สัมประสิทธิ์สหสัมพันธ์ของยศ Spearman Kendall Fechner ค่าสัมประสิทธิ์สหสัมพันธ์อันดับของเคนดัลล์ ดูว่า "ค่าสัมประสิทธิ์สหสัมพันธ์อันดับของเคนดัลลา" ในพจนานุกรมอื่นๆ คืออะไร
ในการคำนวณ ค่าสัมประสิทธิ์เคนดัลล์ค่าของแอตทริบิวต์ของปัจจัยมีการจัดลำดับล่วงหน้า กล่าวคือ อันดับโดย X จะถูกบันทึกอย่างเคร่งครัดในลำดับจากน้อยไปมากของค่าเชิงปริมาณ
1) สำหรับแต่ละอันดับใน Y ให้หาจำนวนรวมของอันดับที่ตามมาซึ่งมีค่ามากกว่าอันดับที่กำหนด จำนวนทั้งหมดของกรณีดังกล่าวถูกนำมาพิจารณาด้วยเครื่องหมาย "+" และแสดงโดย P.
2) สำหรับแต่ละอันดับใน Y จะกำหนดจำนวนอันดับที่ตามมาซึ่งมีค่าน้อยกว่าอันดับที่กำหนด จำนวนรวมของคดีดังกล่าวจะถูกนับด้วยเครื่องหมาย “-” และแสดงด้วย Q
3) คำนวณ S = P + Q = 9 + (- 1) = 8
4) ค่าสัมประสิทธิ์เคนดัลล์คำนวณโดยสูตร:
ค่าสัมประสิทธิ์ของเคนดัลล์สามารถรับค่าได้ตั้งแต่ -1 ถึง +1 และยิ่งใกล้ชิดมากเท่าใด การเชื่อมต่อระหว่างคุณลักษณะก็จะยิ่งแข็งแกร่ง
ในบางกรณี เพื่อกำหนดทิศทางของความสัมพันธ์ระหว่างคุณสมบัติทั้งสอง ให้คำนวณ ค่าสัมประสิทธิ์เฟชเนอร์... ค่าสัมประสิทธิ์นี้อิงจากการเปรียบเทียบพฤติกรรมการเบี่ยงเบนของค่าแต่ละค่าของลักษณะแฟกทอเรียลและประสิทธิผลจากค่าเฉลี่ย ค่าสัมประสิทธิ์ Fechner คำนวณโดยสูตร:
 ; โดยที่ผลรวมของ C คือจำนวนความบังเอิญทั้งหมดของสัญญาณการเบี่ยงเบน ผลรวมของ H คือจำนวนทั้งหมดของสัญญาณการเบี่ยงเบนที่ไม่ตรงกัน
; โดยที่ผลรวมของ C คือจำนวนความบังเอิญทั้งหมดของสัญญาณการเบี่ยงเบน ผลรวมของ H คือจำนวนทั้งหมดของสัญญาณการเบี่ยงเบนที่ไม่ตรงกัน
1) คำนวณค่าเฉลี่ยของแอตทริบิวต์ปัจจัย: ![]()
2) กำหนดสัญญาณของการเบี่ยงเบนของค่าแต่ละค่าของแอตทริบิวต์ปัจจัยจากค่าเฉลี่ย
3) คำนวณค่าเฉลี่ยของตัวบ่งชี้ที่มีประสิทธิภาพ: ![]() .
.
4) ค้นหาสัญญาณของการเบี่ยงเบนของค่าแต่ละค่าของลักษณะที่มีประสิทธิภาพจากค่าเฉลี่ย:

