Che cos'è la codifica unicode. Perché avevi bisogno di Unicode? Prerequisiti per la creazione e lo sviluppo di Unicode
Che cos'è la codifica?
In russo, "set di caratteri" è anche chiamato "set di caratteri" e il processo di utilizzo di questa tabella per tradurre le informazioni da una rappresentazione del computer in una umana e una caratteristica file di testo, che riflette l'uso di un determinato sistema di codici al suo interno durante la visualizzazione del testo.
Il sistema di presentazione è definito da una serie di regole e l'applicazione di queste regole alle informazioni originali viene eseguita dal processo di codifica. Il processo inverso è chiamato decodifica. Quindi esaminiamo aspetti più specifici come la codifica del segnale, la codifica dei caratteri, la codifica del genoma umano e la codifica quantistica. Verranno infine spiegati i concetti base della compressione dei dati e dei metodi di crittografia più comunemente utilizzati.
In questa sezione vedremo come gli esseri umani nel corso della storia hanno fatto grandi sforzi per esprimersi con il resto dei loro parenti in modo semplice e intuitivo, codificando le informazioni utilizzando metodi diversi... Questi metodi si sono evoluti nel corso della storia senza rappresentare i metodi sofisticati che usiamo oggi per i primi che sono stati utilizzati poiché ha richiesto molta evoluzione, come si vedrà in questa sezione.
Come viene codificato il testo
L'insieme dei simboli utilizzati nella scrittura del testo è indicato nella terminologia informatica come alfabeto; il numero di caratteri nell'alfabeto è solitamente chiamato il suo potere. Per la presentazione informazioni di testo il computer utilizza più spesso un alfabeto con una capacità di 256 caratteri. Uno dei suoi caratteri porta 8 bit di informazione, quindi il codice binario di ogni carattere occupa 1 byte di memoria del computer. Tutti i caratteri di tale alfabeto sono numerati da 0 a 255 e ogni numero corrisponde a un codice binario a 8 bit, che è il numero ordinale di un carattere nel sistema di notazione binaria - da 00000000 a 11111111. Solo i primi 128 caratteri con numeri da zero (codice binario 00000000) a 127 (01111111). Questi includono lettere minuscole e lettere maiuscole Alfabeto latino, numeri, segni di punteggiatura, parentesi quadre, ecc. I restanti 128 codici, che iniziano con 128 (codice binario 10000000) e terminano con 255 (11111111), vengono utilizzati per codificare lettere di alfabeti nazionali, simboli di servizio e scientifici.
Evoluzione della codifica del segnale
Essere obsoleti è tutto ciò che sappiamo su questo momento, come avveniva a tempo debito con i metodi precedenti. Nel corso della storia, i marinai hanno usato segnali per trasmettere messaggi urgenti ad altri marinai. Si tratta di segnali luminosi che vengono prodotti utilizzando grandi proiettori con sistemi che consentono esplosioni di luce, solitamente utilizzando reticoli posti davanti al fuoco. Per stabilire una connessione, il codice Morse viene utilizzato attraverso segnali luminosi.
Questi sono segnali trasmessi attraverso vibrazioni nell'aria. A causa della lentezza dei dispositivi necessari per la trasmissione, questo è un mezzo molto lento. I segnali trasmessi utilizzano il codice Morse per trasmettere informazioni. Oltre al tradizionale codice Morse in codice internazionale incluso, ci sono altri tipi di segnali standardizzati e che ogni marinaio dovrebbe capire perfettamente.
