การเข้ารหัสข้อมูลข้อความ การเข้ารหัสอักขระ - PIE wiki
มาตรฐานนี้เสนอในปี 1991 โดย Unicode Consortium, Unicode Inc. ซึ่งเป็นองค์กรไม่แสวงหาผลกำไร การใช้มาตรฐานนี้ทำให้สามารถเข้ารหัสอักขระจำนวนมากจากสคริปต์ต่างๆ ได้: ในเอกสาร Unicode อักขระจีน อักขระคณิตศาสตร์ ตัวอักษรของอักษรกรีก อักษรละติน และอักษรซีริลลิกสามารถอยู่ร่วมกันได้ ดังนั้นการสลับหน้าโค้ดจึงไม่จำเป็น
มาตรฐานประกอบด้วยสองส่วนหลัก: ชุดอักขระสากล (UCS) และรูปแบบการแปลง Unicode (UTF) ชุดอักขระสากลกำหนดความสอดคล้องแบบหนึ่งต่อหนึ่งของอักขระกับรหัส - องค์ประกอบของพื้นที่โค้ดที่แสดงจำนวนเต็มที่ไม่เป็นลบ ตระกูลการเข้ารหัสกำหนดการแสดงเครื่องของลำดับรหัส UCS
มาตรฐาน Unicode ได้รับการพัฒนาโดยมีเป้าหมายเพื่อสร้างการเข้ารหัสอักขระตัวเดียวสำหรับภาษาเขียนสมัยใหม่และภาษาเขียนโบราณจำนวนมาก อักขระแต่ละตัวในมาตรฐานนี้มีการเข้ารหัสแบบ 16 บิต ซึ่งช่วยให้ครอบคลุมอักขระจำนวนมากอย่างไม่มีใครเทียบได้เมื่อเทียบกับการเข้ารหัสแบบ 8 บิตที่ยอมรับก่อนหน้านี้ ข้อแตกต่างที่สำคัญอีกประการหนึ่งระหว่าง Unicode และระบบการเข้ารหัสอื่นๆ คือไม่เพียงแต่กำหนดรหัสเฉพาะให้กับอักขระแต่ละตัวเท่านั้น แต่ยังกำหนดคุณลักษณะต่างๆ ของอักขระนี้ด้วย เช่น:
ประเภทอักขระ (ตัวพิมพ์ใหญ่ ตัวพิมพ์เล็ก ตัวเลข เครื่องหมายวรรคตอน ฯลฯ);
คุณลักษณะของตัวละคร (การแสดงจากซ้ายไปขวาหรือจากขวาไปซ้าย การเว้นวรรค การขึ้นบรรทัดใหม่ ฯลฯ);
ตัวพิมพ์ใหญ่หรือตัวพิมพ์เล็กที่สอดคล้องกัน (สำหรับตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ตามลำดับ);
ค่าตัวเลขที่สอดคล้องกัน (สำหรับอักขระตัวเลข)
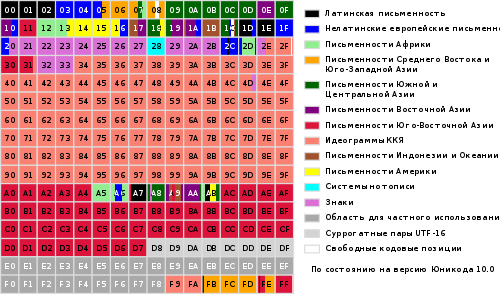
ช่วงทั้งหมดของรหัสตั้งแต่ 0 ถึง FFFF แบ่งออกเป็นชุดย่อยมาตรฐานหลายชุด ซึ่งแต่ละชุดสอดคล้องกับตัวอักษรของภาษาหรือกลุ่ม อักขระพิเศษคล้ายคลึงกันในหน้าที่ของตน แผนภาพด้านล่างแสดงรายการทั่วไปของชุดย่อย Unicode 3.0 (รูปที่ 2)
รูปที่ 2
มาตรฐาน Unicode เป็นพื้นฐานสำหรับการจัดเก็บและข้อความในระบบคอมพิวเตอร์สมัยใหม่จำนวนมาก อย่างไรก็ตาม มันเข้ากันไม่ได้กับอินเทอร์เน็ตโปรโตคอลส่วนใหญ่ เนื่องจากรหัสของมันสามารถมีค่าไบต์ใดๆ และโปรโตคอลมักจะใช้ไบต์ 00 - 1F และ FE - FF เป็นโอเวอร์เฮด เพื่อให้เกิดความเข้ากันได้ จึงมีการพัฒนารูปแบบการแปลง Unicode หลายรูปแบบ (UTF, รูปแบบการแปลง Unicode) ซึ่ง UTF-8 เป็นรูปแบบที่พบบ่อยที่สุดในปัจจุบัน รูปแบบนี้กำหนดกฎการแปลงต่อไปนี้สำหรับแต่ละ รหัสยูนิโค้ดเป็นชุดของไบต์ (หนึ่งถึงสาม) ที่เหมาะสมสำหรับการขนส่งโดยอินเทอร์เน็ตโปรโตคอล
ในที่นี้ x, y, z หมายถึงบิตของซอร์สโค้ดที่ควรแยกออก โดยเริ่มจากบิตที่มีนัยสำคัญน้อยที่สุด และป้อนไบต์ผลลัพธ์จากขวาไปซ้ายจนกระทั่งตำแหน่งที่ระบุทั้งหมดเต็ม
การพัฒนาต่อไปมาตรฐาน Unicode เกี่ยวข้องกับการเพิ่มระดับภาษาใหม่ เช่น อักขระในช่วง 10,000 - 1FFFF, 20000 - 2FFFF เป็นต้น ซึ่งควรจะรวมการเข้ารหัสสำหรับสคริปต์ของภาษาที่ตายแล้วซึ่งไม่รวมอยู่ในตารางด้านบน รูปแบบ UTF-16 ใหม่ได้รับการพัฒนาเพื่อเข้ารหัสอักขระเพิ่มเติมเหล่านี้
ดังนั้นจึงมี 4 วิธีหลักในการเข้ารหัส Unicode ไบต์:
UTF-8: 128 อักขระถูกเข้ารหัสในหนึ่งไบต์ (รูปแบบ ASCII), 1920 อักขระถูกเข้ารหัสใน 2 ไบต์ ((โรมัน, กรีก, ซิริลลิก, คอปติก, อาร์เมเนีย, ฮิบรู, อักขระอารบิก), 63488 อักขระถูกเข้ารหัสใน 3 ไบต์ (ภาษาจีน , ญี่ปุ่นและอื่น ๆ ) อักขระที่เหลือ 2,147,418,112 ตัว (ยังไม่ได้ใช้) สามารถเข้ารหัสได้ 4, 5 หรือ 6 ไบต์
UCS-2: อักขระแต่ละตัวแสดงด้วย 2 ไบต์ การเข้ารหัสนี้รวมเฉพาะอักขระ 65,535 ตัวแรกจากรูปแบบ Unicode
UTF-16: นี่เป็นส่วนขยายของ UCS-2 และมีอักขระ Unicode 1 114 112 ตัว อักขระ 65,535 ตัวแรกจะแสดงด้วย 2 ไบต์ ส่วนที่เหลือเป็น 4 ไบต์
USC-4: อักขระแต่ละตัวถูกเข้ารหัสใน 4 ไบต์
Unicode
โลโก้ Unicode Consortium
Unicode(บ่อยที่สุด) หรือ Unicode(อ. Unicode) เป็นมาตรฐานการเข้ารหัสอักขระที่ช่วยให้สามารถแสดงอักขระในภาษาเขียนเกือบทั้งหมด
มาตรฐานนี้เสนอในปี 1991 โดยองค์กรไม่แสวงหาผลกำไร "Unicode Consortium" (อังกฤษ. Unicode Consortium, Unicode Inc.).
การใช้มาตรฐานนี้ทำให้สามารถเข้ารหัสอักขระจำนวนมากจากสคริปต์ต่างๆ ได้: ในเอกสาร Unicode อักขระจีน อักขระคณิตศาสตร์ ตัวอักษรของอักษรกรีก อักษรละติน และ Cyrillic สามารถอยู่ร่วมกันได้ ดังนั้นการเปลี่ยนหน้าโค้ดจึงไม่จำเป็น
มาตรฐานประกอบด้วยสองส่วนหลัก: ชุดอักขระสากล (อังกฤษ. UCS ชุดอักขระสากล) และตระกูลการเข้ารหัส (eng. UTF รูปแบบการแปลง Unicode).
ชุดอักขระสากลกำหนดความสอดคล้องแบบหนึ่งต่อหนึ่งของอักขระกับรหัส - องค์ประกอบของพื้นที่โค้ดที่แสดงถึงจำนวนเต็มที่ไม่เป็นลบ ตระกูลการเข้ารหัสกำหนดการแสดงเครื่องของลำดับรหัส UCS
รหัส Unicode แบ่งออกเป็นหลายส่วน พื้นที่ที่มีรหัสตั้งแต่ U + 0000 ถึง U + 007F มีอักขระ ASCII พร้อมรหัสที่เกี่ยวข้อง ถัดไปเป็นพื้นที่ของอักขระของสคริปต์ เครื่องหมายวรรคตอน และสัญลักษณ์ทางเทคนิคต่างๆ
รหัสบางส่วนสงวนไว้สำหรับใช้ในอนาคต ภายใต้อักขระ Cyrillic พื้นที่ของอักขระที่มีรหัสจาก U + 0400 ถึง U + 052F จาก U + 2DE0 ถึง U + 2DFF จาก U + A640 ถึง U + A69F จะได้รับการจัดสรร (ดู Cyrillic ใน Unicode)
- 1 ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode
- 2 เวอร์ชัน Unicode
- 3 พื้นที่โค้ด
- 4 ระบบการเข้ารหัส
- 4.1 นโยบายกิจการร่วมค้า
- 4.2 การรวมและการทำซ้ำสัญลักษณ์
- 5 การปรับเปลี่ยนตัวละคร
- 6 อัลกอริธึมการทำให้เป็นมาตรฐาน
- 6.1 NFD
- 6.2 NFC
- 6.3 NFKD
- 6.4 NFKC
- 6.5 ตัวอย่าง
- 7 การเขียนแบบสองทิศทาง
- 8 สัญลักษณ์เด่น
- 9 ISO / IEC 10646
- 10 วิธีในการนำเสนอ
- 10.1 UTF-8
- คำสั่ง 10.2 ไบต์
- 10.3 Unicode และการเข้ารหัสแบบดั้งเดิม
- 10.4 การดำเนินการ
- 11 วิธีการป้อนข้อมูล
- 11.1 Microsoft Windows
- 11.2 แมคอินทอช
- 11.3 GNU / Linux
- 12 ปัญหา Unicode
- 13 "Unicode" หรือ "Unicode"?
ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode
ในช่วงปลายทศวรรษ 1980 อักขระ 8 บิตได้กลายเป็นมาตรฐาน ในเวลาเดียวกัน มีการเข้ารหัส 8 บิตที่แตกต่างกันมากมาย และการเข้ารหัสใหม่ก็ปรากฏขึ้นอย่างต่อเนื่อง
สิ่งนี้อธิบายได้ด้วยการขยายขอบเขตของภาษาที่รองรับอย่างต่อเนื่องและโดยความปรารถนาที่จะสร้างการเข้ารหัสที่เข้ากันได้กับภาษาอื่นบางส่วน (ตัวอย่างทั่วไปคือการเกิดขึ้นของการเข้ารหัสทางเลือกสำหรับภาษารัสเซียเนื่องจากการเอารัดเอาเปรียบของตะวันตก โปรแกรมที่สร้างขึ้นสำหรับการเข้ารหัส CP437)
เป็นผลให้เกิดปัญหาหลายประการ:
- ปัญหาของ "krakozyabr";
- ปัญหาชุดอักขระจำกัด
- ปัญหาในการแปลงการเข้ารหัสแบบหนึ่งเป็นอีกแบบหนึ่ง
- ปัญหาแบบอักษรที่ซ้ำกัน
ปัญหา "krakozyabr"- ปัญหาการแสดงเอกสารเข้ารหัสผิด ปัญหาสามารถแก้ไขได้โดยการแนะนำวิธีการระบุการเข้ารหัสที่ใช้อย่างสม่ำเสมอหรือโดยการแนะนำการเข้ารหัสเดียว (ทั่วไป) สำหรับทุกคน
ปัญหาชุดอักขระจำกัด... ปัญหาสามารถแก้ไขได้ด้วยการเปลี่ยนฟอนต์ภายในเอกสาร หรือโดยการแนะนำการเข้ารหัส "แบบกว้าง" การเปลี่ยนแบบอักษรได้รับการฝึกฝนมาเป็นเวลานานในโปรแกรมประมวลผลคำ และมักใช้แบบอักษรที่มีการเข้ารหัสที่ไม่ได้มาตรฐานซึ่งเรียกว่า "แบบอักษร Dingbat". เป็นผลให้เมื่อพยายามโอนเอกสารไปยังระบบอื่น อักขระที่ไม่ได้มาตรฐานทั้งหมดกลายเป็น "krakozyabry"
ปัญหาของการแปลงการเข้ารหัสหนึ่งเป็นอีกตัวหนึ่ง... ปัญหาสามารถแก้ไขได้ด้วยการรวบรวมตารางการแปลงสำหรับการเข้ารหัสแต่ละคู่หรือโดยการใช้การแปลงระหว่างกลางเป็นการเข้ารหัสที่สามที่มีอักขระทั้งหมดของการเข้ารหัสทั้งหมด
ปัญหาฟอนต์ซ้ำ... สำหรับการเข้ารหัสแต่ละครั้ง แบบอักษรจะถูกสร้างขึ้น แม้ว่าชุดอักขระในการเข้ารหัสจะใกล้เคียงกันเพียงบางส่วนหรือทั้งหมด ปัญหาสามารถแก้ไขได้โดยการสร้างแบบอักษร "ขนาดใหญ่" ซึ่งจะมีการเลือกอักขระที่จำเป็นสำหรับการเข้ารหัสที่กำหนดในภายหลัง อย่างไรก็ตาม สิ่งนี้จำเป็นต้องมีการสร้างรีจีสทรีสัญลักษณ์เดียวเพื่อกำหนดว่าสิ่งใดสอดคล้องกับสิ่งใด
ความต้องการการเข้ารหัส "กว้าง" เดียวได้รับการยอมรับ การเข้ารหัสที่มีความยาวผันแปรซึ่งใช้กันอย่างแพร่หลายในเอเชียตะวันออกพบว่าใช้งานยากเกินไป ดังนั้นจึงตัดสินใจใช้อักขระที่มีความกว้างคงที่
การใช้อักขระแบบ 32 บิตดูสิ้นเปลืองเกินไป ดังนั้นจึงตัดสินใจใช้อักขระแบบ 16 บิต
Unicode เวอร์ชันแรกเป็นการเข้ารหัสที่มีขนาดอักขระคงที่ 16 บิต กล่าวคือ จำนวนรหัสทั้งหมดคือ 2 16 (65 536) ตั้งแต่นั้นมา อักขระต่างๆ ก็ได้แสดงด้วยเลขฐานสิบหกสี่หลัก (เช่น U + 04F0). ในเวลาเดียวกัน มีการวางแผนที่จะเข้ารหัสใน Unicode ไม่ใช่อักขระที่มีอยู่ทั้งหมด แต่เฉพาะที่จำเป็นในชีวิตประจำวันเท่านั้น ต้องวางสัญลักษณ์ที่ใช้ไม่บ่อยใน "พื้นที่ใช้งานส่วนตัว" ซึ่งเดิมครอบครองรหัส U + D800 ... U + F8FF.
