codici ascii 1251 caratteri
Supporti dati
I dati sono una componente dialettica dell'informazione. Sono segnali registrati. Allo stesso tempo, il metodo fisico di registrazione può essere qualsiasi: movimento meccanico di corpi fisici, modifica della loro forma o dei parametri di qualità della superficie, modifica delle caratteristiche elettriche, magnetiche, ottiche, della composizione chimica e (o) della natura dei legami chimici, modifica della stato del sistema elettronico e molto altro.
In base alla modalità di registrazione, i dati possono essere archiviati e trasportati su vari tipi di supporti. Il supporto di memorizzazione più comune, sebbene non il più economico, sembra essere la carta. Sulla carta, i dati vengono registrati modificando le caratteristiche ottiche della sua superficie. La modifica delle proprietà ottiche (modifica della riflettanza della superficie in un determinato intervallo di lunghezze d'onda) viene utilizzata anche nei dispositivi che registrano con un raggio laser su supporti plastici con rivestimento riflettente ( CD ROM). Come supporti che utilizzano la modifica delle proprietà magnetiche, possiamo nominare nastri e dischi magnetici. La registrazione dei dati modificando la composizione chimica delle sostanze superficiali del vettore è ampiamente utilizzata in fotografia. A livello biochimico, c'è un accumulo e una trasmissione di dati nella fauna selvatica.
I supporti dati ci interessano non di per sé, ma nella misura in cui le proprietà dell'informazione sono strettamente correlate alle proprietà dei suoi vettori. Qualsiasi vettore può essere caratterizzato dal parametro risoluzione(la quantità di dati registrati nell'unità di misura adottata per il supporto) e gamma dinamica(rapporto logaritmico dell'intensità delle ampiezze dei segnali massimi e minimi registrati). Tali proprietà delle informazioni come completezza, accessibilità e affidabilità spesso dipendono da queste proprietà del vettore. Quindi, ad esempio, possiamo contare sul fatto che è più facile garantire la completezza delle informazioni in un database che si trova su un CD piuttosto che in un database con scopo simile situato su un floppy disk, poiché nel primo caso la densità di la registrazione dei dati per percorsi di lunghezza unitaria sono molto più elevati. Per il consumatore medio, la disponibilità di informazioni in un libro è notevolmente superiore alle stesse informazioni su un CD, poiché non tutti i consumatori dispongono dell'attrezzatura necessaria. E, infine, è noto che l'effetto visivo della visualizzazione di una diapositiva in un proiettore è molto maggiore rispetto alla visualizzazione di un'illustrazione simile stampata su carta, poiché la gamma dei segnali di luminosità nella luce trasmessa è di due o tre ordini di grandezza maggiore che in luce riflessa.
Il compito di trasformazione dei dati per cambiare il vettore è uno dei compiti più importanti dell'informatica. Nella struttura del costo dei sistemi informatici, i dispositivi per l'input e l'output di dati che funzionano con i supporti di archiviazione rappresentano fino alla metà del costo dell'hardware.
^ Operazioni sui dati
Durante il processo informativo, i dati vengono trasformati da un tipo all'altro utilizzando metodi. L'elaborazione dei dati comprende molte operazioni diverse. Con lo sviluppo del progresso scientifico e tecnologico e la complicazione generale delle comunicazioni nella società umana, il costo del lavoro per l'elaborazione dei dati è in costante aumento. Ciò è dovuto in primo luogo alla continua complicazione delle condizioni di gestione della produzione e della società. Il secondo fattore, che determina anche un aumento generale del volume dei dati trattati, è anche legato al progresso scientifico e tecnologico, ovvero alla rapida comparsa e implementazione di nuovi supporti dati, mezzi di archiviazione e consegna dei dati.
