Special unicode characters. The problem of distinguishing externally similar numbers and letters.
Every Internet user, trying to configure one or another of its functions, at least once saw the written word "Unicode" on the display. You will find out what it is by reading this article.
Definition
Unicode encoding is a character encoding standard. It was offered by the non-profit organization Unicode Inc. in 1991. The standard is designed to combine as many different types of characters as possible in one document. The page that was created on its basis may contain letters and hieroglyphs from different languages(from Russian to Korean) and mathematical signs... In this case, all characters in this encoding are displayed without problems.
Reasons for creation
Once upon a time, long before unified system"Unicode", the encoding was chosen based on the preferences of the author of the document. For this reason, it is often necessary to use different tables to read one document. Sometimes this had to be done several times, which significantly complicated the life of an ordinary user. As already mentioned, a solution to this problem in 1991 was proposed by the non-profit organization Unicode Inc., which proposed a new type of character encoding. It was intended to combine obsolete and diverse standards. "Unicode" is an encoding that allowed to achieve the unthinkable at that time: to create a tool that supports a huge number of characters. The result surpassed many expectations - documents appeared simultaneously containing both English and Russian text, Latin and mathematical expressions.
But the creation of a single coding was preceded by the need to resolve a number of problems that arose due to the huge variety of standards that already existed at that time. The most common ones are:
- elven letters, or "krakozyabry";
- limited character set;
- the problem of converting encodings;
- duplication of fonts.

A small historical excursion
Imagine that it is the 80s. Computer technology is not yet so widespread and has a different form from today. At that time, each OS is unique in its own way and is modified by each enthusiast for specific needs. The need for information exchange turns into additional refinement of everything in the world. An attempt to read a document created under a different OS often displays an incomprehensible set of characters on the screen, and games with an encoding begin. It is not always possible to do this quickly, and sometimes the necessary document can be opened after six months, or even later. People who exchange information frequently create conversion tables for themselves. And so the work on them reveals an interesting detail: they need to be created in two directions: "from mine to yours" and vice versa. The machine cannot make a banal inversion of calculations, for it in the right column is the source, and in the left - the result, but not vice versa. If there was a need to use any Special symbols in the document, they had to first be added, and then also explained to the partner what he needed to do so that these symbols did not turn into "krakozyabry". And let's not forget that for each encoding, you had to develop or implement your own fonts, which led to the creation of a huge number of duplicates in the OS.
Imagine also that on the page of fonts you will see 10 identical Times New Roman with small annotations: for UTF-8, UTF-16, ANSI, UCS-2. Do you understand now that it was imperative to develop a universal standard?

"Creator Fathers"
The origins of Unicode can be traced back to 1987, when Joe Becker of Xerox, along with Lee Collins and Mark Davis of Apple began research into the practical creation of a universal character set. In August 1988, Joe Becker published a draft proposal for a 16-bit international multilingual coding system.
A few months later, the Unicode WG was expanded to include Ken Whistler and Mike Kernegan of the RLG, Glenn Wright of Sun Microsystems and several others, completing the preliminary work on a common coding standard.

general description
Unicode is based on the concept of a character. This definition is understood as an abstract phenomenon that exists in a specific form of writing and is realized through graphemes (their "portraits"). Each character is specified in "Unicode" unique code belonging to a specific block of the standard. For example, there is grapheme B in both English and Russian alphabets, but in Unicode it corresponds to 2 different characters. A transformation is applied to them, that is, each of them is described by a database key, a set of properties and a full name.
Benefits of Unicode
The Unicode encoding differed from the rest of its contemporaries by a huge supply of characters for “encrypting” characters. The fact is that its predecessors had 8 bits, that is, they supported 28 characters, but new development already had 216 characters, which was a giant step forward. This made it possible to encode almost all existing and common alphabets.
With the advent of "Unicode" there was no need to use conversion tables: as a single standard, it simply eliminated their need. Likewise, the "krakozyabry" have sunk into oblivion - a single standard made them impossible, as well as eliminated the need to create duplicate fonts.
Development of Unicode
Of course, progress does not stand still, and 25 years have passed since the first presentation. However, the Unicode encoding stubbornly maintains its position in the world. In many ways, this became possible due to the fact that it became easily implemented and became widespread, being recognized as developers of proprietary (paid) and open source software.

At the same time, one should not assume that today the same Unicode encoding is available to us as a quarter of a century ago. On this moment its version changed to 5.х.х, and the number of encoded characters increased to 231. The ability to use a larger supply of characters was abandoned in order to still maintain support for Unicode-16 (encodings where their maximum number was limited to 216). Since its inception and up to version 2.0.0, the "Unicode Standard" has almost doubled the number of characters it contains. The growth of opportunities continued in the following years. By version 4.0.0, there was a need to increase the standard itself, which was done. As a result, "Unicode" acquired the form in which we know it today.

What else is there in Unicode?
In addition to the huge, constantly growing number of symbols, it has another useful feature. This is the so-called normalization. Instead of scrolling through the entire document character by character and substituting the appropriate icons from the look-up table, one of the existing normalization algorithms is used. What are we talking about?