บทสรุป: การเชื่อมต่อโดยตรง ค่าสัมประสิทธิ์ไม่ได้ระบุความหนาแน่นของการเชื่อมต่อ
เพื่อกำหนดระดับความหนาแน่นของความสัมพันธ์ระหว่างคุณสมบัติสามอันดับ ค่าสัมประสิทธิ์จะถูกคำนวณ ความสอดคล้องคำนวณโดยใช้สูตร:
![]() โดยที่ m คือจำนวนของคุณสมบัติที่จัดอันดับ n คือจำนวนหน่วยสังเกตการณ์ที่มีลำดับชั้น
โดยที่ m คือจำนวนของคุณสมบัติที่จัดอันดับ n คือจำนวนหน่วยสังเกตการณ์ที่มีลำดับชั้น
| อุตสาหกรรม | X1 | X2 | X3 | R1 | R2 | R3 | ||
| วิศวกรรมไฟฟ้า | 7,49 | |||||||
| เชื้อเพลิง | 12,70 | |||||||
| แบล็ค เอ็ม | 5,92 | |||||||
| Tsvetnaya M. | 9,48 | |||||||
| วิศวกรรมเครื่องกล | 4,18 | |||||||
| ผล: |
X1- จำนวนพนักงาน (พันคน) X2- ปริมาณการขายภาคอุตสาหกรรม (พันล้านรูเบิล); X3- เงินเดือนเฉลี่ยต่อเดือน.
1) เราจัดอันดับค่าของคุณสมบัติทั้งหมดและกำหนดอันดับอย่างเคร่งครัดในลำดับจากน้อยไปมากของค่าเชิงปริมาณ
2) ผลรวมของอันดับจะถูกกำหนดสำหรับแต่ละบรรทัด คอลัมน์นี้ใช้ในการคำนวณแถวสุดท้าย
3) คำนวณ ![]() .
.
4) สำหรับแต่ละแถว ให้หากำลังสองของการเบี่ยงเบนของผลรวมของอันดับและค่าของ T สำหรับคอลัมน์เดียวกัน เราจะคำนวณแถวสุดท้ายซึ่งเราแทนด้วย S ![]() ค่าสัมประสิทธิ์ความสอดคล้องสามารถรับค่าได้ตั้งแต่ 0 ถึง 1 และยิ่งเข้าใกล้ 1 มากเท่าใด ความสัมพันธ์ระหว่างคุณลักษณะก็จะยิ่งแข็งแกร่งขึ้น
ค่าสัมประสิทธิ์ความสอดคล้องสามารถรับค่าได้ตั้งแต่ 0 ถึง 1 และยิ่งเข้าใกล้ 1 มากเท่าใด ความสัมพันธ์ระหว่างคุณลักษณะก็จะยิ่งแข็งแกร่งขึ้น
เมื่อจัดอันดับ ผู้เชี่ยวชาญต้องจัดเรียงองค์ประกอบที่ประเมินโดยเรียงลำดับจากน้อยไปมาก (ลดลง) ตามความชอบและกำหนดแต่ละองค์ประกอบให้อยู่ในรูปแบบตัวเลขธรรมชาติ ในการจัดอันดับโดยตรง รายการที่ต้องการมากที่สุดคืออันดับ 1 (บางครั้ง 0) และรายการที่ต้องการน้อยที่สุดคืออันดับ m
หากผู้เชี่ยวชาญไม่สามารถจัดอันดับได้อย่างเคร่งครัดเนื่องจากองค์ประกอบบางอย่างมีความคล้ายคลึงกันในความเห็นของเขา ก็ได้รับอนุญาตให้กำหนดอันดับเดียวกันให้กับองค์ประกอบดังกล่าวได้ เพื่อให้แน่ใจว่าผลรวมของอันดับเท่ากับผลรวมของตำแหน่งขององค์ประกอบที่จัดอันดับ จึงใช้อันดับมาตรฐานที่เรียกว่า อันดับมาตรฐานคือค่าเฉลี่ยเลขคณิตของจำนวนองค์ประกอบในแถวที่มีการจัดอันดับที่เหมือนกันในความต้องการ
ตัวอย่าง 2.6.ผู้เชี่ยวชาญสั่งธาตุทั้ง ๖ ตามความชอบ ดังนี้
จากนั้นอันดับมาตรฐานขององค์ประกอบเหล่านี้จะเป็น
ดังนั้นผลรวมของอันดับที่กำหนดให้กับองค์ประกอบจะเท่ากับผลรวมของตัวเลขในชุดธรรมชาติ
ความถูกต้องของการแสดงความชอบโดยการจัดลำดับองค์ประกอบนั้นขึ้นอยู่กับความสำคัญของชุดการนำเสนอ ขั้นตอนการจัดอันดับให้ผลลัพธ์ที่น่าเชื่อถือที่สุด (ในแง่ของความใกล้เคียงของการตั้งค่าที่เปิดเผยและ "จริง") เมื่อจำนวนองค์ประกอบที่ประเมินแล้วไม่เกิน 10 ลำดับการจำกัดของชุดการนำเสนอไม่ควรเกิน 20
การประมวลผลและการวิเคราะห์การจัดอันดับจะดำเนินการเพื่อสร้างความสัมพันธ์การตั้งค่ากลุ่มตามความชอบส่วนบุคคล ในกรณีนี้ สามารถวางงานต่อไปนี้ได้: ก) การกำหนดความหนาแน่นของการเชื่อมต่อระหว่างการจัดอันดับผู้เชี่ยวชาญสองคนเกี่ยวกับองค์ประกอบของชุดการนำเสนอ ข) กำหนดความสัมพันธ์ระหว่างองค์ประกอบทั้งสองตามความคิดเห็นส่วนบุคคลของสมาชิกกลุ่มเกี่ยวกับลักษณะต่าง ๆ ขององค์ประกอบเหล่านี้ ค) การประเมินความสอดคล้องของความคิดเห็นของผู้เชี่ยวชาญในกลุ่มที่มีผู้เชี่ยวชาญมากกว่าสองคน
ในสองกรณีแรกจะใช้ค่าสัมประสิทธิ์เป็นตัววัดความหนาแน่นของการเชื่อมต่อ ความสัมพันธ์ของอันดับ... ค่าสัมประสิทธิ์สหสัมพันธ์ของ Kendall หรือ Spearman ขึ้นอยู่กับว่าจะอนุญาตเฉพาะอันดับที่เข้มงวดหรือหลวม
ค่าสัมประสิทธิ์สหสัมพันธ์อันดับของเคนดัลล์สำหรับปัญหา (a)
ที่ไหน ม- จำนวนองค์ประกอบ r 1 ฉัน -อันดับที่ได้รับมอบหมายจากผู้เชี่ยวชาญคนแรก ผม−องค์ประกอบ; r 2 ฉัน -เช่นเดียวกันโดยผู้เชี่ยวชาญคนที่สอง
สำหรับปัญหา (b) ส่วนประกอบ (2.5) มีความหมายดังต่อไปนี้ m คือจำนวนคุณลักษณะขององค์ประกอบโดยประมาณทั้งสอง; r 1 ฉัน(ร 2 ผม) - อันดับฉันลักษณะในการจัดอันดับองค์ประกอบแรก (ที่สอง) กำหนดโดยกลุ่มผู้เชี่ยวชาญ
การจัดอันดับที่เข้มงวดใช้ค่าสัมประสิทธิ์สหสัมพันธ์อันดับ Rสเปียร์แมน:
ซึ่งส่วนประกอบมีความหมายเดียวกับข้อ (2.5)
ค่าสัมประสิทธิ์สหสัมพันธ์ (2.5), (2.6) มีค่าตั้งแต่ -1 ถึง +1 ถ้าค่าสัมประสิทธิ์สหสัมพันธ์คือ +1 แสดงว่าอันดับเท่ากัน หากเป็น -1 แสดงว่าอยู่ตรงข้าม (อันดับจะผกผันกัน) ความเท่าเทียมกันของสัมประสิทธิ์สหสัมพันธ์เป็นศูนย์หมายความว่าการจัดอันดับมีความเป็นอิสระเชิงเส้น (ไม่สัมพันธ์กัน)
เนื่องจากด้วยวิธีนี้ (ผู้เชี่ยวชาญคือ "มาตรวัด" ที่มีข้อผิดพลาดแบบสุ่ม) การจัดอันดับแต่ละรายการจึงถือเป็นการสุ่ม ปัญหาจึงเกิดขึ้นจากการทดสอบสมมติฐานทางสถิติเกี่ยวกับความสำคัญของค่าสัมประสิทธิ์สหสัมพันธ์ที่ได้รับ ในกรณีนี้จะใช้เกณฑ์นอยมันน์-เพียร์สัน: กำหนดโดยระดับนัยสำคัญของเกณฑ์ α และเมื่อทราบกฎการกระจายของสัมประสิทธิ์สหสัมพันธ์แล้ว ให้กำหนดค่าเกณฑ์ ค αโดยเปรียบเทียบค่าสัมประสิทธิ์สหสัมพันธ์ที่ได้รับ พื้นที่วิกฤตอยู่ทางด้านขวา (ในทางปฏิบัติ ค่าของเกณฑ์มักจะถูกคำนวณก่อน และระดับของนัยสำคัญจะถูกกำหนดจากมัน ซึ่งเปรียบเทียบกับระดับธรณีประตู α ).
ค่าสัมประสิทธิ์สหสัมพันธ์อันดับของ Kendall τ มีสำหรับ m> 10 การแจกแจงใกล้เคียงกับค่าปกติด้วยพารามิเตอร์ต่อไปนี้:
โดยที่ M [τ] - ความคาดหวังทางคณิตศาสตร์ D [τ] - ความแปรปรวน
ในกรณีนี้ จะใช้ตารางของฟังก์ชันการแจกแจงแบบปกติมาตรฐาน:
และขอบเขต τ α ของบริเวณวิกฤตถูกกำหนดให้เป็นรากของสมการ
หากค่าสัมประสิทธิ์ที่คำนวณได้ τ ≥ τ α การจัดอันดับจะถือว่าอยู่ในข้อตกลงที่ดี โดยปกติ ค่าของ α จะถูกเลือกในช่วง 0.01-0.05 สำหรับ t ≤ 10 การแจกแจงของ t แสดงไว้ในตาราง 2.1.
การตรวจสอบความสำคัญของความสอดคล้องของสองอันดับโดยใช้สัมประสิทธิ์สเปียร์แมน ρ ดำเนินการในลำดับเดียวกันโดยใช้ตารางการแจกแจงของนักเรียนสำหรับ m> 10
ในกรณีนี้ ปริมาณ
