Koliko bitova ima unicode kodiranje. Jedinice mjerenja volumena podataka i kapaciteta memorije: kilobajti, megabajti, gigabajti... Unicode standard za kodiranje znakova
Kodiranje informacija
Bilo koji brojevi (unutar određenih granica) u memoriji računala kodirani su brojevima u binarnom brojevnom sustavu. Za to postoje jednostavna i jasna pravila prijevoda. Međutim, danas se računalo koristi mnogo šire nego u ulozi izvođača radno intenzivnih izračuna. Na primjer, memorija računala pohranjuje tekstualne i multimedijske informacije. Stoga se postavlja prvo pitanje:
Svaki znak je kodiran od 1 do 4 bajta. Zamjenski znakovi koriste 4 bajta i stoga zahtijevaju dodatnu pohranu. Svaki znak je kodiran s najmanje 4 bajta. Alternativno, možete koristiti alat za pretvorbu za automatsku konverziju. Kao što je rečeno, ovo je standard koji dobro odgovara Amerikancima. Kreće se od 0 do 127, a prva 32 i zadnja se smatraju kontrolnim, ostali su "ispisani znakovi", odnosno ljudi prepoznaju. Može se predstaviti samo sa 7 bitova, iako se obično koristi jedan bajt.
Kako se znakovi (slova) spremaju u memoriju računala?
Svako slovo pripada određenoj abecedi u kojoj znakovi slijede jedan za drugim i stoga se mogu numerirati uzastopnim cijelim brojevima. Svako slovo može biti povezano s pozitivnim cijelim brojem i nazvati ga kodom znakova... Upravo će se taj kod pohraniti u memoriju računala, a kada se prikaže na ekranu ili na papiru, bit će "pretvoren" u svoj odgovarajući znak. Da biste razlikovali prikaz brojeva od prikaza znakova u memoriji računala, također morate pohraniti informacije o tome koji su podaci kodirani u određenom području memorije.
Ovisno o kontekstu, pa čak i vremenu, ovo znači nešto drugo. Dakle, ovisi o čemu pričate. Malo znači sama. Postoje neka kodiranja koja koriste ovu akronim. Vrlo su složene i gotovo nitko ne zna kako pravilno iskoristiti njihovu punoću, uključujući i mene.
Ali ne s bilo kojim drugim sustavom kodiranja znakova. Ovo je najkompletnije i najsloženije kodiranje koje postoji. Neki su zaljubljeni u nju, a drugi je mrze, iako prepoznaju njezinu korisnost. Čovjeku je to teško razumjeti, ali je kompjuteru teško nositi se.
Korespondencija slova određene abecede s brojevima-kodovima tvori tzv tablica kodiranja... Drugim riječima, svaki znak određene abecede ima svoj brojčani kod u skladu s određenom tablicom kodiranja.
Međutim, u svijetu postoji mnogo abeceda (engleska, ruska, kineska itd.). Dakle, sljedeće pitanje je:
Postoji usporedba između to dvoje. To je standard za prezentaciju tekstova kreiranih od strane konzorcija. Među normama koje je uspostavio nalaze se neka kodiranja. Ali u stvarnosti, to se odnosi na mnogo više od toga. Članak koji bi svi trebali pročitati, čak i ako se ne slažu sa svime što imaju.
Podržani skupovi znakova podijeljeni su u ravnine. Dva računala koriste različite operacijske sustave; isto se događa sa skupom znakova, strukturom i format datoteke koji su obično različiti. Komunikacija preko upravljačke veze.
Kako kodirati sve abecede koje se koriste na računalu?
Da bismo odgovorili na ovo pitanje, slijedit ćemo povijesni put.
Šezdesetih godina XX stoljeća u Američki nacionalni institut za standarde (ANSI) razvijena je tablica kodiranja znakova koja je naknadno korištena u svim operativnim sustavima. Ova tablica se zove ASCII (američki standardni kod za razmjenu informacija)... Malo kasnije se pojavio proširena ASCII verzija.
