มาตรฐานการเข้ารหัส Unicode จัดสรรให้กับอักขระแต่ละตัว Unicode คืออะไร
Unicode เป็นระบบการเข้ารหัสที่กำหนดรหัสเฉพาะให้กับอักขระใดๆ โดยไม่คำนึงถึงแพลตฟอร์ม โดยไม่คำนึงถึงโปรแกรม โดยไม่คำนึงถึงภาษา
อันที่จริง แม้แต่ในชื่อเรื่องของบันทึกย่อนี้ก็มีความไม่ถูกต้องอยู่บ้าง - หรือค่อนข้างขัดแย้งกัน ความจริงก็คือว่ายังไม่มีความเป็นเอกฉันท์เกี่ยวกับวิธีการสะกดคำภาษาอังกฤษ Unicode ในตัวอักษรรัสเซียอย่างถูกต้อง - Unicode หรือ Unicode ตอนนี้เราจะใช้ตัวเลือกการสะกดคำแรก
บางครั้ง เมื่อคุณเปิดเอกสารหรือดูหน้าแทนตัวอักษรโปแลนด์ อาจมี "พุ่มไม้" อยู่หลายอัน ข้อผิดพลาดเหล่านี้อาจเกิดจากการเข้ารหัสอักขระที่ไม่ถูกต้อง ข้อความที่คุณเห็นบนหน้าจอจะถูกจัดเก็บโดยคอมพิวเตอร์ในรูปแบบของเลขศูนย์และเลข ซึ่งบรรจุเป็นแปดส่วน หนึ่งศูนย์หรือหนึ่งบิต กลุ่มแปดเป็นไบต์ อุปกรณ์อิเล็กทรอนิกส์เก็บข้อมูลเป็นไบต์ รวมทั้งข้อความ
โอเค แต่คอมพิวเตอร์ทั้งหมดนี้จะสร้างประวัติศาสตร์ได้อย่างไร สิบจะมีลักษณะดังนี้: ในการเขียนตัวเลข เราเรียกเลขฐานสอง เราได้เรียนรู้การใช้เลขทศนิยม สิ่งนี้ทำเพื่อให้อักขระแต่ละตัวถูกกำหนดตัวเลข ประโยค "Alla has a cat" เป็นชุดของตัวเลข
Unicode ไม่ได้เป็นเพียงการเข้ารหัสแบบหลายไบต์สำหรับการแสดงอักขระหลายตัว อย่างที่หลายคนคิด แม้ว่าคำจำกัดความดังกล่าวจะถือว่าถูกต้องในระดับหนึ่ง คำจำกัดความอย่างเป็นทางการคือ: Unicode เป็นระบบการเข้ารหัสที่กำหนดรหัสเฉพาะให้กับอักขระใดๆ โดยไม่คำนึงถึงแพลตฟอร์ม โดยไม่คำนึงถึงโปรแกรม โดยไม่คำนึงถึงภาษา
โปรดทราบว่าอักษรตัวพิมพ์ใหญ่และตัวพิมพ์เล็กเป็นอักขระที่แยกจากกันสำหรับคอมพิวเตอร์ และการเว้นวรรคก็เป็นเครื่องหมายเช่นกัน แม้ว่าจะมองไม่เห็นก็ตาม นอกจากนี้ ตัวเลขแต่ละหลักจะได้รับการปฏิบัติเช่นเดียวกัน ตัวอย่างเช่น อักขระ 1 ไม่ได้กำหนดเป็นตัวเลข 1 เท่านั้น
ไม่ แต่คอมพิวเตอร์รู้ได้อย่างไรว่ากำหนดอักขระตัวใดไว้ เบอร์นี้? คำตอบคือการเข้ารหัสอักขระ โดยทั่วไปแล้ว มันคือตารางที่มีสัญลักษณ์และตัวเลขทั้งหมดที่กำหนดให้กับพวกมัน เมื่อเวลาผ่านไป ตัวเลขนี้ไม่เพียงพออีกต่อไป คอมพิวเตอร์ได้รับความสามารถใหม่ๆ และได้รับความนิยมมากขึ้นในประเทศอื่นๆ ด้วยตัวอักษรพิเศษ
มาตรฐานยูนิโค้ดแบ่งออกเป็นสองส่วน ชุดแรกคือชุดตัวเลขที่สอดคล้องกับอักขระแต่ละตัวในตัวอักษรที่รองรับแต่ละตัว เรียกว่าชุดอักขระสากลหรือแค่ UCS ตัวเลขที่ใช้ในพื้นที่โค้ด UCS เป็นจำนวนเต็มและไม่เป็นค่าลบทั้งหมด ตัวเลขเหล่านี้ - ตำแหน่งรหัส - ถูกกำหนดเป็น U + 0000, U + 0001, U + 0002 เป็นต้น ด้วยเหตุนี้ พื้นที่โค้ดจึงไม่เหมือนกัน แต่แบ่งออกเป็นหลายส่วนตามความหมาย รหัสจาก U + 0000 ถึง U + 007F เป็นอักขระ ASCII ตามด้วยอักขระจากตัวอักษรประจำชาติต่างๆ เครื่องหมายวรรคตอน และอักขระทางเทคนิค เช่น แคร่ตลับหมึกเพื่อขึ้นบรรทัดใหม่ ส่วนที่สองของมาตรฐานคือ อันที่จริง การเข้ารหัสที่ให้การแสดงรหัสแต่ละรหัสในข้อความในระดับบิต
