Kodiranje tekstualnih informacija. Kodiranje znakova - PIE wiki
Standard je 1991. godine predložio Unicode konzorcij, Unicode Inc., neprofitna organizacija. Korištenje ovog standarda omogućuje kodiranje vrlo velikog broja znakova iz različitih pisama: kineski znakovi, matematički znakovi, slova grčke abecede, latinična i ćirilična abeceda mogu koegzistirati u dokumentima Unicode, pa mijenjanje kodnih stranica postaje nepotrebno.
Standard se sastoji od dva glavna odjeljka: univerzalnog skupa znakova (UCS) i formata Unicode transformacije (UTF). Univerzalni skup znakova definira međusobnu korespondenciju znakova kodovima-elementima prostora koda koji predstavljaju nenegativne cijele brojeve. Obitelj kodiranja definira strojni prikaz niza UCS kodova.
Standard Unicode razvijen je s ciljem stvaranja jedinstvenog kodiranja znakova za sve moderne i mnoge drevne pisane jezike. Svaki znak u ovom standardu kodiran je u 16 bita, što mu omogućuje da pokrije neusporedivo veći broj znakova od prethodno prihvaćenih 8-bitnih kodiranja. Druga važna razlika između Unicode -a i drugih sustava za kodiranje je ta što ne samo da svakom znaku dodjeljuje jedinstveni kod, već također definira različite karakteristike ovog znaka, na primjer:
Vrsta znaka (veliko slovo, malo slovo, broj, interpunkcijski znak itd.);
Atributi znakova (prikaz slijeva nadesno ili zdesna nalijevo, razmak, prijelom retka itd.);
Odgovarajuća velika ili mala slova (za mala i velika slova);
Odgovarajuća numerička vrijednost (za numeričke znakove).
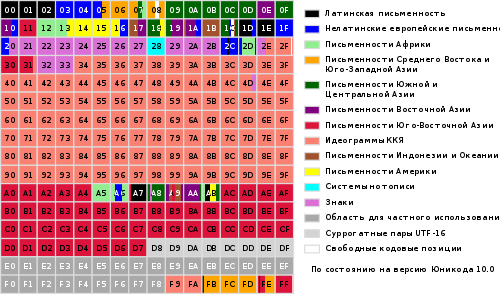
Cijeli raspon kodova od 0 do FFFF podijeljen je u nekoliko standardnih podskupova, od kojih svaki odgovara ili abecedi jezika ili grupi posebni znakovi, sličnih funkcija. Donji dijagram daje opći popis podskupova Unicode 3.0 (slika 2).
Slika 2
Standard Unicode osnova je za pohranu i tekst u mnogim modernim računalnim sustavima. Međutim, nije kompatibilan s većinom internetskih protokola, budući da njegovi kodovi mogu sadržavati bilo koje vrijednosti bajtova, a protokoli obično koriste bajtove 00 - 1F i FE - FF kao opće opterećenje. Kako bi se postigla kompatibilnost, razvijeno je nekoliko formata Unicode transformacije (UTF, Unicode transformacijski formati), od kojih je UTF-8 danas najčešći. Ovaj format za svako definira sljedeća pravila pretvorbe Unicode kôd u skup bajtova (jedan do tri) prikladnih za transport internetskim protokolima.
Ovdje x, y, z označavaju bitove izvornog koda koje treba izdvojiti, počevši od najmanje značajnog, i unijeti u bajtove rezultata zdesna nalijevo dok se ne popune sve navedene pozicije.
Daljnji razvoj standard Unicode povezan je s dodavanjem novih jezičnih ravni, t.j. znakova u rasponima 10000 - 1FFFF, 20000 - 2FFFF itd., gdje se pretpostavlja da uključuje kodiranje skripti mrtvih jezika koji nisu uključeni u gornju tablicu. Za kodiranje ovih dodatnih znakova razvijen je novi format UTF-16.
Dakle, postoje 4 glavna načina kodiranja Unicode bajtova:
UTF-8: 128 znakova kodirano je u jednom bajtu (ASCII format), 1920 znakova kodirano je u 2 bajta ((rimski, grčki, ćirilični, koptski, armenski, hebrejski, arapski znakovi), 63488 znakova kodirano je u 3 bajta (kineski , Japanski i drugi) Preostalih 2.147.418.112 znakova (koji se još ne koriste) mogu se kodirati s 4, 5 ili 6 bajtova.
UCS-2: Svaki znak predstavljen je s 2 bajta. Ovo kodiranje uključuje samo prvih 65 535 znakova iz Unicode formata.
UTF-16: Ovo je proširenje za UCS-2 i uključuje 1 114 112 Unicode znakova. Prvih 65.535 znakova predstavljeno je s 2 bajta, ostali s 4 bajta.
USC-4: Svaki je znak kodiran u 4 bajta.
Unicode
Logotip konzorcija Unicode
Unicode(najčešće) ili Unicode(eng. Unicode) je standard za kodiranje znakova koji omogućuje predstavljanje znakova u gotovo svim pisanim jezicima.
Standard je 1991. godine predložila neprofitna organizacija "Unicode Consortium" (eng. Unicode konzorcij, Unicode Inc.).
Korištenje ovog standarda omogućuje kodiranje vrlo velikog broja znakova iz različitih pisama: kineski znakovi, matematički znakovi, slova grčke abecede, latinična i ćirilična abeceda mogu koegzistirati u dokumentima Unicode, pa mijenjanje kodnih stranica postaje nepotrebno.
Standard se sastoji od dva glavna odjeljka: univerzalni skup znakova (eng. UCS, univerzalni skup znakova) i obitelj kodiranja (eng. UTF, Format transformacije Unicode).
Univerzalni skup znakova definira međusobnu korespondenciju znakova kodovima-elementima prostora koda koji predstavljaju nenegativne cijele brojeve. Obitelj kodiranja definira strojni prikaz niza UCS kodova.
Unicode kodovi podijeljeni su u nekoliko područja. Područje s kodovima od U + 0000 do U + 007F sadrži ASCII znakove s odgovarajućim kodovima. Slijede područja znakova različitih pisama, interpunkcijskih i tehničkih simbola.
Neki od kodova rezervirani su za buduću upotrebu. Ispod ćiriličnih znakova dodjeljuju se područja znakova sa kodovima od U + 0400 do U + 052F, od U + 2DE0 do U + 2DFF, od U + A640 do U + A69F (vidi ćirilicu u Unicodeu).
- 1 Preduvjeti za stvaranje i razvoj Unicodea
- 2 verzije Unicodea
- 3 Kodni prostor
- 4 Sustav kodiranja
- 4.1 Politika konzorcija
- 4.2 Kombiniranje i umnožavanje simbola
- 5 Mijenjanje znakova
- 6 Normalizacijski algoritmi
- 6.1 NFD
- 6.2 NFC
- 6,3 NFKD
- 6,4 NFKC
- 6.5 Primjeri
- 7 Dvosmjerno pisanje
- 8 Istaknuti simboli
- 9 ISO / IEC 10646
- 10 načina predstavljanja
- 10.1 UTF-8
- 10.2 Redoslijed bajtova
- 10.3 Unicode i tradicionalna kodiranja
- 10.4 Implementacije
- 11 Metode unosa
- 11.1 Microsoft Windows
- 11.2 Macintosh
- 11.3 GNU / Linux
- 12 Problemi s Unicodeom
- 13 "Unicode" ili "Unicode"?
Preduvjeti za stvaranje i razvoj Unicodea
Do kraja 1980-ih 8-bitni likovi postali su standard. Istodobno, bilo je mnogo različitih 8-bitnih kodiranja, a stalno su se pojavljivala nova.
To je objašnjeno i stalnim proširenjem raspona podržanih jezika, i željom za stvaranjem kodiranja djelomično kompatibilnog s nekim drugim (tipičan primjer je pojava alternativnog kodiranja za ruski jezik, zbog iskorištavanja zapadnih jezika programi stvoreni za kodiranje CP437).
Kao rezultat toga, pojavilo se nekoliko problema:
- problem "krakozyabr";
- problem ograničenog skupa znakova;
- problem pretvaranja jednog kodiranja u drugi;
- problem dupliciranih fontova.
Problem "krakozyabr"- problem prikaza dokumenata u krivom kodiranju. Problem bi se mogao riješiti ili dosljednim uvođenjem metoda za specifikaciju korištenog kodiranja, ili uvođenjem jedinstvenog (zajedničkog) kodiranja za sve.
Problem ograničenog skupa znakova... Problem se može riješiti ili promjenom fontova unutar dokumenta, ili uvođenjem "širokog" kodiranja. Promjena fontova odavno se prakticira u procesorima za obradu teksta, a često su se koristili i fontovi s nestandardnim kodiranjem, tzv. "Dingbat fontovi". Zbog toga su se, pokušavajući prenijeti dokument na drugi sustav, svi nestandardni znakovi pretvorili u "krakozyabry".
Problem pretvaranja jednog kodiranja u drugo... Problem bi se mogao riješiti ili sastavljanjem tablica pretvorbe za svaki par kodiranja, ili korištenjem posredne konverzije u treće kodiranje koje uključuje sve znakove svih kodiranja.
Problem s dvostrukim fontovima... Za svako kodiranje kreiran je vlastiti font, čak i ako su se skupovi znakova u kodiranjima djelomično ili potpuno podudarali. Problem bi se mogao riješiti stvaranjem "velikih" fontova, iz kojih bi se naknadno odabrali znakovi potrebni za zadano kodiranje. Međutim, to je zahtijevalo stvaranje jedinstvenog registra simbola kako bi se utvrdilo što čemu odgovara.
Prepoznata je potreba za jednim „širokim“ kodiranjem. Kodiranje promjenjive duljine, široko korišteno u istočnoj Aziji, pokazalo se preteškim za uporabu, pa je odlučeno koristiti znakove fiksne širine.
Korištenje 32-bitnih znakova činilo se previše rasipnim, pa je odlučeno koristiti 16-bitne.
