Tabella Ansi per i caratteri russi. Codifiche: informazioni utili e una breve retrospettiva
A volte anche uno specialista abbastanza esperto non ti dirà immediatamente quale valore particolare di pressione o lunghezza in un sistema corrisponde ai valori in un altro sistema di valori.
Per facilitare questo compito, offriamo tabelle del rapporto tra pressione e valori di lunghezza nei sistemi europei e americani con piccoli spiegazioni... Ma prima, qualche parola sugli standard stessi.
DINè lo standard tedesco (sta per Deutsches Institut für Normung, cioè sviluppato dall'Istituto tedesco di normalizzazione), che è sviluppato rigorosamente nell'ambito delle disposizioni dell'Organizzazione internazionale per la normalizzazione - ISO (Organizzazione internazionale per la normalizzazione).
ANSI- lo standard adottato negli Stati Uniti d'America. Sta per American National Standards Institute, cioè lo standard dell'American National Standards Institute.
Di conseguenza, gli standard ANSI sono determinati da questa istituzione e lontano non sempre tra gli standard DIN e ANSI l'esatto conformità in vari campi.
Conversione da ANSI a DIN unità di pressione
Qui tutto è semplice: se lo standard ANSI il numero 150 è opposto alla pressione - ciò significa che la pressione nominale (per la quale è progettata la valvola) è 20 bar, 300 - 50 bar, ecc. Valore massimo di Classe ANSI- 2500 sarà pari a 420 bar secondo lo standard europeo DIN.
Utilizzando questa tabella, non difficile tradurre i valori di pressione e viceversa: da DIN v ANSI, sebbene i nostri ingegneri debbano eseguire molto questa traduzione meno spesso.
Conversione di unità di lunghezza dal sistema americano a quello europeo (russo)
Come è noto, gli americani tutto è misurato in pollici e piedi, e noi e europei- millimetri, centimetri e metri, cioè come la stragrande maggioranza degli stati del mondo in cui viviamo metrica sistema di unità.
Come convertire i pollici in millimetri? In effetti, anche questo non è difficile, ricorda solo che 1 pollice equivale a 25,4 mm. Tuttavia, molto spesso il numero dopo la virgola trascurato e per contare anche indicare che 1 pollice = 25 mm.
Quindi, se, ad esempio, la sezione dell'imboccatura è di 2 pollici secondo il sistema di misure americano, allora, traducendo questo valore nel nostro sistema di misure secondo la regola di cui sopra, otteniamo 50 mm o più precisamente , 51 mm (arrotondamento 50,8 secondo le regole) ...
Resta da aggiungere che il diametro è tecnico le caratteristiche sono contrassegnate con lettere latine DN ed è spesso indicato proprio in pollici, e la pressione è indicata dalle lettere PN ed è indicato più spesso in barre- in ogni caso, usiamo solo un marchio come il più confortevole.
E la seguente tabella aiuterà puoi calcolare non solo preciso il numero di millimetri in un pollice (con una precisione di un millesimo di millimetro), ma ti aiuterà anche a scoprire quanti millimetri sono contenuti, ad esempio, in 2,5 pollici.
Per fare ciò, trova la colonna 2 "" (2 pollici) e a sinistra cerca 1/2. Totale 2,5 pollici = 63,501 mm, che è abbastanza possibile arrotondare fino a 64 mm e, ad esempio, 6,25 pollici (cioè 6 e 1/4) = 158,753 mm o 159 mm.
|
| Pollici "" in millimetri |
|||||||
|
| ||||||||
|
| ||||||||
Se hai solo bisogno di inserirne alcuni personaggi speciali o caratteri, puoi utilizzare la tabella dei caratteri o le scorciatoie da tastiera. Per un elenco di caratteri ASCII, vedere le tabelle seguenti o Inserimento di lettere nazionali utilizzando i tasti di scelta rapida.
Appunti:
Inserimento di caratteri ASCII
Per inserire un carattere ASCII, tenere premuto il tasto ALT, quindi digitare il codice del carattere. Ad esempio, per inserire un segno di grado (º), tieni premuto il tasto ALT e digita tastiera numerica codice 0176.
Nota:
Inserimento di caratteri Unicode
Importante: Alcuni Programmi Microsoft Office, come PowerPoint e InfoPath, non può convertire i codici dei caratteri Unicode. Se è necessario un carattere Unicode e si utilizza uno dei programmi che non supportano i caratteri Unicode, utilizzare per immettere i caratteri, che potrebbero essere necessari.
Appunti:
Esci da tutti i programmi.
Fare doppio clic sull'icona Installazione e rimozione di programmi Su pannelli di controllo.
