จากรหัส Unicode ไปจนถึงตัวอักษร ปัญหาการแยกแยะตัวเลขและตัวอักษรที่คล้ายคลึงกันภายนอก
บางครั้งคุณจำเป็นต้องเพิ่มไอคอนในงานออกแบบของคุณ แต่ไม่อยากใส่รูปภาพเพิ่มเติมหรือแบบอักษรของไอคอนทั้งหมด เช่น Font Awesome ใช่ไหม เรามีข่าวดีสำหรับคุณ - มีคลังไอคอนและสัญลักษณ์มากมายในเบราว์เซอร์ของคุณ เรียกว่า Unicode และเป็นมาตรฐานที่กำหนด ตัวระบุที่ไม่ซ้ำสำหรับสัญลักษณ์และไอคอนที่เพิ่มมากขึ้นเรื่อยๆ (ปัจจุบันมีมากกว่า 110,000 รายการ)
นี่ไม่ได้หมายความว่าคุณมีไอคอนให้เลือกหลายแสนไอคอน ขึ้นอยู่กับเบราว์เซอร์ที่แสดง และใช้แบบอักษรที่ติดตั้งบนระบบเพื่อทำสิ่งนี้ ในบทความนี้ เราได้รวบรวมชุดอักขระจำนวนหนึ่งที่พร้อมใช้งานบน Windows, Linux, OS X, Android และ IOS คุณสามารถใช้มันในการออกแบบของคุณวันนี้!
เคล็ดลับ: ซึ่งจะอธิบายทุกอย่างที่ควรรู้เกี่ยวกับการเข้ารหัสและ Unicode ซึ่งเราแนะนำให้นักพัฒนาซอฟต์แวร์ทุกคนอ่าน
วิธีใช้ไอคอนเหล่านี้
ไอคอนที่แสดงในตารางด้านล่างเป็นสัญลักษณ์ทั่วไปที่คุณสามารถคัดลอกและวางได้เหมือนกับว่าเป็นตัวอักษรของตัวอักษร แต่ถ้าการเข้ารหัสที่ใช้ในการบันทึกไฟล์ HTML / CSS ไม่ใช่ UTF-8พวกเขาจะไม่ปรากฏ นี่คือเหตุผลที่เราแนะนำโค้ดหลีก HTML ที่จะใช้งานได้เสมอ นี่คือสิ่งที่คุณต้องทำเพื่อใช้ไอคอนเหล่านี้:
- ค้นหาไอคอนที่คุณชอบ เราได้จัดเตรียมตัวอย่างขนาดเล็กและขนาดใหญ่
- คัดลอกรหัส
- วางลงใน HTML เป็นข้อความธรรมดา ใน CSS คุณสามารถใช้มันเป็นค่าคุณสมบัติ เนื้อหา... ใน JS, PHP และภาษาการเขียนโปรแกรมอื่นๆ คุณสามารถใช้เป็นข้อความธรรมดาในสตริงได้
- คุณสามารถปรับแต่งไอคอนได้โดยกำหนดขนาดแบบอักษร สี ข้อความและเงาเหมือนกับข้อความปกติ
ไอคอน
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ยิ้ม | ☺ | ☺ | ☺ |
| ป้ายเตือน | ⚠ | ⚠ | ⚠ |
| น้ำพุร้อน | ♨ | ♨ | ♨ |
| วีลแชร์ | ♿ | ♿ | ♿ |
| รีไซเคิล | ♻ | ♻ | ♻ |
| 8-Ball | ➑ | ➑ | ➑ |
| ไฟฟ้าแรงสูง | ⚡ | ⚡ | ⚡ |
| ไวท์สตาร์ | ☆ | ☆ | ☆ |
| ดาวสีดำ | ★ | ★ | ★ |
| หัวใจสีขาว | ♡ | ♡ | ♡ |
| ใจดำ | ❤ | ❤ | ❤ |
| กาแฟ | ☕ | ☕ | ☕ |
| เครื่องบิน | ✈ | ✈ | ✈ |
| นาฬิกาทราย | ⌛ | ⌛ | ⌛ |
| นาฬิกา | ⌚ | ⌚ | ⌚ |
| กรรไกรดำ | ✂ | ✂ | ✂ |
| กรรไกรขาว | ✄ | ✄ | ✄ |
| มงกุฎ | ♕ | ♕ | ♕ |
| สมอ | ⚓ | ⚓ | ⚓ |
| ข้าม | ✝ | ✝ | ✝ |
| วงกลมขาวดำ | ◑ | ◑ | ◑ |
| แปดหมายเหตุ | ♪ | ♪ | ♪ |
| บีมแปดโน้ต | ♫ | ♫ | ♫ |
| เครื่องหมายดอกจันสี่แฉก | ✣ | ✣ | ✣ |
| วงกลมสีขาวดาว | ✪ | ✪ | ✪ |
| ไวท์สตาร์ | ✰ | ✰ | ✰ |
| ดาวสี่แฉกสีขาว | ✧ | ✧ | ✧ |
| ดาวสี่แฉกสีดำ | ✦ | ✦ | ✦ |
| กาเครื่องหมายกล่องลงคะแนน | ☑ | ☑ | ☑ |
| เครื่องหมายถูก | ✔ | ✔ | ✔ |
| เครื่องหมายกากบาท | ✘ | ✘ | ✘ |
| ดินสอ | ✎ | ✎ | ✎ |
| เขียนมือ | ✍ | ✍ | ✍ |
| หญิง | ♀ | ♀ | ♀ |
| ชาย | ♂ | ♂ | ♂ |
| โทรศัพท์สีดำ | ☎ | ☎ | ☎ |
| โทรศัพท์สีขาว | ☏ | ☏ | ☏ |
| ซองจดหมาย | ✉ | ✉ | ✉ |
| ที่ตั้งโทรศัพท์ | ✆ | ✆ | ✆ |
ลูกศร Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ลูกศรซ้าย | ← | ← | ← |
| ลูกศรขวา | → | → | → |
| ลูกศรขึ้น | |||
| ลูกศรชี้ลง | ↓ | ↓ | ↓ |
| ลูกศรซ้ายขวา | ↔ | ↔ | ↔ |
| ลูกศรลง | ↕ | ↕ | ↕ |
| ลูกศรขวาและซ้าย | ⇄ | ⇄ | ⇄ |
| ลูกศรขึ้นและลง | ⇅ | ⇅ | ⇅ |
| ลูกศรลง-ซ้าย 90 องศา | ↲ | ↲ | ↲ |
| ลูกศรลง-ขวา 90 องศา | ↳ | ↳ | ↳ |
| ลูกศรขึ้น-ซ้าย 90 องศา | ↰ | ↰ | ↰ |
| ลูกศรขวา 90 องศา | ↱ | ↱ | ↱ |
| North West Arrow To Corner | ⇱ | ⇱ | ⇱ |
| ลูกศรตะวันออกเฉียงใต้สู่มุม | ⇲ | ⇲ | ⇲ |
| ลูกศรซ้ายไปที่แถบ | ⇤ | ⇤ | ⇤ |
| ลูกศรชี้ขวาไปที่แถบ | ⇥ | ⇥ | ⇥ |
| ลูกศรครึ่งวงกลมทวนเข็มนาฬิกา | ↶ | ↶ | ↶ |
| ลูกศรครึ่งวงกลมตามเข็มนาฬิกา | ↷ | ↷ | ↷ |
| ลูกศรวงกลมทวนเข็มนาฬิกา | ↺ | ↺ | ↺ |
| ลูกศรวงกลมตามเข็มนาฬิกา | ↻ | ↻ | ↻ |
| ลูกศรชี้ขวาหัวกว้าง | ➔ | ➔ | ➔ |
| ลูกศรซิกแซกลง | ↯ | ↯ | ↯ |
| ลูกศรทิศตะวันตกเฉียงเหนือ | ↖ | ↖ | ↖ |
| ลูกศรตะวันออกเฉียงใต้หนัก | ➘ | ➘ | ➘ |
| ลูกศรขวาหนัก | ➙ | ➙ | ➙ |
| ลูกศรตะวันออกเฉียงเหนือหนัก | ➚ | ➚ | ➚ |
| ลูกศรชี้ไปทางขวา | ➟ | ➟ | ➟ |
| ลูกศรชี้ไปทางซ้าย | ⇠ | ⇠ | ⇠ |
| หัวลูกศรขวาสีดำ | ➤ | ➤ | ➤ |
| ลูกศรซ้ายสีขาว | ⇦ | ⇦ | ⇦ |
