ما هو ترميز يونيكود. لماذا تحتاج Unicode؟ المتطلبات الأساسية لإنشاء وتطوير Unicode
ما هو الترميز
في اللغة الروسية ، تسمى "مجموعة الأحرف" أيضًا "مجموعة الأحرف" ، وعملية استخدام هذا الجدول لترجمة المعلومات من تمثيل الكمبيوتر إلى تمثيل بشري ، وعملية ملف نصي، مما يعكس استخدام نظام معين من الرموز فيه عند عرض النص.
يتم تعريف نظام العرض من خلال عدد من القواعد ، ويتم تطبيق هذه القواعد على المعلومات الأصلية من خلال عملية التشفير. تسمى العملية العكسية فك التشفير. ثم نلقي نظرة على جوانب أكثر تحديدًا مثل تشفير الإشارات وترميز الأحرف وترميز الجينوم البشري والتشفير الكمومي. أخيرًا ، سيتم شرح المفاهيم الأساسية لضغط البيانات وطرق التشفير الأكثر شيوعًا.
في هذا القسم ، سنرى كيف بذل البشر عبر التاريخ جهودًا كبيرة للتعبير عن أنفسهم مع بقية أقاربهم بطريقة بسيطة وبديهية ، عن طريق تشفير المعلومات باستخدام طرق مختلفة. لقد تطورت هذه الأساليب عبر التاريخ دون أن تمثل الأساليب المتطورة التي نستخدمها اليوم لأول الأساليب التي تم استخدامها لأنها استغرقت الكثير من التطور ، كما سنرى في هذا القسم.
كيف يتم ترميز النص
يشار إلى مجموعة الرموز المستخدمة في كتابة النص في مصطلحات الكمبيوتر كأبجدية ؛ عادة ما يسمى عدد الأحرف في الأبجدية قوتها. للعرض معلومات نصيةيستخدم الكمبيوتر غالبًا أبجدية بسعة 256 حرفًا. يحمل أحد أحرفه 8 بتات من المعلومات ، وبالتالي ، فإن الرمز الثنائي لكل حرف يأخذ 1 بايت من ذاكرة الكمبيوتر. يتم ترقيم جميع أحرف مثل هذه الأبجدية من 0 إلى 255 ، ويتوافق كل رقم مع رمز ثنائي مكون من 8 بتات ، وهو الرقم الترتيبي للحرف في نظام الترميز الثنائي - من 00000000 إلى 11111111. فقط أول 128 حرفًا مع أرقام من صفر (رمز ثنائي 00000000) إلى 127 (01111111). وتشمل هذه الأحرف الصغيرة و الأحرف الكبيرةالأبجدية اللاتينية والأرقام وعلامات الترقيم والأقواس ، إلخ. تُستخدم الرموز الـ 128 المتبقية ، بدءًا من 128 (الرمز الثنائي 10000000) وتنتهي بـ 255 (11111111) ، لتشفير الأحرف الأبجدية الوطنية والرموز الرسمية والعلمية.
تطور تشفير الإشارة
أن تكون عفا عليه الزمن هو كل ما نعرفه هذه اللحظةحيث كان في الوقت المناسب مع الأساليب السابقة. على مر التاريخ ، استخدم البحارة إشارات لنقل رسائل عاجلة إلى البحارة الآخرين. هذه إشارات ضوئية يتم إنتاجها باستخدام أجهزة عرض كبيرة مزودة بأنظمة تسمح بدفعات ضوئية ، وعادةً ما تستخدم حواجز شبكية موجودة أمام البؤرة. لإجراء اتصال ، يتم استخدام شفرة مورس من خلال الإشارات الضوئية.
هذه إشارات تنتقل من خلال الاهتزاز في الهواء. نظرًا لبطء الأجهزة المطلوبة للإرسال ، يعد هذا وسيطًا بطيئًا للغاية. تستخدم الإشارات المرسلة شفرة مورس لنقل المعلومات. بالإضافة إلى رمز مورس التقليدي في الكود الدولي الذي تم تضمينه ، هناك أنواع أخرى من الإشارات الموحدة التي يجب على كل بحار فهمها تمامًا.