Prva verzija Unicodea bila je kodiranje s fiksnom veličinom znaka od 16 bita, odnosno ukupan broj kodova bio je 2 16 (65 536). Od tada su znakovi označeni s četiri heksadecimalne znamenke (na primjer, U + 04F0). Istodobno je bilo planirano kodiranje u Unicodeu ne svih postojećih znakova, već samo onih koji su neophodni u svakodnevnom životu. Rijetko korišteni simboli morali su biti postavljeni u "područje za privatnu upotrebu" koje je izvorno zauzimalo kodove U + D800 ... U + F8FF.
Kako bi se Unicode koristio i kao posrednik u međusobnoj pretvorbi različitih kodiranja, u njega su uključeni svi znakovi predstavljeni u svim najpoznatijim kodiranjima.
U budućnosti je, međutim, odlučeno kodirati sve simbole i, s tim u vezi, značajno proširiti domenu koda.
Istodobno, kodovi znakova počeli su se smatrati ne 16-bitnim vrijednostima, već apstraktnim brojevima koji se mogu prikazati u računalu na mnogo različitih načina (vidi metode predstavljanja).
Budući da su se u nizu računalnih sustava (na primjer, Windows NT) fiksni 16-bitni znakovi već koristili kao zadano kodiranje, odlučeno je da se svi najvažniji znakovi kodiraju samo unutar prvih 65 536 pozicija (tzv. Engleski). osnovna višejezična ravnina, BMP).
Ostatak prostora koristi se za "dodatne znakove" (eng. dopunski likovi): sustavi pisanja izumrlih jezika ili vrlo rijetko korištenih kineskih znakova, matematičkih i glazbenih simbola.
Radi kompatibilnosti sa starim 16-bitnim sustavima, izumljen je sustav UTF-16, gdje se prvih 65.536 položaja, s izuzetkom položaja iz intervala U + D800 ... U + DFFF, prikazuje izravno kao 16-bitni brojevi, a ostali su predstavljeni kao "zamjenski parovi" (Prvi element para iz regije U + D800 ... U + DBFF, drugi element para iz regije U + DC00 ... U + DFFF). Za zamjenske parove iskorišten je dio prostora koda (2048 pozicija), izdvojen "za privatnu uporabu".
Budući da UTF-16 može prikazati samo 2 20 +2 16 −2048 (1 112 064) znakova, ovaj je broj odabran kao konačna vrijednost Unicode prostora koda (raspon koda: 0x000000-0x10FFFF).
Iako je područje koda Unicode prošireno na 2-16 već u verziji 2.0, prvi znakovi u "vrhunskom" području smješteni su samo u verziji 3.1.
Uloga ovog kodiranja u web sektoru stalno raste. Početkom 2010. udio web stranica koje koriste Unicode iznosio je oko 50%.
Unicode verzije
Rad na dovršenju standarda nastavlja se. Nove se verzije objavljuju kako se tablice simbola mijenjaju i ažuriraju. Paralelno se izdaju novi ISO / IEC 10646 dokumenti.
Prvi standard objavljen je 1991. godine, posljednji 2016. godine, sljedeći se očekuje na ljeto 2017. godine. Verzije standarda 1.0-5.0 objavljene su kao knjige i imaju ISBN.
Broj verzije standarda sastoji se od tri znamenke (na primjer, "4.0.1"). Treća znamenka se mijenja kada se u standard unesu manje izmjene koje ne dodaju nove znakove.
Kodni prostor
Iako obrasci oznaka UTF-8 i UTF-32 dopuštaju kodiranje do 2,331 (2,147,483,648) kodnih točaka, odlučeno je da se za kompatibilnost s UTF-16 koristi samo 1,112,064. Međutim, čak je i to za sada više nego dovoljno - u verziji 6.0 koristi se nešto manje od 110.000 kodnih točaka (109.242 grafičkih i 273 druga simbola).
Kodni prostor podijeljen je na 17 avioni(eng. avioni) 2 16 (65 536) znakova. Zemaljska ravnina ( avion 0) Zove se Osnovni, temeljni (Osnovni, temeljni) i sadrži simbole najčešćih skripti. Ostali avioni su dodatni ( dopunski). Prvi avion ( avion 1) koristi se uglavnom za povijesne skripte, drugi ( avion 2) - za rijetko korištene kineske znakove (CJK), treći ( avion 3) rezervirano je za arhaične kineske znakove. Zrakoplovi 15 i 16 rezervirani su za privatnu uporabu.
Za označavanje Unicode znakovi zapis oblika „U + xxxx"(Za kodove 0 ... FFFF) ili" U + xxxxx"(Za kodove 10000 ... FFFFF) ili" U + xxxxxx"(Za kodove 100000 ... 10FFFF), gdje xxx- heksadecimalne znamenke. Na primjer, znak "i" (U + 044F) ima kod 044F 16 = 1103 10.
Sustav kodiranja
Univerzalni sustav kodiranja (Unicode) skup je grafičkih simbola i način njihovog kodiranja za računalnu obradu tekstualnih podataka.
Grafički simboli su simboli koji imaju vidljivu sliku. Grafički znakovi se razlikuju od kontrolnih i oblikovnih znakova.
Grafički simboli uključuju sljedeće grupe:
- slova sadržana u barem jednoj od podržanih abeceda;
- brojevi;
- interpunkcijski znakovi;
- posebni znakovi (matematički, tehnički, ideogrami itd.);
- separatori.
Unicode je sustav za linearno predstavljanje teksta. Znakovi s dodatnim nadnapisima ili indeksima mogu se predstaviti kao niz kodova izgrađenih prema određenim pravilima (složeni znak) ili kao jedan znak (monolitna verzija, predkomponirani znak). Na ovaj trenutak(2014.) vjeruje se da su sva slova velikih skripti uključena u Unicode, a ako je simbol dostupan u složenoj verziji, nije ga potrebno duplicirati u monolitnom obliku.
Politika konzorcija
Konzorcij ne stvara novi, već navodi ustaljeni poredak stvari. Na primjer, slike emojija dodane su zbog japanskih operatera mobilnih komunikacija naširoko su se koristili.
Da biste to učinili, dodavanje simbola prolazi kroz složen proces. I, na primjer, simbol ruske rublje prošao ga je u tri mjeseca jednostavno zato što je dobio službeni status.
Zaštitni znakovi kodirani su samo iznimno. Dakle, u Unicodeu nema Windows zastavice ili Apple jabuke.
Kad se znak pojavi u kodiranju, više se neće pomaknuti niti nestati. Ako trebate promijeniti redoslijed znakova, to se ne čini promjenom položaja, već nacionalnim redoslijedom sortiranja. Postoje i druga, suptilnija jamstva stabilnosti - na primjer, tablice normalizacije neće se promijeniti.
Kombiniranje i umnožavanje simbola
Isti simbol može imati nekoliko oblika; u Unicodeu ovi su oblici sadržani u jednoj kodnoj točki:
- ako se to povijesno dogodilo. Na primjer, arapska slova imaju četiri oblika: odvojena, na početku, u sredini i na kraju;
- ili ako je jedan jezik usvojen u jednom obliku, a u drugom - drugom. Bugarska ćirilica razlikuje se od ruske, a kineska slova od japanske.
S druge strane, ako su povijesno fontovi imali dvije različite kodne točke, oni ostaju različiti u Unicodeu. Mala grčka sigma ima dva oblika i imaju različite položaje. Prošireno latinsko slovo Å (A s krugom) i znak angstrema Å, Grčko slovoμ i prefiks “mikro” µ različiti su simboli.
Naravno, slični znakovi u nepovezanim skriptama stavljaju se na različite položaje koda. Na primjer, slovo A na latinskom, ćirilici, grčkom i čerokiju različiti su simboli.
Izuzetno je rijetko da se isti znak stavlja na dva različita položaja koda radi pojednostavljenja obrade teksta. Matematički potez i isti potez za označavanje mekoće zvukova različiti su simboli, drugi se smatra slovom.
Mijenjanje znakova
Predstavljanje znaka "Y" (U + 0419) u obliku osnovnog znaka "I" (U + 0418) i modifikacijskog znaka "" (U + 0306)
Grafički znakovi u Unicodeu podijeljeni su na proširene i neproširene (bez širine). Neprošireni znakovi ne zauzimaju mjesto u retku kada su prikazani. To uključuje osobito naglasne znakove i druge dijakritičke znakove. I prošireni i neproduljeni znakovi imaju svoje kodove. Prošireni simboli se inače nazivaju osnovnim (eng. osnovni likovi), i one bez proširenja - mijenjanje (eng. kombinirajući likove); a potonji se ne mogu samostalno sastajati. Na primjer, znak "á" može se predstaviti kao slijed osnovnog znaka "a" (U + 0061) i znaka modifikatora "́" (U + 0301), ili kao monolitni znak "á" (U + 00E1).
Posebna vrsta znakova za izmjenu su birači stilova (eng. birači varijacija). Primjenjuju se samo na one simbole za koje su takve varijante definirane. U verziji 5.0, opcije stila definirane su za niz matematički simboli, za simbole tradicionalne mongolske abecede i za simbole mongolskog kvadratnog pisma.
Normalizacijski algoritmi
Budući da se mogu predstaviti isti simboli različiti kodovi, usporedba nizova po bajt postaje nemoguća. Algoritmi normalizacije normalizacijski oblici) riješiti ovaj problem pretvaranjem teksta u određeni standardni oblik.
Lijevanje se provodi zamjenom simbola ekvivalentnim pomoću tablica i pravila. "Razlaganje" je zamjena (razlaganje) jednog znaka na nekoliko sastavnih znakova, a "sastav", naprotiv, zamjena (povezivanje) više sastavnih znakova s jednim znakom.
Standard Unicode definira 4 algoritma za normalizaciju teksta: NFD, NFC, NFKD i NFKC.
