัญลักษณ์ของสคริปต์ทั่วไป ระนาบแรกใช้สำหรับสคริปต์ประวัติศาสตร์เป็นหลัก ส่วนที่สอง - สำหรับอักขระ CJK ที่ไม่ค่อยได้ใช้ ระนาบที่สามสงวนไว้สำหรับอักขระจีนโบราณ เครื่องบิน 15 และ 16 สงวนไว้สำหรับการใช้งานส่วนตัว
เพื่อแสดงว่า อักขระ Unicodeสัญกรณ์ของแบบฟอร์ม “U + xxxx"(สำหรับรหัส 0 ... FFFF) หรือ" U + xxxxxx"(สำหรับรหัส 10000 ... FFFFF) หรือ" U + xxxxxx"(สำหรับรหัส 100000 ... 10FFFF) โดยที่ xxx- ตัวเลขฐานสิบหก ตัวอย่างเช่น อักขระ "i" (U + 044F) มีรหัส 044F = 1103
ระบบเข้ารหัส
ระบบการเข้ารหัสสากล (Unicode) คือชุดของสัญลักษณ์กราฟิกและวิธีการเข้ารหัสสำหรับการประมวลผลข้อมูลข้อความด้วยคอมพิวเตอร์
สัญลักษณ์กราฟิกเป็นสัญลักษณ์ที่มีภาพที่มองเห็นได้ อักขระกราฟิกตรงข้ามกับตัวควบคุมและการจัดรูปแบบอักขระ
สัญลักษณ์กราฟิกรวมถึงกลุ่มต่อไปนี้:
- ตัวอักษรที่มีอย่างน้อยหนึ่งตัวอักษรที่รองรับ
- ตัวเลข;
- เครื่องหมายวรรคตอน;
- สัญญาณพิเศษ (คณิตศาสตร์, เทคนิค, อุดมคติ ฯลฯ );
- ตัวคั่น
Unicode เป็นระบบสำหรับการแสดงข้อความเชิงเส้น อักขระที่มีตัวยกหรือตัวห้อยเพิ่มเติมสามารถแสดงเป็นลำดับของรหัสที่สร้างขึ้นตามกฎบางอย่าง (อักขระแบบประกอบ) หรือเป็นอักขระตัวเดียว (เวอร์ชันเสาหิน อักขระที่ประกอบล่วงหน้า)
การปรับเปลี่ยนตัวอักษร
การแสดงอักขระ "Y" (U + 0419) ในรูปแบบของอักขระฐาน "I" (U + 0418) และอักขระดัดแปลง "" (U + 0306)
อักขระกราฟิกใน Unicode แบ่งออกเป็นแบบขยายและไม่ขยาย (แบบไม่มีความกว้าง) อักขระที่ไม่ขยายจะไม่ใช้พื้นที่ในบรรทัดเมื่อแสดง โดยเฉพาะอย่างยิ่ง เครื่องหมายเน้นเสียงและเครื่องหมายกำกับเสียงอื่นๆ อักขระทั้งแบบขยายและแบบไม่ขยายมีรหัสของตนเอง สัญลักษณ์เพิ่มเติมจะเรียกว่าพื้นฐาน (อังกฤษ. ตัวละครหลัก) และแบบไม่ขยาย - การแก้ไข (eng. การรวมตัวอักษร); และฝ่ายหลังไม่สามารถพบกันโดยอิสระ ตัวอย่างเช่น อักขระ "á" สามารถแสดงเป็นลำดับของอักขระหลัก "a" (U + 0061) และอักขระตัวแก้ไข "́" (U + 0301) หรือเป็นอักขระแบบเสาหิน "á" (U + 00C1).