Komunikacija se odvija nizom naredbi i odgovora. Ova jednostavna metoda prikladna je za kontrolnu vezu jer možemo slati jednu po jednu naredbu. Svaka naredba ili odgovor obuhvaća jedan redak, tako da ne moramo brinuti o formatu datoteke ili strukturi. Svaki red završava s dva znaka.
Datoteka. Svrha i implementacija podatkovne veze razlikuju se od onih navedenih u kontrolnoj vezi. Osnovna činjenica: želimo prenijeti datoteke preko podatkovne veze. Klijent mora odrediti vrstu datoteke za prijenos, strukturu podataka i način prijenosa.
Prema ASCII tablici kodiranja, 1 bajt (8 bitova) dodjeljuje se za predstavljanje jednog znaka. Skup od 8 ćelija može imati 2 8 = 256 različitih vrijednosti. Prvih 128 vrijednosti (od 0 do 127) su konstantne i čine takozvani glavni dio tablice, koji uključuje decimalne znamenke, slova latinske abecede (velika i mala slova), interpunkcijske znakove (točka, zarez, zagrade , itd.), kao i razmak i razne uslužne znakove (tabelarni prikaz, prijelaz redaka itd.). Vrijednosti od 128 do 255 oblikuju dodatni dio tablice gdje je uobičajeno kodirati simbole nacionalnih abeceda.
Osim toga, prijenos mora biti pripremljen od strane kontrolne veze prije nego što se datoteka može prenijeti preko podatkovne veze. Problem heterogenosti rješava se definiranjem tri atributa veze: vrste datoteke, strukture podataka i načina prijenosa.
Datoteka se šalje kao kontinuirani tok bitova bez ikakvog tumačenja ili kodiranja. Ovaj se format uglavnom koristi za prijenos binarnih datoteka kao što su kompajlirani programi ili slike kodirane u 0 i 1 sekundi. Datoteka ne sadrži okomite specifikacije za ispis. To znači da se datoteka ne može ispisati bez dodatne obrade jer nema razumljivih znakova koji bi se mogli tumačiti vertikalnim pomicanjem ispisnog stroja. Ovaj format koriste datoteke koje će biti pohranjene i obrađene u budućnosti.
Budući da postoji veliki izbor nacionalnih abeceda, proširene ASCII tablice postoje u mnogim varijantama. Čak i za ruski jezik postoji nekoliko tablica kodiranja (Windows-1251 i Koi8-r su uobičajeni). Sve to stvara dodatne poteškoće. Na primjer, šaljemo pismo napisano u jednom kodiranju, a primatelj ga pokušava pročitati drugim. Kao rezultat toga, on vidi krakozyabry. Stoga čitatelj treba primijeniti drugačiju tablicu kodiranja za tekst.
Datoteka se može ispisati nakon prijenosa. Stranice: datoteka je podijeljena na stranice, od kojih je svaka ispravno numerirana i identificirana naslovom. Stranice se mogu spremati ili pristupati, nasumično ili uzastopno. Ako su podaci samo niz bajtova, nije potrebna identifikacija kraja reda. U ovom slučaju, oznaka kraja linije je zatvaranje podatkovne veze od strane odašiljača. Prvi bajt naziva se blok deskriptora; druga dva bajta definiraju veličinu bloka u bajtovima. Kompresija: ako je datoteka prevelika, podaci se mogu komprimirati prije slanja. Uobičajena metoda kompresije uzima jedinicu podataka koja se pojavljuje uzastopno i zamjenjuje je jednom pojavom, nakon čega slijedi niz ponavljanja. V tekstualnu datoteku puno praznih mjesta. U binarnoj datoteci, nulti znakovi su obično komprimirani.
- Datoteke: datoteka nema strukturu.
- Prenosi se u kontinuiranom toku bajtova.
- Ova se vrsta može koristiti samo s tekstualnim datotekama.
- Lanci: Ovo je zadani način rada.
