Kendall Fechner Spearman Hodnostní korelační koeficienty. Kendallův koeficient pořadové korelace. Podívejte se, co je to "Kendallův koeficient korelace pořadí" v jiných slovnících
Vypočítat Kendallův koeficient hodnoty atributu faktoru jsou předběžně seřazeny, to znamená, že pořadí podle X jsou zaznamenány přísně ve vzestupném pořadí kvantitativních hodnot.
1) Pro každou hodnost v Y zjistěte celkový počet hodností za ní, jejichž hodnota je vyšší než daná hodnost. Celkový počet takových případů se bere v úvahu se znaménkem „+“ a označuje se P.
2) Pro každou hodnost v Y se určí počet hodností za ní následujících, které jsou hodnotově menší než daná hodnost. Celkový počet takových případů se bere v úvahu se znaménkem „-“ a označuje se Q.
3) Vypočítejte S=P+Q=9+(-1)=8
4) Kendellův koeficient se vypočítá podle vzorce:
Kendellův koeficient může nabývat hodnot od -1 do +1 a čím blíže k, tím silnější je vztah mezi prvky.
V některých případech pro určení směru vztahu mezi dvěma prvky vypočítejte Fechnerův koeficient. Tento koeficient je založen na porovnání chování odchylek jednotlivých hodnot faktoriálu a výsledných charakteristik od jejich průměrné hodnoty. Fechnerův koeficient se vypočítá podle vzorce:
 ; kde součet C je celkový počet shod znamének odchylek, součet H je celkový počet neshod znamének odchylek.
; kde součet C je celkový počet shod znamének odchylek, součet H je celkový počet neshod znamének odchylek.
1) Vypočítejte průměrnou hodnotu faktoru: ![]()
2) Určete znaménka odchylek jednotlivých hodnot faktorové charakteristiky od průměrné hodnoty.
3) Vypočítejte průměrnou hodnotu efektivního prvku: ![]() .
.
4) Najděte znaménka odchylek jednotlivých hodnot výsledného atributu od průměrné hodnoty:

Závěr: spoj je přímý, koeficient nevypovídá o těsnosti spoje.
Pro určení stupně těsnosti vztahu mezi třemi hodnocenými prvky se vypočítá koeficient konkordance. Vypočítá se podle vzorce:
![]() , kde m je počet hodnocených prvků; n je počet hodnocených pozorovacích jednotek.
, kde m je počet hodnocených prvků; n je počet hodnocených pozorovacích jednotek.
| Průmyslová odvětví | X1 | X2 | X3 | R1 | R2 | R3 | ||
| Energetický průmysl | 7,49 | |||||||
| Palivo | 12,70 | |||||||
| Černý M. | 5,92 | |||||||
| barva M. | 9,48 | |||||||
| strojírenství | 4,18 | |||||||
| Výsledek: |
X1- počet zaměstnanců (tisíc lidí); X2- objem průmyslového prodeje (miliardy rublů); X3- průměrná měsíční mzda.
1) Hodnotíme hodnoty všech funkcí a nastavujeme pořadí přísně ve vzestupném pořadí kvantitativních hodnot.
2) Pro každý řádek je určen součet pořadí. Z tohoto sloupce se vypočítá celkový řádek.
3) Vypočítejte ![]() .
.
4) Pro každý řádek najděte druhé mocniny odchylek součtů pořadí a hodnot T. Pro stejný sloupec vypočítáme výsledný řádek, který označíme S. ![]() Koeficient shody může nabývat hodnot od 0 do 1, a čím blíže je k 1, tím silnější je vztah mezi znaky.
Koeficient shody může nabývat hodnot od 0 do 1, a čím blíže je k 1, tím silnější je vztah mezi znaky.
Při řazení musí expert seřadit hodnocené prvky ve vzestupném (sestupném) pořadí podle jejich preference a každému z nich přiřadit pořadí ve formě přirozených čísel. V přímém hodnocení má nejpreferovanější prvek hodnost 1 (někdy 0) a nejméně preferovaný prvek má hodnost m.
Pokud odborník nemůže provést přísné hodnocení z důvodu, že podle jeho názoru jsou některé prvky přednostně stejné, je povoleno těmto prvkům přiřadit stejné pořadí. Aby byl součet hodností roven součtu míst hodnocených prvků, používají se tzv. standardizované hodnosti. Standardizované pořadí je aritmetický průměr počtu prvků v hodnocené řadě, které jsou preferovány stejně.
Příklad 2.6. Expert seřadil šest položek podle preferencí takto:
Pak budou standardizované řady těchto prvků
Součet úrovní přiřazených prvkům se tedy bude rovnat součtu přirozených čísel.
Přesnost vyjádření preference klasifikačními prvky významně závisí na mohutnosti souboru prezentací. Postup hodnocení dává nejspolehlivější výsledky (podle míry blízkosti odhalené preference a „pravda“), kdy počet hodnocených prvků není větší než 10. Limitující síla prezentační sady by neměla překročit 20.
Zpracování a analýza žebříčků se provádí za účelem vybudování skupinového preferenčního vztahu na základě individuálních preferencí. V tomto případě lze stanovit následující úkoly: a) určení těsnosti souvislosti mezi hodnocením dvou expertů na prvky souboru prezentací; b) určení vztahu mezi dvěma prvky podle individuálních názorů členů skupiny na různé charakteristiky těchto prvků; c) posouzení shody názorů odborníků ve skupině složené z více než dvou odborníků.
V prvních dvou případech se koeficient používá jako míra těsnosti vztahu hodnostní korelace. V závislosti na tom, zda je povoleno pouze přísné nebo nepřísné hodnocení, se použije buď Kendallův nebo Spearmanův koeficient pořadové korelace.
Kendallův korelační koeficient pro problém (a)
kde m− počet prvků; r 1 i – hodnost přidělená prvním expertem i-tý prvek; r 2 i – tentýž, druhý odborník.
Pro úlohu (b) mají složky (2.5) následující význam: m je počet charakteristik dvou hodnocených prvků; r 1 i(r 2 i) - hodnost i charakteristiky v žebříčku prvního (druhého) prvku sestaveného skupinou odborníků.
Přísné hodnocení používá koeficient pořadové korelace R Spearman:
jejichž složky mají stejný význam jako v (2.5).
Korelační koeficienty (2,5), (2,6) se pohybují od -1 do +1. Pokud je korelační koeficient +1, znamená to, že pořadí je stejné; pokud se rovná -1, pak − jsou opačné (hodnocení jsou vzájemně inverzní). Rovnost korelačního koeficientu na nulu znamená, že hodnocení jsou lineárně nezávislá (nekorelovaná).
Protože u tohoto přístupu (expert je „měřicí nástroj“ s náhodnou chybou) jsou jednotlivá pořadí považována za náhodná, vyvstává problém statistického testování hypotézy o významnosti získaného korelačního koeficientu. V tomto případě se používá Neyman-Pearsonův test: jsou stanoveny hladinou významnosti kritéria α a se znalostí distribučních zákonů korelačního koeficientu určují prahovou hodnotu. ca, se kterou se porovnává získaná hodnota korelačního koeficientu. Kritická oblast je pravotočivá (v praxi se obvykle nejprve vypočítá hodnota kritéria a z ní se určí hladina významnosti, která se porovná s prahovou hladinou α ).
Koeficient pořadové korelace τ Kendall má pro m > 10 rozdělení blízké normálu s následujícími parametry:
kde M [τ] je matematické očekávání; D [τ] je disperze.
V tomto případě se používají tabulky funkce standardního normálního rozdělení:
a hranice τ α kritické oblasti je definována jako kořen rovnice
Pokud je vypočtená hodnota koeficientu τ ≥ τ α , pak se má za to, že pořadí jsou ve skutečně dobré shodě. Typicky se hodnota a volí v rozmezí 0,01-0,05. Pro m ≤ 10 je rozdělení m uvedeno v tabulce. 2.1.
Kontrola významnosti konzistence dvou hodnocení pomocí Spearmanova koeficientu ρ se provádí ve stejném pořadí pomocí Studentových distribučních tabulek pro m > 10.
V tomto případě hodnota
má distribuci dobře přibližnou distribuci studenta s m– 2 stupně volnosti. V m> 30, rozdělení ρ je v dobré shodě s normálním, které má M [ρ] = 0 a D [ρ] = .
Pro m ≤ 10 je významnost ρ ověřena pomocí tabulky. 2.2.
Pokud není žebříček přísný, tak Spearmanův koeficient
kde ρ se vypočítá podle (2.6);
