การเข้ารหัสอักขระ Unicode
ฉันชอบมันอาจมีคนสนใจและมีประโยชน์
Unicode ดูสับสนมาก ซึ่งทำให้เกิดคำถามและปัญหามากมาย หลายคนคิดว่านี่คือการเข้ารหัสหรือชุดอักขระซึ่งค่อนข้างถูกต้อง แต่ที่จริงแล้วมันเป็นความเข้าใจผิด ความจริงที่ว่า Unicode ถูกสร้างเป็นการเข้ารหัสและชุดอักขระแต่เดิมตอกย้ำความเข้าใจผิดเท่านั้น นี่คือความพยายามที่จะชี้แจงทุกอย่าง ไม่ใช่แค่เพียงบอกว่า Unicode คืออะไร แต่โดยการให้ แบบจำลองทางจิตยูนิโค้ด
ไม่ถูกต้องทั้งหมด แต่เป็นโมเดลที่มีประโยชน์สำหรับการทำความเข้าใจ Unicode (ต่อไปนี้เรียกว่า PMPY):
- Unicode เป็นวิธีการประมวลผลข้อมูลข้อความ... ไม่ใช่ชุดอักขระหรือการเข้ารหัส
- Unicode คือข้อความ ส่วนอย่างอื่นคือข้อมูลไบนารี... และแม้แต่ข้อความ ASCII ก็เป็นข้อมูลไบนารี
- Unicode ใช้ชุดอักขระ UCS... แต่ UCS ไม่ใช่ Unicode
- Unicode สามารถเข้ารหัสไบนารีโดยใช้UTF... แต่ UTF ไม่ใช่ Unicode
ถ้าคุณรู้บางอย่างเกี่ยวกับ Unicode คุณพูดว่า "ใช่ แต่จริงๆ แล้วไม่ใช่เลย" ดังนั้น เราจะพยายามค้นหาว่าเหตุใดแบบจำลองความเข้าใจนี้ถึงแม้จะไม่ถูกต้อง แต่ก็ยังมีประโยชน์ มาเริ่มกันที่ชุดตัวอักษร ...
เกี่ยวกับชุดอักขระ
ในการประมวลผลข้อความบนคอมพิวเตอร์ คุณต้องจับคู่กราฟที่คุณเขียนบนกระดาษกับตัวเลข การเรียงนี้จะกำหนดโดยชุดอักขระหรือตารางอักขระซึ่งระบุตัวเลขสำหรับอักขระ นี่แหละที่เรียกว่า "ชุดตัวอักษร"... สัญลักษณ์ไม่จำเป็นต้องสอดคล้องกับกราฟใดๆ ตัวอย่างเช่น มีอักขระตรวจสอบ "BEL" ที่ทำให้คอมพิวเตอร์ของคุณ "ส่งเสียงบี๊บ" จำนวนอักขระในชุดอักขระโดยปกติคือ 256 ซึ่งเป็นจำนวนที่พอดีกับหนึ่งไบต์ มีชุดอักขระที่มีความยาวเพียง 6 บิตเท่านั้น เป็นเวลานาน ชุดอักขระ ASCII 7 บิตได้ครอบงำการประมวลผล แต่ชุดอักขระ 8 บิตเป็นชุดที่ใช้บ่อยที่สุด
แต่เห็นได้ชัดว่า 256 ไม่ใช่ตัวเลขที่สามารถรองรับสัญลักษณ์ทั้งหมดที่เราต้องการในโลกของเรา นี่คือสาเหตุที่ Unicode เกิดขึ้น เมื่อฉันบอกว่า Unicode ไม่ใช่ชุดอักขระ ฉันโกหก Unicode เดิมเป็นชุดอักขระ 16 บิต แต่ในขณะที่ผู้สร้าง Unicode เชื่อว่า 16 บิตก็เพียงพอแล้ว (และถูกต้อง) บางคนเชื่อว่า 16 บิตไม่เพียงพอ (และถูกต้องด้วย) ในที่สุดพวกเขาก็สร้างการเข้ารหัสที่แข่งขันกันและเรียกมันว่าชุดอักขระสากล (UCS) หลังจากนั้นไม่นาน ทั้งสองทีมก็ตัดสินใจเข้าร่วมกองกำลังและตัวละครทั้งสองชุดก็เหมือนกัน นี่คือเหตุผลที่เราสามารถสรุปได้ว่า Unicode ใช้ UCS เป็นชุดอักขระ แต่นี่ก็เป็นเรื่องโกหกเช่นกัน อันที่จริง แต่ละมาตรฐานมีชุดอักขระของตัวเอง มันจึงเกิดขึ้นที่เหมือนกัน (แม้ว่า UCS จะล้าหลังเล็กน้อย)
แต่สำหรับ PMPYu ของเรา - "Unicode ไม่ใช่ชุดอักขระ".
เกี่ยวกับ UCS
UCS คือชุดอักขระ 31 บิตที่มีอักขระมากกว่า 100,000 ตัว 31 บิต - เพื่อไม่ให้แก้ปัญหา "ลงนามกับไม่ได้ลงนาม" เนื่องจากขณะนี้มีการใช้อักขระน้อยกว่า 0.005% ของจำนวนอักขระที่เป็นไปได้ บิตพิเศษนี้จึงไม่จำเป็นเลย
แม้ว่า 16 บิตจะไม่เพียงพอสำหรับตัวละครทั้งหมดที่เคยสร้างมาโดยมนุษย์ แต่ก็เพียงพอแล้วหากคุณพร้อมที่จะจำกัดตัวเองในตอนนี้ ภาษาที่มีอยู่... ดังนั้น อักขระ UCS จำนวนมากจึงพอดีกับตัวเลข 65536 ตัวแรก พวกเขาได้รับการตั้งชื่อว่า "Basic Multilingual Plane" หรือ BMP อันที่จริงแล้ว พวกมันคือชุดอักขระ Unicode 16 บิต แม้ว่า UCS แต่ละเวอร์ชันจะขยายด้วยอักขระจำนวนมากขึ้นเรื่อยๆ BMP มีความเกี่ยวข้องเมื่อพูดถึงการเข้ารหัส แต่เพิ่มเติมเกี่ยวกับเรื่องนั้นด้านล่าง
อักขระแต่ละตัวใน UCS มีชื่อและหมายเลข อักขระ "H" มีชื่อว่า "LATIN CAPITAL LETTER H" และเป็นตัวเลข 72 โดยปกติแล้ว ตัวเลขจะเป็นเลขฐานสิบหก และมักนำหน้าด้วย "U +" และ 4, 5 หรือ 6 หลักเพื่อระบุความหมายของอักขระ Unicode ดังนั้นหมายเลขอักขระ "H" จึงมักแสดงเป็น U + 0048 มากกว่า - 72 แม้ว่าจะเป็นสิ่งเดียวกันก็ตาม อีกตัวอย่างหนึ่งคืออักขระ "-" ที่เรียกว่า "EM DASH" หรือ U + 2012 อักขระ "乨" เรียกว่า "CJK UNIFIED IDEOGRAPH-4E68" ซึ่งโดยทั่วไปจะแสดงเป็น U + 4E68 เครื่องหมาย "
เนื่องจากชื่อและจำนวนอักขระใน Unicode และ UCS เหมือนกัน สำหรับ PMPU ของเรา เราจะถือว่า UCS ไม่ใช่ Unicode, แต่ Unicode ใช้UCS... นี่เป็นเรื่องโกหก แต่เป็นคำโกหกที่มีประโยชน์ซึ่งช่วยให้คุณแยกความแตกต่างระหว่าง Unicode และชุดอักขระได้
เกี่ยวกับการเข้ารหัส
ดังนั้น ชุดอักขระจึงเป็นชุดของอักขระ ซึ่งแต่ละตัวมีหมายเลขของตัวเอง แต่คุณควรจัดเก็บหรือส่งไปยังคอมพิวเตอร์เครื่องอื่นอย่างไร สำหรับอักขระ 8 บิต เป็นเรื่องง่าย คุณใช้หนึ่งไบต์ต่ออักขระ แต่ UCS ใช้ 31 บิต และคุณต้องการ 4 ไบต์ต่ออักขระ ซึ่งสร้างปัญหากับการสั่งซื้อไบต์และหน่วยความจำไม่มีประสิทธิภาพ ยังไม่ใช่ทั้งหมด แอปพลิเคชันบุคคลที่สามสามารถทำงานกับอักขระ Unicode ทั้งหมด แต่เรายังต้องโต้ตอบกับแอปพลิเคชันเหล่านี้
ทางออกคือการใช้การเข้ารหัสที่ระบุวิธีการแปลงข้อความ Unicode เป็นข้อมูลไบนารี 8 บิต เป็นที่น่าสังเกตว่า ASCII เป็นการเข้ารหัส และข้อมูล ASCII จากมุมมองของ PMPU เป็นไบนารี!
ในกรณีส่วนใหญ่ การเข้ารหัสเป็นชุดอักขระเดียวกันและตั้งชื่อเหมือนกับชุดอักขระที่เข้ารหัส สิ่งนี้เป็นจริงสำหรับ Latin-1, ISO-8859-15, cp1252, ASCII และอื่นๆ แม้ว่าชุดอักขระส่วนใหญ่จะเข้ารหัสด้วยเช่นกัน แต่กรณีนี้ไม่ใช่สำหรับ UCS นอกจากนี้ยังทำให้สับสนอีกด้วยว่า UCS คือสิ่งที่คุณถอดรหัสและสิ่งที่คุณเข้ารหัส ในขณะที่ชุดอักขระที่เหลือคือสิ่งที่คุณถอดรหัสและสิ่งที่คุณเข้ารหัส (เนื่องจากชื่อของการเข้ารหัสและชุดอักขระเหมือนกัน) ดังนั้น คุณควรถือว่าชุดอักขระและการเข้ารหัสเป็นสิ่งที่ต่างกัน แม้ว่าคำเหล่านี้มักใช้สลับกันในความหมายก็ตาม
เกี่ยวกับ UTF
การเข้ารหัสส่วนใหญ่ทำงานบนชุดอักขระที่เป็นเพียงส่วนเล็กๆ ของ UCS สิ่งนี้กลายเป็นปัญหาสำหรับข้อมูลหลายภาษา ดังนั้นจึงจำเป็นต้องมีการเข้ารหัสที่ใช้อักขระ UCS ทั้งหมด การเข้ารหัสอักขระ 8 บิตทำได้ง่ายมาก เนื่องจากคุณได้รับหนึ่งอักขระจากหนึ่งไบต์ แต่ UCS ใช้ 31 บิต และคุณต้องการ 4 ไบต์ต่ออักขระ ปัญหาของลำดับไบต์เกิดขึ้นเนื่องจากบางระบบใช้ลำดับสูงไปยังลำดับต่ำ และในทางกลับกัน นอกจากนี้ บางไบต์จะว่างเปล่าเสมอ ซึ่งเป็นการสิ้นเปลืองหน่วยความจำ การเข้ารหัสที่ถูกต้องควรใช้จำนวนไบต์ที่แตกต่างกันสำหรับ ตัวละครต่างๆแต่การเข้ารหัสดังกล่าวจะมีผลในบางกรณีและไม่ได้ผลในบางกรณี
วิธีแก้ปริศนานี้คือใช้การเข้ารหัสหลายแบบซึ่งคุณสามารถเลือกรหัสที่เหมาะสมได้ เรียกว่ารูปแบบการแปลง Unicode หรือ UTF
UTF-8 เป็นการเข้ารหัสที่ใช้กันอย่างแพร่หลายบนอินเทอร์เน็ต โดยจะใช้หนึ่งไบต์สำหรับอักขระ ASCII และ 2 หรือ 4 ไบต์สำหรับอักขระ UCS อื่นๆ ทั้งหมด สิ่งนี้มีประสิทธิภาพมากสำหรับภาษาที่ใช้ตัวอักษรละติน เนื่องจากทั้งหมดอยู่ใน ASCII ซึ่งค่อนข้างมีประสิทธิภาพสำหรับภาษากรีก ซิริลลิก ญี่ปุ่น อาร์เมเนีย ซีเรียค อาหรับ ฯลฯ เนื่องจากใช้ 2 ไบต์ต่ออักขระ แต่วิธีนี้ใช้ไม่ได้ผลกับภาษา BMP อื่นๆ ทั้งหมด เนื่องจากจะใช้ 3 ไบต์ต่ออักขระ และสำหรับอักขระ UCS อื่นๆ ทั้งหมด เช่น แบบโกธิก จะใช้ 4 ไบต์
UTF-16 ใช้คำ 16 บิตหนึ่งคำสำหรับอักขระ BMP ทั้งหมด และคำ 16 บิตสองคำสำหรับอักขระอื่นๆ ทั้งหมด ดังนั้น หากคุณไม่ได้ใช้งานภาษาใดภาษาหนึ่งที่กล่าวถึงข้างต้น คุณควรใช้ UTF-16 เนื่องจาก UTF-16 ใช้คำแบบ 16 บิต เราจึงลงเอยด้วยปัญหาลำดับไบต์ มันถูกแก้ไขโดยมีตัวเลือกสามตัว: UTF-16BE สำหรับลำดับไบต์จากสูงไปต่ำ, UTF-16LE - จากต่ำไปสูงและเพียงแค่ UTF-16 ซึ่งสามารถเป็น UTF-16BE หรือ UTF-16LE เมื่อเข้ารหัส a เครื่องหมายถูกใช้ที่จุดเริ่มต้น ซึ่งระบุลำดับของไบต์ เครื่องหมายนี้เรียกว่า "เครื่องหมายลำดับไบต์" หรือ "BOM"
นอกจากนี้ยังมี UTF-32 ซึ่งสามารถอยู่ในสองรสชาติ BE และ LE เช่นเดียวกับ UTF-16 และเก็บอักขระ Unicode เป็นจำนวนเต็ม 32 บิต สิ่งนี้ไม่มีประสิทธิภาพสำหรับอักขระเกือบทั้งหมด ยกเว้นอักขระที่ต้องใช้ 4 ไบต์ในการจัดเก็บ แต่การประมวลผลข้อมูลดังกล่าวทำได้ง่ายมาก เนื่องจากคุณมี 4 ไบต์ต่ออักขระเสมอ
การแยกข้อมูลที่เข้ารหัสออกจากข้อมูล Unicode เป็นสิ่งสำคัญ ดังนั้น อย่าคิดว่าข้อมูล UTF-8/16/32 เป็น Unicode ดังนั้น แม้ว่าการเข้ารหัส UTF ถูกกำหนดไว้ในมาตรฐาน Unicode แต่เราเชื่อว่า UTF ไม่ใช่ Unicode ภายใต้ PMPU
เกี่ยวกับ Unicode
UCS มีอักขระที่เป็นหนึ่งเดียว เช่น trema ซึ่งเพิ่มจุดสองจุดเหนืออักขระ สิ่งนี้นำไปสู่ความกำกวมเมื่อแสดงหนึ่งกราฟ (ตัวอักษรหรือเครื่องหมาย) ผ่านสัญลักษณ์ต่างๆ ใช้ 'ö' เป็นตัวอย่าง ซึ่งสามารถแสดงเป็นอักขระ LATIN SMALL LETTER O กับ DIAERESIS ได้ แต่ในขณะเดียวกันก็เป็นการรวมอักขระ LATIN SMALL LETTER O ตามด้วย COMBINING DIAERESIS
แต่ในชีวิตจริง คุณไม่สามารถเสริมสัญลักษณ์ใดๆ ที่มีสามสัญลักษณ์ได้ ตัวอย่างเช่น การเพิ่มจุดสองจุดเหนือสัญลักษณ์ยูโรนั้นไม่สมเหตุสมผล Unicode มีกฎสำหรับสิ่งเหล่านี้ มันบ่งบอกว่าคุณสามารถแสดง 'ö' ได้สองวิธีและเป็นอักขระเดียวกัน แต่ถ้าคุณใช้สามตัวสำหรับเครื่องหมายยูโร แสดงว่าคุณกำลังทำผิดพลาด ดังนั้น กฎในการรวมอักขระจึงเป็นส่วนหนึ่งของมาตรฐาน Unicode
มาตรฐาน Unicode ยังมีกฎสำหรับการเปรียบเทียบและการเรียงลำดับอักขระ กฎสำหรับการแบ่งข้อความเป็นประโยคและคำ (ถ้าคุณคิดว่ามันง่ายขนาดนั้น จำไว้ว่าภาษาเอเชียส่วนใหญ่ไม่มีการเว้นวรรคระหว่างคำ) และกฎอื่นๆ อีกมากมายที่ กำหนดวิธีการแสดงและประมวลผล ข้อความ คุณอาจไม่จำเป็นต้องรู้ทั้งหมดนี้ ยกเว้นเมื่อใช้ภาษาเอเชีย
เมื่อใช้ PMPU เราได้พิจารณาแล้วว่า Unicode คือ UCS บวกกับกฎการประมวลผลคำ หรืออีกนัยหนึ่ง: Unicode เป็นวิธีการทำงานกับข้อมูลข้อความและไม่สำคัญว่าจะใช้ภาษาหรือตัวอักษรใด ใน Unicode 'H' ไม่ใช่แค่อักขระ แต่มีความหมายบางอย่าง ชุดอักขระระบุว่า 'H' เป็นอักขระหมายเลข 72 ในขณะที่ Unicode บอกคุณว่าเมื่อเรียงลำดับ 'H' มาก่อน 'I' และคุณสามารถใช้จุดสองจุดด้านบนเพื่อรับ 'Ḧ'
ดังนั้น Unicode ไม่ใช่การเข้ารหัสหรือชุดอักขระ แต่เป็นวิธีการทำงานกับข้อมูลข้อความ
ตัวฉันเองไม่ชอบพาดหัวข่าวเช่น "โปเกมอนในน้ำผลไม้ของตัวเองสำหรับหุ่น / หม้อ / กระทะ" แต่ดูเหมือนว่าจะเป็นอย่างนั้น - เราจะพูดถึงสิ่งพื้นฐานซึ่งมักจะนำไปสู่ส่วนที่เต็มไปด้วย การกระแทกและเสียเวลามากกับคำถาม - เหตุใดจึงไม่ทำงาน หากคุณยังกลัวและ / หรือไม่เข้าใจ Unicode ได้โปรดภายใต้ cat
เพื่ออะไร?