NFD
NFD, eng. n ormalizacija f orm D ("D" iz engleskog. d ekompozicija), normalizacijski oblik D je kanonička dekompozicija - algoritam prema kojem se vrši rekurzivna zamjena monolitnih simbola (eng. unaprijed sastavljeni likovi) u nekoliko komponenti (eng. složeni likovi) prema tablicama razlaganja.
Å U + 00C5 →
A U + 0041
̊ U + 030A
ṩ U + 1E69 →
s U + 0073
̣ U + 0323
̇ U + 0307
ḍ̇ U + 1E0B U + 0323 →
d U + 0064
̣ U + 0323
̇ U + 0307
q̣̇ U + 0071 U + 0307 U + 0323 →
q U + 0071
̣ U + 0323
̇ U + 0307 NFC
NFC, eng. n ormalizacija f orm C ("C" iz engleskog. c ompozicija), normalizacijski oblik C je algoritam prema kojem se kanoničko razlaganje i kanonički sastav izvode uzastopno. Prvo, kanonička dekompozicija (NFD algoritam) reducira tekst u oblik D. Zatim kanonička kompozicija, inverzna NFD -u, obrađuje tekst od početka do kraja, uzimajući u obzir sljedeća pravila:
- simbol S broji početni ako ima klasu izmjene jednaku nuli prema tablici znakova Unicode;
- u bilo kojem nizu znakova koji počinju s likom S, simbol C blokiran od S, samo ako između S i C postoji li neki simbol B koja je ili početna ili ima istu ili veću klasu modifikacije od C... Ovo pravilo vrijedi samo za nizove koji su prošli kanoničku dekompoziciju;
- simbol se razmatra primarni složeni ako ima kanoničku dekompoziciju u tablici znakova Unicode (ili kanoničku dekompoziciju za Hangul i nije uključen u popis za izuzimanje);
- simbol x može se prvo kombinirati sa simbolom Y ako i samo ako postoji primarni kompozit Z, kanonski ekvivalentan nizu<x, Y>;
- ako je sljedeći znak C nije blokiran zadnjim navedenim početnim osnovnim znakom L i prvo se može uspješno kombinirati s njim, zatim L zamijenjen kompozitnim L-C, a C uklonjen.
o U + 006F
̂ U + 0302 → →
H U + 0048
① U + 2460 →
1 U + 0031
カ U + FF76 →
カ U + 30AB →
fi U + FB01
fi U + FB01
f i U + 0066 U + 0069
f i U + 0066 U + 0069
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 ⁵ U + 0032 U + 2075
2 5 U + 0032 U + 0035
2 5 U + 0032 U + 0035
ẛ̣ U + 1E9B U + 0323
ſ ̣ ̇ U + 017F U + 0323 U + 0307
ẛ ̣ U + 1E9B U + 0323
s ̣ ̇ U + 0073 U + 0323 U + 0307
ṩ U + 1E69
th U + 0439
i ̆ U + 0438 U + 0306
th U + 0439
i ̆ U + 0438 U + 0306
th U + 0439
e U + 0451
e ̈ U + 0435 U + 0308
e U + 0451
e ̈ U + 0435 U + 0308
e U + 0451
A U + 0410
A U + 0410
A U + 0410
A U + 0410
A U + 0410
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
か ゙ U + 304B U + 3099
が U + 304C
Ⅷ U + 2167
Ⅷ U + 2167
Ⅷ U + 2167
V. Ja Ja Ja U + 0056 U + 0049 U + 0049 U + 0049
V. Ja Ja Ja U + 0056 U + 0049 U + 0049 U + 0049
ç U + 00E7
c ̧ U + 0063 U + 0327
ç U + 00E7
c ̧ U + 0063 U + 0327
ç U + 00E7 Dvosmjerno slovo
Standard Unicode podržava jezike pisanja sa smjerom slijeva nadesno (eng. slijeva nadesno, LTR) i pisanjem zdesna nalijevo (eng. zdesna nalijevo, RTL) - na primjer, arapska i hebrejska slova. U oba slučaja znakovi su pohranjeni u "prirodnom" redoslijedu; njihov prikaz, uzimajući u obzir željeni smjer slova, osigurava aplikacija.
Osim toga, Unicode podržava kombinirane tekstove koji kombiniraju fragmente s različitim smjerovima slova. Ova se značajka naziva dvosmjernost(eng. dvosmjerni tekst, BiDi). Neki pojednostavljeni tekstualni procesori (na primjer, u Mobiteli) može podržati Unicode, ali ne i dvosmjernu podršku. Svi Unicode znakovi podijeljeni su u nekoliko kategorija: napisani slijeva nadesno, napisani zdesna nalijevo i napisani u bilo kojem smjeru. Simboli potonje kategorije (uglavnom interpunkcijski znakovi), kada su prikazani, vode smjer okolnog teksta.
Istaknuti simboli
Dijagram osnovne višejezične ravni Unicodea
Unicode uključuje gotovo sve moderne skripte, uključujući:
- arapski
- Armenac,
- Bengalski,
- Burmanski,
- glagol,
- grčki
- Gruzijski,
- devanagari,
- Židovska,
- Ćirilica,
- Kineski (kineski se znakovi aktivno koriste u japanskom, a povremeno i u korejskom),
- Koptski,
- Kmerski,
- Latinski,
- Tamil,
- Korejski (hangul),
- Cherokee,
- Etiopski,
- Japanski (koji osim slogovne abecede uključuje i kineske znakove)
drugo.
U akademske svrhe dodani su mnogi povijesni spisi, uključujući: germanske rune, staroturške rune, starogrčko pismo, egipatske hijeroglife, klinasto pismo, pisanje Maja, etruščansku abecedu.
Unicode nudi širok raspon matematičkih i glazbenih simbola i piktograma.
U načelu, Unicode ne uključuje državne zastave, logotipe tvrtki i proizvoda, iako se nalaze u fontovima (na primjer, logotip Apple u kodiranju MacRoman (0xF0) ili Windows logotip u fontu Wingdings (0xFF)). U Unicode fontovima logotipe treba postaviti samo u prilagođeno područje znakova.
ISO / IEC 10646
Unicode konzorcij blisko surađuje radna skupina ISO / IEC / JTC1 / SC2 / WG2, koji razvija međunarodni standard 10646 (ISO / IEC 10646). Sinkronizacija je uspostavljena između standarda Unicode i ISO / IEC 10646, iako svaki standard koristi vlastitu terminologiju i sustav dokumentacije.
Suradnja Unicode konzorcija s Međunarodnom organizacijom za standardizaciju (eng. Međunarodna organizacija za standardizaciju, ISO ) započeo je 1991. 1993. ISO je izdao standard DIS 10646.1. Za sinkronizaciju s njim, Konzorcij je odobrio verziju 1.1 standarda Unicode, koja je dodala dodatne znakove iz DIS 10646.1. Zbog toga su vrijednosti kodiranih znakova u Unicode 1.1 i DIS 10646.1 potpuno iste.
U budućnosti se nastavila suradnja dviju organizacija. Godine 2000. standard Unicode 3.0 sinkroniziran je s ISO / IEC 10646-1: 2000. Predstojeća treća verzija ISO / IEC 10646 bit će sinkronizirana s Unicode 4.0. Možda će se te specifikacije čak objaviti kao jedinstveni standard.
Slično formatima UTF-16 i UTF-32 u standardu Unicode, standard ISO / IEC 10646 također ima dva glavna oblika kodiranja znakova: UCS-2 (2 bajta po znaku, slično UTF-16) i UCS-4 (4 bajta po znaku, slično UTF-32). UCS znači univerzalni višeoktet(više bajtova) kodirani skup znakova(eng. univerzalni višekotetni kodirani skup znakova ). UCS-2 se može smatrati podskupom UTF-16 (UTF-16 bez zamjenskih parova), a UCS-4 je sinonim za UTF-32.
Razlike između Unicode i ISO / IEC 10646 standarda:
- male razlike u terminologiji;
- ISO / IEC 10646 ne uključuje odjeljke potrebne za potpunu implementaciju Unicode podrške:
- nema podataka o binarnom kodiranju znakova;
- nema opisa algoritama za usporedbu (eng. uspoređivanje) i rendering (eng. rendering) likovi;
- ne postoji popis svojstava simbola (na primjer, ne postoji popis svojstava potrebnih za implementaciju podrške za dvosmjerno (eng. dvosmjeran) slova).
Metode prezentacije
Unicode ima nekoliko oblika predstavljanja (eng. Format transformacije Unicode, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) i UTF-32 (UTF-32BE, UTF-32LE). Obrazac UTF-7 također je razvijen za prijenos preko sedam-bitnih kanala, ali zbog nekompatibilnosti s ASCII-om nije se proširio i nije uključen u standard. 1. travnja 2005. predložena su dva duhovita podneska: UTF-9 i UTF-18 (RFC 4042).
Sustavi temeljeni na Microsoft Windows NT i Windows 2000 i Windows XP prvenstveno koriste obrazac UTF-16LE. Operacijski sustavi slični UNIX-u GNU / Linux, BSD i Mac OS X prihvaćaju UTF-8 za datoteke i UTF-32 ili UTF-8 za obradu znakova u RAM memorija.
Punycode je drugi oblik kodiranja nizova Unicode znakova u takozvane ACE sekvence, koje se sastoje samo od alfanumeričkih znakova, što je dopušteno u nazivima domena.
UTF-8
UTF-8 je Unicode reprezentacija koja pruža najbolju kompatibilnost sa starijim sustavima koji su koristili 8-bitne znakove.
Tekst koji sadrži samo znakove manje od 128 pretvara se u običan ASCII tekst kada se piše u UTF-8. Nasuprot tome, u tekstu UTF-8 prikazuje se svaki bajt s vrijednošću manjom od 128 ASCII znak s istim kodom.