kde k 1, k 2 je počet různých skupin nepřísných řad v prvním a druhém pořadí; l i je počet stejných pozic v i-tá skupina. Při praktickém použití Spearmanových koeficientů hodnostní korelace ρ a Kendallova τ je třeba mít na paměti, že koeficient ρ poskytuje přesnější výsledek z hlediska minimálního rozptylu.
Tabulka 2.1.Rozdělení Kendallova koeficientu pořadové korelace
Jedním z faktorů omezujících použití kritérií založených na předpokladu normality je velikost vzorku. Pokud je vzorek dostatečně velký (například 100 nebo více pozorování), můžete předpokládat, že rozložení vzorku je normální, i když si nejste jisti, že rozložení proměnné v populaci je normální. Pokud je však vzorek malý, měly by být tyto testy použity pouze v případě, že existuje jistota, že proměnná je skutečně normálně distribuována. Neexistuje však způsob, jak tento předpoklad otestovat na malém vzorku.
Použití kritérií vycházejících z předpokladu normality je také omezeno měřítkem měření (viz kapitola Základní pojmy analýzy dat). Statistické metody jako t-test, regrese atd. předpokládají, že původní data jsou spojitá. Existují však situace, kdy jsou data jednoduše řazena (měřena na ordinální stupnici), spíše než přesně měřena.
Typickým příkladem je hodnocení stránek na internetu: na první pozici je stránka s maximálním počtem návštěvníků, na druhé pozici je stránka s maximální návštěvností mezi zbývajícími stránkami (mezi stránkami, ze kterých první stránka byla odstraněna) atd. Se znalostí hodnocení můžeme říci, že návštěvnost jedné stránky je větší než návštěvnost jiné stránky, ale o kolik více, nelze říci. Představte si, že máte 5 webů: A, B, C, D, E, které se nacházejí na prvních 5 místech. Předpokládejme, že v aktuálním měsíci jsme měli toto uspořádání: A, B, C, D, E a v předchozím měsíci: D, E, A, B, C. Otázkou je, zda došlo k výrazným změnám v hodnocení stránek nebo ne? V této situaci samozřejmě nemůžeme použít t-test k porovnání těchto dvou souborů dat a přesouváme se do oblasti konkrétních pravděpodobnostních výpočtů (a každý statistický test obsahuje pravděpodobnostní výpočet!). Uvažujeme přibližně takto: jak pravděpodobné je, že rozdíl v uspořádání dvou míst je způsoben čistě náhodnými důvody, nebo je tento rozdíl příliš velký a nelze jej vysvětlit čirou náhodou. V těchto diskuzích používáme pouze hodnocení nebo permutace stránek a nepoužíváme konkrétní typ rozložení počtu návštěvníků na nich.
Pro analýzu malých vzorků a pro data naměřená na špatných měřítcích se používají neparametrické metody.
Stručný přehled neparametrických postupů
V podstatě pro každé parametrické kritérium existují alespoň, jedna neparametrická alternativa.
Obecně tyto postupy spadají do jedné z následujících kategorií:
- rozdílová kritéria pro nezávislé vzorky;
- rozdílová kritéria pro závislé vzorky;
- posouzení míry závislosti mezi proměnnými.
Obecně by měl být přístup ke statistickým kritériím při analýze dat pragmatický a nezatížený zbytečnými teoretickými úvahami. S počítačem STATISTICA, který máte k dispozici, můžete na svá data snadno aplikovat několik kritérií. S vědomím některých úskalí metod si vyberete správné řešení pomocí experimentování. Vývoj grafu je zcela přirozený: pokud potřebujete porovnat hodnoty dvou proměnných, použijte t-test. Je však třeba připomenout, že je založen na předpokladu normality a rovnosti rozptylů v každé skupině. Osvobození od těchto předpokladů vede k neparametrickým testům, které jsou užitečné zejména pro malé vzorky.
Vývoj t-testu vede k analýze rozptylu, která se používá, když je počet porovnávaných skupin větší než dvě. Odpovídající rozvoj neparametrických postupů vede k neparametrické analýze rozptylu, i když je mnohem horší než klasická analýza rozptylu.
Pro posouzení závislosti, nebo, poněkud velkolepě řečeno, míry těsnosti souvislosti se počítá Pearsonův korelační koeficient. Přísně vzato má jeho použití omezení spojená např. s typem škály, ve které jsou data měřena a nelinearitou závislosti, proto jako alternativa neparametrické, nebo tzv. hodnostní, korelační koeficienty. se také používají, které se používají například pro řazená data. Pokud jsou data měřena v nominálním měřítku, pak je přirozené je prezentovat v kontingenčních tabulkách, které využívají Pearsonův chí-kvadrát test s různými variacemi a úpravami pro přesnost.
V podstatě tedy existuje jen několik typů kritérií a postupů, které musíte znát a umět je používat, v závislosti na specifikách dat. Musíte určit, jaké kritérium by se mělo v konkrétní situaci použít.
Neparametrické metody jsou nejvhodnější, pokud je velikost vzorku malá. Pokud existuje mnoho dat (například n > 100), často nemá smysl používat neparametrické statistiky.
Pokud je velikost vzorku velmi malá (například n = 10 nebo méně), lze hladiny významnosti pro ty neparametrické testy, které používají normální aproximaci, považovat pouze za hrubé odhady.
Rozdíly mezi nezávislými skupinami. Pokud existují dva vzorky (např. muži a ženy), které je třeba porovnat s ohledem na nějakou střední hodnotu, jako je průměrný krevní tlak nebo počet bílých krvinek, pak lze použít nezávislý vzorkový t-test.
Neparametrické alternativy k tomuto testu jsou Wald-Wolfowitz, Mann-Whitney )/n série test, kde x i - i-tá hodnota, n - počet pozorování. Pokud proměnná obsahuje záporné hodnoty nebo nulu (0), geometrický průměr nelze vypočítat.
Harmonický průměr
Harmonický průměr se někdy používá k průměrování frekvencí. Harmonický průměr se vypočítá podle vzorce: HS = n/S(1/x i) kde HS je harmonický průměr, n je počet pozorování, x i je hodnota pozorování s číslem i. Pokud proměnná obsahuje nulu (0), nelze harmonický průměr vypočítat.
