الحروف الروسية في جدول كود windows. ترميز سيريلي - روسي
ترميزات
عندما بدأت البرمجة في لغة C لأول مرة ، كان برنامجي الأول (بصرف النظر عن HelloWorld) هو برنامج تحويل الترميز ملفات نصيةمن ترميز GOST الرئيسي (تذكر هذا؟ :-) إلى البديل. لقد عاد في عام 1991. لقد تغير الكثير منذ ذلك الحين ، ولكن لسوء الحظ ، لم تفقد هذه البرامج أهميتها على مدى السنوات العشر الماضية. تم بالفعل تجميع قدر كبير جدًا من البيانات في ترميزات مختلفة ويتم استخدام عدد كبير جدًا من البرامج التي يمكن أن تعمل مع ترميز واحد فقط. هناك ما لا يقل عن عشرة ترميزات مختلفة للغة الروسية ، مما يجعل المشكلة أكثر إرباكًا.
من أين أتت كل هذه الترميزات وما الغرض منها؟ لا يمكن لأجهزة الكمبيوتر ، بطبيعتها ، العمل إلا مع الأرقام. من أجل تخزين الحروف في ذاكرة الكمبيوتر ، من الضروري تخصيص رقم معين لكل حرف (تم استخدام نفس المبدأ تقريبًا قبل ظهور أجهزة الكمبيوتر - تذكر نفس رمز مورس). علاوة على ذلك ، فإن الرقم أصغر بشكل مرغوب فيه - فكلما قل عدد الأرقام الثنائية المستخدمة ، زادت كفاءة استخدام الذاكرة. هذا التطابق بين مجموعة من الأحرف والأرقام هو في الواقع ترميز. أدت الرغبة في حفظ الذاكرة بأي ثمن ، وكذلك تفكك مجموعات مختلفة من علماء الكمبيوتر ، إلى الوضع الحالي. أكثر طرق التشفير شيوعًا الآن هي استخدام بايت واحد (8 بتات) لحرف واحد ، والذي يحدد العدد الإجمالي للأحرف في 256 حرفًا. مجموعة الأحرف الـ 128 الأولى موحدة (مجموعة ASCII) وهي نفسها في جميع الترميزات الشائعة (تلك الترميزات التي لا تكون بالفعل خارج نطاق الاستخدام عمليًا). تقع الأحرف الإنجيلية ورموز الترقيم في هذا النطاق ، مما يحدد حيويتها المذهلة في أنظمة الكمبيوتر :-). اللغات الأخرى ليست سعيدة جدًا - يتعين عليهم جميعًا التجمع في الأرقام المتبقية البالغ عددها 128.
يونيكود
في أواخر الثمانينيات ، أدرك الكثيرون الحاجة إلى إنشاء معيار موحد لتشفير الأحرف ، مما أدى إلى ظهور Unicode. Unicode هي محاولة لإصلاح رقم معين لشخص معين بشكل نهائي. من الواضح أن 256 حرفًا لن تتناسب هنا مع كل الرغبة. لفترة طويلة بدا أن 2 بايت (65536 حرفًا) يجب أن تكون كافية. لكن لا - أحدث إصدار من معيار Unicode (3.1) يحدد بالفعل 94.140 حرفًا. لمثل هذا العدد من الأحرف ، ربما يتعين عليك بالفعل استخدام 4 بايت (4294967296 حرفًا). ربما يكفي لبعض الوقت ... :-)
في المجموعة أحرف Unicodeيشمل جميع أنواع الحروف مع جميع أنواع الشرطات والبابينديولكي ، واليونانية ، والرياضية ، والهيروغليفية ، والرموز الرسومية الزائفة ، وما إلى ذلك ، وما إلى ذلك ، بما في ذلك الأحرف السيريلية المفضلة لدينا (نطاق القيم هو 0x0400-0x04ff). لذلك لا يوجد تمييز في هذا الجانب.
إذا كنت مهتمًا برموز أحرف معينة ، فمن الملائم استخدام برنامج "مخطط توزيع الأحرف" من WinNT لعرضها. على سبيل المثال ، هذا هو النطاق السيريلي:
إذا كان لديك نظام تشغيل مختلف أو كنت مهتمًا بالتفسير الرسمي ، فيمكن العثور على المخططات الكاملة على موقع Unicode الرسمي (http://www.unicode.org/charts/web.html).
أنواع الحرف والبايت
تحتوي Java على نوع بيانات char منفصل يبلغ 2 بايت للأحرف. يؤدي هذا غالبًا إلى حدوث ارتباك في أذهان المبتدئين (خاصةً إذا سبق لهم البرمجة بلغات أخرى ، مثل C / C ++). هذا لأن معظم اللغات الأخرى تستخدم أنواع بيانات 1 بايت لمعالجة الأحرف. على سبيل المثال ، في C / C ++ ، يتم استخدام الحرف في الغالب لكل من معالجة الأحرف ومعالجة البايت - لا يوجد فصل. Java لها نوع خاص بها للبايت - نوع البايت. وبالتالي ، فإن الحرف المستند إلى C يتوافق مع Java بايت ، و Java char من عالم C هو الأقرب إلى نوع wchar_t. من الضروري الفصل بوضوح بين مفاهيم الأحرف والبايت - وإلا فإن سوء الفهم والمشاكل مضمونة.
تستخدم Java لترميز الأحرف تقريبًا منذ إنشائها معيار يونيكود... تتوقع وظائف مكتبة Java أن ترى أحرف char يتم تمثيلها بواسطة رموز يونيكود... من حيث المبدأ ، بالطبع ، يمكنك حشو أي شيء هناك - فالأرقام هي أرقام ، وسيتحمل المعالج كل شيء ، ولكن بالنسبة لأي معالجة ، ستعمل وظائف المكتبة على افتراض أنها مُنحت لها ترميز يونيكود... لذلك يمكنك أن تفترض بأمان أن ترميز char تم إصلاحه. لكن هذا داخل JVM. عند قراءة البيانات من الخارج أو تمريرها من الخارج ، يمكن تمثيلها بنوع واحد فقط - نوع البايت. يتم إنشاء جميع الأنواع الأخرى من البايت ، اعتمادًا على تنسيق البيانات المستخدم. هذا هو المكان الذي يتم فيه تشغيل الترميزات - في Java ، إنه مجرد تنسيق بيانات لنقل الأحرف ، والذي يتم استخدامه لتكوين بيانات من نوع char. لكل صفحة رمز ، تحتوي المكتبة على فئتي تحويل (ByteToChar و CharToByte). هذه الفصول موجودة في حزمة sun.io. إذا لم يتم العثور على حرف مطابق عند التحويل من char إلى byte ، فسيتم استبداله بالحرف؟.
بالمناسبة ، تحتوي ملفات صفحة الشفرة هذه في بعض الإصدارات المبكرة من JDK 1.1 على أخطاء تسبب أخطاء التحويل أو حتى استثناءات وقت التشغيل. على سبيل المثال ، يتعلق هذا بتشفير KOI8_R. أفضل ما يمكنك فعله أثناء القيام بذلك هو تغيير الإصدار إلى إصدار لاحق. بناءً على وصف Sun ، تم حل معظم هذه المشكلات في JDK 1.1.6.
قبل إصدار JDK 1.4 ، تم تحديد مجموعة الترميزات المتاحة فقط بواسطة بائع JDK. بدءًا من 1.4 ، ظهرت واجهة برمجة تطبيقات جديدة (حزمة java.nio.charset) ، والتي يمكنك من خلالها بالفعل إنشاء الترميز الخاص بك (على سبيل المثال ، دعم ملف نادر الاستخدام ولكنه ضروري للغاية بالنسبة لك).
فئة السلسلة
في معظم الحالات ، تستخدم Java كائنًا من النوع java.lang.String لتمثيل السلاسل. هذه فئة عادية تخزن داخليًا مصفوفة من الأحرف (char) ، وتحتوي على العديد من الطرق المفيدة لمعالجة الأحرف. الأكثر إثارة للاهتمام هي المنشئات التي تحتوي على مصفوفة بايت كمعامل أول وطرق getBytes (). باستخدام هذه الطرق ، يمكنك إجراء تحويلات من مصفوفات البايت إلى السلاسل والعكس صحيح. من أجل تحديد الترميز الذي يجب استخدامه في نفس الوقت ، تحتوي هذه الطرق على معلمة سلسلة تحدد اسمها. على سبيل المثال ، إليك كيفية تحويل البايت من KOI-8 إلى Windows-1251:
// البيانات المشفرة KOI-8بايت koi8Data = ... ؛ // التحويل من KOI-8 إلى Unicode String string = new String (koi8Data، "KOI8_R") ؛ // التحويل من Unicode إلى Windows-1251بايت winData = string.getBytes ("Cp1251") ؛
يمكن العثور على قائمة ترميزات 8 بت المتوفرة في JDKs الحديثة والحروف الروسية الداعمة أدناه ، في القسم.
نظرًا لأن الترميز هو تنسيق بيانات للأحرف ، بالإضافة إلى ترميزات 8 بت المألوفة في Java ، هناك أيضًا ترميزات متعددة البايت على قدم المساواة. وتشمل هذه UTF-8 و UTF-16 و Unicode وما إلى ذلك ، على سبيل المثال ، هذه هي الطريقة التي يمكنك من خلالها الحصول على وحدات البايت بتنسيق UnicodeLittleUnmarked (ترميز Unicode 16 بت ، وانخفاض البايت أولاً ، وعدم وجود علامة ترتيب بايت):
// التحويل من Unicode إلى Unicodeبيانات البايت = string.getBytes ("UnicodeLittleUnmarked") ؛
من السهل ارتكاب خطأ في مثل هذه التحويلات - إذا كان ترميز بيانات البايت لا يتطابق مع المعلمة المحددة عند التحويل من بايت إلى حرف ، فلن يتم إجراء إعادة الترميز بشكل صحيح. في بعض الأحيان بعد ذلك يكون من الممكن سحب الأحرف الصحيحة ، ولكن في أغلب الأحيان ، سيتم فقد جزء من البيانات بشكل غير قابل للاسترداد.
في برنامج حقيقي ، ليس من الملائم دائمًا تحديد صفحة الرموز بشكل صريح (على الرغم من أنها أكثر موثوقية). لهذا ، تم تقديم الترميز الافتراضي. بشكل افتراضي ، يعتمد ذلك على النظام وإعداداته (تم اعتماد ترميز Cp1251 لنظام التشغيل Windows الروسي) ، ويمكن تغييره في JDKs القديمة عن طريق تعيين ملف خصائص النظام. في JDK 1.3 ، يعمل تغيير هذا الإعداد أحيانًا ، وأحيانًا لا يعمل. يحدث هذا بسبب ما يلي: في البداية ، يتم تعيين file.encoding وفقًا للإعدادات الإقليمية للكمبيوتر. يتم تذكر مرجع الترميز الافتراضي داخليًا أثناء التحويل الأول. في هذه الحالة ، يتم استخدام file.encoding ، ولكن هذا التحويل يحدث حتى قبل استخدام وسيطات بدء تشغيل JVM (في الواقع ، عند تحليلها). في الواقع ، وفقًا لـ Sun ، تعكس هذه الخاصية ترميز النظام ، ولا ينبغي تغييرها في سطر الأوامر (انظر ، على سبيل المثال ، التعليقات على BugID) ومع ذلك ، في JDK 1.4 Beta 2 ، بدأ تغيير هذا الإعداد مرة أخرى في الحصول على تأثير. ما هذا ، تغيير واعي أو عرض جانبي قد يختفي مرة أخرى - لم تعط خروف الشمس إجابة واضحة بعد.
يتم استخدام هذا الترميز عندما لا يتم تحديد اسم الصفحة بشكل صريح. يجب تذكر ذلك دائمًا - لن تحاول Java التنبؤ بتشفير وحدات البايت التي تمررها لإنشاء سلسلة (لن تتمكن أيضًا من قراءة أفكارك حول هذا :-). يستخدم فقط الترميز الافتراضي الحالي. لأن هذا الإعداد هو نفسه لجميع التحولات ، في بعض الأحيان قد تواجه مشكلة.
للتحويل من بايت إلى أحرف والعكس صحيح ، استخدم فقطبهذه الطرق. في معظم الحالات ، لا يمكن استخدام تحويل نوع بسيط - لن يتم أخذ تشفير الأحرف في الاعتبار. على سبيل المثال ، أحد أكثر الأخطاء شيوعًا هو قراءة البيانات حسب البايت باستخدام طريقة read () من InputStream ، ثم تحويل القيمة الناتجة إلى نوع char:
InputStream = ..؛ الباحث ب ؛ StringBuffer sb = new StringBuffer () ؛ بينما ((b = is.read ())! = - 1) (sb.append ((char) b) ؛ // <- так делать нельзя ) String s = sb.toString () ؛
انتبه إلى التلبيس - "(char) b". يتم نسخ قيم البايت ببساطة إلى حرف بدلاً من إعادة ترميزها (نطاق القيم هو 0-0xFF ، وليس النطاق الذي توجد فيه الأبجدية السيريلية). يتوافق هذا النسخ مع ترميز ISO-8859-1 (الذي يتوافق واحد لواحد مع قيم Unicode 256 الأولى) ، مما يعني أنه يمكننا افتراض أن هذا الرمز يستخدمه ببساطة (بدلاً من الرمز الذي تستخدمه الأحرف في البيانات الأصلية مشفرة بالفعل). إذا حاولت عرض القيمة المستلمة ، فستكون هناك أسئلة أو krakozyably على الشاشة. على سبيل المثال ، عند قراءة السلسلة "ABC" في ترميز Windows ، يمكن بسهولة عرض شيء مثل هذا: "АÁВ". غالبًا ما يكتب مبرمجون في الغرب هذا النوع من الأكواد - فهو يعمل مع الأحرف الإنجليزية ، وهذا جيد. يعد إصلاح هذا الرمز أمرًا سهلاً - ما عليك سوى استبدال StringBuffer بـ ByteArrayOutputStream:
InputStream = ..؛ الباحث ب ؛ ByteArrayOutputStream baos = new ByteArrayOutputStream () ؛ بينما ((b = is.read ())! = - 1) (baos.write (b) ؛) // تحويل البايت إلى سلسلة باستخدام التشفير الافتراضي String s = baos.toString () ، // إذا كنت بحاجة إلى ترميز معين ، فما عليك سوى تحديده عند استدعاء toString (): // // s = baos.toString ("Cp1251") ؛لمزيد من المعلومات حول الأخطاء الشائعة ، راجع القسم.
ترميزات 8 بت للأحرف الروسية
فيما يلي ترميزات 8 بت الرئيسية للأحرف الروسية التي انتشرت على نطاق واسع:
بالإضافة إلى الاسم الرئيسي ، يمكنك استخدام المرادفات. قد تختلف مجموعة منهم في إصدارات مختلفة من JDK. هذه قائمة من JDK 1.3.1:
- CP1251:
- نظام التشغيل Windows-1251
- CP866:
- IBM866
- IBM-866
- CP866
- CSIBM866
- KOI8_R:
- KOI8-R
- CSKOI8R
- ISO8859_5:
- ISO8859-5
- ISO-8859-5
- ISO_8859-5
- ISO_8859-5: 1988
- ISO-IR-144
- 8859_5
- السيريلية
- سيريزولاتين سيريليك
- IBM915
- آي بي إم 915
- CP915
علاوة على ذلك ، المرادفات ، على عكس الاسم الرئيسي ، غير حساسة لحالة الأحرف - وهذه سمة من سمات التنفيذ.
