ترميز المعلومات النصية. ترميز الأحرف - PIE wiki
تم اقتراح المعيار في عام 1991 من قبل Unicode Consortium، Unicode Inc. ، وهي منظمة غير ربحية. يتيح استخدام هذا المعيار إمكانية ترميز عدد كبير جدًا من الأحرف من نصوص مختلفة: في مستندات Unicode ، يمكن أن تتعايش الأحرف الصينية والأحرف الرياضية وحروف الأبجدية اليونانية والأبجدية اللاتينية والسيريلية ، وبالتالي يصبح تبديل صفحات الرموز غير ضروري.
يتكون المعيار من قسمين رئيسيين: مجموعة الأحرف العالمية (UCS) وتنسيق تحويل Unicode (UTF). تحدد مجموعة الأحرف العالمية تطابق الأحرف مع الرموز - عناصر مساحة الرمز التي تمثل أعدادًا صحيحة غير سالبة. تحدد عائلة الترميزات تمثيل الجهاز لسلسلة من أكواد UCS.
تم تطوير معيار Unicode بهدف إنشاء ترميز أحرف موحد لجميع اللغات المكتوبة الحديثة والعديد من اللغات المكتوبة القديمة. يتم ترميز كل حرف في هذا المعيار في 16 بت ، مما يسمح له بتغطية عدد أكبر من الأحرف بشكل لا يضاهى من ترميزات 8 بت المقبولة سابقًا. هناك اختلاف مهم آخر بين Unicode وأنظمة التشفير الأخرى وهو أنه لا يتم تعيينه لكل حرف فقط كود فريد، ولكنه يحدد أيضًا الخصائص المختلفة لهذا الرمز ، على سبيل المثال:
نوع الحرف (حرف كبير ، حرف صغير ، رقم ، علامة ترقيم ، إلخ) ؛
سمات الأحرف (العرض من اليسار إلى اليمين أو من اليمين إلى اليسار ، والمسافة ، وفاصل الأسطر ، وما إلى ذلك) ؛
الأحرف الكبيرة أو الصغيرة المقابلة (للأحرف الصغيرة والكبيرة ، على التوالي) ؛
القيمة الرقمية المقابلة (للأحرف الرقمية).
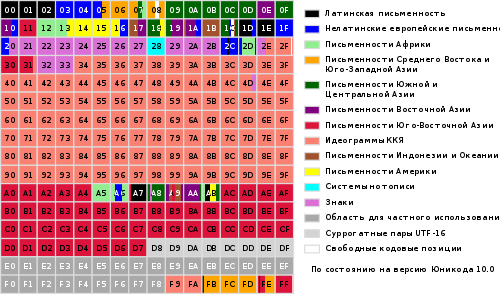
النطاق الكامل للرموز من 0 إلى FFFF مقسم إلى عدة مجموعات فرعية قياسية ، كل منها يتوافق مع أبجدية اللغة أو المجموعة شخصيات خاصة، مماثلة في وظائفهم. يقدم الرسم البياني أدناه قائمة عامة بمجموعات Unicode 3.0 الفرعية (الشكل 2).
الصورة 2
معيار Unicode هو الأساس للتخزين والنصوص في العديد من أنظمة الكمبيوتر الحديثة. ومع ذلك ، فهو غير متوافق مع معظم بروتوكولات الإنترنت ، نظرًا لأن أكواده يمكن أن تحتوي على أي قيم بايت ، وعادةً ما تستخدم البروتوكولات البايتات 00 - 1F و FE - FF كنفقات عامة. لتحقيق إمكانية التشغيل البيني ، تم تطوير العديد من تنسيقات تحويل Unicode (UTFs ، وتنسيقات تحويل Unicode) ، والتي يعتبر UTF-8 أكثرها شيوعًا اليوم. يحدد هذا التنسيق قواعد التحويل التالية لكل منها كود يونيكودفي مجموعة من البايتات (واحد إلى ثلاثة) مناسبة للنقل بواسطة بروتوكولات الإنترنت.
هنا تشير x و y و z إلى بتات الكود المصدري التي يجب استخراجها ، بدءًا من الأقل أهمية ، وإدخالها في وحدات البايت الناتجة من اليمين إلى اليسار حتى يتم ملء جميع المواضع المحددة.
مزيد من التطويريرتبط معيار Unicode بإضافة مستويات لغة جديدة ، أي أحرف في النطاق 10000 - 1FFFF ، 20000 - 2FFFF ، وما إلى ذلك ، حيث من المفترض أن تتضمن ترميز نصوص اللغات الميتة غير المدرجة في الجدول أعلاه. تم تطوير تنسيق UTF-16 جديد لترميز هذه الأحرف الإضافية.
وبالتالي ، هناك 4 طرق رئيسية لتشفير بايتات Unicode:
UTF-8: 128 حرفًا تم ترميزها في بايت واحد (تنسيق ASCII) ، 1920 حرفًا تم ترميزها في 2 بايت ((الأحرف الرومانية ، اليونانية ، السيريلية ، القبطية ، الأرمينية ، العبرية ، العربية) ، 63488 حرفًا تم ترميزها في 3 بايت (الصينية ، اليابانية وغيرها) يمكن تشفير 2،147،418،112 حرفًا المتبقية (لم يتم استخدامها بعد) باستخدام 4 أو 5 أو 6 بايت.
UCS-2: يتم تمثيل كل حرف بـ 2 بايت. يتضمن هذا الترميز أول 65.535 حرفًا فقط من تنسيق Unicode.
UTF-16: هذا امتداد لـ UCS-2 ويتضمن 111112 حرفاً Unicode. يتم تمثيل أول 65535 حرفًا بـ 2 بايت ، والباقي بـ 4 بايت.
USC-4: يتم ترميز كل حرف في 4 بايت.
يونيكود
شعار Unicode Consortium
يونيكود(في أغلب الأحيان) أو يونيكود(م. يونيكود) هو معيار لترميز الأحرف يسمح بتمثيل الأحرف في جميع اللغات المكتوبة تقريبًا.
تم اقتراح المعيار في عام 1991 من قبل المنظمة غير الربحية "Unicode Consortium" (eng. اتحاد يونيكود ، يونيكود إنك.).
يتيح استخدام هذا المعيار إمكانية ترميز عدد كبير جدًا من الأحرف من نصوص مختلفة: في مستندات Unicode ، يمكن أن تتعايش الأحرف الصينية والأحرف الرياضية وحروف الأبجدية اليونانية والأبجدية اللاتينية والسيريلية ، وبالتالي يصبح تبديل صفحات الرموز غير ضروري.
يتكون المعيار من قسمين رئيسيين: مجموعة الأحرف العالمية (eng. UCS ، مجموعة أحرف عالمية) وعائلة الترميزات (م. UTF ، تنسيق تحويل Unicode).
تحدد مجموعة الأحرف العالمية تطابق الأحرف مع الرموز - عناصر مساحة الرمز التي تمثل أعدادًا صحيحة غير سالبة. تحدد عائلة الترميزات تمثيل الجهاز لسلسلة من أكواد UCS.
رموز Unicode مقسمة إلى عدة مناطق. تحتوي المنطقة ذات الرموز من U + 0000 إلى U + 007F على أحرف ASCII مع الرموز المقابلة. فيما يلي مناطق علامات النصوص المختلفة وعلامات الترقيم والرموز الفنية.
بعض الرموز محجوزة للاستخدام في المستقبل. ضمن مناطق الأحرف السيريلية ، يتم تخصيص مناطق الأحرف ذات الرموز من U + 0400 إلى U + 052F ، من U + 2DE0 إلى U + 2DFF ، من U + A640 إلى U + A69F (انظر السيريلية في Unicode).
- 1 المتطلبات الأساسية لإنشاء وتطوير Unicode
- 2 إصدارات Unicode
- 3 مساحة التعليمات البرمجية
- 4 نظام الترميز
- 4.1 سياسة الاتحاد
- 4.2 الجمع بين الرموز ونسخها
- 5 تعديل الحروف
- 6 خوارزميات التطبيع
- 6.1 NFD
- 6.2 NFC
- 6.3 NFKD
- 6.4 نفك
- 6.5 أمثلة
- 7 الكتابة ثنائية الاتجاه
- 8 رموز مميزة
- 9 ISO / IEC 10646
- 10 طرق للعرض
- 10.1 UTF-8
- 10.2 ترتيب البايت
- 10.3 ترميزات يونيكود والتقليدية
- 10.4 عمليات التنفيذ
- 11 طرق الإدخال
- 11.1 مايكروسوفت ويندوز
- 11.2 ماكنتوش
- 11.3 جنو / لينكس
- 12 مشاكل يونيكود
- 13 "Unicode" أم "Unicode"؟
المتطلبات الأساسية لإنشاء وتطوير Unicode
بحلول أواخر الثمانينيات ، أصبحت الأحرف 8 بت هي المعيار. في الوقت نفسه ، كان هناك العديد من ترميزات 8 بت المختلفة ، وظهرت باستمرار ترميزات جديدة.
تم تفسير ذلك من خلال التوسع المستمر في نطاق اللغات المدعومة ، والرغبة في إنشاء ترميز متوافق جزئيًا مع بعض اللغات الأخرى (مثال نموذجي هو ظهور ترميز بديل للغة الروسية ، بسبب استغلال اللغة الغربية. البرامج التي تم إنشاؤها لترميز CP437).
ونتيجة لذلك ظهرت عدة مشاكل:
- مشكلة "krakozyabr" ؛
- مشكلة مجموعة الأحرف المحدودة ؛
- مشكلة تحويل ترميز إلى آخر ؛
- مشكلة الخطوط المكررة.
مشكلة "krakozyabr"- مشكلة عرض المستندات بترميز خاطئ. يمكن حل المشكلة إما عن طريق تقديم طرق لتحديد الترميز المستخدم باستمرار ، أو عن طريق إدخال ترميز واحد (مشترك) للجميع.
مشكلة مجموعة الأحرف المحدودة... يمكن حل المشكلة إما عن طريق تبديل الخطوط داخل المستند ، أو عن طريق إدخال ترميز "واسع". لطالما تم ممارسة تبديل الخطوط في معالجات الكلمات ، وغالبًا ما يتم استخدام الخطوط ذات الترميز غير القياسي ، ما يسمى بـ. "خطوط Dingbat". نتيجة لذلك ، عند محاولة نقل مستند إلى نظام آخر ، تحولت جميع الأحرف غير القياسية إلى "krakozyabry".
مشكلة تحويل ترميز لآخر... يمكن حل المشكلة إما عن طريق تجميع جداول التحويل لكل زوج من الترميزات ، أو باستخدام تحويل وسيط إلى ترميز ثالث يتضمن جميع أحرف جميع الترميزات.
مشكلة الخطوط المكررة... لكل ترميز ، تم إنشاء خط خاص به ، حتى إذا تزامنت مجموعات الأحرف في الترميزات جزئيًا أو كليًا. يمكن حل المشكلة عن طريق إنشاء خطوط "كبيرة" ، يتم من خلالها تحديد الأحرف اللازمة لترميز معين لاحقًا. ومع ذلك ، فقد تطلب ذلك إنشاء سجل واحد للرموز لتحديد ما يتوافق مع ماذا.
تم الاعتراف بالحاجة إلى ترميز واحد "واسع". تم العثور على ترميزات متغيرة الطول ، المستخدمة على نطاق واسع في شرق آسيا ، لتكون صعبة الاستخدام للغاية ، لذلك تقرر استخدام أحرف ذات عرض ثابت.
يبدو أن استخدام أحرف 32 بت مضيعة للغاية ، لذلك تقرر استخدام أحرف 16 بت.
كان الإصدار الأول من Unicode عبارة عن ترميز بحجم حرف ثابت يبلغ 16 بت ، أي أن العدد الإجمالي للرموز كان 2 16 (65536). منذ ذلك الحين ، تم الإشارة إلى الرموز بأربعة أرقام سداسية عشرية (على سبيل المثال ، يو + 04F0). في الوقت نفسه ، تم التخطيط لترميز في Unicode ليس كل الأحرف الموجودة ، ولكن فقط تلك الضرورية في الحياة اليومية. نادرًا ما كان يجب وضع الرموز المستخدمة في "منطقة الاستخدام الخاص" التي احتلت الرموز في الأصل U + D800 ... U + F8FF.
