ทฤษฎีการเข้ารหัสเกิดขึ้นเมื่อใดและเพราะเหตุใด ทฤษฎีการเข้ารหัส ประเภทของการเข้ารหัส การเข้ารหัส แนวคิดพื้นฐาน
ทฤษฎีการเข้ารหัส - การศึกษาคุณสมบัติของรหัสและความเหมาะสมสำหรับการบรรลุเป้าหมายที่กำหนด การเข้ารหัสข้อมูลเป็นกระบวนการของการแปลงจากแบบฟอร์มที่สะดวกสำหรับการใช้งานโดยตรงเป็นรูปแบบที่สะดวกสำหรับการส่ง การจัดเก็บ การประมวลผลอัตโนมัติและการเก็บรักษาจากการเข้าถึงโดยไม่ได้รับอนุญาต ปัญหาหลักของทฤษฎีการเข้ารหัสรวมถึงปัญหาของการเข้ารหัสแบบตัวต่อตัวและความซับซ้อนของการใช้ช่องทางการสื่อสารภายใต้เงื่อนไขที่กำหนด ในเรื่องนี้ ทฤษฎีการเข้ารหัสจะพิจารณาถึงประเด็นต่อไปนี้เป็นหลัก: การบีบอัดข้อมูล การแก้ไขข้อผิดพลาดในการส่งต่อ การเข้ารหัส การเข้ารหัสทางกายภาพ การตรวจจับข้อผิดพลาดและการแก้ไขข้อผิดพลาด
รูปแบบ
หลักสูตรประกอบด้วย 10 สัปดาห์การศึกษา เพื่อแก้ปัญหาส่วนใหญ่จากการทดสอบให้ประสบความสำเร็จ เพียงพอที่จะเชี่ยวชาญเนื้อหาที่บอกในการบรรยาย การสัมมนายังจัดการกับงานที่ซับซ้อนมากขึ้นที่สามารถดึงดูดผู้ฟังที่คุ้นเคยกับพื้นฐานอยู่แล้ว
โปรแกรมคอร์ส
- การเข้ารหัสตามตัวอักษร เงื่อนไขเพียงพอสำหรับการถอดรหัสที่ชัดเจน: ความสม่ำเสมอ คำนำหน้า คำต่อท้าย การรับรู้ถึงเอกลักษณ์: เกณฑ์ของ Markov ค่าประมาณความยาวของคำที่ถอดรหัสได้ไม่ชัดเจน
- ความไม่เท่าเทียมกันของคราฟท์-แมคมิลแลน; การมีอยู่ของรหัสนำหน้าพร้อมชุดความยาวของคำที่กำหนด ผลของความเป็นสากลของรหัสนำหน้า
- รหัสความซ้ำซ้อนขั้นต่ำ: คำชี้แจงปัญหา, ทฤษฎีบทการลดของ Huffman
- งานแก้ไขและตรวจจับข้อผิดพลาด การตีความทางเรขาคณิต ประเภทข้อผิดพลาด เมตริกของ Hamming และ Levenshtein ระยะทางรหัส งานหลักของทฤษฎีรหัสแก้ไขข้อผิดพลาด
- รหัส Varshamov-Tenengolts อัลกอริทึมสำหรับการแก้ไขข้อผิดพลาดเดียวของการดร็อปและแทรกสัญลักษณ์
- ขอบเขตที่ง่ายที่สุดสำหรับพารามิเตอร์ของรหัสแก้ไขข้อผิดพลาดการแทนที่: ขอบเขตการบรรจุทรงกลม, ขอบเขตซิงเกิลตัน, ขอบเขต Plotkin
- การฝังช่องว่างเมตริก เล็มมาเกี่ยวกับจำนวนเวกเตอร์ในอวกาศแบบยุคลิด ชายแดนเอเลียส-บาสซาลิโก
- รหัสไลน์. คำจำกัดความ การสร้างและตรวจสอบเมทริกซ์ ความสัมพันธ์ระหว่างระยะทางของรหัสและเมทริกซ์ตรวจสอบ พรมแดนวาร์ชามอฟ-กิลเบิร์ต การเข้ารหัสอย่างเป็นระบบ การถอดรหัสซินโดรม รหัสแฮมมิ่ง
- รหัสที่เหลือ. เขตแดน Greismer-Solomon-Stiffler
- ความซับซ้อนของปัญหาการถอดรหัสรหัสเชิงเส้น: ปัญหา NCP (ปัญหาเกี่ยวกับคำรหัสที่ใกล้ที่สุด)
- รหัสรีด-โซโลมอน อัลกอริทึมการถอดรหัส Berlekamp-Welch
- รหัส Reed-Muller: ระยะทางของรหัส อัลกอริธึมการถอดรหัสส่วนใหญ่
- ลักษณะทั่วไปของโครงสร้างรีด-มุลเลอร์ เล็มมาแห่งลิปตัน-เดอมิลโล-ชวาร์ตษ์-ซิปเปล แนวคิดของรหัสพีชคณิต
- กราฟขยาย หลักฐานความน่าจะเป็นของการมีอยู่ของตัวขยาย รหัสตามกราฟสองส่วน ระยะทางรหัสของรหัสตามตัวขยาย อัลกอริทึมการถอดรหัส Sipser-Spielman
- ทฤษฎีบทของแชนนอนสำหรับโมเดลช่องสัญญาณความน่าจะเป็น
- แอปพลิเคชั่นรหัสแก้ไขข้อผิดพลาด โปรโตคอลสุ่มในความซับซ้อนของการสื่อสาร การเข้ารหัสลับของ McEliece ชุดที่เป็นเนื้อเดียวกัน (สุ่มเทียม) ตั้งค่าตามรหัส การใช้งานเพื่อถอดรหัสแบบสุ่มในปัญหา MAX-SAT
จากวิกิพีเดีย สารานุกรมเสรี
ทฤษฎีการเข้ารหัส- ศาสตร์แห่งคุณสมบัติของรหัสและความเหมาะสมสำหรับการบรรลุเป้าหมาย
ข้อมูลทั่วไป
การเข้ารหัสเป็นกระบวนการของการแปลงข้อมูลจากแบบฟอร์มที่สะดวกสำหรับการใช้งานโดยตรงเป็นแบบฟอร์มที่สะดวกสำหรับการส่ง การจัดเก็บ การประมวลผลอัตโนมัติ และการเก็บรักษาจากการเข้าถึงโดยไม่ได้รับอนุญาต ปัญหาหลักของทฤษฎีการเข้ารหัสรวมถึงปัญหาของการเข้ารหัสแบบตัวต่อตัวและความซับซ้อนของการใช้ช่องทางการสื่อสารภายใต้เงื่อนไขที่กำหนด:86 ในเรื่องนี้ ทฤษฎีการเข้ารหัส พิจารณาประเด็นต่อไปนี้เป็นหลัก:18:
การบีบอัดข้อมูล
การแก้ไขข้อผิดพลาดไปข้างหน้า
การเข้ารหัส
การเข้ารหัส (จากภาษากรีกอื่น. κρυπτός - ซ่อนและ γράφω - ฉันเขียน) นี่เป็นสาขาความรู้เกี่ยวกับวิธีการรักษาความลับ (ความเป็นไปไม่ได้ของการอ่านข้อมูลให้บุคคลภายนอก) ความสมบูรณ์ของข้อมูล (ความเป็นไปไม่ได้ของการเปลี่ยนแปลงข้อมูลที่ไม่สามารถรับรู้ได้) การรับรองความถูกต้อง (การรับรองความถูกต้องของการประพันธ์หรือคุณสมบัติอื่น ๆ ของวัตถุ) เช่นเดียวกับความเป็นไปไม่ได้ที่จะปฏิเสธการประพันธ์
04/04/2006 Leonid Chernyak หมวดหมู่:เทคโนโลยี
"ระบบเปิด" การสร้างคอมพิวเตอร์จะเป็นไปไม่ได้หากไม่มีการสร้างทฤษฎีการเข้ารหัสสัญญาณพร้อม ๆ กับรูปลักษณ์ ทฤษฎีการเข้ารหัสเป็นหนึ่งในพื้นที่ของคณิตศาสตร์ที่มีอิทธิพลอย่างมากต่อการพัฒนาคอมพิวเตอร์
“ระบบเปิด”
การสร้างคอมพิวเตอร์จะเป็นไปไม่ได้หากไม่มีการสร้างทฤษฎีการเข้ารหัสสัญญาณพร้อม ๆ กับรูปลักษณ์
ทฤษฎีการเข้ารหัสเป็นหนึ่งในสาขาวิชาคณิตศาสตร์ที่มีอิทธิพลอย่างมากต่อการพัฒนาระบบคอมพิวเตอร์ ขอบเขตของมันขยายไปถึงการส่งข้อมูลผ่านช่องสัญญาณจริง (หรือสัญญาณรบกวน) และวัตถุคือการตรวจสอบความถูกต้องของข้อมูลที่ส่ง กล่าวอีกนัยหนึ่งคือศึกษาวิธีที่ดีที่สุดในการแพ็คข้อมูลเพื่อให้หลังจากการส่งสัญญาณข้อมูลที่เป็นประโยชน์สามารถดึงออกจากข้อมูลได้อย่างน่าเชื่อถือและง่ายดาย บางครั้งทฤษฎีการเข้ารหัสสับสนกับการเข้ารหัส แต่สิ่งนี้ไม่เป็นความจริง: การเข้ารหัสช่วยแก้ปัญหาผกผัน เป้าหมายของมันคือทำให้ยากต่อการดึงข้อมูลจากข้อมูล
ความจำเป็นในการเข้ารหัสข้อมูลเกิดขึ้นครั้งแรกเมื่อกว่าร้อยห้าสิบปีที่แล้ว ไม่นานหลังจากการประดิษฐ์โทรเลข ช่องสัญญาณมีราคาแพงและไม่น่าเชื่อถือ ซึ่งทำให้งานลดต้นทุนและเพิ่มความน่าเชื่อถือของการส่งโทรเลขอย่างเร่งด่วน ปัญหารุนแรงขึ้นจากการวางสายเคเบิลข้ามมหาสมุทรแอตแลนติก ตั้งแต่ปี ค.ศ. 1845 มีการนำหนังสือรหัสพิเศษมาใช้ ด้วยความช่วยเหลือของพวกเขา นักโทรเลข "บีบอัด" ข้อความด้วยตนเอง โดยแทนที่ลำดับคำทั่วไปด้วยรหัสที่สั้นกว่า ในเวลาเดียวกันเพื่อตรวจสอบความถูกต้องของการถ่ายโอนก็เริ่มใช้ความเท่าเทียมกันซึ่งเป็นวิธีการที่ใช้ในการตรวจสอบความถูกต้องของการป้อนข้อมูลของบัตรเจาะในคอมพิวเตอร์ของรุ่นแรกและรุ่นที่สอง ในการทำเช่นนี้ การ์ดที่เตรียมไว้เป็นพิเศษพร้อมเช็คซัมถูกเสียบเข้าไปในเด็คอินพุตสุดท้าย หากอุปกรณ์อินพุตไม่น่าเชื่อถือมาก (หรือสำรับใหญ่เกินไป) อาจเกิดข้อผิดพลาดได้ เพื่อแก้ไข ให้ทำซ้ำขั้นตอนการป้อนข้อมูลจนกระทั่งเช็คซัมที่คำนวณได้ตรงกับจำนวนเงินที่จัดเก็บไว้ในการ์ด โครงการนี้ไม่เพียงแต่จะไม่สะดวกเท่านั้น แต่ยังพลาดข้อผิดพลาดซ้ำสองอีกด้วย ด้วยการพัฒนาช่องทางการสื่อสารจำเป็นต้องมีกลไกการควบคุมที่มีประสิทธิภาพมากขึ้น
