จำนวนบิตที่ใช้ในการเข้ารหัส 1 อักขระในยูนิโค้ด การเข้ารหัสข้อความ
เริ่มตั้งแต่ช่วงปลายทศวรรษที่ 60 มีการใช้คอมพิวเตอร์ในการประมวลผลมากขึ้น ข้อมูลข้อความและปัจจุบันส่วนใหญ่ คอมพิวเตอร์ส่วนบุคคลในโลก (และส่วนใหญ่) กำลังยุ่งอยู่กับการประมวลผลข้อมูลที่เป็นข้อความ
ASCII - การเข้ารหัสข้อความพื้นฐานสำหรับอักษรละติน
ตามเนื้อผ้า ในการเข้ารหัสอักขระหนึ่งตัว จำนวนข้อมูลจะใช้เท่ากับ 1 ไบต์นั่นคือ I = 1 ไบต์ = 8 บิต
ในการเข้ารหัสอักขระหนึ่งตัว จำเป็นต้องมีข้อมูล 1 ไบต์ หากเราถือว่าสัญลักษณ์เป็นเหตุการณ์ที่เป็นไปได้ เราสามารถคำนวณได้ว่ามีกี่ตัว ตัวละครต่างๆสามารถเข้ารหัสได้: N = 2I = 28 = 256
จำนวนอักขระนี้เพียงพอสำหรับแสดงข้อมูลที่เป็นข้อความ รวมทั้งตัวพิมพ์ใหญ่และตัวพิมพ์เล็กของตัวอักษรรัสเซียและละติน ตัวเลข ป้าย สัญลักษณ์กราฟิก ฯลฯ การเข้ารหัสหมายความว่าอักขระแต่ละตัวมีการกำหนดรหัสทศนิยมที่ไม่ซ้ำกันตั้งแต่ 0 ถึง 255 หรือที่สอดคล้องกัน รหัสไบนารีจาก 00000000 ถึง 11111111
ดังนั้นบุคคลจึงแยกแยะสัญลักษณ์ตามสไตล์และคอมพิวเตอร์โดยใช้รหัส เมื่อป้อนข้อมูลข้อความลงในคอมพิวเตอร์ การเข้ารหัสแบบไบนารีจะเกิดขึ้น รูปภาพของสัญลักษณ์จะถูกแปลงเป็นรหัสไบนารี
ผู้ใช้กดแป้นที่มีสัญลักษณ์บนแป้นพิมพ์ และลำดับเฉพาะของแรงกระตุ้นไฟฟ้าแปดตัว (รหัสไบนารีของสัญลักษณ์) จะถูกส่งไปยังคอมพิวเตอร์ รหัสอักขระถูกเก็บไว้ใน หน่วยความจำเข้าถึงโดยสุ่มคอมพิวเตอร์ที่ใช้หนึ่งไบต์ ในกระบวนการแสดงอักขระบนหน้าจอคอมพิวเตอร์ กระบวนการย้อนกลับจะดำเนินการ - ถอดรหัส นั่นคือ การแปลงรหัสอักขระเป็นรูปภาพ ตารางรหัส ASCII (รหัส American Standard สำหรับการแลกเปลี่ยนข้อมูล) ถูกนำมาใช้เป็นมาตรฐานสากล ตารางส่วนมาตรฐาน ASCII สิ่งสำคัญคือการกำหนดรหัสเฉพาะให้กับอักขระเป็นเรื่องของข้อตกลงซึ่งได้รับการแก้ไขในตารางรหัส . 33 รหัสแรก (ตั้งแต่ 0 ถึง 32) ไม่ตรงกับอักขระ แต่ใช้กับการดำเนินการ (การป้อนบรรทัด การป้อนช่องว่าง และอื่นๆ) รหัสตั้งแต่ 33 ถึง 127 เป็นรหัสสากลและสอดคล้องกับสัญลักษณ์ของตัวอักษรละติน ตัวเลข เครื่องหมายเลขคณิต และเครื่องหมายวรรคตอน รหัสจาก 128 ถึง 255 เป็นรหัสประจำชาติ กล่าวคือ อักขระต่างกันสอดคล้องกับรหัสเดียวกันในการเข้ารหัสระดับประเทศ
ขออภัย ขณะนี้มีตารางรหัสที่แตกต่างกันห้าตารางสำหรับตัวอักษรรัสเซีย (KOI8, CP1251, CP866, Mac, ISO) ดังนั้นข้อความที่สร้างในการเข้ารหัสหนึ่งจะไม่แสดงอย่างถูกต้องในอีกรูปแบบหนึ่ง
ปัจจุบันเป็นสากลใหม่ มาตรฐานยูนิโค้ดซึ่งไม่ได้จัดสรรหนึ่งไบต์สำหรับแต่ละอักขระ แต่มีสองตัว ดังนั้นจึงสามารถใช้เข้ารหัสได้ไม่ใช่ 256 อักขระ แต่ N = 216 = 65536 ต่างกัน
Unicode - การเกิดขึ้นของการเข้ารหัสข้อความสากล (UTF 32, UTF 16 และ UTF 8)