من أجل استخدام Unicode أيضًا كوسيط في تحويل الترميزات المختلفة لبعضها البعض ، تم تضمين جميع الأحرف الممثلة في جميع الترميزات الأكثر شهرة فيه.
ومع ذلك ، فقد تقرر في المستقبل ترميز جميع الرموز ، وفيما يتعلق بذلك ، توسيع مجال الكود بشكل كبير.
في الوقت نفسه ، بدأ اعتبار رموز الأحرف ليست قيمًا ذات 16 بت ، ولكن كأرقام مجردة يمكن تمثيلها في الكمبيوتر بعدة طرق مختلفة (انظر طرق التمثيل).
نظرًا لأنه في عدد من أنظمة الكمبيوتر (على سبيل المثال ، Windows NT) تم استخدام الأحرف 16 بت الثابتة بالفعل كتشفير افتراضي ، فقد تقرر ترميز جميع الأحرف الأكثر أهمية فقط ضمن أول 65.536 موضعًا (ما يسمى باللغة الإنجليزية. طائرة أساسية متعددة اللغات ، BMP).
يتم استخدام المساحة المتبقية لـ "أحرف إضافية" (eng. الشخصيات التكميلية): أنظمة كتابة اللغات المنقرضة أو الأحرف الصينية النادرة جدًا والرموز الرياضية والموسيقية.
للتوافق مع أنظمة 16 بت القديمة ، تم اختراع نظام UTF-16 ، حيث يتم عرض أول 65.536 موضعًا ، باستثناء المواضع من الفاصل الزمني U + D800 ... U + DFFF ، مباشرة كأرقام 16 بت ، ويتم تمثيل الباقي على أنهم "أزواج بديلة" (العنصر الأول للزوج من منطقة U + D800… U + DBFF ، والعنصر الثاني للزوج من منطقة U + DC00… U + DFFF). بالنسبة للأزواج البديل ، تم استخدام جزء من مساحة الشفرة (2048 وظيفة) المخصصة "للاستخدام الخاص".
نظرًا لأن UTF-16 يمكنه عرض 2 20 + 2 16 −2048 (111064) حرفًا فقط ، فقد تم اختيار هذا الرقم كقيمة نهائية لمساحة رمز Unicode (نطاق الرمز: 0x000000-0x10FFFF).
على الرغم من أن منطقة رمز Unicode قد تم تمديدها إلى ما بعد 2-16 في وقت مبكر من الإصدار 2.0 ، إلا أن الأحرف الأولى في منطقة "الجزء العلوي" تم وضعها فقط في الإصدار 3.1.
دور هذا الترميز في قطاع الويب يتزايد باستمرار. في بداية عام 2010 ، بلغت نسبة مواقع الويب التي تستخدم Unicode حوالي 50٪.
إصدارات يونيكود
يستمر العمل على وضع اللمسات الأخيرة على المعيار. يتم إصدار إصدارات جديدة مع تغير جداول الرموز وتحديثها. بالتوازي مع ذلك ، يتم إصدار وثائق ISO / IEC 10646 جديدة.
تم إصدار المعيار الأول في عام 1991 ، وآخرها في عام 2016 ، ومن المتوقع أن يتم إصدار المعيار التالي في صيف عام 2017. تم نشر إصدارات المعايير 1.0-5.0 في شكل كتب ولها رقم ISBN.
يتكون رقم إصدار المعيار من ثلاثة أرقام (على سبيل المثال ، "4.0.1"). يتم تغيير الرقم الثالث عند إجراء تغييرات طفيفة على المعيار الذي لا يضيف أحرفًا جديدة.
مساحة الرمز
على الرغم من أن نماذج الترميز UTF-8 و UTF-32 تسمح بترميز ما يصل إلى 2،331 (2،147،483،648) نقطة رمز ، فقد تقرر استخدام 1،112،064 فقط للتوافق مع UTF-16. ومع ذلك ، حتى هذا أكثر من كافٍ في الوقت الحالي - في الإصدار 6.0 يتم استخدام أقل بقليل من 110.000 نقطة رمز (109242 رسمًا و 273 رمزًا آخر).
يتم تقسيم مساحة الرمز إلى 17 طائرات(م. طائرات) 2 16 (65536) حرفًا لكل منهما. طائرة ارضية ( الطائرة 0) يسمى أساسي (أساسي) ويحتوي على رموز النصوص الأكثر شيوعًا. بقية الطائرات إضافية ( تكميلي). الطائرة الأولى ( الطائرة 1) يستخدم بشكل أساسي للنصوص التاريخية ، والثاني ( الطائرة 2) - للأحرف الصينية النادرة الاستخدام (CJK) ، الثالث ( الطائرة 3) محجوز للأحرف الصينية القديمة. الطائرتان 15 و 16 محجوزتان للاستخدام الخاص.
للدلالة أحرف Unicodeتدوين على شكل “U + xxxx"(للرموز 0 ... FFFF) ، أو" U + كسكسكسكسكس"(للرموز 10000 ... FFFFF) ، أو" U + xxxxxx"(بالنسبة للرموز 100000 ... 10FFFF) ، أين xxx- أرقام سداسية عشرية. على سبيل المثال ، الحرف "i" (U + 044F) له الرمز 044F 16 = 1103 10.
نظام الترميز
نظام الترميز العالمي (Unicode) عبارة عن مجموعة من الرموز الرسومية وطريقة لتشفيرها لمعالجة البيانات النصية بالكمبيوتر.
الرموز الرسومية هي رموز لها صورة مرئية. تعارض الأحرف الرسومية التحكم في الأحرف وتنسيقها.
تشمل الرموز الرسومية المجموعات التالية:
- الحروف الواردة في واحدة على الأقل من الحروف الهجائية المدعومة ؛
- أعداد؛
- علامات الترقيم؛
- علامات خاصة (رياضية ، تقنية ، إيديوغرام ، إلخ) ؛
- فواصل.
Unicode هو نظام للتمثيل الخطي للنص. يمكن تمثيل الأحرف ذات النصوص المرتفعة أو المنخفضة كسلسلة من الرموز المبنية وفقًا لقواعد معينة (حرف مركب) أو كحرف واحد (نسخة متجانسة ، حرف مركب مسبقًا). تشغيل هذه اللحظة(2014) ، يُعتقد أن جميع أحرف النصوص الكبيرة مدرجة في Unicode ، وإذا كان الرمز متاحًا في إصدار مركب ، فليس من الضروري تكراره في شكل موحد.
سياسة الاتحاد
لا ينشئ الكونسورتيوم اتحادًا جديدًا ، لكنه ينص على الترتيب الثابت للأشياء. على سبيل المثال ، تمت إضافة صور الرموز التعبيرية لأن المشغلين اليابانيين الاتصالات المتنقلةتم استخدامها على نطاق واسع.
للقيام بذلك ، تمر عملية إضافة الرمز بعملية معقدة. وعلى سبيل المثال ، فقد تجاوزه رمز الروبل الروسي في ثلاثة أشهر لمجرد أنه حصل على وضع رسمي.
العلامات التجارية مشفرة فقط عن طريق الاستثناء. لذلك ، في Unicode لا يوجد علم Windows أو Apple apple.
بمجرد ظهور شخصية في الترميز ، فإنها لن تتحرك أو تختفي أبدًا. إذا كنت بحاجة إلى تغيير ترتيب الأحرف ، فلن يتم ذلك عن طريق تغيير المواقف ، ولكن عن طريق ترتيب الفرز الوطني. هناك ضمانات أخرى أكثر دقة للاستقرار - على سبيل المثال ، لن تتغير جداول التسوية.
الجمع بين الرموز ونسخها
يمكن أن يتخذ نفس الرمز عدة أشكال ؛ في Unicode ، يتم تضمين هذه النماذج في نقطة رمز واحدة:
- إذا حدث ذلك تاريخيًا. على سبيل المثال ، الحروف العربية لها أربعة أشكال: منفصلة ، في البداية ، في المنتصف وفي النهاية ؛
- أو إذا تم تبني لغة ما في شكل ، وفي شكل آخر - أخرى. يختلف السيريلية البلغارية عن الأحرف الروسية والصينية عن اليابانية.
من ناحية أخرى ، إذا كانت هناك تاريخيًا نقطتا رمز مختلفتان في الخطوط ، فإنها تظل مختلفة في Unicode. يتكون سيجما اليوناني الصغير من شكلين ، ولهما موقعان مختلفان. الحرف اللاتيني الممتد Å (أ مع دائرة) وعلامة أنجستروم Å ، رسالة يونانيةμ والبادئة "micro" µ هما رمزان مختلفان.
بالطبع ، يتم وضع أحرف متشابهة في البرامج النصية غير ذات الصلة في نقاط رمز مختلفة. على سبيل المثال ، الحرف "أ" باللغات اللاتينية والسيريلية واليونانية والشيروكي هي رموز مختلفة.
من النادر جدًا وضع نفس الحرف في موضعين مختلفين من الرموز لتبسيط معالجة النص. الضربات الرياضية ونفس الضربات الدالة على نعومة الأصوات هما رمزان مختلفان ، والثاني يعتبر حرفًا.
تعديل الشخصيات
تمثيل الحرف "Y" (U + 0419) في شكل الحرف الأساسي "I" (U + 0418) والحرف المعدل "" (U + 0306)
تنقسم الأحرف الرسومية في Unicode إلى موسعة وغير ممتدة (عديمة العرض). لا تشغل الأحرف غير الممتدة مساحة في السطر عند عرضها. وتشمل هذه ، على وجه الخصوص ، علامات التشكيل وعلامات التشكيل الأخرى. كل من الأحرف الموسعة وغير الموسعة لها رموز خاصة بها. تسمى الرموز الممتدة بطريقة أخرى أساسية (eng. الشخصيات الأساسية) ، وغير الموسعة - تعديل (م. الجمع بين الشخصيات) ؛ والأخير لا يمكن أن يجتمع بشكل مستقل. على سبيل المثال ، يمكن تمثيل الحرف "á" كسلسلة من الحرف الأساسي "a" (U + 0061) وحرف المعدل "́" (U + 0301) ، أو كحرف متآلف "á" (U + 00E1).
نوع خاص من تعديل الأحرف هو محددات نمط الوجه (eng. محددات الاختلاف). تنطبق فقط على تلك الرموز التي تم تعريف هذه المتغيرات من أجلها. في الإصدار 5.0 ، تم تحديد خيارات النمط لسلسلة الرموز الرياضية، لرموز الأبجدية المنغولية التقليدية ولرموز الكتابة المربعة المنغولية.
خوارزميات التطبيع
حيث يمكن تمثيل نفس الرموز رموز مختلفة، يصبح من المستحيل مقارنة سلاسل بايت بالبايت. خوارزميات التطبيع أشكال التطبيع) حل هذه المشكلة عن طريق تحويل النص إلى شكل قياسي معين.
يتم إجراء الصب عن طريق استبدال الرموز بأخرى مكافئة باستخدام الجداول والقواعد. "التحلل" هو استبدال (تحلل) حرف واحد إلى عدة أحرف مكونة ، و "التركيب" ، على العكس من ذلك ، هو استبدال (اتصال) عدة أحرف مكونة بحرف واحد.
يحدد معيار Unicode 4 خوارزميات تطبيع النص: NFD و NFC و NFKD و NFKC.
NFD
NFD ، م. ن ormalization Fأورم د ("D" من اللغة الإنجليزية. دالتصدع) ، نموذج التطبيع D هو التحلل الكنسي - خوارزمية يتم بموجبها إجراء الاستبدال المتكرر للرموز المتجانسة (eng. أحرف مسبقة التكوين) في عدة مكونات (هندسة. شخصيات مركبة) حسب جداول التحلل.