| ลูกศรขวาสีขาว | ⇨ | ⇨ | ⇨ |
| เครื่องหมายคำพูดมุมซ้าย | « | « | « |
| เครื่องหมายคำพูดมุมขวา | » | » | » |
| ตัวชี้สีดำขวา | |||
| ตัวชี้สีดำด้านซ้าย | ◀ | ◀ | ◀ |
| ตัวชี้สีดำ | ▲ | ▲ | ▲ |
| ตัวชี้สีดำลง | ▼ | ▼ | ▼ |
| ตัวชี้สีขาวขวา | ▷ | ▷ | ▷ |
| ตัวชี้สีขาวซ้าย | ◁ | ◁ | ◁ |
| ตัวชี้สีขาวขึ้น | △ | △ | △ |
| ตัวชี้สีขาวลง | ▽ | ▽ | ▽ |
| ธนูศร | ➴ | ➴ | ➴ |
อักขระพิเศษในยูนิโค้ด
สกุลเงินยูนิโค้ด
ไอคอนสภาพอากาศ
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ระดับ | ° | ° | ° |
| แดดน้อย | ☀ | ☀ | ☀ |
| บิ๊กซัน | ☼ | ☼ | ☼ |
| คลาวด์ | ☁ | ☁ | ☁ |
| ร่ม | ☔ | ☔ | ☔ |
| เกล็ดหิมะ 1 | ❆ | ❆ | ❆ |
| เกล็ดหิมะ 2 | ❅ | ❅ | ❅ |
| เกล็ดหิมะ 3 | ❄ | ❄ | ❄ |
ตัวชี้ Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ตัวชี้ซ้ายสีดำ | ☚ | ☚ | ☚ |
| ตัวชี้ ขวา สีดำ | ☛ | ☛ | ☛ |
| ตัวชี้ซ้ายสีขาว | ☜ | ☜ | ☜ |
| ตัวชี้ขึ้นสีขาว | ☝ | ☝ | ☝ |
| ตัวชี้ ขวา สีขาว | ☞ | ☞ | ☞ |
| ตัวชี้ลงสีขาว | ☟ | ☟ | ☟ |
ราศีใน Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ราศีเมษ | ♈ | ♈ | ♈ |
| ราศีพฤษภ | ♉ | ♉ | ♉ |
| ฝาแฝด | ♊ | ♊ | ♊ |
| มะเร็ง | ♋ | ♋ | ♋ |
| สิงโต | ♌ | ♌ | ♌ |
| ราศีกันย์ | ♍ | ♍ | ♍ |
| ตาชั่ง | ♎ | ♎ | ♎ |
| แมงป่อง | ♏ | ♏ | ♏ |
| ราศีธนู | ♐ | ♐ | ♐ |
| ราศีมังกร | ♑ | ♑ | ♑ |
| ราศีกุมภ์ | ♒ | ♒ | ♒ |
| ปลา | ♓ | ♓ | ♓ |
อักขระการ์ด Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| Clubs Black | ♠ | ♠ | ♠ |
| Hearts Black | ♥ | ♥ | ♥ |
| เพชรสีดำ | ♦ | ♦ | ♦ |
| โพดำ | ♣ | ♣ | ♣ |
| คลับไวท์ | ♤ | ♤ | ♤ |
| หัวใจสีขาว | ♡ | ♡ | ♡ |
| เพชรขาว | ♢ | ♢ | ♢ |
| โพดำขาว | ♧ | ♧ | ♧ |
ตัวหมากรุกในยูนิโค้ด
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| คิงไวท์ | ♔ | ♔ | ♔ |
| ราชินีขาว | ♕ | ♕ | ♕ |
| Rook สีขาว | ♖ | ♖ | ♖ |
| บิชอปไวท์ | ♗ | ♗ | ♗ |
| อัศวินสีขาว | ♘ | ♘ | ♘ |
| เบี้ยขาว | ♙ | ♙ | ♙ |
| คิงแบล็ค | ♚ | ♚ | ♚ |
| ราชินีดำ | ♛ | ♛ | ♛ |
| โกงดำ | ♜ | ♜ | ♜ |
| บิชอปแบล็ก | ♝ | ♝ | ♝ |
| อัศวินดำ | ♞ | ♞ | ♞ |
| จำนำสีดำ | ♟ | ♟ | ♟ |
เกมลูกเต๋า
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| ลูกเต๋าม้วนหนึ่ง | ⚀ | ⚀ | ⚀ |
| ลูกเต๋าม้วนสอง | ⚁ | ⚁ | ⚁ |
| ลูกเต๋าม้วนสาม | ⚂ | ⚂ | ⚂ |
| ลูกเต๋าม้วนสี่ | ⚃ | ⚃ | ⚃ |
| ลูกเต๋าทอยห้า | ⚄ | ⚄ | ⚄ |
| ลูกเต๋าม้วนหก | ⚅ | ⚅ | ⚅ |
สัญลักษณ์ทางคณิตศาสตร์ Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| อินฟินิตี้ | ∞ | ∞ | ∞ |
| บวก ลบ | ± | ± | ± |
| น้อยกว่าหรือเท่ากับ | ≤ | ≤ | ≤ |
| มากกว่าหรือเท่ากับ | ≥ | ≥ | ≥ |
| ไม่เท่ากับ | ≠ | ≠ | ≠ |
| แผนก | ÷ | ÷ | ÷ |
| คูณ x | × | × | × |
| คูณหนัก x | ✖ | ✖ | ✖ |
| ตัวยกหนึ่ง | ¹ | ¹ | ¹ |
| ตัวยกสอง | ² | ² | ² |
| ตัวยกสาม | ³ | ³ | ³ |
| Circled Plus | ⊕ | ⊕ | ⊕ |
| วงกลมคูณ | ⊗ | ⊗ | ⊗ |
| ตรรกะและ | ∧ | ∧ | ∧ |
| ตรรกะOR | ∨ | ∨ | ∨ |
| เดลต้า | ∆ | ∆ | ∆ |
| พาย | ∏ | ∏ | ∏ |
| ซิกม่า (SUM) | ∑ | ∑ | ∑ |
| โอเมก้า | Ω | Ω | Ω |
| ชุดเปล่า | ∅ | ∅ | ∅ |
| มุม | ∠ | ∠ | ∠ |
| ขนาน | ∥ | ∥ | ∥ |
| ตั้งฉาก | ⊥ | ⊥ | ⊥ |
| เกือบเท่ากับ | ≈ | ≈ | ≈ |
| สามเหลี่ยม | △ | △ | △ |
| วงกลม | ○ | ○ | ○ |
| สี่เหลี่ยม | □ | □ | □ |
เศษส่วน
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| หนึ่งไตรมาส (1/4) | ¼ | ¼ | ¼ |
| ครึ่งเดียว (1/2) | ½ | ½ | ½ |
| สามในสี่ (3/4) | ¾ | ¾ | ¾ |
| หนึ่งในสาม (1/3) | ⅓ | ⅓ | ⅓ |
| สองในสาม (2/3) | ⅔ | ⅔ | ⅔ |
| หนึ่งแปด (1/8) | ⅛ | ⅛ | ⅛ |
| สามแปด (3/8) | ⅜ | ⅜ | ⅜ |
| ห้าแปด (5/8) | ⅝ | ⅝ | ⅝ |
| เซเว่นเอทส์ (7/8) | ⅞ | ⅞ | ⅞ |
ตัวเลขโรมันใน Unicode
| ชื่อ | ดูตัวอย่าง | รหัส | |
|---|---|---|---|
| เลขโรมันหนึ่ง | Ⅰ | Ⅰ | Ⅰ |
| เลขโรมันสอง | Ⅱ | Ⅱ | Ⅱ |
| เลขโรมันสาม | Ⅲ | Ⅲ | Ⅲ |
| เลขโรมันสี่ | Ⅳ | Ⅳ | Ⅳ |
| เลขโรมันห้า | Ⅴ | Ⅴ | Ⅴ |
| เลขโรมันหก | Ⅵ | Ⅵ | Ⅵ |
| เลขโรมันเจ็ด | Ⅶ | Ⅶ | Ⅶ |
| เลขโรมันแปด | Ⅷ | Ⅷ | Ⅷ |
| เลขโรมันเก้า | Ⅸ | Ⅸ | Ⅸ |