แม้ว่าทั้งสองจะมีอักขระมากกว่าสองร้อยห้าสิบตัว แต่ตัวเลขนี้ก็ยังไม่เพียงพอสำหรับทุกภาษา ดังนั้นแต่ละตระกูลภาษาจึงมีเวอร์ชันของการเข้ารหัสเหล่านี้ นี้เรียกว่าหน้ารหัส พวกเขาทั้งหมดมีที่มาเดียวกัน ดังนั้นจึงรวมเครื่องหมายวรรคตอน ตัวอักษรภาษาอังกฤษตัวพิมพ์ใหญ่และตัวพิมพ์เล็ก และตัวเลขด้วย อย่างไรก็ตาม อักขระที่เหลือจะแตกต่างกันไปในแต่ละเวอร์ชัน
แต่แม้กระทั่งการแนะนำหน้าโค้ดก็ไม่สามารถแก้ปัญหาทั้งหมดได้ ประการแรกคือการทำงานร่วมกันมาตรฐาน แม้ว่าอักขระ 127 ตัวแรกจะเหมือนกันสำหรับมาตรฐานทั้งหมด แต่อักขระที่เหลือจะได้รับการจัดลำดับตามการแสดงของตนเอง มุมคำที่เขียนในมุมแรกนี้จะเปิดขึ้นหลังจากที่ระบบเปิดสำหรับมาตรฐานที่สอง
อักขระ Unicode ทั้งหมดแบ่งออกเป็นสองประเภท - แบบขยายและแบบไม่มีความกว้าง (กำลังแก้ไข) อักขระขยายเป็นตัวอักษรปกติที่ใช้พิมพ์บันทึกย่อนี้ การแก้ไขคือเครื่องหมายเหนือตัวอักษร เช่น การเน้นเสียง จุด "ตัวพิมพ์ใหญ่" ฯลฯ เป็นต้น ตัวอักษรส่วนใหญ่ที่มีเครื่องหมายคล้ายกันสำหรับตัวอักษรทั้งหมดจะแสดงเป็นลำดับของสัญลักษณ์ที่ขยายและปรับเปลี่ยน จริงซีริลลิก "e" และ "y" จะแสดงเป็นอักขระขยายที่แยกจากกัน
อีกปัญหาหนึ่งคือ 256 ตัวอักษรยังไม่เพียงพอในการเขียนเอกสารได้อย่างคล่องแคล่ว ในกรณีส่วนใหญ่ก็เพียงพอแล้ว แต่ปัญหาเกิดขึ้นเมื่อคุณต้องการอ้างอิงถึงคุณ Möller, Pütz หรือ Strassmann สำหรับวิทยานิพนธ์ระดับปริญญาโทของเขา แทรก Cyrillic หรือ enter ตัวอักษรกรีกเป็นสูตรทางคณิตศาสตร์ที่ซับซ้อน
จำเป็นต้องมีวิธีการเข้ารหัสใหม่ซึ่งจะรวมอักขระที่เป็นไปได้ทั้งหมดที่ใช้ในทุกภาษาของโลก ทำให้ความผิดพลาดน้อยลง อย่างไรก็ตาม ปัญหาอื่นเกิดขึ้น - อักขระที่เป็นไปได้จำนวนมากจึงไม่อนุญาตให้เขียน 1 ไบต์สำหรับพวกเขา หนึ่งไบต์ประกอบด้วยแปดหรือศูนย์ ซึ่งช่วยให้สามารถจัดระเบียบได้หลายวิธี อักขระจำนวนมากจึงมีหน้ารหัส หากต้องการเพิ่มจำนวนอักขระที่ระบบเข้ารหัสรองรับ คุณต้องเพิ่มจำนวนไบต์ที่จำเป็นในการแทรกตัวอักษร
การใช้งาน Unicode ในทางปฏิบัติที่พบบ่อยที่สุดคือ UTF-8 มาตรฐานนี้มีความเข้ากันได้ดีกับข้อความ ASCII แบบเก่า เนื่องจากอักขระของตัวอักษรภาษาอังกฤษและอักขระทั่วไปอื่นๆ (เช่น อักขระที่มีรหัส ASCII ตั้งแต่ 0 ถึง 127) ถูกเขียนในหนึ่งไบต์ อักขระที่เหลือเขียนด้วยไบต์จำนวนมาก - จากสองถึงหก
เมื่อเร็วๆ นี้ อักขระลีราตุรกีถูกเพิ่มลงในอักขระ Unicode หมายเลขที่กำหนดคือ 110 หากแต่ละตัวอักษรถูกครอบครองโดย 3 ไบต์ แม้แต่ตัวอักษรที่ขึ้นต้นด้วยหนึ่งตัวก็จะเพิ่มพื้นที่ที่จำเป็นในการบันทึกไฟล์ลงดิสก์
นักพัฒนาได้แนวคิดที่ว่าอักขระไม่ควรมีจำนวนไบต์คงที่ และสำหรับสิ่งนี้ เพื่อที่จะทำงานบนคอมพิวเตอร์ มันสอดคล้องกับการเข้ารหัส เปลี่ยนการเข้ารหัสอักขระในแต่ละสามตัวนี้และดูว่าตัวอักษรทั้งหมดแสดงขึ้นหรือไม่ หากคุณต้องการเข้ารหัสหน้าเว็บด้วยวิธีนี้ ให้ดาวน์โหลดแผ่นจดบันทึกที่มีประสิทธิภาพและฟรี
