Codifica delle informazioni di testo. Codifica dei caratteri - wiki PIE
Lo standard è stato proposto nel 1991 dall'Unicode Consortium, Unicode Inc., un'organizzazione senza scopo di lucro. L'uso di questo standard consente di codificare un numero molto elevato di caratteri provenienti da diversi script: nei documenti Unicode possono coesistere caratteri cinesi, caratteri matematici, lettere dell'alfabeto greco, latino e cirillico, quindi non è necessario cambiare code page.
Lo standard è costituito da due sezioni principali: il set di caratteri universale (UCS) e il formato di trasformazione Unicode (UTF). Il set di caratteri universale definisce una corrispondenza uno a uno dei caratteri con i codici - elementi dello spazio del codice che rappresentano numeri interi non negativi. La famiglia delle codifiche definisce la rappresentazione macchina di una sequenza di codici UCS.
Lo standard Unicode è stato sviluppato con l'obiettivo di creare una codifica dei caratteri uniforme per tutte le lingue scritte moderne e molte antiche. Ogni carattere in questo standard è codificato a 16 bit, il che gli consente di coprire un numero di caratteri incomparabilmente maggiore rispetto alle codifiche a 8 bit precedentemente accettate. Un'altra importante differenza tra Unicode e altri sistemi di codifica è che non solo assegna un codice univoco a ciascun carattere, ma definisce anche varie caratteristiche di questo carattere, ad esempio:
Tipo di carattere (lettera maiuscola, lettera minuscola, numero, segno di punteggiatura, ecc.);
Attributi dei caratteri (visualizzazione da sinistra a destra o da destra a sinistra, spazio, interruzione di riga, ecc.);
La lettera maiuscola o minuscola corrispondente (rispettivamente per le lettere minuscole e maiuscole);
Il valore numerico corrispondente (per i caratteri numerici).
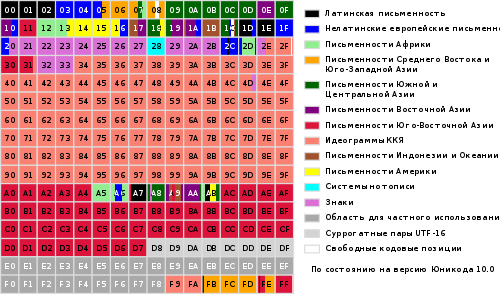
L'intera gamma di codici da 0 a FFFF è suddivisa in diversi sottoinsiemi standard, ciascuno dei quali corrisponde all'alfabeto di una lingua o a un gruppo personaggi speciali, simili nelle loro funzioni. Il diagramma seguente fornisce un elenco generale dei sottoinsiemi Unicode 3.0 (Figura 2).
Immagine 2
Lo standard Unicode è la base per l'archiviazione e il testo in molti moderni sistemi informatici. Tuttavia, non è compatibile con la maggior parte dei protocolli Internet, poiché i suoi codici possono contenere qualsiasi valore di byte e i protocolli di solito utilizzano i byte 00 - 1F e FE - FF come overhead. Per ottenere la compatibilità, sono stati sviluppati diversi formati di trasformazione Unicode (UTF, Unicode Transformation Formats), di cui UTF-8 è oggi il più comune. Questo formato definisce le seguenti regole di conversione per ciascuno Codice Unicode in un insieme di byte (da uno a tre) adatti al trasporto tramite protocolli Internet.
Qui x, y, z denotano i bit del codice sorgente che dovrebbero essere estratti, a partire da quello meno significativo, e inseriti nei byte del risultato da destra a sinistra fino a riempire tutte le posizioni specificate.
Ulteriori sviluppi lo standard Unicode è associato all'aggiunta di nuovi piani linguistici, ad es. caratteri negli intervalli 10000 - 1FFFF, 20000 - 2FFFF, ecc., dove dovrebbe includere la codifica per gli script delle lingue morte non incluse nella tabella sopra. È stato sviluppato un nuovo formato UTF-16 per codificare questi caratteri aggiuntivi.
Pertanto, ci sono 4 modi principali per codificare i byte Unicode:
UTF-8: 128 caratteri sono codificati in un byte (formato ASCII), 1920 caratteri sono codificati in 2 byte ((caratteri romani, greci, cirillici, copti, armeni, ebraici, arabi), 63488 caratteri sono codificati in 3 byte (caratteri cinesi , giapponese e altri) I restanti 2.147.418.112 caratteri (non ancora utilizzati) possono essere codificati con 4, 5 o 6 byte.
UCS-2: ogni carattere è rappresentato da 2 byte. Questa codifica include solo i primi 65.535 caratteri del formato Unicode.
UTF-16: questa è un'estensione di UCS-2 e include 1 114 112 caratteri Unicode. I primi 65.535 caratteri sono rappresentati da 2 byte, il resto da 4 byte.
USC-4: ogni carattere è codificato in 4 byte.
Unicode
Logo del Consorzio Unicode
Unicode(il più delle volte) o Unicode(ing. Unicode) è uno standard di codifica dei caratteri che consente di rappresentare i caratteri in quasi tutte le lingue scritte.
Lo standard è stato proposto nel 1991 dall'organizzazione no profit "Unicode Consortium" (ing. Consorzio Unicode, Unicode Inc.).
L'uso di questo standard consente di codificare un numero molto elevato di caratteri provenienti da diversi script: nei documenti Unicode possono coesistere caratteri cinesi, caratteri matematici, lettere dell'alfabeto greco, latino e cirillico, quindi non è necessario cambiare code page.
Lo standard è composto da due sezioni principali: set di caratteri universale (ing. UCS, set di caratteri universale) e la famiglia delle codifiche (ing. UTF, formato di trasformazione Unicode).
Il set di caratteri universale definisce una corrispondenza uno a uno dei caratteri con i codici - elementi dello spazio del codice che rappresentano numeri interi non negativi. La famiglia delle codifiche definisce la rappresentazione macchina di una sequenza di codici UCS.
I codici Unicode sono suddivisi in diverse aree. L'area con codici da U+0000 a U+007F contiene i caratteri ASCII con i codici corrispondenti. Seguono le aree dei segni di varie scritture, punteggiatura e simboli tecnici.
Alcuni dei codici sono riservati per un uso futuro. Sotto i caratteri cirillici vengono allocate aree di caratteri con codici da U + 0400 a U + 052F, da U + 2DE0 a U + 2DFF, da U + A640 a U + A69F (vedi Cirillico in Unicode).
- 1 Prerequisiti per la creazione e lo sviluppo di Unicode
- 2 versioni Unicode
- 3 Spazio codice
- 4 Sistema di codifica
- 4.1 Politica del Consorzio
- 4.2 Combinazione e duplicazione di simboli
- 5 Modificare i caratteri
- 6 Algoritmi di normalizzazione
- 6.1 DNF
- 6.2 NFC
- 6.3 NFKD
- 6.4 NFKC
- 6.5 Esempi
- 7 Scrittura bidirezionale
- 8 simboli in primo piano
- 9 ISO/IEC 10646
- 10 modi di presentazione
- 10.1 UTF-8
- 10.2 Ordine dei byte
- 10.3 Unicode e codifiche tradizionali
- 10.4 Implementazioni
- 11 metodi di input
- 11.1 Microsoft Windows
- 11.2 Macintosh
- 11.3 GNU/Linux
- 12 problemi di Unicode
- 13 "Unicode" o "Unicode"?
Prerequisiti per la creazione e lo sviluppo di Unicode
Alla fine degli anni '80, i caratteri a 8 bit erano diventati lo standard. Allo stesso tempo, c'erano molte diverse codifiche a 8 bit e ne apparivano costantemente di nuove.
Ciò è stato spiegato sia dalla costante espansione della gamma di lingue supportate, sia dal desiderio di creare una codifica parzialmente compatibile con un'altra (un tipico esempio è l'emergere di una codifica alternativa per la lingua russa, dovuta allo sfruttamento delle lingue occidentali programmi creati per la codifica CP437).
Di conseguenza, sono comparsi diversi problemi:
- il problema di "krakozyabr";
- il problema del set di caratteri limitato;
- il problema di convertire una codifica in un'altra;
- il problema dei caratteri duplicati.
Il problema "krakozyabr"- il problema della visualizzazione dei documenti nella codifica errata. Il problema potrebbe essere risolto sia introducendo coerentemente metodi per specificare la codifica utilizzata, sia introducendo un'unica codifica (comune) per tutti.
Il problema del set di caratteri limitato... Il problema potrebbe essere risolto sia cambiando i caratteri all'interno del documento, sia introducendo una codifica "ampia". La commutazione dei caratteri è stata a lungo praticata negli elaboratori di testi e sono stati spesso utilizzati caratteri con una codifica non standard, i cosiddetti. "Caratteri Dingbat". Di conseguenza, quando si tenta di trasferire un documento su un altro sistema, tutti i caratteri non standard si trasformano in "krakozyabry".
Il problema di convertire una codifica in un'altra... Il problema potrebbe essere risolto sia compilando tabelle di conversione per ogni coppia di codifiche, sia utilizzando una conversione intermedia a una terza codifica che includa tutti i caratteri di tutte le codifiche.
Problema con caratteri duplicati... Per ogni codifica è stato creato un proprio font, anche se i set di caratteri nelle codifiche coincidevano parzialmente o completamente. Il problema potrebbe essere risolto creando dei font "grandi", dai quali sarebbero stati successivamente selezionati i caratteri necessari per una data codifica. Tuttavia, ciò ha richiesto la creazione di un unico registro di simboli per determinare cosa corrisponde a cosa.
È stata riconosciuta la necessità di creare un'unica codifica "wide". Le codifiche a lunghezza variabile, ampiamente utilizzate nell'Asia orientale, sono risultate troppo difficili da utilizzare, quindi si è deciso di utilizzare caratteri a larghezza fissa.