Instead of wasting computing resources on regular checking of the same symbol, which may be similar in different alphabets, a special algorithm is used. It allows you to take out similar characters in a separate column of the substitution table and refer to them, rather than re-checking all the data over and over again.
Four such algorithms have been developed and implemented. In each of them, the transformation takes place according to a strictly defined principle that differs from the others, therefore it is not possible to name any one of them the most effective. Each has been developed for specific needs, has been implemented and is successfully used.

Distribution of the standard
Over the 25 years of its history, the Unicode encoding is probably the most widely used in the world. Programs and web pages are also tailored to this standard. The fact that Unicode is used today by more than 60% of Internet resources can indicate the breadth of application.
Now you know when the Unicode standard came into being. What it is, you also know and will be able to appreciate the full significance of the invention made by a group of specialists from Unicode Inc. over 25 years ago.
Do you need hosting or domain? Click here! Do you want to create an online store? Click here! (Shopify)Sometimes, when writing a post, there is a need for a character (sign) that is not on the keyboard, in such situations the unicode character table will help you. Today we will consider online service, in which all unicode characters are grouped ...
Unicode character table
For those who are interested in the background of the appearance Unicode- here is the link to wikipedia
So let's designate our interests in unicode characters- this is the use of them in their articles, on their sites.
First, let's go to the page service unicode characters:


Let's take a look at the interface of this service a little. At the very top there is a search field, in it it is enough to drive in the name of the element you are looking for, for example: "Arrow" or "Ellipsis", after entering, click on the search to get the result.
Next to the search there is a page language switcher.
Below is a list of frequently requested symbols, perhaps among them there will be the one you need, if so, just click on the symbol to go to the page with detailed information about it.
The main part of the page is occupied by Unicode character table, for a more convenient search, you can also click on "Control Characters" to select a group of characters, for example: "Greek Characters" if you need to insert a Greek character.
Find the item you want in the Unicode character table
For example, let's use search and enter the word "Arrow" into it and press search.

On the search results page, we are looking for the symbol we need and click on it to go to the page detailed information about him.
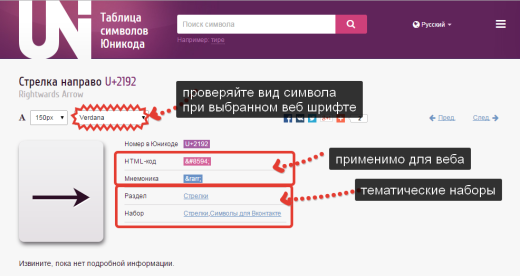
On the page Unicode character we are interested in its HTML code or Mnemonic code, both can be used on a web page, to do this, copy the code and paste it in the right place in the HTML markup, the browser interprets it and displays it as a symbol on the page.
Please note that on the Unicode character page, there is a choice of font. Always test how your font will display with Verdana, Arial (and other web fonts). not all characters are supported by them.
(codes from 0 to 127), i.e. one byte encodes Latin letters, numbers and special characters. Russian letters (Cyrillic) are represented by 16-bit (two-byte) codes:
110XXXXX 10XXXXXX,
where X denotes binary digits for placing the character code in accordance with the table UNICODE.
Unicode (English Unicode) is a character encoding standard that allows characters to be represented in almost all written languages. Unicode characters are encoded as unsigned integers. These numbers will be called unicode character codes or simply UNICODE... Unicode has several forms of representation of characters in a computer: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) and UTF-32 (UTF-32BE, UTF-32LE)... (English Unicode transformation format - UTF).
Consider how it is encoded in UTF-8 letter F... Her UNICODE- 1046 10 or 0416 16 or 10000 010110 2. UNICODE in binary, it is split into two parts: five left bits and six right bits. The left side is padded to a byte with a sign 110 two-byte code UTF-8: 110 10000. Two bits are assigned to the right side 10 sign of continuation of multibyte code: 10 010110. Final letter code F v UTF-8 looks like that:
110
10000 10
010110 2
or D0 96 16
Thus, the Russian letter is encoded twice: first into 11-bit UNICODE and then into 16-bit UTF-8.
In the table below, in addition to the codes UNICODE and UTF-8 in hexadecimal notation, codes are given UTF-8 in decimal notation and for comparison Cyrillic codes in encoding CP-1251, otherwise called windovs-1251.