เพื่อที่จะใช้ Unicode เป็นตัวกลางในการแปลงการเข้ารหัสที่แตกต่างกันให้กันและกัน อักขระทั้งหมดที่แสดงในการเข้ารหัสที่มีชื่อเสียงที่สุดทั้งหมดจึงถูกรวมไว้ด้วย
อย่างไรก็ตาม ในอนาคต ได้มีการตัดสินใจเข้ารหัสสัญลักษณ์ทั้งหมด และด้วยเหตุนี้ จึงมีการขยายโดเมนโค้ดอย่างมาก
ในเวลาเดียวกัน รหัสอักขระเริ่มถูกมองว่าไม่ใช่ค่า 16 บิต แต่เป็นตัวเลขนามธรรมที่สามารถแสดงในคอมพิวเตอร์ได้หลายวิธี (ดูวิธีการแสดง)
เนื่องจากในระบบคอมพิวเตอร์จำนวนหนึ่ง (เช่น Windows NT) อักขระ 16 บิตคงที่ถูกใช้เป็นการเข้ารหัสเริ่มต้นแล้ว จึงตัดสินใจเข้ารหัสอักขระที่สำคัญที่สุดทั้งหมดภายใน 65,536 ตำแหน่งแรกเท่านั้น (ภาษาอังกฤษที่เรียกว่า ระนาบหลายภาษาพื้นฐาน BMP).
พื้นที่ที่เหลือใช้สำหรับ "อักขระเพิ่มเติม" (อังกฤษ. ตัวละครเสริม): ระบบการเขียนภาษาที่สูญพันธุ์หรือตัวอักษรจีน สัญลักษณ์ทางคณิตศาสตร์และดนตรีที่ไม่ค่อยได้ใช้
เพื่อความเข้ากันได้กับระบบ 16 บิตแบบเก่า ระบบ UTF-16 ถูกประดิษฐ์ขึ้นโดยที่ตำแหน่ง 65,536 แรก ยกเว้นตำแหน่งจากช่วง U + D800 ... U + DFFF จะแสดงเป็นตัวเลข 16 บิตโดยตรง และส่วนที่เหลือจะแสดงเป็น "คู่ตัวแทน »(องค์ประกอบแรกของคู่จากภูมิภาค U + D800… U + DBFF องค์ประกอบที่สองของคู่จากภูมิภาค U + DC00… U + DFFF) สำหรับคู่รักตัวแทน ส่วนหนึ่งของโค้ดสเปซ (2048 ตำแหน่ง) ถูกใช้ กัน "สำหรับใช้ส่วนตัว"
เนื่องจาก UTF-16 สามารถแสดงอักขระได้เพียง 2 20 +2 16 −2048 (1 112 064) ตัวเลขนี้จึงถูกเลือกให้เป็นค่าสุดท้ายของพื้นที่โค้ด Unicode (ช่วงโค้ด: 0x000000-0x10FFFF)
แม้ว่าพื้นที่โค้ด Unicode จะขยายเกิน 2-16 เร็วเท่าเวอร์ชัน 2.0 แต่อักขระตัวแรกในพื้นที่ "บนสุด" จะถูกวางไว้ในเวอร์ชัน 3.1 เท่านั้น
บทบาทของการเข้ารหัสนี้ในภาคเว็บมีการเติบโตอย่างต่อเนื่อง เมื่อต้นปี 2010 ส่วนแบ่งของเว็บไซต์ที่ใช้ Unicode อยู่ที่ประมาณ 50%
เวอร์ชัน Unicode
ทำงานในการสรุปมาตรฐานต่อไป เวอร์ชันใหม่จะออกเมื่อตารางสัญลักษณ์เปลี่ยนแปลงและได้รับการอัปเดต ในขณะเดียวกันก็มีการออกเอกสาร ISO / IEC 10646 ใหม่
มาตรฐานแรกเปิดตัวในปี 1991 ครั้งสุดท้ายในปี 2559 มาตรฐานถัดไปคาดว่าในฤดูร้อนปี 2560 มาตรฐานเวอร์ชัน 1.0-5.0 ได้รับการตีพิมพ์เป็นหนังสือและมี ISBN
หมายเลขเวอร์ชันของมาตรฐานประกอบด้วยตัวเลขสามหลัก (เช่น "4.0.1) ตัวเลขที่สามจะเปลี่ยนไปเมื่อมีการเปลี่ยนแปลงเล็กน้อยในมาตรฐานที่ไม่เพิ่มอักขระใหม่
รหัสพื้นที่
แม้ว่าสัญกรณ์รูปแบบ UTF-8 และ UTF-32 จะอนุญาตให้เข้ารหัสจุดโค้ดได้มากถึง 2,331 (2,147,483,648) แต่ได้ตัดสินใจใช้เพียง 1,112,064 เพื่อความเข้ากันได้กับ UTF-16 อย่างไรก็ตาม แม้ในตอนนี้ก็เกินพอแล้ว ในเวอร์ชัน 6.0 ใช้จุดโค้ดน้อยกว่า 110,000 จุดเล็กน้อย (กราฟิก 109,242 และสัญลักษณ์อื่นๆ 273 ตัว)
พื้นที่รหัสแบ่งออกเป็น17 เครื่องบิน(อ. เครื่องบิน) 2 16 (65 536) อักขระแต่ละตัว เครื่องบินภาคพื้นดิน ( เครื่องบิน 0) ถูกเรียก ขั้นพื้นฐาน (ขั้นพื้นฐาน) และมีสัญลักษณ์ของสคริปต์ที่พบบ่อยที่สุด เครื่องบินที่เหลือเป็นส่วนเพิ่มเติม ( เสริม). เครื่องบินลำแรก ( เครื่องบิน 1) ใช้สำหรับสคริปต์ทางประวัติศาสตร์เป็นหลัก ส่วนที่สอง ( เครื่องบิน2) - สำหรับอักษรจีนที่ไม่ค่อยได้ใช้ (CJK) ตัวที่สาม ( เครื่องบิน 3) สงวนไว้สำหรับอักษรจีนโบราณ เครื่องบิน 15 และ 16 สงวนไว้สำหรับการใช้งานส่วนตัว
เพื่อแสดงว่า อักขระ Unicodeสัญกรณ์ของแบบฟอร์ม “U + xxxx"(สำหรับรหัส 0 ... FFFF) หรือ" U + xxxxxx"(สำหรับรหัส 10000 ... FFFFF) หรือ" U + xxxxxx"(สำหรับรหัส 100000 ... 10FFFF) โดยที่ xxx- ตัวเลขฐานสิบหก ตัวอย่างเช่น อักขระ "i" (U + 044F) มีรหัส 044F 16 = 1103 10
ระบบเข้ารหัส
ระบบการเข้ารหัสสากล (Unicode) คือชุดของสัญลักษณ์กราฟิกและวิธีการเข้ารหัสสำหรับการประมวลผลข้อมูลข้อความด้วยคอมพิวเตอร์
สัญลักษณ์กราฟิกเป็นสัญลักษณ์ที่มีภาพที่มองเห็นได้ อักขระกราฟิกตรงข้ามกับตัวควบคุมและการจัดรูปแบบอักขระ
สัญลักษณ์กราฟิกรวมถึงกลุ่มต่อไปนี้:
- ตัวอักษรที่มีอย่างน้อยหนึ่งตัวอักษรที่รองรับ
- ตัวเลข;
- เครื่องหมายวรรคตอน;
- สัญญาณพิเศษ (คณิตศาสตร์, เทคนิค, อุดมการณ์, ฯลฯ );
- ตัวคั่น
Unicode เป็นระบบสำหรับการแสดงข้อความเชิงเส้น อักขระที่มีตัวยกหรือตัวห้อยเพิ่มเติมสามารถแสดงเป็นลำดับของรหัสที่สร้างขึ้นตามกฎบางอย่าง (อักขระประกอบ) หรือเป็นอักขระตัวเดียว (เวอร์ชันเสาหิน อักขระที่ประกอบล่วงหน้า) บน ช่วงเวลานี้(2014) เชื่อกันว่าตัวอักษรของสคริปต์ขนาดใหญ่ทั้งหมดรวมอยู่ใน Unicode และหากสัญลักษณ์มีอยู่ในเวอร์ชันผสมก็ไม่จำเป็นต้องทำซ้ำในรูปแบบเสาหิน
นโยบายสมาคม
สมาคมไม่ได้สร้างกลุ่มใหม่ แต่ระบุลำดับของสิ่งต่าง ๆ ที่กำหนดไว้ ตัวอย่างเช่น เพิ่มรูปภาพอิโมจิเพราะตัวดำเนินการภาษาญี่ปุ่น การสื่อสารเคลื่อนที่พวกเขาถูกนำมาใช้กันอย่างแพร่หลาย
ในการทำเช่นนี้ การเพิ่มสัญลักษณ์จะต้องผ่านกระบวนการที่ซับซ้อน และตัวอย่างเช่น สัญลักษณ์ของรูเบิลรัสเซียผ่านพ้นไปในสามเดือนเพียงเพราะได้รับสถานะทางการ
เครื่องหมายการค้าจะถูกเข้ารหัสโดยวิธีการยกเว้นเท่านั้น ดังนั้นใน Unicode จึงไม่มีการตั้งค่าสถานะ Windows หรือ Apple apple
เมื่ออักขระปรากฏในการเข้ารหัสแล้ว อักขระจะไม่เคลื่อนที่หรือหายไป หากคุณต้องการเปลี่ยนลำดับของอักขระ สิ่งนี้ไม่ได้ทำโดยการเปลี่ยนตำแหน่ง แต่โดยลำดับการจัดเรียงระดับประเทศ มีการรับประกันอื่นๆ ที่ละเอียดกว่าในเรื่องความเสถียร - ตัวอย่างเช่น ตารางการทำให้เป็นมาตรฐานจะไม่เปลี่ยนแปลง
การรวมและการทำซ้ำสัญลักษณ์
สัญลักษณ์เดียวกันสามารถมีได้หลายรูปแบบ ใน Unicode แบบฟอร์มเหล่านี้มีอยู่ในจุดโค้ดเดียว:
- ถ้ามันเกิดขึ้นในอดีต ตัวอย่างเช่น ตัวอักษรภาษาอาหรับมีสี่รูปแบบ: แยกออก ตอนต้น ตรงกลาง และตอนท้าย
- หรือถ้าใช้ภาษาหนึ่งในรูปแบบหนึ่งและอีกภาษาหนึ่ง - อีกภาษาหนึ่ง บัลแกเรีย Cyrillic แตกต่างจากรัสเซียและตัวอักษรจีนจากภาษาญี่ปุ่น
ในทางกลับกัน หากฟอนต์ในอดีตมีจุดโค้ดที่ต่างกันสองจุด ฟอนต์จะยังคงต่างกันใน Unicode ซิกมากรีกตัวพิมพ์เล็กมีสองรูปแบบ และมีตำแหน่งต่างกัน ตัวอักษรละตินขยาย Å (A พร้อมวงกลม) และเครื่องหมายอังสตรอม Å อักษรกรีกμ และคำนำหน้า "ไมโคร" µ เป็นสัญลักษณ์ที่แตกต่างกัน
แน่นอน อักขระที่คล้ายกันในสคริปต์ที่ไม่เกี่ยวข้องจะถูกใส่ในจุดโค้ดที่ต่างกัน ตัวอย่างเช่น ตัวอักษร A ในภาษาละติน ซิริลลิก กรีก และเชอโรคีเป็นสัญลักษณ์ที่แตกต่างกัน
เป็นเรื่องยากมากที่อักขระตัวเดียวกันจะอยู่ในตำแหน่งโค้ดที่แตกต่างกันสองตำแหน่งเพื่อทำให้การประมวลผลข้อความง่ายขึ้น จังหวะทางคณิตศาสตร์และจังหวะเดียวกันเพื่อแสดงความนุ่มนวลของเสียงเป็นสัญลักษณ์ต่างกัน ตัวที่สองถือเป็นตัวอักษร
การปรับเปลี่ยนตัวอักษร
การแสดงอักขระ "Y" (U + 0419) ในรูปแบบของอักขระฐาน "I" (U + 0418) และอักขระดัดแปลง "" (U + 0306)
อักขระกราฟิกใน Unicode แบ่งออกเป็นแบบขยายและไม่ขยาย (แบบไม่มีความกว้าง) อักขระที่ไม่ขยายจะไม่ใช้พื้นที่ในบรรทัดเมื่อแสดง โดยเฉพาะอย่างยิ่ง เครื่องหมายเน้นเสียงและเครื่องหมายกำกับเสียงอื่นๆ อักขระทั้งแบบขยายและแบบไม่ขยายมีรหัสของตนเอง สัญลักษณ์เพิ่มเติมจะเรียกว่าพื้นฐาน (อังกฤษ. ตัวละครหลัก) และแบบไม่ขยาย - ดัดแปลง (eng. การรวมตัวอักษร); และฝ่ายหลังไม่สามารถพบกันได้โดยอิสระ ตัวอย่างเช่น อักขระ "á" สามารถแสดงเป็นลำดับของอักขระหลัก "a" (U + 0061) และอักขระตัวแก้ไข "́" (U + 0301) หรือเป็นอักขระแบบเสาหิน "á" (U + 00E1).