อักขระการปรับเปลี่ยนชนิดพิเศษคือตัวเลือกรูปแบบใบหน้า (อังกฤษ ตัวเลือกรูปแบบต่างๆ). ใช้กับสัญลักษณ์ที่กำหนดตัวแปรดังกล่าวเท่านั้น ในเวอร์ชัน 5.0 ตัวเลือกสไตล์ถูกกำหนดไว้สำหรับซีรีส์ สัญลักษณ์ทางคณิตศาสตร์สำหรับสัญลักษณ์ของอักษรมองโกเลียแบบดั้งเดิมและสำหรับสัญลักษณ์ของการเขียนสี่เหลี่ยมจัตุรัสมองโกเลีย
แบบฟอร์มการทำให้เป็นมาตรฐาน
เนื่องจากสามารถแสดงสัญลักษณ์เดียวกันได้ รหัสต่างๆซึ่งบางครั้งทำให้การประมวลผลซับซ้อน มีกระบวนการทำให้เป็นมาตรฐานที่ออกแบบมาเพื่อนำข้อความไปสู่รูปแบบมาตรฐานบางอย่าง
มาตรฐาน Unicode กำหนดรูปแบบข้อความมาตรฐาน 4 รูปแบบ:
- Normalization Form D (NFD) - การสลายตัวที่เป็นที่ยอมรับ ในกระบวนการแปลงข้อความให้อยู่ในรูปแบบนี้ อักขระผสมทั้งหมดจะถูกแทนที่ซ้ำด้วยอักขระผสมหลายตัวตามตารางการสลายตัว
- Normalization Form C (NFC) คือการสลายตัวตามรูปแบบบัญญัติตามด้วยองค์ประกอบตามรูปแบบบัญญัติ ขั้นแรกให้ลดขนาดข้อความลงในรูปแบบ D หลังจากที่ดำเนินการจัดองค์ประกอบตามรูปแบบบัญญัติ - ข้อความจะถูกประมวลผลตั้งแต่ต้นจนจบและปฏิบัติตามกฎต่อไปนี้:
- สัญลักษณ์ S คือ อักษรย่อหากมีคลาสการแก้ไขเป็นศูนย์ในฐานอักขระ Unicode
- ในลำดับของอักขระใดๆ ที่ขึ้นต้นด้วยอักขระเริ่มต้น S อักขระ C จะถูกบล็อกจาก S หากมีอักขระ B ระหว่าง S และ C ที่เป็นอักขระเริ่มต้นหรือมีคลาสการแก้ไขที่เหมือนกันหรือมากกว่า C กฎใช้เฉพาะกับสตริงที่ผ่านการสลายตัวตามรูปแบบบัญญัติเท่านั้น
- หลักคอมโพสิตคืออักขระที่มีการสลายตัวตามรูปแบบบัญญัติในฐานอักขระ Unicode (หรือการสลายตัวตามรูปแบบบัญญัติสำหรับฮันกุลและไม่รวมอยู่ในรายการข้อยกเว้น)
- อักขระ X สามารถจัดแนวหลักกับอักขระ Y ได้ก็ต่อเมื่อมีคอมโพสิต Z หลักที่เทียบเท่ากับลำดับตามบัญญัติ
- หากอักขระตัวถัดไป C ไม่ถูกบล็อกโดยอักขระฐานเริ่มต้นที่พบล่าสุด L และสามารถจัดตำแหน่งได้สำเร็จ จากนั้น L จะถูกแทนที่ด้วยคอมโพสิต LC และ C จะถูกลบออก
- แบบฟอร์มการทำให้เป็นมาตรฐาน KD (NFKD) - การสลายตัวที่เข้ากันได้ เมื่อส่งลงในแบบฟอร์มนี้ อักขระผสมทั้งหมดจะถูกแทนที่โดยใช้ทั้งแผนที่การสลายตัวแบบ Unicode แบบบัญญัติและแผนที่การสลายตัวที่เข้ากันได้ หลังจากนั้นผลลัพธ์จะอยู่ในลำดับตามรูปแบบบัญญัติ
- แบบฟอร์มการทำให้เป็นมาตรฐาน KC (NFKC) - การสลายตัวที่เข้ากันได้ตามด้วย บัญญัติองค์ประกอบ.