| Symbol | UNICODE | UTF-8 | CP-1251 | ||
|---|---|---|---|---|---|
| Hex | Ten | Hex | Ten | ||
| A | 0410 | 1040 | D090 | 208 144 | 192 |
| B | 0411 | 1041 | D091 | 208 145 | 193 |
| V | 0412 | 1042 | D092 | 208 146 | 194 |
| G | 0413 | 1043 | D093 | 208 147 | 195 |
| D | 0414 | 1044 | D094 | 208 148 | 196 |
| E | 0415 | 1045 | D095 | 208 149 | 197 |
| F | 0416 | 1046 | D096 | 208 150 | 198 |
| Z | 0417 | 1047 | D097 | 208 151 | 199 |
| AND | 0418 | 1048 | D098 | 208 152 | 200 |
| Th | 0419 | 1049 | D099 | 208 153 | 201 |
| TO | 041A | 1050 | D09A | 208 154 | 202 |
| L | 041B | 1051 | D09B | 208 155 | 203 |
| M | 041C | 1052 | D09C | 208 156 | 204 |
| N | 041D | 1053 | D09D | 208 157 | 205 |
| O | 041E | 1054 | D09E | 208 158 | 206 |
| NS | 041F | 1055 | D09F | 208 159 | 207 |
| R | 0420 | 1056 | D0A0 | 208 160 | 208 |
| WITH | 0421 | 1057 | D0A1 | 208 161 | 209 |
| T | 0422 | 1058 | D0A2 | 208 162 | 210 |
| Have | 0423 | 1059 | D0A3 | 208 163 | 211 |
| F | 0424 | 1060 | D0A4 | 208 164 | 212 |
| NS | 0425 | 1061 | D0A5 | 208 165 | 213 |
| C | 0426 | 1062 | D0A6 | 208 166 | 214 |
| H | 0427 | 1063 | D0A7 | 208 167 | 215 |
| NS | 0428 | 1064 | D0A8 | 208 168 | 216 |
| SCH | 0429 | 1065 | D0A9 | 208 169 | 217 |
| B | 042A | 1066 | D0AA | 208 170 | 218 |
| NS | 042B | 1067 | D0AB | 208 171 | 219 |
| B | 042C | 1068 | D0AC | 208 172 | 220 |
| NS | 042D | 1069 | D0AD | 208 173 | 221 |
| NS | 042E | 1070 | D0AE | 208 174 | 222 |
| I AM | 042F | 1071 | D0AF | 208 175 | 223 |
| a | 0430 | 1072 | D0B0 | 208 176 | 224 |
| b | 0431 | 1073 | D0B1 | 208 177 | 225 |
| v | 0432 | 1074 | D0B2 | 208 178 | 226 |
| G | 0433 | 1075 | D0B3 | 208 179 | 227 |
| d | 0434 | 1076 | D0B4 | 208 180 | 228 |
| e | 0435 | 1077 | D0B5 | 208 181 | 229 |
| f | 0436 | 1078 | D0B6 | 208 182 | 230 |
| s | 0437 | 1079 | D0B7 | 208 183 | 231 |
| and | 0438 | 1080 | D0B8 | 208 184 | 232 |
| th | 0439 | 1081 | D0B9 | 208 185 | 233 |
| To | 043A | 1082 | D0BA | 208 186 | 234 |
| l | 043B | 1083 | D0BB | 208 187 | 235 |
| m | 043C | 1084 | D0BC | 208 188 | 236 |
| n | 043D | 1085 | D0BD | 208 189 | 237 |
| O | 043E | 1086 | D0BE | 208 190 | 238 |
| NS | 043F | 1087 | D0BF | 208 191 | 239 |
| R | 0440 | 1088 | D180 | 209 128 | 240 |
| with | 0441 | 1089 | D181 | 209 129 | 241 |
| T | 0442 | 1090 | D182 | 209 130 | 242 |
| at | 0443 | 1091 | D183 | 209 131 | 243 |
| f | 0444 | 1092 | D184 | 209 132 | 244 |
| NS | 0445 | 1093 | D185 | 209 133 | 245 |
| c | 0446 | 1094 | D186 | 209 134 | 246 |
| h | 0447 | 1095 | D187 | 209 135 | 247 |
| NS | 0448 | 1096 | D188 | 209 136 | 248 |
| SCH | 0449 | 1097 | D189 | 209 137 | 249 |
| b | 044A | 1098 | D18A | 209 138 | 250 |
| NS | 044B | 1099 | D18B | 209 139 | 251 |
| b | 044C | 1100 | D18C | 209 140 | 252 |
| NS | 044D | 1101 | D18D | 209 141 | 253 |
| NS | 044E | 1102 | D18E | 209 142 | 254 |
| I am | 044F | 1103 | D18F | 209 143 | 255 |
| Symbols outside the general rule | |||||
| Yo | 0401 | 1025 | D001 | 208 101 | 168 |
| e | 0451 | 1025 | D191 | 209 145 | 184 |
Sometimes you need to add an icon to your design, but don't feel like inserting additional images or an entire icon font like Font Awesome? Then we have good news for you - there is an extensive library of available icons and symbols already in your browser. It's called Unicode, and it's the standard that assigns unique identifiers for an ever-growing number (currently over 110,000) of symbols and icons.
This does not mean that you have a selection of hundreds of thousands of icons, though. It depends on the browser that renders them, and it uses the fonts that are installed on the system to do this. In this article, we have compiled a number of character sets that are available on Windows, Linux, OS X, Android, and IOS. You can use them in your designs today!
Tip: which explains everything there is to know about encodings and Unicode, which we recommend every software developer read.
How to use these icons
The icons shown in the tables below are common symbols that you can copy and paste as if they were letters of the alphabet. But if the encoding used to save the HTML / CSS files not UTF-8 they will not be displayed. This is why we introduced HTML escape code that will always work. Here's what you need to do to use these icons.:
- Find the icon you like. We have provided small and large previews.