คำถามหลักสำหรับผู้เริ่มต้นที่ต้องเผชิญกับการเข้ารหัสจำนวนมากที่น่าประทับใจและกลไกที่ดูเหมือนจะสับสนในการทำงานกับพวกเขา (เช่นใน Python 2.x) คำตอบสั้น ๆ ก็คือเพราะมันเกิดขึ้น :)การเข้ารหัสที่ไม่ทราบคือวิธีการแสดงตัวเลขในหน่วยความจำคอมพิวเตอร์ (อ่าน - เป็นศูนย์ / ตัวเลข) บีชและอักขระอื่น ๆ ทั้งหมด ตัวอย่างเช่น ช่องว่างจะแสดงเป็น 0b100000 (ไบนารี), 32 (ทศนิยม) หรือ 0x20 (ฐานสิบหก)
ดังนั้น เมื่อมีหน่วยความจำน้อยมาก และคอมพิวเตอร์ทุกเครื่องมี 7 บิตเพียงพอที่จะแสดงอักขระที่จำเป็นทั้งหมด (ตัวเลข อักษรละตินตัวพิมพ์เล็ก / ตัวพิมพ์ใหญ่ พวงของอักขระและอักขระที่เรียกว่าอักขระควบคุม - ตัวเลขที่เป็นไปได้ทั้งหมด 127 ตัวถูกมอบให้กับใครบางคน) . ในขณะนั้นมีเพียงการเข้ารหัสเดียว - ASCII เมื่อเวลาผ่านไป ทุกคนมีความสุข และใครก็ตามที่ไม่มีความสุข (อ่าน - ใครไม่มีเครื่องหมาย "" หรือตัวอักษร "u") - ใช้อักขระที่เหลืออีก 128 ตัวตามดุลยพินิจของพวกเขา นั่นคือพวกเขาสร้างการเข้ารหัสใหม่ นี่คือลักษณะที่ ISO-8859-1 และ (นั่นคือ Cyrillic) cp1251 และ KOI8 ของเรา (นั่นคือ Cyrillic) ปรากฏขึ้น เมื่อรวมกับปัญหาในการตีความไบต์เช่น 0b1 ******* (นั่นคืออักขระ / ตัวเลขจาก 128 ถึง 255) ปรากฏขึ้น - ตัวอย่างเช่น 0b11011111 ในการเข้ารหัส cp1251 เป็น "I" ของเราเองในเวลาเดียวกัน ในการเข้ารหัส ISO 8859-1 คือ Eszett เยอรมันกรีก (พร้อมท์) "ß" ตามที่คาดไว้ เครือข่ายการสื่อสารและเพียงแค่การแลกเปลี่ยนไฟล์ระหว่าง คอมพิวเตอร์ต่างๆกลายเป็นเฮก-อะไร-อะไร แม้ว่าจะมีส่วนหัวเช่น "การเข้ารหัสเนื้อหา" ในโปรโตคอล HTTP อีเมลและหน้า HTML ช่วยประหยัดเวลาได้เล็กน้อย
ในขณะนั้น จิตใจที่สดใสได้รวมตัวกันและเสนอมาตรฐานใหม่ - Unicode นี่เป็นมาตรฐาน ไม่ใช่การเข้ารหัส - Unicode เองไม่ได้กำหนดวิธีการเก็บอักขระบนฮาร์ดดิสก์หรือส่งผ่านเครือข่าย กำหนดความสัมพันธ์ระหว่างอักขระและตัวเลขเท่านั้น และรูปแบบตามที่ตัวเลขเหล่านี้จะถูกแปลงเป็นไบต์จะถูกกำหนดโดยการเข้ารหัส Unicode (เช่น UTF-8 หรือ UTF-16) บน ช่วงเวลานี้มีอักขระน้อยกว่า 100,000 ตัวในมาตรฐาน Unicode ในขณะที่ UTF-16 สามารถรองรับได้มากกว่าหนึ่งล้านตัว (UTF-8 มากกว่านั้น)
ฉันแนะนำให้คุณอ่านขั้นต่ำแน่นอน นักพัฒนาซอฟต์แวร์ทุกคนต้องรู้ในเชิงบวกเกี่ยวกับ Unicode และชุดอักขระเพื่อความสนุกสนานมากขึ้นในหัวข้อนี้
เข้าประเด็น!
แน่นอนว่ามีการรองรับ Unicode ใน Python ด้วยเช่นกัน แต่น่าเสียดาย เฉพาะใน Python 3 เท่านั้น สตริงทั้งหมดกลายเป็น unicode และผู้เริ่มต้นต้องฆ่าตัวตายเกี่ยวกับข้อผิดพลาดเช่น:>>> โดยเปิด ("1.txt") เป็น fh: s = fh.read () >>> พิมพ์ s koshchey >>> parser_result = u "baba-yaga" # การกำหนดเพื่อความชัดเจนลองจินตนาการว่านี่คือ ส่งผลให้ parser ทำงาน >>>
หรือเช่นนี้:
>>> str (parser_result) Traceback (การโทรล่าสุดล่าสุด): ไฟล์ "
ลองคิดดู แต่ในการสั่งซื้อ
ทำไมทุกคนถึงใช้ Unicode?
เหตุใด html parser ที่ฉันชอบจึงส่งคืน Unicode ให้มันกลับสตริงธรรมดาและฉันจะจัดการกับมันที่นั่น! ถูกต้อง? ไม่เชิง. แม้ว่าอักขระแต่ละตัวที่มีอยู่ใน Unicode สามารถ (อาจ) แสดงในการเข้ารหัสแบบไบต์เดียว (ISO-8859-1, cp1251 และอื่น ๆ เรียกว่าไบต์เดียวเนื่องจากเข้ารหัสอักขระใด ๆ ในหนึ่งไบต์) แต่จะทำอย่างไร จะทำอย่างไรถ้าควรมีอักขระในสตริงจากการเข้ารหัสที่ต่างกัน? กำหนดการเข้ารหัสแยกให้กับอักขระแต่ละตัวหรือไม่ ไม่ แน่นอน คุณต้องใช้ Unicodeทำไมเราต้องมี "unicode" ชนิดใหม่
ดังนั้นเราจึงได้สิ่งที่น่าสนใจที่สุด สตริงใน Python 2.x คืออะไร? มันง่าย ไบต์... แค่ข้อมูลไบนารีที่สามารถเป็นอะไรก็ได้ อันที่จริง เมื่อเราเขียนบางสิ่งเช่น >>> x = "abcd" >>> x "abcd" ล่ามไม่ได้สร้างตัวแปรที่มีตัวอักษรละตินสี่ตัวแรก แต่มีเพียงลำดับ ("a" , "b "," c "," d ") ที่มีสี่ไบต์ และตัวอักษรละตินถูกใช้ที่นี่เพื่อกำหนดค่าไบต์เฉพาะนี้โดยเฉพาะ ดังนั้น "a" จึงเป็นเพียงคำพ้องความหมายสำหรับ "\ x61" และไม่มากไปกว่านั้น ตัวอย่างเช่น:>>> "\ x61" "a" >>> struct.unpack ("> 4b", x) # "x" เป็นเพียงสี่ตัวอักษรที่มีลายเซ็น / ไม่ได้ลงนาม (97, 98, 99, 100) >>> struct.unpack ("> 2h", x) # หรือสั้นสองอัน (24930, 25444) >>> struct.unpack ("> l", x) # หรือหนึ่งอันยาว (1633837924,) >>> struct.unpack ("> f" , x) # หรือ float (2.6100787562286154e + 20,) >>> struct.unpack ("> d", x * 2) # หรือครึ่งคู่ (1.2926117739473244e + 161,)
และนั่นแหล่ะ!
และคำตอบสำหรับคำถาม - ทำไมเราถึงต้องการ "unicode" นั้นชัดเจนกว่าอยู่แล้ว - เราต้องการประเภทที่จะแสดงด้วยอักขระไม่ใช่ไบต์
โอเค ฉันรู้แล้วว่าสตริงคืออะไร Unicode ใน Python คืออะไร?
"ประเภท unicode" เป็นหลักเป็นนามธรรมที่ใช้แนวคิดของ Unicode (ชุดของอักขระและตัวเลขที่เกี่ยวข้อง) วัตถุประเภท "unicode" ไม่ใช่ลำดับของไบต์อีกต่อไป แต่เป็นลำดับของอักขระจริงโดยไม่ทราบว่าอักขระเหล่านี้สามารถจัดเก็บในหน่วยความจำคอมพิวเตอร์ได้อย่างมีประสิทธิภาพได้อย่างไร ถ้าคุณต้องการมากกว่านี้ ระดับสูงนามธรรมมากกว่าสตริงไบต์ (นี่คือสิ่งที่ Python 3 เรียกว่าสตริงปกติที่ใช้ใน Python 2.6)ฉันจะใช้ Unicode ได้อย่างไร
สตริง Unicode ใน Python 2.6 สามารถสร้างได้สามวิธี (อย่างน้อยก็เป็นธรรมชาติ):- u "" ตามตัวอักษร: >>> u "abc" u "abc"
- วิธีการ "ถอดรหัส" สำหรับสตริงไบต์: >>> "abc" .decode ("ascii") u "abc"
- ฟังก์ชัน "Unicode": >>> unicode ("abc", "ascii") u "abc"
"\ x61" -> การเข้ารหัส ascii -> ละตินตัวพิมพ์เล็ก "a" -> u "\ u0061" (จุด Unicode สำหรับตัวอักษรนี้) หรือ "\ xe0" -> การเข้ารหัส c1251 -> อักษรซีริลลิกตัวพิมพ์เล็ก "a" -> u " \ u0430 "
วิธีรับสตริงปกติจากสตริง Unicode เข้ารหัส:
>>> คุณ "abc" .encode ("ascii") "abc"
อัลกอริธึมการเข้ารหัสนั้นตรงกันข้ามกับอัลกอริธึมที่ให้ไว้ข้างต้น
จำและไม่สับสน - ยูนิโค้ด == อักขระ สตริง == ไบต์ และไบต์ -> สิ่งที่มีความหมาย (อักขระ) คือการถอดรหัส และอักขระ -> ไบต์คือการเข้ารหัส
ไม่ได้เข้ารหัส :(
ลองดูตัวอย่างตั้งแต่ต้นบทความ การต่อสตริงสตริงและยูนิโค้ดทำงานอย่างไร ต้องเปลี่ยนสตริงธรรมดาให้เป็นสตริง Unicode และเนื่องจากล่ามไม่ทราบการเข้ารหัส จึงใช้การเข้ารหัสเริ่มต้น - ascii หากการเข้ารหัสนี้ไม่สามารถถอดรหัสสตริงได้ เราได้รับข้อผิดพลาดที่น่าเกลียด ในกรณีนี้ เราจำเป็นต้องแปลงสตริงเป็นสตริงยูนิโค้ดด้วยตนเอง โดยใช้การเข้ารหัสที่ถูกต้อง:>>> ประเภทการพิมพ์ (parser_result), parser_result
"UnicodeDecodeError" มักจะเป็นตัวบ่งชี้เพื่อถอดรหัสสตริงเป็น Unicode โดยใช้การเข้ารหัสที่ถูกต้อง
ตอนนี้ใช้สตริง "str" และยูนิโค้ด อย่าใช้สตริง "str" และ Unicode :) ใน "str" ไม่มีวิธีระบุการเข้ารหัสดังนั้นการเข้ารหัสเริ่มต้นจะถูกใช้เสมอและอักขระใด ๆ > 128 จะทำให้เกิดข้อผิดพลาด ใช้วิธีการ "เข้ารหัส":
>>> ประเภทการพิมพ์ s
"UnicodeEncodeError" เป็นสัญญาณว่าเราจำเป็นต้องระบุการเข้ารหัสที่ถูกต้องเมื่อแปลงสตริง Unicode เป็นสตริงปกติ (หรือใช้พารามิเตอร์ตัวที่สอง "ละเว้น" \ "แทนที่" \ "xmlcharrefreplace" ในวิธี "เข้ารหัส")
ฉันต้องการมากขึ้น!
โอเค ลองใช้ Baba Yaga จากตัวอย่างด้านบนอีกครั้ง:>>> parser_result = u "baba-yaga" # 1 >>> parser_result u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" # 2 >>> พิมพ์ parser_result áàáà-ÿãà # 3 >>> พิมพ์ parser_result.encode ("latin1") # 4 baba yaga >>> พิมพ์ parser_result.encode ("latin1") ถอดรหัส ("cp1251") # 5 baba yaga >>> พิมพ์ unicode ("baba yaga", "cp1251" ) #6 บาบายากะ
ตัวอย่างไม่ง่ายทั้งหมด แต่มีทุกอย่าง (หรือเกือบทุกอย่าง) เกิดอะไรขึ้นที่นี่:
- เรามีอะไรที่ทางเข้า? ไบต์ที่ IDLE ส่งผ่านไปยังล่าม สิ่งที่คุณต้องการที่ทางออก? Unicode นั่นคืออักขระ มันยังคงเปลี่ยนไบต์เป็นอักขระ - แต่คุณต้องการการเข้ารหัสใช่ไหม จะใช้การเข้ารหัสแบบใด? เรามองต่อไป
- นี่คือจุดสำคัญ: >>> "baba-yaga" "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" >>> u "\ u00e1 \ u00e0 \ u00e1 \ u00e0- \ u00ff \ u00e3 \ u00e0" == u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" จริง อย่างที่คุณเห็น Python ไม่สนใจตัวเลือกการเข้ารหัส - ไบต์ถูกแปลงเป็นจุดยูนิโค้ดอย่างง่าย:
>>> ออด ("a") 224 >>> ออร์ด (u "a") 224 - ที่นี่คือปัญหาเท่านั้น - อักขระตัวที่ 224 ใน cp1251 (การเข้ารหัสที่ใช้โดยล่าม) ไม่เหมือนกับ 224 ใน Unicode เลย เป็นเพราะเหตุนี้ เราจึงถูกแคร็กเมื่อพยายามพิมพ์สตริงยูนิโค้ดของเรา
- จะช่วยผู้หญิงได้อย่างไร? ปรากฎว่าอักขระ Unicode 256 ตัวแรกเหมือนกับในการเข้ารหัส ISO-8859-1 \ latin1 ตามลำดับ หากเราใช้เข้ารหัสสตริง Unicode เราจะได้ไบต์ที่เราป้อนเอง (ผู้สนใจ - Objects) / unicodeobject.c ค้นหาคำจำกัดความของฟังก์ชัน "unicode_encode_ucs1"):
>>> parser_result.encode ("latin1") "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" - คุณจะได้ baba ใน unicode ได้อย่างไร? จำเป็นต้องระบุว่าจะใช้การเข้ารหัสใด:
>>> parser_result.encode ("latin1") ถอดรหัส ("cp1251") u "\ u0431 \ u0430 \ u0431 \ u0430- \ u044f \ u0433 \ u0430" - วิธีการจากข้อ # 5 นั้นไม่ร้อนนัก แต่จะสะดวกกว่ามากหากใช้ Unicode ในตัว
นอกจากนี้ยังมีวิธีใช้ "u" "" เพื่อแทน เช่น Cyrillic โดยไม่ต้องระบุการเข้ารหัสหรือจุด Unicode ที่อ่านไม่ได้ (นั่นคือ "u" \ u1234 "") วิธีนี้ไม่สะดวกนัก แต่ที่น่าสนใจคือการใช้รหัสเอนทิตี Unicode:
>>> s = u "\ N (CYRILLIC SMALL LETTER KA) \ N (CYRILLIC SMALL LETTER O) \ N (CYRILLIC SMALL LETTER SHCHA) \ N (CYRILLIC SMALL LETTER IE) \ N (CYRILLIC SMALL LETTER SHORT I)"> >> พิมพ์ s koshchey
นั่นคือทั้งหมดที่ คำแนะนำหลักคืออย่าสับสน "เข้ารหัส" \ "ถอดรหัส" และทำความเข้าใจความแตกต่างระหว่างไบต์และอักขระ
Python3
ที่นี่ไม่มีรหัสเพราะไม่มีประสบการณ์ พยานบอกว่าที่นั่นทุกอย่างง่ายกว่าและสนุกกว่ามาก ใครจะดำเนินการกับแมวเพื่อแสดงความแตกต่างระหว่างที่นี่ (Python 2.x) และที่นั่น (Python 3.x) - ความเคารพและความเคารพสุขภาพดี
เนื่องจากเรากำลังพูดถึงการเข้ารหัส ฉันจะแนะนำแหล่งข้อมูลที่ช่วยเอาชนะ krakozyabry เป็นครั้งคราว - http://2cyr.com/decode/?lang=ruUnicode HOWTO เป็นเอกสารอย่างเป็นทางการเกี่ยวกับสถานที่ อย่างไร และเหตุใด Unicode ใน Python 2.x
ขอบคุณสำหรับความสนใจ ฉันจะขอบคุณสำหรับความคิดเห็นของคุณเป็นการส่วนตัว เพิ่มแท็ก
จุดโค้ด Unicode และอักขระภาษารัสเซียในซอร์สโค้ดและโปรแกรม Java เจดีเค 1.6.