أنواع الترميزات
أشهر جدول ترميز هو ASCII (الكود القياسي الأمريكي لتبادل المعلومات). تم تطويره في الأصل لنقل النصوص عن طريق التلغراف ، وفي ذلك الوقت كان 7 بت ، أي ، تم استخدام 128 تركيبة 7 بت فقط لترميز الأحرف الإنجليزية ، وأحرف الخدمة والتحكم. في هذه الحالة ، تُستخدم أول 32 مجموعة (رموز) لتشفير إشارات التحكم (بداية النص ، ونهاية السطر ، وإرجاع السطر ، والمكالمة ، ونهاية النص ، وما إلى ذلك). في تطوير أجهزة كمبيوتر IBM الأولى ، تم استخدام هذا الرمز لتمثيل الرموز في الكمبيوتر. منذ ذلك الحين في مصدر الرمزكان ASCII 128 حرفًا فقط ، لأن تشفيرها كان قيمًا كافية للبايت مع بت 8 يساوي 0. تم استخدام قيم البايت مع بت 8 يساوي 1 لتمثيل الأحرف الرسومية الزائفة والعلامات الرياضية وبعض الأحرف من اللغات الإنجليزية (اليونانية ، علامات التشكيل الألمانية ، علامات التشكيل الفرنسية ، إلخ). عندما بدأوا في تكييف أجهزة الكمبيوتر مع البلدان واللغات الأخرى ، لم يعد هناك مساحة كافية للرموز الجديدة. لدعم اللغات الأخرى غير الإنجليزية بشكل كامل ، قامت شركة IBM بتقديم العديد من جداول الرموز الخاصة بكل بلد. لذلك بالنسبة للدول الاسكندنافية ، تم اقتراح الجدول 865 (الشمال) ، للدول العربية - الجدول 864 (عربي) ، لإسرائيل - الجدول 862 (إسرائيل) ، وهكذا. في هذه الجداول ، تم استخدام بعض الرموز من النصف الثاني من جدول الرموز لتمثيل أحرف الأبجديات الوطنية (من خلال استبعاد بعض الأحرف الرسومية الزائفة). تطور الوضع مع اللغة الروسية بطريقة خاصة. من الواضح أنه يمكن استبدال الأحرف في النصف الثاني من جدول الكود طرق مختلفة... لذلك ظهرت عدة جداول مختلفة لترميز الأحرف السيريلية للغة الروسية: KOI8-R و IBM-866 و CP-1251 و ISO-8551-5. كلهم يمثلون رموز النصف الأول من الجدول بنفس الطريقة (من 0 إلى 127) ويختلفون في تمثيل رموز الأبجدية الروسية والرسومات الزائفة. بالنسبة للغات مثل الصينية أو اليابانية ، فإن 256 حرفًا غير كافية بشكل عام. بالإضافة إلى ذلك ، هناك دائمًا مشكلة إخراج النصوص أو حفظها في ملف واحد في نفس الوقت على النصوص لغات مختلفة(على سبيل المثال ، عند الاقتباس). لذلك ، عالمية جدول الكود UNICODE ، تحتوي على رموز مستخدمة بلغات جميع شعوب العالم ، بالإضافة إلى رموز خدمية ومساعدة مختلفة (علامات ترقيم ، رموز رياضية وتقنية ، أسهم ، علامات تشكيل ، إلخ). من الواضح أن بايت واحد لا يكفي لترميز مثل هذه المجموعة الكبيرة من الأحرف. لذلك تستخدم UNICODE رموز 16 بت (2 بايت) لتمثيل 65.536 حرفًا. حتى الآن ، تم استخدام حوالي 49000 رمز (كان آخر تغيير مهم هو إدخال رمز عملة اليورو في سبتمبر 1998). للتوافق مع