Ostatak Unicode znakova predstavljen je nizovima dugim od 2 do 6 bajta (zapravo samo do 4 bajta, budući da u Unicodeu nema znakova s kodom većim od 10FFFF, pa ih nema u planu uvesti u budućnost), u kojem prvi bajt uvijek ima oblik 11xxxxxx, a ostalo - 10xxxxxx... U UTF-8 se ne koriste zamjenski parovi, 4 bajta dovoljna su za upis bilo kojeg unicode znaka.
UTF-8 format izumili su 2. rujna 1992. Ken Thompson i Rob Pike i implementirali u Plan 9... Standard UTF-8 sada je službeno ugrađen u RFC 3629 i ISO / IEC 10646 Prilog D.
UTF-8 znakovi izvedeni su iz Unicodea na sljedeći način:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxx
Teoretski moguće, ali također nije uključeno u standard:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxxxxxxx
Iako vam UTF-8 omogućuje navođenje istog znaka na nekoliko načina, samo je najkraći točan. Ostatak obrazaca treba odbiti iz sigurnosnih razloga.
Redoslijed bajtova
U UTF-16 nizu podataka, niži bajt se može upisati bilo prije visokog (eng. UTF-16 mali endijan), ili nakon starijeg (eng. UTF-16 veliki endian). Slično, postoje dvije varijante kodiranja s četiri bajta-UTF-32LE i UTF-32BE.
Za definiranje formata Unicode prikaza na početku tekstualna datoteka potpis je napisan - znak U + FEFF (neprekinuti razmak s nultom širinom), također pozvan marker sekvence bajtova(eng. oznaka redoslijeda bajtova (BOM)). To omogućuje razlikovanje UTF-16LE i UTF-16BE budući da znak U + FFFE ne postoji. Također se ponekad koristi za označavanje UTF-8 formata, iako se pojam redoslijeda bajtova ne odnosi na ovaj format. Datoteke koje slijede ovu konvenciju započinju ovim nizovima bajtova:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
Nažalost, ova metoda ne razlikuje pouzdano UTF-16LE i UTF-32LE, budući da Unicode dopušta znak U + 0000 (iako pravi tekstovi rijetko počinju s njim).
Datoteke u kodiranjima UTF-16 i UTF-32 koje ne sadrže BOM moraju biti u velikom endian (unicode.org) redoslijedu bajtova.
Unicode i tradicionalna kodiranja
Uvođenjem Unicodea promijenjen je pristup tradicionalnim 8-bitnim kodiranjima. Ako je ranije kodiranje bilo navedeno fontom, sada je specificirano tablicom korespondencije između ovog kodiranja i Unicodea.
Zapravo, 8-bitno kodiranje postalo je oblik predstavljanja podskupa Unicodea. To je uvelike olakšalo stvaranje programa koji trebaju raditi s mnogo različitih kodiranja: sada, kako biste dodali podršku za još jedno kodiranje, samo trebate dodati još jednu Unicode tablicu za pretraživanje.
Osim toga, mnogi formati podataka dopuštaju umetanje bilo kojih Unicode znakova, čak i ako je dokument napisan u starom 8-bitnom kodiranju. Na primjer, možete koristiti znakove znaka & u HTML -u.
Implementacija
Većina modernih operacijskih sustava pruža određeni stupanj podrške za Unicode.
U operacijskim sustavima obitelji Windows NT dvobajtno kodiranje UTF-16LE koristi se za unutarnje predstavljanje naziva datoteka i drugih nizova sustava. Sistemski pozivi koji prihvaćaju parametre niza dostupni su u jednobajtnim i dvobajtnim varijantama. Više informacija potražite u članku Unicode o obitelji operacijskih sustava Microsoft Windows.
UNIX-sličan OS, uključujući GNU / Linux, BSD, OS X, koristite UTF-8 kodiranje za predstavljanje Unicodea. Većina programa može rukovati UTF-8 kao tradicionalnim jednobajtnim kodiranjem, bez obzira na to što je znak predstavljen kao nekoliko uzastopnih bajtova. Za rad s pojedinim znakovima, nizovi se obično kodiraju u UCS-4, tako da svaki znak ima strojnu riječ.
Jedna od prvih uspješnih komercijalnih implementacija Unicodea bila je u srijedu Java programiranje... U osnovi je napustio 8-bitnu reprezentaciju likova u korist 16-bitne. Ovo rješenje povećalo je potrošnju memorije, ali nam je omogućilo da programiranju vratimo važnu apstrakciju: proizvoljni pojedinačni znak (tip char). Konkretno, programer bi mogao raditi sa nizom kao s jednostavnim nizom. Nažalost, uspjeh nije bio konačan, Unicode je prerastao 16 -bitno ograničenje, a prema verziji J2SE 5.0, proizvoljni je znak ponovno počeo zauzimati promjenjiv broj memorijskih jedinica - jednu char ili dva (vidi zamjenski par).
Većina programskih jezika sada podržava Unicode nizove, iako se njihov prikaz može razlikovati ovisno o implementaciji.
Metode unosa
Budući da nijedan raspored tipkovnice ne dopušta unos svih Unicode znakova istovremeno, operacijski sustavi i aplikacije potrebni su za podršku alternativnim metodama za unos proizvoljnih Unicode znakova.
Microsoft Windows
Iako počinje u sustavu Windows 2000, uslužni program Karta znakova (charmap.exe) podržava Unicode znakove i omogućuje vam njihovo kopiranje u međuspremnik, ta je podrška ograničena samo na osnovnu ravninu (kodovi znakova U + 0000 ... U + FFFF). Simboli s kodovima iz U + 10000 "Tablica simbola" se ne prikazuje.
Slična je tablica, na primjer, u Microsoft Word.
Ponekad možete upisati heksadecimalni kôd, pritisnuti Alt + X, a kôd će biti zamijenjen odgovarajućim znakom, na primjer, u WordPadu, Microsoft Wordu. U urednicima Alt + X izvodi i obrnutu transformaciju.
U mnogim programima MS Windows, da biste dobili Unicode znak, morate pritisnuti tipku Alt i upisati decimalnu vrijednost koda znaka na numerička tipkovnica... Na primjer, kombinacije Alt + 0171 ("), Alt + 0187 (") i Alt + 0769 (naglasak) bit će korisne pri upisivanju ćiriličnih tekstova. Zanimljive su i kombinacije Alt + 0133 (…) i Alt + 0151 (-).
Macintosh
Mac OS 8.5 i noviji podržavaju način unosa pod nazivom "Unicode Hex Input". Dok držite tipku Option, morate upisati četveroznamenkasti heksadecimalni kod potrebnog znaka. Ova vam metoda omogućuje unos znakova s kodovima većim od U + FFFF pomoću zamjenskih parova; takve će parove automatski zamijeniti operacijski sustav s jednim znakom. Prije uporabe, ovaj način unosa morate aktivirati u odgovarajućem odjeljku postavki sustava, a zatim odabrati kao trenutni način unosa u izborniku tipkovnice.
Počevši od Mac OS X 10.2, postoji i aplikacija Character Palette koja vam omogućuje odabir znakova iz tablice u kojoj možete odabrati likove iz određenog bloka ili znakove podržane određenim fontom.
GNU / Linux
GNOME također ima uslužni program Map Map (ranije gucharmap) koji vam omogućuje prikaz simbola za određeni blok ili sustav za pisanje i pruža mogućnost pretraživanja po imenu ili opisu simbola. Kad je kôd željenog znaka poznat, može se unijeti u skladu sa standardom ISO 14755: dok držite pritisnute tipke Ctrl + ⇧ Shift, unesite heksadecimalni kôd (počevši od neke verzije GTK +, kôd se mora unijeti pritiskom na "U"). Uneseni heksadecimalni kôd može imati duljinu do 32 bita, što vam omogućuje unos bilo kojih Unicode znakova bez korištenja zamjenskih parova.
Sve aplikacije X Window, uključujući GNOME i KDE, podržavaju unos tipkom Compose. Za tipkovnice koje nemaju namjensku tipku za sastavljanje, u tu svrhu možete dodijeliti bilo koju tipku - na primjer, ⇪ Caps lock.
GNU / Linux konzola također dopušta unos Unicode znaka prema njegovu kodu - za to se decimalni kod znaka mora unijeti kao znamenke proširenog bloka tipkovnice držeći pritisnutu tipku Alt. Znakove možete unijeti prema njihovom heksadecimalnom kodu: za to morate držati pritisnutu tipku AltGr i za unos znamenke A-F koristite tipke na proširenom bloku tipkovnice od NumLock do ↵ Enter (u smjeru kazaljke na satu). Podržan je i unos prema ISO 14755. Da bi gornje metode funkcionirale, morate omogućiti način Unicode u konzoli pozivom unicode_start(1) i pozivanjem odaberite odgovarajući font setfont(8).
Mozilla Firefox za Linux podržava unos znakova ISO 14755.
Problemi s Unicodeom
U Unicodeu engleski "a" i poljski "a" isti su znak. Na isti način, ruski "a" i srpski "a" smatraju se istim simbolom (ali različito od latinskog "a"). Ovo načelo kodiranja nije univerzalno; očito, rješenje "za sve prigode" uopće ne može postojati.
- Kineski, korejski i japanski tekstovi tradicionalno se pišu odozgo prema dolje, počevši od gornjeg desnog kuta. Prebacivanje između vodoravnog i okomitog pravopisa za ove jezike nije predviđeno u Unicodeu - to se mora učiniti pomoću jezika za označavanje ili unutarnjih mehanizama za obradu teksta.
- Unicode omogućuje različite težine istog karaktera, ovisno o jeziku. Dakle, kineski znakovi mogu imati različite težine u kineskom, japanskom (kanji) i korejskom (hancha), ali u isto vrijeme u Unicodeu označeni su istim simbolom (tzv. CJK unifikacija), iako su pojednostavljeni i puni znakovi i dalje imaju različite kodove ... Slično, ruski i srpski jezik koriste različita kurzivna slova. NS i T(na srpskom jeziku izgledaju kao u i w, pogledajte srpski kurziv). Stoga morate osigurati da je tekst uvijek ispravno označen kao povezan s jednim ili drugim jezikom.
