Tabela Ansi za ruske znake. Kodiranje: koristne informacije in kratka retrospektiva
Včasih vam tudi dokaj izkušen specialist ne bo takoj povedal, kakšna določena vrednost tlaka ali dolžine v enem sistemu ustreza vrednostim v drugem sistemu vrednosti.
Za olajšati vam to nalogo ponujamo tabele razmerja vrednosti tlaka in dolžine v evropskem in ameriškem sistemu z majhnimi pojasnila... Najprej pa nekaj besed o samih standardih.
DIN je nemški standard (pomeni Deutsches Institut für Normung, ki ga je razvil Nemški inštitut za standardizacijo), ki je razvit strogo v okviru določb Mednarodne organizacije za standardizacijo - ISO (Mednarodna organizacija za standardizacijo).
ANSI- standard, sprejet v Združenih državah Amerike. Pomeni Ameriški nacionalni inštitut za standarde, to je standard ameriškega nacionalnega inštituta za standarde.
V skladu s tem standarde ANSI določa ta institucija in daleč ni vedno med standardi DIN in ANSI točno skladnost na različnih področjih.
Pretvorba tlačnih enot ANSI v DIN
Tu je vse preprosto: če je standard ANSIštevilka 150 stoji nasproti tlaka - to pomeni, da je nominalni (za katerega je zasnovan ventil) tlak 20 barov, 300 - 50 barov itd. Največja vrednost za ANSI razred- 2500 bo po evropskem standardu enako 420 barov DIN.
Z uporabo te tabele, ni težko prevesti vrednosti tlaka in nazaj: od DIN v ANSI, čeprav morajo naši inženirji tak prevod veliko izvesti manj pogosto.
Pretvorba enote dolžine iz ameriškega sistema v evropski (ruski)
Kot je znano, Američani vse se meri v palcih in stopalih, mi in Evropejci- milimetri, centimetri in metri, torej v veliki večini držav na svetu živimo metrična sistem enot.
Kako pretvoriti palce v milimetre? Pravzaprav tudi to ni težko, samo zapomnite si, da je 1 palec enak 25,4 mm. Vendar pa je pogosto številka za decimalno vejico zanemarjeno in za enakomerno štetje to navedite 1 palec = 25 mm.
Tako, če je na primer prerez dovoda 2 palca po ameriškem sistemu mer, potem, če to vrednost prevedemo v naš sistem mer po zgornjem pravilu, dobimo 50 mm ali, natančneje, 51 mm (zaokroževanje 50,8 po pravilih) ...
Ostaja še dodati, da je premer tehnično lastnosti so označene z latinskimi črkami DN in je pogosto natančno označeno v palcev, in pritisk je označen s črkami PN in je najpogosteje označeno v palice- v vsakem primeru uporabljamo ravno takšno oznako udobno.
In naslednja tabela bo pomagal lahko izračunate ne samo natančnoštevilo milimetrov v enem palcu (z natančnostjo tisočinke milimetra), pomagalo pa vam bo tudi ugotoviti, koliko milimetrov je na primer v 2,5 palca.
Če želite to narediti, poiščite stolpec 2 "" (2 palca) in na levi poiščite 1/2. Skupaj 2,5 palca = 63,501 mm, kar je povsem mogoče zaokrožiti na 64 mm, na primer 6,25 palca (tj. 6 in 1/4) = 158,753 mm ali 159 mm.
|
| Palec "" v milimetrih |
|||||||
|
| ||||||||
|
| ||||||||
Če morate vnesti le nekaj posebni znaki ali znakov, lahko uporabite tabelo znakov ali bližnjice na tipkovnici. Za seznam znakov ASCII glejte spodnje tabele ali razdelek Vstavljanje nacionalnih abeced z bližnjicami na tipkovnici.