L'utilizzo di caratteri a 32 bit sembrava troppo dispendioso, quindi è stato deciso di utilizzare caratteri a 16 bit.
La prima versione di Unicode era una codifica con una dimensione di carattere fissa di 16 bit, ovvero il numero totale di codici era 2 16 (65 536). Da allora, i caratteri sono stati denotati da quattro cifre esadecimali (ad esempio, U + 04F0). Allo stesso tempo, è stato pianificato di codificare in Unicode non tutti i caratteri esistenti, ma solo quelli necessari nella vita di tutti i giorni. I simboli usati raramente dovevano essere collocati nella "zona di uso privato" che originariamente occupava i codici U + D800 ... U + F8FF.
Al fine di utilizzare Unicode anche come intermediario nella conversione di codifiche diverse tra loro, sono stati inclusi tutti i caratteri rappresentati in tutte le codifiche più famose.
In futuro, tuttavia, si è deciso di codificare tutti i simboli e, a questo proposito, espandere notevolmente il dominio del codice.
Allo stesso tempo, i codici carattere iniziarono a essere considerati non come valori a 16 bit, ma come numeri astratti che possono essere rappresentati in un computer in molti modi diversi (vedi metodi di rappresentazione).
Poiché in alcuni sistemi informatici (ad esempio Windows NT) erano già utilizzati caratteri fissi a 16 bit come codifica predefinita, si è deciso di codificare tutti i caratteri più importanti solo all'interno delle prime 65.536 posizioni (il cosiddetto English. piano multilingue di base, BMP).
Il resto dello spazio è utilizzato per "caratteri aggiuntivi" (ing. caratteri supplementari): sistemi di scrittura di lingue estinte o caratteri cinesi usati molto raramente, simboli matematici e musicali.
Per compatibilità con i vecchi sistemi a 16 bit, è stato inventato il sistema UTF-16, in cui le prime 65.536 posizioni, ad eccezione delle posizioni dall'intervallo U + D800 ... U + DFFF, vengono visualizzate direttamente come numeri a 16 bit, e il resto sono rappresentati come "coppie sostitutive" (Il primo elemento della coppia dall'area U + D800… U + DBFF, il secondo elemento della coppia dall'area U + DC00… U + DFFF). Per le coppie surrogate è stata utilizzata una parte del code space (2048 posizioni) destinata ad “uso privato”.
Poiché UTF-16 può visualizzare solo 2 20 +2 16 -2048 (1 112 064) caratteri, questo numero è stato scelto come valore finale dello spazio del codice Unicode (intervallo di codici: 0x000000-0x10FFFF).
Sebbene l'area del codice Unicode sia stata estesa oltre 2-16 già nella versione 2.0, i primi caratteri nell'area "in alto" sono stati inseriti solo nella versione 3.1.
Il ruolo di questa codifica nel settore web è in costante crescita. All'inizio del 2010, la quota di siti Web che utilizzano Unicode era di circa il 50%.
Versioni Unicode
Il lavoro per finalizzare lo standard continua. Nuove versioni vengono rilasciate man mano che le tabelle dei simboli cambiano e vengono aggiornate. Parallelamente vengono emessi nuovi documenti ISO/IEC 10646.
Il primo standard è stato rilasciato nel 1991, l'ultimo nel 2016, il prossimo è previsto nell'estate del 2017. Le versioni degli standard 1.0-5.0 sono state pubblicate come libri e hanno un ISBN.
Il numero di versione dello standard è composto da tre cifre (ad esempio, "4.0.1"). La terza cifra viene modificata quando vengono apportate modifiche minori allo standard che non aggiungono nuovi caratteri.
Spazio codice
Sebbene i moduli di notazione UTF-8 e UTF-32 consentano di codificare fino a 2.331 (2.147.483.648) punti di codice, è stato deciso di utilizzare solo 1.112.064 per la compatibilità con UTF-16. Tuttavia, anche questo è più che sufficiente per il momento: nella versione 6.0 vengono utilizzati poco meno di 110.000 punti di codice (109.242 grafici e 273 altri simboli).
Lo spazio del codice è suddiviso in 17 aerei(ing. aerei) 2 16 (65 536) caratteri ciascuno. Piano terra ( piano 0) è chiamato di base (di base) e contiene i simboli degli script più comuni. Il resto degli aerei sono aggiuntivi ( supplementare). Il primo aereo ( piano 1) è utilizzato principalmente per le scritture storiche, il secondo ( piano 2) - per i caratteri cinesi usati raramente (CJK), il terzo ( piano 3) è riservato ai caratteri cinesi arcaici. Gli aerei 15 e 16 sono riservati ad uso privato.
Per denotare Caratteri Unicode una notazione della forma “U + xxxx"(Per i codici 0 ... FFFF), oppure" U + xxxxx"(Per i codici 10000 ... FFFFF), oppure" U + xxxxxx"(Per i codici 100000 ... 10FFFF), dove xxx- cifre esadecimali. Ad esempio, il simbolo "i" (U + 044F) ha il codice 044F 16 = 1103 10.
Sistema di codifica
Un sistema di codifica universale (Unicode) è un insieme di simboli grafici e un modo per codificarli per l'elaborazione al computer di dati di testo.
I simboli grafici sono simboli che hanno un'immagine visibile. I caratteri grafici si oppongono ai caratteri di controllo e formattazione.
I simboli grafici includono i seguenti gruppi:
- lettere contenute in almeno uno degli alfabeti supportati;
- numeri;
- segni di punteggiatura;
- segni speciali (matematici, tecnici, ideogrammi, ecc.);
- separatori.
Unicode è un sistema per la rappresentazione lineare del testo. I caratteri con apici o pedici aggiuntivi possono essere rappresentati come una sequenza di codici costruiti secondo determinate regole (carattere composto) o come un singolo carattere (versione monolitica, carattere precomposto). Sopra questo momento(2014), si ritiene che tutte le lettere di caratteri di grandi dimensioni siano incluse in Unicode e, se un simbolo è disponibile in una versione composita, non è necessario duplicarlo in una forma monolitica.
Politica consortile
Il consorzio non ne crea uno nuovo, ma stabilisce l'ordine delle cose stabilito. Ad esempio, le immagini emoji sono state aggiunte perché gli operatori giapponesi comunicazioni mobili erano ampiamente utilizzati.
Per fare ciò, l'aggiunta di un simbolo passa attraverso un processo complesso. E, ad esempio, il simbolo del rublo russo lo ha superato in tre mesi semplicemente perché ha ricevuto lo status ufficiale.
I marchi sono codificati solo in via eccezionale. Quindi, in Unicode non c'è il flag di Windows o la mela di Apple.
Una volta che un carattere è apparso nella codifica, non si sposterà o scomparirà mai. Se è necessario modificare l'ordine dei caratteri, ciò viene fatto non modificando le posizioni, ma mediante l'ordinamento nazionale. Esistono altre garanzie di stabilità più sottili: ad esempio, le tabelle di normalizzazione non cambieranno.
Combinazione e duplicazione di simboli
Lo stesso simbolo può assumere diverse forme; in Unicode, queste forme sono contenute in un punto di codice:
- se è successo storicamente. Ad esempio, le lettere arabe hanno quattro forme: staccate, all'inizio, al centro e alla fine;
- o se una lingua viene adottata in una forma e in un'altra - un'altra. Il cirillico bulgaro differisce dal russo e i caratteri cinesi dal giapponese.
D'altra parte, se storicamente i caratteri avevano due punti di codice diversi, rimangono diversi in Unicode. Il sigma greco minuscolo ha due forme e hanno posizioni diverse. Lettera latina estesa Å (A con un cerchio) e segno angstrom Å, lettera grecaμ e il prefisso “micro” µ sono simboli diversi.
Naturalmente, caratteri simili in script non correlati vengono inseriti in posizioni di codice diverse. Ad esempio, la lettera A in latino, cirillico, greco e cherokee sono simboli diversi.
È estremamente raro che lo stesso carattere venga inserito in due posizioni di codice diverse per semplificare l'elaborazione del testo. Il tratto matematico e lo stesso tratto per indicare la morbidezza dei suoni sono simboli diversi, il secondo è considerato una lettera.
Modificare i caratteri
Rappresentazione del carattere "Y" (U + 0419) nella forma del carattere base "I" (U + 0418) e del carattere modificante "" (U + 0306)
I caratteri grafici in Unicode sono divisi in estesi e non estesi (senza larghezza). I caratteri non estesi non occupano spazio nella riga quando vengono visualizzati. Questi includono, in particolare, gli accenti e altri segni diacritici. Sia i caratteri estesi che quelli non estesi hanno i propri codici. I simboli estesi sono altrimenti chiamati di base (ing. personaggi di base), e quelli non estesi - modificativi (ing. combinazione di caratteri); e quest'ultimo non può incontrarsi autonomamente. Ad esempio, il carattere "á" può essere rappresentato come una sequenza del carattere base "a" (U + 0061) e il carattere modificatore "́" (U + 0301), oppure come carattere monolitico "á" (U + 00E1).
Un tipo speciale di caratteri modificabili sono i selettori di stile (ing. selettori di variazione). Si applicano solo a quei simboli per i quali sono definite tali varianti. Nella versione 5.0, le opzioni di stile sono definite per una serie simboli matematici, per i simboli dell'alfabeto tradizionale mongolo e per i simboli della scrittura quadrata mongola.
Algoritmi di normalizzazione
Poiché gli stessi simboli possono essere rappresentati codici diversi, il confronto delle stringhe byte per byte diventa impossibile. Algoritmi di normalizzazione forme di normalizzazione) risolvono questo problema convertendo il testo in un determinato modulo standard.