من الجدير بالذكر أن هذه الترميزات قد لا تكون متاحة في بعض JVMs. على سبيل المثال ، يمكنك تنزيل نسختين مختلفتين من JRE من موقع Sun - الولايات المتحدة والدولية. في إصدار الولايات المتحدة ، لا يوجد سوى حد أدنى - ISO-8859-1 و ASCII و Cp1252 و UTF8 و UTF16 والعديد من أشكال Unicode مزدوجة البايت. كل شيء آخر متاح فقط في النسخة الدولية. في بعض الأحيان لهذا السبب ، يمكنك أن تصطدم بأشجار مع إطلاق البرنامج ، حتى لو لم يكن بحاجة إلى أحرف روسية. خطأ نموذجي يحدث أثناء القيام بذلك:
حدث خطأ أثناء تهيئة VM java / lang / ClassNotFoundException: sun / io / ByteToCharCp1251
ينشأ ، نظرًا لأنه ليس من الصعب التكهن ، نظرًا لحقيقة أن JVM ، استنادًا إلى الإعدادات الإقليمية الروسية ، تحاول تعيين التشفير الافتراضي في Cp1251 ، ولكن منذ ذلك الحين فئة هذا الدعم غائبة في النسخة الأمريكية ، فهي تنقطع بشكل طبيعي.
الملفات وتدفقات البيانات
تمامًا كما يتم فصل البايت من الناحية المفاهيمية عن الأحرف ، تميز Java بين تدفقات البايت وتدفقات الأحرف. يتم تمثيل العمل بالبايت بواسطة الفئات التي ترث فئات InputStream أو OutputStream بشكل مباشر أو غير مباشر (بالإضافة إلى فئة RandomAccessFile الفريدة). العمل مع الرموز يمثله زوجان جميلان من فصول القارئ / الكاتب (وأحفادهم بالطبع).
تُستخدم تدفقات البايت لقراءة / كتابة البايت غير المحول. إذا كنت تعلم أن البايتات تمثل أحرفًا فقط في ترميز معين ، فيمكنك استخدام فئات المحولات الخاصة InputStreamReader و OutputStreamWriter للحصول على دفق من الأحرف والعمل معها مباشرة. عادة ما يكون هذا مفيدًا لملفات النص العادي أو عند العمل مع العديد من بروتوكولات شبكة الإنترنت. في هذه الحالة ، يتم تحديد ترميز الأحرف في مُنشئ فئة المحول. مثال:
// Unicode string String = "..." ؛ // اكتب السلسلة إلى ملف نصي بترميز Cp866 PrintWriter pw = أداة طباعة جديدة // فئة بأساليب كتابة السلاسل(جديد OutputStreamWriter // فئة المحول(ملف جديد FileOutputStream ("file.txt") ، "Cp866") ؛ pw.println (سلسلة نصية) ؛ // اكتب السطر إلى الملف pw.close () ؛
إذا كان الدفق يحتوي على بيانات بترميزات مختلفة أو اختلطت الأحرف مع بيانات ثنائية أخرى ، فمن الأفضل قراءة مصفوفات البايت وكتابتها ، واستخدام الطرق المذكورة بالفعل لفئة String للتحويل. مثال:
// Unicode string String = "..." ؛ // اكتب السلسلة إلى ملف نصي بترميزين (Cp866 و Cp1251) OutputStream os = new FileOutputStream ("file.txt") ؛ // فئة لكتابة بايت للملف // اكتب السلسلة بترميز Cp866 os.write (string.getBytes ("Cp866")) ؛ // اكتب السلسلة بترميز Cp1251 os.write (string.getBytes ("Cp1251")) ؛ os.close () ،
يتم تمثيل وحدة التحكم في Java تقليديًا بواسطة التدفقات ، ولكن للأسف لا يتم تمثيل الأحرف ، ولكن بالبايت. الحقيقة هي أن تدفقات الأحرف ظهرت فقط في JDK 1.1 (جنبًا إلى جنب مع آلية التشفير بالكامل) ، وتم تصميم الوصول إلى وحدة التحكم I / O في JDK 1.0 ، مما أدى إلى ظهور غريب في شكل فئة PrintStream. تُستخدم هذه الفئة في متغيري System.out و System.err ، اللذين يمنحان حق الوصول إلى الإخراج إلى وحدة التحكم. بكل المؤشرات ، هذا تدفق من البايتات ، ولكن مع مجموعة من الأساليب لكتابة السلاسل. عندما تكتب سلسلة فيها ، فإنها تتحول إلى بايت باستخدام الترميز الافتراضي ، وهو أمر غير مقبول عادةً في حالة Windows - سيكون الترميز الافتراضي هو Cp1251 (Ansi) ، وبالنسبة لنافذة وحدة التحكم ، تحتاج عادةً إلى استخدام Cp866 ( OEM). تم تسجيل هذا الخطأ في عام 97 () ولكن يبدو أن Sun-sheep ليست في عجلة من أمرها لإصلاحه. نظرًا لعدم وجود طريقة لتعيين الترميز في PrintStream ، لحل هذه المشكلة ، يمكنك استبدال الفئة القياسية بأخرى خاصة بك باستخدام أساليب System.setOut () و System.setErr (). على سبيل المثال ، هذه هي البداية المعتادة في برامجي:
... رئيسي باطل ثابت عام (سلاسل سلسلة) ( // ضبط إخراج رسائل وحدة التحكم في الترميز المطلوبحاول (String consoleEnc = System.getProperty ("console.encoding"، "Cp866") ؛ System.setOut (new CodepagePrintStream (System.out، consoleEnc)) ؛ System.setErr (CodepagePrintStream (System.err، consoleEnc)) ؛ ) catch (UnsupportedEncodingException e) (System.out.println ("تعذر إعداد صفحة رموز وحدة التحكم:" + e) ؛) ...
يمكنك العثور على مصادر فئة CodepagePrintStream على هذا الموقع: CodepagePrintStream.java.
إذا كنت تقوم بإنشاء تنسيق البيانات بنفسك ، فإنني أوصيك باستخدام أحد ترميزات multibyte. عادةً ما يكون التنسيق الأكثر ملاءمة هو UTF8 - يتم ترميز أول 128 قيمة (ASCII) فيه في بايت واحد ، والذي غالبًا ما يقلل بشكل كبير من إجمالي كمية البيانات (ليس من أجل لا شيء أن يتم أخذ هذا الترميز كأساس في عالم XML). لكن UTF8 له عيب واحد - يعتمد عدد البايت المطلوب على رمز الحرف. عندما يكون هذا أمرًا بالغ الأهمية ، يمكنك استخدام أحد تنسيقات Unicode ثنائية البايت (UnicodeBig أو UnicodeLittle).
قاعدة البيانات
لقراءة الأحرف من قاعدة البيانات بشكل صحيح ، يكفي عادةً إخبار مشغل JDBC بترميز الأحرف المطلوب في قاعدة البيانات. كيف بالضبط يعتمد على السائق المحدد. في الوقت الحاضر ، يدعم العديد من السائقين هذا الإعداد بالفعل ، على عكس الماضي القريب. فيما يلي بعض الأمثلة التي أعرفها.
جسر JDBC-ODBC
هذا هو أحد برامج التشغيل الأكثر استخدامًا. يمكن تكوين الجسر من JDK 1.2 وما بعده بسهولة إلى التشفير المطلوب. يتم ذلك عن طريق إضافة خاصية charSet إضافية إلى مجموعة المعلمات التي تم تمريرها لفتح اتصال بالقاعدة. الافتراضي هو file.encoding. يتم إجراء شيء مثل هذا:
// إنشاء اتصال
برنامج تشغيل Oracle 8.0.5 JDBC-OCI لنظام التشغيل Linux
عند تلقي البيانات من قاعدة البيانات ، يحدد برنامج التشغيل هذا الترميز "الخاص به" باستخدام متغير البيئة NLS_LANG. إذا لم يتم العثور على هذا المتغير ، فإنه يفترض أن الترميز هو ISO-8859-1. الحيلة هي أن NLS_LANG يجب أن يكون متغير بيئة (يتم تعيينه باستخدام الأمر set) ، وليس خاصية نظام Java (مثل file.encoding). إذا تم استخدام برنامج التشغيل داخل محرك Apache + Jserv servlet ، فيمكن تعيين متغير البيئة في ملف jserv.properties:
wrapper.env = NLS_LANG = American_America.CL8KOI8Rأرسل سيرجي بيزروكوف معلومات حول هذا الموضوع ، وشكره بشكل خاص.
برنامج تشغيل JDBC للعمل مع DBF (zyh.sql.dbf.DBFDriver)
لقد تعلم هذا السائق مؤخرًا فقط التعامل مع الحروف الروسية. على الرغم من أنه أبلغ عن طريق getPropertyInfo () أنه يفهم خاصية charSet ، إلا أنها خيال (على الأقل في النسخة من 07/30/2001). في الواقع ، يمكنك تخصيص الترميز عن طريق تعيين خاصية CODEPAGEID. بالنسبة للأحرف الروسية ، تتوفر قيمتان - "66" لـ Cp866 و "C9" لـ Cp1251. مثال:
// معلمات الاتصال الأساسيةخصائص connInfo = خصائص جديدة () ؛ connInfo.put ("CODEPAGEID"، "66") ؛ // ترميز Cp866 // إنشاء اتصالاتصال db = DriverManager.getConnection ("jdbc: DBF: / C: / MyDBFFiles"، connInfo) ؛إذا كان لديك ملفات DBF بتنسيق FoxPro ، فسيكون لديهم تفاصيل خاصة بهم. الحقيقة هي أن FoxPro يحفظ في رأس الملف معرف صفحة الرموز (بايت مع الإزاحة 0x1D) ، والتي تم استخدامها لإنشاء DBF. عند فتح جدول ، يستخدم برنامج التشغيل القيمة من الرأس ، وليس المعلمة "CODEPAGEID" (يتم استخدام المعلمة في هذه الحالة فقط عند إنشاء جداول جديدة). وفقًا لذلك ، لكي يعمل كل شيء بشكل صحيح ، يجب إنشاء ملف DBF بالترميز الصحيح - وإلا فستكون هناك مشكلات.
MySQL (org.gjt.mm.mysql.Driver)
مع برنامج التشغيل هذا ، كل شيء بسيط أيضًا:
// معلمات الاتصال الأساسيةخصائص connInfo = new Poperties () ؛ connInfo.put ("المستخدم" ، المستخدم) ؛ connInfo.put ("كلمة المرور" ، تمرير) ؛ connInfo.put ("useUnicode"، "true") ؛ connInfo.put ("characterEncoding"، "KOI8_R") ؛ اتصال conn = DriverManager.getConnection (dbURL ، الدعائم) ؛
InterBase (interbase.interclient.Driver)
بالنسبة لبرنامج التشغيل هذا ، تعمل معلمة "charSet":// معلمات الاتصال الأساسيةخصائص connInfo = خصائص جديدة () ؛ connInfo.put ("المستخدم" ، اسم المستخدم) ؛ connInfo.put ("كلمة المرور" ، كلمة المرور) ؛ connInfo.put ("charSet"، "Cp1251") ؛ // إنشاء اتصالاتصال db = DriverManager.getConnection (dataurl، connInfo) ؛
ومع ذلك ، لا تنس تحديد ترميز الأحرف عند إنشاء قاعدة البيانات والجداول. بالنسبة للغة الروسية ، يمكنك استخدام القيم "UNICODE_FSS" أو "WIN1251". مثال:
إنشاء قاعدة بيانات "E: \ ProjectHolding \ DataBase \ HOLDING.GDB" PAGE_SIZE 4096 DEFAULT CHARACTER SET UNICODE_FSS ؛ إنشاء جدول RUSSIAN_WORD ("NAME1" VARCHAR (40) CHARACTER SET UNICODE_FSS ليست فارغة ، "NAME2" VARCHAR (40) CHARACTER SET WIN1251 NOT NULL ، PRIMARY KEY ("NAME1")) ؛
يوجد خطأ في الإصدار 2.01 من InterClient - لم يتم تجميع فئات الموارد التي تحتوي على رسائل باللغة الروسية بشكل صحيح هناك. على الأرجح ، نسي المطورون ببساطة تحديد تشفير المصدر عند التجميع. هناك طريقتان لإصلاح هذا الخطأ:
- استخدم interclient-core.jar بدلاً من interclient.jar. في الوقت نفسه ، لن تكون هناك ببساطة موارد روسية ، وسيتم اختيار الموارد الإنجليزية تلقائيًا.
- أعد ترجمة الملفات إلى Unicode العادي. يعد تحليل ملفات الفصل مهمة غير مرغوب فيها ، لذا من الأفضل استخدام JAD. لسوء الحظ ، JAD ، إذا صادفت أحرفًا من مجموعة ISO-8859-1 ، فستخرجها بترميز مكون من 8 أرقام ، لذلك لن تتمكن من استخدام برنامج التشفير الأصلي القياسي - عليك كتابة (برنامج فك الشفرة) الخاص بك. إذا كنت لا تريد أن تهتم بهذه المشاكل ، يمكنك فقط أن تأخذ ملفًا جاهزًا يحتوي على موارد (جرة مصححة مع برنامج التشغيل - interclient.jar ، فئات موارد منفصلة - interclient-rus.jar).
ولكن حتى بعد ضبط برنامج تشغيل JDBC على الترميز المطلوب ، في بعض الحالات ، قد تواجه مشكلة. على سبيل المثال ، عند محاولة استخدام مؤشرات التمرير JDBC 2 الجديدة الرائعة في جسر JDBC-ODBC من JDK 1.3.x ، ستجد بسرعة أن الأحرف الروسية لا تعمل هناك ببساطة (طريقة updateString ()).