อักขระหลายพันตัวจากกลุ่มภาษาเอเชียตะวันออกเฉียงใต้นี้ไม่สามารถอธิบายเป็นไบต์เดียวของข้อมูล ซึ่งได้รับการจัดสรรสำหรับการเข้ารหัสอักขระในการเข้ารหัส ASCII แบบขยาย เป็นผลให้กลุ่มที่เรียกว่า Unicode(Unicode - Unicode Consortium) โดยได้รับความร่วมมือจากผู้นำอุตสาหกรรมไอทีจำนวนมาก (ผู้ผลิตซอฟต์แวร์, ผู้เข้ารหัสฮาร์ดแวร์, ผู้สร้างฟอนต์) ที่มีความสนใจในการเกิดขึ้นของการเข้ารหัสข้อความสากล
การเข้ารหัสข้อความแรกที่เผยแพร่ภายใต้การอุปถัมภ์ของกลุ่ม Unicode คือการเข้ารหัส UTF 32... ตัวเลขในชื่อการเข้ารหัส UTF 32 หมายถึงจำนวนบิตที่ใช้ในการเข้ารหัสอักขระหนึ่งตัว 32 บิตเป็นข้อมูล 4 ไบต์ที่จำเป็นสำหรับการเข้ารหัสอักขระตัวเดียวในการเข้ารหัส Universal UTF 32 ใหม่
ด้วยเหตุนี้ ไฟล์เดียวกันกับที่เข้ารหัสข้อความในการเข้ารหัส ASCII แบบขยายและในการเข้ารหัส UTF 32 ในกรณีหลังจะมีขนาด (น้ำหนัก) มากกว่าสี่เท่า สิ่งนี้ไม่ดี แต่ตอนนี้เรามีโอกาสที่จะเข้ารหัสด้วย UTF 32 จำนวนอักขระเท่ากับสองยกกำลังสามสิบวินาที (อักขระหลายพันล้านตัวที่จะครอบคลุมค่าที่จำเป็นจริงๆ ด้วยระยะขอบมหาศาล)
แต่หลายประเทศที่มีภาษาของกลุ่มยุโรปไม่จำเป็นต้องใช้อักขระจำนวนมากในการเข้ารหัสเลย แต่เมื่อใช้ UTF 32 พวกเขาได้รับน้ำหนักเพิ่มขึ้นสี่เท่าโดยเปล่าประโยชน์ เอกสารข้อความส่งผลให้ปริมาณการรับส่งข้อมูลทางอินเทอร์เน็ตและปริมาณข้อมูลที่จัดเก็บเพิ่มขึ้น มีจำนวนมากและไม่มีใครสามารถจ่ายของเสียได้
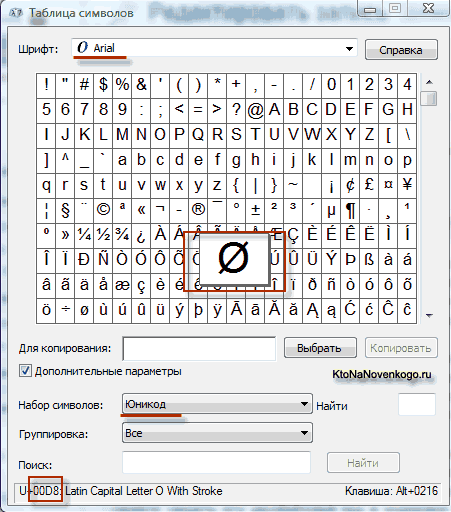
อันเป็นผลมาจากการพัฒนาความเป็นสากล การเข้ารหัส Unicode ปรากฏ UTF 16ซึ่งกลายเป็นว่าประสบความสำเร็จจนเป็นที่ยอมรับโดยค่าเริ่มต้นเป็นพื้นที่ฐานสำหรับสัญลักษณ์ทั้งหมดที่เราใช้ UTF 16 ใช้สองไบต์ในการเข้ารหัสหนึ่งอักขระ เช่น ในห้องผ่าตัด ระบบ Windowsคุณสามารถทำตามเส้นทาง เริ่ม - โปรแกรม - อุปกรณ์เสริม - เครื่องมือระบบ - ตารางสัญลักษณ์
ด้วยเหตุนี้ ตารางที่มีรูปแบบเวกเตอร์ของแบบอักษรทั้งหมดที่ติดตั้งในระบบของคุณจะเปิดขึ้น หากคุณเลือกชุดอักขระ Unicode ในตัวเลือกขั้นสูง คุณจะสามารถดูแบบอักษรแต่ละแบบแยกกันถึงชุดอักขระทั้งหมดที่รวมอยู่ในนั้น อย่างไรก็ตาม เมื่อคลิกที่อักขระใดๆ เหล่านี้ คุณจะเห็นโค้ดสองไบต์ในการเข้ารหัส UTF 16 ซึ่งประกอบด้วยเลขฐานสิบหกสี่หลัก:
สามารถเข้ารหัสอักขระได้กี่ตัวใน UTF 16 ด้วย 16 บิต 65,536 อักขระ (สองยกกำลังสิบหก) ถูกใช้เป็นพื้นที่พื้นฐานใน Unicode นอกจากนี้ มีวิธีการเข้ารหัสด้วย UTF 16 ประมาณสองล้านอักขระ แต่จำกัดเฉพาะพื้นที่ขยายของข้อความหนึ่งล้านอักขระ
แต่ถึงแม้รุ่นเข้ารหัส Unicode ที่ประสบความสำเร็จเรียกว่า UTF 16 ก็ไม่ได้ทำให้ผู้ที่เขียนพึงพอใจมากนัก เช่น โปรแกรมเฉพาะใน ภาษาอังกฤษเนื่องจากหลังจากการเปลี่ยนจากเวอร์ชันขยายของการเข้ารหัส ASCII เป็น UTF 16 น้ำหนักของเอกสารจะเพิ่มเป็นสองเท่า (หนึ่งไบต์สำหรับหนึ่งอักขระใน ASCII และสองไบต์สำหรับอักขระเดียวกันในการเข้ารหัส UTF 16) ได้อย่างแม่นยำเพื่อความพึงพอใจของทุกคนและทุกอย่างในกลุ่ม Unicode ที่ได้รับการตัดสินให้เกิดขึ้น การเข้ารหัสข้อความความยาวผันแปร.