Effettuare una delle seguenti operazioni:
se l'applicazione Microsoft Office installato come parte di Microsoft Office, selezionare Microsoft Office in campo Programmi installati e poi premere il pulsante Sostituire;
Se Applicazione per ufficioè stato installato separatamente, fare clic sul suo nome nell'elenco Programmi installati e poi premere il pulsante Modificare.
I numeri devono essere digitati sul tastierino numerico, non alfanumerico. Se è necessario premere per inserire i numeri sul tastierino numerico Tasto NUM LOCK, assicurati che sia fatto.
Se hai problemi a convertire un codice Unicode in un carattere, digita il codice sul tastierino numerico, selezionalo, quindi premi Alt + X.
V Microsoft Windows XP e le versioni successive di Universal Unicode Font vengono installate automaticamente. In Microsoft Windows 2000, il carattere Unicode deve essere installato manualmente.
Su Microsoft Windows 2000
Nella finestra di dialogo Installazione di Microsoft Office 2003 seleziona un'opzione Aggiungi o rimuovi componenti e poi premere il pulsante Ulteriore.
Si prega di selezionare Personalizzazione aggiuntiva applicazioni e premere il pulsante Ulteriore.
Espandi l'elenco Strumenti comuni di Office.
Espandi l'elenco Supporto multilingue.
Fare clic sull'icona Carattere universale e selezionare l'opzione di installazione desiderata.
Usando la tabella dei simboli
La tabella dei simboli è integrata in Microsoft Programma Windows che consente di visualizzare i caratteri disponibili nel font selezionato. Utilizzando una tabella dei simboli, è possibile copiare singoli simboli o gruppi di simboli negli appunti e quindi incollarli in un programma che li supporti.
Fare clic sul pulsante Cominciare, quindi selezionare Programmi, Standard, Servizio e tabella dei simboli.
Per selezionare un simbolo nella tabella dei simboli, fare clic su di esso, fare clic su Selezionare, clicca clic destro mouse nel punto del documento in cui si desidera aggiungere il simbolo e selezionare il comando Inserire.
Codici caratteri comuni
Per ulteriori caratteri, vedere l'articolo installato sul computer, i codici carattere ASCII o un diagramma di script del codice carattere Unicode.
|
Cartello |
Cartello |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli di valuta |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli legali |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
frazioni |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli di punteggiatura e dialetto |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli di forma |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Codici diacritici comuniPer un elenco completo dei glifi e dei codici dei caratteri associati, vedere.
|
Framework Bootstrap: layout reattivo veloce
Un video tutorial passo passo sulle basi del layout reattivo nel framework Bootstrap.
Impara a comporre in modo semplice, rapido ed efficiente utilizzando uno strumento potente e pratico.
Layout per ordinare e farsi pagare.
Corso gratuito "Sito WordPress"
Vuoi padroneggiare un CMS WordPress?
Ottieni tutorial sul design e il layout del sito Web WordPress.
Impara a lavorare con i temi e affetta il layout.
Videocorso gratuito sulla progettazione del sito di disegno, layout e installazione su CMS WordPress!
* Passa il mouse per mettere in pausa lo scorrimento.
Indietro avanti
Codifiche: informazioni utili e una breve retrospettiva
Ho deciso di scrivere questo articolo come una piccola panoramica sulla questione delle codifiche.
Scopriremo cos'è la codifica in generale e toccheremo la storia di come sono apparsi in linea di principio.
Parleremo di alcune loro caratteristiche e considereremo anche i momenti che ci consentono di lavorare con le codifiche in modo più consapevole ed evitare la comparsa sul sito dei cosiddetti krakozyabrov, cioè. caratteri illeggibili.
Quindi andiamo ...
Che cos'è la codifica?
Per dirla semplicemente, codificaè una tabella di mappature dei caratteri che possiamo vedere sullo schermo, a determinati codici numerici.
Quelli. ogni carattere che inseriamo dalla tastiera, o che vediamo sullo schermo del monitor, è codificato con una certa sequenza di bit (zeri e uno). 8 bit, come probabilmente saprai, equivalgono a 1 byte di informazioni, ma ne parleremo più avanti.
L'aspetto dei simboli stessi è determinato dai file dei caratteri che sono installati sul tuo computer. Pertanto, il processo di visualizzazione del testo sullo schermo può essere descritto come una mappatura costante di sequenze di zero e uno su alcuni caratteri specifici che compongono il carattere.
Si può considerare il capostipite di tutte le codifiche moderne ASCII.
