Od unicode kodova do slova. Problem razlikovanja izvana sličnih brojeva i slova.
Ponekad trebate dodati ikonu u svoj dizajn, ali ne želite umetnuti dodatne slike ili cijeli font ikone poput Font Awesome? Imamo dobre vijesti za vas - u vašem pregledniku već je dostupna opsežna biblioteka ikona i simbola. Zove se Unicode i to je standard koji se dodjeljuje jedinstveni identifikatori za sve veći broj (trenutno preko 110.000) simbola i ikona.
To ipak ne znači da imate izbor stotina tisuća ikona. Ovisi o pregledniku koji ih iscrtava, a za to koristi fontove koji su instalirani u sustavu. U ovom smo članku sastavili niz skupova znakova koji su dostupni u sustavima Windows, Linux, OS X, Android i IOS. Danas ih možete koristiti u svom dizajnu!
Savjet: koji objašnjava sve što trebate znati o kodiranjima i Unicodeu, koje preporučujemo svakom programeru da pročita.
Kako koristiti ove ikone
Ikone prikazane u donjim tablicama uobičajeni su simboli koje možete kopirati i zalijepiti kao da su slova abecede. Ali ako se kodiranje koristi za spremanje HTML / CSS datoteka ne UTF-8 neće biti prikazani. Zato smo uveli HTML kôd za izbjegavanje koji će uvijek raditi. Evo što trebate učiniti da biste koristili ove ikone:
- Pronađite ikonu koja vam se sviđa. Pružili smo male i velike pretpreglede.
- Kopirajte kôd.
- Zalijepite ga u HTML kao običan tekst. U CSS -u ih možete koristiti kao vrijednost svojstva sadržaj... U JS, PHP i drugim programskim jezicima možete ih koristiti kao običan tekst u nizovima.
- Ikone možete prilagoditi postavljanjem veličine fonta, boje, teksta i sjena kao i uobičajenog teksta.
Ikone
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Smiley | ☺ | ☺ | ☺ |
| Znak upozorenja | ⚠ | ⚠ | ⚠ |
| Izvori vruće vode | ♨ | ♨ | ♨ |
| Invalidska kolica | ♿ | ♿ | ♿ |
| Reciklirajte | ♻ | ♻ | ♻ |
| 8-lopta | ➑ | ➑ | ➑ |
| Visoki napon | ⚡ | ⚡ | ⚡ |
| Bijela zvijezda | ☆ | ☆ | ☆ |
| Crna zvijezda | ★ | ★ | ★ |
| Bijelo srce | ♡ | ♡ | ♡ |
| Crno srce | ❤ | ❤ | ❤ |
| Kava | ☕ | ☕ | ☕ |
| Zrakoplov | ✈ | ✈ | ✈ |
| Pješčani sat | ⌛ | ⌛ | ⌛ |
| Sat | ⌚ | ⌚ | ⌚ |
| Crne škare | ✂ | ✂ | ✂ |
| Bijele škare | ✄ | ✄ | ✄ |
| Kruna | ♕ | ♕ | ♕ |
| Sidro | ⚓ | ⚓ | ⚓ |
| Križ | ✝ | ✝ | ✝ |
| Crno-bijeli krug | ◑ | ◑ | ◑ |
| Osam nota | ♪ | ♪ | ♪ |
| Zasijale osme note | ♫ | ♫ | ♫ |
| Četiri zvjezdice s četiri balona | ✣ | ✣ | ✣ |
| Bijela zvijezda zaokružena | ✪ | ✪ | ✪ |
| Bijela zvijezda | ✰ | ✰ | ✰ |
| Bijela četverokraka zvijezda | ✧ | ✧ | ✧ |
| Crna zvijezda sa četiri šiljaka | ✦ | ✦ | ✦ |
| Provjera glasačke kutije | ☑ | ☑ | ☑ |
| Kvačica | ✔ | ✔ | ✔ |
| Križni znak | ✘ | ✘ | ✘ |
| Olovka | ✎ | ✎ | ✎ |
| Ruka za pisanje | ✍ | ✍ | ✍ |
| Žena | ♀ | ♀ | ♀ |
| Muški | ♂ | ♂ | ♂ |
| Crni telefon | ☎ | ☎ | ☎ |
| Bijeli telefon | ☏ | ☏ | ☏ |
| Omotnica | ✉ | ✉ | ✉ |
| Lokacija telefona | ✆ | ✆ | ✆ |
Unicode strelice
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Strelica ulijevo | ← | ← | ← |
| Strelica nadesno | → | → | → |
| Strelica prema gore | |||
| Strelica prema dolje | ↓ | ↓ | ↓ |
| Strelica lijevo desno | ↔ | ↔ | ↔ |
| Strelica gore dolje | ↕ | ↕ | ↕ |
| Strelice desno i lijevo | ⇄ | ⇄ | ⇄ |
| Strelice gore i dolje | ⇅ | ⇅ | ⇅ |
| Strelica dolje lijevo 90 stepeni | ↲ | ↲ | ↲ |
| Strelica dolje desno 90 ° | ↳ | ↳ | ↳ |
| Strelica gore-lijevo 90 stepeni | ↰ | ↰ | ↰ |
| Strelica gore-desno od 90 stupnjeva | ↱ | ↱ | ↱ |
| Sjeverozapadna strelica do ugla | ⇱ | ⇱ | ⇱ |
| Strelica jugoistoka do ugla | ⇲ | ⇲ | ⇲ |
| Strelica ulijevo do trake | ⇤ | ⇤ | ⇤ |
| Strelica nadesno do trake | ⇥ | ⇥ | ⇥ |
| Polukružna strelica u smjeru suprotnom od kazaljke na satu | ↶ | ↶ | ↶ |
| Polukružna strelica u smjeru kazaljke na satu | ↷ | ↷ | ↷ |
| Kružna strelica u smjeru suprotnom od kazaljke na satu | ↺ | ↺ | ↺ |