การเข้ารหัสใน Unicode นี้เรียกว่า UTF8... แม้จะมีชื่อแปดตัว แต่ UTF 8 ก็เป็นการเข้ารหัสที่มีความยาวผันแปรได้อย่างสมบูรณ์เช่น อักขระแต่ละตัวของข้อความสามารถเข้ารหัสเป็นลำดับได้ตั้งแต่หนึ่งถึงหกไบต์ ในทางปฏิบัติ ใน UTF 8 จะใช้ช่วงตั้งแต่หนึ่งถึงสี่ไบต์เท่านั้น เนื่องจากโค้ดเกินสี่ไบต์ ไม่มีทางเป็นไปได้ในทางทฤษฎี
ใน UTF 8 อักขระละตินทั้งหมดจะถูกเข้ารหัสในหนึ่งไบต์ เช่นเดียวกับในการเข้ารหัส ASCII แบบเก่า ที่น่าสังเกตคือ ในกรณีที่เข้ารหัสเฉพาะอักษรละติน แม้แต่โปรแกรมที่ไม่เข้าใจ Unicode ก็ยังอ่านสิ่งที่เข้ารหัสใน UTF 8 นั่นคือ ส่วนพื้นฐานของการเข้ารหัส ASCII ถูกย้ายไปที่ UTF 8
อักขระซิริลลิกใน UTF 8ถูกเข้ารหัสเป็นสองไบต์และตัวอย่างเช่นจอร์เจีย - ในสามไบต์ Unicode Consortium หลังจากสร้างการเข้ารหัส UTF 16 และ UTF 8 ได้แก้ไขปัญหาหลัก - ตอนนี้เรามีพื้นที่โค้ดเดียวในแบบอักษรของเรา สิ่งเดียวที่เหลือสำหรับผู้ผลิตฟอนต์คือการเติมพื้นที่โค้ดนี้ด้วยรูปแบบเวกเตอร์ของอักขระข้อความตามจุดแข็งและความสามารถของพวกเขา
ในทางทฤษฎี มีวิธีแก้ปัญหาเหล่านี้มานานแล้ว ก็เรียกว่า Unicode Unicodeเป็นตารางการเข้ารหัสที่ใช้ 2 ไบต์ในการเข้ารหัสอักขระแต่ละตัว เช่น 16 บิต จากตารางดังกล่าว สามารถเข้ารหัสอักขระ N = 2 16 = 65 536 ตัวได้
Unicode มีสคริปต์สมัยใหม่เกือบทั้งหมด รวมถึง: อาหรับ อาร์เมเนีย เบงกาลี พม่า กรีก จอร์เจีย เทวนาครี ฮีบรู ซิริลลิก คอปติก เขมร ละติน ทมิฬ ฮันกุล ฮัน (จีน ญี่ปุ่น เกาหลี) เชโรกี เอธิโอเปีย ภาษาญี่ปุ่น (คะตะคะนะ ฮิระงะนะ คันจิ) และอื่นๆ
เพื่อวัตถุประสงค์ทางวิชาการ มีการเพิ่มสคริปต์ทางประวัติศาสตร์มากมาย รวมถึง: กรีกโบราณ อักษรอียิปต์โบราณ คิวนิฟอร์ม การเขียนของชาวมายัน ตัวอักษรอิทรุสกัน
Unicode มีสัญลักษณ์ทางคณิตศาสตร์และดนตรีและรูปสัญลักษณ์มากมาย
สำหรับอักขระ Cyrillic ใน Unicode จะมีการจัดสรรช่วงรหัสสองช่วง:
ซิริลลิก (# 0400 - # 04FF)
อาหารเสริมซีริลลิก (# 0500 - # 052F)
แต่การฉีดตาราง Unicodeในรูปแบบบริสุทธิ์มันถูก จำกัด เนื่องจากถ้ารหัสของอักขระหนึ่งตัวจะไม่ใช้หนึ่งไบต์ แต่สองไบต์ จะใช้พื้นที่ดิสก์มากเป็นสองเท่าในการจัดเก็บข้อความ และเวลามากเป็นสองเท่าในการถ่ายโอนผ่านการสื่อสาร ช่อง.
ดังนั้น ในทางปฏิบัติ การแสดง Unicode ของ UTF-8 (รูปแบบการแปลง Unicode) จึงเป็นเรื่องธรรมดามากขึ้น UTF-8 ให้ความเข้ากันได้ดีที่สุดกับระบบที่ใช้อักขระ 8 บิต ข้อความที่มีเฉพาะอักขระที่มีตัวเลขน้อยกว่า 128 จะถูกแปลงเป็นข้อความ ASCII ธรรมดาเมื่อเขียนด้วย UTF-8 อักขระ Unicode ที่เหลือจะแสดงตามลำดับความยาว 2 ถึง 4 ไบต์ โดยทั่วไป เนื่องจากอักขระทั่วไปที่สุดในโลก - อักขระของอักษรละติน - ใน UTF-8 ยังคงใช้ 1 ไบต์ การเข้ารหัสนี้จึงประหยัดกว่า Unicode แท้
ข้อความภาษาอังกฤษที่เข้ารหัสใช้ตัวอักษรละตินเพียง 26 ตัวและเครื่องหมายวรรคตอนอีก 6 ตัว ในกรณีนี้ สามารถรับประกันได้ว่าข้อความที่มีอักขระ 1,000 ตัวจะถูกบีบอัดโดยไม่สูญเสียข้อมูลขนาด:
พจนานุกรมของ Ellochka - "มนุษย์กินคน" (ตัวละครในนวนิยายเรื่อง "The Twelve Chairs") มีคำ 30 คำ มีกี่บิตเพียงพอที่จะเข้ารหัสคำศัพท์ทั้งหมดของ Ellochka ตัวเลือก: 8, 5, 3, 1
หน่วยวัดปริมาณข้อมูลและความจุหน่วยความจำ: กิโลไบต์ เมกะไบต์ กิกะไบต์ ...
ดังนั้น ในเราพบว่าในการเข้ารหัสที่ทันสมัยที่สุด มีการจัดสรร 1 ไบต์สำหรับจัดเก็บอักขระหนึ่งตัวของข้อความบนสื่ออิเล็กทรอนิกส์ เหล่านั้น. หน่วยเป็นไบต์ ปริมาณ (V) ที่ใช้โดยข้อมูลจะถูกวัดระหว่างการจัดเก็บและการส่ง (ไฟล์, ข้อความ)
ปริมาณข้อมูล (V) - จำนวนไบต์ที่ต้องเก็บไว้ในหน่วยความจำของผู้ให้บริการข้อมูลอิเล็กทรอนิกส์
หน่วยความจำสื่อกลับมีจำกัด ความจุ, เช่น. ความสามารถในการบรรจุปริมาณที่แน่นอน แน่นอนว่าความจุของสื่อเก็บข้อมูลอิเล็กทรอนิกส์นั้นวัดเป็นไบต์เช่นกัน
อย่างไรก็ตาม ไบต์เป็นหน่วยขนาดเล็กสำหรับวัดปริมาณข้อมูล ขนาดใหญ่กว่าคือกิโลไบต์ เมกะไบต์ กิกะไบต์ เทราไบต์ ...