Questa abbreviazione sta per Codice Standard Americano per Interscambio di Informazioni(American Standard Code Table per caratteri stampabili e alcuni codici speciali).
esso codifica a byte singolo, che inizialmente conteneva solo 128 caratteri: lettere dell'alfabeto latino, numeri arabi, ecc.

Successivamente è stato ampliato (inizialmente non utilizzava tutti gli 8 bit), quindi è diventato possibile utilizzare non 128, ma 256 (da 2 a 8a potenza) personaggi diversi che può essere codificato in un byte di informazioni.
Questo miglioramento ha permesso di aggiungere ad ASCII simboli delle lingue nazionali, oltre al già esistente alfabeto latino.
Ci sono molte opzioni per la codifica ASCII estesa a causa del fatto che ci sono anche molte lingue nel mondo. Penso che molti di voi abbiano sentito parlare di una codifica come KOI8-R è anche una codifica ASCII estesa progettato per funzionare con i personaggi della lingua russa.
Il prossimo passo nello sviluppo delle codifiche può essere considerato l'emergere del cosiddetto Codifiche ANSI.
In effetti erano uguali versioni ASCII estese tuttavia, sono stati rimossi vari elementi pseudografici e sono stati aggiunti simboli tipografici, per i quali prima non c'era abbastanza "spazio libero".
Un esempio di tale codifica ANSI è il ben noto Windows-1251... Oltre ai caratteri tipografici, questa codifica includeva anche lettere degli alfabeti di lingue vicine al russo (ucraino, bielorusso, serbo, macedone e bulgaro).
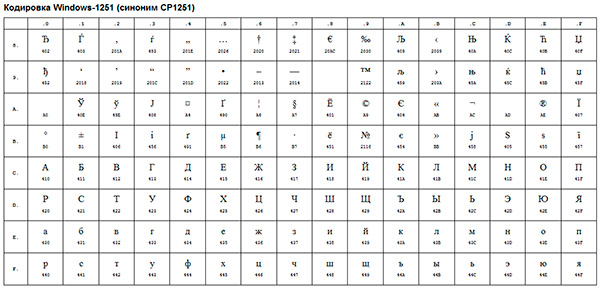
La codifica ANSI è un nome collettivo... In effetti, la codifica effettiva quando si utilizza ANSI sarà determinata da quanto specificato nel registro del tuo sistema operativo Finestre. Nel caso della lingua russa, sarà Windows-1251, tuttavia, per altre lingue sarà un diverso tipo di ANSI.
Come capisci, un sacco di codifiche e la mancanza di uno standard unico non hanno portato a buon fine, motivo per cui frequenti incontri con i cosiddetti krakozyabrami- un insieme di caratteri illeggibili e privi di significato.
La ragione del loro aspetto è semplice: lo è cercando di visualizzare i caratteri codificati con una tabella di codifica utilizzando una tabella di codifica diversa.
Nel contesto dello sviluppo web, possiamo incontrare krakozyabras quando, ad esempio, Il testo russo viene salvato per errore nella codifica errata utilizzata sul server.
Naturalmente, questo non è l'unico caso in cui possiamo ottenere testo illeggibile: ci sono molte opzioni qui, soprattutto se si considera che esiste anche un database in cui sono memorizzate anche le informazioni in una certa codifica, esiste una mappatura di una connessione a un database, ecc.
L'emergere di tutti questi problemi è servito da incentivo per creare qualcosa di nuovo. Doveva essere una codifica in grado di codificare qualsiasi lingua del mondo (dopotutto, con l'aiuto di codifiche a byte singolo, a tutti i costi, non si possono descrivere tutti i caratteri, diciamo, della lingua cinese, dove ci sono chiaramente più di 256 di essi), eventuali caratteri speciali aggiuntivi e tipografia.
Insomma, era necessario creare una codifica universale che risolverebbe il problema di krakozyabrov una volta per tutte.
Unicode - Codifica testo universale (UTF-32, UTF-16 e UTF-8)
Lo standard stesso è stato proposto nel 1991 da un'organizzazione senza scopo di lucro Consorzio Unicode(Unicode Consortium, Unicode Inc.), e il primo risultato del suo lavoro è stata la creazione della codifica UTF-32.
A proposito, l'abbreviazione stessa UTF sta per Formato di trasformazione Unicode(Formato di conversione Unicode).
In questa codifica, per codificare un carattere, doveva usarne tanto 32 bit, cioè. 4 byte di informazioni. Se confrontiamo questo numero con le codifiche a byte singolo, arriviamo a una semplice conclusione: per codificare 1 carattere in questa codifica universale, è necessario 4 volte più bit, che rende il file 4 volte più pesante.
