ترميز الأحرف. يونيكود
أعجبني ذلك ، ربما يكون شخص ما مهتمًا ومفيدًا.
يبدو Unicode محيرًا للغاية ، مما يثير الكثير من الأسئلة والمشكلات. يعتقد الكثير من الناس أن هذا هو ترميز أو مجموعة أحرف ، وهذا صحيح إلى حد ما ، لكنه في الحقيقة وهم. حقيقة أن Unicode تم إنشاؤه في الأصل كمجموعة تشفير وحروف تعزز المفاهيم الخاطئة فقط. هذه محاولة لتوضيح كل شيء ، ليس فقط من خلال إخبار ماهية Unicode ، ولكن من خلال توفيرها نموذج عقلييونيكود.
غير صحيح تمامًا ، ولكنه نموذج مفيد لفهم Unicode (يشار إليه فيما يلي بـ PMPY):
- Unicode هو وسيلة لمعالجة البيانات النصية... إنه ليس مجموعة أحرف أو ترميز.
- Unicode هو نص ، كل شيء آخر هو بيانات ثنائية... وحتى نص ASCII هو بيانات ثنائية.
- يستخدم Unicode مجموعة أحرف UCS... لكن UCS ليس Unicode.
- يمكن ترميز Unicode ثنائي باستخدام UTF... لكن UTF ليس Unicode.
الآن ، إذا كنت تعرف شيئًا عن Unicode ، فستقول ، "حسنًا ، نعم ، لكنها في الحقيقة ليست كذلك." لذلك ، سنحاول معرفة سبب استمرار هذا النموذج من الفهم ، على الرغم من عدم صحته ، مفيدًا. لنبدأ بمجموعة الأحرف ...
حول مجموعة الأحرف
لمعالجة نص على جهاز كمبيوتر ، تحتاج إلى مطابقة حروف الحروف التي تكتبها على الورق مع الأرقام. يتم تحديد هذا الترتيب من خلال مجموعة الأحرف ، أو جدول الأحرف ، الذي يحدد رقم الحرف. هذا ما يسمى "مجموعة الأحرف"... لا يتوافق الرمز بالضرورة مع أي حرف حرفي. على سبيل المثال ، هناك حرف فحص "BEL" يجعل جهاز الكمبيوتر الخاص بك "صوتًا". عادة ما يكون عدد الأحرف في مجموعة الأحرف 256 حرفًا ، وهذا هو مقدار ما يتناسب مع بايت واحد. هناك مجموعات أحرف يبلغ طولها 6 بت فقط. لفترة طويلة ، سيطرت مجموعات أحرف ASCII ذات 7 بتات على الحوسبة ، ولكن 8 بت هي الأكثر شيوعًا.
لكن من الواضح أن 256 ليس الرقم الذي يمكنه استيعاب جميع الرموز التي نحتاجها في عالمنا. هذا هو سبب ظهور Unicode. عندما قلت أن Unicode ليس مجموعة أحرف ، كنت أكذب. كان Unicode في الأصل مجموعة أحرف 16 بت. لكن بينما اعتقد مبتكرو Unicode أن 16 بتًا كانت كافية (وكانوا على حق) ، اعتقد البعض أن 16 بتًا ليست كافية (وكانوا على حق أيضًا). قاموا في النهاية بإنشاء ترميز منافس وأطلقوا عليه مجموعة الأحرف العالمية (UCS). بعد فترة ، قررت الفرق توحيد قواها وأصبحت مجموعتا الشخصيات متماثلتين. هذا هو السبب في أننا يمكن أن نفترض أن Unicode يستخدم UCS كمجموعة أحرف خاصة به. لكن هذه كذبة أيضًا - في الواقع ، كل معيار له مجموعة خاصة به من الشخصيات ، ويصادف أنهم متماثلون (على الرغم من أن UCS متأخرة قليلاً).
ولكن بالنسبة إلى PMPYu لدينا - "Unicode ليس مجموعة أحرف".
حول UCS
UCS عبارة عن مجموعة أحرف 31 بت مع أكثر من 100000 حرف. 31 بت - حتى لا يتم حل مشكلة "الموقعة مقابل غير الموقعة". نظرًا لاستخدام أقل من 0.005٪ من العدد المحتمل للأحرف ، فلن تكون هناك حاجة إلى هذا البت الإضافي على الإطلاق.
على الرغم من أن 16 بتًا لم تكن كافية لاستيعاب جميع الشخصيات التي أنشأتها البشرية على الإطلاق ، إلا أنه يكفي تمامًا إذا كنت مستعدًا لتقييد نفسك الآن فقط. اللغات الموجودة... لذلك ، يتناسب الجزء الأكبر من أحرف UCS مع أول 65536 رقمًا. تم تسميتهم "الطائرة الأساسية متعددة اللغات" أو BMP. في الواقع ، هم مجموعة أحرف Unicode ذات 16 بت ، على الرغم من أن كل إصدار من UCS يوسعها بمزيد من الأحرف. يصبح BMP مناسبًا عندما يتعلق الأمر بالترميز ، ولكن المزيد عن ذلك أدناه.
كل حرف في UCS له اسم ورقم. يُطلق على الحرف "H" اسم "LATIN CAPITAL LETTER H" وهو رقم 72. يكون الرقم عادةً بالنظام السداسي العشري ، وغالبًا ما يكون مسبوقًا بـ "U +" و 4 أو 5 أو 6 أرقام للإشارة إلى المقصود بحرف Unicode. لذلك ، غالبًا ما يتم تمثيل رقم الحرف "H" على أنه U + 0048 بدلاً من - 72 ، على الرغم من أنهما نفس الشيء. مثال آخر هو الحرف "-" المسمى "EM DASH" أو U + 2012. يُطلق على الحرف "乨" اسم "CJK UNIFIED IDEOGRAPH-4E68" ، ويتم تمثيله بشكل أكثر شيوعًا باسم U + 4E68. رمز "
نظرًا لأن أسماء وأرقام الأحرف في Unicode و UCS هي نفسها ، بالنسبة إلى PMPU الخاص بنا ، سنفترض ذلك UCS ليس Unicode، لكن يستخدم Unicode UCS... هذه كذبة ، لكنها كذبة مفيدة تسمح لك بالتمييز بين Unicode ومجموعة الأحرف.
حول الترميزات
وبالتالي ، فإن مجموعة الأحرف هي مجموعة من الأحرف ، لكل منها رقمها الخاص. ولكن كيف يجب تخزينها أو إرسالها إلى كمبيوتر آخر؟ بالنسبة للأحرف ذات 8 بت ، من السهل استخدام بايت واحد لكل حرف. لكن UCS يستخدم 31 بت وتحتاج إلى 4 بايت لكل حرف ، مما يخلق مشكلة في ترتيب البايت وعدم كفاءة الذاكرة. أيضا ، ليس كل شيء تطبيقات الطرف الثالثيمكنه العمل مع جميع أحرف Unicode ، لكننا ما زلنا بحاجة إلى التفاعل مع هذه التطبيقات.
المخرج هو استخدام الترميزات التي تشير إلى كيفية تحويل نص Unicode إلى بيانات ثنائية 8 بت. من الجدير بالذكر أن ASCII عبارة عن ترميز ، وبيانات ASCII من وجهة نظر PMPU ثنائية!
في معظم الحالات ، يكون الترميز هو نفس مجموعة الأحرف ويتم تسميته بنفس اسم مجموعة الأحرف التي يشفرها. هذا صحيح بالنسبة لـ Latin-1 و ISO-8859-15 و cp1252 و ASCII وغيرها. في حين أن معظم مجموعات الأحرف هي أيضًا ترميز ، فإن هذا ليس هو الحال بالنسبة لـ UCS. من المربك أيضًا أن UCS هو ما تقوم بفك التشفير إليه وما تقوم بالتشفير منه ، في حين أن باقي مجموعات الأحرف هي ما تقوم بفك التشفير منه وما تقوم بالتشفير فيه (نظرًا لأن اسم التشفير ومجموعة الأحرف هو نفسه). وبالتالي ، يجب أن تتعامل مع مجموعات الأحرف والتشفيرات على أنها أشياء مختلفة ، على الرغم من أن هذه المصطلحات غالبًا ما تستخدم بالتبادل في المعنى.
حول UTF
تعمل معظم الترميزات على مجموعة أحرف ليست سوى جزء صغير من UCS. تصبح هذه مشكلة بالنسبة للبيانات متعددة اللغات ، لذلك هناك حاجة إلى ترميز يستخدم جميع أحرف UCS. يعد تشفير الأحرف 8 بت بسيطًا جدًا حيث تحصل على حرف واحد من بايت واحد ، لكن UCS يستخدم 31 بتًا وتحتاج إلى 4 بايت لكل حرف. تنشأ مشكلة ترتيب البايت لأن بعض الأنظمة تستخدم الترتيب العالي إلى الترتيب المنخفض ، والبعض الآخر يستخدم العكس. أيضًا ، ستكون بعض البايتات فارغة دائمًا ، وهذا مضيعة للذاكرة. يجب أن يستخدم التشفير الصحيح عددًا مختلفًا من البايت لـ شخصيات مختلفة، ولكن هذا الترميز سيكون فعالا في بعض الحالات وغير فعال في حالات أخرى.
الحل لهذا اللغز هو استخدام العديد من الترميزات التي يمكنك من خلالها اختيار التشفير المناسب. يطلق عليهم اسم تنسيقات تحويل Unicode ، أو UTF.
UTF-8 هو الترميز الأكثر استخدامًا على الإنترنت. يستخدم بايت واحد لأحرف ASCII و 2 أو 4 بايت لجميع أحرف UCS الأخرى. هذا فعال للغاية بالنسبة للغات التي تستخدم الأحرف اللاتينية ، نظرًا لأنها كلها مكتوبة بأحرف ASCII ، وهي فعالة جدًا للغات اليونانية ، والسيريلية ، واليابانية ، والأرمينية ، والسريانية ، والعربية ، وما إلى ذلك ، لأنها تستخدم 2 بايت لكل حرف. لكن هذا ليس ساريًا بالنسبة لجميع لغات BMP الأخرى ، حيث سيتم استخدام 3 بايت لكل حرف ، وسيتم استخدام 4 بايت لجميع أحرف UCS الأخرى ، مثل Gothic.
يستخدم UTF-16 كلمة واحدة 16 بت لجميع أحرف BMP وكلمتين من 16 بت لجميع الأحرف الأخرى. لذلك ، إذا كنت لا تستخدم إحدى اللغات المذكورة أعلاه ، فمن الأفضل لك استخدام UTF-16. نظرًا لأن UTF-16 يستخدم كلمات ذات 16 بت ، فإننا ننتهي بمشكلة ترتيب البايت. يتم حلها من خلال وجود ثلاثة خيارات: UTF-16BE لترتيب البايت من الأعلى إلى المنخفض ، و UTF-16LE - من الأقل إلى الأعلى ، وببساطة UTF-16 ، والتي يمكن أن تكون UTF-16BE أو UTF-16LE ، عند تشفير a يتم استخدام علامة في البداية ، مما يشير إلى ترتيب البايت. تسمى هذه العلامة "علامة ترتيب البايت" أو "قائمة مكونات الصنف".
يوجد أيضًا UTF-32 ، والذي يمكن أن يكون في نسختين BE و LE بالإضافة إلى UTF-16 ، ويخزن حرف Unicode كعدد صحيح 32 بت. هذا غير فعال لجميع الأحرف تقريبًا باستثناء تلك التي تتطلب 4 بايت للتخزين. ولكن من السهل جدًا معالجة مثل هذه البيانات ، نظرًا لأن لديك دائمًا 4 بايت لكل حرف.
من المهم فصل البيانات المشفرة عن بيانات Unicode. لذلك ، لا تفكر في بيانات UTF-8/16/32 على أنها Unicode. وبالتالي ، على الرغم من تعريف ترميزات UTF في معيار Unicode ، فإننا نعتقد أن UTF ليس Unicode ضمن وحدة PMPU.
حول يونيكود
يحتوي UCS على أحرف موحدة ، مثل trema ، والتي تضيف نقطتين فوق الشخصية. هذا يؤدي إلى الغموض عند التعبير عن حرف واحد (حرف أو علامة) من خلال عدة رموز. خذ "ö" كمثال ، والذي يمكن تمثيله على أنه الحرف LATIN SMALL LETTER O WITH DIAERESIS ، ولكن في نفس الوقت كمزيج من الأحرف LATIN SMALL LETTER O متبوعًا بمجموعة DIAERESIS.
لكن في الحياة الواقعية ، لا يمكنك استكمال أي رمز بثلاثة. على سبيل المثال ، ليس من المنطقي إضافة نقطتين فوق رمز اليورو. يحتوي Unicode على قواعد لمثل هذه الأشياء. يشير إلى أنه يمكنك التعبير عن "ö" بطريقتين وهي نفس الحرف ، ولكن إذا استخدمت ثلاثة لإشارة اليورو ، فأنت ترتكب خطأ. لذلك ، تعتبر قواعد دمج الأحرف جزءًا من معيار Unicode.
يحتوي معيار Unicode أيضًا على قواعد لمقارنة الأحرف وفرزها ، وقواعد لتقسيم النص إلى جمل وكلمات (إذا كنت تعتقد أن الأمر بهذه البساطة ، ضع في اعتبارك أن معظم اللغات الآسيوية لا تحتوي على مسافات بين الكلمات) ، والعديد من القواعد الأخرى التي تحديد كيفية عرضه ومعالجته. النص. ربما لن تحتاج إلى معرفة كل هذا ، إلا عند استخدام اللغات الآسيوية.
باستخدام PMPU ، قررنا أن Unicode هو UCS بالإضافة إلى قواعد معالجة الكلمات. أو بعبارة أخرى: Unicode هي طريقة للعمل مع البيانات النصية ولا يهم اللغة أو الحرف الذي يستخدمونه. في Unicode ، "H" ليست مجرد حرف ، بل لها بعض المعنى. تشير مجموعة الأحرف إلى أن الحرف "H" مرقم 72 ، بينما يخبرك Unicode أنه عند فرز "H" يأتي قبل "I" ويمكنك استخدام نقطتين فوقه للحصول على "Ḧ".
وبالتالي ، فإن Unicode ليس ترميزًا أو مجموعة من الأحرف ، بل هو طريقة للعمل مع البيانات النصية.
أنا شخصياً لا أحب عناوين الأخبار مثل "بوكيمون في عصيرهم الخاص للدمى / الأواني / المقالي" ، ولكن يبدو أن هذا هو الحال تمامًا - سنتحدث عن الأشياء الأساسية ، والعمل معها يؤدي غالبًا إلى حجرة مليئة المطبات والكثير من الوقت الضائع حول السؤال - لماذا لا يعمل؟ إذا كنت لا تزال خائفًا و / أو لا تفهم Unicode ، من فضلك ، تحت cat.
لم؟
السؤال الرئيسي للمبتدئين الذين يواجهون عددًا مذهلاً من الترميزات وآليات تبدو مربكة للعمل معهم (على سبيل المثال ، في Python 2.x). الجواب القصير لأنه حدث :)الترميز ، الذي لا يعرف ، هو طريقة التمثيل في ذاكرة الكمبيوتر (اقرأ - بالأصفار - الآحاد / الأرقام) الأرقام والزان وجميع الأحرف الأخرى. على سبيل المثال ، يتم تمثيل المسافة على أنها 0b100000 (ثنائي) ، 32 (عشري) ، أو 0x20 (سداسي عشري).
لذلك ، بمجرد أن يكون هناك القليل جدًا من الذاكرة وكان لدى جميع أجهزة الكمبيوتر ما يكفي من 7 بتات لتمثيل جميع الأحرف الضرورية (الأرقام ، الأبجدية اللاتينية الصغيرة / الكبيرة ، مجموعة من الأحرف وما يسمى بالأحرف الخاضعة للرقابة - تم إعطاء 127 رقمًا ممكنًا لشخص ما) . في ذلك الوقت كان هناك ترميز واحد فقط - ASCII. مع مرور الوقت ، كان الجميع سعداء ، ومن لم يكن سعيدًا (اقرأ - من يفتقر إلى العلامة "" أو الحرف الأصلي "u") - استخدم 128 حرفًا المتبقية وفقًا لتقديرهم ، أي أنهم أنشأوا ترميزات جديدة. هذه هي الطريقة التي ظهرت بها ISO-8859-1 و (أي السيريلية) cp1251 و KOI8. معًا ، ظهرت مشكلة تفسير البايتات مثل 0b1 ******* (أي الأحرف / الأرقام من 128 إلى 255) - على سبيل المثال ، 0b11011111 في تشفير cp1251 هو "I" الخاص بنا ، في نفس الوقت في ترميز ISO 8859-1 هي اليونانية الألمانية Eszett (المطالبات) "ß". كما هو متوقع ، اتصال الشبكة وتبادل الملفات فقط بين أجهزة كمبيوتر مختلفةتحولت إلى هيك ماذا ، على الرغم من حقيقة أن عناوين مثل "ترميز المحتوى" في بروتوكول HTTP ورسائل البريد الإلكتروني وصفحات HTML وفرت اليوم قليلاً.