อักขระการปรับเปลี่ยนชนิดพิเศษคือตัวเลือกรูปแบบ (อังกฤษ ตัวเลือกรูปแบบต่างๆ). ใช้เฉพาะกับสัญลักษณ์ที่กำหนดตัวแปรดังกล่าว ในเวอร์ชัน 5.0 ตัวเลือกสไตล์ถูกกำหนดไว้สำหรับซีรีส์ สัญลักษณ์ทางคณิตศาสตร์สำหรับสัญลักษณ์ของตัวอักษรมองโกเลียแบบดั้งเดิมและสำหรับสัญลักษณ์ของการเขียนสี่เหลี่ยมจัตุรัสมองโกเลีย
อัลกอริธึมการทำให้เป็นมาตรฐาน
เนื่องจากสามารถแสดงสัญลักษณ์เดียวกันได้ รหัสต่างๆการเปรียบเทียบสตริงทีละไบต์เป็นไปไม่ได้ อัลกอริทึมการทำให้เป็นมาตรฐาน แบบฟอร์มการทำให้เป็นมาตรฐาน) แก้ปัญหานี้โดยการแปลงข้อความเป็นรูปแบบมาตรฐาน
การคัดเลือกนักแสดงทำได้โดยการแทนที่สัญลักษณ์ด้วยสัญลักษณ์ที่เทียบเท่ากันโดยใช้ตารางและกฎเกณฑ์ "การสลายตัว" เป็นการแทนที่ (การสลายตัว) ของอักขระหนึ่งตัวเป็นอักขระที่เป็นส่วนประกอบหลายตัว และ "องค์ประกอบ" ในทางกลับกัน เป็นการแทนที่ (การเชื่อมต่อ) ของอักขระที่เป็นส่วนประกอบหลายตัวด้วยอักขระเดียว
มาตรฐาน Unicode กำหนดอัลกอริธึมการปรับข้อความให้เป็นมาตรฐาน 4 แบบ ได้แก่ NFD, NFC, NFKD และ NFKC
NFD
เอ็นเอฟดี อ. NSการทำให้เป็นปกติ NS orm NS ("ด" จากภาษาอังกฤษ. NSสิ่งแวดล้อม) รูปแบบการทำให้เป็นมาตรฐาน D คือการสลายตัวตามรูปแบบบัญญัติ - อัลกอริธึมตามที่ทำการเปลี่ยนสัญลักษณ์เสาหินแบบเรียกซ้ำ (อังกฤษ. อักขระที่เตรียมไว้ล่วงหน้า) เป็นองค์ประกอบหลายอย่าง (อังกฤษ. อักขระผสม) ตามตารางการสลายตัว
Å U + 00C5 →
NS คุณ + 0041
̊ U + 030A
ṩ U + 1E69 →
NS ยู + 0073
̣ คุณ + 0323
̇ คุณ + 0307
ḍ̇ U + 1E0B คุณ + 0323 →
NS คุณ + 0064
̣ คุณ + 0323
̇ คุณ + 0307
NS ยู + 0071 คุณ + 0307 คุณ + 0323 →
NS ยู + 0071
̣ คุณ + 0323
̇ คุณ + 0307 NFC
เอ็นเอฟซี อังกฤษ NSการทำให้เป็นปกติ NS orm ค ("ค" จากภาษาอังกฤษ. คองค์ประกอบ) รูปแบบการทำให้เป็นมาตรฐาน C เป็นอัลกอริธึมตามที่การสลายตัวตามรูปแบบบัญญัติและองค์ประกอบตามรูปแบบบัญญัติถูกดำเนินการตามลำดับ ขั้นแรก การสลายตัวตามรูปแบบบัญญัติ (อัลกอริทึม NFD) จะลดข้อความลงในรูปแบบ D จากนั้นองค์ประกอบตามรูปแบบบัญญัติซึ่งตรงกันข้ามกับ NFD จะประมวลผลข้อความตั้งแต่ต้นจนจบโดยคำนึงถึงกฎต่อไปนี้:
- เครื่องหมาย NSนับ อักษรย่อหากมีคลาสการแก้ไขเท่ากับศูนย์ตามตารางอักขระ Unicode
- ในลำดับของอักขระใด ๆ ที่ขึ้นต้นด้วย character NS, เครื่องหมาย คถูกปิดกั้นจาก NSเฉพาะในกรณีที่ระหว่าง NSและ คมีสัญลักษณ์อะไรบ้าง NSซึ่งเป็นค่าเริ่มต้นหรือมีคลาสการแก้ไขที่เหมือนกันหรือมากกว่า than ค... กฎนี้ใช้กับสตริงที่ผ่านการสลายตัวตามรูปแบบบัญญัติเท่านั้น
- ถือว่าเป็นสัญลักษณ์ หลักคอมโพสิตหากมีการสลายตัวตามรูปแบบบัญญัติในตารางอักขระ Unicode (หรือการสลายตัวตามรูปแบบบัญญัติสำหรับฮันกุลและไม่รวมอยู่ในรายการยกเว้น)
- เครื่องหมาย NSสามารถนำมารวมกับสัญลักษณ์ก่อนได้ Yถ้าหากว่ามีองค์ประกอบหลักอยู่ด้วย Z, เทียบเท่ากับลำดับตามบัญญัติ<NS, Y>;
- ถ้าตัวต่อไป คไม่ถูกบล็อกโดยอักขระฐานเริ่มต้นล่าสุดที่พบ หลี่และสามารถนำมารวมกันได้สำเร็จก่อนจากนั้น หลี่แทนที่ด้วยคอมโพสิต L-C, NS คลบออก.
o U + 006F
̂ คุณ + 0302 → →
ชม คุณ + 0048
① U + 2460 →
1 คุณ + 0031
カ ยู + FF76 →
カ U + 30AB →
fi ยู + FB01
fi ยู + FB01
NS ผม คุณ + 0066 คุณ + 0069
NS ผม คุณ + 0066 คุณ + 0069
2 ⁵ คุณ + 0032 คุณ + 2075
2 ⁵ คุณ + 0032 คุณ + 2075
2 ⁵ คุณ + 0032 คุณ + 2075
2 5 คุณ + 0032 คุณ + 0035
2 5 คุณ + 0032 คุณ + 0035
ẛ̣ U + 1E9B คุณ + 0323
เ ̣ ̇ U + 017F คุณ + 0323 คุณ + 0307
ẛ ̣ U + 1E9B คุณ + 0323
NS ̣ ̇ ยู + 0073 คุณ + 0323 คุณ + 0307
ṩ U + 1E69
NS คุณ + 0439
และ ̆ คุณ + 0438 คุณ + 0306
NS คุณ + 0439
และ ̆ คุณ + 0438 คุณ + 0306
NS คุณ + 0439
อี คุณ + 0451
อี ̈ คุณ + 0435 ยู + 0308
อี คุณ + 0451
อี ̈ คุณ + 0435 ยู + 0308
อี คุณ + 0451
NS คุณ + 0410
NS คุณ + 0410
NS คุณ + 0410
NS คุณ + 0410
NS คุณ + 0410
が U + 304C
か ゙ U + 304B คุณ + 3099
が U + 304C
か ゙ U + 304B คุณ + 3099
が U + 304C
Ⅷ คุณ + 2167
Ⅷ คุณ + 2167
Ⅷ คุณ + 2167
วี ผม ผม ผม U + 0056 U + 0049 U + 0049 U + 0049
วี ผม ผม ผม U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
ค ̧ U + 0063 คุณ + 0327
ç U + 00E7
ค ̧ U + 0063 คุณ + 0327
ç U + 00E7 จดหมายสองทิศทาง
มาตรฐาน Unicode รองรับการเขียนภาษาทั้งในทิศทางจากซ้ายไปขวา (eng. ซ้ายไปขวา LTR) และเขียนจากขวาไปซ้าย (อังกฤษ. ขวาไปซ้าย RTL) - ตัวอย่างเช่น ตัวอักษรอารบิกและฮีบรู ในทั้งสองกรณี อักขระจะถูกจัดเก็บในลำดับที่ "เป็นธรรมชาติ" แอปพลิเคชันให้การแสดงผลโดยคำนึงถึงทิศทางที่ต้องการของจดหมาย
นอกจากนี้ Unicode ยังรองรับข้อความแบบรวมที่รวมส่วนย่อยที่มีทิศทางต่างกันของตัวอักษร คุณลักษณะนี้เรียกว่า แบบสองทิศทาง(อ. ข้อความแบบสองทิศทาง BiDi). ตัวประมวลผลข้อความแบบง่ายบางตัว (เช่น in โทรศัพท์มือถือ) รองรับ Unicode แต่ไม่รองรับแบบสองทิศทาง อักขระ Unicode ทั้งหมดแบ่งออกเป็นหลายประเภท: เขียนจากซ้ายไปขวา เขียนจากขวาไปซ้าย และเขียนในทิศทางใดก็ได้ สัญลักษณ์ของหมวดหมู่หลัง (ส่วนใหญ่เป็นเครื่องหมายวรรคตอน) เมื่อแสดง ให้เปลี่ยนทิศทางของข้อความโดยรอบ
สัญลักษณ์เด่น
ไดอะแกรมของระนาบหลายภาษาพื้นฐานของ Unicode
Unicode มีสคริปต์สมัยใหม่แทบทั้งหมด รวมถึง:
- ภาษาอาหรับ
- อาร์เมเนีย
- เบงกาลี
- พม่า,
- กริยา
- กรีก
- จอร์เจียน
- เทวนาครี,
- ชาวยิว
- ซิริลลิก
- ภาษาจีน (ตัวอักษรจีนถูกใช้อย่างแข็งขันในภาษาญี่ปุ่นและบางครั้งในภาษาเกาหลี)
- คอปติก
- เขมร
- ละติน
- ทมิฬ
- เกาหลี (อังกูล),
- เชอโรกี
- เอธิโอเปีย
- ภาษาญี่ปุ่น (ซึ่งรวมถึงตัวอักษรพยางค์ อักษรจีนด้วย)
อื่น ๆ.
เพื่อวัตถุประสงค์ทางวิชาการ มีการเพิ่มสคริปต์ทางประวัติศาสตร์มากมาย รวมถึง: อักษรรูนดั้งเดิม อักษรรูนตุรกีโบราณ อักษรกรีกโบราณ อักษรอียิปต์โบราณ อักษรรูน การเขียนมายัน ตัวอักษรอิทรุสกัน
Unicode มีสัญลักษณ์ทางคณิตศาสตร์และดนตรีและรูปสัญลักษณ์มากมาย
โดยหลักการแล้ว Unicode ไม่รวมธงประจำรัฐ โลโก้บริษัทและผลิตภัณฑ์ แม้ว่าจะพบในแบบอักษร (เช่น โลโก้ Apple ในการเข้ารหัส MacRoman (0xF0) หรือโลโก้ Windows ในแบบอักษร Wingdings (0xFF)) ในฟอนต์ Unicode โลโก้ควรวางในพื้นที่อักขระที่กำหนดเองเท่านั้น
ISO / IEC 10646
Unicode Consortium ทำงานอย่างใกล้ชิดกับ กลุ่มทำงาน ISO / IEC / JTC1 / SC2 / WG2 ซึ่งกำลังพัฒนามาตรฐานสากล 10646 (ISO / IEC 10646) การซิงโครไนซ์เกิดขึ้นระหว่างมาตรฐาน Unicode และ ISO / IEC 10646 แม้ว่าแต่ละมาตรฐานจะใช้คำศัพท์และระบบเอกสารของตนเอง
ความร่วมมือของ Unicode Consortium กับองค์การระหว่างประเทศเพื่อการมาตรฐาน (eng. องค์การระหว่างประเทศเพื่อการมาตรฐาน ISO ) เริ่มในปี 1991 ในปี 1993 ISO ได้ออกมาตรฐาน DIS 10646.1 ในการซิงโครไนซ์กับมัน Consortium ได้อนุมัติเวอร์ชัน 1.1 ของมาตรฐาน Unicode ซึ่งเพิ่มอักขระเพิ่มเติมจาก DIS 10646.1 เป็นผลให้ค่าของอักขระที่เข้ารหัสใน Unicode 1.1 และ DIS 10646.1 เหมือนกันทุกประการ
ในอนาคตความร่วมมือระหว่างทั้งสององค์กรยังคงดำเนินต่อไป ในปี 2000 มาตรฐาน Unicode 3.0 ถูกซิงโครไนซ์กับ ISO / IEC 10646-1: 2000 ISO / IEC 10646 เวอร์ชันที่สามที่กำลังจะมีขึ้นจะถูกซิงโครไนซ์กับ Unicode 4.0 บางทีข้อกำหนดเหล่านี้อาจได้รับการเผยแพร่เป็นมาตรฐานเดียว
เช่นเดียวกับรูปแบบ UTF-16 และ UTF-32 ในมาตรฐาน Unicode มาตรฐาน ISO / IEC 10646 ยังมีรูปแบบการเข้ารหัสอักขระหลักสองรูปแบบ: UCS-2 (2 ไบต์ต่ออักขระ คล้ายกับ UTF-16) และ UCS-4 (4 ไบต์ต่ออักขระ คล้ายกับ UTF-32) UCS แปลว่า มัลติออคเต็ตอเนกประสงค์(มัลติไบต์) รหัสชุดอักขระ(อ. ชุดอักขระรหัสหลายออคเต็ตสากล ). UCS-2 ถือได้ว่าเป็นส่วนย่อยของ UTF-16 (UTF-16 โดยไม่มีคู่ตัวแทน) และ UCS-4 เป็นคำพ้องความหมายสำหรับ UTF-32
ความแตกต่างระหว่างมาตรฐาน Unicode และ ISO / IEC 10646:
- ความแตกต่างเล็กน้อยในคำศัพท์
- ISO / IEC 10646 ไม่รวมส่วนที่จำเป็นในการปรับใช้การรองรับ Unicode อย่างสมบูรณ์:
- ไม่มีข้อมูลเกี่ยวกับการเข้ารหัสอักขระแบบไบนารี
- ไม่มีคำอธิบายอัลกอริธึมการเปรียบเทียบ (อังกฤษ. การเปรียบเทียบ) และการเรนเดอร์ (eng. การแสดงผล) ตัวอักษร;
- ไม่มีรายการคุณสมบัติของสัญลักษณ์ (เช่น ไม่มีรายการคุณสมบัติที่จำเป็นในการปรับใช้การสนับสนุนแบบสองทิศทาง (อังกฤษ. สองทิศทาง) ตัวอักษร)
วิธีการนำเสนอ
Unicode มีการแสดงหลายรูปแบบ (eng. รูปแบบการแปลง Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) และ UTF-32 (UTF-32BE, UTF-32LE) แบบฟอร์ม UTF-7 ยังได้รับการพัฒนาสำหรับการส่งผ่านช่องสัญญาณเจ็ดบิต แต่เนื่องจากความไม่เข้ากันกับ ASCII จึงไม่แพร่กระจายและไม่รวมอยู่ในมาตรฐาน เมื่อวันที่ 1 เมษายน พ.ศ. 2548 มีการเสนอเรื่องตลกสองเรื่อง: UTF-9 และ UTF-18 (RFC 4042)
ระบบที่ใช้ Microsoft Windows NT และ Windows 2000 และ Windows XP จะใช้แบบฟอร์ม UTF-16LE เป็นหลัก ระบบปฏิบัติการที่คล้ายกับ UNIX GNU / Linux, BSD และ Mac OS X ใช้ UTF-8 สำหรับไฟล์และ UTF-32 หรือ UTF-8 สำหรับการประมวลผลอักขระใน หน่วยความจำเข้าถึงโดยสุ่ม.