Opombe:
Vstavljanje znakov ASCII
Če želite vstaviti znak ASCII, pritisnite in držite tipko ALT ter vnesite kodo znaka. Če želite na primer vstaviti znak stopinje (º), pridržite tipko ALT in vnesite številska tipkovnica koda 0176.
Opomba:
Vstavljanje znakov Unicode
Pomembno: Nekateri Microsoftovi programi Office, na primer PowerPoint in InfoPath, ne more pretvoriti kod znakov Unicode. Če potrebujete znak Unicode in uporabljate enega od programov, ki ne podpirajo znakov Unicode, uporabite za vnos znakov, ki jih boste morda potrebovali.
Opombe:
Zaprite vse programe.
Dvokliknite ikono Namestitev in odstranitev programov naprej nadzorne plošče.
Naredite nekaj od naslednjega:
če je vloga Microsoft Office nameščen kot del programa Microsoft Office, izberite Microsoft Office na terenu Nameščeni programi in nato pritisnite gumb Zamenjati;
Če Pisarniška aplikacija je bil nameščen ločeno, kliknite njegovo ime na seznamu Nameščeni programi in nato pritisnite gumb Spremenite.
Številke je treba vnesti na številsko tipkovnico, ne alfanumerično. Če morate pritisniti za vnos številk na številski tipkovnici Tipka NUM LOCK, preverite, ali je to storjeno.
Če imate težave s pretvorbo kode Unicode v znak, vnesite kodo na številski tipkovnici, jo izberite in pritisnite Alt + X.
V Microsoft Windows XP in novejše različice univerzalne pisave Unicode se samodejno namestijo. V sistemu Microsoft Windows 2000 je treba pisavo Unicode namestiti ročno.
V sistemu Microsoft Windows 2000
V pogovornem oknu Namestitev programa Microsoft Office 2003 izberite možnost Dodajte ali odstranite komponente in nato pritisnite gumb Nadalje.
Prosim izberite Dodatna prilagoditev aplikacije in pritisnite gumb Nadalje.
Razširite seznam Splošna pisarniška orodja.
Razširite seznam Večjezična podpora.
Kliknite ikono Univerzalna pisava in izberite želeno možnost namestitve.
Uporaba tabele simbolov
Tabela simbolov je Microsoftova vgrajena Program Windows ki vam omogoča ogled znakov, ki so na voljo v izbrani pisavi. S tabelo simbolov lahko posamezne simbole ali skupine simbolov kopirate v odložišče in jih nato prilepite v program, ki jih podpira.
Kliknite gumb Začni in nato izberite Programi, Standardno, Storitev in tabela simbolov.
Če želite izbrati simbol v tabeli simbolov, ga kliknite, pritisnite gumb Izberite, kliknite desni klik miško na mestu dokumenta, kamor želite dodati simbol, in izberite ukaz Vstavi.
Pogoste kode znakov
Če želite več znakov, glejte članek, nameščen v vašem računalniku, kode znakov ASCII ali diagram skripta kode znakov Unicode.
|
Podpiši |
Podpiši |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli valut |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Pravni simboli |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Ulomki |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Ločila in narečni simboli |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Simboli obrazcev |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Splošne diakritične kodeZa celoten seznam glif in povezanih kod znakov glejte.
|
Okvir Bootstrap: hitro odzivna postavitev
Video vadnica po korakih o osnovah odzivne postavitve v okviru Bootstrap.
Naučite se preprosto, hitro in učinkovito tipkati z zmogljivim in praktičnim orodjem.
Postavitev po naročilu in plačilo.
Brezplačni tečaj "Spletno mesto WordPress"
Želite obvladati WordPress CMS?
Pridobite vaje o oblikovanju in postavitvi spletnega mesta WordPress.
Naučite se delati s temami in razrezati postavitev.
Brezplačni video tečaj o risanju spletnega mesta, postavitvi in namestitvi na CMS WordPress!
* Premaknite miško, da začasno ustavite drsenje.