Tipi di codifiche
La tabella di codifica più famosa è ASCII (American Standard Code for Information Interchange). È stato originariamente sviluppato per la trasmissione di testi tramite telegrafo e all'epoca era a 7 bit, ovvero solo 128 combinazioni a 7 bit venivano utilizzate per codificare caratteri inglesi, caratteri di servizio e di controllo. In questo caso, le prime 32 combinazioni (codici) servivano a codificare segnali di controllo (inizio testo, fine riga, ritorno a capo, chiamata, fine testo, ecc.). Nello sviluppo dei primi computer IBM, questo codice è stato utilizzato per rappresentare i simboli in un computer. Dal in codice sorgente ASCII era di soli 128 caratteri, per la loro codifica erano sufficienti valori di byte con l'8° bit uguale a 0. I valori di byte con l'8° bit uguale a 1 venivano usati per rappresentare caratteri pseudo-grafici, segni matematici e alcuni caratteri delle lingue Inglese (greco, tedesco dieresi, segni diacritici francesi, ecc.). Quando i computer hanno iniziato ad adattarsi ad altri paesi e lingue, non c'era più spazio sufficiente per nuovi simboli. Per supportare completamente lingue diverse dall'inglese, IBM ha introdotto diverse tabelle di codici specifiche per paese. Quindi per i paesi scandinavi è stata proposta la tabella 865 (nordica), per i paesi arabi - tabella 864 (araba), per Israele - tabella 862 (Israele) e così via. In queste tabelle alcuni dei codici della seconda metà della tabella dei codici sono stati utilizzati per rappresentare i caratteri degli alfabeti nazionali (escludendo alcuni caratteri pseudografici). La situazione con la lingua russa si è sviluppata in modo speciale. Ovviamente si può fare la sostituzione dei caratteri nella seconda metà della tabella codici diversi modi... Quindi, sono apparse diverse tabelle di codifica dei caratteri cirillici per la lingua russa: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Tutti rappresentano i simboli della prima metà della tabella allo stesso modo (da 0 a 127) e differiscono nella rappresentazione dei simboli dell'alfabeto russo e della pseudo-grafica. Per lingue come il cinese o il giapponese, generalmente 256 caratteri non sono sufficienti. Inoltre, c'è sempre il problema di emettere o salvare in un file contemporaneamente i testi su lingue differenti(ad esempio, quando si cita). Pertanto, un universale tabella dei codici UNICODE, contenente simboli utilizzati nelle lingue di tutti i popoli del mondo, oltre a vari simboli di servizio e ausiliari (segni di punteggiatura, simboli matematici e tecnici, frecce, segni diacritici, ecc.). Ovviamente, un byte non è sufficiente per codificare un insieme di caratteri così ampio. Pertanto UNICODE utilizza codici a 16 bit (2 byte) per rappresentare 65.536 caratteri. Ad oggi sono stati utilizzati circa 49.000 codici (l'ultimo cambiamento significativo è stato l'introduzione del simbolo della valuta EURO nel settembre 1998). Per compatibilità con le codifiche precedenti, i primi 256 codici sono gli stessi dello standard ASCII. Nello standard UNICODE, salvo specifiche codice binario(questi codici sono solitamente indicati dalla lettera U, seguita dal segno + e dal codice vero e proprio in rappresentazione esadecimale) ad ogni carattere è assegnato un nome specifico. Un altro componente Norma UNICODE sono algoritmi per la conversione uno a uno di codici UNICODE in una sequenza di byte di lunghezza variabile. La necessità di tali algoritmi è dovuta al fatto che non tutte le applicazioni possono funzionare con UNICODE. Alcune applicazioni comprendono solo i codici ASCII a 7 bit, altre applicazioni comprendono i codici ASCII a 8 bit. Tali applicazioni utilizzano i cosiddetti codici ASCII estesi per rappresentare caratteri che non rientrano, rispettivamente, in un set di 128 o 256 caratteri, quando i caratteri sono codificati con stringhe di byte di lunghezza variabile. UTF-7 viene utilizzato per convertire in modo reversibile i codici UNICODE in codici ASCII estesi a 7 bit e UTF-8 viene utilizzato per convertire in modo reversibile i codici UNICODE in codici ASCII estesi a 8 bit. Nota che sia ASCII che UNICODE e altri standard di codifica dei caratteri non definiscono le immagini dei caratteri, ma solo la composizione del set di caratteri e il modo in cui è rappresentato in un computer. Inoltre (cosa che potrebbe non essere immediatamente ovvia), l'ordine di enumerazione dei caratteri nell'insieme è molto importante, poiché influisce in modo più significativo sugli algoritmi di ordinamento. È la tabella di corrispondenza dei simboli di un certo insieme (diciamo, simboli usati per rappresentare informazioni su lingua inglese, o in lingue diverse, come nel caso di UNICODE) e denotiamo con il termine tabella di codifica dei caratteri o set di caratteri. Ogni codifica standard ha un nome come KOI8-R, ISO_8859-1, ASCII. Sfortunatamente, non esiste uno standard per la codifica dei nomi.
