การเข้ารหัสอักขระ - PIE.Wiki การเข้ารหัสข้อมูลข้อความ
Unicode เป็นระบบการเข้ารหัสอักขระที่คอมพิวเตอร์ใช้เพื่อจัดเก็บและแลกเปลี่ยนข้อมูลที่เป็นข้อความ Unicode มีตัวเลขที่ไม่ซ้ำกัน (หรือจุดรหัส) สำหรับอักขระแต่ละตัวในระบบการเขียนหลักของโลก ระบบนี้ยังรวมถึงสัญลักษณ์ทางเทคนิค เครื่องหมายวรรคตอน และสัญลักษณ์อื่นๆ อีกมากมายที่ใช้ในการเขียน
นอกเหนือจากการเป็นผังอักขระแล้ว Unicode ยังรวมอัลกอริธึมสำหรับการจับคู่และเข้ารหัสสคริปต์สองด้าน เช่น ภาษาอาหรับ ตลอดจนข้อกำหนดสำหรับการปรับรูปแบบข้อความให้เป็นมาตรฐาน
ส่วนนี้ให้คำอธิบายทั่วไปของ Unicode สำหรับข้อมูลเพิ่มเติม ข้อมูลครบถ้วนและสำหรับรายการภาษาที่รองรับซึ่งสามารถเข้ารหัสอักขระได้โดยใช้ Unicode ให้ดูที่เว็บไซต์ Unicode Consortium
โค้ดพอยท์
สัญลักษณ์คือหน่วยของข้อมูลที่สัมพันธ์กันอย่างคร่าวๆ กับหน่วยข้อความในการเขียนภาษาธรรมชาติ Unicode กำหนดวิธีการตีความอักขระมากกว่าแสดง
ภาพอักขระ (สัญลักษณ์) ที่แสดง หรือการแสดงภาพของอักขระ เป็นอักขระที่ปรากฏบนหน้าจอมอนิเตอร์หรือหน้าที่พิมพ์ ในบางระบบการเขียน อักขระหนึ่งตัวสามารถสัมพันธ์กับร่ายมนตร์หลายอัน หรืออักขระหลายตัวสามารถสอดคล้องกับร่ายมนตร์เดียว ตัวอย่างเช่น "ll" ในภาษาสเปนคือหนึ่งสัญลักษณ์ แต่มีอักขระสองตัว: "l" และ "l"
ใน Unicode อักขระจะถูกแปลงเป็นจุดโค้ด จุดรหัสคือตัวเลขที่กำหนดโดย Unicode Consortium ให้กับอักขระแต่ละตัวในระบบสัญกรณ์แต่ละระบบ จุดรหัสจะแสดงเป็น "U +" และตัวเลขสี่ตัวและ / หรือตัวอักษร ต่อไปนี้คือตัวอย่างโค้ดพอยต์สำหรับอักขระสี่ตัวที่แตกต่างกัน: ตัวพิมพ์เล็ก l ตัวพิมพ์เล็ก u พร้อมเครื่องหมาย เบต้า และตัวพิมพ์เล็ก e แบบเฉียบพลัน
Unicode มีจุดรหัส 1,114,112 จุด; จนถึงปัจจุบันมีอักขระมากกว่า 96,000 ตัวที่ได้รับมอบหมาย
ระดับ (เครื่องบิน)
พื้นที่โค้ด Unicode สำหรับอักขระแบ่งออกเป็น 17 ระนาบ โดยแต่ละระนาบมีจุดโค้ด 65,536 จุด
ระดับแรก (ระนาบ) -plane 0- คือ Basic Multilingual Plane (BMP) อักขระที่ใช้มากที่สุดส่วนใหญ่ถูกเข้ารหัสโดยใช้ BMP และนี่คือเลเยอร์ที่มีการเข้ารหัสอักขระส่วนใหญ่ในปัจจุบัน BMP มีโค้ดพอยท์สำหรับอักขระเกือบทั้งหมดในภาษาสมัยใหม่และอีกมาก อักขระพิเศษ... มีจุดรหัสที่ไม่ได้ใช้ประมาณ 6,300 จุดใน BMP ซึ่งจะใช้เพื่อเพิ่มอักขระเพิ่มเติมในอนาคต
ระดับถัดไป (ระนาบ) -เครื่องบิน 1- คือเครื่องบินเสริมหลายภาษา (SMP) SMP ใช้เพื่อเข้ารหัสอักขระโบราณเช่นเดียวกับดนตรีและ สัญลักษณ์ทางคณิตศาสตร์.
การเข้ารหัสอักขระ
การเข้ารหัสอักขระกำหนดอักขระแต่ละตัว จุดโค้ด และวิธีที่จุดโค้ดแสดงเป็นบิต คุณจะไม่สามารถตีความสตริงอักขระได้อย่างถูกต้อง
มีรูปแบบการเข้ารหัสจำนวนมาก แต่การแปลงข้อมูลระหว่างกันเป็นเรื่องยากมาก และมีเพียงไม่กี่รูปแบบที่สามารถพิจารณาการมีอยู่ของอักขระในภาษาต่างๆ มากกว่าสองหรือสามภาษา ตัวอย่างเช่น หากพีซีของคุณถูกตั้งค่าให้ใช้ OEM-Latin II โดยค่าเริ่มต้น และคุณกำลังเรียกดูเว็บไซต์ที่ใช้ IBM EBCDIC-Cyrillic อักขระใดๆ ที่จะแสดงใน Cyrillic ที่จะไม่ถูกเข้ารหัสในสคีมา Latin II จะไม่ จะปรากฏขึ้น อักขระเหล่านี้จะถูกแทนที่ด้วยอักขระอื่นๆ เช่น เครื่องหมายคำถามและสี่เหลี่ยม
เนื่องจาก Unicode มีจุดรหัสสำหรับอักขระส่วนใหญ่ในทั้งหมด ภาษาสมัยใหม่จากนั้นการใช้การเข้ารหัสอักขระ Unicode จะทำให้คอมพิวเตอร์ของคุณตีความอักขระที่รู้จักเกือบทุกตัว
มีรูปแบบ Unicode หลักสามแบบสำหรับการเข้ารหัสอักขระ: UTF-8, UTF-16 และ UTF-32 UTF ย่อมาจาก Unicode Transformation Format ตัวเลขที่ตามหลัง UTF ระบุขนาดของหน่วย (เป็นไบต์) ที่ใช้สำหรับการเข้ารหัส
- UTF-8ใช้หน่วยรหัสความกว้างตัวแปร 8 บิต UTF-8 ใช้ 1 ถึง 6 ไบต์ในการเข้ารหัสอักขระ สามารถใช้ไบต์น้อยกว่า เท่ากัน หรือมากกว่า UTF-16 เพื่อเข้ารหัสอักขระเดียวกันได้ ใน windows-1251 แต่ละรหัสตั้งแต่ 0 ถึง 127 (U + 0000 ถึง U + 0127) จะถูกเก็บไว้ในหนึ่งไบต์ เฉพาะรหัสจุด 128 (U + 0128) ขึ้นไปเท่านั้นที่จัดเก็บโดยใช้ 2 ถึง 6 ไบต์
- UTF-16ใช้หน่วยรหัส 16 บิตความกว้างคงที่หนึ่งหน่วย มีขนาดกะทัดรัดและสามารถเข้ารหัสอักขระที่ใช้บ่อยทั้งหมดด้วยหน่วยรหัส 16 บิตเดียว อักขระอื่นๆ สามารถเข้าถึงได้โดยใช้คู่ของหน่วยรหัส 16 บิต
- UTF-32ใช้เวลา 4 ไบต์ในการเข้ารหัสอักขระใดๆ ในกรณีส่วนใหญ่ เอกสารที่เข้ารหัส UTF-32 จะมีขนาดประมาณสองเท่าของเอกสารที่เข้ารหัส UTF-16 อักขระแต่ละตัวถูกเข้ารหัสในหน่วยเข้ารหัสแบบความกว้างคงที่ 32 บิตหนึ่งหน่วย คุณสามารถใช้ UTF-32 ได้หากคุณไม่มีพื้นที่ดิสก์จำกัด และต้องการใช้โค้ดยูนิตเดียวสำหรับแต่ละอักขระ
การเข้ารหัสทั้งสามรูปแบบสามารถเข้ารหัสอักขระเดียวกันและสามารถแปลจากที่หนึ่งไปยังอีกที่หนึ่งได้โดยไม่สูญเสียข้อมูล
นอกจากนี้ยังมีการเข้ารหัสอื่นๆ เช่น UTF-7 และ UTF-EBCDIC นอกจากนี้ยังมี GB18030 ซึ่งเทียบเท่ากับ UTF-8 ในภาษาจีน และรองรับอักขระจีนตัวย่อและตัวเต็ม สำหรับภาษารัสเซียนั้นสะดวกที่จะใช้ windows-1251
ลิขสิทธิ์ © 1995-2014 Esri. สงวนลิขสิทธิ์.
Unicode เป็นโลกที่ใหญ่และซับซ้อนมาก เนื่องจากมาตรฐานนี้ทำให้คุณสามารถแสดงและทำงานในคอมพิวเตอร์ที่มีสคริปต์หลักทั้งหมดของโลกได้ ระบบการเขียนบางระบบมีมานานกว่าพันปีแล้ว และหลายระบบมีวิวัฒนาการเกือบเป็นอิสระจากกันในส่วนต่างๆ ของโลก ผู้คนคิดค้นหลายสิ่งหลายอย่างและพวกเขามักจะแตกต่างกันมากจนเป็นงานที่ยากและมีความทะเยอทะยานอย่างยิ่งที่จะรวมสิ่งเหล่านี้เป็นมาตรฐานเดียว
เพื่อให้เข้าใจ Unicode อย่างแท้จริง อย่างน้อยคุณต้องจินตนาการถึงคุณลักษณะของสคริปต์ทั้งหมดที่มาตรฐานอนุญาตให้คุณใช้งานได้อย่างผิวเผิน แต่มันจำเป็นสำหรับนักพัฒนาทุกคนจริงๆ หรือ? เราจะบอกว่าไม่ ในการใช้ Unicode ในงานประจำวันส่วนใหญ่ เพียงแค่ทราบข้อมูลขั้นต่ำที่เหมาะสม จากนั้นเจาะลึกมาตรฐานตามความจำเป็น
ในบทความนี้ เราจะพูดถึงหลักการพื้นฐานของ Unicode และเน้นย้ำถึงประเด็นสำคัญในทางปฏิบัติที่นักพัฒนาจะต้องเผชิญในการทำงานประจำวันอย่างแน่นอน
ทำไมคุณถึงต้องการ Unicode
ก่อนการถือกำเนิดของ Unicode มีการใช้การเข้ารหัสแบบไบต์เดี่ยวเกือบทั่วถึง ซึ่งขอบเขตระหว่างตัวอักขระเอง การแทนค่าในหน่วยความจำคอมพิวเตอร์และการแสดงผลบนหน้าจอค่อนข้างจะเป็นไปตามอำเภอใจ หากคุณทำงานกับภาษาประจำชาติหนึ่งหรือภาษาอื่น ระบบของคุณจะมีการติดตั้งการเข้ารหัสแบบอักษรที่เกี่ยวข้อง ซึ่งทำให้สามารถดึงไบต์จากดิสก์บนหน้าจอในลักษณะที่ผู้ใช้เข้าใจได้หากคุณพิมพ์ไฟล์ข้อความบนเครื่องพิมพ์และเห็นชุดของ krakozyabras ที่เข้าใจยากบนหน้ากระดาษ แสดงว่าฟอนต์ที่เกี่ยวข้องไม่ได้โหลดลงในอุปกรณ์การพิมพ์ และไม่ได้ตีความไบต์ในแบบที่คุณต้องการ
วิธีการนี้โดยทั่วไปและการเข้ารหัสแบบไบต์เดี่ยวโดยเฉพาะมีข้อเสียที่สำคัญหลายประการ:
- สามารถทำงานได้พร้อมกันเพียง 256 อักขระและ 128 ตัวแรกถูกสงวนไว้สำหรับอักขระละตินและตัวควบคุมและในช่วงครึ่งหลังนอกเหนือจากอักขระของตัวอักษรประจำชาติแล้วยังจำเป็นต้องหาที่สำหรับหลอกกราฟิก ตัวอักษร (╔ ╗).