Nazaj naprej
Kodiranje: koristne informacije in kratka retrospektiva
Odločil sem se, da bom ta članek napisal kot majhen pregled o kodiranju.
Ugotovili bomo, kaj sploh je kodiranje, in se dotaknili zgodovine, kako so se načeloma pojavili.
Govorili bomo o nekaterih njihovih značilnostih in upoštevali tudi trenutke, ki nam omogočajo bolj zavestno delo s kodiranjem in se izognemo pojavu na spletnem mestu t.i. krakozyabrov, tj. neberljivi znaki.
Pa pojdimo ...
Kaj je kodiranje?
Preprosto povedano, kodiranje je tabela preslikav znakov, ki jih lahko vidimo na zaslonu z določenimi številčnimi kodami.
Tisti. vsak znak, ki ga vnesemo s tipkovnice ali vidimo na zaslonu monitorja, je kodiran z določenim zaporedjem bitov (ničle in enote). 8 bitov, kot verjetno veste, je enako 1 bajtu informacij, o tem pa kasneje.
Videz samih simbolov je odvisen od datotek pisav ki so nameščene v vašem računalniku. Zato lahko postopek prikaza besedila na zaslonu opišemo kot stalno preslikavo zaporedij ničel in enot na nekatere posebne znake, ki sestavljajo pisavo.
Lahko se šteje za prednika vseh sodobnih kodir ASCII.
Ta kratica pomeni Ameriški standardni kodeks za izmenjavo informacij(American Standard Coding Table za znake za tiskanje in nekatere posebne kode).
to enobajtno kodiranje, ki je sprva vsebovala le 128 znakov: črke latinske abecede, arabske številke itd.

Kasneje je bil razširjen (sprva ni uporabljal vseh 8 bitov), zato je bilo mogoče uporabiti ne 128, ampak 256 (2 do 8. stopnje) različni liki ki jih je mogoče kodirati v en bajt informacij.
Ta izboljšava je omogočila dodajanje v ASCII simboli nacionalnih jezikov, poleg že obstoječe latinice.
Obstaja veliko možnosti za razširjeno kodiranje ASCII zaradi dejstva, da je na svetu tudi veliko jezikov. Mislim, da ste mnogi slišali za takšno kodiranje kot KOI8-R je tudi razširjeno kodiranje ASCII zasnovan za delo z liki ruskega jezika.
Naslednji korak v razvoju kodiranja lahko štejemo za pojav t.i ANSI kodiranje.
Pravzaprav sta bila enaka razširjene različice ASCII vendar so bili z njih odstranjeni različni psevdo grafični elementi in dodani tipografski simboli, za katere prej ni bilo dovolj "prostega prostora".
Primer takega kodiranja ANSI je dobro znan Windows-1251... Poleg tipografskih znakov je to kodiranje vključevalo tudi črke abeced jezikov, ki so blizu ruskemu (ukrajinski, beloruski, srbski, makedonski in bolgarski).
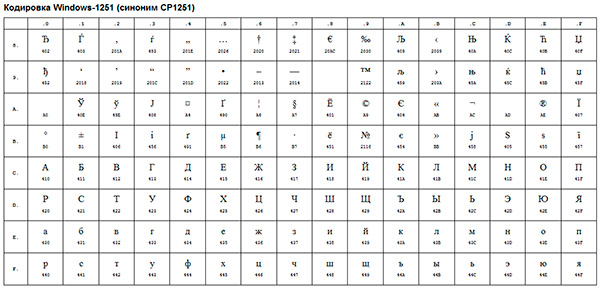
Kodiranje ANSI je skupno ime... Dejansko bo kodiranje pri uporabi ANSI določeno s tem, kar je določeno v vašem registru operacijski sistem Windows. V primeru ruskega jezika bo to Windows-1251, za druge jezike pa druga vrsta ANSI.
