Dai codici unicode alle lettere. Il problema di distinguere numeri e lettere esternamente simili.
A volte devi aggiungere un'icona al tuo design, ma non hai voglia di inserire immagini aggiuntive o un intero carattere dell'icona come Font Awesome? Allora abbiamo buone notizie per te: c'è un'ampia libreria di icone e simboli già disponibile nel tuo browser. Si chiama Unicode, ed è lo standard che assegna identificatori univoci per un numero sempre crescente (attualmente oltre 110.000) di simboli e icone.
Tuttavia, ciò non significa che tu abbia una selezione di centinaia di migliaia di icone. Dipende dal browser che li rende e utilizza i caratteri installati sul sistema per farlo. In questo articolo, abbiamo compilato una serie di set di caratteri disponibili su Windows, Linux, OS X, Android e IOS. Puoi usarli nei tuoi progetti oggi!
Suggerimento: che spiega tutto ciò che c'è da sapere sulle codifiche e Unicode, che consigliamo a tutti gli sviluppatori di software di leggere.
Come usare queste icone
Le icone mostrate nelle tabelle seguenti sono simboli comuni che puoi copiare e incollare come se fossero lettere dell'alfabeto. Ma se la codifica utilizzata per salvare i file HTML / CSS non UTF-8 non verranno visualizzati. Questo è il motivo per cui abbiamo introdotto il codice di escape HTML che funzionerà sempre. Ecco cosa devi fare per utilizzare queste icone:
- Trova l'icona che ti piace. Abbiamo fornito piccole e grandi anteprime.
- Copia il codice.
- Incollalo in HTML come testo normale. In CSS puoi usarli come valore di proprietà contenuto... In JS, PHP e altri linguaggi di programmazione, puoi usarli come testo semplice nelle stringhe.
- Puoi personalizzare le icone impostando la dimensione del carattere, il colore, il testo e le ombre proprio come il testo normale.
Icone
| Nome | Anteprima | Codice | |
|---|---|---|---|
| faccina | ☺ | ☺ | ☺ |
| Segnale di pericolo | ⚠ | ⚠ | ⚠ |
| Sorgenti termali | ♨ | ♨ | ♨ |
| sedia a rotelle | ♿ | ♿ | ♿ |
| Riciclare | ♻ | ♻ | ♻ |
| palla 8 | ➑ | ➑ | ➑ |
| Alta tensione | ⚡ | ⚡ | ⚡ |
| Stella bianca | ☆ | ☆ | ☆ |
| Stella nera | ★ | ★ | ★ |
| Cuore bianco | ♡ | ♡ | ♡ |
| Cuore nero | ❤ | ❤ | ❤ |
| Caffè | ☕ | ☕ | ☕ |
| Aereo | ✈ | ✈ | ✈ |
| Clessidra | ⌛ | ⌛ | ⌛ |
| Orologio | ⌚ | ⌚ | ⌚ |
| Forbici nere | ✂ | ✂ | ✂ |
| Forbici bianche | ✄ | ✄ | ✄ |
| Corona | ♕ | ♕ | ♕ |
| Ancora | ⚓ | ⚓ | ⚓ |
| Attraverso | ✝ | ✝ | ✝ |
| Cerchio bianco-nero | ◑ | ◑ | ◑ |
| Otto note | ♪ | ♪ | ♪ |
| crome con travi | ♫ | ♫ | ♫ |
| Asterisco a quattro raggi a palloncino | ✣ | ✣ | ✣ |
| Stella bianca cerchiata | ✪ | ✪ | ✪ |
| Stella bianca | ✰ | ✰ | ✰ |
| Stella bianca a quattro punte | ✧ | ✧ | ✧ |
| Stella a quattro punte nera | ✦ | ✦ | ✦ |
| Controllo delle urne | ☑ | ☑ | ☑ |
| Segno di spunta | ✔ | ✔ | ✔ |
| Segno di croce | ✘ | ✘ | ✘ |
| Matita | ✎ | ✎ | ✎ |
| Scrivere a mano | ✍ | ✍ | ✍ |
| Femmina | ♀ | ♀ | ♀ |
| Maschio | ♂ | ♂ | ♂ |
| Telefono nero | ☎ | ☎ | ☎ |
| Telefono bianco | ☏ | ☏ | ☏ |
| Busta | ✉ | ✉ | ✉ |
| Posizione del telefono | ✆ | ✆ | ✆ |
Frecce Unicode
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Freccia verso sinistra | ← | ← | ← |
| Freccia verso destra | → | → | → |
| Freccia verso l'alto | |||
| Freccia verso il basso | ↓ | ↓ | ↓ |
| Freccia Sinistra Destra | ↔ | ↔ | ↔ |
| Freccia su giù | ↕ | ↕ | ↕ |
| Frecce destra e sinistra | ⇄ | ⇄ | ⇄ |
| Frecce su e giù | ⇅ | ⇅ | ⇅ |
| Freccia a 90 gradi in basso a sinistra | ↲ | ↲ | ↲ |
| Freccia a 90 gradi in basso a destra | ↳ | ↳ | ↳ |
| Freccia a 90 gradi su-sinistra | ↰ | ↰ | ↰ |
| Freccia a 90 gradi in alto a destra | ↱ | ↱ | ↱ |
| Freccia nord-ovest all'angolo | ⇱ | ⇱ | ⇱ |
| Freccia sud-est verso l'angolo | ⇲ | ⇲ | ⇲ |
| Freccia verso sinistra per barra | ⇤ | ⇤ | ⇤ |
| Freccia verso destra per barra | ⇥ | ⇥ | ⇥ |
| Freccia semicerchio antioraria | ↶ | ↶ | ↶ |
| Freccia semicerchio in senso orario | ↷ | ↷ | ↷ |
| Freccia circolare in senso antiorario | ↺ | ↺ | ↺ |