Punycode เป็นอีกรูปแบบหนึ่งของการเข้ารหัสลำดับของอักขระ Unicode ในสิ่งที่เรียกว่าลำดับ ACE ซึ่งประกอบด้วยเฉพาะอักขระที่เป็นตัวอักษรและตัวเลขคละกัน ตามที่อนุญาตในชื่อโดเมน
UTF-8
UTF-8 คือการแสดง Unicode ที่ให้ความเข้ากันได้ดีที่สุดกับระบบรุ่นเก่าที่ใช้อักขระ 8 บิต
ข้อความที่มีเฉพาะอักขระที่มีตัวเลขน้อยกว่า 128 จะถูกแปลงเป็นข้อความ ASCII ธรรมดาเมื่อเขียนด้วย UTF-8 ในทางกลับกัน ในข้อความ UTF-8 ไบต์ใดๆ ที่มีค่าน้อยกว่า 128 แสดง อักขระ ASCIIด้วยรหัสเดียวกัน
อักขระ Unicode ที่เหลือจะแสดงเป็นลำดับตั้งแต่ 2 ถึง 6 ไบต์ (อันที่จริงแล้วมีเพียง 4 ไบต์เท่านั้น เนื่องจากไม่มีอักขระที่มีโค้ดที่มากกว่า 10FFFF ใน Unicode และไม่มีแผนที่จะแนะนำอักขระเหล่านี้ใน ในอนาคต) ซึ่งไบต์แรกจะมีรูปแบบเสมอ 11xxxxxx, และที่เหลือ - 10xxxxxx... ไม่มีการใช้คู่ตัวแทนใน UTF-8 4 ไบต์เพียงพอที่จะเขียนอักขระ Unicode ใดๆ
รูปแบบ UTF-8 ถูกประดิษฐ์ขึ้นเมื่อวันที่ 2 กันยายน 1992 โดย Ken Thompson และ Rob Pike และนำไปใช้ในแผน 9... ปัจจุบันมาตรฐาน UTF-8 ได้รับการประดิษฐานอย่างเป็นทางการใน RFC 3629 และ ISO / IEC 10646 ภาคผนวก D
อักขระ UTF-8 มาจาก Unicode ดังนี้:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
เป็นไปได้ในทางทฤษฎี แต่ไม่รวมอยู่ในมาตรฐาน:
0x0020000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
แม้ว่า UTF-8 จะอนุญาตให้คุณระบุอักขระเดียวกันได้หลายวิธี แต่อักขระที่สั้นที่สุดเท่านั้นที่ถูกต้อง แบบฟอร์มที่เหลือควรถูกปฏิเสธด้วยเหตุผลด้านความปลอดภัย
ลำดับไบต์
ในสตรีมข้อมูล UTF-16 ไบต์ต่ำสามารถเขียนก่อนไบต์สูง (อังกฤษ UTF-16 little-endian) หรือหลังอันที่เก่ากว่า (eng. UTF-16 บิ๊กเอนด์). ในทำนองเดียวกัน มีสองตัวเลือกสำหรับการเข้ารหัสแบบสี่ไบต์ - UTF-32LE และ UTF-32BE
เพื่อกำหนดรูปแบบของการแสดง Unicode ที่จุดเริ่มต้น ไฟล์ข้อความลายเซ็นถูกเขียน - อักขระ U + FEFF (ช่องว่างไม่แตกที่มีความกว้างเป็นศูนย์) เรียกอีกอย่างว่า เครื่องหมายลำดับไบต์(อ. เครื่องหมายคำสั่งไบต์ (BOM)). ทำให้สามารถแยกความแตกต่างระหว่าง UTF-16LE และ UTF-16BE เนื่องจากไม่มีอักขระ U + FFFE บางครั้งก็ใช้เพื่อแสดงถึงรูปแบบ UTF-8 แม้ว่าแนวคิดของลำดับไบต์จะใช้ไม่ได้กับรูปแบบนี้ ไฟล์ที่เป็นไปตามแบบแผนนี้จะเริ่มต้นด้วยลำดับไบต์เหล่านี้:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
น่าเสียดายที่วิธีนี้ไม่สามารถแยกแยะระหว่าง UTF-16LE และ UTF-32LE ได้อย่างน่าเชื่อถือ เนื่องจาก Unicode อนุญาตให้ใช้อักขระ U + 0000 (แม้ว่าข้อความจริงจะไม่ค่อยขึ้นต้นด้วย)
ไฟล์ในการเข้ารหัส UTF-16 และ UTF-32 ที่ไม่มี BOM ต้องอยู่ในลำดับไบต์ big-endian (unicode.org)
Unicode และการเข้ารหัสแบบดั้งเดิม
การเปิดตัว Unicode ได้เปลี่ยนวิธีการเข้ารหัส 8 บิตแบบเดิม ถ้าก่อนหน้านี้ระบุการเข้ารหัสโดยแบบอักษร ตอนนี้จะถูกระบุโดยตารางการติดต่อระหว่างการเข้ารหัสนี้และ Unicode
อันที่จริงการเข้ารหัสแบบ 8 บิตได้กลายเป็นตัวแทนของชุดย่อยของ Unicode สิ่งนี้ทำให้ง่ายต่อการสร้างโปรแกรมที่ต้องทำงานกับการเข้ารหัสที่หลากหลาย: ตอนนี้ เพื่อเพิ่มการรองรับการเข้ารหัสอีกหนึ่งรายการ คุณเพียงแค่เพิ่มตารางค้นหา Unicode อื่น
นอกจากนี้ รูปแบบข้อมูลจำนวนมากยังช่วยให้คุณแทรกอักขระ Unicode ใดๆ ได้ แม้ว่าเอกสารนั้นจะถูกเขียนด้วยการเข้ารหัสแบบ 8 บิตแบบเก่าก็ตาม ตัวอย่างเช่น คุณสามารถใช้รหัสเครื่องหมายและใน HTML
การดำเนินการ
ระบบปฏิบัติการที่ทันสมัยส่วนใหญ่ให้การสนับสนุน Unicode ในระดับหนึ่ง
ในระบบปฏิบัติการของตระกูล Windows NT การเข้ารหัส UTF-16LE แบบสองไบต์จะใช้สำหรับการแสดงชื่อไฟล์และสตริงระบบอื่นๆ ภายใน การเรียกระบบที่ใช้พารามิเตอร์สตริงมีอยู่ในตัวแปรไบต์เดี่ยวและไบต์คู่ สำหรับข้อมูลเพิ่มเติม โปรดดูบทความ Unicode บนระบบปฏิบัติการตระกูล Microsoft Windows
UNIX เหมือน OSรวมถึง GNU / Linux, BSD, OS X ใช้การเข้ารหัส UTF-8 เพื่อเป็นตัวแทนของ Unicode โปรแกรมส่วนใหญ่สามารถทำงานกับ UTF-8 เป็นการเข้ารหัสแบบไบต์เดียวแบบดั้งเดิม โดยไม่คำนึงถึงข้อเท็จจริงที่ว่าอักขระจะแสดงเป็นไบต์ต่อเนื่องกันหลายไบต์ ในการทำงานกับอักขระแต่ละตัว โดยปกติสตริงจะถูกบันทึกเป็น UCS-4 เพื่อให้อักขระแต่ละตัวมีคำเครื่อง
หนึ่งในการใช้งานเชิงพาณิชย์ที่ประสบความสำเร็จครั้งแรกของ Unicode คือวันพุธ การเขียนโปรแกรม Java... โดยทั่วไปแล้วจะละทิ้งการแสดงอักขระแบบ 8 บิตและแทนที่อักขระแบบ 16 บิต โซลูชันนี้เพิ่มการใช้หน่วยความจำ แต่อนุญาตให้เราส่งคืนสิ่งที่เป็นนามธรรมที่สำคัญในการเขียนโปรแกรม: อักขระตัวเดียวโดยพลการ (type char). โดยเฉพาะอย่างยิ่ง โปรแกรมเมอร์สามารถทำงานกับสตริงได้เช่นเดียวกับอาร์เรย์ธรรมดา น่าเสียดายที่ความสำเร็จยังไม่สิ้นสุด Unicode เกินขีด จำกัด 16 บิตและโดยรุ่น J2SE 5.0 อักขระที่กำหนดเองก็เริ่มครอบครองหน่วยหน่วยความจำจำนวนตัวแปร - หนึ่ง charหรือสอง (ดูคู่ตัวแทน)
ภาษาโปรแกรมส่วนใหญ่รองรับสตริง Unicode แม้ว่าการแสดงอาจแตกต่างกันขึ้นอยู่กับการใช้งาน
วิธีการป้อนข้อมูล
เนื่องจากไม่มีรูปแบบแป้นพิมพ์ใดที่อนุญาตให้ป้อนอักขระ Unicode ทั้งหมดพร้อมกันได้ ระบบปฏิบัติการและแอปพลิเคชันจึงจำเป็นต้องสนับสนุนวิธีการอื่นในการป้อนอักขระ Unicode โดยอำเภอใจ
Microsoft Windows
แม้ว่าจะเริ่มต้นใน Windows 2000 ยูทิลิตี้ผังอักขระ (charmap.exe) รองรับอักขระ Unicode และอนุญาตให้คุณคัดลอกไปยังคลิปบอร์ด การสนับสนุนนี้จำกัดเฉพาะระนาบฐานเท่านั้น (รหัสอักขระ U + 0000… U + FFFF) สัญลักษณ์ที่มีรหัสจาก U + 10000 "ตารางสัญลักษณ์" ไม่แสดง
มีตารางที่คล้ายกัน เช่น in Microsoft Word.
บางครั้ง คุณสามารถพิมพ์รหัสฐานสิบหก กด Alt + X แล้วรหัสจะถูกแทนที่ด้วยอักขระที่เหมาะสม เช่น ใน WordPad, Microsoft Word ในโปรแกรมแก้ไข Alt + X จะทำการแปลงแบบย้อนกลับเช่นกัน
ในโปรแกรม MS Windows หลายๆ โปรแกรม ในการรับอักขระ Unicode คุณต้องกดปุ่ม Alt และพิมพ์ค่าทศนิยมของรหัสอักขระบน แป้นพิมพ์ตัวเลข... ตัวอย่างเช่น ชุดค่าผสม Alt + 0171 ("), Alt + 0187 (") และ Alt + 0769 (เครื่องหมายเน้นเสียง) จะมีประโยชน์เมื่อพิมพ์ข้อความ Cyrillic ชุดค่าผสม Alt + 0133 (…) และ Alt + 0151 (-) ก็น่าสนใจเช่นกัน
Macintosh
Mac OS 8.5 และใหม่กว่ารองรับวิธีการป้อนข้อมูลที่เรียกว่า "Unicode Hex Input" ในขณะที่กดปุ่ม Option ค้างไว้ คุณต้องพิมพ์รหัสฐานสิบหกสี่หลักของอักขระที่ต้องการ วิธีนี้ช่วยให้คุณป้อนอักขระที่มีรหัสมากกว่า U + FFFF โดยใช้คู่ตัวแทน คู่ดังกล่าวจะถูกแทนที่โดยอัตโนมัติโดยระบบปฏิบัติการที่มีอักขระตัวเดียว ก่อนใช้วิธีป้อนข้อมูลนี้ คุณต้องเปิดใช้งานในส่วนที่เกี่ยวข้องของการตั้งค่าระบบ จากนั้นเลือกวิธีการป้อนข้อมูลปัจจุบันในเมนูแป้นพิมพ์
เริ่มต้นด้วย Mac OS X 10.2 นอกจากนี้ยังมีแอปพลิเคชันจานอักขระที่ช่วยให้คุณสามารถเลือกอักขระจากตารางที่คุณสามารถเลือกอักขระจากบล็อกเฉพาะหรืออักขระที่สนับสนุนโดยแบบอักษรเฉพาะ
GNU / Linux
GNOME ยังมียูทิลิตี้ Symbol Map (เดิมคือ gucharmap) ที่ให้คุณแสดงสัญลักษณ์สำหรับบล็อกหรือระบบการเขียนเฉพาะ และให้ความสามารถในการค้นหาตามชื่อหรือคำอธิบายของสัญลักษณ์ เมื่อทราบรหัสของอักขระที่ต้องการแล้วสามารถป้อนได้ตามมาตรฐาน ISO 14755: ขณะกดปุ่ม Ctrl + ⇧ Shift ค้างไว้ให้ป้อนรหัสฐานสิบหก (เริ่มต้นด้วย GTK + บางรุ่นต้องป้อนรหัส โดยกด "ยู"). รหัสเลขฐานสิบหกที่ป้อนสามารถมีความยาวได้ถึง 32 บิต ช่วยให้คุณป้อนอักขระ Unicode ใดๆ โดยไม่ต้องใช้คู่ตัวแทนเสมือน
แอปพลิเคชัน X Window ทั้งหมด รวมถึง GNOME และ KDE รองรับการป้อนข้อมูลด้วยปุ่มเขียน สำหรับแป้นพิมพ์ที่ไม่มีแป้นเขียนเฉพาะ คุณสามารถกำหนดแป้นใดก็ได้เพื่อจุดประสงค์นี้ - ตัวอย่างเช่น ⇪ แคปล็อค.
คอนโซล GNU / Linux ยังอนุญาตให้ป้อนอักขระ Unicode ด้วยรหัส - สำหรับสิ่งนี้ต้องป้อนรหัสทศนิยมของอักขระเป็นตัวเลขของบล็อกแป้นพิมพ์แบบขยายในขณะที่กดปุ่ม Alt ค้างไว้ คุณสามารถป้อนอักขระด้วยรหัสเลขฐานสิบหก: สำหรับสิ่งนี้ คุณต้องกดปุ่ม AltGr ค้างไว้แล้วป้อน ตัวเลข A-Fใช้ปุ่มบนบล็อกแป้นพิมพ์แบบขยายจาก NumLock ถึง ↵ Enter (ตามเข็มนาฬิกา) รองรับการป้อนข้อมูลตามมาตรฐาน ISO 14755 เพื่อให้วิธีการข้างต้นใช้งานได้คุณต้องเปิดใช้งานโหมด Unicode ในคอนโซลโดยการเรียก unicode_start(1) และเลือกแบบอักษรที่เหมาะสมโดยการโทร setfont(8).