Nella struttura delle possibili operazioni con i dati si possono distinguere le seguenti principali:
raccolta dati - accumulo di dati al fine di garantire una sufficiente completezza delle informazioni per il processo decisionale;
formalizzazione dei dati - portare nella stessa forma dati provenienti da fonti diverse per renderli comparabili tra loro, ovvero per aumentarne il livello di accessibilità;
filtraggio dei dati - escludere i dati "ridondanti" non necessari al processo decisionale; allo stesso tempo dovrebbe diminuire il livello di “rumore” e aumentare l'affidabilità e l'adeguatezza dei dati;
ordinamento dei dati - ordinare i dati in base a un determinato attributo per facilità d'uso; aumenta la disponibilità di informazioni;
raggruppamento di dati - combinare i dati in base a un determinato attributo al fine di migliorare la facilità d'uso; aumenta la disponibilità di informazioni;
archiviazione dati - organizzazione della conservazione dei dati in una forma comoda e facilmente accessibile; serve a ridurre i costi economici dell'archiviazione dei dati e aumenta l'affidabilità complessiva del processo informativo nel suo insieme;
protezione dati - un insieme di misure volte a prevenire la perdita, la riproduzione e la modifica dei dati;
trasporto dati - ricezione e trasmissione (consegna e recapito) di dati tra partecipanti remoti al processo informativo; mentre l'origine dati in informatica viene solitamente chiamata server, e il consumatore cliente;
trasformazione dei dati - trasferire i dati da un modulo all'altro o da una struttura all'altra. La conversione dei dati è spesso associata a un cambiamento nel tipo di supporto, ad esempio i libri possono essere archiviati in normale formato cartaceo, ma per questo è possibile utilizzare sia il formato elettronico che il microfilm. La necessità di una trasformazione multipla dei dati sorge anche durante il loro trasporto, soprattutto se effettuata con mezzi non destinati al trasporto di questo tipo di dati. A titolo di esempio si può citare che per trasportare flussi di dati digitali sui canali delle reti telefoniche (che originariamente erano focalizzate solo sulla trasmissione segnali analogici in una stretta gamma di frequenze) è necessario convertire i dati digitali in una sorta di segnali sonori, che è ciò che fanno i dispositivi speciali - modem telefonici.
^ Codifica binaria dei dati
Per automatizzare il lavoro con i dati relativi a tipi diversi, è molto importante unificare la loro forma di presentazione: per questo viene solitamente utilizzata la tecnica codifica, cioè l'espressione di dati di un tipo in termini di dati di un altro tipo. umano naturale lingue - non sono altro che sistemi di codifica dei concetti per esprimere pensieri attraverso la parola. le lingue sono strettamente correlate alfabeto(sistemi per codificare componenti del linguaggio mediante simboli grafici). La storia conosce tentativi interessanti, anche se senza successo, di creare lingue e alfabeti "universali". Apparentemente, il fallimento dei tentativi di attuarli è dovuto al fatto che nazionale e educazione sociale comprendere naturalmente che un cambiamento nel sistema di codifica dei dati pubblici porterà inevitabilmente a un cambiamento nei metodi sociali (cioè nelle norme legali e morali), e questo può essere associato a sconvolgimenti sociali.
Lo stesso problema di uno strumento di codifica universale è implementato con successo in alcuni rami della tecnologia, della scienza e della cultura. Esempi includono il sistema di scrittura di espressioni matematiche, l'alfabeto telegrafico, l'alfabeto della bandiera nautica, il sistema Braille per non vedenti e molto altro.
Riso. 1.8. Esempi di vari sistemi di codifica
Anche la tecnologia informatica ha un proprio sistema: si chiama codifica binaria e si basa sulla rappresentazione dei dati mediante una sequenza di soli due caratteri: 0 e 1. Questi caratteri sono chiamati cifre binarie, in inglese - cifra binaria, o, in breve, bit (bit).
Due concetti possono essere espressi in un bit: 0 o 1 (Sì o no, nero o bianco, vero o Giacente eccetera.). Se il numero di bit viene aumentato a due, si possono già esprimere quattro concetti diversi:
Tre bit possono codificare otto valori diversi:
000 001 010 01l 100 101 110 111
Aumentando di uno il numero di bit nel sistema codifica binaria, raddoppiamo il numero di valori che possono essere espressi in questo sistema.
^ Codifica di numeri interi e reali
Per codificare numeri interi da 0 a 255 è sufficiente avere 8 bit di codice binario (8 bit).
0000 0000 = 0
…………………
1111 1110 = 254
1111 1111 = 255
Sedici bit consentono di codificare numeri interi da 0 a 65535 e 24 bit: più di 16,5 milioni di valori diversi.
I numeri reali vengono codificati utilizzando la codifica a 80 bit. In questo caso, il numero viene prima convertito in forma normalizzata:
3,1415926 = 0,31415926 10 1
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 9
Viene chiamata la prima parte del numero mantissa e il secondo - caratteristica. La maggior parte degli 80 bit vengono allocati per memorizzare la mantissa (insieme a un segno) e un numero fisso di bit viene allocato per memorizzare la caratteristica (anche con segno).
^ Codifica dei dati di testo
Se ogni carattere dell'alfabeto è associato a un determinato numero intero (ad esempio un numero di serie), è possibile codificare anche informazioni testuali con l'aiuto di un codice binario. Otto bit sono sufficienti per codificare 256 vari personaggi. Questo è sufficiente per esprimere in varie combinazioni di otto bit tutti i caratteri dell'alfabeto inglese e russo, sia minuscoli che maiuscoli, oltre a segni di punteggiatura, simboli di operazioni aritmetiche di base e alcuni generalmente accettati Simboli speciali, come il carattere "§".