هناك قصة صغيرة مرتبطة بهذا الخطأ. عندما اكتشفته لأول مرة (تحت JDK 1.3 rc2) ، قمت بتسجيله في BugParade (). عندما ظهر الإصدار التجريبي الأول من JDK 1.3.1 ، تم وضع علامة على هذا الخطأ على أنه تم إصلاحه. مسرور ، لقد قمت بتنزيل هذا الإصدار التجريبي ، وقمت بإجراء الاختبار - إنه لا يعمل. لقد كتبت إلى Sun-sheep حول هذا الأمر - رداً على ذلك كتبوا لي أن الإصلاح سيتم تضمينه في الإصدارات المستقبلية. حسنًا ، فكرت ، دعنا ننتظر. مر الوقت ، تم إطلاق الإصدار 1.3.1 ، ثم الإصدار التجريبي 1.4. أخيرًا ، أخذت الوقت الكافي للتحقق - لا يعمل مرة أخرى. الأم ، الأم ، الأم ... - صدى صدى عادة. بعد خطاب غاضب إلى صن ، أدخلوا خطأ جديدًا () ، أعطوه للفرع الهندي ليتمزق. العبث الهنود بالشفرة ، وقالوا إن كل شيء تم إصلاحه في 1.4 beta3. لقد قمت بتنزيل هذا الإصدار ، وقمت بتشغيل حالة اختبار تحته ، وهذه هي النتيجة -. كما اتضح ، فإن beta3 الموزعة على الموقع (بناء 84) ليست beta3 حيث تم تضمين الإصلاح النهائي (بناء 87). الآن يعدون بأن الإصلاح سيتم تضمينه في 1.4 rc1 ... حسنًا ، بشكل عام ، أنت تفهم :-)
الحروف الروسية في مصادر برامج جافا
كما ذكرنا ، يستخدم البرنامج Unicode عند التنفيذ. تتم كتابة ملفات المصدر في المحررين العاديين. أنا أستخدم Far ، فمن المحتمل أن يكون لديك محررك المفضل. تقوم برامج التحرير هذه بحفظ الملفات بتنسيق 8 بت ، مما يعني أن المنطق المماثل لما ورد أعلاه ينطبق على هذه الملفات أيضًا. تؤدي الإصدارات المختلفة من المترجمات تحويل الأحرف بشكل مختلف قليلاً. تستخدم الإصدارات السابقة من JDK 1.1.x الإعداد file.encoding ، والذي يمكن تجاوزه باستخدام خيار J غير القياسي. في الإصدارات الأحدث (كما ورد من قبل Denis Kokarev - بدءًا من 1.1.4) ، تم تقديم معلمة ترميز إضافية ، والتي يمكنك من خلالها تحديد الترميز المستخدم. في الفصول المترجمة ، يتم تمثيل السلاسل في شكل Unicode (بشكل أكثر دقة ، في نسخة معدلة من تنسيق UTF8) ، لذلك يحدث الشيء الأكثر إثارة للاهتمام أثناء التجميع. لذلك ، فإن أهم شيء هو معرفة ما هو ترميز أكواد المصدر الخاصة بك وتحديد القيمة الصحيحة عند التجميع. بشكل افتراضي ، سيتم استخدام نفس file.encoding سيئ السمعة. مثال على استدعاء المترجم:
بالإضافة إلى استخدام هذا الإعداد ، هناك طريقة أخرى - لتحديد الأحرف بتنسيق "\ uXXXX" ، حيث تتم الإشارة إلى رمز الحرف. تعمل هذه الطريقة مع جميع الإصدارات ، ويمكنك استخدام أداة قياسية للحصول على هذه الرموز.
إذا كنت تستخدم أي IDE ، فقد يكون له بعض الثغرات الخاصة به. غالبًا ما تستخدم IDEs الترميز الافتراضي لقراءة / حفظ المصادر - لذا انتبه إلى الإعدادات الإقليمية لنظام التشغيل الخاص بك. بالإضافة إلى ذلك ، قد تكون هناك أخطاء واضحة - على سبيل المثال ، لا يهضم CodeGuide الجيد على نطاق IDE جيدًا الحرف الروسي الكبير "T". يأخذ محلل الكود المدمج هذا الحرف كاقتباس مزدوج ، مما يؤدي إلى حقيقة أن الكود الصحيح يُنظر إليه على أنه خاطئ. يمكنك محاربة هذا (عن طريق استبدال الحرف "T" برمزه "\ u0422") ، لكن غير محبب. على ما يبدو ، في مكان ما داخل المحلل اللغوي ، يتم استخدام تحويل صريح للأحرف إلى بايت (مثل: byte b = (byte) c) ، لذلك بدلاً من الرمز 0x0422 (رمز الحرف "T") يكون الرمز 0x22 ( رمز الاقتباس المزدوج).
لدى JBuilder مشكلة أخرى ، لكنها أكثر ارتباطًا ببيئة العمل. الحقيقة هي أنه في JDK 1.3.0 ، والذي يعمل بموجبه JBuilder افتراضيًا ، هناك خطأ () ، نظرًا لأن نوافذ واجهة المستخدم الرسومية التي تم إنشاؤها حديثًا ، عند تنشيطها ، تتضمن تلقائيًا تخطيط لوحة المفاتيح اعتمادًا على الإعدادات الإقليمية لنظام التشغيل. أولئك. إذا كانت لديك إعدادات إقليمية روسية ، فستحاول باستمرار التبديل إلى التخطيط الروسي ، الذي يعيق كتابة البرامج. يحتوي موقع JBuilder.ru على اثنين من التصحيحات التي تغير الإعدادات المحلية الحالية في JVM إلى Locale.US ، ولكن أفضل طريقة هي الترقية إلى JDK 1.3.1 ، الذي أصلح هذا الخطأ.
قد يواجه مستخدمو Novice JBuilder أيضًا مثل هذه المشكلة - يتم حفظ الأحرف الروسية كرموز "\ uXXXX". لتجنب ذلك ، في مربع حوار خصائص المشروع الافتراضية ، علامة التبويب عام ، في حقل الترميز ، قم بتغيير الافتراضي إلى Cp1251.
إذا كنت تستخدم لغة javac غير قياسية للتجميع ، ولكن مترجمًا آخر - انتبه إلى كيفية قيامها بتحويل الأحرف. على سبيل المثال ، بعض إصدارات مترجم IBM jikes لا تفهم أن هناك ترميزات أخرى غير ISO-8859-1 :-). هناك إصدارات مصححة في هذا الصدد ، ولكن غالبًا ما يتم أيضًا خياطة بعض الترميز هناك - لا توجد مثل هذه الراحة كما هو الحال في javac.
JavaDoc
لإنشاء وثائق HTML للتعليمات البرمجية المصدر ، يتم استخدام الأداة المساعدة javadoc ، والتي يتم تضمينها في توزيع JDK القياسي. لتحديد الترميزات ، يحتوي على ما يصل إلى 3 معلمات:
- -تشفير - يحدد هذا الإعداد ترميز المصدر. الافتراضي هو file.encoding.
- -docencoding - يحدد هذا الإعداد ترميز ملفات HTML التي تم إنشاؤها. الافتراضي هو file.encoding.
- -charset - يحدد هذا الإعداد الترميز الذي سيتم كتابته إلى رؤوس ملفات HTML التي تم إنشاؤها ( ). من الواضح أنه يجب أن يكون نفس الإعداد السابق. إذا تم حذف هذا الإعداد ، فلن تتم إضافة العلامة الوصفية.
الحروف الروسية في ملفات الخصائص
تستخدم طرق تحميل الموارد لقراءة ملفات الخصائص ، والتي تعمل بطريقة معينة. في الواقع ، يتم استخدام طريقة Properties.load للقراءة ، والتي لا تستخدم ترميز الملف (رمز المصدر مشفر بشكل ثابت بترميز ISO-8859-1) ، لذا فإن الطريقة الوحيدة لتحديد الأحرف الروسية هي استخدام "\ uXXXX" الشكل والفائدة.
تعمل طريقة Properties.save بشكل مختلف في JDK 1.1 و 1.2. في الإصدار 1.1 ، تجاهل ببساطة البايت العالي ، لذلك كان يعمل بشكل صحيح فقط مع الأحرف الإنجليزية. 1.2 يقوم بالتحويل العكسي إلى "\ uXXXX" بحيث يعمل معكوسًا إلى طريقة التحميل.
إذا لم يتم تحميل ملفات الخصائص الخاصة بك كموارد ، ولكن كملفات تكوين عادية ، ولم تكن راضيًا عن هذا السلوك ، فهناك طريقة واحدة فقط للخروج ، اكتب أداة التحميل الخاصة بك.
الحروف الروسية في Servlets.
حسنًا ، ما هي هذه Servlets نفسها ، أعتقد أنك تعرف. إذا لم يكن الأمر كذلك ، فمن الأفضل قراءة الوثائق أولاً. هنا ، يتم وصف خصائص العمل بالحروف الروسية فقط.
إذن ما هي الميزات؟ عندما يرسل Servlet استجابة إلى عميل ، توجد طريقتان لإرسال هذه الاستجابة - عبر طريقة OutputStream (طريقة getOutputStream ()) أو طريقة PrintWriter (getWriter ()). في الحالة الأولى ، أنت تكتب مصفوفات من البايتات ، لذا فإن الأساليب المذكورة أعلاه في الكتابة إلى التدفقات قابلة للتطبيق. في حالة PrintWriter ، فإنه يستخدم مجموعة الترميز. في أي حال ، يجب عليك تحديد الترميز المستخدم بشكل صحيح عند استدعاء طريقة setContentType () ، من أجل تحويل الأحرف الصحيح على جانب الخادم. يجب إجراء هذا التوجيه قبل استدعاء getWriter () أو قبل الكتابة الأولى إلى OutputStream. مثال:
// ضبط ترميز الاستجابة // لاحظ أن بعض المحركات لا تسمح // الفضاء بين "؛" و "محارف" response.setContentType ("text / html ؛ charset = UTF-8") ؛ PrintWriter out = response.getWriter () ، // إخراج التصحيح لاسم الترميز للتحقق منه out.println ("Encoding:" + response.getCharacterEncoding ()) ؛ ... out.close () ؛ )
يتعلق الأمر بإعطاء إجابات للعميل. لسوء الحظ ، ليس الأمر بهذه السهولة مع معلمات الإدخال. يتم ترميز معلمات الإدخال بواسطة بايت المتصفح وفقًا لنوع MIME "application / x-www-form-urlencoded". كما قال Alexey Mendelev ، تقوم المتصفحات بترميز الأحرف الروسية باستخدام الترميز المحدد حاليًا. وبطبيعة الحال ، لم يتم الإبلاغ عن أي شيء عنها. وفقًا لذلك ، على سبيل المثال ، في إصدارات JSDK من 2.0 إلى 2.2 لم يتم التحقق من ذلك بأي شكل من الأشكال ، ويعتمد نوع الترميز الذي سيتم استخدامه للتحويل على المحرك المستخدم. بدءًا من المواصفة 2.3 ، أصبح من الممكن ضبط الترميز لـ javax.servlet.ServletRequest - طريقة setCharacterEncoding (). تدعم أحدث إصدارات Resin و Tomcat هذه المواصفات بالفعل.
وبالتالي ، إذا كنت محظوظًا ولديك خادم يدعم Servlet 2.3 ، فكل شيء بسيط للغاية:
يقوم doPost العام الباطل (طلب HttpServletRequest ، استجابة HttpServletResponse) بإلقاء ServletException و IOException ( // ترميز الرسالة request.setCharacterEncoding ("Cp1251") ؛ قيمة السلسلة = request.getParameter ("value") ؛ ...
هناك دقة واحدة مهمة في تطبيق طريقة request.setCharacterEncoding () - يجب تطبيقها قبلالمكالمة الأولى لطلب بيانات (على سبيل المثال ، request.getParameter ()). إذا كنت تستخدم المرشحات التي تعالج الطلب قبل وصوله إلى servlet ، فهناك فرصة غير صفرية أن أحد المرشحات قد يقرأ بعض المعلمات من الطلب (على سبيل المثال ، للترخيص) ولن يؤدي request.setCharacterEncoding () في servlet العمل ...
لذلك ، فمن الأصح من الناحية الأيديولوجية كتابة مرشح يحدد ترميز الطلب. علاوة على ذلك ، يجب أن يكون الأول في سلسلة المرشحات في web.xml.
مثال على هذا المرشح:
استيراد java.io. * ؛ استيراد java.util. * ؛ استيراد javax.servlet. * ؛ استيراد javax.servlet.http. * ؛ تقوم فئة عامة CharsetFilter بتنفيذ عامل التصفية (// ترميز ترميز سلسلة خاص ؛ يؤدي التهيئة العامة الباطلة (FilterConfig config) إلى طرح ServletException ( // قراءة من ملف التكوينالترميز = config.getInitParameter ("requestEncoding") ؛ // إذا لم يكن مثبتًا ، فقم بتثبيت Cp1251إذا (ترميز == فارغة) ترميز = "Cp1251" ؛ ) يقوم doFilter الباطل العام (طلب ServletRequest ، استجابة ServletResponse ، FilterChain التالي) بإلقاء IOException ، ServletException (request.setCharacterEncoding (ترميز) ؛ next.doFilter (طلب ، استجابة) ؛) تدمير الفراغ العام () ())
والتكوين الخاص به في web.xml:
مرشح مجموعة الأحرف مرشح CharsetFilter مرشح مجموعة الأحرف /*
إذا كنت غير محظوظ ولديك المزيد نسخة قديمة- لتحقيق النتيجة ، يجب أن تنحرف:
-
FOP
إذا كان البرنامج لا يعمل في أي مكان ، فإن المشكلة تكمن فيه فقط وفي يديك. اقرأ بعناية كل ما كتب أعلاه وانظر. إذا ظهرت المشكلة في بيئة معينة فقط ، فقد تكون المشكلة في الإعدادات. حيث يعتمد بالضبط على مكتبة الرسومات التي تستخدمها. إذا كان AWT - التكوين الصحيح لملف font.properties.ru يمكن أن يساعد. يمكن الحصول على مثال لملف صحيح من Java 2. إذا لم يكن لديك هذا الإصدار ، يمكنك تنزيله من هذا الموقع: إصدار Windows ، إصدار Linux (انظر أيضًا أدناه). يحدد هذا الملف الخطوط وصفحات التعليمات البرمجية المراد استخدامها. إذا كان لديك إصدار روسي من نظام التشغيل مثبتًا ، فما عليك سوى إضافة هذا الملف إلى حيث يوجد ملف font.properties. إذا كانت هذه هي النسخة الإنجليزية ، فأنت بحاجة إما إلى إعادة كتابة هذا الملف بدلاً من font.properties أو بالإضافة إلى تغيير الإعدادات الإقليمية الحالية إلى الروسية. في بعض الأحيان ، قد يعمل الإعداد -Duser.language = ru ، ولكنه لن يعمل في أغلب الأحيان. توجد نفس المشكلات تقريبًا كما هو الحال مع file.encoding - سواء كان يعمل أم لا يعتمد على JDK (راجع الخطأ حسب الرقم).
مع مكتبة Swing ، كل شيء أبسط - كل شيء فيه يتم رسمه من خلال نظام Java2D الفرعي. من السهل جدًا تحويل الملصقات في مربعات الحوار القياسية (JOptionPane و JFileChooser و JColorChooser) إلى اللغة الروسية - ما عليك سوى إنشاء العديد من ملفات الموارد. لقد قمت بهذا بالفعل ، لذا يمكنك فقط أخذ الملف النهائي وإضافته إلى lib \ ext أو CLASSPATH. المشكلة الوحيدة التي واجهتها هي أنه في إصدارات JDK بدءًا من 1.2 rc1 و 1.3 beta ، لا يتم عرض الأحرف الروسية ضمن Win9x عند استخدام الخطوط القياسية (Arial و Courier New و Times New Roman وما إلى ذلك) بسبب خطأ في Java2D. الخطأ غريب تمامًا - مع الخطوط القياسية ، لا يتم عرض صور الحروف وفقًا لرموز Unicode ، ولكن وفقًا للجدول Cp1251 ( ترميز Ansi). تم تسجيل هذا الخطأ في BugParade تحت الرقم. بشكل افتراضي ، يستخدم Swing الخطوط المحددة في ملف font.properties.ru ، لذلك يكفي استبدالها بأخرى وستظهر الحروف الروسية. لسوء الحظ ، مجموعة خطوط العمل صغيرة - هذه هي خطوط Tahoma و Tahoma Bold ومجموعتين من الخطوط من توزيع JDK - Lucida Sans * و Lucida Typewriter * (مثال على ملف font.properties.ru). كيف تختلف هذه الخطوط عن الخطوط القياسية ليس واضحًا بالنسبة لي.