วิธีแก้ปัญหาเชิงทฤษฎีครั้งแรกสำหรับปัญหาการส่งข้อมูลผ่านช่องสัญญาณรบกวนถูกเสนอโดย Claude Shannon ผู้ก่อตั้งทฤษฎีข้อมูลสถิติ แชนนอนเป็นดาวเด่นในสมัยของเขา เขาเป็นหนึ่งในนักวิชาการชั้นนำของสหรัฐฯ ในฐานะนักศึกษาระดับบัณฑิตศึกษาที่ Vannevar Bush ในปี 1940 เขาได้รับรางวัลโนเบล (เพื่อไม่ให้สับสนกับรางวัลโนเบล!) ซึ่งมอบให้กับนักวิทยาศาสตร์ที่มีอายุต่ำกว่า 30 ปี ขณะอยู่ที่ Bell Labs แชนนอนเขียน A Mathematical Theory of Message Transmission (1948) ซึ่งเขาแสดงให้เห็นว่าหากแบนด์วิดท์ของช่องสัญญาณมากกว่าเอนโทรปีของแหล่งที่มาของข้อความ ข้อความนั้นก็สามารถเข้ารหัสเพื่อให้ส่งได้โดยไม่ต้อง ล่าช้าเกินควร ข้อสรุปนี้มีอยู่ในทฤษฎีบทหนึ่งที่พิสูจน์โดยแชนนอน ความหมายของมันมาจากข้อเท็จจริงที่ว่าหากมีแชนเนลที่มีแบนด์วิดท์เพียงพอ ข้อความสามารถส่งได้โดยมีความล่าช้าบ้าง นอกจากนี้เขายังแสดงให้เห็นถึงความเป็นไปได้ทางทฤษฎีของการส่งสัญญาณที่เชื่อถือได้เมื่อมีสัญญาณรบกวนในช่อง สูตร C = W log ((P+N)/N) ซึ่งแกะสลักไว้บนอนุสาวรีย์ที่เรียบง่ายของ Shannon ซึ่งติดตั้งในบ้านเกิดของเขาในมิชิแกน ถูกนำมาเปรียบเทียบกับสูตรของ Albert Einstein E = mc 2
งานของแชนนอนทำให้เกิดการวิจัยเพิ่มเติมอีกมากในด้านทฤษฎีข้อมูล แต่ไม่มีการประยุกต์ทางวิศวกรรมในทางปฏิบัติ การเปลี่ยนจากทฤษฎีไปสู่การปฏิบัติเกิดขึ้นได้ด้วยความพยายามของ Richard Hamming เพื่อนร่วมงานของ Shannon ที่ Bell Labs ผู้มีชื่อเสียงจากการค้นพบรหัสประเภทหนึ่งที่เรียกว่า "Hamming codes" มีตำนานเล่าว่าความไม่สะดวกในการทำงานกับบัตรเจาะบนเครื่องคำนวณรีเลย์ Bell Model V ในช่วงกลางทศวรรษที่ 40 ทำให้เกิดการประดิษฐ์รหัส Hamming เขาได้รับเวลาทำงานบนเครื่องในช่วงสุดสัปดาห์เมื่อไม่มีผู้ปฏิบัติงาน และตัวเขาเองก็ต้องเล่นซอกับข้อมูลดังกล่าว อย่างไรก็ตาม แฮมมิงได้เสนอรหัสที่สามารถแก้ไขข้อผิดพลาดในช่องทางการสื่อสาร รวมถึงสายส่งข้อมูลในคอมพิวเตอร์ ระหว่างโปรเซสเซอร์และหน่วยความจำเป็นหลัก รหัสแฮมมิงกลายเป็นหลักฐานว่าความเป็นไปได้ที่ระบุโดยทฤษฎีบทของแชนนอนสามารถรับรู้ได้ในทางปฏิบัติ
Hamming ตีพิมพ์บทความของเขาในปี 1950 แม้ว่ารายงานภายในจะระบุถึงทฤษฎีการเข้ารหัสของเขาจนถึงปี 1947 ดังนั้นบางคนเชื่อว่าแฮมมิงไม่ใช่แชนนอนควรได้รับการพิจารณาว่าเป็นบิดาแห่งทฤษฎีการเข้ารหัส อย่างไรก็ตามในประวัติศาสตร์ของเทคโนโลยีมันไม่มีประโยชน์ที่จะมองหาสิ่งแรก
เป็นที่แน่ชัดว่าแฮมมิงเป็นผู้เสนอ "รหัสแก้ไขข้อผิดพลาด" เป็นครั้งแรก (รหัสแก้ไขข้อผิดพลาด, ECC) การดัดแปลงที่ทันสมัยของรหัสเหล่านี้ถูกนำมาใช้ในระบบจัดเก็บข้อมูลทั้งหมดและสำหรับการแลกเปลี่ยนระหว่างโปรเซสเซอร์และ RAM รหัส Reed-Solomon หนึ่งในตัวแปรที่ใช้ในแผ่นซีดีทำให้สามารถเล่นการบันทึกได้โดยไม่มีเสียงแหลมและเสียงที่อาจทำให้เกิดรอยขีดข่วนและฝุ่นละออง มีโค้ดหลายเวอร์ชันที่อิงตาม Hamming ซึ่งแตกต่างกันในอัลกอริธึมการเข้ารหัสและจำนวนบิตตรวจสอบ รหัสดังกล่าวได้รับความสำคัญเป็นพิเศษเกี่ยวกับการพัฒนาการสื่อสารในห้วงอวกาศกับสถานีอวกาศ ตัวอย่างเช่น มีรหัส Reed-Muller ซึ่งมี 32 บิตควบคุมสำหรับเจ็ดบิตข้อมูล หรือ 26 ต่อ 6 บิต
ในบรรดารหัส ECC ล่าสุด ควรกล่าวถึงรหัส LDPC (Low-Density Parity-check Code) อันที่จริงพวกเขารู้จักกันมาประมาณสามสิบปีแล้ว แต่ในช่วงไม่กี่ปีที่ผ่านมามีการค้นพบความสนใจเป็นพิเศษในพวกเขาเมื่อโทรทัศน์ความละเอียดสูงเริ่มพัฒนา รหัส LDPC ไม่น่าเชื่อถือ 100% แต่อัตราข้อผิดพลาดสามารถปรับได้ตามระดับที่ต้องการ ในขณะที่ใช้แบนด์วิดท์ของช่องสัญญาณให้เต็มที่ “รหัสเทอร์โบ” นั้นใกล้เคียงกัน มีประสิทธิภาพเมื่อทำงานกับวัตถุที่อยู่ในห้วงอวกาศและแบนด์วิดท์ของช่องสัญญาณที่จำกัด
ชื่อของ Vladimir Alexandrovich Kotelnikov ถูกจารึกไว้อย่างแน่นหนาในประวัติศาสตร์ของทฤษฎีการเข้ารหัส ในปี 1933 ใน "Materials on Radio Communications for the First All-Union Congress on the Technical Reconstruction of Communications" เขาตีพิมพ์ผลงานเรื่อง "On the bandwidth? Ether? และ ? ชื่อของ Kotelnikov เท่ากันนั้นรวมอยู่ในชื่อของหนึ่งในทฤษฎีบทที่สำคัญที่สุดในทฤษฎีการเข้ารหัส ทฤษฎีบทนี้กำหนดเงื่อนไขภายใต้การส่งสัญญาณที่สามารถเรียกคืนได้โดยไม่สูญเสียข้อมูล
ทฤษฎีบทนี้ถูกเรียกอย่างหลากหลาย รวมทั้ง "ทฤษฎีบท WKS" (ตัวย่อ WKS นำมาจาก Whittaker, Kotelnikov, Shannon) ในบางแหล่ง ใช้ทั้งทฤษฎีบทการสุ่มตัวอย่าง Nyquist-Shannon และทฤษฎีบทการสุ่มตัวอย่าง Whittaker-Shannon และในตำรามหาวิทยาลัยในประเทศมักพบเพียง "ทฤษฎีบท Kotelnikov" อันที่จริง ทฤษฎีบทมีประวัติศาสตร์ที่ยาวนานกว่า ส่วนแรกได้รับการพิสูจน์ในปี พ.ศ. 2440 โดยนักคณิตศาสตร์ชาวฝรั่งเศส Emile Borel Edmund Whittaker สนับสนุนในปี 1915 ในปี 1920 Kinnosuki Ogura ชาวญี่ปุ่นได้ตีพิมพ์การแก้ไขงานวิจัยของ Whittaker และในปี 1928 American Harry Nyquist ได้ปรับปรุงหลักการของการแปลงเป็นดิจิทัลและการสร้างสัญญาณอะนาล็อกขึ้นใหม่

คลอดด์ แชนนอน(1916 - 2001) จากปีการศึกษาของเขาแสดงความสนใจเท่าเทียมกันในวิชาคณิตศาสตร์และวิศวกรรมไฟฟ้า ในปีพ.ศ. 2475 เขาได้เข้ามหาวิทยาลัยมิชิแกนในปี พ.ศ. 2479 ที่สถาบันเทคโนโลยีแมสซาชูเซตส์ ซึ่งเขาสำเร็จการศึกษาในปี พ.ศ. 2483 โดยได้รับปริญญา 2 องศา ได้แก่ ปริญญาโทสาขาวิศวกรรมไฟฟ้าและปริญญาเอกสาขาคณิตศาสตร์ ในปีพ.ศ. 2484 แชนนอนได้เข้าร่วมกับเบลล์แล็บบอราทอรีส์ ที่นี่เขาเริ่มพัฒนาแนวคิดที่ต่อมาส่งผลให้เกิดทฤษฎีสารสนเทศ ในปีพ. ศ. 2491 แชนนอนได้ตีพิมพ์บทความ "ทฤษฎีทางคณิตศาสตร์ของการสื่อสาร" ซึ่งมีการกำหนดแนวคิดพื้นฐานของนักวิทยาศาสตร์โดยเฉพาะการกำหนดปริมาณข้อมูลผ่านเอนโทรปีและยังเสนอหน่วยข้อมูลที่กำหนดทางเลือกของสอง ตัวเลือกที่น่าจะเป็นพอๆ กัน นั่นคือ สิ่งที่เรียกในภายหลังว่า bit . ในปี 2500-2504 แชนนอนได้ตีพิมพ์ผลงานที่พิสูจน์ทฤษฎีบทปริมาณงานสำหรับช่องทางการสื่อสารที่มีเสียงดัง ซึ่งปัจจุบันเป็นชื่อของเขา ในปี 1957 แชนนอนได้เป็นศาสตราจารย์ที่สถาบันเทคโนโลยีแมสซาชูเซตส์ ซึ่งเขาเกษียณอายุในอีก 21 ปีต่อมา ใน "การพักผ่อนที่สมควรได้รับ" แชนนอนอุทิศตนอย่างเต็มที่กับความหลงใหลในการเล่นกล เขาสร้างเครื่องเล่นกลหลายเครื่องและแม้กระทั่งสร้างทฤษฎีทั่วไปเกี่ยวกับการเล่นกล