الترميزات السابقة ، فإن أول 256 رمزًا هي نفس معيار ASCII. في معيار UNICODE ، باستثناء المواصفات المحددة كود ثنائي(عادةً ما يتم الإشارة إلى هذه الرموز بالحرف U ، متبوعًا بعلامة + والرمز الفعلي في التمثيل السداسي العشري) يتم تعيين اسم محدد لكل حرف. مكون آخر معيار UNICODEهي خوارزميات للتحويل من واحد إلى واحد لرموز UNICODE في تسلسل بايت متغير الطول. ترجع الحاجة إلى مثل هذه الخوارزميات إلى حقيقة أنه لا يمكن لجميع التطبيقات العمل مع UNICODE. بعض التطبيقات لا تفهم سوى رموز ASCII ذات 7 بتات ، بينما تفهم التطبيقات الأخرى رموز ASCII 8 بت. تستخدم هذه التطبيقات ما يسمى برموز ASCII الموسعة لتمثيل الأحرف التي لا تتناسب ، على التوالي ، في مجموعة مكونة من 128 حرفًا أو 256 حرفًا ، عندما يتم تشفير الأحرف بسلاسل بايت متغيرة الطول. يستخدم UTF-7 لتحويل رموز UNICODE بشكل عكسي إلى رموز ASCII ممتدة 7 بت ، ويستخدم UTF-8 لتحويل رموز UNICODE بشكل عكسي إلى رموز ASCII ممتدة 8 بت. لاحظ أن كلاً من ASCII و UNICODE ومعايير ترميز الأحرف الأخرى لا تحدد صور الأحرف ، ولكن فقط تكوين مجموعة الأحرف وطريقة تمثيلها في الكمبيوتر. بالإضافة إلى ذلك (والذي قد لا يكون واضحًا على الفور) ، فإن ترتيب تعداد الأحرف في المجموعة مهم جدًا ، لأنه يؤثر على خوارزميات الفرز بشكل أكثر أهمية. إنه جدول مراسلات الرموز من مجموعة معينة (على سبيل المثال ، الرموز المستخدمة لتمثيل المعلومات عن اللغة الانجليزية، أو بلغات مختلفة ، كما في حالة UNICODE) ويشير إلى مصطلح جدول ترميز الأحرف أو مجموعة أحرف. كل ترميز قياسي له اسم ، على سبيل المثال ، KOI8-R ، ISO_8859-1 ، ASCII. للأسف ، لا يوجد معيار لترميز الأسماء.
يتم استخدامه للاتصال بين السفن القريبة من أجل التمكن من احترام تردد الراديو المستخدم ، وعدم منحه استخدامًا غير ضروري من خلال شغل تلك القناة دون داع ، أو لأن الاتصال يحتاج إلى إنشاء والراديو لا يعمل بشكل صحيح.
تُستخدم الأعلام لإجراء الاتصال ، لذلك اعتمادًا على الموضع الذي يتخذه الشخص الذي يقوم بتنفيذ الإشارات ، سيكون لها قيمة أو أي شيء آخر. المعاني المرتبطة بها هي نفسها استخدام الأعلام مع الأحرف من A إلى Z والأرقام من 0 إلى 9 وإشارات التوقف والخطأ.
التخطيط الراديوي والمهاتفة الراديوية
باستخدام الأساليب التي تمت مناقشتها أعلاه ، يكون الاتصال المتزامن في كلا الاتجاهين مستحيلًا ، لذلك كانا من نقطة إلى نقطة. بفضل ظهور الإبراق الراديوي ، أصبح هذا النوع من الاتصال ممكنًا. يعتمد الرسم الراديوي على نظرية ماكسويل لانتشار الموجات في الفضاء. وهكذا ولد التلغراف اللاسلكي ، وهو أحد أهم التطورات في مجال الاتصالات في كل العصور.