มีการแจกแจงใกล้เคียงกับการแจกแจงของนักเรียนด้วย ม- 2 องศาอิสระ ที่ ม> 30 การกระจายปริมาณ ρ อยู่ในข้อตกลงที่ดีกับการแจกแจงแบบปกติซึ่งมี M [ρ] = 0 และ D [ρ] =
สำหรับ t ≤ 10 ความสำคัญของ ρ จะถูกตรวจสอบโดยใช้ตาราง 2.2.
ถ้าอันดับไม่เข้มงวดก็ค่าสัมประสิทธิ์สเปียร์แมน
โดยที่ ρ คำนวณโดย (2.6);
โดยที่ k 1, k 2 - จำนวนกลุ่มต่าง ๆ ของอันดับที่ไม่เข้มงวดในอันดับที่หนึ่งและสองตามลำดับ l i คือจำนวนอันดับที่เหมือนกันใน ผมกลุ่ม. ในการใช้งานจริงของสัมประสิทธิ์สหสัมพันธ์อันดับ ρ ของ Spearman และ Kendall ควรระลึกไว้เสมอว่าค่าสัมประสิทธิ์ ρ จะให้ผลลัพธ์ที่แม่นยำยิ่งขึ้นในแง่ของความแปรปรวนขั้นต่ำ
ตาราง 2.1.การกระจายค่าสัมประสิทธิ์สหสัมพันธ์อันดับของเคนดัลล์
ปัจจัยหนึ่งที่จำกัดการใช้เกณฑ์ตามสมมติฐานของภาวะปกติคือขนาดกลุ่มตัวอย่าง ตราบใดที่กลุ่มตัวอย่างมีขนาดใหญ่เพียงพอ (เช่น การสังเกต 100 ครั้งขึ้นไป) คุณสามารถสันนิษฐานได้ว่าการกระจายตัวอย่างเป็นเรื่องปกติ แม้ว่าคุณจะไม่แน่ใจว่าการกระจายของตัวแปรในประชากรเป็นเรื่องปกติ อย่างไรก็ตาม หากกลุ่มตัวอย่างมีขนาดเล็ก เกณฑ์เหล่านี้ควรใช้ก็ต่อเมื่อมีความมั่นใจว่าตัวแปรมีการกระจายตามปกติอย่างแท้จริง อย่างไรก็ตาม ไม่มีวิธีทดสอบสมมติฐานนี้ในตัวอย่างขนาดเล็ก
การใช้เกณฑ์ตามสมมติฐานของภาวะปกติยังจำกัดอยู่ที่มาตราส่วนของการวัด (ดูบท แนวคิดพื้นฐานของการวิเคราะห์ข้อมูล) วิธีการทางสถิติ เช่น t-test การถดถอย ฯลฯ ถือว่าข้อมูลเดิมมีความต่อเนื่อง อย่างไรก็ตาม มีบางสถานการณ์ที่ข้อมูลถูกจัดลำดับอย่างง่าย ๆ (วัดจากมาตราส่วนลำดับ) มากกว่าที่จะวัดได้อย่างแม่นยำ
ตัวอย่างทั่วไปได้รับจากการให้คะแนนของไซต์บนอินเทอร์เน็ต: ตำแหน่งแรกคือไซต์ที่มีจำนวนผู้เข้าชมสูงสุด ตำแหน่งที่สองคือไซต์ที่มีจำนวนผู้เข้าชมสูงสุดในไซต์ที่เหลือ (ระหว่างไซต์ จากที่ไซต์แรกถูกลบออก) ฯลฯ เมื่อรู้การจัดอันดับเราสามารถพูดได้ว่าจำนวนผู้เยี่ยมชมไซต์หนึ่งมากกว่าจำนวนผู้เยี่ยมชมไซต์อื่น แต่จะพูดมากกว่านี้ไม่ได้ ลองนึกภาพคุณมี 5 ไซต์: A, B, C, D, E ซึ่งอยู่ใน 5 อันดับแรก สมมติว่าในเดือนปัจจุบัน เรามีการจัดเรียงดังต่อไปนี้: A, B, C, D, E และในเดือนก่อนหน้า: D, E, A, B, C คำถามคือ มีการเปลี่ยนแปลงที่สำคัญในการจัดอันดับเว็บไซต์ หรือไม่? ในสถานการณ์นี้ เห็นได้ชัดว่าเราไม่สามารถใช้ t-test เพื่อเปรียบเทียบข้อมูลสองกลุ่มนี้ และไปยังพื้นที่ของการคำนวณความน่าจะเป็นเฉพาะ (และเกณฑ์ทางสถิติใด ๆ มีการคำนวณความน่าจะเป็น!) เราให้เหตุผลดังนี้: เป็นไปได้มากน้อยเพียงใดที่ความแตกต่างในเค้าโครงไซต์ทั้งสองนั้นเกิดจากเหตุผลแบบสุ่มล้วนๆ หรือความแตกต่างนั้นมากเกินไปและไม่สามารถอธิบายได้ด้วยโอกาสล้วนๆ ด้วยเหตุผลนี้ เราใช้อันดับหรือการเปลี่ยนแปลงของไซต์เท่านั้น และไม่ใช้รูปแบบเฉพาะของการกระจายจำนวนผู้เข้าชมไซต์
สำหรับการวิเคราะห์ตัวอย่างขนาดเล็กและข้อมูลที่วัดได้ในระดับต่ำ จะใช้วิธีแบบไม่อิงพารามิเตอร์
ทัวร์ชมขั้นตอนที่ไม่ใช่พารามิเตอร์อย่างรวดเร็ว
โดยพื้นฐานแล้ว สำหรับแต่ละเกณฑ์พารามิเตอร์ จะมี อย่างน้อยทางเลือกหนึ่งที่ไม่ใช่พารามิเตอร์
โดยทั่วไป ขั้นตอนเหล่านี้จัดอยู่ในประเภทใดประเภทหนึ่งต่อไปนี้:
- เกณฑ์การแยกตัวอย่างอิสระ
- เกณฑ์ความแตกต่างสำหรับตัวอย่างที่ขึ้นต่อกัน
- การประเมินระดับการพึ่งพาอาศัยกันระหว่างตัวแปร
โดยทั่วไป แนวทางสู่เกณฑ์ทางสถิติในการวิเคราะห์ข้อมูลควรเป็นแนวทางปฏิบัติและไม่ต้องแบกรับภาระในการให้เหตุผลทางทฤษฎีที่ไม่จำเป็น ด้วยคอมพิวเตอร์ของ STATISTICA คุณสามารถใช้เกณฑ์ต่างๆ กับข้อมูลของคุณได้อย่างง่ายดาย เมื่อทราบถึงข้อผิดพลาดบางประการของวิธีการ คุณจะเลือกวิธีแก้ปัญหาที่ถูกต้องผ่านการทดลอง การพัฒนาโครงเรื่องค่อนข้างเป็นธรรมชาติ หากคุณต้องการเปรียบเทียบค่าของตัวแปรสองตัว ให้ใช้ t-test อย่างไรก็ตาม ควรจำไว้ว่ามันอยู่บนพื้นฐานของสมมติฐานของภาวะปกติและความเท่าเทียมกันของความแปรปรวนในแต่ละกลุ่ม การหลุดพ้นจากสมมติฐานเหล่านี้ส่งผลให้มีการทดสอบแบบไม่อิงพารามิเตอร์ซึ่งมีประโยชน์อย่างยิ่งสำหรับตัวอย่างขนาดเล็ก
การพัฒนา t-test นำไปสู่การวิเคราะห์ความแปรปรวน ซึ่งใช้เมื่อจำนวนกลุ่มเปรียบเทียบมากกว่าสองกลุ่ม การพัฒนากระบวนการที่ไม่ใช่พารามิเตอร์ที่สอดคล้องกันนำไปสู่การวิเคราะห์ความแปรปรวนแบบไม่อิงพารามิเตอร์ แม้ว่าจะด้อยกว่าการวิเคราะห์ความแปรปรวนแบบดั้งเดิมอย่างมีนัยสำคัญ
ในการประเมินการพึ่งพาอาศัยกันหรือเพื่อให้ค่อนข้างโอ้อวดระดับความหนาแน่นของการเชื่อมต่อคำนวณค่าสัมประสิทธิ์สหสัมพันธ์แบบเพียร์สัน กล่าวโดยเคร่งครัด แอปพลิเคชันมีข้อจำกัดที่เกี่ยวข้อง เช่น ประเภทของมาตราส่วนที่มีการวัดข้อมูลและความไม่เป็นเชิงเส้นของการพึ่งพาอาศัยกัน ดังนั้น ค่าสัมประสิทธิ์สหสัมพันธ์จึงถูกนำมาใช้แทน ใช้ตัวอย่างเช่นสำหรับข้อมูลที่จัดอันดับ หากข้อมูลถูกวัดในระดับเล็กน้อย เป็นเรื่องปกติที่จะนำเสนอในตารางฉุกเฉินที่ใช้การทดสอบไคสแควร์ของ Pearson พร้อมรูปแบบและการแก้ไขที่หลากหลายเพื่อความแม่นยำ
โดยพื้นฐานแล้ว มีเกณฑ์และขั้นตอนเพียงไม่กี่ประเภทที่คุณต้องรู้และใช้งานได้ ทั้งนี้ขึ้นอยู่กับเฉพาะของข้อมูล คุณต้องพิจารณาว่าควรใช้เกณฑ์ใดในสถานการณ์เฉพาะ
วิธีการที่ไม่ใช่พารามิเตอร์จะเหมาะสมที่สุดเมื่อขนาดตัวอย่างมีขนาดเล็ก หากมีข้อมูลจำนวนมาก (เช่น n> 100) การใช้สถิติที่ไม่ใช่พารามิเตอร์มักไม่สมเหตุสมผล
หากขนาดตัวอย่างมีขนาดเล็กมาก (เช่น n = 10 หรือน้อยกว่า) ระดับนัยสำคัญของการทดสอบแบบไม่อิงพารามิเตอร์ที่ใช้การประมาณปกติจะถือเป็นการประมาณคร่าวๆ เท่านั้น
ความแตกต่างระหว่างกลุ่มอิสระ... หากมีตัวอย่างสองตัวอย่าง (เช่น ชายและหญิง) ที่ต้องเปรียบเทียบโดยเทียบกับค่าเฉลี่ยบางอย่าง เช่น ความดันเฉลี่ยหรือจำนวนเม็ดเลือดขาวในเลือด การทดสอบ t ก็สามารถใช้แยกกัน ตัวอย่าง
ทางเลือกที่ไม่ใช่พารามิเตอร์สำหรับการทดสอบนี้คือการทดสอบ Val'd-Wolfowitz, Mann-Whitney series) / n โดยที่ x i - ค่าที่ i, n คือจำนวนการสังเกต หากตัวแปรมีค่าลบหรือศูนย์ (0) จะไม่สามารถคำนวณค่าเฉลี่ยทางเรขาคณิตได้
ค่าเฉลี่ยฮาร์มอนิก