| Kružna strelica u smjeru kazaljke na satu | ↻ | ↻ | ↻ |
| Strijela sa širokom glavom udesno | ➔ | ➔ | ➔ |
| Cik -cak strijela prema dolje | ↯ | ↯ | ↯ |
| Strelica sjeverozapada | ↖ | ↖ | ↖ |
| Teška strelica jugoistoka | ➘ | ➘ | ➘ |
| Teška strelica udesno | ➙ | ➙ | ➙ |
| Teška strijela sjeveroistoka | ➚ | ➚ | ➚ |
| Isprekidana strelica udesno | ➟ | ➟ | ➟ |
| Točkasta strelica ulijevo | ⇠ | ⇠ | ⇠ |
| Crni vrh strelice nadesno | ➤ | ➤ | ➤ |
| Bijela strelica ulijevo | ⇦ | ⇦ | ⇦ |
| Bijela strelica udesno | ⇨ | ⇨ | ⇨ |
| Navodnik za lijevi kut | « | « | « |
| Navodnik pod pravim kutom | » | » | » |
| Desni crni pokazivač | |||
| Lijevi crni pokazivač | ◀ | ◀ | ◀ |
| Gore crni pokazivač | ▲ | ▲ | ▲ |
| Donji crni pokazivač | ▼ | ▼ | ▼ |
| Desni bijeli pokazivač | ▷ | ▷ | ▷ |
| Lijevi bijeli pokazivač | ◁ | ◁ | ◁ |
| Bijeli pokazivač gore | △ | △ | △ |
| Bijeli pokazivač prema dolje | ▽ | ▽ | ▽ |
| Luk strijela | ➴ | ➴ | ➴ |
Posebni znakovi u unicodeu
Unicode valuta
Ikone vremena
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Stupanj | ° | ° | ° |
| Malo sunce | ☀ | ☀ | ☀ |
| Veliko sunce | ☼ | ☼ | ☼ |
| Oblak | ☁ | ☁ | ☁ |
| Kišobran | ☔ | ☔ | ☔ |
| Pahuljica 1 | ❆ | ❆ | ❆ |
| Pahuljica 2 | ❅ | ❅ | ❅ |
| Pahuljica 3 | ❄ | ❄ | ❄ |
Unicode pokazivači
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Pokazivač lijevo crno | ☚ | ☚ | ☚ |
| Pokazivač desno crno | ☛ | ☛ | ☛ |
| Pokazivač lijevo bijelo | ☜ | ☜ | ☜ |
| Bijeli pokazivač | ☝ | ☝ | ☝ |
| Pokazivač desno bijeli | ☞ | ☞ | ☞ |
| Pokazivač dolje bijeli | ☟ | ☟ | ☟ |
Horoskopski znakovi u unicodeu
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Ovan | ♈ | ♈ | ♈ |
| Bik | ♉ | ♉ | ♉ |
| Blizanci | ♊ | ♊ | ♊ |
| Rak | ♋ | ♋ | ♋ |
| Lav | ♌ | ♌ | ♌ |
| Djevica | ♍ | ♍ | ♍ |
| vage | ♎ | ♎ | ♎ |
| Škorpion | ♏ | ♏ | ♏ |
| Strijelac | ♐ | ♐ | ♐ |
| Jarac | ♑ | ♑ | ♑ |
| Vodenjak | ♒ | ♒ | ♒ |
| Ribe | ♓ | ♓ | ♓ |
Znakovi Unicode kartice
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Klubovi crni | ♠ | ♠ | ♠ |
| Srca crna | ♥ | ♥ | ♥ |
| Dijamanti crni | ♦ | ♦ | ♦ |
| Pikovi crni | ♣ | ♣ | ♣ |
| Klubovi bijeli | ♤ | ♤ | ♤ |
| Srca bijela | ♡ | ♡ | ♡ |
| Bijeli dijamanti | ♢ | ♢ | ♢ |
| Pikovi bijeli | ♧ | ♧ | ♧ |
Šahovske figure u unicodeu
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Kralj bijeli | ♔ | ♔ | ♔ |
| Kraljica bijela | ♕ | ♕ | ♕ |
| Rook bijel | ♖ | ♖ | ♖ |
| Biskup White | ♗ | ♗ | ♗ |
| Vitez bijeli | ♘ | ♘ | ♘ |
| Pijenjak bijel | ♙ | ♙ | ♙ |
| Kralj crn | ♚ | ♚ | ♚ |
| Kraljica crna | ♛ | ♛ | ♛ |
| Rook crni | ♜ | ♜ | ♜ |
| Biskup Black | ♝ | ♝ | ♝ |
| Vitez crn | ♞ | ♞ | ♞ |
| Založen crno | ♟ | ♟ | ♟ |
Igra kockica
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Kockice jedne | ⚀ | ⚀ | ⚀ |
| Kockice dvije | ⚁ | ⚁ | ⚁ |
| Kockice tri | ⚂ | ⚂ | ⚂ |
| Kockice četiri | ⚃ | ⚃ | ⚃ |
| Kockica pet | ⚄ | ⚄ | ⚄ |
| Kockica šest | ⚅ | ⚅ | ⚅ |
Matematički simboli Unicode
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Beskonačnost | ∞ | ∞ | ∞ |
| Plus minus | ± | ± | ± |
| Manje ili jednako | ≤ | ≤ | ≤ |
| Više-nego Ili Jednako | ≥ | ≥ | ≥ |
| Nije jednako | ≠ | ≠ | ≠ |
| Podjela | ÷ | ÷ | ÷ |
| Množenje x | × | × | × |
| Teško množenje x | ✖ | ✖ | ✖ |
| Superscript One | ¹ | ¹ | ¹ |
| Superscript Two | ² | ² | ² |
| Superscript three | ³ | ³ | ³ |
| Zaokružen plus | ⊕ | ⊕ | ⊕ |
| Zaokruženo množenje | ⊗ | ⊗ | ⊗ |
| Logičko I | ∧ | ∧ | ∧ |
| Logično ILI | ∨ | ∨ | ∨ |
| Delta | ∆ | ∆ | ∆ |
| Pita | ∏ | ∏ | ∏ |
| Sigma (SUM) | ∑ | ∑ | ∑ |
| Omega | Ω | Ω | Ω |
| Prazan set | ∅ | ∅ | ∅ |
| Kut | ∠ | ∠ | ∠ |
| Paralelno | ∥ | ∥ | ∥ |
| Okomito | ⊥ | ⊥ | ⊥ |
| Gotovo jednako | ≈ | ≈ | ≈ |
| Trokut | △ | △ | △ |
| Krug | ○ | ○ | ○ |
| Kvadrat | □ | □ | □ |
Razlomci
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Jedna četvrtina (1/4) | ¼ | ¼ | ¼ |