Tecnicamente sembra molto semplice, ma ci sono sempre state difficoltà organizzative abbastanza significative. Nei primi anni dello sviluppo della tecnologia informatica, erano associati alla mancanza di standard necessari e ora sono causati, al contrario, dall'abbondanza di standard che agiscono simultaneamente e contrastanti. Affinché il mondo intero codifichi i dati di testo allo stesso modo, sono necessarie tabelle di codifica unificate, e ciò è ancora impossibile a causa delle contraddizioni tra i simboli degli alfabeti nazionali e delle contraddizioni aziendali.
Per in inglese, che si è impadronito di fatto della nicchia dei mezzi di comunicazione internazionali, le contraddizioni sono già state rimosse. Istituto per gli standard degli Stati Uniti (ANSI - Istituto Nazionale Americano di Standardizzazione) implementato un sistema di codifica ASCII (Codice standard americano per lo scambio di informazioni - Codice standard statunitense per lo scambio di informazioni). Nel sistema ASCII due tabelle di codifica sono fisse: di base e esteso. La tabella di base corregge i valori del codice da 0 a 127 e la tabella estesa si riferisce a caratteri con numeri da 128 a 255.
I primi 32 codici della tabella di base, partendo da zero, sono stati consegnati ai produttori di hardware (principalmente produttori di computer e dispositivi di stampa). Quest'area contiene il cosiddetto codici di controllo, che non corrispondono ad alcun carattere delle lingue e, di conseguenza, questi codici non vengono visualizzati né sullo schermo né sui dispositivi di stampa, ma possono essere controllati da come vengono emessi altri dati.
A partire dal codice 32 fino al codice 127, esistono codici per caratteri dell'alfabeto inglese, segni di punteggiatura, numeri, operazioni aritmetiche e alcuni caratteri ausiliari. Tabella di codifica di base ASCIIè riportato nella tabella 1.1.
^ Tabella 1.1. Tabella di codifica ASCII di base
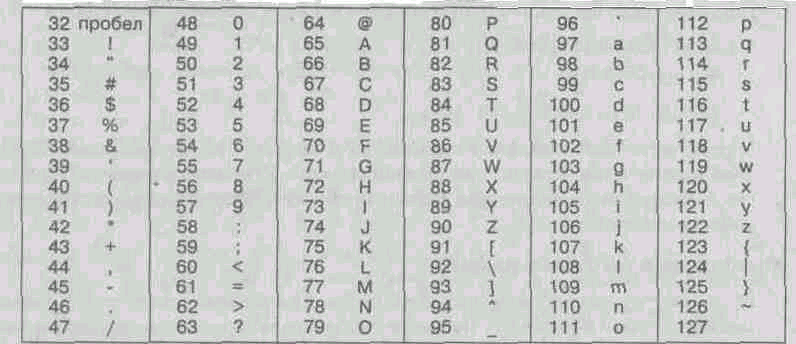
Sistemi di codifica dei dati di testo simili sono stati sviluppati in altri paesi. Quindi, ad esempio, in URSS, il sistema di codifica KOI-7 operava in quest'area. (codice di comunicazione, sette cifre). Tuttavia, il supporto dei produttori di hardware e software ha portato il codice americano ASCII al livello dello standard internazionale, e i sistemi di codifica nazionali hanno dovuto “ritirarsi” nella seconda parte estesa del sistema di codifica, che determina i valori dei codici da 128 a 255. La mancanza di un unico standard in quest'area ha portato a una pluralità di codifiche che agiscono simultaneamente. Solo in Russia è possibile specificare tre standard di codifica attuali e altri due obsoleti.
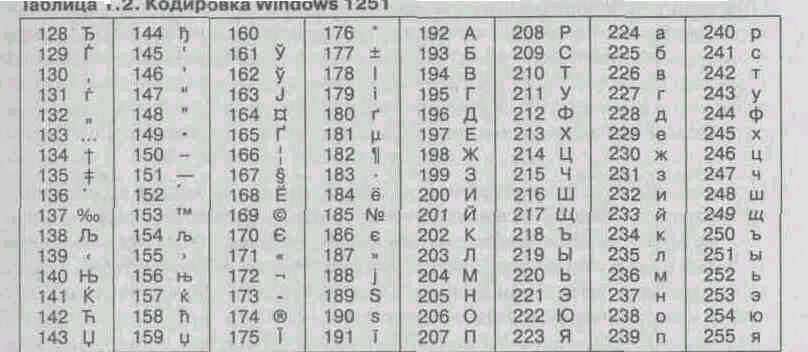
Quindi, ad esempio, la codifica dei caratteri della lingua russa, nota come codifica Windows-1251,è stato introdotto "dall'esterno" - da Microsoft, ma, dato l'uso diffuso dei sistemi operativi e di altri prodotti di questa azienda in Russia, è profondamente radicato e ampiamente utilizzato (Tabella 1.2). Questa codifica è usata dalla maggior parte computer locali in esecuzione su piattaforma Windows. Di fatto, è diventato uno standard nel settore russo del World Wide Web.