ค่าเฉลี่ยฮาร์มอนิกบางครั้งใช้กับความถี่เฉลี่ย ค่าเฉลี่ยฮาร์มอนิกคำนวณโดยสูตร: ГС = n / S (1 / x i) โดยที่ ГС คือค่าเฉลี่ยฮาร์มอนิก n คือจำนวนการสังเกต х i คือค่าของการสังเกตด้วยจำนวน i หากตัวแปรมีค่าเป็นศูนย์ (0) จะไม่สามารถคำนวณค่าเฉลี่ยฮาร์มอนิกได้
การกระจายตัวและส่วนเบี่ยงเบนมาตรฐาน
ความแปรปรวนตัวอย่างและค่าเบี่ยงเบนมาตรฐานเป็นการวัดความแปรปรวน (ความแปรปรวน) ของข้อมูลที่ใช้บ่อยที่สุด ความแปรปรวนคำนวณเป็นผลรวมของกำลังสองของการเบี่ยงเบนของค่าของตัวแปรจากค่าเฉลี่ยตัวอย่าง หารด้วย n-1 (แต่ไม่ใช่ n) ค่าเบี่ยงเบนมาตรฐานคำนวณเป็นรากที่สองของการประมาณค่าความแปรปรวน
แกว่ง
ช่วงของตัวแปรเป็นตัวบ่งชี้ความผันผวน โดยคำนวณเป็นค่าสูงสุดลบค่าต่ำสุด
ขอบเขตควอร์ไทล์
ตามคำนิยาม ช่วงรายไตรมาสคือ: ควอไทล์บนลบควอไทล์ล่าง (เปอร์เซ็นต์ไทล์ 75% ลบเปอร์เซ็นต์ไทล์ 25%) เนื่องจากเปอร์เซ็นไทล์ 75% (ควอร์ไทล์บน) เป็นค่าทางด้านซ้ายซึ่งมีเคสอยู่ 75% และเปอร์เซ็นไทล์ 25% (ควอร์ไทล์ล่าง) เป็นค่าทางด้านซ้ายของซึ่ง 25% ของเคสตั้งอยู่ ควอร์ไทล์ range คือช่วงรอบค่ามัธยฐาน ซึ่งประกอบด้วย 50% ของกรณี (ค่าตัวแปร)
ไม่สมมาตร
ความไม่สมมาตรเป็นลักษณะของรูปร่างของการแจกแจง การกระจายจะเบ้ไปทางซ้ายหากค่าความเบ้เป็นลบ การกระจายจะเบ้ไปทางขวาหากความไม่สมมาตรเป็นค่าบวก ความเบ้ของการแจกแจงแบบปกติมาตรฐานคือ 0 ความเบ้เกี่ยวข้องกับช่วงเวลาที่สามและถูกกำหนดเป็น: ความเบ้ = n × M 3 / [(n-1) × (n-2) × s 3] โดยที่ M 3 คือ: (xi -x ค่าเฉลี่ย x) 3, s 3 คือค่าเบี่ยงเบนมาตรฐานที่ยกกำลังสาม n คือจำนวนการสังเกต
ส่วนเกิน
Kurtosis เป็นลักษณะของรูปร่างของการแจกแจง กล่าวคือ การวัดความรุนแรงของจุดสูงสุด (เทียบกับการกระจายแบบปกติ ความโด่งเท่ากับ 0) ตามกฎแล้ว การแจกแจงที่มีจุดสูงสุดที่คมชัดกว่าปกติจะมีความโด่งเป็นบวก การแจกแจงที่มีจุดสูงสุดน้อยกว่าจุดพีคของการแจกแจงแบบปกติจะมีความโด่งเป็นลบ ส่วนเกินนั้นสัมพันธ์กับช่วงเวลาที่สี่และถูกกำหนดโดยสูตร:
ความโด่ง = / [(n-1) × (n-2) × (n-3) × s 4] โดยที่ M j คือ: (xx ค่าเฉลี่ย x, s 4 คือค่าเบี่ยงเบนมาตรฐานของยกกำลังสี่ n คือ จำนวนการสังเกต ...
ทฤษฎีสั้น
ค่าสัมประสิทธิ์สหสัมพันธ์ของเคนดัลล์ถูกใช้เมื่อตัวแปรถูกแทนด้วยสเกลลำดับสองขั้น โดยจะต้องไม่มีอันดับที่เกี่ยวข้องกัน การคำนวณค่าสัมประสิทธิ์ของเคนดัลล์เกี่ยวข้องกับการนับจำนวนการแข่งขันและการผกผัน
ค่าสัมประสิทธิ์นี้จะแตกต่างกันไปและคำนวณโดยสูตร:
สำหรับการคำนวณ หน่วยทั้งหมดจะถูกจัดลำดับตามแอตทริบิวต์ ตามเกณฑ์อื่น ๆ จำนวนอันดับที่ตามมาเกินหนึ่งที่กำหนด (เราแสดงโดย) และจำนวนอันดับที่ตามมาซึ่งต่ำกว่าอันดับที่กำหนด (เราแสดงโดย) สำหรับแต่ละอันดับ
แสดงว่า
และค่าสัมประสิทธิ์สหสัมพันธ์อันดับของ Kendall สามารถเขียนเป็น
เพื่อทดสอบสมมติฐานว่างที่ระดับนัยสำคัญว่าสัมประสิทธิ์สหสัมพันธ์อันดับทั่วไปของเคนดัลล์เท่ากับศูนย์ภายใต้สมมติฐานที่แข่งขันกัน จำเป็นต้องคำนวณจุดวิกฤต:
ขนาดตัวอย่างอยู่ที่ไหน เป็นจุดวิกฤตของภาควิกฤตสองด้าน ซึ่งหาได้จากตารางฟังก์ชันลาปลาซโดยความเท่าเทียมกัน
ถ้า - ไม่มีเหตุผลที่จะปฏิเสธสมมติฐานว่าง ความสัมพันธ์ของอันดับระหว่างคุณสมบัตินั้นไม่มีนัยสำคัญ
ถ้า - สมมติฐานว่างถูกปฏิเสธ มีความสัมพันธ์อันดับที่มีนัยสำคัญระหว่างคุณลักษณะ
ตัวอย่างการแก้ปัญหา
งาน
ในการสรรหาผู้สมัครเจ็ดตำแหน่งสำหรับตำแหน่งว่าง มีการทดสอบสองครั้ง ผลการทดสอบ (เป็นคะแนน) แสดงในตาราง:
| ทดสอบ | ผู้สมัคร | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 1 | 31 | 82 | 25 | 26 | 53 | 30 | 29 | 2 | 21 | 55 | 8 | 27 | 32 | 42 | 26 |
คำนวณค่าสัมประสิทธิ์สหสัมพันธ์อันดับของ Kendall ระหว่างผลการทดสอบสำหรับการทดสอบสองครั้ง และประเมินความสำคัญที่ระดับ
ทางออกของปัญหา
คำนวณสัมประสิทธิ์ของเคนดัลล์
อันดับของแอตทริบิวต์ของปัจจัยถูกจัดเรียงอย่างเข้มงวดโดยเรียงลำดับจากน้อยไปมาก และอันดับที่สอดคล้องกันของแอตทริบิวต์ที่มีประสิทธิภาพจะถูกบันทึกแบบคู่ขนานกัน สำหรับแต่ละอันดับจากอันดับที่ตามมา จำนวนอันดับที่สูงกว่าจะถูกคำนวณ (ป้อนในคอลัมน์) และจำนวนอันดับที่ต่ำกว่า (ป้อนในคอลัมน์)
| 1 | 1 | 6 | 0 | 2 | 4 | 3 | 2 | 3 | 3 | 3 | 1 | 4 | 6 | 1 | 2 | 5 | 2 | 2 | 0 | 6 | 5 | 1 | 0 | 7 | 7 | 0 | 0 | ซำ | 16 | 5 |
ในการคำนวณค่าสัมประสิทธิ์สหสัมพันธ์อันดับของ Kendall r kจำเป็นต้องจัดลำดับข้อมูลสำหรับแอตทริบิวต์ใดคุณลักษณะหนึ่งตามลำดับจากน้อยไปมาก และกำหนดอันดับที่สอดคล้องกันสำหรับแอตทริบิวต์ที่สอง จากนั้น สำหรับแต่ละอันดับของจุดสนใจที่สอง จะกำหนดจำนวนอันดับที่ตามมาซึ่งมีขนาดมากกว่าอันดับที่ได้รับ และหาผลรวมของตัวเลขเหล่านี้
ค่าสัมประสิทธิ์สหสัมพันธ์อันดับของ Kendall ถูกกำหนดโดยสูตร
ที่ไหน อาร์ ไอ- จำนวนอันดับของตัวแปรที่สอง เริ่มจาก ผม+1 ขนาดที่มากกว่าขนาด ผมอันดับของตัวแปรนี้
มีตารางจุดเปอร์เซ็นต์ของการแจกแจงสัมประสิทธิ์ r kซึ่งช่วยให้ทดสอบสมมติฐานเกี่ยวกับความสำคัญของสัมประสิทธิ์สหสัมพันธ์
 สำหรับตัวอย่างขนาดใหญ่ ค่าวิกฤต r kไม่ได้จัดทำเป็นตาราง และจะต้องคำนวณโดยใช้สูตรโดยประมาณ ซึ่งอิงตามข้อเท็จจริงที่ว่าภายใต้สมมติฐานว่าง H 0: r k= 0 และใหญ่ น ค่าสุ่ม
สำหรับตัวอย่างขนาดใหญ่ ค่าวิกฤต r kไม่ได้จัดทำเป็นตาราง และจะต้องคำนวณโดยใช้สูตรโดยประมาณ ซึ่งอิงตามข้อเท็จจริงที่ว่าภายใต้สมมติฐานว่าง H 0: r k= 0 และใหญ่ น ค่าสุ่ม
กระจายประมาณตามกฎปกติมาตรฐาน
40. ความสัมพันธ์ระหว่างลักษณะที่วัดในมาตราส่วนเล็กน้อยหรือลำดับ
ปัญหามักเกิดขึ้นจากการตรวจสอบความเป็นอิสระของคุณลักษณะสองประการที่วัดในระดับเล็กน้อยหรือลำดับขั้น
ให้วัตถุบางอย่างวัดคุณสมบัติสองอย่าง Xและ Yด้วยจำนวนระดับ rและ สตามลำดับ ผลลัพธ์ของการสังเกตดังกล่าวถูกนำเสนออย่างสะดวกในรูปแบบของตาราง เรียกว่าตารางฉุกเฉิน
ในตาราง คุณ ฉัน(ผม = 1, ..., r) และ วี j (เจ= 1, ..., ส) - ค่าที่ใช้โดยคุณสมบัติ, ค่า น อิจ- จำนวนวัตถุจากจำนวนวัตถุทั้งหมดที่แอตทริบิวต์ Xรับความหมาย คุณ ฉันและเครื่องหมาย Y- ความหมาย วี j

