มีกี่บิตในการเข้ารหัส Unicode หน่วยของปริมาณข้อมูลและการวัดความจุของหน่วยความจำ: กิโลไบต์ เมกะไบต์ กิกะไบต์…. มาตรฐานการเข้ารหัสอักขระ Unicode
การเข้ารหัสข้อมูล
ตัวเลขใดๆ (ภายในขีดจำกัด) ในหน่วยความจำของคอมพิวเตอร์จะถูกเข้ารหัสด้วยตัวเลขในระบบเลขฐานสอง มีกฎการแปลที่ง่ายและชัดเจนสำหรับสิ่งนี้ อย่างไรก็ตาม ทุกวันนี้ คอมพิวเตอร์ถูกใช้อย่างแพร่หลายมากกว่าบทบาทของผู้ทำการคำนวณที่เน้นแรงงานมาก ตัวอย่างเช่น หน่วยความจำคอมพิวเตอร์เก็บข้อมูลข้อความและมัลติมีเดีย ดังนั้นคำถามแรกจึงเกิดขึ้น:
อักขระแต่ละตัวถูกเข้ารหัสตั้งแต่ 1 ถึง 4 ไบต์ อักขระแทนที่ใช้ 4 ไบต์ ดังนั้นจึงต้องการพื้นที่จัดเก็บเพิ่มเติม อักขระแต่ละตัวถูกเข้ารหัสอย่างน้อย 4 ไบต์ หรือคุณสามารถใช้เครื่องมือแปลงเพื่อแปลงโดยอัตโนมัติ อย่างที่บอก นี่เป็นมาตรฐานที่เหมาะกับคนอเมริกันเป็นอย่างดี มีตั้งแต่ 0 ถึง 127 และ 32 ตัวแรกและตัวสุดท้ายถือเป็นตัวควบคุม ส่วนที่เหลือคือ "อักขระที่พิมพ์" ซึ่งเป็นที่ยอมรับของผู้คน สามารถแสดงได้เพียง 7 บิตเท่านั้น แม้ว่าโดยทั่วไปจะใช้หนึ่งไบต์ก็ตาม
อักขระ (ตัวอักษร) ถูกเก็บไว้ในหน่วยความจำของคอมพิวเตอร์อย่างไร?
ตัวอักษรแต่ละตัวเป็นของตัวอักษรบางตัวที่อักขระต่อกัน ดังนั้นจึงสามารถกำหนดหมายเลขด้วยจำนวนเต็มติดต่อกันได้ ตัวอักษรแต่ละตัวสามารถเชื่อมโยงกับจำนวนเต็มบวกและเรียกมันว่ารหัสอักขระ... รหัสนี้จะถูกเก็บไว้ในหน่วยความจำของคอมพิวเตอร์ และเมื่อแสดงบนหน้าจอหรือบนกระดาษ รหัสจะถูก "แปลง" เป็นอักขระที่เกี่ยวข้อง ในการแยกแยะการแสดงตัวเลขจากการแทนตัวอักษรในหน่วยความจำคอมพิวเตอร์ คุณต้องจัดเก็บข้อมูลด้วยว่าข้อมูลใดบ้างที่เข้ารหัสในพื้นที่หน่วยความจำเฉพาะ
ขึ้นอยู่กับบริบทและเวลา นี่หมายถึงอย่างอื่น ดังนั้นมันขึ้นอยู่กับสิ่งที่คุณกำลังพูดถึง แปลว่า เพียงเล็กน้อยเท่านั้น มีการเข้ารหัสบางตัวที่ใช้ตัวย่อนี้ พวกมันซับซ้อนมากและแทบไม่มีใครรู้วิธีใช้ความอิ่มอย่างเหมาะสมรวมถึงตัวฉันด้วย
แต่ไม่ใช่กับระบบเข้ารหัสอักขระอื่นๆ นี่คือการเข้ารหัสที่สมบูรณ์และซับซ้อนที่สุดที่มีอยู่ บางคนหลงรักเธอและบางคนเกลียดเธอ แม้ว่าพวกเขาจะรู้ดีถึงประโยชน์ของเธอ เป็นเรื่องยากสำหรับคนที่จะเข้าใจ แต่สำหรับคอมพิวเตอร์เป็นเรื่องยากที่จะจัดการ