منذ الإصدار 1.3rc1 ، تم إصلاح هذه المشكلة بالفعل ، لذلك تحتاج فقط إلى تحديث JDK. JDK 1.2 قديم جدًا ، لذا لا أوصي باستخدامه. وتجدر الإشارة أيضًا إلى أن الإصدار الأصلي من Win95 يأتي مع خطوط لا تدعم Unicode - في هذه الحالة ، يمكنك ببساطة نسخ الخطوط من Win98 أو WinNT.
أخطاء نموذجية ، أو "أين ذهب الحرف W؟"
حرف ش.
هذا السؤال ("أين ذهب الحرف W؟") غالبًا ما يسأله مبرمجو Java المبتدئين. دعونا نرى إلى أين تذهب في أغلب الأحيان. :-)
إليك برنامج نموذجي على غرار HelloWorld:
اختبار الفئة العامة (الرئيسي العام الثابت الفارغ (سلاسل السلسلة) (System.out.println ("ИЦУКЕНГШЩЗХЪ") ؛))
في Far ، احفظ هذا الرمز في ملف Test.java ، قم بترجمة ...C: \> javac Test.java
و اهرب ...C: \> جافا اختبار YTsUKENG؟ ЩЗХЪ
ماذا حدث؟ أين ذهب الحرف W؟ الحيلة هنا هي أنه كان هناك تعويض متبادل لخطأين. يقوم محرر النص الأقصى افتراضيًا بإنشاء ملف مشفر DOS (Cp866). يستخدم برنامج التحويل البرمجي javac file.encoding لقراءة المصدر (ما لم يتم تحديد خلاف ذلك باستخدام مفتاح -encoding). و في بيئة Windowsباستخدام اللغة الروسية ، يكون الترميز الافتراضي هو Cp1251. هذا هو الخطأ الأول. نتيجة لذلك ، تحتوي الرموز الموجودة في ملف Test.class المترجم على رموز غير صحيحة. الخطأ الثاني هو أن PrintStream القياسي يستخدم للإخراج ، والذي يستخدم أيضًا الإعداد من file.encoding ، لكن نافذة وحدة التحكم في Windows تعرض الأحرف باستخدام تشفير DOS. إذا كان ترميز Cp1251 صالحًا بشكل متبادل ، فلن يكون هناك فقدان للبيانات. لكن الحرف W في Cp866 له رمز 152 ، والذي لم يتم تعريفه في Cp1251 ، وبالتالي يتم تعيينه إلى حرف Unicode 0xFFFD. عند التحويل من حرف إلى بايت ، يتم استبدال "؟" به.
يمكنك الحصول على تعويض مماثل إذا قرأت أحرفًا من ملف نصي باستخدام java.io.FileReader ، ثم عرضها على الشاشة باستخدام System.out.println (). إذا تمت كتابة الملف بترميز Cp866 ، فسيتم تشغيل الإخراج بشكل صحيح ، باستثناء الحرف Ш مرة أخرى.
تحويل البايت المباشر<->شار.
هذا الخطأ مفضل لدى مبرمجي Java الأجانب. تمت مناقشته بشيء من التفصيل في بداية الوصف. إذا نظرت في أي وقت إلى مصادر أشخاص آخرين ، فاحرص دائمًا على الانتباه إلى تحويل النوع الصريح - (بايت) أو (شار). غالبًا ما يتم دفن الخليع في مثل هذه الأماكن.
خوارزمية لإيجاد مشاكل مع الحروف الروسية
إذا لم تكن لديك فكرة عن المكان الذي يمكن أن يحدث فيه فقد الأحرف الروسية في برنامجك ، فيمكنك تجربة الاختبار التالي. يمكن اعتبار أي برنامج معالج بيانات الإدخال. الحروف الروسية هي نفس البيانات ، وعادة ما تمر بثلاث مراحل من المعالجة: تتم قراءتها من مكان ما في ذاكرة البرنامج (الإدخال) ، ومعالجتها داخل البرنامج وعرضها على المستخدم (الإخراج). لتحديد موقع المشكلات ، بدلاً من البيانات ، يجب محاولة خياطة سطر الاختبار التالي في شفرة المصدر: "ABC \ u0410 \ u0411 \ u0412" ، ومحاولة إخراجها. بعد ذلك ، انظر إلى ما حصلت عليه:
- إذا رأيت "ABVABV" ، فإن تجميع المصادر والمخرجات يعملان بشكل صحيح بالنسبة لك.
- إذا رأيت "؟؟؟ ABC" (أو أي أحرف أخرى بخلاف "ABC" بدلاً من الأحرف الثلاثة الأولى) ، فإن الإخراج يعمل بشكل صحيح ، ولكن تجميع المصادر يحدث خطأً - على الأرجح - الترميز المفتاح غير محدد.
- إذا رأيت "؟؟؟؟؟؟" (أو أي رموز أخرى باستثناء "ABC" بدلاً من الأحرف الثلاثة الثانية) ، فإن الإخراج لا يعمل بشكل صحيح بالنسبة لك.
بعد تكوين الإخراج والتجميع ، يمكنك بالفعل معرفة المدخلات بسهولة. بعد إنشاء السلسلة بأكملها ، يجب أن تختفي المشاكل.
حول الأداة native2ascii
هذه الأداة المساعدة جزء من Sun JDK وهي مصممة لتحويل كود المصدر إلى تنسيق ASCII. يقرأ ملف الإدخال باستخدام الترميز المحدد ويكتب الأحرف بتنسيق "\ uXXXX". إذا حددت مفتاح التبديل العكسي ، فسيتم إجراء التحويل العكسي. هذا البرنامج مفيد جدًا في تحويل ملفات الموارد (.properties) أو لمعالجة المصادر إذا كنت تشك في إمكانية تجميعها على أجهزة كمبيوتر ذات إعدادات إقليمية غير روسية.
إذا قمت بتشغيل البرنامج بدون معلمات ، فإنه يعمل مع الإدخال القياسي (stdin) ، ولا يعرض تلميحًا رئيسيًا مثل الأدوات المساعدة الأخرى. يؤدي هذا إلى حقيقة أن الكثيرين لا يدركون حتى أنه من الضروري تحديد المعلمات (باستثناء ، ربما ، أولئك الذين وجدوا القوة والشجاعة للنظر في الوثائق :-). وفي الوقت نفسه ، هذه الأداة العمل الصحيحيجب عليك ، كحد أدنى ، تحديد الترميز المستخدم (باستخدام مفتاح -encoding). إذا لم يتم ذلك ، فسيتم استخدام الترميز الافتراضي (file.encoding) ، والذي قد يختلف نوعًا ما عن المتوقع. نتيجة لذلك ، بعد تلقي رموز أحرف غير صحيحة (بسبب الترميز غير الصحيح) ، يمكنك قضاء الكثير من الوقت في البحث عن أخطاء في رمز صحيح تمامًا.
حول طريقة تحويل الشخصية
كثير من الناس يستخدمون هذه الطريقة بشكل غير صحيح ، وربما لا يفهمون تمامًا جوهرها وقيودها. إنه مصمم لاستعادة رموز الأحرف الصحيحة إذا تم تفسيرها بشكل خاطئ. جوهر الطريقة بسيط: تتم استعادة مصفوفة البايت الأصلية من الأحرف غير الصحيحة المستلمة باستخدام صفحة الرموز المناسبة. بعد ذلك ، من مجموعة البايت هذه ، باستخدام الصفحة الصحيحة بالفعل ، يتم الحصول على رموز الأحرف العادية. مثال:
String res = سلسلة جديدة (src.getBytes ("ISO-8859-1") ، "Cp1251") ؛
يمكن أن يكون هناك العديد من المشاكل في استخدام هذه التقنية. على سبيل المثال ، يتم استخدام الصفحة الخطأ للاسترداد ، أو قد تتغير في بعض المواقف. قد تكون هناك مشكلة أخرى وهي أن بعض الصفحات تقوم بتحويل بايت غامض<->شار. انظر ، على سبيل المثال ، وصف الخطأ بالرقم.
لذلك ، يجب عليك استخدام هذه الطريقة فقط في الحالات القصوى ، عندما لا يساعدك شيء آخر ، ولديك فكرة واضحة عن مكان حدوث التحويل غير الصحيح للأحرف.
الحروف الروسية و MS JVM
من غير الواضح ما هي الأسباب ، لكنها تفتقر إلى جميع الملفات لترميز الأحرف الروسية ، acrome Cp1251 (ربما حاولوا تقليل حجم التوزيع بهذه الطريقة). إذا كنت بحاجة إلى ترميزات أخرى ، على سبيل المثال ، Cp866 ، فأنت بحاجة إلى إضافة الفئات المقابلة إلى CLASSPATH. علاوة على ذلك ، لا تتناسب الفئات من أحدث إصدارات Sun JDK - لقد غيرت Sun هيكلها لفترة طويلة ، لذلك لا تتطابق أحدث إصدارات الفئات مع Microsoft (لا يزال لدى MS هيكل من JDK 1.1.4). على خادم Microsoft ، من حيث المبدأ ، هناك مجموعة كاملة من الترميزات الإضافية ، ولكن هناك ملف يبلغ حجمه حوالي 3 أمتار ، ولا يدعم خادمهم استئناف التنزيل :-). تمكنت من تنزيل هذا الملف ، أعدت تعبئته بالبرطمان ، يمكنك أخذه من هنا.
إذا كنت تكتب تطبيقًا صغيرًا يجب أن يعمل ضمن MS JVM وتحتاج إلى القراءة من مكان ما (على سبيل المثال ، من ملف موجود على الخادم) بايت بترميز روسي بخلاف Cp1251 (على سبيل المثال ، في Cp866) ، فلن تعد قادرًا على القراءة. تكون قادرًا على استخدام آلية التشفير القياسية - يُحظر على التطبيقات الصغيرة إضافة فئات إلى حزم النظام ، والتي تكون في هذه الحالة حزمة sun.io. هناك طريقتان للخروج - إما لإعادة ترميز الملف على الخادم إلى Cp1251 (أو إلى UTF-8) أو قبل التحويل من البايت إلى Unicode ، قم بتحويل البايت من الترميز المطلوب إلى Cp1251.
إضفاء الطابع الروسي على Java لنظام التشغيل Linux
سأقول على الفور - أنا لا أعمل مع Linux ، والمعلومات الواردة هنا تم الحصول عليها من قراء هذا الوصف. إذا وجدت عدم دقة أو تريد أن تضيف - اكتب لي.
توجد مشكلتان متوازيتان عند استخدام Cyrillizing JVM على نظام Linux:
- مشكلة الإخراج السيريلية في مكونات واجهة المستخدم الرسومية
- مشكلة إدخال السيريلية من لوحة المفاتيح (في X11)
يمكن حل مشكلة الانسحاب بهذه الطريقة (تم إرسال هذه الخوارزمية بواسطة Artemy E. Kapitula):
- قم بتثبيت خطوط Windows NT / 200 ttf العادية في X11. أوصي بـ Arial و Times New Roman و Courier New و Verdana و Tahoma - ومن الأفضل توصيلهم ليس من خلال خادم خطوط ، ولكن كدليل يحتوي على ملفات.
- أضف ملف font.properties.ru التالي إلى الدليل $ JAVA_HOME / jre / lib
تم حل مشكلة الإدخال تقريبًا بالطريقة التالية (تم إرسال هذه الخوارزمية بواسطة ميخائيل إيفانوف):
إعداد إدخال الحروف الروسية في التكوين التالي:
- ماندريك لينكس 7.1.1
- XFree86 3.3.6
- IBM Java 1.3.0 (إصدار)
مشكلة:
لا يسمح IBM Java 1.3 بإدخال الأحرف الروسية (مرئية على شكل تماسيح) ، على الرغم من حقيقة أنها مرئية على الملصقات وفي القوائم.
باستخدام XIM (-> xkb) في AWT. (هذا ليس سيئًا في حد ذاته ، إنه يحتاج فقط إلى التعامل معه بعناية مع مثل هذه الأشياء + بعض أدوات xkb لا تعجبه).
تكوين xkb (والإعدادات المحلية (xkb بدون لغة لا تعمل))
إجراء:
- اللغة مكشوفة (في مكان ما مثل / etc / profile أو ~ / .bash_profile)
تصدير LANG = ru_RU.KOI8-R تصدير LC_ALL = ru_RU.KOI8-R
- تحرير (إذا لم يكن قد تم بالفعل) / etc / X11 / XF86Config. يجب أن يحتوي قسم لوحة المفاتيح على شيء مثل هذا:
XkbKeycodes "xfree86" XkbTypes "الافتراضي" XkbCompat "الافتراضي" XkbSymbols "ru" XkbGeometry "pc" XkbRules "xfree86" XkbModel "pc101" XkbLayout "ru" XkbOptions "grp: shift_hogle"
ملاحظة: إعداد xkb هذا غير متوافق مع xrus (وغيره مثل kikbd) وبالتالي عليك أن تقول وداعًا لهم. - يتم إعادة تشغيل X's. تحتاج إلى التحقق من أن كل شيء يعمل (مثل الأحرف الروسية في المحطة والتطبيقات)
- font.properties.ru -> $ JAVA_HOME / jre / lib
- fonts.dir -> $ JAVA_HOME / jre / lib / الخطوط
- cd $ JAVA_HOME / jre / lib / الخطوط ؛ rm fonts.scale ؛ ln -s fonts.dir fonts.scale
الآن يجب إدخال الأحرف الروسية وعرضها في التأرجح دون مشاكل.
يتم تقديم الطريقة الأصلية للعمل مع الترميزات بواسطة Russian Apache - يتم وصفها بالضبط كيف.
مرفق دعم كامل لتوجيهات .htaccess ...
تجديد النطاق 199-00 فرك
الترميز عبارة عن جدول من الأحرف ، حيث يتم تعيين رقم فريد لكل حرف من الأحرف الأبجدية (بالإضافة إلى الأرقام والأحرف الخاصة) - رمز الحرف.
نصف الجدول فقط موحد ، ما يسمى ب. رمز ASCII - أول 128 حرفًا تتضمن أحرف الأبجدية اللاتينية. ولا توجد مشاكل معهم. يُعطى النصف الثاني من الجدول (ويوجد فيه إجمالي 256 رمزًا - وفقًا لعدد الحالات التي يمكن أن يتخذها بايت واحد) تحت الرموز الوطنية ، وهذا الجزء مختلف في كل بلد. لكن في روسيا فقط تمكنوا من ابتكار ما يصل إلى 5 ترميزات مختلفة. مصطلح "مختلف" يعني أن نفس الرمز يتوافق مع رمز رقمي مختلف. أولئك. إذا حددنا ترميز النص بشكل غير صحيح ، فسيتم توجيه انتباهنا إلى نص غير قابل للقراءة على الإطلاق.
ظهرت الترميزات تاريخيا. تم استدعاء أول ترميز روسي واسع الاستخدام KOI-8... تم اختراعه عندما تم تكييف نظام UNIX مع اللغة الروسية. كان هذا في السبعينيات - قبل ظهور أجهزة الكمبيوتر الشخصية. وحتى الآن ، في UNIX ، يعتبر هذا هو الترميز الرئيسي.