- Copy the code.
- Paste it into HTML as plain text. In CSS you can use them as property value content... In JS, PHP, and other programming languages, you can use them as plain text in strings.
- You can customize icons by setting font size, color, text and shadows just like normal text.
Icons
| Name | Preview | Code | |
|---|---|---|---|
| Smiley | ☺ | ☺ | ☺ |
| Warning Sign | ⚠ | ⚠ | ⚠ |
| Hot springs | ♨ | ♨ | ♨ |
| Wheelchair | ♿ | ♿ | ♿ |
| Recycle | ♻ | ♻ | ♻ |
| 8-Ball | ➑ | ➑ | ➑ |
| High Voltage | ⚡ | ⚡ | ⚡ |
| White star | ☆ | ☆ | ☆ |
| Black star | ★ | ★ | ★ |
| White heart | ♡ | ♡ | ♡ |
| Black heart | ❤ | ❤ | ❤ |
| Coffee | ☕ | ☕ | ☕ |
| Airplane | ✈ | ✈ | ✈ |
| Hourglass | ⌛ | ⌛ | ⌛ |
| Clock | ⌚ | ⌚ | ⌚ |
| Black scissors | ✂ | ✂ | ✂ |
| White scissors | ✄ | ✄ | ✄ |
| Crown | ♕ | ♕ | ♕ |
| Anchor | ⚓ | ⚓ | ⚓ |
| Cross | ✝ | ✝ | ✝ |
| Black-white circle | ◑ | ◑ | ◑ |
| Eight note | ♪ | ♪ | ♪ |
| Beamed eighth notes | ♫ | ♫ | ♫ |
| Four Balloon-Spoked Asterisk | ✣ | ✣ | ✣ |
| Circled White Star | ✪ | ✪ | ✪ |
| White star | ✰ | ✰ | ✰ |
| White four pointed star | ✧ | ✧ | ✧ |
| Black four pointed star | ✦ | ✦ | ✦ |
| Ballot box check | ☑ | ☑ | ☑ |
| Check Mark | ✔ | ✔ | ✔ |
| Cross mark | ✘ | ✘ | ✘ |
| Pencil | ✎ | ✎ | ✎ |
| Writing hand | ✍ | ✍ | ✍ |
| Female | ♀ | ♀ | ♀ |
| Male | ♂ | ♂ | ♂ |
| Black telephone | ☎ | ☎ | ☎ |
| White Telephone | ☏ | ☏ | ☏ |
| Envelope | ✉ | ✉ | ✉ |
| Telephone Location | ✆ | ✆ | ✆ |
Unicode arrows
| Name | Preview | Code | |
|---|---|---|---|
| Leftwards arrow | ← | ← | ← |
| Rightwards arrow | → | → | → |
| Upwards Arrow | |||
| Downwards arrow | ↓ | ↓ | ↓ |
| Left Right Arrow | ↔ | ↔ | ↔ |
| Up down arrow | ↕ | ↕ | ↕ |
| Right And Left Arrows | ⇄ | ⇄ | ⇄ |
| Up and down arrows | ⇅ | ⇅ | ⇅ |
| Down-Left 90deg Arrow | ↲ | ↲ | ↲ |
| Down-Right 90deg Arrow | ↳ | ↳ | ↳ |
| Up-Left 90deg Arrow | ↰ | ↰ | ↰ |
| Up-Right 90deg Arrow | ↱ | ↱ | ↱ |
| North West Arrow To Corner | ⇱ | ⇱ | ⇱ |
| South East Arrow To Corner | ⇲ | ⇲ | ⇲ |
| Leftwards Arrow To Bar | ⇤ | ⇤ | ⇤ |
| Rightwards Arrow To Bar | ⇥ | ⇥ | ⇥ |
| Anticlockwise semicircle arrow | ↶ | ↶ | ↶ |
| Clockwise semicircle arrow | ↷ | ↷ | ↷ |
| Anticlockwise circle arrow | ↺ | ↺ | ↺ |
| Clockwise circle arrow | ↻ | ↻ | ↻ |
| Wide-Headed Rightwards Arrow | ➔ | ➔ | ➔ |
| Downwards zigzag arrow | ↯ | ↯ | ↯ |
| North west arrow | ↖ | ↖ | ↖ |
| Heavy south east arrow | ➘ | ➘ | ➘ |
| Heavy rightwards arrow | ➙ | ➙ | ➙ |
| Heavy north east arrow | ➚ | ➚ | ➚ |
| Dashed Rightwards Arrow | ➟ | ➟ | ➟ |
| Dotted Leftwards Arrow | ⇠ | ⇠ | ⇠ |
| Black rightwards arrowhead | ➤ | ➤ | ➤ |
| Leftwards white arrow | ⇦ | ⇦ | ⇦ |
| Rightwards white arrow | ⇨ | ⇨ | ⇨ |
| Left Angle Quotation Mark | « | « | « |
| Right Angle Quotation Mark | » | » | » |
| Right Black Pointer | |||
| Left Black Pointer | ◀ | ◀ | ◀ |
| Up Black Pointer | ▲ | ▲ | ▲ |
| Down black pointer | ▼ | ▼ | ▼ |
| Right White Pointer | ▷ | ▷ | ▷ |
| Left White Pointer | ◁ | ◁ | ◁ |
| Up White Pointer | △ | △ | △ |
| Down white pointer | ▽ | ▽ | ▽ |
| Bow arrow | ➴ | ➴ | ➴ |
Special characters in unicode
Unicode currency
Weather icons
| Name | Preview | Code | |
|---|---|---|---|
| Degree | ° | ° | ° |
| Small sun | ☀ | ☀ | ☀ |
| Big sun | ☼ | ☼ | ☼ |
| Cloud | ☁ | ☁ | ☁ |
| Umbrella | ☔ | ☔ | ☔ |