Rozptyl a směrodatná odchylka
Výběrový rozptyl a směrodatná odchylka jsou nejčastěji používanými měřítky variability (variací) v datech. Rozptyl se vypočítá jako součet čtverců odchylek hodnot proměnné od výběrového průměru dělený n-1 (ale ne n). Směrodatná odchylka se vypočítá jako druhá odmocnina odhadu rozptylu.
rozsah
Rozsah proměnné je mírou volatility, počítá se jako maximum mínus minimum.
Kvartilový rozsah
Čtvrtletní rozmezí podle definice je: horní kvartil mínus spodní kvartil (75% percentil mínus 25% percentil). Protože percentil 75 % (horní kvartil) je hodnota nalevo, od níž je 75 % pozorování, a percentil 25 % (dolní kvartil) je hodnota nalevo od níž je 25 % pozorování, kvartil rozsah je interval kolem mediánu, který obsahuje 50 % pozorování (hodnot proměnné).
Asymetrie
Šikmost je charakteristická pro tvar distribuce. Distribuce je zkosená doleva, pokud je zešikmení záporné. Distribuce je zkosená doprava, pokud je šikmost kladná. Šikmost standardního normálního rozdělení je 0. Šikmost se vztahuje ke třetímu momentu a je definována jako: šikmost = n × M 3 /[(n-1) × (n-2) × s 3 ], kde M 3 je: (x i -xstřední x) 3, s 3 - standardní odchylka zvýšená na třetí mocninu, n - počet pozorování.
Přebytek
Kurtóza je charakteristika tvaru rozdělení, konkrétně míra ostrosti jeho vrcholu (ve vztahu k normálnímu rozdělení, jehož špičatost je 0). Obecně platí, že distribuce s ostřejším vrcholem než normální distribuce mají kladnou špičatost; rozdělení, jejichž vrchol je méně ostrý než vrchol normálního rozdělení, mají zápornou špičatost. Kurtóza je spojena se čtvrtým momentem a je určena vzorcem:
kurtosis = /[(n-1) × (n-2) × (n-3) × s 4 ], kde M j je: (x-x průměr x, s 4 je standardní odchylka od čtvrté mocniny, n je počet pozorování.
Stručná teorie
Kendallův korelační koeficient se používá, když jsou proměnné reprezentovány dvěma ordinálními stupnicemi, za předpokladu, že neexistují žádné související stupně. Výpočet Kendallova koeficientu je spojen s počítáním počtu shod a inverzí.
Tento koeficient se mění v rámci a vypočítává se podle vzorce:
Pro výpočet jsou všechny jednotky seřazeny podle atributu; pro řadu dalších znaků se pro každou hodnost počítá počet následných hodností přesahujících danou (označujeme je ) a počet následujících hodností pod danou (označujeme je ).
Dá se to ukázat
a Kendallův korelační koeficient hodnosti lze zapsat jako
Abychom mohli otestovat nulovou hypotézu o rovnosti Kendallova obecného korelačního koeficientu pořadí na nule pod konkurenční hypotézou na hladině významnosti , je nutné vypočítat kritický bod:
kde je velikost vzorku; - kritický bod oboustranné kritické oblasti, který se zjistí z tabulky Laplaceovy funkce podle rovnosti
Pokud není důvod zamítnout nulovou hypotézu. Pořadová korelace mezi znaky je nevýznamná.
Pokud je nulová hypotéza zamítnuta. Mezi znaky existuje významná korelace pořadí.
Příklad řešení problému
Úkol
Při přijímání sedmi kandidátů na volná místa byly nabídnuty dva testy. Výsledky testu (v bodech) jsou uvedeny v tabulce:
| Test | Kandidát | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 31 | 82 | 25 | 26 | 53 | 30 | 29 | 2 | 21 | 55 | 8 | 27 | 32 | 42 | 26 |
Vypočítejte Kendallův koeficient pořadové korelace mezi výsledky testů pro dva testy a zhodnoťte jeho významnost na úrovni.
Řešení problému
Vypočítejte Kendallův koeficient
Pořadí atributu faktoru jsou uspořádány přísně vzestupně a odpovídající úrovně efektivního atributu jsou zapsány paralelně. U každé hodnosti se z počtu hodností, které za ní následují, započítává počet hodností větších než je ona (zahrnuto ve sloupci ) a počet hodností, které mají menší hodnotu (zahrnuto ve sloupci ).
| 1 | 1 | 6 | 0 | 2 | 4 | 3 | 2 | 3 | 3 | 3 | 1 | 4 | 6 | 1 | 2 | 5 | 2 | 2 | 0 | 6 | 5 | 1 | 0 | 7 | 7 | 0 | 0 | Součet | 16 | 5 |
Pro výpočet Kendallova pořadového korelačního koeficientu rk je nutné seřadit data podle jednoho z prvků ve vzestupném pořadí a určit odpovídající pořadí podle druhého prvku. Potom se pro každou hodnost druhého prvku určí počet následných hodností větších než přijatá hodnost a zjistí se součet těchto čísel.
Kendallův hodnostní korelační koeficient je dán
kde R i je počet úrovní druhé proměnné počínaje i+1, jehož velikost je větší než velikost i pořadí této proměnné.
Existují tabulky rozdělení koeficientů v procentech rk, což umožňuje testovat hypotézu o významnosti korelačního koeficientu.
 Pro velké velikosti vzorků kritické hodnoty rk nejsou tabelovány a je třeba je vypočítat pomocí přibližných vzorců na základě skutečnosti, že podle nulové hypotézy H 0: rk=0 a velké n náhodná hodnota
Pro velké velikosti vzorků kritické hodnoty rk nejsou tabelovány a je třeba je vypočítat pomocí přibližných vzorců na základě skutečnosti, že podle nulové hypotézy H 0: rk=0 a velké n náhodná hodnota
rozděleno přibližně podle standardního normálního zákona.
40. Vztah mezi rysy měřenými v nominálních nebo ordinálních měřítcích
Často se vyskytuje problém kontroly nezávislosti dvou znaků měřených na nominální nebo ordinální stupnici.
Nechť jsou u některých objektů změřeny dva rysy X a Y s počtem úrovní r a s resp. Je vhodné prezentovat výsledky takových pozorování ve formě tabulky zvané kontingenční tabulka prvků.
Stůl u i(i = 1, ..., r) a vj (j= 1, ..., s) jsou hodnoty převzaté funkcemi, hodnotou nij je počet objektů z celkového počtu objektů, které mají atribut X nabralo význam u i a znamení Y- význam vj