Å U + 00C5 →
أ U + 0041
̊ يو + 030 أ
ṩ ش + 1E69 →
س U + 0073
̣ U + 0323
̇ U + 0307
ḍ̇ يو + 1E0B U + 0323 →
د U + 0064
̣ U + 0323
̇ U + 0307
q̣̇ U + 0071 U + 0307 U + 0323 →
ف U + 0071
̣ U + 0323
̇ U + 0307 NFC
NFC ، م. ن ormalization Fأورم ج ("C" من اللغة الإنجليزية. جإغفال) ، نموذج التطبيع C عبارة عن خوارزمية يتم وفقًا لها إجراء التحلل الكنسي والتكوين الكنسي بالتتابع. أولاً ، يؤدي التحليل الكنسي (خوارزمية NFD) إلى تقليل النص إلى النموذج D. ثم يقوم التكوين الكنسي ، وهو معكوس NFD ، بمعالجة النص من البداية إلى النهاية ، مع مراعاة القواعد التالية:
- رمز سالعد مبدئيإذا كانت تحتوي على فئة تعديل تساوي الصفر وفقًا لجدول أحرف Unicode ؛
- في أي تسلسل أحرف يبدأ بالحرف س، رمز جمنعت من س، فقط إذا كان بينهما سو جهل هناك أي رمز بالتي هي إما أولية أو لها نفس فئة التعديل أو أكبر من ج... تنطبق هذه القاعدة فقط على السلاسل التي مرت بالتحلل الكنسي ؛
- رمز مهم الأوليةمركب إذا كان يحتوي على تحلل أساسي في جدول أحرف Unicode (أو تحليل متعارف عليه لـ Hangul ولم يتم تضمينه في قائمة الاستبعاد) ؛
- رمز Xيمكن دمجه مع الرمز أولاً صإذا وفقط إذا كان هناك مركب أساسي ض، مكافئًا قانونيًا للتسلسل<X, ص>;
- إذا كان الحرف التالي جلم يتم حظره بواسطة آخر حرف أساسي للبدء الذي تمت مواجهته إلويمكن دمجه بنجاح أولاً ، ثم إليحل محله مركب LC، أ جإزالة.
ا U + 006F
̂ U + 0302 → →
ح U + 0048
① U + 2460 →
1 U + 0031
カ U + FF76 →
カ U + 30AB →
fi U + FB01
fi U + FB01
F أنا U + 0066 U + 0069
F أنا U + 0066 U + 0069
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 5 U + 0032 U + 0035
2 5 U + 0032 U + 0035
ẛ̣ يو + 1E9B U + 0323
ſ ̣ ̇ U + 017F U + 0323 U + 0307
ẛ ̣ يو + 1E9B U + 0323
س ̣ ̇ U + 0073 U + 0323 U + 0307
ṩ ش + 1E69
ذ يو + 0439
و ̆ يو + 0438 U + 0306
ذ يو + 0439
و ̆ يو + 0438 U + 0306
ذ يو + 0439
ه U + 0451
ه ̈ يو + 0435 U + 0308
ه U + 0451
ه ̈ يو + 0435 U + 0308
ه U + 0451
أ يو + 0410
أ يو + 0410
أ يو + 0410
أ يو + 0410
أ يو + 0410
が ش + 304 ج
か ゙ ش + 304 ب U + 3099
が ش + 304 ج
か ゙ ش + 304 ب U + 3099
が ش + 304 ج
Ⅷ U + 2167
Ⅷ U + 2167
Ⅷ U + 2167
الخامس أنا أنا أنا U + 0056 U + 0049 U + 0049 U + 0049
الخامس أنا أنا أنا U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
ج ̧ U + 0063 U + 0327
ç U + 00E7
ج ̧ U + 0063 U + 0327
ç U + 00E7 خطاب ثنائي الاتجاه
يدعم معيار Unicode لغات الكتابة ذات الاتجاه من اليسار إلى اليمين (eng. من اليسار إلى اليمين ، LTR) ، ومع الكتابة من اليمين إلى اليسار (م. من اليمين إلى اليسار ، من اليمين إلى اليسار ، من اليمين إلى اليسار) - على سبيل المثال ، الحروف العربية والعبرية. في كلتا الحالتين ، يتم تخزين الأحرف بترتيب "طبيعي" ؛ يتم توفير عرضهم ، مع مراعاة الاتجاه المطلوب للرسالة ، من خلال التطبيق.
بالإضافة إلى ذلك ، يدعم Unicode النصوص المدمجة التي تجمع بين الأجزاء ذات الاتجاهات المختلفة للحرف. هذه الميزة تسمى ثنائية الاتجاه(م. نص ثنائي الاتجاه ، ثنائي الاتجاه). بعض معالجات النصوص المبسطة (على سبيل المثال ، بتنسيق هاتف خليوي) يمكن أن يدعم Unicode ، ولكن ليس الدعم ثنائي الاتجاه. يتم تقسيم جميع أحرف Unicode إلى عدة فئات: مكتوبة من اليسار إلى اليمين ، ومكتوبة من اليمين إلى اليسار ، ومكتوبة في أي اتجاه. رموز الفئة الأخيرة (علامات الترقيم بشكل أساسي) ، عند عرضها ، تأخذ اتجاه النص المحيط.
الرموز المميزة
رسم تخطيطي للمستوى الأساسي متعدد اللغات لـ Unicode
يتضمن Unicode تقريبًا جميع البرامج النصية الحديثة ، بما في ذلك:
- عربي
- أرميني ،
- البنغالية ،
- البورمية ،
- الفعل
- اليونانية
- الجورجية ،
- الديفاناغارية
- يهودي،
- السيريلية
- الصينية (تستخدم الأحرف الصينية بنشاط في اللغة اليابانية ، وكذلك في اللغة الكورية أحيانًا) ،
- قبطي
- الخمير ،
- اللاتينية ،
- التاميل
- الكورية (هانغول) ،
- شيروكي
- الاثيوبية ،
- اليابانية (والتي تشمل ، بالإضافة إلى الأبجدية المقطعية ، الأحرف الصينية أيضًا)
آخر.
للأغراض الأكاديمية ، تمت إضافة العديد من النصوص التاريخية ، بما في ذلك: الأحرف الرونية الجرمانية ، والرونية التركية القديمة ، والكتابة اليونانية القديمة ، والهيروغليفية المصرية ، والمسمارية ، وكتابة المايا ، والأبجدية الأترورية.
يوفر Unicode مجموعة كبيرة من الرموز والرسوم التوضيحية الرياضية والموسيقية.
من حيث المبدأ ، لا يتضمن Unicode الأعلام الوطنية وشعارات الشركة والمنتجات ، على الرغم من وجودها في الخطوط (على سبيل المثال ، شعار Apple في ترميز MacRoman (0xF0) أو شعار Windows في خط Wingdings (0xFF)). في خطوط Unicode ، يجب وضع الشعارات في منطقة الأحرف المخصصة فقط.
ISO / IEC 10646
يعمل اتحاد Unicode بشكل وثيق مع فريق العمل ISO / IEC / JTC1 / SC2 / WG2 ، التي تعمل على تطوير المعيار الدولي 10646 (ISO / IEC 10646). تم إنشاء التزامن بين معيار Unicode و ISO / IEC 10646 ، على الرغم من أن كل معيار يستخدم المصطلحات الخاصة به ونظام التوثيق.
تعاون اتحاد يونيكود مع المنظمة الدولية للتوحيد القياسي (م. المنظمة الدولية للتوحيد القياسي ISO ) في عام 1991. في عام 1993 ، أصدرت ISO معيار DIS 10646.1. للمزامنة معها ، وافق الاتحاد على الإصدار 1.1 من معيار Unicode ، والذي تم استكماله بأحرف إضافية من DIS 10646.1. نتيجة لذلك ، فإن قيم الأحرف المشفرة في Unicode 1.1 و DIS 10646.1 هي نفسها تمامًا.
في المستقبل ، استمر التعاون بين المنظمتين. في عام 2000 ، تمت مزامنة معيار Unicode 3.0 مع ISO / IEC 10646-1: 2000. ستتم مزامنة الإصدار الثالث القادم من ISO / IEC 10646 مع Unicode 4.0. ربما سيتم نشر هذه المواصفات كمعيار واحد.
على غرار تنسيقات UTF-16 و UTF-32 في معيار Unicode ، يحتوي معيار ISO / IEC 10646 أيضًا على شكلين رئيسيين لترميز الأحرف: UCS-2 (2 بايت لكل حرف ، على غرار UTF-16) و UCS-4 (4 بايت لكل حرف ، على غرار UTF-32). يعني UCS متعدد ثماني بتات عالمية(متعدد البايت) مجموعة الأحرف المشفرة(م. مجموعة أحرف عالمية متعددة الثماني بتات ). يمكن اعتبار UCS-2 مجموعة فرعية من UTF-16 (UTF-16 بدون أزواج بديلة) و UCS-4 هو مرادف لـ UTF-32.
الاختلافات بين معايير Unicode و ISO / IEC 10646:
- اختلافات طفيفة في المصطلحات ؛
- لا يتضمن ISO / IEC 10646 الأقسام المطلوبة للتنفيذ الكامل لدعم Unicode:
- لا توجد بيانات عن ترميز ثنائيالشخصيات؛
- لا يوجد وصف لخوارزميات المقارنة (هندسة. التجميع) وتقديم (eng. استدعاء) الشخصيات؛
- لا توجد قائمة بخصائص الرموز (على سبيل المثال ، لا توجد قائمة بالخصائص المطلوبة لتنفيذ دعم ثنائي الاتجاه (eng. ثنائي الاتجاه) حروف).
طرق العرض
يحتوي Unicode على عدة أشكال من التمثيل (eng. تنسيق تحويل Unicode ، UTF ): UTF-8 و UTF-16 (UTF-16BE و UTF-16LE) و UTF-32 (UTF-32BE و UTF-32LE). تم تطوير نموذج تمثيل UTF-7 أيضًا للإرسال عبر قنوات سبع بتات ، ولكن نظرًا لعدم التوافق مع ASCII ، لم يتم نشره ولم يتم تضمينه في المعيار. في 1 أبريل 2005 ، تم اقتراح تقديمين مرحين: UTF-9 و UTF-18 (RFC 4042).
تستخدم أنظمة Microsoft Windows NT و Windows 2000 و Windows XP بشكل أساسي نموذج UTF-16LE. أنظمة تشغيل شبيهة بـ UNIX تعتمد GNU / Linux و BSD و Mac OS X على UTF-8 للملفات و UTF-32 أو UTF-8 لمعالجة الأحرف في ذاكرة الوصول العشوائي.
Punycode هو شكل آخر من أشكال ترميز تسلسل أحرف Unicode إلى ما يسمى بتسلسلات ACE ، والتي تتكون فقط من أحرف أبجدية رقمية ، كما هو مسموح به في أسماء المجال.
UTF-8
UTF-8 هو تمثيل Unicode الذي يوفر أفضل توافق مع الأنظمة القديمة التي تستخدم أحرف 8 بت.
يتم تحويل النص الذي يحتوي على أحرف مرقمة أقل من 128 فقط إلى نص ASCII عادي عند كتابته بتنسيق UTF-8. على العكس من ذلك ، في نص UTF-8 ، أي بايت بقيمة أقل من 128 عرضًا حرف ASCIIبنفس الكود.
يتم تمثيل باقي أحرف Unicode بتسلسلات من 2 إلى 6 بايت في الطول (في الواقع ، حتى 4 بايت فقط ، حيث لا توجد أحرف برمز أكبر من 10FFFF في Unicode ، ولا توجد خطط لتقديمها في المستقبل) ، حيث يكون للبايت الأول الشكل دائمًا 11xxxxxxو البقية - 10xxxxxx... لا يتم استخدام أزواج بديلة في UTF-8 ، 4 بايت كافية لكتابة أي حرف يونيكود.
تم اختراع UTF-8 في 2 سبتمبر 1992 بواسطة كين طومسون وروب بايك وتم تنفيذه في الخطة 9... أصبح معيار UTF-8 الآن مكرسًا رسميًا في RFC 3629 و ISO / IEC 10646 Annex D.