| Pola (1/2) | ½ | ½ | ½ |
| Tri četvrtine (3/4) | ¾ | ¾ | ¾ |
| Jedna trećina (1/3) | ⅓ | ⅓ | ⅓ |
| Dvije trećine (2/3) | ⅔ | ⅔ | ⅔ |
| Jedna osmica (1/8) | ⅛ | ⅛ | ⅛ |
| Tri osmice (3/8) | ⅜ | ⅜ | ⅜ |
| Pet osmaka (5/8) | ⅝ | ⅝ | ⅝ |
| Sedam osam (7/8) | ⅞ | ⅞ | ⅞ |
Rimski brojevi u unicodeu
| Ime | Pregled | Kodirati | |
|---|---|---|---|
| Rimski broj jedan | Ⅰ | Ⅰ | Ⅰ |
| Rimski broj dva | Ⅱ | Ⅱ | Ⅱ |
| Rimski broj tri | Ⅲ | Ⅲ | Ⅲ |
| Rimska brojka četiri | Ⅳ | Ⅳ | Ⅳ |
| Rimska brojka pet | Ⅴ | Ⅴ | Ⅴ |
| Rimska brojka šest | Ⅵ | Ⅵ | Ⅵ |
| Rimska brojka sedam | Ⅶ | Ⅶ | Ⅶ |
| Rimska brojka osam | Ⅷ | Ⅷ | Ⅷ |
| Rimska brojka devetka | Ⅸ | Ⅸ | Ⅸ |
| Rimska brojka deset | Ⅹ | Ⅹ | Ⅹ |
| Rimski broj 11 | Ⅺ | Ⅺ | Ⅺ |
| Rimski broj dvanaest | Ⅻ | Ⅻ | Ⅻ |
Postoje neke razlike u prikazivanju ovih simbola u različitim operativnim sustavima Oh. To je uzrokovano različitim oblicima fontova koji se koriste. Osim toga, iOS i Android zamjenjuju neke Unicode znakove emotikonima, stoga svakako provjerite dodane znakove kako biste bili sigurni da se to ne događa i da se ikone prikazuju kako je predviđeno.
Unicode (na engleskom Unicode) standard je za kodiranje znakova. Jednostavno rečeno, ovo je tablica korespondencije tekstualnih znakova (, slova, interpunkcijski elementi) binarni kodovi... Računalo razumije samo niz nula i jedinica. Kako bi znao što bi točno trebao prikazati na ekranu, potrebno je svakom znaku dodijeliti jedinstveni broj. Osamdesetih godina znakovi su kodirani u jednom bajtu, odnosno u osam bitova (svaki bit je 0 ili 1). Tako se pokazalo da jedna tablica (poznata i kao kodiranje ili skup) može sadržavati samo 256 znakova. To možda neće biti dovoljno čak ni za jedan jezik. Stoga se pojavilo mnogo različitih kodiranja čija je zabuna često dovodila do činjenice da se umjesto čitljivog teksta na ekranu pojavio neki čudan krakozyabry. Bio je potreban jedan standard, koji je postao Unicode. Najkorištenije kodiranje je UTF-8 (Unicode transformacijski format), koji koristi 1 do 4 bajta za prikaz znaka.
Simboli
Znakovi u Unicode tablicama numerirani su heksadecimalnim brojevima. Na primjer, veliko ćirilično slovo M označeno je U + 041C. To znači da stoji na sjecištu crte 041 i stupca C. Može se jednostavno kopirati, a zatim negdje zalijepiti. Kako ne biste preturali po popisu od više kilometara, trebali biste koristiti pretraživanje. Nakon što ste ušli na stranicu sa simbolima, vidjet ćete njezin broj u Unicodeu i način na koji je iscrtan u različitim fontovima. Također možete unijeti sam znak u traku za pretraživanje, čak i ako je umjesto njega nacrtan kvadrat, barem kako biste saznali što je to. Također, na ovoj web stranici postoje posebni (i - slučajni) skupovi iste vrste ikona, prikupljeni iz različitih odjeljaka, radi lakšeg korištenja.
Standard Unicode je međunarodni. Sadrži znakove iz gotovo svih skripti na svijetu. Uključujući i one koje se više ne koriste. Egipatski hijeroglifi, germanske rune, pisanje Maja, klinasto pismo i abeceda starih država. Prezentirano i označavanje mjera i utega, notni zapis, matematički pojmovi.
Sam Unicode konzorcij ne izmišlja nove likove. One ikone koje pronađu svoju primjenu u društvu dodaju se u tablice. Na primjer, znak rublje aktivno se koristio šest godina prije nego što je dodan u Unicode. Piktogrami emotikona (emotikoni) također su se prvi put široko koristili u Japanu, a prije nego što su uključeni u kodiranje. No zaštitni znakovi i logotipi tvrtki u načelu se ne dodaju. Čak toliko uobičajeno kao Appleova jabuka ili zastava sustava Windows. Danas je u verziji 8.0 kodirano oko 120 tisuća znakova.
Elementi prostora koda koji predstavljaju negativne cijele brojeve. Obitelj kodiranja definira strojni prikaz niza UCS kodova.