- Prijevod s malih na velika slova također ovisi o jeziku. Na primjer: na turskom postoje slova İi i Iı - stoga su turska pravila o promjeni slova u suprotnosti s engleskim, koja zahtijevaju da se "i" prevede u "ja". Slični problemi postoje i na drugim jezicima- na primjer, na kanadskom dijalektu francuskog, registar je preveden malo drugačije nego u Francuskoj.
- Čak i s arapskim brojevima postoje određene tipografske suptilnosti: brojevi su "velika" i "mala", proporcionalni i jednoprostorni - za Unicode nema razlike među njima. Takve nijanse ostaju kod softvera.
Neki nedostaci nisu povezani sa samim Unicodeom, već sa sposobnostima tekstualnih procesora.
- Datoteke nelatiničkog teksta u Unicodeu uvijek zauzimaju više prostora, budući da je jedan znak kodiran ne jednim bajtom, kao u različitim nacionalnim kodiranjima, već nizom bajtova (iznimka je UTF-8 za jezike čija abeceda odgovara u ASCII, kao i prisutnost dva znaka u tekstu i više jezika, čija je abeceda ne uklapa se u ASCII). Datoteka fontova potrebna za prikaz svih znakova u Unicode tablici zauzima relativno veliku memoriju i računske resurse od fonta samo na nacionalnom jeziku jednog korisnika. S povećanjem snage računalnih sustava i smanjenjem troškova memorije i prostora na disku, ovaj problem postaje sve manje značajan; međutim, ostaje relevantan za prijenosne uređaje poput mobilnih telefona.
- Iako je podrška za Unicode implementirana u najčešće operacijske sustave, još uvijek se ne primjenjuju svi softver podržava ispravan rad s njim. Konkretno, oznake redoslijeda bajtova (BOM) nisu uvijek obrađene, a naglašeni znakovi slabo podržani. Problem je privremen i posljedica je usporedne novosti standarda Unicode (u usporedbi s jednobajtnim nacionalnim kodiranjem).
- Učinkovitost svih programa za obradu nizova (uključujući vrste u bazi podataka) opada kada se koristi Unicode umjesto jednobajtnih kodiranja.
Neki rijetki sustavi pisanja još uvijek nisu pravilno predstavljeni u Unicodeu. Slika "dugih" nadnaslovnih znakova koji se protežu preko nekoliko slova, kao, na primjer, u crkvenoslavenskom, još nije provedena.
Unicode ili Unicode?
"Unicode" je i vlastito ime (ili dio naziva, na primjer, Unicode konzorcij) i uobičajen naziv izveden iz engleskog jezika.
Na prvi pogled, pravopis "Unicode" je poželjniji. U ruskom jeziku već postoje morfemi "uni-" (riječi s latinskim elementom "uni-" tradicionalno su prevedene i napisane kroz "uni-": univerzalno, unipolarno, unifikacija, uniforma) i "kod". Protiv, trgovačke marke, posuđene s engleskog jezika, obično se prenose putem praktične transkripcije, u kojoj je deetimologizirana kombinacija slova "uni-" napisana kao "uni-" ("Unilever", "Unix" itd.), tj. na isti način kao u slučaju kratica po slovo poput UNICEF-a “Međunarodni dječji fond za hitne slučajeve Ujedinjenih naroda”-UNICEF.
Pravopis "Unicode" već je čvrsto ušao u tekstove na ruskom jeziku. Wikipedia koristi češću verziju. U MS Windows -u koristi se opcija Unicode.
Na web stranici Konzorcija postoji posebna stranica na kojoj se nalaze problemi prijenosa riječi "Unicode" u različiti jezici i sustavi pisanja. Za rusku ćirilicu navedena je opcija "Unicode".
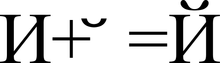
Probleme povezane s kodiranjem obično rješava softver, pa obično nema poteškoća u korištenju kodiranja. Ako se pojave poteškoće, obično ih generiraju loši programi - slobodno ih pošaljite u smeće.
Pozivam sve da se jave
ASCII (engleski standardni kod za razmjenu informacija) je američka standardna tablica kodiranja znakova za ispis i nekih posebnih kodova. U američkom engleskom jeziku [Éski] se izgovara, dok je u Velikoj Britaniji [Aski] izraženije; na ruskom se također izgovara [aski] ili [aski].
ASCII je kodiranje za decimalne znamenke, latinično i nacionalno pismo, interpunkcijske i kontrolne znakove. Izvorno dizajniran kao 7-bitni, s raširenom upotrebom 8-bitnog ASCII bajta, počelo se smatrati polovicom 8-bitnog. Računala obično koriste ASCII proširenja s uključenim 8. bitom i drugom polovicom kodne tablice (na primjer, KOI-8).
Unicode
1991. u Kaliforniji je stvorena neprofitna organizacija Unicode Consortium koja uključuje predstavnike mnogih računalnih tvrtki (Borland, IBM, Lotus, Microsoft, Novell, Sun, WordPerfect itd.), A koja razvija i implementira standard " Standard Unicode "... Standard za kodiranje znakova Unicode postaje dominantan u međunarodnim višejezičnim softverskim okruženjima. Microsoft Windows NT i njegovi potomci Windows 2000, 2003, XP koriste Unicode, točnije UTF-16, kao interni prikaz teksta. Operacijski sustavi nalik UNIX-u, poput Linuxa, BSD-a i Mac OS-a X, usvojili su Unicode (UTF-8) kao primarni prikaz višejezičnog teksta. Unicode rezervira 1.114.112 (220 + 216) kodnih znakova, trenutno se koristi više od 96.000 znakova. Prvih 256 znakovnih kodova točno odgovaraju onima ISO 8859-1, najpopularnije 8-bitne tablice znakova u zapadnom svijetu; kao rezultat toga, prvih 128 znakova također je identično ASCII tablici. Unicode kodni prostor podijeljen je u 17 "ravnina", a svaki plan ima 65536 (= 216) kodnih točaka. Prva ravnina (ravnina 0), Osnovna višejezična ravnina (BMP) je ona u kojoj je opisana većina znakova. BMP sadrži simbole za gotovo svakoga moderni jezici, te veliki broj posebnih znakova. Za "grafičke" simbole koriste se još dvije ravnine. Ravan 1, dopunska višejezična ravnina (SMP) prvenstveno se koristi za povijesne simbole, a također se koristi i za glazbene i matematičke simbole. Plan 2, dopunska ideografska ravnina (SIP), koristi se za približno 40.000 rijetkih kineskih znakova. Plan 15 i Plan 16 otvoreni su za bilo koju privatnu uporabu. Na slici 1.10 prikazan je ruski Unicode blok (U + 0400 do U + 04FF).
Uobičajena kodiranja
ISO 646 ASCII BCDIC EBCDIC ISO 8859: ISO 8859-1, ISO 8859-2, ISO 8859-3, ISO 8859-4, ISO 8859-5, ISO 8859-6, ISO 8859-7, ISO 8859-8, ISO 8859 -9, ISO 8859-10, ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866 , CP869 Microsoftova kodiranja Windows: Windows-1250 za srednjoeuropske jezike koji koriste latinični pravopis (poljski, češki, slovački, mađarski, slovenački, hrvatski, rumunjski i albanski) Windows-1251 za ćirilicu Windows-1252 za zapadne jezike Windows-1253 za Grčki Windows-1254 za turski Windows-1255 za hebrejski Windows-1256 za arapski Windows-1257 za baltičke jezike Windows-1258 za vijetnamski MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI-7 Bugarski ISCII kodiranje VISCII Big5 (najpoznatija varijanta Microsoft CP950) HKSCS Guobiao GB2312 GBK (Microsoft CP936) GB18030 Shift JIS za japanski (Microsoft CP932) EUC-KR za korejski (Microsoft CP949) ISO-2022 i EUC za kineske UTF-8 kodiranja, UTF-16 i UTF-32 Unicode skupovi znakova \
Kodiranje grafičkih informacija
Od 80 -ih godina. razvija se tehnologija obrade grafičkih informacija na računalu. Oblik prikaza na zaslonu grafičke slike koja se sastoji od pojedinačnih točaka (piksela) naziva se raster. Minimalni objekt u uređivaču rasterske grafike je točka. Uređivač rasterske grafike dizajniran je za stvaranje slika, dijagrama. Razlučivost monitora (broj vodoravnih i okomitih točaka), kao i broj mogućih boja svake točke određene su tipom monitora. 1 piksel crno-bijelog zaslona kodiran je s 1 bitom informacija (crna ili bijela točka). Broj različitih boja K i broj bitova za njihovo kodiranje povezani su formulom: K = 2b. Suvremeni monitori imaju sljedeće palete boja: 16 boja, 256 boja; 65.536 boja (visoka boja), 16.777.216 boja (prava boja).
Bitmapa
Uz pomoć povećala možete vidjeti da se crno -bijela grafička slika, na primjer iz novina, sastoji od najmanjih točaka koje čine određeni uzorak - rastera. U Francuskoj je u 19. stoljeću nastao novi smjer u slikarstvu - pointilizam. Njegova se tehnika sastojala u tome što je crtež nanesen na platno četkom u obliku raznobojnih točkica. Također, ova se metoda dugo koristila u tiskarskoj industriji za kodiranje grafičkih podataka. Točnost crteža ovisi o broju točaka i njihovoj veličini. Nakon podjele slike u točke, počevši od lijevog kuta, krećući se linijama s lijeva na desno, možete kodirati boju svake točke. Nadalje, jedna takva točka nazvat će se piksel (podrijetlo ove riječi povezano je s engleskom skraćenicom "element slike" - element slike). Glasnoća rasterske slike određuje se množenjem broja piksela (s volumenom informacija jedne točke, što ovisi o broju mogućih boja. Kvaliteta slike određena je rezolucijom monitora. Što je veća, to je Što je više rasterskih linija i točaka u liniji, to je kvaliteta slike viša. Računala uglavnom koriste sljedeće rezolucije zaslona: 640 na 480, 800 na 600, 1024 na 768 i 1280 na 1024 piksela. Budući da je svjetlina svake točke i njegove linearne koordinate mogu se izraziti pomoću cijelih brojeva, možemo reći da vam ova metoda kodiranja omogućuje korištenje binarnog koda za obradu grafičkih podataka.