- U ovom slučaju, svakom bloku prethodi zaglavlje od 3 bajta.
Postoji i drugi problem. Abecede nekih jezika imaju previše znakova i ne uklapaju se u svoje dodijeljene pozicije od 128 do 255 jednobajtnog kodiranja.
Treći problem je što učiniti ako tekst koristi nekoliko jezika (na primjer, ruski, engleski i francuski)? Ne možete koristiti dva stola odjednom...
Kako bi riješio ove probleme, Unicode kodiranje je razvijeno u jednom potezu.
Mnogi nemaju pojma o razlikama između ovih skupova i drže se onoga što im je blizu. Detalj kodiranja je da su to karte za dvije različite stvari. Prva je mapa numeričkih vrijednosti koja predstavlja određeni znak.
Ostali avioni su dodaci sa likovima koji nadopunjuju funkcije glavnog zrakoplova i drugih "specijalaca" poput "emotikona". U ovim obrascima, svaki ravninski znak je kodiran u samo 1 bajt, pa stoga imamo samo 256 "mogućih" znakova. Moramo, naravno, ukloniti one koje se ne mogu ispisati smanjenjem raspona.
Unicode standard za kodiranje znakova
Za rješavanje gore navedenih problema početkom 90-ih razvijen je standard za kodiranje znakova, tzv Unicode. Ovaj standard omogućuje vam korištenje gotovo svih jezika i simbola u tekstu.
Unicode daje 31 bit za kodiranje znakova (4 bajta minus jedan bit). Broj mogućih kombinacija daje prevelik broj: 2 31 = 2 147 483 684 (tj. više od dvije milijarde). Stoga Unicode opisuje alfabete svih poznatih jezika, čak i "mrtvih" i izmišljenih, uključuje mnoge matematičke i druge Posebni simboli... Međutim, kapacitet informacija 31-bitnog Unicodea je još uvijek prevelik. Stoga se češće koristi skraćena 16-bitna verzija (2 16 = 65 536 vrijednosti) gdje su kodirane sve moderne abecede.
A ako trebate napraviti usporedbe između znakova, nema gubitka performansi, jer usporedba dvije 8-bitne, 16-bitne ili 32-bitne vrijednosti troši isto vrijeme na moderni procesori... Značenje povezano s akronimom je naravno veličina svake jedinice sekvence koja čini kodiranje znakova. Kada kod ima više bitova, koristi se sljedeće kodiranje.
Dakle, bilo koji znak može biti izražen u veličinama od 1 do 4 bajta. Je li ovo jedinstveni "poseban" lik? To znači da su neke od slika likova vrlo slične i ponekad suvišne. Da damo još jedan primjer, prije nekoliko godina bio je vic o promjeni '; ' na '; ' v izvorni kodovi... Dok je sastavljao kod, programer je poludio pokušavajući otkriti problem.
U Unicodeu, prvih 128 kodova je isto kao i ASCII tablica.
Počevši od kasnih 60-ih, računala su se sve više koristila za obradu tekstualne informacije a trenutno većina osobnih računala u svijetu (i većinu vremena) zauzeta je obradom tekstualnih informacija.
ASCII - osnovno kodiranje teksta za latinicu
Tradicionalno, za kodiranje jednog znaka koristi se količina informacija jednaka 1 bajt, odnosno I = 1 bajt = 8 bitova.
Za kodiranje jednog znaka potreban je 1 bajt informacija. Ako simbole smatramo mogućim događajima, onda možemo izračunati koliko različiti likovi može se kodirati: N = 2I = 28 = 256.
Ovaj broj znakova sasvim je dovoljan za predstavljanje tekstualnih informacija, uključujući velika i mala slova ruske i latinične abecede, brojeve, znakove, grafičke simbole itd. Kodiranje znači da se svakom znaku dodjeljuje jedinstveni decimalni kod od 0 do 255 ili odgovarajući binarni kod od 00000000 do 11111111.