- แบบอักษรเชื่อมโยงกับการเข้ารหัสเฉพาะ
- การเข้ารหัสแต่ละอันเป็นตัวแทนของชุดอักขระของตัวเอง และการแปลงจากที่หนึ่งไปเป็นอีกอันหนึ่งทำได้โดยสูญเสียเพียงบางส่วนเท่านั้น เมื่ออักขระที่หายไปถูกแทนที่ด้วยอักขระที่คล้ายคลึงกันแบบกราฟิก
- การถ่ายโอนไฟล์ระหว่างอุปกรณ์ที่ใช้ระบบปฏิบัติการที่แตกต่างกันนั้นทำได้ยาก จำเป็นต้องมีโปรแกรมแปลงไฟล์ หรือมีฟอนต์เพิ่มเติมพร้อมกับไฟล์ การมีอยู่ของอินเทอร์เน็ตอย่างที่เราทราบมันเป็นไปไม่ได้
- ในโลกนี้มีระบบการเขียนที่ไม่ใช่ตัวอักษร (การเขียนอักษรอียิปต์โบราณ) ซึ่งในหลักการแล้วการเข้ารหัสแบบไบต์เดียวไม่สามารถแสดงได้
หลักการพื้นฐานของ Unicode
เราทุกคนเข้าใจเป็นอย่างดีว่าคอมพิวเตอร์ไม่ทราบเกี่ยวกับหน่วยงานในอุดมคติใด ๆ แต่ทำงานด้วยบิตและไบต์ แต่ระบบคอมพิวเตอร์ยังคงถูกสร้างขึ้นโดยผู้คน ไม่ใช่เครื่องจักร และในบางครั้ง มันสะดวกกว่าสำหรับคุณและฉันที่จะใช้แนวคิดแบบเก็งกำไร จากนั้นจึงเปลี่ยนจากนามธรรมไปสู่รูปธรรมสำคัญ!หลักการสำคัญประการหนึ่งในปรัชญา Unicode คือความแตกต่างที่ชัดเจนระหว่างอักขระ การเป็นตัวแทนในคอมพิวเตอร์ และการแสดงผลบนอุปกรณ์ส่งออก
แนวคิดของอักขระยูนิโค้ดที่เป็นนามธรรมได้รับการแนะนำ ซึ่งมีอยู่เฉพาะในรูปแบบของแนวคิดเก็งกำไรและข้อตกลงระหว่างบุคคล ซึ่งประดิษฐานอยู่ในมาตรฐาน อักขระ Unicode แต่ละตัวเชื่อมโยงกับจำนวนเต็มที่ไม่ติดลบซึ่งเรียกว่าจุดโค้ด
ตัวอย่างเช่น อักขระ Unicode U + 041F เป็นตัวพิมพ์ใหญ่ Cyrillic ตัวอักษร P มีหลายวิธีในการแสดงอักขระนี้ในหน่วยความจำของคอมพิวเตอร์ เช่นเดียวกับการแสดงบนหน้าจอมอนิเตอร์หลายพันวิธี แต่ในขณะเดียวกัน P ก็จะเป็น P หรือ U + 041F ในแอฟริกาด้วย
นี่คือการห่อหุ้มที่คุ้นเคย หรือการแยกอินเทอร์เฟซออกจากการใช้งาน ซึ่งเป็นแนวคิดที่ทำงานได้ดีในการเขียนโปรแกรม
ปรากฎว่าตามมาตราฐาน ข้อความใดๆ ก็สามารถเข้ารหัสเป็นลำดับของอักขระ Unicode ได้
สวัสดี คุณ + 041F U + 0440 U + 0438 U + 0432 U + 0435 U + 0442
เขียนลงบนกระดาษ บรรจุในซองแล้วส่งไปยังส่วนใดของโลก หากพวกเขารู้เกี่ยวกับการมีอยู่ของ Unicode พวกเขาก็จะรับรู้ข้อความในลักษณะเดียวกับคุณและฉัน พวกเขาจะไม่ต้องสงสัยเลยแม้แต่น้อยว่าอักขระตัวสุดท้ายคืออักษรตัวพิมพ์เล็กซีริลลิก อี(U + 0435) ไม่พูดภาษาละตินว่าเล็ก อี(U + 0065). โปรดทราบว่าเราไม่ได้พูดอะไรเกี่ยวกับการแสดงไบต์
แม้ว่าอักขระ Unicode จะเรียกว่าสัญลักษณ์ แต่ก็ไม่สอดคล้องกับอักขระในความหมายที่ไร้เดียงสาแบบเดิมเสมอไป เช่น ตัวอักษร ตัวเลข เครื่องหมายวรรคตอน หรืออักษรอียิปต์โบราณ (ดูรายละเอียดเพิ่มเติมใต้สปอยเลอร์)
ตัวอย่างอักขระ Unicode ต่างๆ
มีอักขระ Unicode ทางเทคนิคอย่างหมดจด ตัวอย่างเช่น:
- U + 0000: อักขระว่าง;
- U + D800 – U + DFFF: ตัวแทนรายย่อยและรายใหญ่สำหรับการแสดงทางเทคนิคของจุดรหัสในช่วง 10,000 ถึง 10FFFF (อ่าน: ภายนอก BMP / BMP) ในตระกูลการเข้ารหัส UTF-16
- ฯลฯ
มีพื้นที่ว่างทั้งหมดที่มีความกว้างและวัตถุประสงค์หลากหลาย (ดูบทความ habr ที่ยอดเยี่ยม :):
- U + 0020 (ช่องว่าง);
- U + 00A0 (ช่องว่างไม่แตกใน HTML);
- U + 2002 (ช่องว่างครึ่งวงกลมหรือ En Space);
- U + 2003 (พื้นที่กลมหรือ Em Space);
- ฯลฯ
- U + 0300 และ U + 0301: สัญญาณของความเครียดขั้นต้น (เฉียบพลัน) และระดับทุติยภูมิ (อ่อน);
- U + 0306: สั้น (ตัวยก) เช่นเดียวกับใน th;
- U + 0303: ตัวยกตัวหนอน
- ฯลฯ
สัญลักษณ์คืออะไร อะไรคือความแตกต่างระหว่างคลัสเตอร์กราฟ (อ่าน: รับรู้เป็นภาพสัญลักษณ์เดียว) จากสัญลักษณ์ Unicode และจากรหัสควอนตัม เราจะบอกคุณในครั้งต่อไป
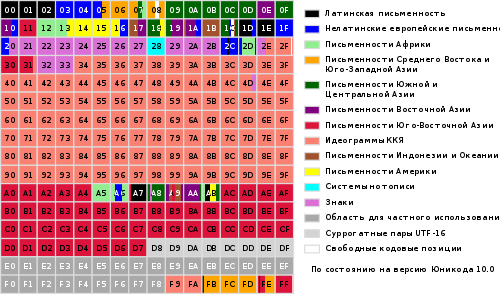
พื้นที่โค้ด Unicode
พื้นที่โค้ด Unicode ประกอบด้วยจุดโค้ด 1 114 112 จุด ตั้งแต่ 0 ถึง 10FFFF ในจำนวนนี้มีเพียง 128,237 ค่าที่ได้รับมอบหมายสำหรับมาตรฐานรุ่นที่ 9 ส่วนหนึ่งของพื้นที่สงวนไว้สำหรับการใช้งานส่วนตัวและกลุ่ม Unicode สัญญาว่าจะไม่กำหนดค่าให้กับตำแหน่งจากพื้นที่พิเศษเหล่านี้เพื่อความสะดวก พื้นที่ทั้งหมดถูกแบ่งออกเป็น 17 ลำ (ปัจจุบันเกี่ยวข้องกันหกลำ) จนกระทั่งเมื่อไม่นานนี้ เป็นเรื่องปกติที่จะพูดว่าเป็นไปได้มากว่าคุณจะต้องเผชิญหน้ากับ Basic Multilingual Plane (BMP) ซึ่งรวมถึงอักขระ Unicode จาก U + 0000 ถึง U + FFFF (มองไปข้างหน้าเล็กน้อย: อักขระ BMP จะแสดงเป็น UTF-16 ในสองไบต์ ไม่ใช่สี่) ในปี 2559 วิทยานิพนธ์ฉบับนี้เป็นที่น่าสงสัยอยู่แล้ว ตัวอย่างเช่น อาจพบอักขระ Emoji ยอดนิยมในข้อความของผู้ใช้ และคุณจำเป็นต้องสามารถดำเนินการได้อย่างถูกต้อง
การเข้ารหัส
หากเราต้องการส่งข้อความทางอินเทอร์เน็ต เราต้องเข้ารหัสลำดับของอักขระยูนิโค้ดเป็นลำดับไบต์มาตรฐาน Unicode ประกอบด้วยการเข้ารหัส Unicode จำนวนหนึ่ง เช่น UTF-8 และ UTF-16BE / UTF-16LE ที่อนุญาตให้เข้ารหัสพื้นที่จุดโค้ดทั้งหมด การแปลงระหว่างการเข้ารหัสเหล่านี้สามารถทำได้โดยอิสระโดยไม่สูญเสียข้อมูล
นอกจากนี้ ยังไม่มีใครยกเลิกการเข้ารหัสแบบไบต์เดียว แต่อนุญาตให้คุณเข้ารหัสส่วนย่อยของสเปกตรัม Unicode ของคุณเองและแคบมาก - 256 จุดหรือน้อยกว่ารหัส สำหรับการเข้ารหัสดังกล่าว ตารางมีอยู่และพร้อมใช้งานสำหรับทุกคน โดยที่แต่ละค่าของไบต์เดี่ยวจะเชื่อมโยงกับอักขระ Unicode (ดู ตัวอย่างเช่น CP1251.TXT) แม้จะมีข้อ จำกัด การเข้ารหัสแบบไบต์เดียวกลับกลายเป็นว่ามีประโยชน์มากเมื่อต้องทำงานกับภาษาเดียวจำนวนมาก ข้อมูลข้อความ.
UTF-8 เป็นการเข้ารหัส Unicode ที่ใช้กันอย่างแพร่หลายบนอินเทอร์เน็ต (ชนะรางวัลในปี 2008) สาเหตุหลักมาจากการประหยัดและความเข้ากันได้ที่โปร่งใสกับ ASCII เจ็ดบิต อักษรละตินและอักขระบริการ เครื่องหมายวรรคตอนพื้นฐานและตัวเลข - เช่น อักขระ ASCII เจ็ดบิตทั้งหมดถูกเข้ารหัสใน UTF-8 ในหนึ่งไบต์ เหมือนกับใน ASCII อักขระของสคริปต์หลักหลายตัว นอกเหนือจากอักขระอักษรอียิปต์โบราณบางตัวที่หายากกว่า จะแสดงด้วยสองหรือสามไบต์ในนั้น จุดรหัสที่ใหญ่ที่สุดที่กำหนดโดยมาตรฐาน 10FFFF ถูกเข้ารหัสในสี่ไบต์
โปรดทราบว่า UTF-8 เป็นการเข้ารหัสความยาวผันแปร อักขระ Unicode แต่ละตัวในนั้นแสดงโดยลำดับของรหัสควอนตัมที่มีความยาวขั้นต่ำหนึ่งควอนตัม ตัวเลข 8 หมายถึงความยาวบิตของหน่วยรหัส - 8 บิต สำหรับการเข้ารหัสตระกูล UTF-16 ขนาดของรหัสควอนตัมคือ 16 บิตตามลำดับ สำหรับ UTF-32 - 32 บิต
หากคุณกำลังส่งหน้า HTML ที่มีข้อความ Cyrillic ผ่านเครือข่าย UTF-8 สามารถให้ประโยชน์ที่เป็นรูปธรรมได้เนื่องจาก มาร์กอัปทั้งหมดรวมถึงบล็อก JavaScript และ CSS จะได้รับการเข้ารหัสอย่างมีประสิทธิภาพในหนึ่งไบต์ ตัวอย่างเช่น หน้าแรก Habra ใน UTF-8 คือ 139Kb และใน UTF-16 จะมีขนาด 256Kb แล้ว สำหรับการเปรียบเทียบ หากคุณใช้ win-1251 โดยสูญเสียความสามารถในการจัดเก็บอักขระบางตัว ขนาดเมื่อเทียบกับ UTF-8 จะลดลงเพียง 11Kb เป็น 128Kb เท่านั้น
ในการจัดเก็บข้อมูลสตริงในแอปพลิเคชัน มักใช้การเข้ารหัสแบบยูนิโค้ดแบบ 16 บิตเนื่องจากความเรียบง่าย เช่นเดียวกับข้อเท็จจริงที่ว่าอักขระของระบบการเขียนหลักของโลกถูกเข้ารหัสในควอนตัมสิบหกบิตหนึ่งตัว ตัวอย่างเช่น Java ใช้ UTF-16 ได้สำเร็จสำหรับการแสดงสตริงภายใน ระบบปฏิบัติการ Windows ยังใช้ UTF-16 ภายในอีกด้วย
ไม่ว่าในกรณีใด ตราบใดที่เรายังคงอยู่ในพื้นที่ Unicode ไม่สำคัญหรอกว่าข้อมูลสตริงจะถูกเก็บไว้อย่างไรในแอปพลิเคชันเดียว หากรูปแบบการจัดเก็บข้อมูลภายในช่วยให้คุณสามารถเข้ารหัสจุดรหัสทั้งหมดได้มากกว่าหนึ่งล้านจุด และไม่มีการสูญเสียข้อมูลที่ขอบเขตของแอปพลิเคชัน เช่น เมื่ออ่านจากไฟล์หรือคัดลอกไปยังคลิปบอร์ด ทุกอย่างก็เรียบร้อย
สำหรับการตีความข้อความที่อ่านจากดิสก์หรือจากซ็อกเก็ตเครือข่ายอย่างถูกต้อง คุณต้องกำหนดการเข้ารหัสก่อน สิ่งนี้ทำได้โดยใช้ข้อมูลเมตาที่ผู้ใช้จัดหาซึ่งเขียนขึ้นในหรือใกล้กับข้อความ หรือถูกกำหนดโดยฮิวริสติก
ในคราบแห้ง
มีข้อมูลมากมายและเหมาะสมที่จะสรุปทุกสิ่งที่เขียนไว้ข้างต้นโดยย่อ:- Unicode กำหนดความแตกต่างที่ชัดเจนระหว่างอักขระ การแทนค่าในคอมพิวเตอร์ และการแสดงผลบนอุปกรณ์ส่งออก
- อักขระ Unicode ไม่สอดคล้องกับอักขระในความหมายที่ไร้เดียงสาแบบเดิมเสมอไป เช่น ตัวอักษร ตัวเลข เครื่องหมายวรรคตอน หรืออักษรอียิปต์โบราณ
- พื้นที่โค้ด Unicode ประกอบด้วยจุดโค้ด 1 114 112 จุด ตั้งแต่ 0 ถึง 10FFFF
- Basic Multilingual Plane ประกอบด้วยอักขระ Unicode U + 0000 ถึง U + FFFF ซึ่งเข้ารหัสเป็น UTF-16 ในสองไบต์
- การเข้ารหัส Unicode ใดๆ ช่วยให้คุณสามารถเข้ารหัสพื้นที่ทั้งหมดของจุดโค้ด Unicode และการแปลงระหว่างการเข้ารหัสที่แตกต่างกันจะดำเนินการโดยไม่สูญเสียข้อมูล
- การเข้ารหัสแบบไบต์เดียวสามารถเข้ารหัสได้เพียงส่วนเล็กๆ ของสเปกตรัมยูนิโค้ด แต่จะมีประโยชน์เมื่อทำงานกับข้อมูลภาษาเดียวจำนวนมาก
- การเข้ารหัสแบบ UTF-8 และ UTF-16 มีความยาวโค้ดที่แปรผันได้ ใน UTF-8 อักขระ Unicode แต่ละตัวสามารถเข้ารหัสได้หนึ่ง สอง สาม หรือสี่ไบต์ ใน UTF-16 สองหรือสี่ไบต์
- รูปแบบภายในของการจัดเก็บข้อมูลที่เป็นข้อความภายในแอปพลิเคชันที่แยกต่างหากสามารถกำหนดเองได้ โดยต้องทำงานอย่างถูกต้องกับพื้นที่ทั้งหมดของจุดโค้ด Unicode และไม่มีการสูญหายในการส่งข้อมูลข้ามพรมแดน
บันทึกย่อเกี่ยวกับการเข้ารหัส
ความสับสนบางอย่างอาจเกิดขึ้นกับการเข้ารหัสระยะ ภายใน Unicode การเข้ารหัสจะเกิดขึ้นสองครั้ง ครั้งแรกที่มีการเข้ารหัสชุดอักขระ ในแง่ที่ว่าอักขระ Unicode แต่ละตัวได้รับการกำหนดจุดโค้ดที่สอดคล้องกัน กระบวนการนี้จะแปลงชุดอักขระ Unicode เป็นชุดอักขระที่เข้ารหัส ครั้งที่สองที่ลำดับของอักขระ Unicode ถูกแปลงเป็นสตริงไบต์ กระบวนการนี้เรียกอีกอย่างว่าการเข้ารหัสในคำศัพท์ภาษาอังกฤษ มีกริยาสองคำที่แตกต่างกันสำหรับโค้ดและการเข้ารหัส แต่แม้แต่เจ้าของภาษาก็มักจะสับสนเกี่ยวกับคำกริยาเหล่านี้ นอกจากนี้ คำว่าชุดอักขระหรือชุดอักขระยังใช้ตรงกันกับชุดอักขระที่เข้ารหัสด้วยคำว่า
ทั้งหมดนี้ เรากล่าวถึงข้อเท็จจริงที่สมเหตุสมผลที่จะให้ความสนใจกับบริบทและแยกแยะสถานการณ์ต่างๆ เมื่อพูดถึงตำแหน่งโค้ดของอักขระ Unicode ที่เป็นนามธรรมและเมื่อพูดถึงการแสดงไบต์
ในที่สุด
Unicode มีแง่มุมต่างๆ มากมายจนไม่สามารถครอบคลุมทุกอย่างในบทความเดียวได้ และไม่จำเป็น ข้อมูลข้างต้นเพียงพอที่จะหลีกเลี่ยงความสับสนในหลักการพื้นฐานและทำงานกับข้อความในงานประจำวันส่วนใหญ่ (อ่าน: ไม่เกิน BMP) ในบทความถัดไปเราจะพูดถึงการทำให้เป็นมาตรฐาน ให้ภาพรวมทางประวัติศาสตร์ที่สมบูรณ์ยิ่งขึ้นของการพัฒนาการเข้ารหัส พูดคุยเกี่ยวกับปัญหาของคำศัพท์ Unicode ภาษารัสเซีย และจัดทำเนื้อหาเกี่ยวกับแง่มุมที่ใช้งานได้จริงของการใช้ UTF-8 และ UTF-16 .Unicode
โลโก้ Unicode Consortium
Unicode(บ่อยที่สุด) หรือ Unicode(อ. Unicode) เป็นมาตรฐานการเข้ารหัสอักขระที่ช่วยให้สามารถแสดงอักขระในภาษาเขียนเกือบทั้งหมด
มาตรฐานนี้เสนอในปี 1991 โดยองค์กรไม่แสวงหาผลกำไร "Unicode Consortium" (อังกฤษ. Unicode Consortium, Unicode Inc.).