| Freccia circolare in senso orario | ↻ | ↻ | ↻ |
| Freccia a punta larga verso destra | ➔ | ➔ | ➔ |
| Freccia a zig-zag verso il basso | ↯ | ↯ | ↯ |
| Freccia nord-ovest | ↖ | ↖ | ↖ |
| Freccia pesante sud-est | ➘ | ➘ | ➘ |
| Freccia pesante verso destra | ➙ | ➙ | ➙ |
| Freccia pesante nord-est | ➚ | ➚ | ➚ |
| Freccia tratteggiata verso destra | ➟ | ➟ | ➟ |
| Freccia puntata verso sinistra | ⇠ | ⇠ | ⇠ |
| Freccia nera verso destra | ➤ | ➤ | ➤ |
| Freccia bianca verso sinistra | ⇦ | ⇦ | ⇦ |
| Freccia bianca verso destra | ⇨ | ⇨ | ⇨ |
| Virgolette angolo sinistro | « | « | « |
| Virgolette ad angolo retto | » | » | » |
| Puntatore nero destro | |||
| Puntatore nero sinistro | ◀ | ◀ | ◀ |
| Puntatore nero su | ▲ | ▲ | ▲ |
| Puntatore nero in basso | ▼ | ▼ | ▼ |
| Puntatore bianco destro | ▷ | ▷ | ▷ |
| Puntatore bianco sinistro | ◁ | ◁ | ◁ |
| Puntatore bianco su | △ | △ | △ |
| Puntatore bianco in basso | ▽ | ▽ | ▽ |
| Arco, freccia | ➴ | ➴ | ➴ |
Caratteri speciali in unicode
Valuta Unicode
Icone del tempo
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Livello | ° | ° | ° |
| piccolo sole | ☀ | ☀ | ☀ |
| Grande sole | ☼ | ☼ | ☼ |
| Nube | ☁ | ☁ | ☁ |
| Ombrello | ☔ | ☔ | ☔ |
| Fiocco di neve 1 | ❆ | ❆ | ❆ |
| Fiocco di neve 2 | ❅ | ❅ | ❅ |
| Fiocco di neve 3 | ❄ | ❄ | ❄ |
Puntatori Unicode
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Puntatore sinistro nero | ☚ | ☚ | ☚ |
| Puntatore destro nero | ☛ | ☛ | ☛ |
| Puntatore sinistro bianco | ☜ | ☜ | ☜ |
| Puntatore su bianco | ☝ | ☝ | ☝ |
| Puntatore destro bianco | ☞ | ☞ | ☞ |
| Puntatore giù bianco | ☟ | ☟ | ☟ |
Segni zodiacali in unicode
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Ariete | ♈ | ♈ | ♈ |
| Toro | ♉ | ♉ | ♉ |
| Gemelli | ♊ | ♊ | ♊ |
| Cancro | ♋ | ♋ | ♋ |
| un leone | ♌ | ♌ | ♌ |
| Vergine | ♍ | ♍ | ♍ |
| bilancia | ♎ | ♎ | ♎ |
| Scorpione | ♏ | ♏ | ♏ |
| Sagittario | ♐ | ♐ | ♐ |
| Capricorno | ♑ | ♑ | ♑ |
| Acquario | ♒ | ♒ | ♒ |
| Pesci | ♓ | ♓ | ♓ |
Caratteri delle carte Unicode
| Nome | Anteprima | Codice | |
|---|---|---|---|
| mazze nere | ♠ | ♠ | ♠ |
| Cuori neri | ♥ | ♥ | ♥ |
| Diamanti neri | ♦ | ♦ | ♦ |
| picche nere | ♣ | ♣ | ♣ |
| Club bianco | ♤ | ♤ | ♤ |
| Cuori Bianchi | ♡ | ♡ | ♡ |
| Diamanti bianchi | ♢ | ♢ | ♢ |
| Picche bianche | ♧ | ♧ | ♧ |
Pezzi degli scacchi in unicode
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Re bianco | ♔ | ♔ | ♔ |
| Regina bianca | ♕ | ♕ | ♕ |
| Torre bianca | ♖ | ♖ | ♖ |
| Vescovo White | ♗ | ♗ | ♗ |
| Cavaliere bianco | ♘ | ♘ | ♘ |
| pedone bianco | ♙ | ♙ | ♙ |
| Re nero | ♚ | ♚ | ♚ |
| Regina nera | ♛ | ♛ | ♛ |
| Torre nera | ♜ | ♜ | ♜ |
| Vescovo Nero | ♝ | ♝ | ♝ |
| Cavaliere nero | ♞ | ♞ | ♞ |
| Pedone nero | ♟ | ♟ | ♟ |
Gioco dei dadi
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Tirare i dadi uno | ⚀ | ⚀ | ⚀ |
| Tirare i dadi due | ⚁ | ⚁ | ⚁ |
| Tirare i dadi tre | ⚂ | ⚂ | ⚂ |
| Tirare i dadi quattro | ⚃ | ⚃ | ⚃ |
| Tirare i dadi cinque | ⚄ | ⚄ | ⚄ |
| Tirare i dadi sei | ⚅ | ⚅ | ⚅ |
Simboli matematici Unicode
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Infinito | ∞ | ∞ | ∞ |
| Più meno | ± | ± | ± |
| Minore o uguale a | ≤ | ≤ | ≤ |
| Più di o uguale a | ≥ | ≥ | ≥ |
| Non uguale a | ≠ | ≠ | ≠ |
| Divisione | ÷ | ÷ | ÷ |
| Moltiplicazione x | × | × | × |
| Moltiplicazione pesante x | ✖ | ✖ | ✖ |
| apice uno | ¹ | ¹ | ¹ |
| Apice due | ² | ² | ² |
| Tre apice | ³ | ³ | ³ |
| Più cerchiato | ⊕ | ⊕ | ⊕ |
| Moltiplicazione cerchiata | ⊗ | ⊗ | ⊗ |
| AND . logico | ∧ | ∧ | ∧ |
| OR logico | ∨ | ∨ | ∨ |
| Delta | ∆ | ∆ | ∆ |
| Torta | ∏ | ∏ | ∏ |
| Sigma (SOMMA) | ∑ | ∑ | ∑ |
| Omega | Ω | Ω | Ω |
| Set vuoto | ∅ | ∅ | ∅ |
| Angolo | ∠ | ∠ | ∠ |
| Parallelo | ∥ | ∥ | ∥ |
| Perpendicolare | ⊥ | ⊥ | ⊥ |
| Quasi uguale a | ≈ | ≈ | ≈ |
| Triangolo | △ | △ | △ |
| Cerchio | ○ | ○ | ○ |
| Quadrato | □ | □ | □ |
frazioni
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Un quarto (1/4) | ¼ | ¼ | ¼ |
| Una metà (1/2) | ½ | ½ | ½ |
| Tre Quarti (3/4) | ¾ | ¾ | ¾ |