| เลขโรมันสิบ | Ⅹ | Ⅹ | Ⅹ |
| เลขโรมันสิบเอ็ด | Ⅺ | Ⅺ | Ⅺ |
| เลขโรมันสิบสอง | Ⅻ | Ⅻ | Ⅻ |
มีความแตกต่างบางประการในการแสดงสัญลักษณ์เหล่านี้ในต่างกัน ระบบปฏิบัติการโอ้. ซึ่งเกิดจากตระกูลฟอนต์ต่างๆ ที่ใช้ นอกจากนี้ iOS และ Android จะแทนที่อักขระ Unicode บางตัวด้วยอีโมติคอน ดังนั้นโปรดตรวจสอบอักขระที่เพิ่มเข้าไปเพื่อให้แน่ใจว่าจะไม่เกิดขึ้นและไอคอนต่างๆ จะแสดงตามที่ตั้งใจไว้
Unicode (อังกฤษ Unicode) เป็นมาตรฐานการเข้ารหัสอักขระ พูดง่ายๆ นี้คือตารางการโต้ตอบของอักขระข้อความ (, ตัวอักษร, องค์ประกอบเครื่องหมายวรรคตอน) รหัสเลขฐานสอง... คอมพิวเตอร์เข้าใจเฉพาะลำดับของศูนย์และตัวเท่านั้น เพื่อให้เขารู้ว่าควรแสดงอะไรบนหน้าจออย่างชัดเจน จึงจำเป็นต้องกำหนดหมายเลขเฉพาะให้กับตัวละครแต่ละตัว ในทศวรรษที่แปด อักขระถูกเข้ารหัสในหนึ่งไบต์ นั่นคือ แปดบิต (แต่ละบิตคือ 0 หรือ 1) ดังนั้นจึงกลายเป็นว่าหนึ่งตาราง (หรือที่เรียกว่าการเข้ารหัสหรือการตั้งค่า) สามารถมีได้เพียง 256 อักขระเท่านั้น นี่อาจไม่เพียงพอแม้แต่กับภาษาเดียว ดังนั้นการเข้ารหัสที่แตกต่างกันจำนวนมากจึงปรากฏขึ้น ความสับสนซึ่งมักจะนำไปสู่ความจริงที่ว่าแทนที่จะเป็นข้อความที่อ่านได้ krakozyabry แปลก ๆ ปรากฏขึ้นบนหน้าจอ จำเป็นต้องมีมาตรฐานเดียว ซึ่งกลายเป็น Unicode การเข้ารหัสที่ใช้มากที่สุดคือ UTF-8 (Unicode Transformation Format) ซึ่งใช้ 1 ถึง 4 ไบต์ในการแสดงอักขระ
สัญลักษณ์
อักขระในตาราง Unicode มีเลขฐานสิบหก ตัวอย่างเช่น อักษรซีริลลิกตัวพิมพ์ใหญ่ M ถูกกำหนดให้เป็น U + 041C ซึ่งหมายความว่ายืนอยู่ที่จุดตัดของบรรทัด 041 และคอลัมน์ C สามารถคัดลอกและวางที่ใดที่หนึ่งได้ เพื่อไม่ให้ค้นหารายชื่อหลายกิโลเมตร คุณควรใช้การค้นหา เมื่อเข้าสู่หน้าสัญลักษณ์แล้ว คุณจะเห็นตัวเลขใน Unicode และวิธีวาดด้วยฟอนต์ต่างๆ คุณยังสามารถใส่เครื่องหมายลงในแถบค้นหาได้ แม้ว่าจะวาดสี่เหลี่ยมแทน อย่างน้อยก็เพื่อค้นหาว่ามันคืออะไร นอกจากนี้ ในเว็บไซต์นี้มีชุดไอคอนประเภทเดียวกันพิเศษ (และ - สุ่ม) ซึ่งรวบรวมจากส่วนต่างๆ เพื่อความสะดวกในการใช้งาน
มาตรฐาน Unicode เป็นมาตรฐานสากล มันมีสัญญาณจากสคริปต์เกือบทั้งหมดในโลก รวมทั้งที่ไม่ได้ใช้แล้ว อักษรอียิปต์โบราณ อักษรรูนดั้งเดิม อักษรมายัน อักษรรูปลิ่ม และอักษรของรัฐโบราณ นำเสนอและกำหนดหน่วยวัดและน้ำหนัก โน้ตดนตรี แนวคิดทางคณิตศาสตร์
Unicode Consortium ไม่ได้คิดค้นอักขระใหม่ ไอคอนเหล่านั้นที่พบในสังคมจะถูกเพิ่มลงในตาราง ตัวอย่างเช่น เครื่องหมายรูเบิลถูกใช้อย่างแข็งขันเป็นเวลาหกปีก่อนที่จะถูกเพิ่มลงใน Unicode รูปสัญลักษณ์อีโมจิ (อิโมติคอน) ยังถูกใช้อย่างกว้างขวางเป็นครั้งแรกในญี่ปุ่นและก่อนที่จะรวมไว้ในการเข้ารหัส แต่หลักการไม่ได้เพิ่มเครื่องหมายการค้าและโลโก้บริษัท เหมือนกับแอปเปิ้ลแอปเปิ้ลหรือแฟล็กของวินโดวส์ วันนี้ในเวอร์ชัน 8.0 มีการเข้ารหัสอักขระประมาณ 120,000 ตัว
องค์ประกอบของพื้นที่โค้ดที่แสดงจำนวนเต็มไม่เป็นลบ ตระกูลการเข้ารหัสกำหนดการแสดงเครื่องของลำดับรหัส UCS
รหัส Unicode แบ่งออกเป็นหลายส่วน พื้นที่ที่มีรหัสตั้งแต่ U + 0000 ถึง U + 007F มีอักขระ ASCII พร้อมรหัสที่เกี่ยวข้อง ถัดไปเป็นพื้นที่ของสัญลักษณ์ของสคริปต์ เครื่องหมายวรรคตอน และสัญลักษณ์ทางเทคนิคต่างๆ รหัสบางส่วนสงวนไว้สำหรับใช้ในอนาคต ภายใต้อักขระ Cyrillic พื้นที่ของอักขระที่มีรหัสจาก U + 0400 ถึง U + 052F จาก U + 2DE0 ถึง U + 2DFF จาก U + A640 ถึง U + A69F จะได้รับการจัดสรร (ดู Cyrillic ใน Unicode)
ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode
เนื่องจากในระบบคอมพิวเตอร์จำนวนหนึ่ง (เช่น Windows NT) อักขระ 16 บิตคงที่ถูกใช้เป็นการเข้ารหัสเริ่มต้นแล้ว จึงตัดสินใจเข้ารหัสอักขระที่สำคัญที่สุดทั้งหมดภายใน 65,536 ตำแหน่งแรกเท่านั้น (ภาษาอังกฤษที่เรียกว่า ระนาบหลายภาษาพื้นฐาน BMP). พื้นที่ที่เหลือใช้สำหรับ "อักขระเพิ่มเติม" (อังกฤษ. ตัวละครเสริม): ระบบการเขียนภาษาที่สูญพันธุ์หรือตัวอักษรจีน สัญลักษณ์ทางคณิตศาสตร์และดนตรีที่ไม่ค่อยได้ใช้