ควรจำไว้ว่าคำนำหน้า "กิโล", "mega", "giga" ... ไม่ใช่ทศนิยมในกรณีนี้ ดังนั้น “กิโล” ในคำว่า “กิโลไบต์” ไม่ได้หมายความว่า “พัน” เช่น ไม่ได้หมายถึง “10 3” บิตเป็นหน่วยเลขฐานสอง และด้วยเหตุนี้ในวิทยาการคอมพิวเตอร์ จึงสะดวกที่จะใช้หน่วยวัดที่เป็นจำนวนทวีคูณของตัวเลข "2" แทนที่จะเป็นตัวเลข "10"
1 ไบต์ = 2 3 = 8 บิต 1 กิโลไบต์ = 2 10 = 1024 ไบต์ในไบนารี 1 กิโลไบต์ = & 1,000,000,000 ไบต์
เหล่านั้น. “กิโล” ในที่นี้หมายถึงจำนวนที่ใกล้เคียงที่สุดกับหลักพัน ซึ่งเป็นกำลังของเลข 2 คือ ซึ่งเป็นตัวเลข "กลม" ในรูปแบบเลขฐานสอง
ตารางที่ 10.
|
การตั้งชื่อ |
การกำหนด |
ค่าเป็นไบต์ |
|
|
กิโลไบต์ | |||
|
เมกะไบต์ |
2 10 Kb = 2 20 b | ||
|
กิกะไบต์ |
2 10 Mb = 2 30 b | ||
|
เทราไบต์ |
2 10 Gb = 2 40 b |
1,099 511 627 776 บ |
|
เนื่องจากหน่วยวัดปริมาตรและความจุของผู้ให้บริการข้อมูลเป็นทวีคูณของ 2 และไม่ใช่ทวีคูณของ 10 ปัญหาส่วนใหญ่ในหัวข้อนี้จะแก้ไขได้ง่ายกว่าเมื่อค่าที่ปรากฏในค่านั้นแสดงด้วยกำลัง 2 . พิจารณาตัวอย่างของปัญหาดังกล่าวและวิธีแก้ไข:
ไฟล์ข้อความประกอบด้วยข้อความ 400 หน้า แต่ละหน้ามีอักขระ 3200 ตัว หากการเข้ารหัสเป็น KOI-8 (8 บิตต่ออักขระ) ขนาดไฟล์จะเป็น:
สารละลาย
กำหนดจำนวนอักขระทั้งหมดในไฟล์ข้อความ ในกรณีนี้ เราแสดงตัวเลขที่เป็นทวีคูณของยกกำลัง 2 เป็นยกกำลัง 2 นั่นคือ แทนที่จะเป็น 4 เราเขียน 2 2 เป็นต้น ตารางที่ 7 สามารถใช้กำหนดระดับได้
ตัวอักษร
2) ตามเงื่อนไขของปัญหา 1 ตัวอักษรใช้ 8 บิตนั่นคือ 1 ไบต์ => ไฟล์ใช้พื้นที่ 2 7 * 10,000 ไบต์
3) 1 กิโลไบต์ = 2 10 ไบต์ => ขนาดไฟล์เป็นกิโลไบต์คือ:
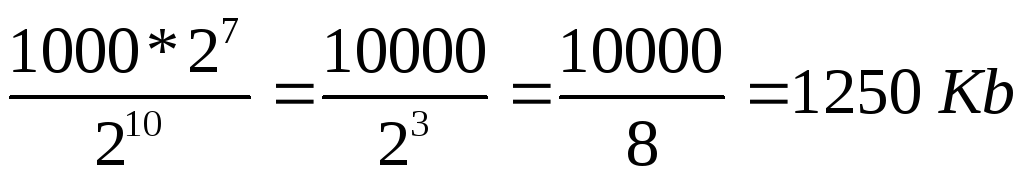 .
.
หนึ่งกิโลไบต์มีกี่บิต?
&10000000000000.
1 MB คืออะไร?
1,000,000 ไบต์
1024 ไบต์;
1024 กิโลไบต์;
ข้อความในหนึ่งส่วนสี่กิโลไบต์มีกี่บิต? ตัวเลือก: 250, 512, 2000, 2048
ปริมาณ ไฟล์ข้อความ 640 Kb... ไฟล์นี้มีหนังสือที่พิมพ์โดยเฉลี่ย 32 บรรทัดต่อหน้าและโดย 64 อักขระในสตริง มีกี่หน้าในหนังสือ: 160, 320, 540, 640, 1280?
เอกสารเกี่ยวกับพนักงาน 8 Mb... แต่ละอันประกอบด้วย 16 หน้า ( 32 เส้นโดย 64 ตัวอักษรต่อบรรทัด) จำนวนพนักงานในองค์กร: 256; 512; 1024; 2048?