ความสอดคล้องของตัวอักษรของตัวอักษรบางตัวที่มีรหัสตัวเลขเรียกว่า ตารางการเข้ารหัส... กล่าวอีกนัยหนึ่ง อักขระแต่ละตัวของตัวอักษรเฉพาะมีรหัสตัวเลขของตัวเองตามตารางการเข้ารหัสเฉพาะ
อย่างไรก็ตาม มีตัวอักษรมากมายในโลก (อังกฤษ รัสเซีย จีน ฯลฯ) ดังนั้นคำถามต่อไปคือ:
มีการเปรียบเทียบระหว่างทั้งสอง เป็นมาตรฐานสำหรับการนำเสนอข้อความที่สร้างขึ้นโดยสมาคม ในบรรดาบรรทัดฐานที่กำหนดโดยเขาคือการเข้ารหัสบางอย่าง แต่ในความเป็นจริง มันมีความหมายมากกว่านั้นมาก บทความที่ทุกคนควรอ่าน แม้ว่าจะไม่เห็นด้วยกับทุกสิ่งที่มีก็ตาม
ชุดอักขระที่รองรับจะแบ่งออกเป็นระนาบ คอมพิวเตอร์สองเครื่องใช้ระบบปฏิบัติการที่แตกต่างกัน เช่นเดียวกันกับชุดอักขระ โครงสร้าง และ รูปแบบไฟล์ซึ่งมักจะแตกต่างกัน การสื่อสารผ่านการเชื่อมต่อการควบคุม
จะเข้ารหัสตัวอักษรทั้งหมดที่ใช้ในคอมพิวเตอร์ได้อย่างไร?
เพื่อตอบคำถามนี้ เราจะเดินตามเส้นทางประวัติศาสตร์
ในยุค 60 ของศตวรรษที่ XX ใน สถาบันมาตรฐานแห่งชาติอเมริกัน (ANSI)มีการพัฒนาตารางการเข้ารหัสอักขระซึ่งต่อมาใช้ในระบบปฏิบัติการทั้งหมด ตารางนี้เรียกว่า ASCII (รหัสอเมริกันสแตนดาร์ดสำหรับการแลกเปลี่ยนข้อมูล)... ไม่นานก็ปรากฏตัว เวอร์ชัน ASCII แบบขยาย.
การสื่อสารเกิดขึ้นผ่านลำดับของคำสั่งและการตอบสนอง วิธีง่ายๆ นี้เหมาะสำหรับการเชื่อมต่อการควบคุม เพราะเราสามารถส่งคำสั่งได้ครั้งละหนึ่งคำสั่ง คำสั่งหรือการตอบสนองแต่ละรายการครอบคลุมหนึ่งบรรทัด ดังนั้นเราจึงไม่จำเป็นต้องกังวลเกี่ยวกับรูปแบบไฟล์หรือโครงสร้าง แต่ละบรรทัดลงท้ายด้วยอักขระสองตัว
ลิงค์ข้อมูล วัตถุประสงค์และการใช้งานการเชื่อมต่อข้อมูลจะแตกต่างจากที่ระบุไว้ในการเชื่อมต่อการควบคุม ข้อเท็จจริงพื้นฐาน: เราต้องการถ่ายโอนไฟล์ผ่านการเชื่อมต่อข้อมูล ลูกค้าต้องกำหนดประเภทของไฟล์ที่จะถ่ายโอน โครงสร้างข้อมูล และโหมดการถ่ายโอน