| Un Terzo (1/3) | ⅓ | ⅓ | ⅓ |
| Due terzi (2/3) | ⅔ | ⅔ | ⅔ |
| Uno Otto (1/8) | ⅛ | ⅛ | ⅛ |
| Tre Otto (3/8) | ⅜ | ⅜ | ⅜ |
| Cinque Otto (5/8) | ⅝ | ⅝ | ⅝ |
| Sette Otto (7/8) | ⅞ | ⅞ | ⅞ |
Numeri romani in unicode
| Nome | Anteprima | Codice | |
|---|---|---|---|
| Numero Romano Uno | Ⅰ | Ⅰ | Ⅰ |
| Numero Romano Due | Ⅱ | Ⅱ | Ⅱ |
| Numero romano tre | Ⅲ | Ⅲ | Ⅲ |
| Numero romano quattro | Ⅳ | Ⅳ | Ⅳ |
| Numero romano cinque | Ⅴ | Ⅴ | Ⅴ |
| Numero romano sei | Ⅵ | Ⅵ | Ⅵ |
| Numero romano sette | Ⅶ | Ⅶ | Ⅶ |
| Numero romano otto | Ⅷ | Ⅷ | Ⅷ |
| Numero romano nove | Ⅸ | Ⅸ | Ⅸ |
| Numero romano dieci | Ⅹ | Ⅹ | Ⅹ |
| Numero romano undici | Ⅺ | Ⅺ | Ⅺ |
| Numero romano dodici | Ⅻ | Ⅻ | Ⅻ |
Ci sono alcune differenze nella resa di questi simboli in diversi sistemi operativi Oh. Ciò è causato dalle diverse famiglie di caratteri utilizzate. Inoltre, iOS e Android sostituiscono alcuni caratteri Unicode con emoticon, quindi assicurati di controllare i caratteri aggiunti per assicurarti che ciò non accada e che le icone vengano visualizzate come previsto.
Unicode (in inglese Unicode) è uno standard di codifica dei caratteri. In poche parole, questa è una tabella di corrispondenza dei caratteri di testo (, lettere, elementi di punteggiatura) codici binari... Il computer comprende solo la sequenza di zero e uno. Affinché sappia esattamente cosa dovrebbe visualizzare sullo schermo, è necessario assegnare un numero univoco a ciascun personaggio. Negli anni ottanta i caratteri venivano codificati in un byte, cioè in otto bit (ogni bit è 0 o 1). Pertanto, si è scoperto che una tabella (nota anche come codifica o set) può contenere solo 256 caratteri. Questo potrebbe non essere sufficiente nemmeno per una lingua. Pertanto, sono apparse molte codifiche diverse, la confusione con la quale spesso ha portato al fatto che invece del testo leggibile, sullo schermo è apparso uno strano krakozyabry. Era richiesto un unico standard, che divenne Unicode. La codifica più utilizzata è UTF-8 (Unicode Transformation Format), che utilizza da 1 a 4 byte per visualizzare un carattere.
Simboli
I caratteri nelle tabelle Unicode sono numerati con numeri esadecimali. Ad esempio, la lettera maiuscola cirillica M è designata U + 041C. Ciò significa che si trova all'intersezione della riga 041 e della colonna C. Può essere semplicemente copiato e incollato da qualche parte. Per non rovistare in un elenco di più chilometri, dovresti usare la ricerca. Entrando nella pagina dei simboli, vedrai il suo numero in Unicode e il modo in cui è disegnato in diversi caratteri. Puoi anche guidare il segno stesso nella barra di ricerca, anche se invece viene disegnato un quadrato, almeno per scoprire cosa fosse. Inoltre, su questo sito ci sono set speciali (e - casuali) dello stesso tipo di icone, raccolte da diverse sezioni, per facilità d'uso.
Lo standard Unicode è internazionale. Include segni di quasi tutti gli script del mondo. Compresi quelli che non vengono più utilizzati. Geroglifici egizi, rune germaniche, scrittura maya, cuneiformi e alfabeti degli antichi stati. Presentato e la designazione di misure e pesi, notazione musicale, concetti matematici.
Lo stesso Consorzio Unicode non inventa nuovi caratteri. Quelle icone che trovano la loro applicazione nella società vengono aggiunte alle tabelle. Ad esempio, il segno del rublo è stato utilizzato attivamente per sei anni prima di essere aggiunto a Unicode. Anche i pittogrammi Emoji (emoticon) sono stati ampiamente utilizzati per la prima volta in Giappone e prima di essere inclusi nella codifica. Ma i marchi e i loghi aziendali non vengono aggiunti in linea di principio. Anche comune come la mela di Apple o la bandiera di Windows. Oggi, nella versione 8.0, vengono codificati circa 120mila caratteri.
Gli elementi dello spazio del codice che rappresentano interi non negativi. La famiglia delle codifiche definisce la rappresentazione macchina di una sequenza di codici UCS.