Viene utilizzato per la comunicazione tra navi vicine al fine di poter rispettare la frequenza della radio in uso, non darne un uso non necessario occupando inutilmente quel canale, o perché la comunicazione deve essere stabilita e la radio non funziona correttamente.
I flag vengono utilizzati per eseguire la comunicazione, quindi a seconda della posizione assunta dalla persona che esegue i segnali, avrà un valore o qualcos'altro. I significati associati sono gli stessi dell'utilizzo di flag con le lettere dalla A alla Z, i numeri da 0 a 9 e i segnali di pausa e di errore.
Radiotelegrafia e radiotelefonia
Con i metodi discussi sopra, la comunicazione simultanea in entrambe le direzioni è impossibile, quindi erano punto a punto. Grazie all'avvento della radiotelegrafia, questo tipo di comunicazione è possibile. La radiotelegrafia si basa sulla teoria della propagazione delle onde nello spazio di Maxwell. Nasce così la telegrafia senza fili, uno dei progressi più importanti nelle telecomunicazioni di tutti i tempi.
Codifiche comuni
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Codifiche Microsoft Windows: o Windows-1250 per le lingue dell'Europa centrale che utilizzano lettere latine o Windows-1251 per gli alfabeti cirillici o Windows-1252 per le lingue occidentali o Windows-1253 per il greco o Windows-1254 per il turco o Windows-1255 per l'ebraico o Windows-1256 per la lingua araba o Windows-1257 per le lingue baltiche o Windows-1258 per la lingua vietnamita MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U...), KOI-7 codifica bulgara ISCII VISCII Big5 (la versione più famosa di Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS per giapponese (Microsoft CP932) EUC-KR per coreano (Microsoft CP949) ISO-2022 ed EUC per scrittura cinese UTF- 8 e UTF-16 codifiche caratteri UnicodeQuesta documentazione è stata spostata nell'archivio e non è più supportata.
Programmare oggi
Ancora avanti sarà la radiotelefonia, che non è altro che la capacità di modulare la voce sulle onde radio usando basi teoriche esibito in radiotelegrafia.
Codifica del segnale
È una procedura molto comunemente usata in cui, prima che una serie di segnali di tipo analogico venga trascritta in segnali tipo digitale... Pertanto, facilita la successiva lavorazione e migliora le caratteristiche fisiche.Cioè il segnale analogico è molto sensibile alle variazioni di possibili interferenze, questo è dovuto al fatto che il segnale originale è molto difficile da recuperare, poiché i valori che questo segnale può avere possono essere infiniti. Se lo confrontiamo con un segnale digitale che ha un certo numero di valori possibili. Questo fatto rende più facile recuperare i valori in un segnale digitale e, quindi, può essere utilizzato per comunicazioni a lunga distanza.
Utilizzo della codifica Unicode
.NET Framework 3.5
Aggiornato: novembre 2007
Le applicazioni runtime comuni utilizzano la codifica per convertire i caratteri dalla rappresentazione interna (Unicode) a un'altra rappresentazione. La decodifica viene utilizzata per riconvertire i caratteri da codifiche esterne (non Unicode) a rappresentazioni interne. Lo spazio dei nomi contiene un numero di classi che consentono alle applicazioni di codificare e decodificare i caratteri. Per una panoramica di queste classi, cfr.
In questa procedura possiamo distinguere tre fasi ben differenziate: campionamento, quantificazione e codifica. Quantificazione: consiste nel valutare il valore di ciascuno dei campioni, in modo che a ciascuno dei campioni sia assegnato uno dei possibili valori della risultante segnale digitale... Il processo di quantizzazione causa rumore di quantizzazione causato dal numero di possibili valori segnale analogico per segnale digitale. Consiste nel convertire i valori ottenuti durante il processo di quantizzazione in un sistema binario utilizzando un numero di codici preimpostati.
- Campionamento: consiste in un campionamento dell'ampiezza del segnale in ingresso.
- Altamente parametro importante in questo processo dal numero di campioni al secondo.
- Codifica.
Utilizzato per la codifica non Unicode. La classe supporta un'ampia gamma di codifiche ANSI/ISO.
L'esempio di codice seguente utilizza il metodo GetEncoding l'oggetto di codifica richiesto per una tabella codici specifica. Metodo Ottieni byte richiamato sull'oggetto di codifica desiderato per convertire la stringa Unicode in rappresentazione in byte nella codifica desiderata. Lo schermo visualizzerà la rappresentazione in byte della stringa in una tabella codici specifica.
