การเข้ารหัส Unicode คืออะไร ทำไมคุณถึงต้องการ Unicode ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode
การเข้ารหัสคืออะไร
ในรัสเซีย "ชุดอักขระ" เรียกอีกอย่างว่า "ชุดอักขระ" และกระบวนการของการใช้ตารางนี้ในการแปลข้อมูลจากการแสดงคอมพิวเตอร์เป็นมนุษย์ และคุณลักษณะ ไฟล์ข้อความสะท้อนถึงการใช้ระบบรหัสบางอย่างในการแสดงข้อความ
ระบบการนำเสนอถูกกำหนดโดยกฎจำนวนหนึ่ง และการนำกฎเหล่านี้ไปใช้กับข้อมูลดั้งเดิมนั้นกระทำโดยกระบวนการเข้ารหัส กระบวนการย้อนกลับเรียกว่าการถอดรหัส จากนั้นเราจะพิจารณาด้านที่เฉพาะเจาะจงมากขึ้น เช่น การเข้ารหัสสัญญาณ การเข้ารหัสอักขระ การเข้ารหัสจีโนมของมนุษย์ และการเข้ารหัสควอนตัม สุดท้ายนี้ จะอธิบายแนวคิดพื้นฐานของการบีบอัดข้อมูลและวิธีการเข้ารหัสที่ใช้บ่อยที่สุด
ในส่วนนี้ เราจะมาดูกันว่ามนุษย์ตลอดประวัติศาสตร์ได้พยายามอย่างมากในการแสดงออกกับญาติคนอื่นๆ ของพวกเขาด้วยวิธีที่เรียบง่ายและเป็นธรรมชาติ โดยการเข้ารหัสข้อมูลโดยใช้วิธีการต่างๆ วิธีการเหล่านี้มีวิวัฒนาการตลอดประวัติศาสตร์โดยไม่แสดงวิธีการที่ซับซ้อนที่เราใช้ในปัจจุบันสำหรับวิธีแรกที่ใช้เนื่องจากต้องใช้วิวัฒนาการอย่างมาก ดังจะเห็นได้ในส่วนนี้
วิธีเข้ารหัสข้อความ
ชุดของสัญลักษณ์ที่ใช้ในการเขียนข้อความถูกอ้างถึงในศัพท์คอมพิวเตอร์ว่าเป็นตัวอักษร จำนวนตัวอักษรในตัวอักษรมักจะเรียกว่ากำลังของมัน สำหรับการนำเสนอ ข้อมูลข้อความคอมพิวเตอร์ส่วนใหญ่มักใช้ตัวอักษรที่มีความจุ 256 อักขระ อักขระตัวหนึ่งมีข้อมูล 8 บิต ดังนั้นรหัสไบนารีของอักขระแต่ละตัวจึงใช้หน่วยความจำคอมพิวเตอร์ 1 ไบต์ อักขระทั้งหมดของตัวอักษรดังกล่าวมีหมายเลขตั้งแต่ 0 ถึง 255 และแต่ละหมายเลขสอดคล้องกับรหัสไบนารี 8 บิต ซึ่งเป็นเลขลำดับของอักขระในระบบเลขฐานสอง - ตั้งแต่ 00000000 ถึง 11111111 เฉพาะอักขระ 128 ตัวแรกที่มี ตัวเลขจากศูนย์ ( รหัสไบนารี 00000000) ถึง 127 (01111111) ซึ่งรวมถึงตัวพิมพ์เล็กและ ตัวพิมพ์ใหญ่ตัวอักษรละติน ตัวเลข เครื่องหมายวรรคตอน วงเล็บ ฯลฯ รหัสที่เหลืออีก 128 รหัส เริ่มต้นด้วย 128 (รหัสไบนารี 10000000) และลงท้ายด้วย 255 (11111111) ใช้ในการเข้ารหัสตัวอักษรของตัวอักษรประจำชาติ สัญลักษณ์ทางการและวิทยาศาสตร์
วิวัฒนาการของการเข้ารหัสสัญญาณ