Il casting viene effettuato sostituendo i simboli con altri equivalenti utilizzando tabelle e regole. "Decomposizione" è la sostituzione (scomposizione) di un carattere in più caratteri costituenti e "composizione", al contrario, è la sostituzione (connessione) di più caratteri costituenti con un carattere.
Lo standard Unicode definisce 4 algoritmi di normalizzazione del testo: NFD, NFC, NFKD e NFKC.
NFD
NFD, ing. n formalizzazione F orm D ("D" dall'inglese. D ecomposizione), la forma di normalizzazione D è la decomposizione canonica - un algoritmo in base al quale viene eseguita la sostituzione ricorsiva di simboli monolitici (ing. personaggi precomposti) in più componenti (ing. caratteri compositi) secondo le tabelle di scomposizione.
Å U + 00C5 →
UN U + 0041
̊ U + 030A
ṩ U + 1E69 →
S U + 0073
̣ U + 0323
̇ U + 0307
ḍ̇ U + 1E0B U + 0323 →
D U + 0064
̣ U + 0323
̇ U + 0307
Q U + 0071 U + 0307 U + 0323 →
Q U + 0071
̣ U + 0323
̇ U + 0307 NFC
NFC, ing. n formalizzazione F orm C ("C" dall'inglese. C omposizione), la forma di normalizzazione C è un algoritmo secondo il quale la decomposizione canonica e la composizione canonica vengono eseguite in sequenza. Innanzitutto, la decomposizione canonica (algoritmo NFD) riduce il testo alla forma D. Quindi la composizione canonica, l'inverso di NFD, elabora il testo dall'inizio alla fine, tenendo conto delle seguenti regole:
- simbolo S conta iniziale se ha una classe di modifica uguale a zero secondo la tabella dei caratteri Unicode;
- in qualsiasi sequenza di caratteri che iniziano con il carattere S, simbolo C bloccato da S, solo se tra S e C c'è qualche simbolo? B che è iniziale o ha la stessa classe di modifica o maggiore di C... Questa regola si applica solo alle stringhe che hanno subito una decomposizione canonica;
- il simbolo è considerato primario un composito se ha una scomposizione canonica nella tabella dei caratteri Unicode (o una scomposizione canonica per Hangul e non è incluso nell'elenco di esclusione);
- simbolo X può essere combinato con il simbolo prima sì se e solo se esiste un composto primario Z, canonicamente equivalente alla successione<X, sì>;
- se il prossimo carattere C non bloccato dall'ultimo carattere base iniziale incontrato l e può essere combinato con successo prima, quindi l sostituito da composito L-C, un C RIMOSSO.
o U + 006F
̂ U + 0302 → →
h U + 0048
① U + 2460 →
1 U + 0031
カ U + FF76 →
カ U + 30AB →
fi U + FB01
fi U + FB01
F io U + 0066 U + 0069
F io U + 0066 U + 0069
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 5 U + 0032 U + 0035
2 5 U + 0032 U + 0035
ẛ̣ U + 1E9B U + 0323
? ̣ ̇ U + 017F U + 0323 U + 0307
ẛ ̣ U + 1E9B U + 0323
S ̣ ̇ U + 0073 U + 0323 U + 0307
ṩ U + 1E69
ns U + 0439
e ̆ U + 0438 U + 0306
ns U + 0439
e ̆ U + 0438 U + 0306
ns U + 0439
e U + 0451
e ̈ U + 0435 U + 0308
e U + 0451
e ̈ U + 0435 U + 0308
e U + 0451
UN U + 0410
UN U + 0410
UN U + 0410
UN U + 0410
UN U + 0410
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
Ⅷ U + 2167
Ⅷ U + 2167
Ⅷ U + 2167
V io io io U + 0056 U + 0049 U + 0049 U + 0049
V io io io U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
C ̧ U + 0063 U + 0327
ç U + 00E7
C ̧ U + 0063 U + 0327
ç U + 00E7 Lettera bidirezionale
Lo standard Unicode supporta la scrittura di lingue sia nella direzione da sinistra a destra (ing. da sinistra a destra, LTR), e con scritta da destra a sinistra (ing. da destra a sinistra, RTL) - ad esempio, lettere arabe ed ebraiche. In entrambi i casi, i caratteri sono memorizzati in un ordine "naturale"; la loro visualizzazione, tenendo conto della direzione desiderata della lettera, è fornita dall'applicazione.
Inoltre, Unicode supporta testi combinati che combinano frammenti con diverse direzioni della lettera. Questa funzione si chiama bidirezionalità(ing. testo bidirezionale, BiDi). Alcuni elaboratori di testo semplificati (ad esempio, in telefono cellulare) può supportare Unicode, ma non il supporto bidirezionale. Tutti i caratteri Unicode sono divisi in diverse categorie: scritti da sinistra a destra, scritti da destra a sinistra e scritti in qualsiasi direzione. I simboli di quest'ultima categoria (principalmente segni di punteggiatura), quando visualizzati, prendono la direzione del testo circostante.
Simboli in primo piano
Diagramma del piano multilingue di base di Unicode
Unicode include praticamente tutti gli script moderni, tra cui:
- Arabo
- Armeno,
- Bengalese,
- Birmano,
- verbo,
- greco
- Georgiano,
- devanagari,
- Ebreo,
- Cirillico,
- Cinese (i caratteri cinesi sono utilizzati attivamente in giapponese e occasionalmente in coreano),
- copto,
- Khmer,
- Latino,
- Tamil,
- coreano (hangul),
- Cherokee,
- Etiope,
- giapponese (che comprende, oltre all'alfabeto sillabico, anche i caratteri cinesi)
Altro.
Per scopi accademici, sono state aggiunte molte scritture storiche, tra cui: rune germaniche, antiche rune turche, scrittura greca antica, geroglifici egizi, cuneiforme, scrittura maya, alfabeto etrusco.
Unicode offre un'ampia gamma di simboli e pittogrammi matematici e musicali.
In linea di principio, Unicode non include bandiere di stato, loghi di società e prodotti, sebbene si trovino nei caratteri (ad esempio, il logo Apple nella codifica MacRoman (0xF0) o il logo Windows nel carattere Wingdings (0xFF)). Nei caratteri Unicode, i loghi devono essere posizionati solo nell'area dei caratteri personalizzati.
ISO/IEC 10646
Il Consorzio Unicode lavora a stretto contatto con gruppo di lavoro ISO/IEC/JTC1/SC2/WG2, che sta sviluppando lo standard internazionale 10646 (ISO/IEC 10646). La sincronizzazione viene stabilita tra lo standard Unicode e ISO / IEC 10646, sebbene ogni standard utilizzi la propria terminologia e il proprio sistema di documentazione.
Collaborazione del Consorzio Unicode con l'Organizzazione internazionale per la standardizzazione (ing. Organizzazione internazionale per la standardizzazione, ISO ) ha avuto inizio nel 1991. Nel 1993, l'ISO ha emesso lo standard DIS 10646,1. Per sincronizzarsi con esso, il Consorzio ha approvato la versione 1.1 dello standard Unicode, che ha aggiunto caratteri aggiuntivi dal DIS 10646.1. Di conseguenza, i valori dei caratteri codificati in Unicode 1.1 e DIS 10646.1 sono esattamente gli stessi.
In futuro è proseguita la collaborazione tra le due organizzazioni. Nel 2000, lo standard Unicode 3.0 è stato sincronizzato con ISO/IEC 10646-1: 2000. La prossima terza versione di ISO/IEC 10646 sarà sincronizzata con Unicode 4.0. Forse queste specifiche saranno anche pubblicate come un unico standard.
Simile ai formati UTF-16 e UTF-32 nello standard Unicode, anche lo standard ISO/IEC 10646 ha due forme principali di codifica dei caratteri: UCS-2 (2 byte per carattere, simile a UTF-16) e UCS-4 (4 byte per carattere, simile a UTF-32). UCS significa multi-ottetto universale(multibyte) set di caratteri codificati(ing. set di caratteri codificati a più ottetti universali ). UCS-2 può essere considerato un sottoinsieme di UTF-16 (UTF-16 senza coppie surrogate) e UCS-4 è sinonimo di UTF-32.
Differenze tra gli standard Unicode e ISO/IEC 10646:
- lievi differenze terminologiche;
- ISO/IEC 10646 non include le sezioni necessarie per implementare completamente il supporto Unicode:
- nessun dato sulla codifica binaria dei caratteri;
- non c'è descrizione di algoritmi di confronto (ing. collazione) e rendering (ing. rendering) caratteri;
- non esiste un elenco di proprietà dei simboli (ad esempio, non esiste un elenco di proprietà necessarie per implementare il supporto per bidirezionale (eng. bidirezionale) lettere).
Metodi di presentazione
Unicode ha diverse forme di rappresentazione (eng. Formato di trasformazione Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) e UTF-32 (UTF-32BE, UTF-32LE). Anche il modulo UTF-7 è stato sviluppato per la trasmissione su canali a sette bit, ma a causa dell'incompatibilità con l'ASCII non è stato diffuso e non è stato incluso nello standard. Il 1 aprile 2005 sono state proposte due presentazioni umoristiche: UTF-9 e UTF-18 (RFC 4042).
I sistemi basati su Microsoft Windows NT e Windows 2000 e Windows XP utilizzano principalmente il modulo UTF-16LE. I sistemi operativi simili a UNIX GNU/Linux, BSD e Mac OS X adottano UTF-8 per i file e UTF-32 o UTF-8 per l'elaborazione dei caratteri in memoria ad accesso casuale.
Punycode è un'altra forma di codifica di sequenze di caratteri Unicode nelle cosiddette sequenze ACE, che consistono solo di caratteri alfanumerici, come consentito nei nomi di dominio.
UTF-8
UTF-8 è la rappresentazione Unicode che offre la migliore compatibilità con i sistemi meno recenti che utilizzavano caratteri a 8 bit.