| Snowflake 1 | ❆ | ❆ | ❆ |
| Snowflake 2 | ❅ | ❅ | ❅ |
| Snowflake 3 | ❄ | ❄ | ❄ |
Unicode pointers
| Name | Preview | Code | |
|---|---|---|---|
| Pointer Left Black | ☚ | ☚ | ☚ |
| Pointer Right Black | ☛ | ☛ | ☛ |
| Pointer Left White | ☜ | ☜ | ☜ |
| Pointer Up White | ☝ | ☝ | ☝ |
| Pointer Right White | ☞ | ☞ | ☞ |
| Pointer Down White | ☟ | ☟ | ☟ |
Zodiac signs in unicode
| Name | Preview | Code | |
|---|---|---|---|
| Aries | ♈ | ♈ | ♈ |
| Taurus | ♉ | ♉ | ♉ |
| Twins | ♊ | ♊ | ♊ |
| Cancer | ♋ | ♋ | ♋ |
| a lion | ♌ | ♌ | ♌ |
| Virgo | ♍ | ♍ | ♍ |
| scales | ♎ | ♎ | ♎ |
| Scorpion | ♏ | ♏ | ♏ |
| Sagittarius | ♐ | ♐ | ♐ |
| Capricorn | ♑ | ♑ | ♑ |
| Aquarius | ♒ | ♒ | ♒ |
| Fishes | ♓ | ♓ | ♓ |
Unicode card symbols
| Name | Preview | Code | |
|---|---|---|---|
| Clubs Black | ♠ | ♠ | ♠ |
| Hearts Black | ♥ | ♥ | ♥ |
| Diamonds black | ♦ | ♦ | ♦ |
| Spades black | ♣ | ♣ | ♣ |
| Clubs White | ♤ | ♤ | ♤ |
| Hearts White | ♡ | ♡ | ♡ |
| Diamonds white | ♢ | ♢ | ♢ |
| Spades white | ♧ | ♧ | ♧ |
Chess pieces in unicode
| Name | Preview | Code | |
|---|---|---|---|
| King white | ♔ | ♔ | ♔ |
| Queen white | ♕ | ♕ | ♕ |
| Rook white | ♖ | ♖ | ♖ |
| Bishop White | ♗ | ♗ | ♗ |
| Knight white | ♘ | ♘ | ♘ |
| Pawn white | ♙ | ♙ | ♙ |
| King black | ♚ | ♚ | ♚ |
| Queen black | ♛ | ♛ | ♛ |
| Rook black | ♜ | ♜ | ♜ |
| Bishop Black | ♝ | ♝ | ♝ |
| Knight black | ♞ | ♞ | ♞ |
| Pawn black | ♟ | ♟ | ♟ |
Game of dice
| Name | Preview | Code | |
|---|---|---|---|
| Dice roll one | ⚀ | ⚀ | ⚀ |
| Dice roll two | ⚁ | ⚁ | ⚁ |
| Dice roll three | ⚂ | ⚂ | ⚂ |
| Dice roll four | ⚃ | ⚃ | ⚃ |
| Dice roll five | ⚄ | ⚄ | ⚄ |
| Dice roll six | ⚅ | ⚅ | ⚅ |
Unicode math symbols
| Name | Preview | Code | |
|---|---|---|---|
| Infinity | ∞ | ∞ | ∞ |
| Plus minus | ± | ± | ± |
| Less-Than Or Equal To | ≤ | ≤ | ≤ |
| More-Than Or Equal To | ≥ | ≥ | ≥ |
| Not Equal To | ≠ | ≠ | ≠ |
| Division | ÷ | ÷ | ÷ |
| Multiplication x | × | × | × |
| Heavy Multiplication x | ✖ | ✖ | ✖ |
| Superscript one | ¹ | ¹ | ¹ |
| Superscript Two | ² | ² | ² |
| Superscript three | ³ | ³ | ³ |
| Circled Plus | ⊕ | ⊕ | ⊕ |
| Circled Multiplication | ⊗ | ⊗ | ⊗ |
| Logical AND | ∧ | ∧ | ∧ |
| Logical OR | ∨ | ∨ | ∨ |
| Delta | ∆ | ∆ | ∆ |
| Pie | ∏ | ∏ | ∏ |
| Sigma (SUM) | ∑ | ∑ | ∑ |
| Omega | Ω | Ω | Ω |
| Empty Set | ∅ | ∅ | ∅ |
| Angle | ∠ | ∠ | ∠ |
| Parallel | ∥ | ∥ | ∥ |
| Perpendicular | ⊥ | ⊥ | ⊥ |
| Almost Equal To | ≈ | ≈ | ≈ |
| Triangle | △ | △ | △ |
| Circle | ○ | ○ | ○ |
| Square | □ | □ | □ |
Fractions
| Name | Preview | Code | |
|---|---|---|---|
| One Quarter (1/4) | ¼ | ¼ | ¼ |
| One Half (1/2) | ½ | ½ | ½ |
| Three Quarters (3/4) | ¾ | ¾ | ¾ |
| One Third (1/3) | ⅓ | ⅓ | ⅓ |
| Two Thirds (2/3) | ⅔ | ⅔ | ⅔ |
| One Eight (1/8) | ⅛ | ⅛ | ⅛ |
| Three Eights (3/8) | ⅜ | ⅜ | ⅜ |
| Five Eights (5/8) | ⅝ | ⅝ | ⅝ |
| Seven Eights (7/8) | ⅞ | ⅞ | ⅞ |
Roman numerals in unicode
| Name | Preview | Code | |
|---|---|---|---|
| Roman Numeral One | Ⅰ | Ⅰ | Ⅰ |
| Roman Numeral Two | Ⅱ | Ⅱ | Ⅱ |
| Roman Numeral Three | Ⅲ | Ⅲ | Ⅲ |
| Roman Numeral Four | Ⅳ | Ⅳ | Ⅳ |
| Roman Numeral Five | Ⅴ | Ⅴ | Ⅴ |
| Roman Numeral Six | Ⅵ | Ⅵ | Ⅵ |
| Roman Numeral Seven | Ⅶ | Ⅶ | Ⅶ |
| Roman Numeral Eight | Ⅷ | Ⅷ | Ⅷ |
| Roman Numeral Nine | Ⅸ | Ⅸ | Ⅸ |
| Roman Numeral Ten | Ⅹ | Ⅹ | Ⅹ |