ตามตารางการเข้ารหัส ASCII มีการจัดสรร 1 ไบต์ (8 บิต) เพื่อแสดงอักขระหนึ่งตัว ชุดละ 8 เซลล์สามารถรับค่าต่างๆ ได้ 2 8 = 256 ค่า 128 ค่าแรก (จาก 0 ถึง 127) เป็นค่าคงที่และเป็นส่วนที่เรียกว่าส่วนหลักของตารางซึ่งรวมถึงตัวเลขทศนิยม, ตัวอักษรของอักษรละติน (ตัวพิมพ์ใหญ่และตัวพิมพ์เล็ก), เครื่องหมายวรรคตอน (จุด, ลูกน้ำ, วงเล็บเหลี่ยม ฯลฯ) รวมถึงการเว้นวรรคและอักขระบริการต่างๆ (การจัดตาราง การป้อนบรรทัด ฯลฯ) ค่าจาก 128 ถึง 255 form ส่วนเสริมตารางที่เป็นเรื่องปกติในการเข้ารหัสสัญลักษณ์ของตัวอักษรประจำชาติ
นอกจากนี้ การเชื่อมต่อจะต้องเตรียมการถ่ายโอนโดยการเชื่อมต่อการควบคุมก่อนจึงจะสามารถถ่ายโอนไฟล์ผ่านดาต้าลิงค์ได้ ปัญหาความไม่เท่าเทียมกันแก้ไขได้ด้วยการกำหนดแอตทริบิวต์สามประการของลิงก์ ได้แก่ ประเภทไฟล์ โครงสร้างข้อมูล และโหมดการถ่ายโอน
ไฟล์จะถูกส่งเป็นกระแสข้อมูลบิตต่อเนื่องโดยไม่มีการตีความหรือการเข้ารหัสใดๆ รูปแบบนี้ใช้เป็นหลักในการถ่ายโอนไฟล์ไบนารีเช่นโปรแกรมที่คอมไพล์หรือภาพที่เข้ารหัสใน 0 และ 1 วินาที ไฟล์ไม่มีข้อกำหนดแนวตั้งสำหรับการพิมพ์ ซึ่งหมายความว่าไม่สามารถพิมพ์ไฟล์ได้หากไม่มีการประมวลผลเพิ่มเติม เนื่องจากไม่มีอักขระที่เข้าใจได้ให้ตีความโดยการเคลื่อนที่ในแนวตั้งของกลไกการพิมพ์ รูปแบบนี้ถูกใช้โดยไฟล์ที่จะจัดเก็บและประมวลผลในอนาคต
เนื่องจากมีตัวอักษรประจำชาติมากมาย ตาราง ASCII แบบขยายจึงมีอยู่ในหลายรูปแบบ แม้แต่ภาษารัสเซียก็มีตารางการเข้ารหัสหลายแบบ (Windows-1251 และ Koi8-r เป็นเรื่องปกติ) ทั้งหมดนี้สร้างปัญหาเพิ่มเติม ตัวอย่างเช่น เราส่งจดหมายที่เขียนด้วยการเข้ารหัสแบบหนึ่ง และผู้รับจะพยายามอ่านในอีกรูปแบบหนึ่ง เป็นผลให้เขาเห็น krakozyabry ดังนั้น ผู้อ่านจำเป็นต้องใช้ตารางการเข้ารหัสที่แตกต่างกันสำหรับข้อความ
ไฟล์สามารถพิมพ์ได้หลังจากส่ง หน้า: ไฟล์ถูกแบ่งออกเป็นหน้า โดยแต่ละหน้ามีหมายเลขและระบุส่วนหัวอย่างถูกต้อง เพจสามารถบันทึกหรือเข้าถึงได้ แบบสุ่มหรือตามลำดับ ถ้าข้อมูลเป็นเพียงสตริงของไบต์ ไม่จำเป็นต้องมีการระบุจุดสิ้นสุดบรรทัด ในกรณีนี้ ตัวบ่งชี้ที่สิ้นสุดบรรทัดคือการปิดการเชื่อมต่อข้อมูลโดยเครื่องส่ง ไบต์แรกเรียกว่า descriptor block; อีกสองไบต์กำหนดขนาดบล็อกเป็นไบต์ การบีบอัด: หากไฟล์มีขนาดใหญ่เกินไป ข้อมูลอาจถูกบีบอัดก่อนส่ง วิธีการบีบอัดที่ใช้กันทั่วไปใช้หน่วยของข้อมูลที่ปรากฏขึ้นตามลำดับและแทนที่ด้วยการเกิดขึ้นครั้งเดียว ตามด้วยการทำซ้ำหลายครั้ง วี ไฟล์ข้อความพื้นที่ว่างมากมาย ในไฟล์ไบนารี อักขระ null มักจะถูกบีบอัด