Unicode kodovi podijeljeni su u nekoliko područja. Područje s kodovima od U + 0000 do U + 007F sadrži ASCII znakove s odgovarajućim kodovima. Slijede područja znakova različitih pisama, interpunkcijskih i tehničkih simbola. Neki od kodova rezervirani su za buduću upotrebu. Ispod ćiriličnih znakova dodjeljuju se područja znakova sa kodovima od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (vidi ćirilicu u Unicodeu).
Preduvjeti za stvaranje i razvoj Unicodea
Budući da su se u nizu računalnih sustava (na primjer, Windows NT) fiksni 16-bitni znakovi već koristili kao zadano kodiranje, odlučeno je da se svi najvažniji znakovi kodiraju samo unutar prvih 65 536 pozicija (tzv. Engleski). osnovna višejezična ravnina, BMP). Ostatak prostora koristi se za "dodatne znakove" (eng. dopunski likovi): sustavi pisanja izumrlih jezika ili vrlo rijetko korištenih kineskih znakova, matematičkih i glazbenih simbola.
Radi kompatibilnosti sa starim 16-bitnim sustavima, izumljen je sustav UTF-16, gdje se prvih 65.536 položaja, s izuzetkom položaja iz intervala U + D800 ... U + DFFF, prikazuje izravno kao 16-bitni brojevi, a ostali su predstavljeni kao "zamjenski parovi" (Prvi element para iz regije U + D800 ... U + DBFF, drugi element para iz regije U + DC00 ... U + DFFF). Za zamjenske parove korišten je dio prostora koda (2048 pozicija) koji je prethodno bio rezerviran za "znakove za privatnu uporabu".
Budući da UTF-16 može prikazati samo 2 20 + 2 16 −2048 (1 112 064) znakova, ovaj je broj odabran kao konačna vrijednost prostora Unicode koda.
Iako je područje koda Unicode prošireno na 2-16 već u verziji 2.0, prvi znakovi u "vrhunskom" području smješteni su samo u verziji 3.1.
Uloga ovog kodiranja u web sektoru stalno raste, početkom 2010. udio web stranica koje koriste Unicode iznosio je oko 50%.
Unicode verzije
Kako se tablica znakova Unicode mijenja i nadopunjuje, tako i nove verzije ovog sustava izlaze - a taj posao je u tijeku, budući da je izvorni Unicode sustav uključivao samo ravninu 0 - dvobajtne kodove - objavljuju se novi ISO dokumenti. Sustav Unicode ukupno postoji u sljedećim verzijama:
- 1.1 (u skladu s ISO / IEC 10646-1: 1993), standardom 1991-1995.
- 2.0, 2.1 (isti standard ISO / IEC 10646-1: 1993 plus dodaci: "Izmjene" 1 do 7 i "Tehničke ispravke" 1 i 2), standard 1996. godine.
- 3.0 (ISO / IEC 10646-1: 2000 standard) 2000 standard.
- 3.1 (ISO / IEC 10646-1: 2000 i ISO / IEC 10646-2: 2001 standardi) standard 2001.
- 3.2, standard 2002.
- 4.0, standard 2003.
- 4.01, standard 2004.
- 4.1, standard 2005.
- 5.0, standard 2006.
- 5.1, standard 2008.
- 5.2, standard 2009.
- 6.0, standard 2010.
- 6.1, standard 2012.
- 6.2, standard 2012.
Kodni prostor
Iako oblici oznaka UTF-8 i UTF-32 omogućuju kodiranje do 2,331 (2,147,483,648) kodnih točaka, odlučeno je da se za kompatibilnost s UTF-16 koristi samo 1,112,064. Međutim, čak je i to više nego dovoljno - danas se (u verziji 6.0) koristi nešto manje od 110.000 kodnih točaka (109.242 grafičkih i 273 drugih simbola).
Kodni prostor podijeljen je na 17 avioni 2 16 (65536) znakova svaki. Nulta ravnina se naziva Osnovni, temeljni, sadrži simbole najčešćih skripti. Prvi se avion koristi uglavnom za povijesne skripte, drugi - za rijetko korištene CJK znakove, treći je rezerviran za arhaična kineska slova. Zrakoplovi 15 i 16 rezervirani su za privatnu uporabu.
Za označavanje Unicode znakovi zapis oblika „U + xxxx"(Za kodove 0 ... FFFF) ili" U + xxxxx"(Za kodove 10000 ... FFFFF) ili" U + xxxxxx"(Za kodove 100000 ... 10FFFF), gdje xxx- heksadecimalne znamenke. Na primjer, znak "i" (U + 044F) ima kod 044F = 1103.
Sustav kodiranja
Univerzalni sustav kodiranja (Unicode) skup je grafičkih simbola i način njihovog kodiranja za računalnu obradu tekstualnih podataka.
Grafički simboli su simboli koji imaju vidljivu sliku. Grafički znakovi se razlikuju od kontrolnih i oblikovnih znakova.
Grafički simboli uključuju sljedeće grupe:
- slova sadržana u barem jednoj od podržanih abeceda;
- brojevi;
- interpunkcijski znakovi;
- posebni znakovi (matematički, tehnički, ideogrami itd.);
- separatori.
Unicode je sustav za linearno predstavljanje teksta. Znakovi koji imaju dodatne superskripte ili indekse mogu se predstaviti kao niz kodova izgrađenih prema određenim pravilima (složeni znak) ili kao jedan znak (monolitna verzija, predkomponirani znak).
Mijenjanje znakova
Predstavljanje znaka "Y" (U + 0419) u obliku osnovnog znaka "I" (U + 0418) i modifikacijskog znaka "" (U + 0306)
Grafički znakovi u Unicodeu podijeljeni su na proširene i neproširene (bez širine). Neprošireni znakovi ne zauzimaju mjesto u retku kada su prikazani. To uključuje, osobito, naglasne znakove i druge dijakritičke znakove. I prošireni i neproduljeni znakovi imaju svoje kodove. Prošireni simboli se inače nazivaju osnovnim (eng. osnovni likovi), i one bez proširenja - mijenjanje (eng. kombinirajući likove); a potonji se ne mogu samostalno sastajati. Na primjer, znak "á" može se predstaviti kao slijed osnovnog znaka "a" (U + 0061) i znaka modifikatora "́" (U + 0301), ili kao monolitni znak "á" (U + 00C1).