นักพัฒนาเพียงพอ ซอฟต์แวร์ในความเป็นจริง ไม่มีความเข้าใจที่ชัดเจนเกี่ยวกับชุดอักขระ การเข้ารหัส Unicode และสื่อที่เกี่ยวข้อง แม้ในปัจจุบันนี้ หลายๆ โปรแกรมมักจะมองข้ามการแปลงอักขระที่พบ แม้แต่โปรแกรมที่ดูเหมือนว่าจะได้รับการออกแบบด้วยเทคโนโลยี Java ที่เป็นมิตรต่อ Unicode มักใช้อักขระ 8 บิตอย่างไม่ระมัดระวัง ทำให้ไม่สามารถพัฒนาเว็บแอปพลิเคชันหลายภาษาที่ดีได้ บทความนี้เป็นการรวบรวมชุดบทความเกี่ยวกับการเข้ารหัส Unicode แต่บทความที่ก้าวล้ำของ Joel Spolsky เป็นผู้พัฒนาซอฟต์แวร์ขั้นต่ำสุดอย่างแท้จริง ซึ่งต้องทราบในเชิงบวกเกี่ยวกับ Unicode และชุดอักขระ (10/08/2003)ประวัติความเป็นมาของการสร้างการเข้ารหัสประเภทต่างๆ
ทุกสิ่งที่ระบุว่า "ข้อความธรรมดา = ASCII = อักขระ 8 บิต" ไม่ถูกต้อง อักขระเดียวที่สามารถแสดงอย่างถูกต้องภายใต้สถานการณ์ใด ๆ คือตัวอักษรภาษาอังกฤษโดยไม่มีเครื่องหมายกำกับเสียงที่มีรหัส 32 ถึง 127 สำหรับอักขระเหล่านี้มีรหัสที่เรียกว่า ASCII ที่สามารถแสดงอักขระทั้งหมดได้ ตัวอักษร "A" จะมีรหัส 65 ช่องว่างจะเป็นรหัส 32 เป็นต้น อักขระเหล่านี้สามารถจัดเก็บได้อย่างสะดวกใน 7 บิต คอมพิวเตอร์ส่วนใหญ่ในสมัยนั้นใช้การลงทะเบียนแบบ 8 บิต ดังนั้นคุณจึงไม่เพียงแต่สามารถจัดเก็บอักขระ ASCII ทุกตัวที่เป็นไปได้เท่านั้น แต่คุณยังประหยัดเงินได้อีกเล็กน้อย ซึ่งหากคุณมีเจตนาดังกล่าว คุณสามารถใช้เพื่อจุดประสงค์ของคุณเองได้ รหัสที่น้อยกว่า 32 เรียกว่าไม่สามารถพิมพ์ได้และใช้สำหรับอักขระควบคุมเช่นอักขระ 7 ทำให้คอมพิวเตอร์ของคุณส่งเสียงบี๊บของลำโพงและอักขระ 12 เป็นอักขระท้ายหน้าทำให้เครื่องพิมพ์เลื่อนแผ่นงานปัจจุบัน ของกระดาษและใส่กระดาษใหม่
เนื่องจากไบต์มีขนาดแปดบิต หลายคนจึงคิดว่า "เราสามารถใช้รหัส 128-255 เพื่อจุดประสงค์ของเราเองได้" ปัญหาคือสำหรับคนจำนวนมาก แนวคิดนี้มาเกือบจะพร้อมกัน แต่ทุกคนมีความคิดของตนเองเกี่ยวกับสิ่งที่ควรวางไว้ด้วยรหัส 128 ถึง 255 IBM-PC มีบางอย่างที่กลายเป็นที่รู้จักในชื่อชุดอักขระ OEM ซึ่งมี เครื่องหมายกำกับเสียงสำหรับภาษายุโรปและชุดอักขระสำหรับการวาดเส้น: แถบแนวนอน, แถบแนวตั้ง, มุม, กากบาท ฯลฯ และคุณสามารถใช้สัญลักษณ์เหล่านี้เพื่อสร้างปุ่มที่สวยงามและวาดเส้นบนหน้าจอที่คุณยังมองเห็นได้บนคอมพิวเตอร์รุ่นเก่าบางเครื่อง ตัวอย่างเช่น ในพีซีบางเครื่อง รหัสอักขระ 130 แสดงเป็น e แต่บนคอมพิวเตอร์ที่จำหน่ายในอิสราเอล จะเป็นตัวอักษรฮีบรู Gimel (?) ถ้าชาวอเมริกันส่งเรซูเม่ไปที่อิสราเอล เรซูเม่จะมาถึงในชื่อ r? Sum ? ในหลายกรณี เช่น ในกรณีของภาษารัสเซีย มีแนวคิดที่แตกต่างกันมากมายเกี่ยวกับสิ่งที่ต้องทำกับอักขระ 128 ตัวบน ดังนั้นคุณจึงไม่สามารถแลกเปลี่ยนเอกสารภาษารัสเซียได้อย่างน่าเชื่อถือ
ในที่สุด การเข้ารหัส OEM ที่หลากหลายก็ลดลงเป็นมาตรฐาน ANSI มาตรฐาน ANSI ระบุว่าอักขระใดต่ำกว่า 128 โดยพื้นฐานแล้วพื้นที่นี้เหมือนกับใน ASCII แต่มีจำนวนมาก วิธีทางที่แตกต่างจัดการอักขระ 128 ขึ้นไปขึ้นอยู่กับว่าคุณอาศัยอยู่ที่ไหน ระบบต่างๆ เหล่านี้เรียกว่าหน้าโค้ด ตัวอย่างเช่น ในอิสราเอล DOS ใช้หน้ารหัส 862 ในขณะที่ผู้ใช้ชาวกรีกใช้หน้า 737 ซึ่งมีค่าต่ำกว่า 128 แต่ต่างจาก 128 ซึ่งอักขระเหล่านี้ทั้งหมดอยู่ รุ่นชาติของ MS-DOS รองรับโค้ดเพจเหล่านี้มากมาย รองรับทุกภาษา ตั้งแต่ภาษาอังกฤษไปจนถึงไอซ์แลนด์ และยังมีโค้ดเพจ "หลายภาษา" สองสามหน้าที่เอสเปรันโตและกาลิเซียนสร้างได้ กลุ่มภาษา แพร่หลายในสเปน ลำโพง 4 ล้านคน) บนคอมพิวเตอร์เครื่องเดียวกัน! แต่การจะพูดภาษาฮีบรูและกรีกบนคอมพิวเตอร์เครื่องเดียวกันนั้นเป็นไปไม่ได้เลย เว้นแต่คุณจะเขียนโปรแกรมของคุณเองที่แสดงทุกอย่างโดยใช้กราฟิกบิตแมป เพราะภาษาฮีบรูและกรีกต้องใช้หน้าโค้ดที่แตกต่างกันซึ่งมีการตีความต่างกัน ตัวเลขหลัก
ในขณะเดียวกัน ในเอเชีย เนื่องจากตัวอักษรเอเชียมีตัวอักษรหลายพันตัวที่ไม่สามารถใส่เป็น 8 บิตได้ ปัญหานี้จึงแก้ไขได้โดยระบบ DBCS ที่สลับซับซ้อน ซึ่งเป็น "ชุดอักขระแบบไบต์คู่" ซึ่งอักขระบางตัวถูกจัดเก็บในหนึ่งไบต์ ขณะที่บางตัว เอาสอง มันง่ายมากที่จะก้าวไปข้างหน้าตามเส้น แต่เป็นไปไม่ได้อย่างแน่นอนที่จะถอยหลัง โปรแกรมเมอร์ไม่สามารถใช้ s ++ และ s- เพื่อเดินหน้าถอยหลังได้ และต้องเรียก ฟังก์ชั่นพิเศษผู้ซึ่งรู้วิธีจัดการกับความยุ่งเหยิงนี้
อย่างไรก็ตาม คนส่วนใหญ่เมินต่อความจริงที่ว่า byte เป็นตัวอักษรและตัวอักษรเป็น 8 bits และตราบเท่าที่คุณไม่จำเป็นต้องย้ายบรรทัดจากคอมพิวเตอร์เครื่องหนึ่งไปยังอีกเครื่องหนึ่งหรือถ้าคุณไม่พูด มากกว่าหนึ่งภาษาก็ใช้งานได้ แต่แน่นอนว่าทันทีที่อินเทอร์เน็ตเริ่มใช้งานอย่างหนาแน่น การถ่ายโอนสายจากคอมพิวเตอร์เครื่องหนึ่งไปยังอีกเครื่องหนึ่งกลายเป็นเรื่องธรรมดา ความวุ่นวายในเรื่องนี้ผ่านพ้นไปได้ด้วย Unicode
Unicode
Unicode เป็นความพยายามอย่างยิ่งยวดในการสร้างชุดอักขระตัวเดียวที่จะรวมระบบการเขียนที่แท้จริงทั้งหมดบนโลกใบนี้ เช่นเดียวกับบางตัวละคร บางคนมีความเข้าใจผิดว่า Unicode เป็นรหัส 16 บิตปกติ โดยที่อักขระแต่ละตัวมีความยาว 16 บิต ดังนั้นจึงมีอักขระที่เป็นไปได้ 65,536 ตัว ในความเป็นจริงนี้ไม่เป็นความจริง นี่เป็นความเข้าใจผิดที่พบบ่อยที่สุดเกี่ยวกับ Unicode
อันที่จริง Unicode ใช้แนวทางที่ผิดปกติเพื่อทำความเข้าใจแนวคิดของตัวละคร จนถึงตอนนี้ เราถือว่าอักขระถูกจับคู่กับชุดของบิตที่คุณสามารถจัดเก็บบนดิสก์หรือในหน่วยความจำ:
เอ - & gt 0100 0001
ใน Unicode อักขระจะจับคู่กับสิ่งที่เรียกว่าจุดโค้ด ซึ่งเป็นเพียงแนวคิดเชิงทฤษฎี วิธีแสดงจุดรหัสนี้ในหน่วยความจำหรือบนดิสก์เป็นอีกเรื่องหนึ่ง วี อักษรยูนิโค้ดและนี่เป็นเพียงความคิดแบบสงบ (eidos) (ประมาณการแปล: แนวคิดของปรัชญาของเพลโต eidos เป็นหน่วยงานในอุดมคติ ไม่มีตัวตน และเป็นความจริงตามวัตถุประสงค์อย่างแท้จริง นอกเหนือจากสิ่งและปรากฏการณ์ที่เฉพาะเจาะจง)
NS NSนั่น Platonov A แตกต่างจาก B และแตกต่างจาก NS, แต่ก็เหมือนกันเป็น NS และก. ความคิดที่ว่า และใน Times New Roman ก็เหมือนกับ A ใน Helvetica แต่ความแตกต่างจากตัว "a" ตัวพิมพ์เล็กนั้นดูเหมือนจะไม่ขัดแย้งกันเกินไปในความเข้าใจของผู้คน แต่จากมุมมองของวิทยาการคอมพิวเตอร์และจากมุมมองของภาษา คำจำกัดความของตัวอักษรนั้นขัดแย้งกัน จดหมายภาษาเยอรมัน ß เป็นจดหมายจริงหรือแค่วิธีเขียน ss แฟนซี? หากการสะกดของตัวอักษรที่ท้ายคำเปลี่ยนไป มันจะกลายเป็นตัวอักษรอื่นหรือไม่? ฮิบรูบอกว่าใช่ อาหรับบอกว่าไม่ใช่ ไม่ว่าจะด้วยวิธีใด คนฉลาดที่กลุ่ม Unicode เข้าใจมันหลังจากการอภิปรายทางการเมืองหลายครั้ง และคุณไม่ต้องกังวลกับเรื่องนี้ ทุกอย่างได้รับการเข้าใจก่อนเราแล้วตัวอักษร Platonic แต่ละตัวในแต่ละตัวอักษรได้รับหมายเลขมหัศจรรย์โดย Unicode consortium ซึ่งเขียนดังนี้: U + 0645 ตัวเลขมหัศจรรย์นี้เรียกว่าจุดรหัส U + ย่อมาจาก "Unicode" และตัวเลขเป็นเลขฐานสิบหก ตัวเลข U + FEC9 เป็นอักษรอารบิก Ain ตัวอักษรภาษาอังกฤษ A สอดคล้องกับ U + 0041
ไม่มีการจำกัดจำนวนตัวอักษรที่สามารถระบุได้ด้วย Unicode และอันที่จริงมันเกินขีดจำกัด 65,536 ตัวแล้ว ดังนั้นไม่ใช่ว่าทุกตัวอักษรจาก Unicode จะถูกบีบอัดเป็นสองไบต์ได้
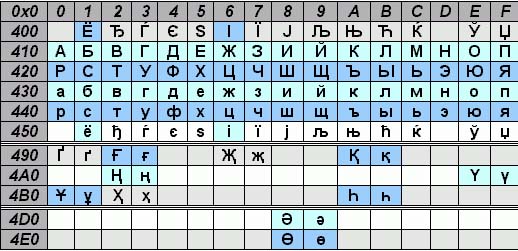
สำหรับ Cyrillic ใน UNICODE ช่วงของรหัสคือตั้งแต่ 0x0400 ถึง 0x04FF ตารางนี้แสดงเฉพาะบางส่วนของอักขระในช่วงนี้ แต่มาตรฐานกำหนดรหัสส่วนใหญ่ในช่วงนี้
ลองนึกภาพว่าเรามีบรรทัด:
เฮ้! ซึ่งใน Unicode จะจับคู่รหัสเจ็ดจุดเหล่านี้: U + 041F U + 0440 U + 0438 U + 0432 U + 0435 U + 0442 U + 0021
เพียงพวงของจุดรหัส ตัวเลขมีจริง
หากต้องการดูว่าไฟล์ข้อความ Unicode จะเป็นอย่างไร คุณสามารถเรียกใช้โปรแกรมแผ่นจดบันทึกใน Windows แทรกบรรทัดที่กำหนด และบันทึก ไฟล์ข้อความเลือกการเข้ารหัส Unicode
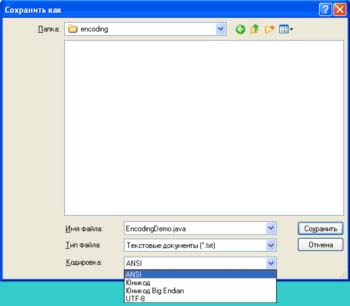
โปรแกรมเสนอการออมในสามแบบ การเข้ารหัส Unicode... ตัวเลือกแรกคือวิธีการเขียนโดยให้ไบต์ที่มีนัยสำคัญน้อยที่สุดอยู่ข้างหน้า (endian น้อย) ตัวเลือกที่สองมีไบต์ที่สำคัญที่สุดอยู่ข้างหน้า (endian ใหญ่) ตัวเลือกใดถูกต้อง
นี่คือไฟล์ดัมพ์ endian ขนาดใหญ่ที่มีสตริง "สวัสดี!" ดูเหมือนว่า:
และนี่คือลักษณะการถ่ายโอนไฟล์ที่มีสตริง "สวัสดี!" ดูเหมือนว่าบันทึกในรูปแบบ Unicode ( endian น้อย):
และนี่คือลักษณะการถ่ายโอนข้อมูลไฟล์ที่มีสตริง "สวัสดี!" ที่บันทึกในรูปแบบ Unicode (UTF-8):
การใช้งานในช่วงแรกๆ ต้องการสามารถจัดเก็บจุดโค้ด Unicode ในรูปแบบไฮเอนด์หรือโลว์เอนด์ได้ ทั้งนี้ขึ้นอยู่กับรูปแบบที่โปรเซสเซอร์ทำงานได้เร็วขึ้น มีสองวิธีในการจัดเก็บ Unicode สิ่งนี้นำไปสู่แบบแผนของการจัดเก็บรหัส \ uFFFE ที่จุดเริ่มต้นของทุกบรรทัด Unicode ลายเซ็นนี้เรียกว่าเครื่องหมายคำสั่งไบต์ หากคุณสลับไบต์สูงและต่ำ \ uFFFE จะต้องอยู่ที่จุดเริ่มต้น และผู้ที่อ่านบรรทัดของคุณจะรู้ว่าต้องสลับไบต์ในแต่ละคู่ ลายเซ็นนี้สงวนไว้ในมาตรฐาน Unicode
มาตรฐาน Unicode กล่าวว่าลำดับไบต์เริ่มต้นคือ endian ใหญ่หรือ endian น้อย อันที่จริง คำสั่งทั้งสองถูกต้อง และผู้ออกแบบระบบเลือกคำสั่งใดคำสั่งหนึ่งด้วยตนเอง ไม่ต้องกังวลหากระบบของคุณสื่อสารกับระบบอื่นและทั้งคู่ใช้ endian เพียงเล็กน้อย
อย่างไรก็ตาม หาก Windows ของคุณสื่อสารกับเซิร์ฟเวอร์ UNIX ที่ใช้ endian ขนาดใหญ่ ระบบใดระบบหนึ่งต้องทำการแปลงรหัส ในกรณีนี้ มาตรฐานยูนิโค้ดระบุว่าคุณสามารถเลือกวิธีแก้ไขปัญหาใด ๆ ต่อไปนี้สำหรับปัญหา:
- เมื่อสองระบบ ใช้คำสั่งไบต์ Unicode ต่างกัน แลกเปลี่ยนข้อมูล (โดยไม่ต้องใช้โปรโตคอลพิเศษใดๆ) ลำดับไบต์ต้องเป็น endian ขนาดใหญ่ มาตรฐานเรียกมันว่า บัญญัติคำสั่งไบต์
- แต่ละสตริง Unicode ต้องขึ้นต้นด้วยรหัส \ uFEFF รหัส \ uFFFE ซึ่งเป็นการผกผันของเครื่องหมายคำสั่ง ดังนั้น หากผู้รับเห็นรหัส \ uFEFF เป็นอักขระตัวแรก แสดงว่าไบต์อยู่ในลำดับ endian เล็กน้อย อย่างไรก็ตาม ในความเป็นจริง ไม่ใช่ทุกสตริง Unicode ที่มีเครื่องหมายลำดับไบต์ที่จุดเริ่มต้น
วิธีที่สองนั้นหลากหลายกว่าและดีกว่า
ในชั่วขณะหนึ่ง ทุกคนดูมีความสุข แต่โปรแกรมเมอร์ที่พูดภาษาอังกฤษมักจะดูข้อความภาษาอังกฤษเป็นส่วนใหญ่ และไม่ค่อยใช้โค้ดที่สูงกว่า U + 00FF ด้วยเหตุผลนี้เพียงอย่างเดียว หลายๆ คนจึงละเลย Unicode มาหลายปีแล้ว
แนวคิดที่ยอดเยี่ยมของ UTF-8 ถูกคิดค้นขึ้นสำหรับสิ่งนี้โดยเฉพาะ
UTF-8
UTF-8 เป็นอีกระบบหนึ่งสำหรับจัดเก็บลำดับของจุดโค้ด Unicode ซึ่งเป็นตัวเลข U + อย่างแท้จริง โดยใช้หน่วยความจำ 8 บิตเดียวกัน ใน UTF-8 โค้ดแต่ละจุดที่มีหมายเลข 0 ถึง 127 ถูกจัดเก็บในไบต์เดียว
อันที่จริงนี่คือการเข้ารหัสที่มีจำนวนตัวแปรของการเข้ารหัสไบต์สำหรับการจัดเก็บ 2, 3 และที่จริงแล้วใช้มากถึง 6 ไบต์ หากอักขระอยู่ในชุด ASCII (รหัสในช่วง 0x00-0x7F) อักขระนั้นจะถูกเข้ารหัสในลักษณะเดียวกับใน ASCII ในหนึ่งไบต์ หากยูนิโค้ดของอักขระมากกว่าหรือเท่ากับ 0x80 บิตของอักขระนั้นจะถูกบรรจุเป็นลำดับไบต์ตามกฎต่อไปนี้:
คุณอาจสังเกตเห็นว่าถ้าไบต์เริ่มต้นด้วยศูนย์บิต แสดงว่าเป็นอักขระ ASCII แบบไบต์เดี่ยว หากไบต์เริ่มต้นด้วย 11 ... นี่คือไบต์เริ่มต้นของลำดับหลายไบต์ที่เข้ารหัสอักขระ จำนวนหน่วยหลักจะเท่ากับจำนวนไบต์ในลำดับ หากไบต์เริ่มต้นด้วย 10 ... แสดงว่าเป็นไบต์ "ขนส่ง" แบบอนุกรมจากลำดับของไบต์ จำนวนที่กำหนดโดยไบต์เริ่มต้น ดีและ บิตยูนิโค้ดอักขระจะถูกบรรจุลงในบิต "ขนส่ง" ของการเริ่มต้นและไบต์อนุกรม ซึ่งระบุในตารางเป็นลำดับ "xx..x"
สามารถดูจำนวนตัวแปรของการเข้ารหัสไบต์ได้จากการถ่ายโอนข้อมูลไฟล์ด้านล่าง
ดัมพ์ไฟล์ที่มีสตริง “สวัสดี!” ที่บันทึกไว้ในรูปแบบ Unicode (UTF-8):
ดัมพ์ไฟล์ที่มีสตริง "สวัสดี!" ที่บันทึกไว้ในรูปแบบ Unicode (UTF-8):
ผลข้างเคียงที่ดีของสิ่งนี้คือข้อความภาษาอังกฤษมีลักษณะเหมือนกันทุกประการใน UTF-8 เช่นเดียวกับใน ASCII ดังนั้นคนอเมริกันจึงไม่สังเกตเห็นว่ามีบางอย่างผิดปกติ มีเพียงส่วนที่เหลือของโลกเท่านั้นที่ต้องเอาชนะอุปสรรค โดยเฉพาะสวัสดี U + 0048 U + 0065 U + 006C U + 006C U + 006F คืออะไรตอนนี้จะถูกเก็บไว้ใน 48 65 6C 6C 6F เช่นเดียวกับ ASCII และ ANSI และสัญลักษณ์ OEM อื่น ๆ ในโลก หากคุณกล้าที่จะใช้เครื่องหมายกำกับเสียงหรือ ตัวอักษรกรีกหรือตัวอักษร Klingon คุณจะต้องใช้หลายไบต์เพื่อเก็บรหัสจุดเดียว แต่คนอเมริกันจะไม่มีวันสังเกตเห็น UTF-8 ยังมีคุณลักษณะที่ดีอีกด้วย: โค้ดเก่า, ไม่สนใจรูปแบบสตริงใหม่ และการจัดการสตริงที่มีไบต์ว่างที่ท้ายบรรทัด จะไม่ตัดทอนสตริง