Richard Hamming(1915 - 1998) เริ่มการศึกษาที่มหาวิทยาลัยชิคาโก ซึ่งเขาได้รับปริญญาตรีในปี 2480 ใน 1,939 เขาได้รับปริญญาโทจากมหาวิทยาลัยเนแบรสกาและปริญญาเอกในคณิตศาสตร์จากมหาวิทยาลัยอิลลินอยส์. ในปีพ.ศ. 2488 แฮมมิงเริ่มทำงานในโครงการแมนฮัตตัน ซึ่งเป็นความพยายามในการวิจัยของรัฐบาลครั้งใหญ่เพื่อสร้างระเบิดปรมาณู ในปีพ.ศ. 2489 แฮมมิงได้ร่วมงานกับเบลล์เทเลโฟนแลบบอราทอรี ซึ่งเขาทำงานร่วมกับโคล้ด แชนนอน ในปีพ.ศ. 2519 แฮมมิงได้รับตำแหน่งประธานที่โรงเรียน Naval Postgraduate School ในเมืองมอนเทอเรย์ รัฐแคลิฟอร์เนีย
ผลงานที่ทำให้เขาโด่งดัง ซึ่งเป็นการศึกษาพื้นฐานของการตรวจจับข้อผิดพลาดและการแก้ไขข้อผิดพลาด เผยแพร่โดย Hamming ในปี 1950 ในปีพ.ศ. 2499 เขามีส่วนร่วมในการพัฒนาเมนเฟรมรุ่นแรกของ IBM 650 งานของเขาวางรากฐานสำหรับภาษาโปรแกรมมิ่งซึ่งต่อมาได้พัฒนาเป็นภาษาโปรแกรมระดับสูง ในการรับรู้ถึงการมีส่วนร่วมของแฮมมิงในด้านวิทยาการคอมพิวเตอร์ IEEE ได้ก่อตั้งเหรียญรางวัลบริการดีเด่นสำหรับทฤษฎีวิทยาการคอมพิวเตอร์และระบบการตั้งชื่อตามเขา

Vladimir Kotelnikov(พ.ศ. 2451 - 2548) ในปี พ.ศ. 2469 เขาเข้าสู่แผนกวิศวกรรมไฟฟ้าของโรงเรียนเทคนิคระดับสูงของมอสโกซึ่งได้รับการตั้งชื่อตาม NE Bauman (MVTU) แต่สำเร็จการศึกษาจากสถาบันวิศวกรรมไฟฟ้าแห่งมอสโก (MPEI) ซึ่งแยกออกจาก MVTU ในฐานะสถาบันอิสระ . ในระหว่างการศึกษาระดับบัณฑิตศึกษา (1931-1933) Kotelnikov ได้กำหนดและพิสูจน์ทางคณิตศาสตร์อย่างแม่นยำว่า "ทฤษฎีบทอ้างอิง" ซึ่งต่อมาได้รับการตั้งชื่อตามเขา หลังจากจบการศึกษาจากบัณฑิตวิทยาลัยในปี 2476 Kotelnikov ยังคงสอนอยู่ที่สถาบันวิศวกรรมพลังงานมอสโก ไปทำงานที่สถาบันวิจัยการสื่อสารกลาง (TsNIIS) ในปี 1941 V. A. Kotelnikov ได้กำหนดจุดยืนที่ชัดเจนเกี่ยวกับข้อกำหนดที่ระบบที่ถอดรหัสไม่ได้ทางคณิตศาสตร์ควรได้รับ และมีการพิสูจน์ให้เห็นถึงความเป็นไปไม่ได้ในการถอดรหัส ในปี ค.ศ. 1944 Kotelnikov ดำรงตำแหน่งศาสตราจารย์คณบดีคณะวิศวกรรมวิทยุของ MPEI ซึ่งเขาทำงานจนถึงปี 1980 ในปี 1953 เมื่ออายุ 45 ปี Kotelnikov ได้รับเลือกให้เป็นสมาชิกเต็มรูปแบบของ USSR Academy of Sciences ทันที จากปี 1968 ถึง 1990 V. A. Kotelnikov ยังเป็นศาสตราจารย์ หัวหน้าภาควิชาที่สถาบันฟิสิกส์และเทคโนโลยีมอสโก
กำเนิดทฤษฎีการเข้ารหัส
ทฤษฎีการเข้ารหัส ประเภทของการเข้ารหัส แนวความคิดพื้นฐานของทฤษฎีการเข้ารหัส ก่อนหน้านี้เครื่องมือการเข้ารหัสมีบทบาทเสริมและไม่ถือว่าเป็นวิชาที่แยกต่างหากของการศึกษาทางคณิตศาสตร์ แต่ด้วยการถือกำเนิดของคอมพิวเตอร์ สถานการณ์เปลี่ยนไปอย่างสิ้นเชิง การเข้ารหัสแทรกซึมเทคโนโลยีสารสนเทศอย่างแท้จริงและเป็นประเด็นสำคัญในการแก้ปัญหาต่างๆ (ในทางปฏิบัติทั้งหมด) การเขียนโปรแกรม: ۞ แสดงข้อมูลในลักษณะที่กำหนดเอง (เช่น ตัวเลข ข้อความ กราฟิก) ในหน่วยความจำคอมพิวเตอร์ ۞ การปกป้องข้อมูลจากการเข้าถึงโดยไม่ได้รับอนุญาต ۞ สร้างภูมิคุ้มกันเสียงในระหว่างการส่งข้อมูลผ่านช่องทางการสื่อสาร ۞ การบีบอัดข้อมูลในฐานข้อมูล ทฤษฎีการเข้ารหัสเป็นสาขาหนึ่งของทฤษฎีข้อมูลที่ศึกษาวิธีการระบุข้อความด้วยสัญญาณที่เป็นตัวแทนของข้อความเหล่านั้น ภารกิจ: ประสานงานแหล่งที่มาของข้อมูลกับช่องทางการสื่อสาร วัตถุ: ข้อมูลที่ไม่ต่อเนื่องหรือต่อเนื่องที่จัดหาให้กับผู้บริโภคผ่านแหล่งข้อมูล การเข้ารหัสคือการแปลงข้อมูลเป็นสูตรที่สะดวกสำหรับการส่งผ่านช่องทางการสื่อสารเฉพาะ ตัวอย่างของการเข้ารหัสในวิชาคณิตศาสตร์คือวิธีการพิกัดที่ Descartes นำเสนอ ซึ่งทำให้สามารถศึกษาวัตถุทางเรขาคณิตผ่านนิพจน์เชิงวิเคราะห์ในรูปแบบของตัวเลข ตัวอักษรและชุดค่าผสม - สูตรได้ แนวคิดของการเข้ารหัสหมายถึงการแปลงข้อมูลให้อยู่ในรูปแบบที่สะดวกสำหรับการส่งผ่านช่องทางการสื่อสารเฉพาะ การถอดรหัสคือการกู้คืนข้อความที่ได้รับจากแบบฟอร์มที่เข้ารหัสให้อยู่ในรูปแบบที่ผู้บริโภคสามารถเข้าถึงได้
หัวข้อ 5.2. การเข้ารหัสตามตัวอักษร ในกรณีทั่วไป ปัญหาการเข้ารหัสสามารถแสดงได้ดังนี้ ให้ตัวอักษร A และ B สองตัว ซึ่งประกอบด้วยอักขระจำนวนจำกัด: และ องค์ประกอบของตัวอักษรเรียกว่าตัวอักษร ชุดคำสั่งในตัวอักษร A จะถูกเรียกว่าคำ โดยที่ n =l()=| |. , ตัวเลข n แสดงจำนวนตัวอักษรในคำและเรียกว่าความยาวของคำ, คำว่างจะแสดง: สำหรับคำ, ตัวอักษร a1 เรียกว่าจุดเริ่มต้นหรือคำนำหน้าของคำ, ตัวอักษร a เป็นการลงท้ายหรือ postfix ของคำ และสามารถรวมคำได้ ในการทำเช่นนี้ คำนำหน้าของคำที่สองจะต้องตามหลังคำนำหน้าของคำแรกทันที ในขณะที่คำใหม่จะสูญเสียสถานะโดยธรรมชาติ เว้นแต่คำใดคำหนึ่งจะว่างเปล่า การรวมของคำและแสดงไว้, การรวมของ n คำที่เหมือนกันจะถูกแสดงนอกจากนี้ ชุดของคำที่ไม่ว่างเปล่าทั้งหมดของตัวอักษร A ถูกแทนด้วย A*: ชุด A เรียกว่าตัวอักษรของข้อความ และชุด B เรียกว่าตัวอักษรเข้ารหัส ชุดคำที่ประกอบด้วยตัวอักษร B จะแสดงด้วย B*
แสดงโดย F การจับคู่คำจากตัวอักษร A ถึงตัวอักษร B จากนั้นคำนั้นเรียกว่ารหัสของคำ การเข้ารหัสเป็นวิธีสากลในการแสดงข้อมูลระหว่างการจัดเก็บ การส่ง และการประมวลผลในรูปแบบของระบบการติดต่อระหว่างองค์ประกอบข้อความและสัญญาณที่องค์ประกอบเหล่านี้สามารถแก้ไขได้ ดังนั้น โค้ดจึงเป็นกฎสำหรับการเปลี่ยนแปลงที่ชัดเจน (เช่น ฟังก์ชัน) ของข้อความจากรูปแบบการแสดงสัญลักษณ์หนึ่ง (ตัวอักษร A เริ่มต้น) ไปยังอีกรูปแบบหนึ่ง (ตัวอักษร B) โดยปกติจะไม่สูญเสียข้อมูลใดๆ กระบวนการแปลง F: A* B*→ คำของตัวอักษร A ดั้งเดิมเป็นตัวอักษร B เรียกว่าการเข้ารหัสข้อมูล กระบวนการแปลงคำกลับเรียกว่าถอดรหัส ดังนั้นการถอดรหัสจึงเป็นสิ่งที่ผกผันของ F นั่นคือ F1. เป็นคำ เนื่องจากการเข้ารหัสใด ๆ จะต้องดำเนินการถอดรหัส การทำแผนที่จะต้องย้อนกลับ (bijection) ถ้า |B|= m ดังนั้น F จะถูกเรียกว่า mimic coding กรณีทั่วไปมากที่สุดคือ B = (0, 1) การเข้ารหัสไบนารี เป็นกรณีนี้ที่พิจารณาด้านล่าง หากคำรหัสทั้งหมดมีความยาวเท่ากัน จะเรียกว่ารหัสชุดหรือชุดบล็อก ตารางรหัสสามารถระบุการเข้ารหัสตามตัวอักษร (หรือทีละตัวอักษร) ได้ การแทนที่บางส่วนจะทำหน้าที่เป็นโค้ดหรือฟังก์ชันการเข้ารหัส แล้วที่, . การเข้ารหัสแบบตัวอักษรต่อตัวอักษรจะแสดงเป็นชุดของรหัสพื้นฐาน การเข้ารหัสตามตัวอักษรใช้ได้กับชุดข้อความใดๆ ดังนั้นการเข้ารหัสตามตัวอักษรจึงเป็นวิธีที่ง่ายที่สุดและสามารถป้อนด้วยตัวอักษรที่ไม่เว้นว่างได้เสมอ . รหัสตัวอักษรจำนวนมาก