Posebna vrsta znakova za izmjenu su birači stilova (eng. birači varijacija). Primjenjuju se samo na one simbole za koje su takve varijante definirane. U verziji 5.0, ponderi su definirani za brojne matematičke simbole, za simbole tradicionalne mongolske abecede i za simbole mongolskog kvadratnog pisma.
Normalizacijski oblici
Budući da se mogu predstaviti isti simboli različiti kodovi, što ponekad otežava obradu, postoje procesi normalizacije osmišljeni da tekst dovedu u određeni standardni oblik.
Standard Unicode definira 4 oblika normalizacije teksta:
- Normalizacijski oblik D (NFD) - kanonička dekompozicija. U procesu pretvaranja teksta u ovaj oblik, svi složeni znakovi se rekurzivno zamjenjuju s nekoliko složenih, u skladu s tablicama razlaganja.
- Normalizacijski oblik C (NFC) kanonička je dekompozicija nakon koje slijedi kanonička kompozicija. Prvo se tekst reducira u oblik D, nakon čega se izvodi kanonska kompozicija - tekst se obrađuje od početka do kraja i poštuju se sljedeća pravila:
- Simbol S je početni ako ima klasu izmjene nula u bazi znakova Unicode.
- U bilo kojem nizu znakova koji počinju početnim znakom S, znak C je blokiran iz S ako i samo ako postoji neki znak B između S i C koji je ili početni znak ili ima istu ili veću klasu modifikacije od C. Ovo pravilo se primjenjuje samo na nizove koji su prošli kanoničku dekompoziciju.
- Primarni Složeni je znak koji ima kanoničku dekompoziciju u bazi znakova Unicode (ili kanoničku dekompoziciju za Hangul i nije uključen u popis za izuzimanje).
- Simbol X može se primarno poravnati sa simbolom Y ako i samo ako postoji primarni Z kompozit kanonski ekvivalentan nizu
- Ako sljedeći C znak nije blokiran posljednjim nađenim početnim osnovnim znakom L i može se s njim uspješno poravnati, tada se L zamjenjuje s L-C kompozitom, a C se uklanja.
- Normalizacijski obrazac KD (NFKD) - kompatibilno razlaganje. Kada se prenose u ovaj oblik, svi složeni znakovi zamjenjuju se pomoću kanonskih Unicodeovih mapa razlaganja i kompatibilnih karti razlaganja, nakon čega se rezultat postavlja kanonskim redoslijedom.
- Normalizacijski oblik KC (NFKC) - kompatibilno razlaganje, nakon čega slijedi kanonski sastav.
Pojmovi "sastav" i "razlaganje" znače povezivanje ili razlaganje simbola na njihove sastavne dijelove.
Primjeri
| Izvorni tekst | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | Franc \ u0327ais | Fran \ xe7ais | Franc \ u0327ais | Fran \ xe7ais |
| A, E, Y | \ u0410, \ u0401, \ u0419 | \ u0410, \ u0415 \ u0308, \ u0418 \ u0306 | \ u0410, \ u0401, \ u0419 | |
| が | \ u304b \ u3099 | \ u304c | \ u304b \ u3099 | \ u304c |
| Henrik IV | Henrik IV | Henrik IV | Henrik IV | Henrik IV |
| Henry Ⅳ | Henry \ u2163 | Henry \ u2163 | Henrik IV | Henrik IV |
Dvosmjerno slovo
Standard Unicode podržava jezike pisanja u smjeru slijeva nadesno (eng. slijeva nadesno, LTR) i pisanjem zdesna nalijevo (eng. zdesna nalijevo, RTL) - na primjer, arapska i hebrejska slova. U oba slučaja znakovi su pohranjeni u "prirodnom" redoslijedu; njihov prikaz, uzimajući u obzir željeni smjer slova, osigurava aplikacija.
Osim toga, Unicode podržava kombinirane tekstove koji kombiniraju fragmente s različitim smjerovima slova. Ova se značajka naziva dvosmjernost(eng. dvosmjerni tekst, BiDi). Neki pojednostavljeni tekstualni procesori (na primjer, u Mobiteli) može podržati Unicode, ali ne i dvosmjernu podršku. Svi Unicode znakovi podijeljeni su u nekoliko kategorija: napisani slijeva nadesno, napisani zdesna nalijevo i napisani u bilo kojem smjeru. Simboli potonje kategorije (uglavnom interpunkcijski znakovi), kada su prikazani, vode smjer okolnog teksta.
Istaknuti simboli
Unicode uključuje gotovo sve moderne skripte, uključujući:
drugo.
U akademske svrhe dodano je mnogo povijesnih pisama, uključujući: rune, starogrčke, egipatske hijeroglife, klinasto pismo, pisanje Maja, etruščansku abecedu.
Unicode nudi širok raspon matematičkih i glazbenih simbola i piktograma.
Međutim, Unicode u osnovi ne uključuje logotipe tvrtki i proizvoda, iako se nalaze u fontovima (na primjer, logotip Apple u kodiranju MacRoman (0xF0) ili logotip sustava Windows u fontu Wingdings (0xFF)). U Unicode fontovima logotipe treba postaviti samo u prilagođeno područje znakova.
ISO / IEC 10646
Unicode konzorcij blisko surađuje radna skupina ISO / IEC / JTC1 / SC2 / WG2, koji razvija međunarodni standard 10646 (ISO / IEC 10646). Sinkronizacija je uspostavljena između standarda Unicode i ISO / IEC 10646, iako svaki standard koristi vlastitu terminologiju i sustav dokumentacije.