È anche ovvio che il numero di caratteri che potrebbero essere potenzialmente descritti utilizzando questa codifica supera tutti i limiti ragionevoli ed è tecnicamente limitato a un numero pari a 2 alla 32a potenza. È chiaro che si trattava di un evidente eccesso e spreco in termini di peso dei file, quindi questa codifica non si è diffusa.
È stata sostituita da nuovo sviluppo- UTF-16.
Come suggerisce il nome, in questa codifica viene codificato un carattere non più 32 bit, ma solo 16(cioè 2 byte). Ovviamente, questo rende qualsiasi carattere due volte più "leggero" rispetto a UTF-32, ma anche due volte più "pesante" di qualsiasi carattere codificato utilizzando una codifica a byte singolo.
Il numero di caratteri disponibili per la codifica in UTF-16 è di almeno 2 alla 16a potenza, ad es. 65536 caratteri. Tutto sembra andare bene, inoltre la dimensione finale dello spazio del codice in UTF-16 è stata estesa a più di 1 milione di caratteri.
Tuttavia, questa codifica non ha soddisfatto pienamente le esigenze degli sviluppatori. Ad esempio, se scrivi utilizzando esclusivamente caratteri latini, dopo essere passato dalla versione estesa della codifica ASCII a UTF-16, il peso di ciascun file è raddoppiato.
Di conseguenza, è stato fatto un altro tentativo di creare qualcosa di universale, e quel qualcosa è la famosa codifica UTF-8.
UTF-8- questo è codifica multibyte con lunghezza dei caratteri variabile... Guardando il nome, si potrebbe pensare, per analogia con UTF-32 e UTF-16, che per codificare un carattere vengano utilizzati 8 bit, ma non è così. Più precisamente, non proprio così.
Questo perché UTF-8 offre la migliore compatibilità con i sistemi meno recenti che utilizzavano caratteri a 8 bit. Per codificare un carattere in UTF-8 viene effettivamente utilizzato da 1 a 4 byte(ipoteticamente sono possibili fino a 6 byte).
In UTF-8, tutti i caratteri latini sono codificati in 8 bit, proprio come nella codifica ASCII... In altre parole, la parte base della codifica ASCII (128 caratteri) è stata spostata in UTF-8, che permette di "spendere" solo 1 byte sulla loro rappresentazione, pur mantenendo l'universalità della codifica, per cui tutto è stato avviato.
Quindi, se i primi 128 caratteri sono codificati con 1 byte, tutti gli altri caratteri sono già codificati con 2 byte o più. In particolare, ogni carattere cirillico è codificato con esattamente 2 byte.
Così, abbiamo ottenuto una codifica universale che ci permette di coprire tutti i possibili caratteri che devono essere visualizzati, senza "pesare" inutilmente i file.
Con o senza distinta base?
Se hai lavorato con editor di testo(editor di codice) like Blocco note ++, phpDesigner, php veloce ecc., probabilmente hai attirato l'attenzione sul fatto che quando specifichi la codifica in cui verrà creata la pagina, puoi scegliere, di regola, 3 opzioni:
ANSI
- UTF-8
- UTF-8 senza BOM
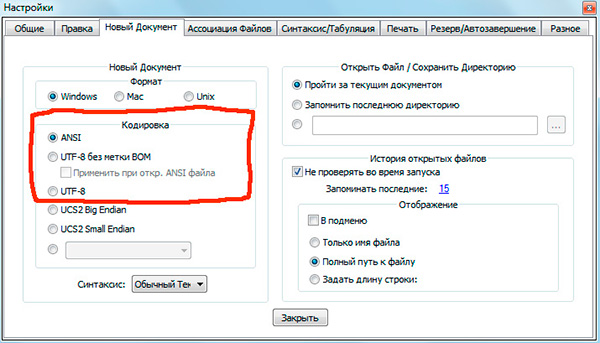

Devo dire subito che è sempre l'ultima opzione che vale la pena scegliere - UTF-8 senza BOM.
Quindi cos'è la distinta base e perché non ne abbiamo bisogno?
BOM sta per Contrassegno dell'ordine dei byte... Questo è un carattere Unicode speciale utilizzato per indicare l'ordine dei byte. file di testo... Secondo la specifica, il suo utilizzo è facoltativo, ma se BOM viene utilizzato, quindi deve essere impostato all'inizio del file di testo.
Non entreremo nei dettagli del lavoro. BOM... Per noi, la conclusione principale è la seguente: l'utilizzo di questo carattere di servizio insieme a UTF-8 impedisce ai programmi di leggere normalmente la codifica, a seguito della quale si verificano errori nel lavoro degli script.