Ako govorimo o crno -bijelim ilustracijama, tada, ako ne koristite polutonove, piksel će poprimiti jedno od dva stanja: osvijetljeno (bijelo) i ne svijetli (crno). A budući da se informacije o boji piksela nazivaju kodom piksela, jedan bit memorije dovoljan je za njihovo kodiranje: 0 - crno, 1 - bijelo. Ako se ilustracije razmatraju u obliku kombinacije točkica sa 256 nijansi sive (naime, one su trenutno općenito prihvaćene), tada je osmobitna binarni broj kako bi se kodirala svjetlina bilo koje točke. V. računalna grafika boja je izuzetno važna. Djeluje kao sredstvo za poboljšanje vizualnog dojma i povećanje informacijske zasićenosti slike. Kako se formira osjećaj boje u ljudskom mozgu? To se događa kao rezultat analize svjetlosnog toka koji ulazi u mrežnicu iz reflektirajućih ili emitirajućih objekata. Općenito je prihvaćeno da su receptori ljudske boje, koji se nazivaju i češeri, podijeljeni u tri skupine, a svaka može percipirati samo jednu boju - crvenu, zelenu ili plavu.
Modeli u boji
Što se tiče kodiranja boje grafičke slike, tada morate razmotriti načelo razgradnje proizvoljne boje na njezine glavne komponente. Koristi se nekoliko sustava kodiranja: HSB, RGB i CMYK. Prvi model boje je jednostavan i intuitivan, odnosno prikladan je za osobu, drugi je najprikladniji za računalo, a posljednji CMYK model za tiskare. Korištenje ovih modela boja posljedica je činjenice da se svjetlosni tok može stvoriti zračenjem, koje je kombinacija "čistih" spektralnih boja: crvene, zelene, plave ili njihovih derivata. Razlikujte aditivnu reprodukciju boja (tipičnu za emitirajuće objekte) i suptraktivnu reprodukciju boje (tipičnu za reflektirajuće objekte). Primjer objekta prve vrste je katodna cijev monitora, druge vrste - ispis.

HSB model karakteriziraju tri komponente: Nijansa, Zasićenost i Svjetlina. Podešavanjem ovih komponenti možete dobiti mnogo proizvoljnih boja. Ovaj model boje najbolje se koristi u njima grafički urednici, u kojima se slike stvaraju same, a ne obrađuju već spremne. Zatim se stvoreno umjetničko djelo može pretvoriti u RGB model boje ako se planira koristiti kao ilustracija na zaslonu, ili CMYK, ako je tiskan. Vrijednost boje odabrana je kao vektor koji izlazi iz središta kruga. Smjer vektora naveden je u kutnim stupnjevima i određuje nijansu. Zasićenost boje određena je duljinom vektora, a svjetlina boje postavljena je na zasebnu os, čija je nulta točka crna. Središnja točka je bijela (neutralna), a točke po obodu čvrste su boje.
Princip RGB metode je sljedeći: poznato je da se svaka boja može predstaviti kao kombinacija tri boje: crvene (crvena, R), zelene (zelena, G), plave (plava, B). Druge boje i njihove nijanse dobivaju se zbog prisutnosti ili odsutnosti ovih komponenti. Od prvih slova primarnih boja sustav je dobio ime - RGB. Ovaj model boje je aditivan, odnosno bilo koja boja može se dobiti kombinacijom osnovnih boja u različitim omjerima. Kad se jedna komponenta primarne boje stavi na drugu, povećava se svjetlina ukupnog zračenja. Kombiniramo li sve tri komponente, tada dobivamo akromatsku sivu boju, s čijim se povećanjem svjetline javlja pristup bijeloj boji.
Sa 256 tonova (svaka točka je kodirana s 3 bajta), minimalne RGB vrijednosti (0,0,0) odgovaraju crnoj, a bijele - maksimalnoj s koordinatama (255, 255, 255). Što je veća vrijednost bajta komponente boje, boja je svjetlija. Na primjer, tamno plava kodirana je s tri bajta (0, 0, 128) i svijetloplavom (0, 0, 255).
Princip CMYK metode. Ovaj model boje koristi se pri pripremi publikacija za tisak. Svakoj od primarnih boja dodjeljuje se komplementarna boja (komplementarna primarnoj boji bijeloj). Dodatna boja dobiva se zbrajanjem para preostalih primarnih boja. To znači da su komplementarne boje za crvenu cijan (cijan, C) = zelena + plava = bijela - crvena, za zelenu - magenta (magenta, M) = crvena + plava = bijela - zelena, za plavo - žuta (žuta, Y) = crveno + zeleno = bijelo - plavo. Štoviše, načelo razlaganja proizvoljne boje na komponente može se primijeniti i na glavnu i na dodatne, odnosno svaka se boja može predstaviti ili kao zbroj crvene, zelene, plave komponente ili kao zbroj cijan, ljubičasta, žuta komponenta. U osnovi, ova je metoda usvojena u tiskarskoj industriji. Ali tamo još uvijek koriste crnu (BlacK, budući da je slovo B već zauzeto plavom bojom, označeno je slovom K). To je zato što preklapanje komplementarnih boja ne proizvodi čistu crnu boju.
Vektorske i fraktalne slike
Vektorska slika je grafički objekt koji se sastoji od elementarnih linija i lukova. Osnovni element slike je linija. Kao i svaki objekt, ima svojstva: oblik (ravno, zaobljeno), debljinu., Boju, stil (točkasto, čvrsto). Zatvorene linije imaju svojstvo popunjavanja (bilo drugim objektima, bilo odabranom bojom). Svi ostali objekti vektorska grafika sastavljen od linija. Budući da se linija matematički opisuje kao jedan objekt, količina podataka za prikaz objekta pomoću vektorske grafike mnogo je manja nego u rasterskoj grafici. Podaci o vektorskoj slici kodirani su kao normalni alfanumerički i obrađuju se posebnim programima.
DO softver stvaranje i obrada vektorske grafike uključuje sljedeće GR: CorelDraw, Adobe Illustrator, kao i vektorizatori (tracer) - specijalizirani paketi za pretvaranje rasterskih slika u vektorske.

Fraktalna grafika temelji se na matematičkim izračunima, baš kao i vektorska grafika. No, za razliku od vektora, njegov osnovni element je sama matematička formula. To dovodi do činjenice da u memoriji računala nema pohranjenih objekata, a slika se gradi samo jednadžbama. Pomoću ove metode možete izgraditi najjednostavnije pravilne strukture, kao i složene ilustracije koje oponašaju krajolike.

Audio kodiranje
Svijet je ispunjen raznim zvukovima: otkucaji satova i brujanje motora, zavijanje vjetra i šuštanje lišća, pjev ptica i glasovi ljudi. O tome kako se zvukovi rađaju i što su, ljudi su davno počeli nagađati. Čak je i starogrčki filozof i znanstvenik - enciklopedist Aristotel, na temelju zapažanja, objasnio prirodu zvuka, vjerujući da zvučno tijelo stvara naizmjenično sažimanje i razrjeđivanje zraka. Dakle, oscilirajući niz ponekad ispušta, a zatim kondenzira zrak, a zbog elastičnosti zraka ti se naizmjenični utjecaji prenose dalje u svemir - iz sloja u sloj nastaju elastični valovi. Kad dođu do našeg uha, djeluju na bubne opne i proizvode osjećaj zvuka.
Po uhu, osoba percipira elastične valove s frekvencijom negdje u rasponu od 16 Hz do 20 kHz (1 Hz - 1 vibracija u sekundi). U skladu s tim, elastični valovi u bilo kojem mediju, čije se frekvencije nalaze unutar navedenih granica, nazivaju se zvučni valovi ili jednostavno zvuk. U proučavanju zvuka važni su pojmovi poput tona i tona zvuka. Svaki pravi zvuk, bilo da je riječ o sviranju glazbala ili glasu osobe, svojevrsna je mješavina mnogih harmonijskih vibracija s određenim skupom frekvencija.
Oscilacija koja ima najmanju frekvenciju naziva se temeljna, ostale se zovu prizvuci.
Timbar je različit broj prizvuka svojstven određenom zvuku, što mu daje posebnu boju. Razlika između jednog i drugog tona nije posljedica samo broja, već i intenziteta prizvuka koji prate zvuk glavnog tona. Po tonu možemo lako razlikovati zvukove glasovira i violine, gitare i flaute te prepoznati glas poznate osobe.
Glazbeni zvuk može se okarakterizirati s tri kvalitete: tonom, odnosno bojom zvuka, koja ovisi o obliku vibracija, visini koja je određena brojem vibracija u sekundi (frekvencijom) i glasnoćom, što ovisi o intenzitetu vibracija.
Računalo se danas široko koristi u raznim područjima. Obrada zvučnih informacija i glazbe nisu bili iznimka. Do 1983. godine sve glazbene snimke objavljivane su na vinilnim pločama i kompaktnim kasetama. Trenutno se CD -i široko koriste. Ako imate računalo na kojemu je instalirana studijska zvučna kartica, s MIDI tipkovnicom i mikrofonom spojenim na nju, tada možete raditi sa specijaliziranim glazbenim softverom.
Digitalno-analogna i analogno-digitalna konverzija audio informacija
Pogledajmo nakratko procese pretvaranja zvuka iz analognog u digitalni i obrnuto. Gruba predodžba o tome što se događa na zvučnoj kartici može pomoći da se izbjegnu neke pogreške pri radu sa zvukom.
Zvučni valovi se pretvaraju u analogni izmjenični električni signal pomoću mikrofona. Prolazi kroz audio stazu i ulazi u analogno-digitalni pretvarač (ADC), uređaj koji pretvara signal u digitalni oblik.