การใช้มาตรฐานนี้ทำให้สามารถเข้ารหัสอักขระจำนวนมากจากสคริปต์ต่างๆ ได้: ในเอกสาร Unicode อักขระจีน อักขระคณิตศาสตร์ ตัวอักษรของอักษรกรีก อักษรละติน และ Cyrillic สามารถอยู่ร่วมกันได้ ดังนั้นการเปลี่ยนหน้าโค้ดจึงไม่จำเป็น
มาตรฐานประกอบด้วยสองส่วนหลัก: ชุดอักขระสากล (อังกฤษ. UCS ชุดอักขระสากล) และตระกูลการเข้ารหัส (eng. UTF รูปแบบการแปลง Unicode).
ชุดอักขระสากลกำหนดความสอดคล้องแบบหนึ่งต่อหนึ่งของอักขระกับรหัส - องค์ประกอบของพื้นที่โค้ดที่แสดงจำนวนเต็มไม่เป็นลบ ตระกูลของการเข้ารหัสกำหนดการแสดงเครื่องของลำดับรหัส UCS
รหัส Unicode แบ่งออกเป็นหลายส่วน พื้นที่ที่มีรหัส U + 0000 ถึง U + 007F มีอักขระ ASCII พร้อมรหัสที่เกี่ยวข้อง ถัดไปเป็นพื้นที่ของสัญลักษณ์ของสคริปต์ เครื่องหมายวรรคตอน และสัญลักษณ์ทางเทคนิคต่างๆ
รหัสบางส่วนสงวนไว้สำหรับใช้ในอนาคต ภายใต้อักขระ Cyrillic พื้นที่ของอักขระที่มีรหัสจาก U + 0400 ถึง U + 052F จาก U + 2DE0 ถึง U + 2DFF จาก U + A640 ถึง U + A69F จะได้รับการจัดสรร (ดู Cyrillic ใน Unicode)
- 1 ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode
- 2 เวอร์ชัน Unicode
- 3 พื้นที่โค้ด
- 4 ระบบการเข้ารหัส
- 4.1 นโยบายกิจการร่วมค้า
- 4.2 การรวมและการทำซ้ำสัญลักษณ์
- 5 การปรับเปลี่ยนอักขระ
- 6 อัลกอริธึมการทำให้เป็นมาตรฐาน
- 6.1 NFD
- 6.2 NFC
- 6.3 NFKD
- 6.4 NFKC
- 6.5 ตัวอย่าง
- 7 การเขียนแบบสองทิศทาง
- 8 สัญลักษณ์เด่น
- 9 ISO / IEC 10646
- 10 วิธีในการนำเสนอ
- 10.1 UTF-8
- ลำดับ 10.2 ไบต์
- 10.3 Unicode และการเข้ารหัสแบบดั้งเดิม
- 10.4 การดำเนินการ
- 11 วิธีการป้อนข้อมูล
- 11.1 Microsoft Windows
- 11.2 แมคอินทอช
- 11.3 GNU / Linux
- 12 ปัญหา Unicode
- 13 "Unicode" หรือ "Unicode"?
ข้อกำหนดเบื้องต้นสำหรับการสร้างและพัฒนา Unicode
ในช่วงปลายทศวรรษ 1980 อักขระ 8 บิตได้กลายเป็นมาตรฐาน ในเวลาเดียวกัน มีการเข้ารหัสแบบ 8 บิตที่แตกต่างกันมากมาย และการเข้ารหัสใหม่ก็ปรากฏขึ้นอย่างต่อเนื่อง
สิ่งนี้อธิบายได้ด้วยการขยายขอบเขตของภาษาที่รองรับอย่างต่อเนื่องและโดยความปรารถนาที่จะสร้างการเข้ารหัสที่เข้ากันได้กับภาษาอื่นบางส่วน (ตัวอย่างทั่วไปคือการเกิดขึ้นของการเข้ารหัสทางเลือกสำหรับภาษารัสเซียเนื่องจากการเอารัดเอาเปรียบของตะวันตก โปรแกรมที่สร้างขึ้นสำหรับการเข้ารหัส CP437)
เป็นผลให้เกิดปัญหาหลายประการ:
- ปัญหาของ "krakozyabr";
- ปัญหาชุดอักขระจำกัด
- ปัญหาในการแปลงการเข้ารหัสแบบหนึ่งเป็นอีกแบบหนึ่ง
- ปัญหาแบบอักษรที่ซ้ำกัน
ปัญหา "krakozyabr"- ปัญหาการแสดงเอกสารเข้ารหัสผิด ปัญหาสามารถแก้ไขได้โดยการแนะนำวิธีการระบุการเข้ารหัสที่ใช้อย่างสม่ำเสมอหรือโดยการแนะนำการเข้ารหัสเดียว (ทั่วไป) สำหรับทุกคน
ปัญหาชุดอักขระจำกัด... ปัญหาสามารถแก้ไขได้ด้วยการเปลี่ยนฟอนต์ภายในเอกสาร หรือโดยการแนะนำการเข้ารหัส "แบบกว้าง" การเปลี่ยนแบบอักษรได้รับการฝึกฝนมาเป็นเวลานานในโปรแกรมประมวลผลคำ และมักใช้แบบอักษรที่มีการเข้ารหัสที่ไม่ได้มาตรฐานซึ่งเรียกว่า "แบบอักษร Dingbat". เป็นผลให้เมื่อพยายามโอนเอกสารไปยังระบบอื่น อักขระที่ไม่ได้มาตรฐานทั้งหมดกลายเป็น "krakozyabry"
ปัญหาการแปลงรหัสหนึ่งเป็นอีกตัวหนึ่ง... ปัญหาสามารถแก้ไขได้ด้วยการรวบรวมตารางการแปลงสำหรับการเข้ารหัสแต่ละคู่หรือโดยการใช้การแปลงระหว่างกลางเป็นการเข้ารหัสที่สามที่มีอักขระทั้งหมดของการเข้ารหัสทั้งหมด
ปัญหาฟอนต์ซ้ำซ้อน... สำหรับการเข้ารหัสแต่ละครั้ง แบบอักษรจะถูกสร้างขึ้น แม้ว่าชุดอักขระในการเข้ารหัสจะใกล้เคียงกันเพียงบางส่วนหรือทั้งหมด ปัญหาสามารถแก้ไขได้โดยการสร้างแบบอักษร "ขนาดใหญ่" ซึ่งจะมีการเลือกอักขระที่จำเป็นสำหรับการเข้ารหัสที่กำหนดในภายหลัง อย่างไรก็ตาม สิ่งนี้จำเป็นต้องมีการสร้างรีจีสทรีสัญลักษณ์เดียวเพื่อกำหนดว่าสิ่งใดสอดคล้องกับสิ่งใด
ความจำเป็นในการเข้ารหัส "กว้าง" เดียวได้รับการยอมรับ การเข้ารหัสที่มีความยาวผันแปรซึ่งใช้กันอย่างแพร่หลายในเอเชียตะวันออกนั้นพบว่าใช้งานยากเกินไป ดังนั้นจึงตัดสินใจใช้อักขระที่มีความกว้างคงที่
การใช้อักขระแบบ 32 บิตดูสิ้นเปลืองเกินไป ดังนั้นจึงตัดสินใจใช้อักขระแบบ 16 บิต
Unicode เวอร์ชันแรกเป็นการเข้ารหัสที่มีขนาดอักขระคงที่ 16 บิต กล่าวคือ จำนวนรหัสทั้งหมดคือ 2 16 (65 536) ตั้งแต่นั้นมา สัญลักษณ์ต่างๆ ก็ได้แสดงด้วยเลขฐานสิบหกสี่หลัก (เช่น U + 04F0). ในเวลาเดียวกัน มีการวางแผนที่จะเข้ารหัสใน Unicode ไม่ใช่อักขระที่มีอยู่ทั้งหมด แต่เฉพาะที่จำเป็นในชีวิตประจำวันเท่านั้น ต้องวางสัญลักษณ์ที่ไม่ค่อยได้ใช้ไว้ใน "พื้นที่ใช้งานส่วนตัว" ซึ่งเดิมครอบครองรหัส U + D800 ... U + F8FF.
เพื่อที่จะใช้ Unicode เป็นตัวกลางในการแปลงการเข้ารหัสที่แตกต่างกันให้กันและกัน อักขระทั้งหมดที่แสดงในการเข้ารหัสที่มีชื่อเสียงที่สุดทั้งหมดจึงถูกรวมไว้ด้วย
อย่างไรก็ตาม ในอนาคต ได้มีการตัดสินใจเข้ารหัสสัญลักษณ์ทั้งหมด และในเรื่องนี้ ได้ขยายขอบเขตโค้ดอย่างมาก
ในเวลาเดียวกัน รหัสอักขระเริ่มถูกมองว่าไม่ใช่ค่า 16 บิต แต่เป็นตัวเลขนามธรรมที่สามารถแสดงในคอมพิวเตอร์ได้หลายวิธี (ดูวิธีการแสดง)
เนื่องจากในระบบคอมพิวเตอร์จำนวนหนึ่ง (เช่น Windows NT) อักขระ 16 บิตแบบคงที่ถูกใช้เป็นการเข้ารหัสเริ่มต้นอยู่แล้ว จึงตัดสินใจเข้ารหัสอักขระที่สำคัญที่สุดทั้งหมดภายใน 65,536 ตำแหน่งแรกเท่านั้น (หรือที่เรียกว่าภาษาอังกฤษ ระนาบหลายภาษาพื้นฐาน BMP).