Si basa sulla codifica a polarità singola, come suggerisce il nome. Quindi, tipicamente un valore binario uguale a uno assume un valore nel segnale di uscita uguale a uno, e un valore uguale a zero permette un valore zero nel segnale di uscita.
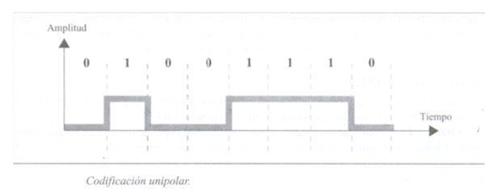
Questo è il tipo di codifica più comunemente usato oggi. Si basa sulla codifica di due polarità per rappresentare le informazioni binarie. Possiamo trovare la seguente classificazione della codifica polare. 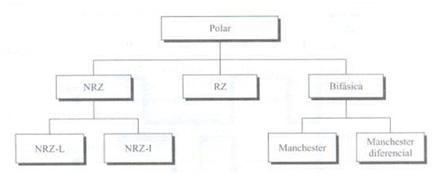
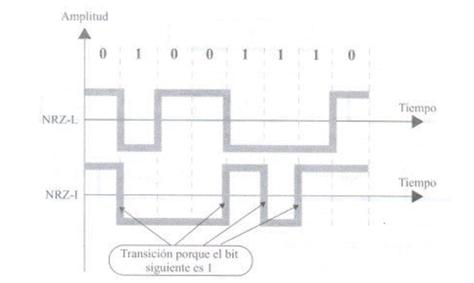
È caratterizzato dal fatto che il segnale ha sempre un valore positivo o negativo. Possiamo distinguere chiaramente tra i tipi.
Imports System Imports System.IO Imports System.Globalization Imports System.Text Public Class Encoding_UnicodeToCP Public Shared Sub Main () "Converte i caratteri ASCII in byte. "Visualizza la stringa" s rappresentazione in byte nel"code page specificata. "La pagina codici 1252 rappresenta i caratteri latini. PrintCPBytes ("Ciao, mondo!", 1252) "La pagina codici 932 rappresenta i caratteri giapponesi. PrintCPBytes ("Ciao, mondo!", 932) "Converte i caratteri giapponesi. PrintCPBytes (, 1252) PrintCPBytes ( "\ u307b, \ u308b, \ u305a, \ u3042, \ u306d", 932) End Sub Public Shared Sub PrintCPBytes (str As String, codePage As Integer) Dim targetEncoding As Encoding Dim encodedChars () As Byte "Ottiene la codifica per la tabella codici specificata. targetEncoding = Encoding.GetEncoding (codePage) "Ottiene la rappresentazione in byte della stringa specificata. encodedChars = targetEncoding.GetBytes (str) "Stampa i byte. Console.WriteLine ( "Rappresentazione in byte di" (0) "in CP" (1) ":", _ str, codePage) Dim i As Integer For i = 0 To encodedChars.Length - 1 Console.WriteLine ("Byte (0): (1)", i, encodedChars (i)) Next i End Sub End Class
Di solito, se un bit è impostato su uno, il segnale sarà positivo, se è zero, il segnale sarà negativo. Pertanto, questo valore dipende non solo dal bit corrente, ma anche dal bit precedente. Quindi, è più affidabile.
Si caratterizza per l'utilizzo di tre possibili livelli di uscita. Il piccolo è rappresentato da un cambiamento da positivo a zero e da zero a negativo a positivo. Ogni transazione avviene a metà dell'intervallo, come mostrato nella figura seguente. Questo tipo di codifica consente anche l'attivazione di una procedura di sincronizzazione utilizzando transizioni generate a metà slot.
 Gioco del volume e dei pulsanti di accensione sull'iPhone: matrimonio o no?
Gioco del volume e dei pulsanti di accensione sull'iPhone: matrimonio o no? La scheda di rete non vede il cavo: istruzioni per risolvere il problema Cosa fare se il cavo Internet non funziona
La scheda di rete non vede il cavo: istruzioni per risolvere il problema Cosa fare se il cavo Internet non funziona StoCard e Wallet: carte sconto dall'applicazione
StoCard e Wallet: carte sconto dall'applicazione