การล้าสมัยคือทุกสิ่งที่เรารู้ ช่วงเวลานี้อย่างที่มันเป็นในระยะเวลาอันควรกับวิธีการก่อนหน้านี้ ตลอดประวัติศาสตร์ ลูกเรือได้ใช้สัญญาณเพื่อส่งข้อความด่วนไปยังลูกเรือคนอื่นๆ นี่คือสัญญาณแสงที่ผลิตขึ้นโดยใช้โปรเจ็กเตอร์ขนาดใหญ่พร้อมระบบที่ช่วยให้แสงระเบิด โดยปกติแล้วจะใช้ตะแกรงที่อยู่ด้านหน้าโฟกัส ในการเชื่อมต่อจะใช้รหัสมอร์สผ่านสัญญาณไฟ
เหล่านี้เป็นสัญญาณที่ส่งผ่านการสั่นสะเทือนในอากาศ เนื่องจากความเฉื่อยของอุปกรณ์ที่จำเป็นสำหรับการส่งสัญญาณ จึงเป็นสื่อที่ช้ามาก สัญญาณที่ส่งใช้รหัสมอร์สในการส่งข้อมูล นอกจากรหัสมอร์สดั้งเดิมในรหัสสากลที่รวมเข้าด้วยกันแล้ว ยังมีสัญญาณมาตรฐานประเภทอื่นๆ ที่กะลาสีทุกคนควรเข้าใจอย่างถ่องแท้
ประเภทของการเข้ารหัส
ตารางการเข้ารหัสที่มีชื่อเสียงที่สุดคือ ASCII (รหัส American Standard สำหรับการแลกเปลี่ยนข้อมูล) เดิมทีได้รับการพัฒนาสำหรับการส่งข้อความทางโทรเลขและในขณะนั้นเป็นแบบ 7 บิตนั่นคือมีเพียง 128 ชุด 7 บิตเท่านั้นที่ใช้ในการเข้ารหัสอักขระภาษาอังกฤษบริการและอักขระควบคุม ในกรณีนี้ ชุดค่าผสม (รหัส) 32 ชุดแรกที่ใช้ในการเข้ารหัสสัญญาณควบคุม (จุดเริ่มต้นของข้อความ สิ้นสุดบรรทัด การขึ้นบรรทัดใหม่ การโทร การสิ้นสุดข้อความ ฯลฯ) ในการพัฒนาคอมพิวเตอร์ IBM เครื่องแรก รหัสนี้ถูกใช้เพื่อแสดงสัญลักษณ์ในคอมพิวเตอร์ ตั้งแต่ใน รหัสแหล่งที่มา ASCII มีอักขระเพียง 128 ตัวสำหรับการเข้ารหัสค่าไบต์ก็เพียงพอแล้วซึ่งบิตที่ 8 เป็น 0 ภาษาอังกฤษ (กรีก, เครื่องหมายเยอรมัน, เครื่องหมายกำกับเสียงภาษาฝรั่งเศส ฯลฯ ) เมื่อพวกเขาเริ่มปรับคอมพิวเตอร์สำหรับประเทศและภาษาอื่น ไม่มีที่ว่างเพียงพอสำหรับสัญลักษณ์ใหม่อีกต่อไป เพื่อรองรับภาษาอื่นนอกเหนือจากภาษาอังกฤษอย่างเต็มที่ IBM ได้แนะนำตารางรหัสเฉพาะประเทศหลายตาราง ดังนั้นสำหรับประเทศสแกนดิเนเวียจึงเสนอตารางที่ 865 (นอร์ดิก) สำหรับประเทศอาหรับ - ตารางที่ 864 (อาหรับ) สำหรับอิสราเอล - ตารางที่ 862 (อิสราเอล) เป็นต้น ในตารางเหล่านี้ รหัสบางส่วนจากครึ่งหลังของตารางรหัสถูกใช้เพื่อแสดงอักขระของตัวอักษรประจำชาติ (โดยไม่รวมอักขระกราฟิกหลอกบางตัว) สถานการณ์ในภาษารัสเซียพัฒนาขึ้นในลักษณะพิเศษ เห็นได้ชัดว่าการแทนที่อักขระในช่วงครึ่งหลังของตารางโค้ดสามารถทำได้ วิธีทางที่แตกต่าง... ดังนั้นตารางการเข้ารหัสอักขระซิริลลิกที่แตกต่างกันจึงปรากฏขึ้นสำหรับภาษารัสเซีย: KOI8-R, IBM-866, CP-1251, ISO-8551-5 