พื้นที่ที่เหลือใช้สำหรับ "อักขระเพิ่มเติม" (อังกฤษ. ตัวละครเสริม): ระบบการเขียนภาษาที่สูญพันธุ์หรือตัวอักษรจีน สัญลักษณ์ทางคณิตศาสตร์และดนตรีที่ไม่ค่อยได้ใช้
เพื่อความเข้ากันได้กับระบบ 16 บิตแบบเก่า ระบบ UTF-16 ถูกประดิษฐ์ขึ้นโดยที่ตำแหน่ง 65,536 แรก ยกเว้นตำแหน่งจากช่วง U + D800 ... U + DFFF จะแสดงเป็นตัวเลข 16 บิตโดยตรง และส่วนที่เหลือจะแสดงเป็น "คู่ตัวแทน" (องค์ประกอบแรกของคู่จากภูมิภาค U + D800… U + DBFF องค์ประกอบที่สองของคู่จากภูมิภาค U + DC00… U + DFFF) สำหรับคู่ตัวแทนเสมือน ส่วนหนึ่งของรหัสพื้นที่ (2048 ตำแหน่ง) ที่จัดสรรไว้สำหรับ "การใช้งานส่วนตัว" ถูกใช้
เนื่องจากสามารถแสดงอักขระได้เพียง 2 20 +2 16 −2048 (1 112 064) ใน UTF-16 ตัวเลขนี้จึงถูกเลือกให้เป็นค่าสุดท้ายของพื้นที่โค้ด Unicode (ช่วงโค้ด: 0x000000-0x10FFFF)
แม้ว่าพื้นที่โค้ด Unicode จะขยายเกิน 2-16 เร็วเท่าเวอร์ชัน 2.0 แต่อักขระตัวแรกในพื้นที่ "บนสุด" จะถูกวางไว้ในเวอร์ชัน 3.1 เท่านั้น
บทบาทของการเข้ารหัสนี้ในภาคเว็บมีการเติบโตอย่างต่อเนื่อง เมื่อต้นปี 2010 ส่วนแบ่งของเว็บไซต์ที่ใช้ Unicode อยู่ที่ประมาณ 50%
เวอร์ชัน Unicode
การทำงานในการสรุปมาตรฐานยังคงดำเนินต่อไป เวอร์ชันใหม่จะออกเมื่อตารางสัญลักษณ์เปลี่ยนแปลงและได้รับการอัปเดต ในขณะเดียวกันก็มีการออกเอกสาร ISO / IEC 10646 ใหม่
มาตรฐานแรกเปิดตัวในปี 1991 ครั้งสุดท้ายในปี 2559 มาตรฐานถัดไปคาดว่าจะมีในฤดูร้อนปี 2560 มาตรฐานเวอร์ชัน 1.0-5.0 ได้รับการตีพิมพ์เป็นหนังสือและมี ISBN
หมายเลขเวอร์ชันของมาตรฐานประกอบด้วยตัวเลขสามหลัก (เช่น "4.0.1) ตัวเลขที่สามจะเปลี่ยนไปเมื่อมีการเปลี่ยนแปลงเล็กน้อยในมาตรฐานที่ไม่เพิ่มอักขระใหม่
รหัสพื้นที่
แม้ว่าสัญกรณ์รูปแบบ UTF-8 และ UTF-32 จะอนุญาตให้เข้ารหัสจุดโค้ดได้มากถึง 2,331 (2,147,483,648) โค้ด แต่ก็ตัดสินใจใช้เพียง 1,112,064 เท่านั้นสำหรับความเข้ากันได้กับ UTF-16 อย่างไรก็ตาม แม้ในตอนนี้ก็เกินพอแล้ว ในเวอร์ชัน 6.0 ใช้จุดโค้ดน้อยกว่า 110,000 จุดเล็กน้อย (กราฟิก 109,242 และสัญลักษณ์อื่นๆ 273 ตัว)
พื้นที่รหัสแบ่งออกเป็น17 เครื่องบิน(อ. เครื่องบิน) 2 16 (65 536) อักขระแต่ละตัว เครื่องบินภาคพื้นดิน ( เครื่องบิน 0) ถูกเรียก ขั้นพื้นฐาน (ขั้นพื้นฐาน) และมีสัญลักษณ์ของสคริปต์ทั่วไป เครื่องบินที่เหลือเป็นส่วนเพิ่มเติม ( เสริม). เครื่องบินลำแรก ( เครื่องบิน 1) ใช้สำหรับสคริปต์ทางประวัติศาสตร์เป็นหลัก ส่วนที่สอง ( เครื่องบิน2) - สำหรับอักษรจีนที่ไม่ค่อยได้ใช้ (CJK) ตัวที่สาม ( เครื่องบิน 3) สงวนไว้สำหรับอักษรจีนโบราณ เครื่องบิน 15 และ 16 สงวนไว้สำหรับการใช้งานส่วนตัว
หากต้องการระบุอักขระ Unicode ให้ใช้สัญลักษณ์เช่น "U + xxxx"(สำหรับรหัส 0 ... FFFF) หรือ" U + xxxxxx"(สำหรับรหัส 10000 ... FFFFF) หรือ" U + xxxxxx"(สำหรับรหัส 100000 ... 10FFFF) โดยที่ xxx- ตัวเลขฐานสิบหก ตัวอย่างเช่น อักขระ "i" (U + 044F) มีรหัส 044F 16 = 1103 10
ระบบเข้ารหัส
ระบบการเข้ารหัสสากล (Unicode) คือชุดของสัญลักษณ์กราฟิกและวิธีการเข้ารหัสสำหรับการประมวลผลข้อมูลข้อความด้วยคอมพิวเตอร์
สัญลักษณ์กราฟิกคือสัญลักษณ์ที่มีภาพที่มองเห็นได้ อักขระกราฟิกตรงข้ามกับตัวควบคุมและการจัดรูปแบบอักขระ
สัญลักษณ์กราฟิกรวมถึงกลุ่มต่อไปนี้:
- ตัวอักษรที่มีอย่างน้อยหนึ่งตัวอักษรที่รองรับ
- ตัวเลข;
- เครื่องหมายวรรคตอน;
- สัญญาณพิเศษ (คณิตศาสตร์, เทคนิค, อุดมคติ ฯลฯ );
- ตัวคั่น
Unicode เป็นระบบสำหรับการแสดงข้อความเชิงเส้น อักขระที่มีตัวยกหรือตัวห้อยเพิ่มเติมสามารถแสดงเป็นลำดับของรหัสที่สร้างขึ้นตามกฎบางอย่าง (อักขระแบบประกอบ) หรือเป็นอักขระตัวเดียว (เวอร์ชันเสาหิน อักขระที่ประกอบล่วงหน้า) บน ช่วงเวลานี้(2014) เชื่อกันว่าตัวอักษรของสคริปต์ขนาดใหญ่ทั้งหมดรวมอยู่ใน Unicode และหากสัญลักษณ์มีอยู่ในเวอร์ชันผสมก็ไม่จำเป็นต้องทำซ้ำในรูปแบบเสาหิน
นโยบายสมาคม
สมาคมไม่ได้สร้างกลุ่มใหม่ แต่ระบุลำดับของสิ่งต่าง ๆ ที่กำหนดไว้ ตัวอย่างเช่น มีการเพิ่มรูปภาพอิโมจิเนื่องจากผู้ให้บริการโทรศัพท์มือถือของญี่ปุ่นใช้รูปภาพเหล่านี้อย่างกว้างขวาง
ในการทำเช่นนี้ การเพิ่มสัญลักษณ์จะต้องผ่านกระบวนการที่ซับซ้อน ตัวอย่างเช่น สัญลักษณ์ของรูเบิลรัสเซียผ่านพ้นไปในสามเดือนเพียงเพราะได้รับสถานะทางการ
เครื่องหมายการค้าจะถูกเข้ารหัสโดยวิธีการยกเว้นเท่านั้น ดังนั้นใน Unicode จึงไม่มีการตั้งค่าสถานะ Windows หรือ Apple apple
เมื่ออักขระปรากฏในการเข้ารหัสแล้ว อักขระจะไม่เคลื่อนที่หรือหายไป หากคุณต้องการเปลี่ยนลำดับของอักขระ สิ่งนี้ไม่ได้ทำโดยการเปลี่ยนตำแหน่ง แต่โดยลำดับการจัดเรียงระดับประเทศ มีการรับประกันอื่นๆ ที่ละเอียดกว่าในเรื่องความเสถียร - ตัวอย่างเช่น ตารางการทำให้เป็นมาตรฐานจะไม่เปลี่ยนแปลง
การรวมและการทำซ้ำสัญลักษณ์
สัญลักษณ์เดียวกันสามารถมีได้หลายรูปแบบ ใน Unicode แบบฟอร์มเหล่านี้มีอยู่ในจุดโค้ดเดียว:
- ถ้ามันเกิดขึ้นในอดีต ตัวอย่างเช่น ตัวอักษรภาษาอาหรับมีสี่รูปแบบ: แยกออก ตอนต้น ตรงกลาง และตอนท้าย
- หรือถ้าใช้ภาษาหนึ่งในรูปแบบหนึ่งและอีกภาษาหนึ่ง - อีกภาษาหนึ่ง บัลแกเรีย Cyrillic แตกต่างจากรัสเซียและตัวอักษรจีนจากภาษาญี่ปุ่น
ในทางกลับกัน หากในอดีตมีจุดโค้ดที่แตกต่างกันสองจุดในฟอนต์ พวกเขาจะยังคงต่างกันใน Unicode ซิกมากรีกตัวพิมพ์เล็กมีสองรูปแบบ และมีตำแหน่งต่างกัน ตัวอักษรละตินขยาย Å (A พร้อมวงกลม) และเครื่องหมายอังสตรอม Å อักษรกรีกμ และคำนำหน้า "ไมโคร" µ เป็นสัญลักษณ์ที่แตกต่างกัน
แน่นอน อักขระที่คล้ายกันในสคริปต์ที่ไม่เกี่ยวข้องจะถูกใส่ในจุดโค้ดที่ต่างกัน ตัวอย่างเช่น ตัวอักษร A ในภาษาละติน ซิริลลิก กรีก และเชอโรคีเป็นสัญลักษณ์ที่แตกต่างกัน
เป็นเรื่องยากมากที่อักขระตัวเดียวกันจะอยู่ในตำแหน่งโค้ดที่แตกต่างกันสองตำแหน่งเพื่อทำให้การประมวลผลข้อความง่ายขึ้น จังหวะทางคณิตศาสตร์และจังหวะเดียวกันเพื่อบ่งชี้ความนุ่มนวลของเสียงเป็นสัญลักษณ์ต่างกัน ตัวที่สองถือเป็นตัวอักษร
การปรับเปลี่ยนตัวอักษร
การแสดงอักขระ "Y" (U + 0419) ในรูปแบบของอักขระฐาน "I" (U + 0418) และอักขระดัดแปลง "" (U + 0306)
อักขระกราฟิกใน Unicode แบ่งออกเป็นแบบขยายและไม่ขยาย (แบบไม่มีความกว้าง) อักขระที่ไม่ขยายจะไม่ใช้พื้นที่ในบรรทัดเมื่อแสดง โดยเฉพาะอย่างยิ่ง เครื่องหมายเน้นเสียงและเครื่องหมายกำกับเสียงอื่นๆ อักขระทั้งแบบขยายและแบบไม่ขยายมีรหัสของตนเอง สัญลักษณ์เพิ่มเติมจะเรียกว่าพื้นฐาน (อังกฤษ. ตัวละครหลัก) และแบบไม่ขยาย - การแก้ไข (eng. การรวมตัวอักษร); และฝ่ายหลังไม่สามารถพบกันโดยอิสระ ตัวอย่างเช่น อักขระ "á" สามารถแสดงเป็นลำดับของอักขระหลัก "a" (U + 0061) และอักขระตัวแก้ไข "́" (U + 0301) หรือเป็นอักขระแบบเสาหิน "á" (U + 00E1).
อักขระการปรับเปลี่ยนชนิดพิเศษคือตัวเลือกรูปแบบใบหน้า (อังกฤษ ตัวเลือกรูปแบบต่างๆ). ใช้กับสัญลักษณ์ที่กำหนดตัวแปรดังกล่าวเท่านั้น ในเวอร์ชัน 5.0 น้ำหนักถูกกำหนดไว้สำหรับสัญลักษณ์ทางคณิตศาสตร์จำนวนหนึ่ง สำหรับสัญลักษณ์ของตัวอักษรมองโกเลียแบบดั้งเดิม และสำหรับสัญลักษณ์ของสคริปต์สี่เหลี่ยมของมองโกเลีย
อัลกอริธึมการทำให้เป็นมาตรฐาน
เนื่องจากสามารถแสดงสัญลักษณ์เดียวกันได้ รหัสต่างๆการเปรียบเทียบสตริงทีละไบต์เป็นไปไม่ได้ อัลกอริธึมการทำให้เป็นมาตรฐาน แบบฟอร์มการทำให้เป็นมาตรฐาน) แก้ปัญหานี้โดยการแปลงข้อความเป็นรูปแบบมาตรฐาน
การคัดเลือกนักแสดงทำได้โดยการแทนที่สัญลักษณ์ด้วยสัญลักษณ์ที่เทียบเท่ากันโดยใช้ตารางและกฎเกณฑ์ "การสลายตัว" เป็นการแทนที่ (การสลายตัว) ของอักขระหนึ่งตัวเป็นอักขระที่เป็นส่วนประกอบหลายตัว และ "องค์ประกอบ" ในทางกลับกัน เป็นการแทนที่ (การเชื่อมต่อ) ของอักขระที่เป็นส่วนประกอบหลายตัวด้วยอักขระเดียว
มาตรฐาน Unicode กำหนดอัลกอริธึมการปรับข้อความให้เป็นมาตรฐาน 4 แบบ ได้แก่ NFD, NFC, NFKD และ NFKC
NFD
เอ็นเอฟดี อ. NSการทำให้เป็นปกติ NS orm NS ("ด" จากภาษาอังกฤษ. NSสิ่งแวดล้อม) รูปแบบการทำให้เป็นมาตรฐาน D คือการสลายตัวตามรูปแบบบัญญัติ - อัลกอริธึมตามที่ทำการเปลี่ยนสัญลักษณ์เสาหินแบบเรียกซ้ำ (อังกฤษ. อักขระที่เตรียมไว้ล่วงหน้า) เป็นองค์ประกอบหลายอย่าง (อังกฤษ. อักขระผสม) ตามตารางการสลายตัว
Å U + 00C5 →
NS คุณ + 0041
̊ U + 030A
ṩ U + 1E69 →
NS ยู + 0073
̣ คุณ + 0323
̇ คุณ + 0307
ḍ̇ U + 1E0B คุณ + 0323 →
NS U + 0064
̣ คุณ + 0323
̇ คุณ + 0307
NS ยู + 0071 คุณ + 0307 คุณ + 0323 →
NS ยู + 0071
̣ คุณ + 0323
̇ คุณ + 0307 NFC
เอ็นเอฟซี อังกฤษ NSการทำให้เป็นปกติ NS orm ค ("ซี" จากภาษาอังกฤษ. คองค์ประกอบ) รูปแบบการทำให้เป็นมาตรฐาน C เป็นอัลกอริธึมตามที่การสลายตัวตามรูปแบบบัญญัติและองค์ประกอบตามรูปแบบบัญญัติถูกดำเนินการตามลำดับ อย่างแรก การสลายตัวตามรูปแบบบัญญัติ (อัลกอริทึม NFD) จะลดข้อความลงในรูปแบบ D จากนั้นองค์ประกอบตามรูปแบบบัญญัติซึ่งอยู่ผกผันของ NFD จะประมวลผลข้อความตั้งแต่ต้นจนจบโดยคำนึงถึงกฎต่อไปนี้:
- เครื่องหมาย NSนับ อักษรย่อหากมีคลาสการแก้ไขเท่ากับศูนย์ตามตารางอักขระ Unicode
- ในลำดับของอักขระใด ๆ ที่ขึ้นต้นด้วย character NS, เครื่องหมาย คถูกปิดกั้นจาก NSเฉพาะในกรณีที่ระหว่าง NSและ คมีสัญลักษณ์อะไรบ้าง NSซึ่งเป็นค่าตั้งต้นหรือมีคลาสการแก้ไขที่เท่ากันหรือมากกว่า than ค... กฎนี้ใช้กับสตริงที่ผ่านการสลายตัวตามรูปแบบบัญญัติเท่านั้น
- การนับสัญลักษณ์ หลักคอมโพสิตหากมีการสลายตัวตามรูปแบบบัญญัติในตารางอักขระ Unicode (หรือการสลายตัวตามรูปแบบบัญญัติสำหรับฮันกุลและไม่รวมอยู่ในรายการยกเว้น)
- เครื่องหมาย NSสามารถนำมารวมกับสัญลักษณ์ก่อนได้ Yถ้าหากว่ามีองค์ประกอบหลักอยู่ด้วย Zเทียบเท่ากับลำดับตามบัญญัติ<NS, Y>;
- ถ้าตัวต่อไป คไม่ถูกบล็อกโดยอักขระฐานเริ่มต้นล่าสุดที่พบ หลี่และสามารถนำมารวมกันได้สำเร็จก่อนจากนั้น หลี่แทนที่ด้วยคอมโพสิต L-C, NS คลบออก.