Dakle, osoba razlikuje simbole po stilu, a računalo - po kodovima. Kada se tekstualna informacija unese u računalo, ona binarno kodiranje, slika simbola se pretvara u svoj binarni kod.
Korisnik pritisne tipku sa simbolom na tipkovnici, a određeni slijed od osam električnih impulsa (binarni kod simbola) šalje se računalu. Kod znakova je pohranjen u RAM memorija računalo gdje zauzima jedan bajt. U procesu prikazivanja znaka na ekranu računala vrši se obrnuti proces - dekodiranje, odnosno pretvaranje koda znaka u njegovu sliku. Tablica kodova ASCII (American Standard Code for Information Interchange) usvojena je kao međunarodni standard.Tablica standardnih dijelova ASCII-a Važno je da je dodjela specifičnog koda znaku stvar dogovora, što je fiksirano u tablici kodova. . Prva 33 koda (od 0 do 32) ne odgovaraju znakovima, već operacijama (pomak reda, unos razmaka i tako dalje). Kodovi od 33 do 127 su međunarodni i odgovaraju simbolima latinične abecede, brojevima, aritmetičkim znakovima i interpunkcijskim znakovima. Kodovi od 128 do 255 su nacionalni, odnosno različiti znakovi odgovaraju istom kodu u nacionalnim kodovima.
Nažalost, trenutno postoji pet različitih tablice kodova za ruska slova (KOI8, CP1251, CP866, Mac, ISO), tako da tekstovi stvoreni u jednom kodiranju neće biti ispravno prikazani u drugom.
Trenutno, nova međunarodna Unicode standard, koji za svaki znak dodjeljuje ne jedan bajt, već dva, tako da se može koristiti za kodiranje ne 256 znakova, već N = 216 = 65536 različitih
Unicode - pojava univerzalnog kodiranja teksta (UTF 32, UTF 16 i UTF 8)
Ove tisuće znakova iz grupe jezika jugoistočne Azije ne mogu se opisati u jednom bajtu informacija, koji je bio dodijeljen za kodiranje znakova u proširenim ASCII kodovima. Kao rezultat toga, stvoren je konzorcij tzv Unicode(Unicode - Unicode Consortium) u suradnji s brojnim liderima IT industrije (onima koji proizvode softver, koji kodiraju hardver, koji kreiraju fontove) koji su bili zainteresirani za pojavu univerzalnog kodiranja teksta.
Prvo kodiranje teksta objavljeno pod okriljem Unicode konzorcija bilo je kodiranje UTF 32... Broj u nazivu UTF 32 kodiranja znači broj bitova koji se koriste za kodiranje jednog znaka. 32 bita su 4 bajta informacija koje će biti potrebne za kodiranje jednog znaka u novom univerzalnom UTF 32 kodiranju.
Kao rezultat toga, ista datoteka s tekstom kodiranim u proširenom ASCII kodiranju i u UTF 32 kodiranju, u potonjem slučaju, imat će četiri puta veću veličinu (težinu). Ovo je loše, ali sada imamo priliku s UTF-om 32 kodirati broj znakova jednak dva na trideset i drugu potenciju (milijarde znakova koje će pokriti svaku stvarno potrebnu vrijednost s kolosalnom marginom).
Ali mnoge zemlje s jezicima europske grupe uopće nisu trebale koristiti tako ogroman broj znakova u kodiranju, ali kada su koristile UTF 32 nikada nisu dobile četverostruko povećanje težine tekstualni dokumenti, a kao rezultat toga, povećanje obujma internetskog prometa i količine pohranjenih podataka. Ovo je puno i nitko si nije mogao priuštiti takav otpad.
Kao rezultat razvoja univerzalne Unicode kodiranje pojavilo se u UTF 16, koji se pokazao toliko uspješnim da je prema zadanim postavkama prihvaćen kao osnovni prostor za sve simbole koje koristimo. UTF 16 koristi dva bajta za kodiranje jednog znaka. Na primjer, u operacijski sustav Windows, možete slijediti put Start - Programi - Pribor - Alati sustava - Karta simbola.