การเข้ารหัส Unicode อื่นๆ
กลับไปที่สามวิธีในการเข้ารหัส Unicode วิธีการแบบดั้งเดิม"เก็บไว้ในสองไบต์" เรียกว่า UCS-2 (เพราะมันมีสองไบต์) หรือ UTF-16 (เพราะมี 16 บิต) และคุณยังต้องหาว่ารหัส UCS-2 ที่มีไบต์สูงอยู่ที่ เริ่มต้นหรือด้วยไบต์ที่สำคัญที่สุดในตอนท้าย และมีมาตรฐาน UTF-8 ยอดนิยม สตริงที่มีคุณสมบัติที่ดีในการทำงานกับโปรแกรมเก่าที่ทำงานกับข้อความภาษาอังกฤษ และในโปรแกรมอัจฉริยะใหม่ที่ทำงานกับชุดอักขระอื่น ๆ ได้อย่างสมบูรณ์แบบนอกเหนือจาก ASCII
จริงๆ แล้วมีวิธีอื่นๆ มากมายในการเข้ารหัส Unicode มีบางอย่างที่เรียกว่า UTF-7 ซึ่งคล้ายกับ UTF-8 มาก แต่ทำให้แน่ใจว่าบิตที่สำคัญที่สุดจะเป็นศูนย์เสมอ จากนั้นมี UCS-4 ซึ่งจัดเก็บโค้ดแต่ละจุดใน 4 ไบต์และรับประกันว่าอักขระทั้งหมดจะถูกจัดเก็บในจำนวนไบต์เท่ากันอย่างแน่นอน แต่การสิ้นเปลืองหน่วยความจำดังกล่าวไม่ได้พิสูจน์ให้เห็นถึงการรับประกันดังกล่าวเสมอไป
ตัวอย่างเช่น คุณสามารถ Unicode สตริง Hello (U + 0048 U + 0065 U + 006C U + 006C U + 006F) ในรูปแบบ ASCII หรือในการเข้ารหัส OEM Greek แบบเก่า หรือในภาษาฮีบรู การเข้ารหัส ANSIหรือในการเข้ารหัสหลายร้อยรายการที่ได้รับการคิดค้นมาจนถึงทุกวันนี้ โดยมีปัญหาอย่างหนึ่ง: อักขระบางตัวอาจไม่ปรากฏ! หากไม่มีจุดโค้ด Unicode ที่เทียบเท่าที่คุณพยายามหาจุดเทียบเท่าในบางส่วน ตารางรหัสที่คุณพยายามจะทำการแปลง คุณมักจะได้รับเครื่องหมายคำถามเล็กน้อย:? หรือถ้าคุณเป็นโปรแกรมเมอร์ที่ดีจริงๆ
มีการเข้ารหัสแบบดั้งเดิมหลายร้อยแบบที่สามารถจัดเก็บโค้ดบางจุดได้อย่างถูกต้องและแทนที่จุดโค้ดอื่นๆ ทั้งหมดด้วยเครื่องหมายคำถาม ตัวอย่างเช่น การเข้ารหัสข้อความภาษาอังกฤษยอดนิยมบางตัวคือ Windows 1252 ( มาตรฐาน Windows 9x สำหรับภาษายุโรปตะวันตก) และ ISO-8859-1 หรือที่รู้จักว่า Latin-1 (เหมาะสำหรับภาษายุโรปตะวันตกด้วย) แต่ลองแปลงตัวอักษรรัสเซียหรือฮีบรูในการเข้ารหัสเหล่านี้ แล้วคุณจะจบลงด้วยเครื่องหมายคำถามจำนวนมาก สิ่งที่ยอดเยี่ยมเกี่ยวกับ UTF 7, 8, 16 และ 32 คือความสามารถในการจัดเก็บจุดโค้ดได้อย่างถูกต้อง
จุดโค้ด 32 บิตสำหรับอักขระ Unicode ใน Java
Java 2 5.0 นำเสนอการปรับปรุงที่สำคัญให้กับประเภทอักขระและสตริงเพื่อรองรับ 32 บิต อักขระ Unicode... ในอดีต อักขระ Unicode ทั้งหมดสามารถจัดเก็บได้เป็นสิบหกบิต ซึ่งเท่ากับขนาดของถ่าน (และขนาดของค่าที่มีอยู่ในวัตถุ Character) เนื่องจากค่าเหล่านี้อยู่ในช่วง 0 ถึง FFFF แต่ในบางครั้ง ชุดอักขระ Unicode ได้รับการขยายและตอนนี้ต้องใช้มากกว่า 16 บิตในการจัดเก็บอักขระ ชุดอักขระ Unicode เวอร์ชันใหม่มีอักขระตั้งแต่ 0 ถึง 10FFFF
จุดรหัสหรือจุดรหัส หน่วยรหัสหรือหน่วยรหัส และอักขระเสริม สำหรับ Java จุดโค้ดคือรหัสอักขระในช่วง 0 ถึง 10FFFF ในภาษา Java คำว่า "code unit" ใช้เพื่ออ้างถึงอักขระ 16 บิต อักขระที่มีค่ามากกว่า FFFF เรียกว่าเสริม
การขยายตัวของชุดอักขระ Unicode สร้างปัญหาพื้นฐานสำหรับ ภาษาจาวา... เนื่องจากอักขระเสริมมีค่ามากกว่าประเภทอักขระที่สามารถรองรับได้ จึงจำเป็นต้องใช้วิธีการบางอย่างในการจัดเก็บและประมวลผลอักขระพิเศษ วี เวอร์ชัน Java 2 5.0 แก้ไขปัญหานี้ในสองวิธี อย่างแรก ภาษา Java ใช้ค่าอักขระสองค่าเพื่อแสดงอักขระเพิ่มเติม ตัวแรกเรียกว่าตัวสูง ตัวที่สองเรียกว่าตัวเตี้ย มีการพัฒนาวิธีการใหม่ เช่น codePointAt () เพื่อแปลงจุดโค้ดเป็นอักขระเสริมและในทางกลับกัน
ประการที่สอง Java โอเวอร์โหลดเมธอดที่มีอยู่แล้วบางส่วนในคลาส Character และ String ตัวแปรที่มากเกินไปของวิธีการใช้ข้อมูลประเภท int แทนถ่าน เนื่องจากขนาดของตัวแปรหรือค่าคงที่ของชนิด int มีขนาดใหญ่พอที่จะรองรับอักขระใดๆ ก็ตามเป็นค่าเดียว จึงสามารถใช้ประเภทนี้เพื่อเก็บอักขระใดก็ได้ ตัวอย่างเช่น ตอนนี้เมธอด isDigit () มีสองตัวเลือกดังที่แสดงด้านล่าง:
ตัวเลือกแรกคือตัวเลือกดั้งเดิม ตัวเลือกที่สองคือเวอร์ชันที่รองรับจุดโค้ด 32 บิต เมธอดทั้งหมดคือ... เช่น isLetter () และ isSpaceChar () มีเวอร์ชันจุดโค้ด เช่นเดียวกับเมธอด to... เช่น toUpperCase () และ toLowerCase ()
นอกเหนือจากเมธอดที่โอเวอร์โหลดสำหรับการจัดการจุดโค้ดแล้ว ภาษา Java ยังมีเมธอดใหม่ในคลาส Character ที่ให้การสนับสนุนเพิ่มเติมสำหรับจุดโค้ด บางส่วนของพวกเขาแสดงอยู่ในตาราง:
| วิธี | คำอธิบาย |
| คงที่ int charCount (int cp) | ส่งกลับ 1 ถ้า cp สามารถแสดงด้วยตัวอักษรตัวเดียว ส่งกลับ 2 ถ้าต้องการค่าถ่านสองค่า |
| สแตติก int codePointAt (อักขระ CharSequence, int loc) | |
| สแตติก int codePointAt (อักขระอักขระ int loc) | ส่งกลับจุดโค้ดสำหรับตำแหน่งอักขระที่ระบุในพารามิเตอร์ loc |
| สแตติก int codePointBefore (อักขระ CharSequence, int loc) | |
| สแตติก int codePointBefore (อักขระอักขระ int loc) | ส่งกลับจุดโค้ดสำหรับตำแหน่งอักขระที่อยู่ก่อนหน้าที่กำหนดในพารามิเตอร์ loc |
| isSupplementaryCodePoint บูลีนแบบคงที่ (int cp) | คืนค่า จริง หาก cp มีอักขระพิเศษ |
| บูลีนแบบคงที่ isHighSurrogate (อักขระ ch) | คืนค่า จริง หาก ch มีตัวแทนอักขระตัวบนที่ถูกต้อง |
| บูลีนแบบคงที่ isLowSurrogate (ถ่าน ch) | คืนค่า จริง หาก ch มีตัวแทนที่ต่ำกว่าที่ถูกต้อง |
| isSurrogatePair บูลีนแบบคงที่ (char highCh, char lowCh) | ส่งกลับจริงถ้า highCh และ lowCh สร้างคู่ตัวแทนที่ถูกต้อง |
| isValidCodePoint บูลีนแบบคงที่ (int cp) | คืนค่า จริง หาก cp มีจุดรหัสที่ถูกต้อง |
| ถ่านคงที่ toChars (int cp) | แปลงจุดรหัสที่มีอยู่ใน cp ให้เทียบเท่ากับถ่าน ซึ่งอาจต้องใช้สองค่าถ่าน ส่งกลับอาร์เรย์ที่มีผลลัพธ์ ... ผนวก !!! |
| int toChars แบบคงที่ (int cp, char เป้าหมาย, int loc) | แปลงจุดโค้ดที่มีอยู่ใน cp ให้เทียบเท่ากับอักขระ เก็บผลลัพธ์ไว้ในเป้าหมาย โดยเริ่มต้นที่ตำแหน่งที่ระบุใน loc คืนค่า 1 หาก cp สามารถแสดงด้วยอักขระตัวเดียวได้ และ 2 ตัวมิฉะนั้น |
| toCodePoint แบบคงที่ (ถ่าน ighCh, ถ่าน lowCh) | แปลง highCh และ lowCh เป็นจุดโค้ดที่เทียบเท่ากัน |
คลาส String มีหลายวิธีในการจัดการจุดโค้ด คอนสตรัคเตอร์ต่อไปนี้ยังถูกเพิ่มในคลาส String เพื่อรองรับชุดอักขระ Unicode แบบขยาย:
สตริง (int codePoints, int startIndex, int numChars)
ในไวยากรณ์ข้างต้น codePoints คืออาร์เรย์ที่มีจุดโค้ด สตริงผลลัพธ์ของความยาว numChars ถูกสร้างขึ้น โดยเริ่มจากตำแหน่ง startIndex
หลายวิธีของคลาสสตริงที่สนับสนุนจุดโค้ด 32 บิตสำหรับอักขระ Unicode
เอาต์พุตคอนโซลใน Windows คำสั่ง Chcp
ข้างมาก โปรแกรมง่ายๆเขียนใน Java ส่งออกข้อมูลใด ๆ ไปยังคอนโซล เอาต์พุตคอนโซลให้ความสามารถในการเลือกการเข้ารหัสที่จะส่งออกข้อมูลโปรแกรมของคุณ คุณสามารถเปิดหน้าต่างคอนโซลได้โดยคลิกเริ่ม -> เรียกใช้ จากนั้นป้อนและเรียกใช้ คำสั่ง cmd... โดยค่าเริ่มต้น เอาต์พุตไปยังคอนโซลใน Windows อยู่ในการเข้ารหัส Cp866 หากต้องการทราบการเข้ารหัสอักขระที่แสดงในคอนโซล คุณควรพิมพ์คำสั่ง chcp เมื่อใช้คำสั่งเดียวกัน คุณสามารถตั้งค่าการเข้ารหัสที่จะแสดงอักขระได้ ตัวอย่างเช่น chcp 1251 อันที่จริง คำสั่งนี้สร้างขึ้นเพื่อสะท้อนหรือเปลี่ยนหมายเลขหน้ารหัสปัจจุบันของคอนโซลเท่านั้น
Codepages อื่นที่ไม่ใช่ Cp866 จะแสดงอย่างถูกต้องในโหมดเต็มหน้าจอหรือในหน้าต่างเท่านั้น บรรทัดคำสั่งโดยใช้แบบอักษร TrueType ตัวอย่างเช่น:
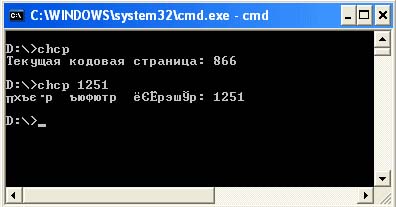
หากต้องการดูผลลัพธ์ที่ตามมา คุณต้องเปลี่ยนแบบอักษรปัจจุบันเป็นแบบอักษร True Type เลื่อนเคอร์เซอร์ไปที่ชื่อของหน้าต่างคอนโซล คลิก คลิกขวาเมาส์และเลือกตัวเลือก "คุณสมบัติ" ในหน้าต่างที่ปรากฏขึ้น ให้ไปที่แท็บ Font แล้วเลือกฟอนต์ตรงข้าม ซึ่งจะมีตัวอักษร T สองตัว ระบบจะให้คุณบันทึก การตั้งค่านี้สำหรับหน้าต่างปัจจุบันหรือสำหรับหน้าต่างทั้งหมด
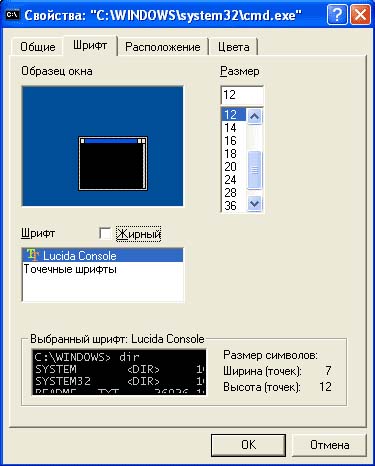
ด้วยเหตุนี้ หน้าต่างคอนโซลของคุณจะมีลักษณะดังนี้:
ดังนั้น ด้วยการจัดการคำสั่งนี้ คุณจะเห็นผลลัพธ์ของผลลัพธ์ของโปรแกรมของคุณ ขึ้นอยู่กับการเข้ารหัส
คุณสมบัติของระบบ file.encoding, console.encoding และเอาต์พุตคอนโซล
ก่อนที่จะพูดถึงหัวข้อการเข้ารหัสในซอร์สโค้ดของโปรแกรม คุณควรเข้าใจให้ชัดเจนว่ามีไว้เพื่ออะไร และคุณสมบัติของระบบ file.encoding และ console.encoding ทำงานอย่างไร นอกจากคุณสมบัติของระบบเหล่านี้แล้ว ยังมีคุณสมบัติอื่นๆ อีกมากมาย คุณสามารถแสดงคุณสมบัติของระบบปัจจุบันทั้งหมดได้โดยใช้โปรแกรมต่อไปนี้:
นำเข้า java.io *; นำเข้า java.util *; คลาสสาธารณะ getPropertiesDemo (โมฆะคงที่สาธารณะหลัก (String args) (String s; for (การแจงนับ e = System.getProperties () propertyNames (); e.hasMoreElements ();) (s = e.nextElement () toString () ; System.out.println (s + "=" + System.getProperty (s));)))
ตัวอย่างผลลัพธ์ของโปรแกรม:
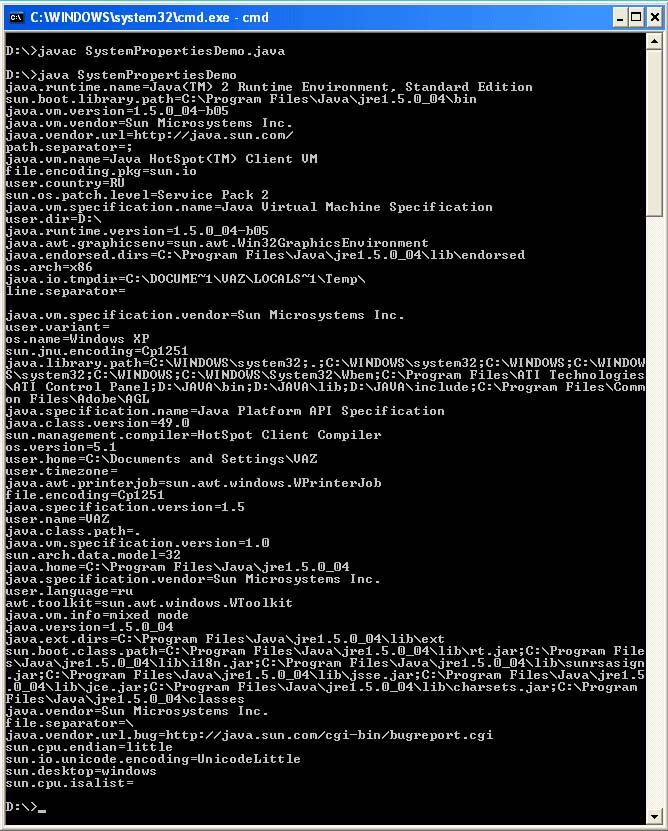
ในระบบปฏิบัติการ Windows โดยค่าเริ่มต้น file.encoding = Сp1251 อย่างไรก็ตาม มีคุณสมบัติอื่นคือ console.encoding ซึ่งระบุว่าการเข้ารหัสใดที่จะส่งออกไปยังคอนโซล file.encoding บอกเครื่อง Java ที่เข้ารหัสเพื่ออ่านซอร์สโค้ดของโปรแกรม หากผู้ใช้ไม่ได้ระบุการเข้ารหัสในระหว่างการคอมไพล์ อันที่จริง คุณสมบัติของระบบนี้ยังใช้กับเอาต์พุตโดยใช้ System.out.println ()
โดยค่าเริ่มต้น คุณสมบัตินี้ไม่ได้รับการตั้งค่า คุณสมบัติของระบบเหล่านี้ยังสามารถตั้งค่าได้ในโปรแกรมของคุณ อย่างไรก็ตาม มันจะไม่เกี่ยวข้องอีกต่อไป เนื่องจากเครื่องเสมือนใช้ค่าที่อ่านก่อนการคอมไพล์และรันโปรแกรมของคุณ นอกจากนี้ ทันทีที่โปรแกรมของคุณทำงาน คุณสมบัติของระบบจะถูกกู้คืน คุณสามารถตรวจสอบได้โดยเรียกใช้โปรแกรมต่อไปนี้สองครั้ง
/ ** * @ผู้เขียน & lta href = "mailto: [ป้องกันอีเมล]"& gt Victor Zagrebin & lt / a & gt * / คลาสสาธารณะ SetPropertyDemo (โมฆะคงที่สาธารณะหลัก (สตริง args) (System.out.println (" file.encoding before = "+ System.getProperty (" file.encoding ") ); ระบบ. out.println ("console.encoding ก่อน =" + System.getProperty ("console.encoding")); System.setProperty ("file.encoding", "Cp866"); System.setProperty ("console. การเข้ารหัส", " Cp866 "); System.out.println (" file.encoding หลัง = "+ System.getProperty (" file.encoding ")); System.out.println (" console.encoding หลัง = "+ System. getProperty (" คอนโซล .encoding "));)) 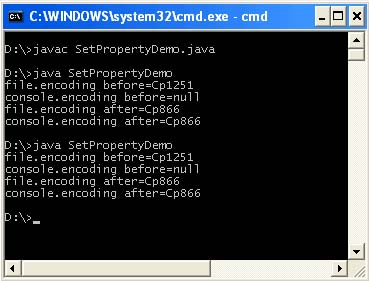
การตั้งค่าคุณสมบัติเหล่านี้ในโปรแกรมมีความจำเป็นเมื่อใช้ในโค้ดที่ตามมาก่อนที่โปรแกรมจะยุติ
ให้เราทำซ้ำตัวอย่างทั่วไปจำนวนหนึ่งเกี่ยวกับปัญหาที่โปรแกรมเมอร์พบระหว่างการส่งออก สมมติว่าเรามีโปรแกรมดังต่อไปนี้:
คลาสสาธารณะ CyryllicDemo (public static void main (String args) (String s1 = ""; String s2 = ""; System.out.println (s1); System.out.println (s1);)) นอกเหนือจากโปรแกรมนี้ เราจะดำเนินการปัจจัยเพิ่มเติม:
- คำสั่งรวบรวม;
- คำสั่งเปิดตัว;
- โปรแกรมเข้ารหัสซอร์สโค้ด (ติดตั้งในโปรแกรมแก้ไขข้อความส่วนใหญ่);
- การเข้ารหัสเอาต์พุตคอนโซล (Cp866 ถูกใช้โดยค่าเริ่มต้นหรือตั้งค่าโดยใช้คำสั่ง chcp)
- เอาต์พุตที่มองเห็นได้ในหน้าต่างคอนโซล
javac CyryllicDemo.java
จาวา CyryllicDemo
การเข้ารหัสไฟล์: Cp1251
การเข้ารหัสคอนโซล: Cp866
เอาท์พุต :
└┴┬├─┼╞╟╚╔╩╦╠═╬╧╨╤╥╙╘╒╓╫╪┘▄█┌▌▐ ▀
rstufhtschshshch'yueyuyoЄєЇїЎў °∙№√ ·¤■
javac CyryllicDemo.java
การเข้ารหัสไฟล์: Cp866
การเข้ารหัสคอนโซล: Cp866
เอาท์พุต :
CyryllicDemo.java:5: คำเตือน: อักขระที่ไม่สามารถแมปสำหรับการเข้ารหัส Cp1251
สตริง s1 = "ABVGDEZHZYKLMNOPRSTUFHTSCH? SHY'EUYA";
javac CyryllicDemo.java -encoding Cp866
จาวา -
การเข้ารหัสไฟล์:ซีพี 866
การเข้ารหัสคอนโซล: Cp866
เอาท์พุต :