เพื่อความเข้ากันได้กับระบบ 16 บิตแบบเก่า ระบบ UTF-16 ถูกประดิษฐ์ขึ้นโดยที่ตำแหน่ง 65,536 แรก ยกเว้นตำแหน่งจากช่วง U + D800 ... U + DFFF จะแสดงเป็นตัวเลข 16 บิตโดยตรง และส่วนที่เหลือจะแสดงเป็น "คู่ตัวแทน »(องค์ประกอบแรกของคู่จากพื้นที่ U + D800… U + DBFF องค์ประกอบที่สองของคู่จากพื้นที่ U + DC00… U + DFFF) สำหรับคู่ตัวแทนเสมือน ส่วนหนึ่งของโค้ดสเปซ (2048 ตำแหน่ง) ที่เคยสงวนไว้ก่อนหน้านี้สำหรับ "อักขระสำหรับใช้ส่วนตัว" ถูกใช้
เนื่องจาก UTF-16 สามารถแสดงอักขระได้เพียง 2 20 + 2 16 −2048 (1 112 064) ตัวเลขนี้จึงถูกเลือกให้เป็นค่าสุดท้ายสำหรับพื้นที่โค้ด Unicode
แม้ว่าพื้นที่โค้ด Unicode จะขยายเกิน 2-16 เร็วเท่าเวอร์ชัน 2.0 แต่อักขระตัวแรกในพื้นที่ "บนสุด" จะถูกวางไว้ในเวอร์ชัน 3.1 เท่านั้น
บทบาทของการเข้ารหัสนี้ในภาคเว็บมีการเติบโตอย่างต่อเนื่อง เมื่อต้นปี 2010 ส่วนแบ่งของเว็บไซต์ที่ใช้ Unicode อยู่ที่ประมาณ 50%
เวอร์ชัน Unicode
เนื่องจากตารางอักขระ Unicode มีการเปลี่ยนแปลงและเติมเต็ม และเวอร์ชันใหม่ของระบบนี้ได้รับการเผยแพร่ - และงานนี้ยังคงดำเนินต่อไป เนื่องจากระบบ Unicode ดั้งเดิมมีเฉพาะ Plane 0 - รหัสสองไบต์เท่านั้น - เอกสาร ISO ใหม่ก็จะถูกเผยแพร่เช่นกัน ระบบ Unicode มีอยู่ในเวอร์ชันต่อไปนี้:
- 1.1 (เป็นไปตามมาตรฐาน ISO / IEC 10646-1: 1993), 1991-1995
- 2.0, 2.1 (มาตรฐานเดียวกัน ISO / IEC 10646-1: 1993 บวกเพิ่มเติม: "การแก้ไข" 1 ถึง 7 และ "Technical Corrigenda" 1 และ 2), 1996 มาตรฐาน
- 3.0 (มาตรฐาน ISO / IEC 10646-1: 2000) มาตรฐาน 2000
- 3.1 (มาตรฐาน ISO / IEC 10646-1: 2000 และ ISO / IEC 10646-2: 2001) มาตรฐาน 2001
- มาตรฐาน 3.2 ปี 2545
- 4.0 มาตรฐาน 2003
- 4.01 มาตรฐานปี 2547
- 4.1 มาตรฐานปี 2548
- 5.0 มาตรฐานปี 2549
- 5.1 มาตรฐาน 2008
- 5.2 มาตรฐานปี 2552
- 6.0 มาตรฐาน 2010
- 6.1 มาตรฐานปี 2555
- 6.2 มาตรฐานปี 2555
รหัสพื้นที่
แม้ว่ารูปแบบสัญกรณ์ UTF-8 และ UTF-32 จะอนุญาตให้เข้ารหัสจุดโค้ดได้มากถึง 2,331 (2,147,483,648) แต่ได้ตัดสินใจใช้เพียง 1,112,064 เท่านั้นเพื่อให้เข้ากันได้กับ UTF-16 อย่างไรก็ตาม เท่านี้ก็เกินพอแล้ว - วันนี้ (ในเวอร์ชัน 6.0) ใช้จุดโค้ดน้อยกว่า 110,000 จุดเล็กน้อย (กราฟิก 109,242 และสัญลักษณ์อื่นๆ 273 ตัว)
พื้นที่รหัสแบ่งออกเป็น17 เครื่องบิน 2 16 (65536) อักขระแต่ละตัว ระนาบศูนย์เรียกว่า ขั้นพื้นฐานซึ่งประกอบด้วยสัญลักษณ์ของสคริปต์ทั่วไป ระนาบแรกใช้เป็นหลักสำหรับสคริปต์ประวัติศาสตร์ ระนาบที่สองใช้สำหรับอักขระ CJK ที่ไม่ค่อยได้ใช้ และระนาบที่สามสงวนไว้สำหรับอักขระจีนโบราณ เครื่องบิน 15 และ 16 สงวนไว้สำหรับการใช้งานส่วนตัว
เพื่อแสดงว่า อักขระ Unicodeสัญกรณ์ของแบบฟอร์ม “U + xxxx"(สำหรับรหัส 0 ... FFFF) หรือ" U + xxxxxx"(สำหรับรหัส 10000 ... FFFFF) หรือ" U + xxxxxx"(สำหรับรหัส 100000 ... 10FFFF) โดยที่ xxx- ตัวเลขฐานสิบหก ตัวอย่างเช่น อักขระ "i" (U + 044F) มีรหัส 044F = 1103
ระบบเข้ารหัส
ระบบการเข้ารหัสสากล (Unicode) คือชุดของสัญลักษณ์กราฟิกและวิธีการเข้ารหัสสำหรับการประมวลผลข้อมูลข้อความด้วยคอมพิวเตอร์
สัญลักษณ์กราฟิกเป็นสัญลักษณ์ที่มีภาพที่มองเห็นได้ อักขระกราฟิกตรงข้ามกับตัวควบคุมและการจัดรูปแบบอักขระ
สัญลักษณ์กราฟิกรวมถึงกลุ่มต่อไปนี้:
- ตัวอักษรที่มีอย่างน้อยหนึ่งตัวอักษรที่รองรับ
- ตัวเลข;
- เครื่องหมายวรรคตอน;
- สัญญาณพิเศษ (คณิตศาสตร์, เทคนิค, อุดมการณ์, ฯลฯ );
- ตัวคั่น
Unicode เป็นระบบสำหรับการแสดงข้อความเชิงเส้น อักขระที่มีตัวยกหรือตัวห้อยเพิ่มเติมสามารถแสดงเป็นลำดับของรหัสที่สร้างขึ้นตามกฎบางอย่าง (อักขระแบบประกอบ) หรือเป็นอักขระตัวเดียว (เวอร์ชันเสาหิน อักขระที่ประกอบล่วงหน้า)
การปรับเปลี่ยนตัวอักษร
การแสดงอักขระ "Y" (U + 0419) ในรูปแบบของอักขระฐาน "I" (U + 0418) และอักขระดัดแปลง "" (U + 0306)
อักขระกราฟิกใน Unicode แบ่งออกเป็นแบบขยายและไม่ขยาย (แบบไม่มีความกว้าง) อักขระที่ไม่ขยายจะไม่ใช้พื้นที่ในบรรทัดเมื่อแสดง โดยเฉพาะอย่างยิ่ง เครื่องหมายเน้นเสียงและเครื่องหมายกำกับเสียงอื่นๆ อักขระทั้งแบบขยายและแบบไม่ขยายมีรหัสของตนเอง สัญลักษณ์เพิ่มเติมจะเรียกว่าพื้นฐาน (อังกฤษ. ตัวละครหลัก) และแบบไม่ขยาย - ดัดแปลง (eng. การรวมตัวอักษร); และคนหลังไม่สามารถพบกันโดยอิสระ ตัวอย่างเช่น อักขระ "á" สามารถแสดงเป็นลำดับของอักขระหลัก "a" (U + 0061) และอักขระตัวแก้ไข "́" (U + 0301) หรือเป็นอักขระแบบเสาหิน "á" (U + 00C1).