Unicode และมาตรฐานที่เกี่ยวข้องกำลังได้รับการพัฒนาโดย Unicode Consortium ตามที่เขียนไว้บนเว็บไซต์อย่างเป็นทางการขององค์กรนี้ www.unicode.org "Unicode Consortium เป็นองค์กรไม่แสวงหาผลกำไรที่ก่อตั้งขึ้นเพื่อพัฒนาและพัฒนามาตรฐาน Unicode ที่กำหนดการแสดงข้อมูลที่เป็นข้อความในผลิตภัณฑ์และมาตรฐานซอฟต์แวร์สมัยใหม่ และ เพื่อส่งเสริมการเผยแพร่และการใช้งานอย่างกว้างขวาง สมาชิก Consortium เป็นองค์กรและองค์กรจำนวนมากที่ทำงานในด้านการประมวลผลข้อมูลและอุตสาหกรรมคอมพิวเตอร์ การสนับสนุนทางการเงินของ Consortium ดำเนินการผ่านค่าธรรมเนียมสมาชิกของสมาชิกเท่านั้น Unicode Consortium เปิดให้องค์กรหรือบุคคลใดๆ ที่สนับสนุนมาตรฐาน Unicode และต้องการช่วยกระจายและนำไปใช้ " เข้าร่วมกับเรา! :)
คำอธิบายในบทความนี้อิงตามเบต้า 8 ซึ่งมีให้เฉพาะผู้ทดสอบเบต้ากลุ่มเล็กๆ เท่านั้น เมื่อการทดสอบเบต้าใกล้จะสิ้นสุดลง มีความเป็นไปได้สูงที่คุณลักษณะและฟังก์ชันการทำงานส่วนใหญ่ที่อธิบายไว้จะปรากฏในรุ่นสุดท้ายจริงๆ เราจะกล่าวถึงการเปลี่ยนแปลงและข่าวสารที่สำคัญที่สุดเกี่ยวกับเวอร์ชันปัจจุบัน 51 ในแต่ละบล็อกเฉพาะเรื่อง
การทำงานกับไฟล์และรูปลักษณ์ของแอพพลิเคชั่น
เวอร์ชันที่หกใหม่ไม่ได้เปลี่ยนแปลงอะไรในองค์กรของพื้นที่ทำงานนี้ แต่จะขยายขีดความสามารถของหน้าต่างทั้งสองนี้อย่างมาก ถ้าถามว่ายังไง คำตอบคือ "บุ๊คมาร์ค" แต่ละหน้าต่างสามารถสลับไปมาระหว่างโฟลเดอร์ที่เรากำหนดได้อย่างรวดเร็ว คุณสามารถสร้างบุ๊กมาร์กได้มากเท่าที่ต้องการ และสลับไปมาระหว่างโฟลเดอร์ต่างๆ ได้อย่างรวดเร็วในหน้าต่างเดียว คุณสามารถใช้งานบุ๊กมาร์กต่อไปได้ แท็บแต่ละแท็บทำงานเหมือนแผงไฟล์ที่แยกจากกัน ดังนั้นเราจึงสามารถทำงานกับแท็บดังกล่าวได้แบบเก่า
มาตรฐาน Unicode หรือ ISO / IEC 10646 เป็นผลมาจากความร่วมมือระหว่างองค์กรระหว่างประเทศเพื่อการมาตรฐาน (ISO) และผู้ผลิตคอมพิวเตอร์ชั้นนำและ ซอฟต์แวร์... เหตุผลที่ระบุไว้ในหน้าก่อนหน้านี้ทำให้พวกเขาสร้างสูตรใหม่โดยพื้นฐานสำหรับคำถาม: เหตุใดจึงใช้ความพยายามในการพัฒนาตารางรหัสที่แยกจากกัน หากสามารถสร้างตารางเดียวสำหรับภาษาประจำชาติทั้งหมดได้ งานดังกล่าวดูทะเยอทะยานเกินไป แต่เพียงแวบแรกเท่านั้น ความจริงก็คือจาก 6,700 ภาษาที่มีชีวิต ประมาณห้าสิบภาษาเป็นภาษาราชการของรัฐ และพวกเขาใช้สคริปต์ที่แตกต่างกันประมาณ 25 แบบ: ตัวเลขสำหรับอายุคอมพิวเตอร์ของเราสามารถคาดการณ์ได้ค่อนข้างมาก
บุ๊กมาร์กจะแสดงก็ต่อเมื่ออยู่ในหน้าต่างโดย อย่างน้อยสอง. เมื่อคัดลอกข้อมูลจำนวนมากที่คงอยู่เป็นเวลานาน อาจใช้สำเนาพื้นหลังในรุ่นก่อนหน้า แน่นอน ฟังก์ชันยอดนิยมนี้ได้รับการเก็บรักษาไว้และนำเสนอเวอร์ชันใหม่หลายรายการในเวอร์ชันใหม่