يتم اشتقاق أحرف UTF-8 من Unicode على النحو التالي:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFFF: 11110xxx 10xxxx 10xxxxxxxxx
ممكن نظريًا ، ولكنه غير مدرج أيضًا في المعيار:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
بالرغم من أن UTF-8 يسمح لك بتحديد نفس الحرف بعدة طرق ، إلا أن أقصرها فقط هو الصحيح. يجب رفض باقي الاستمارات لأسباب أمنية.
ترتيب البايت
في دفق بيانات UTF-16 ، يمكن كتابة البايت المنخفض إما قبل البايت المرتفع (eng. UTF-16 صغير الهند) ، أو بعد الأقدم (م. UTF-16 كبير الهند). وبالمثل ، هناك نوعان مختلفان من التشفير رباعي البايت - UTF-32LE و UTF-32BE.
لتحديد شكل تمثيل Unicode في البداية ملف نصيالتوقيع مكتوب - الحرف U + FEFF (مسافة غير قابلة للكسر بعرض صفري) ، تسمى أيضًا علامة تسلسل البايت(م. علامة ترتيب البايت (BOM)). هذا يجعل من الممكن التمييز بين UTF-16LE و UTF-16BE لأن حرف U + FFFE غير موجود. كما يتم استخدامه أحيانًا للإشارة إلى تنسيق UTF-8 ، على الرغم من أن مفهوم ترتيب البايت لا ينطبق على هذا التنسيق. تبدأ الملفات التي تتبع هذا الاصطلاح بتسلسلات البايت هذه:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
لسوء الحظ ، لا تميز هذه الطريقة بشكل موثوق بين UTF-16LE و UTF-32LE ، نظرًا لأن Unicode يسمح بالحرف U + 0000 (على الرغم من أن النصوص الحقيقية نادرًا ما تبدأ به).
يجب أن تكون الملفات بترميز UTF-16 و UTF-32 التي لا تحتوي على قائمة مكونات الصنف بترتيب بايت كبير (unicode.org).
Unicode والترميزات التقليدية
أدى إدخال Unicode إلى تغيير نهج ترميزات 8 بت التقليدية. إذا تم تحديد الترميز مسبقًا بواسطة الخط ، فسيتم تحديده الآن بواسطة جدول المراسلات بين هذا الترميز و Unicode.
في الواقع ، أصبحت ترميزات 8 بت تمثل مجموعة فرعية من Unicode. جعل هذا الأمر أسهل بكثير لإنشاء البرامج التي يجب أن تعمل مع العديد من الترميزات المختلفة: الآن ، لإضافة دعم لترميز آخر ، تحتاج فقط إلى إضافة جدول بحث Unicode آخر.
بالإضافة إلى ذلك ، تسمح العديد من تنسيقات البيانات بإدراج أي أحرف Unicode ، حتى إذا كان المستند مكتوبًا بترميز 8 بت القديم. على سبيل المثال ، يمكنك استخدام رموز العطف في HTML.
تطبيق
توفر معظم أنظمة التشغيل الحديثة درجة معينة من دعم Unicode.
في أنظمة تشغيل عائلة Windows NT ، يتم استخدام ترميز UTF-16LE مزدوج البايت للتمثيل الداخلي لأسماء الملفات وسلاسل النظام الأخرى. مكالمات النظام التي تأخذ معلمات السلسلة متوفرة في متغيرات أحادية البايت ومزدوجة البايت. لمزيد من المعلومات ، راجع مقالة Unicode عن عائلة أنظمة تشغيل Microsoft Windows.
يونيكس مثل نظام التشغيل، بما في ذلك GNU / Linux و BSD و OS X ، استخدم ترميز UTF-8 لتمثيل Unicode. يمكن لمعظم البرامج التعامل مع UTF-8 كترميز تقليدي أحادي البايت ، بغض النظر عن حقيقة أن الحرف يتم تمثيله في عدة وحدات بايت متتالية. للعمل مع الأحرف الفردية ، يتم عادةً إعادة تشفير السلاسل إلى UCS-4 ، بحيث يكون لكل حرف كلمة آلية.
كان يوم الأربعاء أحد أول التطبيقات التجارية الناجحة لـ Unicode برمجة جافا... لقد تخلت بشكل أساسي عن تمثيل الأحرف 8 بت لصالح 16 بت واحد. زاد هذا الحل من استهلاك الذاكرة ، لكنه سمح لنا بإعادة تجريد مهم إلى البرمجة: حرف واحد عشوائي (نوع شار). على وجه الخصوص ، يمكن للمبرمج أن يعمل مع سلسلة كما هو الحال مع مصفوفة بسيطة. لسوء الحظ ، لم يكن النجاح نهائيًا ، فقد تجاوز Unicode حد 16 بت وبواسطة J2SE 5.0 ، بدأت شخصية تعسفية مرة أخرى في شغل عدد متغير من وحدات الذاكرة - واحدة شارأو اثنين (انظر زوج بديل).
تدعم معظم لغات البرمجة الآن سلاسل Unicode ، على الرغم من أن تمثيلها قد يختلف اعتمادًا على التنفيذ.
طرق الإدخال
نظرًا لعدم وجود تخطيط للوحة المفاتيح يسمح بإدخال جميع أحرف Unicode في نفس الوقت ، فإن الدعم مطلوب من أنظمة التشغيل والتطبيقات. طرق بديلةإدخال أحرف Unicode التعسفي.
مايكروسوفت ويندوز
على الرغم من أن الأداة المساعدة "مخطط توزيع الأحرف" (charmap.exe) تبدأ في نظام التشغيل Windows 2000 ، إلا أنها تدعم أحرف Unicode وتسمح لك بنسخها إلى الحافظة ، وهذا الدعم يقتصر فقط على المستوى الأساسي (رموز الأحرف U + 0000… U + FFFF). الرموز ذات الرموز من U + 10000 لا يتم عرض "جدول الرموز".
يوجد جدول مشابه ، على سبيل المثال ، في مايكروسوفت وورد.
في بعض الأحيان يمكنك كتابة رمز سداسي عشري ، والضغط على Alt + X ، وسيتم استبدال الرمز بالحرف المناسب ، على سبيل المثال ، في WordPad ، Microsoft Word. في المحررين ، يقوم Alt + X بإجراء التحويل العكسي أيضًا.
في العديد من برامج MS Windows ، من أجل الحصول على حرف Unicode ، أثناء الضغط باستمرار على مفتاح Alt ، اكتب القيمة العشرية لرمز الحرف على المفاتيح العددية... على سبيل المثال ، ستكون المجموعات Alt + 0171 (") و Alt + 0187 (") و Alt + 0769 (علامة التشكيل) مفيدة عند كتابة النصوص السيريلية. تعتبر التركيبات Alt + 0133 (...) و Alt + 0151 (-) مثيرة للاهتمام أيضًا.
ماكنتوش
يدعم Mac OS 8.5 والإصدارات الأحدث أسلوب إدخال يسمى "Unicode Hex Input". أثناء الضغط باستمرار على مفتاح الخيار ، تحتاج إلى كتابة الرمز السداسي العشري المكون من أربعة أرقام للحرف المطلوب. تسمح لك هذه الطريقة بإدخال أحرف برموز أكبر من U + FFFF باستخدام أزواج بديلة ؛ سيتم استبدال هذه الأزواج تلقائيًا بنظام التشغيل بأحرف فردية. يجب تنشيط طريقة الإدخال هذه في القسم المناسب قبل الاستخدام. اعدادات النظامثم حدد أسلوب الإدخال الحالي من قائمة لوحة المفاتيح.
بدءًا من نظام التشغيل Mac OS X 10.2 ، يوجد أيضًا تطبيق Character Palette الذي يسمح لك بتحديد أحرف من جدول يمكنك من خلاله تحديد أحرف من كتلة معينة أو أحرف مدعومة بخط معين.
جنو / لينكس
يحتوي جنوم أيضًا على الأداة المساعدة Symbol Map (gucharmap سابقًا) التي تتيح لك عرض الرموز لكتلة أو نظام كتابة معين وتوفر القدرة على البحث بالاسم أو وصف الرمز. عندما يكون رمز الحرف المطلوب معروفًا ، يمكن إدخاله وفقًا لمعيار ISO 14755: أثناء الضغط باستمرار على مفاتيح Ctrl + Shift ، أدخل الرمز السداسي العشري (بدءًا من بعض إصدارات GTK + ، يجب إدخال الرمز عن طريق الضغط "U"). يمكن أن يصل طول الشفرة السداسية العشرية التي تم إدخالها إلى 32 بت ، مما يسمح لك بإدخال أي أحرف Unicode دون استخدام أزواج بديلة.
تدعم جميع تطبيقات X Window ، بما في ذلك GNOME و KDE ، إدخال مفتاح Compose. بالنسبة للوحات المفاتيح التي لا تحتوي على مفتاح إنشاء مخصص ، يمكنك تعيين أي مفتاح لهذا الغرض - على سبيل المثال ، ⇪ Caps Lock.
تسمح وحدة تحكم GNU / Linux أيضًا بإدخال حرف Unicode عن طريق الكود الخاص به - لهذا ، يجب إدخال الرمز العشري للحرف كأرقام من كتلة لوحة المفاتيح الموسعة أثناء الضغط باستمرار على مفتاح Alt. يمكنك إدخال الأحرف عن طريق الكود السداسي عشري: لهذا تحتاج إلى الضغط باستمرار على مفتاح AltGr ، والدخول أرقام A-Fاستخدم المفاتيح الموجودة على لوحة المفاتيح الممتدة من NumLock إلى ↵ Enter (في اتجاه عقارب الساعة). يتم أيضًا دعم الإدخال وفقًا لمعيار ISO 14755. ولكي تعمل الطرق المذكورة أعلاه ، تحتاج إلى تمكين وضع Unicode في وحدة التحكم عن طريق الاتصال unicode_start(1) وحدد الخط المناسب عن طريق الاتصال سيتفونت(8).
يدعم Mozilla Firefox لنظام Linux إدخال الأحرف ISO 14755.
مشاكل يونيكود
في Unicode ، الإنجليزية "a" و "a" البولندية هي نفس الحرف. وبنفس الطريقة ، يعتبر الرمز "a" الروسي و "a" الصربي نفس الرمز (لكنهما مختلفان عن اللاتينية "a"). مبدأ الترميز هذا ليس عالميًا ؛ على ما يبدو ، لا يمكن أن يوجد حل "لجميع المناسبات" على الإطلاق.
- تتم كتابة النصوص الصينية والكورية واليابانية بشكل تقليدي من أعلى إلى أسفل ، بدءًا من الزاوية اليمنى العليا. التبديل بين الهجاء الأفقي والعمودي لهذه اللغات غير منصوص عليه في Unicode - يجب أن يتم ذلك عن طريق لغات الترميز أو الآليات الداخلية لمعالجات الكلمات.
- يسمح Unicode بأوزان مختلفة لنفس الحرف اعتمادًا على اللغة. لذلك ، يمكن أن يكون للأحرف الصينية أنماط مختلفة في الصينية واليابانية (كانجي) والكورية (هانشا) ، ولكن في نفس الوقت في Unicode يتم الإشارة إليها بنفس الرمز (ما يسمى بتوحيد CJK) ، على الرغم من أن الأحرف المبسطة والكاملة لا تزال لها رموز مختلفة ... وبالمثل ، تستخدم اللغات الروسية والصربية أسلوبًا مائلًا مختلفًا. NSو تي(في الصربية يبدون مثل u و w ، انظر مائل الصربية). لذلك ، تحتاج إلى التأكد من أن النص يتم تمييزه دائمًا بشكل صحيح على أنه مرتبط بلغة أو أخرى.
- تعتمد الترجمة من الأحرف الصغيرة إلى الأحرف الكبيرة أيضًا على اللغة. على سبيل المثال: في التركية هناك حرفان Ii و Ii - وبالتالي ، تتعارض قواعد تغيير الحالة التركية مع القواعد الإنجليزية ، والتي تتطلب ترجمة "i" إلى "I". توجد مشاكل مماثلة في لغات أخرى - على سبيل المثال ، في اللهجة الكندية للفرنسية ، تتم ترجمة السجل بشكل مختلف قليلاً عن فرنسا.