- ไฟล์: ไฟล์ไม่มีโครงสร้าง
- มันถูกส่งเป็นกระแสต่อเนื่องของไบต์
- ประเภทนี้สามารถใช้ได้กับไฟล์ข้อความเท่านั้น
- เชน: นี่คือโหมดเริ่มต้น
- ในกรณีนี้ แต่ละบล็อกจะนำหน้าด้วยส่วนหัว 3 ไบต์
มีปัญหาอื่นเช่นกัน ตัวอักษรของบางภาษามีอักขระมากเกินไปและไม่พอดีกับตำแหน่งที่กำหนดตั้งแต่การเข้ารหัสแบบไบต์เดียว 128 ถึง 255
ปัญหาที่สามคือจะทำอย่างไรถ้าข้อความใช้หลายภาษา (เช่นรัสเซียอังกฤษและฝรั่งเศส)? คุณไม่สามารถใช้สองตารางพร้อมกัน ...
เพื่อแก้ปัญหาเหล่านี้ การเข้ารหัส Unicode ได้รับการพัฒนาในครั้งเดียว
หลายคนไม่มีความคิดเกี่ยวกับความแตกต่างระหว่างฉากเหล่านี้และยึดติดกับสิ่งที่ใกล้เคียง รายละเอียดเกี่ยวกับการเข้ารหัสคือมันเป็นแผนที่สำหรับสองสิ่งที่แตกต่างกัน อย่างแรกคือแผนผังค่าตัวเลขที่แสดงอักขระเฉพาะ
เครื่องบินอื่นเป็นส่วนเสริมที่มีอักขระที่ช่วยเสริมการทำงานของเครื่องบินหลักและ "พิเศษ" อื่นๆ เช่น "อีโมติคอน" ในรูปแบบเหล่านี้ อักขระระนาบแต่ละตัวจะถูกเข้ารหัสเพียง 1 ไบต์ ดังนั้นเราจึงมีอักขระ "ที่เป็นไปได้" เพียง 256 ตัวเท่านั้น แน่นอนว่าเราต้องลบสิ่งที่ไม่สามารถพิมพ์ได้โดยการลดช่วง
มาตรฐานการเข้ารหัสอักขระ Unicode
เพื่อแก้ปัญหาข้างต้นในช่วงต้นทศวรรษ 90 ได้มีการพัฒนามาตรฐานการเข้ารหัสอักขระที่เรียกว่า Unicode. มาตรฐานนี้ช่วยให้คุณใช้ภาษาและสัญลักษณ์เกือบทั้งหมดในข้อความ
Unicode มี 31 บิตสำหรับการเข้ารหัสอักขระ (4 ไบต์ลบหนึ่งบิต) จำนวนชุดค่าผสมที่เป็นไปได้ให้จำนวนที่สูงเกินไป: 2 31 = 2 147 483 684 (กล่าวคือ มากกว่าสองพันล้าน) ดังนั้น Unicode จึงอธิบายตัวอักษรของภาษาที่รู้จักทั้งหมด แม้แต่ภาษาที่ "ตาย" และถูกประดิษฐ์ขึ้น รวมถึงคณิตศาสตร์และภาษาอื่นๆ สัญลักษณ์พิเศษ... อย่างไรก็ตาม ความจุข้อมูลของ Unicode 31 บิตยังคงมีขนาดใหญ่เกินไป ดังนั้นจึงมักใช้เวอร์ชันย่อ 16 บิต (2 16 = 65 536 ค่า) โดยที่ตัวอักษรสมัยใหม่ทั้งหมดจะถูกเข้ารหัส