 เราแนะนำตัวแปรสุ่มต่อไปนี้:
เราแนะนำตัวแปรสุ่มต่อไปนี้:
คุณ ฉัน

- จำนวนวัตถุที่มีค่า วี j

นอกจากนี้ยังมีความเท่าเทียมกันที่ชัดเจน



ตัวแปรสุ่มแบบไม่ต่อเนื่อง Xและ Yเป็นอิสระก็ต่อเมื่อ
สำหรับคู่รักทุกคู่ ผม, เจ
ดังนั้น การคาดเดาเกี่ยวกับความเป็นอิสระของตัวแปรสุ่มแบบไม่ต่อเนื่อง Xและ Yสามารถเขียนได้ดังนี้
ในทางกลับกัน ตามกฎแล้ว พวกเขาใช้สมมติฐาน
 ความถูกต้องของสมมติฐาน H 0 ควรตัดสินโดยพิจารณาจากความถี่ตัวอย่าง น อิจตารางฉุกเฉิน ตามกฎหมายจำนวนมากที่ น→ ∞ ความถี่สัมพัทธ์ใกล้เคียงกับความน่าจะเป็นที่สอดคล้องกัน:
ความถูกต้องของสมมติฐาน H 0 ควรตัดสินโดยพิจารณาจากความถี่ตัวอย่าง น อิจตารางฉุกเฉิน ตามกฎหมายจำนวนมากที่ น→ ∞ ความถี่สัมพัทธ์ใกล้เคียงกับความน่าจะเป็นที่สอดคล้องกัน:



เพื่อทดสอบสมมติฐาน H 0 ใช้สถิติ
ซึ่งถ้าสมมุติฐานเป็นจริงก็มีการกระจายตัว χ 2 วินาที rs − (r + ส- 1) องศาของเสรีภาพ
เกณฑ์ความเป็นอิสระ χ 2 ปฏิเสธสมมติฐาน H 0 ที่มีระดับนัยสำคัญ α ถ้า:

41. การวิเคราะห์การถดถอย แนวคิดพื้นฐานของการวิเคราะห์การถดถอย
สำหรับคำอธิบายทางคณิตศาสตร์ของความสัมพันธ์ทางสถิติระหว่างตัวแปรที่ศึกษา ปัญหาต่อไปนี้ควรได้รับการแก้ไข:
ü เลือกคลาสของฟังก์ชันที่แนะนำให้หาสิ่งที่ดีที่สุด (ในแง่หนึ่ง) การประมาณการพึ่งพาความสนใจ
ü ค้นหาค่าประมาณของค่าที่ไม่รู้จักของพารามิเตอร์ที่รวมอยู่ในสมการของการพึ่งพาที่จำเป็น
ü เพื่อสร้างความเพียงพอของสมการที่ได้รับของการพึ่งพาอาศัยที่ต้องการ
ü เพื่อระบุตัวแปรอินพุตที่ให้ข้อมูลมากที่สุด
จำนวนทั้งหมดของงานที่ระบุไว้เป็นเรื่องของการวิจัยในการวิเคราะห์การถดถอย
ฟังก์ชันการถดถอย (หรือการถดถอย) คือการพึ่งพาการคาดหมายทางคณิตศาสตร์ของตัวแปรสุ่มตัวหนึ่งกับค่าที่ตัวแปรสุ่มอีกตัวหนึ่งนำมาซึ่งสร้างระบบสองมิติของตัวแปรสุ่มกับตัวแปรแรก
ให้มีระบบตัวแปรสุ่ม ( X,Y) จากนั้นฟังก์ชันการถดถอย Yบน X
และฟังก์ชันถดถอย Xบน Y
ฟังก์ชันการถดถอย ฉ(x) และ φ (y) ไม่สามารถย้อนกลับกันได้หากมีเพียงความสัมพันธ์ระหว่าง Xและ Yไม่ทำงาน
เมื่อไหร่ น-เวกเตอร์มิติพร้อมพิกัด X 1 , X 2 ,…, X นู๋คุณสามารถพิจารณาการคาดหมายทางคณิตศาสตร์แบบมีเงื่อนไขสำหรับองค์ประกอบใดๆ ตัวอย่างเช่น สำหรับ X 1

เรียกว่า ถดถอย X 1 วัน X 2 ,…, X นู๋.
สำหรับคำจำกัดความที่สมบูรณ์ของฟังก์ชันการถดถอย จำเป็นต้องทราบการกระจายแบบมีเงื่อนไขของตัวแปรเอาต์พุตสำหรับค่าคงที่ของตัวแปรอินพุต
เนื่องจากในสถานการณ์จริงไม่มีข้อมูลดังกล่าว จึงมักถูกจำกัดให้ค้นหาฟังก์ชันการประมาณที่เหมาะสมเท่านั้น ฉ(x) สำหรับ ฉ(x) ตามข้อมูลสถิติของแบบฟอร์ม ( x ฉัน, ฉัน), ผม = 1,…, น... ข้อมูลนี้เป็นผลลัพธ์ นการสังเกตอย่างอิสระ y 1 ,…, y nตัวแปรสุ่ม Yสำหรับค่าของตัวแปรอินพุต x 1 ,…, x นในขณะที่การวิเคราะห์การถดถอยถือว่าค่าของตัวแปรอินพุตถูกระบุอย่างถูกต้อง
ปัญหาของการเลือกฟังก์ชันการประมาณที่ดีที่สุด ฉ(x) เป็นหลักในการวิเคราะห์การถดถอย และไม่มีขั้นตอนที่เป็นทางการสำหรับการแก้ปัญหา บางครั้ง ทางเลือกจะถูกกำหนดโดยการวิเคราะห์ข้อมูลการทดลอง บ่อยครั้งขึ้นจากการพิจารณาทางทฤษฎี
หากถือว่าฟังก์ชันการถดถอยมีความราบรื่นเพียงพอ แสดงว่าฟังก์ชันการประมาณ ฉ(x) สามารถแสดงเป็นชุดค่าผสมเชิงเส้นของชุดฟังก์ชันพื้นฐานอิสระเชิงเส้นได้ ψ k(x), k = 0, 1,…, ม-1 กล่าวคือ ในรูปแบบ