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshchyyueyuya
javac CyryllicDemo.java -encoding Cp1251
จาวา -Dfile.encoding = Cp866 CyryllicDemo
การเข้ารหัสไฟล์: Cp1251
การเข้ารหัสคอนโซล: Cp866
เอาท์พุต :
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshchyyueyuya
ควรให้ความสนใจเป็นพิเศษกับปัญหา "จดหมาย Ш หายไปไหน" จากการเปิดตัวชุดที่สอง คุณควรใส่ใจปัญหานี้มากขึ้น หากคุณไม่ทราบล่วงหน้าว่าข้อความใดจะถูกเก็บไว้ในสตริงเอาต์พุต และจะคอมไพล์โดยไม่ระบุการเข้ารหัสอย่างไร้เดียงสา หากคุณไม่มีตัวอักษร Ш อยู่ในบรรทัด การรวบรวมก็จะสำเร็จและการเปิดตัวก็จะสำเร็จเช่นกัน และในเรื่องนี้ คุณจะลืมไปเลยว่าคุณไม่มีเรื่องเล็ก (ตัวอักษร W) ซึ่งอาจเกิดขึ้นในบรรทัดผลลัพธ์และจะนำไปสู่ข้อผิดพลาดเพิ่มเติมอย่างหลีกเลี่ยงไม่ได้
ในซีรีส์ที่สามและสี่ เมื่อทำการคอมไพล์และรัน คีย์ต่อไปนี้จะถูกใช้: -encoding Cp866 และ -Dfile.encoding = Cp866 สวิตช์ -encoding ระบุการเข้ารหัสที่จะอ่านไฟล์จาก รหัสแหล่งที่มาโปรแกรม สวิตช์ -Dfile.encoding = Cp866 ระบุว่าการเข้ารหัสใดควรส่งออก
คำนำหน้า Unicode \ u และอักขระรัสเซียในซอร์สโค้ด
Java มีคำนำหน้าพิเศษ \ u สำหรับการเขียนอักขระ Unicode ตามด้วยเลขฐานสิบหกสี่หลักที่กำหนดอักขระเอง ตัวอย่างเช่น \ u2122 คืออักขระ ยี่ห้อ(™). สัญกรณ์รูปแบบนี้แสดงอักขระของตัวอักษรใดๆ โดยใช้ตัวเลขและคำนำหน้า - อักขระที่อยู่ในช่วงเสถียรของรหัสตั้งแต่ 0 ถึง 127 ซึ่งจะไม่ได้รับผลกระทบเมื่อมีการแปลงซอร์สโค้ด และตามทฤษฎีแล้ว อักขระ Unicode ใดๆ ก็ตามสามารถใช้ในแอปพลิเคชัน Java หรือแอปเพล็ตได้ แต่จะแสดงผลอย่างถูกต้องบนหน้าจอแสดงผลหรือไม่และจะแสดงหรือไม่นั้นขึ้นอยู่กับปัจจัยหลายประการ สำหรับแอปเพล็ต ประเภทของเบราว์เซอร์มีความสำคัญ และสำหรับโปรแกรมและแอปเพล็ต ประเภทของระบบปฏิบัติการและการเข้ารหัสที่เขียนซอร์สโค้ดของโปรแกรมนั้นมีความสำคัญ
ตัวอย่างเช่น บนคอมพิวเตอร์ที่ใช้เวอร์ชันอเมริกัน ระบบ Windowsไม่สามารถแสดงอักขระภาษาญี่ปุ่นโดยใช้ภาษา Java ได้ เนื่องจากปัญหาเรื่องความเป็นสากล
ตัวอย่างที่สอง เราสามารถอ้างถึงข้อผิดพลาดทั่วไปของโปรแกรมเมอร์ได้ หลายคนคิดว่าการระบุอักขระภาษารัสเซียในรูปแบบ Unicode โดยใช้คำนำหน้า \ u ในซอร์สโค้ดของโปรแกรมสามารถแก้ปัญหาการแสดงอักขระรัสเซียได้ในทุกกรณี ท้ายที่สุด เครื่องเสมือน Java จะแปลซอร์สโค้ดของโปรแกรมเป็น Unicode อย่างไรก็ตาม ก่อนที่จะแปลเป็น Unicode เครื่องเสมือนต้องรู้ว่าการเข้ารหัสซอร์สโค้ดของโปรแกรมของคุณเขียนด้วยอะไร เพราะคุณสามารถเขียนโปรแกรมได้ทั้งในการเข้ารหัส Cp866 (DOS) และ Cp1251 (Windows) ซึ่งเป็นเรื่องปกติสำหรับสถานการณ์นี้ หากคุณไม่ได้ระบุการเข้ารหัสใดๆ เครื่องเสมือน Java จะอ่านไฟล์ของคุณด้วยซอร์สโค้ดของโปรแกรมในการเข้ารหัสที่ระบุในคุณสมบัติระบบ file.encoding
อย่างไรก็ตาม กลับไปที่พารามิเตอร์เริ่มต้น เราจะถือว่า file.encoding = Сp1251 และเอาต์พุตไปยังคอนโซลเสร็จสิ้นใน Cp866 ในกรณีนี้คือสถานการณ์ต่อไปนี้: สมมติว่าคุณมีไฟล์ที่เข้ารหัสในСp1251:
ไฟล์ MsgDemo1.java
MsgDemo1 คลาสสาธารณะ (โมฆะคงที่สาธารณะหลัก (สตริง args) (สตริง s = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A \ u0430"; System.out.println (s );))
และคุณคาดหวังให้พิมพ์คำว่า "การเข้ารหัส" ไปที่คอนโซล แต่คุณจะได้รับ:
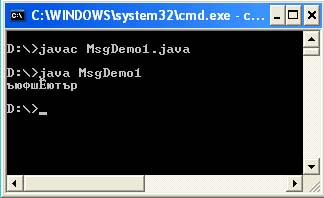
ความจริงก็คือรหัสที่มีคำนำหน้า \ u ที่ระบุไว้ในโปรแกรมเข้ารหัสอักขระ Cyrillic ที่จำเป็นจริง ๆ ในตารางรหัส Unicode อย่างไรก็ตามได้รับการออกแบบมาเพื่อให้ซอร์สโค้ดของโปรแกรมของคุณอ่านได้ใน Cp866 (DOS) การเข้ารหัส โดยค่าเริ่มต้น การเข้ารหัส Cp1251 จะถูกระบุในคุณสมบัติของระบบ (file.encoding = Cp1251) โดยธรรมชาติ สิ่งแรกและสิ่งที่ผิดที่นึกถึงคือเปลี่ยนการเข้ารหัสของไฟล์ด้วยซอร์สโค้ดของโปรแกรมในโปรแกรมแก้ไขข้อความ แต่นั่นจะไม่ทำให้คุณไปไหน Java VM จะยังคงอ่านไฟล์ของคุณในการเข้ารหัส Cp1251 และรหัส \ u ใช้สำหรับ Cp866
มีสามวิธีจากสถานการณ์นี้ ตัวเลือกแรกคือการใช้สวิตช์ -encoding ณ เวลาคอมไพล์และ –Dfile.encoding ที่ขั้นตอนการเปิดโปรแกรม ในกรณีนี้ คุณบังคับให้เครื่องเสมือน Java อ่านไฟล์ต้นทางในการเข้ารหัสและเอาต์พุตที่ระบุในการเข้ารหัสที่ระบุ
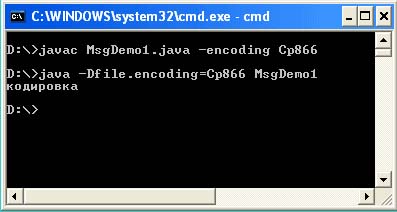
ดังที่คุณเห็นจากเอาต์พุตคอนโซล ต้องตั้งค่าพารามิเตอร์เพิ่มเติม –encoding Cp866 ระหว่างการคอมไพล์ และต้องตั้งค่าพารามิเตอร์ –Dfile.encoding = Cp866 เมื่อเริ่มทำงาน
ตัวเลือกที่สองคือการถอดรหัสอักขระในโปรแกรมเอง ได้รับการออกแบบมาเพื่อกู้คืนรหัสตัวอักษรที่ถูกต้องหากได้รับการตีความผิด สาระสำคัญของวิธีการนั้นง่าย: จากอักขระที่ไม่ถูกต้องที่ได้รับโดยใช้หน้ารหัสที่เหมาะสมจะกู้คืนอาร์เรย์ไบต์ดั้งเดิม จากนั้น จากอาร์เรย์ของไบต์นี้ โดยใช้หน้าที่ถูกต้องแล้ว จะได้รหัสอักขระปกติ
ในการแปลงสตรีมของไบต์เป็นสตริง String และในทางกลับกัน คลาส String มีความสามารถดังต่อไปนี้: คอนสตรัคเตอร์สตริง (ไบต์ไบต์, การเข้ารหัสสตริง) ซึ่งรับสตรีมไบต์เป็นอินพุตพร้อมตัวบ่งชี้การเข้ารหัส หากคุณละเว้นการเข้ารหัส จะยอมรับการเข้ารหัสเริ่มต้นจากคุณสมบัติระบบ file.encoding เมธอด getBytes (String enc) ส่งคืนสตรีมของไบต์ที่เขียนด้วยการเข้ารหัสที่ระบุ การเข้ารหัสสามารถละเว้นได้ และการเข้ารหัสเริ่มต้นจากคุณสมบัติระบบ file.encoding จะได้รับการยอมรับ
ตัวอย่าง:
ไฟล์ MsgDemo2.java
นำเข้า java.io.UnsupportedEncodingException; MsgDemo2 คลาสสาธารณะ (โมฆะคงที่สาธารณะหลัก (สตริง args) พ่น UnsupportedEncodingException (String str = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A \ u043E" + ไบต์ btes ("Cp866"); สตริง str2 = สตริงใหม่ (b, "Cp1251"); System.out.println (str2);))
ผลลัพธ์ของโปรแกรม:
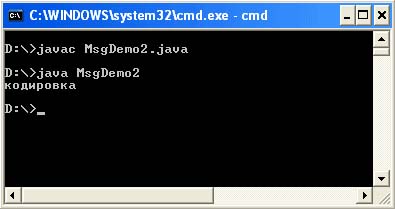
วิธีนี้มีความยืดหยุ่นน้อยกว่าหากคุณได้รับคำแนะนำจากข้อเท็จจริงที่ว่าการเข้ารหัสในคุณสมบัติของระบบ file.encoding จะไม่เปลี่ยนแปลง อย่างไรก็ตาม วิธีนี้จะยืดหยุ่นได้มากที่สุด หากคุณสำรวจคุณสมบัติระบบ file.encoding และแทนที่ค่าการเข้ารหัสที่เป็นผลลัพธ์เมื่อสร้างสตริงในโปรแกรมของคุณ โดยใช้ วิธีนี้คุณควรระวังว่าไม่ใช่ทุกหน้าที่ทำการแปลงถ่านไบต์ที่ชัดเจน
วิธีที่สามคือการเลือกรหัส Unicode ที่ถูกต้องเพื่อแสดงคำว่า "การเข้ารหัส" โดยสันนิษฐานว่าไฟล์จะถูกอ่านในการเข้ารหัสเริ่มต้น - Cp1251 เพื่อวัตถุประสงค์เหล่านี้มี ยูทิลิตี้พิเศษ native2ascii
ยูทิลิตีนี้เป็นส่วนหนึ่งของ Sun JDK และออกแบบมาเพื่อแปลงซอร์สโค้ดเป็นรูปแบบ ASCII เมื่อเปิดใช้งานโดยไม่มีพารามิเตอร์ จะใช้งานได้กับอินพุตมาตรฐาน (stdin) และไม่แสดงคำใบ้คีย์เหมือนกับยูทิลิตี้อื่นๆ สิ่งนี้นำไปสู่ความจริงที่ว่าหลายคนไม่รู้ด้วยซ้ำว่าจำเป็นต้องระบุพารามิเตอร์ (ยกเว้นผู้ที่ดูเอกสารประกอบ) ในขณะเดียวกันยูทิลิตี้นี้สำหรับ งานที่ถูกต้องคุณต้องระบุการเข้ารหัสที่ใช้โดยใช้สวิตช์ -encoding เป็นอย่างน้อย หากยังไม่เสร็จสิ้น ระบบจะใช้การเข้ารหัสเริ่มต้น (file.encoding) ซึ่งอาจแตกต่างไปจากที่คาดไว้เล็กน้อย เป็นผลให้เมื่อได้รับรหัสตัวอักษรที่ไม่ถูกต้อง (เนื่องจากการเข้ารหัสไม่ถูกต้อง) คุณสามารถใช้เวลามากในการค้นหาข้อผิดพลาดในรหัสที่ถูกต้องอย่างแน่นอน
ภาพหน้าจอต่อไปนี้แสดงความแตกต่างในลำดับรหัส Unicode สำหรับคำเดียวกันเมื่อไฟล์ต้นฉบับจะถูกอ่านในการเข้ารหัส Cp866 และการเข้ารหัส Cp1251
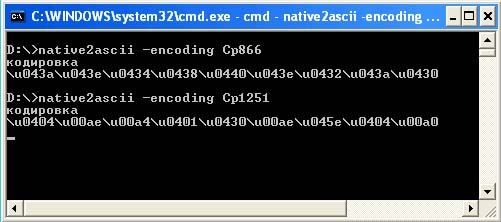
ดังนั้น หากคุณไม่บังคับเข้ารหัสสำหรับ เครื่องเสมือน Java ณ เวลาคอมไพล์และตอนเริ่มต้น และการเข้ารหัสเริ่มต้น (file.encoding) คือ Cp1251 ดังนั้นซอร์สโค้ดของโปรแกรมควรมีลักษณะดังนี้:
ไฟล์ MsgDemo3.java
MsgDemo3 คลาสสาธารณะ (โมฆะคงที่สาธารณะหลัก (สตริง args) (สตริง s = "\ u0404 \ u00AE" + "\ u00A4 \ u0401 \ u0430 \ u00AE \ u045E" + "\ u0404 \ u00A0"; System.out.println (s );)) 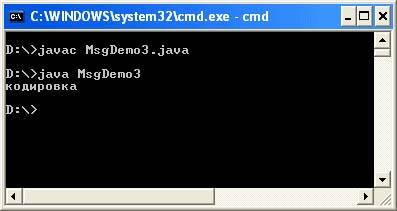
โดยใช้วิธีที่สาม เราสามารถสรุปได้: หากการเข้ารหัสไฟล์ด้วยซอร์สโค้ดในตัวแก้ไขตรงกับการเข้ารหัสในระบบ ข้อความ "การเข้ารหัส" จะปรากฏขึ้นในรูปแบบปกติ
การอ่านและเขียนไฟล์ อักขระรัสเซียแสดงด้วยคำนำหน้า Unicode \ u
หากต้องการอ่านข้อมูลที่เขียนทั้งในรูปแบบ MBCS (โดยใช้การเข้ารหัส UTF-8) และ Unicode คุณสามารถใช้คลาส InputStreamReader จากแพ็คเกจ java.io แทนการเข้ารหัสต่างๆ ในตัวสร้าง OutputStreamWriter ใช้สำหรับเขียน คำอธิบายของแพ็คเกจ java.lang ระบุว่าการใช้งาน JVM แต่ละครั้งจะรองรับการเข้ารหัสต่อไปนี้:
ไฟล์ WriteDemo.java
นำเข้า java.io.Writer; นำเข้า java.io.OutputStreamWriter; นำเข้า java.io.FileOutputStream; นำเข้า java.io.IOException; / ** * ส่งออกสตริง Unicode ไปยังไฟล์ในการเข้ารหัสที่ระบุ * @ผู้เขียน & lta href = "mailto: [ป้องกันอีเมล]"& gt Victor Zagrebin & lt / a & gt * / คลาสสาธารณะ WriteDemo (โมฆะคงที่สาธารณะหลัก (สตริง args) พ่น IOException (String str =" \ u043A \ u043E "+" \ u0434 \ u0438 \ u0440 \ u043E \ u0432 " +" \ u043A \ u0430 "; Writer out1 = OutputStreamWriter ใหม่ ( FileOutputStream ใหม่ (" out1.txt ")," Cp1251 "); Writer out2 = ใหม่ OutputStreamWriter (FileOutputStream ใหม่ (" out2.txt ")," Cp866 "); Writer out3 = OutputStreamWriter ใหม่ (FileOutputStream ใหม่ ("out3.txt"), "UTF-8"); Writer out4 = OutputStreamWriter ใหม่ ( FileOutputStream ใหม่ ("out4.txt"), "Unicode"); out1.write (str) ; out1.close (); out2.write (str); out2.close (); out3.write (str); out3.close (); out4.write (str); out4.close ();)) การรวบรวม: javac WriteDemo.java เรียกใช้: java WriteDemo
อันเป็นผลมาจากการทำงานของโปรแกรม ควรสร้างไฟล์สี่ไฟล์ (out1.txt out2.txt out3.txt out4.txt) ในไดเร็กทอรีการเรียกใช้โปรแกรม ซึ่งแต่ละไฟล์จะมีคำว่า "การเข้ารหัส" ในการเข้ารหัสที่แตกต่างกัน ซึ่งสามารถ ตรวจสอบใน โปรแกรมแก้ไขข้อความหรือโดยการดูการถ่ายโอนข้อมูลไฟล์
โปรแกรมต่อไปนี้จะอ่านและแสดงเนื้อหาของแต่ละไฟล์ที่สร้างขึ้น
นำเข้าไฟล์ ReadDemo.java java.io.Reader; นำเข้า java.io.InputStreamReader; นำเข้า java.io.InputStream; นำเข้า java.io.FileInputStream; นำเข้า java.io.IOException; / ** * อ่านอักขระ Unicode จากไฟล์ในการเข้ารหัสที่ระบุ * @ผู้เขียน & lta href = "mailto: [ป้องกันอีเมล]"& gt Victor Zagrebin & lt / a & gt * / คลาสสาธารณะ ReadDemo (โมฆะคงที่สาธารณะหลัก (สตริง args) พ่น IOException (String out_enc = System.getProperty (" console.encoding "," Cp866 "); System.out เขียน (readStringFromFile ( "out1.txt", "Cp1251", out_enc)); System.out.write ("\ n"); System.out.write (readStringFromFile ("out2.txt", "Cp866", out_enc) ); System. out.write ("\ n"); System.out.write (readStringFromFile ("out3.txt", "UTF-8", out_enc)); System.out.write ("\ n"); System.out. เขียน (readStringFromFile ("out4.txt", "Unicode", out_enc));) ไบต์คงที่สาธารณะ readStringFromFile (ชื่อไฟล์สตริง, สตริง file_enc, สตริง out_enc) พ่น IOException (ขนาด int; InputStream f = ใหม่ FileInputStream (ชื่อไฟล์) ); size = f.available (); Reader in = ใหม่ InputStreamReader (f, file_enc); char ch = ถ่านใหม่; in.read (ch, 0, size); in.close (); return (สตริงใหม่ (ch) )). getBytes (out_enc);)) การรวบรวม: javac ReadDemo.java เรียกใช้: java ReadDemo เอาต์พุตของโปรแกรม: 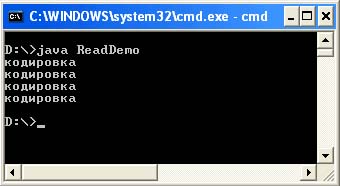
สิ่งที่ควรทราบเป็นพิเศษคือการใช้โค้ดบรรทัดต่อไปนี้ในโปรแกรมนี้:
String out_enc = System.getProperty ("console.encoding", "Cp866");
เมื่อใช้เมธอด getProperty จะมีการพยายามอ่านค่าของคุณสมบัติระบบ console.encoding ซึ่งตั้งค่าการเข้ารหัสซึ่งข้อมูลจะถูกส่งออกไปยังคอนโซล หากไม่ได้ตั้งค่าคุณสมบัตินี้ (มักจะไม่ได้ตั้งค่าไว้) ตัวแปร out_enc จะถูกกำหนด "Cp866" นอกจากนี้ ตัวแปร out_enc ยังถูกใช้ในกรณีที่จำเป็นต้องแปลงสตริงที่อ่านจากไฟล์เป็นการเข้ารหัสที่เหมาะสมสำหรับเอาต์พุตไปยังคอนโซล