o U + 006F
̂ คุณ + 0302 → →
ชม คุณ + 0048
① U + 2460 →
1 คุณ + 0031
カ ยู + FF76 →
カ U + 30AB →
fi ยู + FB01
fi ยู + FB01
NS ผม คุณ + 0066 คุณ + 0069
NS ผม คุณ + 0066 คุณ + 0069
2 ⁵ คุณ + 0032 คุณ + 2075
2 ⁵ คุณ + 0032 คุณ + 2075
2 ⁵ คุณ + 0032 คุณ + 2075
2 5 คุณ + 0032 คุณ + 0035
2 5 คุณ + 0032 คุณ + 0035
ẛ̣ U + 1E9B คุณ + 0323
ſ ̣ ̇ U + 017F คุณ + 0323 คุณ + 0307
ẛ ̣ U + 1E9B คุณ + 0323
NS ̣ ̇ ยู + 0073 คุณ + 0323 คุณ + 0307
ṩ U + 1E69
NS คุณ + 0439
และ ̆ คุณ + 0438 คุณ + 0306
NS คุณ + 0439
และ ̆ คุณ + 0438 คุณ + 0306
NS คุณ + 0439
อี คุณ + 0451
อี ̈ คุณ + 0435 ยู + 0308
อี คุณ + 0451
อี ̈ คุณ + 0435 ยู + 0308
อี คุณ + 0451
NS คุณ + 0410
NS คุณ + 0410
NS คุณ + 0410
NS คุณ + 0410
NS คุณ + 0410
が U + 304C
か ゙ U + 304B คุณ + 3099
が U + 304C
か ゙ U + 304B คุณ + 3099
が U + 304C
Ⅷ คุณ + 2167
Ⅷ คุณ + 2167
Ⅷ คุณ + 2167
วี ผม ผม ผม U + 0056 U + 0049 U + 0049 U + 0049
วี ผม ผม ผม U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
ค ̧ U + 0063 คุณ + 0327
ç U + 00E7
ค ̧ U + 0063 คุณ + 0327
ç U + 00E7 จดหมายสองทิศทาง
มาตรฐาน Unicode รองรับการเขียนภาษาที่มีทิศทางจากซ้ายไปขวา (eng. ซ้ายไปขวา LTR) และเขียนจากขวาไปซ้าย (อังกฤษ. ขวาไปซ้าย RTL) - ตัวอย่างเช่น ตัวอักษรอารบิกและฮีบรู ในทั้งสองกรณี อักขระจะถูกจัดเก็บไว้ในลำดับที่ "เป็นธรรมชาติ" แอปพลิเคชันจัดเตรียมการแสดงผลโดยคำนึงถึงทิศทางที่ต้องการของจดหมาย
นอกจากนี้ Unicode ยังรองรับข้อความแบบรวมที่รวมส่วนย่อยที่มีทิศทางต่างกันของตัวอักษร คุณลักษณะนี้เรียกว่า แบบสองทิศทาง(อ. ข้อความแบบสองทิศทาง BiDi). ตัวประมวลผลข้อความแบบง่ายบางตัว (เช่น in โทรศัพท์มือถือ) รองรับ Unicode แต่ไม่รองรับแบบสองทิศทาง อักขระ Unicode ทั้งหมดแบ่งออกเป็นหลายประเภท: เขียนจากซ้ายไปขวา เขียนจากขวาไปซ้าย และเขียนในทิศทางใดก็ได้ สัญลักษณ์ของหมวดหมู่หลัง (ส่วนใหญ่เป็นเครื่องหมายวรรคตอน) เมื่อแสดง ให้เปลี่ยนทิศทางของข้อความโดยรอบ
สัญลักษณ์เด่น
ไดอะแกรมของระนาบหลายภาษาพื้นฐานของ Unicode
Unicode มีสคริปต์สมัยใหม่แทบทั้งหมด รวมถึง:
- ภาษาอาหรับ
- อาร์เมเนีย
- เบงกาลี
- พม่า,
- กริยา
- กรีก
- จอร์เจียน
- เทวนาครี,
- ชาวยิว
- ซิริลลิก
- ภาษาจีน (ตัวอักษรจีนถูกใช้อย่างแข็งขันในภาษาญี่ปุ่นและบางครั้งในภาษาเกาหลี)
- คอปติก
- เขมร
- ละติน
- ทมิฬ
- เกาหลี (อังกูล),
- เชอโรกี
- เอธิโอเปีย
- ภาษาญี่ปุ่น (ซึ่งรวมถึงตัวอักษรพยางค์ อักษรจีนด้วย)
อื่น ๆ.
เพื่อวัตถุประสงค์ทางวิชาการ มีการเพิ่มสคริปต์ทางประวัติศาสตร์มากมาย รวมถึง: อักษรรูนดั้งเดิม อักษรรูนตุรกีโบราณ อักษรกรีกโบราณ อักษรอียิปต์โบราณ อักษรรูน การเขียนมายัน ตัวอักษรอิทรุสกัน
Unicode มีสัญลักษณ์ทางคณิตศาสตร์และดนตรีและรูปสัญลักษณ์มากมาย
โดยหลักการแล้ว Unicode ไม่รวมธงสถานะ โลโก้บริษัทและผลิตภัณฑ์ แม้ว่าจะพบในแบบอักษร (เช่น โลโก้ Apple ในการเข้ารหัส MacRoman (0xF0) หรือ โลโก้ Windowsในแบบอักษร Wingdings (0xFF)) ในฟอนต์ Unicode โลโก้ต้องวางในพื้นที่อักขระที่กำหนดเองเท่านั้น
ISO / IEC 10646
Unicode Consortium ทำงานอย่างใกล้ชิดกับ กลุ่มทำงาน ISO / IEC / JTC1 / SC2 / WG2 ซึ่งกำลังพัฒนามาตรฐานสากล 10646 (ISO / IEC 10646) การซิงโครไนซ์เกิดขึ้นระหว่างมาตรฐาน Unicode และ ISO / IEC 10646 แม้ว่าแต่ละมาตรฐานจะใช้คำศัพท์และระบบเอกสารของตนเอง
ความร่วมมือของ Unicode Consortium กับองค์การระหว่างประเทศเพื่อการมาตรฐาน (eng. องค์การระหว่างประเทศเพื่อการมาตรฐาน ISO ) เริ่มในปี 1991 ในปี 1993 ISO ได้ออกมาตรฐาน DIS 10646.1 ในการซิงโครไนซ์กับมัน Consortium ได้อนุมัติเวอร์ชัน 1.1 ของมาตรฐาน Unicode ซึ่งเสริมด้วยอักขระเพิ่มเติมจาก DIS 10646.1 เป็นผลให้ค่าของอักขระที่เข้ารหัสใน Unicode 1.1 และ DIS 10646.1 เหมือนกันทุกประการ
ในอนาคตความร่วมมือระหว่างทั้งสององค์กรยังคงดำเนินต่อไป ในปี 2000 มาตรฐาน Unicode 3.0 ถูกซิงโครไนซ์กับ ISO / IEC 10646-1: 2000 ISO / IEC 10646 เวอร์ชันที่สามที่กำลังจะมีขึ้นจะถูกซิงโครไนซ์กับ Unicode 4.0 บางทีข้อกำหนดเหล่านี้อาจได้รับการเผยแพร่เป็นมาตรฐานเดียว
เช่นเดียวกับรูปแบบ UTF-16 และ UTF-32 ในมาตรฐาน Unicode มาตรฐาน ISO / IEC 10646 ยังมีรูปแบบการเข้ารหัสอักขระหลักสองรูปแบบ: UCS-2 (2 ไบต์ต่ออักขระ คล้ายกับ UTF-16) และ UCS-4 (4 ไบต์ต่ออักขระ คล้ายกับ UTF-32) UCS แปลว่า มัลติออคเต็ตอเนกประสงค์(มัลติไบต์) รหัสชุดอักขระ(อ. ชุดอักขระรหัสหลายออคเต็ตสากล ). UCS-2 ถือได้ว่าเป็นส่วนย่อยของ UTF-16 (UTF-16 โดยไม่มีคู่ตัวแทน) และ UCS-4 เป็นคำพ้องความหมายสำหรับ UTF-32
ความแตกต่างระหว่างมาตรฐาน Unicode และ ISO / IEC 10646:
- ความแตกต่างเล็กน้อยในคำศัพท์
- ISO / IEC 10646 ไม่รวมส่วนที่จำเป็นสำหรับการรองรับ Unicode อย่างสมบูรณ์:
- ไม่มีข้อมูลเกี่ยวกับการเข้ารหัสอักขระแบบไบนารี
- ไม่มีคำอธิบายของอัลกอริธึมการเปรียบเทียบ (อังกฤษ. การเปรียบเทียบ) และการเรนเดอร์ (eng. การแสดงผล) ตัวอักษร;
- ไม่มีรายการคุณสมบัติของสัญลักษณ์ (เช่น ไม่มีรายการคุณสมบัติที่จำเป็นในการปรับใช้การสนับสนุนแบบสองทิศทาง (อังกฤษ. สองทิศทาง) ตัวอักษร)
วิธีการนำเสนอ
Unicode มีรูปแบบการแสดงหลายรูปแบบ (eng. รูปแบบการแปลง Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) และ UTF-32 (UTF-32BE, UTF-32LE) แบบฟอร์มการแสดง UTF-7 ยังได้รับการพัฒนาสำหรับการส่งสัญญาณผ่านช่องสัญญาณเจ็ดบิต แต่เนื่องจากความไม่เข้ากันกับ ASCII แบบฟอร์มนี้จึงไม่แพร่กระจายและไม่รวมอยู่ในมาตรฐาน เมื่อวันที่ 1 เมษายน พ.ศ. 2548 มีการเสนอเรื่องตลกสองเรื่อง: UTF-9 และ UTF-18 (RFC 4042)
ระบบที่ใช้ Microsoft Windows NT และ Windows 2000 และ Windows XP จะใช้รูปแบบ UTF-16LE เป็นหลัก บนยูนิกซ์เหมือน ระบบปฏิบัติการ GNU / Linux, BSD และ Mac OS X ใช้รูปแบบ UTF-8 สำหรับไฟล์และ UTF-32 หรือ UTF-8 สำหรับการประมวลผลอักขระใน หน่วยความจำเข้าถึงโดยสุ่ม.