^ Tabella 1.2. Codifica di Windows 1251
Un'altra codifica comune è chiamata KOI-8 (codice di comunicazione, otto cifre) - la sua origine risale all'epoca del Consiglio di Mutua Assistenza Economica degli Stati dell'Est Europa (tabella 1.3). Sulla base di questa codifica, sono ora in vigore le codifiche KOI8-R (russo) e KOI8-U (ucraino). Oggi, la codifica KOI8-R è ampiamente utilizzata nelle reti di computer in Russia e in alcuni servizi del settore russo di Internet. In particolare, in Russia è di fatto standard nei messaggi E-mail e teleconferenza.
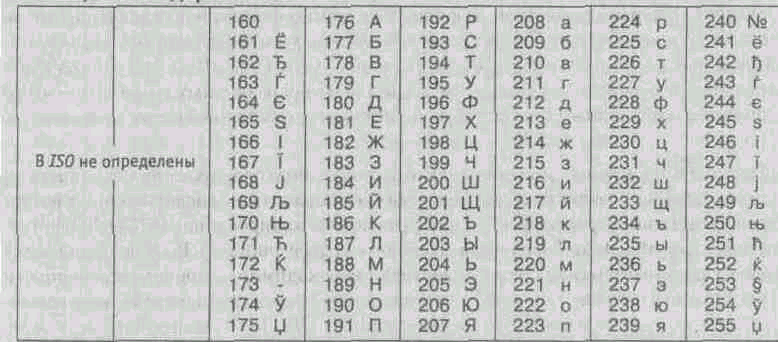
Lo standard internazionale, che prevede la codifica dei caratteri dell'alfabeto russo, è chiamato codifica ISO. (Organizzazione internazionale di standardizzazione - Istituto internazionale di standardizzazione). In pratica, questa codifica è usata raramente (Tabella 1.4).
^ Tabella 1.3. Codifica KOI-8
![]()
Tabella 1.4. codifica ISO
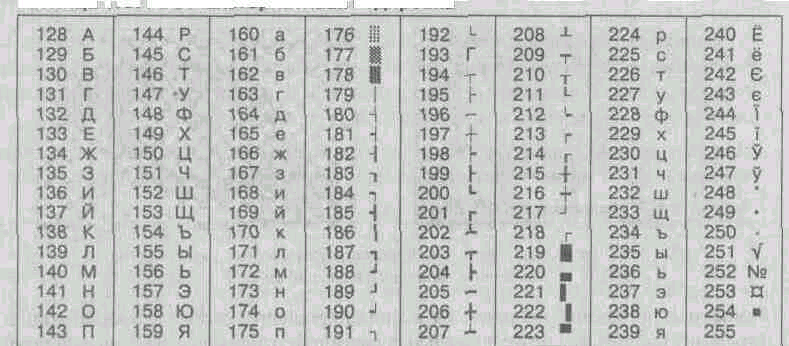
Su computer in esecuzione sistemi operativi MS-DOS, possono operare altre due codifiche (encoding GOST e codifica GOST-alternativa). Il primo di questi era considerato obsoleto anche agli albori del personal computer, ma il secondo è ancora utilizzato oggi (vedi tabella 1.5).
^ Tabella 1.5. Codifica alternativa GOST
A causa dell'abbondanza di sistemi di codifica dei dati di testo che operano in Russia, sorge il problema della conversione dei dati intersistemi: questo è uno dei compiti comuni dell'informatica.
^ Sistema di codifica dei dati di testo universale
Se analizziamo le difficoltà organizzative associate alla creazione di un sistema unificato di codifica dei dati testuali, possiamo concludere che sono causate da un insieme limitato di codici (256). Allo stesso tempo, è ovvio che se, ad esempio, i caratteri sono codificati non da numeri binari a otto bit, ma da numeri con un numero elevato di cifre, l'intervallo dei possibili valori del codice diventerà molto più ampio. Viene chiamato un tale sistema, basato su una codifica dei caratteri a 16 bit universale - UNICODE. Forniscono sedici cifre codici univoci per 65536 simboli diversi: questo campo è sufficiente per inserire in una tabella i simboli della maggior parte delle lingue del pianeta.