I codici Unicode sono suddivisi in diverse aree. L'area con codici da U+0000 a U+007F contiene i caratteri ASCII con i codici corrispondenti. Seguono le aree dei caratteri di vari script, segni di punteggiatura e simboli tecnici. Alcuni dei codici sono riservati per un uso futuro. Sotto i caratteri cirillici vengono allocate aree di caratteri con codici da U + 0400 a U + 052F, da U + 2DE0 a U + 2DFF, da U + A640 a U + A69F (vedi Cirillico in Unicode).
Prerequisiti per la creazione e lo sviluppo di Unicode
Poiché in alcuni sistemi informatici (ad esempio Windows NT) erano già utilizzati caratteri fissi a 16 bit come codifica predefinita, si è deciso di codificare tutti i caratteri più importanti solo all'interno delle prime 65.536 posizioni (il cosiddetto English. piano multilingue di base, BMP). Il resto dello spazio è utilizzato per "caratteri aggiuntivi" (ing. caratteri supplementari): sistemi di scrittura di lingue estinte o caratteri cinesi usati molto raramente, simboli matematici e musicali.
Per compatibilità con i vecchi sistemi a 16 bit, è stato inventato il sistema UTF-16, in cui le prime 65.536 posizioni, ad eccezione delle posizioni dall'intervallo U + D800 ... U + DFFF, vengono visualizzate direttamente come numeri a 16 bit, e il resto sono rappresentati come "coppie sostitutive" (Il primo elemento della coppia dall'area U + D800… U + DBFF, il secondo elemento della coppia dall'area U + DC00… U + DFFF). Per le coppie surrogate è stata utilizzata una parte dello spazio codice (2048 posizioni), precedentemente riservato ai "caratteri per uso privato".
Poiché UTF-16 può visualizzare solo 2 20 + 2 16 -2048 (1 112 064) caratteri, questo numero è stato scelto come valore finale per lo spazio del codice Unicode.
Sebbene l'area del codice Unicode sia stata estesa oltre 2-16 già nella versione 2.0, i primi caratteri nell'area "in alto" sono stati inseriti solo nella versione 3.1.
Il ruolo di questa codifica nel settore web è in costante crescita, all'inizio del 2010 la quota di siti web che utilizzano Unicode era di circa il 50%.
Versioni Unicode
Man mano che la tabella dei caratteri Unicode cambia e si riempie e vengono rilasciate nuove versioni di questo sistema - e questo lavoro è in corso, poiché il sistema Unicode originale includeva solo il piano 0 - codici a due byte - vengono rilasciati anche nuovi documenti ISO. Il sistema Unicode esiste in totale nelle seguenti versioni:
- 1.1 (conforme alla norma ISO/IEC 10646-1: 1993), standard 1991-1995.
- 2.0, 2.1 (stessa norma ISO/IEC 10646-1: 1993 più integrazioni: "Emendamenti" da 1 a 7 e "Corrigenda tecnica" 1 e 2), norma del 1996.
- 3.0 (norma ISO / IEC 10646-1: 2000) norma 2000.
- 3.1 (Norme ISO/IEC 10646-1: 2000 e ISO/IEC 10646-2: 2001) 2001.
- 3.2, norma 2002.
- 4.0, norma 2003.
- 4.01, norma 2004.
- 4.1, norma 2005.
- 5.0, norma 2006.
- 5.1, norma 2008.
- 5.2, norma 2009.
- 6.0, norma 2010.
- 6.1, norma 2012.
- 6.2, norma 2012.
Spazio codice
Sebbene i moduli di notazione UTF-8 e UTF-32 consentano di codificare fino a 2.331 (2.147.483.648) punti di codice, è stato deciso di utilizzare solo 1.112.064 per la compatibilità con UTF-16. Tuttavia, anche questo è più che sufficiente: oggi (nella versione 6.0) vengono utilizzati poco meno di 110.000 punti di codice (109.242 grafici e 273 altri simboli).
Lo spazio del codice è suddiviso in 17 aerei 2 16 (65536) caratteri ciascuno. Il piano zero si chiama di base, contiene i simboli degli script più comuni. Il primo piano è utilizzato principalmente per gli script storici, il secondo - per i caratteri CJK usati raramente, il terzo è riservato ai caratteri cinesi arcaici. Gli aerei 15 e 16 sono riservati ad uso privato.
Per denotare Caratteri Unicode una notazione della forma “U + xxxx"(Per i codici 0 ... FFFF), oppure" U + xxxxx"(Per i codici 10000 ... FFFFF), oppure" U + xxxxxx"(Per i codici 100000 ... 10FFFF), dove xxx- cifre esadecimali. Ad esempio, il carattere "i" (U + 044F) ha il codice 044F = 1103.
Sistema di codifica
Un sistema di codifica universale (Unicode) è un insieme di simboli grafici e un modo per codificarli per l'elaborazione al computer di dati di testo.
I simboli grafici sono simboli che hanno un'immagine visibile. I caratteri grafici si oppongono ai caratteri di controllo e formattazione.
I simboli grafici includono i seguenti gruppi:
- lettere contenute in almeno uno degli alfabeti supportati;
- numeri;
- segni di punteggiatura;
- segni speciali (matematici, tecnici, ideogrammi, ecc.);
- separatori.
Unicode è un sistema per la rappresentazione lineare del testo. I caratteri con apici o pedici aggiuntivi possono essere rappresentati come una sequenza di codici costruiti secondo determinate regole (carattere composto) o come un singolo carattere (versione monolitica, carattere precomposto).
Modificare i caratteri
Rappresentazione del carattere "Y" (U + 0419) nella forma del carattere base "I" (U + 0418) e del carattere modificante "" (U + 0306)
I caratteri grafici in Unicode sono divisi in estesi e non estesi (senza larghezza). I caratteri non estesi non occupano spazio nella riga quando vengono visualizzati. Questi includono, in particolare, gli accenti e altri segni diacritici. Sia i caratteri estesi che quelli non estesi hanno i propri codici. I simboli estesi sono altrimenti chiamati di base (ing. personaggi di base), e quelli non estesi - modificativi (ing. combinazione di caratteri); e quest'ultimo non può incontrarsi autonomamente. Ad esempio, il carattere "á" può essere rappresentato come una sequenza del carattere base "a" (U + 0061) e il carattere modificatore "́" (U + 0301), oppure come carattere monolitico "á" (U + 00C1).