| Roman Numeral Eleven | Ⅺ | Ⅺ | Ⅺ |
| Roman Numeral Twelve | Ⅻ | Ⅻ | Ⅻ |
There are some differences in the rendering of these symbols in different operating systems... This is caused by the different font families that are used. In addition, iOS and Android replace some Unicode characters with emojis, so be sure to check the added characters to make sure they don't and the icons are showing as intended.
The elements of the code space that represent non-negative integers. The family of encodings defines the machine representation of a sequence of UCS codes.
Unicode codes are divided into several areas. The area with codes U + 0000 through U + 007F contains the ASCII characters with corresponding codes. Next are the areas of signs of various scripts, punctuation marks and technical symbols. Some of the codes are reserved for future use. Under the Cyrillic characters areas of characters with codes from U + 0400 to U + 052F, from U + 2DE0 to U + 2DFF, from U + A640 to U + A69F are allocated (see Cyrillic in Unicode).
Prerequisites for the creation and development of Unicode
Since in a number of computer systems (for example, Windows NT) fixed 16-bit characters were already used as the default encoding, it was decided to encode all the most important characters only within the first 65,536 positions (the so-called English. basic multilingual plane, BMP). The rest of the space is used for "additional characters" (eng. supplementary characters): writing systems of extinct languages or very rarely used Chinese characters, mathematical and musical symbols.
For compatibility with old 16-bit systems, the UTF-16 system was invented, where the first 65,536 positions, with the exception of positions from the interval U + D800 ... U + DFFF, are displayed directly as 16-bit numbers, and the rest are represented as "surrogate pairs "(The first element of the pair from the U + D800… U + DBFF region, the second element of the pair from the U + DC00… U + DFFF region). For surrogate pairs, a portion of the code space (2048 positions) previously reserved for "characters for private use" was used.
Since UTF-16 can display only 2 20 + 2 16 −2048 (1 112 064) characters, this number was chosen as the final value for the Unicode code space.
Although the Unicode code area was extended beyond 2-16 as early as version 2.0, the first characters in the "top" area were only placed in version 3.1.
The role of this encoding in the web sector is constantly growing, at the beginning of 2010 the share of websites using Unicode was about 50%.
Unicode versions
As the Unicode character table changes and replenishes and new versions of this system are released - and this work is ongoing, since the original Unicode system included only Plane 0 - two-byte codes - new ISO documents are also released. The Unicode system exists in total in the following versions:
- 1.1 (conforms to ISO / IEC 10646-1: 1993), 1991-1995 standard.
- 2.0, 2.1 (same ISO / IEC 10646-1: 1993 standard plus additions: "Amendments" 1 to 7 and "Technical Corrigenda" 1 and 2), 1996 standard.
- 3.0 (ISO / IEC 10646-1: 2000 standard) 2000 standard.
- 3.1 (ISO / IEC 10646-1: 2000 and ISO / IEC 10646-2: 2001 standards) 2001 standard.
- 3.2 2002 standard.
- 4.0, standard 2003.
- 4.01, standard 2004.
- 4.1, standard 2005.