Mozilla Firefox สำหรับ Linux รองรับการป้อนอักขระ ISO 14755
ปัญหา Unicode
ใน Unicode ภาษาอังกฤษ "a" และภาษาโปแลนด์ "a" เป็นอักขระตัวเดียวกัน ในทำนองเดียวกัน "a" ของรัสเซียและ "a" ของเซอร์เบียถือเป็นสัญลักษณ์เดียวกัน (แต่แตกต่างจากภาษาละติน "a") หลักการเข้ารหัสนี้ไม่เป็นสากล เห็นได้ชัดว่าไม่มีวิธีแก้ปัญหา "สำหรับทุกโอกาส" เลย
- ตามธรรมเนียมแล้ว ภาษาจีน เกาหลีและญี่ปุ่นจะเขียนจากบนลงล่าง โดยเริ่มจากมุมขวาบน การสลับระหว่างการสะกดคำในแนวนอนและแนวตั้งสำหรับภาษาเหล่านี้ไม่ได้ระบุไว้ใน Unicode ซึ่งต้องทำโดยใช้ภาษามาร์กอัปหรือกลไกภายในของโปรแกรมประมวลผลคำ
- Unicode อนุญาตให้ใช้น้ำหนักที่แตกต่างกันของอักขระเดียวกันขึ้นอยู่กับภาษา ดังนั้น อักษรจีนสามารถมีน้ำหนักต่างกันในภาษาจีน ญี่ปุ่น (คันจิ) และเกาหลี (ฮันชา) แต่ในขณะเดียวกันใน Unicode พวกมันจะถูกแสดงด้วยสัญลักษณ์เดียวกัน (ที่เรียกว่าการรวม CJK) แม้ว่าจะยังคงเป็นอักขระตัวย่อและตัวเต็ม มีรหัสต่างกัน ... ภาษารัสเซียและเซอร์เบียก็ใช้ตัวเอียงต่างกันเช่นเดียวกัน NSและ NS(ในภาษาเซอร์เบียจะดูเหมือน u และ w ดูที่ ตัวเอียงเซอร์เบีย) ดังนั้น คุณต้องแน่ใจว่าข้อความถูกทำเครื่องหมายว่าเกี่ยวข้องกับภาษาใดภาษาหนึ่งอย่างถูกต้องเสมอ
- การแปลจากตัวพิมพ์เล็กเป็นตัวพิมพ์ใหญ่นั้นขึ้นอยู่กับภาษาด้วย ตัวอย่างเช่น ในภาษาตุรกีมีตัวอักษร İi และ Iı ดังนั้น กฎการเปลี่ยนตัวพิมพ์ของตุรกีจึงขัดแย้งกับตัวภาษาอังกฤษ ซึ่งกำหนดให้ต้องแปล "i" เป็น "I" ปัญหาที่คล้ายกันมีอยู่ในภาษาอื่น เช่น ในภาษาแคนาดาของฝรั่งเศส ทะเบียนถูกแปลแตกต่างไปจากภาษาฝรั่งเศสเล็กน้อย
- แม้แต่กับตัวเลขอารบิกก็มีความละเอียดอ่อนทางการพิมพ์อยู่บ้าง: ตัวเลขเป็น "ตัวพิมพ์ใหญ่" และ "ตัวพิมพ์เล็ก" แบบสัดส่วนและแบบโมโนสเปซ - สำหรับ Unicode นั้นไม่มีความแตกต่างระหว่างตัวเลขเหล่านี้ ความแตกต่างดังกล่าวยังคงอยู่กับซอฟต์แวร์
ข้อเสียบางประการไม่เกี่ยวข้องกับ Unicode แต่เกี่ยวข้องกับความสามารถของตัวประมวลผลข้อความ
- ไฟล์ข้อความที่ไม่ใช่ภาษาละตินใน Unicode มักใช้พื้นที่มากกว่า เนื่องจากอักขระหนึ่งตัวไม่ได้เข้ารหัสโดยหนึ่งไบต์ เช่นเดียวกับในการเข้ารหัสระดับชาติต่างๆ แต่ตามลำดับไบต์ (ยกเว้น UTF-8 สำหรับภาษาที่มีตัวอักษรพอดี เป็น ASCII เช่นเดียวกับการมีอยู่ของอักขระสองตัวในข้อความและภาษาอื่น ๆ อักษรซึ่ง ไม่เข้ากับ ASCII) ไฟล์ฟอนต์ที่จำเป็นในการแสดงอักขระทั้งหมดในตาราง Unicode ใช้หน่วยความจำและทรัพยากรในการคำนวณที่ค่อนข้างใหญ่ มากกว่าฟอนต์ในภาษาประจำชาติของผู้ใช้เพียงคนเดียว ด้วยพลังของระบบคอมพิวเตอร์ที่เพิ่มขึ้นและต้นทุนของหน่วยความจำและพื้นที่ดิสก์ที่ลดลง ปัญหานี้จึงมีความสำคัญน้อยลงเรื่อยๆ อย่างไรก็ตามยังคงมีความเกี่ยวข้องกับอุปกรณ์พกพาเช่นโทรศัพท์มือถือ
- แม้ว่าการรองรับ Unicode จะถูกนำไปใช้ในระบบปฏิบัติการทั่วไปส่วนใหญ่ แต่ก็ยังไม่ได้นำไปใช้ทั้งหมด ซอฟต์แวร์สนับสนุน งานที่ถูกต้องกับเขา. โดยเฉพาะอย่างยิ่ง Byte Order Marks (BOM) ไม่ได้รับการประมวลผลเสมอไป และอักขระที่มีการเน้นเสียงได้รับการสนับสนุนไม่ดี ปัญหาเกิดขึ้นชั่วคราวและเป็นผลมาจากการเปรียบเทียบความแปลกใหม่ของมาตรฐาน Unicode (เมื่อเปรียบเทียบกับการเข้ารหัสระดับชาติแบบไบต์เดียว)
- ประสิทธิภาพของโปรแกรมประมวลผลสตริงทั้งหมด (รวมถึงการเรียงลำดับในฐานข้อมูล) ลดลงเมื่อใช้ Unicode แทนการเข้ารหัสแบบไบต์เดี่ยว
ระบบการเขียนที่หายากบางระบบยังไม่แสดงอย่างถูกต้องใน Unicode การพรรณนาของอักขระตัวยก "ยาว" ที่ขยายไปตามตัวอักษรหลายตัว เช่น ใน Church Slavonic ยังไม่ได้นำมาใช้
Unicode หรือ Unicode?
"Unicode" เป็นทั้งชื่อเฉพาะ (หรือบางส่วนของชื่อ เช่น Unicode Consortium) และชื่อสามัญที่มาจากภาษาอังกฤษ
เมื่อมองแวบแรก ควรใช้การสะกด "Unicode" ในภาษารัสเซียมีหน่วยคำอยู่แล้ว "uni-" (คำที่มีองค์ประกอบภาษาละติน "uni-" ถูกแปลและเขียนตามประเพณีโดยใช้ "uni-": universal, unipolar, unification, uniform) และ "code" ขัดต่อ, เครื่องหมายการค้าที่ยืมมาจากภาษาอังกฤษ มักจะถูกส่งผ่านการถอดความเชิงปฏิบัติ ซึ่งการรวมตัวอักษร "uni-" ที่ไม่เป็นนิรุกติศาสตร์แล้วเขียนเป็น "uni-" ("Unilever", "Unix" เป็นต้น) นั่นคือ เช่นเดียวกับในกรณีของตัวย่อแบบตัวอักษรต่อตัวอักษรเช่น UNICEF “กองทุนฉุกเฉินเพื่อเด็กแห่งสหประชาชาติ” - UNICEF
การสะกดคำว่า "Unicode" ได้ป้อนข้อความภาษารัสเซียอย่างแน่นหนาแล้ว Wikipedia ใช้เวอร์ชันทั่วไปมากกว่า บน MS Windows จะใช้ตัวเลือก Unicode
มีหน้าพิเศษบนเว็บไซต์ของ Consortium ที่มีปัญหาการโอนคำว่า "Unicode" ไปที่ ภาษาที่แตกต่างกันและระบบการเขียน สำหรับอักษรซีริลลิกรัสเซีย จะระบุตัวเลือก "Unicode"
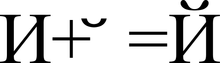
ปัญหาที่เกี่ยวข้องกับการเข้ารหัสมักจะได้รับการดูแลโดยซอฟต์แวร์ ดังนั้นจึงไม่มีปัญหาในการใช้การเข้ารหัส หากเกิดปัญหาขึ้นมักเกิดจากโปรแกรมที่ไม่ดี - อย่าลังเลที่จะส่งไปที่ถังขยะ
เชิญทุกคนออกมาพูดใน
ASCII (English American Standard Code for Information Interchange) - ตารางการเข้ารหัสมาตรฐานอเมริกันสำหรับอักขระที่พิมพ์ได้และรหัสพิเศษบางอย่าง ในภาษาอังกฤษแบบอเมริกัน [eśski] จะออกเสียง ขณะที่ในสหราชอาณาจักร [aski] จะออกเสียงมากกว่า ในภาษารัสเซียออกเสียงว่า [aski] หรือ [aski]
ASCII คือการเข้ารหัสสำหรับตัวเลขทศนิยม ตัวอักษรละตินและตัวอักษรประจำชาติ เครื่องหมายวรรคตอน และอักขระควบคุม เดิมทีได้รับการออกแบบให้เป็น 7 บิต ด้วยการใช้ไบต์ ASCII 8 บิตอย่างแพร่หลาย จึงถูกมองว่าเป็นครึ่งหนึ่งของ 8 บิต คอมพิวเตอร์มักใช้ส่วนขยาย ASCII โดยเกี่ยวข้องกับบิตที่ 8 และครึ่งหลังของตารางโค้ด (เช่น KOI-8)
Unicode
ในปี 1991 องค์กรไม่แสวงหากำไร Unicode Consortium ก่อตั้งขึ้นในแคลิฟอร์เนีย ซึ่งรวมถึงตัวแทนของบริษัทคอมพิวเตอร์หลายแห่ง (Borland, IBM, Lotus, Microsoft, Novell, Sun, WordPerfect เป็นต้น) และกำลังพัฒนาและดำเนินการตามมาตรฐาน " มาตรฐานยูนิโค้ด" ... มาตรฐานการเข้ารหัสอักขระ Unicode กำลังมีบทบาทสำคัญในสภาพแวดล้อมซอฟต์แวร์หลายภาษาระดับสากล Microsoft Windows NT และรุ่นต่อๆ ไปของ Windows 2000, 2003, XP ใช้ Unicode ซึ่งก็คือ UTF-16 ที่แม่นยำยิ่งขึ้น เป็นการแสดงข้อความภายใน ระบบปฏิบัติการที่คล้ายกับ UNIX เช่น Linux, BSD และ Mac OS X ได้นำ Unicode (UTF-8) มาใช้เป็นตัวแทนหลักของข้อความหลายภาษา Unicode สงวนอักขระรหัส 1,114,112 (220 + 216) ไว้ ซึ่งปัจจุบันมีการใช้อักขระมากกว่า 96,000 ตัว รหัสอักขระ 256 ตัวแรกสอดคล้องกับมาตรฐาน ISO 8859-1 ซึ่งเป็นตารางอักขระ 8 บิตที่ได้รับความนิยมมากที่สุดในโลกตะวันตก ด้วยเหตุนี้ 128 อักขระแรกจึงเหมือนกันกับตาราง ASCII พื้นที่รหัส Unicode แบ่งออกเป็น 17 "เครื่องบิน" และแต่ละแผนมีคะแนนรหัส 65536 (= 216) ระนาบแรก (ระนาบ 0) Basic Multilingual Plane (BMP) เป็นระนาบที่อธิบายตัวละครส่วนใหญ่ BMP มีสัญลักษณ์สำหรับเกือบทุกคน ภาษาสมัยใหม่และอักขระพิเศษจำนวนมาก ใช้เครื่องบินอีกสองลำสำหรับสัญลักษณ์ "กราฟิก" ระนาบ 1, ระนาบหลายภาษาเสริม (SMP) ส่วนใหญ่จะใช้สำหรับสัญลักษณ์ทางประวัติศาสตร์ และยังใช้สำหรับสัญลักษณ์ทางดนตรีและทางคณิตศาสตร์ แผน 2, เครื่องบินเสริมจินตนาการ (SIP) ใช้สำหรับอักษรจีนหายากประมาณ 40,000 ตัว แผน 15 และแผน 16 เปิดให้ใช้งานส่วนตัว รูปที่ 1.10 แสดง Russian Unicode block (U + 0400 ถึง U + 04FF)
การเข้ารหัสทั่วไป
ISO 646 ASCII BCDIC EBCDIC ISO 8859: ISO 8859-1, ISO 8859-2, ISO 8859-3, ISO 8859-4, ISO 8859-5, ISO 8859-6, ISO 8859-7, ISO 8859-8, ISO 8859 -9, ISO 8859-10, ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866 , CP869 การเข้ารหัสของ Microsoft Windows: Windows-1250 สำหรับภาษายุโรปกลางที่ใช้การสะกดคำแบบละติน (โปแลนด์ เช็ก สโลวัก ฮังการี สโลวีเนีย โครเอเชีย โรมาเนีย และแอลเบเนีย) Windows-1251 สำหรับอักษรซีริลลิก Windows-1252 สำหรับภาษาตะวันตก Windows-1253 สำหรับ กรีก Windows-1254 สำหรับภาษาตุรกี Windows-1255 สำหรับภาษาฮิบรู Windows-1256 สำหรับภาษาอาหรับ Windows-1257 สำหรับภาษาบอลติก Windows-1258 สำหรับภาษาเวียดนาม MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 บัลแกเรีย การเข้ารหัส ISCII VISCII Big5 (ตัวแปรที่มีชื่อเสียงที่สุดของ Microsoft CP950) HSCS Guobiao GB2312 GBK (Microsoft CP936) GB18030 Shift JIS สำหรับภาษาญี่ปุ่น (Microsoft CP932) EUC-KR สำหรับภาษาเกาหลี (Microsoft CP949) ISO-2022 และ EUC สำหรับการเข้ารหัส UTF-8 ของจีน ชุดอักขระ Unicode UTF-16 และ UTF-32 \
การเข้ารหัสข้อมูลกราฟิก
ตั้งแต่ยุค 80 กำลังพัฒนาเทคโนโลยีการประมวลผลข้อมูลกราฟิกบนพีซี รูปแบบการแสดงบนหน้าจอแสดงผลของภาพกราฟิกที่ประกอบด้วยจุดแต่ละจุด (พิกเซล) เรียกว่าแรสเตอร์ ออบเจ็กต์ขั้นต่ำในโปรแกรมแก้ไขกราฟิกแรสเตอร์คือจุด โปรแกรมแก้ไขกราฟิกแรสเตอร์ออกแบบมาเพื่อสร้างรูปภาพ ไดอะแกรม ความละเอียดของจอภาพ (จำนวนจุดแนวนอนและแนวตั้ง) ตลอดจนจำนวนสีที่เป็นไปได้ของแต่ละจุดจะกำหนดตามประเภทจอภาพ โดย 1 พิกเซลของหน้าจอขาวดำถูกเข้ารหัสด้วยข้อมูล 1 บิต (จุดสีดำหรือจุดสีขาว) จำนวนสีต่างๆ K และจำนวนบิตสำหรับการเข้ารหัสนั้นสัมพันธ์กันโดยสูตร: K = 2b จอภาพสมัยใหม่มีจานสีดังต่อไปนี้: 16 สี, 256 สี; 65,536 สี (สีสูง), 16,777,216 สี (สีจริง)