โพสต์นี้มีไว้สำหรับผู้ที่ไม่เข้าใจว่า UTF-8 คืออะไร แต่ต้องการทำความเข้าใจ และเอกสารที่มีอยู่มักจะครอบคลุมปัญหานี้อย่างกว้างขวาง ฉันจะพยายามอธิบายที่นี่ในแบบที่ฉันเองก็อยากให้ใครซักคนบอกฉันมาก่อน บ่อยครั้งฉันมีความยุ่งเหยิงในหัวเกี่ยวกับ UTF-8
กติกาง่ายๆ
- ดังนั้น UTF-8 จึงเป็นตัวห่อหุ้มรอบ Unicode ไม่ใช่การเข้ารหัสอักขระแยกต่างหาก แต่อยู่ใน Unicode คุณอาจรู้จักการเข้ารหัส Base64 หรือเคยได้ยินมา มันสามารถห่อข้อมูลไบนารีในอักขระที่พิมพ์ได้ Duck, UTF-8 เป็น Base64 เดียวกันสำหรับ Unicode เป็น Base64 สำหรับข้อมูลไบนารี เวลานี้. หากคุณเข้าใจสิ่งนี้ หลายๆ อย่างก็จะชัดเจนขึ้นแล้ว และยังเป็นที่รู้จักในการแก้ปัญหาความเข้ากันได้ของอักขระเช่นเดียวกับ Base64 (Base64 ถูกคิดค้นสำหรับอีเมลเพื่อถ่ายโอนไฟล์ทางไปรษณีย์ซึ่งอักขระทั้งหมดสามารถพิมพ์ได้)
- นอกจากนี้ หากโค้ดใช้งานได้กับ UTF-8 โค้ดภายในจะยังคงใช้งานได้กับการเข้ารหัส Unicode นั่นคือที่ใดที่หนึ่งลึกลงไปข้างในจะมีตารางสัญลักษณ์ของอักขระ Unicode ทุกประการ จริง คุณอาจไม่มีตารางอักขระ Unicode หากคุณต้องการนับจำนวนอักขระในบรรทัด เช่น (ดูด้านล่าง)
- UTF-8 ถูกสร้างขึ้นเพื่อให้โปรแกรมเก่าและคอมพิวเตอร์ในปัจจุบันสามารถทำงานได้ตามปกติด้วยอักขระ Unicode เช่นเดียวกับการเข้ารหัสแบบเก่า เช่น KOI8, Windows-1251 เป็นต้น ใน UTF-8 ไม่มีไบต์ที่มีเลขศูนย์ ไบต์ทั้งหมดคือ ทั้งจาก 0x01 - 0x7F เช่น ASCII ปกติหรือ 0x80 - 0xFF ซึ่งใช้ได้กับโปรแกรมที่เขียนด้วยภาษา C เนื่องจากจะทำงานกับอักขระที่ไม่ใช่ ASCII จริงสำหรับ งานที่ถูกต้องด้วยสัญลักษณ์ โปรแกรมต้องรู้จักตาราง Unicode
- สิ่งใดก็ตามที่มีบิตที่ 7 ที่สำคัญที่สุดในหนึ่งไบต์ (นับบิตจากศูนย์) UTF-8 เป็นส่วนหนึ่งของ Unicode codestream
UTF-8 จากภายในสู่ภายนอก
ถ้าคุณรู้จักระบบบิตแล้วที่นี่เพื่อคุณ บันทึกด่วน UTF-8 เข้ารหัสอย่างไร:
ไบต์ Unicode แรกของอักขระ UTF-8 เริ่มต้นด้วยไบต์ โดยที่บิตที่ 7 จะเป็นหนึ่งเสมอ และบิตที่ 6 จะเป็นหนึ่งเสมอ ในกรณีนี้ ในไบต์แรก หากคุณดูบิตจากซ้ายไปขวา (ที่ 7, 6 และไปเรื่อยๆ จนถึงศูนย์) จะมีหน่วยเท่ากับไบต์ รวมถึงตัวแรก ให้ไปที่การเข้ารหัสอักขระ Unicode หนึ่งตัว ลำดับของหนึ่งลงท้ายด้วยศูนย์ และหลังจากนั้นก็เป็นบิตของอักขระ Unicode เอง ส่วนที่เหลือของบิต Unicode ของอักขระอยู่ในไบต์ที่สอง หรือแม้แต่ไบต์ที่สาม (สูงสุดสาม เหตุผล - ดูด้านล่าง) ไบต์ที่เหลือ ยกเว้นอันแรก มักจะเริ่มต้นด้วย '10' และตามด้วย 6 บิตของส่วนถัดไปของอักขระ Unicode
ตัวอย่าง
ตัวอย่างเช่น: มีไบต์ 110 10000 และที่สอง 10 011110 ... อันแรกเริ่มต้นด้วย '110' ซึ่งหมายความว่าหากมีสองอัน จะมีสตรีม UTF-8 สองไบต์ และไบต์ที่สองก็เหมือนกับ '10' และสองไบต์นี้เข้ารหัสอักขระ Unicode ซึ่งประกอบด้วย 10100 บิตจากอันแรก + 101101 จากอันที่สอง ปรากฎ -> 10000011110 -> 41Eในระบบเลขฐานสิบหกหรือ U + 041Eในการเขียนสัญกรณ์ Unicode นี่คือสัญลักษณ์ของโอรัสเซียตัวใหญ่
สูงสุดกี่ไบต์ต่ออักขระ?
มาดูกันว่าสูงสุดกี่ไบต์ที่ใส่ลงใน UTF-8 เพื่อเข้ารหัส 16 บิตของการเข้ารหัส Unicode ไบต์ที่สองและถัดไปสามารถรองรับได้สูงสุด 6 บิตเสมอ ดังนั้น หากคุณเริ่มต้นด้วยไบต์ต่อท้าย สองไบต์จะหายไปอย่างแน่นอน (ที่ 2 และที่สาม) และไบต์แรกต้องขึ้นต้นด้วย '1110' เพื่อเข้ารหัสสามไบต์ ซึ่งหมายความว่าไบต์แรกในกรณีนี้สามารถเข้ารหัส 4 บิตแรกของอักขระ Unicode ปรากฎว่า 4 + 6 + 6 = 16 ไบต์ ปรากฎว่า UTF-8 สามารถมีได้ 2 หรือ 3 ไบต์ต่ออักขระ Unicode (ไม่สามารถทำได้เนื่องจากไม่จำเป็นต้องเข้ารหัส 6 บิต (8 - 2 บิต '10') - มันจะเป็นอักขระ ASCII นั่นคือเหตุผล ไบต์แรกคือ UTF 8 ไม่สามารถเริ่มต้นด้วย '10')
บทสรุป
ยังไงก็ตาม ด้วยการเข้ารหัสนี้ คุณสามารถใช้ไบต์ใดก็ได้ในสตรีมและพิจารณาว่าไบต์เป็น อักขระ Unicode(ถ้าบิตที่ 7 หมายถึงไม่ใช่ ASCII) ถ้าใช่ แสดงว่าเป็นตัวแรกในสตรีม UTF-8 หรือไม่เป็นตัวแรก (ถ้า '10' ก็ไม่ใช่ตัวแรก) ถ้าไม่ใช่ตัวแรก เราก็สามารถย้อนกลับได้ ไบต์เพื่อค้นหารหัส UTF-8 แรก (โดยที่บิตที่ 6 คือ 1) หรือเลื่อนไปทางขวาและข้าม '10' ไบต์ทั้งหมดเพื่อค้นหาอักขระถัดไป ด้วยการเข้ารหัสนี้ โปรแกรมยังสามารถอ่านจำนวนอักขระในสตริงได้โดยไม่ต้องรู้ Unicode (คำนวณความยาวอักขระเป็นไบต์ตาม UTF-8 ไบต์แรก) โดยทั่วไปแล้ว หากคุณคิดเกี่ยวกับมัน การเข้ารหัส UTF-8 ถูกประดิษฐ์ขึ้นอย่างมีประสิทธิภาพ และในขณะเดียวกันก็มีประสิทธิภาพมาก
การเข้ารหัสข้อมูล
ตัวเลขใดๆ (ภายในขีดจำกัด) ในหน่วยความจำของคอมพิวเตอร์จะถูกเข้ารหัสด้วยตัวเลขในระบบเลขฐานสอง มีกฎการแปลที่ง่ายและชัดเจนสำหรับสิ่งนี้ อย่างไรก็ตาม ทุกวันนี้ คอมพิวเตอร์ถูกใช้อย่างแพร่หลายมากกว่าบทบาทของผู้คำนวณที่ใช้แรงงานเข้มข้น ตัวอย่างเช่น หน่วยความจำคอมพิวเตอร์เก็บข้อมูลข้อความและมัลติมีเดีย ดังนั้น คำถามแรกจึงเกิดขึ้น:
อักขระ (ตัวอักษร) ถูกเก็บไว้ในหน่วยความจำของคอมพิวเตอร์อย่างไร?