ทั้งหมดเป็นตัวแทนของสัญลักษณ์ของครึ่งแรกของตารางในลักษณะเดียวกัน (จาก 0 ถึง 127) และแตกต่างกันในการแสดงสัญลักษณ์ของตัวอักษรรัสเซียและกราฟิกหลอก สำหรับภาษาอย่างจีนหรือญี่ปุ่น โดยทั่วไป 256 ตัวอักษรไม่เพียงพอ นอกจากนี้ยังมีปัญหาในการส่งออกหรือบันทึกในไฟล์เดียวในเวลาเดียวกันข้อความบน ภาษาที่แตกต่างกัน(เช่น เมื่ออ้างอิง) ดังนั้น สากล ตารางรหัส UNICODE ที่มีสัญลักษณ์ที่ใช้ในภาษาของทุกคนในโลก รวมถึงบริการและสัญลักษณ์เสริมต่างๆ (เครื่องหมายวรรคตอน สัญลักษณ์ทางคณิตศาสตร์และทางเทคนิค ลูกศร เครื่องหมายกำกับเสียง ฯลฯ ) เห็นได้ชัดว่า หนึ่งไบต์ไม่เพียงพอสำหรับการเข้ารหัสอักขระจำนวนมาก ดังนั้น UNICODE จึงใช้รหัส 16 บิต (2 ไบต์) เพื่อแสดงอักขระ 65,536 ตัว จนถึงปัจจุบันมีการใช้รหัสประมาณ 49,000 รหัส (การเปลี่ยนแปลงที่สำคัญครั้งล่าสุดคือการแนะนำสัญลักษณ์สกุลเงินยูโรในเดือนกันยายน 1998) เพื่อความเข้ากันได้กับการเข้ารหัสก่อนหน้า 256 รหัสแรกจะเหมือนกับมาตรฐาน ASCII ในมาตรฐาน UNICODE ยกเว้นเฉพาะ รหัสไบนารี(รหัสเหล่านี้มักจะแสดงด้วยตัวอักษร U ตามด้วยเครื่องหมาย + และรหัสจริงในรูปแบบเลขฐานสิบหก) อักขระแต่ละตัวจะได้รับชื่อเฉพาะ องค์ประกอบอื่น มาตรฐานยูนิโคดเป็นอัลกอริธึมสำหรับการแปลงรหัส UNICODE แบบหนึ่งต่อหนึ่งตามลำดับไบต์ที่มีความยาวผันแปรได้ ความต้องการอัลกอริธึมดังกล่าวเกิดจากการที่แอพพลิเคชั่นบางตัวไม่สามารถทำงานร่วมกับ UNICODE ได้ แอปพลิเคชั่นบางตัวเข้าใจเฉพาะรหัส ASCII 7 บิต แอปพลิเคชั่นอื่นเข้าใจรหัส ASCII 8 บิต แอปพลิเคชันดังกล่าวใช้รหัส ASCII แบบขยายที่เรียกว่าเพื่อแทนอักขระที่ไม่พอดีตามลำดับในชุดอักขระ 128 ตัวหรือ 256 อักขระ เมื่ออักขระถูกเข้ารหัสด้วยสตริงไบต์ที่มีความยาวผันแปรได้ UTF-7 ใช้เพื่อแปลงรหัส UNICODE แบบย้อนกลับเป็นรหัส ASCII 7 บิตแบบขยาย และ UTF-8 ใช้เพื่อแปลงรหัส UNICODE แบบย้อนกลับเป็นรหัส ASCII 8 บิตแบบขยาย โปรดทราบว่าทั้ง ASCII และ UNICODE และมาตรฐานการเข้ารหัสอักขระอื่นๆ ไม่ได้กำหนดภาพของอักขระ แต่มีเพียงองค์ประกอบของชุดอักขระและลักษณะที่แสดงในคอมพิวเตอร์เท่านั้น นอกจากนี้ (ซึ่งอาจไม่ชัดเจนในทันที) ลำดับของการแจงนับอักขระในชุดมีความสำคัญมาก เนื่องจากจะส่งผลต่ออัลกอริธึมการจัดเรียงในลักษณะที่สำคัญที่สุด เป็นตารางความสอดคล้องของสัญลักษณ์จากชุดใดชุดหนึ่ง (กล่าวคือ สัญลักษณ์ที่ใช้แสดงข้อมูลบน ภาษาอังกฤษหรือในภาษาต่างๆ เช่นในกรณีของ UNICODE) และแสดงถึงตารางการเข้ารหัสอักขระหรือชุดอักขระ การเข้ารหัสมาตรฐานแต่ละรายการมีชื่อเช่น KOI8-R, ISO_8859-1, ASCII ขออภัย ไม่มีมาตรฐานสำหรับการเข้ารหัสชื่อ