في تلك اللحظة ، اجتمعت العقول الساطعة واقترحت معيارًا جديدًا - Unicode. هذا معيار وليس ترميزًا - لا يحدد Unicode نفسه كيفية تخزين الأحرف على القرص الثابت أو نقلها عبر الشبكة. إنها تحدد فقط العلاقة بين حرف ورقم معين ، ويتم تحديد التنسيق الذي سيتم تحويل هذه الأرقام وفقًا له إلى بايت بواسطة ترميزات Unicode (على سبيل المثال ، UTF-8 أو UTF-16). على ال هذه اللحظةهناك ما يزيد قليلاً عن 100 ألف حرف في معيار Unicode ، بينما يمكن لـ UTF-16 دعم أكثر من مليون (UTF-8 أكثر من ذلك).
أنصحك بقراءة الحد الأدنى المطلق لكل مطور برامج على الإطلاق ، بشكل إيجابي يجب أن يعرفه عن Unicode ومجموعات الأحرف لمزيد من المرح حول هذا الموضوع.
أوضح ماذا تقصد!
بطبيعة الحال ، هناك دعم لـ Unicode في Python. لكن لسوء الحظ ، فقط في Python 3 أصبحت جميع السلاسل unicode ، ويجب على المبتدئين أن يقتلوا أنفسهم بسبب خطأ مثل:>>> مع open ("1.txt") كـ fh: s = fh.read () >>> طباعة s koshchey >>> parser_result = u "baba-yaga" # تعيين للوضوح ، فلنتخيل أن هذا هو ينتج عن بعض أعمال المحلل اللغوي >>>
او مثل هذا:
>>> str (parser_result) Traceback (آخر استدعاء): ملف "
دعونا نفهم ذلك ، ولكن بالترتيب.
لماذا قد يستخدم أي شخص Unicode؟
لماذا يقوم محلل html المفضل بإرجاع Unicode؟ دعها تعيد سلسلة عادية ، وسوف أتعامل معها هناك! حق؟ ليس حقيقيا. على الرغم من أنه يمكن (على الأرجح) تمثيل كل حرف من الأحرف الموجودة في Unicode في بعض الترميز أحادي البايت (ISO-8859-1 و cp1251 وغيرها يطلق عليها أحادية البايت ، لأنها ترمز أي حرف إلى بايت واحد بالضبط) ، ولكن ماذا تريد افعل إذا كان يجب أن يكون هناك أحرف في السلسلة من ترميزات مختلفة؟ تعيين ترميز منفصل لكل حرف؟ لا ، بالطبع عليك استخدام Unicode.لماذا نحتاج إلى نوع جديد "يونيكود"؟
لذلك وصلنا إلى الشيء الأكثر إثارة للاهتمام. ما هي السلسلة في Python 2.x؟ انه سهل بايت... مجرد بيانات ثنائية يمكن أن تكون أي شيء. في الواقع ، عندما نكتب شيئًا مثل: >>> x = "abcd" >>> x "abcd" لا يُنشئ المترجم متغيرًا يحتوي على الأحرف الأربعة الأولى من الأبجدية اللاتينية ، ولكن فقط التسلسل ("a" ، "b" ، "c" ، "d") بأربعة بايت ، وتستخدم الأحرف اللاتينية هنا حصريًا لتعيين قيمة البايت المحددة هذه. لذا فإن كلمة "a" هنا هي مجرد مرادف لـ "\ x61" ، وليس أكثر من ذلك بقليل. على سبيل المثال:>>> "\ x61" "a" >>> architecture.unpack ("> 4b"، x) # "x" هي فقط أربعة أحرف موقعة / غير موقعة (97 ، 98 ، 99 ، 100) >>> architecture.unpack ("> 2h"، x) # or two short (24930، 25444) >>> architecture.unpack ("> l"، x) # أو واحدة طويلة (1633837924،) >>> architecture.unpack ("> f" ، x) # or float (2.6100787562286154e + 20،) >>> architecture.unpack ("> d"، x * 2) # well، or half a double (1.2926117739473244e + 161،)
وهذا كل شيء!
والإجابة على السؤال - لماذا نحتاج إلى "unicode" أصبحت أكثر وضوحًا بالفعل - نحتاج إلى نوع يتم تمثيله بالأحرف وليس بالبايت.
حسنًا ، لقد اكتشفت ما هو الخيط. إذن ما هو Unicode في Python؟
"اكتب unicode" هو في الأساس تجريد يطبق فكرة Unicode (مجموعة من الأحرف والأرقام المرتبطة). لم يعد كائن من النوع "unicode" سلسلة من البايتات ، بل سلسلة من الأحرف الفعلية دون أي فكرة عن كيفية تخزين هذه الأحرف بشكل فعال في ذاكرة الكمبيوتر. إذا كنت تريد هذا أكثر مستوى عالالتجريد من سلاسل البايت (هذا ما يسميه Python 3 السلاسل العادية المستخدمة في Python 2.6).كيف أستخدم Unicode؟
يمكن إنشاء سلسلة Unicode في Python 2.6 بثلاث طرق (على الأقل بشكل طبيعي):- u "" الحرفية: >>> u "abc" u "abc"
- أسلوب "فك التشفير" لسلسلة البايت: >>> "abc" .decode ("ascii") u "abc"
- وظيفة "Unicode": >>> unicode ("abc"، "ascii") u "abc"
"\ x61" -> ترميز ascii -> أحرف لاتينية صغيرة "a" -> u "\ u0061" (نقطة unicode لهذا الحرف) أو "\ xe0" -> ترميز c1251 -> أحرف صغيرة "a" -> u " \ u0430 "
كيفية الحصول على سلسلة منتظمة من سلسلة يونيكود؟ تشفيرها:
>>> u "abc" .encode ("ascii") "abc"
خوارزمية الترميز هي بطبيعة الحال عكس تلك المذكورة أعلاه.
تذكر وليس مشوشًا - unicode == أحرف ، وسلسلة == بايت ، وبايت -> يتم فك تشفير شيء ذي معنى (أحرف) ، ويتم تشفير الأحرف -> بايت.
غير مشفر :(
دعونا نلقي نظرة على أمثلة من بداية المقال. كيف يعمل تسلسل السلسلة النصية و unicode؟ يجب تحويل سلسلة بسيطة إلى سلسلة unicode ، وبما أن المترجم الفوري لا يعرف الترميز ، فإنه يستخدم التشفير الافتراضي - ascii. إذا فشل هذا الترميز في فك تشفير السلسلة ، فسنحصل على خطأ قبيح. في هذه الحالة ، نحتاج إلى تحويل السلسلة إلى سلسلة Unicode بأنفسنا ، باستخدام التشفير الصحيح:>>> نوع الطباعة (parser_result) ، parser_result
عادةً ما يكون "UnicodeDecodeError" مؤشرًا لفك تشفير السلسلة إلى Unicode باستخدام التشفير الصحيح.
الآن باستخدام سلاسل "str" و unicode. لا تستخدم سلاسل "str" و unicode :) في "str" لا توجد طريقة لتحديد الترميز ، لذلك سيتم دائمًا استخدام الترميز الافتراضي وأي أحرف> 128 ستؤدي إلى حدوث خطأ. استخدم طريقة "التشفير":
>>> نوع (أنواع) الطباعة ، الصورة
"UnicodeEncodeError" هو علامة نحتاجها لتحديد الترميز الصحيح عند تحويل سلسلة unicode إلى سلسلة عادية (أو استخدم المعلمة الثانية "ignore" \ "replace" \ "xmlcharrefreplace" في طريقة "التشفير").
انا اريد اكثر!
حسنًا ، لنستخدم Baba Yaga من المثال أعلاه مرة أخرى:>>> parser_result = u "baba-yaga" # 1 >>> parser_result u "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" # 2 >>> print parser_result áááà-ÿãà # 3 >>> print parser_result.encode ("latin1") # 4 baba yaga >>> print parser_result.encode ("latin1"). فك الشفرة ("cp1251") # 5 baba yaga >>> print unicode ("baba yaga"، "cp1251" ) # 6 بابا ياجا
المثال ليس بسيطًا تمامًا ، ولكن يوجد كل شيء (حسنًا ، أو تقريبًا كل شيء). ما الذي يحدث هنا:
- ماذا لدينا عند المدخل؟ وحدات البايت التي يمررها IDLE إلى المترجم. ماذا تحتاج عند المخرج؟ يونيكود ، أي الشخصيات. يبقى تحويل البايت إلى أحرف - لكنك بحاجة إلى ترميز ، أليس كذلك؟ ما هو الترميز الذي سيتم استخدامه؟ نحن ننظر إلى أبعد من ذلك.
- هذه نقطة مهمة: >>> "baba-yaga" "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" >>> u "\ u00e1 \ u00e0 \ u00e1 \ u00e0- \ u00ff \ u00e3 \ u00e0 "== u" \ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0 "صحيح ، كما ترى ، لا تهتم Python باختيار التشفير - يتم تحويل البايت ببساطة إلى نقاط Unicode:
>>> ord ("a") 224 >>> ord (u "a") 224 - هنا فقط تكمن المشكلة - الحرف 224 في cp1251 (الترميز المستخدم من قبل المترجم الفوري) ليس هو نفسه على الإطلاق 224 في Unicode. وبسبب هذا ، فإننا نتصدع عند محاولة طباعة سلسلة unicode الخاصة بنا.
- كيف تساعد امرأة؟ اتضح أن أول 256 حرفًا من أحرف Unicode هي نفسها الموجودة في ترميز ISO-8859-1 \ latin1 ، على التوالي ، إذا استخدمناها لتشفير سلسلة Unicode ، نحصل على وحدات البايت التي أدخلناها بأنفسنا (من يهمه الأمر - الكائنات) / unicodeobject.c ، يبحث عن تعريف الوظيفة "unicode_encode_ucs1"):
>>> parser_result.encode ("latin1") "\ xe1 \ xe0 \ xe1 \ xe0- \ xff \ xe3 \ xe0" - كيف تحصل على بابا في يونيكود؟ من الضروري تحديد الترميز الذي يجب استخدامه:
>>> parser_result.encode ("latin1"). فك الشفرة ("cp1251") u "\ u0431 \ u0430 \ u0431 \ u0430- \ u044f \ u0433 \ u0430" - الطريقة من النقطة رقم 5 ليست ساخنة بالتأكيد ، فهي أكثر ملاءمة لاستخدام يونيكود مدمج.
هناك أيضًا طريقة لاستخدام "u" "" لتمثيل ، على سبيل المثال ، السيريلية ، دون تحديد الترميز أو نقاط unicode غير القابلة للقراءة (أي ، "u" \ u1234 ""). الطريقة ليست مريحة تمامًا ، ولكنها مثيرة للاهتمام هي استخدام أكواد كيانات يونيكود:
>>> s = u "\ N (CYRILLIC SMALL LETTER KA) \ N (CYRILLIC SMALL LETTER O) \ N (CYRILLIC SMALL LETTER SHCHA) \ N (CYRILLIC SMALL LETTER IE) \ N (CYRILLIC SMALL LETTER SHORT I)"> >> طباعة s koshchey
حسنا هذا كل شيء. النصيحة الرئيسية هي عدم الخلط بين "التشفير" \ "فك الشفرة" وفهم الاختلافات بين البايت والأحرف.
بايثون 3
هنا بدون رمز ، لأنه لا توجد خبرة. يقول الشهود إن كل شيء هناك أبسط وأكثر متعة. من سيتولى على القطط إظهار الاختلافات بين هنا (Python 2.x) و (Python 3.x) - الاحترام والاحترام.صحيح
نظرًا لأننا نتحدث عن الترميزات ، فإنني أوصي بمورد يساعد من وقت لآخر في التغلب على krakozyabry - http://2cyr.com/decode/؟lang=ru.Unicode HOWTO هي وثيقة رسمية حول مكان وكيفية ولماذا Unicode في Python 2.x.
شكرا لاهتمامكم. سأكون ممتنا لتعليقاتك على انفراد. اضف اشارة
نقاط رمز Unicode والأحرف الروسية في أكواد وبرامج Java المصدر. دينار 1.6.
ما يكفي من المطورين البرمجياتفي الواقع ، ليس لديك فهم واضح لمجموعات الأحرف والتشفيرات و Unicode والمواد ذات الصلة. حتى في الوقت الحاضر ، غالبًا ما تتجاهل العديد من البرامج تحويلات الأحرف التي تمت مواجهتها ، حتى البرامج التي يبدو أنها مصممة بتقنيات Java متوافقة مع Unicode. غالبًا ما تستخدم بلا مبالاة مع أحرف 8 بت ، مما يجعل من المستحيل تطوير تطبيقات ويب متعددة اللغات جيدة. هذه المقالة عبارة عن مجموعة من المقالات حول ترميز Unicode ، ولكن المقالة الرائدة التي كتبها Joel Spolsky هي الحد الأدنى المطلق الذي يجب أن يعرفه كل مطور برامج تمامًا ، بشكل إيجابي ، عن Unicode ومجموعات الأحرف (10/08/2003).تاريخ إنشاء أنواع مختلفة من الترميزات
كل الأشياء التي تقول "نص عادي = ASCII = أحرف 8 بت" غير صحيحة. كانت الأحرف الوحيدة التي يمكن عرضها بشكل صحيح تحت أي ظرف من الظروف هي الأحرف الإنجليزية بدون علامات التشكيل برموز 32 إلى 127. بالنسبة لهذه الأحرف ، يوجد رمز يسمى ASCII كان قادرًا على تمثيل جميع الأحرف. سيكون للحرف "A" رمز 65 ، والمسافة ستكون رمز 32 ، وهكذا. يمكن تخزين هذه الأحرف بشكل ملائم في 7 بتات. استخدمت معظم أجهزة الكمبيوتر في تلك الأيام سجلات 8 بت ، لذلك لا يمكنك فقط تخزين كل حرف ASCII ممكن ، ولكن لديك أيضًا قدرًا كبيرًا من المدخرات ، إذا كان لديك مثل هذه النزوة ، يمكنك استخدامها لأغراضك الخاصة. تم استدعاء الرموز الأقل من 32 غير قابلة للطباعة وتم استخدامها لأحرف التحكم ، على سبيل المثال ، تسبب الحرف 7 في إصدار جهاز الكمبيوتر الخاص بك صوت صفير ، وكان الحرف 12 هو حرف نهاية الصفحة ، مما تسبب في قيام الطابعة بتمرير الورقة الحالية من الورق وتحميل واحدة جديدة.
نظرًا لأن البايت هي ثمانية بتات ، فقد اعتقد الكثير "أنه يمكننا استخدام الرموز 128-255 لأغراضنا الخاصة." تكمن المشكلة في أنه بالنسبة للعديد من الأشخاص جاءت هذه الفكرة في وقت واحد تقريبًا ، ولكن كان لكل شخص أفكاره الخاصة حول ما يجب وضعه في مكانه باستخدام الرموز من 128 إلى 255. كان لدى IBM-PC شيء أصبح يُعرف باسم مجموعة الأحرف OEM ، والتي كان لها بعض علامات التشكيل للغات الأوروبية ومجموعة من الأحرف لرسم الخطوط: خطوط أفقية ، خطوط عمودية ، زوايا ، تقاطعات ، إلخ. ويمكنك استخدام هذه الرموز لعمل أزرار أنيقة ورسم خطوط على الشاشة لا يزال بإمكانك رؤيتها على بعض أجهزة الكمبيوتر القديمة. على سبيل المثال ، في بعض أجهزة الكمبيوتر ، تم عرض رمز الحرف 130 على أنه e ، ولكن على أجهزة الكمبيوتر المباعة في إسرائيل كان الحرف العبري Gimel (؟). إذا أرسل الأمريكيون سيرتهم الذاتية إلى إسرائيل ، فستصل كـ r؟ Sum. في كثير من الحالات ، كما في حالة اللغة الروسية ، كانت هناك العديد من الأفكار المختلفة حول ما يجب فعله مع الأحرف الـ 128 العليا ، وبالتالي لا يمكنك حتى تبادل المستندات باللغة الروسية بشكل موثوق.