ตัวอย่าง ให้ตัวอักษร A = (0, 1, 2, 3, 4, 5, 6, 7, 8, 9) B = (0, 1) จากนั้นตารางการเข้ารหัสสามารถทดแทนได้: นี่คือการเข้ารหัส BCD เป็นหนึ่งต่อหนึ่งและสามารถถอดรหัสได้ อย่างไรก็ตาม สคีมาไม่ใช่แบบหนึ่งต่อหนึ่ง ตัวอย่างเช่น ชุดของหก 111111 สามารถจับคู่ทั้งคำ 333 และ 77 รวมทั้ง 111111, 137, 3311 หรือ 7111 บวกกับการเรียงสับเปลี่ยนใดๆ รูปแบบการเข้ารหัสตามตัวอักษรเรียกว่าคำนำหน้าหากรหัสพื้นฐานของตัวอักษรหนึ่งตัวไม่ใช่คำนำหน้าของรหัสพื้นฐานของตัวอักษรอื่น รูปแบบการเข้ารหัสตามตัวอักษรกล่าวกันว่าสามารถแยกออกได้หากคำใด ๆ ที่ประกอบด้วยรหัสพื้นฐานแยกออกเป็นรหัสพื้นฐานในลักษณะที่ไม่ซ้ำกัน การเข้ารหัสตามตัวอักษรด้วยรูปแบบที่แยกได้ช่วยให้ถอดรหัสได้ สามารถพิสูจน์ได้ว่ารูปแบบคำนำหน้านั้นแยกออกได้ เพื่อให้รูปแบบการเข้ารหัสตามตัวอักษรสามารถแยกออกได้ ความยาวของรหัสพื้นฐานต้องเป็นไปตามความสัมพันธ์ที่เรียกว่าความไม่เท่าเทียมกันของมักมิลลัน ความไม่เท่าเทียมกันของมักมิลลัน ถ้ารูปแบบการเข้ารหัสตามตัวอักษร
แยกออกไม่ได้ แล้วอสมการต่อไปนี้จะคงอยู่ รหัสเบื้องต้นของตัวอักษร a คือส่วนนำหน้าของรหัสเบื้องต้นของตัวอักษร b หัวข้อ 5.3. รหัสซ้ำซ้อนขั้นต่ำ ในทางปฏิบัติ รหัสข้อความต้องสั้นที่สุดเท่าที่จะทำได้ การเข้ารหัสตามตัวอักษรเหมาะสำหรับข้อความใดๆ แต่ถ้าไม่ทราบเกี่ยวกับชุดของคำทั้งหมดของตัวอักษร A ก็ยากที่จะกำหนดปัญหาการปรับให้เหมาะสมได้อย่างแม่นยำ อย่างไรก็ตาม ในทางปฏิบัติมักจะมีข้อมูลเพิ่มเติม ตัวอย่างเช่น สำหรับข้อความที่นำเสนอในภาษาธรรมชาติ ข้อมูลเพิ่มเติมดังกล่าวอาจเป็นการแจกแจงความน่าจะเป็นของการเกิดตัวอักษรในข้อความ จากนั้นปัญหาในการสร้างโค้ดที่เหมาะสมที่สุดจะได้รับสูตรทางคณิตศาสตร์ที่แน่นอนและวิธีแก้ปัญหาที่เข้มงวด
ให้รูปแบบการเข้ารหัสตามตัวอักษรที่แยกออกได้บางส่วน จากนั้นรูปแบบใดๆ ที่ชุดที่สั่งซื้อเป็นการเรียงสับเปลี่ยนของชุดที่สั่งซื้อก็จะแยกออกไม่ได้เช่นกัน ในกรณีนี้ หากความยาวของชุดรหัสเบื้องต้นเท่ากัน การเรียงสับเปลี่ยนในโครงการจะไม่ส่งผลต่อความยาวของข้อความที่เข้ารหัส ในกรณีที่ความยาวของรหัสพื้นฐานแตกต่างกัน ความยาวของรหัสข้อความจะขึ้นอยู่กับรหัสพื้นฐานที่ตรงกับตัวอักษรใด และองค์ประกอบของตัวอักษรในข้อความ ด้วยข้อความเฉพาะและรูปแบบการเข้ารหัสเฉพาะ คุณสามารถเลือกการเรียงสับเปลี่ยนของรหัส ซึ่งความยาวของรหัสข้อความจะน้อยที่สุด อัลกอริทึมสำหรับการกำหนดรหัสพื้นฐานซึ่งความยาวของรหัสข้อความคงที่ S จะน้อยที่สุดสำหรับรูปแบบคงที่: ۞ จัดเรียงตัวอักษรในลำดับจากมากไปน้อยของจำนวนครั้งที่เกิดขึ้น ۞ เรียงรหัสเบื้องต้นตามลำดับความยาว ۞ ใส่รหัสตามตัวอักษรตามลำดับที่กำหนด ให้ตัวอักษรและความน่าจะเป็นของการเกิดตัวอักษรในข้อความได้รับ:
โดยที่ pi คือความน่าจะเป็นของการปรากฏตัวของตัวอักษร ai และไม่รวมตัวอักษรที่มีความน่าจะเป็นเป็นศูนย์ในข้อความ และเรียงลำดับตัวอักษรจากมากไปหาน้อยของความน่าจะเป็นของข้อความที่เกิดขึ้น ซึ่งกำหนดและกำหนดไว้เป็นตัวอย่าง สำหรับรูปแบบการเข้ารหัสตามตัวอักษรที่แยกออกได้ A=(a,b), B=(0,1) ภายใต้การแจกแจงความน่าจะเป็น ต้นทุนการเข้ารหัสคือ และภายใต้การแจกแจงความน่าจะเป็น ต้นทุนการเข้ารหัสคือ
หัวข้อ 5.4. การเข้ารหัส Huffman อัลกอริธึมนี้ถูกประดิษฐ์ขึ้นในปี 1952 โดย David Huffman หัวข้อ 5.5. การเข้ารหัสเลขคณิต เช่นเดียวกับในอัลกอริธึม Huffman ทุกอย่างเริ่มต้นด้วยตารางองค์ประกอบและความน่าจะเป็นที่สอดคล้องกัน สมมติว่าตัวอักษรที่ป้อนประกอบด้วยสามองค์ประกอบเท่านั้น: a1, a2 และ a3 และในเวลาเดียวกัน P(a1) = 1/2 P(a2) = 1/3 P(a3) = 1/6 สมมติว่าเราต้องการ เพื่อเข้ารหัสลำดับ a1, a1, a2, a3 ให้เราแบ่งช่วงเวลา โดยที่ p เป็นจำนวนคงที่ 0<р<(r1)/2r, а "мощностная" граница где Tr(p)=p logr(p/(r 1))(1р)logr(l p), существенно улучшена. Имеется предположение, чт о верхняя граница полученная методом случайного выбора кода, является асимптотически точной, т. е. Ir(п,[ рп])~пТ r(2р).Доказательство или опровержение этого предположения одна из центральны х задач теории кодирования. Большинство конструкций помехоустойчивых кодов являются эффективными, когда длин а пкода достаточновелика. В связи с этим особое значение приобретают вопросы, связанны е со сложностью устройств,осуществляющих кодирование и декодирование (кодера и деко дера). Ограничения на допустимый типдекодера или его сложность могут приводить к увел ичению избыточности, необходимой для обеспечениязаданной помехоустойчивости. Напр., минимальная избыточность кода в В n 2, для крого существует декодер,состоящий из регист
ra shift และองค์ประกอบส่วนใหญ่หนึ่งรายการและแก้ไขข้อผิดพลาดหนึ่งรายการมีคำสั่ง (เปรียบเทียบกับ (2)) ในทางคณิตศาสตร์ โมเดลตัวเข้ารหัสและตัวถอดรหัสมักจะพิจารณาจากวงจรขององค์ประกอบการทำงานและความซับซ้อนจะเข้าใจได้ว่าเป็นจำนวนขององค์ประกอบในวงจร สำหรับรหัสการแก้ไขข้อผิดพลาดในคลาสที่รู้จัก ได้ทำการศึกษาอัลกอริธึมที่เป็นไปได้สำหรับ K. และ D. และได้รับขอบเขตบนของความซับซ้อนของตัวเข้ารหัสและตัวถอดรหัส ความสัมพันธ์บางอย่างยังพบได้ระหว่างอัตราการเข้ารหัส การป้องกันเสียงรบกวนของการเข้ารหัส และความซับซ้อนของตัวถอดรหัส (ดู ) อีกทิศทางหนึ่งของการวิจัยในทฤษฎีการเข้ารหัสเกี่ยวข้องกับข้อเท็จจริงที่ว่าผลลัพธ์จำนวนมาก (เช่น ทฤษฎีบทของแชนนอนและขอบเขต (3)) ไม่ได้ "สร้างสรรค์" แต่เป็นทฤษฎีบทเกี่ยวกับการมีอยู่ของลำดับอนันต์ของรหัส (Kn) ในเรื่องนี้ คำนึงถึงความพยายามที่จะทำ เพื่อพิสูจน์ผลลัพธ์เหล่านี้ในคลาสของลำดับของรหัส (Kn) สำหรับ kp มีเครื่องทัวริงที่รับรู้ว่าคำใดความยาว l เป็นของชุดในเวลาซึ่งมี ลำดับการเติบโตที่ช้าเมื่อเทียบกับ l (เช่น llog l) โครงสร้างและวิธีการใหม่บางอย่างในการหาขอบเขตที่พัฒนาขึ้นในทฤษฎีการเข้ารหัสได้นำไปสู่ความก้าวหน้าที่สำคัญในเรื่องที่ในแวบแรกนั้นห่างไกลจากปัญหาดั้งเดิมของทฤษฎีการเข้ารหัส ที่นี่เราควรชี้ให้เห็นการใช้รหัสสูงสุดด้วยการแก้ไขข้อผิดพลาดหนึ่งในวิธีการที่เหมาะสมที่สุดตามอาการของการตระหนักถึงฟังก์ชั่นของพีชคณิตของตรรกะโดยวงจรสัมผัส; การปรับปรุงพื้นฐานของขอบเขตบนสำหรับความหนาแน่นของการบรรจุซ้ำ พื้นที่แบบยุคลิดมิติด้วยลูกบอลเท่ากัน เกี่ยวกับการใช้ความไม่เท่าเทียมกัน (1) ในการประเมินความซับซ้อนของการดำเนินการตามสูตรของฟังก์ชันชั้นหนึ่งของพีชคณิตของตรรกะ แนวคิดและผลลัพธ์ของทฤษฎีการเข้ารหัสพบการพัฒนาเพิ่มเติมในปัญหาการสังเคราะห์วงจรที่แก้ไขตัวเองและวงจรที่เชื่อถือได้จากองค์ประกอบที่ไม่น่าเชื่อถือ Lit.: Shannon K., ทำงานเกี่ยวกับทฤษฎีสารสนเทศและไซเบอร์เนติกส์, ทรานส์. จากภาษาอังกฤษ, M. , 1963; Berlekamp E. , ทฤษฎีการเข้ารหัสเกี่ยวกับพีชคณิต, ทรานส์. จากภาษาอังกฤษ, M. , 1971; Peterson, W. , Weldon, E., รหัสการแก้ไขข้อผิดพลาด, ทรานส์ จากภาษาอังกฤษ 2nd ed., M. , 1976; Discrete Mathematics and Mathematical Questions of Cybernetics, vol. 1, M. , 1974, ส่วนที่ 5; Bassalygo L. A. , Zyablov V. V. , Pinsker M. S. , "ปัญหาในการส่งข้อมูล", 1977, vol. 13, No. 3, p. 517; [ใน] V. M. Sidelnikov "Mat. Sat.", 1974, v. 95, c. 1, น. 148 58. V.I. Levenshtein