อักขระการปรับเปลี่ยนชนิดพิเศษคือตัวเลือกรูปแบบ (อังกฤษ ตัวเลือกรูปแบบต่างๆ). ใช้เฉพาะกับสัญลักษณ์ที่กำหนดตัวแปรดังกล่าว ในเวอร์ชัน 5.0 ตัวเลือกแบบอักษรถูกกำหนดไว้สำหรับสัญลักษณ์ทางคณิตศาสตร์จำนวนหนึ่ง สำหรับสัญลักษณ์ของตัวอักษรมองโกเลียแบบดั้งเดิม และสำหรับสัญลักษณ์ของสคริปต์สี่เหลี่ยมของมองโกเลีย
แบบฟอร์มการทำให้เป็นมาตรฐาน
เนื่องจากสามารถแสดงสัญลักษณ์เดียวกันได้ รหัสต่างๆซึ่งบางครั้งทำให้การประมวลผลซับซ้อน มีกระบวนการทำให้เป็นมาตรฐานที่ออกแบบมาเพื่อนำข้อความไปสู่รูปแบบมาตรฐานบางอย่าง
มาตรฐาน Unicode กำหนดรูปแบบข้อความมาตรฐาน 4 รูปแบบ:
- Normalization Form D (NFD) - การสลายตัวที่เป็นที่ยอมรับ ในกระบวนการแปลงข้อความให้อยู่ในรูปแบบนี้ อักขระผสมทั้งหมดจะถูกแทนที่ซ้ำด้วยอักขระผสมหลายตัวตามตารางการสลายตัว
- Normalization Form C (NFC) คือการสลายตัวตามรูปแบบบัญญัติตามด้วยองค์ประกอบตามรูปแบบบัญญัติ ขั้นแรกให้ลดขนาดข้อความลงในรูปแบบ D หลังจากที่ดำเนินการจัดองค์ประกอบตามรูปแบบบัญญัติ - ข้อความจะถูกประมวลผลตั้งแต่ต้นจนจบและปฏิบัติตามกฎต่อไปนี้:
- สัญลักษณ์ S คือ อักษรย่อหากมีคลาสการแก้ไขเป็นศูนย์ในฐานอักขระ Unicode
- ในลำดับของอักขระใดๆ ที่ขึ้นต้นด้วยอักขระเริ่มต้น S อักขระ C จะถูกบล็อกจาก S หากมีอักขระ B ระหว่าง S และ C ที่เป็นอักขระเริ่มต้นหรือมีคลาสการแก้ไขที่เหมือนกันหรือมากกว่า C กฎใช้เฉพาะกับสตริงที่ผ่านการสลายตัวตามรูปแบบบัญญัติเท่านั้น
- หลักคอมโพสิตคืออักขระที่มีการสลายตัวตามรูปแบบบัญญัติในฐานอักขระ Unicode (หรือการสลายตัวตามรูปแบบบัญญัติสำหรับฮันกุลและไม่รวมอยู่ในรายการยกเว้น)
- สัญลักษณ์ X สามารถจัดแนวหลักกับสัญลักษณ์ Y ได้ก็ต่อเมื่อมี Z หลักที่เทียบเท่ากับลำดับตามบัญญัติ
- หากอักขระ C ตัวถัดไปไม่ถูกบล็อกโดยอักขระฐานเริ่มต้นที่พบล่าสุด L และสามารถจัดตำแหน่งได้สำเร็จ จากนั้น L จะถูกแทนที่ด้วยคอมโพสิต L-C และ C จะถูกลบออก
- แบบฟอร์มการทำให้เป็นมาตรฐาน KD (NFKD) - การสลายตัวที่เข้ากันได้ เมื่อส่งลงในแบบฟอร์มนี้ อักขระผสมทั้งหมดจะถูกแทนที่โดยใช้แผนที่การสลายตัวแบบ Unicode แบบบัญญัติและแผนที่การสลายตัวที่เข้ากันได้ หลังจากนั้นผลลัพธ์จะอยู่ในลำดับตามรูปแบบบัญญัติ
- แบบฟอร์มการทำให้เป็นมาตรฐาน KC (NFKC) - การสลายตัวที่เข้ากันได้ตามด้วย บัญญัติองค์ประกอบ.
คำว่า "องค์ประกอบ" และ "การสลายตัว" หมายถึงการเชื่อมต่อหรือการสลายตัวของสัญลักษณ์ตามลำดับเป็นส่วนที่เป็นส่วนประกอบ
ตัวอย่างของ
| ข้อความที่มา | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| ฝรั่งเศส | ฟรังก์ \ u0327ais | ฟราน \ xe7ais | ฟรังก์ \ u0327ais | ฟราน \ xe7ais |
| A,E,Y | \ u0410, \ u0401, \ u0419 | \ u0410, \ u0415 \ u0308, \ u0418 \ u0306 | \ u0410, \ u0401, \ u0419 | |
| が | \ u304b \ u3099 | \ u304c | \ u304b \ u3099 | \ u304c |
| Henry IV | Henry IV | Henry IV | Henry IV | Henry IV |
| เฮนรี่ Ⅳ | เฮนรี่ \ u2163 | เฮนรี่ \ u2163 | Henry IV | Henry IV |
จดหมายสองทิศทาง
มาตรฐาน Unicode รองรับการเขียนภาษาทั้งในทิศทางจากซ้ายไปขวา (eng. ซ้ายไปขวา LTR) และเขียนจากขวาไปซ้าย (อังกฤษ. ขวาไปซ้าย RTL) - ตัวอย่างเช่น ตัวอักษรอารบิกและฮีบรู ในทั้งสองกรณี อักขระจะถูกจัดเก็บไว้ในลำดับที่ "เป็นธรรมชาติ" แอปพลิเคชันให้การแสดงผลโดยคำนึงถึงทิศทางที่ต้องการของจดหมาย
นอกจากนี้ Unicode ยังรองรับข้อความแบบรวมที่รวมส่วนย่อยที่มีทิศทางต่างกันของตัวอักษร คุณลักษณะนี้เรียกว่า แบบสองทิศทาง(อ. ข้อความแบบสองทิศทาง BiDi). ตัวประมวลผลข้อความแบบง่ายบางตัว (เช่น in โทรศัพท์มือถือ) รองรับ Unicode แต่ไม่รองรับแบบสองทิศทาง อักขระ Unicode ทั้งหมดแบ่งออกเป็นหลายประเภท: เขียนจากซ้ายไปขวา เขียนจากขวาไปซ้าย และเขียนในทิศทางใดก็ได้ สัญลักษณ์ของหมวดหมู่หลัง (ส่วนใหญ่เป็นเครื่องหมายวรรคตอน) เมื่อแสดง ให้เปลี่ยนทิศทางของข้อความโดยรอบ
สัญลักษณ์เด่น
Unicode มีสคริปต์สมัยใหม่แทบทั้งหมด รวมถึง:
อื่น ๆ.
เพื่อวัตถุประสงค์ทางวิชาการ มีการเพิ่มสคริปต์ทางประวัติศาสตร์มากมาย เช่น อักษรรูน กรีกโบราณ อักษรอียิปต์โบราณ อักษรคิวนิฟอร์ม การเขียนของชาวมายัน ตัวอักษรอิทรุสกัน
Unicode มีสัญลักษณ์ทางคณิตศาสตร์และดนตรีและรูปสัญลักษณ์มากมาย
อย่างไรก็ตาม โดยพื้นฐานแล้ว Unicode ไม่รวมโลโก้บริษัทและผลิตภัณฑ์ แม้ว่าจะพบในแบบอักษร (เช่น โลโก้ Apple ในการเข้ารหัส MacRoman (0xF0) หรือโลโก้ Windows ในแบบอักษร Wingdings (0xFF)) ในฟอนต์ Unicode โลโก้ควรวางในพื้นที่อักขระที่กำหนดเองเท่านั้น
ISO / IEC 10646
Unicode Consortium ทำงานอย่างใกล้ชิดกับ กลุ่มทำงาน ISO / IEC / JTC1 / SC2 / WG2 ซึ่งกำลังพัฒนามาตรฐานสากล 10646 (ISO / IEC 10646) การซิงโครไนซ์ถูกสร้างขึ้นระหว่างมาตรฐาน Unicode และ ISO / IEC 10646 แม้ว่าแต่ละมาตรฐานจะใช้คำศัพท์และระบบเอกสารของตนเอง
ความร่วมมือของ Unicode Consortium กับองค์การระหว่างประเทศเพื่อการมาตรฐาน (eng. องค์การระหว่างประเทศเพื่อการมาตรฐาน ISO ) เริ่มในปี 1991 ในปี 1993 ISO ได้ออกมาตรฐาน DIS 10646.1 ในการซิงโครไนซ์กับมัน Consortium ได้อนุมัติเวอร์ชัน 1.1 ของมาตรฐาน Unicode ซึ่งเพิ่มอักขระเพิ่มเติมจาก DIS 10646.1 เป็นผลให้ค่าของอักขระที่เข้ารหัสใน Unicode 1.1 และ DIS 10646.1 เหมือนกันทุกประการ
ในอนาคตความร่วมมือระหว่างทั้งสององค์กรยังคงดำเนินต่อไป ในปี 2000 มาตรฐานยูนิโค้ด 3.0 ซิงโครไนซ์กับ ISO / IEC 10646-1: 2000 แล้ว ISO / IEC 10646 เวอร์ชันที่สามที่กำลังจะมีขึ้นจะถูกซิงโครไนซ์กับ Unicode 4.0 บางทีข้อกำหนดเหล่านี้อาจได้รับการเผยแพร่เป็นมาตรฐานเดียว