คำว่า "องค์ประกอบ" และ "การสลายตัว" หมายถึงการเชื่อมต่อหรือการสลายตัวของสัญลักษณ์ตามลำดับเป็นส่วนที่เป็นส่วนประกอบ
ตัวอย่างของ
| ข้อความที่มา | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| ฝรั่งเศส | ฟรังก์ \ u0327ais | ฟราน \ xe7ais | ฟรังก์ \ u0327ais | ฟราน \ xe7ais |
| A,E,Y | \ u0410, \ u0401, \ u0419 | \ u0410, \ u0415 \ u0308, \ u0418 \ u0306 | \ u0410, \ u0401, \ u0419 | |
| が | \ u304b \ u3099 | \ u304c | \ u304b \ u3099 | \ u304c |
| Henry iv | Henry iv | Henry iv | Henry iv | Henry iv |
| เฮนรี่ Ⅳ | เฮนรี่ \ u2163 | เฮนรี่ \ u2163 | Henry iv | Henry iv |
จดหมายสองทิศทาง
มาตรฐาน Unicode รองรับการเขียนภาษาที่มีทิศทางจากซ้ายไปขวา (eng. ซ้ายไปขวา LTR) และเขียนจากขวาไปซ้าย (อังกฤษ. ขวาไปซ้าย RTL) - ตัวอย่างเช่น ตัวอักษรอารบิกและฮีบรู ในทั้งสองกรณี อักขระจะถูกจัดเก็บไว้ในลำดับที่ "เป็นธรรมชาติ" แอปพลิเคชันจัดเตรียมการแสดงผลโดยคำนึงถึงทิศทางที่ต้องการของจดหมาย
นอกจากนี้ Unicode ยังรองรับข้อความแบบรวมที่รวมส่วนย่อยที่มีทิศทางต่างกันของตัวอักษร คุณลักษณะนี้เรียกว่า แบบสองทิศทาง(อ. ข้อความแบบสองทิศทาง BiDi). ตัวประมวลผลข้อความแบบง่ายบางตัว (เช่น in โทรศัพท์มือถือ) รองรับ Unicode แต่ไม่รองรับแบบสองทิศทาง อักขระ Unicode ทั้งหมดแบ่งออกเป็นหลายประเภท: เขียนจากซ้ายไปขวา เขียนจากขวาไปซ้าย และเขียนในทิศทางใดก็ได้ สัญลักษณ์ของหมวดหมู่หลัง (ส่วนใหญ่เป็นเครื่องหมายวรรคตอน) เมื่อแสดง ให้เปลี่ยนทิศทางของข้อความโดยรอบ
สัญลักษณ์เด่น
Unicode มีสคริปต์สมัยใหม่แทบทั้งหมด รวมถึง:
อื่น ๆ.
เพื่อวัตถุประสงค์ทางวิชาการ มีการเพิ่มสคริปต์ทางประวัติศาสตร์มากมาย เช่น อักษรรูน กรีกโบราณ อักษรอียิปต์โบราณ คิวนิฟอร์ม การเขียนของชาวมายัน ตัวอักษรอิทรุสกัน
Unicode มีสัญลักษณ์ทางคณิตศาสตร์และดนตรีและรูปสัญลักษณ์มากมาย
อย่างไรก็ตาม โดยพื้นฐานแล้ว Unicode ไม่รวมโลโก้บริษัทและผลิตภัณฑ์ แม้ว่าจะพบในแบบอักษร (เช่น โลโก้ Apple ในการเข้ารหัส MacRoman (0xF0) หรือโลโก้ Windows ในแบบอักษร Wingdings (0xFF)) ในฟอนต์ Unicode โลโก้ต้องวางในพื้นที่อักขระที่กำหนดเองเท่านั้น
ISO / IEC 10646
Unicode Consortium ทำงานอย่างใกล้ชิดกับ กลุ่มทำงาน ISO / IEC / JTC1 / SC2 / WG2 ซึ่งกำลังพัฒนามาตรฐานสากล 10646 (ISO / IEC 10646) การซิงโครไนซ์เกิดขึ้นระหว่างมาตรฐาน Unicode และ ISO / IEC 10646 แม้ว่าแต่ละมาตรฐานจะใช้คำศัพท์และระบบเอกสารของตนเอง