ثم ظهرت أجهزة الكمبيوتر الشخصية الأولى ، وبدأت مسيرة DOS المظفرة. بدلاً من استخدام ترميز تم اختراعه بالفعل ، قررت Microsoft إنشاء ترميز خاص بها لا يتوافق مع أي شيء. هكذا ظهر ترميز DOS(أو 866 صفحة الرموز). بالمناسبة ، أدخلت أحرفًا خاصة لإطارات الرسم ، والتي كانت تستخدم على نطاق واسع في البرامج المكتوبة تحت DOS. على سبيل المثال ، في نفس نورتون كوماندر.
تم تطوير أجهزة كمبيوتر Macintosh بالتوازي مع الأجهزة المتوافقة مع IBM. على الرغم من حقيقة أن حصتهم في روسيا صغيرة جدًا ، إلا أن هناك حاجة إلى الترويس ، وبالطبع تم اختراع ترميز آخر - ماك.
مر الوقت ، وفي عام 1990 سلطت مايكروسوفت الضوء على أول نجاح نسخة ويندوز 3.0-3.11. وإلى جانب ذلك ، دعم اللغات الوطنية. ومرة أخرى ، تم تنفيذ نفس الحيلة كما هو الحال مع DOS. لسبب غير معروف ، لم يدعموا أيًا من تلك الموجودة سابقًا (كما فعل OS / 2 ، الذي اعتمد ترميز DOS كمعيار) ، لكنهم اقترحوا نظامًا جديدًا فوز الترميز(أو صفحة الرموز 1251 ). في الواقع ، أصبح الأكثر انتشارًا في روسيا.
وأخيرًا ، لم يعد خيار الترميز الخامس مرتبطًا بشركة معينة ، ولكن بمحاولات لتوحيد الترميز على مستوى الكوكب بأكمله. تم القيام بذلك من قبل ISO ، وهي منظمة معايير دولية. وخمنوا ماذا فعلوا باللغة الروسية؟ بدلاً من الخلط بين أي مما سبق على أنه "روسي قياسي" ، توصلوا إلى (!) آخر (!) وأطلقوا عليه مزيجًا طويلًا غير قابل للهضم ISO-8859-5... بالطبع ، تبين أيضًا أنه لا يتوافق مع أي شيء. وفي الوقت الحالي ، لا يتم استخدام هذا الترميز عمليًا في أي مكان. يبدو أنه يستخدم فقط في قاعدة بيانات Oracle. على الأقل لم أر النص بهذا الترميز مطلقًا. ومع ذلك ، فهو مدعوم في جميع المتصفحات.
نعمل الآن على إنشاء ترميز عالمي جديد ( يونيكود) ، حيث من المفترض حشر جميع لغات العالم في جدول رمز واحد. ثم بالتأكيد لن تكون هناك مشاكل. لهذا ، تم تخصيص 2 بايت لكل حرف. وبالتالي ، فقد تم توسيع الحد الأقصى لعدد الأحرف في الجدول إلى 65535. ولكن لا يزال هناك الكثير من الوقت قبل أن يقوم الجميع بالتبديل إلى UNICODE.
هنا نستطرد قليلاً ونأخذ في الاعتبار العلامة الوصفية - نوع المحتوى للحصول على تصور شامل.
تُستخدم العلامات الوصفية لوصف خصائص مستند HTML ويجب تضمينها في علامة HEAD. تحتوي العلامات الوصفية مثل NAME على معلومات نصية حول المستند ومؤلفه وبعض التوصيات لمحركات البحث. على سبيل المثال: الروبوتات ، الوصف ، الكلمات الرئيسية ، المؤلف ، حقوق النشر.
تؤثر العلامات الوصفية لنوع HTTP-EQUIV على تشكيل رأس المستند وتحديد طريقة معالجته.
نوع محتوى العلامة الوصفية - مسؤول عن تحديد نوع المستند وترميز الأحرف.
من الضروري استخدام العلامة الوصفية لنوع المحتوى فقط مع مراعاة بعض الفروق الدقيقة:
أولاً ، يجب أن يتطابق ترميز أحرف النص مع الترميز المحدد في العلامة.
ثانيًا ، يجب ألا يغير الخادم تشفير النص عند معالجة طلب المتصفح.
ثالثًا ، إذا قام الخادم بتغيير ترميز النص ، فيجب أن يصحح العلامة الوصفية لنوع المحتوى أو يزيلها.
يمكن أن يؤدي عدم الامتثال لهذه المتطلبات إلى ما يلي: سيكتشف خادم الويب تلقائيًا ترميز طلب العميل ويعطي الصفحة المعاد ترميزها إلى متصفح الويب. سيقوم المستعرض بدوره بقراءة المستند وفقًا للعلامة الوصفية لنوع المحتوى. وإذا لم تتطابق الترميزات ، فلا يمكن قراءة المستند إلا بعد سلسلة من التلاعبات المعقدة. هذا ينطبق بشكل خاص على المتصفحات القديمة.
انتباه! غالبًا ما يتم إدراج علامة Meta Content-Type مولدات HTMLالشفرة.
أنواع الترميز الأكثر شيوعًا هي:
Windows-1251 - السيريلية (Windows).
KOI8-r - السيريلية (KOI8-R)
cp866 - السيريلية (DOS).
Windows-1252 - أوروبا الغربية (Windows).
Windows-1250 - وسط أوروبا (Windows).
بالتأكيد يعرف الجميع العلامة الوصفية -
الخامس هذه المادةتستخدم مقتطفات من المقال من الموقع http://cherry-design.ru/
المجالات التي تم إصدارها مؤخرًا مع PR و TIC:
خدمة http://reg.ru - أكبر شركة استضافة ومسجل مجال ، تتيح لك التقدم بطلب لتسجيل اسم المجال ، والذي تم إصداره مؤخرًا بواسطة المسؤول السابق. غالبًا ما تحتوي المجالات التي تم إصدارها على معدلات TIC و PR عالية وقد يكون من المثير للاهتمام الحصول عليها.
|
تم إصدار المجالات .RU c TIC: |
المجالات المميزة المجانية: |
كمية المعلومات: 7659 بايت
تاريخيًا ، تم تخصيص 7 بتات لتمثيل الأحرف المطبوعة (ترميز النص) في أجهزة الكمبيوتر الأولى. 2 7 = 128. كان هذا المبلغ كافياً لتشفير كل الأحرف الصغيرة و الأحرف الكبيرةالأبجدية اللاتينية ، عشرة أرقام وعلامات وأقواس مختلفة. هذا هو بالضبط جدول 7 بت أحرف ASCII(الكود القياسي الأمريكي لتبادل المعلومات) ، معلومات مفصلةوالتي يمكنك الحصول عليها بأمر رجل أسكي نظام التشغيللينكس.
عندما أصبح من الضروري تشفير الأبجديات الوطنية ، لم يكن 128 حرفًا كافيًا. تقرر التبديل إلى الترميز باستخدام 8 بت (أي بايت واحد). نتيجة لذلك ، أصبح عدد الأحرف التي يمكن تشفيرها بهذه الطريقة يساوي 2 8 = 256. في هذه الحالة ، كانت رموز الأبجديات الوطنية موجودة في النصف الثاني من جدول الرموز ، أي أنها تحتوي على وحدة في أهم بت من البايت المخصص لتشفير الحرف. هكذا ظهر معيار ISO 8859 ، الذي يحتوي على العديد من الترميزات للغات الأكثر شيوعًا.
كان من بينها أحد الجداول الأولى لتشفير الحروف الروسية - ISO 8859-5(استخدم الأمر man iso_8859_1 للحصول على رموز الأحرف الروسية في هذا الجدول).
نقل المهام معلومات نصيةعبر الشبكة ، أُجبروا على تطوير ترميز آخر للأحرف الروسية ، يُدعى كوي 8-ر(رمز عرض المعلومات هو 8 بت ، ينضم إلى اللغة الروسية). ضع في اعتبارك موقفًا عندما يتم إرسال رسالة تحتوي على نص روسي عبر البريد الإلكتروني... حدث أنه في عملية الانتقال عبر الشبكات ، تمت معالجة الرسالة بواسطة برنامج يعمل بترميز 7 بت ويصفّر البت الثامن. نتيجة لهذا التحول ، تم تقليل رمز الحرف بمقدار 128 ، وتحول إلى رمز الأحرف في الأبجدية اللاتينية. كانت هناك حاجة لزيادة استقرار المعلومات النصية المرسلة لتصفير 8 بتات.
لحسن الحظ ، هناك عدد كبير من الحروف السيريلية لها نظائر صوتية في الأبجدية اللاتينية. على سبيل المثال ، Ф و F و P و R. هناك العديد من الأحرف التي تتطابق حتى في المخطط التفصيلي. ترتيب الحروف الروسية في جدول الكودفي مثل هذه الطريقة أن التعليمات البرمجية الخاصة بهم تتجاوز الرمز لاتينية مماثلةبالنسبة للرقم 128 ، فقد توصلوا إلى أن فقدان الجزء الثامن قلب النص ، على الرغم من أنه يتكون من أبجدية لاتينية واحدة ، ولكن لا يزال يفهمها المستخدم الناطق باللغة الروسية.
نظرًا لأنه من بين جميع أنظمة التشغيل المنتشرة في ذلك الوقت ، فإن أكثر الوسائل ملاءمة للعمل مع الشبكة كانت تمتلكها نسخ مختلفة من التشغيل أنظمة يونكسثم أصبح هذا الترميز هو المعيار الفعلي في هذه الأنظمة. لا يزال هذا هو الحال في لينكس. وغالبًا ما يستخدم هذا الترميز لتبادل البريد والأخبار على الإنترنت.
ثم جاء العصر حواسيب شخصيةونظام التشغيل MS DOS. كما اتضح ، لم يكن ترميز Koi8-R مناسبًا لها (تمامًا مثل ISO 8859-5) ، في جدولها كانت بعض الأحرف الروسية في تلك الأماكن التي افترضت العديد من البرامج أنها مليئة بالرسم الكاذب (خطوط أفقية ورأسية ، زوايا ، إلخ. .). الخ). لذلك ، تم اختراع ترميز سيريلي آخر ، وفي جدوله "تتدفق" الأحرف الروسية "حول" رموز بيانية من جميع الجوانب. يسمى هذا الترميز لبديل(بديل) لأنه كان بديلاً للمعيار الرسمي ، وهو ترميز ISO-8859-5. الميزة التي لا جدال فيها لهذا الترميز هي أن الحروف الروسية فيه مرتبة حسب الترتيب الأبجدي.
بعد ظهور Windows من Microsoft ، اتضح أن الترميز البديل لسبب ما غير مناسب له. نقل الأحرف الروسية في الجدول مرة أخرى (كانت هناك فرصة - بعد كل شيء ، الرسومات الزائفة في Windows ليست مطلوبة) ، حصلنا على التشفير نظام التشغيل Windows 1251(Win-1251).
لكن تقنيات الكمبيوتر تتحسن باستمرار وفي الوقت الحالي بدأ عدد متزايد من البرامج في دعم معيار Unicode ، والذي يسمح لك بترميز جميع لغات ولهجات سكان الأرض تقريبًا.
لذلك ، في أنظمة التشغيل المختلفة ، يتم إعطاء الأفضلية للترميزات المختلفة. من أجل التمكن من قراءة وتحرير النص المكتوب بترميز مختلف ، يتم استخدام برامج تحويل ترميز النص الروسي. بعض محرري النصوصتحتوي على محولات مضمنة تسمح لك بقراءة النص بترميزات مختلفة (Word ، إلخ). لتحويل الملفات ، سنستخدم عددًا من الأدوات المساعدة في Linux ، والغرض منها واضح من الاسم: alt2koi ، win2koi ، koi2win ، alt2win ، win2alt ، koi2alt (من حيث ، حيث ، الرقم 2 (اثنان) مشابه في الصوت لحرف الجر إلى ، مشيرا إلى الاتجاه). هذه الأوامر لها نفس بناء الجملة: command<входной_файл >ملف إلاخراج.
مثال
دعنا نعيد ترميز النص المكتوب في محرر التحرير في بيئة MS DOS إلى ترميز Koi8-R. للقيام بذلك ، قم بتشغيل الأمر
alt2koi file1.txt> ملف
نظرًا لأن موجزات الأسطر يتم ترميزها بشكل مختلف في MS DOS و Linux ، فمن المستحسن أيضًا تنفيذ الأمر "fromdos":
fromdos filenew> file2.txt
يسمى الأمر العكسي "todos" وله نفس الصيغة.
مثال
لنقم بفرز ملف List.txt الذي يحتوي على قائمة بأسماء العائلة ويتم إعداده بترميز Koi8-R بترتيب أبجدي. دعنا نستخدم أمر الفرز ، الذي يفرز الملف النصي بترتيب تصاعدي أو تنازلي لرموز الأحرف. إذا قمت بتطبيقه على الفور ، فعندئذٍ ، على سبيل المثال ، الحرف الخامسسيكون في نهاية القائمة ، على غرار الحرف المقابل من الأبجدية اللاتينية الخامس... تذكر أنه في الترميز البديل ، يتم ترتيب الأحرف الروسية بشكل صارم أبجديًا ، سنقوم بعدد من العمليات: إعادة ترميز النص إلى ترميز بديل ، وفرزه وإعادته مرة أخرى إلى ترميز Koi8-R. باستخدام خط أنابيب الأوامر ، نحصل على
koi2alt List.txt | فرز | alt2koi> List_Sort.txt
في توزيعات Linux الحديثة ، ترتبط العديد من المشكلات بامتداد الموقع البرمجيات... على وجه الخصوص ، تأخذ أداة الفرز الآن في الاعتبار خصائص ترميز Koi8-R ، ولفرز الملف بالترتيب الأبجدي ، ما عليك سوى تشغيل الأمر
ترميزات
عندما بدأت البرمجة لأول مرة في C ، كان برنامجي الأول (بصرف النظر عن HelloWorld) برنامجًا لتحويل الملفات النصية من ترميز GOST الرئيسي (تذكر هذا؟ :-) إلى برنامج بديل. لقد عاد في عام 1991. لقد تغير الكثير منذ ذلك الحين ، ولكن لسوء الحظ ، لم تفقد هذه البرامج أهميتها على مدى السنوات العشر الماضية. تم بالفعل تجميع قدر كبير جدًا من البيانات في ترميزات مختلفة ويتم استخدام عدد كبير جدًا من البرامج التي يمكن أن تعمل مع ترميز واحد فقط. هناك ما لا يقل عن عشرة ترميزات مختلفة للغة الروسية ، مما يجعل المشكلة أكثر إرباكًا.
من أين أتت كل هذه الترميزات وما الغرض منها؟ لا يمكن لأجهزة الكمبيوتر ، بطبيعتها ، العمل إلا مع الأرقام. من أجل تخزين الحروف في ذاكرة الكمبيوتر ، من الضروري تخصيص رقم معين لكل حرف (تم استخدام نفس المبدأ تقريبًا قبل ظهور أجهزة الكمبيوتر - تذكر نفس رمز مورس). علاوة على ذلك ، فإن الرقم أصغر بشكل مرغوب فيه - فكلما قل عدد الأرقام الثنائية المستخدمة ، زادت كفاءة استخدام الذاكرة. هذا التطابق بين مجموعة من الأحرف والأرقام هو في الواقع ترميز. أدت الرغبة في حفظ الذاكرة بأي ثمن ، وكذلك تفكك مجموعات مختلفة من علماء الكمبيوتر ، إلى الوضع الحالي. أكثر طرق التشفير شيوعًا الآن هي استخدام بايت واحد (8 بتات) لحرف واحد ، والذي يحدد العدد الإجمالي للأحرف في 256 حرفًا. مجموعة الأحرف الـ 128 الأولى موحدة (مجموعة ASCII) وهي نفسها في جميع الترميزات الشائعة (تلك الترميزات التي لا تكون بالفعل خارج نطاق الاستخدام عمليًا). تقع الأحرف الإنجيلية ورموز الترقيم في هذا النطاق ، مما يحدد حيويتها المذهلة في أنظمة الكمبيوتر :-). اللغات الأخرى ليست سعيدة جدًا - يتعين عليهم جميعًا التجمع في الأرقام المتبقية البالغ عددها 128.