- حتى مع الأرقام العربية ، هناك بعض التفاصيل الدقيقة المطبعية: يمكن أن تكون الأرقام "كبيرة" و "صغيرة" ، متناسبة وأحادية المسافة - بالنسبة إلى Unicode ، لا يوجد فرق بينهما. تبقى هذه الفروق الدقيقة مع البرنامج.
لا تتعلق بعض العيوب بـ Unicode نفسه ، بل بإمكانيات معالجات النصوص.
- تشغل ملفات النص غير اللاتيني في Unicode دائمًا مساحة أكبر ، نظرًا لأن حرفًا واحدًا لا يتم ترميزه ببايت واحد ، كما هو الحال في مختلف الترميزات الوطنية ، ولكن بتسلسل البايت (الاستثناء هو UTF-8 للغات التي تناسب أبجديتها إلى ASCII ، بالإضافة إلى وجود حرفين في النص والمزيد من اللغات ، الأبجدية منها ليسيناسب ASCII). يشغل ملف الخط المطلوب لعرض جميع الأحرف في جدول Unicode مساحة ذاكرة كبيرة نسبيًا وهو أكثر كثافة من الناحية الحسابية من خط اللغة الوطنية للمستخدم وحده. مع زيادة قوة أنظمة الكمبيوتر وانخفاض تكلفة الذاكرة ومساحة القرص ، تصبح هذه المشكلة أقل أهمية ؛ ومع ذلك ، تظل مناسبة للأجهزة المحمولة مثل الهواتف المحمولة.
- على الرغم من تطبيق دعم Unicode في أكثر أنظمة التشغيل شيوعًا ، إلا أنه لا يتم تطبيقه كلها البرمجياتيدعم العمل الصحيحمعه. على وجه الخصوص ، لا تتم معالجة علامات ترتيب البايت (BOM) دائمًا ولا يتم دعم الأحرف المحركة بشكل جيد. المشكلة مؤقتة وهي نتيجة الجدة المقارنة لمعايير Unicode (بالمقارنة مع الترميزات الوطنية أحادية البايت).
- ينخفض أداء جميع برامج معالجة السلاسل (بما في ذلك الأنواع الموجودة في قاعدة البيانات) عند استخدام Unicode بدلاً من الترميزات أحادية البايت.
لا تزال بعض أنظمة الكتابة النادرة غير ممثلة بشكل صحيح في Unicode. لم يتم بعد تنفيذ تصوير الأحرف المرتفعة "الطويلة" الممتدة على عدة أحرف ، كما هو الحال ، على سبيل المثال ، في الكنيسة السلافية.
يونيكود أو يونيكود؟
"Unicode" هو اسم علم (أو جزء من اسم ، على سبيل المثال ، Unicode Consortium) واسم شائع مشتق من اللغة الإنجليزية.
للوهلة الأولى ، يفضل استخدام التهجئة "Unicode". في اللغة الروسية ، هناك بالفعل مورفيمات "uni-" (الكلمات التي تحتوي على العنصر اللاتيني "uni-" تمت ترجمتها وكتابتها تقليديًا من خلال "uni-": عالمي ، أحادي القطب ، توحيد ، موحد) و "رمز". ضد، العلامات التجارية، المستعارة من اللغة الإنجليزية ، يتم نقلها عادةً عن طريق النسخ العملي ، حيث يتم كتابة المجموعة غير الأصلية من الأحرف "uni-" في شكل "uni-" ("Unilever" ، "Unix" ، إلخ.) ، وهذا هو ، بنفس الطريقة كما في حالة الاختصارات حرفًا بحرف مثل اليونيسف "صندوق الطوارئ الدولي للأطفال التابع للأمم المتحدة" - اليونيسف.
لقد دخلت تهجئة "Unicode" بقوة في النصوص الصادرة باللغة الروسية. تستخدم ويكيبيديا الإصدار الأكثر شيوعًا. في MS Windows ، يتم استخدام خيار Unicode.
توجد صفحة خاصة على موقع الكونسورتيوم ، حيث توجد مشاكل نقل كلمة "Unicode" إليها لغات مختلفةوأنظمة الكتابة. بالنسبة للأبجدية السيريلية الروسية ، تم تحديد خيار "Unicode".
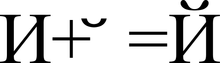
عادةً ما يتم التعامل مع المشكلات المرتبطة بالترميز بواسطة البرنامج ، لذلك لا توجد عادةً صعوبة في استخدام الترميزات. إذا ظهرت صعوبات ، فعادة ما يتم إنشاؤها بواسطة برامج سيئة - لا تتردد في إرسالها إلى سلة المهملات.
أدعو الجميع للتحدث
ASCII (الكود القياسي الأمريكي لتبادل المعلومات) - جدول الترميز القياسي الأمريكي للأحرف القابلة للطباعة وبعض الرموز الخاصة. تُنطق اللغة الإنجليزية الأمريكية [aski] ، بينما تُنطق كلمة [aski] في المملكة المتحدة ؛ باللغة الروسية يتم نطقها أيضًا [aski] أو [aski].
ASCII هو ترميز للأرقام العشرية والأبجديات اللاتينية والوطنية وعلامات الترقيم وأحرف التحكم. تم تصميمه في الأصل على أنه 7 بت ، مع الاستخدام الواسع لبايت ASCII 8 بت ، وأصبح يُنظر إليه على أنه نصف 8 بت. تستخدم أجهزة الكمبيوتر عادةً امتدادات ASCII مع البتة الثامنة المتضمنة والنصف الثاني من جدول الكود (على سبيل المثال ، KOI-8).
يونيكود
في عام 1991 ، تم إنشاء منظمة Unicode Consortium غير الربحية في كاليفورنيا ، والتي تضم ممثلين عن العديد من شركات الكمبيوتر (Borland ، و IBM ، و Lotus ، و Microsoft ، و Novell ، و Sun ، و WordPerfect ، وما إلى ذلك) ، والتي تعمل على تطوير وتنفيذ المعيار " معيار يونيكود "... أصبح معيار ترميز أحرف Unicode هو السائد في بيئات البرامج الدولية متعددة اللغات. Microsoft Windows NT و Windows 2000 ، 2003 ، XP يستخدم Unicode ، بشكل أكثر دقة UTF-16 ، كتمثيل نص داخلي. اعتمدت أنظمة التشغيل المشابهة لـ UNIX مثل Linux و BSD و Mac OS X Unicode (UTF-8) كتمثيل أساسي للنص متعدد اللغات. يحتفظ Unicode بـ 1،114،112 (220 + 216) رمز رمز ، حاليًا يتم استخدام أكثر من 96000 حرف. أول 256 حرفًا تتطابق بشكل وثيق مع رموز ISO 8859-1 ، جدول الأحرف الأكثر شيوعًا المكون من 8 بتات في العالم الغربي ؛ نتيجة لذلك ، تتطابق الأحرف 128 الأولى أيضًا مع جدول ASCII. يتم تقسيم مساحة رمز Unicode إلى 17 "مستوى" ، وتحتوي كل خطة على 65536 (= 216) نقطة رمز. المستوى الأول (المستوى 0) ، المستوى الأساسي متعدد اللغات (BMP) هو المستوى الذي يتم فيه وصف معظم الأحرف. يحتوي BMP على رموز للجميع تقريبًا اللغات الحديثة، وعدد كبير من الشخصيات الخاصة. يتم استخدام طائرتين إضافيتين للرموز "الرسومية". المستوى 1 ، المستوى التكميلي متعدد اللغات (SMP) يستخدم بشكل أساسي للرموز التاريخية ، ويستخدم أيضًا للرموز الموسيقية والرياضية. تُستخدم الخطة 2 ، المستوى الأيديوغرافي التكميلي (SIP) ، لما يقرب من 40000 حرف صيني نادر. الخطة 15 والخطة 16 مفتوحان لأي استخدام خاص. يوضح الشكل 1.10 كتلة Unicode الروسية (U + 0400 إلى U + 04FF).
الترميزات الشائعة
ISO 646 ASCII BCDIC EBCDIC ISO 8859: ISO 8859-1، ISO 8859-2، ISO 8859-3، ISO 8859-4، ISO 8859-5، ISO 8859-6، ISO 8859-7، ISO 8859-8، ISO 8859 -9 ، ISO 8859-10 ، ISO 8859-11 ، ISO 8859-13 ، ISO 8859-14 ، ISO 8859-15 CP437 ، CP737 ، CP850 ، CP852 ، CP855 ، CP857 ، CP858 ، CP860 ، CP861 ، CP863 ، CP865 ، CP866 ، CP869 ترميزات Microsoft Windows: Windows-1250 للغات وسط أوروبا التي تستخدم تهجئة لاتينية (البولندية والتشيكية والسلوفاكية والمجرية والسلوفينية والكرواتية والرومانية والألبانية) Windows-1251 للأبجدية السيريلية Windows-1252 للغات الغربية Windows-1253 لـ اليونانية Windows-1254 لـ التركية Windows-1255 للعبرية Windows-1256 للعربية Windows-1257 للغات البلطيق Windows-1258 للفيتنامية MacRoman ، MacCyrillic KOI8 (KOI8-R ، KOI8-U ...) ، KOI-7 البلغارية تشفير ISCII VISCII Big5 (البديل الأكثر شهرة من Microsoft CP950) HKSCS Guobiao GB2312 GBK (Microsoft CP936) GB18030 Shift JIS للغة اليابانية (Microsoft CP932) EUC-KR للكورية (Microsoft CP949) ISO-2022 و EUC لترميزات UTF-8 الصينية ، مجموعات أحرف UTF-16 و UTF-32 Unicode \
ترميز المعلومات الرسومية
منذ الثمانينيات. تتطور تقنية معالجة المعلومات الرسومية على جهاز الكمبيوتر. شكل التمثيل على شاشة العرض لصورة رسومية تتكون من نقاط فردية (بكسل) يسمى نقطية. الحد الأدنى للكائن في محرر الرسومات النقطية هو نقطة. تم تصميم محرر الرسوم النقطية لإنشاء صور ومخططات. يتم تحديد دقة الشاشة (عدد النقاط الأفقية والعمودية) ، بالإضافة إلى عدد الألوان الممكنة لكل نقطة حسب نوع الشاشة. يتم ترميز 1 بكسل من الشاشة بالأبيض والأسود مع 1 بت من المعلومات (نقطة سوداء أو نقطة بيضاء). يرتبط عدد الألوان المختلفة K وعدد البتات الخاصة بتشفيرها بالصيغة: K = 2b. تحتوي الشاشات الحديثة على لوحات الألوان التالية: 16 لونًا ، 256 لونًا ؛ 65.536 لونًا (لون عالي الجودة) ، 16777216 لونًا (لون حقيقي).
نقطية
بمساعدة العدسة المكبرة ، يمكنك أن ترى أن الصورة الرسومية بالأبيض والأسود ، على سبيل المثال من صحيفة ، تتكون من أصغر النقاط التي تشكل نمطًا معينًا - خطوط المسح. في فرنسا في القرن التاسع عشر ، ظهر اتجاه جديد في الرسم - التنقيط. تتمثل تقنيته في حقيقة أن الرسم تم تطبيقه على القماش بفرشاة على شكل نقاط متعددة الألوان. أيضًا ، لطالما استخدمت هذه الطريقة في صناعة الطباعة لتشفير المعلومات الرسومية. تعتمد دقة الرسم على عدد النقاط وحجمها. بعد تقسيم الصورة إلى نقاط ، بدءًا من الزاوية اليسرى ، والتحرك على طول الخطوط من اليسار إلى اليمين ، يمكنك ترميز لون كل نقطة. علاوة على ذلك ، ستُطلق على إحدى هذه النقاط اسم بكسل (يرتبط أصل هذه الكلمة بالاختصار الإنجليزي "عنصر صورة" - عنصر صورة). يتم تحديد حجم الصورة النقطية بضرب عدد البيكسلات (بحجم المعلومات لنقطة واحدة ، والذي يعتمد على عدد الألوان الممكنة. يتم تحديد جودة الصورة من خلال دقة الشاشة. وكلما كانت أعلى ، هو ، كلما زاد عدد الخطوط النقطية والنقاط في الخط ، زادت جودة الصورة. تستخدم أجهزة الكمبيوتر بشكل أساسي دقة الشاشة التالية: 640 × 480 ، 800 × 600 ، 1024 × 768 و 1280 × 1024 بكسل. منذ سطوع كل نقطة و يمكن التعبير عن إحداثياتها الخطية باستخدام الأعداد الصحيحة ، ويمكننا القول أن طريقة التشفير هذه تسمح لك باستخدام رمز ثنائي لمعالجة البيانات الرسومية.