في النهاية ، تم تقليل تنوع ترميزات OEM إلى معيار ANSI. حدد معيار ANSI الأحرف التي تقل عن 128 ، وكانت هذه المنطقة في الأساس هي نفسها كما في ASCII ، ولكن كان هناك العديد من طرق مختلفةتتعامل مع الأحرف 128 وما فوق حسب المكان الذي تعيش فيه. تم استدعاء هذه الأنظمة المختلفة صفحات الرموز. على سبيل المثال ، في إسرائيل ، استخدم DOS صفحة الرموز 862 ، بينما استخدم المستخدمون اليونانيون الصفحة 737. كانوا متماثلين أقل من 128 ، لكنهم مختلفون عن 128 ، حيث توجد كل هذه الأحرف. دعمت الإصدارات الوطنية من MS-DOS العديد من صفحات الرموز هذه ، وتعاملت مع جميع اللغات من الإنجليزية إلى الأيسلندية ، وكان هناك عدد قليل من صفحات الرموز "متعددة اللغات" التي يمكن أن تجعلها الإسبرانتو والجاليكية. مجموعة من اللغات ، منتشرة في إسبانيا ، أصلية 4 ملايين شخص) على نفس الكمبيوتر! لكن الحصول ، لنقل ، العبرية واليونانية على نفس الكمبيوتر كان مستحيلًا تمامًا ، إلا إذا كتبت برنامجك الخاص الذي يعرض كل شيء باستخدام رسومات نقطية ، لأن اللغتين العبرية واليونانية تتطلبان صفحات رموز مختلفة بتفسيرات مختلفة ، وأرقام رئيسية.
في غضون ذلك ، في آسيا ، نظرًا لحقيقة أن الأبجدية الآسيوية تحتوي على آلاف الأحرف التي لا يمكن أن تتناسب أبدًا مع 8 بتات ، فقد تمت معالجة هذه المشكلة من خلال نظام DBCS المعقد ، وهو "مجموعة أحرف مزدوجة البايت" حيث تم تخزين بعض الأحرف في بايت واحد ، في حين أن البعض الآخر استغرق اثنين. كان من السهل جدًا المضي قدمًا على طول الخط ، لكن من المستحيل تمامًا التحرك إلى الخلف. لم يتمكن المبرمجون من استخدام s ++ و s-- للمضي قدمًا وللخلف ، وكان عليهم الاتصال وظائف خاصةمن عرف كيف يتعامل مع هذه الفوضى.
ومع ذلك ، فإن معظم الناس يغضون الطرف عن حقيقة أن البايت كان حرفًا وأن الحرف كان 8 بت ، وطالما لم يكن عليك نقل سطر من كمبيوتر إلى آخر ، أو إذا لم تتحدث أكثر من لغة ، لقد نجحت. ولكن ، بالطبع ، بمجرد أن بدأ استخدام الإنترنت بشكل جماعي ، أصبح من الشائع جدًا نقل الخطوط من كمبيوتر إلى آخر. تم التغلب على الفوضى في هذا الأمر باستخدام Unicode.
يونيكود
كانت Unicode محاولة جريئة لإنشاء مجموعة أحرف واحدة تتضمن جميع أنظمة الكتابة الحقيقية على هذا الكوكب ، بالإضافة إلى بعض الأنظمة الخيالية. لدى بعض الناس فكرة خاطئة مفادها أن Unicode هو رمز عادي من 16 بت حيث يبلغ طول كل حرف 16 بت وبالتالي هناك 65536 حرفًا محتملاً. في الواقع، وهذا ليس صحيحا. هذا هو المفهوم الخاطئ الأكثر شيوعًا حول Unicode.
في الواقع ، يتخذ Unicode نهجًا غير عادي لفهم مفهوم الشخصية. حتى الآن ، افترضنا أنه يتم تعيين الأحرف إلى مجموعة من وحدات البت التي يمكنك تخزينها على القرص أو في الذاكرة:
أ - & GT 0100 0001
في Unicode ، يرسم حرف ما إلى شيء يسمى نقطة الرمز ، وهو مجرد مفهوم نظري. كيف يتم تمثيل نقطة الرمز هذه في الذاكرة أو على القرص هي قصة أخرى. الخامس حرف Unicodeوهذه مجرد فكرة أفلاطونية (eidos) (ترجمة تقريبًا: مفهوم فلسفة أفلاطون ، eidos هي كيانات مثالية ، خالية من المادية وهي حقيقة موضوعية حقًا ، خارج أشياء وظواهر محددة).
أ هالذي - التي بلاتونوفيختلف "أ" عن "ب" ويختلف عن أ, لكنها نفس الشيءأ أ و أ. فكرة ذلك وفي Times New Roman هي نفسها A في Helvetica ، لكنها تختلف عن الأحرف الصغيرة "a" لا تبدو مثيرة للجدل في فهم الناس. ولكن من وجهة نظر علوم الكمبيوتر ومن وجهة نظر اللغة ، فإن تعريف الحرف نفسه متناقض. هل الحرف الألماني ß حرف حقيقي أم مجرد طريقة رائعة لكتابة ss؟ إذا تغيرت هجاء حرف في نهاية الكلمة ، فهل يصبح حرفًا مختلفًا؟ تقول العبرية "نعم" ، والعربية تقول "لا". في كلتا الحالتين ، اكتشف الأشخاص الأذكياء في اتحاد Unicode ذلك بعد الكثير من الجدل السياسي ، ولا داعي للقلق بشأن ذلك. لقد تم بالفعل فهم كل شيء أمامنا.تم تخصيص رقم سحري لكل حرف أفلاطوني في كل أبجدية من قبل اتحاد Unicode ، والذي تمت كتابته على النحو التالي: U + 0645. هذا الرقم السحري يسمى رمز نقطة. يرمز U + إلى "Unicode" والأرقام سداسية عشرية. الرقم U + FEC9 هو الحرف العربي Ain. يتوافق الحرف الإنجليزي A مع U + 0041.
لا يوجد حد فعليًا لعدد الأحرف التي يمكن تحديدها بواسطة Unicode ، وفي الواقع لقد تجاوزوا بالفعل الحد البالغ 65.536 ، لذلك لا يمكن ضغط كل حرف من Unicode في الواقع إلى وحدتي بايت.
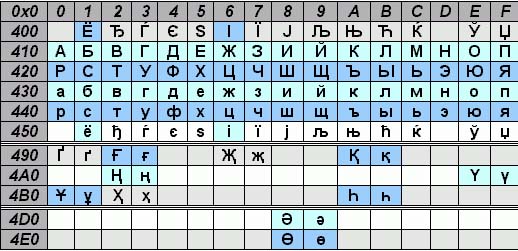
بالنسبة إلى السيريلية في UNICODE ، يتراوح نطاق الرموز من 0x0400 إلى 0x04FF. يعرض هذا الجدول جزءًا فقط من الأحرف في هذا النطاق ، لكن المعيار يحدد معظم الرموز في هذا النطاق.
لنتخيل أن لدينا خطًا:
مهلا! والتي ، في Unicode ، تطابق نقاط الكود السبع هذه: U + 041F U + 0440 U + 0438 U + 0432 U + 0435 U + 0442 U + 0021
مجرد مجموعة من نقاط التعليمات البرمجية. الأرقام حقيقية.
لمعرفة الشكل الذي سيبدو عليه ملف نصي Unicode ، يمكنك تشغيل برنامج المفكرة في Windows ، وإدخال السطر المحدد ، ثم حفظه ملف نصياختر ترميز Unicode.
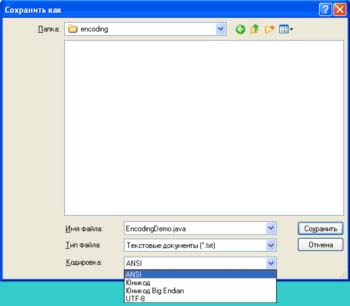
يقدم البرنامج التوفير في ثلاثة أصناف ترميزات يونيكود... الخيار الأول هو طريقة للكتابة مع بايت أقل أهمية في المقدمة (endian الصغير) ، والثاني مع البايت الأكثر أهمية في المقدمة (endian كبير). أي خيار هو الصحيح؟
هذا ما يشبه ملف التفريغ الداخلي الكبير بالسلسلة "Hello!"
وهذه هي الطريقة التي يبدو بها ملف تفريغ بالسلسلة "Hello!" ، محفوظ بتنسيق Unicode (القليل من endian):
وهذه هي الطريقة التي يبدو بها ملف تفريغ بالسلسلة "Hello!" ، محفوظ بتنسيق Unicode (UTF-8):
أرادت التطبيقات المبكرة أن تكون قادرة على تخزين نقاط كود Unicode بتنسيق عالي أو منخفض ، اعتمادًا على التنسيق الذي كان المعالج فيه أسرع. ثم كانت هناك طريقتان لتخزين Unicode. أدى ذلك إلى اصطلاح خيالي لتخزين \ uFFFE كود في بداية كل سطر Unicode. يسمى هذا التوقيع علامة ترتيب البايت. إذا قمت بتبديل وحدات البايت العالية والمنخفضة ، فيجب أن تكون \ uFFFE في البداية ، وسيعرف الشخص الذي يقرأ الخط الخاص بك أنه يتبادل البايت في كل زوج. هذا التوقيع محجوز في معيار Unicode.
ينص معيار Unicode على أن ترتيب البايت الافتراضي هو إما endian كبير أو endian صغير. في الواقع ، كلا الأمرين صحيحان ، ويختار مصممو النظام أحدهما لأنفسهم. لا تقلق إذا كان نظامك يتصل بنظام آخر ويستخدم كلاهما نظام endian الصغير.
ومع ذلك ، إذا كان Windows الخاص بك يتصل بخادم UNIX يستخدم نظام endian كبير ، فيجب أن يقوم أحد الأنظمة بعملية تحويل الشفرة. في هذه الحالة معيار يونيكودتنص على أنه يمكنك اختيار أي من الحلول التالية للمشكلة:
- عندما يقوم نظامان ، باستخدام ترتيب بايت Unicode مختلف ، بتبادل البيانات (بدون استخدام أي بروتوكولات خاصة) ، يجب أن يكون ترتيب البايت كبير. المعيار يسميها العنوان الأساسيترتيب البايت.
- يجب أن تبدأ كل سلسلة Unicode برمز \ uFEFF. رمز \ uFFFE ، وهو انعكاس لإشارة الطلب. لذلك ، إذا رأى المستلم الرمز \ uFEFF باعتباره الحرف الأول ، فهذا يعني أن البايت بترتيب endian صغير. ومع ذلك ، في الواقع ، ليست كل سلسلة Unicode لها علامة ترتيب بايت في البداية.
الطريقة الثانية هي الأكثر تنوعًا والأفضل.
لفترة من الوقت ، بدا الجميع سعداء ، لكن المبرمجين الناطقين باللغة الإنجليزية نظروا إلى النص الإنجليزي في الغالب ونادرًا ما استخدموا نقاط الرمز فوق U + 00FF. لهذا السبب وحده ، تجاهل الكثيرون Unicode لعدة سنوات.
تم اختراع المفهوم الرائع لـ UTF-8 خصيصًا لهذا الغرض.
UTF-8
كان UTF-8 نظامًا آخر لتخزين تسلسل نقاط رمز Unicode ، أرقام U + ذاتها ، باستخدام نفس 8 بتات في الذاكرة. في UTF-8 ، تم تخزين كل نقطة رمز مرقمة من 0 إلى 127 في بايت واحد.
في الواقع ، هذا ترميز مع عدد متغير من بايتات التشفير للتخزين ، يتم استخدام 2 ، 3 ، وفي الواقع ، ما يصل إلى 6 بايت. إذا كان الحرف ينتمي إلى مجموعة ASCII (رمز في النطاق 0x00-0x7F) ، فسيتم تشفيره بنفس الطريقة كما في ASCII في بايت واحد. إذا كان الرمز الموحد للحرف أكبر من أو يساوي 0x80 ، فإن وحدات البت الخاصة به يتم تجميعها في تسلسل من البايت وفقًا للقاعدة التالية:
قد تلاحظ أنه إذا بدأ البايت بصفر بت ، فإنه يكون حرف ASCII أحادي البايت. إذا بدأ البايت بالرقم 11 ... ، فهذا هو بايت البداية لتسلسل متعدد البايتات يشفر حرفًا ، وعدد وحدات الرأس التي يساوي عدد وحدات البايت في التسلسل. إذا بدأ البايت بـ 10 ... ، فهو عبارة عن بايت "نقل" تسلسلي من سلسلة من البايتات ، تم تحديد رقمها بواسطة بايت البداية. حسنا و بت يونيكوديتم تعبئة الأحرف في بتات "النقل" من البايتات الأولية والبايت التسلسلي ، والمشار إليها في الجدول على أنها التسلسل "xx..x".
يمكن رؤية العدد المتغير لبايتات التشفير من ملف تفريغ الملف أدناه.
ملف تفريغ بسلسلة "مرحبًا!" محفوظ بتنسيق Unicode (UTF-8):
ملف تفريغ بالسلسلة "مرحبًا!" محفوظ بتنسيق Unicode (UTF-8):
أحد الآثار الجانبية الرائعة لهذا هو أن النص الإنجليزي يبدو تمامًا في UTF-8 كما هو الحال في ASCII ، لذلك لا يلاحظ الأمريكيون حتى أن هناك شيئًا خاطئًا. فقط بقية العالم يجب أن يتغلب على العقبات. على وجه التحديد ، مرحبًا ، ما كان U + 0048 U + 0065 U + 006C U + 006C U + 006F سيتم تخزينه الآن في نفس 48 65 6C 6C 6F ، تمامًا مثل ASCII و ANSI وأي رموز OEM محددة أخرى على هذا الكوكب. إذا كنت شجاعًا بما يكفي لاستخدام علامات التشكيل أو الحروف اليونانيةأو الأحرف Klingon ، سيتعين عليك استخدام وحدات بايت متعددة لتخزين نقطة رمز واحدة ، لكن الأمريكيين لن يلاحظوا ذلك أبدًا. يحتوي UTF-8 أيضًا على ميزة لطيفة: الكود القديم ، الجاهل بتنسيق السلسلة الجديد ، والتعامل مع السلاسل ذات البايت الفارغ في نهاية السطر ، لن يقطع السلاسل.
ترميزات Unicode الأخرى
دعنا نعود إلى الطرق الثلاث لترميز Unicode. الطرق التقليديةيسمى "تخزينه في 2 بايت" UCS-2 (لأنه يحتوي على وحدتي بايت) أو UTF-16 (لأنه يحتوي على 16 بت) ، ولا يزال يتعين عليك معرفة ما إذا كان رمز UCS-2 ذو البايت العالي في البداية أو مع البايت الأكثر أهمية في النهاية. وهناك معيار UTF-8 الشهير ، حيث تتمتع السلاسل بميزة رائعة للعمل أيضًا في البرامج القديمة التي تعمل مع النص الإنجليزي ، وفي البرامج الذكية الجديدة التي تعمل بشكل مثالي على مجموعات الأحرف الأخرى إلى جانب ASCII.
هناك بالفعل مجموعة كاملة من الطرق الأخرى لترميز Unicode. هناك شيء يسمى UTF-7 ، وهو يشبه إلى حد كبير UTF-8 ، ولكنه يضمن أن يكون البت الأكثر أهمية هو صفر دائمًا. ثم هناك UCS-4 ، الذي يخزن كل نقطة رمز في 4 بايت ويضمن أن يتم تخزين جميع الأحرف تمامًا بنفس عدد البايت ، ولكن مثل هذا الضياع في الذاكرة لا يتم تبريره دائمًا بمثل هذا الضمان.