Nonostante la banale ovvietà di un tale approccio, una semplice transizione meccanica a questo sistema è stata trattenuta per molto tempo a causa delle risorse insufficienti di apparecchiature informatiche (nel sistema di codifica UNICODE tutti i documenti di testo diventano automaticamente lunghi il doppio). Nella seconda metà degli anni '90 mezzi tecnici hanno raggiunto il livello richiesto di dotazione di risorse e oggi assistiamo a una graduale transizione di documenti e software verso un sistema di codifica universale. Per i singoli utenti, ciò ha aggiunto ancora più preoccupazioni sul coordinamento dei documenti realizzati sistemi diversi codifica, con strumenti software, ma questo deve essere inteso come le difficoltà del periodo transitorio.
^ Codifica dei dati dell'immagine
Se guardi un'immagine grafica in bianco e nero stampata su un giornale o un libro con una lente d'ingrandimento, puoi vedere che è composta da minuscoli punti che formano un motivo caratteristico chiamato raster(Fig. 1.9).

Riso. 1.9. Un raster è un metodo di codifica delle informazioni grafiche che è stato a lungo accettato nell'industria della stampa.
Poiché le coordinate lineari e le singole proprietà di ciascun punto (luminosità) possono essere espresse utilizzando numeri interi, si può affermare che la codifica raster consente l'uso del codice binario per rappresentare dati grafici. Oggi è generalmente accettato rappresentare illustrazioni in bianco e nero come una combinazione di punti con 256 sfumature di grigio, quindi un numero binario di otto bit è solitamente sufficiente per codificare la luminosità di qualsiasi punto.
Per codificare il colore immagini grafiche applicato principio di decomposizione colore arbitrario nei componenti principali. Tre colori primari sono usati come tali componenti: il rosso (Rosso, R), verde (Verde, G) e blu (Blu, V). In pratica si ritiene (sebbene in teoria ciò non sia del tutto vero) che qualsiasi colore visibile all'occhio umano possa essere ottenuto miscelando meccanicamente questi tre colori primari. Un tale sistema di codifica è chiamato sistema RGB dalle prime lettere dei nomi dei colori primari.
Se vengono utilizzati 256 valori (otto bit) per codificare la luminosità di ciascuno dei componenti principali, come è consuetudine per le immagini in bianco e nero a mezzitoni, è necessario spendere 24 bit per codificare il colore di un punto. Allo stesso tempo, il sistema di codifica fornisce una definizione univoca di 16,5 milioni di colori diversi, che è in realtà vicina alla sensibilità dell'occhio umano. Viene chiamata la modalità per rappresentare la grafica a colori utilizzando 24 bit a colori (True Color).
A ciascuno dei colori primari può essere assegnato un colore complementare, ovvero un colore che integra il colore primario con il bianco. È facile vedere che per uno qualsiasi dei colori primari, il colore complementare è formato dalla somma di una coppia di altri colori primari. Di conseguenza, i colori complementari sono: blu (Ciano, C), viola (Magenta, M) e giallo ( Giallo, Y). Il principio di scomposizione di un colore arbitrario in componenti costitutivi può essere applicato non solo ai colori primari, ma anche a quelli aggiuntivi, ovvero qualsiasi colore può essere rappresentato come la somma dei componenti ciano, magenta e giallo. Questo metodo di codifica a colori è accettato nell'industria della stampa, ma il quarto inchiostro viene utilizzato anche nell'industria della stampa: il nero (Nero, K). Così questo sistema la codifica è indicata da quattro lettere CMYK(il colore nero è indicato dalla lettera A, perché la lettera v già occupato dal blu) e per rappresentare la grafica a colori in questo sistema, è necessario disporre di 32 bit. Questa modalità è anche chiamata a colori (True Color).
Se si riduce il numero di bit utilizzati per codificare il colore di ciascun punto, è possibile ridurre la quantità di dati, ma l'intervallo dei colori codificati viene notevolmente ridotto. La codifica della grafica a colori con numeri binari a 16 bit è chiamata modalità colore alto.
Quando si codificano le informazioni sul colore con otto bit di dati, possono essere trasmesse solo 256 sfumature di colore. Questo metodo di codifica a colori viene chiamato indice. Il significato del nome è che, poiché 256 valori sono del tutto insufficienti a veicolare l'intera gamma di colori accessibile all'occhio umano, il codice di ogni pixel del raster non esprime il colore stesso, ma solo il suo numero. (indice) in una tabella di ricerca chiamata tavolozza. Naturalmente, questa tavolozza dovrebbe essere applicata ai dati grafici - senza di essa, è impossibile utilizzare i metodi di riproduzione delle informazioni su uno schermo o su carta (ovvero, è possibile utilizzarla, ma a causa dell'incompletezza dei dati , le informazioni ricevute non saranno adeguate: il fogliame degli alberi potrebbe risultare rosso e il cielo è verde).