Il testo contenente solo caratteri con un numero inferiore a 128 viene convertito in testo ASCII semplice quando scritto in UTF-8. Al contrario, nel testo UTF-8, viene visualizzato qualsiasi byte con un valore inferiore a 128 carattere ASCII con lo stesso codice.
Il resto dei caratteri Unicode è rappresentato da sequenze lunghe da 2 a 6 byte (in realtà solo fino a 4 byte, poiché in Unicode non esistono caratteri con codice maggiore di 10FFFF e non si prevede di introdurli nel future), in cui il primo byte ha sempre la forma 11xxxxxx, e il resto - 10xxxxxx... Nessuna coppia di surrogati viene utilizzata in UTF-8, 4 byte sono sufficienti per scrivere qualsiasi carattere unicode.
Il formato UTF-8 è stato inventato il 2 settembre 1992 da Ken Thompson e Rob Pike e implementato nel Piano 9... Lo standard UTF-8 è ora ufficialmente sancito dalla RFC 3629 e dall'ISO/IEC 10646 Allegato D.
I caratteri UTF-8 sono derivati da Unicode come segue:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Teoricamente possibile, ma anche non incluso nello standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Sebbene UTF-8 ti permetta di specificare lo stesso carattere in diversi modi, solo il più corto è corretto. Il resto dei moduli dovrebbe essere rifiutato per motivi di sicurezza.
Ordine dei byte
In un flusso di dati UTF-16, il byte basso può essere scritto sia prima di quello alto (eng. UTF-16 little-endian), o dopo il più antico (ing. UTF-16 big-endian). Allo stesso modo, ci sono due opzioni per la codifica a quattro byte: UTF-32LE e UTF-32BE.
Per definire il formato della rappresentazione Unicode all'inizio file di testo la firma è scritta - il carattere U + FEFF (spazio unificatore con larghezza zero), chiamato anche marcatore di sequenza di byte(ing. byte order mark (BOM)). Ciò consente di distinguere tra UTF-16LE e UTF-16BE poiché il carattere U + FFFE non esiste. A volte è anche usato per indicare il formato UTF-8, sebbene la nozione di ordine dei byte non si applichi a questo formato. I file che seguono questa convenzione iniziano con queste sequenze di byte:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Sfortunatamente, questo metodo non distingue in modo affidabile tra UTF-16LE e UTF-32LE, poiché il carattere U + 0000 è consentito da Unicode (sebbene i testi reali inizino raramente con esso).
I file nelle codifiche UTF-16 e UTF-32 che non contengono un BOM devono essere in ordine di byte big-endian (unicode.org).
Unicode e codifiche tradizionali
L'introduzione di Unicode ha cambiato l'approccio alle tradizionali codifiche a 8 bit. Se prima la codifica era specificata dal carattere, ora è specificata dalla tabella di corrispondenza tra questa codifica e Unicode.
In effetti, le codifiche a 8 bit sono diventate una forma di rappresentazione di un sottoinsieme di Unicode. Ciò ha reso molto più semplice creare programmi che devono funzionare con molte codifiche diverse: ora, per aggiungere il supporto per un'altra codifica, è sufficiente aggiungere un'altra tabella di ricerca Unicode.
Inoltre, molti formati di dati consentono di inserire qualsiasi carattere Unicode, anche se il documento è scritto nella vecchia codifica a 8 bit. Ad esempio, puoi utilizzare i codici e commerciali in HTML.
Implementazione
La maggior parte dei sistemi operativi moderni fornisce un certo grado di supporto Unicode.
Nei sistemi operativi della famiglia Windows NT, la codifica UTF-16LE a doppio byte viene utilizzata per la rappresentazione interna dei nomi dei file e di altre stringhe di sistema. Le chiamate di sistema che accettano parametri stringa sono disponibili nelle varianti a byte singolo e doppio. Per ulteriori informazioni, vedere l'articolo Unicode sulla famiglia di sistemi operativi Microsoft Windows.
Simile a UNIX OS, inclusi GNU/Linux, BSD, OS X, usano la codifica UTF-8 per rappresentare Unicode. La maggior parte dei programmi può funzionare con UTF-8 come codifiche tradizionali a byte singolo, indipendentemente dal fatto che un carattere sia rappresentato come diversi byte consecutivi. Per lavorare con i singoli caratteri, le stringhe vengono solitamente ricodificate in UCS-4, in modo che ogni carattere abbia una parola macchina.
Una delle prime implementazioni commerciali di successo di Unicode è stata mercoledì Programmazione Java... Fondamentalmente ha abbandonato la rappresentazione dei caratteri a 8 bit in favore di quella a 16 bit. Questa soluzione ha aumentato il consumo di memoria, ma ci ha permesso di restituire un'astrazione importante alla programmazione: un singolo carattere arbitrario (tipo char). In particolare, un programmatore potrebbe lavorare con una stringa come con un semplice array. Sfortunatamente, il successo non è stato definitivo, Unicode ha superato il limite di 16 bit e dalla versione J2SE 5.0, un carattere arbitrario ha ricominciato a occupare un numero variabile di unità di memoria: una char o due (vedi coppia surrogata).
La maggior parte dei linguaggi di programmazione ora supporta le stringhe Unicode, sebbene la loro rappresentazione possa differire a seconda dell'implementazione.
Metodi di input
Poiché nessun layout di tastiera può consentire l'immissione contemporanea di tutti i caratteri Unicode, è necessario che i sistemi operativi e le applicazioni supportino metodi alternativi per l'immissione di caratteri Unicode arbitrari.
Microsoft Windows
Sebbene a partire da Windows 2000, l'utilità Mappa caratteri (charmap.exe) supporti i caratteri Unicode e ti consenta di copiarli negli appunti, questo supporto è limitato solo al piano di base (codici carattere U + 0000… U + FFFF). I simboli con codici da U + 10000 "Tabella dei simboli" non vengono visualizzati.
C'è una tabella simile, per esempio, in Microsoft Word.
A volte puoi digitare un codice esadecimale, premere Alt + X e il codice verrà sostituito con il carattere appropriato, ad esempio in WordPad, Microsoft Word. Negli editor, Alt + X esegue anche la trasformazione inversa.
In molti programmi MS Windows, per ottenere un carattere Unicode, è necessario premere il tasto Alt e digitare il valore decimale del codice carattere su tastiera numerica... Ad esempio, le combinazioni Alt + 0171 ("), Alt + 0187 (") e Alt + 0769 (accento) saranno utili durante la digitazione di testi in cirillico. Interessanti anche le combinazioni Alt + 0133 (…) e Alt + 0151 (-).
Macintosh
Mac OS 8.5 e versioni successive supportano un metodo di input chiamato "Input esadecimale Unicode". Tenendo premuto il tasto Opzione, è necessario digitare il codice esadecimale di quattro cifre del carattere richiesto. Questo metodo consente di inserire caratteri con codici maggiori di U + FFFF utilizzando coppie di surrogati; tali coppie verranno automaticamente sostituite dal sistema operativo con caratteri singoli. Prima dell'uso, questo metodo di input deve essere attivato nella sezione appropriata delle impostazioni di sistema e quindi selezionare come metodo di input corrente nel menu della tastiera.
A partire da Mac OS X 10.2, esiste anche un'applicazione Character Palette che consente di selezionare caratteri da una tabella in cui è possibile selezionare caratteri da un blocco specifico o caratteri supportati da un font specifico.
GNU/Linux
GNOME ha anche un'utilità Mappa dei simboli (precedentemente gucharmap) che consente di visualizzare i simboli per un blocco specifico o un sistema di scrittura e fornisce la possibilità di cercare per nome o descrizione di un simbolo. Quando si conosce il codice del carattere desiderato, lo si può inserire secondo lo standard ISO 14755: tenendo premuti i tasti Ctrl + ⇧ Shift, inserire il codice esadecimale (a partire da alcune versioni di GTK +, il codice deve essere inserito premendo "tu"). Il codice esadecimale inserito può avere una lunghezza massima di 32 bit, consentendo di inserire qualsiasi carattere Unicode senza utilizzare coppie di surrogati.
Tutte le applicazioni X Window, inclusi GNOME e KDE, supportano l'input del tasto Compose. Per le tastiere che non dispongono di un tasto Componi dedicato, puoi assegnare qualsiasi tasto a questo scopo, ad esempio ⇪ Blocco maiuscole.
La console GNU / Linux consente anche di inserire un carattere Unicode tramite il suo codice - per questo, il codice decimale del carattere deve essere inserito come cifre del blocco tastiera esteso tenendo premuto il tasto Alt. Puoi inserire i caratteri tramite il loro codice esadecimale: per questo devi tenere premuto il tasto AltGr, e per inserire cifre A-F utilizzare i tasti sul blocco tastiera esteso da BlocNum a Invio (in senso orario). È supportato anche l'input in conformità con ISO 14755. Affinché i metodi di cui sopra funzionino, è necessario abilitare la modalità Unicode nella console chiamando unicode_start(1) e seleziona un carattere adatto chiamando setfont(8).
Mozilla Firefox per Linux supporta l'immissione di caratteri ISO 14755.
Problemi Unicode
In Unicode, l'inglese "a" e il polacco "a" sono lo stesso carattere. Allo stesso modo, la "a" russa e la "a" serba sono considerate lo stesso simbolo (ma diverso dalla "a" latina). Questo principio di codifica non è universale; a quanto pare, una soluzione "per tutte le occasioni" non può affatto esistere.
- Cinese, coreano e giapponese sono tradizionalmente scritti dall'alto verso il basso, a partire dall'angolo in alto a destra. Il passaggio dall'ortografia orizzontale a quella verticale per queste lingue non è previsto in Unicode - questo deve essere fatto tramite linguaggi di markup o meccanismi interni di elaboratori di testi.