ที่ไหน ม- จำนวนพารามิเตอร์ที่ไม่รู้จัก θ k(ในกรณีทั่วไป ไม่ทราบค่า ปรับปรุงระหว่างการสร้างแบบจำลอง)
ฟังก์ชันดังกล่าวเป็นพารามิเตอร์เชิงเส้น ดังนั้น ในกรณีที่อยู่ระหว่างการพิจารณา เราพูดถึงโมเดลฟังก์ชันการถดถอยที่เป็นพารามิเตอร์เชิงเส้น
แล้วปัญหาการหาค่าประมาณที่ดีที่สุดสำหรับเส้นถดถอย ฉ(x) ลดลงเพื่อค้นหาค่าพารามิเตอร์ดังกล่าวซึ่ง ฉ(x; θ) เพียงพอที่สุดสำหรับข้อมูลที่มีอยู่ วิธีหนึ่งในการแก้ปัญหานี้คือวิธีกำลังสองน้อยที่สุด
42. วิธีกำลังสองน้อยที่สุด
ให้เซตของคะแนน ( x ฉัน, ฉัน), ผม= 1,…, นอยู่บนเครื่องบินตามแนวเส้นตรงบางเส้น
 จากนั้นเป็นหน้าที่ ฉ(x) การประมาณฟังก์ชันการถดถอย ฉ(x) = เอ็ม [Y|x] เป็นเรื่องปกติที่จะรับ ฟังก์ชันเชิงเส้นการโต้เถียง x:
จากนั้นเป็นหน้าที่ ฉ(x) การประมาณฟังก์ชันการถดถอย ฉ(x) = เอ็ม [Y|x] เป็นเรื่องปกติที่จะรับ ฟังก์ชันเชิงเส้นการโต้เถียง x:

นั่นคือเลือกฟังก์ชั่นพื้นฐานที่นี่ ψ 0 (x) ≡1 และ ψ 1 (x)≡x... การถดถอยนี้เรียกว่าการถดถอยเชิงเส้นอย่างง่าย
ถ้าเซตของคะแนน ( x ฉัน, ฉัน), ผม= 1,…, นอยู่ตามโค้งบาง ๆ แล้ว as ฉ(x) เป็นธรรมดาที่จะลองเลือกตระกูลพาราโบลา


ฟังก์ชันนี้ไม่เป็นเชิงเส้นในพารามิเตอร์ θ 0 และ θ 1 อย่างไรก็ตาม โดยการแปลงฟังก์ชัน (ในกรณีนี้ ลอการิทึม) สามารถลดลงเป็น ฟังก์ชั่นใหม่ ฉ'a(x) พารามิเตอร์เชิงเส้น:
43. การถดถอยเชิงเส้นอย่างง่าย
แบบจำลองการถดถอยที่ง่ายที่สุดคือแบบง่าย (หนึ่งมิติ ทางเดียว จับคู่) แบบจำลองเชิงเส้นซึ่งมีรูปแบบดังนี้


ที่ไหน ε ฉัน- ตัวแปรสุ่ม (ข้อผิดพลาด) ไม่สัมพันธ์กัน ไม่มีความคาดหวังทางคณิตศาสตร์และความแปรปรวนเท่ากัน σ 2 , เอและ ข- ค่าสัมประสิทธิ์คงที่ (พารามิเตอร์) ที่ต้องประมาณจากค่าการตอบสนองที่วัดได้ ฉัน.
เพื่อหาค่าประมาณพารามิเตอร์ เอและ ขการถดถอยเชิงเส้น กำหนดเส้นตรงที่ตรงกับข้อมูลการทดลองมากที่สุด:

ใช้วิธีการกำลังสองน้อยที่สุด
 ตาม สี่เหลี่ยมน้อยที่สุด
การประมาณค่าพารามิเตอร์ เอและ ขหาได้จากเงื่อนไขการลดผลรวมกำลังสองของค่าเบี่ยงเบนของค่าต่างๆ ฉันในแนวตั้งจากเส้นถดถอย "จริง":
ตาม สี่เหลี่ยมน้อยที่สุด
การประมาณค่าพารามิเตอร์ เอและ ขหาได้จากเงื่อนไขการลดผลรวมกำลังสองของค่าเบี่ยงเบนของค่าต่างๆ ฉันในแนวตั้งจากเส้นถดถอย "จริง":
ให้มีการสังเกตตัวแปรสุ่มสิบครั้ง Yด้วยค่าคงที่ของตัวแปร X


เพื่อลดขนาด ดีเราเท่ากับศูนย์อนุพันธ์ย่อยในส่วนที่เกี่ยวกับ เอและ ข:


ดังนั้นเราจึงได้ระบบสมการในการหาค่าประมาณดังต่อไปนี้ เอและ ข:


การแก้สมการทั้งสองนี้จะให้:


นิพจน์สำหรับการประมาณค่าพารามิเตอร์ เอและ ขยังสามารถแสดงเป็น:


แล้วสมการเชิงประจักษ์ของเส้นถดถอย Yบน Xสามารถเขียนเป็น:

 ค่าประมาณความแปรปรวนที่ไม่เอนเอียง σ
2 ความเบี่ยงเบนของค่า ฉันจากเส้นตรงติดของการถดถอยถูกกำหนดโดยนิพจน์
ค่าประมาณความแปรปรวนที่ไม่เอนเอียง σ
2 ความเบี่ยงเบนของค่า ฉันจากเส้นตรงติดของการถดถอยถูกกำหนดโดยนิพจน์
มาคำนวณค่าพารามิเตอร์ของสมการถดถอยกัน



ดังนั้น เส้นการถดถอยมีลักษณะดังนี้:

และการประมาณค่าความแปรปรวนส่วนเบี่ยงเบนของค่า ฉันจากเส้นตรงติดของการถดถอย

44. การตรวจสอบความสำคัญของเส้นถดถอย
พบค่าประมาณ ข≠ 0 สามารถทำให้เป็นจริงของตัวแปรสุ่มได้ ความคาดหวังทางคณิตศาสตร์ที่เป็นศูนย์ นั่นคือ ปรากฎว่าไม่มีการพึ่งพาการถดถอยจริงๆ
เพื่อจัดการกับสถานการณ์นี้ คุณควรทดสอบสมมติฐาน H 0: ข= 0 ด้วยสมมติฐานที่แข่งขันกัน H 1: ข ≠ 0.
การทดสอบความสำคัญของเส้นการถดถอยสามารถทำได้โดยใช้การวิเคราะห์ความแปรปรวน
พิจารณาเอกลักษณ์ต่อไปนี้:
ขนาด ฉัน− ŷ ฉัน = ε ฉันเรียกว่า ส่วนที่เหลือ และเป็นความแตกต่างระหว่างปริมาณสองปริมาณ:
ü การเบี่ยงเบนของค่าที่สังเกตได้ (การตอบสนอง) จากการตอบสนองเฉลี่ยทั้งหมด
ü การเบี่ยงเบนของค่าการตอบสนองที่คาดการณ์ไว้ ŷ ฉันจากค่าเฉลี่ยเดียวกัน

อัตลักษณ์ที่เป็นลายลักษณ์อักษรสามารถเขียนได้เป็น
เมื่อยกกำลังสองส่วนแล้วสรุปยอด ผม, เราได้รับ:

 ที่มีชื่อปริมาณ:
ที่มีชื่อปริมาณ:
ผลรวมของกำลังสองของ SC n ซึ่งเท่ากับผลรวมของกำลังสองของการเบี่ยงเบนของการสังเกตที่สัมพันธ์กับค่าเฉลี่ยของการสังเกต

ผลรวมของกำลังสองเนื่องจากการถดถอยของ SK p ซึ่งเท่ากับผลรวมของกำลังสองของการเบี่ยงเบนของค่าเส้นการถดถอยที่สัมพันธ์กับค่าเฉลี่ยของการสังเกต
 ผลรวมของกำลังสอง SK 0 ซึ่งเท่ากับผลรวมของกำลังสองของส่วนเบี่ยงเบนของการสังเกตที่สัมพันธ์กับค่าของเส้นถดถอย
ผลรวมของกำลังสอง SK 0 ซึ่งเท่ากับผลรวมของกำลังสองของส่วนเบี่ยงเบนของการสังเกตที่สัมพันธ์กับค่าของเส้นถดถอย
ดังนั้นการแพร่กระจาย Y-kov ที่สัมพันธ์กับค่าเฉลี่ยสามารถนำมาประกอบกับข้อเท็จจริงที่ว่าการสังเกตทั้งหมดไม่ได้อยู่บนเส้นการถดถอย หากเป็นกรณีนี้ ผลรวมของกำลังสองที่สัมพันธ์กับการถดถอยจะเป็นศูนย์ ตามมาว่าการถดถอยจะมีนัยสำคัญหากผลรวมของกำลังสองของ SC p มากกว่าผลรวมของกำลังสองของ SC 0
การคำนวณการทดสอบนัยสำคัญการถดถอยจะดำเนินการในตาราง ANOVA ต่อไปนี้