นอกจากนี้ คำถามเชิงตรรกะก็เกิดขึ้น: "เหตุใดจึงใช้ System.out.write ไม่ใช่ System.out.println" ตามที่อธิบายไว้ข้างต้น file.encoding คุณสมบัติของระบบไม่ได้ใช้เพื่ออ่านไฟล์ต้นฉบับเท่านั้น แต่ยังใช้เพื่อส่งออกโดยใช้ System.out.println ซึ่งในกรณีนี้จะนำไปสู่ผลลัพธ์ที่ไม่ถูกต้อง
การแสดงการเข้ารหัสที่ไม่ถูกต้องในโปรแกรมเชิงเว็บ
โปรแกรมเมอร์ควรรู้ก่อน: มันไม่สมเหตุสมผลเลยที่จะมีสตริงโดยไม่รู้ว่ากำลังใช้การเข้ารหัสอะไรอยู่... ไม่มีข้อความธรรมดาใน ASCII หากคุณมีสตริง ในหน่วยความจำ ในไฟล์ หรือในข้อความ อีเมลคุณต้องรู้ว่ามันเข้ารหัสอะไร มิฉะนั้น คุณจะไม่สามารถตีความได้อย่างถูกต้องหรือแสดงให้ผู้ใช้เห็น
ปัญหาดั้งเดิมเกือบทั้งหมด เช่น "เว็บไซต์ของฉันดูเหมือนพูดพล่อยๆ" หรือ "อีเมลของฉันไม่สามารถอ่านได้หากฉันใช้อักขระเน้นเสียง" เป็นความรับผิดชอบของโปรแกรมเมอร์ที่ไม่เข้าใจข้อเท็จจริงง่ายๆ ว่าถ้าคุณไม่รู้ว่าการเข้ารหัส UTF-8 คืออะไร string อยู่ในหรือ ASCII หรือ ISO 8859-1 (Latin-1) หรือ Windows 1252 (Western European) คุณจะไม่สามารถแสดงผลได้อย่างถูกต้อง มีการเข้ารหัสอักขระมากกว่าร้อยตัวที่อยู่เหนือรหัสจุด 127 และไม่มีข้อมูลที่จะพิจารณาว่าการเข้ารหัสใดที่จำเป็น เราจะจัดเก็บข้อมูลเกี่ยวกับสตริงการเข้ารหัสที่ใช้อย่างไร มีอยู่ วิธีการมาตรฐานเพื่อระบุข้อมูลนี้ สำหรับข้อความอีเมล คุณต้องใส่บรรทัดในส่วนหัว HTTP
เนื้อหาประเภท: ข้อความ / ธรรมดา; ชุดอักขระ = "UTF-8"
สำหรับหน้าเว็บ แนวคิดเดิมคือเว็บเซิร์ฟเวอร์จะส่งส่วนหัว HTTP เองก่อนหน้านี้ หน้า HTML... แต่สิ่งนี้ทำให้เกิดปัญหาบางอย่าง สมมติว่าคุณมีเว็บเซิร์ฟเวอร์ขนาดใหญ่ที่มีไซต์จำนวนมากและหน้าเว็บหลายร้อยหน้าที่สร้างขึ้นโดยผู้คนจำนวนมากในจำนวนมาก ภาษาที่แตกต่างกันและพวกเขาทั้งหมดไม่ได้ใช้การเข้ารหัสเฉพาะ เว็บเซิร์ฟเวอร์เองไม่ทราบจริงๆ ว่าการเข้ารหัสแต่ละไฟล์คืออะไร ดังนั้นจึงไม่สามารถส่งส่วนหัวที่ระบุประเภทเนื้อหาได้ ดังนั้น เพื่อระบุการเข้ารหัสที่ถูกต้องในส่วนหัว http จึงยังคงเก็บข้อมูลการเข้ารหัสไว้ในไฟล์ html โดยการแทรกแท็กพิเศษ จากนั้นเซิร์ฟเวอร์จะอ่านชื่อการเข้ารหัสจากเมตาแท็กและใส่ไว้ในส่วนหัวของ HTTP
คำถามที่เกี่ยวข้องเกิดขึ้น: "จะเริ่มต้นอ่านไฟล์ HTML ได้อย่างไรจนกว่าคุณจะรู้ว่ามันใช้การเข้ารหัสอะไร! โชคดีที่การเข้ารหัสเกือบทั้งหมดใช้ตารางอักขระเดียวกันกับรหัสตั้งแต่ 32 ถึง 127 และโค้ด HTML เองประกอบด้วยอักขระเหล่านี้ และคุณอาจไม่เห็นข้อมูลการเข้ารหัสในไฟล์ html หากประกอบด้วยอักขระดังกล่าวทั้งหมด ดังนั้น ตามหลักการแล้ว แท็ก & ltmeta & gt ที่ระบุการเข้ารหัสควรอยู่ในบรรทัดแรกสุดในส่วน & lthead & gt เพราะทันทีที่เว็บเบราว์เซอร์เห็นเครื่องหมายนี้ จะหยุดแยกวิเคราะห์หน้าและเริ่มต้นใหม่ทั้งหมด อีกครั้งโดยใช้การเข้ารหัสที่คุณระบุ
& lthtml & gt & lthead & gt & ltmeta http-equiv = เนื้อหา "ประเภทเนื้อหา" = "ข้อความ / html; ชุดอักขระ = utf-8" & gt
เว็บเบราว์เซอร์ทำอะไรได้บ้างหากไม่พบ Content-Type ทั้งในส่วนหัว http หรือใน Meta tag Internet Explorerอันที่จริงมันทำสิ่งที่น่าสนใจทีเดียว: มันพยายามจดจำการเข้ารหัสและภาษาตามความถี่ที่ไบต์ต่าง ๆ ปรากฏในข้อความทั่วไปในการเข้ารหัสทั่วไปของภาษาต่างๆ เนื่องจากหน้าโค้ดขนาด 8 ไบต์แบบเก่าต่างวางต่างกัน สัญลักษณ์ประจำชาติระหว่าง 128 ถึง 255 และเนื่องจากภาษามนุษย์ทั้งหมดมีความน่าจะเป็นในการใช้ตัวอักษรที่แตกต่างกัน วิธีนี้จึงมักใช้ได้ผลดี
ค่อนข้างแปลก แต่ดูเหมือนว่าจะทำงานค่อนข้างบ่อยและผู้เขียนหน้าเว็บไร้เดียงสาที่ไม่เคยรู้ว่าพวกเขาต้องการแท็กประเภทเนื้อหาในชื่อหน้าเพื่อให้หน้าแสดงอย่างถูกต้องจนถึงวันนั้นที่สวยงาม เมื่อพวกเขาเขียนอะไรบางอย่างที่ ไม่ตรงกับการกระจายความถี่ทั่วไปของตัวอักษรภาษาแม่ของพวกเขาทุกประการ และ Internet Explorer จะตัดสินใจว่าเป็นภาษาเกาหลีและแสดงตามนั้น
อย่างไรก็ตาม จะเหลืออะไรให้ผู้อ่านเว็บไซต์นี้ ซึ่งเขียนเป็นภาษาบัลแกเรียแต่แสดงเป็นภาษาเกาหลี (และไม่ได้มีความหมายในภาษาเกาหลีเลย) ใช้มุมมอง | เข้ารหัสและลองเข้ารหัสหลายๆ แบบ (มีอย่างน้อยหนึ่งโหลสำหรับภาษายุโรปตะวันออก) จนกว่าภาพจะชัดเจนขึ้น ถ้าหากเขารู้วิธีที่จะทำเพราะคนส่วนใหญ่ไม่รู้เรื่องนี้
เป็นที่น่าสังเกตว่าสำหรับ UTF-8 ซึ่งได้รับการสนับสนุนอย่างสมบูรณ์จากเว็บเบราว์เซอร์มานานหลายปี ยังไม่มีใครพบปัญหาเกี่ยวกับการแสดงหน้าเว็บที่ถูกต้อง
ลิงค์:
- โจเอล สปอลสกี้. นักพัฒนาซอฟต์แวร์ทุกคนจะต้องรู้อย่างน้อยที่สุดอย่างแน่นอนเกี่ยวกับ Unicode และชุดอักขระ (ไม่มีข้อแก้ตัว!) 10/08/2003 http://www.joelonsoftware.com/articles/Unicode.html
- เซอร์เกย์ อัสตาคอฟ
- เซอร์เกย์ เซมิคาตอฟ. ... 08.2000 - 27.07.2005
- Horstman K.S. , Cornell G. ห้องสมุดมืออาชีพ Java 2 เล่มที่ 1 พื้นฐาน - M.: Williams Publishing House, 2003 .-- 848 น.
- แดน ชิสโฮล์มส์. การสอบจำลองโปรแกรมเมอร์ Java วัตถุประสงค์ 2, InputStream และ OutputStream Reader / Writer การเข้ารหัสอักขระ Java: UTF และ Unicode http://www.jchq.net/certkey/1102_12certkey.htm
- แพ็คเกจ java.io ข้อมูลจำเพาะ JavaTM 2 Platform Standard Edition 6.0 API
Unicode: UTF-8, UTF-16, UTF-32.
Unicode คือชุดของอักขระกราฟิกและวิธีการเข้ารหัสสำหรับการประมวลผลข้อมูลข้อความของคอมพิวเตอร์
Unicode ไม่เพียงกำหนดให้กับอักขระแต่ละตัวเท่านั้น รหัสเฉพาะแต่ยังกำหนดลักษณะต่าง ๆ ของสัญลักษณ์นี้ เช่น:
ประเภทอักขระ (ตัวพิมพ์ใหญ่, ตัวพิมพ์เล็ก, ตัวเลข, เครื่องหมายวรรคตอน, ฯลฯ );
คุณลักษณะของอักขระ (การแสดงจากซ้ายไปขวาหรือจากขวาไปซ้าย ช่องว่าง ตัวแบ่งบรรทัด ฯลฯ );
ตัวพิมพ์ใหญ่หรือตัวพิมพ์เล็กที่สอดคล้องกัน (สำหรับตัวพิมพ์เล็กและ ตัวพิมพ์ใหญ่ตามลำดับ);
ค่าตัวเลขที่สอดคล้องกัน (สำหรับอักขระตัวเลข)
มาตรฐาน UTF(ตัวย่อสำหรับรูปแบบการแปลง Unicode) เพื่อแสดงอักขระ:
UTF-16: Windows Vista ใช้ UTF-16 เพื่อแสดงอักขระ Unicode ทั้งหมด ใน UTF-16 อักขระจะถูกแทนด้วยสองไบต์ (16 บิต) การเข้ารหัสนี้ใช้ใน Windows เนื่องจากค่า 16 บิตสามารถแสดงอักขระที่ประกอบเป็นตัวอักษรของภาษาส่วนใหญ่ในโลกได้ ซึ่งช่วยให้โปรแกรมประมวลผลสตริงและคำนวณความยาวได้เร็วยิ่งขึ้น อย่างไรก็ตาม 16 บิตไม่เพียงพอสำหรับการแสดงตัวอักษรในบางภาษา สำหรับกรณีดังกล่าว UTE-16 รองรับการเข้ารหัสแบบ "ตัวแทน" ทำให้สามารถเข้ารหัสอักขระแบบ 32 บิต (4 ไบต์) ได้ อย่างไรก็ตาม มีแอปพลิเคชั่นบางตัวที่ต้องจัดการกับอักขระของภาษาดังกล่าว ดังนั้น UTF-16 จึงเป็นการประนีประนอมที่ดีระหว่างการบันทึกหน่วยความจำและความง่ายในการเขียนโปรแกรม โปรดทราบว่าใน .NET Framework อักขระทั้งหมดจะถูกเข้ารหัสโดยใช้ UTF-16 ดังนั้นให้ใช้ UTF-16 ใน แอพพลิเคชั่น Windowsปรับปรุงประสิทธิภาพและลดการใช้หน่วยความจำเมื่อส่งผ่านสตริงระหว่างโค้ดเนทีฟและโค้ดที่ได้รับการจัดการ
UTF-8: ในการเข้ารหัส UTF-8 อักขระต่างๆ สามารถแสดงด้วย 1,2,3 หรือ 4 ไบต์ อักขระที่มีค่าน้อยกว่า 0x0080 จะถูกบีบอัดเป็น 1 ไบต์ ซึ่งสะดวกมากสำหรับอักขระของสหรัฐฯ อักขระที่ตรงกับค่าในช่วง 0x0080-0x07FF จะถูกแปลงเป็นค่า 2 ไบต์ ซึ่งทำงานได้ดีกับตัวอักษรยุโรปและตะวันออกกลาง อักขระที่มีค่ามากกว่าจะถูกแปลงเป็นค่า 3 ไบต์ ซึ่งมีประโยชน์สำหรับการทำงานกับภาษาเอเชียกลาง สุดท้าย คู่ตัวแทนจะถูกเขียนในรูปแบบ 4 ไบต์ UTF-8 เป็นการเข้ารหัสที่ได้รับความนิยมอย่างมาก อย่างไรก็ตาม จะมีประสิทธิภาพน้อยกว่า UTF-16 หากมีการใช้อักขระที่มีค่า 0x0800 ขึ้นไปบ่อยๆ
UTF-32: ใน UTF-32 อักขระทั้งหมดจะแสดงด้วย 4 ไบต์ การเข้ารหัสนี้สะดวกสำหรับการเขียนอัลกอริธึมอย่างง่ายสำหรับการแจงนับอักขระในภาษาใดๆ ที่ไม่ต้องการการประมวลผลอักขระที่แสดงด้วยจำนวนไบต์ที่ต่างกัน ตัวอย่างเช่น เมื่อใช้ UTF-32 คุณจะลืมคำว่า "ตัวแทนเสมือน" ไปได้เลย เนื่องจากอักขระใดๆ ในการเข้ารหัสนี้จะมี 4 ไบต์แทน เห็นได้ชัดว่า จากมุมมองการใช้หน่วยความจำ ประสิทธิภาพของ UTF-32 นั้นยังห่างไกลจากอุดมคติ ดังนั้นการเข้ารหัสนี้จึงไม่ค่อยใช้ในการถ่ายโอนสตริงผ่านเครือข่ายและบันทึกลงในไฟล์ โดยทั่วไปแล้ว UTF-32 จะใช้เป็นรูปแบบภายในสำหรับการนำเสนอข้อมูลในโปรแกรม
UTF-8
ในอนาคตอันใกล้ รูปแบบ Unicode (และ ISO 10646) พิเศษที่เรียกว่า UTF-8... การเข้ารหัส "ที่ได้รับ" นี้ใช้สตริงไบต์ที่มีความยาวต่างกัน (ตั้งแต่หนึ่งถึงหก) เพื่อเขียนอักขระ ซึ่งจะถูกแปลงเป็นโค้ด Unicode โดยใช้อัลกอริธึมอย่างง่าย โดยมีสตริงที่สั้นกว่าซึ่งสอดคล้องกับอักขระทั่วไป ข้อได้เปรียบหลักของรูปแบบนี้คือเข้ากันได้กับ ASCII ไม่เพียง แต่ในค่าของรหัสเท่านั้น แต่ยังรวมถึงจำนวนบิตต่ออักขระด้วยเนื่องจากหนึ่งไบต์เพียงพอที่จะเข้ารหัสอักขระ 128 ตัวแรกใน UTF-8 (แม้ว่า ตัวอย่างเช่น สำหรับอักษรซีริลลิก สองไบต์)
รูปแบบ UTF-8 ถูกประดิษฐ์ขึ้นเมื่อวันที่ 2 กันยายน 1992 โดย Ken Thompson และ Rob Pike และนำไปใช้ในแผนงานที่ 9 ปัจจุบันมาตรฐาน UTF-8 ได้รับการกำหนดเป็นมาตรฐานใน RFC 3629 และ ISO / IEC 10646 ภาคผนวก D
สำหรับนักออกแบบเว็บไซต์ การเข้ารหัสนี้มีความสำคัญเป็นพิเศษ เนื่องจากเป็นการเข้ารหัสที่ได้รับการประกาศให้เป็น "การเข้ารหัสเอกสารมาตรฐาน" ใน HTML ตั้งแต่เวอร์ชัน 4
ข้อความที่มีเฉพาะอักขระที่มีตัวเลขน้อยกว่า 128 จะถูกแปลงเป็นข้อความ ASCII ธรรมดาเมื่อเขียนด้วย UTF-8 ในทางกลับกัน ในข้อความ UTF-8 ไบต์ใดๆ ที่มีค่าน้อยกว่า 128 แสดงถึงอักขระ ASCII ที่มีโค้ดเดียวกัน อักขระ Unicode ที่เหลือจะแสดงตามลำดับความยาวตั้งแต่ 2 ถึง 6 ไบต์ (จริงๆ แล้วสูงสุด 4 ไบต์เท่านั้น เนื่องจากไม่มีการวางแผนการใช้รหัสที่มากกว่า 221) ซึ่งไบต์แรกจะดูเหมือน 11xxxxxx เสมอ และส่วนที่เหลือ - 10xxxxxx.
พูดง่ายๆ ในรูปแบบ UTF-8 อักขระละติน เครื่องหมายวรรคตอน และตัวควบคุม อักขระ ASCIIถูกเขียนด้วยรหัส US-ASCII และอักขระอื่นๆ ทั้งหมดจะถูกเข้ารหัสโดยใช้อ็อกเทตหลายตัวที่มีบิตที่สำคัญที่สุดเท่ากับ 1 ซึ่งมีผลสองประการ
แม้ว่าโปรแกรมจะไม่รู้จัก Unicode, ตัวอักษรละติน, ตัวเลขอารบิกและเครื่องหมายวรรคตอนจะแสดงอย่างถูกต้อง
หากตัวอักษรละตินและเครื่องหมายวรรคตอนธรรมดา (รวมการเว้นวรรค) ใช้ข้อความเป็นจำนวนมาก UTF-8 จะให้ปริมาณที่เพิ่มขึ้นเมื่อเทียบกับ UTF-16
เมื่อมองแวบแรก ดูเหมือนว่า UTF-16 จะสะดวกกว่า เนื่องจากอักขระส่วนใหญ่ถูกเข้ารหัสในสองไบต์พอดี อย่างไรก็ตาม สิ่งนี้ถูกปฏิเสธโดยความจำเป็นในการสนับสนุนคู่ตัวแทนเสมือน ซึ่งมักถูกมองข้ามเมื่อใช้ UTF-16 ซึ่งรองรับเฉพาะอักขระ UCS-2 เท่านั้น
Unicode
จากวิกิพีเดีย สารานุกรมเสรี
ไปที่: การนำทาง, ค้นหา
Unicod (บ่อยที่สุด) หรือ Unicode (ภาษาอังกฤษ Unicode) - มาตรฐาน การเข้ารหัสอักขระช่วยให้คุณแสดงสัญลักษณ์ของการเขียนเกือบทั้งหมด ภาษา.
มาตรฐานที่เสนอใน ปี 1991องค์กรไม่แสวงหาผลกำไร "Unicode Consortium" ( ภาษาอังกฤษ Unicode กิจการร่วมค้า, Unicode Inc. ). การใช้มาตรฐานนี้ทำให้สามารถเข้ารหัสอักขระจำนวนมากจากสคริปต์ต่างๆ ได้: ในเอกสาร Unicode ภาษาจีน อักษรอียิปต์โบราณ, สัญลักษณ์ทางคณิตศาสตร์, ตัวอักษร อักษรกรีก, ละตินและ ซิริลลิกในกรณีนี้ไม่จำเป็นต้องเปลี่ยน โค้ดเพจ.
มาตรฐานประกอบด้วยสองส่วนหลัก: ชุดอักขระสากล ( ภาษาอังกฤษ UCS ชุดอักขระสากล) และตระกูลของการเข้ารหัส ( ภาษาอังกฤษ. UTF รูปแบบการแปลง Unicode). ชุดอักขระสากลระบุการโต้ตอบแบบหนึ่งต่อหนึ่งระหว่างอักขระ รหัส- องค์ประกอบของพื้นที่โค้ดที่แสดงถึงจำนวนเต็มที่ไม่เป็นลบ ตระกูลของการเข้ารหัสกำหนดการแสดงเครื่องของลำดับรหัส UCS
รหัส Unicode แบ่งออกเป็นหลายส่วน พื้นที่ที่มีรหัสจาก U + 0000 ถึง U + 007F มีอักขระโทรออก ASCIIด้วยรหัสที่เกี่ยวข้อง ถัดไปเป็นพื้นที่ของสัญลักษณ์ของสคริปต์ เครื่องหมายวรรคตอน และสัญลักษณ์ทางเทคนิคต่างๆ รหัสบางส่วนสงวนไว้สำหรับใช้ในอนาคต ภายใต้อักขระ Cyrillic พื้นที่ของอักขระที่มีรหัสจาก U + 0400 ถึง U + 052F จาก U + 2DE0 ถึง U + 2DFF จาก U + A640 ถึง U + A69F (ดู ซิริลลิกใน Unicode).