إذا تحدثنا عن الرسوم التوضيحية بالأبيض والأسود ، فعندئذٍ إذا كنت لا تستخدم الألوان النصفية ، فسيفترض البيكسل إحدى حالتين: مضاءة (بيضاء) وليست مضاءة (سوداء). وبما أن المعلومات حول لون البكسل تسمى رمز البكسل ، فإن بت واحد من الذاكرة يكفي لترميزه: 0 - أسود ، 1 - أبيض. إذا تم النظر في الرسوم التوضيحية في شكل مجموعة من النقاط ذات 256 درجة من الرمادي (وهي مقبولة حاليًا بشكل عام) ، فإن الرقم الثنائي المكون من ثمانية بتات يكفي لترميز سطوع أي نقطة. الخامس رسومات الحاسوباللون مهم للغاية. يعمل كوسيلة لتحسين الانطباع البصري وزيادة تشبع المعلومات للصورة. كيف تتشكل حاسة اللون في دماغ الإنسان؟ يحدث هذا نتيجة لتحليل تدفق الضوء الداخل إلى شبكية العين من الأجسام العاكسة أو المنبعثة. من المقبول عمومًا أن مستقبلات اللون البشري ، والتي تسمى أيضًا المخاريط ، تنقسم إلى ثلاث مجموعات ، ويمكن لكل منها إدراك لون واحد فقط - أحمر ، أو أخضر ، أو أزرق.
نماذج الألوان
عندما يتعلق الأمر بترميز اللون الصور الرسومية، فأنت بحاجة إلى مراعاة مبدأ تحلل اللون التعسفي إلى مكوناته الرئيسية. يتم استخدام العديد من أنظمة الترميز: HSB و RGB و CMYK. يعتبر نموذج اللون الأول بسيطًا وبديهيًا ، أي أنه مناسب للشخص ، والثاني هو الأكثر ملاءمة لجهاز الكمبيوتر ، وآخر طراز CMYK مخصص لدور الطباعة. يرجع استخدام نماذج الألوان هذه إلى حقيقة أن التدفق الضوئي يمكن أن يتشكل عن طريق الإشعاع ، وهو مزيج من الألوان الطيفية "النقية": الأحمر أو الأخضر أو الأزرق أو مشتقاتهما. يميز بين إعادة إنتاج اللون الإضافي (نموذجي للكائنات المنبعثة) وإعادة إنتاج اللون الطرحي (نموذجي للأشياء العاكسة). مثال على كائن من النوع الأول هو أنبوب أشعة الكاثود لشاشة ، من النوع الثاني - طباعة.

يتميز نموذج HSB بثلاثة مكونات: تدرج اللون والتشبع والسطوع. يمكنك الحصول على الكثير من الألوان العشوائية عن طريق ضبط هذه المكونات. هذا النموذج اللوني هو الأفضل في هؤلاء محرري الرسوم، حيث يتم إنشاء الصور من تلقاء نفسها ، ولم تتم معالجتها بالفعل وهي جاهزة. ثم يمكن تحويل عملك الفني الذي تم إنشاؤه إلى نموذج ألوان RGB إذا كنت تخطط لاستخدامه كتوضيح على الشاشة ، أو CMYK ، إذا تمت طباعته. يتم تحديد قيمة اللون كمتجه صادر من مركز الدائرة. يتم تحديد اتجاه المتجه بالدرجات الزاوية ويحدد تدرج اللون. يتم تحديد تشبع اللون من خلال طول المتجه ، ويتم تعيين سطوع اللون على محور منفصل ، نقطة الصفر منه سوداء. النقطة المركزية بيضاء (محايدة) ، والنقاط حول المحيط ألوان صلبة.
مبدأ طريقة RGB هو كما يلي: من المعروف أن أي لون يمكن تمثيله على أنه مزيج من ثلاثة ألوان: أحمر (أحمر ، R) ، أخضر (أخضر ، G) ، أزرق (أزرق ، B). يتم الحصول على ألوان أخرى وظلالها بسبب وجود أو عدم وجود هذه المكونات.من الأحرف الأولى من الألوان الأساسية ، حصل النظام على اسمه - RGB. نموذج الألوان هذا مضاف ، أي أنه يمكن الحصول على أي لون من خلال الجمع بين الألوان الأساسية بنسب مختلفة. عندما يتم فرض أحد مكونات اللون الأساسي على عنصر آخر ، يزداد سطوع إجمالي الإشعاع. إذا قمنا بدمج جميع المكونات الثلاثة ، فسنحصل على لون رمادي متلألئ ، مع زيادة في السطوع يقترب من الأبيض.
مع 256 نغمة (يتم تشفير كل نقطة بـ 3 بايت) ، تتوافق قيم RGB الدنيا (0،0،0) مع الأسود والأبيض - إلى الحد الأقصى مع الإحداثيات (255 ، 255 ، 255). كلما زادت قيمة البايت لمكون اللون ، زاد سطوع هذا اللون. على سبيل المثال ، يتم ترميز اللون الأزرق الداكن بثلاثة بايت (0 ، 0 ، 128) والأزرق الساطع (0 ، 0 ، 255).
مبدأ طريقة CMYK. يُستخدم نموذج الألوان هذا عند إعداد المنشورات للطباعة. يتم تخصيص لون تكميلي لكل لون أساسي (مكمل للون الأساسي للأبيض). يتم الحصول على لون إضافي عن طريق تلخيص زوج من الألوان الأساسية المتبقية. هذا يعني أن الألوان التكميلية للأحمر سماوي (سماوي ، سي) = أخضر + أزرق = أبيض - أحمر ، للأخضر - أرجواني (أرجواني ، M) = أحمر + أزرق = أبيض - أخضر ، للأزرق - أصفر (أصفر ، Y) = أحمر + أخضر = أبيض - أزرق. علاوة على ذلك ، يمكن تطبيق مبدأ تحلل اللون التعسفي إلى مكونات لكل من العناصر الرئيسية والإضافية ، أي أنه يمكن تمثيل أي لون إما كمجموع للمكون الأحمر والأخضر والأزرق أو كمجموع المكون السماوي والأرجواني والأصفر. في الأساس ، يتم اعتماد هذه الطريقة في صناعة الطباعة. لكنهم ما زالوا يستخدمون اللون الأسود (BlacK ، نظرًا لأن الحرف B مشغول بالفعل باللون الأزرق ، يُشار إليه بالحرف K). هذا لأن تراكب الألوان التكميلية لا ينتج عنه أسود نقي.
الصور المتجهية والفركتلية
الصورة المتجهة هي كائن رسومي يتكون من خطوط وأقواس أولية. العنصر الأساسي للصورة هو الخط. مثل أي كائن ، له خصائص: الشكل (مستقيم ، منحنى) ، سمك. ، لون ، نمط (منقط ، صلب). تتميز الخطوط المغلقة بخاصية التعبئة (إما مع كائنات أخرى أو بلون محدد). كل الأشياء الأخرى رسومات فيكتورتتكون من خطوط. نظرًا لأن السطر موصوف رياضيًا ككائن واحد ، فإن مقدار البيانات لعرض كائن عن طريق الرسومات المتجهة يكون أقل بكثير مما هو عليه في الرسومات النقطية. يتم ترميز المعلومات الخاصة بالصورة المتجهة على أنها أبجدية رقمية عادية ومعالجتها بواسطة برامج خاصة.
إلى البرمجياتيتضمن إنشاء ومعالجة الرسومات المتجهة GR التالية: CorelDraw و Adobe Illustrator وكذلك vectorizers (tracer) - وهي حزم متخصصة لتحويل الصور النقطية إلى متجه.

تستند الرسومات النمطي هندسي متكرر إلى العمليات الحسابية ، تمامًا مثل الرسومات المتجهة. ولكن على عكس المتجه ، فإن عنصره الأساسي هو الصيغة الرياضية نفسها. هذا يؤدي إلى حقيقة أنه لا توجد كائنات مخزنة في ذاكرة الكمبيوتر وأن الصورة مبنية فقط من خلال المعادلات. باستخدام هذه الطريقة ، يمكنك بناء أبسط الهياكل العادية ، وكذلك الرسوم التوضيحية المعقدة التي تحاكي المناظر الطبيعية.

ترميز الصوت
يمتلئ العالم بمجموعة متنوعة من الأصوات: دقات الساعات وطنين المحركات ، وعواء الريح وحفيف أوراق الشجر ، وغناء الطيور وأصوات الناس. بدأ الناس في التخمين حول كيفية تولد الأصوات وما هي عليه لفترة طويلة جدًا. حتى الفيلسوف والعالم اليوناني القديم - الموسوعي أرسطو ، بناءً على الملاحظات ، أوضح طبيعة الصوت ، معتقدًا أن الجسم السبر يخلق ضغطًا متناوبًا وخلخلة للهواء. لذلك ، أحيانًا يفرغ الخيط المتأرجح ، ثم يكثف الهواء ، وبسبب مرونة الهواء ، تنتقل هذه التأثيرات المتناوبة إلى الفضاء - من طبقة إلى أخرى ، تنشأ موجات مرنة. عندما تصل إلى أذننا ، فإنها تعمل على طبلة الأذن وتنتج إحساسًا بالصوت.
عن طريق الأذن ، يرى الشخص موجات مرنة بتردد في مكان ما في النطاق من 16 هرتز إلى 20 كيلو هرتز (1 هرتز - 1 اهتزاز في الثانية). وفقًا لهذا ، فإن الموجات المرنة في أي وسط ، والتي تقع تردداتها ضمن الحدود المحددة ، تسمى الموجات الصوتية أو الصوت ببساطة. في دراسة الصوت ، تعتبر مفاهيم مثل نغمة الصوت وجرسه مهمة. أي صوت حقيقي ، سواء كان عزفًا على الآلات الموسيقية أو صوت شخص ، هو نوع من مزيج من العديد من الاهتزازات التوافقية مع مجموعة معينة من الترددات.
التذبذب الذي لديه أكثر تردد منخفض، تسمى النغمة الرئيسية ، والبعض الآخر يسمى الإيحاءات.
Timbre هو عدد مختلف من النغمات الكامنة في صوت معين ، مما يمنحه لونًا خاصًا. لا يرجع الاختلاف بين جرس وآخر إلى العدد فحسب ، بل يرجع أيضًا إلى شدة النغمات المصاحبة لصوت النغمة الرئيسية. من خلال الجرس يمكننا بسهولة التمييز بين أصوات البيانو والكمان ، والجيتار والناي ، والتعرف على صوت شخص مألوف.
يمكن أن يتسم الصوت الموسيقي بثلاث صفات: الجرس ، أي لون الصوت الذي يعتمد على شكل الاهتزازات ، والارتفاع الذي يتحدد بعدد الاهتزازات في الثانية (التردد) ، والجهارة التي تعتمد على الصوت. على شدة الاهتزازات.
يستخدم الكمبيوتر الآن على نطاق واسع في مختلف المجالات. لم تكن معالجة المعلومات الصوتية والموسيقى استثناءً. حتى عام 1983 ، تم إصدار جميع تسجيلات الموسيقى على أسطوانات الفينيل والأشرطة المدمجة. حاليا ، تستخدم الأقراص المدمجة على نطاق واسع. إذا كان لديك جهاز كمبيوتر مثبت عليه بطاقة صوت استوديو ، ولوحة مفاتيح MIDI وميكروفون متصل به ، فيمكنك حينئذٍ العمل باستخدام برنامج موسيقى متخصص.