U pojednostavljenom obliku, princip rada ADC -a je sljedeći: mjeri amplitudu signala u pravilnim intervalima i dalje prenosi, već putem digitalne staze, niz brojeva koji nose informacije o promjenama amplitude. Tijekom analogno-digitalne pretvorbe ne dolazi do fizičke pretvorbe. Otisak ili uzorak se, takoreći, uklanja s električnog signala, što je digitalni model fluktuacija napona u audio stazi. Ako je to prikazano u obliku dijagrama, tada je ovaj model predstavljen u obliku niza stupaca, od kojih svaki odgovara određenoj numeričkoj vrijednosti. Digitalni signal je diskretne prirode - odnosno diskontinuiran pa se digitalni model ne podudara baš s analognim valnim oblikom.
Uzorak je vremenski interval između dva mjerenja amplitude analognog signala.
Uzorak doslovno s engleskog znači "uzorak". U multimedijskoj i stručnoj audio terminologiji ova riječ ima nekoliko značenja. Osim vremenskog razdoblja, uzorak se naziva i bilo koji niz digitalnih podataka koji je dobiven analogno-digitalnom pretvorbom. Sam proces pretvorbe naziva se uzorkovanje. Na ruskom tehničkom jeziku naziva se diskretizacija.
Digitalni zvuk emitira se digitalno-analognim pretvaračem (DAC), koji na temelju dolaznih digitalnih podataka u odgovarajuće vrijeme generira električni signal potrebne amplitude
Opcije uzorkovanja
Učestalost i dubina bita važni su parametri uzorkovanja. Frekvencija - broj mjerenja amplitude analognog signala u sekundi.
Ako frekvencija uzorkovanja nije veća od dvostruke frekvencije gornje granice raspona zvuka, uključite visoke frekvencije nastat će gubici. To objašnjava zašto je standardna frekvencija audio CD -a 44,1 kHz. Budući da je raspon oscilacija zvučnih valova u rasponu od 20 Hz do 20 kHz, broj mjerenja signala u sekundi mora biti veći od broja oscilacija u istom vremenskom razdoblju. Ako je brzina uzorkovanja znatno niža od frekvencije zvučnog vala, tada se amplituda signala ima vremena promijeniti nekoliko puta tijekom vremena između mjerenja, a to dovodi do činjenice da digitalni otisak prsta nosi kaotičan skup podataka. Tijekom digitalno-analogne konverzije takav uzorak ne prenosi glavni signal, već samo proizvodi šum.
U novom DVD formatu Audio DVD, signal se mjeri 96.000 puta u jednoj sekundi, tj. koristi se brzina uzorkovanja od 96 kHz. Za uštedu prostora na tvrdom disku u multimedijskim aplikacijama često se koriste niže frekvencije: 11, 22, 32 kHz. To dovodi do smanjenja zvučnog frekvencijskog raspona, što znači da dolazi do jakog izobličenja onoga što se čuje.
Ako u obliku grafikona predstavljamo isti zvuk s visinom od 1 kHz (nota do sedme oktave klavira približno odgovara ovoj frekvenciji), ali uzorkovano s drugom frekvencijom (donji dio sinusoide je nisu prikazani na svim grafikonima), tada će razlike biti vidljive. Jedna podjela na vodoravnoj osi, koja prikazuje vrijeme, odgovara 10 uzoraka. Skala je ista. Možete vidjeti da na frekvenciji od 11 kHz postoji oko pet oscilacija zvučnog vala na svakih 50 uzoraka, odnosno da se jedno razdoblje sinusnog vala prikazuje koristeći samo 10 vrijednosti. Ovo je prilično neprecizan prijenos. Istodobno, ako uzmemo u obzir frekvenciju uzorkovanja od 44 kHz, tada za svako razdoblje sinusoide postoji već gotovo 50 uzoraka. To vam omogućuje dobivanje signala dobre kvalitete.
Dubina bita označava točnost s kojom se mijenja amplituda analognog signala. Točnost s kojom se prenosi vrijednost amplitude signala u svakom trenutku tijekom digitalizacije određuje kvalitetu signala nakon digitalno-analogne konverzije. Točnost rekonstrukcije valnog oblika ovisi o dubini bita.
Vrijednost amplitude kodira se pomoću principa binarnog kodiranja. Zvučni signal treba predstaviti kao niz električnih impulsa (binarne nule i jedinice). Obično se koriste 8, 16 ili 20 bitni prikazi vrijednosti amplitude. Kad je binarno kodiranje kontinuirano zvučni signal zamjenjuje se nizom diskretnih razina signala. Kvaliteta kodiranja ovisi o brzini uzorkovanja (broju mjerenja razine signala po jedinici vremena). S povećanjem brzine uzorkovanja povećava se točnost binarnog prikaza informacija. Na frekvenciji od 8 kHz (broj mjerenja u sekundi je 8000), kvaliteta uzorkovanog zvučnog signala odgovara kvaliteti radijskog emitiranja, a na frekvenciji od 48 kHz (broj mjerenja u sekundi je 48000) - na kvalitetu zvuka audio CD -a.
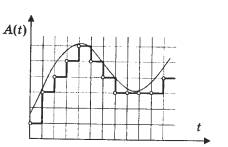
Trenutno postoji novi potrošački digitalni format Audio DVD koji koristi 24-bitnu i 96 kHz brzinu uzorkovanja. Pomoću nje može se izbjeći gore navedeni nedostatak 16-bitnog kodiranja.
Do modernog digitalnog zvučni uređaji Instalirani su 20-bitni pretvarači. Zvuk ostaje 16-bitni, instalirani su pretvarači povećane dubine bita radi poboljšanja kvalitete snimanja na niskim razinama. Njihovo načelo rada je sljedeće: izvorni analogni signal digitalizira se sa širinom od 20 bita. Tada digitalni procesor signala DSPP smanjuje svoju širinu na 16 bita. U tom slučaju koristi se poseban algoritam izračuna, uz pomoć kojeg je moguće smanjiti izobličenje signala niske razine. Tijekom digitalno-analogne konverzije uočava se suprotan proces: dubina bita povećava se sa 16 na 20 bita pomoću posebnog algoritma koji vam omogućuje preciznije određivanje vrijednosti amplitude. Odnosno, zvuk ostaje 16-bitni, ali postoji općenito poboljšanje kvalitete zvuka.
Što je kodiranje
Na ruskom se "skup znakova" naziva i tablica "skup znakova", a postupak korištenja ove tablice za prevođenje informacija iz računalnog prikaza u ljudski i karakteristika tekstualne datoteke koja odražava upotrebu određene sustav kodova u njemu prilikom prikaza teksta.
Kako je tekst kodiran
Skup simbola koji se koriste u pisanju teksta naziva se računalnom terminologijom kao abeceda; broj znakova u abecedi obično se naziva njegova moć. Za prezentaciju tekstualne informacije računalo najčešće koristi abecedu kapaciteta 256 znakova. Jedan od njegovih znakova nosi 8 bitova informacija, stoga binarni kod svakog znaka zauzima 1 bajt računalne memorije. Svi znakovi takve abecede numerirani su od 0 do 255, a svaki broj odgovara 8 -bitnom binarnom kodu, koji je redni broj znaka u binarnom brojevnom sustavu - od 00000000 do 11111111. Samo prvih 128 znakova s brojevi od nule (binarni kod 00000000) do 127 (01111111). To uključuje mala slova i velika slova Latinska abeceda, brojevi, interpunkcijski znakovi, zagrade itd. Preostalih 128 kodova, počevši od 128 (binarni kod 10000000) i završavajući s 255 (11111111), koriste se za kodiranje slova nacionalnih abeceda, službenih i znanstvenih simbola.