على سبيل المثال ، يمكنك Unicode السلسلة Hello (U + 0048 U + 0065 U + 006C U + 006C U + 006F) في ASCII أو OEM اليونانية القديمة أو العبرية ترميز ANSI، أو في أي من مئات الترميزات التي تم اختراعها حتى يومنا هذا ، مع مشكلة واحدة: قد لا يتم عرض بعض الشخصيات! إذا لم يكن هناك ما يعادل نقطة رمز Unicode التي تحاول العثور على مكافئ لها في البعض جدول الكودالتي تحاول إجراء التحويل لها ، فعادة ما تحصل على علامة استفهام صغيرة :؟ أو ، إذا كنت مبرمجًا جيدًا حقًا ، فأنت مربع.
هناك المئات من الترميزات التقليدية التي يمكنها فقط تخزين بعض نقاط الكود بشكل صحيح واستبدال جميع نقاط الكود الأخرى بعلامات استفهام. على سبيل المثال ، بعض ترميزات النص الإنجليزية الشائعة هي Windows 1252 ( معيار Windows 9x للغات أوروبا الغربية) و ISO-8859-1 ، المعروف أيضًا باسم Latin-1 (مناسب أيضًا لأي لغة أوروبية غربية). لكن حاول تحويل الأحرف الروسية أو العبرية في هذه الترميزات ، وسوف ينتهي بك الأمر بعدد لا بأس به من علامات الاستفهام. إن الشيء العظيم في UTF 7 و 8 و 16 و 32 هو قدرتها على تخزين أي نقطة رمز بشكل صحيح.
32 نقطة رمز بت لأحرف Unicode في Java
يقدم Java 2 5.0 تحسينات كبيرة لأنواع الأحرف والسلسلة لدعم 32 بت أحرف Unicode... في الماضي ، كان من الممكن تخزين جميع أحرف Unicode في ستة عشر بتًا ، والتي تساوي حجم قيمة char (وحجم القيمة الموجودة في كائن Character) ، نظرًا لأن هذه القيم كانت في النطاق من 0 إلى FFFF . ولكن لبعض الوقت ، تم توسيع مجموعة أحرف Unicode وتتطلب الآن أكثر من 16 بتًا لتخزين حرف. يتضمن الإصدار الجديد من مجموعات أحرف Unicode أحرفًا تتراوح من 0 إلى 10FFFF.
نقطة رمز أو نقطة رمز ، وحدة رمز أو وحدة رمز ، وحرف تكميلي. بالنسبة إلى Java ، تعد نقطة الرمز رمز حرف يقع في النطاق من 0 إلى 10FFFF. في لغة Java ، يُستخدم المصطلح "وحدة التعليمات البرمجية" للإشارة إلى أحرف 16 بت. الأحرف ذات القيم الأكبر من FFFF تسمى مكملة.
أدى توسيع مجموعة أحرف Unicode إلى خلق مشاكل أساسية لـ لغة جافا... نظرًا لأن الحرف التكميلي له قيمة أكبر مما يمكن أن يستوعبه نوع الحرف ، فقد تطلب الأمر بعض الوسائل لتخزين ومعالجة الأحرف الإضافية. الخامس إصدارات Javaيعمل الإصدار 2 5.0 على إصلاح هذه المشكلة بطريقتين. أولاً ، تستخدم لغة Java قيمتي حرف لتمثيل حرف إضافي. الأول يسمى البديل العالي والثاني يسمى البديل المنخفض. تم تطوير طرق جديدة ، مثل codePointAt () ، لتحويل نقاط الرمز إلى أحرف تكميلية والعكس صحيح.
ثانيًا ، تقوم Java بتحميل بعض الطرق الموجودة مسبقًا في صنف Character و String. تستخدم المتغيرات المحملة بشكل زائد في الأساليب بيانات من النوع int بدلاً من char. نظرًا لأن حجم متغير أو ثابت من النوع int كبير بما يكفي لاستيعاب أي حرف كقيمة واحدة ، يمكن استخدام هذا النوع لتخزين أي حرف. على سبيل المثال ، الطريقة isDigit () لديها الآن خياران ، كما هو موضح أدناه:
أول هذه الخيارات هو الأصل ، والثاني هو الإصدار الذي يدعم نقاط كود 32 بت. كل الطرق… ، مثل isLetter () و isSpaceChar () ، لها إصدارات من رمز نقطة ، مثلها مثل ... طرق مثل toUpperCase () و toLowerCase ().
بالإضافة إلى الطرق المحملة أكثر من اللازم لمعالجة نقاط الرمز ، تتضمن لغة Java طرقًا جديدة في فئة الأحرف توفر دعمًا إضافيًا لنقاط التعليمات البرمجية. بعضها مذكور في الجدول:
| طريقة | وصف |
| static int charCount (int cp) | تُرجع 1 إذا كان من الممكن تمثيل cp بحرف واحد. تُرجع 2 إذا كانت هناك حاجة إلى قيمتي أحرف. |
| ثابت int codePointAt (CharSequence chars، int loc) | |
| ثابت int codePointAt (chars، int loc) | تُرجع نقطة الرمز لموضع الحرف المحدد في المعلمة loc |
| ثابت int codePointBefore (CharSequence chars، int loc) | |
| ثابت int codePointBefore (chars، int loc) | تُرجع نقطة الرمز لموضع الحرف الذي يسبق الموضع المحدد في المعلمة loc |
| ثابت منطقي هو SublementaryCodePoint (int cp) | إرجاع صحيح إذا احتوى cp على حرف إضافي |
| قيمة منطقية ثابتة هي عالية السوروجيت (شار تش) | إرجاع صحيح إذا كان ch يحتوي على حرف مركب أعلى صالح. |
| ثابت منطقي isLowSerogate (شار تش) | إرجاع صحيح إذا كان ch يحتوي على حرف بديل صالح. |
| ثابت منطقي isSurrogatePair (char highCh، char lowCh) | يعود صحيحًا إذا كان كل من highCh و lowCh يشكلان زوجًا بديلًا صالحًا. |
| ثابت منطقي isValidCodePoint (int cp) | إرجاع صحيح إذا احتوت cp على نقطة رمز صالحة. |
| حرف ثابت toChars (int cp) | يحول نقطة الشفرة الموجودة في cp إلى مكافئها من char ، والذي قد يتطلب قيمتي char. إرجاع مصفوفة تحتوي على النتيجة ... إلحاق !!! |
| static int toChars (int cp ، char target ، int loc) | يحول نقطة الشفرة الموجودة في cp إلى مكافئها من char ، ويخزن النتيجة في الهدف ، بدءًا من الموضع المحدد في loc. تُرجع 1 إذا كان من الممكن تمثيل cp بحرف واحد ، و 2 بخلاف ذلك. |
| ثابت int toCodePoint (char ighCh، char lowCh) | يحول highCh و lowCh إلى نقاط الرمز المكافئة لهما. |
تحتوي فئة String على عدد من الطرق للتعامل مع نقاط الرمز. تمت إضافة المُنشئ التالي أيضًا إلى فئة String لدعم مجموعة أحرف Unicode الممتدة:
سلسلة (int codePoints، int startIndex، int numChars)
في الصيغة أعلاه ، تعد CodePoints مصفوفة تحتوي على نقاط رمز. يتم تشكيل سلسلة الطول الناتجة من numChars ، بدءًا من موضع مؤشر البداية.
عدة طرق لفئة String توفر دعمًا لنقطة رمز 32 بت لأحرف Unicode.
إخراج وحدة التحكم في Windows. أمر Chcp
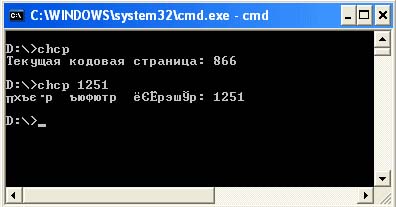
أغلبية برامج بسيطةمكتوب بلغة جافا إخراج أي بيانات إلى وحدة التحكم. يوفر إخراج وحدة التحكم القدرة على اختيار الترميز الذي سيتم إخراج بيانات برنامجك به. يمكنك تشغيل نافذة وحدة التحكم بالنقر فوق ابدأ -> تشغيل ، ثم الدخول والتشغيل الأمر cmd... بشكل افتراضي ، يكون الإخراج إلى وحدة التحكم في Windows بترميز Cp866. لمعرفة ما هو ترميز الأحرف التي يتم عرضها في وحدة التحكم ، يجب عليك كتابة الأمر chcp. باستخدام نفس الأمر ، يمكنك ضبط الترميز الذي سيتم عرض الأحرف به. على سبيل المثال chcp 1251. في الواقع ، يتم إنشاء هذا الأمر فقط لعكس أو تغيير رقم صفحة التعليمات البرمجية الحالية لوحدة التحكم.
سيتم عرض صفحات الترميز بخلاف Cp866 بشكل صحيح فقط في وضع ملء الشاشة أو في نافذة سطر الأوامرباستخدام خطوط تروتايب. على سبيل المثال:
لمشاهدة المخرجات اللاحقة ، تحتاج إلى تغيير الخط الحالي إلى خط True Type. حرك المؤشر فوق عنوان نافذة وحدة التحكم ، انقر فوق انقر على اليمينالماوس وحدد خيار "خصائص". في النافذة التي تظهر ، انتقل إلى علامة التبويب "الخط" وفيها حدد الخط المقابل الذي سيكون هناك حرف مزدوج T. سيُطلب منك الحفظ. هذا الإعدادللنافذة الحالية أو لجميع النوافذ.
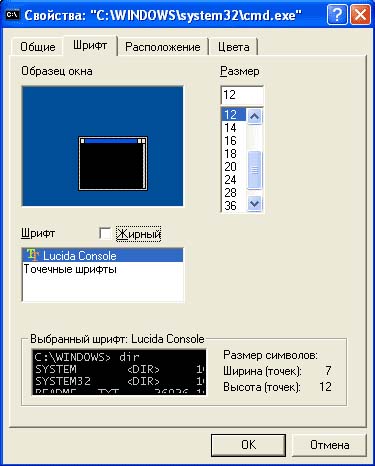
نتيجة لذلك ، ستبدو نافذة وحدة التحكم الخاصة بك كما يلي:
وبالتالي ، من خلال معالجة هذا الأمر ، يمكنك رؤية نتائج إخراج برنامجك ، اعتمادًا على الترميز.
خصائص النظام file.encoding و console.encoding وإخراج وحدة التحكم
قبل التطرق إلى موضوع الترميزات في أكواد البرامج المصدرية ، يجب أن تفهم بوضوح الغرض منها وكيف تعمل خصائص نظام file.encoding و console.encoding. بالإضافة إلى خصائص النظام هذه ، هناك عدد من الخصائص الأخرى. يمكنك عرض جميع خصائص النظام الحالية باستخدام البرنامج التالي:
استيراد java.io. * ؛ استيراد java.util. * ؛ فئة عامة getPropertiesDemo (عامة ثابتة باطلة رئيسية (String args) (String s ؛ لـ (Enumeration e = System.getProperties (). propertyNames () ؛ e.hasMoreElements () ؛) (s = e.nextElement (). toString () ؛ System.out.println (s + "=" + System.getProperty (s)) ؛)))
عينة من مخرجات البرنامج:
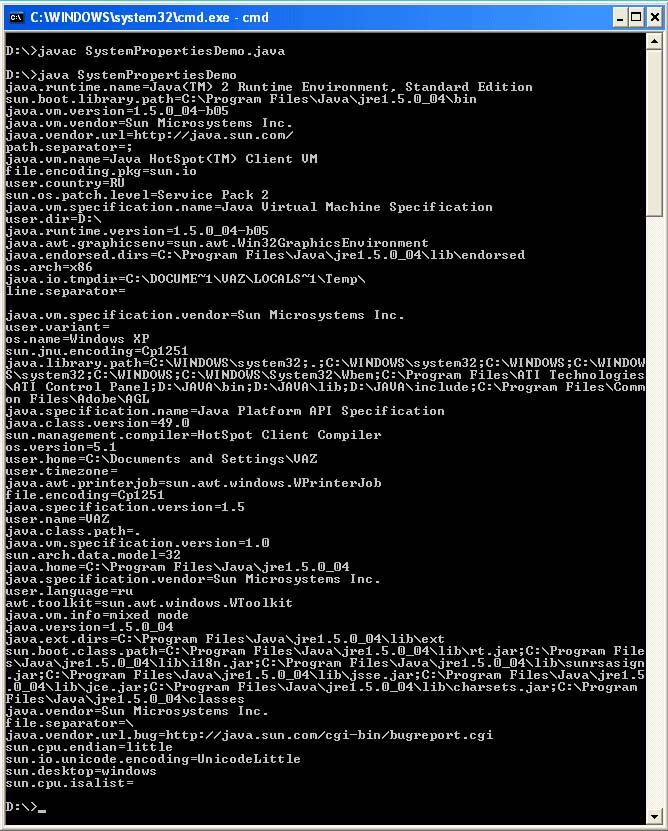
في نظام التشغيل Windows ، بشكل افتراضي file.encoding = Сp1251. ومع ذلك ، هناك خاصية أخرى ، console.encoding ، والتي تحدد الترميز الذي سيتم إخراجه إلى وحدة التحكم. يخبر file.encoding جهاز Java عن الترميز لقراءة أكواد المصدر للبرامج ، إذا لم يتم تحديد الترميز من قبل المستخدم أثناء التجميع. في الواقع ، تنطبق خاصية النظام هذه أيضًا على الإخراج باستخدام System.out.println ().
بشكل افتراضي ، لم يتم تعيين هذه الخاصية. يمكن أيضًا تعيين خصائص النظام هذه في برنامجك ، ومع ذلك ، لن تكون ذات صلة بعد الآن ، نظرًا لأن الجهاز الظاهري يستخدم القيم التي تمت قراءتها قبل تجميع البرنامج وتشغيله. أيضًا ، بمجرد تشغيل البرنامج ، تتم استعادة خصائص النظام. يمكنك التحقق من ذلك عن طريق تشغيل البرنامج التالي مرتين.
/ ** *author & lta href = "mailto: [بريد إلكتروني محمي]"& gt Victor Zagrebin & lt / a & gt * / public class SetPropertyDemo (عامة ثابتة باطلة رئيسية (سلاسل سلسلة) (System.out.println (" file.encoding before = "+ System.getProperty (" file.encoding ") )؛ System. out.println ("console.encoding before =" + System.getProperty ("console.encoding")) ؛ System.setProperty ("file.encoding"، "Cp866")؛ System.setProperty ("وحدة التحكم. encoding "،" Cp866 ")؛ System.out.println (" file.encoding after = "+ System.getProperty (" file.encoding "))؛ System.out.println (" console.encoding after = "+ System. getProperty ("console .encoding")) ؛)) 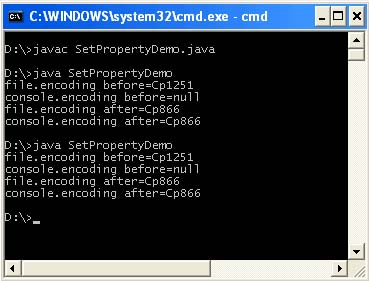
يعد تعيين هذه الخصائص في البرنامج ضروريًا عند استخدامه في الكود التالي قبل إنهاء البرنامج.
دعونا نعيد إنتاج عدد من الأمثلة النموذجية للمشاكل التي يواجهها المبرمجون أثناء الإخراج. لنفترض أن لدينا البرنامج التالي:
فئة عامة CyryllicDemo (عامة ثابتة باطلة رئيسية (String args) (String s1 = ""؛ String s2 = ""؛ System.out.println (s1)؛ System.out.println (s1)؛)) بالإضافة إلى هذا البرنامج ، سنعمل على عوامل إضافية:
- أمر التجميع
- أمر إطلاق؛
- ترميز شفرة مصدر البرنامج (مثبت في معظم برامج تحرير النصوص) ؛
- ترميز خرج وحدة التحكم (يتم استخدام Cp866 افتراضيًا أو تعيينه باستخدام الأمر chcp) ؛
- الإخراج المرئي في نافذة وحدة التحكم.