Suradnja Unicode konzorcija s Međunarodnom organizacijom za standardizaciju (eng. Međunarodna organizacija za standardizaciju, ISO ) započeo je 1991. 1993. ISO je izdao standard DIS 10646.1. Za sinkronizaciju s njim, Konzorcij je odobrio verziju 1.1 standarda Unicode, koja je dodala dodatne znakove iz DIS 10646.1. Zbog toga su vrijednosti kodiranih znakova u Unicode 1.1 i DIS 10646.1 potpuno iste.
U budućnosti se nastavila suradnja dviju organizacija. Godine 2000 Unicode standard 3.0 je sinkroniziran s ISO / IEC 10646-1: 2000. Predstojeća treća verzija ISO / IEC 10646 bit će sinkronizirana s Unicode 4.0. Možda će se te specifikacije čak objaviti kao jedinstveni standard.
Slično formatima UTF-16 i UTF-32 u standardu Unicode, standard ISO / IEC 10646 također ima dva glavna oblika kodiranja znakova: UCS-2 (2 bajta po znaku, slično UTF-16) i UCS-4 (4 bajta po znaku, slično UTF-32). UCS znači univerzalni višeoktet(više bajtova) kodirani skup znakova(eng. univerzalni višekotetni kodirani skup znakova ). UCS-2 se može smatrati podskupom UTF-16 (UTF-16 bez zamjenskih parova), a UCS-4 je sinonim za UTF-32.
Metode prezentacije
Unicode ima nekoliko oblika predstavljanja (eng. Format transformacije Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) i UTF-32 (UTF-32BE, UTF-32LE). Obrazac UTF-7 također je razvijen za prijenos preko sedmobitnih kanala, ali zbog nekompatibilnosti s ASCII nije se proširio i nije uključen u standard. 1. travnja 2005. predložena su dva duhovita podneska: UTF-9 i UTF-18 (RFC 4042).
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Teoretski moguće, ali također nije uključeno u standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxxxxxxx
Iako vam UTF-8 omogućuje navođenje istog znaka na nekoliko načina, samo je najkraći točan. Ostatak obrazaca treba odbiti iz sigurnosnih razloga.
Redoslijed bajtova
U UTF-16 nizu podataka, visoki bajt se može upisati ili ispred niskog (eng. UTF-16 veliki endian), ili nakon mlađeg (eng. UTF-16 mali endijan). Slično, postoje dvije varijante kodiranja s četiri bajta-UTF-32BE i UTF-32LE.
Za definiranje formata Unicode prikaza na početku tekstualna datoteka potpis je napisan - znak U + FEFF (neprekinuti razmak s nultom širinom), također pozvan oznaka redoslijeda bajtova(eng. oznaka redoslijeda bajtova, BOM ). To omogućuje razlikovanje između UTF-16LE i UTF-16BE budući da znak U + FFFE ne postoji. Također se ponekad koristi za označavanje UTF-8 formata, iako se pojam redoslijeda bajtova ne odnosi na ovaj format. Datoteke koje slijede ovu konvenciju započinju ovim nizovima bajtova:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Nažalost, ova metoda ne razlikuje pouzdano UTF-16LE i UTF-32LE, budući da Unicode dopušta znak U + 0000 (iako pravi tekstovi rijetko počinju s njim).
Datoteke u kodiranjima UTF-16 i UTF-32 koje ne sadrže BOM moraju biti u velikom endian (unicode.org) redoslijedu bajtova.
Unicode i tradicionalna kodiranja
Uvođenjem Unicodea promijenjen je pristup tradicionalnim 8-bitnim kodiranjima. Ako je ranije kodiranje bilo navedeno fontom, sada je specificirano tablicom korespondencije između ovog kodiranja i Unicodea. Zapravo, 8-bitno kodiranje postalo je oblik predstavljanja podskupa Unicodea. To je uvelike olakšalo stvaranje programa koji trebaju raditi s mnogo različitih kodiranja: sada, kako biste dodali podršku za još jedno kodiranje, samo trebate dodati još jednu Unicode tablicu za pretraživanje.
Osim toga, mnogi formati podataka dopuštaju umetanje bilo kojih Unicode znakova, čak i ako je dokument napisan u starom 8-bitnom kodiranju. Na primjer, možete koristiti znakove znaka & u HTML -u.
Implementacija
Većina modernih operacijskih sustava pruža određeni stupanj Unicode podrške.
U operacijskim sustavima obitelji Windows NT dvobajtno kodiranje UTF-16LE koristi se za unutarnje predstavljanje naziva datoteka i drugih nizova sustava. Sistemski pozivi koji prihvaćaju parametre niza dostupni su u jednobajtnim i dvobajtnim varijantama. Za više detalja pogledajte članak
Ako trebate unijeti samo nekoliko posebni znakovi ili znakove, možete koristiti tablicu znakova ili tipkovne prečace. Popis ASCII znakovi pogledajte donje tablice ili pogledajte Umetanje nacionalnih abeceda pomoću tipkovnih prečaca.
Bilješke:
Umetanje ASCII znakova
Da biste umetnuli ASCII znak, pritisnite i držite tipku ALT, a zatim upišite kod znaka. Na primjer, da biste umetnuli znak stupnja (º), držite pritisnutu tipku ALT i upišite numerička tipkovnica kod 0176.
Bilješka:
Umetanje Unicode znakova
Važno: Neki Microsoftovih programa Office, kao što su PowerPoint i InfoPath, ne može pretvoriti Unicode kodove znakova. Ako vam je potreban Unicode znak i koristite neki od programa koji ne podržavaju Unicode znakove, upotrijebite za unos znakova koji vam mogu zatrebati.
Bilješke:
Zatvorite sve programe.
Dvaput kliknite ikonu Instalacija i uklanjanje programa na upravljačke ploče.