يونيكود
في أواخر الثمانينيات ، أدرك الكثيرون الحاجة إلى إنشاء معيار موحد لتشفير الأحرف ، مما أدى إلى ظهور Unicode. Unicode هي محاولة لإصلاح رقم معين لشخص معين بشكل نهائي. من الواضح أن 256 حرفًا لن تتناسب هنا مع كل الرغبة. لفترة طويلة بدا أن 2 بايت (65536 حرفًا) يجب أن تكون كافية. لكن لا - أحدث إصدار من معيار Unicode (3.1) يحدد بالفعل 94.140 حرفًا. لمثل هذا العدد من الأحرف ، ربما يتعين عليك بالفعل استخدام 4 بايت (4294967296 حرفًا). ربما يكفي لبعض الوقت ... :-)
تتضمن مجموعة أحرف Unicode جميع أنواع الحروف مع جميع أنواع الشرطات والبابينديولكي واليوناني والرياضي والهيروغليفية والرموز الرسومية الزائفة وما إلى ذلك ، بما في ذلك الأحرف السيريلية المفضلة لدينا (نطاق القيم هو 0x0400-0x04ff) . لذلك لا يوجد تمييز في هذا الجانب.
إذا كنت مهتمًا برموز أحرف معينة ، فمن الملائم استخدام برنامج "مخطط توزيع الأحرف" من WinNT لعرضها. على سبيل المثال ، هذا هو النطاق السيريلي:
إذا كان لديك نظام تشغيل مختلف أو كنت مهتمًا بالتفسير الرسمي ، فيمكن العثور على المخططات الكاملة على موقع Unicode الرسمي (http://www.unicode.org/charts/web.html).
أنواع الحرف والبايت
تحتوي Java على نوع بيانات char منفصل يبلغ 2 بايت للأحرف. يؤدي هذا غالبًا إلى حدوث ارتباك في أذهان المبتدئين (خاصةً إذا سبق لهم البرمجة بلغات أخرى ، مثل C / C ++). هذا لأن معظم اللغات الأخرى تستخدم أنواع بيانات 1 بايت لمعالجة الأحرف. على سبيل المثال ، في C / C ++ ، يتم استخدام الحرف في الغالب لكل من معالجة الأحرف ومعالجة البايت - لا يوجد فصل. Java لها نوع خاص بها للبايت - نوع البايت. وبالتالي ، فإن الحرف المستند إلى C يتوافق مع Java بايت ، و Java char من عالم C هو الأقرب إلى نوع wchar_t. من الضروري الفصل بوضوح بين مفاهيم الأحرف والبايت - وإلا فإن سوء الفهم والمشاكل مضمونة.
تستخدم Java معيار Unicode لترميز الأحرف منذ إنشائها تقريبًا. تتوقع وظائف مكتبة Java أن ترى أحرف Unicode في متغيرات char. من حيث المبدأ ، بالطبع ، يمكنك حشو أي شيء هناك - فالأرقام هي أرقام ، وسيتحمل المعالج كل شيء ، ولكن بالنسبة لأي معالجة ، ستعمل وظائف المكتبة على افتراض أنها حصلت على ترميز Unicode. لذلك يمكنك أن تفترض بأمان أن ترميز char تم إصلاحه. لكن هذا داخل JVM. عند قراءة البيانات من الخارج أو تمريرها من الخارج ، يمكن تمثيلها بنوع واحد فقط - نوع البايت. يتم إنشاء جميع الأنواع الأخرى من البايت ، اعتمادًا على تنسيق البيانات المستخدم. هذا هو المكان الذي يتم فيه تشغيل الترميزات - في Java ، إنه مجرد تنسيق بيانات لنقل الأحرف ، والذي يتم استخدامه لتكوين بيانات من نوع char. لكل صفحة رمز ، تحتوي المكتبة على فئتي تحويل (ByteToChar و CharToByte). هذه الفصول موجودة في حزمة sun.io. إذا لم يتم العثور على حرف مطابق عند التحويل من char إلى byte ، فسيتم استبداله بالحرف؟.
بالمناسبة ، تحتوي ملفات صفحة الشفرة هذه في بعض الإصدارات المبكرة من JDK 1.1 على أخطاء تسبب أخطاء التحويل أو حتى استثناءات وقت التشغيل. على سبيل المثال ، يتعلق هذا بتشفير KOI8_R. أفضل ما يمكنك فعله أثناء القيام بذلك هو تغيير الإصدار إلى إصدار لاحق. بناءً على وصف Sun ، تم حل معظم هذه المشكلات في JDK 1.1.6.
قبل إصدار JDK 1.4 ، تم تحديد مجموعة الترميزات المتاحة فقط بواسطة بائع JDK. بدءًا من 1.4 ، ظهرت واجهة برمجة تطبيقات جديدة (حزمة java.nio.charset) ، والتي يمكنك من خلالها بالفعل إنشاء الترميز الخاص بك (على سبيل المثال ، دعم ملف نادر الاستخدام ولكنه ضروري للغاية بالنسبة لك).
فئة السلسلة
في معظم الحالات ، تستخدم Java كائنًا من النوع java.lang.String لتمثيل السلاسل. هذه فئة عادية تخزن داخليًا مصفوفة من الأحرف (char) ، وتحتوي على العديد من الطرق المفيدة لمعالجة الأحرف. الأكثر إثارة للاهتمام هي المنشئات التي تحتوي على مصفوفة بايت كمعامل أول وطرق getBytes (). باستخدام هذه الطرق ، يمكنك إجراء تحويلات من مصفوفات البايت إلى السلاسل والعكس صحيح. من أجل تحديد الترميز الذي يجب استخدامه في نفس الوقت ، تحتوي هذه الطرق على معلمة سلسلة تحدد اسمها. على سبيل المثال ، إليك كيفية تحويل البايت من KOI-8 إلى Windows-1251:
// البيانات المشفرة KOI-8بايت koi8Data = ... ؛ // التحويل من KOI-8 إلى Unicode String string = new String (koi8Data، "KOI8_R") ؛ // التحويل من Unicode إلى Windows-1251بايت winData = string.getBytes ("Cp1251") ؛
يمكن العثور على قائمة ترميزات 8 بت المتوفرة في JDKs الحديثة والحروف الروسية الداعمة أدناه ، في القسم.
نظرًا لأن الترميز هو تنسيق بيانات للأحرف ، بالإضافة إلى ترميزات 8 بت المألوفة في Java ، هناك أيضًا ترميزات متعددة البايت على قدم المساواة. وتشمل هذه UTF-8 و UTF-16 و Unicode وما إلى ذلك ، على سبيل المثال ، هذه هي الطريقة التي يمكنك من خلالها الحصول على وحدات البايت بتنسيق UnicodeLittleUnmarked (ترميز Unicode 16 بت ، وانخفاض البايت أولاً ، وعدم وجود علامة ترتيب بايت):
// التحويل من Unicode إلى Unicodeبيانات البايت = string.getBytes ("UnicodeLittleUnmarked") ؛
من السهل ارتكاب خطأ في مثل هذه التحويلات - إذا كان ترميز بيانات البايت لا يتطابق مع المعلمة المحددة عند التحويل من بايت إلى حرف ، فلن يتم إجراء إعادة الترميز بشكل صحيح. في بعض الأحيان بعد ذلك يكون من الممكن سحب الأحرف الصحيحة ، ولكن في أغلب الأحيان ، سيتم فقد جزء من البيانات بشكل غير قابل للاسترداد.
في برنامج حقيقي ، ليس من الملائم دائمًا تحديد صفحة الرموز بشكل صريح (على الرغم من أنها أكثر موثوقية). لهذا ، تم تقديم الترميز الافتراضي. بشكل افتراضي ، يعتمد ذلك على النظام وإعداداته (تم اعتماد ترميز Cp1251 لنظام التشغيل Windows الروسي) ، ويمكن تغييره في JDKs القديمة عن طريق تعيين ملف خصائص النظام. في JDK 1.3 ، يعمل تغيير هذا الإعداد أحيانًا ، وأحيانًا لا يعمل. يحدث هذا بسبب ما يلي: في البداية ، يتم تعيين file.encoding وفقًا للإعدادات الإقليمية للكمبيوتر. يتم تذكر مرجع الترميز الافتراضي داخليًا أثناء التحويل الأول. في هذه الحالة ، يتم استخدام file.encoding ، ولكن هذا التحويل يحدث حتى قبل استخدام وسيطات بدء تشغيل JVM (في الواقع ، عند تحليلها). في الواقع ، وفقًا لـ Sun ، تعكس هذه الخاصية ترميز النظام ، ولا ينبغي تغييرها في سطر الأوامر (انظر ، على سبيل المثال ، التعليقات على BugID) ومع ذلك ، في JDK 1.4 Beta 2 ، بدأ تغيير هذا الإعداد مرة أخرى في الحصول على تأثير. ما هذا ، تغيير واعي أو عرض جانبي قد يختفي مرة أخرى - لم تعط خروف الشمس إجابة واضحة بعد.
يتم استخدام هذا الترميز عندما لا يتم تحديد اسم الصفحة بشكل صريح. يجب تذكر ذلك دائمًا - لن تحاول Java التنبؤ بتشفير وحدات البايت التي تمررها لإنشاء سلسلة (لن تتمكن أيضًا من قراءة أفكارك حول هذا :-). يستخدم فقط الترميز الافتراضي الحالي. لأن هذا الإعداد هو نفسه لجميع التحولات ، في بعض الأحيان قد تواجه مشكلة.
للتحويل من بايت إلى أحرف والعكس صحيح ، استخدم فقطبهذه الطرق. في معظم الحالات ، لا يمكن استخدام تحويل نوع بسيط - لن يتم أخذ تشفير الأحرف في الاعتبار. على سبيل المثال ، أحد أكثر الأخطاء شيوعًا هو قراءة البيانات حسب البايت باستخدام طريقة read () من InputStream ، ثم تحويل القيمة الناتجة إلى نوع char:
InputStream = ..؛ الباحث ب ؛ StringBuffer sb = new StringBuffer () ؛ بينما ((b = is.read ())! = - 1) (sb.append ((char) b) ؛ // <- так делать нельзя ) String s = sb.toString () ؛
انتبه إلى التلبيس - "(char) b". يتم نسخ قيم البايت ببساطة إلى حرف بدلاً من إعادة ترميزها (نطاق القيم هو 0-0xFF ، وليس النطاق الذي توجد فيه الأبجدية السيريلية). يتوافق هذا النسخ مع ترميز ISO-8859-1 (الذي يتوافق واحد لواحد مع قيم Unicode 256 الأولى) ، مما يعني أنه يمكننا افتراض أن هذا الرمز يستخدمه ببساطة (بدلاً من الرمز الذي تستخدمه الأحرف في البيانات الأصلية مشفرة بالفعل). إذا حاولت عرض القيمة المستلمة ، فستكون هناك أسئلة أو krakozyably على الشاشة. على سبيل المثال ، عند قراءة السلسلة "ABC" في ترميز Windows ، يمكن بسهولة عرض شيء مثل هذا: "АÁВ". غالبًا ما يكتب مبرمجون في الغرب هذا النوع من الأكواد - فهو يعمل مع الأحرف الإنجليزية ، وهذا جيد. يعد إصلاح هذا الرمز أمرًا سهلاً - ما عليك سوى استبدال StringBuffer بـ ByteArrayOutputStream:
InputStream = ..؛ الباحث ب ؛ ByteArrayOutputStream baos = new ByteArrayOutputStream () ؛ بينما ((b = is.read ())! = - 1) (baos.write (b) ؛) // تحويل البايت إلى سلسلة باستخدام التشفير الافتراضي String s = baos.toString () ، // إذا كنت بحاجة إلى ترميز معين ، فما عليك سوى تحديده عند استدعاء toString (): // // s = baos.toString ("Cp1251") ؛لمزيد من المعلومات حول الأخطاء الشائعة ، راجع القسم.
ترميزات 8 بت للأحرف الروسية
فيما يلي ترميزات 8 بت الرئيسية للأحرف الروسية التي انتشرت على نطاق واسع:
بالإضافة إلى الاسم الرئيسي ، يمكنك استخدام المرادفات. قد تختلف مجموعة منهم في إصدارات مختلفة من JDK. هذه قائمة من JDK 1.3.1:
- CP1251:
- نظام التشغيل Windows-1251
- CP866:
- IBM866
- IBM-866
- CP866
- CSIBM866
- KOI8_R:
- KOI8-R
- CSKOI8R
- ISO8859_5:
- ISO8859-5
- ISO-8859-5
- ISO_8859-5
- ISO_8859-5: 1988
- ISO-IR-144
- 8859_5
- السيريلية
- سيريزولاتين سيريليك
- IBM915
- آي بي إم 915
- CP915
علاوة على ذلك ، المرادفات ، على عكس الاسم الرئيسي ، غير حساسة لحالة الأحرف - وهذه سمة من سمات التنفيذ.
من الجدير بالذكر أن هذه الترميزات قد لا تكون متاحة في بعض JVMs. على سبيل المثال ، يمكنك تنزيل نسختين مختلفتين من JRE من موقع Sun - الولايات المتحدة والدولية. في إصدار الولايات المتحدة ، لا يوجد سوى حد أدنى - ISO-8859-1 و ASCII و Cp1252 و UTF8 و UTF16 والعديد من أشكال Unicode مزدوجة البايت. كل شيء آخر متاح فقط في النسخة الدولية. في بعض الأحيان لهذا السبب ، يمكنك أن تصطدم بأشجار مع إطلاق البرنامج ، حتى لو لم يكن بحاجة إلى أحرف روسية. خطأ نموذجي يحدث أثناء القيام بذلك:
حدث خطأ أثناء تهيئة VM java / lang / ClassNotFoundException: sun / io / ByteToCharCp1251
ينشأ ، نظرًا لأنه ليس من الصعب التكهن ، نظرًا لحقيقة أن JVM ، استنادًا إلى الإعدادات الإقليمية الروسية ، تحاول تعيين التشفير الافتراضي في Cp1251 ، ولكن منذ ذلك الحين فئة هذا الدعم غائبة في النسخة الأمريكية ، فهي تنقطع بشكل طبيعي.
الملفات وتدفقات البيانات
تمامًا كما يتم فصل البايت من الناحية المفاهيمية عن الأحرف ، تميز Java بين تدفقات البايت وتدفقات الأحرف. يتم تمثيل العمل بالبايت بواسطة الفئات التي ترث فئات InputStream أو OutputStream بشكل مباشر أو غير مباشر (بالإضافة إلى فئة RandomAccessFile الفريدة). العمل مع الرموز يمثله زوجان جميلان من فصول القارئ / الكاتب (وأحفادهم بالطبع).