และหากคุณต้องการเปรียบเทียบระหว่างอักขระก็จะไม่สูญเสียประสิทธิภาพ เนื่องจากการเปรียบเทียบค่า 8 บิต 16 บิต หรือ 32 บิต 2 ค่าจะใช้เวลาเท่ากัน โปรเซสเซอร์ที่ทันสมัย... ความหมายที่เกี่ยวข้องกับคำย่อคือขนาดของแต่ละหน่วยลำดับที่ประกอบขึ้นเป็นการเข้ารหัสอักขระ เมื่อโค้ดมีบิตมากขึ้น การเข้ารหัสต่อไปนี้จะถูกนำมาใช้
ดังนั้น อักขระใดๆ สามารถแสดงได้ในขนาดตั้งแต่ 1 ถึง 4 ไบต์ นี่เป็นตัวละคร "พิเศษ" ที่ไม่เหมือนใครหรือไม่? ซึ่งหมายความว่าภาพตัวละครบางภาพมีความคล้ายคลึงกันมากและบางครั้งก็ซ้ำซ้อน อีกตัวอย่างหนึ่ง เมื่อสองสามปีที่แล้ว มีเรื่องตลกเกี่ยวกับการเปลี่ยน '; ' บน '; ' วี รหัสที่มา... ขณะรวบรวมโค้ด โปรแกรมเมอร์เริ่มคลั่งไคล้และพยายามหาทางแก้ปัญหา
ใน Unicode 128 โค้ดแรกจะเหมือนกับตาราง ASCII
เริ่มตั้งแต่ช่วงปลายทศวรรษที่ 60 มีการใช้คอมพิวเตอร์ในการประมวลผลมากขึ้น ข้อมูลข้อความและปัจจุบันส่วนใหญ่ คอมพิวเตอร์ส่วนบุคคลในโลก (และส่วนใหญ่) กำลังยุ่งอยู่กับการประมวลผลข้อมูลที่เป็นข้อความ
ASCII - การเข้ารหัสข้อความพื้นฐานสำหรับอักษรละติน
ตามเนื้อผ้า ในการเข้ารหัสอักขระหนึ่งตัว จำนวนข้อมูลจะใช้เท่ากับ 1 ไบต์นั่นคือ I = 1 ไบต์ = 8 บิต
ในการเข้ารหัสอักขระหนึ่งตัว จำเป็นต้องมีข้อมูล 1 ไบต์ หากเราถือว่าสัญลักษณ์เป็นเหตุการณ์ที่เป็นไปได้ เราสามารถคำนวณได้ว่ามีกี่ตัว ตัวละครต่างๆสามารถเข้ารหัสได้: N = 2I = 28 = 256
จำนวนอักขระนี้เพียงพอสำหรับแสดงข้อมูลที่เป็นข้อความ รวมทั้งตัวพิมพ์ใหญ่และตัวพิมพ์เล็กของตัวอักษรรัสเซียและละติน ตัวเลข ป้าย สัญลักษณ์กราฟิก ฯลฯ การเข้ารหัสหมายความว่าอักขระแต่ละตัวมีการกำหนดรหัสทศนิยมที่ไม่ซ้ำกันตั้งแต่ 0 ถึง 255 หรือที่สอดคล้องกัน รหัสไบนารีจาก 00000000 ถึง 11111111
ดังนั้นบุคคลจึงแยกแยะสัญลักษณ์ตามสไตล์และคอมพิวเตอร์โดยใช้รหัส เมื่อป้อนข้อมูลข้อความลงในคอมพิวเตอร์ ให้ การเข้ารหัสไบนารี, ภาพสัญลักษณ์จะถูกแปลงเป็นรหัสไบนารี