หากคุณเลือก คุณจะเห็นกล่องโต้ตอบการคัดลอกพื้นหลังแบบขยาย ซึ่งคุณสามารถหยุดการคัดลอกชั่วคราวและตั้งค่าบิตเรตสูงสุดที่จะคัดลอกได้ นอกจากนี้ยังสามารถเพิ่มไฟล์ลงในหน้าต่างนี้ได้อย่างต่อเนื่อง โหมดนี้ "จัดการ" ปัญหาของผู้ใช้บางคนที่กำลังเผชิญปัญหาอย่างหนักในหลายหน้าต่างในขณะรันไทม์ - สามารถติดตั้งได้ ความเร็วสูงสุดถ่ายโอนและจัดเรียงไฟล์ตามลำดับในคิวเพื่อลดโหลดดิสก์โดยรวมอย่างมาก
การประมาณการเบื้องต้นพบว่าช่วง 16 บิตเพียงพอที่จะเข้ารหัสสคริปต์เหล่านี้ทั้งหมด นั่นคือช่วงตั้งแต่ 0000 ถึง FFFF แต่ละสคริปต์ได้รับการจัดสรรบล็อกของตัวเองในช่วงนี้ ซึ่งค่อยๆ เต็มไปด้วยรหัสของอักขระของสคริปต์นี้ ทุกวันนี้การเข้ารหัสของสคริปต์ทางการที่มีชีวิตทั้งหมดถือได้ว่าสมบูรณ์
ตอนนี้ฟังก์ชันการสร้างโฟลเดอร์ยังสามารถสร้างโครงสร้างไดเร็กทอรีได้อีกด้วย การปรับปรุงเพิ่มเติมเมื่อทำงานกับไฟล์ การซิงโครไนซ์ไดเรกทอรีมีการปรับปรุงที่สำคัญสองประการ ในโมดูลการเปลี่ยนชื่อหลัก เพิ่มตัวเลือกสำหรับบันทึกการตั้งค่าและเครื่องมือสำหรับการสร้างไฟล์เขียนทับด้วยภาพ
ไคลเอ็นต์ยังสามารถตรวจจับการเชื่อมต่อที่ถูกขัดจังหวะได้อย่างต่อเนื่องและสามารถเชื่อมต่อใหม่ได้โดยอัตโนมัติเมื่อเปิดเครื่อง คุณลักษณะใหม่อื่นๆ ได้แก่ การรองรับพร็อกซีเซิร์ฟเวอร์ประเภทใหม่ การแทนที่อักขระต้องห้ามในชื่อการสมัครใช้งานโดยอัตโนมัติ และการกำหนดค่าการเชื่อมต่อใหม่ในกล่องโต้ตอบการตั้งค่า
วิธีการที่พัฒนาขึ้นมาอย่างดีสำหรับการวิเคราะห์และอธิบายระบบการเขียนช่วยให้กลุ่ม Unicode ย้ายเมื่อเร็ว ๆ นี้เพื่อเข้ารหัสสคริปต์ที่เหลือของโลกที่น่าสนใจ: สคริปต์เหล่านี้คือภาษาที่ตายแล้ว อักษรอียิปต์โบราณที่เลิกใช้ในปัจจุบัน , ตัวอักษรที่ประดิษฐ์ขึ้นเอง ฯลฯ เพื่อแสดงถึงทุกสิ่งที่ความมั่งคั่งของการเข้ารหัส 16 บิตไม่เพียงพออีกต่อไป และวันนี้ Unicode ใช้พื้นที่รหัส 21 บิต (000000 - 10FFFF) ซึ่งแบ่งออกเป็น 16 โซนที่เรียกว่าระนาบ จนถึงตอนนี้ แผน Unicode มีเครื่องบินดังต่อไปนี้:
ด้วยตัวเลือกที่ทำในเวอร์ชันก่อนหน้า ไดอะล็อกการกำหนดค่าดั้งเดิมจึงไม่ชัดเจน กล่องโต้ตอบการกำหนดค่าใหม่จะแบ่งออกเป็นหมวดหมู่ที่อ่านง่ายยิ่งขึ้น โดยแต่ละส่วนจะทุ่มเทให้กับ หน้าแยกบทสนทนา คุณจะพบพารามิเตอร์ส่วนใหญ่ที่รู้จักจาก รุ่นก่อนหน้าและทางเลือกใหม่ๆ มากมาย
เป็นการเข้ารหัสอักขระระดับโลก อักขระพิเศษส่วนใหญ่ในทุกภาษาของโลกมีอยู่แล้ว คาถาของ "สำนวนปกติ" - หลายคนกลัว ทั้งหมดที่เขาต้องทำคือดูการแนะนำตัวอย่างเป็นทางการของเขา อักขระแบบไบต์คู่คือโค้ดอักขระแบบไบต์คู่แบบหลายภาษา สัญลักษณ์ส่วนใหญ่ที่ใช้เมื่อใช้คอมพิวเตอร์ทั่วโลก รวมถึงสัญลักษณ์ทางเทคนิคและ สัญลักษณ์พิเศษสามารถแสดงเป็นอักขระ Unicode เป็นอักขระแบบไบต์คู่
Plane 0 (รหัส 000000 - 00FFFF) - BMP, Basic Multilingual Plane (BMP, Basic Multilingual Plane) สอดคล้องกับช่วง Unicode ดั้งเดิม
เครื่องบิน 1 (รหัส 010000 - 01FFFF) - DMP, เครื่องบินหลายภาษาเสริม (SMP) มีไว้สำหรับสคริปต์ที่ไม่ทำงาน