ตัวอักษรแต่ละตัวเป็นของตัวอักษรบางตัวที่อักขระต่อกัน ดังนั้นจึงสามารถกำหนดหมายเลขด้วยจำนวนเต็มติดต่อกันได้ ตัวอักษรแต่ละตัวสามารถเชื่อมโยงกับจำนวนเต็มบวกและเรียกมันว่ารหัสอักขระ... รหัสนี้จะถูกเก็บไว้ในหน่วยความจำของคอมพิวเตอร์ และเมื่อแสดงบนหน้าจอหรือบนกระดาษ รหัสจะถูก "แปลง" เป็นอักขระที่เกี่ยวข้อง หากต้องการแยกแยะการแสดงตัวเลขจากการแทนตัวอักษรในหน่วยความจำคอมพิวเตอร์ คุณต้องจัดเก็บข้อมูลประเภทใดที่เข้ารหัสไว้ในพื้นที่หน่วยความจำเฉพาะ
ความสอดคล้องของตัวอักษรของตัวอักษรบางตัวที่มีรหัสตัวเลขเรียกว่า ตารางการเข้ารหัส... กล่าวอีกนัยหนึ่ง อักขระแต่ละตัวของตัวอักษรเฉพาะมีรหัสตัวเลขของตัวเองตามตารางการเข้ารหัสเฉพาะ
อย่างไรก็ตาม มีตัวอักษรมากมายในโลก (อังกฤษ รัสเซีย จีน ฯลฯ) ดังนั้นคำถามต่อไปคือ:
จะเข้ารหัสตัวอักษรทั้งหมดที่ใช้ในคอมพิวเตอร์ได้อย่างไร?
เพื่อตอบคำถามนี้ เราจะเดินตามเส้นทางประวัติศาสตร์
ในยุค 60 ของศตวรรษที่ XX ใน สถาบันมาตรฐานแห่งชาติอเมริกัน (ANSI)มีการพัฒนาตารางการเข้ารหัสอักขระซึ่งต่อมาใช้ในทั้งหมด ระบบปฏิบัติการ... ตารางนี้เรียกว่า ASCII (รหัสอเมริกันสแตนดาร์ดสำหรับการแลกเปลี่ยนข้อมูล)... ไม่นานก็ปรากฏตัว เวอร์ชัน ASCII แบบขยาย.
ตามตารางการเข้ารหัส ASCII มีการจัดสรร 1 ไบต์ (8 บิต) เพื่อแสดงอักขระหนึ่งตัว ชุดเซลล์ 8 เซลล์สามารถรับค่าต่างๆ ได้ 2 8 = 256 ค่า 128 ค่าแรก (จาก 0 ถึง 127) เป็นค่าคงที่และเป็นส่วนที่เรียกว่าส่วนหลักของตารางซึ่งรวมถึงตัวเลขทศนิยม, ตัวอักษรของอักษรละติน (ตัวพิมพ์ใหญ่และตัวพิมพ์เล็ก), เครื่องหมายวรรคตอน (จุด, ลูกน้ำ, วงเล็บเหลี่ยม ฯลฯ) ตลอดจนช่องว่างและอักขระบริการต่างๆ (การจัดตาราง การป้อนบรรทัด ฯลฯ) ค่าจาก 128 ถึง 255 form ส่วนเสริมตารางที่เป็นเรื่องปกติในการเข้ารหัสสัญลักษณ์ของตัวอักษรประจำชาติ
เนื่องจากมีตัวอักษรประจำชาติมากมาย ตาราง ASCII แบบขยายจึงมีอยู่ในหลายรูปแบบ แม้แต่ภาษารัสเซียก็มีตารางการเข้ารหัสหลายแบบ (Windows-1251 และ Koi8-r เป็นเรื่องปกติ) ทั้งหมดนี้สร้างปัญหาเพิ่มเติม ตัวอย่างเช่น เราส่งจดหมายที่เขียนด้วยการเข้ารหัสแบบหนึ่ง และผู้รับจะพยายามอ่านอีกฉบับหนึ่ง เป็นผลให้เขาเห็น krakozyabry ดังนั้น ผู้อ่านจำเป็นต้องใช้ตารางการเข้ารหัสที่แตกต่างกันสำหรับข้อความ
มีปัญหาอื่นเช่นกัน ตัวอักษรของบางภาษามีอักขระมากเกินไปและไม่พอดีกับตำแหน่งที่กำหนดตั้งแต่การเข้ารหัสแบบไบต์เดียว 128 ถึง 255
ปัญหาที่สามคือจะทำอย่างไรถ้าข้อความใช้หลายภาษา (เช่นรัสเซียอังกฤษและฝรั่งเศส)? คุณไม่สามารถใช้สองตารางพร้อมกัน ...