Kot razumete, kup kodiranj in pomanjkanje enotnega standarda nista prinesla sreče, kar je bil razlog za pogosta srečanja s t.i. krakozyabrami- neberljiv nesmiselni nabor znakov.
Razlog za njihov videz je preprost - tako je poskuša prikazati znake, kodirane z eno tabelo za kodiranje, z uporabo druge tabele za kodiranje.
V okviru spletnega razvoja se lahko srečamo s krakozyabrami, ko npr. Rusko besedilo je pomotoma shranjeno v napačnem kodiranju, ki se uporablja na strežniku.
Seveda to ni edini primer, ko lahko dobimo neberljivo besedilo - tukaj je veliko možnosti, še posebej, če upoštevate, da obstaja tudi baza podatkov, v kateri so informacije shranjene tudi v določenem kodiranju, obstaja preslikava povezava z bazo podatkov itd.
Pojav vseh teh težav je bil spodbuda za ustvarjanje nečesa novega. Morala je biti kodiranje, ki bi lahko kodiralo kateri koli jezik na svetu (navsezadnje s pomočjo enobajtnih kodiranj po vsej želji ni mogoče opisati vseh znakov, recimo kitajskega jezika, kjer je očitno več kot 256 od njih), vse dodatne posebne znake in tipografijo.
Skratka, ustvarjati je bilo treba univerzalno kodiranje, ki bi enkrat za vselej rešilo problem krakozyabrova.
Unicode-Univerzalno kodiranje besedila (UTF-32, UTF-16 in UTF-8)
Sam standard je leta 1991 predlagala neprofitna organizacija Konzorcij Unicode(Konzorcij Unicode, Unicode Inc.), prvi rezultat njegovega dela pa je bila izdelava kodiranja UTF-32.
Mimogrede, sama okrajšava UTF pomeni Format transformacije Unicode(Format pretvorbe Unicode).
V tem kodiranju naj bi za kodiranje enega znaka uporabili toliko 32 bit, tj. 4 bajti informacij. Če primerjamo to število z enobajtnimi kodiranji, potem pridemo do preprostega zaključka: če želite kodirati 1 znak v tem univerzalnem kodiranju, potrebujete 4 -krat več kosov, zaradi česar je datoteka 4 -krat težja.
Očitno je tudi, da število znakov, ki bi jih lahko opisali s tem kodiranjem, presega vse razumne meje in je tehnično omejeno na število, ki je enako 2 do 32. moči. Jasno je, da je bilo to očitno pretiravanje in izguba glede na težo datotek, zato to kodiranje ni postalo razširjeno.
Zamenjala jo je nov razvoj- UTF-16.
Kot pove že ime, je v tem kodiranju en znak kodiran ne več 32 bitov, ampak le 16(to je 2 bajta). Očitno je zaradi tega vsak znak dvakrat "lažji" od UTF-32, vendar dvakrat "težji" od katerega koli enobajtnega kodiranega znaka.
Število znakov, ki so na voljo za kodiranje v UTF-16, je najmanj 2 do 16. stopnje, tj. 65536 znakov. Zdi se, da je vse v redu, poleg tega, da je bila končna velikost kodnega prostora v UTF-16 razširjena na več kot 1 milijon znakov.
Vendar to kodiranje ni v celoti zadovoljilo potreb razvijalcev. Če na primer pišete z uporabo izključno latinskih znakov, se je teža vsake datoteke po prehodu s razširjene različice kodiranja ASCII na UTF-16 podvojila.
Kot rezultat, bil je še en poskus ustvariti nekaj univerzalnega, in da je nekaj dobro znano kodiranje UTF-8.
UTF-8- to je večbajtno kodiranje s spremenljivo dolžino znakov... Če pogledamo ime, bi lahko po analogiji z UTF-32 in UTF-16 pomislili, da se za kodiranje enega znaka uporablja 8 bitov, vendar temu ni tako. Natančneje, ne čisto tako.