ความร่วมมือของ Unicode Consortium กับองค์การระหว่างประเทศเพื่อการมาตรฐาน (eng. องค์การระหว่างประเทศเพื่อการมาตรฐาน ISO ) เริ่มในปี 1991 ในปี 1993 ISO ได้ออกมาตรฐาน DIS 10646.1 ในการซิงโครไนซ์กับมัน Consortium ได้อนุมัติเวอร์ชัน 1.1 ของมาตรฐาน Unicode ซึ่งเสริมด้วยอักขระเพิ่มเติมจาก DIS 10646.1 เป็นผลให้ค่าของอักขระที่เข้ารหัสใน Unicode 1.1 และ DIS 10646.1 เหมือนกันทุกประการ
ในอนาคตความร่วมมือระหว่างทั้งสององค์กรยังคงดำเนินต่อไป ในปี 2000 มาตรฐานยูนิโค้ด 3.0 ซิงโครไนซ์กับ ISO / IEC 10646-1: 2000 แล้ว ISO / IEC 10646 เวอร์ชันที่สามที่กำลังจะมีขึ้นจะถูกซิงโครไนซ์กับ Unicode 4.0 บางทีข้อกำหนดเหล่านี้อาจได้รับการเผยแพร่เป็นมาตรฐานเดียว
เช่นเดียวกับรูปแบบ UTF-16 และ UTF-32 ในมาตรฐาน Unicode มาตรฐาน ISO / IEC 10646 ยังมีรูปแบบการเข้ารหัสอักขระหลักสองรูปแบบ: UCS-2 (2 ไบต์ต่ออักขระ คล้ายกับ UTF-16) และ UCS-4 (4 ไบต์ต่ออักขระ คล้ายกับ UTF-32) UCS แปลว่า มัลติออคเต็ตอเนกประสงค์(มัลติไบต์) รหัสชุดอักขระ(อ. ชุดอักขระรหัสหลายออคเต็ตสากล ). UCS-2 ถือได้ว่าเป็นส่วนย่อยของ UTF-16 (UTF-16 โดยไม่มีคู่ตัวแทน) และ UCS-4 เป็นคำพ้องความหมายสำหรับ UTF-32
วิธีการนำเสนอ
Unicode มีรูปแบบการแสดงหลายรูปแบบ (eng. รูปแบบการแปลง Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) และ UTF-32 (UTF-32BE, UTF-32LE) แบบฟอร์มการแสดง UTF-7 ยังได้รับการพัฒนาสำหรับการส่งสัญญาณผ่านช่องสัญญาณเจ็ดบิต แต่เนื่องจากความไม่เข้ากันกับ ASCII แบบฟอร์มนี้จึงไม่แพร่กระจายและไม่รวมอยู่ในมาตรฐาน เมื่อวันที่ 1 เมษายน พ.ศ. 2548 มีการเสนอเรื่องตลกสองเรื่อง: UTF-9 และ UTF-18 (RFC 4042)
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
เป็นไปได้ในทางทฤษฎี แต่ไม่รวมอยู่ในมาตรฐาน:
0x0020000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
แม้ว่า UTF-8 จะอนุญาตให้คุณระบุอักขระเดียวกันได้หลายวิธี แต่อักขระที่สั้นที่สุดเท่านั้นที่ถูกต้อง แบบฟอร์มที่เหลือควรถูกปฏิเสธด้วยเหตุผลด้านความปลอดภัย
ลำดับไบต์
ในสตรีมข้อมูล UTF-16 ไบต์สูงสามารถเขียนก่อนค่าต่ำสุด (eng. UTF-16 บิ๊กเอนด์) หรือหลังน้อง (อังกฤษ. UTF-16 little-endian). ในทำนองเดียวกัน มีสองตัวเลือกสำหรับการเข้ารหัสแบบสี่ไบต์ - UTF-32BE และ UTF-32LE