เพื่อแก้ปัญหาเหล่านี้ การเข้ารหัส Unicode ได้รับการพัฒนาในครั้งเดียว
มาตรฐานการเข้ารหัสอักขระ Unicode
เพื่อแก้ปัญหาข้างต้นในช่วงต้นทศวรรษ 90 ได้มีการพัฒนามาตรฐานการเข้ารหัสอักขระที่เรียกว่า Unicode. มาตรฐานนี้ช่วยให้คุณใช้ภาษาและสัญลักษณ์เกือบทุกชนิดในข้อความ
Unicode มี 31 บิตสำหรับการเข้ารหัสอักขระ (4 ไบต์ลบหนึ่งบิต) จำนวนชุดค่าผสมที่เป็นไปได้ให้จำนวนที่สูงเกินไป: 2 31 = 2 147 483 684 (กล่าวคือ มากกว่าสองพันล้าน) ดังนั้น Unicode จึงอธิบายตัวอักษรของภาษาที่รู้จักทั้งหมด แม้กระทั่ง "ตาย" และถูกประดิษฐ์ขึ้น รวมถึงคณิตศาสตร์และภาษาอื่นๆ สัญลักษณ์พิเศษ... อย่างไรก็ตาม ความจุข้อมูลของ Unicode 31 บิตยังคงมีขนาดใหญ่เกินไป ดังนั้นจึงมักใช้เวอร์ชันย่อ 16 บิต (2 16 = 65 536 ค่า) โดยที่ตัวอักษรสมัยใหม่ทั้งหมดจะถูกเข้ารหัส
ใน Unicode 128 โค้ดแรกจะเหมือนกับตาราง ASCII
ในปัจจุบัน ผู้ใช้ส่วนใหญ่ที่ใช้คอมพิวเตอร์ประมวลผลข้อมูลที่เป็นข้อความ ซึ่งประกอบด้วยสัญลักษณ์: ตัวอักษร ตัวเลข เครื่องหมายวรรคตอน ฯลฯ
บนพื้นฐานของเซลล์หนึ่งเซลล์ที่มีความจุข้อมูล 1 บิต สามารถเข้ารหัสได้เพียง 2 สถานะที่แตกต่างกัน เพื่อให้อักขระแต่ละตัวที่สามารถป้อนจากแป้นพิมพ์ในทะเบียนละตินเพื่อรับรหัสไบนารีที่ไม่ซ้ำกันจึงต้องใช้ 7 บิต ตามลำดับ 7 บิตตามสูตร Hartley N = 2 7 = 128 ชุดค่าผสมที่แตกต่างกันของศูนย์และค่าต่างๆ เช่น รหัสไบนารี โดยการเชื่อมโยงอักขระแต่ละตัวกับรหัสไบนารี เราจะได้ตารางการเข้ารหัส บุคคลทำงานด้วยสัญลักษณ์ คอมพิวเตอร์ - ด้วยรหัสไบนารี่ของพวกเขา
สำหรับรูปแบบแป้นพิมพ์ภาษาละติน ตารางการเข้ารหัสดังกล่าวเป็นตารางสำหรับทั้งโลก ดังนั้นข้อความที่พิมพ์โดยใช้รูปแบบแป้นพิมพ์ภาษาละตินจะแสดงบนคอมพิวเตอร์ทุกเครื่องอย่างเพียงพอ ตารางนี้เรียกว่า ASCII(American Standard Code of Information Interchange) ในภาษาอังกฤษออกเสียงว่า [eski] ในภาษารัสเซียจะออกเสียงว่า [aski] ด้านล่างนี้คือตาราง ASCII ทั้งหมด รหัสที่ระบุในรูปแบบทศนิยม สามารถใช้เพื่อตรวจสอบว่าเมื่อคุณป้อนอักขระ "*" จากแป้นพิมพ์คอมพิวเตอร์จะรับรู้ว่าเป็นรหัส 42 (10) ในทางกลับกัน 42 (10) = 101010 (2) - นี่คือรหัสไบนารี ของอักขระ “* ” รหัส 0 ถึง 31 ไม่ได้ใช้ในตารางนี้
ตาราง อักขระ ASCII
| รหัส | เครื่องหมาย | รหัส | เครื่องหมาย | รหัส | เครื่องหมาย | รหัส | เครื่องหมาย | รหัส | เครื่องหมาย | รหัส | เครื่องหมาย |
| ช่องว่าง | . | @ | NS | " | NS | ||||||
| ! | NS | NS | NS | NS | |||||||
| " | NS | NS | NS | NS | |||||||
| # | ค | NS | ค | NS | |||||||
| $ | NS | NS | NS | NS | |||||||
| % | อี | ยู | อี | ยู | |||||||
| & | NS | วี | NS | วี | |||||||
| " | NS | W | NS | w | |||||||
| ( | ชม | NS | ชม | NS | |||||||
| ) | ผม | Y | ผม | y | |||||||
| * | NS | Z | NS | z | |||||||
| + | : | K | [ | k | { | ||||||
| , | ; | หลี่ | \ | l | | | ||||||
| - | < | NS | ] | NS | } | ||||||
| . | > | NS | ^ | NS | ~ | ||||||
| / | ? | อู๋ | _ | o | DEL |
ในการเข้ารหัสอักขระหนึ่งตัว จะใช้จำนวนข้อมูลเท่ากับ 1 ไบต์ นั่นคือ I = 1 ไบต์ = 8 บิต การใช้สูตรที่เชื่อมโยงจำนวนของเหตุการณ์ที่เป็นไปได้ K และจำนวนข้อมูล I คุณสามารถคำนวณจำนวนสัญลักษณ์ต่างๆ ที่สามารถเข้ารหัสได้ (สมมติว่าสัญลักษณ์เป็นเหตุการณ์ที่เป็นไปได้):
K = 2 ผม = 2 8 = 256,
นั่นคือตัวอักษรที่มีความจุ 256 อักขระสามารถใช้เพื่อแสดงข้อมูลที่เป็นข้อความ