บิตแมป
ด้วยความช่วยเหลือของแว่นขยาย คุณจะเห็นว่าภาพกราฟิกขาวดำ ตัวอย่างเช่น จากหนังสือพิมพ์ ประกอบด้วยจุดที่เล็กที่สุดที่ประกอบขึ้นเป็นลวดลายบางอย่าง - แรสเตอร์ ในฝรั่งเศสในศตวรรษที่ 19 ทิศทางใหม่ในการวาดภาพเกิดขึ้น - pointillism เทคนิคของเขาประกอบด้วยการใช้ภาพวาดบนผืนผ้าใบด้วยพู่กันในรูปแบบของจุดหลากสี นอกจากนี้ วิธีนี้มีการใช้กันอย่างแพร่หลายในอุตสาหกรรมการพิมพ์เพื่อเข้ารหัสข้อมูลกราฟิก ความแม่นยำของการวาดภาพขึ้นอยู่กับจำนวนจุดและขนาด หลังจากแบ่งรูปภาพออกเป็นส่วนๆ เริ่มจากมุมซ้าย เลื่อนไปตามเส้นจากซ้ายไปขวา คุณสามารถเข้ารหัสสีของแต่ละจุดได้ นอกจากนี้ จุดหนึ่งจุดดังกล่าวจะเรียกว่าพิกเซล (ที่มาของคำนี้เกี่ยวข้องกับตัวย่อภาษาอังกฤษ "องค์ประกอบรูปภาพ" - องค์ประกอบรูปภาพ) ปริมาณของภาพแรสเตอร์ถูกกำหนดโดยการคูณจำนวนพิกเซล (โดยปริมาณข้อมูลหนึ่งจุดซึ่งขึ้นอยู่กับจำนวนสีที่เป็นไปได้ คุณภาพของภาพจะถูกกำหนดโดยความละเอียดของจอภาพ ยิ่งสูงเท่าใด คือ ยิ่งเส้นแรสเตอร์และจุดในหนึ่งบรรทัดมากเท่าใด คุณภาพของภาพก็จะยิ่งสูงขึ้น พีซีส่วนใหญ่ใช้ความละเอียดหน้าจอต่อไปนี้: 640 x 480, 800 x 600, 1024 x 768 และ 1280 x 1024 พิกเซล เนื่องจากความสว่างของแต่ละจุดและ พิกัดเชิงเส้นของมันสามารถแสดงได้โดยใช้จำนวนเต็ม เราสามารถพูดได้ว่าวิธีการเข้ารหัสนี้อนุญาตให้ใช้รหัสไบนารี่เพื่อประมวลผลข้อมูลกราฟิก
หากเราพูดถึงภาพประกอบขาวดำ หากคุณไม่ใช้ฮาล์ฟโทน พิกเซลจะถือว่าหนึ่งในสองสถานะ: สว่าง (สีขาว) และไม่สว่าง (สีดำ) และเนื่องจากข้อมูลเกี่ยวกับสีของพิกเซลเรียกว่ารหัสพิกเซล หน่วยความจำเพียงบิตเดียวก็เพียงพอที่จะเข้ารหัสได้: 0 - สีดำ 1 - สีขาว หากพิจารณาภาพประกอบในรูปแบบของจุดรวมกันที่มีเฉดสีเทา 256 เฉด (กล่าวคือ สิ่งเหล่านี้เป็นที่ยอมรับโดยทั่วไปในปัจจุบัน) แสดงว่าเป็นแปดบิต เลขฐานสองเพื่อเข้ารหัสความสว่างของจุดใดๆ วี คอมพิวเตอร์กราฟฟิคสีมีความสำคัญอย่างยิ่ง มันทำหน้าที่เป็นวิธีการในการเพิ่มความประทับใจทางสายตาและเพิ่มความอิ่มตัวของข้อมูลของภาพ ความรู้สึกของสีเกิดขึ้นในสมองของมนุษย์อย่างไร? สิ่งนี้เกิดขึ้นจากการวิเคราะห์ฟลักซ์แสงที่เข้าสู่เรตินาจากวัตถุสะท้อนแสงหรือเปล่งแสง เป็นที่ยอมรับกันโดยทั่วไปว่าตัวรับสีของมนุษย์ซึ่งเรียกอีกอย่างว่ากรวยนั้นแบ่งออกเป็นสามกลุ่มและแต่ละกลุ่มสามารถรับรู้ได้เพียงสีเดียว - สีแดงหรือสีเขียวหรือสีน้ำเงิน
รุ่นสี
เมื่อพูดถึงการเข้ารหัสสี ภาพกราฟิกจากนั้นคุณต้องพิจารณาหลักการสลายตัวของสีตามอำเภอใจเป็นส่วนประกอบหลัก ใช้ระบบการเข้ารหัสหลายระบบ: HSB, RGB และ CMYK รุ่นสีแรกนั้นเรียบง่ายและใช้งานง่าย กล่าวคือ สะดวกสำหรับบุคคล รุ่นที่สองสะดวกที่สุดสำหรับคอมพิวเตอร์ และรุ่น CMYK รุ่นสุดท้ายใช้สำหรับโรงพิมพ์ การใช้แบบจำลองสีเหล่านี้เกิดจากการที่ฟลักซ์การส่องสว่างสามารถเกิดขึ้นได้จากการแผ่รังสี ซึ่งเป็นการรวมกันของสีสเปกตรัมที่ "บริสุทธิ์" ได้แก่ สีแดง สีเขียว สีฟ้า หรืออนุพันธ์ของสี แยกแยะระหว่างการสร้างสีเสริม (โดยทั่วไปสำหรับวัตถุที่เปล่งแสง) และการสร้างสีแบบลบ (โดยทั่วไปสำหรับวัตถุสะท้อนแสง) ตัวอย่างของวัตถุประเภทแรกคือหลอดรังสีแคโทดของจอภาพ ประเภทที่สอง - งานพิมพ์

โมเดล HSB มีลักษณะเด่น 3 องค์ประกอบ ได้แก่ Hue, Saturation และ Brightness คุณสามารถได้สีตามอำเภอใจมากมายโดยการปรับส่วนประกอบเหล่านี้ โมเดลสีนี้เหมาะที่สุดสำหรับตัวเหล่านั้น บรรณาธิการกราฟิกซึ่งภาพถูกสร้างขึ้นมาเองและยังไม่พร้อมประมวลผล จากนั้นอาร์ตเวิร์กที่สร้างขึ้นสามารถแปลงเป็นโมเดลสี RGB ได้หากมีการวางแผนเพื่อใช้เป็นภาพประกอบบนหน้าจอ หรือ CMYK หากพิมพ์ ค่าสีจะถูกเลือกเป็นเวกเตอร์ที่ส่งออกจากศูนย์กลางของวงกลม ทิศทางของเวกเตอร์ถูกกำหนดเป็นองศาเชิงมุมและกำหนดสี ความอิ่มตัวของสีถูกกำหนดโดยความยาวเวกเตอร์ และความสว่างของสีถูกตั้งค่าบนแกนที่แยกจากกัน ซึ่งจุดศูนย์เป็นสีดำ จุดศูนย์กลางเป็นสีขาว (เป็นกลาง) และจุดรอบปริมณฑลเป็นสีทึบ
หลักการของวิธี RGB มีดังนี้: เป็นที่ทราบกันดีอยู่แล้วว่าสีใดๆ สามารถแสดงเป็นสามสีผสมกัน: สีแดง (สีแดง, R), สีเขียว (สีเขียว, G), สีฟ้า (สีน้ำเงิน, B) สีและเฉดสีอื่น ๆ ได้มาจากการมีหรือไม่มีส่วนประกอบเหล่านี้ จากตัวอักษรตัวแรกของสีหลัก ระบบได้ชื่อมา - RGB โมเดลสีนี้เป็นสารเติมแต่ง กล่าวคือ สีใดๆ ก็สามารถหาได้จากการผสมของสีหลักในสัดส่วนต่างๆ เมื่อองค์ประกอบหนึ่งของสีหลักซ้อนทับกัน ความสว่างของรังสีทั้งหมดจะเพิ่มขึ้น หากเรารวมทั้งสามองค์ประกอบเข้าด้วยกันเราจะได้สีเทาที่ไม่มีสีซึ่งมีความสว่างเพิ่มขึ้นซึ่งจะเข้าใกล้สีขาว
ด้วย 256 โทน (แต่ละจุดเข้ารหัสด้วย 3 ไบต์) ค่า RGB ขั้นต่ำ (0,0,0) จะสอดคล้องกับสีดำและสีขาว - สูงสุดพร้อมพิกัด (255, 255, 255) ยิ่งค่าไบต์ขององค์ประกอบสีมากเท่าใด สีนี้ก็จะยิ่งสว่างขึ้น ตัวอย่างเช่น สีน้ำเงินเข้มถูกเข้ารหัสด้วยสามไบต์ (0, 0, 128) และสีน้ำเงินสว่าง (0, 0, 255)
หลักการของวิธี CMYK โมเดลสีนี้ใช้เมื่อเตรียมสิ่งพิมพ์สำหรับการพิมพ์ แม่สีแต่ละสีถูกกำหนดให้เป็นสีเสริม (เสริมจากสีหลักเป็นสีขาว) ได้สีเพิ่มเติมโดยการสรุปคู่ของสีหลักที่เหลือ ซึ่งหมายความว่าสีเสริมสำหรับสีแดงคือ สีฟ้า (Cyan, C) = สีเขียว + สีน้ำเงิน = สีขาว - สีแดง สำหรับสีเขียว - สีม่วงแดง (Magenta, M) = สีแดง + สีน้ำเงิน = สีขาว - สีเขียว สำหรับสีน้ำเงิน - สีเหลือง (Yellow, Y) = แดง + เขียว = ขาว - น้ำเงิน นอกจากนี้ หลักการสลายตัวของสีตามอำเภอใจเป็นส่วนประกอบยังสามารถใช้ได้ทั้งสำหรับสีหลักและสีเพิ่มเติม กล่าวคือ สีใดๆ สามารถแสดงเป็นผลรวมขององค์ประกอบสีแดง สีเขียว สีฟ้า หรือผลรวมของ ส่วนประกอบสีฟ้า สีม่วง สีเหลือง โดยทั่วไป วิธีนี้ใช้ในอุตสาหกรรมการพิมพ์ แต่พวกเขายังคงใช้สีดำอยู่ (BlacK เนื่องจากตัวอักษร B มีสีน้ำเงินอยู่แล้วจึงแสดงด้วยตัวอักษร K) เนื่องจากการวางสีเสริมทับซ้อนกันไม่ได้สร้างสีดำบริสุทธิ์
ภาพเวกเตอร์และเศษส่วน
ภาพเวกเตอร์เป็นวัตถุกราฟิกที่ประกอบด้วยเส้นพื้นฐานและส่วนโค้ง องค์ประกอบพื้นฐานของภาพคือเส้น เช่นเดียวกับวัตถุใด ๆ มันมีคุณสมบัติ: รูปร่าง (ตรง, โค้ง), ความหนา, สี, ลักษณะ (จุด, ทึบ) เส้นปิดมีคุณสมบัติของการเติม (ไม่ว่าจะกับวัตถุอื่นหรือด้วยสีที่เลือก) วัตถุอื่นๆ ทั้งหมด กราฟิกแบบเวกเตอร์ประกอบด้วยเส้น เนื่องจากเส้นถูกอธิบายทางคณิตศาสตร์ว่าเป็นวัตถุชิ้นเดียว จำนวนข้อมูลสำหรับการแสดงวัตถุโดยใช้กราฟิกแบบเวกเตอร์จึงน้อยกว่าในกราฟิกแรสเตอร์มาก ข้อมูลเกี่ยวกับภาพเวกเตอร์ถูกเข้ารหัสเป็นตัวอักษรและตัวเลขปกติและประมวลผลโดยโปรแกรมพิเศษ
ถึง ซอฟต์แวร์การสร้างและการประมวลผลกราฟิกแบบเวกเตอร์รวมถึง GR ต่อไปนี้: CorelDraw, Adobe Illustrator รวมถึง vectorizers (ตัวติดตาม) - แพ็คเกจเฉพาะสำหรับการแปลงภาพแรสเตอร์เป็นเวกเตอร์

กราฟิกเศษส่วนใช้การคำนวณทางคณิตศาสตร์ เช่นเดียวกับกราฟิกแบบเวกเตอร์ แต่ต่างจากเวกเตอร์ องค์ประกอบพื้นฐานของมันคือสูตรทางคณิตศาสตร์นั่นเอง สิ่งนี้นำไปสู่ความจริงที่ว่าไม่มีวัตถุใดถูกเก็บไว้ในหน่วยความจำของคอมพิวเตอร์และรูปภาพนั้นสร้างขึ้นโดยสมการเท่านั้น ด้วยวิธีนี้ คุณสามารถสร้างโครงสร้างปกติที่ง่ายที่สุด รวมถึงภาพประกอบที่ซับซ้อนซึ่งเลียนแบบทิวทัศน์ได้

การเข้ารหัสเสียง
โลกนี้เต็มไปด้วยเสียงต่างๆ นานา: เสียงนาฬิกาและเสียงครวญครางของเครื่องยนต์ เสียงหอนของลมและเสียงใบไม้ที่ร่วงโรย เสียงนกร้องและเสียงผู้คน ผู้คนเริ่มเดากันมานานแล้วเกี่ยวกับการกำเนิดของเสียงและสิ่งที่พวกเขาเป็น แม้แต่นักปรัชญาและนักวิทยาศาสตร์ชาวกรีกโบราณ - อาริสโตเติลนักสารานุกรมซึ่งอิงจากการสังเกตได้อธิบายธรรมชาติของเสียงโดยเชื่อว่าร่างกายที่เปล่งเสียงจะสร้างการบีบอัดและการแยกตัวของอากาศสลับกัน ดังนั้นบางครั้งสตริงที่แกว่งไปมาจะคายประจุออกมา จากนั้นจึงควบแน่นอากาศ และเนื่องจากความยืดหยุ่นของอากาศ อิทธิพลที่สลับกันเหล่านี้จะถูกส่งต่อไปในอวกาศ - จากชั้นหนึ่งไปอีกชั้นหนึ่งจึงเกิดคลื่นยืดหยุ่นขึ้น เมื่อมันมาถึงหูของเรา มันจะทำหน้าที่เกี่ยวกับแก้วหูและทำให้เกิดความรู้สึกของเสียง
โดยหูบุคคลจะรับรู้คลื่นยืดหยุ่นที่มีความถี่อยู่ในช่วงตั้งแต่ 16 Hz ถึง 20 kHz (การสั่นสะเทือน 1 Hz - 1 ต่อวินาที) ตามนี้ คลื่นยืดหยุ่นในตัวกลางใดๆ ซึ่งความถี่อยู่ภายในขอบเขตที่กำหนด เรียกว่า คลื่นเสียง หรือเสียงธรรมดา ในการศึกษาเสียง แนวคิด เช่น โทนเสียงและโทนเสียงมีความสำคัญ เสียงจริงใด ๆ ไม่ว่าจะเป็นการเล่นเครื่องดนตรีหรือเสียงของบุคคล เป็นการผสมผสานระหว่างการสั่นแบบฮาร์มอนิกจำนวนมากกับชุดความถี่ที่แน่นอน
การสั่นที่มีความถี่ต่ำที่สุดเรียกว่าพื้นฐาน ส่วนอื่นๆ เรียกว่าหวือหวา
Timbre เป็นจำนวนเสียงหวือหวาที่แตกต่างกันซึ่งมีอยู่ในเสียงใดเสียงหนึ่ง ซึ่งทำให้มันเป็นสีพิเศษ ความแตกต่างระหว่างเสียงต่ำกับเสียงอื่นไม่ได้เกิดจากจำนวนเท่านั้น แต่ยังรวมถึงความเข้มของเสียงหวือหวาที่มากับเสียงของโทนเสียงหลักด้วย ด้วยเสียงต่ำทำให้เราสามารถแยกความแตกต่างระหว่างเสียงของแกรนด์เปียโนและไวโอลิน กีตาร์และฟลุตได้อย่างง่ายดาย และจดจำเสียงของบุคคลที่คุ้นเคยได้