Punycode เป็นอีกรูปแบบหนึ่งของการเข้ารหัสลำดับของอักขระ Unicode ในสิ่งที่เรียกว่าลำดับ ACE ซึ่งประกอบด้วยเฉพาะอักขระที่เป็นตัวอักษรและตัวเลขคละกัน ตามที่อนุญาตในชื่อโดเมน
UTF-8
UTF-8 คือการแสดง Unicode ที่ให้ความเข้ากันได้ดีที่สุดกับระบบรุ่นเก่าที่ใช้อักขระ 8 บิต
ข้อความที่มีเฉพาะอักขระที่มีตัวเลขน้อยกว่า 128 จะถูกแปลงเป็นข้อความ ASCII ธรรมดาเมื่อเขียนด้วย UTF-8 ในทางกลับกัน ในข้อความ UTF-8 ไบต์ใดๆ ที่มีค่าน้อยกว่า 128 แสดง อักขระ ASCIIด้วยรหัสเดียวกัน
อักขระ Unicode ที่เหลือจะแสดงเป็นลำดับตั้งแต่ 2 ถึง 6 ไบต์ (อันที่จริงแล้วมีเพียง 4 ไบต์เท่านั้น เนื่องจากไม่มีอักขระที่มีโค้ดที่มากกว่า 10FFFF ใน Unicode และไม่มีแผนที่จะแนะนำอักขระเหล่านี้ใน ในอนาคต) ซึ่งไบต์แรกจะมีรูปแบบเสมอ 11xxxxxxและที่เหลือ - 10xxxxxx... ไม่มีการใช้คู่ตัวแทนใน UTF-8 4 ไบต์เพียงพอที่จะเขียนอักขระ Unicode ใดๆ
UTF-8 ถูกประดิษฐ์ขึ้นเมื่อวันที่ 2 กันยายน 1992 โดย Ken Thompson และ Rob Pike และนำไปใช้ในแผน 9... ปัจจุบันมาตรฐาน UTF-8 ได้รับการประดิษฐานอย่างเป็นทางการใน RFC 3629 และ ISO / IEC 10646 ภาคผนวก D
อักขระ UTF-8 มาจาก Unicode ดังนี้:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
เป็นไปได้ในทางทฤษฎี แต่ไม่รวมอยู่ในมาตรฐาน:
0x0020000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
แม้ว่า UTF-8 จะอนุญาตให้คุณระบุอักขระเดียวกันได้หลายวิธี แต่อักขระที่สั้นที่สุดเท่านั้นที่ถูกต้อง แบบฟอร์มที่เหลือควรถูกปฏิเสธด้วยเหตุผลด้านความปลอดภัย
ลำดับไบต์
ในสตรีมข้อมูล UTF-16 ไบต์ต่ำสามารถเขียนก่อนไบต์สูง (อังกฤษ UTF-16 little-endian) หรือหลังอันที่เก่ากว่า (eng. UTF-16 บิ๊กเอนด์). ในทำนองเดียวกัน การเข้ารหัสแบบสี่ไบต์มีสองรูปแบบ - UTF-32LE และ UTF-32BE
เพื่อกำหนดรูปแบบของการแสดง Unicode ที่จุดเริ่มต้น ไฟล์ข้อความลายเซ็นเขียน - อักขระ U + FEFF (ช่องว่างไม่แตกที่มีความกว้างเป็นศูนย์) หรือที่เรียกว่า เครื่องหมายลำดับไบต์(อ. เครื่องหมายคำสั่งไบต์ (BOM)). ทำให้สามารถแยกแยะระหว่าง UTF-16LE และ UTF-16BE เนื่องจากไม่มีอักขระ U + FFFE บางครั้งก็ใช้เพื่อแสดงถึงรูปแบบ UTF-8 แม้ว่าแนวคิดของลำดับไบต์จะใช้ไม่ได้กับรูปแบบนี้ ไฟล์ที่เป็นไปตามแบบแผนนี้จะเริ่มต้นด้วยลำดับไบต์เหล่านี้:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
น่าเสียดายที่วิธีนี้ไม่สามารถแยกความแตกต่างระหว่าง UTF-16LE และ UTF-32LE ได้อย่างน่าเชื่อถือ เนื่องจาก Unicode อนุญาตให้ใช้อักขระ U + 0000 (แม้ว่าข้อความจริงจะไม่ค่อยขึ้นต้นด้วย)
ไฟล์ในการเข้ารหัส UTF-16 และ UTF-32 ที่ไม่มี BOM ต้องอยู่ในลำดับไบต์ big-endian (unicode.org)
Unicode และการเข้ารหัสแบบดั้งเดิม
การเปิดตัว Unicode ได้เปลี่ยนวิธีการเข้ารหัส 8 บิตแบบเดิม ถ้าก่อนหน้านี้ระบุการเข้ารหัสโดยแบบอักษร ตอนนี้จะถูกระบุโดยตารางการติดต่อระหว่างการเข้ารหัสนี้และ Unicode
อันที่จริงการเข้ารหัสแบบ 8 บิตได้กลายเป็นตัวแทนของชุดย่อยของ Unicode สิ่งนี้ทำให้ง่ายต่อการสร้างโปรแกรมที่ต้องทำงานกับการเข้ารหัสที่หลากหลาย: ตอนนี้ เพื่อเพิ่มการรองรับการเข้ารหัสอีกหนึ่งรายการ คุณเพียงแค่เพิ่มตารางค้นหา Unicode อื่น
นอกจากนี้ รูปแบบข้อมูลจำนวนมากยังอนุญาตให้แทรกอักขระ Unicode ใดๆ ได้ แม้ว่าเอกสารจะเขียนด้วยการเข้ารหัส 8 บิตแบบเก่าก็ตาม ตัวอย่างเช่น คุณสามารถใช้รหัสเครื่องหมายและใน HTML
การดำเนินการ
ระบบปฏิบัติการที่ทันสมัยส่วนใหญ่ให้การสนับสนุน Unicode ในระดับหนึ่ง
ในระบบปฏิบัติการของตระกูล Windows NT การเข้ารหัส UTF-16LE แบบสองไบต์จะใช้สำหรับการแสดงชื่อไฟล์ภายในและสตริงระบบอื่นๆ การเรียกระบบที่ใช้พารามิเตอร์สตริงมีอยู่ในตัวแปรไบต์เดี่ยวและไบต์คู่ สำหรับข้อมูลเพิ่มเติม โปรดดูบทความ Unicode บนระบบปฏิบัติการตระกูล Microsoft Windows
ระบบปฏิบัติการที่คล้ายกับ UNIX รวมถึง GNU / Linux, BSD, OS X ใช้การเข้ารหัส UTF-8 เพื่อเป็นตัวแทนของ Unicode โปรแกรมส่วนใหญ่สามารถจัดการ UTF-8 เป็นการเข้ารหัสแบบไบต์เดียวแบบดั้งเดิม โดยไม่คำนึงถึงข้อเท็จจริงที่ว่าอักขระจะถูกแสดงเป็นไบต์ต่อเนื่องกันหลายไบต์ ในการทำงานกับอักขระแต่ละตัว โดยปกติสตริงจะถูกบันทึกเป็น UCS-4 เพื่อให้อักขระแต่ละตัวมีคำเครื่อง
หนึ่งในการใช้งานเชิงพาณิชย์ที่ประสบความสำเร็จครั้งแรกของ Unicode คือวันพุธ การเขียนโปรแกรม Java... โดยพื้นฐานแล้วจะละทิ้งการแสดงอักขระแบบ 8 บิตและแทนที่อักขระแบบ 16 บิต โซลูชันนี้เพิ่มการใช้หน่วยความจำ แต่อนุญาตให้เราส่งคืนสิ่งที่เป็นนามธรรมที่สำคัญในการเขียนโปรแกรม: อักขระเดี่ยวโดยพลการ (type char). โดยเฉพาะอย่างยิ่ง โปรแกรมเมอร์สามารถทำงานกับสตริงได้เช่นเดียวกับอาร์เรย์ธรรมดา น่าเสียดายที่ความสำเร็จยังไม่สิ้นสุด Unicode เกินขีด จำกัด 16 บิตและโดย J2SE 5.0 อักขระโดยพลการก็เริ่มครอบครองหน่วยหน่วยความจำจำนวนตัวแปร - หนึ่ง charหรือสอง (ดูคู่ตัวแทน)
ภาษาโปรแกรมส่วนใหญ่รองรับสตริง Unicode แม้ว่าการแสดงอาจแตกต่างกันขึ้นอยู่กับการใช้งาน
วิธีการป้อนข้อมูล
เนื่องจากไม่มีรูปแบบแป้นพิมพ์ใดที่อนุญาตให้ป้อนอักขระ Unicode ทั้งหมดได้พร้อมกัน จึงจำเป็นต้องได้รับการสนับสนุนจากระบบปฏิบัติการและแอปพลิเคชัน วิธีทางเลือกป้อนอักขระ Unicode โดยพลการ
Microsoft Windows
แม้ว่าจะเริ่มต้นใน Windows 2000 ยูทิลิตี้ผังอักขระ (charmap.exe) รองรับอักขระ Unicode และอนุญาตให้คุณคัดลอกไปยังคลิปบอร์ด การสนับสนุนนี้จำกัดเฉพาะระนาบฐานเท่านั้น (รหัสอักขระ U + 0000… U + FFFF) สัญลักษณ์ที่มีรหัสจาก U + 10000 "ตารางสัญลักษณ์" ไม่แสดง
มีตารางที่คล้ายกัน เช่น in ไมโครซอฟ เวิร์ด.
บางครั้ง คุณสามารถพิมพ์รหัสฐานสิบหก กด Alt + X แล้วรหัสจะถูกแทนที่ด้วยอักขระที่เหมาะสม เช่น ใน WordPad, Microsoft Word ในโปรแกรมแก้ไข Alt + X จะทำการแปลงแบบย้อนกลับเช่นกัน
ในโปรแกรม MS Windows หลายๆ โปรแกรม เพื่อรับ อักขระ Unicodeขณะที่กดปุ่ม Alt ค้างไว้ ให้พิมพ์ค่าทศนิยมของรหัสอักขระบน แป้นพิมพ์ตัวเลข... ตัวอย่างเช่น ชุดค่าผสม Alt + 0171 ("), Alt + 0187 (") และ Alt + 0769 (เครื่องหมายเน้นเสียง) จะมีประโยชน์เมื่อพิมพ์ข้อความ Cyrillic ชุดค่าผสม Alt + 0133 (…) และ Alt + 0151 (-) ก็น่าสนใจเช่นกัน
Macintosh
Mac OS 8.5 และใหม่กว่ารองรับวิธีการป้อนข้อมูลที่เรียกว่า "Unicode Hex Input" ในขณะที่กดปุ่ม Option ค้างไว้ คุณต้องพิมพ์รหัสฐานสิบหกสี่หลักของอักขระที่ต้องการ วิธีนี้ช่วยให้คุณป้อนอักขระที่มีรหัสมากกว่า U + FFFF โดยใช้คู่ตัวแทน คู่ดังกล่าวจะถูกแทนที่โดยอัตโนมัติโดยระบบปฏิบัติการที่มีอักขระตัวเดียว ก่อนใช้วิธีป้อนข้อมูลนี้ คุณต้องเปิดใช้งานในส่วนที่เกี่ยวข้องของการตั้งค่าระบบ จากนั้นเลือกเป็นวิธีป้อนข้อมูลปัจจุบันในเมนูแป้นพิมพ์
เริ่มต้นด้วย Mac OS X 10.2 นอกจากนี้ยังมีแอปพลิเคชันจานอักขระที่ช่วยให้คุณสามารถเลือกอักขระจากตารางที่คุณสามารถเลือกอักขระจากบล็อกเฉพาะหรืออักขระที่สนับสนุนโดยแบบอักษรเฉพาะ
GNU / Linux
GNOME ยังมียูทิลิตี้ Symbol Map (เดิมคือ gucharmap) ที่ให้คุณแสดงสัญลักษณ์สำหรับบล็อกหรือระบบการเขียนเฉพาะ และให้ความสามารถในการค้นหาตามชื่อหรือคำอธิบายของสัญลักษณ์ เมื่อทราบรหัสของอักขระที่ต้องการแล้วสามารถป้อนได้ตามมาตรฐาน ISO 14755: ขณะกดปุ่ม Ctrl + ⇧ Shift ค้างไว้ให้ป้อนรหัสฐานสิบหก (เริ่มต้นด้วย GTK + บางรุ่นต้องป้อนรหัส โดยกด "ยู"). รหัสเลขฐานสิบหกที่ป้อนสามารถยาวได้ถึง 32 บิต ช่วยให้คุณป้อนอักขระ Unicode ใดๆ โดยไม่ต้องใช้คู่ตัวแทนเสมือน
แอปพลิเคชัน X Window ทั้งหมด รวมทั้ง GNOME และ KDE รองรับการป้อนข้อมูลด้วยปุ่มเขียน สำหรับแป้นพิมพ์ที่ไม่มีแป้นเขียนเฉพาะ คุณสามารถกำหนดแป้นใดก็ได้เพื่อจุดประสงค์นี้ - ตัวอย่างเช่น ⇪ แคปล็อค.
คอนโซล GNU / Linux ยังอนุญาตให้ป้อนอักขระ Unicode ด้วยรหัส - สำหรับสิ่งนี้จะต้องป้อนรหัสทศนิยมของอักขระเป็นตัวเลขของบล็อกแป้นพิมพ์แบบขยายในขณะที่กดปุ่ม Alt ค้างไว้ คุณสามารถป้อนอักขระด้วยรหัสฐานสิบหก: สำหรับสิ่งนี้ คุณต้องกดปุ่ม AltGr ค้างไว้แล้วป้อน ตัวเลข A-Fใช้ปุ่มบนบล็อกแป้นพิมพ์แบบขยายจาก NumLock ถึง ↵ Enter (ตามเข็มนาฬิกา) รองรับการป้อนข้อมูลตามมาตรฐาน ISO 14755 เพื่อให้วิธีการข้างต้นใช้งานได้คุณต้องเปิดใช้งานโหมด Unicode ในคอนโซลโดยการโทร unicode_start(1) และเลือกแบบอักษรที่เหมาะสมโดยการโทร setfont(8).