เช่นเดียวกับรูปแบบ UTF-16 และ UTF-32 ในมาตรฐาน Unicode มาตรฐาน ISO / IEC 10646 ยังมีรูปแบบการเข้ารหัสอักขระหลักสองรูปแบบ: UCS-2 (2 ไบต์ต่ออักขระ คล้ายกับ UTF-16) และ UCS-4 (4 ไบต์ต่ออักขระ คล้ายกับ UTF-32) UCS แปลว่า มัลติออคเต็ตอเนกประสงค์(มัลติไบต์) รหัสชุดอักขระ(อ. ชุดอักขระรหัสหลายออคเต็ตสากล ). UCS-2 ถือได้ว่าเป็นส่วนย่อยของ UTF-16 (UTF-16 โดยไม่มีคู่ตัวแทน) และ UCS-4 เป็นคำพ้องความหมายสำหรับ UTF-32
วิธีการนำเสนอ
Unicode มีการแสดงหลายรูปแบบ (eng. รูปแบบการแปลง Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) และ UTF-32 (UTF-32BE, UTF-32LE) แบบฟอร์ม UTF-7 ยังได้รับการพัฒนาสำหรับการส่งผ่านช่องสัญญาณเจ็ดบิต แต่เนื่องจากความไม่เข้ากันกับ ASCII จึงไม่แพร่กระจายและไม่รวมอยู่ในมาตรฐาน เมื่อวันที่ 1 เมษายน พ.ศ. 2548 มีการเสนอเรื่องตลกสองเรื่อง: UTF-9 และ UTF-18 (RFC 4042)
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
เป็นไปได้ในทางทฤษฎี แต่ไม่รวมอยู่ในมาตรฐาน:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
แม้ว่า UTF-8 จะอนุญาตให้คุณระบุอักขระเดียวกันได้หลายวิธี แต่อักขระที่สั้นที่สุดเท่านั้นที่ถูกต้อง แบบฟอร์มที่เหลือควรถูกปฏิเสธด้วยเหตุผลด้านความปลอดภัย
ลำดับไบต์
ในสตรีมข้อมูล UTF-16 ไบต์สูงสามารถเขียนก่อนค่าต่ำสุด (eng. UTF-16 บิ๊กเอนด์) หรือหลังน้อง (อังกฤษ. UTF-16 little-endian). ในทำนองเดียวกัน การเข้ารหัสแบบสี่ไบต์มีสองรูปแบบ - UTF-32BE และ UTF-32LE
เพื่อกำหนดรูปแบบของการแสดง Unicode ที่จุดเริ่มต้น ไฟล์ข้อความลายเซ็นถูกเขียน - อักขระ U + FEFF (ช่องว่างไม่แตกที่มีความกว้างเป็นศูนย์) เรียกอีกอย่างว่า เครื่องหมายคำสั่งไบต์(อ. เครื่องหมายคำสั่งไบต์ BOM ). ทำให้สามารถแยกความแตกต่างระหว่าง UTF-16LE และ UTF-16BE เนื่องจากไม่มีอักขระ U + FFFE นอกจากนี้ บางครั้งวิธีนี้ยังใช้เพื่อระบุรูปแบบ UTF-8 แม้ว่าแนวคิดของลำดับไบต์จะใช้ไม่ได้กับรูปแบบนี้ ไฟล์ที่เป็นไปตามแบบแผนนี้จะเริ่มต้นด้วยลำดับไบต์เหล่านี้:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
น่าเสียดายที่วิธีนี้ไม่สามารถแยกแยะระหว่าง UTF-16LE และ UTF-32LE ได้อย่างน่าเชื่อถือ เนื่องจาก Unicode อนุญาตให้ใช้อักขระ U + 0000 (แม้ว่าข้อความจริงจะไม่ค่อยขึ้นต้นด้วย)
ไฟล์ในการเข้ารหัส UTF-16 และ UTF-32 ที่ไม่มี BOM ต้องอยู่ในลำดับไบต์ big-endian (unicode.org)
Unicode และการเข้ารหัสแบบดั้งเดิม
การเปิดตัว Unicode ได้เปลี่ยนวิธีการเข้ารหัส 8 บิตแบบเดิม ถ้าก่อนหน้านี้การเข้ารหัสถูกกำหนดโดยฟอนต์ ตอนนี้จะถูกตั้งค่าโดยตารางการติดต่อระหว่างการเข้ารหัสนี้กับ Unicode อันที่จริงการเข้ารหัสแบบ 8 บิตได้กลายเป็นรูปแบบหนึ่งของการแสดงชุดย่อยของ Unicode สิ่งนี้ทำให้ง่ายต่อการสร้างโปรแกรมที่ต้องทำงานกับการเข้ารหัสที่หลากหลาย: ตอนนี้ เพื่อเพิ่มการรองรับการเข้ารหัสอีกหนึ่งรายการ คุณเพียงแค่เพิ่มตารางค้นหา Unicode อื่น
นอกจากนี้ รูปแบบข้อมูลจำนวนมากยังอนุญาตให้แทรกอักขระ Unicode ใดๆ ได้ แม้ว่าเอกสารจะเขียนด้วยการเข้ารหัส 8 บิตแบบเก่าก็ตาม ตัวอย่างเช่น คุณสามารถใช้รหัสเครื่องหมายและใน HTML
การดำเนินการ
ระบบปฏิบัติการที่ทันสมัยส่วนใหญ่ให้การสนับสนุน Unicode ในระดับหนึ่ง
ในระบบปฏิบัติการของตระกูล Windows NT การเข้ารหัส UTF-16LE แบบสองไบต์จะใช้สำหรับการแสดงชื่อไฟล์และสตริงระบบอื่นๆ ภายใน การเรียกระบบที่ใช้พารามิเตอร์สตริงมีอยู่ในตัวแปรไบต์เดี่ยวและไบต์คู่ ดูรายละเอียดเพิ่มเติมได้ที่บทความ
หากคุณต้องการป้อนเพียงไม่กี่ อักขระพิเศษหรืออักขระ คุณสามารถใช้ตารางอักขระหรือแป้นพิมพ์ลัด รายการ อักขระ ASCIIดูตารางด้านล่าง หรือดูการแทรกตัวอักษรประจำชาติโดยใช้แป้นพิมพ์ลัด
หมายเหตุ:
การแทรกอักขระ ASCII
เมื่อต้องการแทรกอักขระ ASCII ให้กดแป้น ALT ค้างไว้ แล้วพิมพ์รหัสอักขระ ตัวอย่างเช่น หากต้องการแทรกเครื่องหมายองศา (º) ให้กดปุ่ม ALT ค้างไว้แล้วพิมพ์ แป้นพิมพ์ตัวเลขรหัส 0176
บันทึก:
การแทรกอักขระ Unicode
สำคัญ:บาง โปรแกรมไมโครซอฟต์ Office เช่น PowerPoint และ InfoPath ไม่สามารถแปลงรหัสอักขระ Unicode หากคุณต้องการอักขระ Unicode และใช้โปรแกรมใดโปรแกรมหนึ่งที่ไม่สนับสนุนอักขระ Unicode ให้ป้อนอักขระที่คุณอาจต้องใช้
หมายเหตุ:
ออกจากโปรแกรมทั้งหมด
ดับเบิลคลิกที่ไอคอน การติดตั้งและการลบโปรแกรมบน แผงควบคุม.
ทำอย่างใดอย่างหนึ่งต่อไปนี้:
ถ้าสมัคร Microsoft Officeติดตั้งเป็นส่วนหนึ่งของ Microsoft Office เลือก Microsoft Officeในสนาม โปรแกรมที่ติดตั้ง แล้วกดปุ่ม แทนที่;
ถ้า ใบสมัครสำนักงานติดตั้งแยกต่างหาก คลิกชื่อในรายการ โปรแกรมที่ติดตั้งแล้วกดปุ่ม เปลี่ยน.
ควรพิมพ์ตัวเลขบนแป้นตัวเลข ไม่ใช่ตัวอักษรและตัวเลข หากจำเป็นต้องกดเพื่อป้อนตัวเลขบนแป้นตัวเลข NUM คีย์ LOCK ตรวจสอบให้แน่ใจว่าเสร็จสิ้น
หากคุณมีปัญหาในการแปลงรหัส Unicode เป็นอักขระ ให้พิมพ์รหัสบนแป้นพิมพ์ตัวเลข เลือกรหัส จากนั้นกด Alt + X
วี Microsoft Windows XP และเวอร์ชันที่ใหม่กว่าของ Universal Unicode Font ได้รับการติดตั้งโดยอัตโนมัติ ใน Microsoft Windows 2000 ต้องติดตั้งฟอนต์ Unicode ด้วยตนเอง
บน Microsoft Windows 2000
ในกล่องโต้ตอบ การติดตั้ง Microsoft Office 2003เลือกตัวเลือก เพิ่มหรือลบส่วนประกอบแล้วกดปุ่ม ไกลออกไป.
โปรดเลือก การปรับแต่งเพิ่มเติมแอปพลิเคชั่นและกดปุ่ม ไกลออกไป.