สารานุกรมคณิตศาสตร์. - ม.: สารานุกรมโซเวียต. ไอ.เอ็ม.วิโนกราดอฟ 2520-2528. การเข้ารหัส ALPHABETIC COEUCLIDAN SPACE ดูเพิ่มเติมในพจนานุกรมอื่นๆ: การถอดรหัส - ดู การเข้ารหัสและการถอดรหัส ... สารานุกรมของคณิตศาสตร์ การเข้ารหัสเสียง - บทความนี้ควรเป็นวิกิ โปรดจัดรูปแบบตามกฎการจัดรูปแบบบทความ พื้นฐานของการเข้ารหัสเสียงโดยใช้พีซีคือกระบวนการแปลงการสั่นสะเทือนของอากาศเป็นการสั่นสะเทือนทางไฟฟ้า ... ภาพโค้ด Wikipedia) ดำเนินการตามคำจำกัดความ กฎเกณฑ์จำนวนทั้งสิ้นของ k ryh naz cipher K. , ... ... สารานุกรมเชิงปรัชญา การเข้ารหัสข้อมูล - การสร้างการติดต่อระหว่างองค์ประกอบข้อความและสัญญาณด้วยความช่วยเหลือซึ่งองค์ประกอบเหล่านี้สามารถแก้ไขได้ ให้ B เป็นชุดขององค์ประกอบข้อความ A เป็นตัวอักษรที่มีสัญลักษณ์ ให้เรียกลำดับสัญลักษณ์ที่จำกัด ในคำใน ... ... สารานุกรมทางกายภาพ OPTIMAL CODING - (ในด้านจิตวิทยาวิศวกรรม) (eng. การเข้ารหัสที่เหมาะสมที่สุด) การสร้างรหัสที่รับรองความเร็วและความน่าเชื่อถือสูงสุดของการรับและประมวลผลข้อมูลเกี่ยวกับวัตถุที่ควบคุมโดยผู้ปฏิบัติงานที่เป็นมนุษย์ (ดูการรับข้อมูล การถอดรหัส) ปัญหาของ K. o. ... ... สารานุกรมจิตวิทยาขนาดใหญ่ DECODING (ในด้านจิตวิทยาวิศวกรรม) - (ถอดรหัสภาษาอังกฤษ) การดำเนินการขั้นสุดท้ายของกระบวนการรับข้อมูลโดยผู้ดำเนินการของมนุษย์ประกอบด้วยการเข้ารหัสพารามิเตอร์ที่แสดงลักษณะซ้ำอีกครั้ง สถานะของวัตถุควบคุมและแปลเป็นภาพของวัตถุควบคุม ( ดูการเข้ารหัส ... ... สารานุกรมทางจิตวิทยาที่ยอดเยี่ยม
การถอดรหัส - การกู้คืนข้อความที่เข้ารหัสโดยสัญญาณที่ส่งและรับสัญญาณ (ดู การเข้ารหัส) ... พจนานุกรมเศรษฐศาสตร์และคณิตศาสตร์ CODING - CODING ขั้นตอนหนึ่งของการสร้างคำพูด ในขณะที่ "ถอดรหัส" คือการรับและตีความ ซึ่งเป็นกระบวนการในการทำความเข้าใจข้อความคำพูด ดูจิตศาสตร์... พจนานุกรมใหม่เกี่ยวกับคำศัพท์และแนวความคิดเกี่ยวกับระเบียบวิธี (ทฤษฎีและการปฏิบัติของการสอนภาษา) CODING - (การเข้ารหัสภาษาอังกฤษ) 1. การแปลงสัญญาณจากรูปแบบพลังงานหนึ่งไปเป็นอีกรูปแบบหนึ่ง 2. การแปลงสัญญาณหรือสัญญาณระบบหนึ่งไปเป็นระบบอื่นซึ่งมักเรียกว่า "การแปลงรหัส", "การเปลี่ยนรหัส" (สำหรับคำพูด, "การแปล") 3. K. (ช่วยในการจำ) ... ... สารานุกรมจิตวิทยาขนาดใหญ่ การถอดรหัส - บทความนี้เกี่ยวกับรหัสในทฤษฎีข้อมูล สำหรับความหมายอื่นของคำนี้ ดูที่ รหัส (แก้ความกำกวม) รหัสเป็นกฎ (อัลกอริทึม) สำหรับจับคู่ข้อความเฉพาะแต่ละข้อความกับชุดสัญลักษณ์ (อักขระ) (หรือสัญญาณ) ที่กำหนดไว้อย่างเคร่งครัด เรียกอีกอย่างว่ารหัส... ... การเข้ารหัสที่เหมาะสมที่สุด ข้อความเดียวกันสามารถเข้ารหัสได้หลายวิธี รหัสที่เข้ารหัสอย่างเหมาะสมคือรหัสที่ใช้เวลาน้อยที่สุดในการส่งข้อความ หากการส่งอักขระพื้นฐาน (0 หรือ 1) แต่ละตัวใช้เวลาเท่ากัน รหัสที่เหมาะสมที่สุดจะเป็นรหัสที่มีความยาวน้อยที่สุด ตัวอย่างที่ 1 กำหนดให้มีตัวแปรสุ่ม X(x1,x2,x3,x4,x5,x6,x7,x8) มีแปดสถานะพร้อมการแจกแจงความน่าจะเป็น ในการเข้ารหัสตัวอักษรแปดตัวด้วยรหัสไบนารี่แบบเดียวกัน เราต้องการสามตัว ตัวอักษร: 000, 001, 010, 011, 100, 101, 110, 111 นี้เพื่อตอบว่ารหัสนี้ดีหรือไม่คุณต้องเปรียบเทียบกับค่าที่เหมาะสมที่สุดนั่นคือกำหนดเอนโทรปี
เมื่อพิจารณาความซ้ำซ้อน L ด้วยสูตร L=1H/H0=12.75/3=0.084 เราจะเห็นว่าสามารถลดความยาวโค้ดได้ 8.4% คำถามเกิดขึ้น: เป็นไปได้ไหมที่จะเขียนรหัสโดยโดยเฉลี่ยแล้วจะมีอักขระพื้นฐานน้อยกว่าต่อตัวอักษร รหัสดังกล่าวมีอยู่ นี่คือรหัส ShannonFano และ Huffman หลักการของการสร้างรหัสที่เหมาะสมที่สุด: 1. อักขระระดับประถมศึกษาแต่ละตัวต้องมีข้อมูลจำนวนสูงสุด ด้วยเหตุนี้ จึงจำเป็นที่อักขระระดับประถมศึกษา (0 และ 1) ในข้อความที่เข้ารหัสนั้นต้องเกิดขึ้นโดยเฉลี่ยบ่อยเท่าๆ กัน เอนโทรปีในกรณีนี้จะสูงสุด 2. จำเป็นสำหรับตัวอักษรของตัวอักษรหลักซึ่งมีความเป็นไปได้สูงกว่า จะต้องกำหนดคำรหัสที่สั้นกว่าของตัวอักษรรอง
ในการวิเคราะห์แหล่งข้อมูลต่างๆ เช่นเดียวกับช่องทางการส่งข้อมูล จำเป็นต้องมีมาตรการเชิงปริมาณที่จะทำให้สามารถประมาณปริมาณข้อมูลที่อยู่ในข้อความและนำส่งโดยสัญญาณได้ การวัดดังกล่าวถูกนำมาใช้ในปี 1946 โดยนักวิทยาศาสตร์ชาวอเมริกัน C. Shannon
นอกจากนี้ เราคิดว่าแหล่งที่มาของข้อมูลไม่ต่อเนื่อง โดยให้ลำดับของข้อความเบื้องต้น (i) ซึ่งแต่ละข้อความถูกเลือกจากชุดที่ไม่ต่อเนื่อง (ตัวอักษร) a, a 2 ,...,d A; ถึงคือปริมาณตัวอักษรของแหล่งข้อมูล
ข้อความพื้นฐานแต่ละข้อความมีข้อมูลบางอย่างเป็นชุดข้อมูล (ในตัวอย่างที่พิจารณา) เกี่ยวกับสถานะของแหล่งข้อมูลที่พิจารณา ในการหาปริมาณการวัดของข้อมูลนี้ เนื้อหาเชิงความหมาย ตลอดจนระดับความสำคัญของข้อมูลนี้สำหรับผู้รับนั้นไม่สำคัญ โปรดทราบว่าก่อนที่จะได้รับข้อความ ผู้รับมักมีความไม่มั่นใจว่าฉันเป็นข้อความใด พระองค์จะทรงประทานให้จากบรรดาสิ่งที่เป็นไปได้ ความไม่แน่นอนนี้ถูกประมาณโดยใช้ความน่าจะเป็นก่อนหน้า P(i,) ของการส่งข้อความ i เราสรุปได้ว่าการวัดเชิงปริมาณตามวัตถุประสงค์ของข้อมูลที่มีอยู่ในข้อความเบื้องต้นของแหล่งข้อมูลที่ไม่ต่อเนื่องถูกกำหนดโดยความน่าจะเป็นของการเลือกข้อความที่กำหนดและกำหนด cc เป็นฟังก์ชันของความน่าจะเป็นนี้ ฟังก์ชันเดียวกันนี้แสดงถึงระดับความไม่แน่นอนที่ผู้รับข้อมูลมีเกี่ยวกับสถานะของแหล่งที่ไม่ต่อเนื่อง สรุปได้ว่าระดับความไม่แน่นอนเกี่ยวกับข้อมูลที่คาดหวังเป็นตัวกำหนดข้อกำหนดสำหรับช่องทางการส่งข้อมูล
โดยทั่วไป ความน่าจะเป็น ป(ก,)ทางเลือกของแหล่งที่มาของข้อความพื้นฐานบางอย่าง i (ต่อไปนี้เราจะเรียกว่าสัญลักษณ์) ขึ้นอยู่กับสัญลักษณ์ที่เลือกไว้ก่อนหน้านี้เช่น เป็นความน่าจะเป็นแบบมีเงื่อนไขและจะไม่ตรงกับความน่าจะเป็นก่อนหน้าของตัวเลือกดังกล่าว
ทิม นั่น ^ ป(อะ:) = 1 เนื่องจากฉันทั้งหมดเป็นกลุ่มของกิจกรรมที่สมบูรณ์
gyi) และการเลือกสัญลักษณ์เหล่านี้ดำเนินการโดยใช้การพึ่งพาฟังก์ชันบางอย่าง เจ(ก,)= P(a,) = 1 หากการเลือกสัญลักษณ์โดยแหล่งที่มาเป็นลำดับความสำคัญที่กำหนด เจ(ก,)= a „ a พี(เอ ที ก)- ความน่าจะเป็นของตัวเลือกดังกล่าว จากนั้นปริมาณข้อมูลที่มีอยู่ในสัญลักษณ์คู่หนึ่งจะเท่ากับผลรวมของจำนวนข้อมูลที่มีอยู่ในสัญลักษณ์แต่ละอัน i และ i คุณสมบัติของการวัดข้อมูลเชิงปริมาณนี้เรียกว่าการเติม .