สาระสำคัญของการเข้ารหัสคืออักขระแต่ละตัวถูกกำหนดรหัสไบนารีจาก 00000000 ถึง 11111111 หรือรหัสทศนิยมที่สอดคล้องกันตั้งแต่ 0 ถึง 255
ต้องจำไว้ว่าในปัจจุบัน สำหรับการเข้ารหัสภาษารัสเซีย ตัวอักษรใช้ตารางรหัสที่แตกต่างกันห้าตาราง (ก้อย - 8, CP1251, CP866, Mac, ISO),นอกจากนี้ ข้อความที่เข้ารหัสโดยใช้ตารางหนึ่งจะไม่แสดงอย่างถูกต้องในการเข้ารหัสอื่น สิ่งนี้สามารถแสดงได้อย่างชัดเจนว่าเป็นส่วนหนึ่งของตารางการเข้ารหัสอักขระแบบรวม
สัญลักษณ์ที่แตกต่างกันถูกกำหนดให้กับรหัสไบนารีเดียวกัน
| รหัสไบนารี | รหัสทศนิยม | KOI8 | CP1251 | CP866 | Mac | ISO |
| NS | วี | - | - | NS |
อย่างไรก็ตาม ในกรณีส่วนใหญ่ ผู้ใช้จะดูแลการแปลงรหัสเอกสารข้อความและ โปรแกรมพิเศษ- ตัวแปลงที่สร้างขึ้นในแอปพลิเคชัน
ตั้งแต่ 1997 เวอร์ชั่นล่าสุด Microsoft Officeรองรับการเข้ารหัสใหม่ มันถูกเรียกว่า ยูนิโค้ด (ยูนิโค้ด). Unicodeเป็นตารางการเข้ารหัสที่ใช้ 2 ไบต์ในการเข้ารหัสอักขระแต่ละตัว เช่น 16 บิต จากตารางดังกล่าว สามารถเข้ารหัสอักขระ N = 2 16 = 65 536 ตัวได้
Unicode มีสคริปต์สมัยใหม่เกือบทั้งหมด รวมถึง: อาหรับ อาร์เมเนีย เบงกาลี พม่า กรีก จอร์เจีย เทวนาครี ฮีบรู ซิริลลิก คอปติก เขมร ละติน ทมิฬ ฮันกุล ฮัน (จีน ญี่ปุ่น เกาหลี) เชโรกี เอธิโอเปีย ภาษาญี่ปุ่น (คะตะคะนะ ฮิระงะนะ คันจิ) และอื่นๆ
เพื่อวัตถุประสงค์ทางวิชาการ มีการเพิ่มสคริปต์ทางประวัติศาสตร์มากมาย รวมถึง: กรีกโบราณ อักษรอียิปต์โบราณ คิวนิฟอร์ม การเขียนของชาวมายัน ตัวอักษรอิทรุสกัน
Unicode มีสัญลักษณ์ทางคณิตศาสตร์และดนตรีและรูปสัญลักษณ์มากมาย
สำหรับอักขระ Cyrillic ใน Unicode จะมีการจัดสรรช่วงรหัสสองช่วง:
ซิริลลิก (# 0400 - # 04FF)
อาหารเสริมซีริลลิก (# 0500 - # 052F)
แต่การนำตาราง Unicode ไปใช้ในรูปแบบบริสุทธิ์นั้นถูกระงับไว้เนื่องจากว่าหากรหัสของอักขระตัวหนึ่งจะไม่ใช่หนึ่งไบต์ แต่เป็นสองไบต์สำหรับการจัดเก็บข้อความจะใช้พื้นที่ดิสก์มากเป็นสองเท่าและสำหรับ โอนผ่านช่องทางการสื่อสาร - นานเป็นสองเท่า
ดังนั้น ในทางปฏิบัติ การแสดง Unicode ของ UTF-8 (รูปแบบการแปลง Unicode) จึงเป็นเรื่องธรรมดามากกว่า UTF-8 ให้ความเข้ากันได้ดีที่สุดกับระบบที่ใช้อักขระ 8 บิต ข้อความที่มีเฉพาะอักขระที่มีตัวเลขน้อยกว่า 128 จะถูกแปลงเป็นข้อความ ASCII ธรรมดาเมื่อเขียนด้วย UTF-8 อักขระ Unicode ที่เหลือจะแสดงตามลำดับความยาว 2 ถึง 4 ไบต์ โดยทั่วไป เนื่องจากอักขระทั่วไปที่สุดในโลก - อักขระของอักษรละติน - ใน UTF-8 ยังคงใช้ 1 ไบต์ การเข้ารหัสนี้จึงประหยัดกว่า Unicode แท้
ในการกำหนดรหัสอักขระที่เป็นตัวเลข คุณสามารถใช้ ตารางรหัส... ในการดำเนินการนี้ ให้เลือกรายการ "แทรก" - "สัญลักษณ์" ในเมนู หลังจากนั้นกล่องโต้ตอบสัญลักษณ์จะปรากฏขึ้นบนหน้าจอ ตารางสัญลักษณ์สำหรับแบบอักษรที่เลือกจะปรากฏในกล่องโต้ตอบ อักขระในตารางนี้จัดเรียงทีละบรรทัด ตามลำดับจากซ้ายไปขวา โดยเริ่มจากอักขระ Space
 สมาร์ทโฟนการชาร์จแบบไร้สาย A5 รองรับการชาร์จแบบไร้สาย
สมาร์ทโฟนการชาร์จแบบไร้สาย A5 รองรับการชาร์จแบบไร้สาย ทำไมไม่ส่ง sms ของ MTS มาที่โทรศัพท์
ทำไมไม่ส่ง sms ของ MTS มาที่โทรศัพท์ ทำไมคุณถึงต้องการการรีเซ็ตเป็นค่าเริ่มต้นจากโรงงานบน Android หรือวิธีคืนค่า Android กลับเป็นการตั้งค่าจากโรงงาน
ทำไมคุณถึงต้องการการรีเซ็ตเป็นค่าเริ่มต้นจากโรงงานบน Android หรือวิธีคืนค่า Android กลับเป็นการตั้งค่าจากโรงงาน