- 5.0, standard 2006.
- 5.1, standard 2008.
- 5.2, standard 2009.
- 6.0, standard 2010.
- 6.1, standard 2012.
- 6.2, standard 2012.
Code space
Although the notation forms UTF-8 and UTF-32 allow up to 2,331 (2,147,483,648) code points to be encoded, it was decided to use only 1,112,064 for compatibility with UTF-16. However, even this is more than enough - today (in version 6.0) slightly less than 110,000 code points (109,242 graphic and 273 other symbols) are used.
The code space is split into 17 planes 2 16 (65536) characters each. The zero plane is called basic, it contains the symbols of the most common scripts. The first plane is used mainly for historical scripts, the second - for rarely used CJK characters, the third is reserved for archaic Chinese characters. Planes 15 and 16 are reserved for private use.
To denote Unicode characters a notation of the form “U + xxxx"(For codes 0 ... FFFF), or" U + xxxxx"(For codes 10000 ... FFFFF), or" U + xxxxxx"(For codes 100000 ... 10FFFF), where xxx- hexadecimal digits. For example, the character "i" (U + 044F) has the code 044F = 1103.
Coding system
The universal coding system (Unicode) is a set of graphic symbols and a way of encoding them for computer processing of text data.
Graphic symbols are symbols that have a visible image. Graphical characters are opposed to control and formatting characters.
Graphic symbols include the following groups:
- letters contained in at least one of the supported alphabets;
- numbers;
- punctuation marks;
- special signs (mathematical, technical, ideograms, etc.);
- separators.
Unicode is a system for the linear representation of text. Characters with additional superscripts or subscripts can be represented as a sequence of codes built according to certain rules (composite character) or as a single character (monolithic version, precomposed character).
Modifying characters
Representation of the character "Y" (U + 0419) in the form of the base character "I" (U + 0418) and the modifying character "" (U + 0306)
Graphic characters in Unicode are divided into extended and non-extended (widthless). Non-extended characters do not take up space in the line when displayed. These include, in particular, accent marks and other diacritical marks. Both extended and non-extended characters have their own codes. Extended symbols are otherwise called basic (eng. base characters), and non-extended ones - modifying (eng. combining characters); and the latter cannot meet independently. For example, the character "á" can be represented as a sequence of the base character "a" (U + 0061) and the modifier character "́" (U + 0301), or as a monolithic character "á" (U + 00C1).
A special type of modifying characters are face style selectors (eng. variation selectors). They only apply to those symbols for which such variants are defined. In version 5.0, style options are defined for a series mathematical symbols, for the symbols of the traditional Mongolian alphabet and for the symbols of the Mongolian square writing.
Normalization forms
Since the same symbols can be represented different codes, which sometimes complicates processing, there are normalization processes designed to bring the text to a certain standard form.
The Unicode standard defines 4 forms of text normalization:
- Normalization Form D (NFD) - Canonical Decomposition. In the process of converting the text into this form, all compound characters are recursively replaced by several compound ones, in accordance with the decomposition tables.
- Normalization Form C (NFC) is canonical decomposition followed by canonical composition. First, the text is reduced to the D form, after which the canonical composition is performed - the text is processed from beginning to end and the following rules are followed:
- The S symbol is initial if it has a modification class of zero in the Unicode character base.
- In any sequence of characters starting with an initial character S, a character C is blocked from S if and only if there is any character B between S and C that is either an initial character or has the same or greater modification class than C. This rule applies only to strings that have gone through canonical decomposition.
- Primary A composite is a character that has a canonical decomposition in the Unicode character base (or canonical decomposition for Hangul and is not included in the exceptions list).
- The X character can be primary aligned with the Y character if and only if there is a primary composite Z canonically equivalent to the sequence
- If the next character C is not blocked by the last encountered initial base character L and it can be successfully aligned with it, then L is replaced by the composite L-C, and C is removed.
- Normalization Form KD (NFKD) - Compatible Decomposition. When cast into this form, all composite characters are replaced using both the canonical Unicode decomposition maps and compatible decomposition maps, after which the result is placed in canonical order.
- Normalization Form KC (NFKC) - Compatible Decomposition followed by canonical composition.
The terms "composition" and "decomposition" mean, respectively, the connection or decomposition of symbols into their constituent parts.
Examples of
| Source text | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | Franc \ u0327ais | Fran \ xe7ais | Franc \ u0327ais | Fran \ xe7ais |
| A, E, Y | \ u0410, \ u0401, \ u0419 | \ u0410, \ u0415 \ u0308, \ u0418 \ u0306 | \ u0410, \ u0401, \ u0419 | |
| が | \ u304b \ u3099 | \ u304c | \ u304b \ u3099 | \ u304c |
| Henry iv | Henry iv | Henry iv | Henry iv | Henry iv |
| Henry Ⅳ | Henry \ u2163 | Henry \ u2163 | Henry iv | Henry iv |
Bi-directional letter
The Unicode standard supports writing languages with a left-to-right direction (eng. left-to-right, LTR), and with writing from right to left (eng. right-to-left, RTL) - for example, Arabic and Hebrew letters. In both cases, the characters are stored in a "natural" order; their display, taking into account the desired direction of the letter, is provided by the application.