Pertanto, quando si lavora con UTF-8, utilizzare esattamente l'opzione "UTF-8 senza BOM"... È anche meglio non utilizzare editor in cui, in linea di principio, non è possibile specificare la codifica (ad esempio, Taccuino dai programmi standard a finestre).
La codifica del file correntemente aperto nell'editor di codice è solitamente indicata nella parte inferiore della finestra.
Si prega di notare che la voce "ANSI come UTF-8" nell'editor Blocco note ++ significa lo stesso di "UTF-8 senza BOM"... Questo è lo stesso.
![]()
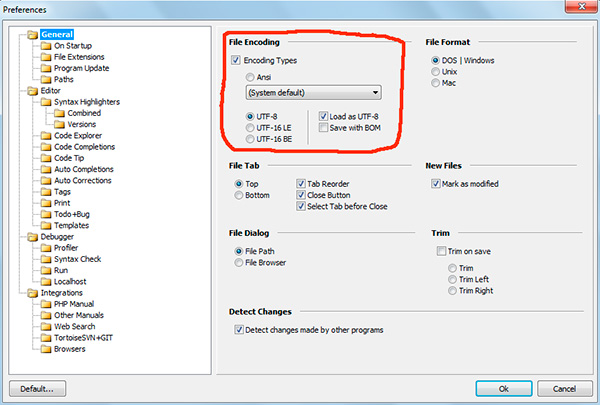
In un programma phpDesigner non puoi dire immediatamente con certezza se è usato BOM, o no. Per fare ciò, fai clic con il pulsante destro del mouse sull'iscrizione "UTF-8", dopodiché nella finestra pop-up puoi vedere se BOM(opzione Risparmia con BOM).
Nell'editor php veloce codifica UTF-8 senza BOM indicato come "UTF-8 *".
Come puoi immaginare, in diversi editor tutto sembra leggermente diverso, ma ottieni l'idea principale.
Dopo che il documento è stato salvato in UTF-8 senza BOM, devi anche assicurarti che la codifica corretta sia specificata nell'apposito meta tag nella sezione testa il tuo documento html:
Seguire queste semplici regole ti permetterà già di evitare molti spazi con le codifiche.
Questo è tutto, spero che questa breve escursione e le spiegazioni ti abbiano aiutato a capire meglio cosa sono le codifiche, cosa sono e come funzionano.
Se sei interessato a questo argomento da un punto di vista più applicato, ti consiglio di studiare il mio video tutorial.
Dmitry Naumenko.
P.S. Dai un'occhiata più da vicino ai tutorial premium su vari aspetti della costruzione del sito, così come corso gratuito sulla creazione da zero del proprio sistema CMS in PHP. Tutto questo ti aiuterà a padroneggiare varie tecnologie di sviluppo web più velocemente e più facilmente.
Ti è piaciuto il materiale e vuoi ringraziarti?
Basta condividere con i tuoi amici e colleghi!
|
Codice (binario) |
(decimale senza segno) |
(con segno decimale) |
|
|
A (latino grande) | |||
|
B (latino grande) | |||
|
a (piccolo latino) | |||
|
A (grande russo) Nella codifica ANSI | |||
|
A (grande russo) Nella codifica ASCII |
Un codice simile, come mostrato sopra, corrisponde anche a un numero intero compreso tra 0 e 255 in formato senza segno. Pertanto, ogni carattere ha un numero intero, chiamato anche codice carattere. Viene chiamata la raccolta di codici carattere tabella dei codici o codifica .
Per i personal computer, il più comune tabelle di codici ANSI (American National Standard Institute) e ASCII (American Standard Code for Information Interchange). La tabella ANSI è utilizzata in Windows e ASCII è stato utilizzato in DOS. Tuttavia, in queste due tabelle, i primi 128 codici (da 0 a 127) incontro ; differiscono solo nei successivi 128 codici utilizzati per memorizzare lettere e simboli nazionali (russi) di "pseudo-grafica".
Nelle tabelle fornite, la designazione KS significa "codice carattere" e INSIEME A- "simbolo".
Parte standard della tabella dei caratteri (ascii-ansi)
Alcuni dei simboli di cui sopra hanno significati speciali. Così, ad esempio, un carattere con codice 9 denota un carattere di tabulazione orizzontale, un carattere con codice 10 è un carattere di avanzamento riga e un carattere con codice 13 è un carattere di ritorno a capo.
 Differenze tra strutture di partizione GPT e MBR
Differenze tra strutture di partizione GPT e MBR Cancella Internet Explorer in modo pulito
Cancella Internet Explorer in modo pulito Gli aggiornamenti di Windows vengono scaricati ma non installati
Gli aggiornamenti di Windows vengono scaricati ma non installati