Vrste kodiranja
Najpoznatija tablica kodiranja je ASCII (američki standardni kod za razmjenu informacija). Prvotno je razvijen za prijenos tekstova telegrafom, a tada je bio 7-bitan, odnosno samo 128 7-bitnih kombinacija korišteno je za kodiranje engleskih znakova, servisnih i kontrolnih znakova. U ovom slučaju, prve 32 kombinacije (kodovi) služile su za kodiranje kontrolnih signala (početak teksta, kraj retka, povratak nosača, poziv, kraj teksta itd.). U razvoju prvih IBM računala ovaj je kôd korišten za predstavljanje simbola u računalu. Od godine u izvorni kod ASCII je imao samo 128 znakova, jer je njihovo kodiranje imalo dovoljno vrijednosti bajta s 8. bitom jednakim 0. Vrijednosti bajta s 8. bitom jednakim 1 korištene su za predstavljanje pseudo-grafičkih znakova, matematičkih znakova i nekih znakova iz jezika Engleski (grčki, njemački umlauti, francuska dijakritika itd.). Kad su se računala počela prilagođavati drugim zemljama i jezicima, više nije bilo dovoljno mjesta za nove simbole. Kako bi u potpunosti podržao druge jezike osim engleskog, IBM je uveo nekoliko kodnih tablica specifičnih za pojedine zemlje. Tako je za skandinavske zemlje predložena tablica 865 (nordijska), za arapske zemlje - tablica 864 (arapski), za Izrael - tablica 862 (Izrael) itd. U ovim tablicama neki su kodovi iz druge polovice tablice kodova korišteni za predstavljanje znakova nacionalnih abeceda (isključujući neke pseudo-grafičke znakove). Situacija s ruskim jezikom razvila se na poseban način. Očigledno je da se zamjena znakova u drugoj polovici tablice kodova može izvršiti različiti putevi... Tako se za ruski jezik pojavilo nekoliko različitih tablica kodiranja ćiriličnih znakova: KOI8-R, IBM-866, CP-1251, ISO-8551-5. Svi oni predstavljaju simbole prve polovice tablice na isti način (od 0 do 127), a razlikuju se u predstavljanju simbola ruske abecede i pseudo-grafike. Za jezike poput kineskog ili japanskog 256 znakova općenito nije dovoljno. Osim toga, uvijek postoji problem ispisivanja ili spremanja u jednu datoteku u isto vrijeme na različiti jezici(na primjer, prilikom citiranja). Stoga, univerzalni tablica kodova UNICODE, koji sadrži simbole koji se koriste u jezicima svih naroda svijeta, kao i razne službene i pomoćne simbole (interpunkcijski znakovi, matematički i tehnički simboli, strelice, dijakritičke oznake itd.). Očigledno, jedan bajt nije dovoljan za kodiranje tako velikog skupa znakova. Stoga UNICODE koristi 16-bitne (2-bajtne) kodove za predstavljanje 65.536 znakova. Do danas je korišteno oko 49.000 kodova (posljednja značajna promjena bila je uvođenje simbola valute EURO u rujnu 1998.). Radi kompatibilnosti s prethodnim kodiranjima, prvih 256 kodova je isto što i ASCII standard. U standardu UNICODE, osim određenog binarnog koda (ti se kodovi obično označavaju slovom U, nakon čega slijedi znak + i stvarni kôd u heksadecimalnom prikazu), svakom znaku se dodjeljuje i poseban naziv. Još jedna komponenta UNICODE standard su algoritmi za konverziju jedan-na-jedan UNICODE kodova u nizu bajtova promjenjive duljine. Potreba za takvim algoritmima nastaje zbog činjenice da sve aplikacije ne mogu raditi s UNICODE -om. Neke aplikacije razumiju samo 7-bitne ASCII kodove, druge aplikacije razumiju 8-bitne ASCII kodove. Takve aplikacije koriste takozvane proširene ASCII kodove za predstavljanje znakova koji se ne uklapaju u skup od 128 znakova ili 256 znakova, kada su znakovi kodirani nizovima bajtova promjenjive duljine. UTF-7 se koristi za reverzibilno pretvaranje UNICODE kodova u proširene 7-bitne ASCII kodove, a UTF-8 se koristi za reverzibilno pretvaranje UNICODE kodova u proširene 8-bitne ASCII kodove. Imajte na umu da i ASCII i UNICODE i drugi standardi kodiranja znakova ne definiraju slike znakova, već samo sastav skupa znakova i način na koji je predstavljen u računalu. Osim toga (što možda nije odmah očito), redoslijed nabrajanja znakova u skupu vrlo je važan jer utječe na algoritme sortiranja na najznačajniji način. To je tablica korespondencije simbola iz određenog skupa (recimo, simboli koji se koriste za predstavljanje informacija o Engleski jezik, ili na različitim jezicima, kao u slučaju UNICODE -a) i označavaju izraz tablica kodiranja znakova ili skup znakova. Svako standardno kodiranje ima naziv, na primjer KOI8-R, ISO_8859-1, ASCII. Nažalost, ne postoji standard za kodiranje imena.
Uobičajena kodiranja
ISO 646 o ASCII EBCDIC ISO 8859: o ISO 8859-1-ISO 8859-11, ISO 8859-13, ISO 8859-14, ISO 8859-15 o CP437, CP737, CP850, CP852, CP855, CP857, CP858, CP860, CP861, CP863, CP865, CP866, CP869 Kodiranja u sustavu Microsoft Windows: o Windows-1250 za srednjoeuropske jezike koji koriste latinična slova o Windows-1251 za ćirilična pisma o Windows-1252 za zapadne jezike o Windows-1253 za grčki o Windows -1254 za turski o Windows-1255 za hebrejski o Windows-1256 za arapski o Windows-1257 za baltičke jezike o Windows-1258 za vijetnamski MacRoman, MacCyrillic KOI8 (KOI8-R, KOI8-U ...), KOI -7 bugarsko kodiranje ISCII VISCII Big5 (najpoznatija varijanta Microsoft CP950) o HKSCS Guobiao o GB2312 o GBK (Microsoft CP936) o GB18030 Shift JIS za japanski (Microsoft CP932) EUC-KR za korejski (Microsoft CP949) ISO-2022 i EUC za kodiranje kineskog sustava za pisanje UTF-8 i UTF-16 skupa znakova Yong IcodeU sustavu kodiranja ASCII(Američki standardni kôd za razmjenu informacija) svaki je znak predstavljen jednim bajtom koji može kodirati 256 znakova.
ASCII ima dvije tablice kodiranja - osnovnu i proširenu. Osnovna tablica popravlja vrijednosti kodova od 0 do 127, a proširena se odnosi na znakove s brojevima od 128 do 255. To je dovoljno da se različitim kombinacijama od osam bitova izraze svi znakovi engleskog i ruskog jezika , mala i velika slova, te interpunkcijski znakovi, simboli za osnovne aritmetičke operacije i uobičajeni posebni simboli koji se mogu vidjeti na tipkovnici.
Prvih 32 koda osnovne tablice, počevši od nule, dobivaju proizvođači hardvera (prvenstveno proizvođači računala i tiskarskih uređaja). Ovo područje sadrži takozvane kontrolne kodove, koji ne odgovaraju nijednom znaku jezika, pa se, prema tome, ti kodovi ne prikazuju niti na ekranu niti na ispisnim uređajima, ali se njima može kontrolirati način na koji se drugi podaci ispisuju. Počevši od koda 32 do koda 127, postavljaju se simboli engleske abecede, interpunkcijski znakovi, brojevi, aritmetičke operacije i pomoćni simboli, svi se mogu vidjeti na latiničnom dijelu tipkovnice računala.
Drugi, prošireni dio daje se nacionalnim sustavima kodiranja. U svijetu postoji mnogo nelatiničnih abeceda (arapski, hebrejski, grčki itd.), Uključujući i ćirilicu. Također, njemački, francuski, španjolski raspored tipkovnice razlikuju se od engleskih.
Engleski dio tipkovnice nekada je imao mnogo standarda, ali sada su svi zamijenjeni jednim ASCII kodom. Bilo je i mnogo standarda za rusku tipkovnicu: GOST, GOST -alternativa, ISO (Međunarodna organizacija za standarde - Međunarodni institut za standardizaciju), no ta su tri standarda zapravo izumrla, iako se mogu sastati negdje, u nekim pomoćnim računalima ili u računalima mrežama.
Kodiranje glavnih znakova ruskog jezika, koje se koristi u računalima s operativnim sustavom Windows sustav zvao Windows-1251, za ćirilicu je razvio Microsoft. Naravno, apsolutna većina računalnih tekstualnih podataka kodirana je u sustavu Windows-1251. Usput, Microsoft je razvio kodiranja s različitim četveroznamenkastim brojem za druga uobičajena pisma: arapski, japanski i druga.
Još jedno uobičajeno kodiranje se naziva KOI-8(kôd za razmjenu informacija, osmoznamenkasti) - njegovo podrijetlo datira iz vremena Vijeća za uzajamnu ekonomsku pomoć istočnoeuropskih država. Danas je kodiranje KOI-8 rašireno u računalnim mrežama na teritoriju Rusije i u ruskom sektoru interneta. Dogodi se da neki tekst pisma ili nešto drugo nije čitljivo, što znači da morate prijeći s KOI-8 na Windows-1251. deset
U 90 -ima najveći proizvođači softvera: Microsoft, Borland, isti Adobe odlučio je o potrebi razvoja drugog sustava za kodiranje teksta, u kojem će svakom znaku biti dodijeljeno ne 1, već 2 bajta. Dobila je ime Unicode, a moguće je kodirati 65.536 znakova ovog polja dovoljno je da stane u jednu tablicu nacionalnih abeceda za sve jezike planeta. Većina Unicodea (oko 70%) zauzimaju kineski znakovi, u Indiji postoji 11 različitih nacionalnih abeceda, ima mnogo egzotičnih naziva, na primjer: pisanje kanadskih domorodaca.
Budući da se kodiranju svakog znaka u Unicodeu dodjeljuje ne 8, već 16 bita, veličina tekstualne datoteke se udvostručuje. To je nekad bila prepreka uvođenju 16-bitnog sustava. a sada s gigabajtnim tvrdim diskovima, stotinama megabajta RAM -a, gigahercnim procesorima, udvostručavanjem volumena tekstualnih datoteka, koje u usporedbi, na primjer, s grafikom, zauzimaju vrlo malo prostora, nije mnogo važno.
Ćirilica u Unicodeu ima od 768 do 923 (osnovni znakovi) i od 924 do 1023 (proširena ćirilica, razna rjeđa nacionalna slova). Ako program nije prilagođen za ćirilični Unicode, tada je moguće da se tekstualni znakovi prepoznaju ne kao ćirilica, već kao proširena latinica (kodovi od 256 do 511). I u ovom slučaju, umjesto teksta, na ekranu se pojavljuje besmisleni skup raznih egzotičnih simbola.
To je moguće ako je program zastario, kreiran prije 1995. Ili rijetka, o kojoj se nitko nije potrudio rusificirati. Moguće je i da OS Windows instaliran na računalu nije u potpunosti konfiguriran za ćirilicu. U tom slučaju morate unijeti odgovarajuće unose u registar.
 Alternative zamjeni ključa naredbenog retka programa Microsoft Office Visio
Alternative zamjeni ključa naredbenog retka programa Microsoft Office Visio Instalacija i postavljanje Mhotspota Računalo se nije ponovo pokrenulo nakon instalacije
Instalacija i postavljanje Mhotspota Računalo se nije ponovo pokrenulo nakon instalacije Priča o tri dugmeta. Kolumna Evgenija Zobnina. Dobivamo prilagodljive zaslonske gumbe Početna, Natrag i Izbornik na bilo kojem Android uređaju (lebdeće meke tipke) Dodjela gumba na telefonu
Priča o tri dugmeta. Kolumna Evgenija Zobnina. Dobivamo prilagodljive zaslonske gumbe Početna, Natrag i Izbornik na bilo kojem Android uređaju (lebdeće meke tipke) Dodjela gumba na telefonu