^ Codifica audio
Le tecniche e i metodi di lavoro con le informazioni sonore sono arrivati alla tecnologia informatica più recenti. Inoltre, a differenza dei dati numerici, testuali e grafici, le registrazioni sonore non avevano la stessa lunga e comprovata storia di codifica. Di conseguenza, i metodi per codificare le informazioni audio nel codice binario sono lontani dalla standardizzazione. Molte singole aziende hanno sviluppato i propri standard aziendali.
Un creatore di siti Web deve sempre affrontare un problema: in quale codifica creare un progetto. Su Internet di lingua russa vengono utilizzate due codifiche:
UTF-8(dall'inglese. Formato di trasformazione Unicode) è una codifica attualmente comune che implementa una rappresentazione Unicode compatibile con la codifica del testo a 8 bit.
Windows-1251(o cp1251) è un set di caratteri e una codifica, che è la codifica standard a 8 bit per tutte le versioni russe di Microsoft Windows.
UTF-8 è più promettente. Ma tutto ha dei difetti. E la decisione di utilizzare una sorta di codifica solo perché promettente, senza considerare molti altri fattori, non sembra giusta. La scelta sarà ottimale solo quando terrà pienamente conto di tutte le sfumature di un particolare progetto. Un'altra cosa è che prevedere tutte le sfumature non è facile di per sé.
Riteniamo che l'utilizzo di UTF-8 sia preferibile, ma spetta allo sviluppatore del progetto decidere cosa scegliere. E per facilitare questa scelta, utilizzare una tabella comparativa delle caratteristiche di entrambe le codifiche.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Come tradurre un sito dalla codifica win1251 a UTF-8
Procedura generale:
1. Ricodifica l'intero database in UTF-8 (molto probabilmente dovrai contattare l'amministratore del server per assistenza).
2. Ricodifica tutti i file del sito in UTF-8 (puoi farlo da solo).
3. Aggiungi le seguenti righe al file /bitrix/php_interface/dbconn.php:
4. Aggiungi le seguenti righe al file /.htaccess:
php_value mbstring.func_overload 2 php_value mbstring.internal_encoding UTF-8
Puoi ricodificare tutti i file del sito in UTF-8 (secondo punto) eseguendo il comando tramite SSH nella cartella principale del sito:
trovare. -name "*.php" -type f -exec iconv -fcp1251 -tutf8 -o /tmp/tmp_file () \; -exec mv /tmp/tmp_file() \;
La codifica di Windows 1251 è stata creata all'inizio degli anni '90 per la russificazione prodotti software prodotto da Microsoft Corporation:
La codifica è a 8 bit e include i simboli del gruppo linguistico slavo, che include russo, bielorusso, ucraino, bulgaro, macedone, serbo: questo offre un vantaggio rispetto ad altre codifiche cirilliche ( ISO 8859-5, KOI8-R, CP866). Tuttavia, la codifica 1251 presenta anche notevoli svantaggi:
- 0xFF (25510) è il codice riservato al carattere "i". I programmi che non supportano un puro 8° bit hanno spesso problemi imprevedibili;
- Non esiste una pseudo grafica presente in KOI8, CP866.
Di seguito sono riportati i simboli della Code Page 1251 o abbreviati come CP1251 ( i numeri sotto i caratteri sono il codice esadecimale dello stesso carattere Unicode):
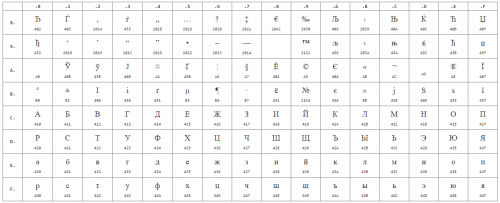
Spesso sviluppatori web e blogger con qualifiche diverse hanno problemi con la codifica delle pagine: al posto del testo preparato compaiono caratteri sconosciuti e illeggibili. Per affrontare questo problema, è necessario comprendere l'essenza del termine " codifica della pagina».
Il testo nella memoria del computer viene archiviato come un certo numero di byte e non nella forma in cui viene visualizzato editor di testo. Ogni byte è un codice che corrisponde a un carattere. Affinché il testo sulla pagina venga visualizzato correttamente, è necessario indicare al browser quale tabella di codici per la decrittazione e la visualizzazione dovrebbe utilizzare.