Mozilla Firefox สำหรับ Linux รองรับการป้อนอักขระ ISO 14755
ปัญหา Unicode
ใน Unicode ภาษาอังกฤษ "a" และภาษาโปแลนด์ "a" เป็นอักขระตัวเดียวกัน ในทำนองเดียวกัน "a" ของรัสเซียและ "a" ของเซอร์เบียถือเป็นสัญลักษณ์เดียวกัน (แต่แตกต่างจากภาษาละติน "a") หลักการเข้ารหัสนี้ไม่เป็นสากล เห็นได้ชัดว่าไม่มีวิธีแก้ปัญหา "สำหรับทุกโอกาส" เลย
- ตามธรรมเนียมแล้ว ข้อความภาษาจีน เกาหลี และญี่ปุ่นจะเขียนจากบนลงล่าง โดยเริ่มจากมุมขวาบน การสลับระหว่างการสะกดคำแนวนอนและแนวตั้งสำหรับภาษาเหล่านี้ไม่ได้ระบุไว้ใน Unicode ซึ่งต้องทำโดยใช้ภาษามาร์กอัปหรือกลไกภายในของโปรแกรมประมวลผลคำ
- Unicode อนุญาตให้ใช้น้ำหนักที่แตกต่างกันของอักขระเดียวกันขึ้นอยู่กับภาษา ดังนั้น อักษรจีนสามารถมีรูปแบบที่แตกต่างกันในภาษาจีน ญี่ปุ่น (คันจิ) และเกาหลี (ฮันชา) แต่ในขณะเดียวกันใน Unicode พวกมันจะถูกแสดงด้วยสัญลักษณ์เดียวกัน (ที่เรียกว่าการรวม CJK) แม้ว่าอักขระตัวย่อและตัวเต็มจะยังคง มีรหัสต่างกัน ... ภาษารัสเซียและเซอร์เบียก็ใช้รูปแบบตัวเอียงต่างกันเช่นเดียวกัน NSและ NS(ในภาษาเซอร์เบียจะดูเหมือน u และ w ดูที่ ตัวเอียงเซอร์เบีย) ดังนั้น คุณต้องแน่ใจว่าข้อความถูกทำเครื่องหมายว่าเกี่ยวข้องกับภาษาใดภาษาหนึ่งอย่างถูกต้องเสมอ
- การแปลจากตัวพิมพ์เล็กเป็นตัวพิมพ์ใหญ่นั้นขึ้นอยู่กับภาษาด้วย ตัวอย่างเช่น: ในภาษาตุรกีมีตัวอักษร İi และ Iı ดังนั้น กฎการเปลี่ยนตัวพิมพ์ของตุรกีจะขัดแย้งกับตัวภาษาอังกฤษ ซึ่งต้องใช้ "i" เพื่อแปลเป็น "I" ปัญหาที่คล้ายกันมีอยู่ในภาษาอื่น เช่น ในภาษาแคนาดาของภาษาฝรั่งเศส ทะเบียนถูกแปลแตกต่างไปจากภาษาฝรั่งเศสเล็กน้อย
- แม้แต่กับตัวเลขอารบิก ก็มีความละเอียดอ่อนในการพิมพ์อยู่บ้าง: ตัวเลขสามารถเป็น "ตัวพิมพ์ใหญ่" และ "ตัวพิมพ์เล็ก" ได้สัดส่วนและเว้นวรรค - สำหรับ Unicode นั้นไม่มีความแตกต่างระหว่างตัวเลขเหล่านี้ ความแตกต่างดังกล่าวยังคงอยู่กับซอฟต์แวร์
ข้อเสียบางประการไม่เกี่ยวข้องกับ Unicode แต่เกี่ยวข้องกับความสามารถของตัวประมวลผลข้อความ
- ไฟล์ข้อความที่ไม่ใช่ภาษาละตินใน Unicode มักใช้พื้นที่มากกว่า เนื่องจากอักขระหนึ่งตัวไม่ได้เข้ารหัสโดยหนึ่งไบต์ เช่นเดียวกับในการเข้ารหัสระดับชาติต่างๆ แต่ตามลำดับไบต์ (ยกเว้น UTF-8 สำหรับภาษาที่มีตัวอักษรพอดี เป็น ASCII เช่นเดียวกับการมีอยู่ของอักขระสองตัวในข้อความและภาษาอื่น ๆ อักษรซึ่ง ไม่เข้ากับ ASCII) ไฟล์ฟอนต์ที่จำเป็นในการแสดงอักขระทั้งหมดในตาราง Unicode ใช้พื้นที่หน่วยความจำที่ค่อนข้างใหญ่และมีความเข้มข้นในการคำนวณมากกว่าฟอนต์ภาษาประจำชาติของผู้ใช้เพียงอย่างเดียว ด้วยพลังของระบบคอมพิวเตอร์ที่เพิ่มขึ้นและต้นทุนของหน่วยความจำและพื้นที่ดิสก์ที่ลดลง ปัญหานี้จึงมีความสำคัญน้อยลงเรื่อยๆ อย่างไรก็ตามยังคงมีความเกี่ยวข้องกับอุปกรณ์พกพาเช่นโทรศัพท์มือถือ
- แม้ว่าการรองรับ Unicode จะถูกนำไปใช้ในระบบปฏิบัติการทั่วไปส่วนใหญ่ แต่ก็ยังใช้ไม่ได้ทั้งหมด ซอฟต์แวร์สนับสนุน งานที่ถูกต้องกับเขา. โดยเฉพาะอย่างยิ่ง Byte Order Marks (BOM) ไม่ได้รับการประมวลผลเสมอไป และอักขระที่มีการเน้นเสียงได้รับการสนับสนุนไม่ดี ปัญหาเกิดขึ้นชั่วคราวและเป็นผลมาจากการเปรียบเทียบความแปลกใหม่ของมาตรฐาน Unicode (เมื่อเปรียบเทียบกับการเข้ารหัสระดับชาติแบบไบต์เดียว)
- ประสิทธิภาพของโปรแกรมประมวลผลสตริงทั้งหมด (รวมถึงการเรียงลำดับในฐานข้อมูล) ลดลงเมื่อใช้ Unicode แทนการเข้ารหัสแบบไบต์เดียว
ระบบการเขียนหายากบางระบบยังไม่แสดงอย่างถูกต้องใน Unicode การแสดงภาพของอักขระตัวยก "ยาว" ที่ขยายทับตัวอักษรหลายตัว เช่น ใน Church Slavonic ยังไม่ได้นำมาใช้
Unicode หรือ Unicode?
"Unicode" เป็นทั้งชื่อเฉพาะ (หรือบางส่วนของชื่อ เช่น Unicode Consortium) และชื่อสามัญที่มาจากภาษาอังกฤษ
เมื่อมองแวบแรก ควรใช้การสะกดคำว่า "Unicode" ในภาษารัสเซียมีหน่วยคำอยู่แล้ว "uni-" (คำที่มีองค์ประกอบภาษาละติน "uni-" ถูกแปลและเขียนตามประเพณีโดยใช้ "uni-": สากล, unipolar, unification, uniform) และ "code" ขัดต่อ, เครื่องหมายการค้าที่ยืมมาจากภาษาอังกฤษ มักจะถ่ายทอดผ่านการถอดความเชิงปฏิบัติ ซึ่งการรวมตัวอักษร "uni-" ที่แยกนิรุกติศาสตร์ออกแล้วเขียนเป็น "uni-" ("Unilever", "Unix" เป็นต้น) กล่าวคือ เช่นเดียวกับในกรณีของตัวย่อแบบตัวอักษรต่อตัวอักษรเช่น UNICEF “กองทุนฉุกเฉินเพื่อเด็กแห่งสหประชาชาติ” - UNICEF
การสะกดคำว่า "Unicode" ได้ป้อนข้อความภาษารัสเซียอย่างแน่นหนาแล้ว Wikipedia ใช้เวอร์ชันทั่วไป บน MS Windows จะใช้ตัวเลือก Unicode
มีหน้าพิเศษบนเว็บไซต์ของ Consortium ที่มีปัญหาการโอนคำว่า "Unicode" ไปที่ ภาษาที่แตกต่างกันและระบบการเขียน สำหรับอักษรซีริลลิกรัสเซีย จะระบุตัวเลือก "Unicode"
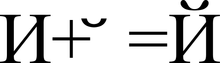
ปัญหาที่เกี่ยวข้องกับการเข้ารหัสมักจะได้รับการดูแลโดยซอฟต์แวร์ ดังนั้นจึงไม่มีปัญหาในการใช้การเข้ารหัส หากเกิดปัญหาขึ้นมักเกิดจากโปรแกรมที่ไม่ดี - อย่าลังเลที่จะส่งไปที่ถังขยะ
เชิญทุกคนออกมาพูดใน
การเข้ารหัสคืออะไร
ในรัสเซีย "ชุดอักขระ" เรียกอีกอย่างว่าตาราง "ชุดอักขระ" และขั้นตอนการใช้ตารางนี้เพื่อแปลข้อมูลจากการแสดงคอมพิวเตอร์เป็นมนุษย์ และลักษณะของไฟล์ข้อความที่สะท้อนถึงการใช้งานบางอย่าง ระบบรหัสในนั้นเมื่อแสดงข้อความ
วิธีเข้ารหัสข้อความ
ชุดของสัญลักษณ์ที่ใช้ในการเขียนข้อความถูกอ้างถึงในศัพท์คอมพิวเตอร์ว่าเป็นตัวอักษร จำนวนสัญลักษณ์ในตัวอักษรมักจะเรียกว่ากำลังของมัน ในการแสดงข้อมูลที่เป็นข้อความในคอมพิวเตอร์ มักใช้ตัวอักษรที่มีความจุ 256 อักขระ อักขระตัวหนึ่งมีข้อมูล 8 บิต ดังนั้นรหัสไบนารีของอักขระแต่ละตัวจึงใช้หน่วยความจำคอมพิวเตอร์ 1 ไบต์ อักขระทั้งหมดของตัวอักษรดังกล่าวมีหมายเลขตั้งแต่ 0 ถึง 255 และแต่ละหมายเลขสอดคล้องกับรหัสไบนารี 8 บิต ซึ่งเป็นเลขลำดับของอักขระในระบบเลขฐานสอง - ตั้งแต่ 00000000 ถึง 11111111 เฉพาะอักขระ 128 ตัวแรกที่มี ตัวเลขจากศูนย์ ( รหัสไบนารี 00000000) ถึง 127 (01111111) ซึ่งรวมถึงตัวพิมพ์เล็กและ ตัวพิมพ์ใหญ่อักษรละติน ตัวเลข เครื่องหมายวรรคตอน วงเล็บ ฯลฯ รหัสที่เหลืออีก 128 รหัส เริ่มต้นด้วย 128 (รหัสไบนารี 10000000) และลงท้ายด้วย 255 (11111111) ใช้ในการเข้ารหัสตัวอักษรของตัวอักษรประจำชาติ บริการ และสัญลักษณ์ทางวิทยาศาสตร์
ประเภทของการเข้ารหัส
ตารางการเข้ารหัสที่มีชื่อเสียงที่สุดคือ ASCII (รหัส American Standard สำหรับการแลกเปลี่ยนข้อมูล) เดิมทีได้รับการพัฒนาสำหรับการส่งข้อความทางโทรเลขและในขณะนั้นเป็นแบบ 7 บิตนั่นคือมีเพียง 128 ชุด 7 บิตเท่านั้นที่ใช้ในการเข้ารหัสอักขระภาษาอังกฤษบริการและอักขระควบคุม ในกรณีนี้ ชุดค่าผสม (รหัส) 32 ชุดแรกที่ใช้ในการเข้ารหัสสัญญาณควบคุม (จุดเริ่มต้นของข้อความ สิ้นสุดบรรทัด การขึ้นบรรทัดใหม่ การโทร การสิ้นสุดข้อความ ฯลฯ) ในการพัฒนาคอมพิวเตอร์ IBM เครื่องแรก รหัสนี้ถูกใช้เพื่อแสดงสัญลักษณ์ในคอมพิวเตอร์ ตั้งแต่ใน รหัสแหล่งที่มา ASCII มีอักขระเพียง 128 ตัวสำหรับการเข้ารหัสค่าไบต์ก็เพียงพอแล้วซึ่งบิตที่ 8 เป็น 0 ค่าไบต์ที่มีบิตที่ 8 เท่ากับ 1 เริ่มใช้แทนอักขระกราฟิกหลอกเครื่องหมายทางคณิตศาสตร์ และอักขระบางตัวจากภาษาอื่นที่ไม่ใช่ภาษาอังกฤษ (กรีก เครื่องหมายเยอรมัน เครื่องหมายกำกับภาษาฝรั่งเศส ฯลฯ) เมื่อพวกเขาเริ่มปรับคอมพิวเตอร์สำหรับประเทศและภาษาอื่น ไม่มีที่ว่างเพียงพอสำหรับสัญลักษณ์ใหม่อีกต่อไป เพื่อรองรับภาษาอื่นนอกเหนือจากภาษาอังกฤษอย่างเต็มที่ IBM ได้แนะนำตารางรหัสเฉพาะประเทศหลายตาราง ดังนั้นสำหรับประเทศสแกนดิเนเวียจึงเสนอตารางที่ 865 (นอร์ดิก) สำหรับประเทศอาหรับ - ตารางที่ 864 (อาหรับ) สำหรับอิสราเอล - ตารางที่ 862 (อิสราเอล) เป็นต้น ในตารางเหล่านี้ รหัสบางส่วนจากช่วงครึ่งหลังของตารางรหัสถูกใช้เพื่อแสดงอักขระของตัวอักษรประจำชาติ (โดยไม่รวมอักขระกราฟิกหลอกบางตัว) สถานการณ์ในภาษารัสเซียพัฒนาขึ้นในลักษณะพิเศษ เห็นได้ชัดว่าการแทนที่อักขระในช่วงครึ่งหลังของตารางโค้ดสามารถทำได้ วิธีทางที่แตกต่าง... ดังนั้นตารางการเข้ารหัสอักขระซิริลลิกที่แตกต่างกันหลายตารางจึงปรากฏขึ้นสำหรับภาษารัสเซีย: KOI8-R, IBM-866, CP-1251, ISO-8551-5 ทั้งหมดเป็นตัวแทนของสัญลักษณ์ของครึ่งแรกของตารางในลักษณะเดียวกัน (จาก 0 ถึง 