เราเชื่อว่า ป(ก,)- ความน่าจะเป็นแบบมีเงื่อนไขในการเลือกอักขระ i หลังจากอักขระทั้งหมดที่อยู่ข้างหน้า และ พี(เอ,,i,) คือความน่าจะเป็นแบบมีเงื่อนไขของการเลือกสัญลักษณ์ i; หลังจากฉันและคนก่อนหน้าทั้งหมด แต่เนื่องจาก P (a 1, a 1) \u003d P (a) P(i,|i y) สามารถเขียนเงื่อนไขการบวกได้
เราแนะนำสัญกรณ์ ป(ก) = P p P (ar) \u003d Qและเขียนเงื่อนไข (5.1):
เราเชื่อว่า R, O* 0. ใช้นิพจน์ (5.2) เรากำหนดรูปแบบของฟังก์ชัน (p (ร).โดยแยกความแตกต่างคูณด้วย อาร์* 0 และแสดงถึง RO = อาร์เขียนลงไป
โปรดทราบว่าความสัมพันธ์ (5.3) เป็นที่พอใจสำหรับทุกๆ R f O u^^O. อย่างไรก็ตาม ข้อกำหนดนี้นำไปสู่ความคงตัวของด้านขวาและด้านซ้ายของ (5.3): Pq>"(P)=อา"(/?) - ถึง -คอนสตรัค แล้วเราก็มาถึงสมการ พีซี> "(ป) = ถึงและหลังจากบูรณาการ เราก็จะได้
ลองพิจารณาว่าเราจะเขียนใหม่
ดังนั้นภายใต้การปฏิบัติตามเงื่อนไขสองประการเกี่ยวกับคุณสมบัติของ J(a,) ปรากฎว่ารูปแบบของการพึ่งพาฟังก์ชัน เจ(ก,)เกี่ยวกับความน่าจะเป็นของการเลือกสัญลักษณ์ ที่จนถึงค่าสัมประสิทธิ์คงที่ ถึงกำหนดไว้ไม่ซ้ำกัน
ค่าสัมประสิทธิ์ ถึงมีผลเฉพาะมาตราส่วนและกำหนดระบบหน่วยวัดปริมาณข้อมูล ตั้งแต่ ln[P] F 0 ถ้าอย่างนั้นก็สมเหตุสมผลที่จะเลือก ถึง Os เพื่อให้การวัดปริมาณข้อมูล เจ(ก)เป็นบวก
ยอมรับแล้ว K=-1 จดบันทึก
ตามมาด้วยหน่วยของปริมาณข้อมูลเท่ากับข้อมูลที่เหตุการณ์เกิดขึ้นซึ่งความน่าจะเป็นเท่ากับ ฉัน.หน่วยปริมาณข้อมูลดังกล่าวเรียกว่าหน่วยธรรมชาติ มักจะสันนิษฐานว่า ถึง= - แล้ว
ดังนั้นเราจึงมาถึงหน่วยไบนารีของปริมาณข้อมูลที่มีข้อความเกี่ยวกับเหตุการณ์ที่น่าจะเป็นไปได้เท่ากันหนึ่งในสองเหตุการณ์และเรียกว่า "บิต" หน่วยนี้แพร่หลายเนื่องจากการใช้รหัสไบนารีในเทคโนโลยีการสื่อสาร การเลือกฐานของลอการิทึมในกรณีทั่วไป เราจะได้
โดยที่ลอการิทึมสามารถอยู่กับฐานใดก็ได้
คุณสมบัติการเติมของการวัดเชิงปริมาณของข้อมูลทำให้บนพื้นฐานของการแสดงออก (5.9) เพื่อกำหนดปริมาณของข้อมูลในข้อความที่ประกอบด้วยลำดับของอักขระ ความน่าจะเป็นของแหล่งที่มาที่เลือกลำดับดังกล่าวจะพิจารณาจากข้อความที่มีอยู่ทั้งหมดก่อนหน้านี้
การวัดเชิงปริมาณของข้อมูลที่มีอยู่ในข้อความเบื้องต้น a ( ไม่ได้ให้แนวคิดเกี่ยวกับจำนวนข้อมูลโดยเฉลี่ย เจ(อา) ออกโดยแหล่งที่มาเมื่อเลือกข้อความพื้นฐานหนึ่งข้อความ ดิ
จำนวนข้อมูลโดยเฉลี่ยเป็นตัวกำหนดแหล่งที่มาของข้อมูลโดยรวม และเป็นหนึ่งในลักษณะที่สำคัญที่สุดของระบบการสื่อสาร
ให้เรากำหนดลักษณะนี้สำหรับแหล่งที่มาของข้อความอิสระที่มีตัวอักษร ถึง.แสดงโดย บน)จำนวนข้อมูลเฉลี่ยต่ออักขระและเป็นการคาดหมายทางคณิตศาสตร์ของตัวแปรสุ่ม L - จำนวนข้อมูลที่มีอยู่ในอักขระที่เลือกแบบสุ่ม เอ
จำนวนข้อมูลเฉลี่ยต่อสัญลักษณ์เรียกว่าเอนโทรปีของแหล่งที่มาของข้อความอิสระ เอนโทรปีเป็นตัวบ่งชี้ค่าเฉลี่ยความไม่แน่นอนระดับความสำคัญเมื่อเลือกอักขระตัวถัดไป
จากนิพจน์ (5.10) ว่าถ้าความน่าจะเป็นอย่างใดอย่างหนึ่ง ป(ก)เท่ากับหนึ่ง (ดังนั้น อื่นๆ ทั้งหมดจะเท่ากับศูนย์) จากนั้นเอนโทรปีของแหล่งข้อมูลจะเท่ากับศูนย์ - ข้อความถูกกำหนดโดยสมบูรณ์
เอนโทรปีจะสูงสุดหากความน่าจะเป็นก่อนหน้าของสัญลักษณ์ที่เป็นไปได้ทั้งหมดเท่ากัน ถึง, เช่น. ร(() = 1 /ถึง,แล้ว
หากแหล่งที่มาเลือกสัญลักษณ์ไบนารีที่มีความน่าจะเป็น P อย่างอิสระ = พี(a x)และ P 2 \u003d 1 - P จากนั้นเอนโทรปีต่ออักขระจะเป็น
ในรูป 16.1 แสดงการพึ่งพาเอนโทรปีของแหล่งไบนารีบนความน่าจะเป็นของการเลือกจากสองสัญลักษณ์ไบนารี ตัวเลขนี้ยังแสดงให้เห็นว่าเอนโทรปีมีค่าสูงสุดที่ R = R 2 = 0,5
1 o 1 dvd - และในหน่วยไบนารีบันทึก 2 2 = 1-

ข้าว. 5.1. การพึ่งพาเอนโทรปีที่ เค = 2 กับความน่าจะเป็นของการเลือกหนึ่งในนั้น
เอนโทรปีของแหล่งที่มาพร้อมตัวเลือกสัญลักษณ์ที่เหมาะสม แต่มีขนาดตัวอักษรต่างกัน ถึง,เพิ่มขึ้นแบบลอการิทึมกับการเติบโต ถึง.
หากความน่าจะเป็นในการเลือกสัญลักษณ์ต่างกัน แสดงว่าเอนโทรปีของแหล่งที่มาลดลง ฉัน(เอ)เทียบกับค่าสูงสุดที่เป็นไปได้ H(A) psh =บันทึก ถึง.
ยิ่งมีความสัมพันธ์กันระหว่างสัญลักษณ์มากเท่าใด เสรีภาพในการเลือกสัญลักษณ์ที่ตามมาก็จะยิ่งน้อยลง และข้อมูลของสัญลักษณ์ที่เลือกใหม่ยิ่งน้อยลง เนื่องจากความไม่แน่นอนของการแจกแจงแบบมีเงื่อนไขต้องไม่เกินเอนโทรปีของการแจกแจงแบบไม่มีเงื่อนไข ระบุเอนโทรปีของแหล่งที่มาด้วยหน่วยความจำและตัวอักษร ถึงข้าม เอช(AA"),และเอนโทรปีของแหล่งที่มาไม่มีหน่วยความจำ แต่ในตัวอักษรเดียวกัน - ผ่าน บน)และพิสูจน์ความไม่เท่าเทียมกัน
โดยการแนะนำสัญกรณ์ ป(อ๊าาา")สำหรับความน่าจะเป็นแบบมีเงื่อนไขของการเลือกสัญลักษณ์ a,(/ = 1, 2, ถึง)สมมติว่าสัญลักษณ์ถูกเลือกไว้ก่อนหน้านี้ อาจิจ =1,2,ถึง)และละเว้นการเปลี่ยนแปลงเราเขียนโดยไม่มีการพิสูจน์

ซึ่งพิสูจน์ความไม่เท่าเทียมกัน (5.13)
ความเท่าเทียมกันใน (5.13) หรือ (5.14) จะเกิดขึ้นเมื่อ
ซึ่งหมายความว่าความน่าจะเป็นแบบมีเงื่อนไขในการเลือกสัญลักษณ์จะเท่ากับความน่าจะเป็นแบบไม่มีเงื่อนไขในการเลือกสัญลักษณ์นั้น ซึ่งเป็นไปได้เฉพาะแหล่งที่ไม่มีหน่วยความจำเท่านั้น
ที่น่าสนใจคือเอนโทรปีของข้อความในภาษารัสเซียคือ 1.5 หน่วยไบนารีต่ออักขระ พร้อมกันด้วยอักษรตัวเดียวกัน K= 32 ด้วยเงื่อนไขของสัญลักษณ์ที่เป็นอิสระและเป็นไปได้ H(A) tp = 5 ไบนารีต่ออักขระ ดังนั้นการมีลิงก์ภายในจึงลดเอนโทรปีลงได้ประมาณ 3.3 เท่า
ลักษณะสำคัญของแหล่งที่ไม่ต่อเนื่องคือความซ้ำซ้อน p และ:
ความซ้ำซ้อนของแหล่งข้อมูลเป็นปริมาณไร้มิติภายใน โดยธรรมชาติในกรณีที่ไม่มีความซ้ำซ้อน p u = 0
ในการส่งข้อมูลจำนวนหนึ่งจากแหล่งที่ไม่มีความสัมพันธ์ระหว่างสัญลักษณ์ ด้วยความน่าจะเป็นที่เท่ากันของสัญลักษณ์ทั้งหมด จำนวนการส่งสัญลักษณ์ขั้นต่ำที่เป็นไปได้ /7 นาที: /r 0 (/7 0 R (L สูงสุด)) ต้องระบุ. ในการส่งข้อมูลจำนวนเท่ากันจากแหล่งที่มีเอนโทรปี (สัญลักษณ์เชื่อมต่อถึงกันและมีความเป็นไปได้ไม่เท่ากัน) ต้องใช้จำนวนเฉลี่ยของสัญลักษณ์ n = n„H(A) ม. JH(A).