ใช้สำหรับการสื่อสารระหว่างเรือใกล้เคียงเพื่อให้สามารถเคารพความถี่ของวิทยุที่ใช้ ไม่ใช้โดยไม่จำเป็นโดยการใช้ช่องนั้นโดยไม่จำเป็น หรือเนื่องจากต้องมีการสร้างการสื่อสารและวิทยุทำงานไม่ถูกต้อง
แฟล็กถูกใช้ในการสื่อสาร ดังนั้นขึ้นอยู่กับตำแหน่งที่บุคคลที่ทำการส่งสัญญาณ จะมีค่าหรืออย่างอื่น ความหมายที่เกี่ยวข้องจะเหมือนกับการใช้แฟล็กที่มีตัวอักษร A ถึง Z ตัวเลข 0 ถึง 9 และสัญญาณหยุดชั่วคราวและข้อผิดพลาด
วิทยุโทรเลขและวิทยุโทรเลข
ด้วยวิธีการที่กล่าวข้างต้น การสื่อสารพร้อมกันในทั้งสองทิศทางเป็นไปไม่ได้ ดังนั้นจึงเป็นแบบจุดต่อจุด ด้วยการถือกำเนิดของ radiotelegraphy การสื่อสารประเภทนี้จึงเป็นไปได้ Radiotelegraphy ขึ้นอยู่กับทฤษฎีการแพร่กระจายคลื่นในอวกาศของ Maxwell ดังนั้นโทรเลขไร้สายจึงถือกำเนิดขึ้น ซึ่งเป็นหนึ่งในความก้าวหน้าที่สำคัญที่สุดในการสื่อสารโทรคมนาคมตลอดกาล
การเข้ารหัสทั่วไป
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 การเข้ารหัสของ Microsoft Windows: o Windows-1250 สำหรับภาษายุโรปกลางที่ใช้ตัวอักษรละติน o Windows-1251 สำหรับตัวอักษร Cyrillic o Windows-1252 สำหรับภาษาตะวันตก o Windows-1253 สำหรับกรีก o Windows-1254 สำหรับตุรกี o Windows-1255 สำหรับภาษาฮีบรู o Windows-1256 สำหรับภาษาอาหรับ o Windows-1257 สำหรับภาษาบอลติก o Windows-1258 สำหรับภาษาเวียดนาม MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 การเข้ารหัสบัลแกเรีย ISCII VISCII Big5 (เวอร์ชันที่มีชื่อเสียงที่สุดของ Microsoft CP950 ) o HSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS สำหรับภาษาญี่ปุ่น (Microsoft CP932) EUC-KR สำหรับภาษาเกาหลี (Microsoft CP949) ISO-2022 และ EUC สำหรับการเขียนภาษาจีน UTF- การเข้ารหัส 8 และ UTF-16 อักขระ Unicodeเอกสารนี้ถูกย้ายไปยังที่เก็บถาวรและไม่ได้รับการสนับสนุน
การเข้ารหัสวันนี้
ข้างหน้าจะเป็นวิทยุโทรศัพท์ ซึ่งไม่มีอะไรมากไปกว่าความสามารถในการปรับเสียงผ่านคลื่นวิทยุโดยใช้ พื้นฐานทางทฤษฎีแสดงในวิทยุโทรเลข
การเข้ารหัสสัญญาณ