الترميزات الشائعة
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11، ISO 8859-13، ISO 8859-14، ISO 8859-15 o CP437، CP737، CP850، CP852، CP855، CP857، CP858، CP860، CP861، CP863، CP865، CP866، CP869 ترميزات Microsoft Windows: o Windows-1250 للغات وسط أوروبا التي تستخدم الأحرف اللاتينية o Windows-1251 للأبجدية السيريلية o Windows-1252 للغات الغربية o Windows-1253 للغة اليونانية o Windows-1254 للغة التركية o Windows-1255 للعبرية o Windows-1256 للغة العربية o Windows-1257 للغات البلطيق o Windows-1258 للغة الفيتنامية MacRoman و MacCyrillic KOI8 (KOI8-R ، KOI8-U ...) ، KOI-7 الترميز البلغاري ISCII VISCII Big5 (الإصدار الأكثر شهرة من Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS للغة اليابانية (Microsoft CP932) EUC-KR للكورية (Microsoft CP949) ISO-2022 و EUC للكتابة الصينية UTF- 8 و UTF-16 ترميز أحرف Unicodeتم نقل هذه الوثائق إلى الأرشيف وهي غير مدعومة.
الترميز اليوم
لا يزال أمامنا مهاتفة راديوية ، وهي ليست أكثر من القدرة على تعديل الصوت عبر موجات الراديو باستخدام اساس نظرىمعروضة في الإبراق الراديوي.
ترميز الإشارة
هذا إجراء شائع الاستخدام يتم فيه ، قبل سلسلة من الإشارات نوع التناظريةنسخها في الإشارات الرقمية. وبالتالي ، فإنه يسهل المعالجة اللاحقة وكذلك يحسن الخصائص الفيزيائية.أي أن الإشارة التناظرية حساسة للغاية للتغيرات في التداخل المحتمل ، ويرجع ذلك إلى حقيقة أنه من الصعب للغاية استرداد الإشارة الأصلية ، لأن القيم التي يمكن أن تكون لهذه الإشارة يمكن أن تكون غير محدودة. إذا قارناه بإشارة رقمية تحتوي على عدد معين من القيم الممكنة. هذه الحقيقة تجعل من السهل استرداد القيم في إشارة رقمية وبالتالي يمكن استخدامها للاتصال لمسافات طويلة.
باستخدام ترميز Unicode
.الإطار الصافي 3.5
تم التحديث: نوفمبر 2007
تستخدم تطبيقات وقت التشغيل الشائعة التشفير لتحويل الأحرف من التمثيل الداخلي (Unicode) إلى تمثيل آخر. يتم استخدام فك التشفير لتحويل الأحرف مرة أخرى من الترميزات الخارجية (غير Unicode) إلى التمثيل الداخلي. تحتوي مساحة الاسم على عدد من الفئات التي تمكّن التطبيقات من تشفير الأحرف وفك تشفيرها. للحصول على نظرة عامة على هذه الفئات ، انظر.
في هذا الإجراء ، يمكننا التمييز بين ثلاث مراحل متمايزة جيدًا: أخذ العينات والتقدير الكمي والتدوين. التحديد الكمي: يتمثل في تقييم قيمة كل عينة ، بحيث يتم تخصيص إحدى القيم المحتملة لكل عينة من العينات الناتجة. الإشارات الرقمية... تسبب عملية التكميم ضوضاء تكميم ناتجة عن عدد القيم الممكنة الإشارات التناظريةللإشارة الرقمية. يتكون من تحويل القيم التي تم الحصول عليها أثناء عملية التكميم إلى نظام ثنائي باستخدام عدد من الرموز المحددة مسبقًا.
- أخذ العينات: يتكون من أخذ عينات من اتساع إشارة الدخل.
- جدا معلمة مهمةفي هذه العملية بعدد العينات في الثانية.
- الترميز.
تستخدم في ترميز non-Unicode. يدعم الفصل مجموعة واسعة من ترميزات ANSI / ISO.
يستخدم مثال الرمز أدناه الطريقة GetEncodingكائن الترميز المطلوب لصفحة رموز معينة. طريقة GetBytesتم استدعاؤه على كائن الترميز المطلوب لتحويل سلسلة Unicode إلى تمثيل بايت في الترميز المطلوب. ستعرض الشاشة تمثيل البايت للسلسلة في صفحة رموز محددة.