เครื่องบิน 2 (รหัส 020000 - 02FFFF) - DIP ซึ่งเป็นระนาบอักษรอียิปต์โบราณเพิ่มเติม (SIP, เครื่องบิน Ideographic เสริม) มีไว้สำหรับอักษรอียิปต์โบราณที่ไม่รวมอยู่ใน BMP
เนื่องจากแต่ละอักขระแบบไบต์คู่จะแสดงในขนาด 16 บิตคงที่ ความกว้างของอักขระจึงทำให้การเขียนโปรแกรมง่ายขึ้นโดยใช้ชุดอักขระสากล โดยทั่วไป ความกว้างของอักขระจะใช้พื้นที่หน่วยความจำมากกว่าอักขระแบบหลายไบต์ แต่จะประมวลผลได้เร็วกว่า
ถ้าเป็นสตริงปกติ เธอจะพูดว่า ถ้าเป็นสตริง Unicode เธอจะพูดว่า อันดับแรก โดยปกติ หน้าต่างเทอร์มินัลจะได้รับการกำหนดค่าให้แสดงอักขระจากชุดภาษาที่จำกัดเท่านั้น หากคุณออกคำสั่งการพิมพ์บนสตริง Unicode อาจแสดงไม่ถูกต้องในหน้าต่างเทอร์มินัล ในที่นี้ อักขระ Unicode แต่ละตัวต้องเข้ารหัสเป็น "ไบต์" อย่างน้อยหนึ่งตัวสำหรับการจัดเก็บในไฟล์
เครื่องบิน 14 (รหัส 0E0000 - 0EFFFF) เป็นแผ่นไม้อัดซึ่งเป็นระนาบพิเศษเพิ่มเติม (SSP, เครื่องบินวัตถุประสงค์พิเศษเสริม) ซึ่งมีไว้สำหรับอักขระวัตถุประสงค์พิเศษ
เครื่องบิน 15 (รหัส 0F0000 - 0FFFFF) - เครื่องบินส่วนตัวซึ่งมีไว้สำหรับสัญลักษณ์ของการเขียนเทียม
เครื่องบิน 16 (รหัส 100000 - 10FFFF) - เครื่องบินส่วนตัวสำหรับใช้เป็นสัญลักษณ์ของการเขียนเทียม
เราได้หลีกเลี่ยงข้อมูลการเข้ารหัสข้อมูลระดับต่ำแล้ว แต่การทำความเข้าใจบิตและไบต์เพียงเล็กน้อยจะช่วยให้คุณเข้าใจได้ นี่เป็นค่าเดียวที่ถูกจำกัดโดยความเป็นไปได้สองอย่าง ซึ่งตามปกติแล้วเราจะเขียนเป็น 0 หรือคอมพิวเตอร์เก็บบิตเป็นประจุไฟฟ้าหรือขั้วแม่เหล็ก หรือในอีกทางหนึ่งที่เราไม่ต้องรบกวน ลำดับของแปด 0-1 บิตเรียกว่าไบต์
มีการเข้ารหัสที่เป็นไปได้มากมาย อักขระ Unicode หนึ่งตัวถูกแมปกับลำดับสูงสุดสี่ไบต์ คุณสามารถทำได้ด้วยวิธีใดวิธีหนึ่งจากสองวิธี ทุกอย่างจะทำงานได้ดีจนกว่าคุณจะพยายามพิมพ์หรือเขียนเนื้อหาลงในไฟล์ หากคุณกำลังพิมพ์และไม่ได้กำหนดค่าหน้าต่างเทอร์มินัลให้แสดงภาษานั้น คุณอาจแสดงผลลัพธ์ที่แปลก
การแยก BMP ออกเป็นบล็อคมีให้ใน WDH: Unicode Standard ที่นี่เราทราบเพียงว่า 128 รหัสแรก (00000 - 0007F) สอดคล้องกับรหัส ASCII และเข้ารหัสบล็อกละตินฐาน เลย์เอาต์ของสคริปต์สำหรับช่วง Unicode จะอธิบายโดยละเอียดในบทความของฉัน "Unicode และสคริปต์ของโลก" เนื่องจากในอนาคตเราจะสนใจเฉพาะสัญลักษณ์ BMP เท่านั้น ฉันจึงใช้รหัส 16 บิตในรูปแบบ XXXX (บิตที่สำคัญที่สุดมีค่าเท่ากับศูนย์และไม่ได้ระบุ)
หากคุณพยายามเขียนไปยังไฟล์ คุณอาจได้รับข้อความแสดงข้อผิดพลาด วิธีนี้ช่วยให้คุณเขียนในเอกสารเดียวได้ เช่น วนซ้ำและตัวอักษรโปแลนด์ นี่เป็นมาตรฐานที่หลากหลายที่สุด แน่นอนว่าพวกเขาทั้งหมดใช้อาร์เรย์เดียวกันและมีความสามารถเหมือนกัน ความแตกต่างเพียงอย่างเดียวคือวิธีการเขียนที่แตกต่างกัน การพกพาที่ใหญ่ที่สุดคือเอกสาร Unicode ของคุณ parser ทุกคนต้องสนับสนุน คุณไม่มีการค้ำประกันสำหรับมาตรฐานเดียว