ขยายรายการ เครื่องมือสำนักงานทั่วไป.
ขยายรายการ รองรับหลายภาษา.
คลิกที่ไอคอน แบบอักษรสากลและเลือกตัวเลือกการติดตั้งที่ต้องการ
การใช้ตารางสัญลักษณ์
ตารางสัญลักษณ์เป็น .ในตัวของ Microsoft โปรแกรมวินโดว์ซึ่งช่วยให้คุณสามารถดูอักขระที่มีอยู่ในแบบอักษรที่เลือกได้ คุณสามารถใช้ตารางสัญลักษณ์เพื่อคัดลอกสัญลักษณ์หรือกลุ่มของสัญลักษณ์ไปยังคลิปบอร์ดแล้ววางลงในโปรแกรมที่รองรับ
คลิกที่ปุ่ม เริ่มแล้วเลือก โปรแกรม, มาตรฐาน, บริการและ ตารางสัญลักษณ์.
ในการเลือกสัญลักษณ์ในตารางสัญลักษณ์ ให้คลิกที่สัญลักษณ์นั้น คลิก เลือก, คลิก คลิกขวาวางเมาส์ในตำแหน่งของเอกสารที่คุณต้องการเพิ่มสัญลักษณ์แล้วเลือกคำสั่ง แทรก.
รหัสอักขระทั่วไป
สำหรับอักขระอักขระเพิ่มเติม โปรดดูบทความที่ติดตั้งบนคอมพิวเตอร์ของคุณ รหัสอักขระ ASCII หรือไดอะแกรมสคริปต์โค้ดอักขระ Unicode
|
เข้าสู่ระบบ |
เข้าสู่ระบบ |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
สัญลักษณ์สกุลเงิน |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
สัญลักษณ์ทางกฎหมาย |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
เศษส่วน |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
เครื่องหมายวรรคตอนและสัญลักษณ์ภาษาถิ่น |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
สัญลักษณ์แบบฟอร์ม |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
รหัสกำกับเสียงทั่วไปสำหรับรายการร่ายมนตร์และรหัสอักขระที่เกี่ยวข้อง โปรดดูที่
|
Unicode เป็นมาตรฐานการเข้ารหัสอักขระสากลที่ช่วยให้สามารถแสดงข้อความได้อย่างสม่ำเสมอบนคอมพิวเตอร์เครื่องใดก็ได้ในโลก โดยไม่คำนึงถึงภาษาของระบบที่ใช้
พื้นฐาน
เพื่อให้เข้าใจว่าตารางอักขระ Unicode มีไว้เพื่ออะไร เรามาทำความเข้าใจกลไกในการแสดงข้อความบนหน้าจอมอนิเตอร์กันก่อน คอมพิวเตอร์อย่างที่เราทราบ ประมวลผลข้อมูลทั้งหมดในรูปแบบดิจิทัล และต้องแสดงเป็นภาพกราฟิกเพื่อการรับรู้ที่ถูกต้องของมนุษย์ ดังนั้น เพื่อให้เราอ่านข้อความนี้ จำเป็นต้องแก้ไขงานอย่างน้อยสองอย่าง:
- แปลงตัวอักษรที่พิมพ์ได้
- จัดเตรียมระบบปฏิบัติการที่มีความสามารถในการจับคู่รูปแบบดิจิทัลกับอักขระเวกเตอร์หรืออีกนัยหนึ่งคือค้นหาตัวอักษรที่ถูกต้อง
การเข้ารหัสครั้งแรก
American ASCII ถือเป็นบรรพบุรุษของการเข้ารหัสทั้งหมด มันอธิบายใช้ใน ภาษาอังกฤษตัวอักษรละตินที่มีเครื่องหมายวรรคตอนและตัวเลขอารบิก มันคือ 128 อักขระที่ใช้ในนั้นซึ่งกลายเป็นพื้นฐานสำหรับการพัฒนาที่ตามมา - แม้แต่ตารางอักขระ Unicode ที่ทันสมัยก็ใช้พวกมัน ตั้งแต่นั้นมา ตัวอักษรของอักษรละตินได้ครอบครองตำแหน่งแรกในการเข้ารหัสใดๆ
โดยรวมแล้ว ASCII อนุญาตให้จัดเก็บอักขระได้ 256 ตัว แต่เนื่องจาก 128 ตัวแรกถูกครอบครองโดยตัวอักษรละติน ส่วนที่เหลืออีก 128 ตัวจึงเริ่มถูกใช้ทั่วโลกเพื่อสร้างมาตรฐานระดับชาติ ตัวอย่างเช่น ในรัสเซีย CP866 และ KOI8-R ถูกสร้างขึ้นบนพื้นฐานของมัน รูปแบบดังกล่าวเรียกว่า ASCII เวอร์ชันเพิ่มเติม
หน้ารหัสและ "krakozyabry"
การพัฒนาเทคโนโลยีเพิ่มเติมและการเกิดขึ้นของส่วนต่อประสานกราฟิกนำไปสู่ความจริงที่ว่า American Institute for Standardization ถูกสร้างขึ้น การเข้ารหัส ANSI... สำหรับผู้ใช้ชาวรัสเซียโดยเฉพาะผู้มีประสบการณ์ เวอร์ชันนี้เป็นที่รู้จักภายใต้ ชื่อวินโดว์ 1251 เป็นคนแรกที่ใช้แนวคิด "หน้าโค้ด" ด้วยความช่วยเหลือของหน้ารหัสซึ่งมีสัญลักษณ์ของตัวอักษรประจำชาติอื่นที่ไม่ใช่ภาษาละติน จึงมีการสร้าง "ความเข้าใจซึ่งกันและกัน" ระหว่างคอมพิวเตอร์ที่ใช้ในประเทศต่างๆ
อย่างไรก็ตาม การมีการเข้ารหัสที่แตกต่างกันจำนวนมากที่ใช้สำหรับหนึ่งภาษาเริ่มก่อให้เกิดปัญหา ที่เรียกว่า krakozyabry ปรากฏขึ้น เกิดขึ้นจากความไม่ตรงกันระหว่างโค้ดเพจเดิม ซึ่งข้อมูลใดๆ ถูกสร้างขึ้น และโค้ดเพจที่ใช้โดยค่าเริ่มต้นบนคอมพิวเตอร์ของผู้ใช้ปลายทาง

ตัวอย่างเช่น การเข้ารหัสซีริลลิกด้านบน CP866 และ KOI8-R สามารถอ้างอิงได้ ตัวอักษรในนั้นแตกต่างกันในตำแหน่งรหัสและหลักการจัดวาง ในตอนแรกพวกเขาถูกจัดเรียงตามลำดับตัวอักษรและในลำดับที่สอง - ตามลำดับโดยพลการ คุณสามารถจินตนาการถึงสิ่งที่เกิดขึ้นต่อหน้าต่อตาของผู้ใช้ที่พยายามเปิดข้อความดังกล่าวโดยไม่ต้องมีหน้ารหัสที่จำเป็นหรือเมื่อคอมพิวเตอร์ตีความผิด
การสร้าง Unicode
การขยายตัวของอินเทอร์เน็ตและเทคโนโลยีที่เกี่ยวข้อง เช่น อีเมลนำไปสู่ความจริงที่ว่าในที่สุดสถานการณ์ที่มีการบิดเบือนข้อความก็ไม่เหมาะกับทุกคน บริษัทไอทีชั้นนำได้ก่อตั้ง Unicode Consortium ตารางอักขระที่เขาแนะนำในปี 1991 ภายใต้ชื่อ UTF-32 สามารถจัดเก็บอักขระที่ไม่ซ้ำกันได้มากกว่าหนึ่งพันล้านตัว มันเป็น ขั้นตอนสำคัญเกี่ยวกับวิธีการถอดรหัสข้อความ