ผู้ใช้กดปุ่มที่มีสัญลักษณ์บนแป้นพิมพ์ และลำดับของแรงกระตุ้นไฟฟ้าแปดตัว (รหัสไบนารีของสัญลักษณ์) จะถูกส่งไปยังคอมพิวเตอร์ รหัสอักขระถูกเก็บไว้ใน หน่วยความจำเข้าถึงโดยสุ่มคอมพิวเตอร์ที่ใช้หนึ่งไบต์ ในกระบวนการแสดงอักขระบนหน้าจอคอมพิวเตอร์ กระบวนการย้อนกลับจะดำเนินการ - ถอดรหัส นั่นคือ การแปลงรหัสอักขระเป็นรูปภาพ ตารางรหัส ASCII (รหัส American Standard สำหรับการแลกเปลี่ยนข้อมูล) ถูกนำมาใช้เป็นมาตรฐานสากล ตารางส่วนมาตรฐาน ASCII สิ่งสำคัญคือการกำหนดรหัสเฉพาะให้กับอักขระเป็นเรื่องของข้อตกลงซึ่งได้รับการแก้ไขในตารางรหัส . 33 รหัสแรก (จาก 0 ถึง 32) ไม่ตรงกับอักขระ แต่สำหรับการดำเนินการ (การป้อนบรรทัด การป้อนช่องว่าง และอื่นๆ) รหัสตั้งแต่ 33 ถึง 127 เป็นรหัสสากลและสอดคล้องกับสัญลักษณ์ของตัวอักษรละติน ตัวเลข เครื่องหมายเลขคณิต และเครื่องหมายวรรคตอน รหัสจาก 128 ถึง 255 เป็นรหัสประจำชาติ กล่าวคือ อักขระต่างกันสอดคล้องกับรหัสเดียวกันในการเข้ารหัสระดับประเทศ
ขออภัย ขณะนี้มีห้าที่แตกต่างกัน ตารางรหัสสำหรับตัวอักษรรัสเซีย (KOI8, CP1251, CP866, Mac, ISO) ดังนั้นข้อความที่สร้างด้วยการเข้ารหัสแบบหนึ่งจะไม่แสดงในอีกรูปแบบหนึ่งอย่างถูกต้อง
ปัจจุบันเป็นสากลใหม่ มาตรฐานยูนิโค้ดซึ่งไม่ได้จัดสรรหนึ่งไบต์สำหรับแต่ละอักขระ แต่มีสองตัว ดังนั้นจึงสามารถใช้เข้ารหัสได้ไม่ใช่ 256 อักขระ แต่ N = 216 = 65536 ต่างกัน
Unicode - การเกิดขึ้นของการเข้ารหัสข้อความสากล (UTF 32, UTF 16 และ UTF 8)
อักขระหลายพันตัวจากกลุ่มภาษาเอเชียตะวันออกเฉียงใต้นี้ไม่สามารถอธิบายได้ในข้อมูลหนึ่งไบต์ ซึ่งได้รับการจัดสรรสำหรับการเข้ารหัสอักขระในการเข้ารหัส ASCII แบบขยาย จึงมีการสร้างสมาคมขึ้นเรียกว่า Unicode(Unicode - Unicode Consortium) โดยได้รับความร่วมมือจากผู้นำอุตสาหกรรมไอทีจำนวนมาก (ผู้ผลิตซอฟต์แวร์, ผู้เข้ารหัสฮาร์ดแวร์, ผู้สร้างฟอนต์) ที่มีความสนใจในการเกิดขึ้นของการเข้ารหัสข้อความสากล
การเข้ารหัสข้อความแรกที่เผยแพร่ภายใต้การอุปถัมภ์ของกลุ่ม Unicode คือการเข้ารหัส UTF 32... ตัวเลขในชื่อการเข้ารหัส UTF 32 หมายถึงจำนวนบิตที่ใช้ในการเข้ารหัสอักขระหนึ่งตัว 32 บิตเป็นข้อมูล 4 ไบต์ที่จำเป็นสำหรับการเข้ารหัสอักขระตัวเดียวในการเข้ารหัส Universal UTF 32 ใหม่