 Zavádíme následující náhodné proměnné:
Zavádíme následující náhodné proměnné:
u i

- počet objektů, které mají hodnotu vj

Kromě toho existují zjevné rovnosti



Diskrétní náhodné veličiny X a Y nezávislý tehdy a jen tehdy
pro všechny páry i, j
Proto hypotéza o nezávislosti diskrétních náhodných veličin X a Y lze napsat takto:
Jako alternativu zpravidla použijte hypotézu
 Platnost hypotézy H 0 by měla být posouzena na základě vzorových četností nij kontingenční tabulky. Podle zákona velkých čísel, n→∞ relativní četnosti jsou blízké odpovídajícím pravděpodobnostem:
Platnost hypotézy H 0 by měla být posouzena na základě vzorových četností nij kontingenční tabulky. Podle zákona velkých čísel, n→∞ relativní četnosti jsou blízké odpovídajícím pravděpodobnostem:



K testování hypotézy H 0 se používá statistika
který při platnosti hypotézy má rozdělení χ 2 s rs − (r + s− 1) stupně volnosti.
Kritérium nezávislosti χ 2 zamítá hypotézu H 0 s hladinou významnosti α, pokud:

41. Regresní analýza. Základní pojmy regresní analýzy
Pro matematický popis statistických vztahů mezi studovanými proměnnými by měly být vyřešeny následující úlohy:
ü zvolit třídu funkcí, ve které je vhodné hledat nejlepší (v určitém smyslu) aproximaci závislosti zájmu;
ü najít odhady neznámých hodnot parametrů zahrnutých v rovnicích požadované závislosti;
ü stanovit adekvátnost získané rovnice požadované závislosti;
ü identifikovat nejinformativnější vstupní proměnné.
Souhrn těchto úloh je předmětem výzkumu regresní analýzy.
Regresní funkce (neboli regrese) je závislost matematického očekávání jedné náhodné veličiny na hodnotě jiné náhodné veličiny, která s první tvoří dvourozměrný systém náhodných veličin.
Nechť existuje systém náhodných proměnných ( X,Y), pak regresní funkce Y na X
A regresní funkce X na Y
Regresní funkce F(X) a φ (y), nejsou vzájemně vratné, ledaže by vztah mezi X a Y není funkční.
Když n-rozměrný vektor se souřadnicemi X 1 , X 2 ,…, X n je možné uvažovat o podmíněném matematickém očekávání pro jakoukoli složku. Například pro X 1

tzv. regrese X 1 na X 2 ,…, X n.
Pro plnou definici regresní funkce je nutné znát podmíněné rozdělení výstupní proměnné pro pevné hodnoty vstupní proměnné.
Protože v reálné situaci takové informace nejsou k dispozici, omezí se většinou na hledání vhodné aproximační funkce f a(X) pro F(X), na základě statistických údajů formuláře ( x i, y i), i = 1,…, n. Tato data jsou výsledkem n nezávislá pozorování y 1 ,…, y n náhodná proměnná Y na hodnotách vstupní proměnné X 1 ,…, x n, zatímco v regresní analýze se předpokládá, že hodnoty vstupní proměnné jsou přesně specifikovány.
Problém výběru nejlepší aproximační funkce f a(X), která je hlavní v regresní analýze a nemá formalizované postupy pro její řešení. Někdy je výběr určen na základě analýzy experimentálních dat, častěji z teoretických úvah.
Pokud se předpokládá, že regresní funkce je dostatečně hladká, pak funkce, která ji aproximuje f a(X) lze reprezentovat jako lineární kombinaci nějaké množiny lineárně nezávislých bázových funkcí ψ k(X), k = 0, 1,…, m−1, tedy ve tvaru

kde m je počet neznámých parametrů θ k(obecně je hodnota neznámá, upřesňuje se při konstrukci modelu).
Taková funkce je v parametrech lineární, proto se v posuzovaném případě hovoří o modelu regresní funkce lineárně v parametrech.
Pak problém najít nejlepší aproximaci pro regresní přímku F(X) se redukuje na nalezení takových hodnot parametrů, pro které f a(X;θ) je vzhledem k dostupným údajům nejpřiměřenější. Jednou z metod řešení tohoto problému je metoda nejmenších čtverců.
42. Metoda nejmenších čtverců
Nechte množinu bodů ( x i, y i), i= 1,…, n umístěný v rovině podél nějaké přímky
 Pak jako funkce f a(X) aproximující regresní funkci F(X) = M [Y|X] přirozeně brát lineární funkce argument X:
Pak jako funkce f a(X) aproximující regresní funkci F(X) = M [Y|X] přirozeně brát lineární funkce argument X:

To znamená, že jsme zde zvolili základní funkce ψ 0 (X)≡1 a ψ 1 (X)≡X. Tato regrese se nazývá jednoduchá lineární regrese.
Pokud soubor bodů ( x i, y i), i= 1,…, n umístěné podél nějaké křivky, pak jako f a(X) je přirozené pokusit se vybrat rodinu parabol


Tato funkce je v parametrech nelineární θ 0 a θ 1, nicméně funkční transformací (v tomto případě logaritmováním) jej lze redukovat na nová vlastnost f'a(X), lineární v parametrech:
43. Jednoduchá lineární regrese
Nejjednodušší regresní model je jednoduchý (jednorozměrný, jednofaktorový, párový) lineární model, který má následující podobu:


kde ε i- nekorelované náhodné veličiny (chyby) s nulovými matematickými očekáváními a stejnými rozptyly σ 2 , A a b jsou konstantní koeficienty (parametry), které je potřeba odhadnout z naměřených hodnot odezvy y i.
Chcete-li najít odhady parametrů A a b lineární regrese, která určuje přímku, která nejlépe vyhovuje experimentálním datům:

používá se metoda nejmenších čtverců.
 Podle nejmenší čtverce
odhady parametrů A a b se zjistí z podmínky minimalizace součtu kvadrátů odchylek hodnot y i svisle od „skutečné“ regresní přímky:
Podle nejmenší čtverce
odhady parametrů A a b se zjistí z podmínky minimalizace součtu kvadrátů odchylek hodnot y i svisle od „skutečné“ regresní přímky:
Nechť existuje deset pozorování náhodné veličiny Y pro pevné hodnoty proměnné X


Chcete-li minimalizovat D rovnají se nule parciální derivace s ohledem na A a b:


Ve výsledku získáme následující soustavu rovnic pro nalezení odhadů A a b:


Řešení těchto dvou rovnic dává:


Výrazy pro odhady parametrů A a b může být také reprezentován jako:


Potom empirická rovnice regresní přímky Y na X lze napsat jako:

 Nestranný odhad rozptylu σ
2 odchylky hodnot y i z proložené regresní přímky je dána
Nestranný odhad rozptylu σ
2 odchylky hodnot y i z proložené regresní přímky je dána
Vypočítejte parametry regresní rovnice



Přímá regrese tedy vypadá takto:

A odhad rozptylu odchylek hodnot y i z proložené přímé regresní přímky

44. Kontrola významnosti regresní linie
Nalezený odhad b≠ 0 může být realizace náhodné veličiny, jejíž matematické očekávání se rovná nule, tj. může se ukázat, že ve skutečnosti neexistuje žádná regresní závislost.
Abyste se s touto situací vypořádali, měli byste otestovat hypotézu H 0: b= 0 podle konkurenční hypotézy H 1: b ≠ 0.
Významnost regresní přímky lze testovat pomocí analýzy rozptylu.
Zvažte následující identitu:
Hodnota y i− ŷ i = ε i se nazývá zbytek a je to rozdíl mezi těmito dvěma veličinami:
ü odchylka pozorované hodnoty (odpovědi) od obecného průměru odpovědí;
ü odchylka předpokládané hodnoty odezvy ŷ i ze stejného průměru

Výše uvedená identita může být zapsána jako
Umocněním obou stran a sečtením i, dostaneme:

 Kde jsou pojmenována množství:
Kde jsou pojmenována množství:
úplný (celkový) součet čtverců SC n, který se rovná součtu čtverců odchylek pozorování ve vztahu ke střední hodnotě pozorování

součet čtverců v důsledku regrese SC p, který se rovná součtu čtverců odchylek hodnot regresní přímky vzhledem k průměru pozorování.
 zbytkový součet čtverců SC 0 . což se rovná součtu čtverců odchylek pozorování vzhledem k hodnotám regresní přímky
zbytkový součet čtverců SC 0 . což se rovná součtu čtverců odchylek pozorování vzhledem k hodnotám regresní přímky
Tedy šíření Y-kov vzhledem k jejich průměru lze do určité míry přičíst skutečnosti, že ne všechna pozorování leží na regresní přímce. Pokud by tomu tak bylo, pak by součet čtverců vzhledem k regresi byl nulový. Z toho vyplývá, že regrese bude významná, pokud součet čtverců SC p je větší než součet druhých mocnin SC 0 .
Výpočty pro testování významnosti regrese se provádějí v následující analýze tabulky rozptylů