- Unicode consente pesi diversi dello stesso carattere a seconda della lingua. Quindi, i caratteri cinesi possono avere pesi diversi in cinese, giapponese (kanji) e coreano (hancha), ma allo stesso tempo in Unicode sono indicati dallo stesso simbolo (la cosiddetta unificazione CJK), sebbene caratteri semplificati e completi ancora hanno codici diversi... Allo stesso modo, le lingue russa e serba usano corsivi corsivi diversi. NS e T(in serbo assomigliano a u e w, vedi corsivo serbo). Pertanto, è necessario assicurarsi che il testo sia sempre contrassegnato correttamente come correlato all'una o all'altra lingua.
- La traduzione da minuscolo a maiuscolo dipende anche dalla lingua. Ad esempio: in turco ci sono le lettere İi e Iı - quindi, le regole di cambio di caso turche sono in conflitto con quelle inglesi, che richiedono che "i" sia tradotto in "I". Esistono problemi simili in altre lingue: ad esempio, nel dialetto canadese del francese, il registro è tradotto in modo leggermente diverso rispetto alla Francia.
- Anche con i numeri arabi, ci sono alcune sottigliezze tipografiche: i numeri sono "maiuscoli" e "minuscoli", proporzionali e monospaziati - per Unicode non c'è differenza tra loro. Tali sfumature rimangono con il software.
Alcuni degli svantaggi non sono legati a Unicode stesso, ma piuttosto alle capacità dei processori di testo.
- I file di testo non latino in Unicode occupano sempre più spazio, poiché un carattere è codificato non da un byte, come in varie codifiche nazionali, ma da una sequenza di byte (l'eccezione è UTF-8 per le lingue il cui alfabeto si adatta in ASCII, nonché la presenza di due caratteri nel testo e più lingue, il cui alfabeto non rientra in ASCII). Il file di font richiesto per visualizzare tutti i caratteri nella tabella Unicode occupa una memoria e risorse di calcolo relativamente grandi rispetto a un font in una sola lingua nazionale dell'utente. Con l'aumento della potenza dei sistemi informatici e la riduzione del costo della memoria e dello spazio su disco, questo problema diventa sempre meno significativo; tuttavia, rimane rilevante per i dispositivi portatili come i telefoni cellulari.
- Sebbene il supporto Unicode sia implementato nei sistemi operativi più comuni, finora non tutti applicati Software supporti lavoro corretto con lui. In particolare, i Byte Order Mark (BOM) non vengono sempre elaborati e i caratteri accentati sono scarsamente supportati. Il problema è temporaneo ed è una conseguenza della novità comparativa degli standard Unicode (rispetto alle codifiche nazionali a byte singolo).
- Le prestazioni di tutti i programmi di elaborazione delle stringhe (inclusi gli ordinamenti nel database) diminuiscono quando viene utilizzato Unicode invece delle codifiche a byte singolo.
Alcuni rari sistemi di scrittura non sono ancora rappresentati correttamente in Unicode. La rappresentazione di caratteri apici "lunghi" che si estendono su più lettere, come, ad esempio, nello slavo ecclesiastico, non è stata ancora implementata.
Unicode o Unicode?
"Unicode" è sia un nome proprio (o parte di un nome, ad esempio Unicode Consortium) sia un nome comune derivato dalla lingua inglese.
A prima vista, è preferibile utilizzare l'ortografia "Unicode". Nella lingua russa esistono già morfemi "uni-" (le parole con l'elemento latino "uni-" erano tradizionalmente tradotte e scritte attraverso "uni-": universale, unipolare, unificazione, uniforme) e "codice". Contro, marchi di fabbrica, mutuati dalla lingua inglese, vengono solitamente trasmessi attraverso la trascrizione pratica, in cui la combinazione di lettere "uni-" de-etimologizzata è scritta come "uni-" ("Unilever", "Unix", ecc.), cioè, allo stesso modo del caso di acronimi lettera per lettera come UNICEF "Fondo di emergenza internazionale per l'infanzia delle Nazioni Unite" - UNICEF.
L'ortografia di "Unicode" è già entrata saldamente nei testi in lingua russa. Wikipedia usa una versione più comune. Su MS Windows viene utilizzata l'opzione Unicode.
C'è una pagina speciale sul sito del Consorzio, dove i problemi di trasferimento della parola "Unicode" a lingue differenti e sistemi di scrittura. Per l'alfabeto cirillico russo, è specificata l'opzione "Unicode".
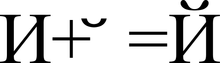
I problemi associati alle codifiche sono generalmente gestiti dal software, quindi di solito non ci sono difficoltà nell'uso delle codifiche. Se sorgono difficoltà, di solito sono generate da programmi non validi: sentiti libero di inviarle nel cestino.
Invito tutti a parlare in
ASCII (English American Standard Code for Information Interchange) è la tabella di codifica standard americana per i caratteri stampabili e alcuni codici speciali. In inglese americano, [Éski] è pronunciato, mentre nel Regno Unito, [Aski] è più pronunciato; in russo si pronuncia anche [aski] o [aski].
ASCII è una codifica per cifre decimali, alfabeti latini e nazionali, punteggiatura e caratteri di controllo. Originariamente progettato come 7 bit, con l'uso diffuso del byte ASCII a 8 bit, è stato pensato come la metà degli 8 bit. I computer di solito usano estensioni ASCII con l'ottavo bit coinvolto e la seconda metà della tabella dei codici (ad esempio, KOI-8).
Unicode
Nel 1991 in California è stata creata un'organizzazione senza scopo di lucro Unicode Consortium, che comprende rappresentanti di molte aziende informatiche (Borland, IBM, Lotus, Microsoft, Novell, Sun, WordPerfect, ecc.) E che sta sviluppando e implementando lo standard " Lo standard Unicode"... Lo standard di codifica dei caratteri Unicode sta diventando dominante negli ambienti software multilingue internazionali. Microsoft Windows NT ei suoi discendenti Windows 2000, 2003, XP utilizzano Unicode, più precisamente UTF-16, come rappresentazione del testo interno. I sistemi operativi simili a UNIX come Linux, BSD e Mac OS X hanno adottato Unicode (UTF-8) come rappresentazione principale del testo multilingue. Unicode riserva 1.114.112 (220 + 216) caratteri di codice, attualmente vengono utilizzati oltre 96.000 caratteri. I primi codici a 256 caratteri corrispondono esattamente a quelli della ISO 8859-1, la tabella di caratteri a 8 bit più diffusa nel mondo occidentale; di conseguenza, anche i primi 128 caratteri sono identici alla tabella ASCII. Lo spazio del codice Unicode è diviso in 17 "piani" e ogni piano ha 65536 (= 216) punti di codice. Il primo piano (piano 0), il Basic Multilingual Plane (BMP) è quello in cui è descritta la maggior parte dei caratteri. BMP contiene simboli per quasi tutti lingue moderne e un gran numero di caratteri speciali. Altri due piani vengono utilizzati per i simboli "grafici". Plane 1, Supplementary Multilingual Plane (SMP) viene utilizzato principalmente per simboli storici e viene utilizzato anche per simboli musicali e matematici. Plan 2, Supplementary Ideographic Plane (SIP), viene utilizzato per circa 40.000 caratteri cinesi rari. Il Piano 15 e il Piano 16 sono aperti a qualsiasi uso privato. La Figura 1.10 mostra il blocco Unicode russo (da U + 0400 a U + 04FF).
Codifiche comuni
ISO 646 ASCII BCDIC EBCDIC ISO 8859: ISO 8859-1, ISO 8859-2, ISO 8859-3, ISO 8859-4, ISO 8859-5, ISO 8859-6, ISO 8859-7, ISO 8859-8, ISO 8859 -9, ISO 8859-10, ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866 , CP869 Codifiche Microsoft Windows: Windows-1250 per le lingue dell'Europa centrale che utilizzano l'ortografia latina (polacco, ceco, slovacco, ungherese, sloveno, croato, rumeno e albanese) Windows-1251 per gli alfabeti cirillici Windows-1252 per le lingue occidentali Windows-1253 per Greco Windows-1254 per il turco Windows-1255 per l'ebraico Windows-1256 per l'arabo Windows-1257 per le lingue baltiche Windows-1258 per il vietnamita MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U...), KOI-7 Bulgaro Codifica ISCII VISCII Big5 (la variante più famosa di Microsoft CP950) HKSCS Guobiao GB2312 GBK (Microsoft CP936) GB18030 Shift JIS per il giapponese (Microsoft CP932) EUC-KR per il coreano (Microsoft CP949) ISO-2022 e EUC per le codifiche cinesi UTF-8, Set di caratteri Unicode UTF-16 e UTF-32 \
Codifica delle informazioni grafiche
Dagli anni '80. si sta sviluppando la tecnologia di elaborazione delle informazioni grafiche su PC. La forma di rappresentazione sullo schermo di un'immagine grafica costituita da singoli punti (pixel) è chiamata raster. L'oggetto minimo nell'editor di grafica raster è un punto. L'editor grafico raster è progettato per creare immagini, diagrammi. La risoluzione del monitor (il numero di punti orizzontali e verticali), così come il numero di possibili colori di ciascun punto sono determinati dal tipo di monitor 1 pixel di uno schermo in bianco e nero è codificato con 1 bit di informazioni (punto nero o punto bianco). Il numero di diversi colori K e il numero di bit per la loro codifica sono legati dalla formula: K = 2b. I monitor moderni hanno le seguenti tavolozze di colori: 16 colori, 256 colori; 65.536 colori (high color), 16.777.216 colori (true color).