تُستخدم تدفقات البايت لقراءة / كتابة البايت غير المحول. إذا كنت تعلم أن البايتات تمثل أحرفًا فقط في ترميز معين ، فيمكنك استخدام فئات المحولات الخاصة InputStreamReader و OutputStreamWriter للحصول على دفق من الأحرف والعمل معها مباشرة. عادة ما يكون هذا مفيدًا لملفات النص العادي أو عند العمل مع العديد من بروتوكولات شبكة الإنترنت. في هذه الحالة ، يتم تحديد ترميز الأحرف في مُنشئ فئة المحول. مثال:
// Unicode string String = "..." ؛ // اكتب السلسلة إلى ملف نصي بترميز Cp866 PrintWriter pw = أداة طباعة جديدة // فئة بأساليب كتابة السلاسل(جديد OutputStreamWriter // فئة المحول(ملف جديد FileOutputStream ("file.txt") ، "Cp866") ؛ pw.println (سلسلة نصية) ؛ // اكتب السطر إلى الملف pw.close () ؛
إذا كان الدفق يحتوي على بيانات بترميزات مختلفة أو اختلطت الأحرف مع بيانات ثنائية أخرى ، فمن الأفضل قراءة مصفوفات البايت وكتابتها ، واستخدام الطرق المذكورة بالفعل لفئة String للتحويل. مثال:
// Unicode string String = "..." ؛ // اكتب السلسلة إلى ملف نصي بترميزين (Cp866 و Cp1251) OutputStream os = new FileOutputStream ("file.txt") ؛ // فئة لكتابة بايت للملف // اكتب السلسلة بترميز Cp866 os.write (string.getBytes ("Cp866")) ؛ // اكتب السلسلة بترميز Cp1251 os.write (string.getBytes ("Cp1251")) ؛ os.close () ،
يتم تمثيل وحدة التحكم في Java تقليديًا بواسطة التدفقات ، ولكن للأسف لا يتم تمثيل الأحرف ، ولكن بالبايت. الحقيقة هي أن تدفقات الأحرف ظهرت فقط في JDK 1.1 (جنبًا إلى جنب مع آلية التشفير بالكامل) ، وتم تصميم الوصول إلى وحدة التحكم I / O في JDK 1.0 ، مما أدى إلى ظهور غريب في شكل فئة PrintStream. تُستخدم هذه الفئة في متغيري System.out و System.err ، اللذين يمنحان حق الوصول إلى الإخراج إلى وحدة التحكم. بكل المؤشرات ، هذا تدفق من البايتات ، ولكن مع مجموعة من الأساليب لكتابة السلاسل. عندما تكتب سلسلة فيها ، فإنها تتحول إلى بايت باستخدام الترميز الافتراضي ، وهو أمر غير مقبول عادةً في حالة Windows - سيكون الترميز الافتراضي هو Cp1251 (Ansi) ، وبالنسبة لنافذة وحدة التحكم ، تحتاج عادةً إلى استخدام Cp866 ( OEM). تم تسجيل هذا الخطأ في عام 97 () ولكن يبدو أن Sun-sheep ليست في عجلة من أمرها لإصلاحه. نظرًا لعدم وجود طريقة لتعيين الترميز في PrintStream ، لحل هذه المشكلة ، يمكنك استبدال الفئة القياسية بأخرى خاصة بك باستخدام أساليب System.setOut () و System.setErr (). على سبيل المثال ، هذه هي البداية المعتادة في برامجي:
... رئيسي باطل ثابت عام (سلاسل سلسلة) ( // ضبط إخراج رسائل وحدة التحكم في الترميز المطلوبحاول (String consoleEnc = System.getProperty ("console.encoding"، "Cp866") ؛ System.setOut (new CodepagePrintStream (System.out، consoleEnc)) ؛ System.setErr (CodepagePrintStream (System.err، consoleEnc)) ؛ ) catch (UnsupportedEncodingException e) (System.out.println ("تعذر إعداد صفحة رموز وحدة التحكم:" + e) ؛) ...
يمكنك العثور على مصادر فئة CodepagePrintStream على هذا الموقع: CodepagePrintStream.java.
إذا كنت تقوم بإنشاء تنسيق البيانات بنفسك ، فإنني أوصيك باستخدام أحد ترميزات multibyte. عادةً ما يكون التنسيق الأكثر ملاءمة هو UTF8 - يتم ترميز أول 128 قيمة (ASCII) فيه في بايت واحد ، والذي غالبًا ما يقلل بشكل كبير من إجمالي كمية البيانات (ليس من أجل لا شيء أن يتم أخذ هذا الترميز كأساس في عالم XML). لكن UTF8 له عيب واحد - يعتمد عدد البايت المطلوب على رمز الحرف. عندما يكون هذا أمرًا بالغ الأهمية ، يمكنك استخدام أحد تنسيقات Unicode ثنائية البايت (UnicodeBig أو UnicodeLittle).
قاعدة البيانات
لقراءة الأحرف من قاعدة البيانات بشكل صحيح ، يكفي عادةً إخبار مشغل JDBC بترميز الأحرف المطلوب في قاعدة البيانات. كيف بالضبط يعتمد على السائق المحدد. في الوقت الحاضر ، يدعم العديد من السائقين هذا الإعداد بالفعل ، على عكس الماضي القريب. فيما يلي بعض الأمثلة التي أعرفها.
جسر JDBC-ODBC
هذا هو أحد برامج التشغيل الأكثر استخدامًا. يمكن تكوين الجسر من JDK 1.2 وما بعده بسهولة إلى التشفير المطلوب. يتم ذلك عن طريق إضافة خاصية charSet إضافية إلى مجموعة المعلمات التي تم تمريرها لفتح اتصال بالقاعدة. الافتراضي هو file.encoding. يتم إجراء شيء مثل هذا:
// إنشاء اتصال
برنامج تشغيل Oracle 8.0.5 JDBC-OCI لنظام التشغيل Linux
عند تلقي البيانات من قاعدة البيانات ، يحدد برنامج التشغيل هذا الترميز "الخاص به" باستخدام متغير البيئة NLS_LANG. إذا لم يتم العثور على هذا المتغير ، فإنه يفترض أن الترميز هو ISO-8859-1. الحيلة هي أن NLS_LANG يجب أن يكون متغير بيئة (يتم تعيينه باستخدام الأمر set) ، وليس خاصية نظام Java (مثل file.encoding). إذا تم استخدام برنامج التشغيل داخل محرك Apache + Jserv servlet ، فيمكن تعيين متغير البيئة في ملف jserv.properties:
wrapper.env = NLS_LANG = American_America.CL8KOI8Rأرسل سيرجي بيزروكوف معلومات حول هذا الموضوع ، وشكره بشكل خاص.
برنامج تشغيل JDBC للعمل مع DBF (zyh.sql.dbf.DBFDriver)
لقد تعلم هذا السائق مؤخرًا فقط التعامل مع الحروف الروسية. على الرغم من أنه أبلغ عن طريق getPropertyInfo () أنه يفهم خاصية charSet ، إلا أنها خيال (على الأقل في النسخة من 07/30/2001). في الواقع ، يمكنك تخصيص الترميز عن طريق تعيين خاصية CODEPAGEID. بالنسبة للأحرف الروسية ، تتوفر قيمتان - "66" لـ Cp866 و "C9" لـ Cp1251. مثال:
// معلمات الاتصال الأساسيةخصائص connInfo = خصائص جديدة () ؛ connInfo.put ("CODEPAGEID"، "66") ؛ // ترميز Cp866 // إنشاء اتصالاتصال db = DriverManager.getConnection ("jdbc: DBF: / C: / MyDBFFiles"، connInfo) ؛إذا كان لديك ملفات DBF بتنسيق FoxPro ، فسيكون لديهم تفاصيل خاصة بهم. الحقيقة هي أن FoxPro يحفظ في رأس الملف معرف صفحة الرموز (بايت مع الإزاحة 0x1D) ، والتي تم استخدامها لإنشاء DBF. عند فتح جدول ، يستخدم برنامج التشغيل القيمة من الرأس ، وليس المعلمة "CODEPAGEID" (يتم استخدام المعلمة في هذه الحالة فقط عند إنشاء جداول جديدة). وفقًا لذلك ، لكي يعمل كل شيء بشكل صحيح ، يجب إنشاء ملف DBF بالترميز الصحيح - وإلا فستكون هناك مشكلات.
MySQL (org.gjt.mm.mysql.Driver)
مع برنامج التشغيل هذا ، كل شيء بسيط أيضًا:
// معلمات الاتصال الأساسيةخصائص connInfo = new Poperties () ؛ connInfo.put ("المستخدم" ، المستخدم) ؛ connInfo.put ("كلمة المرور" ، تمرير) ؛ connInfo.put ("useUnicode"، "true") ؛ connInfo.put ("characterEncoding"، "KOI8_R") ؛ اتصال conn = DriverManager.getConnection (dbURL ، الدعائم) ؛
InterBase (interbase.interclient.Driver)
بالنسبة لبرنامج التشغيل هذا ، تعمل معلمة "charSet":// معلمات الاتصال الأساسيةخصائص connInfo = خصائص جديدة () ؛ connInfo.put ("المستخدم" ، اسم المستخدم) ؛ connInfo.put ("كلمة المرور" ، كلمة المرور) ؛ connInfo.put ("charSet"، "Cp1251") ؛ // إنشاء اتصالاتصال db = DriverManager.getConnection (dataurl، connInfo) ؛
ومع ذلك ، لا تنس تحديد ترميز الأحرف عند إنشاء قاعدة البيانات والجداول. بالنسبة للغة الروسية ، يمكنك استخدام القيم "UNICODE_FSS" أو "WIN1251". مثال:
إنشاء قاعدة بيانات ′ E: ProjectHoldingDataBaseHOLDING.GDB ′ PAGE_SIZE 4096 مجموعة أحرف افتراضية UNICODE_FSS ؛ إنشاء جدول RUSSIAN_WORD ("NAME1" VARCHAR (40) CHARACTER SET UNICODE_FSS ليست فارغة ، "NAME2" VARCHAR (40) CHARACTER SET WIN1251 NOT NULL ، PRIMARY KEY ("NAME1")) ؛
يوجد خطأ في الإصدار 2.01 من InterClient - لم يتم تجميع فئات الموارد التي تحتوي على رسائل باللغة الروسية بشكل صحيح هناك. على الأرجح ، نسي المطورون ببساطة تحديد تشفير المصدر عند التجميع. هناك طريقتان لإصلاح هذا الخطأ:
- استخدم interclient-core.jar بدلاً من interclient.jar. في الوقت نفسه ، لن تكون هناك ببساطة موارد روسية ، وسيتم اختيار الموارد الإنجليزية تلقائيًا.
- أعد ترجمة الملفات إلى Unicode العادي. يعد تحليل ملفات الفصل مهمة غير مرغوب فيها ، لذا من الأفضل استخدام JAD. لسوء الحظ ، JAD ، إذا صادفت أحرفًا من مجموعة ISO-8859-1 ، فستخرجها بترميز مكون من 8 أرقام ، لذلك لن تتمكن من استخدام برنامج التشفير الأصلي القياسي - عليك كتابة (برنامج فك الشفرة) الخاص بك. إذا كنت لا تريد أن تهتم بهذه المشاكل ، يمكنك فقط أن تأخذ ملفًا جاهزًا يحتوي على موارد (جرة مصححة مع برنامج التشغيل - interclient.jar ، فئات موارد منفصلة - interclient-rus.jar).
ولكن حتى بعد ضبط برنامج تشغيل JDBC على الترميز المطلوب ، في بعض الحالات ، قد تواجه مشكلة. على سبيل المثال ، عند محاولة استخدام مؤشرات التمرير JDBC 2 الجديدة الرائعة في جسر JDBC-ODBC من JDK 1.3.x ، ستجد بسرعة أن الأحرف الروسية لا تعمل هناك ببساطة (طريقة updateString ()).
هناك قصة صغيرة مرتبطة بهذا الخطأ. عندما اكتشفته لأول مرة (تحت JDK 1.3 rc2) ، قمت بتسجيله في BugParade (). عندما ظهر الإصدار التجريبي الأول من JDK 1.3.1 ، تم وضع علامة على هذا الخطأ على أنه تم إصلاحه. مسرور ، لقد قمت بتنزيل هذا الإصدار التجريبي ، وقمت بإجراء الاختبار - إنه لا يعمل. لقد كتبت إلى Sun-sheep حول هذا الأمر - رداً على ذلك كتبوا لي أن الإصلاح سيتم تضمينه في الإصدارات المستقبلية. حسنًا ، فكرت ، دعنا ننتظر. مر الوقت ، تم إطلاق الإصدار 1.3.1 ، ثم الإصدار التجريبي 1.4. أخيرًا ، أخذت الوقت الكافي للتحقق - لا يعمل مرة أخرى. الأم ، الأم ، الأم ... - صدى صدى عادة. بعد خطاب غاضب إلى صن ، أدخلوا خطأ جديدًا () ، أعطوه للفرع الهندي ليتمزق. العبث الهنود بالشفرة ، وقالوا إن كل شيء تم إصلاحه في 1.4 beta3. لقد قمت بتنزيل هذا الإصدار ، وقمت بتشغيل حالة اختبار تحته ، وهذه هي النتيجة -. كما اتضح ، فإن beta3 الموزعة على الموقع (بناء 84) ليست beta3 حيث تم تضمين الإصلاح النهائي (بناء 87). الآن يعدون بأن الإصلاح سيتم تضمينه في 1.4 rc1 ... حسنًا ، بشكل عام ، أنت تفهم :-)
الحروف الروسية في مصادر برامج جافا
كما ذكرنا ، يستخدم البرنامج Unicode عند التنفيذ. تتم كتابة ملفات المصدر في المحررين العاديين. أنا أستخدم Far ، فمن المحتمل أن يكون لديك محررك المفضل. تقوم برامج التحرير هذه بحفظ الملفات بتنسيق 8 بت ، مما يعني أن المنطق المماثل لما ورد أعلاه ينطبق على هذه الملفات أيضًا. تؤدي الإصدارات المختلفة من المترجمات تحويل الأحرف بشكل مختلف قليلاً. تستخدم الإصدارات السابقة من JDK 1.1.x الإعداد file.encoding ، والذي يمكن تجاوزه باستخدام خيار J غير القياسي. في الإصدارات الأحدث (كما ورد من قبل Denis Kokarev - بدءًا من 1.1.4) ، تم تقديم معلمة ترميز إضافية ، والتي يمكنك من خلالها تحديد الترميز المستخدم. في الفصول المترجمة ، يتم تمثيل السلاسل في شكل Unicode (بشكل أكثر دقة ، في نسخة معدلة من تنسيق UTF8) ، لذلك يحدث الشيء الأكثر إثارة للاهتمام أثناء التجميع. لذلك ، فإن أهم شيء هو معرفة ما هو ترميز أكواد المصدر الخاصة بك وتحديد القيمة الصحيحة عند التجميع. بشكل افتراضي ، سيتم استخدام نفس file.encoding سيئ السمعة. مثال على استدعاء المترجم:
بالإضافة إلى استخدام هذا الإعداد ، هناك طريقة أخرى - لتحديد الأحرف بتنسيق "uXXXX" ، حيث تتم الإشارة إلى رمز الحرف. تعمل هذه الطريقة مع جميع الإصدارات ، ويمكنك استخدام أداة قياسية للحصول على هذه الرموز.