ด้วยเหตุนี้ ไฟล์เดียวกันกับที่เข้ารหัสข้อความในการเข้ารหัส ASCII แบบขยายและในการเข้ารหัส UTF 32 ในกรณีหลังจะมีขนาด (น้ำหนัก) มากกว่าสี่เท่า สิ่งนี้ไม่ดี แต่ตอนนี้ เรามีโอกาสที่จะเข้ารหัสโดยใช้ UTF 32 จำนวนอักขระเท่ากับสองยกกำลังสามสิบวินาที (อักขระหลายพันล้านตัวที่จะครอบคลุมค่าที่จำเป็นจริงๆ ด้วยระยะขอบมหาศาล)
แต่หลายประเทศที่มีภาษาของกลุ่มยุโรปไม่จำเป็นต้องใช้อักขระจำนวนมากในการเข้ารหัสเลย แต่เมื่อใช้ UTF 32 พวกเขาไม่เคยได้รับน้ำหนักเพิ่มขึ้นสี่เท่า เอกสารข้อความส่งผลให้ปริมาณการรับส่งข้อมูลทางอินเทอร์เน็ตและปริมาณข้อมูลที่จัดเก็บเพิ่มขึ้น มีจำนวนมากและไม่มีใครสามารถจ่ายของเสียได้
อันเป็นผลมาจากการพัฒนาความเป็นสากล การเข้ารหัส Unicode ปรากฏ UTF 16ซึ่งกลายเป็นว่าประสบความสำเร็จจนเป็นที่ยอมรับโดยค่าเริ่มต้นเป็นพื้นที่ฐานสำหรับสัญลักษณ์ทั้งหมดที่เราใช้ UTF 16 ใช้สองไบต์ในการเข้ารหัสหนึ่งอักขระ ตัวอย่างเช่น ใน ระบบปฏิบัติการ Windows คุณสามารถปฏิบัติตามเส้นทาง Start - Programs - Accessories - System Tools - Symbol Map
ด้วยเหตุนี้ ตารางที่มีรูปแบบเวกเตอร์ของแบบอักษรทั้งหมดที่ติดตั้งในระบบของคุณจะเปิดขึ้น หากคุณเลือกชุดอักขระ Unicode ในตัวเลือกขั้นสูง คุณจะสามารถดูแบบอักษรแต่ละแบบแยกกันถึงชุดอักขระทั้งหมดที่รวมอยู่ในนั้น อย่างไรก็ตาม เมื่อคลิกที่อักขระใดๆ เหล่านี้ คุณจะเห็นโค้ดสองไบต์ในการเข้ารหัส UTF 16 ซึ่งประกอบด้วยเลขฐานสิบหกสี่หลัก:
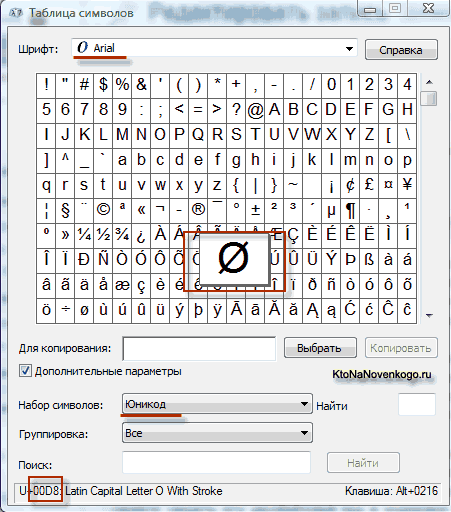
สามารถเข้ารหัสอักขระได้กี่ตัวใน UTF 16 ด้วย 16 บิต 65,536 อักขระ (สองยกกำลังสิบหก) ถูกใช้เป็นพื้นที่พื้นฐานใน Unicode นอกจากนี้ มีวิธีการเข้ารหัสด้วย UTF 16 ประมาณสองล้านอักขระ แต่จำกัดเฉพาะพื้นที่ขยายของข้อความหนึ่งล้านอักขระ
แต่ถึงแม้รุ่นเข้ารหัส Unicode ที่ประสบความสำเร็จเรียกว่า UTF 16 ก็ไม่ได้สร้างความพึงพอใจให้กับผู้เขียนมากนัก เช่น โปรแกรมเฉพาะใน ภาษาอังกฤษเนื่องจากหลังจากการเปลี่ยนจากเวอร์ชันขยายของการเข้ารหัส ASCII เป็น UTF 16 น้ำหนักของเอกสารจะเพิ่มเป็นสองเท่า (หนึ่งไบต์สำหรับหนึ่งอักขระใน ASCII และสองไบต์สำหรับอักขระเดียวกันในการเข้ารหัส UTF 16) ถูกต้องแม่นยำสำหรับความพึงพอใจของทุกคนและทุกอย่างในกลุ่ม Unicode ที่ตัดสินใจสร้างขึ้น การเข้ารหัสข้อความความยาวผันแปร.