Un tipo speciale di caratteri modificabili sono i selettori di stile (ing. selettori di variazione). Si applicano solo a quei simboli per i quali sono definite tali varianti. Nella versione 5.0, le opzioni dei caratteri sono definite per un numero di simboli matematici, per i simboli dell'alfabeto mongolo tradizionale e per i simboli della scrittura quadrata mongola.
Moduli di normalizzazione
Poiché gli stessi simboli possono essere rappresentati codici diversi, che a volte complica l'elaborazione, esistono processi di normalizzazione progettati per portare il testo a una certa forma standard.
Lo standard Unicode definisce 4 forme di normalizzazione del testo:
- Normalizzazione Modulo D (NFD) - Decomposizione canonica. Nel processo di conversione del testo in questa forma, tutti i caratteri composti vengono sostituiti ricorsivamente da diversi caratteri composti, secondo le tabelle di scomposizione.
- La forma di normalizzazione C (NFC) è la decomposizione canonica seguita dalla composizione canonica. Innanzitutto, il testo viene ridotto alla forma D, dopodiché viene eseguita la composizione canonica: il testo viene elaborato dall'inizio alla fine e vengono seguite le seguenti regole:
- Il simbolo S è iniziale se ha una classe di modifica pari a zero nella base di caratteri Unicode.
- In qualsiasi sequenza di caratteri che iniziano con un carattere di inizio S, un carattere C è bloccato da S se e solo se c'è un carattere B tra S e C che è un carattere di inizio o ha una classe di modifica uguale o maggiore di C. Questo la regola si applica solo alle stringhe che sono passate attraverso la decomposizione canonica.
- Primario Un composto è un carattere che ha una scomposizione canonica nella base di caratteri Unicode (o scomposizione canonica per Hangul e non è incluso nell'elenco di esclusione).
- Il simbolo X può essere allineato primariamente con il simbolo Y se e solo se esiste un composto Z primario canonicamente equivalente alla sequenza
- Se il successivo carattere C non è bloccato dall'ultimo carattere di base iniziale L incontrato e può essere allineato con successo per primo, allora L viene sostituito con il composto L-C e C viene rimosso.
- Modulo di normalizzazione KD (NFKD) - Decomposizione compatibile. Quando vengono convertiti in questa forma, tutti i caratteri compositi vengono sostituiti utilizzando sia le mappe di decomposizione canoniche Unicode che le mappe di decomposizione compatibili, dopodiché il risultato viene posizionato in ordine canonico.
- Forma di normalizzazione KC (NFKC) - decomposizione compatibile seguita da canonico composizione.
I termini "composizione" e "decomposizione" indicano, rispettivamente, la connessione o la scomposizione di simboli nelle loro parti costitutive.
Esempi di
| Testo di partenza | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| francese | Franco \ u0327ais | Fran \ xe7ais | Franco \ u0327ais | Fran \ xe7ais |
| A, E, Y | \ u0410, \ u0401, \ u0419 | \ u0410, \ u0415 \ u0308, \ u0418 \ u0306 | \ u0410, \ u0401, \ u0419 | |
| が | \u304b\u3099 | \ u304c | \u304b\u3099 | \ u304c |
| Enrico IV | Enrico IV | Enrico IV | Enrico IV | Enrico IV |
| Enrico | Henry \ u2163 | Henry \ u2163 | Enrico IV | Enrico IV |
Lettera bidirezionale
Lo standard Unicode supporta la scrittura di lingue sia nella direzione da sinistra a destra (ing. da sinistra a destra, LTR), e con scritta da destra a sinistra (ing. da destra a sinistra, RTL) - ad esempio, lettere arabe ed ebraiche. In entrambi i casi, i caratteri sono memorizzati in un ordine "naturale"; la loro visualizzazione, tenendo conto della direzione desiderata della lettera, è fornita dall'applicazione.
Inoltre, Unicode supporta testi combinati che combinano frammenti con diverse direzioni della lettera. Questa funzione è chiamata bidirezionalità(ing. testo bidirezionale, BiDi). Alcuni elaboratori di testo semplificati (ad esempio, in telefono cellulare) può supportare Unicode, ma non il supporto bidirezionale. Tutti i caratteri Unicode sono divisi in diverse categorie: scritti da sinistra a destra, scritti da destra a sinistra e scritti in qualsiasi direzione. I simboli di quest'ultima categoria (principalmente segni di punteggiatura), quando visualizzati, prendono la direzione del testo circostante.
Simboli in primo piano
Unicode include praticamente tutti gli script moderni, tra cui:
Altro.
Per scopi accademici, sono state aggiunte molte scritture storiche, tra cui: rune, greco antico, geroglifici egizi, cuneiforme, scrittura Maya, alfabeto etrusco.
Unicode offre un'ampia gamma di simboli e pittogrammi matematici e musicali.
Tuttavia, Unicode fondamentalmente non include i loghi di società e prodotti, sebbene si trovino nei caratteri (ad esempio, il logo Apple nella codifica MacRoman (0xF0) o il logo Windows nel carattere Wingdings (0xFF)). Nei caratteri Unicode, i loghi devono essere posizionati solo nell'area dei caratteri personalizzati.
ISO/IEC 10646
Il Consorzio Unicode lavora a stretto contatto con gruppo di lavoro ISO/IEC/JTC1/SC2/WG2, che sta sviluppando lo standard internazionale 10646 (ISO/IEC 10646). La sincronizzazione viene stabilita tra lo standard Unicode e ISO / IEC 10646, sebbene ogni standard utilizzi la propria terminologia e il proprio sistema di documentazione.