جافاك CyryllicDemo.java
جافا CyryllicDemo
ترميز الملف: Cp1251
ترميز وحدة التحكم: CP866
استنتاج :
└┴┬├─┼╞╟╚╔╩╦╠═╬╧╨╤╥╙╘╒╓╫╪┘▄█┌▌▐ ▀
rstufhtschshshch'yueyuyoЄєЇїЎў °∙№√ ·¤■
جافاك CyryllicDemo.java
ترميز الملف: Cp866
ترميز وحدة التحكم: Cp866
استنتاج :
CyryllicDemo.java:5: تحذير: حرف غير قابل للتعيين لترميز Cp1251
String s1 = "ABVGDEZHZYKLMNOPRSTUFHTSCH؟ SHY'EUYA" ؛
جافاك CyryllicDemo.java -تشفير Cp866
جافا -
ترميز الملف:كب 866
ترميز وحدة التحكم: Cp866
استنتاج :
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshshchyyueyuya
جافاك CyryllicDemo.java - ترميز Cp1251
جافا -Dfile.encoding = Cp866 CyryllicDemo
ترميز الملف: Cp1251
ترميز وحدة التحكم: CP866
استنتاج :
ABVGDEZHZYKLMNOPRSTUFKHTSZHSHCHYYUYA
abvgdezhziyklmnoprstufkhtschshshchyyueyuya
يجب إيلاء اهتمام خاص لمشكلة "أين ذهب الحرف؟" من السلسلة الثانية لعمليات الإطلاق. يجب أن تكون أكثر انتباهاً لهذه المشكلة إذا كنت لا تعرف مسبقًا النص الذي سيتم تخزينه في سلسلة الإخراج ، وبسذاجة ، ستقوم بالتجميع دون تحديد الترميز. إذا لم يكن لديك حرف Ш في السطر حقًا ، فسيكون التجميع ناجحًا وسيكون الإطلاق ناجحًا أيضًا. وفي هذا الصدد ، ستنسى أيضًا أنك تفتقد عنصرًا تافهًا (الحرف W) ، والذي من المحتمل أن يحدث في سطر الإخراج وسيؤدي حتماً إلى مزيد من الأخطاء.
في السلسلة الثالثة والرابعة ، عند التحويل البرمجي والتشغيل ، يتم استخدام المفاتيح التالية: -تشفير Cp866 و -Dfile.encoding = Cp866. يحدد رمز التبديل -encoding الترميز لقراءة الملف منه مصدر الرمزالبرامج. يشير رمز التبديل -Dfile.encoding = Cp866 إلى ما يجب إخراج الترميز.
بادئة Unicode \ u والأحرف الروسية في أكواد المصدر
تحتوي Java على بادئة خاصة \ u لكتابة أحرف Unicode ، متبوعة بأربعة أرقام سداسية عشرية تحدد الحرف نفسه. على سبيل المثال ، \ u2122 هو الحرف ماركة(™). يعبر هذا الشكل من التدوين عن حرف من أي حرف أبجدي باستخدام الأرقام والبادئة - الأحرف الموجودة في النطاق الثابت للرموز من 0 إلى 127 ، والتي لا تتأثر عندما يتم تحويل رمز المصدر. ومن الناحية النظرية ، يمكن استخدام أي حرف Unicode في تطبيق Java أو تطبيق صغير ، ولكن ما إذا كان سيتم عرضه بشكل صحيح على شاشة العرض وما إذا كان سيتم عرضه على الإطلاق يعتمد على العديد من العوامل. بالنسبة إلى التطبيقات الصغيرة ، فإن نوع المستعرض مهم ، وبالنسبة للبرامج والتطبيقات الصغيرة ، فإن نوع نظام التشغيل والتشفير الذي تتم كتابة التعليمات البرمجية المصدر للبرنامج به مهمان.
على سبيل المثال ، على أجهزة الكمبيوتر التي تعمل بالإصدار الأمريكي أنظمة النوافذ، لا يمكن عرض الأحرف اليابانية باستخدام لغة Java بسبب مشكلة التدويل.
كمثال ثان ، يمكننا الاستشهاد بخطأ شائع جدًا للمبرمجين. يعتقد الكثير من الناس أن تحديد الأحرف الروسية بتنسيق Unicode باستخدام البادئة \ u في الكود المصدري للبرنامج يمكن أن يحل مشكلة عرض الأحرف الروسية تحت أي ظرف من الظروف. بعد كل شيء ، تقوم آلة Java الافتراضية بترجمة الكود المصدري للبرنامج إلى Unicode. ومع ذلك ، قبل الترجمة إلى Unicode ، يجب أن يعرف الجهاز الظاهري ما هو ترميز الكود المصدري لبرنامجك. بعد كل شيء ، يمكنك كتابة برنامج بترميز Cp866 (DOS) و Cp1251 (Windows) ، وهو أمر نموذجي في هذا الموقف. إذا لم تحدد أي ترميز ، فإن جهاز Java الظاهري يقرأ ملفك مع الكود المصدري للبرنامج في الترميز المحدد في ملف خصائص النظام .encoding.
ومع ذلك ، بالعودة إلى المعلمات الافتراضية ، سنفترض أن file.encoding = Сp1251 ، ويتم إخراج وحدة التحكم في Cp866. في هذه الحالة يظهر الموقف التالي: لنفترض أن لديك ملفًا مشفرًا في Сp1251:
ملف MsgDemo1.java
فئة عامة MsgDemo1 (رئيسي عام ثابت باطل (String args) (String s = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u043A \ u0430"؛ System.out.println (s ) ؛))
وتتوقع أن تتم طباعة كلمة "ترميز" على وحدة التحكم ، لكنك تحصل على:
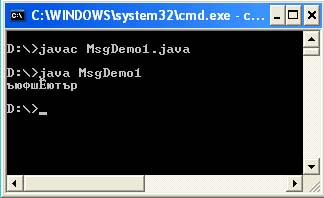
الحقيقة هي أن الأكواد التي تحتوي على البادئة المدرجة في البرنامج تقوم بالفعل بترميز الأحرف السيريلية الضرورية في جدول كود Unicode ، ومع ذلك ، فهي مصممة لحقيقة أن الكود المصدري لبرنامجك سيُقرأ في Cp866 (DOS) التشفير. بشكل افتراضي ، يتم تحديد تشفير Cp1251 في خصائص النظام (file.encoding = Cp1251). بطبيعة الحال ، فإن الشيء الأول والخطأ الذي يتبادر إلى الذهن هو تغيير ترميز الملف باستخدام الكود المصدري للبرنامج في محرر نصوص. لكن هذا لن يأخذك إلى أي مكان. سيظل Java VM يقرأ ملفك بترميز Cp1251 ، والأكواد \ u مخصصة لـ Cp866.
هناك ثلاث طرق للخروج من هذا الموقف. الخيار الأول هو استخدام مفتاح -encoding في وقت الترجمة و -Dfile.encing في مرحلة إطلاق البرنامج. في هذه الحالة ، تقوم بإجبار جهاز Java الظاهري على قراءة الملف المصدر بالترميز المحدد والإخراج بالترميز المحدد.
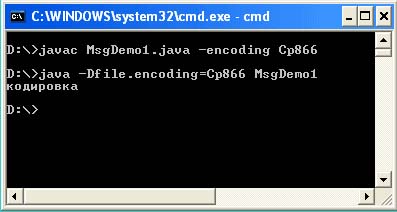
كما ترى من إخراج وحدة التحكم ، يجب تعيين المعامل الإضافي –تشفير Cp866 أثناء التحويل البرمجي ، ويجب تعيين المعلمة –Dfile.encoding = Cp866 عند بدء التشغيل.
الخيار الثاني هو إعادة ترميز الأحرف في البرنامج نفسه. إنه مصمم لاستعادة رموز الأحرف الصحيحة إذا تم تفسيرها بشكل خاطئ. جوهر الطريقة بسيط: من الأحرف غير الصحيحة المستلمة ، باستخدام صفحة التعليمات البرمجية المناسبة ، تتم استعادة مصفوفة البايت الأصلية. بعد ذلك ، من مجموعة البايت هذه ، باستخدام الصفحة الصحيحة بالفعل ، يتم الحصول على رموز الأحرف العادية.
لتحويل دفق البايت إلى سلسلة والعكس صحيح ، تتمتع فئة String بالقدرات التالية: مُنشئ السلسلة (بايت بايت ، String enc) ، الذي يتلقى دفقًا من البايتات كمدخلات مع الإشارة إلى تشفيرها ؛ إذا حذفت الترميز ، فسيقبل الترميز الافتراضي من ملف خصائص النظام. تقوم طريقة getBytes (String enc) بإرجاع دفق من البايتات المكتوبة بالترميز المحدد ؛ يمكن أيضًا حذف الترميز وسيتم قبول الترميز الافتراضي من خاصية نظام تشفير الملفات.
مثال:
ملف MsgDemo2.java
استيراد java.io.UnsupportedEncodingException ؛ فئة عامة MsgDemo2 (رئيسية ثابتة باطلة عامة (String args) تلقي UnsupportedEncodingException (String str = "\ u043A \ u043E" + "\ u0434 \ u0438 \ u0440 \ u043E \ u0432" + "\ u str043A \ u0430 getBes b = ("Cp866") ؛ String str2 = سلسلة جديدة (b، "Cp1251") ؛ System.out.println (str2) ؛))
مخرجات البرنامج:
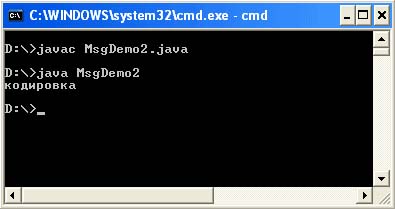
هذه الطريقة أقل مرونة إذا كنت تسترشد بحقيقة أن الترميز في خاصية نظام تشفير الملفات لن تتغير. ومع ذلك ، يمكن أن تصبح هذه الطريقة الأكثر مرونة إذا قمت باستقصاء خاصية file.encoding system واستبدلت قيمة التشفير الناتجة عند تكوين سلاسل في برنامجك. استخدام هذه الطريقةيجب أن تكون حريصًا على عدم إجراء جميع الصفحات تحويلاً واضحًا للبايت شار.
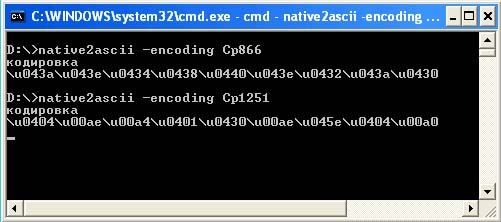
الطريقة الثالثة هي تحديد أكواد Unicode الصحيحة لعرض كلمة "encoding" على افتراض أن الملف سيُقرأ في الترميز الافتراضي - Cp1251. لهذه الأغراض ، هناك فائدة خاصة original2ascii.
هذه الأداة المساعدة جزء من Sun JDK وهي مصممة لتحويل كود المصدر إلى تنسيق ASCII. عندما يتم تشغيله بدون معلمات ، فإنه يعمل مع الإدخال القياسي (stdin) ، ولا يعرض تلميحًا رئيسيًا مثل الأدوات المساعدة الأخرى. يؤدي هذا إلى حقيقة أن الكثيرين لا يدركون حتى أنه من الضروري تحديد المعلمات (باستثناء أولئك الذين اطلعوا على الوثائق). وفي الوقت نفسه ، هذه الأداة العمل الصحيحيجب عليك ، كحد أدنى ، تحديد الترميز المستخدم باستخدام مفتاح التشفير. إذا لم يتم ذلك ، فسيتم استخدام التشفير الافتراضي (file.encoding) ، والذي قد يختلف نوعًا ما عن المتوقع. نتيجة لذلك ، بعد تلقي رموز أحرف غير صحيحة (بسبب الترميز غير الصحيح) ، يمكنك قضاء الكثير من الوقت في البحث عن أخطاء في رمز صحيح تمامًا.
توضح لقطة الشاشة التالية الاختلاف في تسلسلات كود Unicode لنفس الكلمة عندما تتم قراءة الملف المصدر بترميز Cp866 وتشفير Cp1251.
وبالتالي ، إذا كنت لا تفرض التشفير لـ آلة افتراضية Java في وقت الترجمة وعند بدء التشغيل ، والتشفير الافتراضي (file.encoding) هو Cp1251 ، ثم يجب أن تبدو الكود المصدري للبرنامج كما يلي:
ملف MsgDemo3.java
فئة عامة MsgDemo3 (رئيسي عام ثابت باطل (String args) (String s = "\ u0404 \ u00AE" + "\ u00A4 \ u0401 \ u0430 \ u00AE \ u045E" + "\ u0404 \ u00A0"؛ System.out.println (s ) ؛)) 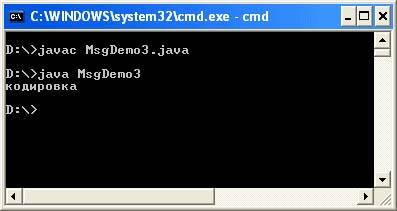
باستخدام الطريقة الثالثة ، يمكننا أن نستنتج: إذا تزامن ترميز الملف مع الكود المصدري في المحرر مع الترميز في النظام ، فستظهر رسالة "الترميز" بشكلها العادي.
القراءة والكتابة إلى ملف الأحرف الروسية المعبر عنها ببادئة Unicode \ u
لقراءة البيانات المكتوبة بتنسيق MBCS (باستخدام ترميز UTF-8) وتنسيق Unicode ، يمكنك استخدام فئة InputStreamReader من حزمة java.io ، لتحل محل الترميزات المختلفة في مُنشئها. يتم استخدام OutputStreamWriter للكتابة. يوضح وصف حزمة java.lang أن كل تطبيق JVM سيدعم الترميزات التالية:
ملف WriteDemo.java
استيراد java.io.Writer ؛ استيراد java.io.OutputStreamWriter ؛ استيراد java.io.FileOutputStream ؛ استيراد java.io.IOException ؛ / ** * إخراج سلسلة Unicode إلى ملف بالترميز المحدد. *author & lta href = "mailto: [بريد إلكتروني محمي]"& gt Victor Zagrebin & lt / a & gt * / public class WriteDemo (main (String args) ثابتة عامة) يرمي IOException (String str =" \ u043A \ u043E "+" \ u0434 \ u0438 \ u0440 \ u043E \ u0432 " + "\ u043A \ u0430"؛ Writer out1 = new OutputStreamWriter (new FileOutputStream ("out1.txt")، "Cp1251")؛ Writer out2 = new OutputStreamWriter (جديد FileOutputStream ("out2.txt") ، "Cp866") ؛ Writer out3 = new OutputStreamWriter (new FileOutputStream ("out3.txt") ، "UTF-8") ؛ Writer out4 = new OutputStreamWriter (new FileOutputStream ("out4.txt") ، "Unicode") ؛ out1.write (str) ؛ out1.close ()؛ out2.write (str)؛ out2.close ()؛ out3.write (str)؛ out3.close ()؛ out4.write (str)؛ out4.close ()؛)) التجميع: javac WriteDemo.java تشغيل: java WriteDemo
نتيجة لتنفيذ البرنامج ، يجب إنشاء أربعة ملفات (out1.txt out2.txt out3.txt out4.txt) في دليل تشغيل البرنامج ، سيحتوي كل منها على كلمة "ترميز" بترميز مختلف ، والذي يمكنه يتم تسجيل الوصول محرري النصوصأو عن طريق عرض ملف تفريغ.
سيقوم البرنامج التالي بقراءة وعرض محتويات كل ملف من الملفات التي تم إنشاؤها.