Pokud chyby ε i rozdělené podle normálního zákona, pak je-li hypotéza H 0 pravdivá: b= 0 statistika:

rozdělené podle Fisherova zákona s počtem stupňů volnosti 1 a n−2.
Nulová hypotéza bude zamítnuta na hladině významnosti α, pokud je vypočtená hodnota statistiky F bude větší než α-procentní bod F 1;n−2;α Fisherova rozdělení.
45. Kontrola adekvátnosti regresního modelu. Zbytková metoda
Adekvátnost konstruovaného regresního modelu je chápána jako skutečnost, že žádný jiný model neposkytuje významné zlepšení v predikci odezvy.
Pokud jsou všechny hodnoty odezvy získány při různých hodnotách X, tj. pro totéž není získáno několik hodnot odezvy x i, pak lze provést pouze omezený test přiměřenosti lineárního modelu. Základem pro takovou kontrolu jsou zbytky:


Odchylky od zavedeného vzoru:
Pokud X je jednorozměrná proměnná, body ( x i, d i) lze znázornit na rovině ve formě tzv. zbytkového pozemku. Taková reprezentace někdy umožňuje detekovat určitou pravidelnost v chování zbytků. Kromě toho nám analýza reziduí umožňuje analyzovat předpoklad týkající se zákona rozdělení chyb.


V případě, kdy jsou chyby rozděleny podle normálního zákona a existuje apriorní odhad jejich rozptylu σ 2 (odhad získaný na základě dříve provedených měření), pak je možné přesnější posouzení přiměřenosti modelu.
Přes F-Fischerův test, můžete zkontrolovat, zda je zbytkový rozptyl významný s 0 2 se liší od apriorního odhadu. Je-li výrazně větší, jedná se o nedostatečnost a model by měl být revidován.
Pokud apriorní odhad σ 2 ne, ale měření odezvy Y opakovat dvakrát nebo vícekrát se stejnými hodnotami X, pak lze tato opakovaná pozorování použít k získání dalšího odhadu σ 2 (první je zbytkový rozptyl). O takovém odhadu se říká, že představuje „čistou“ chybu, protože pokud uděláme X stejné pro dvě nebo více pozorování, pak pouze náhodné změny mohou ovlivnit výsledky a vytvořit mezi nimi rozptyl.
Výsledný odhad se ukazuje jako spolehlivější odhad rozptylu než odhad získaný jinými metodami. Z tohoto důvodu má při plánování experimentů smysl nastavit experimenty s opakováním.
 Předpokládejme, že existuje m různé významy X : X 1 , X 2 , ..., x m. Nechť pro každou z těchto hodnot x i k dispozici n i pozorování odezvy Y. Celkový počet pozorování je:
Předpokládejme, že existuje m různé významy X : X 1 , X 2 , ..., x m. Nechť pro každou z těchto hodnot x i k dispozici n i pozorování odezvy Y. Celkový počet pozorování je:
Pak lze jednoduchý lineární regresní model zapsat jako:





 Pojďme najít rozptyl „čistých“ chyb. Tento rozptyl je odhad kombinovaného rozptylu σ
2, pokud uvedeme hodnoty odezvy yij v X = x i jako vzorkovací objem n i. V důsledku toho se rozptyl „čistých“ chyb rovná:
Pojďme najít rozptyl „čistých“ chyb. Tento rozptyl je odhad kombinovaného rozptylu σ
2, pokud uvedeme hodnoty odezvy yij v X = x i jako vzorkovací objem n i. V důsledku toho se rozptyl „čistých“ chyb rovná:
Tento rozptyl slouží jako odhad σ 2 bez ohledu na to, zda je osazený model správný.
Ukažme, že součet čtverců „čistých chyb“ je součástí zbytkového součtu čtverců (součet čtverců zahrnutých ve výrazu pro zbytkový rozptyl). Zbývá pro j pozorování v x i lze napsat jako:
Pokud odmocníme obě strany této rovnice a pak je sečteme j a podle i, pak dostaneme:
Na levé straně této rovnice je zbytkový součet čtverců. První člen na pravé straně je součtem druhých mocnin „čistých“ chyb, druhý člen lze nazvat součtem druhých mocnin neadekvátnosti. Poslední částka má m−2 stupně volnosti, tedy rozptyl nepřiměřenosti