แหล่งที่มาที่ไม่ต่อเนื่องยังมีลักษณะเฉพาะด้วยประสิทธิภาพ ซึ่งกำหนดโดยจำนวนสัญลักษณ์ต่อหน่วยเวลา v H:
ถ้าประสิทธิภาพ ฉัน(เอ)กำหนดเป็นหน่วยไบนารี และเวลาเป็นวินาที จากนั้น บน) -คือจำนวนหน่วยไบนารีต่อวินาที สำหรับแหล่งที่มาที่ไม่ต่อเนื่องซึ่งสร้างลำดับอักขระที่อยู่กับที่ซึ่งมีความยาวเพียงพอ /? แนวคิดต่อไปนี้จะถูกนำมาใช้: ลำดับอักขระที่มาแบบทั่วไปและแบบผิดปกติ ซึ่งลำดับของความยาวทั้งหมด ป.ลำดับทั่วไปทั้งหมด NlMl (A)ที่มาที่ พี-»oo มีความน่าจะเป็นที่จะเกิดขึ้นเท่ากันโดยประมาณ
ความน่าจะเป็นรวมของการเกิดขึ้นของลำดับผิดปรกติทั้งหมดมีแนวโน้มที่จะเป็นศูนย์ ตามความเท่าเทียมกัน (5.11) สมมติว่าความน่าจะเป็นของลำดับทั่วไป /N rm (A),เอนโทรปีของแหล่งที่มาคือ logN TIin (,4) แล้ว
พิจารณาปริมาณและความเร็วในการส่งข้อมูลผ่านช่องทางแยกที่มีสัญญาณรบกวน ก่อนหน้านี้ เราพิจารณาข้อมูลที่ผลิตโดยแหล่งที่ไม่ต่อเนื่องในรูปแบบของลำดับของอักขระ (i,)
สมมติว่าข้อมูลต้นฉบับถูกเข้ารหัสและแสดงลำดับของสัญลักษณ์รหัส (ข, (/ = 1,2,..ท -ฐานรหัส) สอดคล้องกับช่องทางการส่งข้อมูลแบบไม่ต่อเนื่องที่เอาต์พุตซึ่งมีสัญลักษณ์ปรากฏขึ้น
เราคิดว่าการดำเนินการเข้ารหัสเป็นแบบหนึ่งต่อหนึ่ง - โดยลำดับของอักขระ (ข)หนึ่งสามารถคืนค่าลำดับ (i,) เช่น ด้วยสัญลักษณ์รหัสทำให้สามารถกู้คืนข้อมูลต้นฉบับได้อย่างสมบูรณ์
อย่างไรก็ตามหากเราพิจารณาตัวละครหลบหนี |?. j และสัญลักษณ์อินพุต (/>,) ดังนั้นเนื่องจากมีการรบกวนในช่องสัญญาณการรับส่งข้อมูล การกู้คืนจึงเป็นไปไม่ได้ เอนโทรปีของลำดับเอาต์พุต //(/?)
อาจมากกว่าเอนโทรปีของลำดับอินพุต HB) แต่ปริมาณข้อมูลสำหรับผู้รับไม่เพิ่มขึ้น
ในกรณีที่ดีที่สุด ความสัมพันธ์แบบหนึ่งต่อหนึ่งระหว่างอินพุตและเอาต์พุตเป็นไปได้ และข้อมูลที่เป็นประโยชน์จะไม่สูญหาย ในกรณีที่เลวร้ายที่สุด ไม่มีอะไรสามารถพูดเกี่ยวกับสัญลักษณ์อินพุตจากสัญลักษณ์เอาต์พุตของช่องสัญญาณการรับส่งข้อมูล ข้อมูลที่เป็นประโยชน์หายไปในช่องอย่างสมบูรณ์
ให้เราประเมินการสูญเสียข้อมูลในช่องสัญญาณรบกวนและปริมาณข้อมูลที่ส่งผ่านช่องสัญญาณรบกวน เราถือว่าตัวละครถูกส่งอย่างถูกต้องหากได้รับอักขระที่ส่ง 6
สัญลักษณ์ bjด้วยหมายเลขเดียวกัน (/= เจ)สำหรับช่องสัญญาณในอุดมคติที่ไม่มีสัญญาณรบกวน เราเขียนว่า:

โดยสัญลักษณ์ bj- ที่ช่องสัญญาณออกเนื่องจากความไม่เท่าเทียมกัน (5.21)
ความไม่แน่นอนเป็นสิ่งที่หลีกเลี่ยงไม่ได้ เราสามารถสันนิษฐานได้ว่าข้อมูลในสัญลักษณ์ ข ฉันไม่ส่งอย่างสมบูรณ์และบางส่วนหายไปในช่องเนื่องจากการรบกวน ตามแนวคิดของการวัดข้อมูลเชิงปริมาณ เราจะถือว่านิพจน์เชิงตัวเลขของความไม่แน่นอนที่เกิดขึ้นที่เอาต์พุตของช่องสัญญาณหลังจากได้รับสัญลักษณ์ ft ; :
และกำหนดปริมาณข้อมูลที่สูญหายในช่องระหว่างการส่งสัญญาณ
แก้ไขฟุต และค่าเฉลี่ย (5.22) จากสัญลักษณ์ที่เป็นไปได้ทั้งหมด เราได้รับผลรวม
ซึ่งกำหนดปริมาณข้อมูลที่สูญหายในช่องเมื่อส่งสัญลักษณ์พื้นฐานผ่านช่องสัญญาณโดยไม่มีหน่วยความจำเมื่อได้รับสัญลักษณ์ bj(ท).
เมื่อหาค่าเฉลี่ยผลรวม (5.23) ของฟุตทั้งหมด เราจะได้ค่า Z?) ซึ่งเราแทนด้วย n(ใน/ใน-กำหนดจำนวนข้อมูลที่สูญเสียไปเมื่อส่งอักขระหนึ่งตัวผ่านช่องสัญญาณแบบไม่มีหน่วยความจำ:

ที่ไหน P^bjbjj-ความน่าจะเป็นร่วมกันของเหตุการณ์ที่เมื่อถ่ายทอด
สัญลักษณ์ ข.มันจะใช้สัญลักษณ์ ขที
เอช [w/ขึ้นอยู่กับลักษณะของแหล่งข้อมูลบน
อินพุตช่อง วีและลักษณะความน่าจะเป็นของช่องทางการสื่อสาร ตามแชนนอนในทฤษฎีการสื่อสารทางสถิติ n(ใน/ในเรียกว่าไม่น่าเชื่อถือของช่อง
เอนโทรปีแบบมีเงื่อนไข HB/B, เอนโทรปีของแหล่งที่ไม่ต่อเนื่อง
ที่ช่องสัญญาณเข้า สูง(W)และเอนโทรปี และ ^B) ที่เอาต์พุตไม่สามารถ
เชิงลบ. ในแชนเนลที่ปราศจากการรบกวน ความไม่น่าเชื่อถือของแชนเนล
n(v/v = 0. ตาม (5.20) เราสังเกตว่า H^v/v^
และความเท่าเทียมกันจะเกิดขึ้นก็ต่อเมื่ออินพุตและเอาต์พุตของช่องสัญญาณมีความเป็นอิสระทางสถิติเท่านั้น:
สัญลักษณ์เอาต์พุตไม่ได้ขึ้นอยู่กับสัญลักษณ์อินพุต - กรณีของช่องสัญญาณขาดหรือสัญญาณรบกวนที่รุนแรงมาก
เช่นเคย สำหรับลำดับทั่วไป เราสามารถเขียน
ที่กล่าวว่าในที่ที่ไม่มีการแทรกแซง, ความไม่น่าเชื่อถือของมัน
ภายใต้ข้อมูลที่ส่งโดยเฉลี่ยผ่านช่องทาง J[ b/ ต่อสัญลักษณ์ เราเข้าใจความแตกต่างระหว่างปริมาณข้อมูลที่ช่องสัญญาณเข้า เจ(บี)และข้อมูลหายในช่อง /?)