1 ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode 2 เวอร์ชัน Unicode 3 พื้นที่โค้ด 4 ระบบการเข้ารหัส 5 การปรับเปลี่ยนอักขระ 6 รูปแบบของการทำให้เป็นมาตรฐาน 7 การเขียนแบบสองทิศทาง 8 สัญลักษณ์เด่น 9 ISO / IEC 10646 10 วิธีในการนำเสนอ 11 วิธีการป้อนข้อมูล 12 ปัญหา Unicode 13 "Unicode" หรือ "Unicode"? 14 ดูเพิ่มเติม |
ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode
ในตอนท้าย ทศวรรษ 1980อักขระ 8 บิตกลายเป็นมาตรฐาน ในขณะที่มีการเข้ารหัส 8 บิตที่แตกต่างกันมากมาย และอักขระใหม่ก็ปรากฏขึ้นอย่างต่อเนื่อง สิ่งนี้อธิบายได้ด้วยการขยายขอบเขตของภาษาที่รองรับอย่างต่อเนื่อง และโดยความปรารถนาที่จะสร้างการเข้ารหัสที่เข้ากันได้บางส่วนกับภาษาอื่นๆ บางส่วน (ตัวอย่างทั่วไปคือการเกิดขึ้น การเข้ารหัสทางเลือกสำหรับภาษารัสเซียเนื่องจากการเอารัดเอาเปรียบของโปรแกรมตะวันตกที่สร้างขึ้นสำหรับการเข้ารหัส CP437). เป็นผลให้เกิดปัญหาหลายประการ:
ปัญหา " คราโคซิยาบร»(แสดงเอกสารในการเข้ารหัสที่ไม่ถูกต้อง): สามารถแก้ไขได้โดยการแนะนำวิธีการระบุการเข้ารหัสที่ใช้อย่างสม่ำเสมอหรือโดยการแนะนำการเข้ารหัสเดียวสำหรับทุกคน
ปัญหาชุดอักขระจำกัด: สามารถแก้ไขได้โดยการเปลี่ยนแบบอักษรภายในเอกสารหรือโดยการแนะนำการเข้ารหัส "กว้าง" การเปลี่ยนแบบอักษรได้รับการฝึกฝนมายาวนานใน โปรแกรมประมวลผลคำและมักใช้ แบบอักษรที่มีการเข้ารหัสที่ไม่ได้มาตรฐาน, ที. น. "แบบอักษร Dingbat" - ดังนั้นเมื่อพยายามโอนเอกสารไปยังระบบอื่น อักขระที่ไม่ได้มาตรฐานทั้งหมดจะกลายเป็น krakozyabry
ปัญหาของการแปลงการเข้ารหัสหนึ่งเป็นอีกการเข้ารหัสหนึ่ง: สามารถแก้ไขได้โดยการรวบรวมตารางการแปลงสำหรับการเข้ารหัสแต่ละคู่หรือโดยการใช้การแปลงระหว่างกลางเป็นการเข้ารหัสที่สามที่มีอักขระทั้งหมดของการเข้ารหัสทั้งหมด
ปัญหาของการทำสำเนาแบบอักษร: ตามเนื้อผ้าสำหรับการเข้ารหัสแต่ละครั้ง แบบอักษรที่แตกต่างกันถูกสร้างขึ้นแม้ว่าการเข้ารหัสเหล่านี้บางส่วน (หรือทั้งหมด) ประจวบในชุดของอักขระ: ปัญหานี้สามารถแก้ไขได้โดยการสร้างแบบอักษร "ใหญ่" ซึ่งอักขระ ที่จำเป็นสำหรับการเข้ารหัสนี้จะถูกเลือก - อย่างไรก็ตาม จำเป็นต้องมีการสร้างรีจีสทรีสัญลักษณ์เดียวเพื่อกำหนดว่ารายการใดที่ตรงกัน
จำเป็นต้องสร้างการเข้ารหัสแบบ "กว้าง" เดียว การเข้ารหัสที่มีความยาวผันแปรซึ่งใช้กันอย่างแพร่หลายในเอเชียตะวันออกนั้นพบว่าใช้งานยากเกินไป ดังนั้นจึงตัดสินใจใช้อักขระที่มีความกว้างคงที่ การใช้อักขระแบบ 32 บิตดูสิ้นเปลืองเกินไป ดังนั้นจึงตัดสินใจใช้อักขระแบบ 16 บิต
ดังนั้น Unicode เวอร์ชันแรกจึงเป็นการเข้ารหัสด้วยขนาดอักขระคงที่ที่ 16 บิต นั่นคือจำนวนรหัสทั้งหมดคือ 2 16 (65 536) จากนี้ไปเป็นแนวทางปฏิบัติในการตั้งชื่ออักขระด้วยเลขฐานสิบหกสี่หลัก (เช่น U + 04F0) ในเวลาเดียวกัน มีการวางแผนที่จะเข้ารหัสใน Unicode ไม่ใช่อักขระที่มีอยู่ทั้งหมด แต่เฉพาะที่จำเป็นในชีวิตประจำวันเท่านั้น ต้องวางสัญลักษณ์ที่ไม่ค่อยได้ใช้ไว้ใน "พื้นที่ใช้งานส่วนตัว" ซึ่งเดิมใช้รหัส U + D800… U + F8FF เพื่อที่จะใช้ Unicode เป็นตัวกลางในการแปลงการเข้ารหัสที่ต่างกันให้กันและกัน อักขระทั้งหมดที่แสดงในการเข้ารหัสที่มีชื่อเสียงที่สุดทั้งหมดจึงถูกรวมไว้ด้วย
อย่างไรก็ตาม ในอนาคต ได้มีการตัดสินใจเข้ารหัสสัญลักษณ์ทั้งหมด และในเรื่องนี้ ได้ขยายขอบเขตโค้ดอย่างมาก ในเวลาเดียวกัน รหัสอักขระเริ่มถูกมองว่าไม่ใช่ค่า 16 บิต แต่เป็นตัวเลขนามธรรมที่สามารถแสดงในคอมพิวเตอร์เป็นชุดได้ วิธีทางที่แตกต่าง(ซม. วิธีการนำเสนอ).
เนื่องจากในระบบคอมพิวเตอร์หลายระบบ (เช่น Windows NT ) อักขระ 16 บิตคงที่ถูกใช้เป็นการเข้ารหัสเริ่มต้นแล้วจึงตัดสินใจเข้ารหัสอักขระที่สำคัญที่สุดทั้งหมดภายใน 65 536 ตำแหน่งแรกเท่านั้น (เรียกว่า ภาษาอังกฤษ ขั้นพื้นฐาน พูดได้หลายภาษา เครื่องบิน, BMP). พื้นที่ที่เหลือใช้สำหรับ "อักขระพิเศษ" ( ภาษาอังกฤษ เสริม ตัวอักษร): ระบบการเขียนภาษาที่สูญพันธุ์หรือไม่ค่อยได้ใช้ ภาษาจีนอักษรอียิปต์โบราณ สัญลักษณ์ทางคณิตศาสตร์และดนตรี
เพื่อความเข้ากันได้กับระบบ 16 บิตที่เก่ากว่า ได้มีการคิดค้นระบบขึ้น UTF-16โดยที่ตำแหน่ง 65,536 แรก ยกเว้นตำแหน่งจากช่วง U + D800 ... U + DFFF จะแสดงโดยตรงเป็นตัวเลข 16 บิต และส่วนที่เหลือจะแสดงเป็น "คู่ตัวแทน" (องค์ประกอบแรกของ a คู่จาก U + D800 ... U + DBFF องค์ประกอบที่สองของคู่จากภูมิภาค U + DC00 ... U + DFFF) สำหรับคู่ตัวแทนเสมือน ส่วนหนึ่งของพื้นที่รหัส (2048 ตำแหน่ง) ที่สงวนไว้ก่อนหน้านี้สำหรับ "อักขระสำหรับใช้ส่วนตัว" ก่อนหน้านี้ถูกใช้
เนื่องจาก UTF-16 สามารถแสดงอักขระได้เพียง 2 20 + 2 16 −2048 (1 112 064) ตัวเลขนี้จึงถูกเลือกให้เป็นค่าสุดท้ายสำหรับพื้นที่โค้ด Unicode
แม้ว่าพื้นที่โค้ด Unicode จะขยายเกิน 2-16 เร็วเท่าเวอร์ชัน 2.0 แต่อักขระตัวแรกในพื้นที่ "บนสุด" จะถูกวางไว้ในเวอร์ชัน 3.1 เท่านั้น
บทบาทของการเข้ารหัสในภาคเว็บนั้นเพิ่มขึ้นอย่างต่อเนื่อง เมื่อต้นปี 2010 ส่วนแบ่งของเว็บไซต์ที่ใช้ Unicode อยู่ที่ประมาณ 50%
เวอร์ชัน Unicode
เนื่องจากตารางอักขระ Unicode มีการเปลี่ยนแปลงและเติมเต็ม และเวอร์ชันใหม่ของระบบนี้ได้รับการเผยแพร่ และงานนี้ก็มีการดำเนินการอย่างต่อเนื่อง เนื่องจากในขั้นต้นระบบ Unicode ได้รวมเฉพาะ Plane 0 - รหัสสองไบต์เท่านั้น - เอกสารใหม่ก็ออกมาเช่นกัน ISO... ระบบ Unicode มีอยู่ในเวอร์ชันต่อไปนี้:
1.1 (สอดคล้องกับ ISO / IEC 10646-1: 1993 ) มาตราฐาน 2534-2538
2.0, 2.1 (มาตรฐานเดียวกัน ISO / IEC 10646-1: 1993 บวกเพิ่มเติม: "การแก้ไข" 1 ถึง 7 และ "Technical Corrigenda" 1 และ 2), 1996 มาตรฐาน
3.0 (มาตรฐาน ISO / IEC 10646-1: 2000) มาตรฐาน 2000
3.1 (มาตรฐาน ISO / IEC 10646-1: 2000 และ ISO / IEC 10646-2: 2001) มาตรฐาน 2001
3.2 มาตรฐาน ปี 2545.
มาตรฐาน 4.0 2003 .
4.01 มาตรฐาน 2004 .
4.1 มาตรฐาน 2005 .
5.0 มาตรฐาน 2006 .
5.1 มาตรฐาน 2008 .
5.2 มาตรฐาน 2009 .
6.0 มาตรฐาน 2010 .
6.1 มาตรฐาน 2012 .
6.2 มาตรฐาน 2012 .
รหัสพื้นที่
แม้ว่าสัญกรณ์รูปแบบ UTF-8 และ UTF-32 จะอนุญาตให้เข้ารหัสจุดโค้ดได้มากถึง 2,331 (2,147,483,648) โค้ด แต่ก็ตัดสินใจใช้เพียง 1,112,064 เท่านั้นสำหรับความเข้ากันได้กับ UTF-16 อย่างไรก็ตาม แม้ในตอนนี้ก็เกินพอแล้ว ในเวอร์ชัน 6.0 นั้นใช้จุดโค้ดน้อยกว่า 110,000 จุด (กราฟิก 109,242 และสัญลักษณ์อื่นๆ 273 ตัว) เล็กน้อย
พื้นที่รหัสแบ่งออกเป็น17 เครื่องบิน 2 16 (65536) อักขระแต่ละตัว ระนาบศูนย์เรียกว่า ขั้นพื้นฐานมีสัญลักษณ์ของสคริปต์ทั่วไป ระนาบแรกใช้เป็นหลักสำหรับสคริปต์ทางประวัติศาสตร์ ระนาบที่สองสำหรับอักษรอียิปต์โบราณที่ไม่ค่อยได้ใช้ CJK, ตัวที่สามสงวนไว้สำหรับอักษรจีนโบราณ ... เครื่องบิน 15 และ 16 สงวนไว้สำหรับการใช้งานส่วนตัว
หากต้องการระบุอักขระ Unicode ให้ใช้สัญลักษณ์เช่น "U + xxxx"(สำหรับรหัส 0 ... FFFF) หรือ" U + xxxxxx"(สำหรับรหัส 10000 ... FFFFF) หรือ" U + xxxxxx"(สำหรับรหัส 100000 ... 10FFFF) โดยที่ xxx - เลขฐานสิบหกตัวเลข ตัวอย่างเช่น อักขระ "i" (U + 044F) มีรหัส 044F 16 = 1103 10 .
ระบบเข้ารหัส
Universal Coding System (Unicode) คือชุดของสัญลักษณ์กราฟิกและวิธีการเข้ารหัสสำหรับ คอมพิวเตอร์การประมวลผลข้อมูลข้อความ
สัญลักษณ์กราฟิกคือสัญลักษณ์ที่มีภาพที่มองเห็นได้ อักขระกราฟิกตรงข้ามกับตัวควบคุมและการจัดรูปแบบอักขระ
สัญลักษณ์กราฟิกรวมถึงกลุ่มต่อไปนี้:
เครื่องหมายวรรคตอน;
อักขระพิเศษ ( คณิตศาสตร์, เทคนิค, อุดมการณ์เป็นต้น);
ตัวคั่น
Unicode เป็นระบบสำหรับการแสดงข้อความเชิงเส้น อักขระที่มีตัวยกหรือตัวห้อยเพิ่มเติมสามารถแสดงเป็นลำดับของรหัสที่สร้างขึ้นตามกฎบางอย่าง (อักขระแบบประกอบ) หรือเป็นอักขระตัวเดียว (เวอร์ชันเสาหิน อักขระที่ประกอบล่วงหน้า)
การปรับเปลี่ยนตัวอักษร
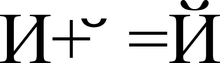
การแสดงอักขระ "Y" (U + 0419) ในรูปแบบของอักขระฐาน "I" (U + 0418) และอักขระดัดแปลง "" (U + 0306)
อักขระกราฟิกใน Unicode แบ่งออกเป็นแบบขยายและไม่ขยาย (แบบไม่มีความกว้าง) อักขระที่ไม่ขยายเมื่อแสดงไม่ใช้พื้นที่ใน ไลน์... ซึ่งรวมถึงเครื่องหมายเน้นเสียงและอื่นๆ กำกับเสียง... อักขระทั้งแบบขยายและแบบไม่ขยายมีรหัสของตนเอง อักขระขยายจะเรียกว่าพื้นฐาน ( ภาษาอังกฤษ ฐาน ตัวอักษร) และแบบไม่ขยาย - การแก้ไข ( ภาษาอังกฤษ รวมกัน ตัวอักษร); และฝ่ายหลังไม่สามารถพบกันโดยอิสระ ตัวอย่างเช่น อักขระ "á" สามารถแสดงเป็นลำดับของอักขระหลัก "a" (U + 0061) และอักขระตัวแก้ไข "́" (U + 0301) หรือเป็นอักขระแบบเสาหิน "á" (U + 00C1).
อักขระการปรับเปลี่ยนชนิดพิเศษคือตัวเลือกรูปแบบใบหน้า ( ภาษาอังกฤษ การเปลี่ยนแปลง ตัวเลือก). ใช้กับสัญลักษณ์ที่กำหนดตัวแปรดังกล่าวเท่านั้น ในเวอร์ชัน 5.0 ตัวเลือกสไตล์ถูกกำหนดไว้สำหรับซีรีส์ สัญลักษณ์ทางคณิตศาสตร์, สำหรับสัญลักษณ์ดั้งเดิม อักษรมองโกเลียและสำหรับสัญลักษณ์ การเขียนตารางมองโกเลีย.
แบบฟอร์มการทำให้เป็นมาตรฐาน
เนื่องจากอักขระเดียวกันสามารถแสดงด้วยรหัสที่แตกต่างกัน ซึ่งบางครั้งทำให้การประมวลผลซับซ้อน จึงมีกระบวนการทำให้เป็นมาตรฐานที่ออกแบบมาเพื่อนำข้อความไปยังรูปแบบมาตรฐานบางรูปแบบ
มาตรฐาน Unicode กำหนดรูปแบบข้อความมาตรฐาน 4 รูปแบบ:
สัญลักษณ์ S คือ อักษรย่อหากมีคลาสการแก้ไขเป็นศูนย์ในฐานอักขระ Unicode
ในลำดับของอักขระใดๆ ที่ขึ้นต้นด้วยอักขระเริ่มต้น S อักขระ C จะถูกบล็อกจาก S หากมีอักขระ B ใดๆ ระหว่าง S และ C ที่เป็นอักขระเริ่มต้นหรือมีคลาสการแก้ไขที่เหมือนกันหรือมากกว่า C สิ่งนี้ กฎใช้เฉพาะกับสตริงที่ผ่านการสลายตัวตามรูปแบบบัญญัติเท่านั้น
หลักคอมโพสิตเป็นสัญลักษณ์ที่มีการสลายตัวตามรูปแบบบัญญัติในฐานอักขระ Unicode (หรือการสลายตัวตามรูปแบบบัญญัติสำหรับ อังกูลและไม่รวมอยู่ใน รายการยกเว้น).
อักขระ X สามารถจัดแนวหลักกับอักขระ Y ได้ก็ต่อเมื่อมีคอมโพสิต Z หลักที่เทียบเท่ากับลำดับตามบัญญัติ
หากอักขระตัวถัดไป C ไม่ถูกบล็อกโดยอักขระฐานเริ่มต้นที่พบล่าสุด L และสามารถจัดตำแหน่งได้สำเร็จ จากนั้น L จะถูกแทนที่ด้วยคอมโพสิต LC และ C จะถูกลบออก
Normalization Form D (NFD) - การสลายตัวที่เป็นที่ยอมรับ ในกระบวนการแปลงข้อความให้อยู่ในรูปแบบนี้ อักขระผสมทั้งหมดจะถูกแทนที่ซ้ำด้วยอักขระผสมหลายตัวตามตารางการสลายตัว
Normalization Form C (NFC) คือการสลายตัวตามรูปแบบบัญญัติตามด้วยองค์ประกอบตามรูปแบบบัญญัติ ขั้นแรกให้ลดขนาดข้อความลงในรูปแบบ D หลังจากที่ดำเนินการจัดองค์ประกอบตามรูปแบบบัญญัติ - ข้อความจะถูกประมวลผลตั้งแต่ต้นจนจบและปฏิบัติตามกฎต่อไปนี้:
แบบฟอร์มการทำให้เป็นมาตรฐาน KD (NFKD) - การสลายตัวที่เข้ากันได้ เมื่อส่งลงในแบบฟอร์มนี้ อักขระผสมทั้งหมดจะถูกแทนที่โดยใช้ทั้งแผนที่การสลายตัวแบบ Unicode แบบบัญญัติและแผนที่การสลายตัวที่เข้ากันได้ หลังจากนั้นผลลัพธ์จะอยู่ในลำดับตามรูปแบบบัญญัติ
แบบฟอร์มการทำให้เป็นมาตรฐาน KC (NFKC) - การสลายตัวที่เข้ากันได้ตามด้วย บัญญัติองค์ประกอบ.