La tabella di codifica non è universale, ovvero per decrittare il testo, è necessario utilizzare quella che corrisponde alla codifica dei caratteri:

Affinché il documento html venga visualizzato correttamente nel browser, è necessario specificare la codifica utilizzata. Questo viene fatto come segue:
Tra tag
e chiudendolo devi registrarti - in base a questa stringa, il browser utilizzerà i caratteri dell'alfabeto russo per visualizzare il testo sulla pagina.Windows che codifica 1251 in PHP
Non è un segreto per nessuno che la generazione della pagina avvenga recuperando e utilizzando alcune delle informazioni memorizzate nel database. Quando si scrive un sito in PHP, il più delle volte è mysql.
3 votiCiao cari lettori del mio blog. Oggi parleremo con te della codifica. Se leggi il mio articolo su questo, allora sai che qualsiasi documento su Internet non è archiviato nella forma in cui siamo abituati a vederlo. È scritto con l'aiuto di simboli e segni incomprensibili per una persona. Lo stesso vale per il testo.
Esistono diverse codifiche e, quindi, a volte vengono visualizzati caratteri incomprensibili quando si apre un libro applicazione mobile o caricando un articolo sul sito, tu, modificando alcuni valori nelle impostazioni, vedrai l'alfabeto familiare alla vista.

Codifica Windows-1251: cos'è, cosa significa durante la creazione di un sito, quali caratteri saranno disponibili ed è soluzione migliore ad oggi? Tutto questo nell'articolo di oggi. Come sempre, linguaggio semplice, il più chiaro possibile e con un numero minimo di termini.
Un po' di teoria
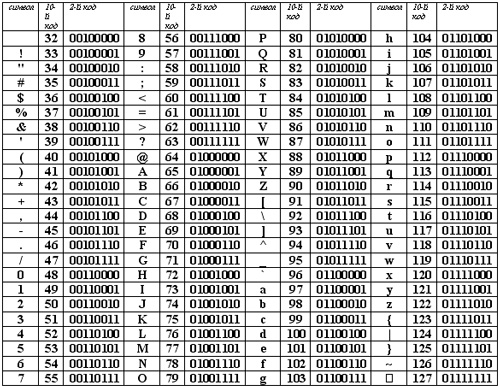
Qualsiasi documento su un computer o su Internet, come ho detto, viene archiviato come codice binario. Ad esempio, se si utilizza la codifica ASCII, la lettera "K" verrà scritta come 10001010 e Windows 1251 nasconde il simbolo - Љ sotto questo numero. Di conseguenza, se il browser o il programma accede a un'altra tabella e considera invece ASCII codici di Windows 1251, il lettore vedrà un simbolo per lui del tutto incomprensibile.
La domanda è logica, perché era necessario inventare molte tabelle con codici? Il fatto è che oltre all'alfabeto russo, c'è anche inglese, tedesco, cinese. Secondo alcune stime, ci sono circa 200.000 caratteri. Anche se non mi fido molto di queste statistiche, ricordando il giapponese.
Non dimenticare che devi inventare il tuo codice per le lettere maiuscole e minuscole, ci sono virgole, trattini e così via.
Più simboli nella tabella, più lungo è il codice di ciascuno di essi, e quindi il peso del documento aumenta.
Immagina se un libro pesasse 4 GB! Ci vorrebbe molto tempo per caricare, occupare tutto posto libero sul computer. La decisione di scaricare sarebbe stata difficile.
Se pensi ai siti web, generalmente fa paura pensare a cosa accadrebbe. Ogni pagina è stata aperta anche su fibra ottica ad alta velocità per più di un'ora! Pensare, cellulari potrebbe essere tranquillamente buttato via. Li usi all'aperto anche con il 4G? Io dubito.
Per questi motivi, ogni programmatore ha cercato contemporaneamente di creare la propria tabella dei simboli. In modo che sia comodo da usare e il peso sia mantenuto ottimale.
Microsoft, ad esempio, ha creato Windows-1251 per il segmento di lingua russa. Sicuramente ha i suoi vantaggi e svantaggi. Proprio come qualsiasi altro prodotto.
Già solo il 2% di tutte le pagine su Internet sono scritte nel 1251. La maggior parte dei webmaster usa UTF-8. Perché?
Svantaggi e vantaggi
UTF-8, a differenza di Windows-1251, è una codifica universale, contiene lettere di vari alfabeti. C'è persino UTF-128, dove generalmente ci sono tutte le lingue: teulu, swahili, laotiano, maltese e così via.

UTF-8 è più povero, le lettere occupano molto meno spazio e occupano solo un byte di memoria, come nel 1251. UTF ha caratteri rari di altre lingue o caratteri speciali. Pesano 5-6 byte ciascuno, ma sono usati raramente nel documento.
Questa codifica è più ponderata e quindi la maggior parte delle applicazioni la utilizza per impostazione predefinita. Cioè, se non dici al programma quale codifica stai usando, la prima cosa che verificherà è UTF-8 .