استيراد ملف ReadDemo.java java.io.Reader ؛ استيراد java.io.InputStreamReader ؛ استيراد java.io.InputStream ؛ استيراد java.io.FileInputStream ؛ استيراد java.io.IOException ؛ / ** * قراءة أحرف Unicode من ملف بالترميز المحدد. *author & lta href = "mailto: [بريد إلكتروني محمي]"& gt Victor Zagrebin & lt / a & gt * / public class ReadDemo (مفتاح عام ثابت فارغ (سلاسل سلسلة) يلقي IOException (String out_enc = System.getProperty (" console.encoding "،" Cp866 ")؛ System.out. write (readStringFromFile ("out1.txt"، "Cp1251"، out_enc))؛ System.out.write ("\ n")؛ System.out.write (readStringFromFile ("out2.txt"، "Cp866"، out_enc) )؛ System. out.write ("\ n")؛ System.out.write (readStringFromFile ("out3.txt"، "UTF-8"، out_enc))؛ System.out.write ("\ n")؛ System.out. write (readStringFromFile ("out4.txt" ، "Unicode" ، out_enc)) ؛) قراءة بايت ثابت عام readStringFromFile (اسم ملف سلسلة ، سلسلة file_enc ، سلسلة out_enc) يطرح IOException (حجم int ؛ InputStream f = FileInputStream جديد (اسم ملف )؛ size = f.available ()؛ Reader in = new InputStreamReader (f، file_enc)؛ char ch = new char؛ in.read (ch، 0، size)؛ in.close ()؛ return (new String (ch )). getBytes (out_enc)؛)) التجميع: javac ReadDemo.java Run: java ReadDemo Output of the program: 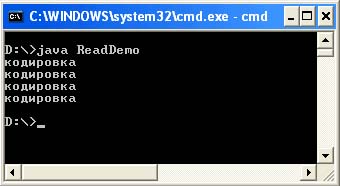
وتجدر الإشارة بشكل خاص إلى استخدام سطر التعليمات البرمجية التالي في هذا البرنامج:
String out_enc = System.getProperty ("console.encoding"، "Cp866") ؛
باستخدام طريقة getProperty ، يتم إجراء محاولة لقراءة قيمة خاصية نظام console.encoding ، والتي تحدد الترميز الذي سيتم فيه إخراج البيانات إلى وحدة التحكم. إذا لم يتم تعيين هذه الخاصية (غالبًا لم يتم تعيينها) ، فسيتم تعيين المتغير out_enc إلى "Cp866". علاوة على ذلك ، يتم استخدام المتغير out_enc عندما يكون من الضروري تحويل سلسلة مقروءة من ملف إلى ترميز مناسب للإخراج إلى وحدة التحكم.
أيضًا ، يظهر سؤال منطقي: "لماذا يتم استخدام System.out.write وليس System.out.println"؟ كما هو موضح أعلاه ، يتم استخدام ملف خصائص النظام file.encoding ليس فقط لقراءة الملف المصدر ، ولكن أيضًا للإخراج باستخدام System.out.println ، والذي سيؤدي في هذه الحالة إلى إخراج غير صحيح.
عرض غير صحيح للتشفير في البرامج الموجهة للويب
يجب أن يعرف المبرمج أولاً: ليس من المنطقي أن يكون لديك سلسلة دون معرفة الترميز الذي تستخدمه... لا يوجد شيء مثل نص عادي في ASCII. إذا كان لديك سلسلة في الذاكرة أو في ملف أو في رسالة بريد الالكتروني، يجب أن تعرف ماهية الترميز ، وإلا فلن تتمكن من تفسيره بشكل صحيح أو إظهاره للمستخدم.
تقع مسؤولية جميع المشكلات التقليدية تقريبًا مثل "يبدو موقع الويب الخاص بي على أنه رطانة" أو "لا يمكن قراءة رسائل البريد الإلكتروني الخاصة بي إذا استخدمت أحرفًا معلمة" على عاتق المبرمج الذي لا يفهم الحقيقة البسيطة القائلة بأنه إذا كنت لا تعرف ما هو ترميز UTF-8 السلسلة في ASCII أو ISO 8859-1 (لاتيني -1) أو Windows 1252 (أوروبا الغربية) ، لن تتمكن من إخراجها بشكل صحيح. يوجد أكثر من مائة حرف ترميز فوق نقطة الرمز 127 ، ولا توجد معلومات لمعرفة الترميز المطلوب. كيف نقوم بتخزين المعلومات حول ما تستخدمه سلاسل التشفير؟ موجود الطرق القياسيةللإشارة إلى هذه المعلومات. بالنسبة لرسائل البريد الإلكتروني ، يجب أن تضع السطر في رأس HTTP
نوع المحتوى: نص / عادي ؛ محارف = "UTF-8"
بالنسبة لصفحة الويب ، كانت الفكرة الأصلية هي أن خادم الويب سيرسل رأس HTTP نفسه ، قبل ذلك مباشرة صفحة HTML... لكن هذا يسبب مشاكل معينة. لنفترض أن لديك خادم ويب كبير به عدد كبير من المواقع ومئات الصفحات التي أنشأها عدد كبير من الأشخاص على عدد هائل لغات مختلفةوجميعهم لا يستخدمون ترميزًا معينًا. لا يستطيع خادم الويب نفسه معرفة ما هو ترميز كل ملف ، وبالتالي لا يمكنه إرسال رأس يحدد نوع المحتوى. لذلك ، للإشارة إلى التشفير الصحيح في رأس http ، بقي الاحتفاظ بمعلومات التشفير داخل ملف html عن طريق إدخال علامة خاصة. سيقرأ الخادم بعد ذلك اسم الترميز من العلامة الوصفية ويضعه في رأس HTTP.
يطرح السؤال المناسب: "كيف تبدأ قراءة ملف HTML حتى تعرف ما هو الترميز الذي يستخدمه ؟! لحسن الحظ ، تستخدم جميع الترميزات تقريبًا نفس جدول الأحرف مع الرموز من 32 إلى 127 ، ويتكون رمز HTML نفسه من هذه الأحرف ، وقد لا ترى حتى معلومات الترميز في ملف html إذا كان يتكون بالكامل من هذه الأحرف. لذلك ، من الناحية المثالية ، يجب أن تكون العلامة & ltmeta & gt التي تشير إلى الترميز في السطر الأول في قسم & lthead & gt ، لأنه بمجرد أن يرى متصفح الويب هذه العلامة ، سيتوقف عن تحليل الصفحة ويبدأ من جديد مرة أخرى باستخدام الترميز الذي حددته.
& lthtml & gt & lthead & gt & ltmeta http-equiv = "نوع المحتوى" content = "text / html؛ charset = utf-8" & gt
ماذا تفعل متصفحات الويب إذا لم تجد أي نوع محتوى ، لا في رأس http ولا في علامة التعريف؟ متصفح الانترنتفي الواقع ، إنه يفعل شيئًا مثيرًا للاهتمام: فهو يحاول التعرف على الترميز واللغة بناءً على التردد الذي تظهر به وحدات البايت المختلفة في نص نموذجي في ترميزات نموذجية للغات مختلفة. منذ أن تم وضع صفحات الرموز القديمة المختلفة المكونة من 8 بايت بشكل مختلف رموز وطنيةبين 128 و 255 ، وبما أن جميع اللغات البشرية لها احتمالات تردد مختلفة لاستخدام الحروف ، فإن هذا النهج غالبًا ما يعمل بشكل جيد.
إنه أمر غريب تمامًا ، ولكن يبدو أنه يعمل كثيرًا ، ومؤلفو صفحات الويب الساذجون الذين لم يعرفوا أبدًا أنهم بحاجة إلى علامة نوع المحتوى في عناوين صفحاتهم حتى يتم عرض الصفحات بشكل صحيح حتى ذلك اليوم الجميل. عندما يكتبون شيئًا لا يتطابق تمامًا مع التوزيع التكراري المعتاد لأحرف لغتهم الأم ، ويقرر Internet Explorer أنه كوري ويعرضها وفقًا لذلك.
على أي حال ، ماذا بقي لقارئ هذا الموقع ، الذي كتب باللغة البلغارية لكنه عُرض باللغة الكورية (وليس حتى الكورية ذات المعنى)؟ يستخدم طريقة العرض | تشفير ومحاولة العديد من الترميزات المختلفة (هناك على الأقل دزينة للغات أوروبا الشرقية) حتى تصبح الصورة أكثر وضوحًا. إذا كان يعرف بالطبع كيف يفعل ذلك ، لأن معظم الناس لا يعرفون ذلك.
تجدر الإشارة إلى أنه بالنسبة إلى UTF-8 ، الذي تم دعمه بشكل مثالي بواسطة متصفحات الويب لسنوات ، لم يواجه أحد مشكلة في العرض الصحيح لصفحات الويب.
الروابط:
- جويل سبولسكي. الحد الأدنى المطلق يجب أن يعرفه كل مطور برامج بشكل إيجابي عن Unicode ومجموعات الأحرف (لا أعذار!) 10/08/2003 http://www.joelonsoftware.com/articles/Unicode.html
- سيرجي أستاخوف.
- سيرجي سيمخاتوف. ... 08.2000 - 27.07.2005
- Horstman K.S.، Cornell G. مكتبة المحترفين. جافا 2. المجلد 1. الأساسيات. - م: دار ويليامز للنشر ، 2003 - 848 ص.
- دان تشيشولمز. امتحانات وهمية لمبرمج جافا. الهدف 2 ، InputStream و OutputStream Reader / Writer. ترميز أحرف جافا: UTF و Unicode. http://www.jchq.net/certkey/1102_12certkey.htm
- حزمة java.io. مواصفات واجهة برمجة تطبيقات JavaTM 2 Platform Standard Edition 6.0.
يونيكود: UTF-8، UTF-16 ، UTF-32.
Unicode عبارة عن مجموعة من الأحرف الرسومية وطريقة لترميزها لمعالجة البيانات النصية بالكمبيوتر.
لا يقوم Unicode بتعيين كل حرف فقط كود فريد، ولكنه يحدد أيضًا الخصائص المختلفة لهذا الرمز ، على سبيل المثال:
نوع الحرف (حرف كبير ، حرف صغير ، رقم ، علامة ترقيم ، إلخ) ؛
سمات الشخصية (العرض من اليسار إلى اليمين أو من اليمين إلى اليسار ، والمسافة ، وفاصل الأسطر ، وما إلى ذلك) ؛
الحرف الكبير المقابل أو الحرف الصغير المقابل (للأحرف الصغيرة و الأحرف الكبيرةعلى التوالى)؛
القيمة الرقمية المقابلة (للأحرف الرقمية).
المعايير UTF(اختصار لـ Unicode Transformation Format) لتمثيل الأحرف:
UTF-16: يستخدم Windows Vista UTF-16 لتمثيل جميع أحرف Unicode. في UTF-16 ، يتم تمثيل الأحرف ببايتَين (16 بت). يتم استخدام هذا الترميز في Windows لأن قيم 16 بت يمكن أن تمثل الأحرف التي تشكل الأبجدية لمعظم اللغات في العالم ، وهذا يسمح للبرامج بمعالجة السلاسل وحساب طولها بشكل أسرع. ومع ذلك ، لا يكفي 16 بت لتمثيل الأحرف الأبجدية في بعض اللغات. في مثل هذه الحالات ، يدعم UTE-16 الترميزات "البديلة" ، مما يسمح بترميز الأحرف في 32 بت (4 بايت). ومع ذلك ، هناك عدد قليل من التطبيقات التي يجب أن تتعامل مع أحرف هذه اللغات ، لذا فإن UTF-16 يعد حلاً وسطاً جيداً بين حفظ الذاكرة وسهولة البرمجة. لاحظ أنه في .NET Framework ، يتم تشفير جميع الأحرف باستخدام UTF-16 ، لذلك باستخدام UTF-16 في تطبيقات الويندوزيحسن الأداء ويقلل من استهلاك الذاكرة عند تمرير سلاسل بين التعليمات البرمجية الأصلية والمدارة.
UTF-8: في ترميز UTF-8 ، يمكن تمثيل الأحرف المختلفة بـ 1،2،3 أو 4 بايت. يتم ضغط الأحرف ذات القيم الأقل من 0x0080 إلى بايت واحد ، وهو أمر ملائم جدًا للأحرف الأمريكية. يتم تحويل الأحرف التي تطابق القيم في النطاق 0x0080-0x07FF إلى قيم ثنائية البايت ، والتي تعمل بشكل جيد مع الأبجدية الأوروبية والشرق أوسطية. يتم تحويل الأحرف ذات القيم الأكبر إلى قيم 3 بايت ، وهي مفيدة للعمل مع لغات آسيا الوسطى. أخيرًا ، تتم كتابة الأزواج البديلة بتنسيق 4 بايت. UTF-8 هو ترميز شائع للغاية. ومع ذلك ، يكون أقل فعالية من UTF-16 إذا تم استخدام الأحرف ذات القيم 0x0800 وما فوقها بشكل متكرر.
UTF-32: في UTF-32 ، يتم تمثيل جميع الأحرف بـ 4 بايت. يعد هذا الترميز مناسبًا لكتابة خوارزميات بسيطة لتعداد الأحرف في أي لغة لا تتطلب معالجة الأحرف التي يتم تمثيلها بعدد مختلف من البايتات. على سبيل المثال ، عند استخدام UTF-32 ، يمكنك أن تنسى "البدائل" ، حيث يتم تمثيل أي حرف في هذا الترميز بـ 4 بايت. من الواضح ، من وجهة نظر استخدام الذاكرة ، أن كفاءة UTF-32 بعيدة عن المثالية. لذلك ، نادرًا ما يتم استخدام هذا الترميز لنقل السلاسل عبر الشبكة وحفظها في الملفات. عادةً ما يتم استخدام UTF-32 كتنسيق داخلي لعرض البيانات في برنامج.
UTF-8
في المستقبل القريب ، تم استدعاء تنسيق Unicode خاص (و ISO 10646) UTF-8... يستخدم هذا الترميز "المشتق" سلاسل من البايت بأطوال مختلفة (من واحد إلى ستة) لكتابة الأحرف ، والتي يتم تحويلها إلى رموز Unicode باستخدام خوارزمية بسيطة ، مع سلاسل أقصر تتوافق مع أحرف أكثر شيوعًا. الميزة الرئيسية لهذا التنسيق هي التوافق مع ASCII ليس فقط في قيم الرموز ، ولكن أيضًا في عدد البتات لكل حرف ، نظرًا لأن بايت واحد يكفي لترميز أي من الأحرف 128 الأولى في UTF-8 (على الرغم من ، على سبيل المثال ، للأحرف السيريلية ، اثنان بايت).
تم اختراع تنسيق UTF-8 في 2 سبتمبر 1992 بواسطة كين تومسون وروب بايك وتم تنفيذه في الخطة 9. أصبح معيار UTF-8 رسميًا الآن في RFC 3629 و ISO / IEC 10646 الملحق د.
بالنسبة لمصمم الويب ، يعد هذا الترميز ذا أهمية خاصة ، لأنه تم الإعلان عنه "ترميز المستند القياسي" في HTML منذ الإصدار 4.
يتم تحويل النص الذي يحتوي على أحرف مرقمة أقل من 128 فقط إلى نص ASCII عادي عند كتابته بتنسيق UTF-8. على العكس من ذلك ، في نص UTF-8 ، فإن أي بايت بقيمة أقل من 128 يمثل حرف ASCII بنفس الرمز. يتم تمثيل بقية أحرف Unicode بتسلسلات من 2 إلى 6 بايت (في الواقع ما يصل إلى 4 بايت فقط ، نظرًا لأن استخدام الرموز الأكبر من 221 غير مخطط له) ، حيث يبدو البايت الأول دائمًا مثل 11xxxxxx ، والباقي - 10xxxxxx.
ببساطة ، بتنسيق UTF-8 ، أحرف لاتينية وعلامات ترقيم وعناصر تحكم أحرف ASCIIتتم كتابتها برموز US-ASCII ، ويتم تشفير جميع الأحرف الأخرى باستخدام عدة ثماني بتات مع البت الأكثر أهمية من 1. وهذا له تأثيران.
حتى إذا لم يتعرف البرنامج على Unicode ، فسيتم عرض الأحرف اللاتينية والأرقام العربية وعلامات الترقيم بشكل صحيح.
إذا كانت الأحرف اللاتينية وعلامات الترقيم البسيطة (بما في ذلك المسافة) تشغل قدرًا كبيرًا من النص ، فإن UTF-8 يعطي زيادة في الحجم مقارنةً بـ UTF-16.
للوهلة الأولى ، قد يبدو أن UTF-16 أكثر ملاءمة ، حيث يتم تشفير معظم الأحرف في وحدتي بايت بالضبط. ومع ذلك ، يتم إبطال هذا من خلال الحاجة إلى دعم أزواج بديلة ، والتي غالبًا ما يتم تجاهلها عند استخدام UTF-16 ، مع تطبيق دعم أحرف UCS-2 فقط.
يونيكود
من ويكيبيديا، الموسوعة الحرة
اذهب إلى: ارشاد, بحث
يونيكود (في أغلب الأحيان) أو يونيكود (إنجليزي يونيكود) - اساسي ترميز الأحرف، مما يسمح لك بتمثيل علامات جميع المكتوبة تقريبًا اللغات.