คำว่า "องค์ประกอบ" และ "การสลายตัว" หมายถึงการเชื่อมต่อหรือการสลายตัวของสัญลักษณ์ตามลำดับเป็นส่วนที่เป็นส่วนประกอบ
ตัวอย่างของ
|
ข้อความที่มา | ||||
|
\ u0410, \ u0401, \ u0419 |
\ u0410, \ u0415 \ u0308, \ u0418 \ u0306 |
\ u0410, \ u0401, \ u0419 |
||
จดหมายสองทิศทาง
มาตรฐาน Unicode รองรับการเขียนภาษาทั้งจากซ้ายไปขวา ( ภาษาอังกฤษ ซ้าย- ถึง- ขวา, Ltr) และเขียนจากขวาไปซ้าย ( ภาษาอังกฤษ ขวา- ถึง- ซ้าย, RTL) - ตัวอย่างเช่น, ภาษาอาหรับและ ชาวยิวจดหมาย. ในทั้งสองกรณี อักขระจะถูกจัดเก็บไว้ในลำดับที่ "เป็นธรรมชาติ" แอปพลิเคชันจัดเตรียมการแสดงผลโดยคำนึงถึงทิศทางที่ต้องการของจดหมาย
นอกจากนี้ Unicode ยังรองรับข้อความแบบรวมที่รวมส่วนย่อยที่มีทิศทางต่างกันของตัวอักษร คุณลักษณะนี้เรียกว่า แบบสองทิศทาง (ภาษาอังกฤษ แบบสองทิศทาง ข้อความ, BiDi). ตัวประมวลผลข้อความแบบง่ายบางตัว (เช่น in โทรศัพท์มือถือ) รองรับ Unicode แต่ไม่รองรับแบบสองทิศทาง อักขระ Unicode ทั้งหมดแบ่งออกเป็นหลายประเภท: เขียนจากซ้ายไปขวา เขียนจากขวาไปซ้าย และเขียนในทิศทางใดก็ได้ สัญลักษณ์ของหมวดสุดท้าย (ส่วนใหญ่ เครื่องหมายวรรคตอน) เมื่อแสดงขึ้น ให้ใช้ทิศทางของข้อความรอบข้าง
สัญลักษณ์เด่น
บทความหลัก: อักขระที่แสดงใน Unicode

สคีมาระนาบฐาน Unicode ดู คำอธิบาย
Unicode มีความทันสมัยเกือบทั้งหมด การเขียน, รวมทั้ง:
อาหรับ,
อาร์เมเนีย,
เบงกาลี,
พม่า,
กริยา,
กรีก,
จอร์เจียน,
เทวนาครี,
ชาวยิว,
ซิริลลิก,
ภาษาจีน(อักษรจีนถูกใช้อย่างแข็งขันใน ญี่ปุ่นและค่อนข้างน้อยใน เกาหลี),
คอปติก,
เขมร,
ละติน,
ภาษาทมิฬ,
ภาษาเกาหลี (อังกูล),
เชอโรกี,
เอธิโอเปีย,
ญี่ปุ่น(ซึ่งรวมถึงนอกจาก อักษรจีนอีกด้วย พยางค์),
อื่น ๆ.
มีการเพิ่มสคริปต์ทางประวัติศาสตร์จำนวนมากเพื่อวัตถุประสงค์ทางวิชาการ ได้แก่ : อักษรรูนดั้งเดิม, อักษรรูนเตอร์กโบราณ, กรีกโบราณ, อักษรอียิปต์โบราณ, คิวนิฟอร์ม, มายาเขียน, อักษรอีทรัสคัน.
Unicode ให้หลากหลาย คณิตศาสตร์และ ดนตรีตัวละครด้วย รูปสัญลักษณ์.
อย่างไรก็ตาม โดยพื้นฐานแล้ว Unicode ไม่รวมโลโก้บริษัทและผลิตภัณฑ์ แม้ว่าจะพบในแบบอักษร (เช่น โลโก้ แอปเปิ้ลเข้ารหัส MacRoman(0xF0) หรือโลโก้ Windowsในแบบอักษร Wingdings (0xFF)) ในฟอนต์ Unicode โลโก้ต้องวางในพื้นที่อักขระที่กำหนดเองเท่านั้น
ISO / IEC 10646
Unicode Consortium ทำงานอย่างใกล้ชิดกับคณะทำงาน ISO / IEC / JTC1 / SC2 / WG2 ซึ่งกำลังพัฒนามาตรฐานสากล 10646 ( ISO/IEC 10646) การซิงโครไนซ์เกิดขึ้นระหว่างมาตรฐาน Unicode และ ISO / IEC 10646 แม้ว่าแต่ละมาตรฐานจะใช้คำศัพท์และระบบเอกสารของตนเอง
ความร่วมมือของ Unicode Consortium กับองค์การระหว่างประเทศเพื่อการมาตรฐาน ( ภาษาอังกฤษ องค์การระหว่างประเทศเพื่อการมาตรฐาน ISO) เริ่มใน 1991 ปี... วี 1993 ปี ISO ได้ออกมาตรฐาน DIS 10646.1 ในการซิงโครไนซ์กับมัน Consortium ได้อนุมัติเวอร์ชัน 1.1 ของมาตรฐาน Unicode ซึ่งเสริมด้วยอักขระเพิ่มเติมจาก DIS 10646.1 เป็นผลให้ค่าของอักขระที่เข้ารหัสใน Unicode 1.1 และ DIS 10646.1 เหมือนกันทุกประการ
ในอนาคตความร่วมมือระหว่างทั้งสององค์กรยังคงดำเนินต่อไป วี 2000 ปีมาตรฐาน Unicode 3.0 ได้รับการซิงโครไนซ์กับ ISO / IEC 10646-1: 2000 ISO / IEC 10646 เวอร์ชันที่สามที่กำลังจะมีขึ้นจะถูกซิงโครไนซ์กับ Unicode 4.0 บางทีข้อกำหนดเหล่านี้อาจได้รับการเผยแพร่เป็นมาตรฐานเดียว
เช่นเดียวกับรูปแบบ UTF-16 และ UTF-32 ในมาตรฐาน Unicode มาตรฐาน ISO / IEC 10646 ยังมีรูปแบบการเข้ารหัสอักขระหลักสองรูปแบบ: UCS-2 (2 ไบต์ต่ออักขระ คล้ายกับ UTF-16) และ UCS-4 (4 ไบต์ต่ออักขระ คล้ายกับ UTF-32) UCS แปลว่า มัลติออคเต็ตอเนกประสงค์(มัลติไบต์) รหัสชุดอักขระ (ภาษาอังกฤษ สากล หลายรายการ- ออกเตต เข้ารหัส อักขระ ชุด). UCS-2 ถือได้ว่าเป็นส่วนย่อยของ UTF-16 (UTF-16 โดยไม่มีคู่ตัวแทน) และ UCS-4 เป็นคำพ้องความหมายสำหรับ UTF-32
วิธีการนำเสนอ
Unicode มีการแสดงหลายรูปแบบ ( ภาษาอังกฤษ รูปแบบการแปลง Unicode, UTF): UTF-8, UTF-16(UTF-16BE, UTF-16LE) และ UTF-32 (UTF-32BE, UTF-32LE) แบบฟอร์มการแสดง UTF-7 ยังได้รับการพัฒนาสำหรับการส่งผ่านช่องสัญญาณเจ็ดบิต แต่เนื่องจากความไม่ลงรอยกันกับ ASCIIยังไม่ได้รับการแจกจ่ายและไม่รวมอยู่ในมาตรฐาน 1 เมษายน ปี 2548มีการเสนอรูปแบบการนำเสนอการ์ตูนสองรูปแบบ: UTF-9 และ UTF-18 ( RFC 4042).
วี Microsoft Windows NTและระบบบนพื้นฐานของมัน Windows 2000และ Windows XPส่วนใหญ่ ใช้โดยแบบฟอร์ม UTF-16LE วี UNIX-ชอบ ระบบปฏิบัติการ GNU / Linux, BSDและ Mac OS Xแบบฟอร์มที่ยอมรับคือ UTF-8 สำหรับไฟล์และ UTF-32 หรือ UTF-8 สำหรับการจัดการอักขระใน หน่วยความจำเข้าถึงโดยสุ่ม.
Punycode- รูปแบบอื่นของลำดับการเข้ารหัสของอักขระ Unicode เป็นลำดับ ACE ที่เรียกว่า ซึ่งประกอบด้วยอักขระที่เป็นตัวอักษรและตัวเลขเท่านั้น ตามที่อนุญาตในชื่อโดเมน
บทความหลัก: UTF-8
UTF-8 คือการแสดง Unicode ที่ให้ความเข้ากันได้ดีที่สุดกับระบบรุ่นเก่าที่ใช้อักขระ 8 บิต ข้อความที่มีเฉพาะอักขระที่มีตัวเลขน้อยกว่า 128 จะถูกแปลงเป็นข้อความธรรมดาเมื่อเขียนด้วย UTF-8 ASCII... ในทางกลับกัน ในข้อความ UTF-8, any ไบต์ที่มีค่าน้อยกว่า 128 จะแสดงอักขระ ASCII ด้วยรหัสเดียวกัน อักขระ Unicode ที่เหลือจะแสดงเป็นลำดับตั้งแต่ 2 ถึง 6 ไบต์ (อันที่จริงแล้วมีเพียง 4 ไบต์เท่านั้น เนื่องจากไม่มีอักขระที่มีโค้ดที่มากกว่า 10FFFF ใน Unicode และไม่มีแผนที่จะแนะนำอีกในอนาคต ) ซึ่งไบต์แรกมักจะดูเหมือน 11xxxxxx และที่เหลือ - 10xxxxxx
UTF-8 ถูกคิดค้น กันยายน 2 ปี 1992 เคน ทอมป์สันและ ร็อบ ไพค์และนำไปปฏิบัติใน แผน 9 ... ตอนนี้มาตรฐาน UTF-8 ได้รับการประดิษฐานอย่างเป็นทางการในเอกสาร RFC 3629และ ISO / IEC 10646 ภาคผนวก ง.
อักขระ UTF-8 มาจาก Unicode ด้วยวิธีดังต่อไปนี้:
0x00000000 - 0x0000007F: 0xxxxxxx
0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
เป็นไปได้ในทางทฤษฎี แต่ไม่รวมอยู่ในมาตรฐาน:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
แม้ว่า UTF-8 จะอนุญาตให้คุณระบุอักขระเดียวกันได้หลายวิธี แต่อักขระที่สั้นที่สุดเท่านั้นที่ถูกต้อง แบบฟอร์มที่เหลือควรถูกปฏิเสธด้วยเหตุผลด้านความปลอดภัย
ลำดับไบต์
ในสตรีมข้อมูล UTF-16 ไบต์สูงสามารถเขียนก่อนค่าต่ำสุด ( ภาษาอังกฤษ UTF-16 little-endian) หรือหลังน้อง ( ภาษาอังกฤษ. UTF-16 บิ๊กเอนด์). ในทำนองเดียวกัน การเข้ารหัสแบบสี่ไบต์มีสองรูปแบบ - UTF-32LE และ UTF-32BE
เพื่อกำหนดรูปแบบของการแสดง Unicode ที่จุดเริ่มต้นของไฟล์ข้อความจะถูกเขียน ลายเซ็น- อักขระ U + FEFF (ช่องว่างไม่แบ่งความกว้างศูนย์) หรือเรียกอีกอย่างว่า เครื่องหมายคำสั่งไบต์ (ภาษาอังกฤษ ไบต์ คำสั่ง เครื่องหมาย, บอม ). ทำให้สามารถแยกแยะระหว่าง UTF-16LE และ UTF-16BE เนื่องจากไม่มีอักขระ U + FFFE บางครั้งก็ใช้เพื่อแสดงถึงรูปแบบ UTF-8 แม้ว่าแนวคิดของลำดับไบต์จะใช้ไม่ได้กับรูปแบบนี้ ไฟล์ที่เป็นไปตามแบบแผนนี้จะเริ่มต้นด้วยลำดับไบต์เหล่านี้:
น่าเสียดายที่วิธีนี้ไม่สามารถแยกความแตกต่างระหว่าง UTF-16LE และ UTF-32LE ได้อย่างน่าเชื่อถือ เนื่องจาก Unicode อนุญาตให้ใช้อักขระ U + 0000 (แม้ว่าข้อความจริงจะไม่ค่อยขึ้นต้นด้วย)
ไฟล์ในการเข้ารหัส UTF-16 และ UTF-32 ที่ไม่มี BOM ต้องอยู่ในลำดับไบต์ขนาดใหญ่ ( unicode.org).
Unicode และการเข้ารหัสแบบดั้งเดิม
การเปิดตัว Unicode ได้เปลี่ยนวิธีการเข้ารหัส 8 บิตแบบเดิม ถ้าก่อนหน้านี้ระบุการเข้ารหัสโดยแบบอักษร ตอนนี้จะถูกระบุโดยตารางการติดต่อระหว่างการเข้ารหัสนี้และ Unicode อันที่จริงการเข้ารหัสแบบ 8 บิตได้กลายเป็นตัวแทนของชุดย่อยของ Unicode สิ่งนี้ทำให้ง่ายต่อการสร้างโปรแกรมที่ต้องทำงานกับการเข้ารหัสที่หลากหลาย: ตอนนี้ เพื่อเพิ่มการรองรับการเข้ารหัสอีกหนึ่งรายการ คุณเพียงแค่เพิ่มตารางค้นหา Unicode อื่น
นอกจากนี้ รูปแบบข้อมูลจำนวนมากยังอนุญาตให้แทรกอักขระ Unicode ใดๆ ได้ แม้ว่าเอกสารจะเขียนด้วยการเข้ารหัส 8 บิตแบบเก่าก็ตาม ตัวอย่างเช่น ใน HTML สามารถใช้ เครื่องหมายและรหัส.
การดำเนินการ
ระบบปฏิบัติการที่ทันสมัยส่วนใหญ่ให้การสนับสนุน Unicode ในระดับหนึ่ง
ในระบบปฏิบัติการของครอบครัว Windows NTชื่อไฟล์และสตริงระบบอื่นๆ จะแสดงภายในโดยใช้การเข้ารหัสแบบสองไบต์แบบ UTF-16LE การเรียกระบบที่ใช้พารามิเตอร์สตริงมีอยู่ในตัวแปรไบต์เดี่ยวและไบต์คู่ สำหรับรายละเอียดเพิ่มเติมโปรดดูบทความ .
UNIX- ระบบปฏิบัติการที่คล้ายคลึงกัน รวมถึง GNU / Linux, BSD, Mac OS Xใช้การเข้ารหัส UTF-8 เพื่อแสดง Unicode โปรแกรมส่วนใหญ่สามารถจัดการ UTF-8 เป็นการเข้ารหัสแบบไบต์เดียวแบบดั้งเดิม โดยไม่คำนึงถึงข้อเท็จจริงที่ว่าอักขระจะถูกแสดงเป็นไบต์ต่อเนื่องกันหลายไบต์ ในการทำงานกับอักขระแต่ละตัว โดยปกติสตริงจะถูกบันทึกเป็น UCS-4 เพื่อให้อักขระแต่ละตัวมีค่าที่สอดคล้องกัน คำเครื่อง.
หนึ่งในการใช้งานเชิงพาณิชย์ที่ประสบความสำเร็จครั้งแรกของ Unicode คือสภาพแวดล้อมการเขียนโปรแกรม Java... โดยพื้นฐานแล้วจะละทิ้งการแสดงอักขระแบบ 8 บิตและแทนที่อักขระแบบ 16 บิต โซลูชันนี้เพิ่มการใช้หน่วยความจำ แต่ช่วยให้เราสามารถส่งคืนสิ่งที่เป็นนามธรรมที่สำคัญในการเขียนโปรแกรม: อักขระตัวเดียวตามอำเภอใจ (ประเภทถ่าน) โดยเฉพาะอย่างยิ่ง โปรแกรมเมอร์สามารถทำงานกับสตริงได้เช่นเดียวกับอาร์เรย์ธรรมดา น่าเสียดายที่ความสำเร็จยังไม่สิ้นสุด Unicode เกินขีด จำกัด 16 บิตและโดย J2SE 5.0 อักขระโดยพลการก็เริ่มครอบครองหน่วยหน่วยความจำจำนวนตัวแปร - หนึ่งหรือสองอักขระ (ดู ตัวแทนคู่รัก).
ภาษาโปรแกรมส่วนใหญ่รองรับสตริง Unicode แม้ว่าการแสดงอาจแตกต่างกันขึ้นอยู่กับการใช้งาน
วิธีการป้อนข้อมูล
ตั้งแต่ไม่มี รูปแบบแป้นพิมพ์ไม่อนุญาตให้ป้อนอักขระ Unicode ทั้งหมดพร้อมกันจาก ระบบปฏิบัติการและ ใบสมัครต้องการการสนับสนุนวิธีการป้อนข้อมูลทางเลือกสำหรับอักขระ Unicode โดยอำเภอใจ
Microsoft Windows
บทความหลัก: Unicode บนระบบปฏิบัติการ Microsoft
เริ่มต้นด้วย Windows 2000ยูทิลิตี้ Charmap (charmap.exe) จะแสดงอักขระทั้งหมดในระบบปฏิบัติการและอนุญาตให้คุณคัดลอกไปยัง คลิปบอร์ด... มีตารางที่คล้ายกัน เช่น in ไมโครซอฟ เวิร์ด.
บางครั้งคุณสามารถพิมพ์ เลขฐานสิบหกรหัส กด Alt+ X และโค้ดจะถูกแทนที่ด้วยอักขระที่เกี่ยวข้อง เช่น in WordPad,ไมโครซอฟต์เวิร์ด. ในโปรแกรมแก้ไข Alt + X จะทำการแปลงแบบย้อนกลับเช่นกัน
ในโปรแกรม MS Windows หลายๆ โปรแกรม ในการรับอักขระ Unicode คุณต้องกดปุ่ม Alt และพิมพ์ค่าทศนิยมของรหัสอักขระบน แป้นพิมพ์ตัวเลข... ตัวอย่างเช่น ชุดค่าผสม Alt + 0171 (") และ Alt + 0187 (") จะมีประโยชน์เมื่อพิมพ์ข้อความ Cyrillic ชุดค่าผสม Alt + 0133 (…) และ Alt + 0151 (-) ก็น่าสนใจเช่นกัน
Macintosh
วี Mac OS 8.5 และใหม่กว่า รองรับวิธีการป้อนข้อมูลที่เรียกว่า "Unicode Hex Input" ในขณะที่กดปุ่ม Option ค้างไว้ คุณต้องพิมพ์รหัสฐานสิบหกสี่หลักของอักขระที่ต้องการ วิธีนี้ช่วยให้คุณป้อนอักขระที่มีรหัสมากกว่า U + FFFF โดยใช้คู่ตัวแทน คู่ดังกล่าว ระบบปฏิบัติการจะถูกแทนที่โดยอัตโนมัติด้วยอักขระเดี่ยว ก่อนใช้วิธีป้อนข้อมูลนี้ คุณต้องเปิดใช้งานในส่วนที่เกี่ยวข้องของการตั้งค่าระบบ จากนั้นเลือกวิธีการป้อนข้อมูลปัจจุบันในเมนูแป้นพิมพ์
เริ่มต้นด้วย Mac OS X 10.2 นอกจากนี้ยังมีแอปพลิเคชั่น "จานสีตัวละคร" ซึ่งช่วยให้คุณสามารถเลือกอักขระจากตารางที่คุณสามารถเลือกอักขระของบล็อกเฉพาะหรืออักขระที่รองรับโดยแบบอักษรเฉพาะ
GNU / Linux
วี GNOMEนอกจากนี้ยังมียูทิลิตี้ "Symbol Table" ที่ให้คุณแสดงสัญลักษณ์ของบล็อกหรือระบบการเขียนบางอย่างและให้ความสามารถในการค้นหาโดยใช้ชื่อหรือคำอธิบายของสัญลักษณ์ เมื่อทราบรหัสอักขระที่ต้องการแล้ว สามารถป้อนได้ตามมาตรฐาน ISO 14755: ขณะที่กด Ctrl + ⇧ . ค้างไว้ กะป้อนรหัสฐานสิบหก (เริ่มต้นด้วย GTK + บางรุ่นต้องป้อนรหัสโดยกดปุ่ม "ยู"). รหัสเลขฐานสิบหกที่ป้อนสามารถยาวได้ถึง 32 บิต ช่วยให้คุณป้อนอักขระ Unicode ใดๆ โดยไม่ต้องใช้คู่ตัวแทนเสมือน
 จะปิดการใช้งานบริการ "คุณได้รับสาย" จาก MTS ได้อย่างไร?
จะปิดการใช้งานบริการ "คุณได้รับสาย" จาก MTS ได้อย่างไร? รีเซ็ตเป็นค่าจากโรงงานและฮาร์ดรีเซ็ต Apple iPhone
รีเซ็ตเป็นค่าจากโรงงานและฮาร์ดรีเซ็ต Apple iPhone รีเซ็ตเป็นค่าจากโรงงานและฮาร์ดรีเซ็ต Apple iPhone
รีเซ็ตเป็นค่าจากโรงงานและฮาร์ดรีเซ็ต Apple iPhone