หากคุณใช้สิ่งนี้ คุณไม่จำเป็นต้องมีข้อมูลการเข้ารหัสใดๆ ข้อมูลบางอย่างเกี่ยวกับโปรแกรมที่สามารถช่วยคุณเข้ารหัสและแปลงอักขระได้ในส่วน "เครื่องมือ" บทช่วยสอนนี้แสดงเฉพาะขั้นตอนที่คุณต้องปฏิบัติตามเพื่อเพิ่มแบบอักษรที่มีทั้งตัวพิมพ์ใหญ่และตัวพิมพ์เล็ก และเครื่องหมายกำกับเสียงเฉพาะสำหรับภาษาโรมาเนีย การเขียนโดยไม่มีเครื่องหมายกำกับเสียงสามารถนำไปสู่การแสดงออกที่คลุมเครือ เช่น "รถถังอายุ 12 ปี" "นวนิยายที่เกิดในกรุงโรม"
คำอธิบายทั่วไป
Unicode ขึ้นอยู่กับแนวคิดของตัวละคร สัญลักษณ์เป็นแนวคิดนามธรรมที่มีอยู่ในระบบการเขียนเฉพาะและรับรู้ผ่านรูปภาพ (กราฟ) ซึ่งหมายความว่าแต่ละตัวอักษรจะได้รับ รหัสเฉพาะและเป็นของบล็อก Unicode เฉพาะ ตัวอย่างเช่น มีกราฟ A ในตัวอักษรภาษาอังกฤษ รัสเซีย และกรีก อย่างไรก็ตาม ใน Unicode จะสอดคล้องกับอักขระสามตัวที่แตกต่างกัน "อักษรละตินตัวพิมพ์ใหญ่ A" (รหัส 0041), "ตัวอักษร Cyrillic ตัวพิมพ์ใหญ่ A" (รหัส 0410) และ "ตัวพิมพ์ใหญ่ภาษากรีก ALPHA" (รหัส 0391) หากตอนนี้เราใช้การแปลงเป็นอักษรตัวพิมพ์เล็กกับอักขระเหล่านี้ เราจะได้รับ "อักษรตัวพิมพ์เล็กละติน A" ตามลำดับ (รหัส 0061, กราฟ a), "อักษรตัวพิมพ์เล็ก Cyrillic A" (รหัส 0430, grapheme a) และ "อักษรตัวพิมพ์เล็กกรีก ALPHA" (รหัส 03B1, กราฟ α), เช่น กราฟต่างๆ
เครื่องหมายกำกับเสียงคือหมวก - สำหรับสิ่งนั้น - ซองจดหมาย ลูกน้ำและลูกน้ำ - ภาษาสำหรับชาวโรมาเนีย มันถูกออกแบบมาสำหรับตัวอักษรใดๆ ในภาษาใดๆ บนฮาร์ดแวร์หรือแพลตฟอร์มซอฟต์แวร์ใดๆ เพื่อให้ตรงกับหมายเลขที่ไม่ซ้ำกันและชัดเจน ตอนนี้จะมีรูปร่างและขนาดของร่ายมนตร์
เราจะเลือกเครื่องหมายจุลภาคกราฟิก โครงร่างสีแดงของสัญลักษณ์หมายถึงมันถูกเลือก สำหรับตัวกำกับเสียงภาษาโรมาเนียอื่นๆ จะมีการดัดแปลงแบบเดียวกัน กล่องโต้ตอบข้อมูลแบบอักษรจะปรากฏขึ้น เราเพิ่มในช่องนามสกุลชื่อที่เราต้องการสำหรับแบบอักษร
คำถามอาจเกิดขึ้น: การแปลงเป็นตัวพิมพ์เล็กคืออะไร? เรามาถึงจุดที่น่าสนใจและสำคัญที่สุดในมาตรฐาน ประเด็นคือ Unicode ไม่ใช่เรื่องง่าย ตารางรหัส... แนวคิดของสัญลักษณ์นามธรรมทำให้ผู้สร้าง Unicode สามารถสร้างฐานข้อมูลอักขระที่อธิบายอักขระแต่ละตัวด้วยรหัสที่ไม่ซ้ำกัน (คีย์ฐานข้อมูล) ชื่อเต็ม และชุดของคุณสมบัติ ตัวอย่างเช่น สัญลักษณ์ที่มีรหัส 0410 อธิบายไว้ในฐานข้อมูลนี้ดังนี้:
0410; อักษรตัวใหญ่ซิริลลิก A; Lu; 0; L ;;;;; N ;;;; 0430;
มาถอดรหัสรายการนี้กัน หมายความว่ารหัส 0410 ถูกกำหนดให้กับ "Cyrillic ตัวพิมพ์ใหญ่А "(ชื่อเต็มของสัญลักษณ์) ซึ่งมีคุณสมบัติดังต่อไปนี้:
| หมวดหมู่ทั่วไป | อักษรตัวพิมพ์เล็ก (Lu = ตัวอักษร, ตัวพิมพ์ใหญ่) |
| คลาสผสม | 0 |
| ทิศทางเอาท์พุท | ซ้ายไปขวา (L) |
| การสลายตัวของสัญลักษณ์ | เลขที่ |
| ทศนิยม | เลขที่ |
| ตัวเลข | เลขที่ |
| ค่าตัวเลข | เลขที่ |