المعيار المقترح في عام 1991منظمة غير ربحية "Unicode Consortium" ( إنجليزي يونيكود التحالف, يونيكود المؤتمر الوطني العراقي. ). يسمح استخدام هذا المعيار بتشفير عدد كبير جدًا من الأحرف من نصوص مختلفة: في مستندات Unicode ، الصينية الهيروغليفيةرموز الرياضيات الحروف الأبجدية اليونانية, لاتينيو السيريلية، في هذه الحالة يصبح التبديل غير ضروري صفحات الرموز.
يتكون المعيار من قسمين رئيسيين: مجموعة الأحرف العالمية ( إنجليزي UCS ، مجموعة أحرف عالمية) وعائلة الترميزات ( إنجليزي. UTF ، تنسيق تحويل Unicode). تحدد مجموعة الأحرف العامة المراسلات الفردية بين الأحرف رموز- عناصر فضاء الكود تمثل الأعداد الصحيحة غير السالبة. تحدد عائلة الترميزات تمثيل الجهاز لسلسلة من أكواد UCS.
رموز Unicode مقسمة إلى عدة مناطق. المنطقة التي بها رموز من U + 0000 إلى U + 007F تحتوي على أحرف اتصال ASCIIمع الرموز المقابلة. فيما يلي مناطق علامات النصوص المختلفة وعلامات الترقيم والرموز الفنية. بعض الرموز محجوزة للاستخدام في المستقبل. تحت الأحرف السيريلية ، مناطق الأحرف ذات الرموز من U + 0400 إلى U + 052F ، من U + 2DE0 إلى U + 2DFF ، من U + A640 إلى U + A69F (انظر. السيريلية في Unicode).
1 المتطلبات الأساسية لإنشاء وتطوير Unicode 2 إصدارات Unicode 3 مساحة التعليمات البرمجية 4 نظام الترميز 5 تعديل الحروف 6 أشكال التطبيع 7 الكتابة ثنائية الاتجاه 8 رموز مميزة 9 ISO / IEC 10646 10 طرق للعرض 11 طرق الإدخال 12 مشاكل يونيكود 13 "Unicode" أم "Unicode"؟ 14 انظر أيضا |
المتطلبات الأساسية لإنشاء وتطوير Unicode
بالنهاية الثمانينياتأصبحت الأحرف 8 بت هي المعيار ، بينما كان هناك العديد من ترميزات 8 بت المختلفة ، وظهرت ترميزات جديدة باستمرار. تم تفسير ذلك من خلال التوسع المستمر في نطاق اللغات المدعومة ، والرغبة في إنشاء ترميز متوافق جزئيًا مع بعض اللغات الأخرى (المثال النموذجي هو ظهور ترميز بديلللغة الروسية ، بسبب استغلال البرامج الغربية التي تم إنشاؤها للترميز CP437). ونتيجة لذلك ظهرت عدة مشاكل:
مشكلة " krakozyabr»(عرض المستندات بترميز خاطئ): يمكن حلها إما عن طريق تقديم طرق لتحديد الترميز المستخدم باستمرار ، أو عن طريق إدخال تشفير واحد للجميع.
مشكلة مجموعة الأحرف المحدودة: يمكن حلها إما عن طريق تبديل الخطوط داخل المستند ، أو عن طريق إدخال ترميز "واسع". لطالما تم ممارسة تبديل الخطوط في معالجات النصوص، وكثيرا ما كانت تستخدم الخطوط ذات الترميز غير القياسي، ر. "خطوط Dingbat" - نتيجة لذلك ، عند محاولة نقل مستند إلى نظام آخر ، تحولت جميع الأحرف غير القياسية إلى krakozyabry.
مشكلة تحويل ترميز إلى آخر: يمكن حلها إما عن طريق تجميع جداول التحويل لكل زوج من الترميزات ، أو باستخدام تحويل وسيط إلى ترميز ثالث يتضمن جميع الأحرف من جميع الترميزات.
مشكلة تكرار الخط: تقليديًا ، لكل ترميز ، تم عمل خط مختلف ، حتى لو تزامنت هذه الترميزات جزئيًا (أو كليًا) في مجموعة الأحرف: يمكن حل هذه المشكلة عن طريق إنشاء خطوط "كبيرة" ، والتي من خلالها المطلوبة لهذا الترميز ثم يتم تحديدها - ومع ذلك يتطلب إنشاء سجل واحد من الرموز لتحديد أي التطابقات.
كان من الضروري إنشاء تشفير "واسع" واحد. تم العثور على ترميزات متغيرة الطول ، المستخدمة على نطاق واسع في شرق آسيا ، لتكون صعبة الاستخدام للغاية ، لذلك تقرر استخدام أحرف ذات عرض ثابت. يبدو أن استخدام أحرف 32 بت مضيعة للغاية ، لذلك تقرر استخدام أحرف 16 بت.
وبالتالي ، كان الإصدار الأول من Unicode عبارة عن ترميز بحجم حرف ثابت يبلغ 16 بت ، أي أن العدد الإجمالي للرموز كان 2 16 (65536). من هنا تأتي ممارسة تسمية الأحرف بأربعة أرقام سداسية عشرية (على سبيل المثال ، U + 04F0). في الوقت نفسه ، تم التخطيط لترميز في Unicode ليس كل الأحرف الموجودة ، ولكن فقط تلك الضرورية في الحياة اليومية. نادرًا ما كان يجب وضع الرموز المستخدمة في "منطقة الاستخدام الخاص" ، والتي احتلت في الأصل رموز U + D800… U + F8FF. من أجل استخدام Unicode أيضًا كوسيط في تحويل الترميزات المختلفة لبعضها البعض ، تم تضمين جميع الأحرف الممثلة في جميع الترميزات الأكثر شهرة فيه.
ومع ذلك ، فقد تقرر في المستقبل ترميز جميع الرموز ، وفيما يتعلق بذلك ، توسيع مجال الكود بشكل كبير. في الوقت نفسه ، بدأ عرض رموز الأحرف ليس كقيم 16 بت ، ولكن كأرقام مجردة يمكن تمثيلها في الكمبيوتر بواسطة مجموعة طرق مختلفة(سم. طرق العرض).
منذ في عدد من أنظمة الكمبيوتر (على سبيل المثال ، نظام التشغيل Windows NT ) تم استخدام الأحرف الثابتة 16 بت بالفعل كتشفير افتراضي ، وقد تقرر ترميز جميع الأحرف الأكثر أهمية فقط ضمن أول 65536 موضعًا (ما يسمى إنجليزي أساسي متعدد اللغات طائرة, BMP). يتم استخدام المساحة المتبقية لـ "الأحرف الزائدة" ( إنجليزي تكميلي الشخصيات): أنظمة كتابة للغات منقرضة أو نادرًا ما تستخدم صينىالهيروغليفية والرموز الرياضية والموسيقية.
من أجل التوافق مع أنظمة 16 بت الأقدم ، تم اختراع النظام UTF-16، حيث يتم عرض أول 65.536 موضعًا ، باستثناء المواضع من U + D800 ... الفاصل الزمني U + DFFF ، مباشرةً كأرقام 16 بت ، ويتم تمثيل الباقي على أنهم "أزواج بديلة" (العنصر الأول من زوج من U + D800 ... U + DBFF ، العنصر الثاني للزوج من المنطقة U + DC00 ... U + DFFF). بالنسبة للأزواج البديلة ، تم استخدام جزء من مساحة الرمز (2048 موضعًا) محجوزًا مسبقًا لـ "الأحرف للاستخدام الخاص".
نظرًا لأن UTF-16 يمكنه عرض 2 20 + 2 16 −2048 (111064) حرفًا ، فقد تم اختيار هذا الرقم كقيمة نهائية لمساحة رمز Unicode.
على الرغم من أن منطقة رمز Unicode قد تم تمديدها إلى ما بعد 2-16 في وقت مبكر من الإصدار 2.0 ، إلا أن الأحرف الأولى في منطقة "الجزء العلوي" تم وضعها فقط في الإصدار 3.1.
يتزايد دور هذا الترميز في قطاع الويب باستمرار ، في بداية عام 2010 كانت حصة المواقع التي تستخدم Unicode حوالي 50٪.
إصدارات يونيكود
مع تغير جدول أحرف Unicode وتجديده وإصدار إصدارات جديدة من هذا النظام - ويتم تنفيذ هذا العمل باستمرار ، حيث تضمن نظام Unicode في البداية المستوى 0 فقط - رموز ثنائية البايت - تظهر أيضًا مستندات جديدة. ISO... يوجد نظام Unicode بشكل إجمالي في الإصدارات التالية:
1.1 (يتوافق مع ISO / IEC 10646-1: 1993 ) ، المعيار 1991-1995.
2.0 ، 2.1 (نفس المعيار ISO / IEC 10646-1: 1993 بالإضافة إلى الإضافات: "التعديلات" 1 إلى 7 و "التصويبات الفنية" 1 و 2) ، معيار 1996.
3.0 (معيار ISO / IEC 10646-1: 2000).
3.1 (معايير ISO / IEC 10646-1: 2000 و ISO / IEC 10646-2: 2001) معيار 2001.
3.2 ، قياسي عام 2002.
4.0 قياسي 2003 .
4.01 ، قياسي 2004 .
4.1 ، قياسي 2005 .
5.0 ، قياسي 2006 .
5.1 ، قياسي 2008 .
5.2 ، قياسي 2009 .
6.0 ، قياسي 2010 .
6.1 ، قياسي 2012 .
6.2 ، قياسي 2012 .
مساحة الرمز
على الرغم من أن نماذج الترميز UTF-8 و UTF-32 تسمح بترميز ما يصل إلى 2،331 (2،147،483،648) نقطة رمز ، فقد تقرر استخدام 1،112،064 فقط للتوافق مع UTF-16. ومع ذلك ، حتى هذا أكثر من كافٍ في الوقت الحالي - في الإصدار 6.0 يتم استخدام أقل بقليل من 110.000 نقطة رمز (109242 رسمًا و 273 رمزًا آخر).
يتم تقسيم مساحة الرمز إلى 17 طائرات 2 16 (65536) حرفًا لكل منهما. يسمى المستوى الصفري أساسي، فهو يحتوي على رموز النصوص الأكثر شيوعًا. يستخدم المستوى الأول بشكل أساسي للنصوص التاريخية ، بينما يستخدم المستوى الثاني للكتابة الهيروغليفية التي نادرًا ما تستخدم. CJK، والثالث مخصص للأحرف الصينية القديمة ... الطائرتان 15 و 16 محجوزتان للاستخدام الخاص.
للإشارة إلى أحرف Unicode ، استخدم تدوينًا مثل "U + xxxx"(للرموز 0 ... FFFF) ، أو" U + كسكسكسكسكس"(للرموز 10000 ... FFFFF) ، أو" U + xxxxxx"(بالنسبة للرموز 100000 ... 10FFFF) ، أين xxx - السداسي عشريأعداد. على سبيل المثال ، الحرف "i" (U + 044F) له الرمز 044F 16 = 1103 10 .
نظام الترميز
نظام الترميز العالمي (Unicode) عبارة عن مجموعة من الرموز الرسومية وطريقة لتشفيرها الحاسوبمعالجة البيانات النصية.
الرموز الرسومية هي رموز لها صورة مرئية. تعارض الأحرف الرسومية التحكم في الأحرف وتنسيقها.
تشمل الرموز الرسومية المجموعات التالية:
علامات الترقيم؛
أحرف خاصة ( رياضي، تقني، إيديوغرامإلخ.)؛
فواصل.
Unicode هو نظام للتمثيل الخطي للنص. يمكن تمثيل الأحرف ذات النصوص المرتفعة أو المنخفضة كسلسلة من الرموز المبنية وفقًا لقواعد معينة (حرف مركب) أو كحرف واحد (نسخة متجانسة ، حرف مركب مسبقًا).
تعديل الشخصيات
تمثيل الحرف "Y" (U + 0419) في شكل الحرف الأساسي "I" (U + 0418) والحرف المعدل "" (U + 0306)
تنقسم الأحرف الرسومية في Unicode إلى موسعة وغير ممتدة (عديمة العرض). لا تشغل الأحرف غير الممتدة عند عرضها مساحة خط... وتشمل هذه ، على وجه الخصوص ، علامات التمييز وغيرها علامات التشكيل... كل من الأحرف الموسعة وغير الموسعة لها رموز خاصة بها. تسمى الأحرف الممتدة بطريقة أخرى أساسية ( إنجليزي قاعدة الشخصيات) ، وغير الموسعة - التعديل ( إنجليزي الجمع الشخصيات) ؛ والأخير لا يمكن أن يجتمع بشكل مستقل. على سبيل المثال ، يمكن تمثيل الحرف "á" كسلسلة من الحرف الأساسي "a" (U + 0061) وحرف المعدل "́" (U + 0301) ، أو كحرف متآلف "á" (U + 00C1).
نوع خاص من أحرف التعديل هو محددات نمط الوجه ( إنجليزي الاختلاف المحددات). تنطبق فقط على تلك الرموز التي تم تعريف هذه المتغيرات من أجلها. في الإصدار 5.0 ، تم تحديد خيارات النمط لسلسلة الرموز الرياضيةللرموز التقليدية الأبجدية المنغوليةوللرموز الكتابة المنغولية المربعة.
أشكال التطبيع
نظرًا لأنه يمكن تمثيل الأحرف نفسها بواسطة أكواد مختلفة ، مما يؤدي أحيانًا إلى تعقيد المعالجة ، فهناك عمليات تطبيع مصممة لإحضار النص إلى نموذج قياسي معين.
يحدد معيار Unicode 4 أشكال من تسوية النص:
الرمز S هو مبدئيإذا كان يحتوي على فئة تعديل صفرية في قاعدة أحرف Unicode.
في أي تسلسل من الأحرف يبدأ بحرف البداية S ، يتم حظر الحرف C من S إذا وفقط إذا كان هناك أي حرف B بين S و C يكون إما حرف بداية أو له نفس فئة التعديل أو أكبر من C. هذا القاعدة تنطبق فقط على السلاسل التي مرت بالتحلل الكنسي.
خبراتالمركب هو رمز يحتوي على تحلل أساسي في قاعدة أحرف Unicode (أو التحلل الكنسي لـ الهانغولولم يتم تضمينه في قائمة الاستبعاد).
يمكن محاذاة الحرف X الأساسي مع الحرف Y إذا وفقط إذا كان هناك مركب أساسي Z مكافئ قانونيًا للتسلسل
إذا لم يتم حظر الحرف C التالي بواسطة الحرف الأساسي L الأخير الذي تمت مواجهته ويمكن محاذاته بنجاح ، فسيتم استبدال L بالحرف LC المركب ، وإزالة C.
نموذج التطبيع D (NFD) - التحلل المتعارف عليه. في عملية تحويل النص إلى هذا النموذج ، يتم استبدال جميع الأحرف المركبة بشكل متكرر بعدة أحرف مركبة ، وفقًا لجداول التحليل.
نموذج التطبيع C (NFC) هو تحلل أساسي متبوعًا بتكوين أساسي. أولاً ، يتم تقليل النص إلى نموذج D ، وبعد ذلك يتم تنفيذ التكوين الأساسي - تتم معالجة النص من البداية إلى النهاية ويتم اتباع القواعد التالية:
نموذج التطبيع KD (NFKD) - التحلل المتوافق. عند الإدلاء بهذا النموذج ، يتم استبدال جميع الأحرف المركبة باستخدام كل من خرائط تحليل Unicode المتعارف عليها وخرائط التحلل المتوافقة ، وبعد ذلك يتم وضع النتيجة بترتيب أساسي.
نموذج التطبيع KC (NFKC) - التحلل المتوافق متبوعًا بـ العنوان الأساسيتعبير.
المصطلحان "تكوين" و "تحلل" يعني ، على التوالي ، اتصال أو تحلل الرموز إلى الأجزاء المكونة لها.
أمثلة على
|
النص الأصلي | ||||
|
\ u0410 ، \ u0401 ، \ u0419 |
\ u0410 ، \ u0415 \ u0308 ، \ u0418 \ u0306 |
\ u0410 ، \ u0401 ، \ u0419 |
||
خطاب ثنائي الاتجاه
يدعم معيار Unicode لغات الكتابة باللغتين من اليسار إلى اليمين ( إنجليزي اليسار- ل- الصحيح, لتر) ، ومع الكتابة من اليمين إلى اليسار ( إنجليزي الصحيح- ل- اليسار, RTL) - فمثلا، عربىو يهوديرسالة. في كلتا الحالتين ، يتم تخزين الأحرف بترتيب "طبيعي" ؛ يتم توفير عرضهم ، مع مراعاة الاتجاه المطلوب للرسالة ، من خلال التطبيق.