إذا كنت تستخدم أي IDE ، فقد يكون له بعض الثغرات الخاصة به. غالبًا ما تستخدم IDEs الترميز الافتراضي لقراءة / حفظ المصادر - لذا انتبه إلى الإعدادات الإقليمية لنظام التشغيل الخاص بك. بالإضافة إلى ذلك ، قد تكون هناك أخطاء واضحة - على سبيل المثال ، لا يهضم CodeGuide الجيد على نطاق IDE جيدًا الحرف الروسي الكبير "T". يأخذ محلل الكود المدمج هذا الحرف كاقتباس مزدوج ، مما يؤدي إلى حقيقة أن الكود الصحيح يُنظر إليه على أنه خاطئ. يمكنك محاربة هذا (باستبدال الحرف "T" برمزه "u0422") ، لكن غير محبب. على ما يبدو ، في مكان ما داخل المحلل اللغوي ، يتم استخدام تحويل صريح للأحرف إلى بايت (مثل: byte b = (byte) c) ، لذلك بدلاً من الرمز 0x0422 (رمز الحرف "T") يكون الرمز 0x22 ( رمز الاقتباس المزدوج).
لدى JBuilder مشكلة أخرى ، لكنها أكثر ارتباطًا ببيئة العمل. الحقيقة هي أنه في JDK 1.3.0 ، والذي يعمل بموجبه JBuilder افتراضيًا ، هناك خطأ () ، نظرًا لأن نوافذ واجهة المستخدم الرسومية التي تم إنشاؤها حديثًا ، عند تنشيطها ، تتضمن تلقائيًا تخطيط لوحة المفاتيح اعتمادًا على الإعدادات الإقليمية لنظام التشغيل. أولئك. إذا كانت لديك إعدادات إقليمية روسية ، فستحاول باستمرار التبديل إلى التخطيط الروسي ، الذي يعيق كتابة البرامج. يحتوي موقع JBuilder.ru على اثنين من التصحيحات التي تغير الإعدادات المحلية الحالية في JVM إلى Locale.US ، ولكن أفضل طريقة هي الترقية إلى JDK 1.3.1 ، الذي أصلح هذا الخطأ.
قد يواجه مستخدمو Novice JBuilder أيضًا مثل هذه المشكلة - يتم حفظ الأحرف الروسية كرموز "uXXXX". لتجنب ذلك ، في مربع حوار خصائص المشروع الافتراضية ، علامة التبويب عام ، في حقل الترميز ، قم بتغيير الافتراضي إلى Cp1251.
إذا كنت تستخدم لغة javac غير قياسية للتجميع ، ولكن مترجمًا آخر - انتبه إلى كيفية قيامها بتحويل الأحرف. على سبيل المثال ، بعض إصدارات مترجم IBM jikes لا تفهم أن هناك ترميزات أخرى غير ISO-8859-1 :-). هناك إصدارات مصححة في هذا الصدد ، ولكن غالبًا ما يتم أيضًا خياطة بعض الترميز هناك - لا توجد مثل هذه الراحة كما هو الحال في javac.
JavaDoc
لإنشاء وثائق HTML للتعليمات البرمجية المصدر ، يتم استخدام الأداة المساعدة javadoc ، والتي يتم تضمينها في توزيع JDK القياسي. لتحديد الترميزات ، يحتوي على ما يصل إلى 3 معلمات:
- -تشفير - يحدد هذا الإعداد ترميز المصدر. الافتراضي هو file.encoding.
- -docencoding - يحدد هذا الإعداد ترميز ملفات HTML التي تم إنشاؤها. الافتراضي هو file.encoding.
- -charset - يحدد هذا الإعداد الترميز الذي سيتم كتابته إلى رؤوس ملفات HTML التي تم إنشاؤها ( ). من الواضح أنه يجب أن يكون نفس الإعداد السابق. إذا تم حذف هذا الإعداد ، فلن تتم إضافة العلامة الوصفية.
الحروف الروسية في ملفات الخصائص
تستخدم طرق تحميل الموارد لقراءة ملفات الخصائص ، والتي تعمل بطريقة معينة. في الواقع ، يتم استخدام طريقة Properties.load للقراءة ، والتي لا تستخدم تشفير الملفات (ترميز ISO-8859-1 مشفر بشكل ثابت في المصادر) ، لذا فإن الطريقة الوحيدة لتحديد الأحرف الروسية هي استخدام تنسيق "uXXXX" والفائدة.
تعمل طريقة Properties.save بشكل مختلف في JDK 1.1 و 1.2. في الإصدار 1.1 ، تجاهل ببساطة البايت العالي ، لذلك كان يعمل بشكل صحيح فقط مع الأحرف الإنجليزية. في 1.2 ، يتم التحويل مرة أخرى إلى "uXXXX" بحيث يعمل معكوسًا إلى طريقة التحميل.
إذا لم يتم تحميل ملفات الخصائص الخاصة بك كموارد ، ولكن كملفات تكوين عادية ، ولم تكن راضيًا عن هذا السلوك ، فهناك طريقة واحدة فقط للخروج ، اكتب أداة التحميل الخاصة بك.
الحروف الروسية في Servlets.
حسنًا ، ما هي هذه Servlets نفسها ، أعتقد أنك تعرف. إذا لم يكن الأمر كذلك ، فمن الأفضل قراءة الوثائق أولاً. هنا ، يتم وصف خصائص العمل بالحروف الروسية فقط.
إذن ما هي الميزات؟ عندما يرسل Servlet استجابة إلى عميل ، توجد طريقتان لإرسال هذه الاستجابة - عبر طريقة OutputStream (طريقة getOutputStream ()) أو طريقة PrintWriter (getWriter ()). في الحالة الأولى ، أنت تكتب مصفوفات من البايتات ، لذا فإن الأساليب المذكورة أعلاه في الكتابة إلى التدفقات قابلة للتطبيق. في حالة PrintWriter ، فإنه يستخدم مجموعة الترميز. في أي حال ، يجب عليك تحديد الترميز المستخدم بشكل صحيح عند استدعاء طريقة setContentType () ، من أجل تحويل الأحرف الصحيح على جانب الخادم. يجب إجراء هذا التوجيه قبل استدعاء getWriter () أو قبل الكتابة الأولى إلى OutputStream. مثال:
// ضبط ترميز الاستجابة // لاحظ أن بعض المحركات لا تسمح // مسافة بين "؛" و "محارف" response.setContentType ("text / html ؛ charset = UTF-8") ؛ PrintWriter out = response.getWriter () ، // إخراج التصحيح لاسم الترميز للتحقق منه out.println ("Encoding:" + response.getCharacterEncoding ()) ؛ ... out.close () ؛ )
يتعلق الأمر بإعطاء إجابات للعميل. لسوء الحظ ، ليس الأمر بهذه السهولة مع معلمات الإدخال. يتم ترميز معلمات الإدخال بواسطة بايت المتصفح وفقًا لنوع MIME "application / x-www-form-urlencoded". كما قال Alexey Mendelev ، تقوم المتصفحات بترميز الأحرف الروسية باستخدام الترميز المحدد حاليًا. وبطبيعة الحال ، لم يتم الإبلاغ عن أي شيء عنها. وفقًا لذلك ، على سبيل المثال ، في إصدارات JSDK من 2.0 إلى 2.2 لم يتم التحقق من ذلك بأي شكل من الأشكال ، ويعتمد نوع الترميز الذي سيتم استخدامه للتحويل على المحرك المستخدم. بدءًا من المواصفة 2.3 ، أصبح من الممكن ضبط الترميز لـ javax.servlet.ServletRequest - طريقة setCharacterEncoding (). تدعم أحدث إصدارات Resin و Tomcat هذه المواصفات بالفعل.
وبالتالي ، إذا كنت محظوظًا ولديك خادم يدعم Servlet 2.3 ، فكل شيء بسيط للغاية:
يقوم doPost العام الباطل (طلب HttpServletRequest ، استجابة HttpServletResponse) بإلقاء ServletException و IOException ( // ترميز الرسالة request.setCharacterEncoding ("Cp1251") ؛ قيمة السلسلة = request.getParameter ("value") ؛ ...
هناك دقة واحدة مهمة في تطبيق طريقة request.setCharacterEncoding () - يجب تطبيقها قبلالمكالمة الأولى لطلب بيانات (على سبيل المثال ، request.getParameter ()). إذا كنت تستخدم المرشحات التي تعالج الطلب قبل وصوله إلى servlet ، فهناك فرصة غير صفرية أن أحد المرشحات قد يقرأ بعض المعلمات من الطلب (على سبيل المثال ، للترخيص) ولن يؤدي request.setCharacterEncoding () في servlet العمل ...
لذلك ، فمن الأصح من الناحية الأيديولوجية كتابة مرشح يحدد ترميز الطلب. علاوة على ذلك ، يجب أن يكون الأول في سلسلة المرشحات في web.xml.
مثال على هذا المرشح:
استيراد java.io. * ؛ استيراد java.util. * ؛ استيراد javax.servlet. * ؛ استيراد javax.servlet.http. * ؛ تقوم فئة عامة CharsetFilter بتنفيذ عامل التصفية (// ترميز ترميز سلسلة خاص ؛ يؤدي التهيئة العامة الباطلة (FilterConfig config) إلى طرح ServletException ( // قراءة من ملف التكوينالترميز = config.getInitParameter ("requestEncoding") ؛ // إذا لم يكن مثبتًا ، فقم بتثبيت Cp1251إذا (ترميز == فارغة) ترميز = "Cp1251" ؛ ) يقوم doFilter الباطل العام (طلب ServletRequest ، استجابة ServletResponse ، FilterChain التالي) بإلقاء IOException ، ServletException (request.setCharacterEncoding (ترميز) ؛ next.doFilter (طلب ، استجابة) ؛) تدمير الفراغ العام () ())
والتكوين الخاص به في web.xml:
مرشح مجموعة الأحرف مرشح CharsetFilter مرشح مجموعة الأحرف /*
إذا كنت غير محظوظ ولديك إصدار أقدم ، فسيتعين عليك منحرف لتحقيق النتيجة:
-
FOP
تم تصميم حزمة FOP لمعالجة المستندات وفقًا لمعيار XSL FO (Formating Objects). على وجه الخصوص ، يسمح لك بإنشاء مستندات PDF بناءً على ملفات مستندات XML... تستخدم حزمة FOP معالج Xalan XSLT المقترن بـ Xerces افتراضيًا للتحويل من XML الأصلي إلى FO. لإنشاء الصورة النهائية في FOP ، تحتاج إلى توصيل الخطوط التي تدعم الحروف الروسية. إليك كيفية القيام بذلك للإصدار 0.20.1:
- انسخ ملفات ttf من دليل نظام Windows إلى الدليل الفرعي conffonts (على سبيل المثال ، في c: fop-0.20.1conffonts). تتطلب ملفات Arial عادي / عادي ، عادي / غامق ، مائل / عادي ، ومائل / غامق ملفات arial.ttf و arialbd.ttf و ariali.ttf و arialbi.ttf.
- قم بإنشاء ملفات وصف الخط (مثل arial.xml). للقيام بذلك ، لكل خط ، تحتاج إلى تشغيل الأمر (هذا لـ Arial عادي / عادي ، الكل في سطر واحد):
جافا -cp ؛ ج: fop-0.20.1uildfop.jar ؛ ج: fop-0.20.1libatik.jar ؛ ج: fop-0.20.1libxalan-2.0.0.jar ؛ ج: fop-0.20.1libxerces.jar ؛ c: fop-0.20.1libjimi-1.0.jar org.apache.fop.fonts.apps.TTFReader Fontsarial.ttf Fontsarial.xml
- في FOP أضف إلى conf / userconfig.xml وصفًا للخط بأحرف روسية ، مثل:
تتم إضافة Arial عادي / غامق ومائل / عادي ومائل / غامق بالمثل. - عند استدعاء FOP من سطر الأوامربعد org.apache.fop.apps.Fop write -c c: fop-0.20.1confuserconfig.xml إذا كنت بحاجة إلى استخدام FOP من servlet ، فأنت بحاجة إلى ذلك في servlet بعد السطر
سائق سائق= سائق جديد () ؛
أضف سطورًا:// تم إنشاء دليل الخطوط (c: weblogicfonts) للتسهيل فقط. String userConfig = "Fonts / userconfig.xml"؛ ملف userConfigFile = ملف جديد (userConfig) ، خيارات الخيارات = خيارات جديدة (userConfigFile) ؛
ثم يمكن تحديد موقع ملفات ttf في ملف userconfig.xml بالنسبة إلى جذر خادم التطبيق ، دون تحديد المسار المطلق: - في ملف FO (أو XML و XSL) ، قبل استخدام الخط ، اكتب:
font-family = "Arial" font-weight = "bold" (في حالة استخدام Arial bold) font-style = "italic" (في حالة استخدام Arial مائل)
تم إرسال هذه الخوارزمية بواسطة Alexey Tyurin ، والتي شكره عليها بشكل خاص.
إذا كنت تستخدم العارض المدمج في FOP ، فأنت بحاجة إلى مراعاة خصائصه. على وجه الخصوص ، على الرغم من أنه من المفترض أن تكون النقوش الواردة فيه موطنًا للغة الروسية ، إلا أنها في الواقع تم إجراؤها مع وجود خطأ (في الإصدار 0.19.0). لتحميل الملصقات من ملفات الموارد ، تستخدم الحزمة org.apache.fop.viewer.resources أداة التحميل الخاصة بها (فئة org.apache.fop.viewer.LoadableProperties). يتم ترميز القراءة بترميز ثابت هناك (8859_1 ، كما في حالة Properties.load ()) ، ولكن لم يتم تنفيذ دعم النوع "uXXXX". لقد أبلغت المطورين عن هذا الخطأ ، وقاموا بتضمين إصلاح في خططهم.
من بين أشياء أخرى ، هناك موقع مخصص لترويس FOP (http://www.openmechanics.org/rusfop/) هناك يمكنك العثور على مجموعة توزيع FOP مع أخطاء ثابتة بالفعل وخطوط روسية متصلة.
كوربا
يوفر معيار CORBA نوعًا يتوافق مع نوع سلسلة Java. هذا هو نوع wstring. كل شيء على ما يرام ، لكن بعض خوادم CORBA لا تدعم
يتم تقديم الطريقة الأصلية للعمل مع الترميزات بواسطة Russian Apache - يتم وصفها بالضبط كيف.
 يدعم الشحن اللاسلكي للهواتف الذكية A5 الشحن اللاسلكي
يدعم الشحن اللاسلكي للهواتف الذكية A5 الشحن اللاسلكي لماذا لا تأتي MTS sms للهاتف؟
لماذا لا تأتي MTS sms للهاتف؟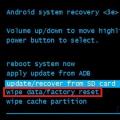 لماذا تحتاج إلى إعادة ضبط المصنع بالكامل على Android أو كيفية إعادة Android إلى إعدادات المصنع
لماذا تحتاج إلى إعادة ضبط المصنع بالكامل على Android أو كيفية إعادة Android إلى إعدادات المصنع