Collaborazione del Consorzio Unicode con l'Organizzazione internazionale per la standardizzazione (ing. Organizzazione internazionale per la standardizzazione, ISO ) ha avuto inizio nel 1991. Nel 1993, l'ISO ha emesso lo standard DIS 10646,1. Per sincronizzarsi con esso, il Consorzio ha approvato la versione 1.1 dello standard Unicode, che ha aggiunto caratteri aggiuntivi dal DIS 10646.1. Di conseguenza, i valori dei caratteri codificati in Unicode 1.1 e DIS 10646.1 sono esattamente gli stessi.
In futuro è proseguita la collaborazione tra le due organizzazioni. Nel 2000 Standard Unicode 3.0 è stato sincronizzato con ISO/IEC 10646-1: 2000. La prossima terza versione di ISO/IEC 10646 sarà sincronizzata con Unicode 4.0. Forse queste specifiche saranno anche pubblicate come un unico standard.
Simile ai formati UTF-16 e UTF-32 nello standard Unicode, anche lo standard ISO/IEC 10646 ha due forme principali di codifica dei caratteri: UCS-2 (2 byte per carattere, simile a UTF-16) e UCS-4 (4 byte per carattere, simile a UTF-32). UCS significa multi-ottetto universale(multibyte) set di caratteri codificati(ing. set di caratteri codificati a più ottetti universali ). UCS-2 può essere considerato un sottoinsieme di UTF-16 (UTF-16 senza coppie surrogate) e UCS-4 è sinonimo di UTF-32.
Metodi di presentazione
Unicode ha diverse forme di rappresentazione (eng. Formato di trasformazione Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) e UTF-32 (UTF-32BE, UTF-32LE). Anche il modulo UTF-7 è stato sviluppato per la trasmissione su canali a sette bit, ma a causa dell'incompatibilità con l'ASCII non è stato diffuso e non è stato incluso nello standard. Il 1 aprile 2005 sono state proposte due presentazioni umoristiche: UTF-9 e UTF-18 (RFC 4042).
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Teoricamente possibile, ma anche non incluso nello standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Sebbene UTF-8 ti permetta di specificare lo stesso carattere in diversi modi, solo il più corto è corretto. Il resto dei moduli dovrebbe essere rifiutato per motivi di sicurezza.
Ordine dei byte
In un flusso di dati UTF-16, il byte alto può essere scritto prima del byte basso (eng. UTF-16 big-endian), o dopo il più giovane (ing. UTF-16 little-endian). Allo stesso modo, esistono due varianti della codifica a quattro byte: UTF-32BE e UTF-32LE.
Per definire il formato della rappresentazione Unicode all'inizio file di testo la firma è scritta - il carattere U + FEFF (spazio unificatore con larghezza zero), chiamato anche contrassegno dell'ordine dei byte(ing. contrassegno dell'ordine dei byte, BOM ). Ciò rende possibile distinguere tra UTF-16LE e UTF-16BE poiché non esiste un carattere U + FFFE. A volte è anche usato per indicare il formato UTF-8, sebbene la nozione di ordine dei byte non si applichi a questo formato. I file che seguono questa convenzione iniziano con queste sequenze di byte:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Sfortunatamente, questo metodo non distingue in modo affidabile tra UTF-16LE e UTF-32LE, poiché il carattere U + 0000 è consentito da Unicode (sebbene i testi reali inizino raramente con esso).
I file nelle codifiche UTF-16 e UTF-32 che non contengono un BOM devono essere in ordine di byte big-endian (unicode.org).
Unicode e codifiche tradizionali
L'introduzione di Unicode ha cambiato l'approccio alle tradizionali codifiche a 8 bit. Se prima la codifica era specificata dal carattere, ora è specificata dalla tabella di corrispondenza tra questa codifica e Unicode. In effetti, le codifiche a 8 bit sono diventate una rappresentazione di un sottoinsieme di Unicode. Ciò ha reso molto più semplice creare programmi che devono funzionare con molte codifiche diverse: ora, per aggiungere il supporto per un'altra codifica, è sufficiente aggiungere un'altra tabella di ricerca Unicode.
Inoltre, molti formati di dati consentono di inserire qualsiasi carattere Unicode, anche se il documento è scritto nella vecchia codifica a 8 bit. Ad esempio, puoi utilizzare i codici e commerciali in HTML.
Implementazione
La maggior parte dei sistemi operativi moderni fornisce un certo grado di supporto Unicode.
Nei sistemi operativi della famiglia Windows NT, la codifica UTF-16LE a doppio byte viene utilizzata per la rappresentazione interna dei nomi dei file e di altre stringhe di sistema. Le chiamate di sistema che accettano parametri stringa sono disponibili nelle varianti a byte singolo e doppio. Per maggiori dettagli, vedere l'articolo
Se hai solo bisogno di inserirne alcuni personaggi speciali o caratteri, puoi utilizzare la tabella dei caratteri o le scorciatoie da tastiera. Elenco caratteri ASCII vedere le tabelle seguenti o vedere Inserimento di alfabeti nazionali utilizzando le scorciatoie da tastiera.
Appunti:
Inserimento di caratteri ASCII
Per inserire un carattere ASCII, tenere premuto il tasto ALT, quindi digitare il codice del carattere. Ad esempio, per inserire un segno di grado (º), tieni premuto il tasto ALT e digita tastiera numerica codice 0176.
Nota:
Inserimento di caratteri Unicode
Importante: Alcuni Programmi Microsoft Office, come PowerPoint e InfoPath, non può convertire i codici dei caratteri Unicode. Se è necessario un carattere Unicode e si utilizza uno dei programmi che non supportano i caratteri Unicode, utilizzare per immettere i caratteri, che potrebbero essere necessari.
Appunti:
Esci da tutti i programmi.
Fare doppio clic sull'icona Installazione e rimozione di programmi Su pannelli di controllo.
Effettuare una delle seguenti operazioni:
se l'applicazione Microsoft Office installato come parte di Microsoft Office, selezionare Microsoft Office in campo Programmi installati e poi premere il pulsante Sostituire;
Se Applicazione per ufficioè stato installato separatamente, fare clic sul suo nome nell'elenco Programmi installati e poi premere il pulsante Modificare.