127) และแตกต่างกันในการแสดงสัญลักษณ์ของตัวอักษรรัสเซียและกราฟิกหลอก สำหรับภาษาอย่างจีนหรือญี่ปุ่น โดยทั่วไป 256 ตัวอักษรไม่เพียงพอ นอกจากนี้ยังมีปัญหาในการส่งออกหรือบันทึกในไฟล์เดียวในเวลาเดียวกันข้อความบน ภาษาที่แตกต่างกัน(เช่น เมื่ออ้างอิง) ดังนั้น ความเป็นสากล ตารางรหัส UNICODE ที่มีสัญลักษณ์ที่ใช้ในภาษาของทุกชนชาติทั่วโลกรวมถึงบริการและสัญลักษณ์เสริมต่างๆ (เครื่องหมายวรรคตอน สัญลักษณ์ทางคณิตศาสตร์และทางเทคนิค ลูกศร เครื่องหมายกำกับเสียง ฯลฯ ) แน่นอน หนึ่งไบต์ไม่เพียงพอที่จะเข้ารหัสอักขระจำนวนมากเช่นนี้ ดังนั้น UNICODE จึงใช้รหัส 16 บิต (2 ไบต์) เพื่อแสดงอักขระ 65,536 ตัว จนถึงปัจจุบันมีการใช้รหัสประมาณ 49,000 รหัส (การเปลี่ยนแปลงที่สำคัญครั้งล่าสุดคือการแนะนำสัญลักษณ์สกุลเงินยูโรในเดือนกันยายน 1998) เพื่อความเข้ากันได้กับการเข้ารหัสก่อนหน้า 256 รหัสแรกจะเหมือนกับในมาตรฐาน ASCII ในมาตรฐาน UNICODE ยกเว้นเฉพาะ รหัสไบนารี(รหัสเหล่านี้มักจะแสดงด้วยตัวอักษร U ตามด้วยเครื่องหมาย + และรหัสจริงในรูปแบบเลขฐานสิบหก) อักขระแต่ละตัวจะได้รับชื่อเฉพาะ องค์ประกอบอื่นของมาตรฐาน UNICODE คืออัลกอริธึมสำหรับการแปลงรหัส UNICODE แบบหนึ่งต่อหนึ่งตามลำดับไบต์ของความยาวผันแปร ความต้องการอัลกอริธึมดังกล่าวเกิดจากการที่แอพพลิเคชั่นบางตัวไม่สามารถทำงานกับ UNICODE ได้ แอปพลิเคชั่นบางตัวเข้าใจเฉพาะรหัส ASCII 7 บิต แอปพลิเคชั่นอื่นเข้าใจรหัส ASCII 8 บิต แอปพลิเคชันดังกล่าวใช้โค้ด ASCII แบบขยายที่เรียกว่าเพื่อแทนอักขระที่ไม่พอดีตามลำดับในชุดอักขระ 128 ตัวหรือชุดอักขระ 256 ตัว เมื่ออักขระถูกเข้ารหัสด้วยสตริงไบต์ที่มีความยาวผันแปรได้ UTF-7 ใช้เพื่อแปลงกลับรหัส UNICODE เป็นรหัส ASCII 7 บิตแบบขยาย และ UTF-8 ใช้เพื่อแปลงรหัส UNICODE กลับเป็นรหัส ASCII 8 บิตแบบขยาย โปรดทราบว่าทั้ง ASCII และ UNICODE และมาตรฐานการเข้ารหัสอักขระอื่นๆ ไม่ได้กำหนดรูปภาพของอักขระ แต่มีเพียงองค์ประกอบของชุดอักขระและลักษณะที่แสดงในคอมพิวเตอร์เท่านั้น นอกจากนี้ (ซึ่งอาจไม่ชัดเจนในทันที) ลำดับของการแจงนับอักขระในชุดมีความสำคัญมาก เนื่องจากจะส่งผลต่ออัลกอริธึมการจัดเรียงในลักษณะที่สำคัญที่สุด เป็นตารางความสอดคล้องของสัญลักษณ์จากชุดใดชุดหนึ่ง (กล่าวคือ สัญลักษณ์ที่ใช้แสดงข้อมูลบน ภาษาอังกฤษหรือในภาษาต่าง ๆ เช่นในกรณีของ UNICODE) และแสดงโดยตารางการเข้ารหัสอักขระระยะหรือชุดอักขระ การเข้ารหัสมาตรฐานแต่ละรายการมีชื่อ เช่น KOI8-R, ISO_8859-1, ASCII ขออภัย ไม่มีมาตรฐานสำหรับการเข้ารหัสชื่อ
การเข้ารหัสทั่วไป
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 การเข้ารหัสของ Microsoft Windows: o Windows-1250 สำหรับภาษายุโรปกลางที่ใช้ตัวอักษรละติน o Windows-1251 สำหรับตัวอักษร Cyrillic o Windows-1252 สำหรับภาษาตะวันตก o Windows-1253 สำหรับกรีก o Windows-1254 สำหรับตุรกี o Windows-1255 สำหรับภาษาฮีบรู o Windows-1256 สำหรับภาษาอาหรับ o Windows-1257 สำหรับภาษาบอลติก o Windows-1258 สำหรับภาษาเวียดนาม MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 การเข้ารหัสบัลแกเรีย ISCII VISCII Big5 (ที่มีชื่อเสียงที่สุด เวอร์ชันของ Microsoft CP950 ) o HSCCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS สำหรับภาษาญี่ปุ่น (Microsoft CP932) EUC-KR สำหรับภาษาเกาหลี (Microsoft CP949) ISO-2022 และ EUC สำหรับการเขียนภาษาจีน UTF-8 และ UTF-16 การเข้ารหัสอักขระ Unicodeในระบบการเข้ารหัส ASCII(รหัสมาตรฐานอเมริกันสำหรับการแลกเปลี่ยนข้อมูล) อักขระแต่ละตัวจะแสดงด้วยหนึ่งไบต์ ซึ่งสามารถเข้ารหัสได้ 256 อักขระ
ASCII มีตารางการเข้ารหัสสองตาราง - แบบพื้นฐานและแบบขยาย ตารางฐานแก้ไขค่าของรหัสตั้งแต่ 0 ถึง 127 และตัวขยายหมายถึงอักขระที่มีตัวเลขตั้งแต่ 128 ถึง 255 ซึ่งเพียงพอสำหรับการแสดงชุดอักขระภาษาอังกฤษและรัสเซียทั้งหมดแปดบิต ทั้งตัวพิมพ์เล็กและตัวพิมพ์ใหญ่ ตลอดจนเครื่องหมายวรรคตอน สัญลักษณ์สำหรับการคำนวณทางคณิตศาสตร์พื้นฐาน และสัญลักษณ์พิเศษทั่วไปที่สามารถสังเกตได้บนแป้นพิมพ์
รหัส 32 ตัวแรกของตารางฐานซึ่งเริ่มต้นด้วยศูนย์จะมอบให้กับผู้ผลิตฮาร์ดแวร์ (โดยหลักแล้วสำหรับผู้ผลิตคอมพิวเตอร์และอุปกรณ์การพิมพ์) พื้นที่นี้ประกอบด้วยรหัสควบคุมที่เรียกว่า ซึ่งไม่ตรงกับอักขระภาษาใดๆ ดังนั้น รหัสเหล่านี้จะไม่ปรากฏบนหน้าจอหรือบนอุปกรณ์การพิมพ์ แต่สามารถควบคุมได้ว่าจะส่งออกข้อมูลอื่นอย่างไร ตั้งแต่รหัส 32 ถึงรหัส 127 สัญลักษณ์ของตัวอักษรภาษาอังกฤษ เครื่องหมายวรรคตอน ตัวเลข การคำนวณทางคณิตศาสตร์ และสัญลักษณ์เสริม ทั้งหมดนี้สามารถเห็นได้ในส่วนละตินของแป้นพิมพ์คอมพิวเตอร์
ส่วนที่สองที่ขยายออกไปนั้นมอบให้กับระบบการเข้ารหัสระดับประเทศ มีตัวอักษรที่ไม่ใช่ภาษาละตินจำนวนมากในโลก (อาหรับ ฮีบรู กรีก ฯลฯ) รวมถึงอักษรซีริลลิก นอกจากนี้ รูปแบบแป้นพิมพ์ภาษาเยอรมัน ฝรั่งเศส และสเปนยังแตกต่างจากรูปแบบภาษาอังกฤษ
ส่วนภาษาอังกฤษของแป้นพิมพ์เคยมีมาตรฐานมากมาย แต่ตอนนี้พวกเขาทั้งหมดถูกแทนที่ด้วยรหัส ASCII เดียว สำหรับแป้นพิมพ์ภาษารัสเซีย ยังมีมาตรฐานอีกหลายมาตรฐาน: GOST, GOST-alternative, ISO (International Standard Organization - International Institute for Standardization) แต่มาตรฐานทั้งสามนี้หมดไปจริง ๆ แม้ว่าพวกเขาจะพบที่ไหนสักแห่งในคอมพิวเตอร์เก่าบางเครื่องหรือใน เครือข่ายคอมพิวเตอร์
การเข้ารหัสอักขระหลักของภาษารัสเซียซึ่งใช้ในคอมพิวเตอร์ที่มีระบบปฏิบัติการ ระบบ Windowsเรียกว่า Windows-1251ได้รับการพัฒนาสำหรับอักษรซีริลลิกโดย Microsoft โดยปกติ ข้อมูลข้อความคอมพิวเตอร์ส่วนใหญ่จะถูกเข้ารหัสใน Windows-1251 อย่างไรก็ตาม Microsoft พัฒนาการเข้ารหัสด้วยตัวเลขสี่หลักที่แตกต่างกันสำหรับตัวอักษรทั่วไปอื่นๆ ได้แก่ อาหรับ ญี่ปุ่น และอื่นๆ
การเข้ารหัสทั่วไปอื่นเรียกว่า KOI-8(รหัสแลกเปลี่ยนข้อมูลแปดหลัก) - ที่มาของวันที่ย้อนกลับไปในช่วงเวลาของสภาเพื่อความช่วยเหลือทางเศรษฐกิจร่วมกันของรัฐยุโรปตะวันออก วันนี้การเข้ารหัส KOI-8 แพร่หลายในเครือข่ายคอมพิวเตอร์ในอาณาเขตของรัสเซียและในภาคอินเทอร์เน็ตของรัสเซีย มันจึงเกิดขึ้นที่ข้อความในจดหมายหรืออย่างอื่นไม่สามารถอ่านได้ ซึ่งหมายความว่าคุณต้องเปลี่ยนจาก KOI-8 เป็น Windows-1251 สิบ
ในยุค 90 ผู้ผลิตซอฟต์แวร์รายใหญ่ที่สุด: Microsoft, Borland, Adobe คนเดียวกันได้ตัดสินใจเกี่ยวกับความจำเป็นในการพัฒนาระบบการเข้ารหัสข้อความที่แตกต่างกัน ซึ่งอักขระแต่ละตัวจะได้รับการจัดสรรไม่ใช่ 1 แต่ 2 ไบต์ เธอได้ชื่อ Unicodeและเป็นไปได้ที่จะเข้ารหัสอักขระ 65,536 ตัวของฟิลด์นี้เพียงพอที่จะใส่ลงในตารางตัวอักษรประจำชาติสำหรับทุกภาษาของโลก Unicode ส่วนใหญ่ (ประมาณ 70%) ถูกครอบครองโดยตัวอักษรจีน ในอินเดียมีตัวอักษรประจำชาติ 11 ตัว มีชื่อแปลก ๆ มากมาย เช่น การเขียนของชาวอะบอริจินในแคนาดา
เนื่องจากการเข้ารหัสของอักขระแต่ละตัวใน Unicode ไม่ได้รับการจัดสรร 8 บิต แต่เป็น 16 บิต ขนาดของไฟล์ข้อความจึงเพิ่มขึ้นเป็นสองเท่า ซึ่งครั้งหนึ่งเคยเป็นอุปสรรคต่อการแนะนำระบบ 16 บิต และตอนนี้ด้วยฮาร์ดไดรฟ์กิกะไบต์, RAM หลายร้อยเมกะไบต์, โปรเซสเซอร์กิกะเฮิร์ตซ์, การเพิ่มปริมาณไฟล์ข้อความเป็นสองเท่าซึ่งเมื่อเปรียบเทียบกับกราฟิกใช้พื้นที่น้อยมากไม่สำคัญ
อักษรซีริลลิกใน Unicode มีตั้งแต่ 768 ถึง 923 (อักขระพื้นฐาน) และตั้งแต่ 924 ถึง 1023 (อักษรซีริลลิกแบบขยาย อักษรประจำชาติต่างๆ ที่ไม่ค่อยแพร่หลาย) หากโปรแกรมไม่ได้รับการดัดแปลงสำหรับ Cyrillic Unicode เป็นไปได้ว่าอักขระข้อความไม่เป็นที่รู้จักในฐานะ Cyrillic แต่เป็นภาษาละตินแบบขยาย (รหัสจาก 256 ถึง 511) และในกรณีนี้ แทนที่จะเป็นข้อความ ชุดสัญลักษณ์แปลก ๆ ที่ไม่มีความหมายปรากฏขึ้นบนหน้าจอ
สิ่งนี้เป็นไปได้หากโปรแกรมล้าสมัย ซึ่งสร้างก่อนปี 1995 หรือหายากซึ่งไม่มีใครสนใจ Russify อาจเป็นไปได้ว่าระบบปฏิบัติการ Windows ที่ติดตั้งบนคอมพิวเตอร์ไม่ได้รับการกำหนดค่าอย่างสมบูรณ์สำหรับอักษรซีริลลิก ในกรณีนี้ คุณต้องสร้างรายการที่เหมาะสมในรีจิสทรี
 ซอฟต์แวร์ที่ปรับแต่งได้
ซอฟต์แวร์ที่ปรับแต่งได้ Windows 8 จะคืนปุ่มเริ่มต้น
Windows 8 จะคืนปุ่มเริ่มต้น การติดตั้ง Skype บนคอมพิวเตอร์ (คำแนะนำทีละขั้นตอน)
การติดตั้ง Skype บนคอมพิวเตอร์ (คำแนะนำทีละขั้นตอน)