Bitmap
Con l'aiuto di una lente d'ingrandimento, puoi vedere che un'immagine grafica in bianco e nero, ad esempio da un giornale, è composta dai punti più piccoli che compongono un determinato motivo: un raster. In Francia nel XIX secolo sorse una nuova direzione nella pittura: il puntinismo. La sua tecnica consisteva nel fatto che il disegno veniva applicato sulla tela con un pennello sotto forma di punti multicolori. Inoltre, questo metodo è stato a lungo utilizzato nell'industria della stampa per codificare le informazioni grafiche. La precisione del disegno dipende dal numero di punti e dalla loro dimensione. Dopo aver diviso l'immagine in punti, partendo dall'angolo sinistro, spostandosi lungo le linee da sinistra a destra, è possibile codificare il colore di ciascun punto. Inoltre, uno di questi punti sarà chiamato pixel (l'origine di questa parola è associata all'abbreviazione inglese "elemento immagine" - un elemento immagine). Il volume di un'immagine raster è determinato moltiplicando il numero di pixel (per il volume di informazioni di un punto, che dipende dal numero di colori possibili. La qualità dell'immagine è determinata dalla risoluzione del monitor. Maggiore è, che vale a dire, maggiore è il numero di linee e punti raster in una linea, maggiore è la qualità dell'immagine.I PC utilizzano principalmente le seguenti risoluzioni dello schermo: 640 per 480, 800 per 600, 1024 per 768 e 1280 per 1024 pixel. ogni punto e le sue coordinate lineari possono essere espresse utilizzando numeri interi, possiamo dire che questo metodo di codifica consente l'utilizzo di codice binario per elaborare dati grafici.
Se parliamo di illustrazioni in bianco e nero, quindi, se non usi i mezzitoni, il pixel assumerà uno dei due stati: acceso (bianco) e non acceso (nero). E poiché le informazioni sul colore di un pixel sono chiamate codice pixel, è sufficiente un bit di memoria per codificarlo: 0 - nero, 1 - bianco. Se le illustrazioni sono considerate sotto forma di una combinazione di punti con 256 sfumature di grigio (vale a dire, queste sono attualmente generalmente accettate), allora un otto bit numero binario per codificare la luminosità di qualsiasi punto. V computer grafica il colore è estremamente importante. Agisce come mezzo per migliorare l'impressione visiva e aumentare la saturazione delle informazioni dell'immagine. Come si forma il senso del colore nel cervello umano? Ciò si verifica a seguito dell'analisi del flusso luminoso che entra nella retina da oggetti riflettenti o emettitori. È generalmente accettato che i recettori del colore umano, chiamati anche coni, siano divisi in tre gruppi e ciascuno possa percepire un solo colore: rosso, verde o blu.
Modelli di colore
Quando si tratta di codificare il colore immagini grafiche, quindi è necessario considerare il principio di scomposizione di un colore arbitrario nei suoi componenti principali. Vengono utilizzati diversi sistemi di codifica: HSB, RGB e CMYK. Il primo modello a colori è semplice e intuitivo, ovvero è conveniente per una persona, il secondo è il più conveniente per un computer e l'ultimo modello CMYK è per le tipografie. L'uso di questi modelli di colore è dovuto al fatto che il flusso luminoso può essere formato dalla radiazione, che è una combinazione di colori spettrali "puri": rosso, verde, blu o loro derivati. Distinguere tra riproduzione additiva del colore (tipica per oggetti che emettono) e riproduzione sottrattiva (tipica per oggetti riflettenti). Un esempio di un oggetto del primo tipo è un tubo a raggi catodici di un monitor, del secondo tipo: una stampa.

Il modello HSB è caratterizzato da tre componenti: tonalità, saturazione e luminosità. Puoi ottenere molti colori arbitrari regolando questi componenti. Questo modello di colore è meglio utilizzato in quelli editori grafici, in cui le immagini vengono create da sole, e non elaborate già preparate. Quindi l'opera d'arte creata può essere convertita in modello di colore RGB se è pianificato per essere utilizzato come illustrazione su schermo o CMYK, se viene stampata.Il valore del colore viene selezionato come vettore in uscita dal centro del cerchio. La direzione del vettore è specificata in gradi angolari e determina la tonalità. La saturazione del colore è determinata dalla lunghezza del vettore e la luminosità del colore è impostata su un asse separato, il cui punto zero è nero. Il punto centrale è bianco (neutro) e i punti attorno al perimetro sono a tinta unita.
Il principio del metodo RGB è il seguente: è noto che qualsiasi colore può essere rappresentato come una combinazione di tre colori: rosso (Rosso, R), verde (Verde, G), blu (Blu, B). Altri colori e le loro sfumature sono ottenuti a causa della presenza o dell'assenza di questi componenti Dalle prime lettere dei colori primari, il sistema ha preso il nome: RGB. Questo modello di colore è additivo, ovvero qualsiasi colore può essere ottenuto da una combinazione di colori primari in varie proporzioni. Quando una componente del colore primario si sovrappone ad un'altra, la luminosità della radiazione totale aumenta. Se combiniamo tutti e tre i componenti, otteniamo un colore grigio acromatico, con un aumento della luminosità del quale si verifica un approccio al bianco.
Con 256 toni (ogni punto è codificato con 3 byte), i valori RGB minimi (0,0,0) corrispondono al nero e al bianco - al massimo con le coordinate (255, 255, 255). Maggiore è il valore in byte del componente colore, più luminoso è questo colore. Ad esempio, il blu scuro è codificato con tre byte (0, 0, 128) e il blu brillante (0, 0, 255).
Il principio del metodo CMYK. Questo modello di colore viene utilizzato durante la preparazione delle pubblicazioni per la stampa. A ciascuno dei colori primari viene assegnato un colore complementare (complementare al colore primario al bianco). Un colore aggiuntivo si ottiene sommando una coppia dei restanti colori primari. Ciò significa che i colori complementari per il rosso sono ciano (ciano, C) = verde + blu = bianco - rosso, per verde - magenta (Magenta, M) = rosso + blu = bianco - verde, per blu - giallo (giallo, Y) = rosso + verde = bianco - blu. Inoltre, il principio di scomposizione di un colore arbitrario in componenti può essere applicato sia per i principali che per quelli aggiuntivi, ovvero qualsiasi colore può essere rappresentato sia come somma della componente rossa, verde, blu, sia come somma di il componente ciano, viola, giallo. Fondamentalmente, questo metodo è adottato nell'industria della stampa. Ma lì usano ancora il nero (BlacK, poiché la lettera B è già occupata dal blu, è indicata dalla lettera K). Questo perché la sovrapposizione di colori complementari non produce il nero puro.
Immagini vettoriali e frattali
Un'immagine vettoriale è un oggetto grafico costituito da linee e archi elementari. L'elemento base dell'immagine è una linea. Come ogni oggetto, ha proprietà: forma (retta, curva), spessore., Colore, stile (punteggiato, solido). Le linee chiuse hanno la proprietà di riempirsi (o con altri oggetti o con un colore selezionato). Tutti gli altri oggetti grafica vettoriale composto da linee. Poiché una linea è descritta matematicamente come un singolo oggetto, la quantità di dati per la visualizzazione di un oggetto mediante la grafica vettoriale è molto inferiore rispetto alla grafica raster. Le informazioni su un'immagine vettoriale sono codificate come normali caratteri alfanumerici ed elaborate da programmi speciali.
A Software la creazione e l'elaborazione di grafica vettoriale includono i seguenti GR: CorelDraw, Adobe Illustrator, nonché vettori (tracer) - pacchetti specializzati per la conversione di immagini raster in vettoriali.

La grafica frattale si basa su calcoli matematici, proprio come la grafica vettoriale. Ma a differenza del vettore, il suo elemento di base è la formula matematica stessa. Questo porta al fatto che nessun oggetto è immagazzinato nella memoria del computer e l'immagine è costruita solo da equazioni. Usando questo metodo, puoi costruire le strutture regolari più semplici, nonché illustrazioni complesse che imitano i paesaggi.

Codifica audio
Il mondo è pieno di un'ampia varietà di suoni: il ticchettio degli orologi e il ronzio dei motori, l'ululato del vento e il fruscio delle foglie, il canto degli uccelli e le voci delle persone. Su come nascono i suoni e cosa sono, le persone hanno iniziato a indovinare molto tempo fa. Anche l'antico filosofo e scienziato greco - l'enciclopedista Aristotele, sulla base delle osservazioni, ha spiegato la natura del suono, credendo che il corpo che suona crea compressione alternata e rarefazione dell'aria. Quindi, una corda oscillante a volte si scarica, quindi condensa l'aria e, a causa dell'elasticità dell'aria, queste influenze alternate vengono trasmesse ulteriormente nello spazio - da uno strato all'altro, sorgono onde elastiche. Quando raggiungono il nostro orecchio, agiscono sui timpani e producono la sensazione del suono.
A orecchio, una persona percepisce onde elastiche con una frequenza da qualche parte nell'intervallo da 16 Hz a 20 kHz (1 Hz - 1 vibrazione al secondo). In conformità con ciò, le onde elastiche in qualsiasi mezzo, le cui frequenze rientrano nei limiti specificati, sono chiamate onde sonore o semplicemente suono. Nello studio del suono sono importanti concetti come tono e timbro del suono. Qualsiasi suono reale, che sia il suono di strumenti musicali o la voce di una persona, è una sorta di miscela di molte vibrazioni armoniche con un certo insieme di frequenze.
L'oscillazione che ha la frequenza più bassa è detta fondamentale, altre sono dette armoniche.
Il timbro è un numero diverso di sfumature inerenti a un suono particolare, che gli conferisce un colore speciale. La differenza tra un timbro e l'altro è dovuta non solo al numero, ma anche all'intensità degli armonici che accompagnano il suono del tono principale. È dal timbro che possiamo facilmente distinguere tra i suoni di un pianoforte e un violino, una chitarra e un flauto, e riconoscere la voce di una persona familiare.