يعتمد على ترميز قطبية واحدة ، كما يوحي الاسم. وبالتالي ، عادةً ما تفترض القيمة الثنائية التي تساوي واحدًا أن قيمة إشارة الخرج تساوي واحدًا ، وتسمح القيمة المساوية للصفر بقيمة صفرية في إشارة الخرج.
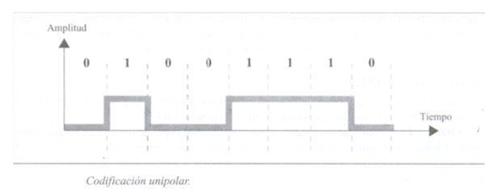
هذا هو نوع الترميز الأكثر استخدامًا اليوم. يعتمد على ترميز قطبين لتمثيل المعلومات الثنائية. يمكننا العثور على التصنيف التالي للتشفير القطبي. 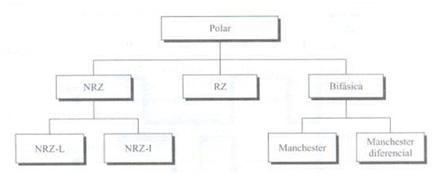
يتميز بحقيقة أن الإشارة لها دائمًا قيمة موجبة أو سلبية. يمكننا التمييز بوضوح بين الأنواع.
نظام الواردات نظام الاستيراد. "تحويل أحرف ASCII إلى بايت. يعرض تمثيل بايت السلسلة في"صفحة الرموز المحددة. "رمز الصفحة 1252 يمثل الأحرف اللاتينية. PrintCPBytes ("Hello، World!"، 1252) "رمز الصفحة 932 يمثل الأحرف اليابانية. PrintCPBytes ("Hello، World!"، 932) "تحويل الأحرف اليابانية. PrintCPBytes (، 1252) PrintCPBytes ( "\ u307b ، \ u308b ، \ u305a ، \ u3042 ، \ u306d"، 932) End Sub Public Shared Sub PrintCPBytes (str As String، codePage As Integer) Dim targetEncoding as encoding dim encodedChars () as Byte "يحصل على الترميز لصفحة الرموز المحددة. targetEncoding = Encoding.GetEncoding (codePage) "يحصل على تمثيل البايت للسلسلة المحددة. encodedChars = targetEncoding.GetBytes (str) "يطبع البايت. Console.WriteLine ( "تمثيل بايت لـ" (0) "في CP" (1) ":"، _ str، codePage) Dim i As Integer For i = 0 To encodedChars.Length - 1 Console.WriteLine ("Byte (0): (1)"، i، encodedChars (i)) Next i End Sub End Class
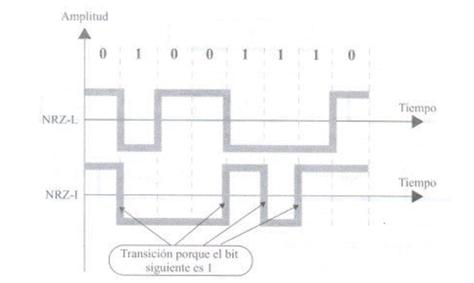
عادة ، إذا تم ضبط البت على واحد ، ستكون الإشارة موجبة ؛ إذا كانت صفرًا ، ستكون الإشارة سلبية. وبالتالي ، لا تعتمد هذه القيمة على البتة الحالية فحسب ، بل تعتمد أيضًا على البتة السابقة. وبالتالي ، فهي أكثر موثوقية.
يتميز باستخدام ثلاثة مستويات إخراج محتملة. يتم تمثيل القليل من خلال التغيير من موجب إلى صفر ومن صفر إلى سلبي إلى إيجابي. تحدث كل معاملة في منتصف الفترة الزمنية ، كما هو موضح في الشكل التالي. يسمح هذا النوع من التشفير أيضًا ببدء إجراء التزامن باستخدام انتقالات تم إنشاؤها في أنصاف الفتحات.
 البق في التفرد؟
البق في التفرد؟ Just Cause 2 تعطل
Just Cause 2 تعطل Terraria لن تبدأ ، ماذا علي أن أفعل؟
Terraria لن تبدأ ، ماذا علي أن أفعل؟