นี่เป็นขั้นตอนที่ใช้กันทั่วไปซึ่งก่อนชุดสัญญาณ ประเภทอนาล็อกถ่ายทอดเป็นสัญญาณดิจิตอล ดังนั้นจึงอำนวยความสะดวกในการประมวลผลในภายหลังรวมทั้งปรับปรุงลักษณะทางกายภาพกล่าวคือ สัญญาณแอนะล็อกมีความไวต่อการเปลี่ยนแปลงของการรบกวนที่อาจเกิดขึ้น เนื่องจากสัญญาณดั้งเดิมนั้นยากต่อการฟื้นตัว เนื่องจากค่าที่สัญญาณนี้สามารถมีได้ไม่จำกัด หากเราเปรียบเทียบกับสัญญาณดิจิทัลที่มีค่าที่เป็นไปได้จำนวนหนึ่ง ข้อเท็จจริงนี้ทำให้ง่ายต่อการดึงค่าในสัญญาณดิจิตอล ดังนั้นจึงสามารถใช้สำหรับการสื่อสารทางไกลได้
การใช้การเข้ารหัส Unicode
.NET Framework 3.5
อัปเดตเมื่อ: พ.ย. 2550
แอปพลิเคชันรันไทม์ทั่วไปใช้การเข้ารหัสเพื่อแปลงอักขระจากการแทนค่าภายใน (Unicode) เป็นการแสดงอื่น การถอดรหัสใช้เพื่อแปลงอักขระกลับจากการเข้ารหัสภายนอก (ไม่ใช่ Unicode) เป็นการแสดงภายใน เนมสเปซมีจำนวนคลาสที่ช่วยให้แอปพลิเคชันสามารถเข้ารหัสและถอดรหัสอักขระได้ สำหรับภาพรวมของชั้นเรียนเหล่านี้ โปรดดูที่
ในขั้นตอนนี้ เราสามารถแยกความแตกต่างได้สามขั้นตอน: การสุ่มตัวอย่าง การหาปริมาณ และการประมวลผล การหาปริมาณ: ประกอบด้วยการประเมินมูลค่าของแต่ละตัวอย่างเพื่อให้แต่ละตัวอย่างได้รับการกำหนดค่าที่เป็นไปได้อย่างใดอย่างหนึ่งของผลลัพธ์ สัญญาณดิจิตอล... กระบวนการ quantization ทำให้เกิดเสียง quantization ที่เกิดจากจำนวนค่าที่เป็นไปได้ สัญญาณอนาล็อกสำหรับสัญญาณดิจิตอล ประกอบด้วยการแปลงค่าที่ได้รับระหว่างกระบวนการควอนไทเซชันเป็นระบบไบนารีโดยใช้รหัสที่ตั้งไว้ล่วงหน้าจำนวนหนึ่ง
- การสุ่มตัวอย่าง: ประกอบด้วยการสุ่มตัวอย่างแอมพลิจูดของสัญญาณอินพุต
- อย่างสูง พารามิเตอร์ที่สำคัญในกระบวนการนี้ด้วยจำนวนตัวอย่างต่อวินาที
- การเข้ารหัส
ใช้สำหรับการเข้ารหัสที่ไม่ใช่ Unicode คลาสรองรับการเข้ารหัส ANSI / ISO ที่หลากหลาย
ตัวอย่างโค้ดด้านล่างใช้เมธอด GetEncodingออบเจ็กต์การเข้ารหัสที่จำเป็นสำหรับหน้ารหัสเฉพาะ วิธี GetBytesเรียกใช้บนอ็อบเจ็กต์การเข้ารหัสที่ต้องการเพื่อแปลงสตริง Unicode เป็นการแสดงไบต์ในการเข้ารหัสที่ต้องการ หน้าจอจะแสดงการแสดงไบต์ของสตริงที่หน้ารหัสเฉพาะ
มันขึ้นอยู่กับการเข้ารหัสขั้วเดียวตามชื่อที่แนะนำ ดังนั้น โดยทั่วไปแล้ว ค่าไบนารีที่มีค่าเท่ากับหนึ่งจะถือว่าค่าในสัญญาณเอาท์พุตเท่ากับหนึ่ง และค่าที่เท่ากับศูนย์จะยอมให้ค่าศูนย์ในสัญญาณเอาท์พุต
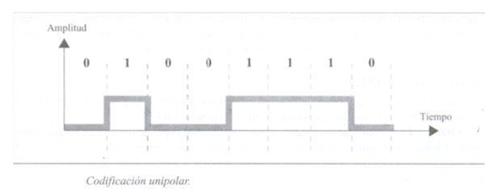