Učinite nešto od sljedećeg:
ako je aplikacija Microsoft Office instaliran kao dio programa Microsoft Office, odaberite Microsoft Office na terenu Instalirani programi a zatim pritisnite gumb Zamijeniti;
Ako Uredska aplikacija je instaliran zasebno, kliknite na njegovo ime na popisu Instalirani programi a zatim pritisnite gumb Promijeniti.
Brojeve treba upisivati na numeričku tipkovnicu, a ne alfanumeričke. Ako trebate pritisnuti za unos brojeva na numeričkoj tipkovnici NUM tipka ZAKLJUČAJ, provjeri je li to učinjeno.
Ako imate problema s pretvaranjem Unicode koda u znak, upišite kôd na numeričkoj tipkovnici, odaberite ga, a zatim pritisnite Alt + X.
V. Microsoft Windows XP i novije verzije univerzalnog Unicode fonta instaliraju se automatski. U sustavu Microsoft Windows 2000 font Unicode mora se instalirati ručno.
U sustavu Microsoft Windows 2000
U dijaloškom okviru Instaliranje sustava Microsoft Office 2003 odaberite opciju Dodajte ili uklonite komponente a zatim pritisnite gumb Unaprijediti.
Molimo izaberite Dodatna prilagodba aplikacije i pritisnite tipku Unaprijediti.
Proširite popis Uobičajeni uredski alati.
Proširite popis Podrška za više jezika.
Pritisnite ikonu Univerzalni font i odaberite željenu opciju instalacije.
Pomoću tablice simbola
Tablica simbola ugrađena je u Microsoft Windows program, koji vam omogućuje pregled znakova dostupnih u odabranom fontu. Pomoću tablice simbola možete kopirati pojedinačne simbole ili skupine simbola u međuspremnik, a zatim ih zalijepiti u program koji ih podržava.
Pritisnite gumb Početak, a zatim odaberite Programi, Standard, Servis i tablica simbola.
Da biste odabrali simbol u tablici simbola, kliknite ga, kliknite Odaberi, kliknite desni klik mišem na mjestu dokumenta u koji želite dodati simbol i odaberite naredbu Umetnuti.
Uobičajeni kodovi znakova
Za više znakova znakova pogledajte članak instaliran na vašem računalu, kodove znakova ASCII ili dijagram skripte koda znaka Unicode.
|
Znak |
Znak |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli valute |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Pravni simboli |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Razlomci |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Znakovi interpunkcije i dijalekta |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli obrazaca |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Uobičajeni dijakritički kodoviZa potpuni popis glifova i pridruženih kodova znakova pogledajte.
|
Unicode je međunarodni standard za kodiranje znakova koji omogućuje dosljedan prikaz teksta na bilo kojem računalu u svijetu, bez obzira na jezik sustava koji se na njemu koristi.
Osnove
Da bismo razumjeli čemu služi tablica znakova Unicode, najprije razumimo mehanizam za prikaz teksta na zaslonu monitora. Računalo, kao što znamo, obrađuje sve informacije u digitalnom obliku i mora ih prikazati grafički radi ispravne ljudske percepcije. Dakle, da bismo mogli pročitati ovaj tekst, potrebno je riješiti najmanje dva zadatka:
- Digitalizirajte likove za ispis.
- Omogućite operacijskom sustavu mogućnost usklađivanja digitalnih oblika s vektorskim znakovima, drugim riječima, pronađite ispravna slova.
Prva kodiranja
Američki ASCII smatra se pretkom svih kodiranja. Opisano je da se koristi u Engleski jezik Latinska abeceda s interpunkcijskim znakovima i arapskim brojevima. Upravo 128 znakova koji su u njemu korišteni postali su osnova za daljnji razvoj - čak ih koristi i moderna Unicode tablica znakova. Od tada su slova latinične abecede zauzela prva mjesta u bilo kojem kodiranju.
ASCII je ukupno dopustio pohranu 256 znakova, ali budući da je prvih 128 zauzelo latinično pismo, preostalih 128 počelo se koristiti u cijelom svijetu za stvaranje nacionalnih standarda. Na primjer, u Rusiji su na njegovoj osnovi stvoreni CP866 i KOI8-R. Takve su se varijacije nazivale proširene verzije ASCII.
Kodne stranice i "krakozyabry"
Daljnji razvoj tehnologije i pojava grafičkog sučelja doveli su do činjenice da je osnovan Američki institut za standardizaciju ANSI kodiranje... Ruskim korisnicima, osobito s iskustvom, njegova je verzija poznata pod Naziv Windows 1251. Prvi put je uveo koncept „kodne stranice“. Uz pomoć kodnih stranica, koje su sadržavale simbole nacionalnih abeceda osim latinskog, uspostavljeno je "međusobno razumijevanje" između računala koja se koriste u različitim zemljama.
Međutim, prisutnost velikog broja različitih kodiranja korištenih za jedan jezik počela je stvarati probleme. Pojavio se takozvani krakozyabry. Do njih je došlo zbog neusklađenosti izvorne kodne stranice na kojoj su stvorene sve informacije i kodne stranice koja se prema zadanim postavkama koristi na računalu krajnjeg korisnika.

Kao primjer, mogu se navesti gornja ćirilična kodiranja CP866 i KOI8-R. Slova u njima razlikovala su se kodnim položajima i načelima postavljanja. U prvom su bili poredani abecednim redom, a u drugom - proizvoljnim redoslijedom. Možete zamisliti što se događalo pred očima korisnika koji je pokušao otvoriti takav tekst bez potrebne šifre ili kada ga je računalo pogrešno protumačilo.
Stvaranje Unicodea
Širenje Interneta i srodnih tehnologija kao što su E -pošta, dovelo je do toga da na kraju situacija s iskrivljenjem tekstova prestala svima odgovarati. Vodeće IT tvrtke osnovale su Unicode konzorcij. Tablica znakova koju je 1991. predstavio pod imenom UTF-32 mogla je pohraniti više od milijardu jedinstvenih znakova. Bilo je presudan korak na putu dešifriranja tekstova.