 Testovací statistika pro testování hypotézy H 0: jednoduchý lineární model je adekvátní, proti hypotéze H 1: jednoduchý lineární model je nedostatečný, je náhodná veličina
Testovací statistika pro testování hypotézy H 0: jednoduchý lineární model je adekvátní, proti hypotéze H 1: jednoduchý lineární model je nedostatečný, je náhodná veličina
Pokud je nulová hypotéza pravdivá, hodnota F má Fisherovo rozdělení se stupni volnosti m−2 a n−m. Hypotéza linearity regresní přímky by měla být zamítnuta s hladinou významnosti α, pokud je výsledná statistická hodnota větší než α-procentní bod Fisherova rozdělení s počtem stupňů volnosti. m−2 a n−m.
46. Kontrola adekvátnosti regresního modelu (viz 45). Analýza rozptylu
47. Kontrola adekvátnosti regresního modelu (viz 45). Koeficient determinace
 Někdy se pro charakterizaci kvality regresní přímky používá výběrový koeficient determinace. R 2, ukazující, jaká část (podíl) součtu čtverců v důsledku regrese, SC p je v celkovém součtu čtverců SC n:
Někdy se pro charakterizaci kvality regresní přímky používá výběrový koeficient determinace. R 2, ukazující, jaká část (podíl) součtu čtverců v důsledku regrese, SC p je v celkovém součtu čtverců SC n:
Blíže R 2 ku jedné, čím lépe se regrese blíží experimentálním datům, tím blíže jsou pozorování k regresní přímce. Pokud R 2 = 0, pak změny odezvy jsou zcela způsobeny vlivem nezapočtených faktorů a regresní přímka je rovnoběžná s osou X-ov. V případě jednoduché lineární regrese koeficient determinace R 2 se rovná druhé mocnině korelačního koeficientu r 2 .
Maximální hodnoty R 2 =1 lze dosáhnout pouze v případě, kdy byla pozorování provedena při různých hodnotách x-s. Pokud jsou v datech opakované zkušenosti, pak hodnota R 2 nemůže dosáhnout jednoty, bez ohledu na to, jak dobrý je model.
48. Intervaly spolehlivosti pro jednoduché lineární regresní parametry
Stejně jako je výběrový průměr odhadem skutečného průměru (střední hodnota populace), tak jsou i výběrové parametry regresní rovnice A a b- nic víc než odhady skutečných regresních koeficientů. Různé vzorky poskytují různé odhady střední hodnoty, stejně jako různé vzorky poskytují různé odhady regresních koeficientů.

 Za předpokladu, že zákon o rozdělení chyb ε i jsou popsány normálním zákonem, odhadem parametru b bude mít normální rozdělení s parametry:
Za předpokladu, že zákon o rozdělení chyb ε i jsou popsány normálním zákonem, odhadem parametru b bude mít normální rozdělení s parametry:

 Od odhadu parametru A je lineární kombinací nezávislých normálně rozdělených proměnných, bude mít také normální rozdělení se střední hodnotou a rozptylem:
Od odhadu parametru A je lineární kombinací nezávislých normálně rozdělených proměnných, bude mít také normální rozdělení se střední hodnotou a rozptylem:


V tomto případě (1 − α) interval spolehlivosti pro odhad rozptylu σ 2, s přihlédnutím k tomu, že poměr ( n−2)s 0 2 /σ 2 distribuované ze zákona χ 2 s počtem stupňů volnosti n−2 bude určeno výrazem

49. Intervaly spolehlivosti pro regresní přímku. Interval spolehlivosti pro hodnoty závislé proměnné
Obvykle neznáme skutečné hodnoty regresních koeficientů A a b. Známe pouze jejich odhady. Jinými slovy, skutečná regresní přímka může jít výše nebo níže, být strmější nebo plošší než ta, která je postavena na vzorových datech. Vypočítali jsme intervaly spolehlivosti pro regresní koeficienty. Můžete také vypočítat oblast spolehlivosti pro samotnou regresní přímku.
 Nechť pro jednoduchou lineární regresi je nutné sestrojit (1− α
) interval spolehlivosti pro matematické očekávání odezvy Y s hodnotou X = X 0 Toto matematické očekávání je A+bx 0 a její odhad
Nechť pro jednoduchou lineární regresi je nutné sestrojit (1− α
) interval spolehlivosti pro matematické očekávání odezvy Y s hodnotou X = X 0 Toto matematické očekávání je A+bx 0 a její odhad


Protože tedy.
 Získaný odhad matematického očekávání je lineární kombinací nekorelovaných normálně rozdělených veličin, a proto má také normální rozdělení se středem v bodě skutečné hodnoty podmíněného matematického očekávání a rozptylu.
Získaný odhad matematického očekávání je lineární kombinací nekorelovaných normálně rozdělených veličin, a proto má také normální rozdělení se středem v bodě skutečné hodnoty podmíněného matematického očekávání a rozptylu.
Proto interval spolehlivosti pro regresní přímku u každé hodnoty X 0 může být reprezentováno jako

Jak vidíte, minimální interval spolehlivosti se získá, když X 0 se rovná průměrné hodnotě a zvyšuje se jako X 0 se „vzdálí“ od střední hodnoty v libovolném směru.
 Chcete-li získat sadu společných intervalů spolehlivosti vhodných pro celou regresní funkci, po celé její délce, ve výše uvedeném výrazu, namísto t n −2,α
/2 musí být nahrazeno
Chcete-li získat sadu společných intervalů spolehlivosti vhodných pro celou regresní funkci, po celé její délce, ve výše uvedeném výrazu, namísto t n −2,α
/2 musí být nahrazeno

 MNP pro blbce: jak přejít k jinému mobilnímu operátorovi bez změny čísla
MNP pro blbce: jak přejít k jinému mobilnímu operátorovi bez změny čísla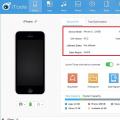 Jak změnit jazyk v iTools Jak si vybrat ruský jazyk na itools
Jak změnit jazyk v iTools Jak si vybrat ruský jazyk na itools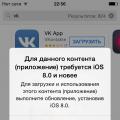 Jaké aplikace přicházejí s ios 7
Jaké aplikace přicházejí s ios 7