To je zato, ker UTF-8 zagotavlja najboljšo združljivost s starejšimi sistemi, ki uporabljajo 8-bitne znake. Za kodiranje enega znaka v UTF-8 se dejansko uporablja 1 do 4 bajti(hipotetično je možno do 6 bajtov).
V UTF-8 so vsi latinični znaki kodirani v 8 bitih, tako kot v kodiranju ASCII... Z drugimi besedami, osnovni del kodiranja ASCII (128 znakov) se je premaknil v UTF-8, ki vam omogoča, da za njihovo predstavitev "porabite" le 1 bajt, hkrati pa ohranite univerzalnost kodiranja, za katerega se je vse začelo.
Torej, če je prvih 128 znakov kodiranih z 1 bajtom, so vsi drugi znaki kodirani z 2 ali več bajti. Zlasti je vsak cirilični znak kodiran z natančno 2 bajtoma.
Tako smo dobili univerzalno kodiranje, ki nam omogoča, da pokrijemo vse možne znake, ki jih je treba prikazati, ne da bi po nepotrebnem "utežili" datoteke.
Z BOM ali brez?
Če ste delali z urejevalniki besedil(urejevalniki kod) kot Beležnica ++, phpDesigner, hiter php itd., ste verjetno opozorili na dejstvo, da lahko pri določanju kodiranja, v katerem bo stran ustvarjena, praviloma izberete 3 možnosti:
ANSI
- UTF-8
- UTF-8 brez BOM
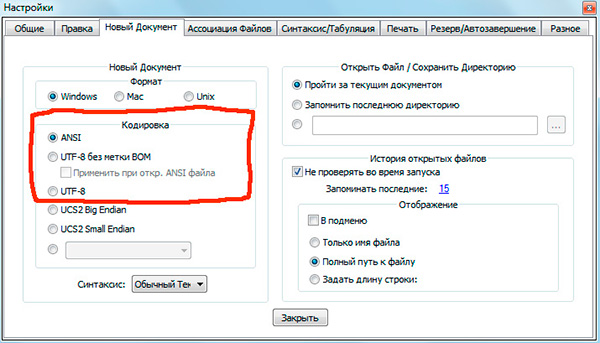

Takoj moram reči, da je vedno zadnja možnost, ki jo je vredno izbrati - UTF-8 brez BOM.
Kaj je torej specifikacija in zakaj je ne potrebujemo?
BOM pomeni Oznaka vrstnega reda bajtov... To je poseben znak Unicode, ki se uporablja za označevanje vrstnega reda bajtov. besedilno datoteko... V skladu s specifikacijo je njegova uporaba neobvezna, če pa BOM se uporablja, nato pa ga je treba nastaviti na začetku besedilne datoteke.
Ne bomo se spuščali v podrobnosti dela. BOM... Za nas je glavni zaključek naslednji: uporaba tega znaka storitve skupaj z UTF-8 preprečuje, da bi programi normalno brali kodiranje, zaradi česar pri delu skriptov pride do napak.
Zato pri delu z UTF-8 uporabite natančno to možnost "UTF-8 brez BOM"... Prav tako je bolje, da ne uporabljate urejevalnikov, v katerih načeloma ne morete določiti kodiranja (recimo, Beležnica od standardnih programov do Windows).
Kodiranje trenutne datoteke, odprte v urejevalniku kod, je običajno označeno na dnu okna.
Upoštevajte, da vnos "ANSI kot UTF-8" v uredniku Beležnica ++ pomeni isto kot "UTF-8 brez BOM"... To je isto.