تحويل المعلومات الصوتية من رقمي إلى تمثيلي ومن تناظري إلى رقمي
دعونا نلقي نظرة سريعة على عمليات تحويل الصوت من التناظرية إلى الرقمية والعكس صحيح. يمكن أن تساعد الفكرة التقريبية لما يحدث في بطاقة الصوت في تجنب بعض الأخطاء عند العمل مع الصوت.
يتم تحويل الموجات الصوتية إلى إشارة كهربائية متناوبة تناظرية باستخدام ميكروفون. يمر عبر مسار الصوت ويصل إلى المحول التناظري إلى الرقمي (ADC) - جهاز يحول الإشارة إلى شكل رقمي.
في شكل مبسط ، يكون مبدأ تشغيل ADC كما يلي: يقيس اتساع الإشارة على فترات منتظمة وينقل أكثر ، بالفعل عبر المسار الرقمي ، سلسلة من الأرقام التي تحمل معلومات حول تغيرات السعة. أثناء التحويل من التناظرية إلى الرقمية ، لا يحدث أي تحويل مادي. تتم إزالة بصمة أو عينة من الإشارة الكهربائية ، وهي نموذج رقمي لتقلبات الجهد في مسار الصوت. إذا تم تصوير هذا في شكل رسم بياني ، فسيتم تقديم هذا النموذج في شكل سلسلة من الأعمدة ، يتوافق كل منها مع قيمة عددية محددة. الإشارات الرقميةمنفصلة بطبيعتها - أي غير متصلة ، وبالتالي فإن النموذج الرقمي لا يتطابق تمامًا مع شكل موجة الإشارة التناظرية.
العينة هي الفترة الزمنية بين قياسين لسعة الإشارة التناظرية.
عينة تترجم حرفيا من اللغة الإنجليزية على أنها "عينة". في الوسائط المتعددة والمصطلحات الصوتية الاحترافية ، تحتوي هذه الكلمة على عدة معانٍ. بالإضافة إلى فترة زمنية ، تسمى العينة أيضًا أي تسلسل من البيانات الرقمية تم الحصول عليها عن طريق التحويل التناظري إلى الرقمي. عملية التحويل نفسها تسمى أخذ العينات. في اللغة التقنية الروسية ، يطلق عليه التقديرية.
يتم إخراج الصوت الرقمي باستخدام محول من رقمي إلى تناظري (DAC) ، والذي ، بناءً على البيانات الرقمية الواردة في الأوقات المناسبة ، يولد إشارة كهربائية بالسعة المطلوبة
خيارات أخذ العينات
يعد التردد وعمق البت معلمات مهمة لأخذ العينات. التردد - عدد قياسات سعة الإشارة التناظرية في الثانية.
إذا كان تردد أخذ العينات لا يزيد عن ضعف تردد الحد الأعلى لمدى الصوت ، فعندئذٍ قم بتشغيل ترددات عاليةسوف تحدث الخسائر. هذا ما يفسر سبب كون التردد القياسي للقرص المضغوط الصوتي هو 44.1 كيلو هرتز. نظرًا لأن نطاق تذبذبات الموجات الصوتية يتراوح من 20 هرتز إلى 20 كيلو هرتز ، يجب أن يكون عدد قياسات الإشارة في الثانية أكبر من عدد التذبذبات خلال نفس الفترة الزمنية. إذا كان معدل أخذ العينات أقل بكثير من تردد الموجة الصوتية ، فإن سعة الإشارة لديها وقت للتغيير عدة مرات خلال الفترة الفاصلة بين القياسات ، وهذا يؤدي إلى حقيقة أن البصمة الرقمية تحمل مجموعة بيانات فوضوية. مع التحويل من رقمي إلى تمثيلي ، لا تنقل هذه العينة الإشارة الرئيسية ، ولكنها تنتج ضوضاء فقط.
في تنسيق CD Audio DVD الجديد ، يتم قياس الإشارة 96000 مرة في ثانية واحدة ، أي استخدام معدل أخذ العينات 96 كيلو هرتز. لتوفير مساحة على القرص الصلب في تطبيقات الوسائط المتعددة ، غالبًا ما يتم استخدام الترددات المنخفضة: 11 ، 22 ، 32 كيلو هرتز. وهذا يؤدي إلى انخفاض في نطاق الترددات المسموعة ، مما يعني وجود تشويه قوي لما يُسمع.
إذا كنا في شكل رسم بياني نمثل نفس الصوت بارتفاع 1 كيلو هرتز (ملاحظة تصل إلى الأوكتاف السابع للبيانو تتوافق تقريبًا مع هذا التردد) ، ولكن تم أخذ عينات منها بتردد مختلف (الجزء السفلي من الجيب هو لا تظهر في جميع الرسوم البيانية) ، فستكون الاختلافات مرئية. قسم واحد على المحور الأفقي ، والذي يوضح الوقت ، يتوافق مع 10 عينات. المقياس هو نفسه. يمكنك أن ترى أنه عند 11 كيلو هرتز ، يوجد حوالي خمسة اهتزازات للموجة الصوتية لكل 50 عينة ، أي يتم عرض فترة واحدة من الموجة الجيبية باستخدام 10 قيم فقط. هذا نقل غير دقيق إلى حد ما. في الوقت نفسه ، إذا أخذنا في الاعتبار تردد أخذ العينات البالغ 44 كيلو هرتز ، فهناك بالفعل ما يقرب من 50 عينة لكل فترة من الجيوب الأنفية. هذا يسمح لك بالحصول على إشارة ذات جودة جيدة.
يشير عمق البت إلى الدقة التي يتغير بها اتساع الإشارة التناظرية. تحدد الدقة التي يتم بها إرسال قيمة سعة الإشارة في كل نقطة زمنية أثناء التحويل الرقمي جودة الإشارة بعد التحويل من رقمي إلى تمثيلي. تعتمد موثوقية إعادة بناء شكل الموجة على عمق البت.
يتم ترميز قيمة الاتساع باستخدام مبدأ التشفير الثنائي. يجب تقديم الإشارة الصوتية على شكل سلسلة من النبضات الكهربائية (أصفار ثنائية وواحدة). تُستخدم عادةً تمثيلات 8 أو 16 بت أو 20 بت لقيم الاتساع. عندما الترميز الثنائي مستمر إشارة صوتيةيتم استبداله بسلسلة من مستويات الإشارة المنفصلة. تعتمد جودة التشفير على معدل أخذ العينات (عدد قياسات مستوى الإشارة لكل وحدة زمنية). مع زيادة معدل أخذ العينات ، تزداد دقة التمثيل الثنائي للمعلومات. عند تردد 8 كيلو هرتز (عدد القياسات في الثانية 8000) ، تتوافق جودة الإشارة الصوتية التي تم أخذ عينات منها مع جودة البث الإذاعي ، وبتردد 48 كيلو هرتز (عدد القياسات في الثانية هو 48000) - لجودة صوت قرص مضغوط صوتي.
يوجد حاليًا قرص DVD صوتي جديد للمستهلك بتنسيق رقمي ، يستخدم عمق بت يبلغ 24 بت ومعدل أخذ عينات يبلغ 96 كيلو هرتز. بمساعدتها ، يمكن تجنب العيب المذكور أعلاه لترميز 16 بت.
إلى الرقمية الحديثة أجهزة الصوتتم تثبيت محولات 20 بت. يظل الصوت 16 بت ومحولات عالية بت مثبتة لتحسين جودة التسجيل بمستويات منخفضة. مبدأ عملها على النحو التالي: يتم رقمنة الإشارة التناظرية الأصلية بعرض 20 بت. ثم يقوم معالج الإشارات الرقمية DSPP بتقليل عرضه إلى 16 بت. في هذه الحالة ، يتم استخدام خوارزمية حسابية خاصة ، والتي يمكن من خلالها تقليل تشويه الإشارات منخفضة المستوى. تتم ملاحظة العملية المعاكسة أثناء التحويل من رقمي إلى تمثيلي: يزداد عمق البت من 16 إلى 20 بتًا باستخدام خوارزمية خاصة تسمح لك بتحديد قيم السعة بدقة أكبر. أي أن الصوت يظل 16 بت ، ولكن هناك تحسن عام في جودة الصوت.
ما هو الترميز
في اللغة الروسية ، يُطلق على "مجموعة الأحرف" أيضًا جدول "مجموعة الأحرف" ، وعملية استخدام هذا الجدول لترجمة المعلومات من تمثيل الكمبيوتر إلى تمثيل بشري ، وخاصية ملف نصي ، مما يعكس استخدام نظام معين من الرموز فيه عند عرض النص.
كيف يتم تشفير النص
يشار إلى مجموعة الرموز المستخدمة في كتابة النص في مصطلحات الكمبيوتر كأبجدية ؛ عادة ما يسمى عدد الرموز في الأبجدية قوتها. للعرض معلومات نصيةيستخدم الكمبيوتر غالبًا أبجدية بسعة 256 حرفًا. يحمل أحد أحرفه 8 بتات من المعلومات ، وبالتالي ، فإن الرمز الثنائي لكل حرف يأخذ 1 بايت من ذاكرة الكمبيوتر. يتم ترقيم جميع أحرف مثل هذه الأبجدية من 0 إلى 255 ، ويتوافق كل رقم مع رمز ثنائي مكون من 8 بتات ، وهو الرقم الترتيبي للحرف في نظام الأرقام الثنائية - من 00000000 إلى 11111111. فقط أول 128 حرفًا مع أرقام من صفر (رمز ثنائي 00000000) إلى 127 (01111111). وتشمل هذه الأحرف الصغيرة و الأحرف الكبيرةالأبجدية اللاتينية والأرقام وعلامات الترقيم والأقواس ، إلخ. تُستخدم الرموز الـ 128 المتبقية ، بدءًا من 128 (الرمز الثنائي 10000000) وتنتهي بـ 255 (11111111) ، لتشفير الأحرف الأبجدية الوطنية والرموز الرسمية والعلمية.