بالإضافة إلى ذلك ، يدعم Unicode النصوص المدمجة التي تجمع بين الأجزاء ذات الاتجاهات المختلفة للحرف. هذه الميزة تسمى ثنائية الاتجاه (إنجليزي ثنائي الاتجاه نص, ثنائية). بعض معالجات النصوص المبسطة (على سبيل المثال ، بتنسيق هاتف خليوي) يمكن أن يدعم Unicode ، ولكن ليس الدعم ثنائي الاتجاه. يتم تقسيم جميع أحرف Unicode إلى عدة فئات: مكتوبة من اليسار إلى اليمين ، ومكتوبة من اليمين إلى اليسار ، ومكتوبة في أي اتجاه. رموز الفئة الأخيرة (بشكل رئيسي علامات الترقيم) عند عرضها ، خذ اتجاه النص المحيط.
الرموز المميزة
مقالة مفصلة: يتم تمثيل الأحرف في Unicode

مخطط مستوى قاعدة يونيكود ، انظر وصف
يشتمل Unicode على جميع الأجهزة الحديثة تقريبًا جاري الكتابة، بما فيها:
عرب,
أرميني,
البنغالية,
البورمية,
الفعل,
اليونانية,
الجورجية,
الديفاناغارية,
يهودي,
السيريلية,
صينى(يتم استخدام الأحرف الصينية بنشاط في اليابانية، ونادرًا جدًا أيضًا الكورية),
قبطي,
الخمير,
لاتيني,
التاميل,
الكورية (هانغول),
شيروكي,
إثيوبي,
اليابانية(الذي يتضمن إلى جانب الحروف الصينيةايضا مقطعي),
آخر.
تمت إضافة العديد من النصوص التاريخية للأغراض الأكاديمية ، بما في ذلك: الرونية الجرمانية, الرونية التركية القديمة, اليونانية القديمة, الهيروغليفية المصرية, المسمارية, كتابة مايا, الأبجدية الأترورية.
يوفر Unicode مجموعة واسعة من ملفات رياضيو موسيقيالشخصيات كذلك الصور التوضيحية.
ومع ذلك ، لا يتضمن Unicode بشكل أساسي شعارات الشركة والمنتج ، على الرغم من وجودها في الخطوط (على سبيل المثال ، الشعار تفاحمشفر ماكرومان(0xF0) أو الشعار شبابيكفي Wingdings الخط (0xFF)). في خطوط Unicode ، يجب وضع الشعارات في منطقة الأحرف المخصصة فقط.
ISO / IEC 10646
يعمل اتحاد Unicode بشكل وثيق مع مجموعة العمل ISO / IEC / JTC1 / SC2 / WG2 ، التي تعمل على تطوير المعيار الدولي 10646 ( ISO/اللجنة الكهروتقنية الدولية 10646). تم إنشاء التزامن بين معيار Unicode و ISO / IEC 10646 ، على الرغم من أن كل معيار يستخدم المصطلحات الخاصة به ونظام التوثيق.
تعاون اتحاد يونيكود مع المنظمة الدولية للتوحيد القياسي ( إنجليزي المنظمة الدولية للتوحيد القياسي ISO) بدأ في 1991 عام... الخامس 1993 عامأصدرت ISO معيار DIS 10646.1. للمزامنة معه ، وافق الاتحاد على الإصدار 1.1 من معيار Unicode ، والذي تم استكماله بأحرف إضافية من DIS 10646.1. نتيجة لذلك ، فإن قيم الأحرف المشفرة في Unicode 1.1 و DIS 10646.1 هي نفسها تمامًا.
في المستقبل ، استمر التعاون بين المنظمتين. الخامس 2000 سنةتمت مزامنة معيار Unicode 3.0 مع ISO / IEC 10646-1: 2000. ستتم مزامنة الإصدار الثالث القادم من ISO / IEC 10646 مع Unicode 4.0. ربما سيتم نشر هذه المواصفات كمعيار واحد.
على غرار تنسيقات UTF-16 و UTF-32 في معيار Unicode ، يحتوي معيار ISO / IEC 10646 أيضًا على شكلين رئيسيين لترميز الأحرف: UCS-2 (2 بايت لكل حرف ، على غرار UTF-16) و UCS-4 (4 بايت لكل حرف ، على غرار UTF-32). يعني UCS متعدد ثماني بتات عالمية(متعدد البايت) مجموعة الأحرف المشفرة (إنجليزي عالمي مضاعف- ثماني مشفر حرف تعيين). يمكن اعتبار UCS-2 مجموعة فرعية من UTF-16 (UTF-16 بدون أزواج بديلة) و UCS-4 هو مرادف لـ UTF-32.
طرق العرض
يحتوي Unicode على عدة أشكال من التمثيل ( إنجليزي تنسيق تحويل Unicode ، UTF): UTF-8, UTF-16(UTF-16BE ، UTF-16LE) و UTF-32 (UTF-32BE ، UTF-32LE). كما تم تطوير نموذج تمثيل UTF-7 للإرسال عبر قنوات ذات سبع بتات ، ولكن بسبب عدم التوافق معها ASCIIلم يتم توزيعه ولم يتم تضمينه في المعيار. 1 أبريل عام 2005تم اقتراح شكلين للعرض الهزلي: UTF-9 و UTF-18 ( RFC 4042).
الخامس مايكروسوفت نظام التشغيل Windows NTوالأنظمة القائمة عليه نظام التشغيل Windows 2000و ويندوز إكس بيفي المقام الأول استعمل من قبلشكل UTF-16LE. الخامس يونيكس-مثل أنظمة التشغيل جنو / لينكس, BSDو نظام التشغيل Mac OS Xالنموذج المقبول هو UTF-8 للملفات و UTF-32 أو UTF-8 لمعالجة الأحرف بتنسيق ذاكرة الوصول العشوائي.
بوني كود- شكل آخر من أشكال ترميز متواليات أحرف Unicode إلى ما يسمى متواليات ACE ، والتي تتكون فقط من أحرف أبجدية رقمية ، كما هو مسموح به في أسماء المجال.
مقالة مفصلة: UTF-8
UTF-8 هو تمثيل Unicode الذي يوفر أفضل توافق مع الأنظمة القديمة التي تستخدم أحرف 8 بت. يتم تحويل النص الذي يحتوي فقط على أحرف مرقمة أقل من 128 إلى نص عادي عند كتابته بتنسيق UTF-8 ASCII... على العكس من ذلك ، في نص UTF-8 ، أي بايتبقيمة أقل من 128 يعرض حرف ASCII بنفس الرمز. يتم تمثيل باقي أحرف Unicode بتسلسلات من 2 إلى 6 بايت (في الواقع ، حتى 4 بايت فقط ، نظرًا لعدم وجود أحرف برمز أكبر من 10FFFF في Unicode ، ولا توجد خطط لتقديمها في المستقبل ) ، حيث يبدو البايت الأول دائمًا مثل 11xxxxxx ، والباقي - 10xxxxxx.
تم اختراع UTF-8 2 سبتمبر عام 1992 كين طومسونو روب بايكونفذت في الخطة 9 ... الآن تم تضمين معيار UTF-8 رسميًا في المستندات RFC 3629و ISO / IEC 10646 الملحق د.
يتم اشتقاق أحرف UTF-8 من Unicode بالطريقة الآتية:
0x00000000 - 0x0000007F: 0xxxxxxx
0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
ممكن نظريًا ، ولكنه غير مدرج أيضًا في المعيار:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
بالرغم من أن UTF-8 يسمح لك بتحديد نفس الحرف بعدة طرق ، إلا أن أقصرها فقط هو الصحيح. يجب رفض باقي الاستمارات لأسباب أمنية.
ترتيب البايت
في دفق بيانات UTF-16 ، يمكن كتابة البايت العالي إما قبل المستوى المنخفض ( إنجليزي UTF-16 صغير الهند) ، أو بعد الأصغر ( إنجليزي. UTF-16 كبير الهند). وبالمثل ، هناك نوعان مختلفان من التشفير رباعي البايت - UTF-32LE و UTF-32BE.
لتحديد تنسيق تمثيل Unicode ، يتم كتابة بداية الملف النصي توقيع- الحرف U + FEFF (مسافة غير قابلة للكسر بعرض صفري) ، يشار إليها أيضًا باسم علامة ترتيب البايت (إنجليزي بايت طلب علامة, BOM ). هذا يجعل من الممكن التمييز بين UTF-16LE و UTF-16BE لأن حرف U + FFFE غير موجود. كما يتم استخدامه أحيانًا للإشارة إلى تنسيق UTF-8 ، على الرغم من أن مفهوم ترتيب البايت لا ينطبق على هذا التنسيق. تبدأ الملفات التي تتبع هذا الاصطلاح بتسلسلات البايت هذه:
لسوء الحظ ، لا تميز هذه الطريقة بشكل موثوق بين UTF-16LE و UTF-32LE ، نظرًا لأن Unicode يسمح بالحرف U + 0000 (على الرغم من أن النصوص الحقيقية نادرًا ما تبدأ به).
يجب أن تكون الملفات بترميز UTF-16 و UTF-32 التي لا تحتوي على قائمة مكونات الصنف بترتيب بايت كبير ( unicode.org).
Unicode والترميزات التقليدية
أدى إدخال Unicode إلى تغيير نهج ترميزات 8 بت التقليدية. إذا تم تحديد الترميز مسبقًا بواسطة الخط ، فسيتم تحديده الآن بواسطة جدول المراسلات بين هذا الترميز و Unicode. في الواقع ، أصبحت ترميزات 8 بت تمثل مجموعة فرعية من Unicode. هذا جعل الأمر أسهل بكثير لإنشاء البرامج التي يجب أن تعمل مع العديد من الترميزات المختلفة: الآن ، لإضافة دعم لترميز آخر ، تحتاج فقط إلى إضافة جدول بحث Unicode آخر.
بالإضافة إلى ذلك ، تسمح العديد من تنسيقات البيانات بإدراج أي أحرف Unicode ، حتى إذا كان المستند مكتوبًا بترميز 8 بت القديم. على سبيل المثال ، في HTML يمكن للمرء استخدام رموز العطف.
التنفيذ
توفر معظم أنظمة التشغيل الحديثة درجة معينة من دعم Unicode.
في أنظمة تشغيل الأسرة نظام التشغيل Windows NTيتم تمثيل أسماء الملفات وسلاسل النظام الأخرى داخليًا باستخدام تشفير UTF-16LE مزدوج البايت. مكالمات النظام التي تأخذ معلمات السلسلة متوفرة في متغيرات أحادية البايت ومزدوجة البايت. لمزيد من التفاصيل انظر المقال .
يونيكس- مثل أنظمة التشغيل ، بما في ذلك جنو / لينكس, BSD, نظام التشغيل Mac OS Xاستخدم ترميز UTF-8 لتمثيل Unicode. يمكن لمعظم البرامج التعامل مع UTF-8 كترميز تقليدي أحادي البايت ، بغض النظر عن حقيقة أن الحرف يتم تمثيله في عدة وحدات بايت متتالية. للعمل مع الأحرف الفردية ، يتم عادةً إعادة تشفير السلاسل إلى UCS-4 ، بحيث يكون لكل حرف مقابل كلمة آلة.
كانت بيئة البرمجة واحدة من أولى التطبيقات التجارية الناجحة لـ Unicode جافا... لقد تخلت بشكل أساسي عن تمثيل الأحرف 8 بت لصالح 16 بت واحد. زاد هذا الحل من استهلاك الذاكرة ، لكنه سمح لنا بإعادة تجريد مهم إلى البرمجة: حرف واحد عشوائي (نوع char). على وجه الخصوص ، يمكن للمبرمج أن يعمل مع سلسلة كما هو الحال مع مصفوفة بسيطة. لسوء الحظ ، لم يكن النجاح نهائيًا ، فقد تجاوز Unicode حد 16 بت وبحلول J2SE 5.0 ، بدأت شخصية عشوائية مرة أخرى في شغل عدد متغير من وحدات الذاكرة - حرف واحد أو اثنين (انظر. زوجان بديلان).
تدعم معظم لغات البرمجة الآن سلاسل Unicode ، على الرغم من أن تمثيلها قد يختلف اعتمادًا على التنفيذ.
طرق الإدخال
منذ لا شيء تخطيط لوحة المفاتيحلا يمكن السماح بإدخال جميع أحرف Unicode في نفس الوقت ، من أنظمة التشغيلو برامج التطبيقاتيتطلب دعمًا لطرق الإدخال البديلة لأحرف Unicode التعسفية.
مايكروسوفت ويندوز
مقالة مفصلة: Unicode على أنظمة تشغيل Microsoft
بادئ ذي بدء نظام التشغيل Windows 2000، تُظهر الأداة المساعدة Charmap (charmap.exe) جميع الأحرف في نظام التشغيل وتسمح لك بنسخها إلى ملفات الحافظة... يوجد جدول مشابه ، على سبيل المثال ، في مايكروسوفت وورد.
في بعض الأحيان يمكنك الكتابة السداسي عشريكود ، اضغط بديل+ X ، وسيتم استبدال الرمز بالحرف المقابل ، على سبيل المثال ، في الدفتر، مايكروسوفت وورد. في المحررين ، يقوم Alt + X بإجراء التحويل العكسي أيضًا.
في العديد من برامج MS Windows ، للحصول على رمز Unicode ، تحتاج إلى الضغط على مفتاح Alt واكتب القيمة العشرية لرمز الحرف على المفاتيح العددية... على سبيل المثال ، ستكون التركيبات Alt + 0171 (") و Alt + 0187 (") مفيدة عند كتابة النصوص السيريلية. تعتبر التركيبات Alt + 0133 (...) و Alt + 0151 (-) مثيرة للاهتمام أيضًا.
ماكنتوش
الخامس نظام التشغيل Mac OS 8.5 وما بعده ، يتم دعم طريقة إدخال تسمى "Unicode Hex Input". أثناء الضغط باستمرار على مفتاح الخيار ، تحتاج إلى كتابة الرمز السداسي العشري المكون من أربعة أرقام للحرف المطلوب. تسمح لك هذه الطريقة بإدخال أحرف برموز أكبر من U + FFFF باستخدام أزواج بديلة ؛ مثل هؤلاء الأزواج نظام التشغيلسيتم استبداله تلقائيًا بأحرف فردية. قبل استخدام طريقة الإدخال هذه ، تحتاج إلى التنشيط في القسم المقابل من إعدادات النظام ثم تحديد طريقة الإدخال الحالية في قائمة لوحة المفاتيح.
بادئ ذي بدء نظام التشغيل Mac OS X 10.2 ، هناك أيضًا تطبيق "Character Palette" ، والذي يسمح لك بتحديد أحرف من جدول يمكنك من خلاله تحديد أحرف كتلة أو أحرف معينة مدعومة بخط معين.
جنو / لينكس
الخامس جنومهناك أيضًا أداة مساعدة "Symbol Table" تتيح لك عرض رموز كتلة معينة أو نظام كتابة وتوفر القدرة على البحث عن طريق اسم أو وصف الرمز. عندما يتم معرفة رمز الحرف المطلوب ، يمكن إدخاله وفقًا للمعيار ISO 14755: أثناء الضغط باستمرار على Ctrl + ⇧ تحولأدخل رمزًا سداسيًا عشريًا (بدءًا من بعض إصدارات GTK + ، يجب إدخال الرمز بالضغط على المفتاح "U"). يمكن أن يصل طول الشفرة السداسية العشرية التي تم إدخالها إلى 32 بت ، مما يسمح لك بإدخال أي أحرف Unicode دون استخدام أزواج بديلة.
 راشكا سترة مبطن سترة كاريكاتير مبطن
راشكا سترة مبطن سترة كاريكاتير مبطن طرق للتحقق من باقي حركة المرور على الخط المباشر. التحقق من حركة المرور على مودم الخط المباشر
طرق للتحقق من باقي حركة المرور على الخط المباشر. التحقق من حركة المرور على مودم الخط المباشر قم بإنشاء Twitch Stream
قم بإنشاء Twitch Stream