Kao rezultat, otvorit će se tablica s vektorskim oblicima svih fontova instaliranih u vašem sustavu. Ako odaberete Unicode skup znakova u naprednim opcijama, moći ćete vidjeti za svaki font zasebno cijeli asortiman znakova koji su u njemu uključeni. Usput, klikom na bilo koji od ovih znakova, možete vidjeti njegov dvobajtni kod u UTF 16 kodiranju, koji se sastoji od četiri heksadecimalne znamenke:
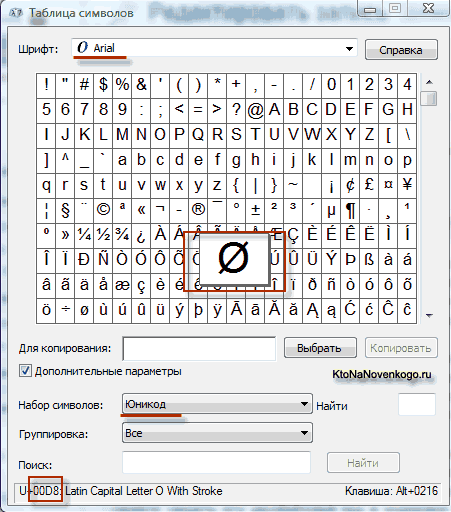
Koliko znakova se može kodirati u UTF 16 sa 16 bita? 65.536 znakova (dva na stepen šesnaest) uzeto je kao osnovni prostor u Unicodeu. Osim toga, postoje načini za kodiranje s UTF 16 oko dva milijuna znakova, ali oni su bili ograničeni na prošireni prostor od milijun znakova teksta.
Ali čak ni uspješna verzija Unicode kodiranja pod nazivom UTF 16 nije donijela puno zadovoljstva onima koji su, na primjer, pisali programe samo u Engleski jezik, jer se nakon prijelaza s proširene verzije ASCII kodiranja na UTF 16 težina dokumenata udvostručila (jedan bajt za jedan znak u ASCII i dva bajta za isti znak u UTF 16 kodiranju). Upravo na zadovoljstvo svih i svega u Unicode konzorciju odlučeno je osmisliti kodiranje teksta promjenjive duljine.
Ovo kodiranje u Unicodeu je nazvano UTF 8... Unatoč osmici u nazivu, UTF 8 je punopravno kodiranje promjenjive duljine, t.j. svaki znak teksta može se kodirati u niz od jednog do šest bajtova. U praksi se u UTF-u 8 koristi samo raspon od jednog do četiri bajta, jer dalje od četiri bajta koda ništa nije ni teoretski moguće zamisliti.
U UTF-u 8 svi latinični znakovi su kodirani u jednom bajtu, baš kao u starom ASCII kodiranju. Ono što je vrijedno napomenuti, u slučaju kodiranja samo latinice, čak i oni programi koji ne razumiju Unicode i dalje će čitati ono što je kodirano u UTF 8. Odnosno, osnovni dio ASCII kodiranja premješten je u UTF 8.
Ćirilični znakovi u UTF 8 su kodirani u dva bajta, a, na primjer, gruzijski - u tri bajta. Unicode konzorcij, nakon kreiranja UTF 16 i UTF 8 kodiranja, riješio je glavni problem - sada imamo jedan prostor koda u našim fontovima. Jedino što preostaje proizvođačima fontova je da ovaj prostor koda popune vektorskim oblicima tekstualnih simbola na temelju njihovih snaga i mogućnosti.
 Rješavanje problema s nedostajućim obrisom kista u Photoshopu
Rješavanje problema s nedostajućim obrisom kista u Photoshopu Tehnički detalji PSD datoteka
Tehnički detalji PSD datoteka Besplatno preuzmite razne teksture akvarela s mrljama
Besplatno preuzmite razne teksture akvarela s mrljama