| สัญลักษณ์กระจก | หายไป (N) |
| ชื่อเต็มใน Unicode 1.0 | อีกด้วย |
| ความคิดเห็น | เลขที่ |
| การทำแผนที่ตัวพิมพ์ใหญ่ | เลขที่ |
| แสดงเป็นตัวพิมพ์เล็ก | 0430 |
| การแมปไปที่อักษรชื่อ | เลขที่ |
คุณสมบัติที่แสดงไว้ถูกกำหนดสำหรับอักขระ Unicode แต่ละตัว สิ่งนี้ทำให้นักพัฒนาสามารถสร้างอัลกอริธึมมาตรฐานที่กำหนดโดยยึดตามคุณสมบัติของสัญลักษณ์ กฎสำหรับการแสดงผล การเรียงลำดับ และการแปลงเป็นอักษรตัวพิมพ์ใหญ่/ตัวพิมพ์เล็ก
โดยสรุป เราสามารถพูดได้ว่ามาตรฐาน Unicode ประกอบด้วยสามส่วนที่เกี่ยวข้องกัน:
ฐานข้อมูลสัญลักษณ์
ฐานของกราฟ (ร่ายมนตร์) ซึ่งกำหนดการแสดงสัญลักษณ์เหล่านี้
ชุดของอัลกอริทึมที่กำหนดกฎสำหรับการทำงานกับสัญลักษณ์
โดยสรุปในส่วนนี้ เราขอนำเสนอกราฟของบล็อกซีริลลิก (รหัส 0400 - 04FF) โปรดทราบว่าไม่เพียงแต่รวมตัวอักษรของอักษรซีริลลิกสมัยใหม่ (รัสเซีย ยูเครน เบลารุส บัลแกเรีย เซอร์เบีย มาซิโดเนีย ฯลฯ) แต่ยังรวมถึงตัวอักษรทั้งหมดของอักษรซีริลลิกดั้งเดิมที่ใช้ในงานเขียนภาษาสลาฟของคริสตจักร

รูปแบบการแปลงร่าง
ดังที่เราได้เห็น อักขระ Unicode แต่ละตัวมีจุดรหัส 21 บิตที่ไม่ซ้ำกัน อย่างไรก็ตาม สำหรับการนำไปใช้จริง การเข้ารหัสอักขระดังกล่าวไม่สะดวก ความจริงก็คือระบบปฏิบัติการและ โปรโตคอลเครือข่ายตามธรรมเนียมปฏิบัติกับข้อมูลเป็นกระแสข้อมูลของไบต์ สิ่งนี้นำไปสู่ปัญหาอย่างน้อยสองประการ:
ลำดับของไบต์ในคำนั้นแตกต่างกันสำหรับโปรเซสเซอร์ที่ต่างกัน โปรเซสเซอร์ Intel, DEC และตัวประมวลผลอื่นๆ จะเก็บไบต์ที่สำคัญที่สุดไว้ในไบต์แรกของคำเครื่อง ขณะที่ Motorola, Sparc และตัวประมวลผลอื่นๆ จะเก็บไบต์ที่มีนัยสำคัญน้อยที่สุด พวกมันถูกเรียกว่า little-endian และ big-endian ตามลำดับ (คำเหล่านี้มาจาก "spikes" และ "blunts" ของ Swift ซึ่งเป็นการโต้เถียงกันเกี่ยวกับจุดสิ้นสุดของการทำลายไข่)
ระบบและโปรโตคอลเชิงไบต์จำนวนมากอนุญาตเฉพาะไบต์จากช่วงที่ระบุเป็นข้อมูล ส่วนที่เหลือของไบต์ถือเป็นโอเวอร์เฮด โดยเฉพาะอย่างยิ่ง เป็นเรื่องปกติที่จะใช้ไบต์ว่างเป็นอักขระสิ้นสุดบรรทัด เนื่องจาก Unicode เข้ารหัสอักขระในแถว การส่งรหัสโดยตรงเป็นสตริงไบต์อาจขัดแย้งกับกฎของโปรโตคอลการถ่ายโอนข้อมูล
เพื่อแก้ปัญหาเหล่านี้ มาตรฐานได้รวมรูปแบบการแปลงสามรูปแบบ UTF-8, UTF-16 และ UTF-32 ซึ่งกำหนดกฎสำหรับการเข้ารหัสอักขระ Unicode เป็นสตริงไบต์ คู่คำ 16 บิต และคำ 32 บิตตามลำดับ การเลือกรูปแบบที่จะใช้ขึ้นอยู่กับสถาปัตยกรรมของระบบคอมพิวเตอร์และการจัดเก็บข้อมูลและมาตรฐานการรับส่งข้อมูล คำอธิบายสั้น ๆ ของรูปแบบการแปลงมีอยู่ใน WDH: Unicode Standard
ปัญหาการใช้งาน