I numeri devono essere digitati sul tastierino numerico, non alfanumerico. Se è necessario premere per inserire i numeri sul tastierino numerico Tasto NUM LOCK, assicurati che sia fatto.
Se hai problemi a convertire un codice Unicode in un carattere, digita il codice sul tastierino numerico, selezionalo, quindi premi Alt + X.
V Microsoft Windows XP e le versioni successive di Unicode Universal Font vengono installate automaticamente. In Microsoft Windows 2000, il carattere Unicode deve essere installato manualmente.
Su Microsoft Windows 2000
Nella finestra di dialogo Installazione di Microsoft Office 2003 seleziona un'opzione Aggiungi o rimuovi componenti e poi premere il pulsante Ulteriore.
Si prega di selezionare Personalizzazione aggiuntiva applicazioni e premere il pulsante Ulteriore.
Espandi l'elenco Strumenti comuni di Office.
Espandi l'elenco Supporto multilingue.
Fare clic sull'icona Carattere universale e selezionare l'opzione di installazione desiderata.
Usando la tabella dei simboli
La tabella dei simboli è integrata in Microsoft Programma Windows che consente di visualizzare i caratteri disponibili nel font selezionato. Utilizzando una tabella dei simboli, è possibile copiare singoli simboli o gruppi di simboli negli appunti e quindi incollarli in un programma che li supporti.
Fare clic sul pulsante Cominciare, quindi selezionare Programmi, Standard, Servizio e tabella dei simboli.
Per selezionare un simbolo nella tabella dei simboli, fare clic su di esso, fare clic su Selezionare, clicca clic destro mouse nel punto del documento in cui si desidera aggiungere il simbolo e selezionare il comando Inserire.
Codici caratteri comuni
Per ulteriori caratteri, vedere l'articolo installato sul computer, i codici dei caratteri ASCII o un diagramma di script del codice dei caratteri Unicode.
|
Cartello |
Cartello |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli di valuta |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli legali |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
frazioni |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli di punteggiatura e dialetto |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli di forma |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Codici diacritici comuniPer un elenco completo dei glifi e dei codici dei caratteri associati, vedere.
|
Unicode è uno standard internazionale di codifica dei caratteri che consente di visualizzare il testo in modo coerente su qualsiasi computer nel mondo, indipendentemente dalla lingua di sistema utilizzata su di esso.
Le basi
Per capire a cosa serve la tabella dei caratteri Unicode, capiamo prima il meccanismo per visualizzare il testo sullo schermo di un monitor. Un computer, come sappiamo, elabora tutte le informazioni in forma digitale, e deve visualizzarle graficamente per una corretta percezione umana. Quindi, per poter leggere questo testo, è necessario risolvere almeno due compiti:
- Digitalizza caratteri stampabili.
- Fornire al sistema operativo la possibilità di abbinare i moduli digitali ai caratteri vettoriali, in altre parole, trovare le lettere corrette.
Prime codifiche
L'ASCII americano è considerato l'antenato di tutte le codifiche. Ha descritto usato in lingua inglese Alfabeto latino con segni di punteggiatura e numeri arabi. Sono stati i 128 caratteri utilizzati in esso che sono diventati la base per gli sviluppi successivi - anche la moderna tabella dei caratteri Unicode li usa. Da allora, le lettere dell'alfabeto latino hanno occupato le prime posizioni in qualsiasi codifica.
In totale, ASCII consentiva di memorizzare 256 caratteri, ma poiché i primi 128 erano occupati dall'alfabeto latino, i restanti 128 iniziarono ad essere utilizzati in tutto il mondo per creare standard nazionali. Ad esempio, in Russia, CP866 e KOI8-R sono stati creati sulla base. Tali variazioni sono state chiamate versioni estese di ASCII.
Pagine codici e "krakozyabry"
L'ulteriore sviluppo della tecnologia e l'emergere di un'interfaccia grafica hanno portato alla creazione dell'American Institute for Standardization Codifica ANSI... Per gli utenti russi, soprattutto con esperienza, la sua versione è nota sotto Nome di Windows 1251. Ha introdotto per la prima volta il concetto di “code page”. Fu con l'aiuto di pagine di codice, che contenevano simboli di alfabeti nazionali diversi dal latino, che fu stabilita la "comprensione reciproca" tra computer utilizzati in diversi paesi.
Tuttavia, la presenza di un gran numero di codifiche diverse utilizzate per una lingua ha iniziato a causare problemi. Apparve il cosiddetto krakozyabry. Sono nati da una mancata corrispondenza tra la tabella codici originale, in cui è stata creata qualsiasi informazione, e la tabella codici utilizzata per impostazione predefinita sul computer dell'utente finale.

A titolo di esempio, si possono citare le codifiche cirilliche di cui sopra CP866 e KOI8-R. Le lettere in esse differivano nelle posizioni del codice e nei principi di posizionamento. Nel primo, erano disposti in ordine alfabetico e nel secondo in un ordine arbitrario. Potete immaginare cosa succedeva davanti agli occhi di un utente che cercava di aprire un testo del genere senza avere la code page richiesta o quando veniva male interpretato dal computer.
Creazione di Unicode
La proliferazione di Internet e delle tecnologie correlate come E-mail, ha portato al fatto che alla fine la situazione con la distorsione dei testi ha cessato di accontentare tutti. Le principali aziende IT hanno formato il Consorzio Unicode. La tabella dei caratteri che ha introdotto nel 1991 con il nome UTF-32 potrebbe memorizzare oltre un miliardo di caratteri univoci. Era passo cruciale sulla strada per decifrare i testi.

Tuttavia, la prima tabella universale Unicode di codici carattere, UTF-32, non è stata ampiamente adottata. Il motivo principale era la ridondanza delle informazioni memorizzate. È stato rapidamente calcolato che per i paesi che utilizzano l'alfabeto latino codificato con la nuova tabella universale, il testo occuperebbe quattro volte lo spazio rispetto a quando si utilizza la tabella ASCII estesa.