Il suono musicale può essere caratterizzato da tre qualità: timbro, cioè il colore del suono, che dipende dalla forma delle vibrazioni, l'altezza, che è determinata dal numero di vibrazioni al secondo (frequenza), e il volume, che dipende dall'intensità delle vibrazioni.
Il computer è ora ampiamente utilizzato in vari campi. L'elaborazione delle informazioni sonore e della musica non ha fatto eccezione. Fino al 1983, tutte le registrazioni di musica sono state pubblicate su dischi in vinile e cassette compatte. Attualmente, i CD sono ampiamente utilizzati. Se hai un computer su cui è installata una scheda audio da studio, con una tastiera MIDI e un microfono collegati, puoi lavorare con un software musicale specializzato.
Conversione da digitale ad analogico e da analogico a digitale di informazioni audio
Diamo una rapida occhiata ai processi di conversione del suono da analogico a digitale e viceversa. Un'idea approssimativa di ciò che sta accadendo nella scheda audio può aiutare a evitare alcuni errori quando si lavora con l'audio.
Le onde sonore vengono convertite in un segnale elettrico alternato analogico utilizzando un microfono. Passa attraverso il percorso audio e in un convertitore analogico-digitale (ADC), un dispositivo che converte il segnale in forma digitale.
In forma semplificata, il principio di funzionamento dell'ADC è il seguente: misura l'ampiezza del segnale a intervalli regolari e trasmette ulteriormente, già attraverso il percorso digitale, una sequenza di numeri che portano informazioni sulle variazioni di ampiezza. Durante la conversione da analogico a digitale, non avviene alcuna conversione fisica. Un'impronta o un campione viene preso dal segnale elettrico, per così dire, che è un modello digitale delle fluttuazioni di tensione nel percorso audio. Se questo è rappresentato sotto forma di diagramma, questo modello viene presentato sotto forma di una sequenza di colonne, ognuna delle quali corrisponde a un valore numerico specifico. Il segnale digitale è di natura discreta, cioè discontinuo, quindi il modello digitale non corrisponde esattamente alla forma d'onda analogica.
Un campione è l'intervallo di tempo tra due misurazioni dell'ampiezza di un segnale analogico.
Il campione si traduce letteralmente dall'inglese come "campione". Nella terminologia multimediale e audio professionale, questa parola ha diversi significati. Oltre a un periodo di tempo, un campione è anche chiamato qualsiasi sequenza di dati digitali ottenuta mediante conversione da analogico a digitale. Il processo di conversione stesso è chiamato campionamento. Nel linguaggio tecnico russo si chiama discretizzazione.
Il suono digitale viene emesso utilizzando un convertitore digitale-analogico (DAC), che, sulla base dei dati digitali in ingresso nei momenti appropriati, genera un segnale elettrico dell'ampiezza richiesta
Opzioni di campionamento
La frequenza e la profondità di bit sono parametri di campionamento importanti. Frequenza: il numero di misurazioni dell'ampiezza del segnale analogico al secondo.
Se la frequenza di campionamento non è più del doppio della frequenza del limite superiore della gamma sonora, allora on alte frequenze si verificheranno perdite. Questo spiega perché la frequenza standard del CD audio è 44,1 kHz. Poiché l'intervallo di oscillazioni delle onde sonore è nell'intervallo da 20 Hz a 20 kHz, il numero di misurazioni del segnale al secondo deve essere maggiore del numero di oscillazioni nello stesso periodo di tempo. Se la frequenza di campionamento è significativamente inferiore alla frequenza dell'onda sonora, l'ampiezza del segnale ha il tempo di cambiare più volte durante il tempo tra le misurazioni e ciò porta al fatto che l'impronta digitale trasporta un set di dati caotico. Durante la conversione da digitale ad analogico, tale campione non trasmette il segnale principale, ma produce solo rumore.
Nel nuovo formato CD Audio DVD, il segnale viene misurato 96.000 volte in un secondo, ad es. utilizzare una frequenza di campionamento di 96 kHz. Per risparmiare spazio sull'hard disk nelle applicazioni multimediali, vengono spesso utilizzate frequenze più basse: 11, 22, 32 kHz. Ciò porta a una diminuzione della gamma di frequenze udibili, il che significa che c'è una forte distorsione di ciò che si sente.
Se sotto forma di grafico rappresentiamo lo stesso suono con un'altezza di 1 kHz (una nota fino alla settima ottava del pianoforte corrisponde grosso modo a questa frequenza), ma campionato con una frequenza diversa (la parte inferiore della sinusoide è non mostrato in tutti i grafici), allora le differenze saranno visibili. Una divisione sull'asse orizzontale, che mostra l'ora, corrisponde a 10 campioni. La scala è la stessa. Puoi vedere che a una frequenza di 11 kHz, ci sono circa cinque oscillazioni dell'onda sonora ogni 50 campioni, ovvero un periodo dell'onda sinusoidale viene visualizzato utilizzando solo 10 valori. Questa è una trasmissione piuttosto imprecisa. Allo stesso tempo, se consideriamo la frequenza di campionamento di 44 kHz, per ogni periodo della sinusoide ci sono già quasi 50 campioni. Ciò consente di ottenere un segnale di buona qualità.
La profondità di bit indica la precisione con cui cambia l'ampiezza del segnale analogico. L'accuratezza con cui il valore dell'ampiezza del segnale in ogni momento viene trasmesso durante la digitalizzazione determina la qualità del segnale dopo la conversione da digitale ad analogico. L'accuratezza della ricostruzione della forma d'onda dipende dalla profondità di bit.
Il valore dell'ampiezza è codificato utilizzando il principio della codifica binaria. Il segnale audio dovrebbe essere presentato come una sequenza di impulsi elettrici (zeri e uno binari). In genere vengono utilizzate rappresentazioni a 8, 16 o 20 bit dei valori di ampiezza. Quando la codifica binaria continua segnale sonoroè sostituito da una sequenza di livelli di segnale discreti. La qualità della codifica dipende dalla frequenza di campionamento (il numero di misurazioni del livello del segnale per unità di tempo). Con un aumento della frequenza di campionamento, aumenta l'accuratezza della rappresentazione binaria delle informazioni. Alla frequenza di 8 kHz (il numero di misurazioni al secondo è 8000), la qualità del segnale sonoro campionato corrisponde alla qualità della trasmissione radio, e alla frequenza di 48 kHz (il numero di misurazioni al secondo è 48000) - alla qualità del suono di un CD audio.
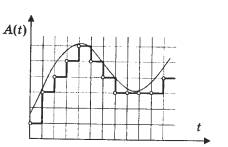
Attualmente, è disponibile un nuovo formato digitale consumer Audio DVD, che utilizza una frequenza di campionamento a 24 bit e 96 kHz. Con il suo aiuto, è possibile evitare lo svantaggio sopra menzionato della codifica a 16 bit.
Al digitale moderno dispositivi audio Sono installati convertitori a 20 bit. Il suono rimane a 16 bit, vengono installati convertitori ad alto bit per migliorare la qualità di registrazione a bassi livelli. Il loro principio di funzionamento è il seguente: il segnale analogico originale viene digitalizzato con una larghezza di 20 bit. Quindi il processore di segnale digitale DSPP riduce la sua larghezza a 16 bit. In questo caso viene utilizzato uno speciale algoritmo di calcolo, con l'aiuto del quale è possibile ridurre la distorsione dei segnali di basso livello. Il processo opposto si osserva durante la conversione da digitale ad analogico: la profondità di bit aumenta da 16 a 20 bit utilizzando uno speciale algoritmo che consente di determinare con maggiore precisione i valori di ampiezza. Cioè, il suono rimane a 16 bit, ma c'è un miglioramento generale della qualità del suono.
Che cos'è la codifica?
In russo, "set di caratteri" è anche chiamato tabella "set di caratteri" e il processo di utilizzo di questa tabella per tradurre le informazioni da una rappresentazione del computer in una umana e una caratterizzazione di un file di testo che riflette l'uso di un certo sistema di codici in esso durante la visualizzazione del testo.
Come viene codificato il testo
L'insieme dei simboli utilizzati nella scrittura del testo è indicato nella terminologia informatica come alfabeto; il numero di caratteri nell'alfabeto è solitamente chiamato il suo potere. Per la presentazione informazioni di testo il computer utilizza più spesso un alfabeto con una capacità di 256 caratteri. Uno dei suoi caratteri porta 8 bit di informazione, quindi il codice binario di ogni carattere occupa 1 byte di memoria del computer. Tutti i caratteri di tale alfabeto sono numerati da 0 a 255 e ogni numero corrisponde a un codice binario a 8 bit, che è il numero ordinale di un carattere nel sistema di notazione binaria - da 00000000 a 11111111. Solo i primi 128 caratteri con numeri da zero (codice binario 00000000) a 127 (01111111). Questi includono lettere minuscole e lettere maiuscole Alfabeto latino, numeri, segni di punteggiatura, parentesi quadre, ecc. I restanti 128 codici, che iniziano con 128 (codice binario 10000000) e terminano con 255 (11111111), vengono utilizzati per codificare lettere di alfabeti nazionali, simboli di servizio e scientifici.