أنواع الترميزات
أشهر جدول ترميز هو ASCII (الكود القياسي الأمريكي لتبادل المعلومات). تم تطويره في الأصل لنقل النصوص عن طريق التلغراف ، وفي ذلك الوقت كان 7 بت ، أي ، تم استخدام 128 تركيبة 7 بت فقط لترميز الأحرف الإنجليزية ، وأحرف الخدمة والتحكم. في هذه الحالة ، تم استخدام أول 32 مجموعة (رموز) لتشفير إشارات التحكم (بداية النص ، ونهاية السطر ، وعودة أول السطر ، والمكالمة ، ونهاية النص ، وما إلى ذلك). في تطوير أجهزة كمبيوتر IBM الأولى ، تم استخدام هذا الرمز لتمثيل الرموز في الكمبيوتر. منذ ذلك الحين في مصدر الرمزكان ASCII 128 حرفًا فقط ، لأن تشفيرها كان قيمًا كافية للبايت مع بت 8 يساوي 0. بدأ استخدام قيم البايت مع بت 8 يساوي 1 لتمثيل الأحرف الرسومية الزائفة والعلامات الرياضية وبعض الأحرف من لغات أخرى غير الإنجليزية (اليونانية ، علامات التشكيل الألمانية ، علامات التشكيل الفرنسية ، إلخ). عندما بدأوا في تكييف أجهزة الكمبيوتر مع البلدان واللغات الأخرى ، لم يعد هناك مساحة كافية للرموز الجديدة. لدعم اللغات الأخرى غير الإنجليزية بشكل كامل ، قامت شركة IBM بتقديم العديد من جداول الرموز الخاصة بكل بلد. لذلك بالنسبة للدول الاسكندنافية ، تم اقتراح الجدول 865 (الشمال) ، للدول العربية - الجدول 864 (عربي) ، لإسرائيل - الجدول 862 (إسرائيل) ، وهكذا. في هذه الجداول ، تم استخدام بعض الرموز من النصف الثاني من جدول الرموز لتمثيل أحرف الأبجديات الوطنية (من خلال استبعاد بعض الأحرف الرسومية الزائفة). تطور الوضع مع اللغة الروسية بطريقة خاصة. من الواضح أنه يمكن استبدال الأحرف في النصف الثاني من جدول الرموز طرق مختلفة... لذلك ، ظهرت عدة جداول مختلفة لترميز الأحرف السيريلية للغة الروسية: KOI8-R و IBM-866 و CP-1251 و ISO-8551-5. كلهم يمثلون رموز النصف الأول من الجدول بنفس الطريقة (من 0 إلى 127) ويختلفون في تمثيل رموز الأبجدية الروسية والرسومات الزائفة. بالنسبة للغات مثل الصينية أو اليابانية ، فإن 256 حرفًا غير كافية بشكل عام. بالإضافة إلى ذلك ، هناك دائمًا مشكلة إخراج النصوص أو حفظها في ملف واحد في نفس الوقت على النصوص لغات مختلفة(على سبيل المثال ، عند الاقتباس). لذلك ، عالمية جدول الكود UNICODE ، تحتوي على رموز مستخدمة في لغات جميع شعوب العالم ، بالإضافة إلى رموز خدمية ومساعدة مختلفة (علامات ترقيم ، رموز رياضية وتقنية ، أسهم ، علامات تشكيل ، إلخ). من الواضح أن بايت واحد لا يكفي لترميز مثل هذا العدد الكبير من الأحرف. لذلك تستخدم UNICODE رموز 16 بت (2 بايت) لتمثيل 65536 حرفًا. حتى الآن ، تم استخدام حوالي 49000 رمز (كان آخر تغيير مهم هو إدخال رمز عملة اليورو في سبتمبر 1998). للتوافق مع الترميزات السابقة ، فإن أول 256 رمزًا هي نفسها الموجودة في معيار ASCII. في معيار UNICODE ، بالإضافة إلى رمز ثنائي معين (عادةً ما يتم الإشارة إلى هذه الرموز بالحرف U ، متبوعًا بعلامة + والرمز الفعلي في التمثيل السداسي العشري) ، يتم تعيين اسم محدد لكل حرف. مكون آخر معيار UNICODEهي خوارزميات للتحويل من واحد إلى واحد لرموز UNICODE في تسلسل بايت متغير الطول. ترجع الحاجة إلى مثل هذه الخوارزميات إلى حقيقة أنه ليس كل التطبيقات قادرة على العمل مع UNICODE. بعض التطبيقات لا تفهم سوى رموز ASCII ذات 7 بتات ، بينما تفهم التطبيقات الأخرى رموز ASCII ذات 8 بتات. تستخدم هذه التطبيقات ما يسمى برموز ASCII الموسعة لتمثيل الأحرف التي لا تتناسب مع مجموعة مكونة من 128 حرفًا أو 256 حرفًا ، على التوالي ، عندما يتم تشفير الأحرف بسلاسل بايت متغيرة الطول. يستخدم UTF-7 لتحويل رموز UNICODE بشكل عكسي إلى رموز ASCII الممتدة 7 بت ، ويستخدم UTF-8 لتحويل رموز UNICODE بشكل عكسي إلى رموز ASCII ممتدة 8 بت. لاحظ أن كلاً من ASCII و UNICODE ومعايير ترميز الأحرف الأخرى لا تحدد صور الأحرف ، ولكن فقط تكوين مجموعة الأحرف وطريقة تمثيلها في الكمبيوتر. بالإضافة إلى ذلك (والذي قد لا يكون واضحًا على الفور) ، فإن ترتيب تعداد الأحرف في المجموعة مهم جدًا ، لأنه يؤثر على خوارزميات الفرز بشكل أكثر أهمية. إنه جدول مراسلات الرموز من مجموعة معينة (على سبيل المثال ، الرموز المستخدمة لتمثيل المعلومات عن اللغة الانجليزية، أو بلغات مختلفة ، كما في حالة UNICODE) ويُشار إليها بمصطلح جدول ترميز الأحرف أو مجموعة أحرف. كل ترميز قياسي له اسم ، على سبيل المثال ، KOI8-R ، ISO_8859-1 ، ASCII. لسوء الحظ ، لا يوجد معيار لترميز الأسماء.
الترميزات الشائعة
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11، ISO 8859-13، ISO 8859-14، ISO 8859-15 o CP437، CP737، CP850، CP852، CP855، CP857، CP858، CP860، CP861، CP863، CP865، CP866، CP869 Microsoft Windows ترميزات: o Windows-1250 للغات وسط أوروبا التي تستخدم الأحرف اللاتينية o Windows-1251 للأبجديات السيريلية o Windows-1252 للغات الغربية o Windows-1253 للغة اليونانية o Windows -1254 للتركية o Windows-1255 للغة العبرية o Windows-1256 للعربية o Windows-1257 للغات البلطيق o Windows-1258 للغة الفيتنامية MacRoman و MacCyrillic KOI8 (KOI8-R، KOI8-U ...) -7 الترميز البلغاري ISCII VISCII Big5 (البديل الأكثر شهرة من Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS للغة اليابانية (Microsoft CP932) EUC-KR للكورية (Microsoft CP949) ISO-2022 و EUC لنظام الكتابة الصيني UTF-8 وترميزات UTF-16 لمجموعة أحرف Yong اي كودفي نظام الترميز ASCII(الكود القياسي الأمريكي لتبادل المعلومات) يتم تمثيل كل حرف ببايت واحد ، والذي يمكنه تشفير 256 حرفًا.
يحتوي ASCII على جدولين ترميز - أساسي وممتد. يعمل الجدول الأساسي على إصلاح قيم الرموز من 0 إلى 127 ، ويشير الجدول الموسع إلى أحرف بأرقام من 128 إلى 255. وهذا يكفي للتعبير عن مجموعات مختلفة من ثمانية بتات جميع أحرف اللغتين الإنجليزية والروسية ، بالأحرف الصغيرة والكبيرة ، بالإضافة إلى علامات الترقيم ، ورموز العمليات الحسابية الأساسية والرموز الخاصة الشائعة التي يمكن ملاحظتها على لوحة المفاتيح.
يتم إعطاء الرموز 32 الأولى من الجدول الأساسي ، بدءًا من الصفر ، لمصنعي الأجهزة (بشكل أساسي لمصنعي أجهزة الكمبيوتر وأجهزة الطباعة). تحتوي هذه المنطقة على ما يسمى برموز التحكم ، والتي لا تتوافق مع أي أحرف لغة ، وبالتالي ، لا يتم عرض هذه الرموز سواء على الشاشة أو على أجهزة الطباعة ، ولكن يمكن التحكم في كيفية إخراج البيانات الأخرى. بدءًا من الرمز 32 إلى الكود 127 ، يتم وضع رموز الأبجدية الإنجليزية وعلامات الترقيم والأرقام والعمليات الحسابية والرموز المساعدة ، ويمكن رؤيتها جميعًا على الجزء اللاتيني من لوحة مفاتيح الكمبيوتر.
الجزء الثاني الممتد مخصص لأنظمة التشفير الوطنية. هناك العديد من الأبجديات غير اللاتينية في العالم (العربية والعبرية واليونانية وما إلى ذلك) ، بما في ذلك الأبجدية السيريلية. أيضًا ، تختلف تخطيطات لوحة المفاتيح الألمانية والفرنسية والإسبانية عن تلك الموجودة في اللغة الإنجليزية.
كان الجزء الإنجليزي من لوحة المفاتيح يحتوي على العديد من المعايير ، ولكن الآن تم استبدالها جميعًا برمز ASCII واحد. بالنسبة للوحة المفاتيح الروسية ، كان هناك أيضًا العديد من المعايير: GOST ، GOST- البديل ، ISO (المنظمة الدولية للمعايير - المعهد الدولي للتوحيد القياسي) ، ولكن هذه المعايير الثلاثة قد تلاشت بالفعل ، على الرغم من أنها يمكن أن تلتقي في مكان ما ، في بعض أجهزة الكمبيوتر ما قبل الطوفان أو في شبكات الكمبيوتر.
ترميز الحرف الرئيسي للغة الروسية ، والذي يستخدم في أجهزة الكمبيوتر ذات التشغيل نظام ويندوزمسمى نظام التشغيل Windows-1251، تم تطويره من أجل الأبجدية السيريلية بواسطة Microsoft. بطبيعة الحال ، يتم ترميز الغالبية العظمى من بيانات نص الكمبيوتر في نظام التشغيل Windows-1251. بالمناسبة ، تم تطوير ترميزات بأرقام مختلفة مكونة من أربعة أرقام بواسطة Microsoft للأبجديات الشائعة الأخرى: العربية واليابانية وغيرها.
ترميز شائع آخر يسمى KOI-8(رمز تبادل المعلومات ، مكون من ثمانية أرقام) - يعود أصله إلى أوقات مجلس المساعدة الاقتصادية المتبادلة لدول أوروبا الشرقية. اليوم ، ينتشر ترميز KOI-8 على نطاق واسع في شبكات الكمبيوتر على أراضي روسيا وفي قطاع الإنترنت الروسي. يحدث أن بعض نصوص الرسالة أو أي شيء آخر غير قابل للقراءة ، مما يعني أنك بحاجة إلى التبديل من KOI-8 إلى Windows-1251. عشرة
في التسعينيات ، قررت كبرى الشركات المصنعة للبرامج: Microsoft ، Borland ، نفس Adobe ، الحاجة إلى تطوير نظام تشفير نص مختلف ، حيث يتم تخصيص كل حرف ليس 1 ، ولكن 2 بايت. حصلت على الاسم يونيكود، ومن الممكن ترميز 65.536 حرفًا من هذا المجال بما يكفي لاحتوائه في جدول واحد من الأبجديات الوطنية لجميع لغات الكوكب. معظم أحرف Unicode (حوالي 70٪) مشغولة بالحروف الصينية ، وفي الهند يوجد 11 حرفًا أبجديًا وطنيًا مختلفًا ، وهناك العديد من الأسماء الغريبة ، على سبيل المثال: كتابة السكان الأصليين الكنديين.
نظرًا لأن ترميز كل حرف في Unicode لا يتم تخصيص 8 بت ، بل 16 بت ، فإن حجم الملف النصي يتضاعف. كان هذا في يوم من الأيام عقبة أمام إدخال نظام 16 بت. والآن ، مع محركات الأقراص الصلبة بالجيجابايت ، ومئات الميجابايت من ذاكرة الوصول العشوائي ، ومعالجات جيجاهيرتز ، ومضاعفة حجم الملفات النصية ، والتي ، على سبيل المثال ، مع الرسومات ، تشغل مساحة صغيرة جدًا ، لا يهم حقًا.
يتم ترتيب الأبجدية السيريلية في Unicode من 768 إلى 923 (أحرف أساسية) ومن 924 إلى 1023 (حروف سيريلية ممتدة ، ومختلف الأحرف الوطنية الأقل شيوعًا). إذا لم يتم تكييف البرنامج مع Cyrillic Unicode ، فمن الممكن أن يتم التعرف على الأحرف النصية ليس على أنها سيريلية ، ولكن على أنها لاتينية ممتدة (رموز من 256 إلى 511). وفي هذه الحالة ، بدلاً من النص ، تظهر على الشاشة مجموعة لا معنى لها من الرموز الغريبة المتنوعة.
هذا ممكن إذا كان البرنامج قديمًا ، تم إنشاؤه قبل عام 1995. أو واحدة نادرة ، لم يزعجها أحد بالترويس. من الممكن أيضًا أن يكون نظام التشغيل Windows المثبت على الكمبيوتر غير مهيأ بالكامل للأبجدية السيريلية. في هذه الحالة ، تحتاج إلى عمل الإدخالات المناسبة في التسجيل.
 بنية نظام التحكم الموزع على أساس بيئة الحوسبة متعددة خطوط الأنابيب القابلة لإعادة التكوين L-Net أنظمة الملفات الموزعة "الشفافة"
بنية نظام التحكم الموزع على أساس بيئة الحوسبة متعددة خطوط الأنابيب القابلة لإعادة التكوين L-Net أنظمة الملفات الموزعة "الشفافة" صفحة إرسال البريد الإلكتروني ملء ملف relay_recipients بالعناوين من Active Directory
صفحة إرسال البريد الإلكتروني ملء ملف relay_recipients بالعناوين من Active Directory شريط اللغة مفقود في Windows - ماذا تفعل؟
شريط اللغة مفقود في Windows - ماذا تفعل؟