อย่างไรก็ตาม ตาราง Unicode สากลแรกของรหัสอักขระ UTF-32 นั้นไม่ได้รับการยอมรับอย่างกว้างขวาง สาเหตุหลักมาจากความซ้ำซ้อนของข้อมูลที่เก็บไว้ มีการคำนวณอย่างรวดเร็วว่าสำหรับประเทศที่ใช้ตัวอักษรละตินที่เข้ารหัสด้วยตารางสากลใหม่ ข้อความจะใช้พื้นที่มากกว่าสี่เท่าเมื่อใช้ตาราง ASCII แบบขยาย
การพัฒนา Unicode
ตารางอักขระ Unicode UTF-16 ต่อไปนี้ได้แก้ไขปัญหานี้ การเข้ารหัสในนั้นดำเนินการในครึ่งหนึ่งของจำนวนบิต แต่ในขณะเดียวกันจำนวนชุดค่าผสมที่เป็นไปได้ก็ลดลงเช่นกัน แทนที่จะเก็บอักขระได้หลายพันล้านตัว แต่จะเก็บได้เพียง 65,536 ตัว อย่างไรก็ตาม ประสบความสำเร็จอย่างมากที่ Consortium ตัดสินใจว่าตัวเลขนั้นเป็นพื้นที่จัดเก็บพื้นฐานสำหรับอักขระ Unicode
แม้จะประสบความสำเร็จเช่นนี้ UTF-16 ก็ไม่เหมาะกับทุกคน เนื่องจากปริมาณการจัดเก็บและ ข้อมูลที่ส่งยังคงเป็นสองเท่า โซลูชันสากลคือ UTF-8 ซึ่งเป็นตารางอักขระ Unicode ที่มีความยาวผันแปรได้ เรียกได้ว่าเป็นความก้าวหน้าในด้านนี้เลยก็ว่าได้

ดังนั้น ด้วยการแนะนำสองมาตรฐานสุดท้าย ตารางอักขระ Unicode ได้แก้ปัญหาของพื้นที่โค้ดเดียวสำหรับแบบอักษรทั้งหมดที่ใช้อยู่ในปัจจุบัน
Unicode สำหรับภาษารัสเซีย
เนื่องจากความยาวของรหัสที่ใช้แสดงอักขระที่แปรผันได้ ภาษาละตินจึงถูกเข้ารหัสใน Unicode ในลักษณะเดียวกับใน ASCII บรรพบุรุษ นั่นคือในบิตเดียว สำหรับตัวอักษรอื่นๆ รูปภาพอาจดูแตกต่างออกไป ตัวอย่างเช่น อักขระของอักษรจอร์เจียใช้สามไบต์สำหรับการเข้ารหัส และอักขระของอักษรซีริลลิกใช้สองอักขระ ทั้งหมดนี้เป็นไปได้ภายใต้กรอบของการใช้มาตรฐาน UTF-8 Unicode (ตารางอักขระ) ภาษารัสเซียหรืออักษรซีริลลิกมีตำแหน่ง 448 ตำแหน่งในพื้นที่รหัสทั้งหมด แบ่งออกเป็นห้าช่วงตึก
![]()
ห้าช่วงตึกนี้ประกอบด้วยตัวอักษร Cyrillic และ Church Slavonic พื้นฐานตลอดจนตัวอักษรเพิ่มเติมของภาษาอื่น ๆ โดยใช้ตัวอักษร Cyrillic มีการเน้นตำแหน่งจำนวนหนึ่งเพื่อแสดงรูปแบบตัวอักษรซีริลลิกแบบเก่า และ 22 ตำแหน่งจากจำนวนทั้งหมดยังคงว่างอยู่
Unicode เวอร์ชันปัจจุบัน
ด้วยการแก้ปัญหาของงานหลัก ซึ่งก็คือการกำหนดมาตรฐานของฟอนต์และสร้างพื้นที่โค้ดเดียวสำหรับพวกเขา สมาคมฯ ไม่หยุดงาน Unicode มีการพัฒนาและขยายอย่างต่อเนื่อง เวอร์ชันปัจจุบันล่าสุดของมาตรฐานนี้คือ 9.0 เปิดตัวในปี 2016 รวมตัวอักษรเพิ่มเติมหกตัวและขยายรายการอีโมจิมาตรฐาน
ฉันต้องบอกว่าเพื่อทำให้การวิจัยง่ายขึ้น แม้แต่ภาษาที่เรียกกันว่าที่ตายแล้วก็ถูกเพิ่มลงใน Unicode พวกเขาได้ชื่อนี้เพราะไม่มีคนที่เขาจะเป็นชาวพื้นเมือง กลุ่มนี้ยังรวมถึงภาษาที่ลงมาในยุคของเราเท่านั้นในรูปแบบของอนุเสาวรีย์ที่เป็นลายลักษณ์อักษร
โดยหลักการแล้ว ทุกคนสามารถใช้เพื่อเพิ่มอักขระในข้อกำหนด Unicode ใหม่ได้ จริงสำหรับสิ่งนี้คุณต้องกรอกจำนวนที่เหมาะสม เอกสารต้นทางและใช้เวลามาก ตัวอย่างที่มีชีวิตคือเรื่องราวของโปรแกรมเมอร์เทอเรนซ์ อีเดน ในปี พ.ศ. 2556 เขายื่นคำร้องเพื่อรวมไว้ในข้อกำหนดของสัญลักษณ์ที่เกี่ยวข้องกับการกำหนดปุ่มควบคุมพลังงานของคอมพิวเตอร์ มีการใช้ในเอกสารทางเทคนิคตั้งแต่กลางทศวรรษที่ 70 ของศตวรรษที่ผ่านมา แต่จนกระทั่งมีการเปิดตัวข้อกำหนด 9.0 สิ่งเหล่านี้ไม่ได้เป็นส่วนหนึ่งของ Unicode
ตารางสัญลักษณ์
คอมพิวเตอร์ทุกเครื่อง โดยไม่คำนึงถึงระบบปฏิบัติการที่ใช้ จะใช้ตารางอักขระ Unicode วิธีใช้ตารางเหล่านี้ จะหาได้จากที่ไหน และเหตุใดจึงมีประโยชน์สำหรับผู้ใช้ทั่วไป
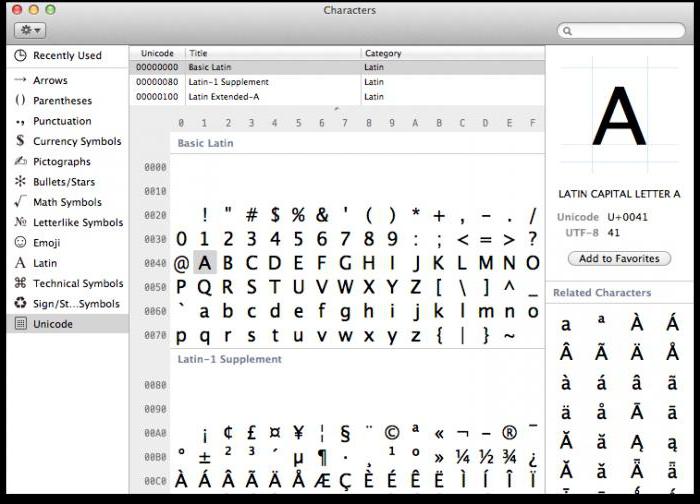
ใน OS โต๊ะวินโดว์สัญลักษณ์จะอยู่ในส่วน "บริการ" ของเมนู ในระบบปฏิบัติการตระกูล Linux มักพบได้ในส่วนย่อย "มาตรฐาน" และใน MacOS ในการตั้งค่าแป้นพิมพ์ จุดประสงค์หลักของตารางนี้คือเพื่อเข้าสู่ เอกสารข้อความอักขระที่ไม่ได้อยู่บนแป้นพิมพ์
แอปพลิเคชันสำหรับตารางดังกล่าวสามารถพบได้กว้างที่สุด: จากการป้อนสัญลักษณ์ทางเทคนิคและไอคอนของระบบการเงินของประเทศไปจนถึงการเขียนคำแนะนำสำหรับการใช้ไพ่ทาโรต์ในทางปฏิบัติ
ในที่สุด
Unicode ถูกใช้ทุกที่และเข้ามาในชีวิตของเราพร้อมกับการพัฒนาอินเทอร์เน็ตและ เทคโนโลยีมือถือ... ต้องขอบคุณการใช้งาน ระบบการสื่อสารระหว่างชาติพันธุ์จึงเรียบง่ายขึ้นอย่างมาก เราสามารถพูดได้ว่าการเปิดตัว Unicode เป็นเครื่องบ่งชี้ แต่ไม่สามารถมองเห็นได้จากตัวอย่างภายนอกของการใช้เทคโนโลยีเพื่อประโยชน์ส่วนรวมของมวลมนุษยชาติ
 ข้อบกพร่องในภาวะเอกฐาน?
ข้อบกพร่องในภาวะเอกฐาน? Just Cause 2 ล่ม
Just Cause 2 ล่ม Terraria ไม่เริ่มทำงาน ฉันควรทำอย่างไร?
Terraria ไม่เริ่มทำงาน ฉันควรทำอย่างไร?