เสียงเพลงสามารถกำหนดลักษณะได้สามประการ: แบบเสียงต่ำ นั่นคือ สีของเสียงซึ่งขึ้นอยู่กับรูปร่างของการสั่นสะเทือน ระดับเสียง ซึ่งกำหนดโดยจำนวนการสั่นสะเทือนต่อวินาที (ความถี่) และความดัง ซึ่งขึ้นกับความแรงของแรงสั่นสะเทือน
ปัจจุบันมีการใช้คอมพิวเตอร์อย่างกว้างขวางในด้านต่างๆ การประมวลผลข้อมูลเสียงและดนตรีก็ไม่มีข้อยกเว้น จนถึงปี 1983 การบันทึกเพลงทั้งหมดได้รับการเผยแพร่บนแผ่นเสียงไวนิลและเทปคาสเซ็ตขนาดกะทัดรัด ปัจจุบันมีการใช้ซีดีกันอย่างแพร่หลาย หากคุณมีคอมพิวเตอร์ที่ติดตั้งการ์ดเสียงสำหรับสตูดิโอ โดยเชื่อมต่อกับคีย์บอร์ด MIDI และไมโครโฟน คุณสามารถทำงานกับซอฟต์แวร์เพลงเฉพาะทางได้
การแปลงข้อมูลเสียงแบบดิจิทัลเป็นแอนะล็อกและแอนะล็อกเป็นดิจิทัล
มาดูขั้นตอนการแปลงเสียงจากแอนะล็อกเป็นดิจิทัลอย่างรวดเร็วกัน และในทางกลับกัน ความคิดคร่าวๆ ว่าเกิดอะไรขึ้นในการ์ดเสียงสามารถช่วยหลีกเลี่ยงข้อผิดพลาดบางอย่างเมื่อทำงานกับเสียง
คลื่นเสียงจะถูกแปลงเป็นสัญญาณไฟฟ้าสลับแบบแอนะล็อกโดยใช้ไมโครโฟน โดยจะผ่านเส้นทางเสียงและเข้าสู่ตัวแปลงอนาล็อกเป็นดิจิตอล (ADC) ซึ่งเป็นอุปกรณ์ที่แปลงสัญญาณเป็นรูปแบบดิจิทัล
ในรูปแบบที่เรียบง่าย หลักการทำงานของ ADC มีดังต่อไปนี้ โดยจะวัดแอมพลิจูดของสัญญาณในช่วงเวลาปกติ และส่งต่อไปผ่านเส้นทางดิจิทัล ซึ่งเป็นลำดับของตัวเลขที่มีข้อมูลเกี่ยวกับการเปลี่ยนแปลงของแอมพลิจูด ระหว่างการแปลงแอนะล็อกเป็นดิจิทัล จะไม่มีการแปลงทางกายภาพเกิดขึ้น รอยประทับหรือตัวอย่างถูกนำมาจากสัญญาณไฟฟ้าดังที่เป็นอยู่ ซึ่งเป็นแบบจำลองดิจิทัลของความผันผวนของแรงดันไฟฟ้าในเส้นทางเสียง หากแสดงในรูปของไดอะแกรม โมเดลนี้จะแสดงเป็นลำดับของคอลัมน์ ซึ่งแต่ละคอลัมน์จะสอดคล้องกับค่าตัวเลขเฉพาะ สัญญาณดิจิตอลมีลักษณะไม่ต่อเนื่อง กล่าวคือ ไม่ต่อเนื่อง ดังนั้นรูปแบบดิจิทัลจึงไม่ตรงกับรูปคลื่นแอนะล็อกทุกประการ
ตัวอย่างคือช่วงเวลาระหว่างการวัดแอมพลิจูดของสัญญาณแอนะล็อกสองครั้ง
ตัวอย่างแปลตามตัวอักษรภาษาอังกฤษว่า "ตัวอย่าง" ในคำศัพท์มัลติมีเดียและเสียงระดับมืออาชีพ คำนี้มีความหมายหลายประการ นอกจากช่วงเวลาหนึ่งแล้ว ตัวอย่างยังเรียกอีกอย่างว่าลำดับของข้อมูลดิจิทัลที่ได้รับจากการแปลงแอนะล็อกเป็นดิจิทัล กระบวนการแปลงเองเรียกว่าการสุ่มตัวอย่าง ในภาษาทางเทคนิคของรัสเซียเรียกว่า discretization
เสียงดิจิตอลถูกส่งออกโดยใช้ตัวแปลงดิจิตอลเป็นอนาล็อก (DAC) ซึ่งจะสร้างสัญญาณไฟฟ้าของแอมพลิจูดตามข้อมูลดิจิตอลที่เข้ามาในเวลาที่เหมาะสม
ตัวเลือกการสุ่มตัวอย่าง
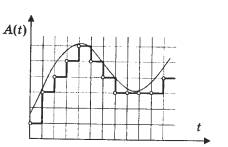
ความถี่และความลึกของบิตเป็นพารามิเตอร์การสุ่มตัวอย่างที่สำคัญ ความถี่ - จำนวนการวัดแอมพลิจูดของสัญญาณแอนะล็อกต่อวินาที
หากความถี่การสุ่มตัวอย่างไม่เกินสองเท่าของความถี่ของขอบเขตบนของช่วงเสียง ให้เปิด ความถี่สูงการสูญเสียจะเกิดขึ้น สิ่งนี้อธิบายได้ว่าทำไมความถี่ซีดีเพลงมาตรฐานคือ 44.1 kHz เนื่องจากช่วงการสั่นของคลื่นเสียงอยู่ในช่วงตั้งแต่ 20 Hz ถึง 20 kHz จำนวนการวัดสัญญาณต่อวินาทีจึงต้องมากกว่าจำนวนการสั่นในช่วงเวลาเดียวกัน หากอัตราการสุ่มตัวอย่างต่ำกว่าความถี่ของคลื่นเสียงอย่างมาก แอมพลิจูดของสัญญาณจะมีเวลาเปลี่ยนแปลงหลายครั้งในระหว่างการวัด ซึ่งนำไปสู่ความจริงที่ว่าลายนิ้วมือดิจิทัลมีชุดข้อมูลที่ไม่เป็นระเบียบ ด้วยการแปลงจากดิจิตอลเป็นแอนะล็อก ตัวอย่างดังกล่าวจะไม่ส่งสัญญาณหลัก แต่สร้างสัญญาณรบกวนเท่านั้น
ในซีดีเพลงรูปแบบใหม่ Audio DVD สัญญาณจะถูกวัด 96,000 ครั้งในหนึ่งวินาที ใช้อัตราการสุ่มตัวอย่าง 96 kHz เพื่อประหยัดพื้นที่บนฮาร์ดดิสก์ในแอปพลิเคชันมัลติมีเดีย มักใช้ความถี่ต่ำ: 11, 22, 32 kHz ส่งผลให้ช่วงความถี่ที่ได้ยินลดลง ซึ่งหมายความว่ามีการบิดเบือนอย่างมากของสิ่งที่ได้ยิน
หากอยู่ในรูปของกราฟ เราเป็นตัวแทนของเสียงเดียวกันที่มีความสูง 1 kHz (โน้ตที่สูงถึง 7 octave ของเปียโนจะสัมพันธ์กับความถี่นี้โดยประมาณ) แต่สุ่มตัวอย่างด้วยความถี่ที่ต่างกัน (ส่วนล่างของไซน์ซอยด์คือ ไม่แสดงในกราฟทั้งหมด) จากนั้นจะเห็นความแตกต่าง การหารหนึ่งบนแกนนอน ซึ่งแสดงเวลา ตรงกับ 10 ตัวอย่าง มาตราส่วนก็เหมือนกัน คุณจะเห็นได้ว่าที่ความถี่ 11 kHz มีการสั่นของคลื่นเสียงประมาณห้าครั้งสำหรับตัวอย่างทุก ๆ 50 ตัวอย่าง นั่นคือช่วงหนึ่งของคลื่นไซน์จะแสดงโดยใช้ค่าเพียง 10 ค่าเท่านั้น นี่เป็นการส่งสัญญาณที่ค่อนข้างไม่แม่นยำ ในเวลาเดียวกัน หากเราพิจารณาความถี่สุ่มตัวอย่างที่ 44 kHz ดังนั้นในแต่ละช่วงของไซนัสนั้นจะมีตัวอย่างเกือบ 50 ตัวอย่างอยู่แล้ว ช่วยให้คุณได้รับสัญญาณคุณภาพดี
ความลึกของบิตระบุถึงความแม่นยำในการเปลี่ยนแปลงแอมพลิจูดของสัญญาณแอนะล็อก ความแม่นยำในการส่งค่าแอมพลิจูดของสัญญาณในแต่ละจุดของเวลาระหว่างการแปลงเป็นดิจิทัลจะกำหนดคุณภาพของสัญญาณหลังจากการแปลงแบบดิจิทัลเป็นแอนะล็อก ความแม่นยำของการสร้างรูปคลื่นขึ้นใหม่ขึ้นอยู่กับความลึกของบิต
ค่าแอมพลิจูดถูกเข้ารหัสโดยใช้หลักการเข้ารหัสแบบไบนารี ควรนำเสนอสัญญาณเสียงเป็นลำดับของแรงกระตุ้นทางไฟฟ้า (เลขศูนย์ไบนารีและหนึ่ง) โดยทั่วไปจะใช้การแสดงค่าแอมพลิจูด 8, 16 บิตหรือ 20 บิต เมื่อการเข้ารหัสไบนารีต่อเนื่อง สัญญาณเสียงมันถูกแทนที่ด้วยลำดับของระดับสัญญาณที่ไม่ต่อเนื่อง คุณภาพการเข้ารหัสขึ้นอยู่กับอัตราการสุ่มตัวอย่าง (จำนวนการวัดระดับสัญญาณต่อหน่วยเวลา) ด้วยอัตราการสุ่มตัวอย่างที่เพิ่มขึ้น ความถูกต้องของการแสดงข้อมูลแบบไบนารีจะเพิ่มขึ้น ที่ความถี่ 8 kHz (จำนวนการวัดต่อวินาทีคือ 8000) คุณภาพของสัญญาณเสียงที่สุ่มตัวอย่างจะสอดคล้องกับคุณภาพของการออกอากาศทางวิทยุ และที่ความถี่ 48 kHz (จำนวนการวัดต่อวินาทีคือ 48000) - เพื่อคุณภาพเสียงของซีดีเพลง
ปัจจุบัน มีดีวีดีเสียงรูปแบบดิจิทัลสำหรับผู้บริโภคแบบใหม่ ซึ่งใช้อัตราการสุ่มตัวอย่างแบบ 24 บิตและ 96 kHz ด้วยความช่วยเหลือของมันสามารถหลีกเลี่ยงข้อเสียที่กล่าวถึงข้างต้นของการเข้ารหัส 16 บิตได้
สู่ดิจิทัลยุคใหม่ เครื่องเสียงติดตั้งตัวแปลง 20 บิตแล้ว เสียงยังคงเป็น 16 บิต ติดตั้งตัวแปลงความลึกบิตที่เพิ่มขึ้นเพื่อปรับปรุงคุณภาพการบันทึกที่ระดับต่ำ หลักการทำงานมีดังนี้ สัญญาณแอนะล็อกดั้งเดิมถูกแปลงเป็นดิจิทัลด้วยความกว้าง 20 บิต จากนั้นตัวประมวลผลสัญญาณดิจิตอล DSPP จะลดความกว้างลงเหลือ 16 บิต ในกรณีนี้จะใช้อัลกอริธึมการคำนวณพิเศษซึ่งช่วยลดความผิดเพี้ยนของสัญญาณระดับต่ำได้ มีการสังเกตกระบวนการที่ตรงกันข้ามระหว่างการแปลงแบบดิจิทัลเป็นแอนะล็อก: ความลึกของบิตเพิ่มขึ้นจาก 16 เป็น 20 บิตโดยใช้อัลกอริธึมพิเศษที่ช่วยให้คุณกำหนดค่าแอมพลิจูดได้แม่นยำยิ่งขึ้น นั่นคือเสียงยังคงเป็น 16 บิต แต่มีการปรับปรุงคุณภาพเสียงโดยรวม
การเข้ารหัสคืออะไร
ในรัสเซีย "ชุดอักขระ" เรียกอีกอย่างว่าตาราง "ชุดอักขระ" และขั้นตอนการใช้ตารางนี้เพื่อแปลข้อมูลจากการแสดงคอมพิวเตอร์เป็นมนุษย์ และลักษณะของไฟล์ข้อความที่สะท้อนถึงการใช้งานบางอย่าง ระบบรหัสในนั้นเมื่อแสดงข้อความ
วิธีเข้ารหัสข้อความ
ชุดของสัญลักษณ์ที่ใช้ในการเขียนข้อความถูกอ้างถึงในศัพท์คอมพิวเตอร์ว่าเป็นตัวอักษร จำนวนตัวอักษรในตัวอักษรมักจะเรียกว่ากำลังของมัน สำหรับการนำเสนอ ข้อมูลข้อความคอมพิวเตอร์ส่วนใหญ่มักใช้ตัวอักษรที่มีความจุ 256 อักขระ อักขระตัวหนึ่งมีข้อมูล 8 บิต ดังนั้นรหัสไบนารีของอักขระแต่ละตัวจึงใช้หน่วยความจำคอมพิวเตอร์ 1 ไบต์ อักขระทั้งหมดของตัวอักษรดังกล่าวมีหมายเลขตั้งแต่ 0 ถึง 255 และแต่ละหมายเลขสอดคล้องกับรหัสไบนารี 8 บิต ซึ่งเป็นเลขลำดับของอักขระในระบบเลขฐานสอง - ตั้งแต่ 00000000 ถึง 11111111 เฉพาะอักขระ 128 ตัวแรกที่มี ตัวเลขจากศูนย์ ( รหัสไบนารี 00000000) ถึง 127 (01111111) ซึ่งรวมถึงตัวพิมพ์เล็กและ ตัวพิมพ์ใหญ่ตัวอักษรละติน ตัวเลข เครื่องหมายวรรคตอน วงเล็บ ฯลฯ รหัสที่เหลืออีก 128 รหัส เริ่มต้นด้วย 128 (รหัสไบนารี 10000000) และลงท้ายด้วย 255 (11111111) ใช้เพื่อเข้ารหัสตัวอักษรของตัวอักษรประจำชาติ บริการ และสัญลักษณ์ทางวิทยาศาสตร์
ประเภทของการเข้ารหัส