ฉันคิดว่าแม้จากข้างต้น คำอธิบายสั้น ๆ มาตรฐานยูนิโค้ดเป็นที่ชัดเจนว่าได้รับการสนับสนุนอย่างเต็มที่จาก major ระบบปฏิบัติการจะทำให้เกิดการปฏิวัติในการประมวลผลคำ ผู้ใช้ที่นั่งอยู่ที่เว็บเทอร์มินัลจะสามารถเลือกรูปแบบแป้นพิมพ์ พิมพ์ข้อความในภาษาใดก็ได้ และส่งไปยังคอมพิวเตอร์เครื่องใดก็ได้ที่จะแสดงข้อความนี้อย่างถูกต้อง ฐานข้อมูลจะสามารถจัดเก็บ จัดเรียง และแสดงผลในรายงานได้อย่างถูกต้อง ข้อมูลข้อความอีกครั้งในภาษาใดก็ได้ เพื่อให้สวรรค์แห่งนี้มาจำเป็นต้องมีห้าสิ่ง:
ระบบปฏิบัติการต้องสนับสนุนรูปแบบการแปลง Unicode ที่ระดับอินพุต ที่จัดเก็บ และการแสดงสตริงข้อความ
เราต้องการไดรเวอร์แป้นพิมพ์อัจฉริยะที่ช่วยให้เราป้อนอักขระในบล็อก Unicode ใดๆ และส่งรหัสไปยังระบบปฏิบัติการได้
โปรแกรมแก้ไขข้อความควรสนับสนุนการแสดงอักขระ Unicode ทั้งหมดและดำเนินการชุดอักขระทั่วไปกับอักขระดังกล่าว
DBMS จะต้องทำเช่นเดียวกันอย่างถูกต้องสำหรับฟิลด์ข้อความและบันทึกช่วยจำ
เนื่องจากการเข้ารหัสระดับประเทศจะอยู่ร่วมกับ Unicode เป็นเวลานาน จึงจำเป็นต้องสนับสนุนการแปลงข้อความระหว่างกัน
น่าเสียดายที่เราต้องยอมรับว่าในสิบปี (Unicode 1.0 ปรากฏในปี 1991) มีการดำเนินการในทิศทางนี้น้อยกว่าที่เราต้องการมาก แม้แต่ Windows ซึ่งมีการรองรับ Unicode ที่สม่ำเสมอที่สุดในระดับระบบก็ยังเต็มไปด้วยข้อจำกัดที่ไม่ลงตัวโดยสิ้นเชิงอันเนื่องมาจากการพัฒนาในอดีตเท่านั้น สถานการณ์เลวร้ายยิ่งกว่าบน Unix เนื่องจากการรองรับ Unicode ได้ถูกย้ายจากเคอร์เนลไปยังแอพพลิเคชั่นเฉพาะ เรียกได้ว่า Unicode ได้รับการสนับสนุนอย่างหนักที่สุดในปัจจุบันในสองสภาพแวดล้อม: เว็บเบราว์เซอร์และเครื่องเสมือน Java ไม่น่าแปลกใจเลย เนื่องจากแต่เดิมสภาพแวดล้อมทั้งสองได้รับการออกแบบมาให้ไม่ขึ้นกับระบบ
ปัญหาวัตถุประสงค์ในการสนับสนุน Unicode ควรสังเกตด้วย ตัวอย่างเช่น เราจะเน้นที่การแสดงกราฟเท่านั้น ซึ่งคุณต้องติดตั้งฟอนต์ที่เหมาะสมในระบบ ปัญหาคือฟอนต์ที่มีกราฟ Unicode ทั้งหมดจะมีขนาดที่น่าอึดอัดใจอย่างยิ่ง ตัวอย่างเช่น แบบอักษร TrueType Arial Unicode MS ซึ่งมีอักขระ Unicode ส่วนใหญ่ "หนัก" 24MB เมื่อ Unicode เติมบล็อกใหม่ ขนาดของฟอนต์ดังกล่าวจะเข้าใกล้ 100MB ทางออกของสถานการณ์คือการโหลดสัญลักษณ์ตามความต้องการของ Microsoft ซึ่งยอมรับในเบราว์เซอร์ Internet Explorer... อย่างไรก็ตามในขณะที่มาตรฐานเกี่ยวกับกฎสำหรับการสร้างแบบอักษร Unicode นั้นเงียบ
วิธีการทำงานด้วย อักขระ Unicodeและการเข้ารหัสระดับประเทศในสภาพแวดล้อมที่สำคัญที่สุดและระบบการเขียนโปรแกรมจะกล่าวถึงในบทความต่อไปนี้
ไม่มีหน้าดังกล่าว
เธออาจจะเป็น สักวันหนึ่ง ก่อนหน้านี้. หรืออย่างอื่นในแผนเท่านั้น แต่ตอนนี้เธอจากไปแล้ว
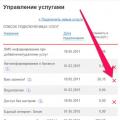 จะปิดการใช้งานบริการ "คุณได้รับสาย" จาก MTS ได้อย่างไร?
จะปิดการใช้งานบริการ "คุณได้รับสาย" จาก MTS ได้อย่างไร? รีเซ็ตเป็นค่าจากโรงงานและฮาร์ดรีเซ็ต Apple iPhone
รีเซ็ตเป็นค่าจากโรงงานและฮาร์ดรีเซ็ต Apple iPhone รีเซ็ตเป็นค่าจากโรงงานและฮาร์ดรีเซ็ต Apple iPhone
รีเซ็ตเป็นค่าจากโรงงานและฮาร์ดรีเซ็ต Apple iPhone