หากผิดพลาด ε ฉันกระจายตามกฎปกติแล้วถ้าสมมติฐาน H 0 ถูกต้อง: ข= 0 สถิติ:

เผยแพร่ตามกฎหมายของฟิชเชอร์ด้วยจำนวนองศาอิสระ 1 และ น−2.
สมมติฐานว่างจะถูกปฏิเสธที่ระดับนัยสำคัญ α ถ้าค่าสถิติที่คำนวณได้ Fจะมากกว่าจุดเปอร์เซ็นต์ α ฉ 1;น-2; α ของการกระจายฟิชเชอร์
45. การตรวจสอบความเพียงพอของแบบจำลองการถดถอย วิธีตกค้าง
ความเพียงพอของแบบจำลองการถดถอยที่สร้างขึ้นนั้นเป็นที่เข้าใจกันว่าไม่มีแบบจำลองอื่นใดให้การปรับปรุงอย่างมีนัยสำคัญในการทำนายการตอบสนอง
หากได้ค่าของการตอบสนองทั้งหมดที่มีค่าต่างกัน xนั่นคือไม่มีค่าการตอบสนองหลายอย่างที่ได้รับเหมือนกัน x ฉันจากนั้นจะทำการทดสอบความเพียงพอของตัวแบบเชิงเส้นอย่างจำกัดเท่านั้น พื้นฐานสำหรับเช็คดังกล่าวคือของเหลือ:


ความเบี่ยงเบนจากรูปแบบที่กำหนดไว้:
ตราบเท่าที่ X- ตัวแปรหนึ่งมิติ จุด ( x ฉัน, ฉัน) สามารถพล็อตบนระนาบในรูปแบบของพล็อตที่เหลือที่เรียกว่า การเป็นตัวแทนดังกล่าวบางครั้งทำให้สามารถค้นหาความสม่ำเสมอในพฤติกรรมของสิ่งตกค้าง นอกจากนี้ การวิเคราะห์ส่วนที่เหลือยังช่วยให้คุณวิเคราะห์สมมติฐานเกี่ยวกับการกระจายข้อผิดพลาดได้


ในกรณีที่มีการกระจายข้อผิดพลาดตามกฎปกติและมีค่าประมาณการล่วงหน้าของความแปรปรวน σ 2 (ค่าประมาณที่ได้รับจากการวัดที่ดำเนินการก่อนหน้านี้) จากนั้นจึงทำการประเมินความเพียงพอของแบบจำลองได้แม่นยำยิ่งขึ้น
ทาง F-เกณฑ์ของฟิชเชอร์ใช้ตรวจสอบว่าความแปรปรวนที่เหลือมีนัยสำคัญหรือไม่ ส 0 2 แตกต่างจากการประมาณการเบื้องต้น หากมากกว่านั้นมาก แสดงว่ามีความไม่เพียงพอและควรแก้ไขแบบจำลอง
ถ้าประมาณการล่วงหน้า σ 2 ไม่ใช่ แต่การวัดการตอบสนอง Yทำซ้ำสองครั้งขึ้นไปด้วยค่าเดียวกัน Xจากนั้นการสังเกตซ้ำเหล่านี้สามารถใช้เพื่อรับค่าประมาณอื่นได้ σ 2 (อันแรกคือค่าความแปรปรวนคงเหลือ) การประมาณการดังกล่าวถือเป็นข้อผิดพลาดที่ “บริสุทธิ์” เนื่องจาก if xเหมือนกันสำหรับการสังเกตสองครั้งขึ้นไป จากนั้นเฉพาะการเปลี่ยนแปลงแบบสุ่มเท่านั้นที่สามารถส่งผลต่อผลลัพธ์และสร้างการกระจายระหว่างกัน
ค่าประมาณที่ได้จะกลายเป็นค่าประมาณความแปรปรวนที่เชื่อถือได้มากกว่าค่าประมาณที่ได้จากวิธีอื่น ด้วยเหตุนี้ เมื่อวางแผนการทดลอง คุณควรตั้งค่าการทดลองซ้ำๆ
 สมมติว่าเรามี มความหมายต่างกัน X : x 1 , x 2 , ..., x ม... ให้สำหรับแต่ละค่าเหล่านี้ x ฉันมี ฉันการสังเกตการตอบสนอง Y... ได้รับการสังเกตทั้งหมด:
สมมติว่าเรามี มความหมายต่างกัน X : x 1 , x 2 , ..., x ม... ให้สำหรับแต่ละค่าเหล่านี้ x ฉันมี ฉันการสังเกตการตอบสนอง Y... ได้รับการสังเกตทั้งหมด:
จากนั้นตัวแบบการถดถอยเชิงเส้นอย่างง่ายสามารถเขียนได้ดังนี้:





 มาหาความแปรปรวนของข้อผิดพลาด "บริสุทธิ์" ความแปรปรวนนี้เป็นค่าประมาณรวมของความแปรปรวน σ
2 ถ้าเราแทนค่าของการตอบสนอง y ijที่ x = x ฉันเป็นปริมาตรตัวอย่าง ฉัน... ด้วยเหตุนี้ ความแปรปรวนของข้อผิดพลาด "บริสุทธิ์" คือ:
มาหาความแปรปรวนของข้อผิดพลาด "บริสุทธิ์" ความแปรปรวนนี้เป็นค่าประมาณรวมของความแปรปรวน σ
2 ถ้าเราแทนค่าของการตอบสนอง y ijที่ x = x ฉันเป็นปริมาตรตัวอย่าง ฉัน... ด้วยเหตุนี้ ความแปรปรวนของข้อผิดพลาด "บริสุทธิ์" คือ:
ความแปรปรวนนี้ทำหน้าที่เป็นค่าประมาณ σ 2 ไม่ว่ารุ่นที่ติดตั้งจะถูกต้องหรือไม่
ให้เราแสดงให้เห็นว่าผลรวมของกำลังสองของ "ข้อผิดพลาดล้วนๆ" เป็นส่วนหนึ่งของผลรวมของกำลังสองที่เหลือ (ผลรวมของกำลังสองที่รวมอยู่ในนิพจน์สำหรับความแปรปรวนที่เหลือ) เหลือสำหรับ เจการสังเกตที่ x ฉันสามารถเขียนเป็น:
ถ้าคุณยกกำลังสองข้างของความเสมอภาคนี้แล้วรวมมันเข้าด้วยกัน เจและโดย ผม, เราได้รับ:
ทางด้านซ้ายของความเท่าเทียมกันนี้คือผลรวมของกำลังสองที่เหลือ เทอมแรกทางด้านขวาคือผลรวมของกำลังสองของข้อผิดพลาด "บริสุทธิ์" เทอมที่สองสามารถเรียกได้ว่าเป็นผลรวมของกำลังสองของความไม่เพียงพอ จำนวนเงินสุดท้ายมี ม−2 องศาอิสระ ดังนั้น ความแปรปรวนของความไม่เพียงพอ