Tipi di codifiche
La tabella di codifica più famosa è ASCII (American Standard Code for Information Interchange). È stato originariamente sviluppato per la trasmissione di testi tramite telegrafo e all'epoca era a 7 bit, ovvero solo 128 combinazioni a 7 bit venivano utilizzate per codificare caratteri inglesi, caratteri di servizio e di controllo. In questo caso, le prime 32 combinazioni (codici) servivano a codificare segnali di controllo (inizio testo, fine riga, ritorno a capo, chiamata, fine testo, ecc.). Nello sviluppo dei primi computer IBM, questo codice è stato utilizzato per rappresentare i simboli in un computer. Dal in codice sorgente ASCII era solo 128 caratteri, per la loro codifica, erano sufficienti i valori dei byte, in cui l'ottavo bit è 0. Inglese (greco, dieresi tedesco, segni diacritici francesi, ecc.). Quando i computer hanno cominciato ad adattarsi ad altri paesi e lingue, non c'era più spazio sufficiente per nuovi simboli. Per supportare completamente lingue diverse dall'inglese, IBM ha introdotto diverse tabelle di codici specifiche per paese. Quindi per i paesi scandinavi è stata proposta la tabella 865 (nordica), per i paesi arabi - tabella 864 (araba), per Israele - tabella 862 (Israele) e così via. In queste tabelle sono stati utilizzati alcuni codici della seconda metà della tabella dei codici per rappresentare i caratteri degli alfabeti nazionali (escludendo alcuni caratteri pseudografici). La situazione con la lingua russa si è sviluppata in modo speciale. Ovviamente si può fare la sostituzione dei caratteri nella seconda metà della tabella codici diversi modi... Quindi, sono apparse diverse tabelle di codifica dei caratteri cirillici per la lingua russa: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Tutti rappresentano i simboli della prima metà della tabella allo stesso modo (da 0 a 127) e differiscono nella rappresentazione dei simboli dell'alfabeto russo e della pseudo-grafica. Per lingue come il cinese o il giapponese, generalmente 256 caratteri non sono sufficienti. Inoltre, c'è sempre il problema di emettere o salvare in un file contemporaneamente i testi su lingue differenti(ad esempio, quando si cita). Pertanto, un universale tabella dei codici UNICODE, contenente simboli utilizzati nelle lingue di tutti i popoli del mondo, oltre a vari simboli di servizio e ausiliari (segni di punteggiatura, simboli matematici e tecnici, frecce, segni diacritici, ecc.). Ovviamente, un byte non è sufficiente per codificare un numero così elevato di caratteri. Pertanto UNICODE utilizza codici a 16 bit (2 byte) per rappresentare 65.536 caratteri. Ad oggi sono stati utilizzati circa 49.000 codici (l'ultimo cambiamento significativo è stato l'introduzione del simbolo della valuta EURO nel settembre 1998). Per compatibilità con le codifiche precedenti, i primi 256 codici sono gli stessi dello standard ASCII. Nello standard UNICODE, oltre ad un determinato codice binario (questi codici sono solitamente indicati dalla lettera U, seguita dal segno + e dal codice vero e proprio in rappresentazione esadecimale), ad ogni carattere viene assegnato un nome specifico. Un altro componente Norma UNICODE sono algoritmi per la conversione uno a uno di codici UNICODE in una sequenza di byte di lunghezza variabile. La necessità di tali algoritmi è dovuta al fatto che non tutte le applicazioni possono funzionare con UNICODE. Alcune applicazioni comprendono solo i codici ASCII a 7 bit, altre applicazioni comprendono i codici ASCII a 8 bit. Tali applicazioni utilizzano i cosiddetti codici ASCII estesi per rappresentare caratteri che non rientrano, rispettivamente, in un set di 128 o 256 caratteri, quando i caratteri sono codificati con stringhe di byte di lunghezza variabile. UTF-7 viene utilizzato per convertire in modo reversibile i codici UNICODE in codici ASCII estesi a 7 bit e UTF-8 viene utilizzato per convertire in modo reversibile i codici UNICODE in codici ASCII estesi a 8 bit. Nota che sia ASCII che UNICODE e altri standard di codifica dei caratteri non definiscono le immagini dei caratteri, ma solo la composizione del set di caratteri e il modo in cui è rappresentato in un computer. Inoltre (cosa che potrebbe non essere immediatamente ovvia), l'ordine di enumerazione dei caratteri nell'insieme è molto importante, poiché influisce in modo più significativo sugli algoritmi di ordinamento. È la tabella di corrispondenza dei simboli di un certo insieme (diciamo, simboli usati per rappresentare informazioni su lingua inglese, o in lingue diverse, come nel caso di UNICODE) e denotano il termine tabella di codifica dei caratteri o set di caratteri. Ogni codifica standard ha un nome, ad esempio KOI8-R, ISO_8859-1, ASCII. Sfortunatamente, non esiste uno standard per la codifica dei nomi.
Codifiche comuni
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1 - ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Codifiche Microsoft Windows: o Windows-1250 per le lingue dell'Europa centrale che utilizzano lettere latine o Windows-1251 per gli alfabeti cirillici o Windows-1252 per le lingue occidentali o Windows-1253 per il greco o Windows -1254 per il turco o Windows-1255 per l'ebraico o Windows-1256 per l'arabo o Windows-1257 per le lingue baltiche o Windows-1258 per il vietnamita MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U...), KOI -7 Bulgaro ISCII VISCII Big5 (variante più famosa di Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS per il giapponese (Microsoft CP932) EUC-KR per il coreano (Microsoft CP949) ISO-2022 e EUC per Codifiche di scrittura cinese UTF-8 e UTF-16 del set di caratteri Yong icodeNel sistema di codifica ASCII(American Standard Code for Information Interchange) ogni carattere è rappresentato da un byte, che può codificare 256 caratteri.
ASCII ha due tabelle di codifica: base ed estesa. La tabella base fissa i valori dei codici da 0 a 127, e quella estesa si riferisce a caratteri con numeri da 128 a 255. Questo è sufficiente per esprimere con varie combinazioni di otto bit tutti i caratteri delle lingue inglese e russa , sia minuscolo che maiuscolo, nonché segni di punteggiatura, simboli per operazioni aritmetiche di base e simboli speciali comuni che possono essere osservati sulla tastiera.
I primi 32 codici della tabella base, partendo da zero, vengono dati ai produttori di hardware (principalmente ai produttori di computer e dispositivi di stampa). Quest'area contiene i cosiddetti codici di controllo, che non corrispondono ad alcun carattere di lingua, e, di conseguenza, questi codici non vengono visualizzati né sullo schermo né sui dispositivi di stampa, ma possono essere controllati come vengono emessi altri dati. A partire dal codice 32 al codice 127, vengono collocati i simboli dell'alfabeto inglese, segni di punteggiatura, numeri, operazioni aritmetiche e simboli ausiliari, tutti visibili sulla parte latina della tastiera del computer.
La seconda parte estesa è dedicata ai sistemi di codifica nazionali. Ci sono molti alfabeti non latini nel mondo (arabo, ebraico, greco, ecc.), incluso l'alfabeto cirillico. Inoltre, i layout di tastiera tedesca, francese e spagnola sono diversi da quelli inglesi.
La parte inglese della tastiera aveva molti standard, ma ora sono stati tutti sostituiti da un unico codice ASCII. Per la tastiera russa c'erano anche molti standard: GOST, GOST-alternative, ISO (International Standard Organization - International Institute for Standardization), ma questi tre standard sono effettivamente scomparsi, sebbene possano incontrarsi da qualche parte, in alcuni computer antidiluviani o in reti informatiche.
La codifica dei caratteri principali della lingua russa, utilizzata nei computer con un'operazione Sistema Windows chiamato Windows-1251, è stato sviluppato per gli alfabeti cirillici da Microsoft. Naturalmente, la maggioranza assoluta dei dati di testo del computer è codificata in Windows-1251. A proposito, Microsoft ha sviluppato codifiche con un numero di quattro cifre diverso per altri alfabeti comuni: arabo, giapponese e altri.
Un'altra codifica comune è chiamata KOI-8(codice di scambio di informazioni, otto cifre) - la sua origine risale ai tempi del Consiglio per la mutua assistenza economica degli Stati dell'Europa orientale. Oggi la codifica KOI-8 è diffusa nelle reti di computer sul territorio della Russia e nel settore russo di Internet. Succede che parte del testo della lettera o qualcos'altro non sia leggibile, il che significa che è necessario passare da KOI-8 a Windows-1251. dieci
Negli anni '90, i più grandi produttori di software: Microsoft, Borland, la stessa Adobe decisero la necessità di sviluppare un diverso sistema di codifica del testo, in cui non 1, ma 2 byte sarebbero stati assegnati a ciascun carattere. Ha preso il nome Unicode, ed è possibile codificare 65.536 caratteri di questo campo è sufficiente per inserirsi in una tabella di alfabeti nazionali per tutte le lingue del pianeta. La maggior parte di Unicode (circa il 70%) è occupata da caratteri cinesi, in India ci sono 11 diversi alfabeti nazionali, ci sono molti nomi esotici, ad esempio: la scrittura degli aborigeni canadesi.
Poiché la codifica di ciascun carattere in Unicode non è assegnata a 8, ma a 16 bit, la dimensione del file di testo è raddoppiata. Questo una volta era un ostacolo all'introduzione di un sistema a 16 bit. e ora con dischi rigidi da gigabyte, centinaia di megabyte di RAM, processori gigahertz, raddoppiando il volume dei file di testo, che, rispetto, ad esempio, alla grafica, occupano pochissimo spazio, non importa molto.
L'alfabeto cirillico in Unicode va da 768 a 923 (caratteri di base) e da 924 a 1023 (cirillico esteso, varie lettere nazionali meno comuni). Se il programma non è adattato per l'Unicode cirillico, è possibile che i caratteri di testo non vengano riconosciuti come cirillici, ma come latini estesi (codici da 256 a 511). E in questo caso, invece del testo, sullo schermo appare un insieme insignificante di vari simboli esotici.
Ciò è possibile se il programma è obsoleto, creato prima del 1995. O uno raro, di cui nessuno si è preoccupato di russificare. È anche possibile che il sistema operativo Windows installato sul computer non sia completamente configurato per l'alfabeto cirillico. In questo caso, è necessario inserire le voci appropriate nel registro.
 Bug nella singolarità?
Bug nella singolarità? Just Cause 2 va in crash
Just Cause 2 va in crash Terraria non si avvia, cosa devo fare?
Terraria non si avvia, cosa devo fare?