![]()
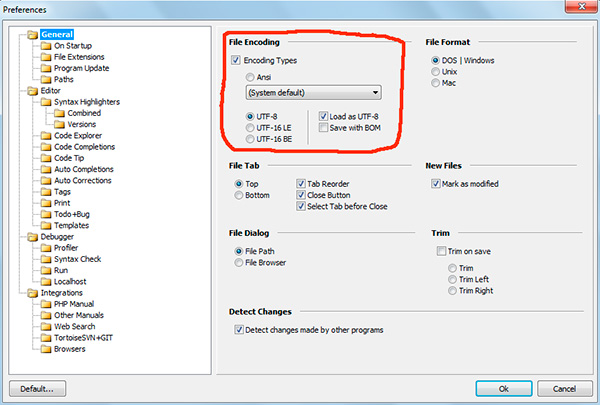
V programu phpDesigner ne morete takoj zagotovo reči, ali se uporablja BOM, ali ne. Če želite to narediti, z desno miškino tipko kliknite napis "UTF-8", nato pa v pojavnem oknu vidite, če BOM(možnost Shranite z BOM).
V urejevalniku hiter php kodiranje UTF-8 brez BOM označeno kot "UTF-8 *".
Kot si lahko predstavljate, je v različnih urednikih vse videti nekoliko drugače, vendar dobite glavno idejo.
Ko je dokument shranjen v UTF-8 brez BOM, prav tako se morate prepričati, da je v posebni meta oznaki v razdelku podano pravilno kodiranje glavo vaš html dokument:
Upoštevanje teh preprostih pravil vam bo že omogočilo, da se izognete številnim presledkom s kodiranjem.
To je vse, upam, da vam je ta majhen izlet in pojasnila pomagal bolje razumeti, kaj so kodiranja, kaj so in kako delujejo.
Če vas ta tema zanima z bolj uporabnega vidika, vam priporočam, da preučite mojo video vadnico.
Dmitrij Naumenko.
P.S. Podrobneje si oglejte vrhunske vaje o različnih vidikih gradnje spletnih mest brezplačen tečaj o ustvarjanju lastnega sistema CMS v PHP od začetka. Vse to vam bo pomagalo hitreje in lažje obvladati različne tehnologije spletnega razvoja.
Vam je bil material všeč in se vam želimo zahvaliti?
Samo delite s prijatelji in sodelavci!
|
Koda (binarna) |
(decimalno podpisano) |
(podpisana decimalka) |
|
|
A (velika latinica) | |||
|
B (velika latinica) | |||
|
a (mala latinica) | |||
|
A (velik ruski) Pri kodiranju ANSI | |||
|
A (velik ruski) Pri kodiranju ASCII |
Podobna koda, kot je prikazano zgoraj, se ujema tudi s celim številom od 0 do 255 v nepodpisani obliki. Tako ima vsak znak celo število, imenovano tudi koda znakov. Zbira se zbirka kod znakov kodna miza ali kodiranje .
Za osebne računalnike najpogostejši kodne tabele ANSI (American National Standard Institute) in ASCII (American Standard Code for Information Interchange). Tabela ANSI se uporablja v sistemu Windows, ASCII pa v sistemu DOS. Vendar pa je v teh dveh tabelah prvih 128 kod (od 0 do 127) ujemati ; razlikujejo se le v naslednjih 128 kodah, ki se uporabljajo za shranjevanje nacionalnih (ruskih) črk in simbolov "psevdo-grafike".
V danih tabelah oznaka KS pomeni "kodo znakov" in Z- "simbol".
Standardni del tabele znakov (ascii-ansi)
Nekateri od zgornjih simbolov imajo poseben pomen. Tako na primer znak s kodo 9 označuje vodoravni tabulacijski znak, znak s kodo 10 - znak za vrstico, znak s kodo 13 - znak za vrnitev nosilca.
 Razlike med particijskimi strukturami GPT in MBR
Razlike med particijskimi strukturami GPT in MBR Čisto obrišite Internet Explorer
Čisto obrišite Internet Explorer Posodobitve sistema Windows se prenesejo, vendar niso nameščene
Posodobitve sistema Windows se prenesejo, vendar niso nameščene