In addition, Unicode supports combined texts that combine fragments with different directions of the letter. This feature is called bidirectionality(eng. bidirectional text, BiDi). Some simplified text processors (for example, in cell phones) can support Unicode, but not bidirectional support. All Unicode characters are divided into several categories: written from left to right, written from right to left, and written in any direction. Symbols of the latter category (mainly punctuation marks), when displayed, take the direction of the surrounding text.
Featured symbols
Unicode includes virtually all modern scripts, including:
other.
For academic purposes, many historical scripts have been added, including: runes, ancient Greek, Egyptian hieroglyphs, cuneiform, Mayan writing, Etruscan alphabet.
Unicode provides a wide range of mathematical and musical symbols and pictograms.
However, Unicode fundamentally does not include company and product logos, although they are found in fonts (for example, the Apple logo in the MacRoman encoding (0xF0) or the Windows logo in the Wingdings font (0xFF)). In Unicode fonts, logos must be placed in the custom character area only.
ISO / IEC 10646
The Unicode Consortium works closely with working group ISO / IEC / JTC1 / SC2 / WG2, which is developing international standard 10646 (ISO / IEC 10646). Synchronization is established between the Unicode standard and ISO / IEC 10646, although each standard uses its own terminology and documentation system.
Cooperation of the Unicode Consortium with the International Organization for Standardization (eng. International Organization for Standardization, ISO ) began in 1991. In 1993, ISO issued the DIS 10646.1 standard. To synchronize with it, the Consortium approved the version 1.1 of the Unicode standard, which was supplemented with additional characters from DIS 10646.1. As a result, the values of the encoded characters in Unicode 1.1 and DIS 10646.1 are exactly the same.
In the future, cooperation between the two organizations continued. In 2000 Unicode standard 3.0 has been synchronized with ISO / IEC 10646-1: 2000. The upcoming third version of ISO / IEC 10646 will be synchronized with Unicode 4.0. Perhaps these specifications will even be published as a single standard.
Similar to the UTF-16 and UTF-32 formats in the Unicode standard, the ISO / IEC 10646 standard also has two main forms of character encoding: UCS-2 (2 bytes per character, similar to UTF-16) and UCS-4 (4 bytes per character, similar to UTF-32). UCS means universal multi-octet(multibyte) coded character set(eng. universal multiple-octet coded character set ). UCS-2 can be considered a subset of UTF-16 (UTF-16 without surrogate pairs) and UCS-4 is a synonym for UTF-32.
Presentation methods
Unicode has several forms of representation (eng. Unicode transformation format, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) and UTF-32 (UTF-32BE, UTF-32LE). The UTF-7 representation form was also developed for transmission over seven-bit channels, but due to incompatibility with ASCII, it was not spread and was not included in the standard. On April 1, 2005, two humorous submissions were proposed: UTF-9 and UTF-18 (RFC 4042).
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Theoretically possible, but also not included in the standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Although UTF-8 allows you to specify the same character in several ways, only the shortest one is correct. The rest of the forms should be rejected for security reasons.
Byte order
In a UTF-16 data stream, the high byte can be written either before the low (eng. UTF-16 big-endian), or after the younger (eng. UTF-16 little-endian). Similarly, there are two options for the four-byte encoding - UTF-32BE and UTF-32LE.
To define the format of the Unicode representation at the beginning text file the signature is written - the character U + FEFF (non-breaking space with zero width), also called byte order mark(eng. byte order mark, BOM ). This makes it possible to distinguish between UTF-16LE and UTF-16BE since the U + FFFE character does not exist. It is also sometimes used to denote the UTF-8 format, although the notion of byte order does not apply to this format. Files that follow this convention begin with these byte sequences:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Unfortunately, this method does not reliably distinguish between UTF-16LE and UTF-32LE, since the character U + 0000 is allowed by Unicode (although real texts rarely start with it).
Files in UTF-16 and UTF-32 encodings that do not contain a BOM must be in big-endian (unicode.org) byte order.
Unicode and traditional encodings
The introduction of Unicode changed the approach to traditional 8-bit encodings. If earlier the encoding was specified by the font, now it is specified by the correspondence table between this encoding and Unicode. In fact, 8-bit encodings have become a representation of a subset of Unicode. This made it much easier to create programs that have to work with many different encodings: now, to add support for one more encoding, you just need to add another Unicode lookup table.
In addition, many data formats allow any Unicode characters to be inserted, even if the document is written in the old 8-bit encoding. For example, you can use ampersand codes in HTML.
Implementation
Most modern operating systems provide some degree of Unicode support.
In operating systems of the Windows NT family, the double-byte UTF-16LE encoding is used for the internal representation of file names and other system strings. System calls that take string parameters are available in single-byte and double-byte variants. For more details see the article
 Odnoklassniki: Registration and profile creation
Odnoklassniki: Registration and profile creation E is. E (functions E). Expressions in terms of trigonometric functions
E is. E (functions E). Expressions in terms of trigonometric functions Social networks of Russia Now in social networks
Social networks of Russia Now in social networks