เพื่อกำหนดรูปแบบของการแสดง Unicode ที่จุดเริ่มต้น ไฟล์ข้อความลายเซ็นเขียน - อักขระ U + FEFF (ช่องว่างไม่แตกที่มีความกว้างเป็นศูนย์) หรือที่เรียกว่า เครื่องหมายคำสั่งไบต์(อ. เครื่องหมายคำสั่งไบต์ BOM ). ทำให้สามารถแยกแยะระหว่าง UTF-16LE และ UTF-16BE เนื่องจากไม่มีอักขระ U + FFFE บางครั้งก็ใช้เพื่อแสดงถึงรูปแบบ UTF-8 แม้ว่าแนวคิดของลำดับไบต์จะใช้ไม่ได้กับรูปแบบนี้ ไฟล์ที่เป็นไปตามแบบแผนนี้จะเริ่มต้นด้วยลำดับไบต์เหล่านี้:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
น่าเสียดายที่วิธีนี้ไม่สามารถแยกความแตกต่างระหว่าง UTF-16LE และ UTF-32LE ได้อย่างน่าเชื่อถือ เนื่องจาก Unicode อนุญาตให้ใช้อักขระ U + 0000 (แม้ว่าข้อความจริงจะไม่ค่อยขึ้นต้นด้วย)
ไฟล์ในการเข้ารหัส UTF-16 และ UTF-32 ที่ไม่มี BOM ต้องอยู่ในลำดับไบต์ big-endian (unicode.org)
Unicode และการเข้ารหัสแบบดั้งเดิม
การเปิดตัว Unicode ได้เปลี่ยนวิธีการเข้ารหัส 8 บิตแบบเดิม ถ้าก่อนหน้านี้ระบุการเข้ารหัสโดยแบบอักษร ตอนนี้จะถูกระบุโดยตารางการติดต่อระหว่างการเข้ารหัสนี้และ Unicode อันที่จริงการเข้ารหัสแบบ 8 บิตได้กลายเป็นตัวแทนของชุดย่อยของ Unicode สิ่งนี้ทำให้ง่ายต่อการสร้างโปรแกรมที่ต้องทำงานกับการเข้ารหัสที่หลากหลาย: ตอนนี้ เพื่อเพิ่มการรองรับการเข้ารหัสอีกหนึ่งรายการ คุณเพียงแค่เพิ่มตารางค้นหา Unicode อื่น
นอกจากนี้ รูปแบบข้อมูลจำนวนมากยังอนุญาตให้แทรกอักขระ Unicode ใดๆ ได้ แม้ว่าเอกสารจะเขียนด้วยการเข้ารหัส 8 บิตแบบเก่าก็ตาม ตัวอย่างเช่น คุณสามารถใช้รหัสเครื่องหมายและใน HTML
การดำเนินการ
ระบบปฏิบัติการที่ทันสมัยส่วนใหญ่ให้การสนับสนุน Unicode ในระดับหนึ่ง
ในระบบปฏิบัติการของตระกูล Windows NT การเข้ารหัส UTF-16LE แบบสองไบต์จะใช้สำหรับการแสดงชื่อไฟล์ภายในและสตริงระบบอื่นๆ การเรียกระบบที่ใช้พารามิเตอร์สตริงมีอยู่ในตัวแปรไบต์เดี่ยวและไบต์คู่ สำหรับรายละเอียดเพิ่มเติมโปรดดูบทความ
 ตัวอย่างของฟังก์ชัน jQuery setTimeout () Javascript ป้องกันไม่ให้ตัวจับเวลาหลายตัวเรียกใช้ setinterval ในเวลาเดียวกัน
ตัวอย่างของฟังก์ชัน jQuery setTimeout () Javascript ป้องกันไม่ให้ตัวจับเวลาหลายตัวเรียกใช้ setinterval ในเวลาเดียวกัน DIY วงจรวิทยุสมัครเล่นและผลิตภัณฑ์ทำเอง
DIY วงจรวิทยุสมัครเล่นและผลิตภัณฑ์ทำเอง ครอบตัดข้อความที่มีความสูงหนึ่งหรือหลายบรรทัดด้วยการเพิ่มจุดไข่ปลา การเพิ่มการไล่ระดับสีให้กับข้อความ
ครอบตัดข้อความที่มีความสูงหนึ่งหรือหลายบรรทัดด้วยการเพิ่มจุดไข่ปลา การเพิ่มการไล่ระดับสีให้กับข้อความ