Sviluppo di Unicode
La seguente tabella di caratteri Unicode UTF-16 ha risolto questo problema. La codifica in esso è stata eseguita nella metà del numero di bit, ma allo stesso tempo è diminuito anche il numero di combinazioni possibili. Invece di miliardi di caratteri, ne memorizza solo 65.536. Tuttavia, ha avuto un tale successo che il Consorzio ha deciso che il numero era lo spazio di archiviazione di base per i caratteri Unicode.
Nonostante questo successo, UTF-16 non andava bene per tutti, poiché la quantità di immagazzinato e informazioni trasmesse era ancora raddoppiato. La soluzione universale era UTF-8, una tabella di caratteri Unicode a lunghezza variabile. Questo può essere definito un passo avanti in questo settore.

Così, con l'introduzione degli ultimi due standard, la tabella dei caratteri Unicode ha risolto il problema di un unico spazio di codice per tutti i font attualmente utilizzati.
Unicode per il russo
A causa della lunghezza variabile del codice utilizzato per visualizzare i caratteri, il latino è codificato in Unicode allo stesso modo del suo predecessore ASCII, ovvero in un bit. Per altri alfabeti, l'immagine potrebbe avere un aspetto diverso. Ad esempio, i caratteri dell'alfabeto georgiano utilizzano tre byte per la codifica e i caratteri dell'alfabeto cirillico ne utilizzano due. Tutto ciò è possibile nell'ambito dell'utilizzo dello standard Unicode UTF-8 (tabella dei caratteri). La lingua russa o l'alfabeto cirillico occupa 448 posizioni nello spazio totale del codice, suddiviso in cinque blocchi.
![]()
Questi cinque blocchi includono gli alfabeti cirillico e slavo ecclesiastico di base, nonché lettere aggiuntive di altre lingue che utilizzano l'alfabeto cirillico. Sono evidenziate alcune posizioni per la visualizzazione di antiche forme di rappresentazione delle lettere cirilliche e 22 posizioni sul totale sono ancora libere.
Versione attuale di Unicode
Con la soluzione del suo compito primario, che era quello di standardizzare i caratteri e creare un unico spazio di codice per loro, il Consorzio non ha interrotto il suo lavoro. Unicode è in continua evoluzione ed espansione. L'ultima versione corrente di questo standard, 9.0, è stata rilasciata nel 2016. Includeva sei alfabeti aggiuntivi e ampliava l'elenco degli emoji standardizzati.
Devo dire che per semplificare la ricerca, a Unicode vengono aggiunte anche le cosiddette lingue morte. Hanno preso questo nome perché non esistono persone per le quali sarebbe nativo. Questo gruppo include anche lingue che sono arrivate fino ai nostri tempi solo sotto forma di monumenti scritti.
In linea di principio, chiunque può richiedere di aggiungere caratteri alla nuova specifica Unicode. È vero, per questo devi compilare una quantità decente documenti di origine e trascorri molto tempo. Un esempio vivente di ciò è la storia del programmatore Terence Eden. Nel 2013, ha chiesto l'inclusione nella specifica dei simboli relativi alla designazione dei pulsanti di controllo dell'alimentazione del computer. Sono stati utilizzati nella documentazione tecnica dalla metà degli anni '70 del secolo scorso, ma fino all'introduzione della specifica 9.0 non facevano parte di Unicode.
tabella dei simboli
Ogni computer, indipendentemente dal sistema operativo utilizzato, utilizza una tabella di caratteri Unicode. Come utilizzare queste tabelle, dove trovarle e perché possono essere utili a un utente normale?
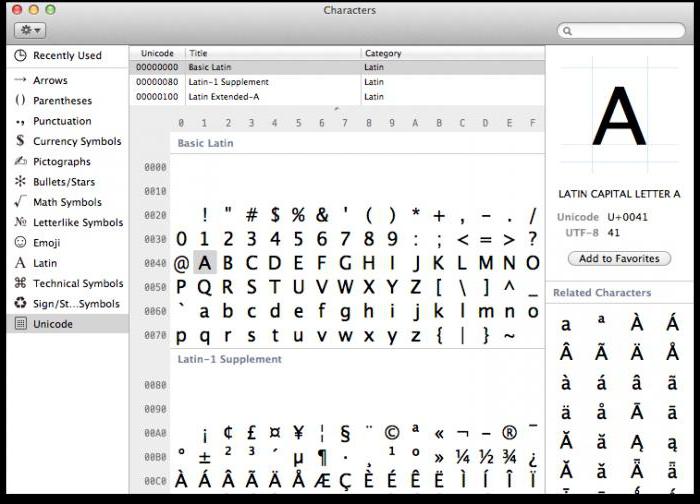
nel sistema operativo Tavolo Windows simboli si trova nella sezione "Servizio" del menu. Nella famiglia di sistemi operativi Linux, di solito si trova nella sottosezione "Standard" e in MacOS, nelle preferenze della tastiera. Lo scopo principale di questa tabella è entrare in documenti di testo caratteri che non si trovano sulla tastiera.
L'applicazione per tali tabelle può essere trovata la più ampia: dall'inserimento di simboli tecnici e icone dei sistemi monetari nazionali alla scrittura di istruzioni per l'uso pratico delle carte dei Tarocchi.
Finalmente
Unicode è utilizzato ovunque ed è entrato nella nostra vita insieme allo sviluppo di Internet e tecnologie mobili... Grazie al suo utilizzo, il sistema di comunicazioni interetniche è stato notevolmente semplificato. Possiamo dire che l'introduzione di Unicode è un esempio indicativo, ma del tutto invisibile dall'esterno, dell'uso della tecnologia per il bene comune di tutta l'umanità.
 Bug nella singolarità?
Bug nella singolarità? Just Cause 2 va in crash
Just Cause 2 va in crash Terraria non si avvia, cosa devo fare?
Terraria non si avvia, cosa devo fare?