นี่คือประเภทของการเข้ารหัสที่ใช้กันมากที่สุดในปัจจุบัน มันขึ้นอยู่กับการเข้ารหัสของสองขั้วเพื่อแสดงข้อมูลไบนารี เราสามารถหาการจำแนกประเภทของขั้วการเข้ารหัสดังต่อไปนี้ 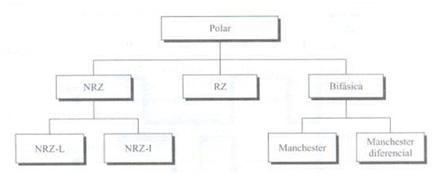
เป็นลักษณะความจริงที่ว่าสัญญาณมีค่าบวกหรือลบเสมอ เราสามารถแยกแยะความแตกต่างระหว่างประเภทได้อย่างชัดเจน
นำเข้าระบบ นำเข้า System.IO นำเข้า System.Globalization นำเข้า System.Text Public Class Encoding_UnicodeToCP Public Shared Sub Main () "แปลงอักขระ ASCII เป็นไบต์ "แสดงการแทนค่าไบต์สตริง" ใน"หน้ารหัสที่ระบุ "รหัสหน้า 1252 หมายถึงอักขระละติน PrintCPBytes ("สวัสดีชาวโลก!", 1252) "รหัสหน้า 932 หมายถึงอักขระภาษาญี่ปุ่น PrintCPBytes ("สวัสดีชาวโลก!", 932) "แปลงอักษรญี่ปุ่น PrintCPBytes (, 1252) PrintCPBytes ( "\ u307b, \ u308b, \ u305a, \ u3042, \ u306d", 932 สิ้นสุดย่อยย่อยสาธารณะย่อยที่ใช้ร่วมกัน PrintCPBytes (str As String, codePage เป็นจำนวนเต็ม) Dim targetEncoding As Encoding Dim encodedChars () As Byte "รับการเข้ารหัสสำหรับหน้ารหัสที่ระบุ targetEncoding = การเข้ารหัส GetEncoding (codePage) "รับการแสดงไบต์ของสตริงที่ระบุ encodedChars = targetEncoding.GetBytes (str) "พิมพ์ไบต์ Console.WriteLine ( "การแสดงไบต์ของ" (0) "ใน CP" (1) ":", _ str, codePage) Dim i As Integer For i = 0 To encodedChars.Length - 1 Console.WriteLine ("Byte (0): (1)", i, encodedChars (i)) Next i End Sub End Class
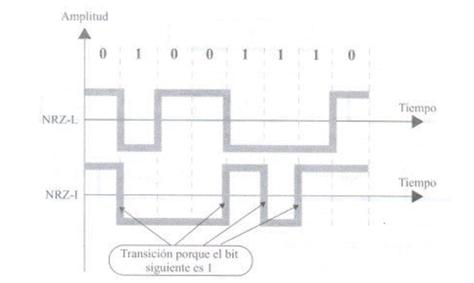
โดยปกติ ถ้าบิตถูกตั้งค่าเป็นหนึ่ง สัญญาณจะเป็นบวก ถ้าเป็นศูนย์ สัญญาณจะเป็นลบ ดังนั้น ค่านี้ไม่ได้ขึ้นอยู่กับบิตปัจจุบันเท่านั้น แต่ยังขึ้นกับบิตก่อนหน้าด้วย ดังนั้นจึงมีความน่าเชื่อถือมากขึ้น
โดดเด่นด้วยการใช้ระดับเอาต์พุตที่เป็นไปได้สามระดับ เด็กน้อยดูเหมือนจะเปลี่ยนจากบวกเป็นศูนย์และจากศูนย์เป็นลบเป็นบวก แต่ละธุรกรรมเกิดขึ้นในช่วงกลางของช่วงเวลา ดังแสดงในรูปต่อไปนี้ การเข้ารหัสประเภทนี้ยังช่วยให้สามารถทริกเกอร์ขั้นตอนการซิงโครไนซ์ได้โดยใช้การเปลี่ยนที่สร้างขึ้นที่ครึ่งช่อง
 ข้อบกพร่องในภาวะเอกฐาน?
ข้อบกพร่องในภาวะเอกฐาน? Just Cause 2 ล่ม
Just Cause 2 ล่ม Terraria ไม่เริ่มทำงาน ฉันควรทำอย่างไร?
Terraria ไม่เริ่มทำงาน ฉันควรทำอย่างไร?