Međutim, prva univerzalna Unicode tablica kodova znakova, UTF-32, nije bila široko prihvaćena. Glavni razlog bila je višak pohranjenih podataka. Brzo je izračunato da će za zemlje koje koriste latinično pismo kodirano novom univerzalnom tablicom tekst zauzeti četiri puta veći prostor nego pri korištenju proširene ASCII tablice.
Razvoj Unicodea
Sljedeća tablica znakova Unicode UTF-16 riješila je ovaj problem. Kodiranje u njemu provedeno je u pola broja bitova, ali se istovremeno smanjio i broj mogućih kombinacija. Umjesto milijardi znakova, pohranjuje samo 65 536. Međutim, bio je toliko uspješan da je Konzorcij odlučio da je taj broj osnovni prostor za pohranu Unicode znakova.
Unatoč tom uspjehu, UTF-16 nije odgovarao svima, budući da je količina pohranjenih i prenesene informacije je još uvijek bio udvostručen. Univerzalno rješenje bio je UTF-8, tablica znakova Unicode promjenjive duljine. To se može nazvati probojem na ovom području.

Tako je uvođenjem posljednja dva standarda tablica znakova Unicode riješila problem jedinstvenog prostora koda za sve fontove koji se danas koriste.
Unicode za ruski
Zbog promjenjive duljine koda koji se koristi za prikaz znakova, latinica je kodirana u Unicodeu na isti način kao i u njenom pretku ASCII, to jest u jednom bitu. Za ostale abecede slika može izgledati drugačije. Na primjer, znakovi gruzijske abecede koriste tri bajta za kodiranje, a znakovi ćirilice koriste dva. Sve je to moguće u okviru korištenja UTF-8 Unicode standarda (tablica znakova). Ruski jezik ili ćirilično pismo zauzima 448 mjesta u ukupnom prostoru koda, podijeljenih u pet blokova.
![]()
Ovih pet blokova uključuje osnovnu ćirilicu i crkvenoslavensko pismo, kao i dodatna slova iz drugih jezika koji koriste ćirilicu. Istaknuta su brojna mjesta za prikaz starih oblika predstavljanja ćiriličnih slova, a 22 mjesta od ukupnog broja još su slobodna.
Trenutna verzija Unicodea
Rješenjem svog primarnog zadatka, a to je bilo standardiziranje fontova i stvaranje jedinstvenog prostora za njih, Konzorcij nije prestao s radom. Unicode se stalno razvija i širi. Posljednja trenutna verzija ovog standarda, 9.0, objavljena je 2016. godine. Uključio je šest dodatnih abeceda i proširio popis standardiziranih emojija.
Moram reći da se radi pojednostavljenja istraživanja u Unicode dodaju čak i takozvani mrtvi jezici. Ovo ime su dobili jer ljudi za koje bi on bio rodni ne postoje. U ovu skupinu spadaju i jezici koji su se u naše vrijeme spustili samo u obliku pisanih spomenika.
U načelu, svatko se može prijaviti za dodavanje znakova u novu specifikaciju Unicodea. Istina, za to morate popuniti pristojan iznos izvorni dokumenti i provesti mnogo vremena. Živi primjer toga je priča o programerki Terence Eden. Godine 2013. prijavio se za uključivanje u specifikaciju simbola koji se odnose na označavanje gumba za upravljanje napajanjem računala. Koristili su se u tehničkoj dokumentaciji od sredine 70-ih godina prošlog stoljeća, ali do uvođenja specifikacije 9.0 nisu bili dio Unicodea.
tablica simbola
Svako računalo, bez obzira na operativni sustav koji koristi, koristi tablicu znakova Unicode. Kako koristiti ove tablice, gdje ih pronaći i zašto mogu biti korisne običnom korisniku?
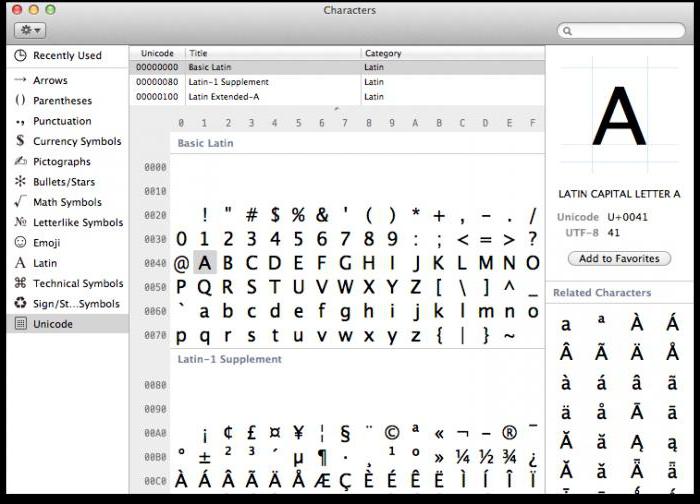
U OS -u Windows stol simboli nalazi se u odjeljku "Usluga" izbornika. U obitelji operacijskih sustava Linux obično se može pronaći u pododjeljku "Standard", a u MacOS -u u postavkama tipkovnice. Glavna svrha ove tablice je ući u tekstualni dokumenti znakovi koji se ne nalaze na tipkovnici.
Aplikacija za takve tablice može se naći najširu: od unosa tehničkih simbola i ikona nacionalnih monetarnih sustava do pisanja uputa za praktičnu uporabu Tarot karata.
Konačno
Unicode se koristi posvuda i ušao je u naš život zajedno s razvojem interneta i mobilne tehnologije... Zahvaljujući njegovoj uporabi, sustav međunacionalnih komunikacija znatno je pojednostavljen. Možemo reći da je uvođenje Unicodea indikativan, ali izvana potpuno nevidljiv primjer korištenja tehnologije za opće dobro cijelog čovječanstva.
 Greške u singularnosti?
Greške u singularnosti? Samo se uzrok 2 ruši
Samo se uzrok 2 ruši Terraria se neće pokrenuti, što da radim?
Terraria se neće pokrenuti, što da radim?