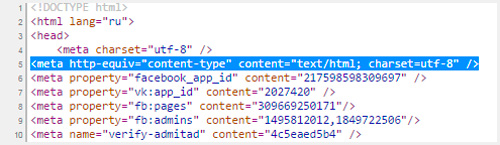
Quando crei un documento html per un sito web, dici ai browser quale tabella cercare durante la decifrazione dei record.
Per fare ciò, è necessario inserire i seguenti dati nel tag head. Dopo i caratteri "charset =" viene visualizzato utf o windows, come nell'esempio seguente.
| <meta http-equiv="Tipo di contenuto" contenuto= "testo/html; set di caratteri=windows-1251"> |
Se in futuro vuoi cambiare qualcosa e inserire una frase in albanese usando questa tabella di decrittazione, allora non funzionerà nulla, perché la codifica non supporta questa lingua. UTF-8 ti consentirà di farlo senza problemi.
Se sei interessato alla corretta creazione del sito, allora posso consigliarti il corso di Mikhail Rusakov " Creazione e promozione del sito dalla A alla Z ».

Contiene molto: 256 lezioni che riguardano , JavaScript e XML. Oltre ai linguaggi di programmazione, sarai in grado di capire come monetizzare il sito, ovvero realizzare un profitto prima e di più. Uno dei pochi corsi che spiega tutto ciò di cui hai bisogno in modo così dettagliato.
Studio da un anno ormai alla scuola dei blogger Alexander Borisov . Ci vuole molte volte più tempo, la fine non è ancora visibile, ma non è meno esaustivo e disciplinato. Motiva a continuare a svilupparsi.
Bene, se hai domande, non è necessario cercare su Internet. C'è sempre un buon mentore.

Qualcosa mi sono allontanato dall'argomento. Torniamo alle codifiche.
Basi da bagno
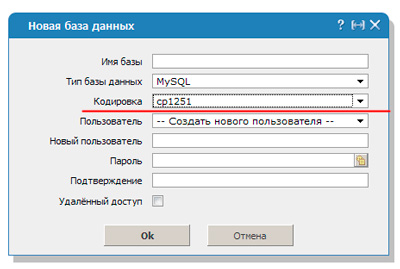
Quando si tratta di php, tutto è generalmente spaventoso. Ho già parlato di database, servono per velocizzare il sito. Di solito non li contatti, ma quando diventa necessario trasferire il sito, diventa scomodo.
Le difficoltà accadono a tutti, indipendentemente dall'esperienza lavorativa, dall'anzianità di servizio e dall'anzianità di servizio. Alcune pagine del database possono contenere tutti i caratteri disponibili per Windows-1251, altre, ad esempio, nei modelli di pagina, con una codifica diversa.
Fino a quando non è necessario un trasferimento, tutto funziona e funziona, anche se non del tutto correttamente. Ma dopo il trasloco, iniziano i guai. Idealmente, dovresti usare solo UTF o Windows-1251, ma in realtà tali carenze accadono sempre a tutti.
Affinché la decrittazione sia coerente, è necessario inserire il codice mysql_query ("SET NAMES cp1251"). In questo caso, la conversione verrà eseguita utilizzando un protocollo diverso - cp1251.
htaccess
Se hai deciso costantemente di utilizzare 1251 sul sito, dovresti trovare o creare un file htaccess. È responsabile delle impostazioni di configurazione. Dovranno essere aggiunte altre tre righe in modo che tutto combaci.
DefaultLanguage it; AddDefaultCharset windows-1251; php_value default_charset "cp1251"
Consiglio ancora vivamente di considerare l'utilizzo di UTF-8. È più popolare, semplice e ricco. Qualunque decisione prendi ora, è importante che tu possa correggerla in seguito. Sarà molto più semplice aggiungere una versione inglese del sito utilizzando questa codifica. Niente deve essere riparato.
La decisione spetta a te. Iscriviti alla newsletter per scoprire il più velocemente possibile dove studiare, per non ripetere gli errori degli altri, e quali blogger ottengono più visitatori.
Fino a quando non ci incontreremo di nuovo e buona fortuna per i tuoi sforzi.
 Istruzioni per l'uso del fluido di lavaggio
Istruzioni per l'uso del fluido di lavaggio Perché le testine di stampa si bruciano sulle stampanti Epson?
Perché le testine di stampa si bruciano sulle stampanti Epson? Installazione e configurazione della stampante Canon i-SENSYS MF3010 Scarica il driver per canon 3010 per la scansione
Installazione e configurazione della stampante Canon i-SENSYS MF3010 Scarica il driver per canon 3010 per la scansione