ตารางการเข้ารหัสที่มีชื่อเสียงที่สุดคือ ASCII (รหัส American Standard สำหรับการแลกเปลี่ยนข้อมูล) เดิมทีได้รับการพัฒนาสำหรับการส่งข้อความทางโทรเลขและในขณะนั้นเป็นแบบ 7 บิตนั่นคือมีเพียง 128 ชุด 7 บิตเท่านั้นที่ใช้ในการเข้ารหัสอักขระภาษาอังกฤษบริการและอักขระควบคุม ในกรณีนี้ ชุดค่าผสม (รหัส) 32 ชุดแรกที่ใช้ในการเข้ารหัสสัญญาณควบคุม (จุดเริ่มต้นของข้อความ สิ้นสุดบรรทัด การขึ้นบรรทัดใหม่ การโทร การสิ้นสุดข้อความ ฯลฯ) ในการพัฒนาคอมพิวเตอร์ IBM เครื่องแรก รหัสนี้ถูกใช้เพื่อแสดงสัญลักษณ์ในคอมพิวเตอร์ ตั้งแต่ใน รหัสแหล่งที่มา ASCII มีอักขระเพียง 128 ตัวสำหรับการเข้ารหัสมีค่าไบต์เพียงพอโดยที่บิตที่ 8 เท่ากับ 0 ค่าไบต์ที่มีบิตที่ 8 เท่ากับ 1 ใช้เพื่อแทนอักขระกราฟิกหลอก เครื่องหมายทางคณิตศาสตร์ และอักขระบางตัวจากภาษา อังกฤษ (กรีก เครื่องหมายเยอรมัน เครื่องหมายกำกับภาษาฝรั่งเศส ฯลฯ) เมื่อคอมพิวเตอร์เริ่มปรับตัวสำหรับประเทศและภาษาอื่น ไม่มีที่ว่างเพียงพอสำหรับสัญลักษณ์ใหม่อีกต่อไป เพื่อรองรับภาษาอื่นนอกเหนือจากภาษาอังกฤษอย่างเต็มที่ IBM ได้แนะนำตารางรหัสเฉพาะประเทศหลายตาราง ดังนั้นสำหรับประเทศสแกนดิเนเวียจึงเสนอตารางที่ 865 (นอร์ดิก) สำหรับประเทศอาหรับ - ตารางที่ 864 (อาหรับ) สำหรับอิสราเอล - ตารางที่ 862 (อิสราเอล) เป็นต้น ในตารางเหล่านี้ รหัสบางส่วนจากช่วงครึ่งหลังของตารางรหัสถูกใช้เพื่อแสดงอักขระของตัวอักษรประจำชาติ (โดยไม่รวมอักขระกราฟิกหลอกบางตัว) สถานการณ์ในภาษารัสเซียพัฒนาขึ้นในลักษณะพิเศษ เห็นได้ชัดว่าการแทนที่อักขระในช่วงครึ่งหลังของตารางโค้ดสามารถทำได้ วิธีทางที่แตกต่าง... ดังนั้นตารางการเข้ารหัสอักขระซิริลลิกที่แตกต่างกันจึงปรากฏขึ้นสำหรับภาษารัสเซีย: KOI8-R, IBM-866, CP-1251, ISO-8551-5 ทั้งหมดเป็นตัวแทนของสัญลักษณ์ของครึ่งแรกของตารางในลักษณะเดียวกัน (จาก 0 ถึง 127) และแตกต่างกันในการแสดงสัญลักษณ์ของตัวอักษรรัสเซียและกราฟิกหลอก สำหรับภาษาอย่างจีนหรือญี่ปุ่น โดยทั่วไป 256 ตัวอักษรไม่เพียงพอ นอกจากนี้ยังมีปัญหาในการส่งออกหรือบันทึกในไฟล์เดียวในเวลาเดียวกันข้อความบน ภาษาที่แตกต่างกัน(เช่น เมื่ออ้างอิง) ดังนั้น สากล ตารางรหัส UNICODE ที่มีสัญลักษณ์ที่ใช้ในภาษาของทุกคนในโลกตลอดจนบริการและสัญลักษณ์เสริมต่างๆ (เครื่องหมายวรรคตอน สัญลักษณ์ทางคณิตศาสตร์และทางเทคนิค ลูกศร เครื่องหมายกำกับเสียง ฯลฯ ) เห็นได้ชัดว่า หนึ่งไบต์ไม่เพียงพอสำหรับการเข้ารหัสอักขระจำนวนมาก ดังนั้น UNICODE จึงใช้รหัส 16 บิต (2 ไบต์) เพื่อแสดงอักขระ 65,536 ตัว จนถึงปัจจุบันมีการใช้รหัสประมาณ 49,000 รหัส (การเปลี่ยนแปลงที่สำคัญครั้งล่าสุดคือการแนะนำสัญลักษณ์สกุลเงินยูโรในเดือนกันยายน 1998) เพื่อความเข้ากันได้กับการเข้ารหัสก่อนหน้า 256 รหัสแรกจะเหมือนกับมาตรฐาน ASCII ในมาตรฐาน UNICODE นอกเหนือจากรหัสไบนารีบางตัว (รหัสเหล่านี้มักจะแสดงด้วยตัวอักษร U ตามด้วยเครื่องหมาย + และรหัสจริงในรูปแบบเลขฐานสิบหก) อักขระแต่ละตัวจะได้รับชื่อเฉพาะ องค์ประกอบอื่น มาตรฐานยูนิโคดเป็นอัลกอริธึมสำหรับการแปลงรหัส UNICODE แบบหนึ่งต่อหนึ่งตามลำดับไบต์ที่มีความยาวผันแปรได้ ความต้องการอัลกอริธึมดังกล่าวเกิดจากการที่แอพพลิเคชั่นบางตัวไม่สามารถทำงานร่วมกับ UNICODE ได้ แอปพลิเคชั่นบางตัวเข้าใจเฉพาะรหัส ASCII 7 บิต แอปพลิเคชั่นอื่นเข้าใจรหัส ASCII 8 บิต แอปพลิเคชันดังกล่าวใช้รหัส ASCII แบบขยายที่เรียกว่าเพื่อแทนอักขระที่ไม่พอดีตามลำดับในชุดอักขระ 128 ตัวหรือ 256 อักขระ เมื่ออักขระถูกเข้ารหัสด้วยสตริงไบต์ที่มีความยาวผันแปรได้ UTF-7 ใช้เพื่อแปลงรหัส UNICODE แบบย้อนกลับเป็นรหัส ASCII 7 บิตแบบขยาย และ UTF-8 ใช้เพื่อแปลงรหัส UNICODE แบบย้อนกลับเป็นรหัส ASCII 8 บิตแบบขยาย โปรดทราบว่าทั้ง ASCII และ UNICODE และมาตรฐานการเข้ารหัสอักขระอื่นๆ ไม่ได้กำหนดรูปภาพของอักขระ แต่มีเพียงองค์ประกอบของชุดอักขระและลักษณะที่แสดงในคอมพิวเตอร์เท่านั้น นอกจากนี้ (ซึ่งอาจไม่ชัดเจนในทันที) ลำดับของการแจงนับอักขระในชุดมีความสำคัญมาก เนื่องจากจะส่งผลต่ออัลกอริธึมการจัดเรียงในลักษณะที่สำคัญที่สุด เป็นตารางความสอดคล้องของสัญลักษณ์จากชุดใดชุดหนึ่ง (กล่าวคือ สัญลักษณ์ที่ใช้แสดงข้อมูลบน ภาษาอังกฤษหรือในภาษาต่าง ๆ เช่นในกรณีของ UNICODE) และแสดงโดยตารางการเข้ารหัสอักขระระยะหรือชุดอักขระ การเข้ารหัสมาตรฐานแต่ละรายการมีชื่อเช่น KOI8-R, ISO_8859-1, ASCII ขออภัย ไม่มีมาตรฐานสำหรับการเข้ารหัสชื่อ
การเข้ารหัสทั่วไป
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 การเข้ารหัส Microsoft Windows: o Windows-1250 สำหรับภาษายุโรปกลางที่ใช้อักษรละติน o Windows-1251 สำหรับอักษรซีริลลิก o Windows-1252 สำหรับภาษาตะวันตก o Windows-1253 สำหรับภาษากรีก o Windows -1254 สำหรับภาษาตุรกี o Windows-1255 สำหรับภาษาฮิบรู o Windows-1256 สำหรับภาษาอาหรับ o Windows-1257 สำหรับภาษาบอลติก o Windows-1258 สำหรับภาษาเวียดนาม MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI -7 การเข้ารหัสภาษาบัลแกเรีย ISCII VISCII Big5 (ตัวแปรที่มีชื่อเสียงที่สุดของ Microsoft CP950) o HSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS สำหรับภาษาญี่ปุ่น (Microsoft CP932) EUC-KR สำหรับภาษาเกาหลี (Microsoft CP949) ISO-2022 และ EUC สำหรับการเข้ารหัสระบบการเขียนภาษาจีนแบบ UTF-8 และ UTF-16 ของชุดอักขระยง รหัสในระบบการเข้ารหัส ASCII(รหัสมาตรฐานอเมริกันสำหรับการแลกเปลี่ยนข้อมูล) อักขระแต่ละตัวจะแสดงด้วยหนึ่งไบต์ซึ่งสามารถเข้ารหัสได้ 256 อักขระ
ASCII มีตารางการเข้ารหัสสองตาราง - แบบพื้นฐานและแบบขยาย ตารางฐานแก้ไขค่าของรหัสตั้งแต่ 0 ถึง 127 และตัวขยายหมายถึงอักขระที่มีตัวเลขตั้งแต่ 128 ถึง 255 ซึ่งเพียงพอสำหรับการแสดงชุดอักขระภาษาอังกฤษและรัสเซียทั้งหมดแปดบิต ทั้งตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ ตลอดจนเครื่องหมายวรรคตอน สัญลักษณ์สำหรับการคำนวณทางคณิตศาสตร์พื้นฐาน และสัญลักษณ์พิเศษทั่วไปที่สามารถสังเกตได้บนแป้นพิมพ์
รหัส 32 ตัวแรกของตารางฐานเริ่มต้นจากศูนย์จะมอบให้กับผู้ผลิตฮาร์ดแวร์ (โดยหลักแล้วสำหรับผู้ผลิตคอมพิวเตอร์และอุปกรณ์การพิมพ์) ในพื้นที่นี้ มีการวางรหัสควบคุมที่เรียกว่า ซึ่งไม่ตรงกับอักขระภาษาใดๆ และด้วยเหตุนี้ รหัสเหล่านี้จะไม่ปรากฏบนหน้าจอหรือบนอุปกรณ์การพิมพ์ แต่สามารถควบคุมวิธีการส่งออกข้อมูลอื่นๆ ได้ เริ่มตั้งแต่รหัส 32 ถึงรหัส 127 สัญลักษณ์ของตัวอักษรภาษาอังกฤษ เครื่องหมายวรรคตอน ตัวเลข การคำนวณทางคณิตศาสตร์ และสัญลักษณ์เสริม ทั้งหมดนี้สามารถเห็นได้ในส่วนภาษาละตินของแป้นพิมพ์คอมพิวเตอร์
ส่วนที่สองที่ขยายออกไปนั้นมอบให้กับระบบการเข้ารหัสระดับประเทศ มีตัวอักษรที่ไม่ใช่ภาษาละตินจำนวนมากในโลก (อาหรับ ฮีบรู กรีก ฯลฯ) รวมถึงอักษรซีริลลิก นอกจากนี้ รูปแบบแป้นพิมพ์ภาษาเยอรมัน ฝรั่งเศส และสเปนยังแตกต่างจากรูปแบบภาษาอังกฤษ
ส่วนภาษาอังกฤษของแป้นพิมพ์เคยมีมาตรฐานมากมาย แต่ตอนนี้พวกเขาทั้งหมดถูกแทนที่ด้วยรหัส ASCII เดียว นอกจากนี้ยังมีมาตรฐานมากมายสำหรับแป้นพิมพ์ภาษารัสเซีย: GOST, GOST-alternative, ISO (International Standard Organisation - International Institute for Standardization) แต่มาตรฐานทั้งสามนี้ได้หมดไปจริง ๆ แม้ว่าพวกเขาจะพบที่ไหนสักแห่งในคอมพิวเตอร์เก่าหรือในคอมพิวเตอร์ เครือข่าย
การเข้ารหัสอักขระหลักของภาษารัสเซียซึ่งใช้ในคอมพิวเตอร์ที่มีระบบปฏิบัติการ ระบบ Windowsเรียกว่า Windows-1251ได้รับการพัฒนาสำหรับอักษรซีริลลิกโดย Microsoft โดยปกติ ข้อมูลข้อความคอมพิวเตอร์ส่วนใหญ่จะถูกเข้ารหัสใน Windows-1251 อย่างไรก็ตาม Microsoft พัฒนาการเข้ารหัสด้วยตัวเลขสี่หลักที่แตกต่างกันสำหรับตัวอักษรทั่วไปอื่นๆ ได้แก่ อาหรับ ญี่ปุ่น และอื่นๆ
การเข้ารหัสทั่วไปอื่นเรียกว่า KOI-8(รหัสแลกเปลี่ยนข้อมูลแปดหลัก) - ต้นกำเนิดของมันย้อนกลับไปในช่วงเวลาของสภาเพื่อความช่วยเหลือทางเศรษฐกิจร่วมกันของรัฐยุโรปตะวันออก วันนี้การเข้ารหัส KOI-8 แพร่หลายในเครือข่ายคอมพิวเตอร์ในอาณาเขตของรัสเซียและในภาคอินเทอร์เน็ตของรัสเซีย มันจึงเกิดขึ้นที่ข้อความในจดหมายหรืออย่างอื่นไม่สามารถอ่านได้ ซึ่งหมายความว่าคุณต้องเปลี่ยนจาก KOI-8 เป็น Windows-1251 สิบ
ในยุค 90 ผู้ผลิตซอฟต์แวร์รายใหญ่ที่สุด: Microsoft, Borland, Adobe คนเดียวกันได้ตัดสินใจเกี่ยวกับความจำเป็นในการพัฒนาระบบการเข้ารหัสข้อความที่แตกต่างกัน ซึ่งแต่ละอักขระจะได้รับการจัดสรรไม่ใช่ 1 แต่ 2 ไบต์ เธอได้ชื่อ Unicodeและเป็นไปได้ที่จะเข้ารหัสอักขระ 65,536 ตัวของฟิลด์นี้เพียงพอที่จะใส่ลงในตารางตัวอักษรประจำชาติสำหรับทุกภาษาของโลก Unicode ส่วนใหญ่ (ประมาณ 70%) ถูกครอบครองโดยตัวอักษรจีน ในอินเดียมีตัวอักษรประจำชาติ 11 ตัว มีชื่อแปลก ๆ มากมาย เช่น การเขียนของชาวอะบอริจินในแคนาดา
เนื่องจากการเข้ารหัสของอักขระแต่ละตัวใน Unicode ไม่ได้รับการจัดสรร 8 บิต แต่เป็น 16 บิต ขนาดของไฟล์ข้อความจึงเพิ่มขึ้นเป็นสองเท่า ซึ่งครั้งหนึ่งเคยเป็นอุปสรรคต่อการแนะนำระบบ 16 บิต และตอนนี้ด้วยฮาร์ดไดรฟ์กิกะไบต์, RAM หลายร้อยเมกะไบต์, โปรเซสเซอร์กิกะเฮิร์ตซ์, การเพิ่มปริมาณไฟล์ข้อความเป็นสองเท่าซึ่งเมื่อเปรียบเทียบกับกราฟิกใช้พื้นที่น้อยมากไม่สำคัญ
อักษรซีริลลิกใน Unicode มีตั้งแต่ 768 ถึง 923 (อักขระพื้นฐาน) และตั้งแต่ 924 ถึง 1023 (อักษรซีริลลิกแบบขยาย อักษรประจำชาติต่างๆ หากโปรแกรมไม่ได้รับการดัดแปลงสำหรับ Cyrillic Unicode เป็นไปได้ว่าอักขระข้อความไม่เป็นที่รู้จักในฐานะ Cyrillic แต่เป็นภาษาละตินแบบขยาย (รหัสจาก 256 ถึง 511) และในกรณีนี้ แทนที่จะเป็นข้อความ ชุดสัญลักษณ์แปลก ๆ ที่ไม่มีความหมายปรากฏขึ้นบนหน้าจอ
เป็นไปได้หากโปรแกรมล้าสมัย ซึ่งสร้างก่อนปี 1995 หรือหายากซึ่งไม่มีใครสนใจ Russify อาจเป็นไปได้ว่าระบบปฏิบัติการ Windows ที่ติดตั้งบนคอมพิวเตอร์ไม่ได้รับการกำหนดค่าอย่างสมบูรณ์สำหรับอักษรซีริลลิก ในกรณีนี้ คุณต้องสร้างรายการที่เหมาะสมในรีจิสทรี
 ข้อบกพร่องในภาวะเอกฐาน?
ข้อบกพร่องในภาวะเอกฐาน? Just Cause 2 ล่ม
Just Cause 2 ล่ม Terraria ไม่เริ่มทำงาน ฉันควรทำอย่างไร?
Terraria ไม่เริ่มทำงาน ฉันควรทำอย่างไร?