 สถิติของเกณฑ์การทดสอบสมมติฐาน H 0: ตัวแบบเชิงเส้นอย่างง่ายเพียงพอ เทียบกับสมมติฐาน H 1: ตัวแบบเชิงเส้นอย่างง่ายไม่เพียงพอ ตัวแปรสุ่มคือ
สถิติของเกณฑ์การทดสอบสมมติฐาน H 0: ตัวแบบเชิงเส้นอย่างง่ายเพียงพอ เทียบกับสมมติฐาน H 1: ตัวแบบเชิงเส้นอย่างง่ายไม่เพียงพอ ตัวแปรสุ่มคือ
หากสมมติฐานว่างเป็นจริง ค่า Fมีการแจกแจงแบบฟิชเชอร์ด้วยองศาอิสระ ม-2 และ น−ม... สมมติฐานความเป็นเส้นตรงของเส้นการถดถอยควรถูกปฏิเสธด้วยระดับนัยสำคัญ α หากค่าที่ได้รับของสถิติมากกว่าจุดเปอร์เซ็นต์ α ของการแจกแจงแบบฟิชเชอร์ด้วยจำนวนองศาอิสระ ม-2 และ น−ม.
46. การตรวจสอบความเพียงพอของแบบจำลองการถดถอย (ดู 45) ANOVA
47. การตรวจสอบความเพียงพอของแบบจำลองการถดถอย (ดู 45) สัมประสิทธิ์ความมุ่งมั่น
 บางครั้ง ในการอธิบายลักษณะคุณภาพของเส้นการถดถอย จะใช้ค่าสัมประสิทธิ์ตัวอย่างของการกำหนด R 2 แสดงว่าส่วนใด (เศษส่วน) ของผลรวมของกำลังสอง เนื่องจากการถดถอย SK p อยู่ในผลรวมของกำลังสองทั้งหมด SK n:
บางครั้ง ในการอธิบายลักษณะคุณภาพของเส้นการถดถอย จะใช้ค่าสัมประสิทธิ์ตัวอย่างของการกำหนด R 2 แสดงว่าส่วนใด (เศษส่วน) ของผลรวมของกำลังสอง เนื่องจากการถดถอย SK p อยู่ในผลรวมของกำลังสองทั้งหมด SK n:
ใกล้ชิด R 2 ต่อ 1 ยิ่งการถดถอยใกล้เคียงกับข้อมูลการทดลองมากเท่าใด การสังเกตก็จะยิ่งอยู่ใกล้เส้นการถดถอยมากขึ้นเท่านั้น ถ้า R 2 = 0 ดังนั้นการเปลี่ยนแปลงในการตอบสนองจะสมบูรณ์เนื่องจากอิทธิพลของปัจจัยที่ไม่ได้นับและเส้นการถดถอยจะขนานกับแกน x-ov. ในกรณีของการถดถอยเชิงเส้นอย่างง่าย สัมประสิทธิ์การกำหนด R 2 เท่ากับกำลังสองของสัมประสิทธิ์สหสัมพันธ์ r 2 .
ค่าสูงสุด R 2 = 1 สามารถทำได้เฉพาะในกรณีที่มีการสังเกตด้วยค่า x-ov ที่แตกต่างกัน หากมีการทดลองซ้ำในข้อมูล ค่าของ R 2 ก็ไม่สามารถเข้าถึงความเป็นเอกภาพได้ ไม่ว่าแบบจำลองจะดีเพียงใด
48. ช่วงความเชื่อมั่นสำหรับพารามิเตอร์การถดถอยเชิงเส้นอย่างง่าย
เฉกเช่นค่าเฉลี่ยตัวอย่างคือค่าประมาณของค่าเฉลี่ยจริง (ค่าเฉลี่ยประชากร) พารามิเตอร์ตัวอย่างของสมการถดถอยก็เช่นกัน เอและ ข- ไม่มีอะไรมากไปกว่าค่าประมาณของสัมประสิทธิ์การถดถอยที่แท้จริง ตัวอย่างที่ต่างกันให้ค่าประมาณของค่าเฉลี่ยต่างกัน - เช่นเดียวกับตัวอย่างที่ต่างกันจะให้ค่าประมาณสัมประสิทธิ์การถดถอยที่ต่างกัน

 สมมติว่ากฎหมายการกระจายข้อผิดพลาด ε ฉันอธิบายโดยกฎปกติ การประมาณค่าพารามิเตอร์ ขจะมีการแจกแจงแบบปกติพร้อมพารามิเตอร์:
สมมติว่ากฎหมายการกระจายข้อผิดพลาด ε ฉันอธิบายโดยกฎปกติ การประมาณค่าพารามิเตอร์ ขจะมีการแจกแจงแบบปกติพร้อมพารามิเตอร์:

 เนื่องจากค่าประมาณพารามิเตอร์ เอคือผลรวมเชิงเส้นของปริมาณแบบกระจายปกติอิสระ มันจะมีการแจกแจงแบบปกติที่มีค่าเฉลี่ยและความแปรปรวนด้วย:
เนื่องจากค่าประมาณพารามิเตอร์ เอคือผลรวมเชิงเส้นของปริมาณแบบกระจายปกติอิสระ มันจะมีการแจกแจงแบบปกติที่มีค่าเฉลี่ยและความแปรปรวนด้วย:


ในกรณีนี้ ช่วงความเชื่อมั่น (1 - α) สำหรับการประมาณค่าความแปรปรวน σ 2 โดยคำนึงถึงอัตราส่วน ( น−2)ส 0 2 /σ 2 จัดจำหน่ายโดยกฎหมาย χ 2 กับจำนวนองศาอิสระ น-2 จะถูกกำหนดโดยนิพจน์

49. ช่วงความเชื่อมั่นสำหรับเส้นการถดถอย ช่วงความเชื่อมั่นสำหรับค่าตัวแปรตาม
เรามักจะไม่ทราบค่าที่แท้จริงของสัมประสิทธิ์การถดถอย เอและ ข... เรารู้แค่การประมาณการของพวกเขาเท่านั้น กล่าวอีกนัยหนึ่ง เส้นถดถอยที่แท้จริงอาจสูงหรือต่ำกว่า ชันหรือตื้นกว่าเส้นที่สร้างขึ้นจากข้อมูลตัวอย่าง เราคำนวณช่วงความเชื่อมั่นสำหรับสัมประสิทธิ์การถดถอย คุณยังสามารถคำนวณขอบเขตความเชื่อมั่นสำหรับเส้นการถดถอยได้อีกด้วย
 ปล่อยให้การถดถอยเชิงเส้นอย่างง่ายจำเป็นต้องสร้าง (1− α
) ช่วงความเชื่อมั่นสำหรับความคาดหวังทางคณิตศาสตร์ของการตอบสนอง Yที่มูลค่า X = X 0. ความคาดหวังทางคณิตศาสตร์นี้คือ เอ+bx 0 และค่าประมาณ
ปล่อยให้การถดถอยเชิงเส้นอย่างง่ายจำเป็นต้องสร้าง (1− α
) ช่วงความเชื่อมั่นสำหรับความคาดหวังทางคณิตศาสตร์ของการตอบสนอง Yที่มูลค่า X = X 0. ความคาดหวังทางคณิตศาสตร์นี้คือ เอ+bx 0 และค่าประมาณ


ตั้งแต่นั้นเป็นต้นมา
 ค่าประมาณการที่คาดหวังทางคณิตศาสตร์ที่ได้รับคือผลรวมเชิงเส้นของค่าการกระจายแบบปกติที่ไม่สัมพันธ์กัน ดังนั้นจึงมีการแจกแจงแบบปกติที่จุดศูนย์กลางของค่าที่แท้จริงของการคาดหมายทางคณิตศาสตร์แบบมีเงื่อนไขและความแปรปรวน
ค่าประมาณการที่คาดหวังทางคณิตศาสตร์ที่ได้รับคือผลรวมเชิงเส้นของค่าการกระจายแบบปกติที่ไม่สัมพันธ์กัน ดังนั้นจึงมีการแจกแจงแบบปกติที่จุดศูนย์กลางของค่าที่แท้จริงของการคาดหมายทางคณิตศาสตร์แบบมีเงื่อนไขและความแปรปรวน
ดังนั้น ช่วงความเชื่อมั่นของเส้นถดถอยที่แต่ละค่า x 0 สามารถแสดงเป็น

อย่างที่คุณเห็น ช่วงความเชื่อมั่นขั้นต่ำจะได้มาที่ x 0 เท่ากับค่าเฉลี่ยและเพิ่มขึ้นเป็น x 0 “เคลื่อนออก” จากตรงกลางไปในทิศทางใดก็ได้
 เพื่อให้ได้ชุดของช่วงความเชื่อมั่นร่วมที่เหมาะสมกับฟังก์ชันการถดถอยทั้งหมดตลอดความยาว ในนิพจน์ข้างต้นแทน t n −2,α
/ 2 จะต้องถูกแทนที่
เพื่อให้ได้ชุดของช่วงความเชื่อมั่นร่วมที่เหมาะสมกับฟังก์ชันการถดถอยทั้งหมดตลอดความยาว ในนิพจน์ข้างต้นแทน t n −2,α
/ 2 จะต้องถูกแทนที่

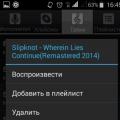 วิธีใส่เมโลดี้ (ริงโทน) ในการโทรสำหรับ ZTE Blade M, L4, V956, v815w ดาวน์โหลดริงโทน zte
วิธีใส่เมโลดี้ (ริงโทน) ในการโทรสำหรับ ZTE Blade M, L4, V956, v815w ดาวน์โหลดริงโทน zte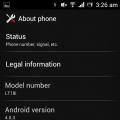 วิธีใส่เมโลดี้ (ริงโทน) ในการโทรสำหรับ ZTE Blade M, L4, V956, v815w Phone zte 320 วิธีตั้งค่าเมโลดี้
วิธีใส่เมโลดี้ (ริงโทน) ในการโทรสำหรับ ZTE Blade M, L4, V956, v815w Phone zte 320 วิธีตั้งค่าเมโลดี้ วิธีฮาร์ดรีเซ็ต LG Optimus L5 และ Android Lji ที่คล้ายกัน
วิธีฮาร์ดรีเซ็ต LG Optimus L5 และ Android Lji ที่คล้ายกัน