การเข้ารหัสใน Unicode นี้เรียกว่า UTF8... แม้จะมีชื่อแปดตัว แต่ UTF 8 ก็เป็นการเข้ารหัสความยาวผันแปรที่เต็มเปี่ยมเช่น อักขระแต่ละตัวของข้อความสามารถเข้ารหัสเป็นลำดับได้ตั้งแต่หนึ่งถึงหกไบต์ ในทางปฏิบัติ ใน UTF 8 จะใช้เฉพาะช่วงตั้งแต่หนึ่งถึงสี่ไบต์เท่านั้น เนื่องจากโค้ดเกินสี่ไบต์ ไม่มีอะไรที่ในทางทฤษฎีจะจินตนาการได้
ใน UTF 8 อักขระละตินทั้งหมดจะถูกเข้ารหัสในหนึ่งไบต์ เช่นเดียวกับในการเข้ารหัส ASCII แบบเก่า ที่น่าสังเกตคือ ในกรณีที่เข้ารหัสเฉพาะอักษรละติน แม้แต่โปรแกรมที่ไม่เข้าใจ Unicode ก็ยังอ่านสิ่งที่เข้ารหัสใน UTF 8 นั่นคือ ย้ายส่วนพื้นฐานของการเข้ารหัส ASCII ไปยัง UTF 8
อักขระซิริลลิกใน UTF 8ถูกเข้ารหัสเป็นสองไบต์และตัวอย่างเช่นจอร์เจีย - ในสามไบต์ Unicode Consortium หลังจากสร้างการเข้ารหัส UTF 16 และ UTF 8 ได้แก้ปัญหาหลัก - ตอนนี้เรามีพื้นที่โค้ดเดียวในแบบอักษรของเรา สิ่งเดียวที่เหลือสำหรับผู้ผลิตฟอนต์คือการเติมพื้นที่โค้ดนี้ด้วยรูปแบบเวกเตอร์ของสัญลักษณ์ข้อความตามจุดแข็งและความสามารถของพวกเขา
 ตัวอย่างของฟังก์ชัน jQuery setTimeout () Javascript ป้องกันไม่ให้ตัวจับเวลาหลายตัวเรียกใช้ setinterval ในเวลาเดียวกัน
ตัวอย่างของฟังก์ชัน jQuery setTimeout () Javascript ป้องกันไม่ให้ตัวจับเวลาหลายตัวเรียกใช้ setinterval ในเวลาเดียวกัน DIY วงจรวิทยุสมัครเล่นและผลิตภัณฑ์ทำเอง
DIY วงจรวิทยุสมัครเล่นและผลิตภัณฑ์ทำเอง ครอบตัดข้อความที่มีความสูงหนึ่งหรือหลายบรรทัดด้วยการเพิ่มจุดไข่ปลา การเพิ่มการไล่ระดับสีให้กับข้อความ
ครอบตัดข้อความที่มีความสูงหนึ่งหรือหลายบรรทัดด้วยการเพิ่มจุดไข่ปลา การเพิ่มการไล่ระดับสีให้กับข้อความ