หากแหล่งข้อมูลและช่องสัญญาณไม่มีหน่วยความจำแล้ว
นิพจน์ (5.27) กำหนดเอนโทรปีของสัญลักษณ์เอาต์พุตของช่อง ข้อมูลบางส่วนที่เอาต์พุตของช่องสัญญาณมีประโยชน์ และส่วนที่เหลือเป็นเท็จ เนื่องจากสร้างขึ้นจากการรบกวนในช่อง ขอให้สังเกตว่า น[v/ 2?) แสดงข้อมูลเกี่ยวกับการรบกวนในช่อง และความแตกต่าง i(d)-I(d/d) - ข้อมูลที่เป็นประโยชน์ที่ส่งผ่านช่อง
โปรดทราบว่าลำดับส่วนใหญ่ที่เกิดขึ้นที่เอาต์พุตของช่องสัญญาณนั้นผิดปรกติและมีความเป็นไปได้โดยรวมน้อยมาก
ตามกฎแล้วประเภทการรบกวนที่พบบ่อยที่สุดจะถูกนำมาพิจารณา - เสียงเสริม ยังไม่มีข้อความ(t);สัญญาณที่เอาต์พุตของช่องสัญญาณมีรูปแบบ:
สำหรับสัญญาณที่ไม่ต่อเนื่อง สัญญาณรบกวนที่เทียบเท่าตาม (5.28) จะมีโครงสร้างที่ไม่ต่อเนื่อง สัญญาณรบกวนเป็นลำดับสุ่มแบบไม่ต่อเนื่อง คล้ายกับลำดับของสัญญาณอินพุตและเอาต์พุต ให้เราแสดงสัญลักษณ์ของตัวอักษรของสัญญาณรบกวนเพิ่มเติมในช่องที่ไม่ต่อเนื่องเป็น C1 = 0, 1,2, ตู่- หนึ่ง). ความน่าจะเป็นของการเปลี่ยนแปลงแบบมีเงื่อนไขในช่องดังกล่าว
เพราะ และ (^B/?) และ (B) ดังนั้นข้อมูลของลำดับเอาต์พุตของช่องสัญญาณแบบไม่ต่อเนื่อง #(/) สัมพันธ์กับอินพุต ข(ท)หรือในทางกลับกัน และ (B) - H ^ ใน / ใน) (5)
กล่าวอีกนัยหนึ่ง ข้อมูลที่ส่งผ่านช่องสัญญาณต้องไม่เกินข้อมูลที่ป้อน
หากช่องอินพุตได้รับค่าเฉลี่ย x kสัญลักษณ์ในหนึ่งวินาทีจึงเป็นไปได้ที่จะกำหนดอัตราการถ่ายโอนข้อมูลโดยเฉลี่ยผ่านช่องสัญญาณที่มีสัญญาณรบกวน:
ที่ไหน Н(В) = วี k J(B,B^ -ประสิทธิภาพของแหล่งสัญญาณที่ช่องสัญญาณเข้า; n (ใน / ใน) \u003d U ถึง n (ใน, ใน) ~ความไม่น่าเชื่อถือของช่องต่อหน่วยเวลา H (B) = V k H^B^- ประสิทธิภาพของแหล่งที่มาที่เกิดจากเอาต์พุตของช่อง (ให้ส่วนหนึ่งของข้อมูลที่เป็นประโยชน์และเป็นส่วนหนึ่งของข้อมูลเท็จ) H ^ ใน / B ^ \u003d U ถึง 1 / (ใน / นิ้ว)- จำนวนข้อมูลเท็จ
สร้างการรบกวนในช่องต่อหน่วยเวลา
แนวคิดเกี่ยวกับจำนวนและความเร็วในการส่งข้อมูลผ่านช่องทางหนึ่งๆ สามารถนำไปใช้กับส่วนต่างๆ ของช่องทางการสื่อสารได้ นี่อาจเป็นส่วน "อินพุตตัวเข้ารหัส - เอาต์พุตตัวถอดรหัส"
โปรดทราบว่าการขยายส่วนของช่องที่อยู่ระหว่างการพิจารณา เป็นไปไม่ได้ที่จะเกินความเร็วของส่วนประกอบใดๆ การเปลี่ยนแปลงที่ไม่สามารถย้อนกลับได้จะทำให้ข้อมูลสูญหาย การแปลงแบบย้อนกลับไม่ได้ไม่เพียงแต่ผลกระทบจากการรบกวนเท่านั้น แต่ยังรวมถึงการตรวจจับ การถอดรหัสด้วยรหัสที่มีความซ้ำซ้อน มีวิธีลดความสูญเสียที่ได้รับ นี่คือ "แผนกต้อนรับโดยทั่วไป"
พิจารณาแบนด์วิดท์ของช่องสัญญาณที่ไม่ต่อเนื่องและทฤษฎีบทการเข้ารหัสที่เหมาะสมที่สุด แชนนอนแนะนำคุณลักษณะที่กำหนดอัตราการถ่ายโอนข้อมูลสูงสุดที่เป็นไปได้ผ่านช่องสัญญาณที่มีคุณสมบัติที่ทราบ (สัญญาณรบกวน) ภายใต้ข้อจำกัดจำนวนหนึ่งเกี่ยวกับชุดสัญญาณอินพุต นี่คือแบนด์วิดท์ของช่อง C สำหรับช่องสัญญาณแบบแยก

โดยที่ค่าสูงสุดได้รับการปกป้องโดยแหล่งสัญญาณเข้าที่เป็นไปได้ วีที่ให้ไว้ วีคและระดับเสียงของตัวอักษรที่ป้อนเข้า ต.
ตามคำจำกัดความของปริมาณงานของช่องสัญญาณแบบแยก เราเขียน
โปรดทราบว่า C = 0 พร้อมอินพุตและเอาต์พุตอิสระ (ระดับเสียงสูงในช่อง) และตามนั้น
ในกรณีที่ไม่มีสัญญาณรบกวนสัญญาณรบกวน
สำหรับช่องสัญญาณสมมาตรแบบไบนารีที่ไม่มีหน่วยความจำ

ข้าว. 5.2.
กราฟของการพึ่งพาความจุของช่องสัญญาณไบนารีบนพารามิเตอร์ Rแสดงในรูป 5.2. ที่ R= แบนด์วิดธ์ 1/2 ช่องสัญญาณ ค = 0, เงื่อนไขเอนโทรปี
//(/?//?) = 1. ความสนใจในทางปฏิบัติ
กราฟแสดงที่ 0
ทฤษฎีบทพื้นฐานของแชนนอนเกี่ยวกับการเข้ารหัสที่เหมาะสมที่สุดนั้นเกี่ยวข้องกับแนวคิดเรื่องความจุ สูตรสำหรับช่องสัญญาณแยกมีดังนี้: ถ้าประสิทธิภาพของแหล่งข้อความ บน)น้อยกว่าแบนด์วิดท์ของช่อง C:
มีวิธีการเข้ารหัสและถอดรหัสที่เหมาะสมที่สุดภายใต้ความน่าจะเป็นของข้อผิดพลาดหรือความไม่น่าเชื่อถือของช่อง n[a!A j อาจมีขนาดเล็กตามอำเภอใจ ถ้า
ไม่มีทางเช่นนั้น
ตามทฤษฎีบทของแชนนอน ค่าจำกัด กับคือค่าขีดจำกัดของอัตราการถ่ายโอนข้อมูลที่ปราศจากข้อผิดพลาดผ่านช่องสัญญาณ แต่สำหรับช่องสัญญาณที่มีเสียงดัง จะไม่มีการระบุวิธีการค้นหารหัสที่เหมาะสมที่สุด อย่างไรก็ตาม ทฤษฎีบทได้เปลี่ยนมุมมองเกี่ยวกับความเป็นไปได้พื้นฐานของเทคโนโลยีการส่งข้อมูลอย่างรุนแรง ก่อนแชนนอน เชื่อกันว่าในช่องสัญญาณรบกวน มีความเป็นไปได้ที่จะเกิดข้อผิดพลาดเล็กน้อยโดยพลการโดยลดอัตราการถ่ายโอนข้อมูลเป็นศูนย์ ตัวอย่างเช่น การเพิ่มขึ้นของความแม่นยำในการสื่อสารอันเป็นผลมาจากการซ้ำซ้อนของอักขระในช่องสัญญาณแบบไม่มีหน่วยความจำ
เป็นที่ทราบกันดีว่ามีหลักฐานมากมายเกี่ยวกับทฤษฎีบทของแชนนอน ทฤษฎีบทได้รับการพิสูจน์ว่าเป็นแชนเนลที่ไม่มีหน่วยความจำแบบไม่ต่อเนื่องโดยการเข้ารหัสแบบสุ่ม ในกรณีนี้ ชุดของรหัสที่สุ่มเลือกทั้งหมดสำหรับแหล่งที่มาที่กำหนดและช่องที่กำหนดจะได้รับการพิจารณา และข้อเท็จจริงของแนวทางเชิงซีมโทติคเป็นศูนย์ของความน่าจะเป็นเฉลี่ยของการถอดรหัสที่ผิดพลาดเหนือรหัสทั้งหมดจะถูกยืนยันด้วยการเพิ่มระยะเวลาไม่จำกัดของ ลำดับข้อความ ดังนั้น มีเพียงความจริงของการมีอยู่ของรหัสที่ให้ความเป็นไปได้ของการถอดรหัสที่ปราศจากข้อผิดพลาดเท่านั้นที่พิสูจน์ได้ อย่างไรก็ตาม วิธีการเข้ารหัสที่ไม่คลุมเครือไม่ได้เสนอให้ ในเวลาเดียวกัน ในการพิสูจน์ เป็นที่แน่ชัดว่าในขณะที่รักษาความเท่าเทียมกันของเอนโทรปีของชุดของลำดับข้อความและชุดรหัสที่สอดคล้องกันแบบหนึ่งต่อหนึ่งที่ใช้สำหรับการส่งทั้งมวล วีควรมีการแนะนำความซ้ำซ้อนเพิ่มเติมเพื่อเพิ่มการพึ่งพาซึ่งกันและกันของลำดับของสัญลักษณ์รหัส ซึ่งสามารถทำได้โดยการขยายชุดของลำดับรหัสที่เลือกคำรหัส
แม้ว่าที่จริงแล้วทฤษฎีบทการเข้ารหัสหลักสำหรับช่องสัญญาณที่มีเสียงดังไม่ได้บ่งบอกถึงวิธีการเลือกรหัสใดรหัสหนึ่งที่ชัดเจนและไม่มีการพิสูจน์ทฤษฎีบท แต่ก็สามารถแสดงให้เห็นได้ว่ารหัสที่เลือกแบบสุ่มส่วนใหญ่เมื่อเข้ารหัสข้อความที่มีความยาวเพียงพอ ลำดับ เกินความน่าจะเป็นเฉลี่ยของการถอดรหัสที่ผิดพลาดเล็กน้อย อย่างไรก็ตาม ความเป็นไปได้ในทางปฏิบัติของการเข้ารหัสในบล็อคแบบยาวนั้นถูกจำกัด เนื่องจากความยากลำบากในการใช้ระบบหน่วยความจำและการประมวลผลเชิงตรรกะของลำดับขององค์ประกอบโค้ดจำนวนมาก ตลอดจนความล่าช้าในการส่งและการประมวลผลข้อมูลที่เพิ่มขึ้น อันที่จริง สิ่งที่น่าสนใจเป็นพิเศษคือผลลัพธ์ที่ทำให้สามารถกำหนดความน่าจะเป็นของการถอดรหัสที่ผิดพลาดในระยะเวลาจำกัด พีบล็อกรหัสที่ใช้ ในทางปฏิบัติจะถูก จำกัด ไว้ที่ค่าความล่าช้าปานกลางและเพิ่มความน่าจะเป็นในการส่งโดยใช้แบนด์วิดท์ของช่องสัญญาณที่ไม่สมบูรณ์
 การเลือกโปรแกรมประมวลผล GIS
การเลือกโปรแกรมประมวลผล GIS การคำนวณและวิเคราะห์วงจรไฟฟ้ากระแสสลับ
การคำนวณและวิเคราะห์วงจรไฟฟ้ากระแสสลับ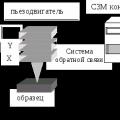 กล้องจุลทรรศน์โพรบสแกน สถานะปัจจุบันและการพัฒนาของกล้องจุลทรรศน์โพรบสแกน
กล้องจุลทรรศน์โพรบสแกน สถานะปัจจุบันและการพัฒนาของกล้องจุลทรรศน์โพรบสแกน